Active Contours in the Complex Domain for Salient Object Detection


Abstract
1. Introduction
- An important consideration is that the proposed algorithm can assist as a smooth-edge detector that draws strong edges and helps to preserve edges. This is beneficial in the implementation of the edge sensitivity contour method.
- Initialization is a critical step that significantly influences the final performance. In a complex domain, the initialization process is seamlessly carried out, which is most suitable for salient object detection.
- In practice, the reinitialization process can be quite complex and costly and have side effects. Our algorithm eliminates reinitialization.
- The proposed ACCD_SOD algorithm has been applied to both simulated and real images and outputs precise results. In particular, it appears to perform robustly when there are weak boundaries.
- The complex force function has a relatively extensive capture range and accommodates small concavities.
- The parameter setting process plays an important role in the ultimate result of ACMs and it can produce a great performance improvement if the proper parameters are given to an active contour model. Our model uses a fixed parameter and it shows good performance when compared to state-of-the-art models.
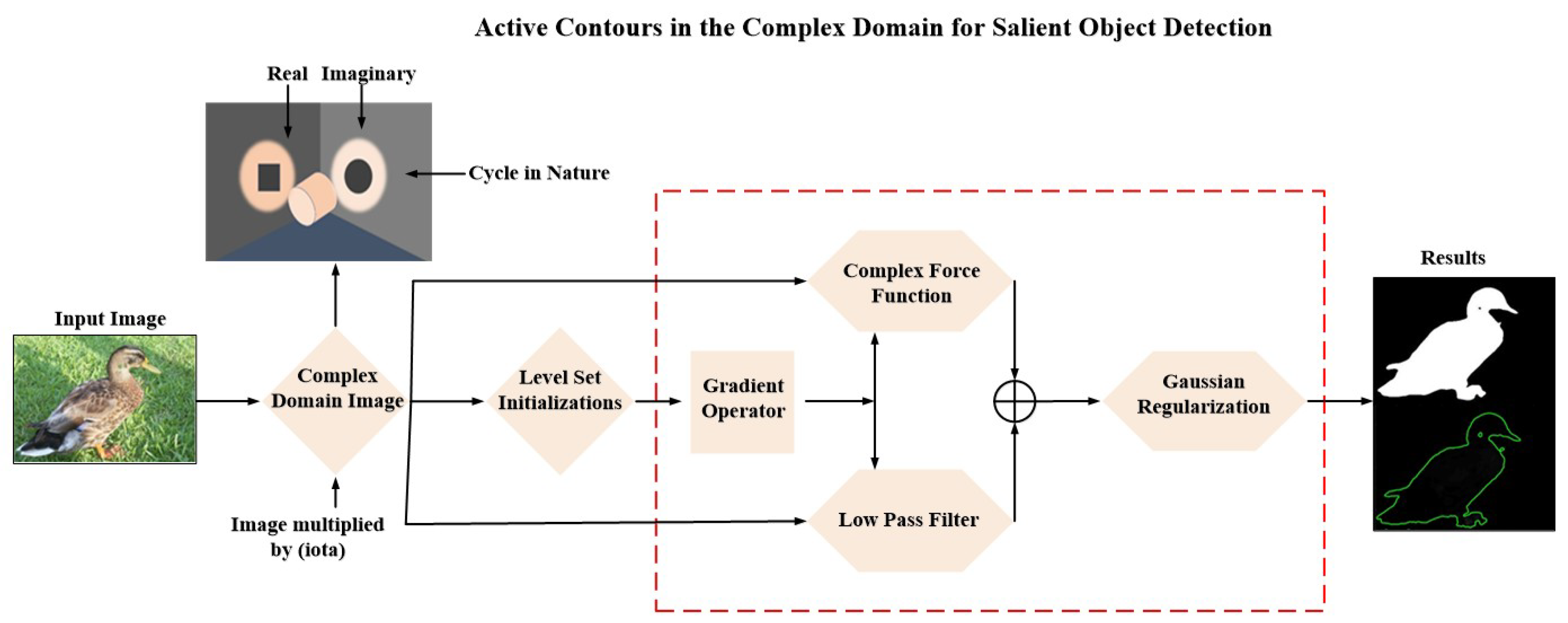
- First, we convert the image to the complex domain. The complex transformation provides salience cues. Salience detection serves as the initialization for our active contour model, which quickly converges to the edge structure of the input image.
- We then use a low-pass filter in the complex domain to discover the objects of interest, which serves as the initialization step and eliminates reinitialization.
- Subsequently, we define a force function in the complex domain, resulting in a complex-force function, which is used to distinguish the object from the background for the active contour.
- Finally, we combine salient object discovery and the complex force and implement the active contours in the complex domain for salient object detection.
2. Related Work
2.1. Geodesic Active Contour (GAC) Model
2.2. Chan-Vese Model
2.3. Active Contours with Selective Local or Global Segmentation (ACSLGS)
3. Proposed Method
3.1. Complex Domain Transformation
3.2. Low-Pass Filter
3.3. Complex Force Function
| Algorithm 1. Steps for our proposed algorithm active contours in the complex domain for salient object detection (ACCD_SOD) |
| Input: Reading in an image. Image transformation: 1: Transformation of original image into complex domain according to (16); Initialization: 2: Initialize contour according to (23); if ; otherwise ; 3: Initialize the related parameters α = 0.4, σ = 4 and ; set n = 0; Repeat: 4: While n < iteration, do 5: Compute low-pass filter with Equation (21); 6: Compute complex force function with Equation (22); 7: Update the level-set function according to Equation (23); 8: n = n + 1; end 9: If converge, end 10: Compute Gaussian filter for regularization according to Equation (2); 11: end 12: Output: The resultant salient object . |
4. Experiment Analysis and Results
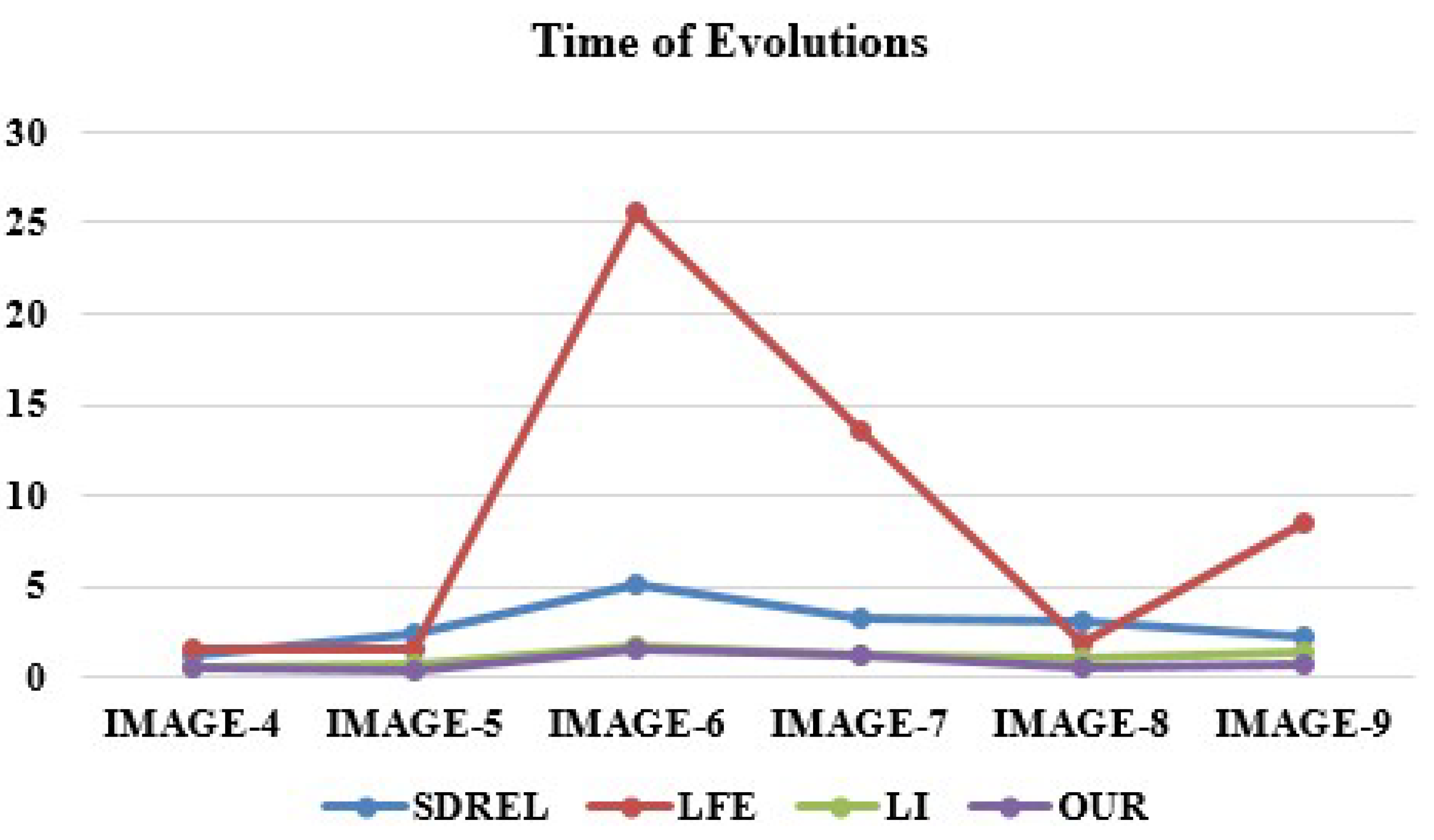
4.1. Computational Efficiency
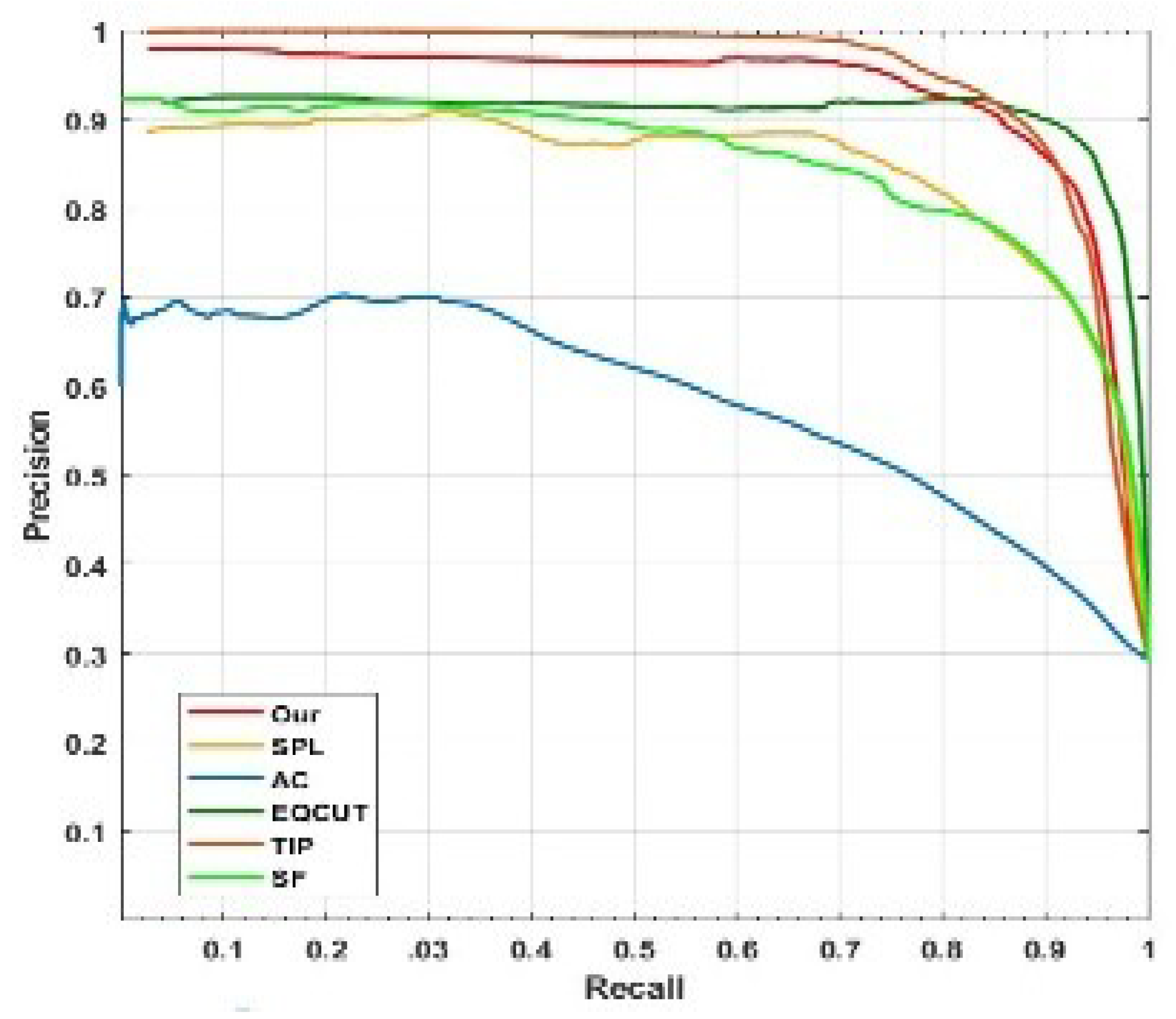
4.2. Comparison with Recent State-of-the-Art Models for Active Contours
4.3. Comparison with Recent Models without Active Contour
4.4. Discussion
5. Conclusions and Future Research
Author Contributions
Funding
Conflicts of Interest
References
- Gong, M.; Qian, Y.; Cheng, L. Integrated Foreground Segmentation and Boundary Matting for Live Videos. IEEE Trans. Image Process. 2015, 24, 1356–1370. [Google Scholar] [CrossRef] [PubMed]
- Qian, Y.; Gong, M.; Cheng, L. STOCS: An efficient self-tuning multiclass classification approach. In Applications of Evolutionary Computation; Springer International Publishing: Cham, Switzerland, 2015; Volume 9091, pp. 291–306. [Google Scholar]
- Qian, Y.; Yuan, H.; Gong, M. Budget-driven big data classification. In Applications of Evolutionary Computation; Springer International Publishing: Cham, Switzerland, 2015; Volume 9091, pp. 71–83. [Google Scholar]
- Itti, L.; Koch, C.; Niebur, E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar] [CrossRef]
- Yin, S.; Zhang, Y.; Karim, S. Large scale remote sensing image segmentation based on fuzzy region competition and gaussian mixture model. IEEE Access 2018, 6, 26069–26080. [Google Scholar] [CrossRef]
- Singh, D.; Mohan, C.K. Graph formulation of video activities for abnormal activity recognition. Pattern Recognit. 2017, 65, 265–272. [Google Scholar] [CrossRef]
- Amit, Y. 2D Object Detection and Recognition; MIT Press: Cambridge, MA, USA, 2002. [Google Scholar]
- Shan, X.; Gong, X.; Nandi, A.K. Active contour model based on local intensity fitting energy for image segmentation and bias estimation. IEEE Access 2018, 6, 49817–49827. [Google Scholar] [CrossRef]
- Ammar, A.; Bouattane, O.; Youssfi, M. Review and comparative study of three local based active contours optimizers for image segmentation. In Proceedings of the 2019 5th International Conference on Optimization and Applications (ICOA), Kenitra, Morocco, 25–26 April 2019; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Zhang, K.; Zhang, L.; Lam, K.-M.; Zhang, L. A Level Set Approach to Image Segmentation with Intensity Inhomogeneity. IEEE Trans. Cybern. 2016, 46, 546–557. [Google Scholar] [CrossRef]
- Yu, H.-P.; He, F.; Pan, Y. A novel segmentation model for medical images with intensity inhomogeneity based on adaptive perturbation. Multimedia Tools Appl. 2018, 78, 11779–11798. [Google Scholar] [CrossRef]
- Lopez-Alanis, A.; Lizarraga-Morales, R.A.; Sanchez-Yanez, R.E.; Martinez-Rodriguez, D.E.; Contreras-Cruz, M.A. Visual Saliency Detection Using a Rule-Based Aggregation Approach. Appl. Sci. 2019, 9, 2015. [Google Scholar] [CrossRef]
- Yang, L.; Xin, D.; Zhai, L.; Yuan, F.; Li, X. Active Contours Driven by Visual Saliency Fitting Energy for Image Segmentation in SAR Images. In Proceedings of the 2019 IEEE 4th International Conference on Cloud Computing and Big Data Analysis (ICCCBDA), Chengdu, China, 12–15 April 2019; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2019; pp. 393–397. [Google Scholar]
- Zhu, X.; Xu, X.; Mu, N. Saliency detection based on the combination of high-level knowledge and low-level cues in foggy images. Entropy 2019, 21, 374. [Google Scholar] [CrossRef]
- Xia, X.; Lin, T.; Chen, Z.; Xu, H. Salient object segmentation based on active contouring. PLoS ONE 2017, 12, e0188118. [Google Scholar] [CrossRef]
- Li, N.; Bi, H.; Zhang, Z.; Kong, X.; Lü, D. Performance comparison of saliency detection. Adv. Multimedia 2018, 2018, 1–13. [Google Scholar] [CrossRef]
- Zhu, G.; Wang, Q.; Yuan, Y. Tag-Saliency: Combining bottom-up and top-down information for saliency detection. Comput. Vis. Image Underst. 2014, 118, 40–49. [Google Scholar] [CrossRef]
- Borji, A.; Sihite, D.N.; Itti, L. Probabilistic learning of task-specific visual attention. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2012; pp. 470–477. [Google Scholar]
- Koch, C.; Ullman, S. Shifts in selective visual attention: Towards the underlying neural circuitry. In Matters of Intelligence; Springer: Dordrecht, The Netherlands, 1987; pp. 115–141. [Google Scholar]
- Ma, Y.-F.; Zhang, H.-J. Contrast-Based Image Attention Analysis by Using Fuzzy Growing. In Proceedings of the eleventh ACM international conference on Multimedia, Berkeley, CA, USA, November 2003; pp. 374–381. [Google Scholar]
- Bruce, N.; Tsotsos, J. Saliency based on information maximization. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2006; pp. 155–162. [Google Scholar]
- Cheng, M.-M.; Mitra, N.J.; Huang, X.; Torr, P.H.S.; Hu, S.-M. Global Contrast Based Salient Region Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 569–582. [Google Scholar] [CrossRef] [PubMed]
- Judd, T.; Ehinger, K.; Durand, F.; Torralba, A. Learning to predict where humans look. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2009; pp. 2106–2113. [Google Scholar]
- Xie, Y.; Lu, H.; Yang, M.-H. Bayesian Saliency via Low and Mid Level Cues. IEEE Trans. Image Process. 2012, 22, 1689–1698. [Google Scholar] [CrossRef] [PubMed]
- Chan, T.; Vese, L. An active contour model without edges. In International Conference on Scale-Space Theories in Computer Vision; Springer: Berlin/Heidelberg, Germany, 1999; pp. 141–151. [Google Scholar]
- Lie, J.; Lysaker, M.; Tai, X.-C. A binary level set model and some applications to Mumford-Shah image segmentation. IEEE Trans. Image Process. 2006, 15, 1171–1181. [Google Scholar] [CrossRef] [PubMed]
- Ronfard, R. Region-based strategies for active contour models. Int. J. Comput. Vis. 1994, 13, 229–251. [Google Scholar] [CrossRef]
- Samson, C.; Blanc-Feraud, L.; Aubert, G.; Zerubia, J. A variational model for image classification and restoration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 460–472. [Google Scholar] [CrossRef]
- Chan, T.F.; Vese, L. Active contours without edges. IEEE Trans. Image Process. 2001, 10, 266–277. [Google Scholar] [CrossRef]
- Xu, J.; Wang, H.; Cui, C.; Liu, P.; Zhao, Y.; Li, B. Oil spill segmentation in ship-borne radar images with an improved active contour model. Remote. Sens. 2019, 11, 1698. [Google Scholar] [CrossRef]
- Wu, H.; Liu, L.; Lan, J. 3D flow entropy contour fitting segmentation algorithm based on multi-scale transform contour constraint. Symmetry 2019, 11, 857. [Google Scholar] [CrossRef]
- Fang, J.; Liu, H.; Zhang, L.; Liu, J.; Liu, H. Active contour driven by weighted hybrid signed pressure force for image segmentation. IEEE Access 2019, 7, 97492–97504. [Google Scholar] [CrossRef]
- Wong, O.Q.; Rajendran, P. Image Segmentation using Modified Region-Based Active Contour Model. J. Eng. Appl. Sci. 2019, 14, 5710–5718. [Google Scholar]
- Li, Y.; Cao, G.; Wang, T.; Cui, Q.; Wang, B. A novel local region-based active contour model for image segmentation using Bayes theorem. Inf. Sci. 2020, 506, 443–456. [Google Scholar] [CrossRef]
- Kimmel, R.; Amir, A.; Bruckstein, A. Finding shortest paths on surfaces using level sets propagation. IEEE Trans. Pattern Anal. Mach. Intell. 1995, 17, 635–640. [Google Scholar] [CrossRef]
- Caselles, V.; Kimmel, R.; Sapiro, G. Geodesic active contours. Int. J. Comput. Vis. 1997, 22, 61–79. [Google Scholar] [CrossRef]
- Vese, L.; Chan, T.F. A multiphase level set framework for image segmentation using the mumford and shah model. Int. J. Comput. Vis. 2002, 50, 271–293. [Google Scholar] [CrossRef]
- Li, C.; Kao, C.-Y.; Gore, J.C.; Ding, Z. Implicit Active Contours Driven by Local Binary Fitting Energy. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2007; pp. 1–7. [Google Scholar]
- Li, C.; Xu, C.; Gui, C.; Fox, M.D. Distance regularized level set evolution and its application to image segmentation. IEEE Trans. Image Process. 2010, 19, 3243–3254. [Google Scholar] [CrossRef]
- Zhang, K.; Song, H.; Zhang, K. Active contours driven by local image fitting energy. Pattern Recognit. 2010, 43, 1199–1206. [Google Scholar] [CrossRef]
- Zhang, K.; Zhang, K.; Song, H.; Zhou, W. Active contours with selective local or global segmentation: A new formulation and level set method. Image Vis. Comput. 2010, 28, 668–676. [Google Scholar] [CrossRef]
- Gobbino, M. Finite difference approximation of the Mumford-Shah functional. Courant Inst. Math. Sci. 1998, 51, 197–228. [Google Scholar] [CrossRef]
- Osher, S.; Fedkiw, R.; Piechor, K. Level set methods and dynamic implicit surfaces. Appl. Mech. Rev. 2004, 57, B15. [Google Scholar] [CrossRef]
- Schrödinger, E. Energieaustausch nach der Wellenmechanik. Ann. der Phys. 1927, 388, 956–968. [Google Scholar] [CrossRef]
- Cross, M.C.; Hohenberg, P.C. Pattern formation outside of equilibrium. Rev. Mod. Phys. 1993, 65, 851–1112. [Google Scholar] [CrossRef]
- Newell, A.C. Nonlinear wave motion. LApM 1974, 15, 143–156. [Google Scholar]
- Tanguay, P.N. Quantum wave function realism, time, and the imaginary unit i. Phys. Essays 2015. [Google Scholar] [CrossRef]
- Gilboa, G.; Sochen, N.; Zeevi, Y. Image enhancement and denoising by complex diffusion processes. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 1020–1036. [Google Scholar] [CrossRef]
- Hussain, S.; Khan, M.S.; Asif, M.R.; Chun, Q. Active contours for image segmentation using complex domain-based approach. IET Image Process. 2016, 10, 121–129. [Google Scholar] [CrossRef]
- Zhi, X.-H.; Shen, H.-B. Saliency driven region-edge-based top down level set evolution reveals the asynchronous focus in image segmentation. Pattern Recognit. 2018, 80, 241–255. [Google Scholar] [CrossRef]
- Lankton, S.; Tannenbaum, A. Localizing region-based active contours. IEEE Trans. Image Process. 2008, 17, 2029–2039. [Google Scholar] [CrossRef]
- Li, C.; Kao, C.-Y.; Gore, J.C.; Ding, Z. Minimization of region-scalable fitting energy for image segmentation. IEEE Trans. Image Process. 2008, 17, 1940–1949. [Google Scholar] [CrossRef]
- Shi, J.; Yan, Q.; Xu, L.; Jia, J. Hierarchical image saliency detection on extended cssd. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 717–729. [Google Scholar] [CrossRef] [PubMed]
- Rand, W.M. Objective criteria for the evaluation of clustering methods. J. Am. Stat. Assoc. 1971, 66, 846–850. [Google Scholar] [CrossRef]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A Database of Human Segmented Natural Images and Its Application to Evaluating Segmentation Algorithms and Measuring Ecological Statistics. In Proceedings of the Eighth IEEE International Conference on Computer Vision, Vancouver, BC, Canada, 7–14 July 2001. [Google Scholar]
- Fu, K.; Gong, C.; Gu, I.Y.-H.; Yang, J. Normalized cut-based saliency detection by adaptive multi-level region merging. IEEE Trans. Image Process. 2015, 24, 5671–5683. [Google Scholar] [CrossRef] [PubMed]
- Aytekin, Ç.; Ozan, E.C.; Kiranyaz, S.; Gabbouj, M. Visual saliency by extended quantum cuts. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 1692–1696. [Google Scholar]
- Goferman, S.; Zelnik-Manor, L.; Tal, A. Context-aware saliency detection. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 1915–1926. [Google Scholar] [CrossRef]
- Achanta, R.; Susstrunk, S. Saliency detection using maximum symmetric surround. In Proceedings of the 2010 IEEE International Conference on Image Processing, Hong Kong, China, 26–29 September 2010; pp. 2653–2656. [Google Scholar]
- Perazzi, F.; Krähenbühl, P.; Pritch, Y.; Hornung, A. Saliency filters: Contrast based filtering for salient region detection. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2012; pp. 733–740. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| METHOD. | RI | GCE | VOI | F-M |
|---|---|---|---|---|
| SDREL | 0.616 | 0.255 | 1.631 | 0.612 |
| RBS | 0.600 | 0.203 | 1.729 | 0.607 |
| CV | 0.603 | 0.199 | 1.958 | 0.567 |
| Ll | 0.570 | 0.215 | 1.631 | 0.353 |
| DRLSE | 0.535 | 0.277 | 1.568 | 0.599 |
| OUR | 0.6219 | 0.185 | 1.546 | 0.634 |
| Method | TIP | EQCUT | CA | AC | SF | Ours |
|---|---|---|---|---|---|---|
| Time (seconds) | 2.6 | 0.852 | 64.313 | 20.13 | 0.458 | 0.519 |
| Code | MATLAB | MATLAB | MATLAB | C++ | C++ | MATLAB |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, U.S.; Zhang, X.; Su, Y. Active Contours in the Complex Domain for Salient Object Detection. Appl. Sci. 2020, 10, 3845. https://doi.org/10.3390/app10113845
Khan US, Zhang X, Su Y. Active Contours in the Complex Domain for Salient Object Detection. Applied Sciences. 2020; 10(11):3845. https://doi.org/10.3390/app10113845
Chicago/Turabian StyleKhan, Umer Sadiq, Xingjun Zhang, and Yuanqi Su. 2020. "Active Contours in the Complex Domain for Salient Object Detection" Applied Sciences 10, no. 11: 3845. https://doi.org/10.3390/app10113845
APA StyleKhan, U. S., Zhang, X., & Su, Y. (2020). Active Contours in the Complex Domain for Salient Object Detection. Applied Sciences, 10(11), 3845. https://doi.org/10.3390/app10113845