Evaluating the Performance of Individual and Novel Ensemble of Machine Learning and Statistical Models for Landslide Susceptibility Assessment at Rudraprayag District of Garhwal Himalaya

 , ,
, ,  and
and
Abstract
1. Introduction
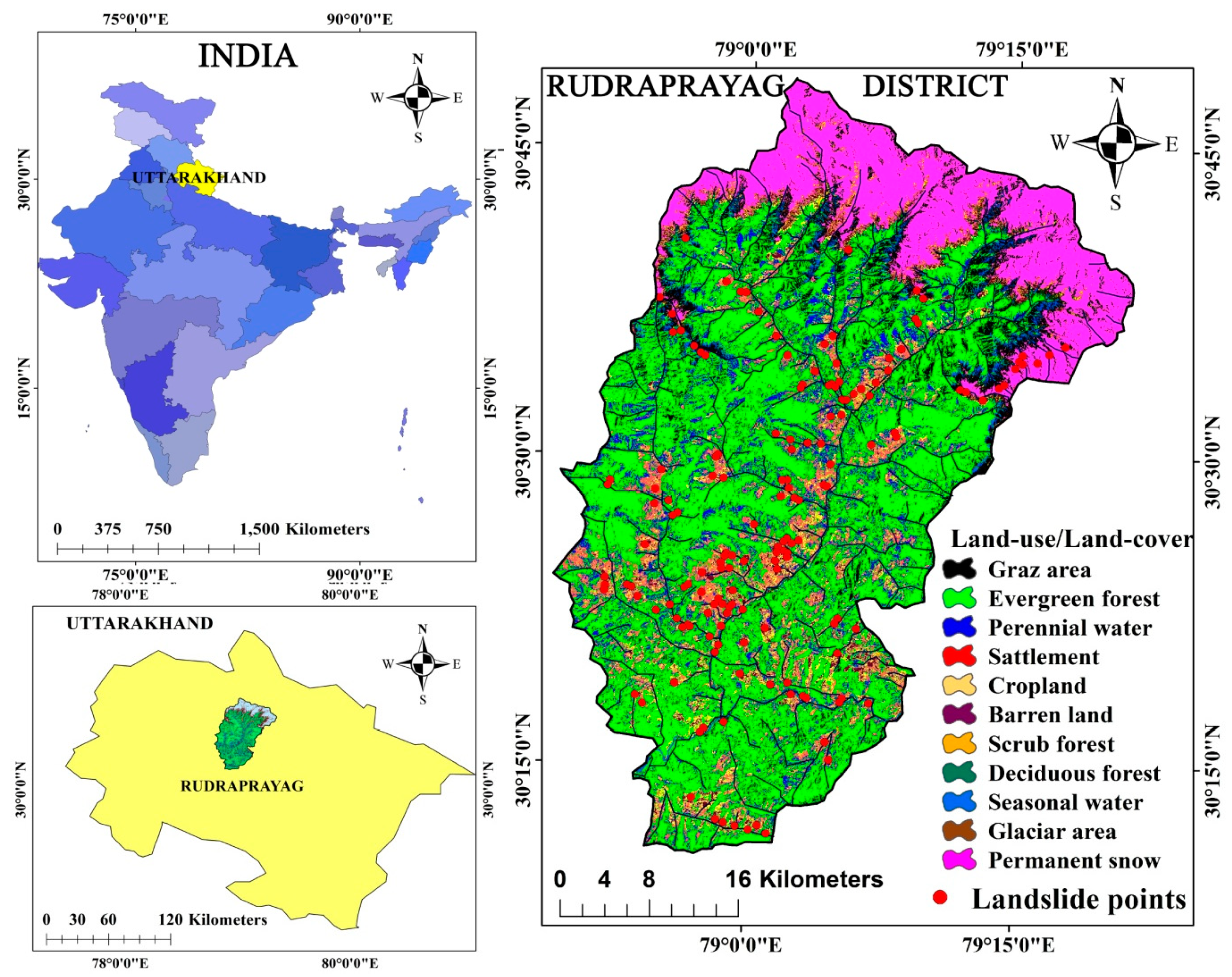
2. Study Area
3. Materials Used
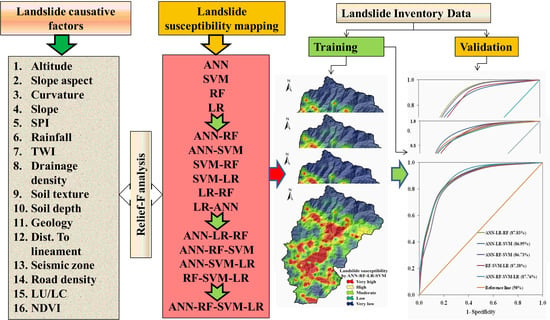
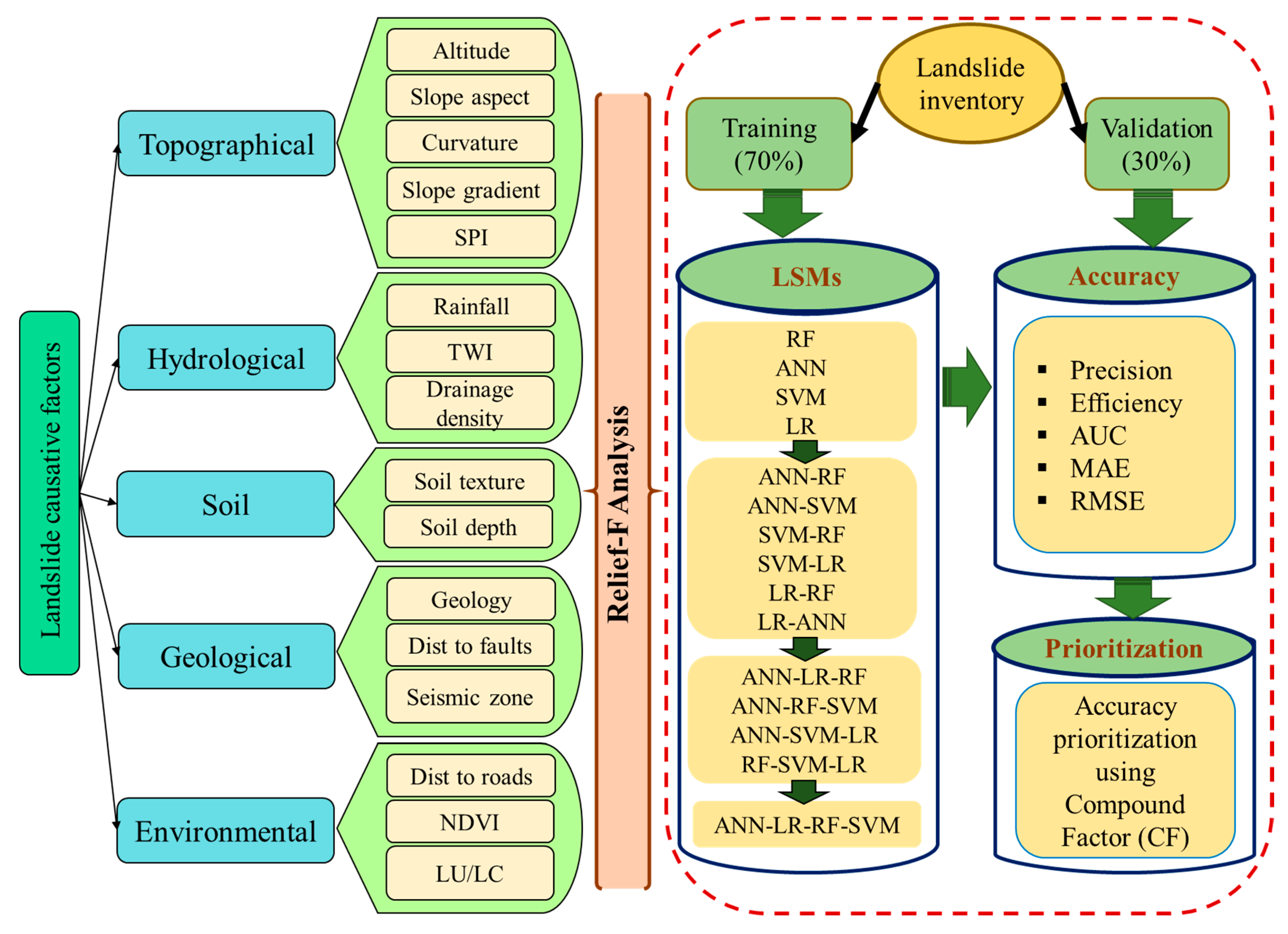
4. Methodology
- (i)
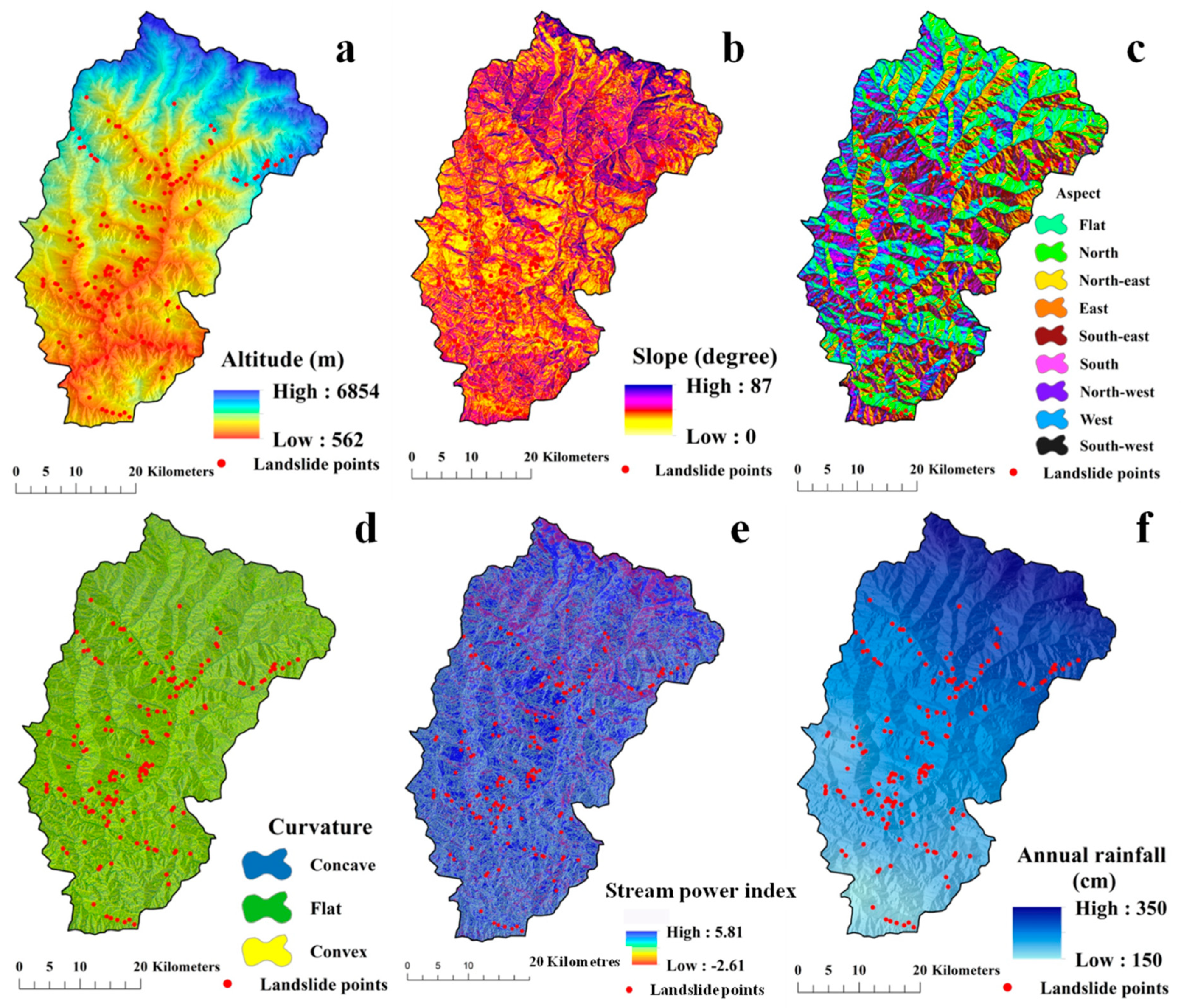
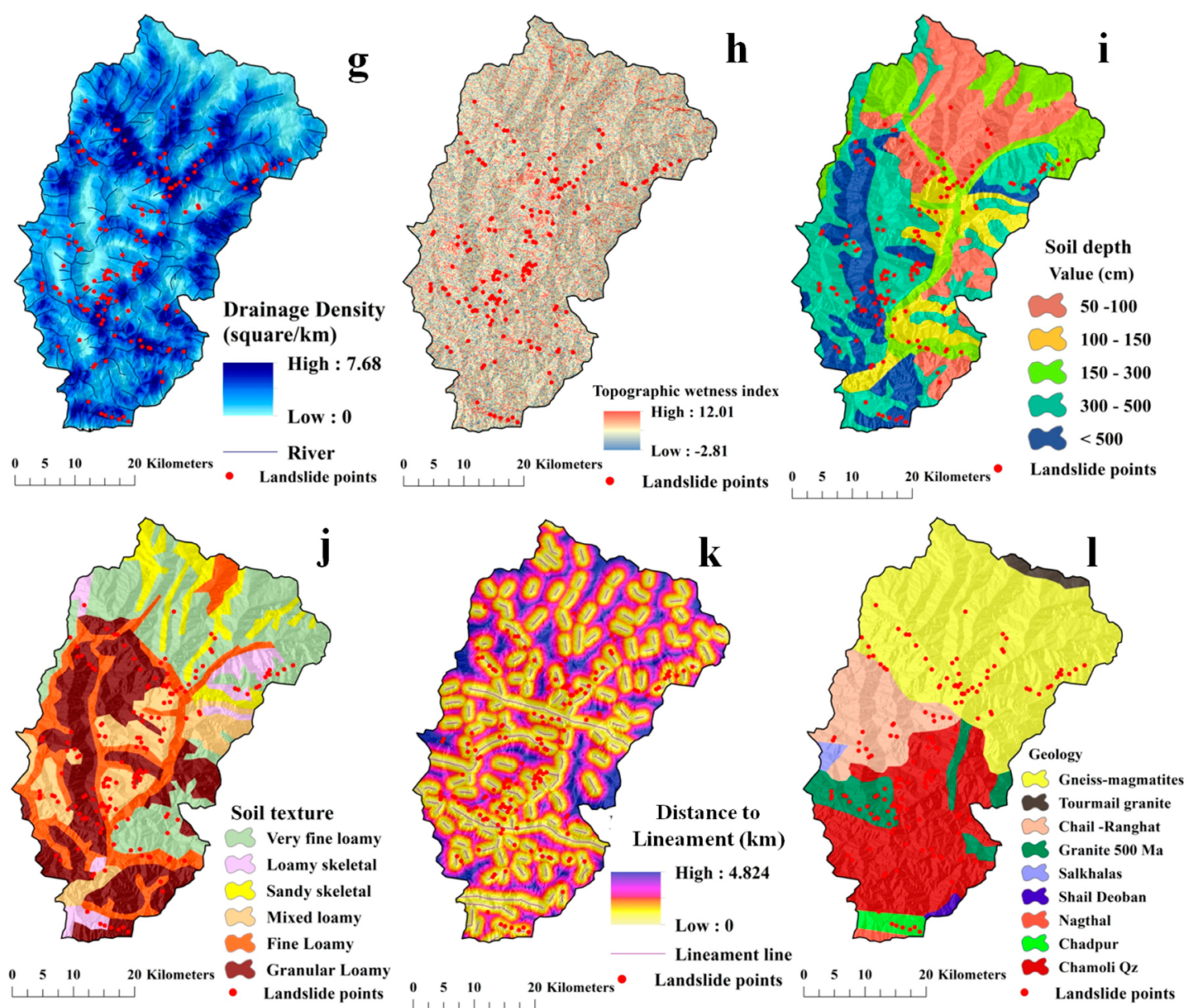
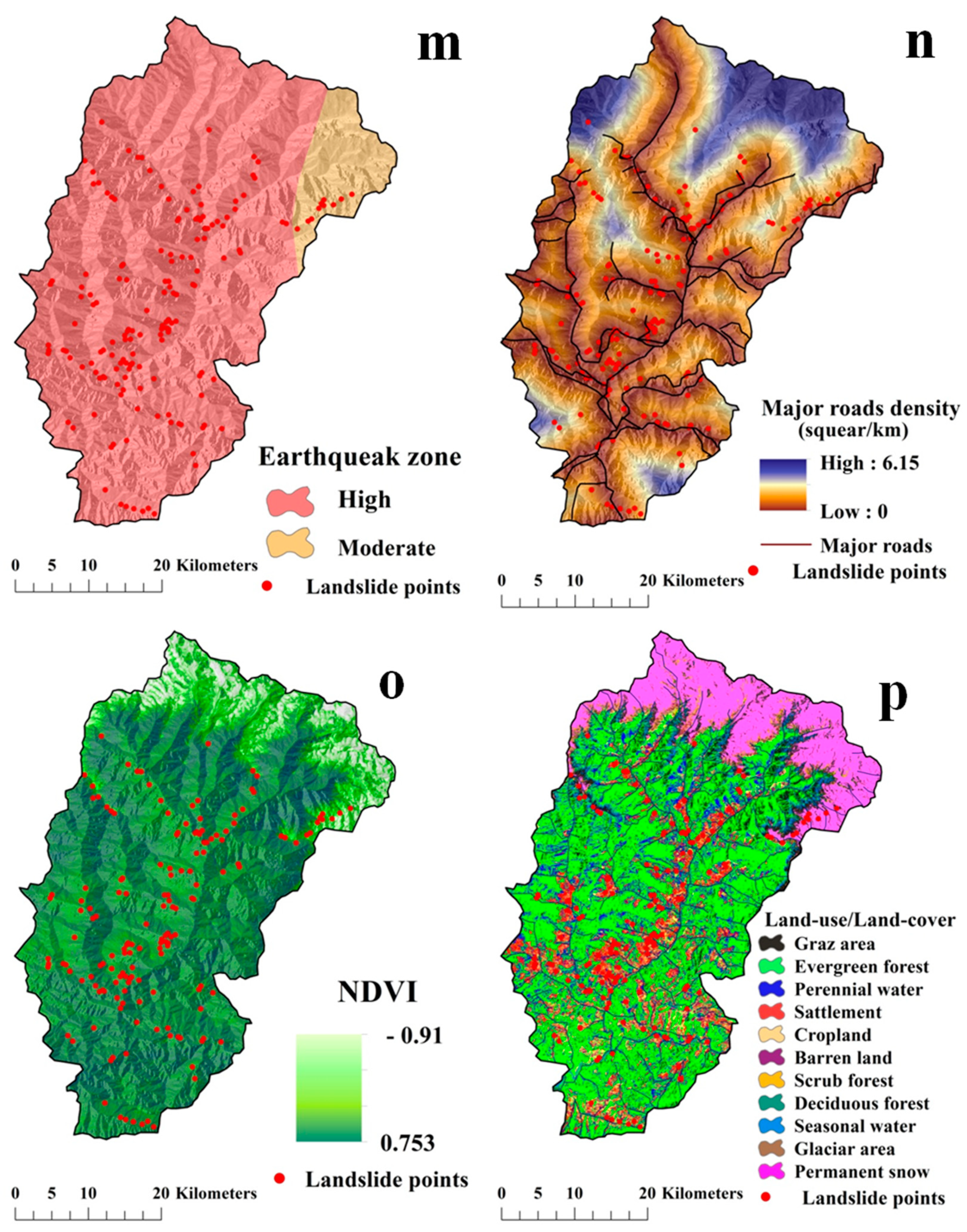
- A total of 223 landslide locations were identified using the high-resolution Google earth images and afterward these locations were verified through field investigation with a global positioning system (GPS) which was conducted during April 2018 and September 2019. The same number of non landslide points as landslide locations were taken randomly for training the models. The 16 environmental factors were considered for modeling (Table 1).
- (ii)
- Relief-F technique was used to judge the effectiveness of the landslide conditioning factors (LCFs) for LSS mapping.
- (iii)
- LSS maps first were prepared using ANN, SVM, LR, and RF models. The ensemble models were prepared combining the two, three and four models subsequently.
- (iv)
- The contribution of the LCFs was assessed using the random forest (RF) model,
- (v)
- The LSS model’s performances were evaluated through the area under receiver operating characteristic curve (AUCROC), precision, accuracy, mean-absolute-error (MAE), and root-mean-square-error (RMSE).
- (vi)
- Finally, compound factor (CF) method was used to choose the best model.
4.1. Generation of Landslide Inventory (GLI)
4.2. Relief-F Method
4.3. Preparation of the Landslide Causative Factors (LCFs)
4.4. Methods of Landslide Modeling
4.4.1. RF Model
4.4.2. ANN
4.4.3. SVM
4.4.4. Logistic Regression (LR)
4.5. Ensemble of Models
4.6. Validation Techniques
4.6.1. Discrimination Accuracy Measures
4.6.2. Reliability Accuracy Measures
4.6.3. Model Prioritization Using Compound Factor
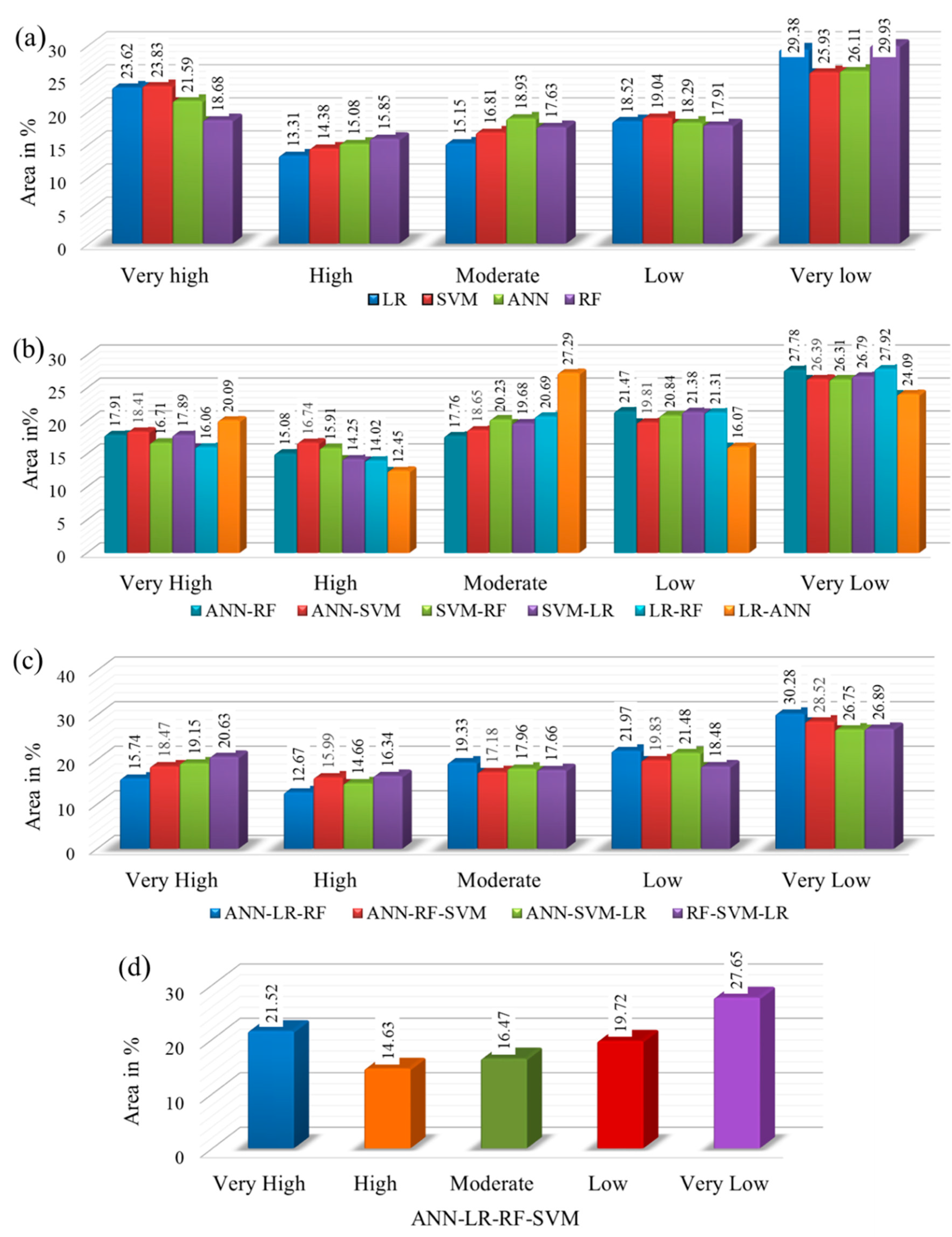
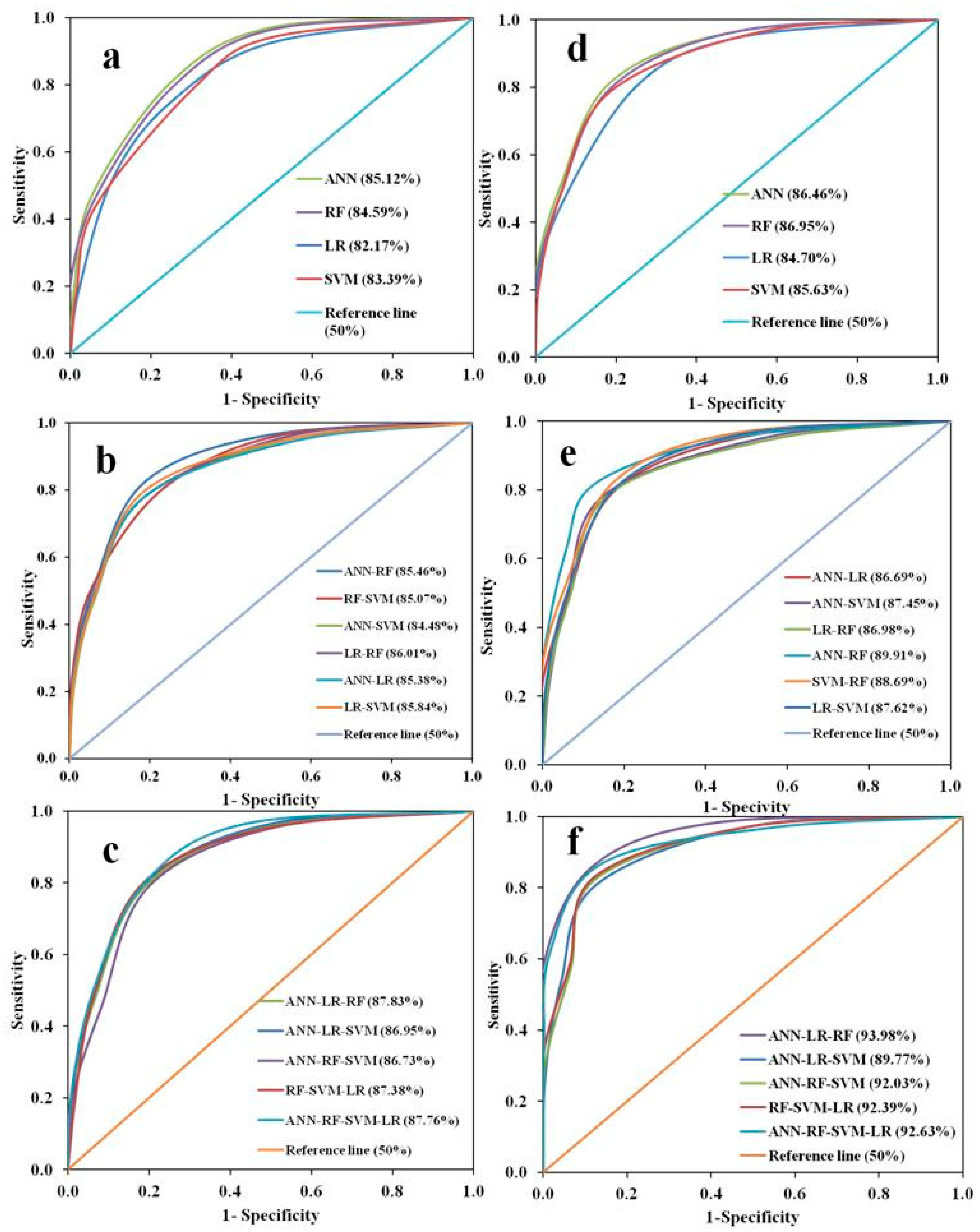
5. Results
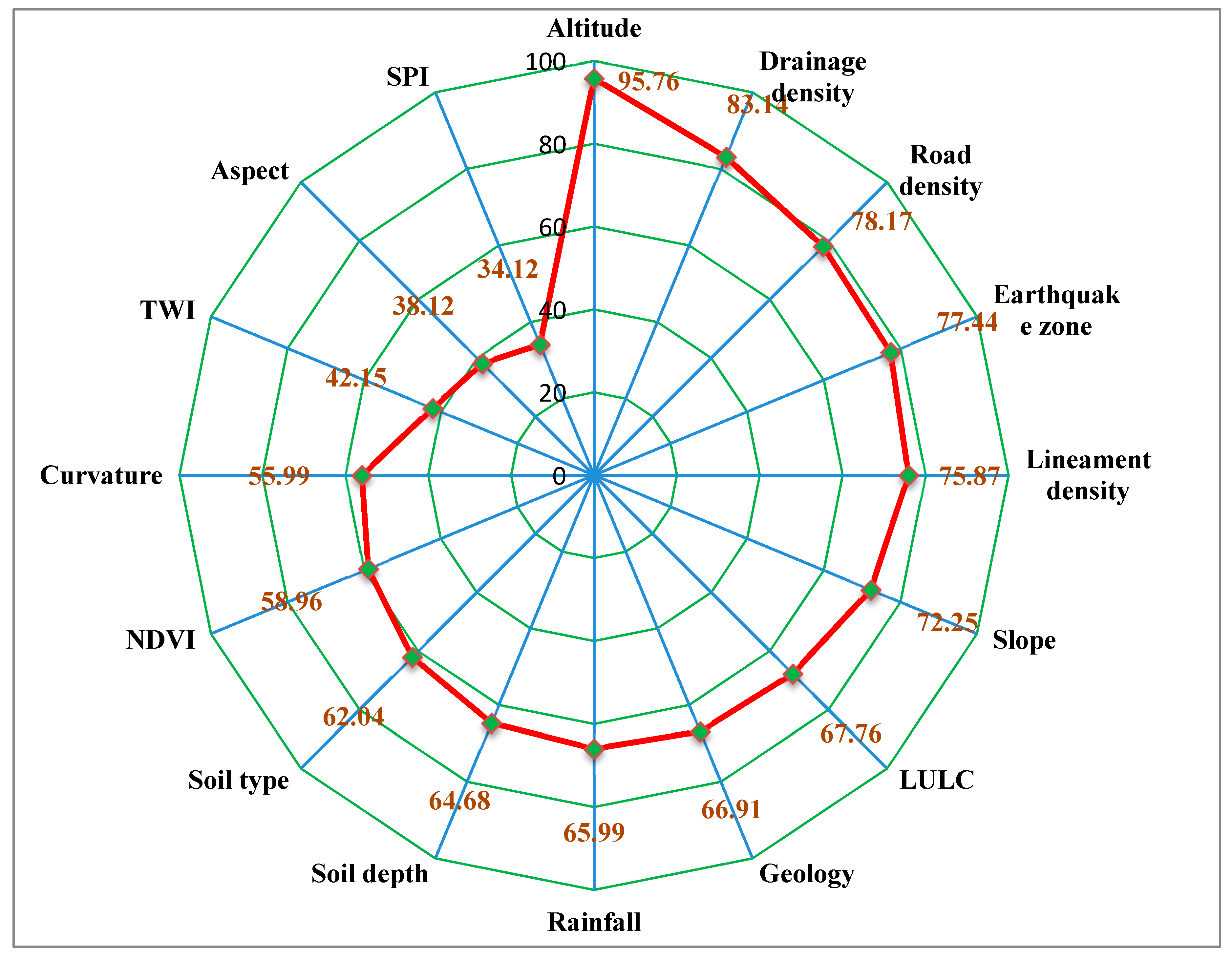
5.1. Result of Relief-F Analysis
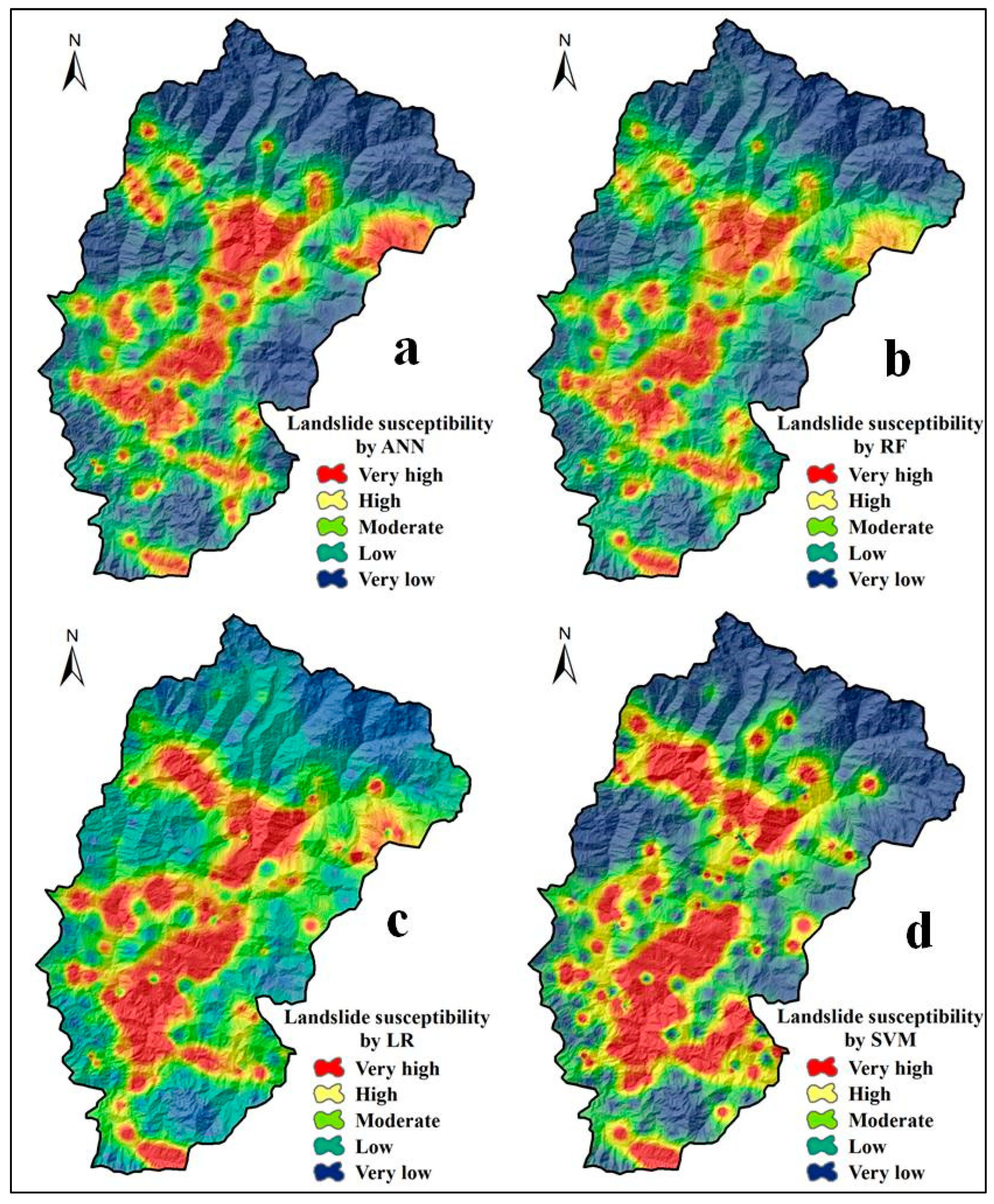
5.2. LSMs by Individual Models
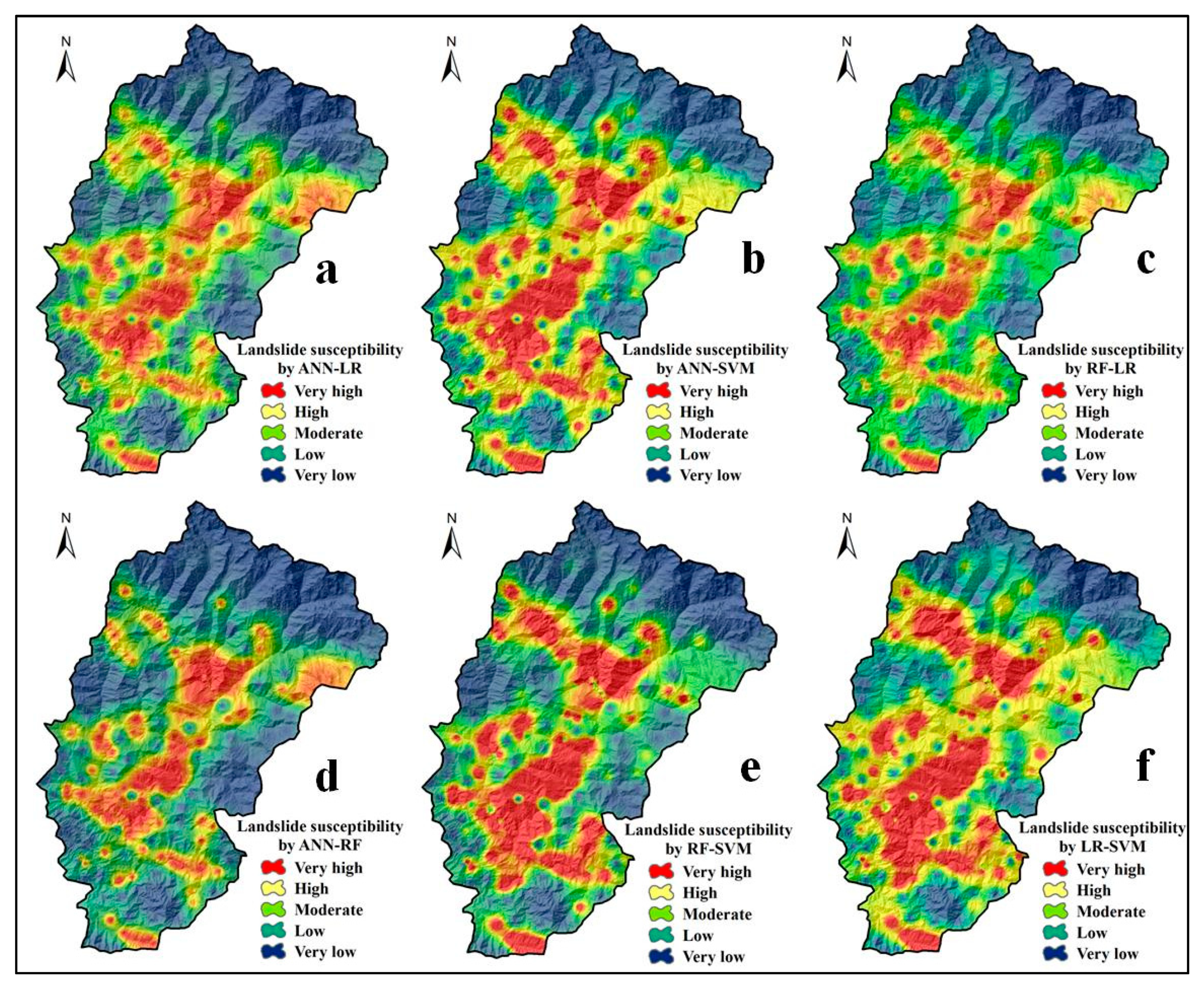
5.3. LSMs by Two Ensemble Models
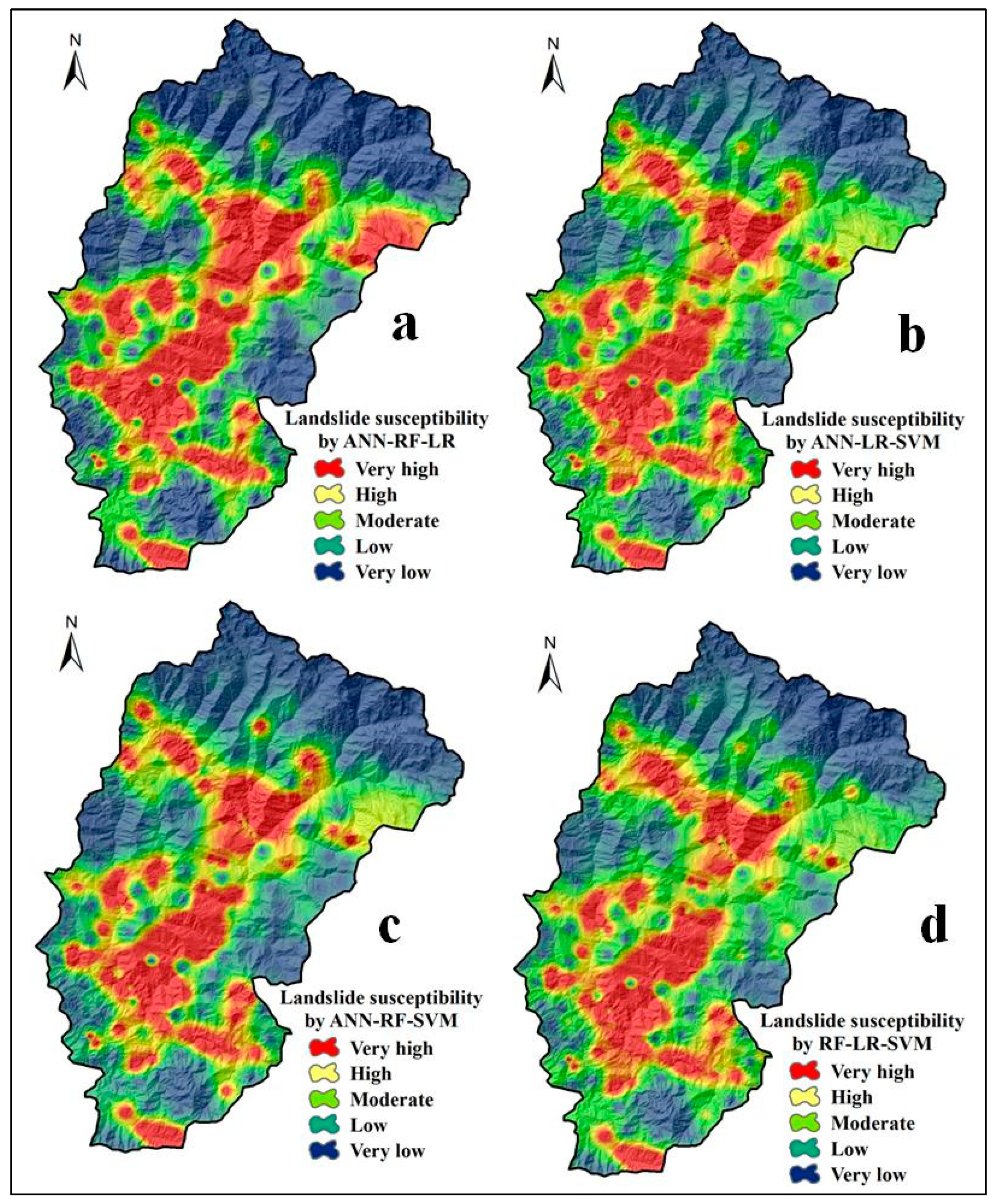
5.4. LSMs by Ensemble of Three-Models
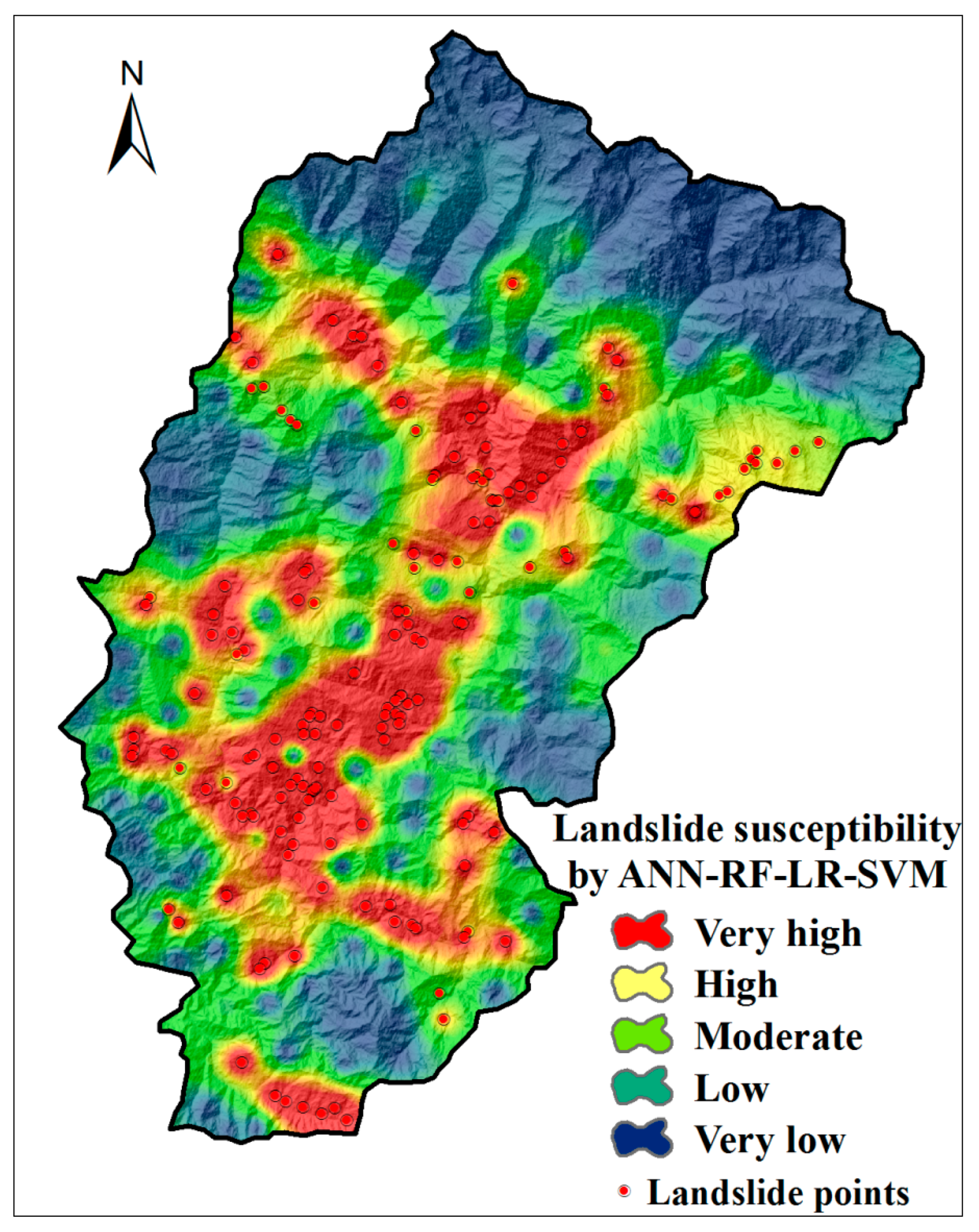
5.5. LSMs by Ensemble of Four-Models
5.6. Results of the Validation Techniques
5.7. Result of Variable Importance Analysis
6. Discussion
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- IAEG Commission on Landslides. Suggested nomenclature for landslides. Bull. Int. Assoc. Eng. Geol. 1990, 41, 3–16. [Google Scholar]
- Nadim, F.; Kjekstad, O.; Peduzzi, P. Global landslide and avalanche hotspots. Landslides 2006, 3, 159–173. [Google Scholar] [CrossRef]
- Geertsema, M.; Highland, L.; Vaugeouis, L. Environmental impact of landslides. In Landslides–Disaster Risk Reduction; Springer: Berlin, Germany, 2009; pp. 589–607. [Google Scholar]
- Faiz, M.A.; Liu, D.; Fu, Q.; Sun, Q.; Li, M.; Baig, F.; Li, T.; Cui, S. How accurate are the performances of gridded precipitation data products over Northeast China? Atmos. Res. 2018, 211, 12–20. [Google Scholar]
- Raman, R.; Punia, M. The application of GIS-based bivariate statistical methods for landslide hazards assessment in the upper Tons river valley, Western Himalaya, India. Georisk: Assess. Manag. Risk Eng. Syst. Geohazards 2012, 6, 145–161. [Google Scholar]
- Ray, P.C.; Parvaiz, I.; Jayangondaperumal, R.; Thakur, V.C.; Dadhwal, V.K.; Bhat, F.A. Analysis of seismicity-induced landslides due to the 8 October 2005 earthquake in Kashmir Himalaya. Curr. Sci. 2009, 25, 1742–1751. [Google Scholar]
- Ghosh, S.; Chakraborty, I.; Bhattacharya, D. Generating field-based inventory of earthquake-induced landslides in the Himalayas—An aftermath of the 18 September 2011 Sikkim earthquake. Indian J. Geosci. 2012, 66, 27–38. [Google Scholar]
- Maheshwari, B.K. Earthquake-induced landslide hazard assessment of chamoli district, uttarakhand using relative frequency ratio method. Indian Geotech. J. 2019, 49, 108–123. [Google Scholar] [CrossRef]
- Moreiras, S.M. Landslide susceptibility zonation in the Rio Mendoza Valley, Argentina. Geomorphology 2005, 66, 345–357. [Google Scholar]
- Wadhawan, S.K. Landslide susceptibility mapping, vulnerability and risk assessment for development of early warning systems in India. In Landslides: Theory, Practice and Modelling; Springer: Cham, Switzerland, 2019; pp. 145–172. [Google Scholar]
- Choi, J.; Oh, H.J.; Lee, H.J.; Lee, C.; Lee, S. Combining landslide susceptibility maps obtained from frequency ratio, logistic regression, and artificial neural network models using ASTER images and GIS. Eng. Geol. 2011, 124, 12–23. [Google Scholar] [CrossRef]
- Youssef, A.M.; Pradhan, B.; Jebur, M.N.; El-Harbi, H.M. Landslide susceptibility mapping using ensemble bivariate and multivariate statistical models in Fayfa area, Saudi Arabia. Environ. Earth Sci. 2014, 73, 3745–3761. [Google Scholar]
- Chen, W.; Pourghasemi, H.R.; Zhao, Z. A GIS-based comparative study of Dempster-Shafer, logistic regression and artificial neural network models for landslide susceptibility mapping. Geocarto Int. 2017, 32, 367–385. [Google Scholar] [CrossRef]
- Pradhan, B. A comparative study on the predictive ability of the decision tree, support vector machine and neuro-fuzzy models in landslide susceptibility mapping using GIS. Comput. Geosci. 2013, 51, 350–365. [Google Scholar] [CrossRef]
- Chen, W.; Xie, X.; Wang, J.; Pradhan, B.; Hong, H.; Bui, D.T.; Duan, Z.; Ma, J. A comparative study of logistic model tree, random forest, and classification and regression tree models for spatial prediction of landslide susceptibility. Catena 2017, 151, 147–160. [Google Scholar] [CrossRef]
- Raja, N.B.; Çiçek, I.; Türkoğlu, N.; Aydin, O.; Kawasaki, A. Landslide susceptibility mapping of the Sera River basin using logistic regression model. Nat. Hazards 2017, 85, 1323–1346. [Google Scholar] [CrossRef]
- Tsangaratos, P.; Ilia, I.; Hong, H.; Chen, W.; Xu, C. Applying information theory and GIS-based quantitative methods to produce landslide susceptibility maps in Nancheng County, China. Landslide 2017, 14, 1091–1111. [Google Scholar]
- Goetz, J.; Brenning, A.; Petschko, H.; Leopold, P. Evaluating machine learning and statistical prediction techniques for landslide susceptibility modeling. Comput. Geosci. 2015, 81, 1–11. [Google Scholar] [CrossRef]
- Hong, H.; Pourghasemi, H.R.; Pourtaghi, Z.S. Landslide susceptibility assessment in Lianhua County (China): A comparison between a random forest data mining technique and bivariate and multivariate statistical models. Geomorphology 2016, 259, 105–118. [Google Scholar] [CrossRef]
- Shirzadi, A.; Bui, D.T.; Pham, B.T.; Solaimani, K.; Chapi, K.; Kavian, A.; Shahabi, H.; Revhaug, I. Shallow landslide susceptibility assessment using a novel hybrid intelligence approach. Environ. Earth Sci. 2017, 76, 60. [Google Scholar] [CrossRef]
- Tsangaratos, P.; Ilia, I. Landslide susceptibility mapping using a modified decision tree classifier in the Xanthi Perfection, Greece. Landslides 2016, 13, 305–320. [Google Scholar] [CrossRef]
- Dou, J.; Yamagishi, H.; Pourghasemi, H.R.; Yunus, A.P.; Song, X.; Xu, Y.; Zhu, Z. An integrated artificial neural network model for the landslide susceptibility assessment of Osado Island, Japan. Nat. Hazards 2015, 78, 1749–1776. [Google Scholar]
- Benediktsson, J.; Swain, P.H.; Ersoy, O.K. Neural network approaches versus statistical methods in classification of multisource remote sensing data. IEEE T Geosci Remote 1990, 28, 540–552. [Google Scholar]
- Tehrany, M.S.; Pradhan, B.; Jebur, M.N. Spatial prediction of flood susceptible areas using rule based decision tree (DT) and a novel ensemble bivariate and multivariate statistical models in GIS. J. Hydrol. 2014, 504, 69–79. [Google Scholar] [CrossRef]
- Hembram, T.K.; Paul, G.C.; Saha, S. Modelling of gully erosion risk using new ensemble of conditional probability and index of entropy in Jainti River basin of Chotanagpur Plateau Fringe Area, India. Appl. Geomat. 2020, 1–24. [Google Scholar] [CrossRef]
- Pourghasemi, H.R.; Yousefi, S.; Kornejady, A.; Cerdà, A. Performance assessment of individual and ensemble data-mining techniques for gully erosion modeling. Sci. Total Environ. 2017, 609, 764–775. [Google Scholar] [CrossRef] [PubMed]
- Barzegar, R.; Moghaddam, A.A.; Deo, R.; Fijani, E.; Tziritis, E. Mapping groundwater contamination risk of multiple aquifers using multi-model ensemble of machine learning algorithms. Sci. Total Environ. 2018, 621, 697–712. [Google Scholar] [CrossRef] [PubMed]
- Naghibi, S.A.; Pourghasemi, H.R.; Dixon, B. GIS-based groundwater potential mapping using boosted regression tree, classification and regression tree, and random forest machine learning models in Iran. Environ. Monit. Assess. 2016, 188, 44. [Google Scholar]
- Mojaddadi, H.; Pradhan, B.; Nampak, H.; Ahmad, N.; Ghazali, A.H.B. Ensemble machine-learning-based geospatial approach for flood risk assessment using multi-sensor remote-sensing data and GIS. Geomat. Nat. Hazards Risk 2017, 8, 1080–1102. [Google Scholar] [CrossRef]
- Kadavi, P.R.; Lee, C.W.; Lee, S. Application of ensemble-based machine learning models to landslide susceptibility mapping. Remote Sens. 2018, 10, 1252. [Google Scholar] [CrossRef]
- Aghdam, I.N.; Varzandeh, M.H.M.; Pradhan, B. Landslide susceptibility mapping using an ensemble statistical index (Wi) and adaptive neuro-fuzzy inference system (ANFIS) model at Alborz Mountains (Iran). Environ. Earth Sci. 2016, 75, 553. [Google Scholar]
- The Pioneer. Available online: https://www.dailypioneer.com/2019/state-editions/landslide-at-rudraprayag-kills-8.html (accessed on 21 October 2019).
- Indian Meteorological Department. Available online: https://mausam.imd.gov.in/ (accessed on 24 November 2019).
- US Geological Survey Earthexplorer. Available online: https://earthexplorer.usgs.gov/ (accessed on 20 December 2019).
- Bhuvan. Available online: http://bhuvan.nrsc.gov.in/ (accessed on 22 December 2019).
- Yilmaz, C.; Topal, T.; Suzen, M.L. GIS-based landslide susceptibility mapping using bivariate statistical analysis in Devrek (Zonguldak-Turkey). Environ. Earth Sci. 2012, 65, 2161–2178. [Google Scholar] [CrossRef]
- Van Westen, C.J.; van Asch, T.W.J.; Soeters, R. Landslide hazard and risk zonation—Why is it still so difficult? Bull. Eng. Geol. Environ. 2006, 65, 167–184. [Google Scholar] [CrossRef]
- Kononenko, I. Estimating attributes: Analysis and extensions of RELIEF. In European Conference on Machine Learning; Springer: Berlin/Heidelberg, Germany, 1994; pp. 171–182. [Google Scholar]
- Wang, L.-J.; Guo, M.; Sawada, K.; Lin, J.; Zhang, J. A comparative study of landslide susceptibility maps using logistic regression, frequency ratio, decision tree, weights of evidence and artificial neural network. Geosci. J. 2016, 20, 117–136. [Google Scholar] [CrossRef]
- Pham, B.T.; Bui, D.T.; Prakash, I.; Dholakia, M. Hybrid integration of Multilayer Perceptron Neural Networks and machine learning ensembles for landslide susceptibility assessment at Himalayan area (India) using GIS. Catena 2017, 149, 52–63. [Google Scholar]
- Pham, B.T.; Jaafari, A.; Prakash, I.; Bui, D.T. A novel hybrid intelligent model of support vector machines and the MultiBoost ensemble for landslide susceptibility modeling. Bull. Eng. Geol. Environ. 2019, 76, 2865–2886. [Google Scholar]
- Li, Z.; Zhu, Q.; Gold, C. Digital Terrain Modeling: Principles and Methodology; CRC Press: Boca Raton, FL, USA, 2005. [Google Scholar]
- Wentworth, C.K. A simplified method of determining the average slope of land surfaces. Am. J. Sci. 1930, 117, 184–194. [Google Scholar]
- Burrough, P.A.; McDonell, R.A. Principles of Geographical Information Systems; Oxford University Press: New York, NY, USA, 1998; p. 190. [Google Scholar]
- Moore, I.D.; Grayson, R.B.; Ladson, A.R. Digital terrain modelling: A review of hydrological, geomorphological, and biological applications. Hydrol. Process. 1991, 5, 3–30. [Google Scholar] [CrossRef]
- Bayraktar, H.; Turalioglu, S. A Kriging-based approach for locating a sampling site—In the assessment of airquality. Stoch. Environ. Res. Risk Assess. 2005, 19, 301–305. [Google Scholar] [CrossRef]
- Moore, I.D.; Burch, G.J. Physical basis of the length slope factor in the universal soil loss equation. Soil Sci. Soc. Am. 1986, 50, 1294–1298. [Google Scholar] [CrossRef]
- Ay, N.; Amari, S.-I. A novel approach to canonical divergences within information geometry. Entropy 2015, 17, 8111–8129. [Google Scholar] [CrossRef]
- Chawla, A.; Pasupuleti, S.; Chawla, S.; Rao, A.C.S.; Sarkar, K.; Dwivedi, R. Landslide susceptibility zonation mapping: A case study from darjeeling district, Eastern Himalayas, India. J. Indian Soc. Remote Sens. 2019, 47, 497–511. [Google Scholar]
- Crippen, R.E. Calculating the vegetation index faster. Remote Sens. Environ. 1990, 34, 71–73. [Google Scholar] [CrossRef]
- Myung, I.J. Tutorial on maximum likelihood estimation. J. Math. Psychol. 2003, 47, 90–100. [Google Scholar] [CrossRef]
- Prasad, K.; Gopi, S.; Rao, R. Demarcation of Priority Macro-Watersheds in Mahbubnagar District, AP Using Remote Sensing Techniques; Tata McGraw-Hill: New York, NY, USA, 1992; pp. 263–269. [Google Scholar]
- Poudyal, C.P.; Chang, C.; Oh, H.-J.; Lee, S. Landslide susceptibility maps comparing frequency ratio and artificial neural networks: A case study from the Nepal Himalaya. Environ. Earth Sci. 2010, 61, 1049–1064. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Gayen, A.; Pourghasemi, H.R.; Saha, S.; Keesstra, S.; Bai, S. Gully erosion susceptibility assessment and management of hazard-prone areas in India using different machine learning algorithms. Sci. Total Environ. 2019, 668, 124–138. [Google Scholar] [CrossRef] [PubMed]
- Trigila, A.; Iadanza, C.; Esposito, C.; Scarascia-Mugnozza, G. Comparison of logistic regression and random forests techniques for shallow landslide susceptibility assessment in Giampilieri (NE Sicily, Italy). Geomorphology 2015, 249, 119–136. [Google Scholar] [CrossRef]
- Micheletti, N.; Foresti, L.; Robert, S.; Leuenberger, M.; Pedrazzini, A.; Jaboyedoff, M.; Kanevski, M. Machine learning feature selection methods for landslide susceptibility mapping. Math. Geosci. 2014, 46, 33–57. [Google Scholar] [CrossRef]
- Aditian, A.; Kubota, T.; Shinohara, Y. Comparison of GIS-based landslide susceptibility models using frequency ratio, logistic regression, and artificial neural network in a tertiary region of Ambon, Indonesia. Geomorphology 2018, 318, 101–111. [Google Scholar] [CrossRef]
- Jing, L. A review of techniques, advances and outstanding issues in numerical modelling for rock mechanics and rock engineering. Int. J. Rock Mech. Min. Sci. 2003, 40, 283–353. [Google Scholar] [CrossRef]
- Yao, X.; Tham, L.G.; Dai, F.C. Landslide susceptibility mapping based on support vector machine: A case study on natural slopes of Hong Kong, China. Geomorphology 2008, 101, 572–582. [Google Scholar] [CrossRef]
- Rahmati, O.; Tahmasebipour, N.; Haghizadeh, A.; Pourghasemi, H.R.; Feizizadeh, B. Evaluation of different machine learning models for predicting and mapping the susceptibility of gully erosion. Geomorphology 2017, 298, 118–137. [Google Scholar] [CrossRef]
- Tien Bui, D.; Pradhan, B.; Lofman, O.; Revhaug, I. Landslide susceptibility assessment in Vietnam using support vector machines, decision tree, and Naïve Bayes Models. Math. Probl. Eng. 2012, 2012, 974638. [Google Scholar] [CrossRef]
- Roy, J.; Saha, S. Landslide susceptibility mapping using knowledge driven statistical models in Darjeeling District, West Bengal, India. Geoenvironmental Disasters 2019, 6, 11. [Google Scholar] [CrossRef]
- Menard, S. Coefficients of determination for multiple logistic regression analysis. Am. Statistician. 2000, 54, 17–24. [Google Scholar]
- Akgun, A. A comparison of landslide susceptibility maps produced by logistic regression, multi-criteria decision, and likelihood ratio methods: A case study at İzmir, Turkey. Landslides 2012, 9, 93–106. [Google Scholar] [CrossRef]
- Rokach, L. Ensemble-based classifiers. Artif. Intell. Rev. 2010, 33, 1–39. [Google Scholar] [CrossRef]
- Lee, M.J.; Choi, J.W.; Oh, H.J.; Won, J.S.; Park, I.; Lee, S. Ensemble-based landslide susceptibility maps in Jinbu area, Korea. Environ. Earth Sci. 2012, 67, 23–37. [Google Scholar] [CrossRef]
- Jebur, M.N.; Pradhan, B.; Tehrany, M.S. Optimization of landslide conditioning factors using very high-resolution airborne laser scanning (LiDAR) data at catchment scale. Remote Sens. Environ. 2014, 152, 150–165. [Google Scholar] [CrossRef]
- Gayen, A.; Saha, S. Application of weights-of-evidence (WoE) and evidential belief function (EBF) models for the delineation of soil erosion vulnerable zones: A study on Pathro river basin, Jharkhand, India. Modeling Earth Syst. Environ. 2017, 3, 1123–1139. [Google Scholar] [CrossRef]
- Gayen, A.; Saha, S. Deforestation probable area predicted by logistic regression in Pathro river basin: A tributary of Ajay River. Spat. Inf. Res. 2018, 26, 1–9. [Google Scholar] [CrossRef]
- Frattini, P.; Crosta, G.; Carrara, A. Techniques for evaluating the performance of landslide susceptibility models. Eng. Geol. 2010, 111, 62–72. [Google Scholar] [CrossRef]
- Hembram, T.K.; Paul, G.C.; Saha, S. Comparative Analysis between Morphometry and Geo-Environmental Factor Based Soil Erosion Risk Assessment Using Weight of Evidence Model: A Study on Jainti River Basin, Eastern India. Environ. Process. 2019, 6, 883–913. [Google Scholar] [CrossRef]
- Can, T.; Nefeslioglu, H.; Gokceoglu, C.; Sonmez, H.; Duman, T.Y. Susceptibility assessments of shallow earthflows triggered by heavy rainfall at three catchments by logistic regression analysis. Geomorphology 2005, 72, 250–271. [Google Scholar] [CrossRef]
- Altaf, S.; Meraj, G.; Ahmad Romshoo, S. Morphometry and land cover based multicriteria analysis for assessing the soil erosion susceptibility of the western Himalayan watershed. Environ. Monit. Assess. 2014, 186, 8391–8412. [Google Scholar] [CrossRef]
- Hembram, T.K.; Saha, S. Prioritization of sub-watersheds for soil erosion based on morphometric attributes using fuzzy AHP and compound factor in Jainti River basin, Jharkhand, Eastern India. Environ. Dev. Sustain. 2018, 22, 1241–1268. [Google Scholar]
- Kutlug Sahin, E.; Ipbuker, C.; Kavzoglu, T. Investigation of automatic feature weighting methods (Fisher, Chi-square and Relief-F) for landslide susceptibility mapping. Geocarto Int. 2017, 32, 956–977. [Google Scholar]
- Tien Bui, D.; Shahabi, H.; Shirzadi, A.; Chapi, K.; Pradhan, B.; Chen, W.; Khosravi, K.; Panahi, M.; Bin Ahmad, B.; Saro, L. Land subsidence susceptibility mapping in south korea using machine learning algorithms. Sensors 2018, 18, 2464. [Google Scholar]
- Pradhan, B. Flood susceptible mapping and risk area delineation using logistic regression, GIS and remote sensing. J. Spat Hydrol. 2010, 9, 1–18. [Google Scholar]
- Conoscenti, C.; Angileri, S.; Cappadonia, C.; Rotigliano, E.; Agnesi, V.; Märker, M. Gully erosion susceptibility assessment by means of GIS-based logistic regression: A case of Sicily (Italy). Geomorphology 2014, 204, 399–411. [Google Scholar] [CrossRef]
- Lombardo, L.; Cama, M.; Conoscenti, C.; Märker, M.; Rotigliano, E. Binary logistic regression versus stochastic gradient boosted decision trees in assessing landslide susceptibility for multiple-occurring landslide events: Application to the 2009 storm event in Messina (Sicily, southern Italy). Nat. Hazards 2015, 79, 1621–1648. [Google Scholar]
- Suzen, M.L.; Doyuran, V. A comparison of the GIS based landslide susceptibility assessment methods: Multivariate versus bivariate. Environ. Geol. 2004, 45, 665–679. [Google Scholar]
- Arabameri, A.; Pradhan, B.; Rezaei, K.; Sohrabi, M.; Kalantari, Z. GIS-based landslide susceptibility mapping using numerical risk factor bivariate model and its ensemble with linear multivariate regression and boosted regression tree algorithms. J. Mt. Sci. 2019, 16, 595–618. [Google Scholar] [CrossRef]
- Glade, T.; Crozier, M.J. Landslide hazard and risk: Concluding comment and perspectives. In Landslide Hazard Risk; Wiley: Chichester, UK, 2005; pp. 767–774. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| LCFS | Data Used | Scale | Sources | Method and Formula | References |
|---|---|---|---|---|---|
| Altitude | PALSAR DEM | 12.5 m × 12. 5 m | Alaska Satellite | 12.5 m × 12. 5 m digital elevation model | [42] |
| Slope | N = No. of Contour Cutting; I = Contour Interval | [43] | |||
| aspect | where, Here, a to i indicates the cell value of 3 × 3 window. | [44] | |||
| Curvature | where Z1–Z9 are altitude values in 3 × 3 cellular networks and denotes the cell size. | [45] | |||
| SPI | where ‘As’ is the specific catchment area in meters. | [46] | |||
| Rainfall (cm) | Indian meteorological department | - | https://mausam.imd.gov.in/ | Kriging Interpolation method | [47] |
| Drainage density (sq. km) | Open series toposheets | 1:50,000 | Survey of India | where “L” is stream length and “A” is the study area. | [47] |
| TWI | PALSAR DEM | 12.5 m × 12. 5 m | Alaska Satellite | where ‘As’ is the specific catchment area in meter and slope in degrees. | [48] |
| Soil type | Reference district soil map | 1:50,000 | National Bureau of Soil Survey and Land Use Planning | Digitization process | [49] |
| Soil depth (m) | Reference district soil map | 1:50,000 | National Bureau of Soil Survey and Land Use Planning | Digitization process | [49] |
| Geology | Reference geological map | 1:250,000 | Geological Survey of India | Digitization process | [49] |
| Distance to lineaments | Lineaments | 1: 50,000 | http://bhuvan.nrsc.gov.in | Euclidean distance buffering | [49] |
| Seismic zones | Last 200 years point data of earthquake | 30 m × 30 m | National Centre for Seismology, New Delhi, India | Gridding and interpolation (inverse distance weight method) | [50] |
| Road Density | Open series toposheets | 1:50,000 | SOI | where “Lr” is road length and “A” is the study area. | [49] |
| NDVI | Sentinel-2 | 10 m × 10 m | https://earthexplorer.usgs.gov. | where, NIR is near infrared band and IR is the infrared band. | [51] |
| LU/LC | Supervised classification (Maximum likelihood) | [10] |
| Earthquake Zone | MSK Scale | Characteristics |
|---|---|---|
| Zone-4 | VII. Very strong | Most dwellers are frightened and try to escape outside. Low to medium landmass moved downward. |
| VIII. Damaging | Formation of wave on loose surface. Wider cracks and breaches introduce the breakdown of ice. | |
| IX. Distractive | Disruption of underground pipes. Surface fracturing, large size landfalls. | |
| Zone-5 | X. Devastating | Massive landslide may stimulate flooding at surrounding areas and create new bodies of water. |
| XI. Catastrophic | Most of the houses/settlements and civil structures are crumbled. Widespread and huge landfall occurs. | |
| XII. Very catastrophic | Extreme demolition of underground and above-surface infrastructure and households. Landscape transformation, drainage or channel shifting happens. |
| Sl. No | LCFs | Average Merit (AM) |
|---|---|---|
| 1 | Altitude | 0.05082 |
| 2 | Drainage density | 0.03908 |
| 3 | Road density | 0.03446 |
| 4 | Earthquake zone | 0.03378 |
| 5 | Distance to lineaments | 0.03232 |
| 6 | Slope gradient | 0.02895 |
| 7 | LU/LC | 0.02478 |
| 8 | Geology | 0.02399 |
| 9 | Rainfall | 0.02313 |
| 10 | Soil depth | 0.02191 |
| 11 | Soil type | 0.01946 |
| 12 | NDVI | 0.01659 |
| 13 | Curvature | 0.01383 |
| 14 | TWI | 0.00861 |
| 15 | Slope aspect | 0.00338 |
| 16 | SPI | 0.00326 |
| Matrix | Training Data Set | Rank | Rank Total | CF | Priority Rank | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision | Efficiency | AUC | MAE | RMSE | Precision | Efficiency | AUC | MAE | RMSE | ||||
| ANN | 0.718 | 0.722 | 85.12 | 0.038 | 0.058 | 9 | 9 | 10 | 3 | 3 | 34 | 6.8 | 4 |
| SVM | 0.695 | 0.703 | 83.39 | 0.096 | 0.156 | 10 | 10 | 14 | 5 | 6 | 45 | 9 | 11 |
| RF | 0.665 | 0.667 | 84.59 | 0.036 | 0.052 | 13 | 13 | 12 | 2 | 2 | 42 | 8.4 | 10 |
| LR | 0.636 | 0.665 | 82.17 | 0.237 | 0.432 | 15 | 15 | 15 | 13 | 15 | 73 | 14.6 | 15 |
| ANN-SVM | 0.678 | 0.687 | 85.07 | 0.365 | 0.107 | 12 | 12 | 11 | 15 | 5 | 55 | 11 | 12 |
| ANN-LR | 0.685 | 0.69 | 85.46 | 0.267 | 0.249 | 11 | 11 | 8 | 14 | 13 | 57 | 11.4 | 13 |
| LR-SVM | 0.663 | 0.683 | 85.84 | 0.182 | 0.266 | 14 | 14 | 6 | 10 | 14 | 58 | 11.6 | 14 |
| LR-RF | 0.857 | 0.871 | 85.48 | 0.206 | 0.245 | 2 | 2 | 7 | 12 | 12 | 35 | 7 | 6 |
| SVM-RF | 0.77 | 0.785 | 85.38 | 0.163 | 0.069 | 7 | 7 | 9 | 7 | 4 | 34 | 6.8 | 5 |
| ANN-RF | 0.775 | 0.789 | 84.01 | 0.093 | 0.168 | 6 | 6 | 13 | 4 | 7 | 36 | 7.2 | 8 |
| ANN-LR-SVM | 0.766 | 0.784 | 86.95 | 0.182 | 0.231 | 8 | 8 | 4 | 9 | 10 | 39 | 7.8 | 9 |
| ANN-RF-SVM | 0.791 | 0.796 | 86.73 | 0.191 | 0.242 | 4 | 4 | 5 | 11 | 11 | 35 | 7 | 7 |
| RF-SVM-LR | 0.846 | 0.861 | 87.38 | 0.165 | 0.215 | 3 | 3 | 3 | 8 | 9 | 26 | 5.2 | 2 |
| ANN-LR-RF | 0.871 | 0.878 | 87.83 | 0.016 | 0.019 | 1 | 1 | 1 | 1 | 1 | 5 | 1 | 1 |
| ANN-RF-SVM-LR | 0.784 | 0.804 | 87.76 | 0.151 | 0.195 | 5 | 5 | 2 | 6 | 8 | 26 | 5.2 | 3 |
| Matrix | Testing Data Set | Rank | Rank Total | CF | Priority Rank | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision | Efficiency | AUC | MAE | RMSE | Precision | Efficiency | AUC | MAE | RMSE | ||||
| ANN | 0.817 | 0.838 | 86.45 | 0.027 | 0.164 | 7 | 6 | 13 | 1 | 7 | 34 | 6.8 | 5 |
| SVM | 0.785 | 0.792 | 85.63 | 0.067 | 0.125 | 9 | 10 | 14 | 2 | 2 | 37 | 7.4 | 7 |
| RF | 0.667 | 0.708 | 86.95 | 0.085 | 0.146 | 14 | 14 | 11 | 4 | 4 | 47 | 9.4 | 10 |
| LR | 0.825 | 0.829 | 84.7 | 0.131 | 0.18 | 5 | 8 | 15 | 9 | 10 | 47 | 9.4 | 11 |
| ANN-SVM | 0.715 | 0.723 | 87.45 | 0.302 | 0.387 | 12 | 12 | 9 | 15 | 15 | 63 | 12.6 | 15 |
| ANN-LR | 0.705 | 0.709 | 86.69 | 0.139 | 0.186 | 13 | 13 | 12 | 10 | 11 | 59 | 11.8 | 14 |
| LR-SVM | 0.667 | 0.708 | 87.62 | 0.228 | 0.0287 | 15 | 15 | 8 | 14 | 1 | 53 | 10.6 | 13 |
| LR-RF | 0.748 | 0.77 | 86.98 | 0.102 | 0.159 | 11 | 11 | 10 | 6 | 6 | 44 | 8.8 | 9 |
| SVM-RF | 0.859 | 0.881 | 88.69 | 0.189 | 0.217 | 3 | 5 | 7 | 13 | 12 | 40 | 8 | 8 |
| ANN-RF | 0.821 | 0.885 | 89.91 | 0.109 | 0.164 | 6 | 4 | 5 | 7 | 8 | 30 | 6 | 4 |
| ANN-LR-SVM | 0.785 | 0.812 | 89.77 | 0.163 | 0.275 | 10 | 9 | 6 | 11 | 14 | 50 | 10 | 12 |
| ANN-RF-SVM | 0.857 | 0.889 | 92.03 | 0.172 | 0.241 | 4 | 3 | 4 | 12 | 13 | 36 | 7.2 | 6 |
| RF-SVM-LR | 0.815 | 0.835 | 92.29 | 0.089 | 0.149 | 8 | 7 | 3 | 5 | 5 | 28 | 5.6 | 3 |
| ANN-LR-RF | 0.878 | 0.893 | 93.98 | 0.117 | 0.138 | 1 | 1 | 1 | 8 | 3 | 14 | 2.8 | 1 |
| ANN-RF-SVM-LR | 0.873 | 0.889 | 92.63 | 0.0761 | 0.172 | 2 | 2 | 2 | 3 | 9 | 18 | 3.6 | 2 |
| Landslide Causative Factors | Coefficients of Logistic Regression (B) | Landslide Causative Factors | Coefficients of Logistic Regression (B) |
|---|---|---|---|
| Altitude | 1.461 | Geology (Gneiss-magmatites) | 0.122 |
| Slope | 0.028 | Geology (Tourmail granite) | 2.478 |
| Aspect (Flat) | −1.185 | Geology (Chail-Ranghat) | −3.412 |
| Aspect (North) | −0.179 | Geology (Granite 500Ma) | −1.744 |
| Aspect (North-east) | 0.348 | Geology (Salkhlas) | 1.062 |
| Aspect (East) | −0.447 | Geology (Shail Deoban) | −0.513 |
| Aspect (South-east) | 0.531 | Geology (Nagthal) | −1.185 |
| Aspect (South) | −0.632 | Geology (Chadpur) | −0.179 |
| Aspect (South-west) | −1.185 | Geology (Chamoli Qz) | 0.348 |
| Aspect (West) | −1.32 | Earthquake zone (High) | 0.348 |
| Aspect (North-West) | −2.199 | Earthquake zone (Moderate) | −0.447 |
| Curvature | 0.976 | Major Road density | 1.241 |
| SPI | 0.026 | NDVI | −0.005 |
| Rainfall | 1.076 | LULC (Graz area) | 0.078 |
| Drainage density | 1.016 | LULC (Evergreen forest) | −0.048 |
| TWI | 0.034 | LULC (Perennial water) | 0.122 |
| Soil depth | 0.084 | LULC (Settlement) | 2.478 |
| Soil texture (Very fine) | −0.334 | LULC (Cropland) | 1.412 |
| Soil texture (Loamy skeletal) | 1.476 | LULC (Barren land) | −1.744 |
| Soil texture (Sandy skeletal) | −1.194 | LULC (Scrub forest) | 1.062 |
| Soil texture (Mixed loamy) | 1.445 | LULC (Deciduous forest) | −0.513 |
| Soil texture (Fine loamy) | −0.119 | LULC (Seasonal water) | −1.185 |
| Soil texture (Granular loamy) | 1.114 | LULC (Glacial area) | −0.513 |
| Distance from lineament | 1.102 | LULC (Permanent snow) | −1.185 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saha, S.; Saha, A.; Hembram, T.K.; Pradhan, B.; Alamri, A.M. Evaluating the Performance of Individual and Novel Ensemble of Machine Learning and Statistical Models for Landslide Susceptibility Assessment at Rudraprayag District of Garhwal Himalaya. Appl. Sci. 2020, 10, 3772. https://doi.org/10.3390/app10113772
Saha S, Saha A, Hembram TK, Pradhan B, Alamri AM. Evaluating the Performance of Individual and Novel Ensemble of Machine Learning and Statistical Models for Landslide Susceptibility Assessment at Rudraprayag District of Garhwal Himalaya. Applied Sciences. 2020; 10(11):3772. https://doi.org/10.3390/app10113772
Chicago/Turabian StyleSaha, Sunil, Anik Saha, Tusar Kanti Hembram, Biswajeet Pradhan, and Abdullah M. Alamri. 2020. "Evaluating the Performance of Individual and Novel Ensemble of Machine Learning and Statistical Models for Landslide Susceptibility Assessment at Rudraprayag District of Garhwal Himalaya" Applied Sciences 10, no. 11: 3772. https://doi.org/10.3390/app10113772
APA StyleSaha, S., Saha, A., Hembram, T. K., Pradhan, B., & Alamri, A. M. (2020). Evaluating the Performance of Individual and Novel Ensemble of Machine Learning and Statistical Models for Landslide Susceptibility Assessment at Rudraprayag District of Garhwal Himalaya. Applied Sciences, 10(11), 3772. https://doi.org/10.3390/app10113772