Dual Pointer Network for Fast Extraction of Multiple Relations in a Sentence †



Abstract
:Featured Application
Abstract
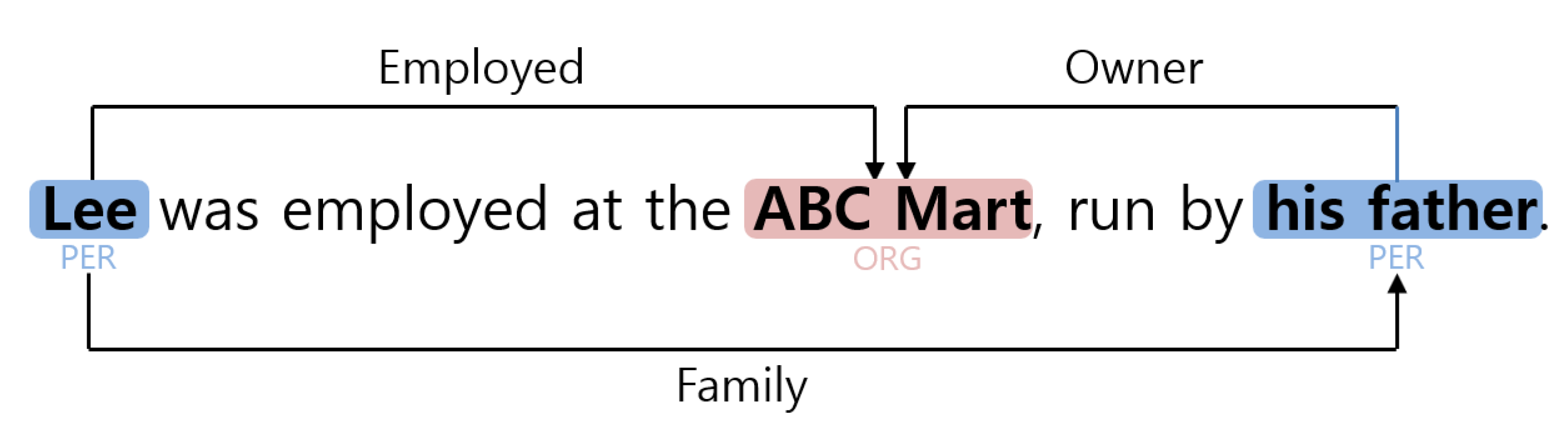
1. Introduction
2. Previous Works
3. Dual Pointer Network Model for Relation Extraction
3.1. Context and Entity Encoder
3.2. Dual Pointer Network Decoder
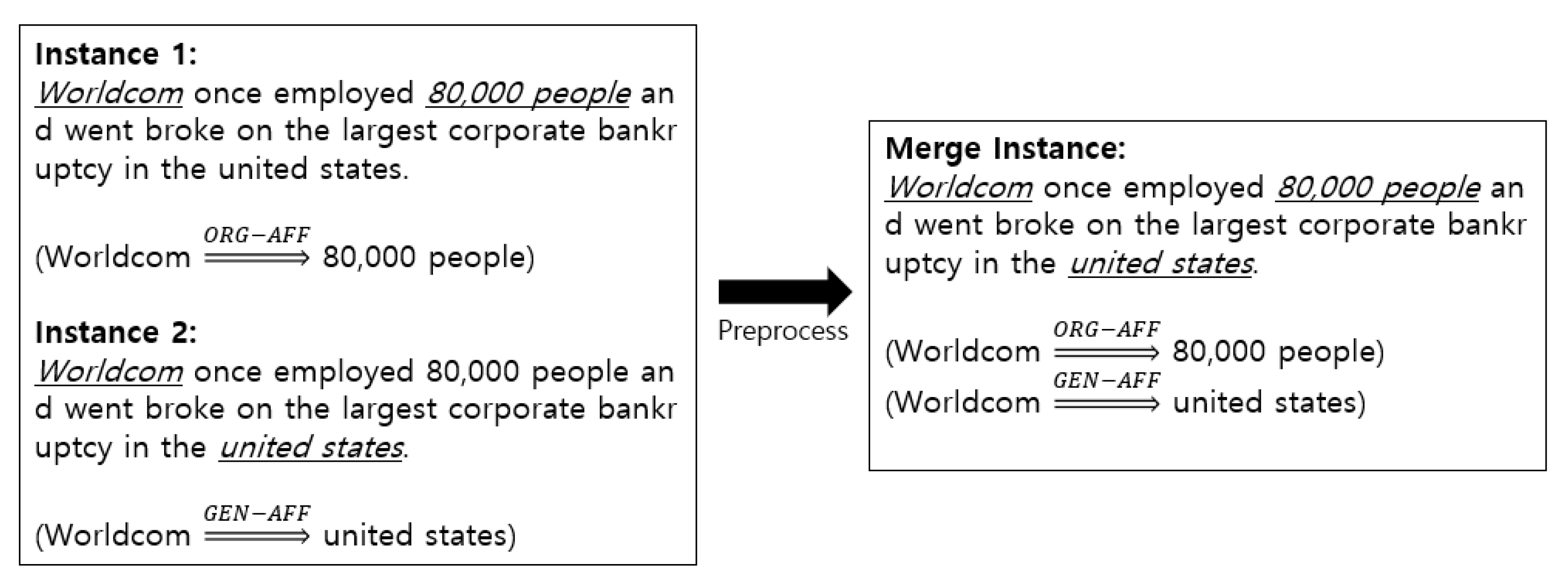
3.3. Implementation detail
4. Evaluation
4.1. Datasets and Experimental Setting
4.2. Experimental Results
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Choi, M.; Kim, H. Extraction of Instances with Social Relations for Automatic Construction of a Social Network. J. KIISE Comput. Pract. Lett. 2011, 17, 548–552. (In Korean) [Google Scholar]
- Zeng, X.; Zeng, D.; He, S.; Liu, K.; Zhao, J. Extracting Relational Facts by an End-to-End Neural Model with Copy Mechanism. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; pp. 506–514. [Google Scholar]
- Zeng, D.; Liu, K.; Lai, S.; Zhou, G.; Zhao, J. Relation Classification via Convolutional Deep Neural Network. In Proceedings of the 24th International Conference on Computational Linguistics, Dublin, Ireland, 23–29 August 2014; pp. 2335–2344. [Google Scholar]
- Nguyen, T.H.; Grishman, R. Relation extraction: Perspective from convolutional neural networks. In Proceedings of the North American Chapter of the Association for Computational Linguistics on Human Language Technology, Denver, CO, USA, 31 May–5 June 2015; pp. 39–48. [Google Scholar]
- Yu, J.; Jiang, J. Pairwise Relation Classification with Mirror Instances and a Combined Convolutional Neural Network. In Proceedings of the 26th International Conference on Computational Linguistics, Osaka, Japan, 11–16 December 2016; pp. 2366–2377. [Google Scholar]
- Zhang, Y.; Qi, P.; Manning, C.D. Graph Convolution over Pruned Dependency Trees Improves Relation Extraction. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 2205–2215. [Google Scholar]
- Miwa, M.; Bansal, N. End-to-End Relation Extraction using LSTMs on Sequences and Tree Structures. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 1105–1116. [Google Scholar]
- Zhang, Y.; Zhong, V.; Chen, D.; Angeli, G.; Manning, C.D. Positionaware Attention and Supervised Data Improve Slot Filling. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017; pp. 35–45. [Google Scholar]
- Luan, Y.; Wadden, D.; He, L.; Shah, A.; Ostendorf, M.; Hajishirzi, H. A General Framework for Information Extraction using Dynamic Span Graphs. In Proceedings of the North American Chapter of the Association for Computational Linguistics on Human Language Technology, Minneapolis, MN, USA, 2–7 June 2019; pp. 3036–3046. [Google Scholar]
- Vinyals, O.; Fortunato, M.; Jaitly, N. Pointer Networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 2692–2700. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. In Proceedings of the International Conference on Learning Representations 2015 (ICLR 2015), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global Vectors for Word Representation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Park, S.; Jang, Y.; Park, K.; Kim, H. Named Entity Recognizer Using Gloval Vector and Convolutional Neural Network Embedding. J. KITI Telecommun. Inf. 2018, 22, 30–32. (In Korean) [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention All You Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- ACE 2005 Multilingual Training Corpus. Available online: https://catalog.ldc.upenn.edu/LDC2006T06 (accessed on 31 May 2020).
- Ren, X.; Wu, Z.; He, W.; Qu, M.; Voss, C.R.; Ji, H.; Abdelzaher, T.F.; Han, J. Cotype: Joint Extraction of Typed Entities and Relations with Knowledge Bases. In Proceedings of the International World Wide Web Conference, Perth, Australia, 3–7 April 2017; pp. 1015–1024. [Google Scholar]
- Zheng, S.; Wang, F.; Bao, H.; Hao, Y.; Zhou, P.; Xu, B. Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1227–1236. [Google Scholar]
- Seo, M.; Kembhavi, A.; Farhadi, A.; Hajishirz, H. Bi-Directional Attention Flow for Machine Comprehension. In Proceedings of the International Conference on Learning Representations 2017 (ICLR 2017), Toulon, France, 24–26 April 2017. [Google Scholar]
- Gormley, M.R.; Yu, M.; Dredze, M. Improved Relation Extraction with Feature-Rich Compositional Embedding Models. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1774–1784. [Google Scholar]
- Dixit, K.; Onaizan, Y.A. Span-Level Model for Relation Extraction. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 5308–5314. [Google Scholar]
- Kim, S.; Choi, S. Relation Extraction using Hybrid Convolutional and Recurrent Networks. In Proceedings of the Korea Computer Congress 2018 (KCC 2018), Jeju, Korea, 20–22 June 2018; pp. 619–621. (In Korean). [Google Scholar]
- Christopoulou, F.; Miwa, M.; Ananiadou1, S. A Walk-based Model on Entity Graphs for Relation Extraction. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; pp. 81–88. [Google Scholar]
- Fu, T.J.; Li, P.H.; Ma, W.Y. GraphRel: Modeling Text as Relational Graphs for Joint Entity and Relation Extraction. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 1409–1418. [Google Scholar]
- Kipf, T.; Welling, M. Semisupervised Classification with Graph Convolutional Networks. In Proceedings of the International Conference on Learning Representations 2017 (ICLR 2017), Toulon, France, 24–26 April 2017. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the North American Chapter of the Association for Computational Linguistics on Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # of entities per sentence (avg/max) | 3.5/22 |
| # of triples per sentence (avg/max) | 1.5/11 |
| # of entity types | 7 |
| # of relation types | 7 |
| # of entities per sentence (avg/max) | 3.2/20 |
| # of triples per sentence (avg/max) | 1.7/26 |
| # of entity types | 3 |
| # of relation types | 25 |
| Dataset | Sentence | Triple |
|---|---|---|
| ACE-2005 | Do you travel to meet up with family or friends during the holidays? | {you, PER-SOC, family}, {you, PER-SOC, friends} |
| NYT | Clarence Charles Newcomer was born on Jan. 18, 1923, in the Lancaster County town of Mount Joy, Pa. | {Lancaster County,/location/location/contains, Mount Joy}, {Clarence Charles Newcomer,/people/person/place_of_birth, Mount Joy} |
| Model | Recall | Precision | F1-Score |
|---|---|---|---|
| Single-head | 0.800 | 0.759 | 0.779 |
| Multi-head | 0.832 | 0.787 | 0.808 |
| Model | Recall | Precision | F1-Score |
|---|---|---|---|
| BIDAF-C2Q | 0.819 | 0.766 | 0.792 |
| BIDAF-C2Q&Q2C | 0.821 | 0.792 | 0.806 |
| Multi-head | 0.832 | 0.787 | 0.808 |
| Model | Recall | Precision | F1-Score |
|---|---|---|---|
| SPTree [6] | 0.54 | 0.57 | 0.56 |
| FCM [19] | 0.49 | 0.72 | 0.58 |
| DYGIE [9] | 0.57 | 0.64 | 0.60 |
| Span-Level [20] | 0.58 | 0.68 | 0.63 |
| HRCNN [21] | - | - | 0.74 |
| Walk-Based [22] | 0.60 | 0.70 | 0.64 |
| Our model | 0.83 | 0.79 | 0.81 |
| Model | Recall | Precision | F1-Score |
|---|---|---|---|
| NovelTag [17] | 0.414 | 0.615 | 0.495 |
| MultiDecoder [2] | 0.566 | 0.610 | 0.587 |
| GraphRE [23] | 0.600 | 0.639 | 0.619 |
| Our model | 0.820 | 0.749 | 0.783 |
| Input Sentence | Correct Relation | Predicted Relation |
|---|---|---|
| Iraqi forces responded with artillery fire | {Iraqi forces, ART, artillery} {Iraqi forces, GEN-AFF, Iraqi} | {Iraqi forces, PART-WHOLE, Iraqi} {Iraqi forces, GEN-AFF, Iraqi} |
| It is the first time they have had freedom of movement with cars and weapons since the start of the intifada | {they, ART, cars} {they, ART, weapons} | {they, ART, cars} |
| It was in northern Iraq today that an eight artillery round hit the site occupied by Kurdish fighters near Chamchamal | {Kurdish fighters, PHYS, the site} {the site, PHYS, Chamchamal} {Kurdish, GEN-AFF, Kurdish fighters} {the site, PART-WHOLE, northern Iraq} | {Kurdish fighters, PHYS, the site} {the site, PHYS, Chamchamal} {the site, PART-WHOLE, northern Iraq} {Kurdish fighters, ART, artillery} |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, S.; Kim, H. Dual Pointer Network for Fast Extraction of Multiple Relations in a Sentence. Appl. Sci. 2020, 10, 3851. https://doi.org/10.3390/app10113851
Park S, Kim H. Dual Pointer Network for Fast Extraction of Multiple Relations in a Sentence. Applied Sciences. 2020; 10(11):3851. https://doi.org/10.3390/app10113851
Chicago/Turabian StylePark, Seongsik, and Harksoo Kim. 2020. "Dual Pointer Network for Fast Extraction of Multiple Relations in a Sentence" Applied Sciences 10, no. 11: 3851. https://doi.org/10.3390/app10113851
APA StylePark, S., & Kim, H. (2020). Dual Pointer Network for Fast Extraction of Multiple Relations in a Sentence. Applied Sciences, 10(11), 3851. https://doi.org/10.3390/app10113851