Skeleton-Based Dynamic Hand Gesture Recognition Using an Enhanced Network with One-Shot Learning

Abstract
1. Introduction
- Section 2 details the related work of skeleton-based dynamic hand gesture recognition and one-shot learning.
- The GREN network is introduced in Section 3.
- The experiments of skeleton-based dynamic hand gesture recognition are explained in detail in Section 4.
- In Section 5, results and discussion are presented.
- The conclusions are given in Section 6.
2. Related Work
2.1. Skeleton-Based Dynamic Hand Gesture Recognition
2.2. One-Shot Learning
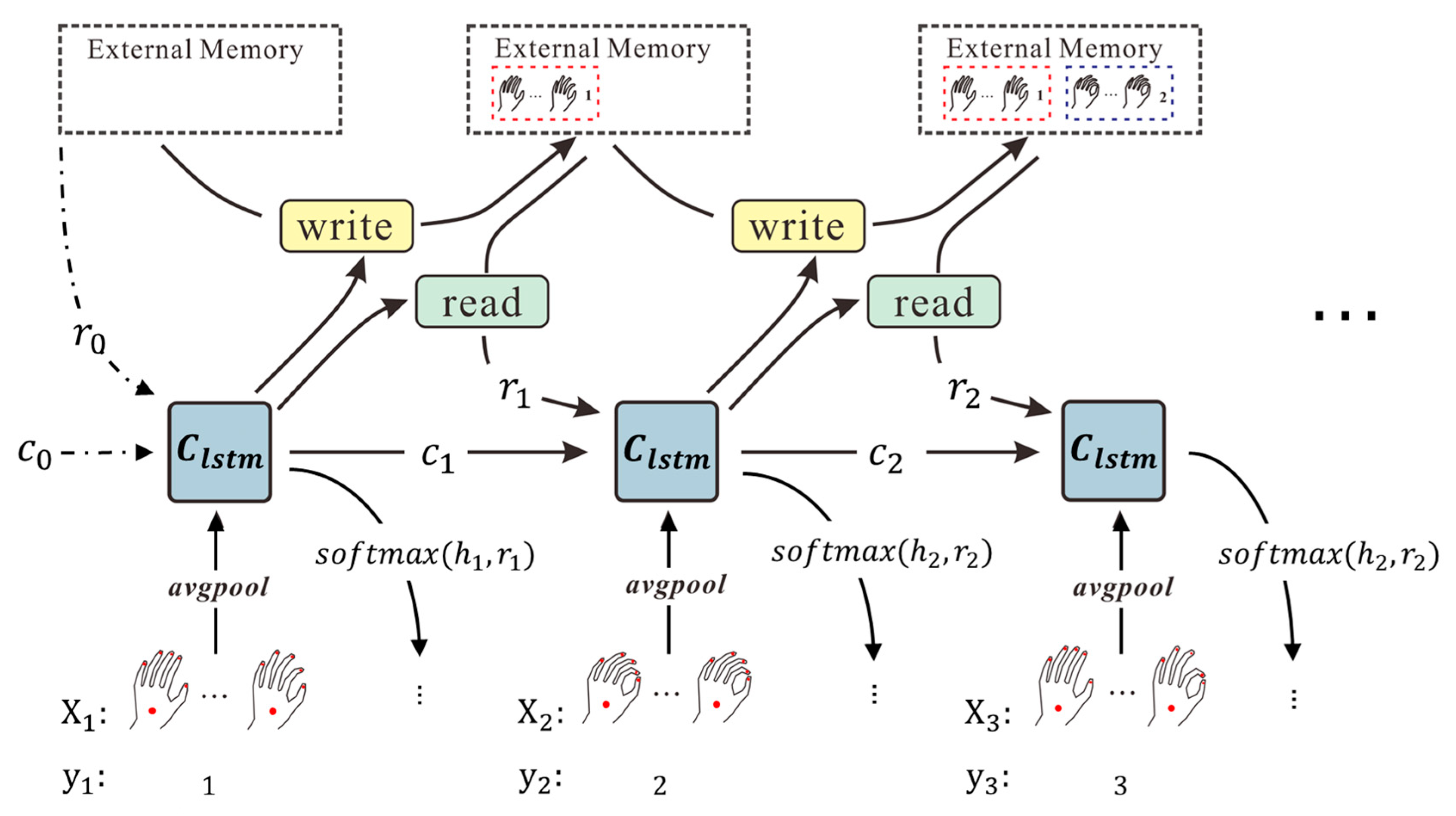
3. Dynamic Hand Gesture Recognition with the GREN Network
| Algorithm 1: GREN | |
| Input: Given N samples belonging to C classes with Sample-classes ; | |
| Output: A softmax layer for class prediction; | |
| 1 | Initialization: |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | |
| 8 | |
| 9 | |
| 10 | |
| 11 | |
| 12 | |
| 13 | |
| 14 | |
| 15 | Memory Retrieval: |
| 16 | |
| 17 | |
| 18 | ; |
| 19 | Memory Encoding (LRUA): |
| 20 | |
| 21 | |
| 22 | |
| 23 | |
| 24 | |
| 25 | ; |
| 26 | |
| 27 | |
| 28 | |
| 29 | |
| 30 | ; |
| 31 | |
| 32 | |
| 33 | |
| 34 | |
| 35 | |
| 36 | |
| 37 | |
| 38 | end |
4. Experiments
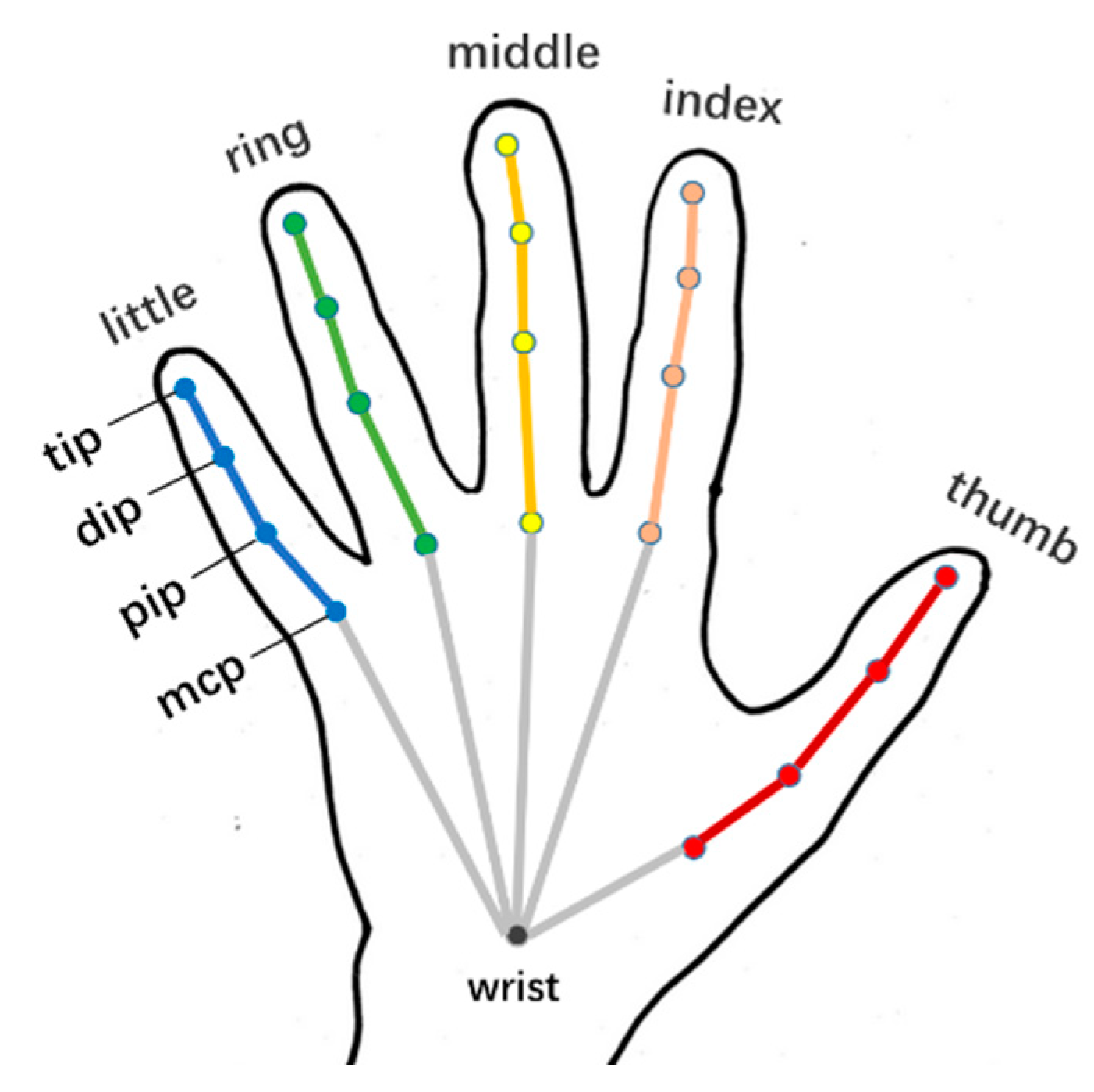
4.1. Datasets
4.1.1. DHGD Hand Gesture Dataset
4.1.2. MSRA Hand Gesture Dataset
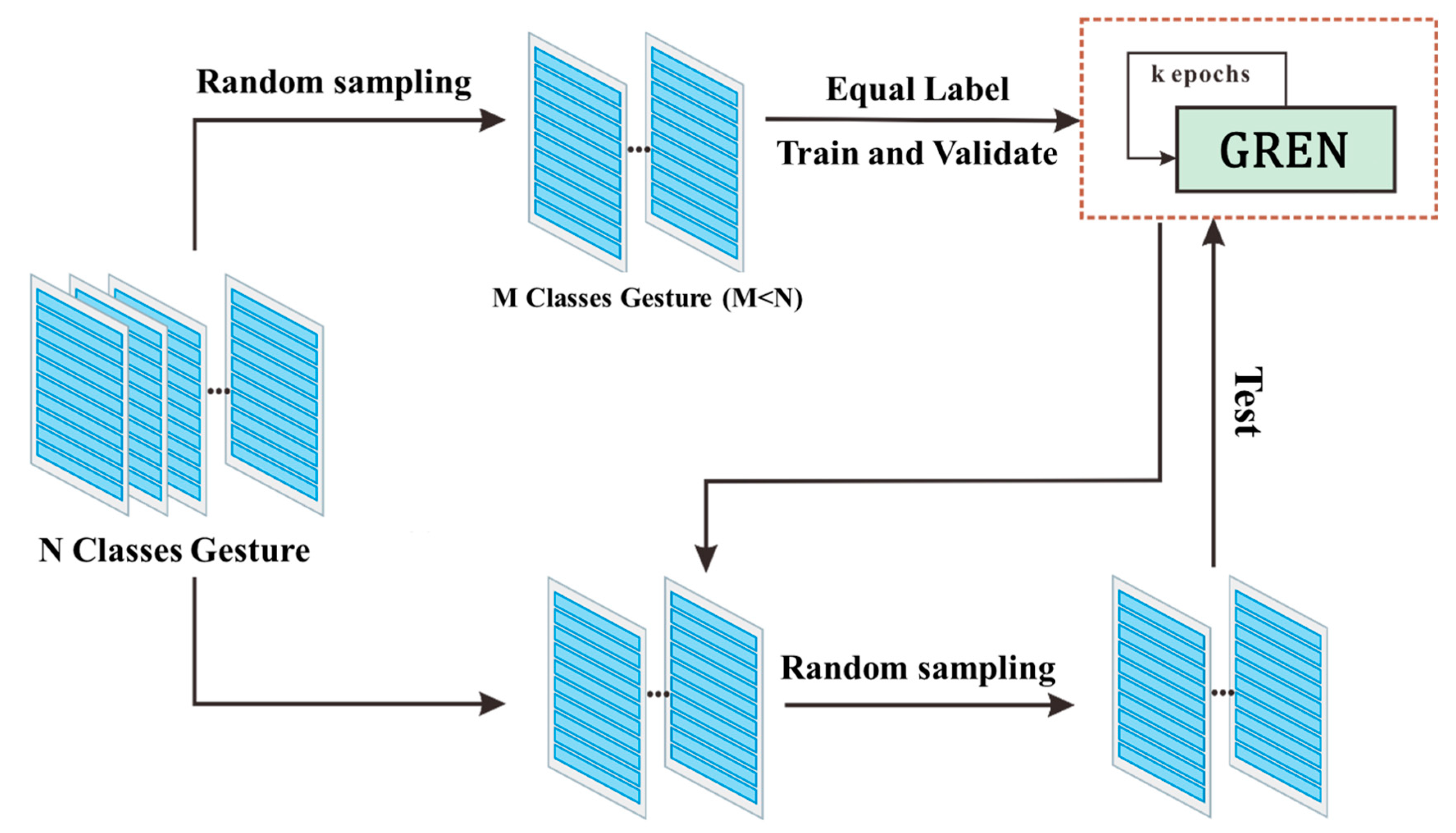
4.2. Experimental Setup
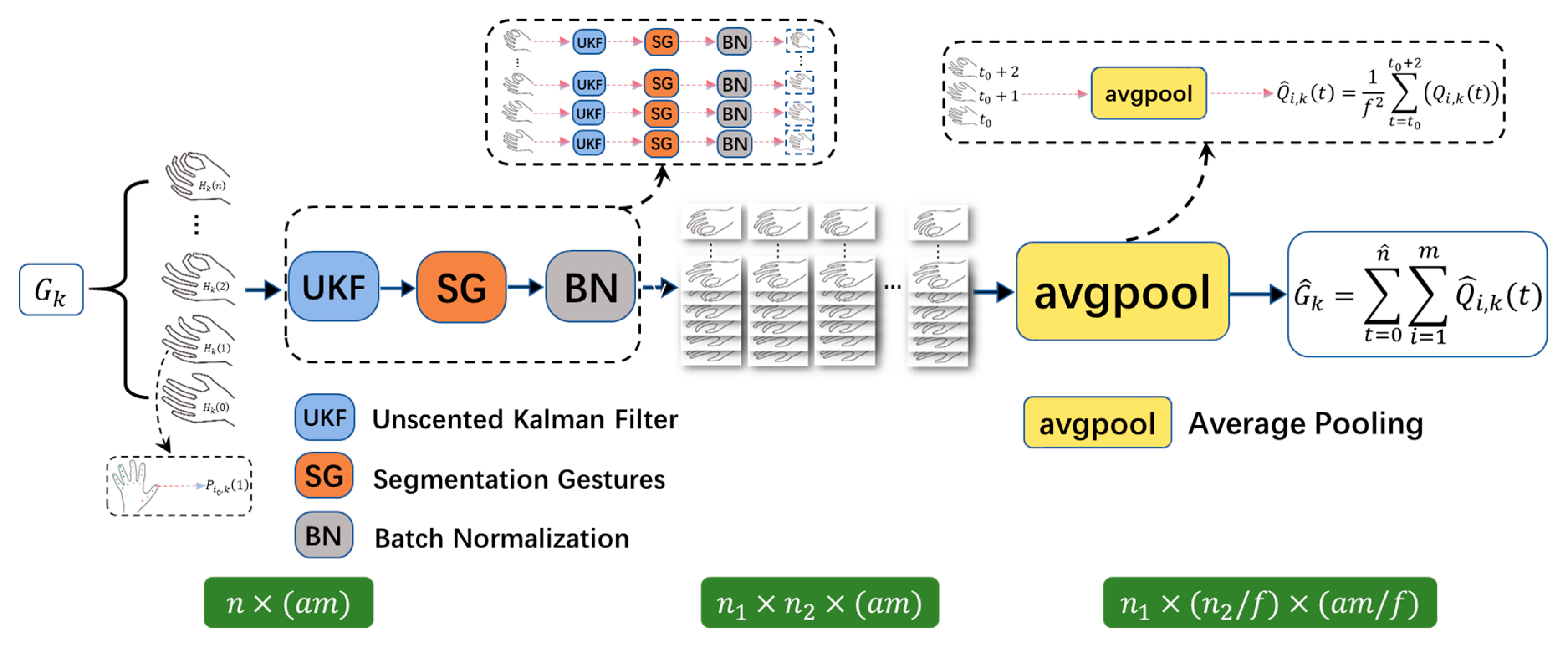
4.2.1. Data Pre-Process
4.2.2. Implementation
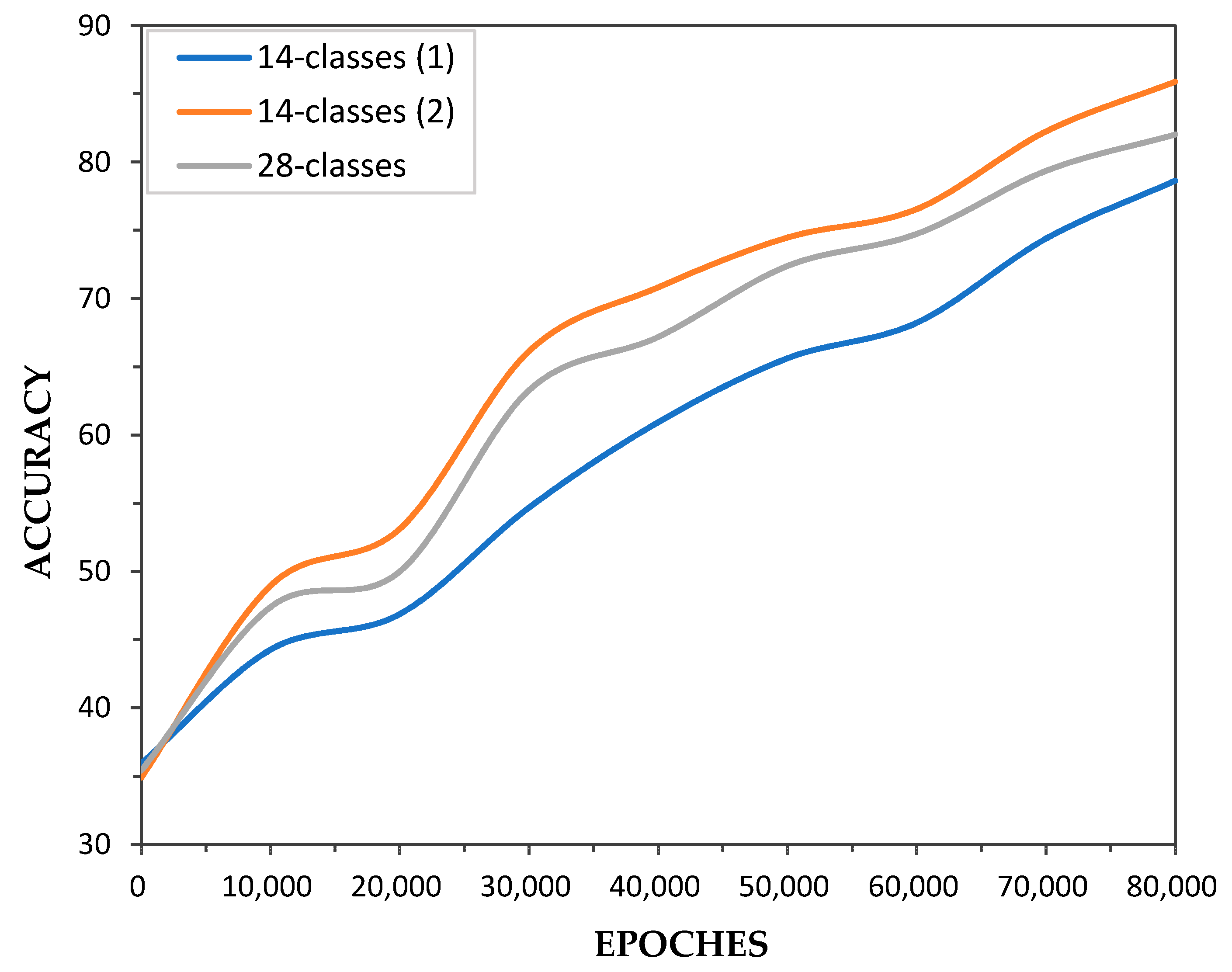
5. Results and Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Si, C.; Chen, W.; Wang, W.; Wang, L.; Tan, T. An attention enhanced graph convolutional lstm network for skeleton-based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 1227–1236. [Google Scholar]
- Lv, Z.; Halawani, A.; Feng, S.; Ur Réhman, S.; Li, H. Touch-less interactive augmented reality game on vision-based wearable device. Pers. Ubiquitous Comput. 2015, 19, 551–567. [Google Scholar] [CrossRef]
- Liu, J.; Wang, G.; Duan, L.; Abdiyeva, K.; Kot, A.C. Skeleton-based human action recognition with global context-aware attention lstm networks. IEEE Trans. Image Process. 2018, 27, 1586–1599. [Google Scholar] [CrossRef] [PubMed]
- Nie, Q.; Wang, J.; Wang, X.; Liu, Y. View-invariant human action recognition based on a 3d bio-constrained skeleton model. IEEE Trans. Image Process. 2019, 28, 3959–3972. [Google Scholar] [CrossRef] [PubMed]
- Lv, Z.; Halawani, A.; Feng, S.; Li, H.; Réhman, S.U. Multimodal hand and foot gesture interaction for handheld devices. ACM Trans. Multimed. Comput. Commun. Appl. 2014, 11, 10. [Google Scholar] [CrossRef]
- Liu, X.; Su, Y. Tracking skeletal fusion feature for one shot learning gesture recognition. In Proceedings of the International Conference on Image, Vision and Computing, Chengdu, China, 2–4 June 2017; pp. 194–200. [Google Scholar] [CrossRef]
- Zhu, W.; Lan, C.; Xing, J.; Zeng, W.; Li, Y.; Shen, L.; Xie, X. Co-occurrence feature learning for skeleton based action recognition using regularized deep LSTM networks. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 3697–3703. [Google Scholar]
- Liu, J.; Shahroudy, A.; Xu, D.; Wang, G. Spatio-temporal lstm with trust gates for 3d human action recognition. Proceedings of 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 816–833. [Google Scholar] [CrossRef]
- Santoro, A.; Bartunov, S.; Botvinick, M.; Wierstra, D.; Lillicrap, T. Meta-learning with memory-augmented neural networks. In Proceeding of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1842–1850. [Google Scholar]
- Deng, L.; Yu, D. Deep learning: Methods and applications. Found. Trends Signal Process. 2014, 7, 197–387. [Google Scholar] [CrossRef]
- Besak, D.; Bodeker, D. Hard thermal loops for soft or collinear external momenta. J. High Energy Phys. 2010, 5, 7. [Google Scholar] [CrossRef]
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive subgradient methods for online learning and stochastic optimization. J. Mach. Learn. Res. 2011, 12, 2121–2159. [Google Scholar]
- Howard, J.; Ruder, S. Universal Language Model Fine-tuning for Text Classification. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 328–339. [Google Scholar] [CrossRef]
- Bengio, Y. Deep learning of representations for unsupervised and transfer learning. In Proceedings of the ICML Workshop on Unsupervised and Transfer Learning, Edinburgh, UK, 26 June–1 July 2012; pp. 17–36. [Google Scholar]
- Kirkpatrick, J.; Pascanu, R.; Rabinowitz, N.C. Overcoming catastrophic forgetting in neural networks. Proc. Natl. Acad. Sci. USA 2017, 114, 3521–3526. [Google Scholar] [CrossRef]
- Greve, R.; Jacobsen, E.J.; Risi, S. Evolving neural turing machines for reward-based learning. In Proceedings of the Genetic and Evolutionary Computation Conference, Denver, CO, USA, 20–24 July 2016; pp. 117–124. [Google Scholar] [CrossRef]
- Li, Z.; Hoiem, D. Learning without forgetting. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 2935–2947. [Google Scholar] [CrossRef]
- De Smedt, Q.; Wannous, H.; Vandeborre, J.P.; Guerry, J.; LeSaux, B.; Filliat, D. 3D hand gesture recognition using a depth and skeletal dataset: SHREC’17 track. In Proceedings of the Workshop on 3D Object Retrieval. Eurographics Association, Lyon, France, 23–24 April 2017; pp. 33–38. [Google Scholar] [CrossRef]
- Sun, X.; Wei, Y.; Liang, S.; Tang, X.; Sun, J. Cascaded hand pose regression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 824–832. [Google Scholar] [CrossRef]
- Tan, D.J.; Cashman, T.; Taylor, J.; Fitzgibbon, A.; Tarlow, D.; Khamis, S.; Shotton, J.; Izadi, S. Fits like a glove: Rapid and reliable hand shape personalization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5610–5619. [Google Scholar] [CrossRef]
- Supančič, J.S.; Rogez, G.; Yang, Y.; Shotton, J.; Ramanan, D. Depth-based hand pose estimation: Methods, data, and challenges. Int. J. Comput. Vis. 2018, 126, 1180–1198. [Google Scholar] [CrossRef]
- Lv, Z. Wearable smartphone: Wearable hybrid framework for hand and foot gesture interaction on smartphone. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Sydney, Australia, 1–8 December 2013; pp. 436–443. [Google Scholar] [CrossRef]
- Oberweger, M.; Wohlhart, P.; Lepetit, V. Training a feedback loop for hand pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3316–3324. [Google Scholar] [CrossRef]
- Tang, D.; Taylor, J.; Kohli, P.; Keskin, C.; Kim, T.K.; Shotton, J. Opening the black box: Hierarchical sampling optimization for estimating human hand pose. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3325–3333. [Google Scholar] [CrossRef]
- Ye, Q.; Yuan, S.; Kim, T.K. Spatial attention deep net with partial pso for hierarchical hybrid hand pose estimation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 346–361. [Google Scholar] [CrossRef]
- Guo, H.; Wang, G.; Chen, X.; Zhang, C.; Qiao, F.; Yang, H. Region ensemble network: Improving convolutional network for hand pose estimation. In Proceedings of the IEEE International Conference on Image Processing, Beijing, China, 17–20 September 2017; pp. 4512–4516. [Google Scholar] [CrossRef]
- Chen, X.; Wang, G.; Guo, H.; Zhang, C. Pose guided structured region ensemble network for cascaded hand pose estimation. Neurocomputing 2019, 395, 138–149. [Google Scholar] [CrossRef]
- Wang, G.; Chen, X.; Guo, H.; Zhang, C. Region ensemble network: Towards good practices for deep 3d hand pose estimation. J. Visual Commun. Image Represent. 2018, 55, 404–414. [Google Scholar] [CrossRef]
- Chen, X.; Wang, G.; Guo, H.; Zhang, C.; Wang, H.; Zhang, L. MFA-Net: Motion feature augmented network for dynamic hand gesture recognition from skeletal data. Sensors 2019, 19, 239. [Google Scholar] [CrossRef]
- Chen, X.; Guo, H.; Wang, G.; Zhang, L. Motion feature augmented recurrent neural network for skeleton-based dynamic hand gesture recognition. In Proceedings of the IEEE International Conference on Image Processing, Beijing, China, 17–20 September 2017; pp. 2881–2885. [Google Scholar] [CrossRef]
- Chin-Shyurng, F.; Lee, S.E.; Wu, M.L. Real-time musical conducting gesture recognition based on a dynamic time warping classifier using a single-depth camera. Appl. Sci. 2019, 9, 528. [Google Scholar] [CrossRef]
- Ding, J.; Chang, C.W. An adaptive hidden Markov model-based gesture recognition approach using Kinect to simplify large-scale video data processing for humanoid robot imitation. Multimed. Tools Appl. 2016, 75, 15537–15551. [Google Scholar] [CrossRef]
- Kumar, P.; Saini, R.; Roy, P.P.; Dogra, D.P. A position and rotation invariant framework for sign language recognition (SLR) using Kinect. Multimed. Tools Appl. 2018, 77, 8823–8846. [Google Scholar] [CrossRef]
- Mazhar, O.; Navarro, B.; Ramdani, S.; Passama, R.; Cherubini, A. A real-time human-robot interaction framework with robust background invariant hand gesture detection. Robot. Comput. Integr. Manuf. 2019, 60, 34–48. [Google Scholar] [CrossRef]
- Lin, C.; Lin, X.; Xie, Y.; Liang, Y. Abnormal gesture recognition based on multi-model fusion strategy. Mach. Vision Appl. 2019, 30, 889–900. [Google Scholar] [CrossRef]
- Nunez, J.C.; Cabido, R.; Pantrigo, J.J.; Montemayor, A.S.; Velez, J.F. Convolutional neural networks and long short-term memory for skeleton-based human activity and hand gesture recognition. Pattern Recognit. 2018, 76, 80–94. [Google Scholar] [CrossRef]
- Lake, B.M.; Salakhutdinov, R.; Tenenbaum, J.B. Human-level concept learning through probabilistic program induction. Science 2015, 350, 1332–1338. [Google Scholar] [CrossRef] [PubMed]
- Snell, J.; Swersky, K.; Zemel, R. Prototypical networks for few-shot learning. Adv. Neural Inf. Process. Syst. 2017, 4077–4087. [Google Scholar]
- Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese neural networks for one-shot image recognition. In Proceedings of the ICML Deep Learning Workshop, Lille, France, 10–11 July 2015; Volume 2. [Google Scholar]
- Cai, Q.; Pan, Y.; Yao, T.; Yan, C.; Mei, T. Memory matching networks for one-shot image recognition. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- Ravi, S.; Larochelle, H. Optimization as a model for few-shot learning. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Ma, C.; Wang, A.; Chen, G.; Xu, C. Hand joints-based gesture recognition for noisy dataset using nested interval unscented Kalman filter with LSTM network. Visual Comput. 2018, 34, 1053–1063. [Google Scholar] [CrossRef]
- Pontes, F.J.; Amorim, G.F.; Balestrassi, P.P.; De Paiva, A.P.; Ferreira, J.R. Design of experiments and focused grid search for neural network parameter optimization. Neurocomputing 2016, 186, 22–34. [Google Scholar] [CrossRef]
- Oreifej, O.; Liu, Z. Hon4d: Histogram of oriented 4d normals for activity recognition from depth sequences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 716–723. [Google Scholar] [CrossRef]
- Devanne, M.; Wannous, H.; Berretti, S.; Pala, P.; Daoudi, M.; Del Bimbo, A. 3-d human action recognition by shape analysis of motion trajectories on riemannian manifold. IEEE Trans. Cybern. 2014, 45, 1340–1352. [Google Scholar] [CrossRef] [PubMed]
- Ohn-Bar, E.; Trivedi, M. Joint angles similarities and HOG2 for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Portland, OR, USA, 23–28 June 2013; pp. 465–470. [Google Scholar] [CrossRef]
- De Smedt, Q.; Wannous, H.; Vandeborre, J.P. Skeleton-based dynamic hand gesture recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1–9. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name of the Gesture | Type of the Gesture | Type of the Gesture |
|---|---|---|
| 1 | Grab | Fine |
| 2 | Tap | Coarse |
| 3 | Expand | Fine |
| 4 | Pinch | Fine |
| 5 | Rotation Clockwise | Fine |
| 6 | Rotation Counter Clockwise | Fine |
| 7 | Swipe Right | Coarse |
| 8 | Swipe Left | Coarse |
| 9 | Swipe Up | Coarse |
| 10 | Swipe Down | Coarse |
| 11 | Swipe X | Coarse |
| 12 | Swipe + | Coarse |
| 13 | Swipe V | Coarse |
| 14 | Shake | Coarse |
| Type | LSTM (%) | GREN (%) | |
|---|---|---|---|
| 14-classes | 1 | 75.18 | 78.65 |
| 2 | 79.82 | 85.90 | |
| 28-classes | both | 76.89 | 82.03 |
| Learning | Methods | Accuracy 14-Classes Gestures | Accuracy 28-Classes Gestures |
|---|---|---|---|
| Large-samples | HON4D: Histogram of Oriented 4D Normals for Activity Recognition from Depth Sequences [46] | 75.53% | 74.03% |
| 3-D Human Action Recognition by Shape Analysis Of Motion Trajectories on Riemannian Manifold [47] | 79.61% | 62.00% | |
| Joint Angles Similarities and HOG2 for Action Recognition [48] | 80.85% | 76.53% | |
| Key Frames with Convolutional Neural Network [18] | 82.90% | 71.90% | |
| Skeleton-Based Dynamic Hand Gesture Recognition [49] | 83.07% | 79.14% | |
| NIUKF-LSTM [44] | 84.92% | 80.44% | |
| SL-Fusion-Average [36] | 85.46% | 74.19% | |
| MFA-Net [29] | 85.75% | 81.04% | |
| One-shot | GREN | 82.29% | 82.03% |
| Type | LSTM (%) | GREN (%) |
|---|---|---|
| 17-classes | 72.92 | 79.17 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, C.; Zhang, S.; Wang, A.; Qi, Y.; Chen, G. Skeleton-Based Dynamic Hand Gesture Recognition Using an Enhanced Network with One-Shot Learning. Appl. Sci. 2020, 10, 3680. https://doi.org/10.3390/app10113680
Ma C, Zhang S, Wang A, Qi Y, Chen G. Skeleton-Based Dynamic Hand Gesture Recognition Using an Enhanced Network with One-Shot Learning. Applied Sciences. 2020; 10(11):3680. https://doi.org/10.3390/app10113680
Chicago/Turabian StyleMa, Chunyong, Shengsheng Zhang, Anni Wang, Yongyang Qi, and Ge Chen. 2020. "Skeleton-Based Dynamic Hand Gesture Recognition Using an Enhanced Network with One-Shot Learning" Applied Sciences 10, no. 11: 3680. https://doi.org/10.3390/app10113680
APA StyleMa, C., Zhang, S., Wang, A., Qi, Y., & Chen, G. (2020). Skeleton-Based Dynamic Hand Gesture Recognition Using an Enhanced Network with One-Shot Learning. Applied Sciences, 10(11), 3680. https://doi.org/10.3390/app10113680