2.2.1. Algorithm and task mapping scheme
Large fluid machinery has a physical structure that consists of multiplexers, multiblade rows, multiblade channels, and multi-regions [
24]. Correspondingly, it is necessary to communicate the boundary data between blade rows when designing simulations. In addition, blade channel boundary and regional boundary communication are required, as illustrated in
Figure 2. In order to illustrate the blade row and blade channel, the geometric model of the axial compressor is shown in
Figure 3, in which red blades represent rotor blades, green blades are stator blades, and the polygon stands for the blade channel. The blade channel can be divided into blade regions. The full circle is the blade row.
Similarly, the Sunway TaihuLight has a multilayer hardware architecture that consists of cabinets, supernodes, processors, and CGs, as shown as in
Figure 4. From the bottom up, the main components are the CG of MPE+64CPEs, the SW26010 processor, which is composed of four CGs, and the super nodes, which are composed of 256 nodes. The four supernodes constitute the cabinet. The multilevel parallelism of the fluid mechanical model and the multilayer hardware architecture of the Sunway TaihuLight naturally correspond to each other, which provides favorable conditions for the task mapping of them.
swHPFM adopts two levels of parallelism: coarse-grained task parallelism and fine-grained data parallelism. Before submitting the simulation job to the Sunway TaihuLight supercomputer, the cost of MPI communication among nodes,
, was calculated. The MPI tasks are allocated under the principle of minimizing the communication cost. The mapping scheme of swHPFM for the simulation model and the hardware architecture is illustrated in
Figure 4.
Thanks to its powerful logic control and interruption handling capabilities, the MPE on the node is responsible for handling complex scheduling tasks and decomposing the tasks of the blade rows into computing tasks of the kernel functions, shown as Equation (1), to complete the iterative calculation of the flow field. swHPFM distributes the kernel functions to the CPEs. Simultaneously, during the simulation, each CG returns data that are calculated by the CPE cluster in the main process to determine whether the calculation has converged and whether to exit the flow field simulation.
The algorithm of the axial compressor rotor designed in this paper is suitable for the finite volume method. The differential form of the fluid control equations is expressed in Equation (1)
where
U stands for the conservation-type solving vector,
, and
are the convection vectors along the coordinate directions
x,
y, and
z, respectively,
,
, and
denote the viscous vectors along the three coordinate directions, and
I represents the source term. In addition, each vector has six components, which represent the continuity equation, the three-directional momentum component equation in Cartesian coordinates, the energy equation, and the S-A (Spalart-Allmaras) turbulence equation [
25]. The expressions of the terms are shown in Equations (2) and (3).
where
stands for the density,
,
, and
mean the absolute velocity component in three coordinate directions,
,
, and
represent the absolute velocity component in three coordinate directions,
is the ratio of the total energy, and
is the eddy current viscosity variable. The physical meanings and expressions of the other items can be seen in reference [
26].
To increase the convergence speed, the solver uses the Runge-Kutta (R-K) explicit time method to simulate the flow field. The convection term and the diffusion term in the solver are discretized via the central differential scheme. In addition, to improve the accuracy and efficiency of the algorithm, redundant terms were constructed. The local time step method and implicit residual smoothing method are used to accelerate the convergence. Among them, since the second-order explicit central scheme of the non-convective diffusion equation is unstable, the R-K method constructs an explicit artificial viscous smoothing numerical oscillation. The implicit residual smoothing replaces the original residual value by weighting the residual at the nodes and the adjacent nodes, accelerating the smoothing of the residual and enlarging the stability range of the time step. In addition, to smooth the residual, while reducing the calculational burden, the residual smoothing is performed only at odd steps in the R-K time marching method [
24].
In this paper, a multigrid method, namely, the full multigrid (FMG) method, was used to accelerate the algorithm, which is illustrated in
Figure 5. First, the iteration was performed on the coarse grid (Level 3) until the error satisfied convergence criteria, and the iteration process on this layer was completed. Then, the numerical solutions and errors were interpolated to the medium grid (Level 2), where they were iterated via the V-cycle approach, until the convergence criterion was satisfied. Finally, the results were interpolated to the fine grid (Level 1) [
27]. This process was iterated, until the convergence of the numerical solution on Level 1 was obtained.
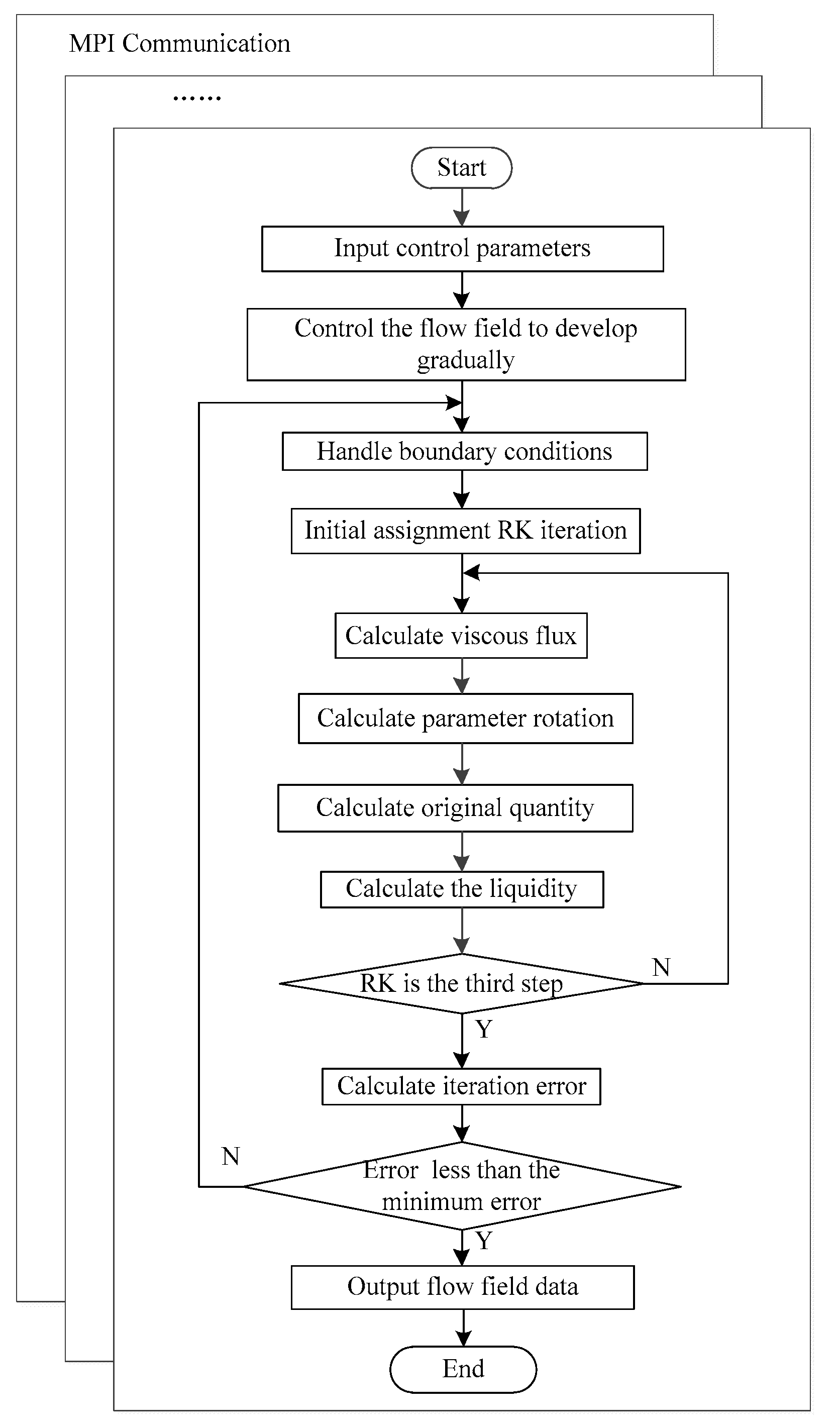
The algorithm flow chart in each node is illustrated in
Figure 6. First, the flow field was initialized by reading the input grid file, which specifies the number of grids, the grid coordinates, the grid values, and various physical parameters. Then, the core iteration process of the algorithm, namely, the R-K explicit time marching method, was executed, whose main objective was to solve the equation via iteration, until the results converged. At the same time, multiple nodes were executed in parallel, and the data between nodes communicated through MPI.
Correspondingly, the swHPFM simulation computing on each CG of SW26010 processor is illustrated in
Figure 7. As previously analyzed in this paper, the MPE is responsible for judging and controlling the whole simulation cycle, including calling the file reading module to read the grid data and communicating the boundary data by using the MPI. The CPE is responsible for data parallel computing. Therefore, kernel functions, such as the original quantity, residual, and source term, are distributed to exploit the computing performance.
For the structured grid fluid mechanical simulation algorithm, the main computing characteristic is regular memory access. In detail, the access mode is continuous access and regular stride access. However, in the innermost part of the array, although it is regular, the stride size is so large that the mode is close to discrete access, and the memory access cost is high [
28].
To efficiently distribute data to the CPEs, the SPM access strategy, which is based on the computing characteristics, serpentine register communication, and SIMD was proposed to improve the computing performance.
2.2.2. SPM Access Strategy Based on DMA
In the structured grid axial compressor rotor algorithm, the array structure can be divided into two regions, namely, an outer layer and an inner layer, as illustrated in
Figure 8. For many functions, such as the original quantity, residual, and source item, only the inner layer is calculated, without communicating the outer-layer data. Since the size of the SPM is only 64 KB, it is wasteful to transmit redundant data to the SPM. The proposed SPM access strategy (SAS) can effectively overcome this problem by only reading the valid data.
When the SW26010 processor transfers data from its main memory to the its CPE’ SPM of its CPE, it is limited in four aspects: space, transmission efficiency, mapping, and data dependence. The space limitation refers to the SPM space of the CPE being only 64 KB, and the user-available space in the LDM being limited to about 60 KB, namely, LDMsize ≤ 60 KB. The transmission efficiency limitation refers to the peak performance of the DMA access being reached only if the main memory address of the data is 128-byte-aligned, and its size being a multiple of 128 bytes. To ensure transmission efficiency, Blocksize%128 = 0 should be guaranteed on the premise of the alignment of the main memory addresses. The mapping and data dependence limitations means that the amount of transferred data must guarantee the integrity of a kernel function.
Blocking rules that are based on the space, transmission efficiency, mapping, and data dependence limitations are presented, as shown in Equation (4), in which
Totalsize denotes the size of the data to be transferred, and
core_number represents the total number of computing cores, whose value is 64, if all the slave cores are used.
Block denotes the total number of blocks that are required for transmission.
To effectively utilize the space of the SPM, only the valid data of the inner layer can be transmitted; hence, the stride access method was used.
First, when executing the data transmission, the stride on the main memory should be calculated, according to the outer and inner data sizes. For double-precision data,
Stride =
Boundarysize × 8 bytes, wherein
Boundarysize denotes the number of boundary layers in the three-dimensional array of the fluid machinery algorithm. Then,
Carrysize, which denotes the amount of data that are passed by the DMA, is calculated via Equation (5), wherein
Valid_Datasize represents the size of the valid data of the inner part.
Finally, the data on the CPE are tiled based on the mapping rules, as expressed in Equation (6). When CPE initiates a load/store data request, it is necessary to map each required datum to the main memory address. Our method enables continuous data blocks to be executed in the same time step. In Equation (6), Bias represents the offset of the main memory,
Blockindex denotes the index of the current data block, and
Threadindex denotes the current number of threads of the CPE.
Meanwhile, to achieve an overlap between the computing and data transmission between the MPE and the CPE cluster, double buffering technology, which doubles the required space from the CPE’s SPM, is used to load/store data. The SPM access strategy can fully utilize the SPM and improve the CPE’s computing performance.
2.2.3. Serpentine Register Communication
When analyzing the structured grid rotor solver algorithm, in many kernel functions, such as the viscous flux, convective flux, and parameter rotation, stencil computing is used. There is a backward or forward dependence on the x-, y- and z-axes of the neighboring data. For instance, in the function viscous flux, the absolute velocity components, namely, vx, vy, and vz, the original conserved quantity, and the derivatives of the flow parameters at the interface are needed in order to update the value of the function.
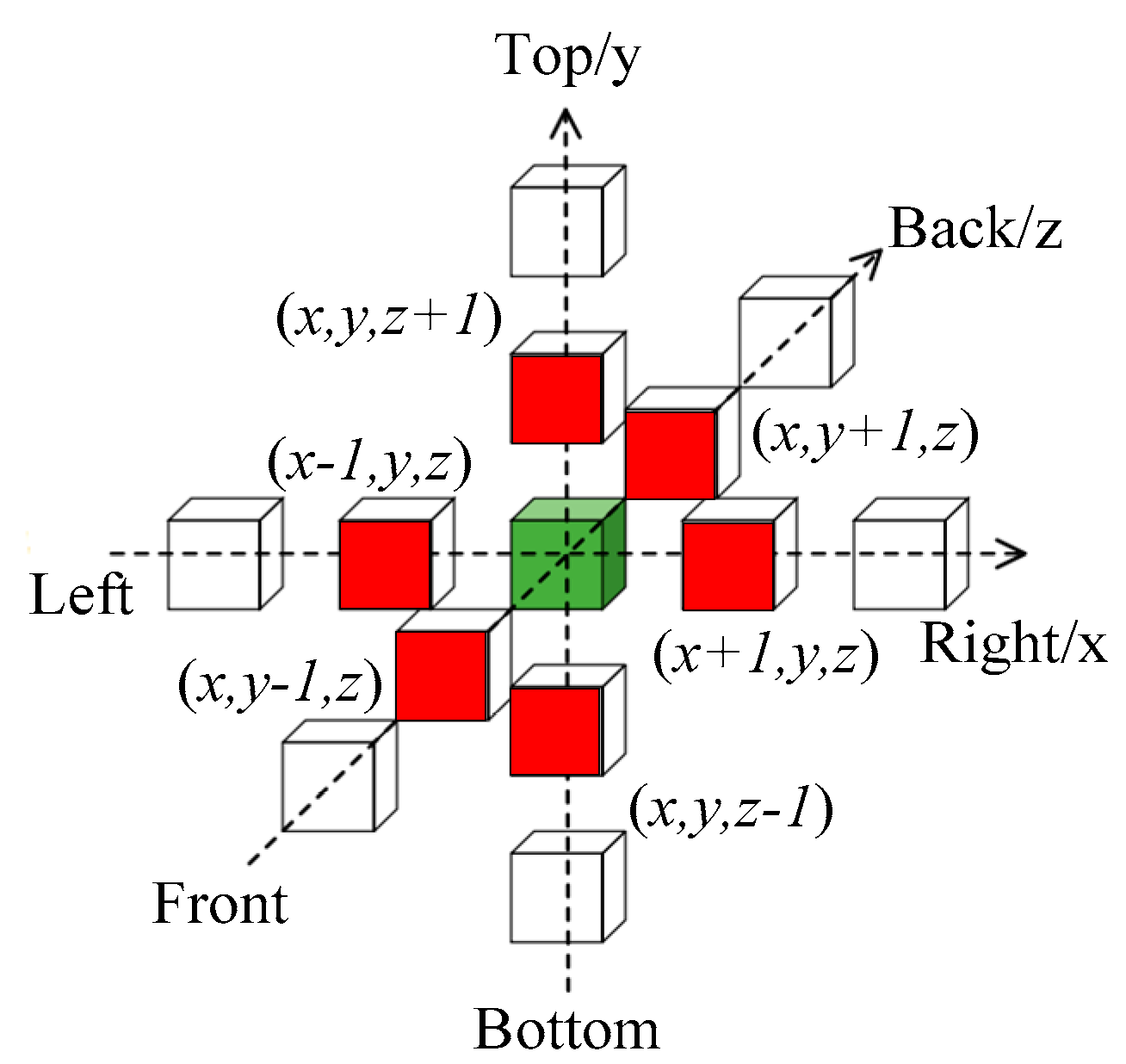
In this paper, a scenario in which both forward and backward data are needed was considered as an example, as illustrated in
Figure 9. The green cube stands for the current grid that needs to be updated. The red cubes represent the adjacent grids, on which the green one depends. When updating the green grid data block, it is necessary to simultaneously read the forward data and the backward adjacent red blocks of other data. When executing the data transmission, the
x-axis data are continuous; hence, the
x-axis data must be completely transmitted. When the data on the discontinuous latitude in the
y-axis direction are distributed to the CPE, only one datum value can be updated for every three data blocks, and the data utilization rate is so low that the parallel computing performance is severely degraded. In this case, serpentine register communication (SRC) is proposed to improve the data utilization and reduce the number of invalid communications.
In each SW26010 processor, register communication is designed to directly communicate only between the same row or the same column. To briefly explain the serpentine method used in this paper, it is supposed that there are 9 CPE resources, which form a 3 × 3 mesh. As in the actual scenario, the registers can only communicate within the same row or the same column. Data blocks 1–27 must be updated, and being limited by the SPM space, the SPM for each CPE can store up to 4 data blocks. Simultaneously, each calculation requires one forward data block and one backward data block. The data layout of the original register communication is illustrated in
Figure 10a, in which the first CPE and the last CPE receive four data blocks: 1, 2, 3, and 4, as well as 25, 26, 27, and 28, respectively. The middle CPEs store three data blocks. Before communicating, the intermediate data are updated, such as data 5 in CPE1 and data 8 in CPE2. Then, forward communication is performed, and the data of the non-first column are sent forward in the same row. For example, data 4 are transmitted to the CPE0, and the location of data block 0 is covered to update data 3. However, the data in the first and last column, such as CPE3 and CPE2, must be diagonally communicated. Then, backward communication is executed, and the data of the non-last column are sent backward in the same row. For example, data 15 are transmitted to CPE5 to update data 16. The last-column data, such as CPE5 and CPE6, must be diagonally communicated.
However, diagonal communication, such as the communication of CPE2 and CPE3, is limited by its design. It must communicate in the same row, initially to transmit data from CPE2 to CPE0, and subsequently to communicate with CPE3 via column communication. This communication method is complicated and time-consuming. For this scenario, serpentine register communication was proposed. By changing the logical CPE thread number to a snake-like consecutive number, as illustrated in
Figure 10b, the number of communications was effectively reduced.
To complete the serpentine register communication, first, the thread numbers of the serpentine CPE are reordered by mapping the number of CPE threads to snake-type number to build the list of neighbors that must be communicated. The neighbor list builder pseudo-code is presented as Algorithm 1, in which
row_front denotes the thread number of the previous CPE,
row_back represents the thread number of the next CPE,
column_front is the previous column of the CPE, and
column_back denotes the thread number of the next column of the CPE. When the serpentine neighbor list is built, the data distribution will change accordingly, as illustrated in
Figure 10.
| Algorithm 1. Serpentine Neighbor List Builder. |
| Initialize the original thread ID of CPE |
| Get the thread number of the current CPE, thread_id ← athread_get_id(−1); |
| Obtain the row number of the CPE, row ← thread_id / 8; |
| Obtain the row number of the CPE, column ← thread_id % 8; |
| if row%2==0: |
| serpentine_column ← 7-column; |
| else serpentine_column ← column; |
| end if |
| Update the thread ID of the serpentine CPEs, Serpentine_CPE_thread ← row*8+serpentine_ column; |
| row_front ← serpentine_column −1; |
| row_back ← serpentine_column +1; |
| if row_front==−1: |
| column_front ← row+1; |
| end if |
| if row_back==8: |
| column_back ← row−1; |
| end if |
Finally, register communication was executed according to the neighbor list. Since the calculation relies on the forward and backward data, it is necessary to communicate forward and backward. The pseudo-code of the serpentine register communication is presented, as shown in Algorithm 2. In this way, diagonal communication can be executed directly, without intermediate routing registers, and the register communications can be effectively reduced.
2.2.4. Vectorization
In the SW26010 processor, each CPE has a 256-bit-wide SIMD floating-point unit, whose instruction pipeline is fixed to up to 8 stages. To analyze its main cost, an aligned vectorized and nonvectorized test set was designed, in which 512-cycle addition, subtraction, multiplication, and division operations were compared. The results demonstrate that, for the aligned SIMD vectorized program, the computing performance can be accelerated by as much as 3.956x, compared to the scalar operation, as listed in
Table 2.
| Algorithm 2. Serpentine Register Communication. |
| Initialize serpentine neighbor list |
| while completing false target data communication: |
| if serpentine_column != 0: |
| send target data to the row_front via row communication; |
| else if Serpentine_CPE_thread != 0: |
| send target data to column_front via column communication; |
| end if |
| waiting for the transmission to complete and receiving the data; |
| if serpentine_column != 7: |
| send target data to the row_back via row communication; |
| else if Serpentine_CPE_thread != 63 |
| send target data to column_back via column communication; |
| end if |
| waiting for the transmission to complete and receiving the data; |
| end while |
However, to use simd_load/simd_store for vectorization, it is necessary to ensure that the standard-type variable is 32-byte-aligned (for floatv4, only 16-byte-aligned). The compiler can only guarantee that the head address of the array is aligned. The remainder of the data address is required for a programming guarantee. If unaligned memory access is executed, the MPE automatically degenerates into unaligned access, executed by simd_loadu/simd_storeu extension functions. However, a higher price will be paid. However, the CPEs will directly output the “Unaligned Exception” error.
In the CPEs, it is necessary to explicitly use the simd_loadu/ simd_storeu extension functions or the vldd_ul/vldd_uh/ vstd_ul/vstd_uh instructions to execute the unaligned operation. Comparing the unaligned vectorized and nonvectorized 512-cycle addition, subtraction, multiplication and division operations, the results demonstrate that the unaligned SIMD vectorized program only realizes an average speedup of 1.822×, compared to the scalar operation, as listed in
Table 3.
Comparing
Table 2 and
Table 3, the unaligned SPM access severely degraded the vectorization performance. The absolute latency of the unaligned access was even higher. In addition, the latency of the vectorization operation, which includes the arithmetic and permutation operations [
22], is listed in
Table 4.
The instruction prefix ‘v’ stands for the vector operations. The instruction suffixes ‘d’/‘s’ and ‘w’/‘f’ represent double/single-precision and word/ floating-point vectors, respectively. The permutation instructions ‘ins’/‘ext’/‘shf’ correspond to insertion/ extraction/shuffle operations. Therefore, to fully utilize the SW26010 vectorization, the kernel array was converted from an array of structures (AOS) into a structure of arrays (SOA) to facilitate the alignment operation in the CPE. In addition, since the shuffling operation has a lower latency than unaligned access, a fine-grained shuffling operation is used to generate data to reduce the number of unaligned loadu/stroeu operations.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}