Comparing the Quality and Speed of Sentence Classification with Modern Language Models




Abstract
:1. Introduction
2. General Framework
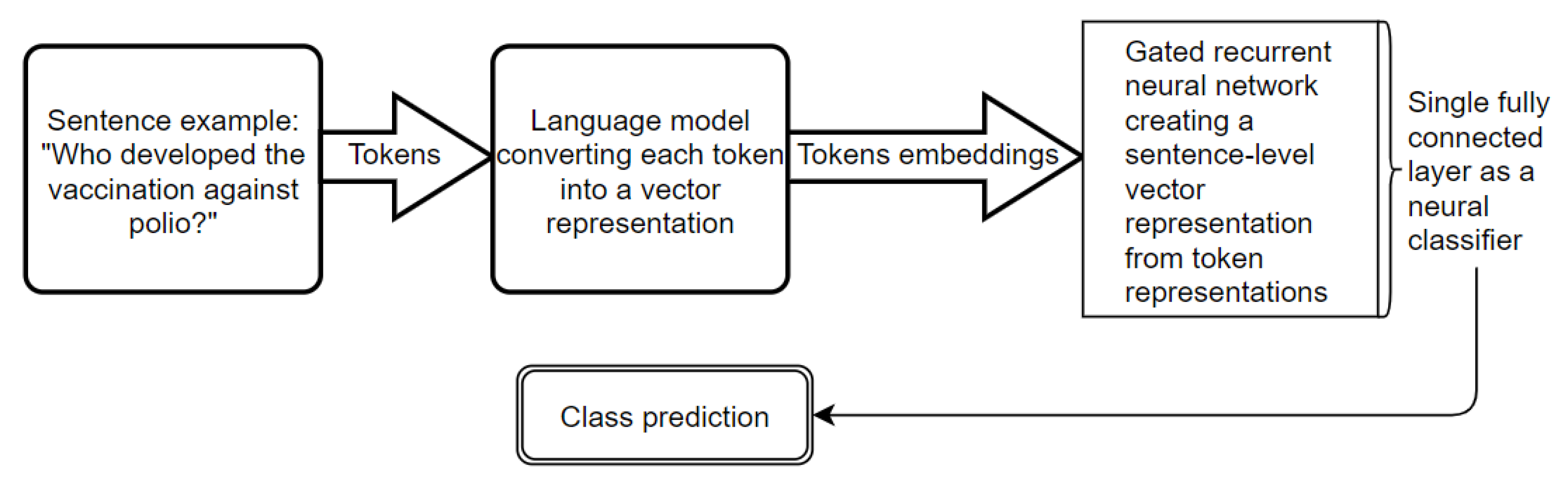
2.1. Text Classification
2.2. Selection of the LMs
2.3. Data Used for Benchmarking
2.4. Performance Metrics
3. Methods and Procedures
3.1. Training and Testing Procedure
3.2. Statistics
3.3. Preliminary Study to Identify Framework Parameters and the Training Regimen
3.4. Principal Component Analysis for Visualization of the LMs’ Quality
4. Results and Discussion
4.1. Preliminary Study
4.2. Results of the Main Study
5. Conclusions
6. Study Limitations and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Pennington, J.; Socher, R.; Manning, C. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Vosoughi, S.; Vijayaraghavan, P.; Roy, D. Tweet2vec: Learning tweet embeddings using character-level cnn-lstm encoder-decoder. In Proceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval, Pisa, Italy, 17–21 July 2016; pp. 1041–1044. [Google Scholar]
- Santos, C.D.; Zadrozny, B. Learning character-level representations for part-of-speech tagging. In Proceedings of the 31st International Conference on Machine Learning (ICML-14), Bejing, China, 22–24 June 2014; pp. 1818–1826. [Google Scholar]
- Santos, C.N.D.; Guimaraes, V. Boosting named entity recognition with neural character embeddings. arXiv 2015, arXiv:1505.05008. [Google Scholar]
- Prabhu, A.; Joshi, A.; Shrivastava, M.; Varma, V. Towards sub-word level compositions for sentiment analysis of hindi-english code mixed text. arXiv 2016, arXiv:1611.00472. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. arXiv 2018, arXiv:1802.05365. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.; Le, Q.V. XLNet: Generalized Autoregressive Pretraining for Language Understanding. arXiv 2019, arXiv:1906.08237. [Google Scholar]
- Beloki, Z.; Artola, X.; Soroa, A. A scalable architecture for data-intensive natural language processing. Nat. Lang. Eng. 2017, 23, 709–731. [Google Scholar] [CrossRef]
- Akbik, A.; Bergmann, T.; Blythe, D.; Rasul, K.; Schweter, S.; Vollgraf, R. Flair: An easy-to-use framework for state-of-the-art nlp. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (Demonstrations), Minneapolis, MN, USA, 2–7 June 2019; pp. 54–59. [Google Scholar]
- Gardner, M.; Grus, J.; Neumann, M.; Tafjord, O.; Dasigi, P.; Liu, N.; Zettlemoyer, L. Allennlp: A deep semantic natural language processing platform. arXiv 2018, arXiv:1803.07640. [Google Scholar]
- Cer, D.; Yang, Y.; Kong, S.Y.; Hua, N.; Limtiaco, N.; John, R.S.; Constant, N.; Guajardo-Cespedes, M.; Yuan, S.; Tar, C.; et al. Universal sentence encoder. arXiv 2018, arXiv:1803.11175. [Google Scholar]
- Perone, C.S.; Silveira, R.; Paula, T.S. Evaluation of sentence embeddings in downstream and linguistic probing tasks. arXiv 2018, arXiv:1806.06259. [Google Scholar]
- Conneau, A.; Kiela, D.; Schwenk, H.; Barrault, L.; Bordes, A. Supervised learning of universal sentence representations from natural language inference data. arXiv 2017, arXiv:1705.02364. [Google Scholar]
- Talman, A.; Yli-Jyrä, A.; Tiedemann, J. Sentence Embeddings in NLI with Iterative Refinement Encoders. arXiv 2018, arXiv:1808.08762. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Roth, D. Learning question classifiers. In Proceedings of the 19th international Conference on Computational linguistics-Volume 1, Taipei, Taiwan,, 24 August–1 September 2002; Association for Computational Linguistics: Stroudsburg, PA, USA, 2002; pp. 1–7. [Google Scholar]
- Fiok, K. Meetings Preliminary Data Set. 2019. Available online: https://github.com/krzysztoffiok/MPD-data set (accessed on 15 January 2020).
- Xu, Q.S.; Liang, Y.Z. Monte Carlo cross validation. Chemometr. Intell. Lab. Syst. 2001, 56, 1–11. [Google Scholar] [CrossRef]
- Akbik, A.; Blythe, D.; Vollgraf, R. Contextual string embeddings for sequence labeling. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 1638–1649. [Google Scholar]
- Mikolov, T.; Grave, E.; Bojanowski, P.; Puhrsch, C.; Joulin, A. Advances in pre-training distributed word representations. arXiv 2017, arXiv:1712.09405. [Google Scholar]
- Heinzerling, B.; Strube, M. Bpemb: Tokenization-free pre-trained subword embeddings in 275 languages. arXiv 2017, arXiv:1710.02187. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A robustly optimized BERT pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Chelba, C.; Mikolov, T.; Schuster, M.; Ge, Q.; Brants, T.; Koehn, P.; Robinson, T. One billion word benchmark for measuring progress in statistical language modeling. arXiv 2013, arXiv:1312.3005. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Matthews, B.W. Comparison of the predicted and observed secondary structure of T4 phage lysozyme. Biochim. Biophys. Acta (BBA)-Protein Struct. 1975, 405, 442–451. [Google Scholar] [CrossRef]
- Chicco, D. Ten quick tips for machine learning in computational biology. BioData Min. 2017, 10, 35. [Google Scholar] [CrossRef]
- Dubitzky, W.; Granzow, M.; Berrar, D.P. (Eds.) Fundamentals of Data Mining in Genomics and Proteomics; Springer Science & Business Media: New York, NY, USA, 2007. [Google Scholar]
- Shapiro, S.S.; Wilk, M.B. An analysis of variance test for normality (complete samples). Biometrika 1965, 52, 591–611. [Google Scholar] [CrossRef]
- Murphy, K.P. Machine Learning: A Probabilistic Perspective; MIT Press: Cambridge, MA, USA, 2012; p. 247. ISBN 978-0-262-01802-9. [Google Scholar]
- Liu, N.F.; Gardner, M.; Belinkov, Y.; Peters, M.; Smith, N.A. Linguistic knowledge and transferability of contextual representations. arXiv 2019, arXiv:1903.08855. [Google Scholar]
- Shen, Z.; Liu, Z.; Li, J.; Jiang, Y.G.; Chen, Y.; Xue, X. Object detection from scratch with deep supervision. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 398–412. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Li, Y.; Chen, Y.; Wang, N.; Zhang, Z. Scale-aware trident networks for object detection. arXiv 2019, arXiv:1901.01892. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| LM | Publication | Comment |
|---|---|---|
| Glove | [1] | Static 100-dimension word embeddings, vocabulary size 400 k |
| Fast Text (wiki-news) | [2] | Static 300-dimension word embeddings, sub-word information, 1 M vocabulary size |
| Byte Pair Embeddings | [22] | Static 50-dimension sub-word embeddings, lightweight model, 100 k vocabulary size |
| Flair News | [20] | Combination of forward- and backward-trained models, each creating 2048-dimension word embeddings; context-aware models trained on a 1-billion-word benchmark [24] |
| Flair News Fast | [20] | 1024-dimension version of Flair embeddings |
| Elmo Original | [7] | Contextualized 3072-dimension word embeddings, “original” version, 93.6 M parameters |
| BERT uncased large, layers −1, −2, −3, −4 | [8] | Contextualized 4096-dimension embeddings, 340 M parameters, default output layers |
| BERT uncased large, layers 0–24, scalar mix | [8] | Contextualized 4096-dimension embeddings, 340 M parameters, scalar mix of all output layers |
| RoBERTa base layer −1 | [23] | Contextualized 768-dimension word embeddings, base version, default output layer, 125 M parameters |
| RoBERTa large layer −1 | [23] | Contextualized 1024-dimension word embeddings, large version, default output layer, 355 M parameters |
| RoBERTa large, layers 0–24, scalar Mix | [23] | Contextualized 1024-dimension word embeddings, large version with scalar mix of all output layers, 355 M parameters |
| XLNet layer 1 | [9] | Contextualized 2048-dimension word embeddings, large-case version, default output layer, 340 M parameters |
| XLNey layers 0–24, scalar Mix | [9] | Contextualized 2048-dimension word embeddings, large-case version, scalar mix of all output layers, 340 M parameters |
| DistilBert | [25] | Contextualized 768-dimension word embeddings, 66 M parameters; model obtained through a knowledge distillation concept introduced by Hinton et al. [26] |
| The Sixth Text REtrieval Conference (TREC6) | |||||||
| Class | Description | Entity | Abbreviation | Human | Location | Numerical | Total |
| Sentences (count) | 1162 | 1250 | 86 | 1223 | 835 | 896 | 5452 |
| Sentences (percent) | 21.31 | 22.93 | 1.58 | 22.43 | 15.32 | 16.43 | 100 |
| Meetings Preliminary Data Set (MPD) | |||||||
| Class | Performance Assessment | Subject | Recommendations | Time | Technical | Total | |
| Sentences (count) | 358 | 228 | 217 | 94 | 103 | 1000 | |
| Sentences (percent) | 35.8 | 22.8 | 21.7 | 9.4 | 10.3 | 100 | |
| MCC Score | Training Time (TT) | |||
|---|---|---|---|---|
| Training Regime | MPD | TREC6 | MPD | TREC6 |
| p5lr.1mlr.0001a.5 | 0.475 ± 0.042 | 0.923 ± 0.007 | 0.051 ± 0.008 | 0.362 ± 0.037 |
| p10lr.1mlr.0001a.5 | 0.477 ± 0.054 | 0.923 ± 0.01 | 0.079 ± 0.018 | 0.56 ± 0.087 |
| p15lr.1mlr.0001a.5 | 0.477 ± 0.044 | 0.925 ± 0.007 | 0.103 ± 0.011 | 0.699 ± 0.094 |
| p20lr.1mlr.0001a.5 | 0.472 ± 0.029 | 0.928 ± 0.005 | 0.145 ± 0.026 | 0.761 ± 0.057 |
| p25lr.1mlr.0001a.5 | 0.468 ± 0.03 | 0.931 ± 0.008 | 0.158 ± 0.029 | 0.91 ± 0.067 |
| p20lr.1mlr.001a.4 | 0.473 ± 0.043 | 0.928 ± 0.008 | 0.1 ± 0.02 | 0.438 ± 0.057 |
| p20lr.2mlr.01a.5 | 0.475 ± 0.056 | 0.92 ± 0.015 | 0.082 ± 0.02 | 0.367 ± 0.078 |
| p5lr.2mlr.008a.5 | 0.437 ± 0.05 | 0.92 ± 0.015 | 0.042 ± 0.01 | 0.167 ± 0.031 |
| p10lr.05mlr.001a.5 | 0.477 ± 0.055 | 0.916 ± 0.012 | 0.063 ± 0.011 | 0.359 ± 0.042 |
| p15lr.1mlr.001a.5 | 0.471 ± 0.049 | 0.929 ± 0.005 | 0.086 ± 0.01 | 0.618 ± 0.096 |
| p10lr.3mlr.01a.3 | 0.484 ± 0.027 | 0.898 ± 0.012 | 0.051 ± 0.013 | 0.119 ± 0.02 |
| p25lr.15mlr.001a.5 | 0.463 ± 0.04 | 0.934 ± 0.007 | 0.132 ± 0.025 | 0.645 ± 0.112 |
| p20lr.1mlr.002a.5 | 0.487 ± 0.046 | 0.933 ± 0.005 | 0.098 ± 0.014 | 0.269 ± 0.02 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fiok, K.; Karwowski, W.; Gutierrez, E.; Reza-Davahli, M. Comparing the Quality and Speed of Sentence Classification with Modern Language Models. Appl. Sci. 2020, 10, 3386. https://doi.org/10.3390/app10103386
Fiok K, Karwowski W, Gutierrez E, Reza-Davahli M. Comparing the Quality and Speed of Sentence Classification with Modern Language Models. Applied Sciences. 2020; 10(10):3386. https://doi.org/10.3390/app10103386
Chicago/Turabian StyleFiok, Krzysztof, Waldemar Karwowski, Edgar Gutierrez, and Mohammad Reza-Davahli. 2020. "Comparing the Quality and Speed of Sentence Classification with Modern Language Models" Applied Sciences 10, no. 10: 3386. https://doi.org/10.3390/app10103386
APA StyleFiok, K., Karwowski, W., Gutierrez, E., & Reza-Davahli, M. (2020). Comparing the Quality and Speed of Sentence Classification with Modern Language Models. Applied Sciences, 10(10), 3386. https://doi.org/10.3390/app10103386