Histogram-Based Descriptor Subset Selection for Visual Recognition of Industrial Parts



Abstract
1. Introduction
2. Background
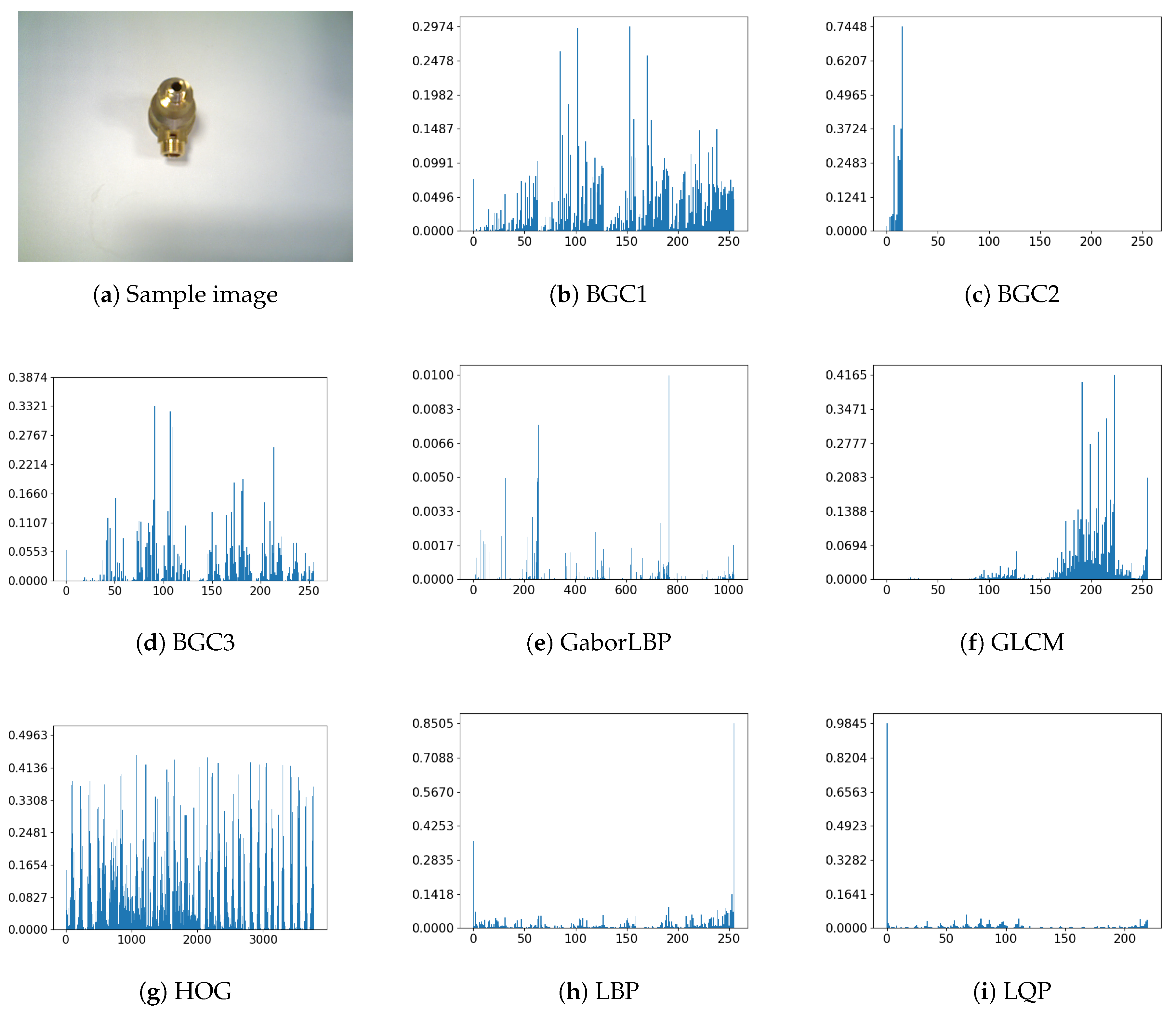
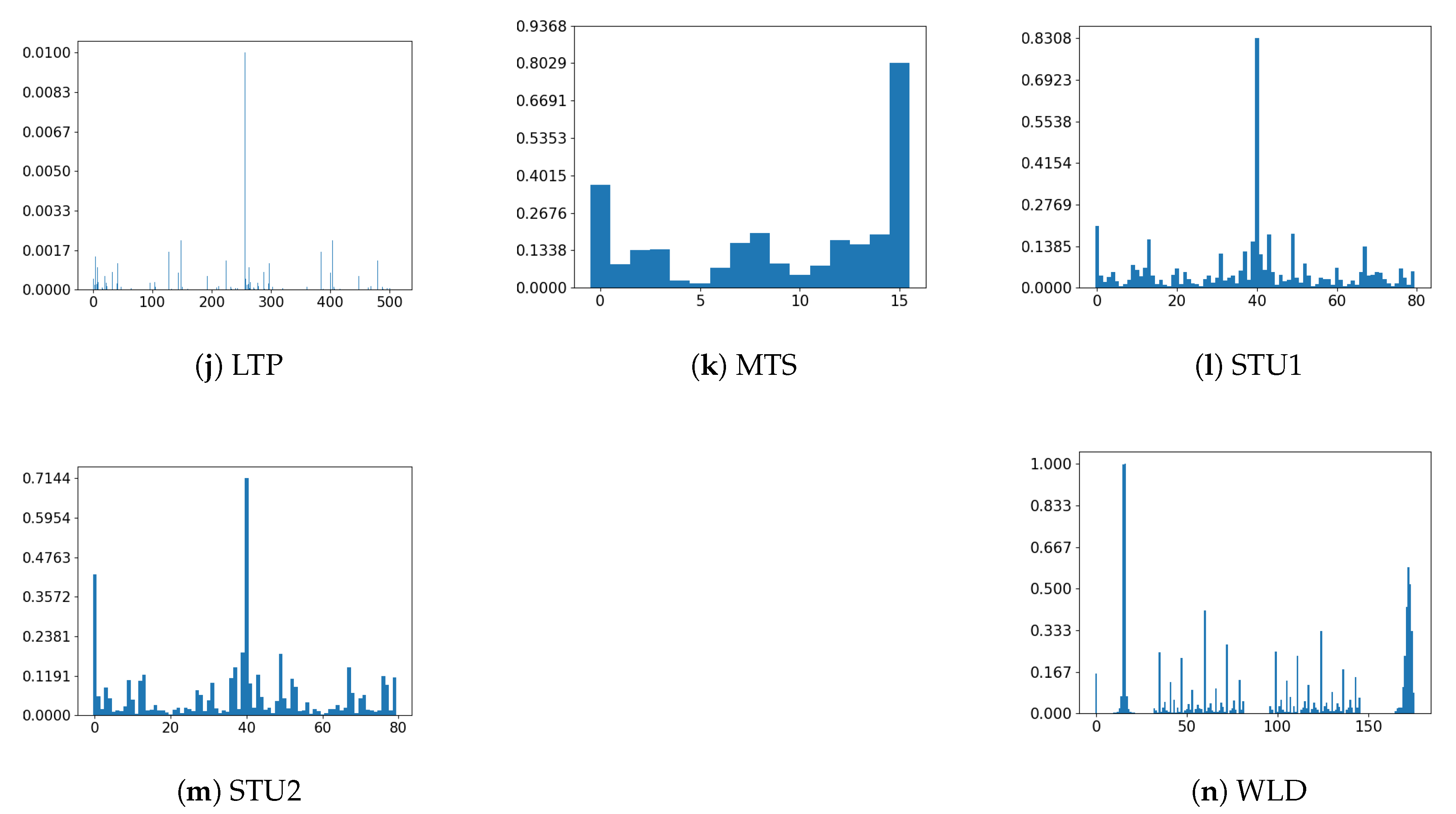
2.1. Features Descriptors
2.2. Classifiers
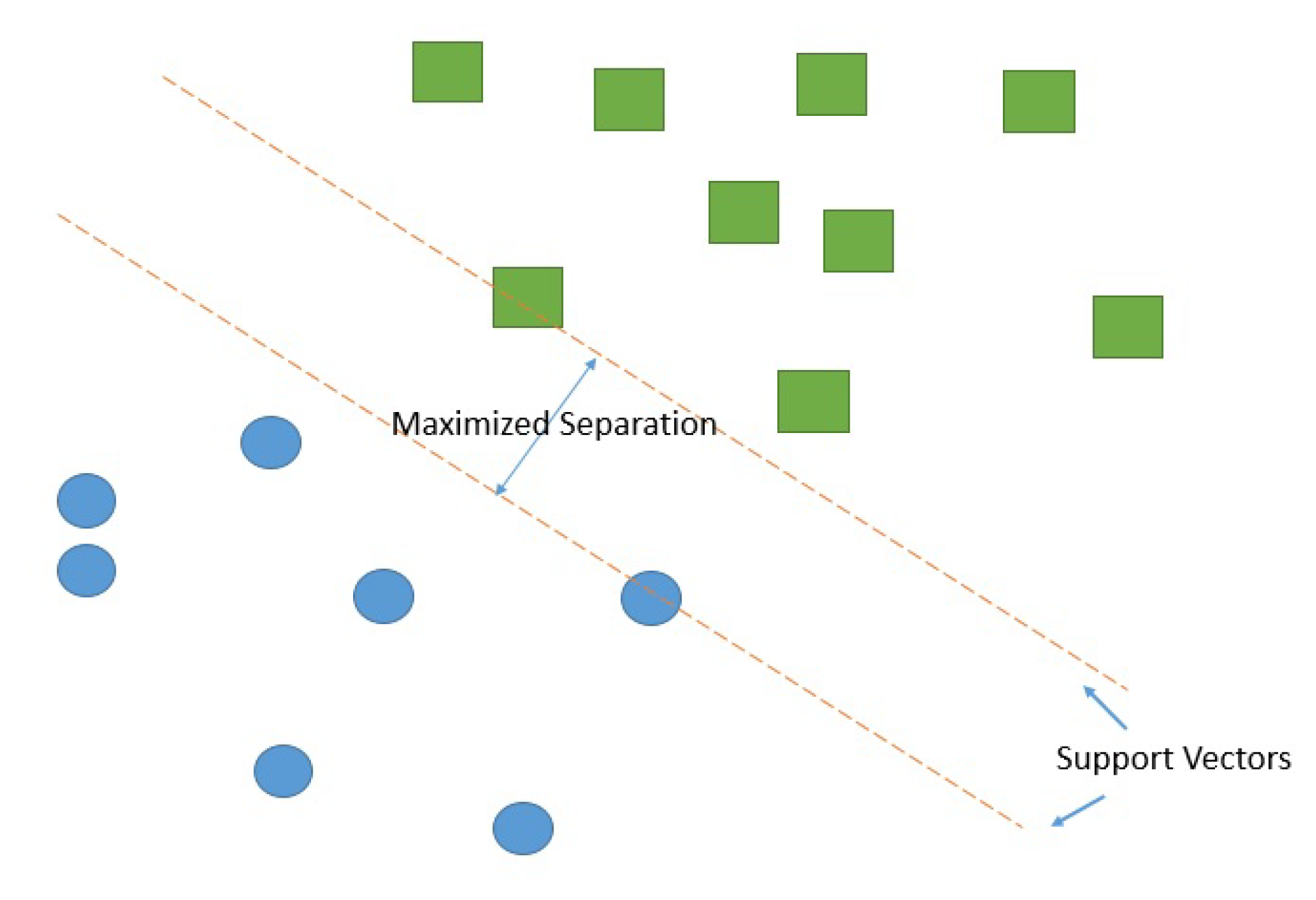
2.3. Feature Selection
3. Proposed Approach
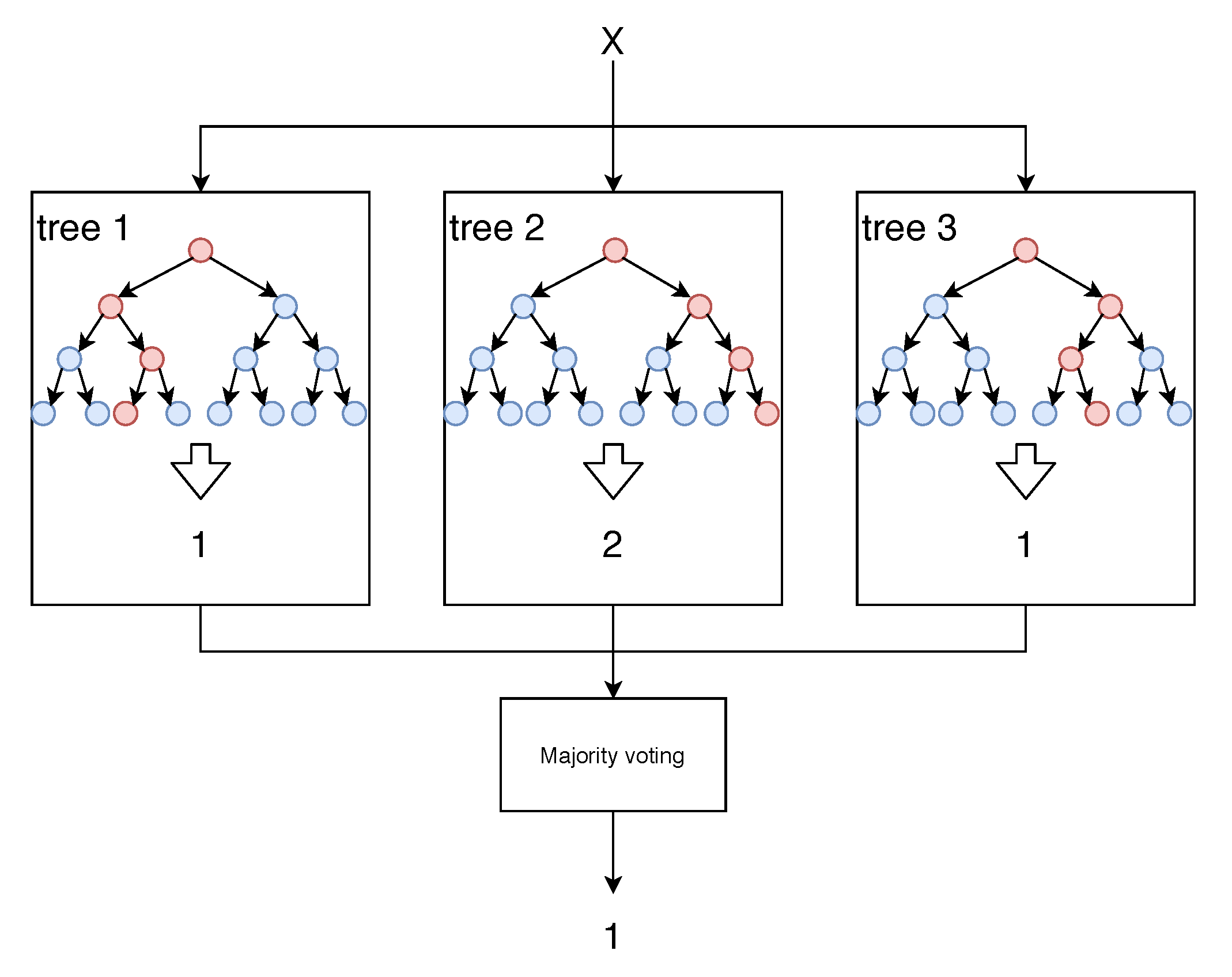
3.1. Classification
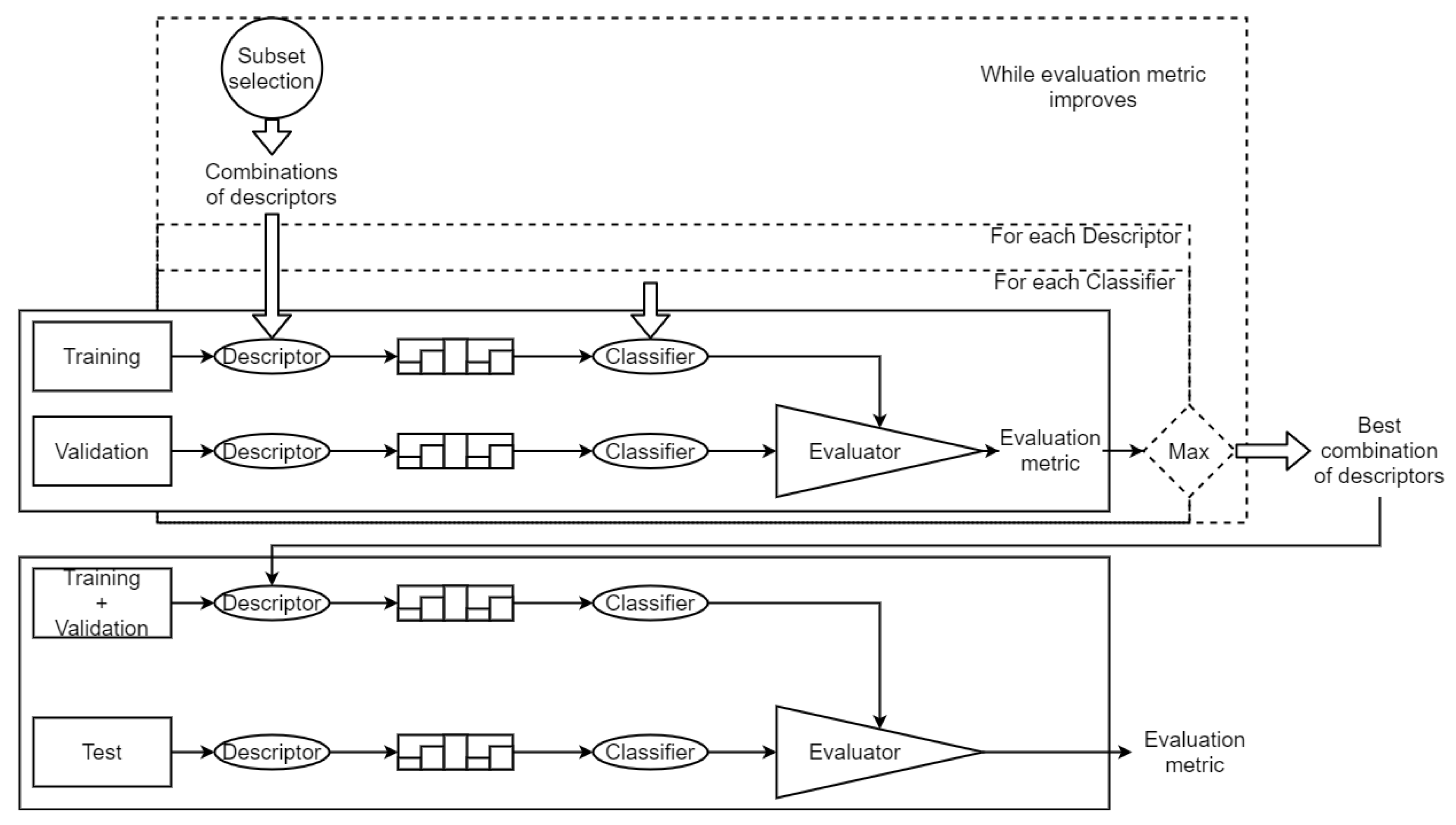
3.2. Feature Selection Techniques
| Algorithm 1: Sequential Forward Subset Selection |
 |
| Algorithm 2: Sequential Backward Subset Selection |
 |
3.3. Evaluation Measure
3.4. Full Pipeline
4. Experiments and Results
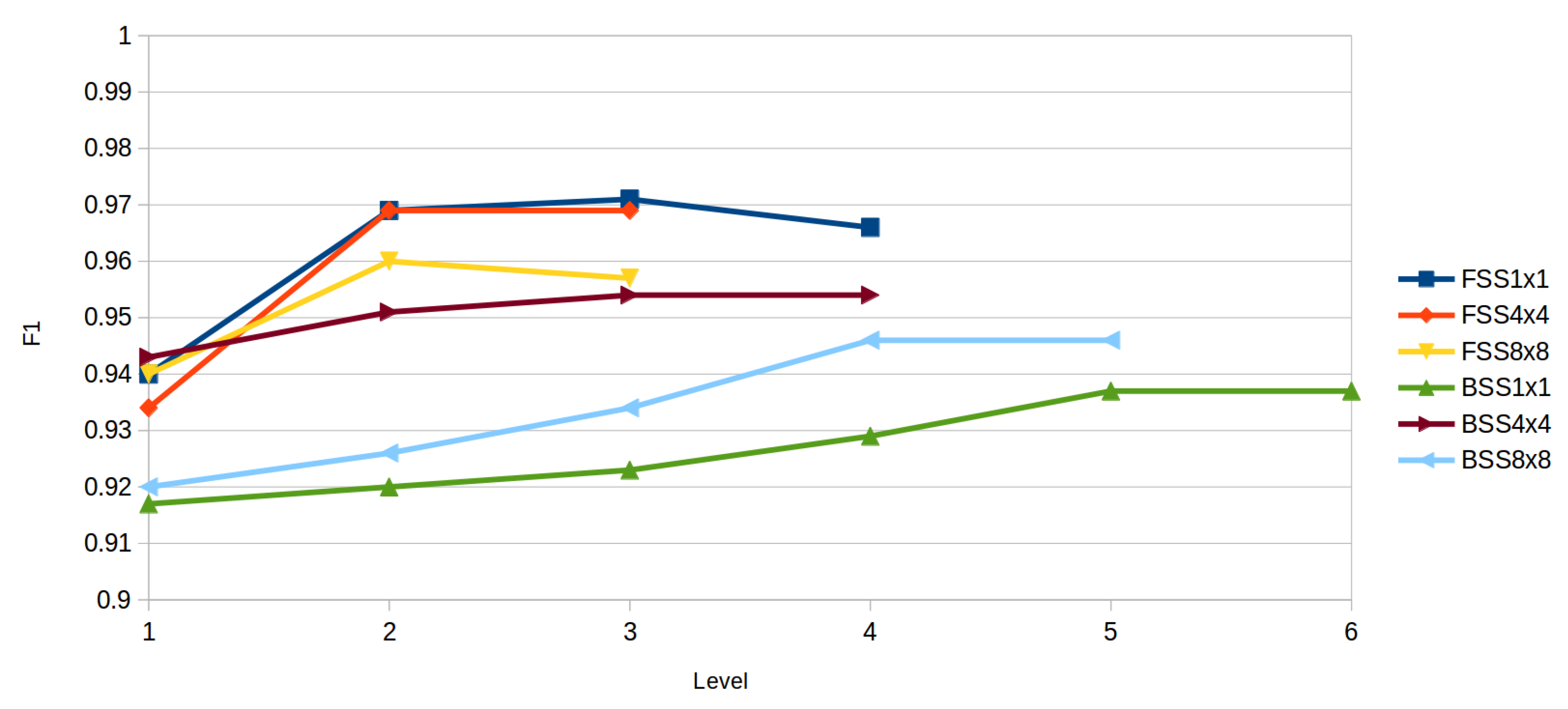
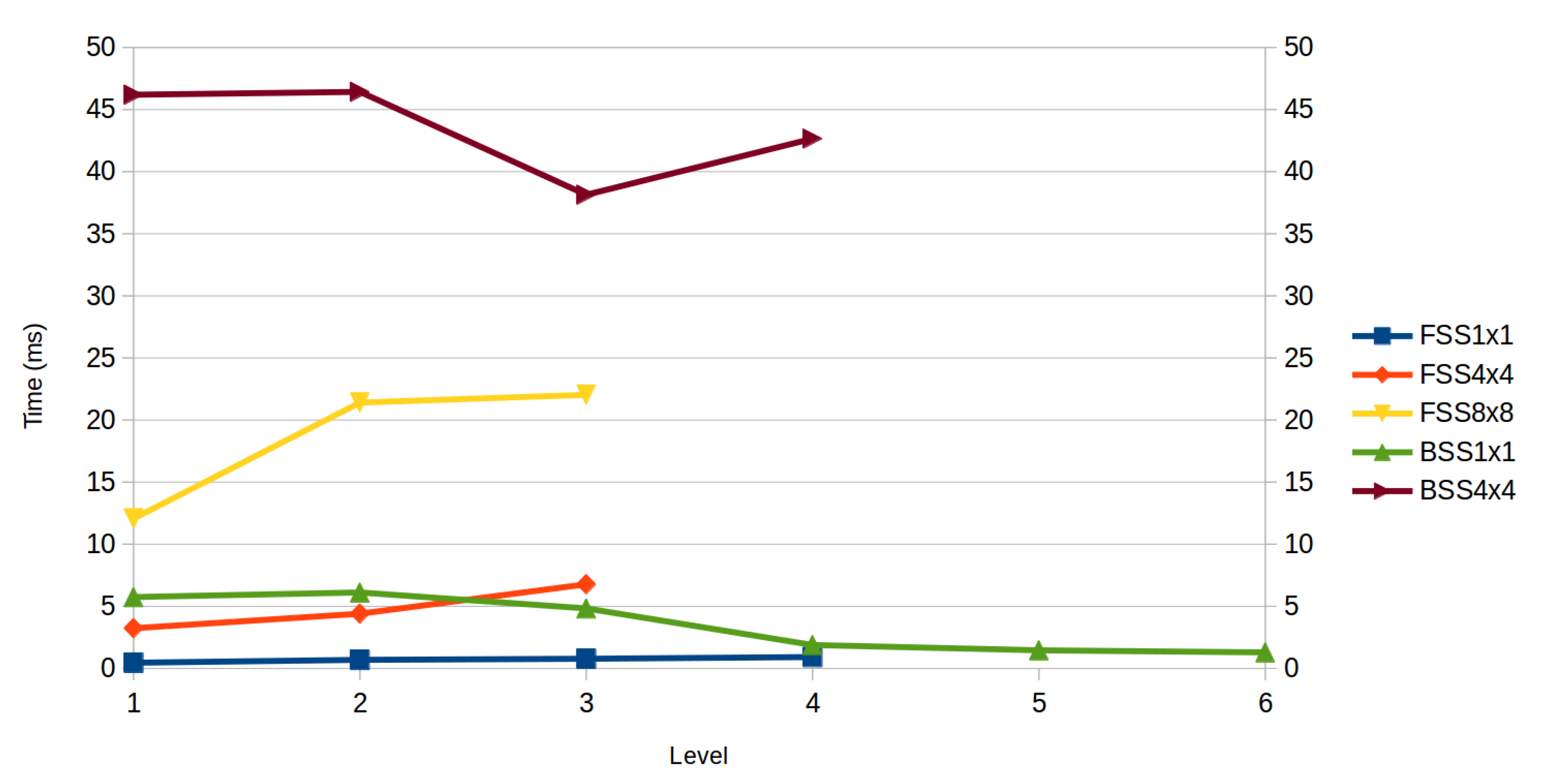
4.1. Forward Subset Selection
4.2. Backward Subset Selection
4.3. Comparative between Methods
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A. Parameters

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Parameter | Description of the Parameter | Value |
|---|---|---|---|
| KNN | K | number of neighbors | 1 |
| SVM SMO | C | parameter C | 1.0 |
| L | tolerance | 0.001 | |
| P | epsilon for round-off error | ||
| N | Normalization | true | |
| V | calibration folds | −1 | |
| K | Kernel | PolyKernel | |
| C PolyKernel | Cache size of the kernel | 250,007 | |
| E PolyKernel | Exponent value of the kernel | 2.0 | |
| SVM SGD | M | Multiclass type | 1-against-all |
| F | Loss function | hinge loss | |
| L | Learning rate | 0.001 | |
| R | Regulation constant | 0.0001 | |
| E | Number of epochs to perform | 500 | |
| C | Epsilon threshold for loss function | 0.001 | |
| RC | W | The base classifier to be used | RandomTree |
| K | Number of choosen attributes in the RandomTree | ||
| M RandomTree | Minimum total weight in a leaf | 1.0 | |
| V RandomTree | Minimum proportion of variance | 0.001 | |
| RF | P | Size of each bag | 100 |
| I | Number of iterations | 100 | |
| K | Number of randomly choosen attributes | ||
| M RandomTree | Minimum total weight in a leaf | 1.0 | |
| V RandomTree | Minimum proportion of variance | 0.001 | |
| Bagging | P | Size of each bag | 100 |
| I | Number of iterations | 10 | |
| W | The base classifier to be used | REPTree (Fast Decision Tree) | |
| M REPTree | Minimum total weight in a leaf | 2 | |
| V REPTree | Minimum proportion of variance | 0.001 | |
| N REPTree | Amount of data used for prunning | 3 | |
| L REPTree | Maximum depth of the tree | −1 (no restriction) | |
| I REPTree | Initial class value count | 0.0 |
References
- Teichmann, M.; Weber, M.; Zoellner, M.; Cipolla, R.; Urtasun, R. MultiNet: Real-time Joint Semantic Reasoning for Autonomous Driving. arXiv 2016, arXiv:cs.CV/1612.07695. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:cs.CV/1505.04597. [Google Scholar]
- Yan, M.; Zhao, M.; Xu, Z.; Zhang, Q.; Wang, G.; Su, Z. VarGFaceNet: An Efficient Variable Group Convolutional Neural Network for Lightweight Face Recognition. arXiv 2019, arXiv:cs.CV/1910.04985. [Google Scholar]
- Liu, Y.; Wang, Y.; Wang, S.; Liang, T.; Zhao, Q.; Tang, Z.; Ling, H. CBNet: A Novel Composite Backbone Network Architecture for Object Detection. arXiv 2019, arXiv:cs.CV/1909.03625. [Google Scholar]
- Yuan, Y.; Chen, X.; Wang, J. Object-Contextual Representations for Semantic Segmentation. arXiv 2019, arXiv:cs.CV/1909.11065. [Google Scholar]
- Gómez, A.; de la Fuente, D.C.; García, N.; Rosillo, R.; Puche, J. A vision of industry 4.0 from an artificial intelligence point of view. In Proceedings of the 18th International Conference on Artificial Intelligence, Varna, Bulgaria, 25–28 July 2016; p. 407. [Google Scholar]
- Chen, C.; Liu, M.Y.; Tuzel, O.; Xiao, J. R-CNN for Small Object Detection. In Computer Vision—ACCV 2016; Lai, S.H., Lepetit, V., Nishino, K., Sato, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 214–230. [Google Scholar]
- Xie, Q.; Luong, M.T.; Hovy, E.; Le, Q.V. Self-training with Noisy Student improves ImageNet classification. arXiv 2020, arXiv:1911.04252. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Mane, D.; Vasudevan, V.; Le, Q.V. AutoAugment: Learning Augmentation Policies from Data. arXiv 2019, arXiv:1805.09501. [Google Scholar]
- Kolesnikov, A.; Beyer, L.; Zhai, X.; Puigcerver, J.; Yung, J.; Gelly, S.; Houlsby, N. Large Scale Learning of General Visual Representations for Transfer. arXiv 2019, arXiv:1912.11370. [Google Scholar]
- Wang, J.; Chen, Y.; Yu, H.; Huang, M.; Yang, Q. Easy Transfer Learning By Exploiting Intra-domain Structures. arXiv 2019, arXiv:cs.LG/1904.01376. [Google Scholar]
- Nannia, L.; Ghidonia, S.; Brahnamb, S.; Le, Q.V. Handcrafted vs. non-handcrafted features for computer vision classification. Pattern Recognit. 2017, 71, 158–172. [Google Scholar]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; Volume 2, pp. 1150–1157. [Google Scholar]
- Bay, H.; Tuytelaars, T.; Van Gool, L. SURF: Speeded Up Robust Features. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 404–417. [Google Scholar]
- Ojala, T.; Pietikäinen, M.; Harwood, D. A comparative study of texture measures with classification based on featured distributions. Pattern Recognit. 1996, 29, 51–59. [Google Scholar] [CrossRef]
- Fernández, A.; Álvarez, M.X.; Bianconi, F. Texture Description Through Histograms of Equivalent Patterns. J. Math. Imaging Vis. 2013, 45, 76–102. [Google Scholar] [CrossRef]
- Merino, I.; Azpiazu, J.; Remazeilles, A.; Sierra, B. 2D Features-based Detector and Descriptor Selection System for Hierarchical Recognition of Industrial Parts. IJAIA 2019, 10, 1–13. [Google Scholar] [CrossRef]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I. Textural Features for Image Classification. IEEE Trans. Syst. Man Cybern. 1973, SMC-3, 610–621. [Google Scholar] [CrossRef]
- Wang, L.; He, D.C. Texture classification using texture spectrum. Pattern Recognit. 1990, 23, 905–910. [Google Scholar]
- Madrid-Cuevas, F.J.; Medina, R.; Prieto, M.; Fernández, N.L.; Carmona, A. Simplified Texture Unit: A New Descriptor of the Local Texture in Gray-Level Images. In Pattern Recognition and Image Analysis; Springer: Berlin/Heidelberg, Germany, 2003; Volume 2652, pp. 470–477. [Google Scholar]
- Xu, B.; Gong, P.; Seto, E.; Spear, R. Comparison of Gray-Level Reduction and Different Texture Spectrum Encoding Methods for Land-Use Classification Using a Panchromatic Ikonos Image. Photogramm. Eng. Remote Sens. 2003, 69, 529–536. [Google Scholar]
- Zhang, W.; Shan, S.; Gao, W.; Chen, X.; Zhang, H. Local Gabor binary pattern histogram sequence (LGBPHS): A novel non-statistical model for face representation and recognition. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05) Volume 1, Beijing, China, 17–21 October 2005; Volume 1, pp. 786–791. [Google Scholar]
- Tan, X.; Triggs, W. Enhanced local texture feature sets for face recognition under difficult lighting conditions. IEEE Trans. Image Process. 2010, 19, 1635–1650. [Google Scholar]
- Fernández, A.; Álvarez, M.X.; Bianconi, F. Image classification with binary gradient contours. Opt. Lasers Eng. 2011, 49, 1177–1184. [Google Scholar]
- Hussain, S.U.; Napoléon, T.; Jurie, F. Face Recognition using Local Quantized Patterns. In Procedings of the British Machine Vision Conference 2012; British Machine Vision Association: Guildford, UK, 2012; pp. 99.1–99.11. [Google Scholar]
- Chen, J.; Shan, S.; He, C.; Zhao, G.; Pietikainen, M.; Chen, X.; Gao, W. WLD: A Robust Local Image Descriptor. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1705–1720. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; IEEE: Piscataway, NJ, USA, 2005; Volume 1, pp. 886–893. [Google Scholar]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar]
- Rish, I. An empirical study of the naive Bayes classifier. In IJCAI 2001 Workshop on Empirical Methods in Artificial Intelligence; IBM: New York, NY, USA, 2001; Volume 3, pp. 41–46. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Lira, M.M.S.; de Aquino, R.R.B.; Ferreira, A.A.; Carvalho, M.A.; Neto, O.N.; Santos, G.S.M. Combining Multiple Artificial Neural Networks Using Random Committee to Decide upon Electrical Disturbance Classification. In Proceedings of the 2007 International Joint Conference on Neural Networks, Orlando, FL, USA, 12–17 August 2007; pp. 2863–2868. [Google Scholar]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Shahlaei, M. Descriptor Selection Methods in Quantitative Structure–Activity Relationship Studies: A Review Study. Chem. Rev. 2013, 113, 8093–8103. [Google Scholar] [CrossRef] [PubMed]
- Rasines, I.; Remazeilles, A.; Bengoa, P.M.I. Feature selection for hand pose recognition in human-robot object exchange scenario. In Proceedings of the 2014 IEEE Emerging Technology and Factory Automation (ETFA), Barcelona, Spain, 16–19 September 2014; pp. 1–8. [Google Scholar]
- Molina, L.; Belanche, L.; Nebot, A. Feature selection algorithms: A survey and experimental evaluation. In Proceedings of the 2002 IEEE International Conference on Data Mining, Maebashi City, Japan, 9–12 December 2002; pp. 306–313. [Google Scholar] [CrossRef]
- Chinchor, N. MUC-4 Evaluation Metrics. In Proceedings of the 4th Conference on Message Understanding; Association for Computational Linguistics: Stroudsburg, PA, USA, 1992; pp. 22–29. [Google Scholar] [CrossRef]
- Forman, G.; Scholz, M. Apples-to-Apples in Cross-Validation Studies: Pitfalls in Classifier Performance Measurement. SIGKDD Explor. Newsl. 2010, 12, 49–57. [Google Scholar] [CrossRef]
- Platt, J.C. Sequential Minimal Optimization: A Fast Algorithm for Training Support Vector Machines; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Robbins, H.; Monro, S. A Stochastic Approximation Method. Ann. Math. Statist. 1951, 22, 400–407. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning With Depthwise Separable Convolutions. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Melekhov, I.; Kannala, J.; Rahtu, E. Siamese network features for image matching. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 378–383. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2818–2826. [Google Scholar]









| Descriptor | Level 1 | Level 2 | Level 3 | Level 4 |
|---|---|---|---|---|
| WLD + | WLD + BGC2 + | WLD + BGC2 + MTS + | ||
| BGC1 | 0.66 (RF) | 0.931 (RF) | 0.937 (SVM) | 0.934 (SVM/RF) |
| BGC2 | 0.489 (SVM) | 0.969 (SVM) | — | — |
| BGC3 | 0.611 (SVM) | 0.937 (RC) | 0.929 (RF) | 0.929 (RF) |
| GaborLBP | 0.671 (RF) | 0.931 (RF) | 0.903 (RF) | 0.906 (RF) |
| GLCM | 0.811 (RF) | 0.951 (RF) | 0.903 (RF) | 0.963 (SVM) |
| HOG | 0.84 (SVM) | 0.923 (SVM) | 0.923 (SVM) | 0.923 (SVM) |
| LBP | 0.611 (RF) | 0.946 (RF) | 0.917 (SVM) | 0.923 (RF) |
| LQP | 0.697 (RF) | 0.949 (SVM) | 0.954 (SVM) | 0.949 (SVM) |
| LTP | 0.563 (RF) | 0.966 (SVM) | 0.969 (SVM) | 0.966 (SVM) |
| MTS | 0.666 (KNN) | 0.966 (SVM) | 0.971 (SVM) | — |
| STU1 | 0.746 (SVM) | 0.951 (SVM) | 0.951 (SVM) | 0.948 (SVM) |
| STU2 | 0.74 (SVM) | 0.951 (SVM) | 0.957 (SVM) | 0.957 (SVM) |
| WLD | 0.94 (RF) | — | — | — |
| Descriptor | Level 1 | Level 2 | Level 3 |
|---|---|---|---|
| STU1 + | STU1 + WLD + | ||
| BGC1 | 0.877 (SVM) | 0.908 (SVM-SGD) | 0.934 (SVM) |
| BGC2 | 0.903 (SVM) | 0.931 (SVM) | 0.969 (SVM) |
| BGC3 | 0.857 (SVM) | 0.906 (SVM) | 0.931 (SVM) |
| GaborLBP | 0.834 (SVM) | 0.883 (SVM) | 0.903 (SVM) |
| GLCM | 0.923 (RF) | 0.957 (SVM) | 0.966 (SVM) |
| HOG | 0.846 (KNN) | 0.917 (SVM) | 0.94 (SVM) |
| LBP | 0.874 (SVM) | 0.906 (SVM) | 0.929 (SVM) |
| LQP | 0.911 (SVM) | 0.94 (SVM) | 0.969 (SVM) |
| LTP | 0.889 (SVM) | 0.931 (SVM) | 0.96 (SVM) |
| MTS | 0.909 (SVM) | 0.94 (SVM) | 0.96 (SVM) |
| STU1 | 0.934 (SVM) | — | — |
| STU2 | 0.914 (SVM) | 0.931 (SVM) | 0.96 (SVM) |
| WLD | 0.931 (SVM) | 0.969 (SVM) | — |
| Descriptor | Level 1 | Level 2 | Level 3 |
|---|---|---|---|
| WLD + | WLD + MTS + | ||
| BGC1 | 0.845 (SVM) | 0.877 (SVM) | 0.897 (SVM) |
| BGC2 | 0.911 (SVM) | 0.954 (SVM) | 0.957 (SVM) |
| BGC3 | 0.843 (SVM) | 0.863 (RC) | 0.877 (SVM) |
| GaborLBP | 0.783 (SVM) | 0.849 (Bagging) | 0.869 (Bagging) |
| GLCM | 0.909 (SVM) | 0.92 (SVM) | 0.923 (SVM) |
| HOG | 0.846 (KNN) | 0.923 (SVM) | 0.909 (SVM) |
| LBP | 0.831 (SVM) | 0.886 (Bagging) | 0.889 (Bagging) |
| LQP | 0.897 (SVM) | 0.929 (SVM) | 0.931 (SVM) |
| LTP | 0.9 (SVM) | 0.951 (SVM) | 0.954 (SVM) |
| MTS | 0.903 (SVM) | 0.96 (SVM) | — |
| STU1 | 0.921 (SVM) | 0.94 (SVM) | 0.949 (SVM) |
| STU2 | 0.917 (SVM) | 0.929 (SVM) | 0.937 (SVM) |
| WLD | 0.94 (RF) | — | — |
| Descriptor | Level 1 | Level 2 | Level 3 | Level 4 | Level 5 | Level 6 |
|---|---|---|---|---|---|---|
| D | D\ | D\ GaborLBP + | D\ GaborLBP + HOG + | D\ GaborLBP + HOG + BGC1 + | D\ GaborLBP + HOG + BGC1 + LBP + | |
| BGC1 | 0.917 (SVM) | 0.92 (SVM) | 0.923 (SVM) | 0.929 (SVM) | — | — |
| BGC2 | 0.914 (SVM) | 0.92 (SVM) | 0.92 (RF) | 0.937 (SVM) | 0.931 (SVM) | |
| BGC3 | 0.917 (SVM) | 0.92 (SVM) | 0.929 (SVM) | 0.934 (SVM) | 0.937 (SVM) | |
| LBP | 0.914 (SVM) | 0.92 (SVM) | 0.926 (RF) | 0.937 (SVM) | — | |
| GaborLBP | 0.92 (SVM) | — | — | — | — | |
| GLCM | 0.914 (SVM) | 0.914 (SVM) | 0.92 (SVM) | 0.929 (SVM) | 0.923 (SVM) | |
| HOG | 0.903 (SVM) | 0.923 (SVM) | — | — | — | |
| LQP | 0.917 (RF) | 0.92 (SVM) | 0.923 (SVM) | 0.923 (SVM) | 0.934 (SVM) | |
| LTP | 0.909 (SVM) | 0.92 (SVM) | 0.92 (RF) | 0.926 (SVM) | 0.929 (SVM) | |
| MTS | 0.914 (SVM) | 0.92 (SVM) | 0.923 (SVM) | 0.929 (SVM) | 0.931 (SVM) | |
| STU1 | 0.917 (SVM) | 0.92 (SVM) | 0.923 (RF) | 0.923 (SVM) | 0.926 (SVM) | |
| STU2 | 0.914 (SVM) | 0.92 (SVM) | 0.926 (RF) | 0.931 (SVM) | 0.926 (SVM) | |
| WLD | 0.914 (SVM) | 0.891 (SVM) | 0.82 (RF) | 0.834 (RF) | 0.934 (RF) |
| Descriptor | Level 1 | Level 2 | Level 3 | Level 4 |
|---|---|---|---|---|
| D | D \ | D \ LBP + | D \ LBP + STU1 + | |
| BGC1 | 0.943 (SVM) | 0.95 (SVM) | 0.951 (SVM) | 0.949 (SVM) |
| BGC2 | 0.946 (SVM) | 0.951 (SVM) | 0.954 (SVM) | |
| BGC3 | 0.949 (SVM) | 0.95 (SVM) | 0.945 (SVM) | |
| LBP | 0.951 (SVM) | — | — | |
| GaborLBP | 0.946 (SVM) | 0.951 (RF) | 0.949 (RF) | |
| GLCM | 0.937 (SVM) | 0.937 (SVM) | 0.94 (SVM) | |
| HOG | 0.94 (SVM) | 0.943 (SVM) | 0.946 (SVM) | |
| LQP | 0.946 (RF) | 0.946 (SVM) | 0.946 (SVM) | |
| LTP | 0.946 (SVM) | 0.951 (SVM) | 0.949 (SVM) | |
| MTS | 0.946 (SVM) | 0.951 (SVM) | 0.954 (SVM) | |
| STU1 | 0.946 (SVM) | 0.954 (SVM) | — | |
| STU2 | 0.949 (SVM) | 0.95 (SVM) | 0.949 (SVM) | |
| WLD | 0.946 (SVM) | 0.946 (SVM) | 0.946 (SVM) |
| Descriptor | Level 1 | Level 2 | Level 3 | Level 4 | Level 5 |
|---|---|---|---|---|---|
| D | D\ | D\ LBP + | D\ LBP + GaborLBP + | D\ LBP + GaborLBP + BGC3 + | |
| BGC1 | 0.92 (SVM) | 0.914 (SVM) | 0.923 (SVM) | 0.943 (SVM) | 0.931 (SVM) |
| BGC2 | 0.909 (SVM) | 0.929 (SVM) | 0.934 (SVM) | 0.943 (SVM) | |
| BGC3 | 0.917 (SVM) | 0.926 (SVM) | 0.946 (SVM) | — | |
| LBP | 0.926 (SVM) | — | — | — | |
| GaborLBP | 0.92 (SVM) | 0.934 (RF) | — | — | |
| GLCM | 0.894 (SVM) | 0.9 (SVM) | 0.917 (SVM) | 0.929 (SVM) | |
| HOG | 0.903 (SVM) | 0.914 (SVM) | 0.934 (SVM) | 0.946 (SVM) | |
| LQP | 0.906 (RF) | 0.917 (SVM) | 0.931 (SVM) | 0.934 (SVM) | |
| LTP | 0.909 (SVM) | 0.914 (SVM) | 0.929 (SVM) | 0.934 (SVM) | |
| MTS | 0.909 (SVM) | 0.937 (SVM) | 0.929 (SVM) | 0.946 (SVM) | |
| STU1 | 0.906 (SVM) | 0.929 (SVM) | 0.934 (SVM) | 0.937 (SVM) | |
| STU2 | 0.914 (SVM) | 0.929 (SVM) | 0.937 (SVM) | 0.943 (SVM) | |
| WLD | 0.906 (SVM) | 0.923 (SVM) | 0.931 (SVM) | 0.943 (SVM) |
| Method | F1 |
|---|---|
| Xception | 0.35 |
| Siamese | 0.89 |
| Our proposal (FSS) | 0.97 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Merino, I.; Azpiazu, J.; Remazeilles, A.; Sierra, B. Histogram-Based Descriptor Subset Selection for Visual Recognition of Industrial Parts. Appl. Sci. 2020, 10, 3701. https://doi.org/10.3390/app10113701
Merino I, Azpiazu J, Remazeilles A, Sierra B. Histogram-Based Descriptor Subset Selection for Visual Recognition of Industrial Parts. Applied Sciences. 2020; 10(11):3701. https://doi.org/10.3390/app10113701
Chicago/Turabian StyleMerino, Ibon, Jon Azpiazu, Anthony Remazeilles, and Basilio Sierra. 2020. "Histogram-Based Descriptor Subset Selection for Visual Recognition of Industrial Parts" Applied Sciences 10, no. 11: 3701. https://doi.org/10.3390/app10113701
APA StyleMerino, I., Azpiazu, J., Remazeilles, A., & Sierra, B. (2020). Histogram-Based Descriptor Subset Selection for Visual Recognition of Industrial Parts. Applied Sciences, 10(11), 3701. https://doi.org/10.3390/app10113701