1. Introduction
The role and importance played by language in organizational culture has long been recognized, although since the early 2000s they have attracted increasing research and theoretical development within the domains of organizational and management studies, as well as in evaluation research (e.g.,
Andriessen and van den Boom 2007;
Hopson 2000;
Tietze et al. 2003). Many of these studies have attended to the constitutive effects of language (
von Krogh and Roos 1995a), especially in the construction, articulation, and maintenance of organizational culture (
Krippendorff 2008) or how language informs organizational decision making (
Thibodeau and Boroditsky 2011), as well as the conversational aspects of knowledge production and sharing within organizations (
Stacey 2001). Along with the proliferation of Web 2.0 and social media applications, which has given rise to big data in both numeric and textual formats, interest in mining textual data statistically has become a field of research attracting increased attention from developers and researchers alike (
Francis 2006). In effect, these analyses are treating textual data as codified or explicit knowledge (
Nonaka and Takeuchi 1995;
Polanyi 1983). In fact, some commentators define text mining itself as “the process of distilling actionable insights from text” (
Kwartler 2017, p. 1) including “candidate perceptions of the organization” one works for (p. 2). Consequently, as a means through which to obtain insights into how team members of an organization perceive, understand, and act upon their sense-making activities, which was the objective in the present study, text mining offers a statistically robust and replicable methodology with which to do so.
While the statistical analysis of language-in-use has begun to make significant inroads into organizational and knowledge management research (e.g.,
Kumar and Ravi 2016), there are, to date, few studies wherein such methods have been applied to community-based organizations, far less sustainability-oriented projects. There have been efforts to analyze how the environment and its politics are constructed through discourse (
Audet 2014;
Ponton 2015), and the relationship between languaging and sustainability has also been explored by a few commentators (
Hukkinen 2012,
2014;
Mitchell et al. 2019;
Paschen and Ison 2014), but to date the statistical analysis of language use in community-based sustainability projects remains largely unexplored. As a result, how language usage informs the production and articulation of knowledge in sustainability-oriented organizations remains a predominantly untapped domain. Nevertheless, such projects are potentially rich sources of learning and knowledge concerning the practical application of ideas and approaches that have been drawn from a range of disciplines to address the problems associated with social-scale adaptations to climate change and other Anthropocene events (
Oreskes and Conway 2014). Reasons for this oversight are not immediately obvious and may be related to such projects typically being short-lived, activity-centered, and characterized by semiformal collectives of activists attracted by the prospect of taking concrete action to facilitate change. Where such projects benefit from external funding, these are inevitably linked to externally defined targets, and project members may lack both the opportunities and capacity to engage in critical reflection on what it is that they do and have learned (
Hobson et al. 2016). Even when project actors do have the opportunity to reflect on their learning, it is difficult to ascertain if such learning remains at the level of single-loop learning or whether project staffs are able to acquire learning about how to learn, a meta-level process of understanding the conditions within which one learns applies, described variously as deutero- (
Bateson 1972), ‘second-order’ (
Mitchell 2019), or, in
Argyris and Schön’s (
1978) terms, ‘double-loop’, learning. Clearly, there is much yet to discover about the knowledge management and learning processes of such organizations. In this paper, we report on an attempt to gain insight into the knowing and learning such organizations give rise to through the textual and thematic analytics of transcripts from five facilitated action research meetings with the team members of a funded community-based sustainability project. Specifically, we endeavor to gain insight into how staff in a funded sustainability transition project (STP) make sense of what it is that they are doing in attempting to leverage transitions toward community-scale sustainability. STPs are discussed here as learning organizations because they generate Mode-2 knowledge, on the basis that they draw on the pragmatic applications of cross-disciplinary, joined-up thinking, and social inclusion as fundamental strategies for responding to complex social-ecological issues. The knowledge generated by such organizations is, therefore, critical in learning how to learn under the uncertain conditions of the Anthropocene, and this paper deployed an approach to systematically capture such learning.
The context for this study is a five-year funded STP in an East Midlands town in the United Kingdom. Using the transcripts of facilitated action research conversations with the team members of the project, natural language processing (NLP) (e.g.,
Kilgarriff 2001,
2005) methods were employed to highlight and extract patterns underlying textual accounts of experience and to explore how the learning and knowing relative to STP objectives were articulated. The case project was tasked with improving local sustainability around more economically efficient use of local natural resources, the reduction in greenhouse gas emissions, and the increase in local biodiversity. The transcribed records of these facilitated reflective conversations were considered from two complementary analytic methodologies. The first, drawing on text mining, involved converting the text into a document term matrix (DTM), permitting the text to be treated as a ‘bag of words’ suitable for word (token) frequency and cluster analysis. The second involved coding the records according to five predetermined themes, viz., governance, delivery, networks, challenges, and learning. The results of these analyses are discussed in relation to how STP staff articulate their experience of learning how to leverage community-scale transitions toward sustainability.
2. Sustainability Transition Projects as Sources of Mode-2 Knowledge Generation
The theoretical basis underpinning a facilitation of societal-scale transitions toward sustainability currently expresses an amalgam of psychological motivation and learning theory, even though more recent developments in cognitive science suggest these lack applicability (
Caracciolo 2012;
Mitchell 2020;
Thompson and Varela 2001;
Varela et al. 1991). Consequently, many of the strategic decisions taken by a STP are constrained by a pragmatic necessity incumbent upon staff tasked with delivering on sustainability transition project objectives to just ‘get on with it’ (
Hobson et al. 2016;
Mitchell 2020). Pressure to generate linear changes at community scales tends to be evaluated against a handful of specific quantitative objectives, assessed relative to a suite of key performance indicators (
Bell and Morse 2008;
Ika and Donnelly 2017;
Turcu 2013). This expectation to generate quantifiable changes holds for many STPs despite an absence of any coherent theoretical approach or ‘objective’ indicators that such projects might draw upon to calibrate such metrics. Moreover, those indicators of progress proposed thus far actually evidence a number of problems when applied in practice (
Bell and Morse 2008;
Byrne and Callaghan 2014;
Feola and Nunes 2013;
Ramalingam 2013;
Turcu 2013).
As a result, we have begun to realize that sustainability reflects a complex (
Levin 1998) and wicked problem (
Mitchell et al. 2020;
Rittel and Webber 1973), commensurate with all of the challenges associated with this class of problem (
Frame and Brown 2008). Perhaps, then, we should not be surprised that traditional, indicator-based approaches appear to be ill fitted for assessing impacts relative to complex and adaptive social-ecological systems. Given the complexity of the systems involved, it is difficult to attribute change to a given community-based sustainability initiative (
Bamberger et al. 2016;
Burns and Worsley 2015) or to ascribe counterfactual influences coalescing at the focal scale as an accumulative effect of slower-moving variables (
Garmestani et al. 2009;
Holling 2001).
The advent of community-based projects which endeavor to elicit shifts in local behaviors and consumer decision making is a relatively recent phenomenon. These sustainability transition projects (STPs) are quite novel methods for engaging members of local communities to induce changes in behavior and ways of living and draw on a considerable variation of methods and philosophies (
TESS 2016). Generally, few projects receive adequate funding and those that do are relatively short lived. Doubtless these factors constrain the efficacy of many endeavors. While STPs have tended to be self-organizing grassroot groups, over the last few decades, a number of initiatives have developed more strategic interventions, even though these still remain largely under-researched or evaluated with respect to any relative efficacy. However, over the last decade, this has begun to change and there is increasing interest in community-based sustainability initiatives and the potential for wider changes they might effectuate (
Hargreaves et al. 2013;
Middlemiss and Parrish 2010;
Seyfang et al. 2013). There is also an emerging interest in the potential shifts in learning and knowledge production capacities represented by such organizations (
Antal and Hukkinen 2010;
Ison et al. 2013;
Mitchell 2020;
Mitchell et al. 2020), particularly with respect to any insights offered relative to viable pathways for mitigation of and adaptation to climate change and other existential threats posed by the Anthropocene (
Fox 2007;
Ghosh 2017).
STPs, therefore, represent a potentially rich research opportunity for generating experience-based insight into how members of the public and local communities might be engaged in those practices that are associated with, for example, reducing one’s carbon footprint, supporting local economic actors, conserving and enhancing biodiversity, and making consumer decisions oriented toward increasingly sustainable supply chains. As such, these are practical modes of knowing and, given its direct ‘real world’ applicability, characterizes what has been dubbed ‘Mode-2 knowledge’ generation (
Gibbons et al. 1994), produced within the context of its specific range of application (
Nowotny et al. 2001). To better understand Mode-2 knowledge, we can briefly contrast it with what would be a Mode-1 form of knowing, as summarized in
Table 1.
Mode-2 research legitimizes the use of methods that subvert the traditional approach of controlled experimental protocols. The implication of this is that field-based research is no longer beholden to a specific discipline and that the roles of researcher and research subjects shift accordingly. In Mode-2 research, for example, research subjects become active participants in the research process, resulting in a shift in the traditionally implicit power dynamic of the research setting, so that they now actively engage in making a contribution to the flow of the research process. Areas of concern can be surfaced and ameliorated in the form of a dialogue between the researcher and the participants, resulting in research that is co-produced and concerns the specific domain of activity within which stakeholders are engaged.
Case studies of STPs, therefore, offer opportunities to co-produce insight into the scope and nature of the challenges encountered and solutions proposed by project teams in their efforts to deliver transitions toward sustainability. STPs further present the chance for researchers to garner a more nuanced appreciation of the discourses and dynamics through which the contested concept of sustainability might be interpreted and operationalized to be delivered in practice. The focal community becomes, in effect, a laboratory for testing the project team’s own understanding of the nature of the problems and how these might be more effectively addressed. Moreover, while there are likely to be certain parallels and cross-situational interventions, which may work regardless of the specifics of place and time, there are almost certainly going to be interventions that, because of the vagaries of place and the composition of the communities involved, are likely to only work in some settings but less well in others. Consequently then, STP teams appear to satisfy the criteria to be recognized as potential Mode-2 learning organizations and, therefore, deserve to be studied as such.
While no two STPs are the same (
TESS 2016), the capacity for STP teams to engage in single- and double-loop learning processes is especially critical when their work is viewed against the challenge of applying theory to practical situations. The concept of double-loop learning was described as a process through which corporate managers revisited fundamental assumptions, norms, and strategies in light of emergent insights into and knowledge about operational realities (
Argyris and Schön 1978). It was the organization’s theory-in-use, rather than its espoused theory. The concept of a learning loop referred to cybernetic feedbacks enabling both error detection and the resolution of error and conflicts within the organizational mindset. In Argyris and Schön’s work, a single learning loop reflected linear error correction, while the double loop represented a reflexive process that corrected the fundamental assumptions underpinning the specifics of an approach to delivery. In other words, double-loop learning describes a process of learning
about learning, a
meta learning, where interventions are intended to “
resolve incompatible organizational norms by setting new priorities and weightings of norms, or by restructuring the norms themselves together with associated strategies and assumptions” (
Argyris and Schön 1978, p. 24. Italics in original). If learning involves adjusting the fundamental assumptions and norms that informed the strategies deployed by an organization then, according to this definition, one can argue that double-loop learning has occurred. With STPs, one can discern a similar set of tensions between the espoused theory and the theory-in-use. A few examples will help to illustrate some of these tensions.
Despite well-established and accepted psychological theories about motivational drivers for behavior change, individual and social learning processes, and the use of incentives to ‘hook’ public interest in participating in sustainability campaigns, the application of these in the field suggests a shortfall between theory and outcomes (
Mitchell 2020). One example of this shortfall is the surprisingly common ‘knowledge-action gap’. This concept refers to the misalignment between what is known and what is done. Examples include people who, despite being well informed about the environmental impacts of their behavior and the availability of viable low-impact alternatives, nevertheless still engage in high-impact behaviors (
Kollmuss and Agyeman 2002), or the failure of conservation policies to be implemented, despite being backed by robust evidence (
Knight et al. 2008). A second example concerns the so-called ‘rebound effect’, which describes practices among some people who, through engaging in energy-efficient behaviors, use any financial savings accrued to go on long-haul airplane journeys for their holidays, which undermines any initial reductions in carbon emissions (
Azevedo et al. 2013;
Hertwich 2005;
Santin 2013). Eliciting long-lasting and meaningful changes among the public in the context of geographical communities is clearly a difficult, complex, and multidimensional challenge. In effect, a wicked problem (
Rittel and Webber 1973)
par excellence.
But the tensions between espoused theories and theories-in-use are not restricted only to the knowledge-action gap or the rebound effect, however. Research suggests that, contrary to the
Homo economicus model of human motivation prevalent within neo-liberal discourse (
Harvey 2005), financial incentives seem to only work for a limited duration before people return to pre-intervention behavior patterns (
Abrahamse et al. 2005;
Bolderdijk et al. 2012). Evidence points to a misalignment between those behaviors typically proposed through governmental policy levers for climate change adaptations (e.g., domestic energy efficiency measures, reduction in single-occupant vehicle trips, etc.) and the behaviors that are actually commonly practiced by members of the public even though these have little impact relative to climate change mitigation (e.g., recycling) (
Whitmarsh 2009).
A third and final set of examples emphasizes the socio-technical infrastructures that constrain the scope for meaningful change at the level of individuals. These constraints are characterized by regime-scale, path-dependent systems that lock society into a default set of arrangements (
Geels 2011;
Kern 2012). Such infrastructure lock-ins considerably raise the bar for members of society seeking to live more sustainably, such that the public must deliberately seek out more sustainable alternatives to, for example, the global food supply chain (
Foster et al. 2006;
Kirwan et al. 2013) and the use of private transport due to poorly designed and coordinated public alternatives (
Larsen et al. 2006;
Whitmarsh 2012), all the while being continually exposed to advertising that exhorts the public to purchase goods and contribute to the consumer economy (
H.M. Government 2005;
Soini and Birkeland 2014). Participants in STPs face challenging circumstances in which they will have to acquire credible technical and practical knowledge to engage members of the public meaningfully in strategies to reduce household emissions of greenhouse gases and to develop locally sourced food supply chains. Often, technical knowledge will have to be picked up on the job, although there are a number of resources from which technical details can be acquired. However, what cannot be acquired in the same way as specifications for renewable energy sources or domestic thermal control interfaces are the so-called ‘softer’ or people skills necessary for engaging members of the public in the sustainability-related activities.
From these examples, it is evident that responding to the challenges of sustainability invokes complex chains of influence and impact, across multiple scales, many still lacking suitable metrics with which to determine relative impacts. Moreover, sustainability indices do not account for the so-called rebound effect or for policy-action shortfalls and, while individual behavior change is to be encouraged, when socio-technical systems are locked into historical configurations that are predicated on the use of fossil fuels, private transportation systems, and a consumer economy, it becomes an almost overwhelming challenge for most people to make meaningful and lasting changes. From the perspective of their unique position as located within focal communities, STPs highlight the tensions between theories-in-use and those espoused as effective. STPs then are, in effect, well positioned to be Mode-2 learning laboratories to engage in not only single-loop learning but also potentially double-loop learning. When STP staff members are supported in articulating their own experiences of responding to these multi-level challenges, these reflections offer potential insights that can be gleaned and applied to other contexts, to be tested for goodness of fit and viability.
It is evident from the examples discussed above that STP actors are engaged in a highly challenging but critically necessary domain of operation. Arguably, they occupy the front lines of grappling with the wicked problems of community sustainability, resilience, and adaptation in the face of climate change and the Anthropocene (
Lyons et al. 2015;
Waters et al. 2016;
Zalasiewicz et al. 2014). It is within this domain that relevant knowledge is being produced and applied, wherein espoused theories are applied but are often found wanting and where action-based learning informs innovation and strategy. As producers of practical (Mode-2) knowledge about sustainability transitions, workers in STPs have a potential wealth of learning to share about a range of practical and theoretical elements about, for example:
how to productively engage members of the public in behavioral and attitudinal changes;
how to employ what works in building social networks of active participants;
knowing which practical activities to reduce domestic energy consumption rates are correlated with higher take-up by the public; and
knowing what sustainability-related activities garner the most interest and support from the general public.
Moreover, STPs that are formally constituted with funding and resource supports and that are aligned with specified project objectives and targets may generate pragmatic insights into setting up realistic performance indicators, along with manageable monitoring and evaluation frameworks. They may also provide valuable intelligence to inform how future STPs are developed and implemented.
It is clear, therefore, that the scope and range of the learning and the knowledge that STPs hold is a potentially rich resource that can be deployed to benefit not only geographic communities in becoming more sustainable, but also help shape the future of community-based STP activity. However, as this is an organizational sector that has only relatively recently attracted the interest of researchers, there have been very few attempts to mine the knowledge such organizations hold. Consequently, it is difficult to map out what STP actors know, tacitly or explicitly, and the actual value of this knowledge for feeding forward to inform future applications remains untested. This paper is an initial contribution toward addressing this gap in the literature.
3. The Case Study Sustainable Transition Project
The STP studied here was the result of a two-step process involving an initial Expression of Interest (EOI) by the local chapter of the Transition Town network (
Brangwyn and Hopkins 2008;
Hopkins 2008), which responded to a call by the philanthropic branch of the United Kingdom’s National Lottery corporation for a Communities Living Sustainably grant. The EOI secured a bid development grant of £10,000 (~
$13k) for the group to undertake initial research into the local community’s needs, resources, and profile, and to recruit, if necessary, additional help in putting the bid together. The site for the STP is a market town dating back to the 12th century as a trading village between two large Medieval cities and on the border of two midland counties. The town itself is home to a relatively affluent but aging population of approximately 22,000, with a mixed housing stock of approximately 18,000, the majority of which is privately owned.
A county-based rural community development agency was recruited to help with the bid development and, as per the funding conditions, assumed the role of the lead or senior partner if the bid was successful. When the funding was awarded following the submission of the bid, £998,000 was allocated to the STP for the period of five years starting in January 2013 and, again, as per the funding conditions, a group of partner organizations were required to agree to form a steering and governance board. The board was comprised of the rural community development agency, which served as the senior partner, bearing ultimate accountability for the fund and the implementation of the STP’s work, and representation from the district- and county-tier local authorities, as well as from the largest social housing provider in the region, a university, a charitable organization for the support of market towns, and a trust organization for the local river, together with representation from the UK Environment Agency and also from the regional electricity distribution network operator.
Formed in early 2013, the STP was one of 12 sister projects across England, each of which was located in a different regional profile of the country, including inner cities with high levels of deprivation. All of the sister projects were coordinated by a multi-agency body called Communities Living Sustainably (CLS), and the projects were conceived, funded, and implemented as explicitly ‘test-and-learn’ projects to support and help empower the focal communities to adapt to future environmental and climatic changes as well as to address the vulnerability of fuel-poor households. The STP case study comprised one project manager and three project officers, all of whom were employed full time on the project. The STP itself pursued two broad streams of work: energy- and food-related projects.
The food project stream involved developing and consolidating a locally sourced food supply chain, which led to the development of a local food producer and retailer map, which, due to its popularity, was updated a couple of years after the first issue. The STP board also approved pump-priming start-up funding of £10,000 to an online, click-and-collect, community-based retailer of locally sourced and produced food and drink. This company was limited by guarantee with social enterprise clauses and which subsequently became a co-operative community interest company within 12 months of its incorporation. This company, referred to as the food hub, provided an online menu of food and drink produced within a 20-mile radius of the town. Although some work had gone into raising the profile of a local food brand, enthusiasm for this project among the volunteer cohort and the general public was initially quite low, but over the last year of the STP’s funding cycle, these efforts culminated in a local food brand and tourism offer. Finally, a community garden was started using a plot of land on a nearby farm owned by one of the food project steering group volunteers, and has generated a number of harvests and now continues independently of the project, which ceased at the ending of its funding period at the end of 2017.
The energy project stream initially was geared toward working in the domestic sector, but aside from a small group of ‘green home’ enthusiasts, few homeowners engaged. Consequently, the STP repurposed its approach and engaged with local businesses instead, beginning an ‘energy club’, which raised issues about optimizing energy efficiencies in the workplace. A second component of the energy-related work stream involved attracting crowd funding and investment for the installation of solar photovoltaic panels on the rooftops of some privately owned businesses and the establishment of a community-owned energy co-operative, which continues to manage the investments and the returns paid to investors. As part of their contribution to the STP, the local social housing provider also retrofitted an end-of-terrace house with high U-value insulation and windows to reduce heat loss, a small photovoltaic (PV) array, and various energy-efficient modifications. Readings from the PV array and general gas and electricity meter readings were monitored for trends demonstrating how a retrofitted social housing estate could roll out modifications across existing stock to achieve both cost savings and reductions in greenhouse gas emissions.
As a condition of funding, the STP was bound by six outcomes to be achieved by the end of its funding period in December 2017, and these outcomes were supported by a suite of 14 indicators. Additionally, the STP regularly reported to the funding body, providing updates on activities, progress, budgetary allocations, and so on. The project team also met with the steering board quarterly to advise on progress and challenges and to decide on strategy. One of the conditions written into the contract was—because the project fund was explicitly ‘test and learn’ in nature—for the project team to engage in action research meetings with an independent facilitator and these took place once every six weeks throughout the period of funding. The audio recordings of some of these meetings were transcribed and these are the texts that were analyzed and discussed in this paper. While all participants gave their consent for this research, nevertheless, all data were anonymized.
Having set out the context for the present study, we will briefly introduce the method of analysis deployed here in the analysis of some of the transcribed conversations from the action research meetings, referred to above.
4. Materials and Methods
As discussed at length earlier, this study was motivated by the objective to gain insights into the knowledge and learning generated by the staff of a STP organization during the course of helping to bring about community-scale transitions toward sustainability. That is, what sense did the case study STP team members make of what they were doing in the course of performing their roles? How did they understand and respond to the numerous challenges they encountered? How do such personnel learn about becoming effective, in situ, while trying to address the wicked problems of sustainability locally?
Although it is improbable that the answers to such questions can be entirely addressed, and certainly not within the context of this paper alone, the objective here was to develop some initial inroads into this under-explored domain of study and to open up some potentially rich seams for future research. While impact evaluations and quantitative metrics of performance against specified indicators have their place in a what works study, these measures offer little traction into understanding the nature of Mode-2 learning projects, such as this case study. For this we are better off turning to the compelling body of research in the knowledge management literature emphasizing how knowledge (or, more precisely,
knowing) is generated and shared through human conversations (
Goldspink and Kay 2003;
Koskinen 2010;
Stacey 2001,
2010;
von Krogh et al. 1998). This paper took the conversation among the case study team members within the context of action research meetings, which were explicitly intended to be reflective, as primary data for study. With these transcribed conversations as the object of study, the following paragraphs elaborate on the methods of analysis employed. Two complementary methods were recruited for exploring the relatively uncharted territory of STPs as generators of Mode-2 learning. The first drew on textual analytic or ‘text mining’ approaches, while the second deployed a thematic analysis.
Human conversations, when transcribed, are unstructured data, and the task of text mining is to convert these into a structured format, which it does by treating transcribed talk as ‘bags of words’. The distinction between unstructured and unordered is important here. Unstructured data are only defined as such because they do not lend themselves to analysis—the order of the spoken words convey meaning, but are problematic for statistical analysis. Consequently, in a statistical approach, the order and sequencing of the words that were spoken are broken apart and rearranged in a way that lends itself to statistical treatments. The analogy is taking all the words on a page and tipping these into a bag that is then shaken up. The order and sequence of the sentence constructions are—for the first approach—unimportant. In text mining, however, what is important are the frequencies of word (token) usage and the frequencies with which certain tokens co-occur. Text preprocessing converts text into matrices, generally of the form listing the token and the raw count, or frequency, of that token’s occurrence in the text being analyzed.
In all conversations and texts, a significant percentage of the content will be made up of common ‘function’ words that act as grammatical ‘glue’ holding sentences together but that, in themselves, have no lexical significance (
Turney and Pantel 2010). These are words such as ‘the’, ‘and’, ‘it’, etc. Lexically significant words may themselves only occur infrequently within a text and, as a result, document term matrices (DTM), discussed shortly, are generally very sparse. That is, because there is a high proportion of terms that are used infrequently, a matrix is populated with a large number of zeroes. In text mining applications, this effect, known as Zipf’s Law, is commonly taken into account through the use of a list of ‘stop words’. Stop words are generally a predefined list of commonly occurring words that do not add anything semantically to the text but only serve functional purposes in the correct grammatical construction of sentences. The ‘stop words’ are removed from the text to be analyzed, leaving behind the lexically more salient words to be compared for relative frequency of occurrence (
Feinerer et al. 2008;
Francis 2006;
Francis and Flynn 2010). In addition to the list of common English words that text mining packages include, an extended list of words from the text that identified individuals by name, role, or location were also added as a bespoke list of stop words to preserve the anonymity of participants and stakeholders. Nevertheless, what this does mean is that text mining is not, in itself, a complete method for analyzing texts, and that a healthy degree of caution needs to be maintained in undertaking a statistical analysis of texts. Simply counting frequencies can be misleading and, as others have pointed out, the text does not speak for itself Therefore, interpretation is a critical stage in text mining applications (
Kayser and Blind 2017).
The use of text analysis requires that the rich complexity of textual data is in some way reduced, and the challenge for analysts “is choosing a strategy for information loss that yields substantially interesting and theoretically useful generalizations while reducing the amount of information analyzed and reported by the investigator” (
Weber 1990, p. 41). This is accomplished through the use of basic word frequencies, key word in context (KWIC) lists, classification of words into content categories, concordancing, and cluster analysis, among other methods (
Baron et al. 2009;
Cheng 2012).
The texts were analyzed and preprocessed, as will be discussed below, and text analysis was performed using the R programming and statistical language platform (
R Core Team 2014), using the
tm (
Feinerer and Hornik 2014) and
tidytext (
Silge and Robinson 2016;
Silge et al. 2016) packages. For the text mining, three stop word (or token exclusion) lists were used, one which comes as part of the
tm package and a second which is native to the
tidytext package, both of which exclude commonly occurring English words. The third, as noted above, was bespoke and excluded the names and other identifying information to preserve the anonymity of the project team and associated stakeholders, as well as the names of businesses, etc. referred to in the course of the conversations. Lemmatization was applied, meaning that the variations on stem words were not retained, so that, for example, ‘business’ and ‘businesses’ were both lemmatized as ‘busi’. The preprocessing stage of the analysis is complete once the corpus is converted into a document term matrix (DTM).
The DTM comprises a number of rows corresponding to the number of documents in the corpus. So, in this instance the DTM had five rows, while the number of columns was the total of all unique words used across the corpus. The structure is such that each column represents a word and each cell lists the number of times that word is found in a specific document. Consequently, as noted above, DTMs are very sparse—there will always be many more cells in the matrix that only contain zeros because a given term (as per the column name) does not appear in the text. For terms that only appear once in the corpus, all other cells in that column will, therefore, be populated by zeroes. Ordinarily, this is not problematic, but must be accounted for in hierarchical clustering. In this paper, this was addressed through applying the term frequency inverse document frequency (Tf-Idf) weighting method, which is discussed in further detail in the next section.
The second method recruited in this study complements the statistically oriented analysis by reading the text for emergent themes and, using a set of predefined codes, explores how the project team articulates its understanding of and learning about governance, delivery, networks, challenges, and learning within the context of facilitating interventions intended to leverage shifts in the local community toward more sustainable living. The findings from this analysis are discussed in
Section 6, below.
5. Results from the Quantitative Textual Analysis Phase
Following the steps for preparing and cleaning the text data outlined in
Section 4, two parallel analyses were performed using different weightings. The first, discussed shortly, used standard term frequency (TF), a simple count of the number of terms across all the source documents. The second analysis used the term frequency-inverse document frequency
1 (Tf-Idf) weighting. This latter weighting removes frequently common words that are indiscriminate with respect to where they are located. Put differently, while TF counts the number of terms, yielding a matrix of terms and the frequency with which they appear in the text, regardless of whether they are in all or only some of the source documents, the Tf-Idf weighting removes those words that are frequently found across all documents. The idea behind the second weighting method is that by reducing the ‘noise’ generated by high-frequency terms that are also frequent across all of the documents in a corpus, a clearer sense of what is actually important can be obtained by counterbalancing term frequency and its relative rarity across the source documents.
Using the TF (term frequency) weighting, topics were modelled using latent Dirichlet Allocation (LDA) to fit a statistical topic model using unsupervised learning to reveal semantic structures and patterns within the texts. A topic can be thought of a cluster of terms that frequently co-occur, and modeling these helps identify the emergent themes discussed. More specifically, a topic is “distribution over all observed words in the texts such that the words that are strongly associated with the texts’ dominant topics have a higher chance of being included within the text’s bag of words” (
Ignatow and Mihalcea 2018, p. 209). In other words, and given the context of the documents analyzed here as transcriptions of conversations, the value of topic modeling is that it shows a “cluster of words that tend to come up in a discussion and, therefore, to co-occur more frequently than they otherwise would” (
Ignatow and Mihalcea 2018, p. 208). LDA assumes that each of the documents analyzed comprises a mix of topics, the structure of which is unknown, or latent, and infers the structure of the topics with reference to known words and documents (
Blei et al. 2003). Because it is measuring distributions, LDA requires TF, rather than Tf-Idf. For the purposes of this calculation, the
k means was set at 5 to reflect the number of documents used. The
k represents the number of groups that can be prespecified by the analyst and classifies terms in multiple groups or clusters so that the contents of those clusters are as similar as possible. In other words, clusters represent high intraclass similarities among terms, and this permits clusters to be compared with other clusters. The objective, then, of using LDA is to identify the main topics of the transcribed conversation and the distribution of these across the five documents (k = 5).
Applying the Tf-Idf weighting to the document term matrix (DTM), those terms that were both frequent and unique within the documents were examined using hierarchical clustering, with a k means of 3. This k means was determined using an optimization algorithm, which will be discussed in greater detail in
Section 5.2, below. Using both the TF and Tf-Idf weightings enables a richer analysis of the texts.
With a range of between 14,105 and 27,885 words per document,
Table 2 summarizes the raw word count per document, showing an average word count of just under 25,000 words for each transcribed conversation.
As will be seen during the subsequent sections of this discussion, despite an average of 25,000 words per document, many of these terms are used multiple times, and so the first task was to reduce the number of words used to the number of unique terms and their respective frequencies. This was accomplished initially through a simple term frequency (TF) calculation and then through a term frequency-inverse document frequency (Tf-Idf) calculation.
5.1. Term Frequency (TF) Analysis
The corpus comprised 3477 unique stemmed terms distributed across five documents, each representing a transcribed audio recording of action research meetings that were held over a period of a year during the initial 18 months of the STP’s funding. As
Table 2 summarizes, these meetings were held on 2 April 2014, 23 July 2014, 17 December 2014, 27 March 2015, and 3 June 2015. In preparing the data for analysis, each of the terms was stemmed (or lemmatized) to reduce variance. This process reduces the complexity of terms to their root and subsumes variations on that root arising from different suffices or plural forms and includes these as part of the count for that term within the DTM. So, while the average number of raw words across the five documents was just under 25,000, when processed, this variance was reduced to just under 3500 unique terms. This demonstrates the degree of redundancy in spoken language.
Applying the simpler term frequency weighting, only frequent words are returned, on the naïve assumption that raw use frequency denotes importance.
Table 3 summarizes the 20 most frequently occurring terms and gives their frequency of occurrence and their relative frequency (rounded up) per 3477 unique terms.
In looking at
Table 3, the first thing to notice is that across the 20 most frequently used terms in a corpus of 3477 unique terms, is the precipitous drop-off between the second and third most frequently used terms, with the former being almost twice as frequently used as the latter. We notice the range between the first and the 20th terms, with the former being used five times as frequently as the latter. Assuming frequency corresponds to salience, then the core of the project’s concerns would appear to be ‘peopl’, (or ‘people’), followed closely by the term ‘know’ (including ‘know’, ‘knowing’, ‘known’, and ‘knowledge’), with use frequencies of 810 and 735 times, respectively. The significance of these two terms can be demonstrated not only by the frequency differences between the second and third terms, but also the high use count clustering of these two terms compared with the closely aligned frequency clusters, ranging from 4.5% to 10.6%, a span of frequencies that are noticeably different from the most frequently occurring cluster. It does not mean that the couplet is ‘peopl’ and ‘know’, but rather reflects a broader account wherein the terms ‘peopl’ and ‘know’ co-occur within the same frequencies of use. Clearly, a more nuanced approach to analysis is required to tease out the relationship between these terms than text mining can provide here, and corpus linguistic methods are likely to be appropriate at this juncture.
The most salient terms in the five transcribed action research conversations among the community-based sustainability transition project (STP) stakeholders over the first 18 months of its funding cycle emphasized the frequently occurring terms ‘peopl’ and ‘know’, as assessed according to the term-frequency (TF) weighting criteria. That these terms were tightly coupled and were marked by a sharp distinction between this and the next frequency cluster may infer a salience in semantic association. Indeed, such clustering might even suggest a phrase structure that links what and how ‘peopl’ ‘know’. Should this be the case, then the term-use association raises linguistically interesting questions. For example, are questions being asked about what people might or do know or does it reflect an opinion that everyone thinks in similar ways as does the speaker, as in the declaration that assumes people know something, as in the phrase “people know that”, which activates and aligns itself with a particular discourse around taken-for-granted knowledge and ways of seeing the world?
Put differently, given the statistical frequency of each term, questions can be raised about how knowledge may be construed as a resource upon which local stakeholders are thought to draw (i.e., skills, experience, connections, etc.), or, rather, does it reflect an assumption on the part of the project team about how the world is thought to work, describing an assumed convergence of opinion around an account of what is or about should be taken for granted, according to the speaker’s position? While intriguing, these lines of enquiry unfortunately exceed the scope of the present study, even though they do signpost opportunities for exploring the cognitive linguistic constructions arising from actor reflections on the practice of community-based sustainability activities. These remain questions for future research.
The next frequent term concerns ‘time’, and it is conceivable that project actors are concerned about the passage of time given the time-limited nature of their funding. One might anticipate that during the early phases of a funded project, even while the arrow of time extends forward into a future that has yet to be defined and determined by the actions taken in the present, the pressure to meet expectations, to lay down an informed foundation in order to minimize downstream errors and missteps will be a key concern to project actors. Project teams will be in planning mode at this stage of the project’s lifecycle, and the constraints and opportunities afforded by time will be key to these planning decisions.
The third frequency clustering appears logically coherent: ‘project’, ‘food’, and ‘work’ each link to the pragmatics of doing a project like this. In the early days of the project, engaging members of the community with the two primary work streams of energy efficiency-related and sustainable and local food supplies was core to the project team’s priorities. Of these, however, they did experience a number of challenges regarding the degree of engagement with the public about energy efficiency, leading ultimately to a shift in emphasis away from domestic energy efficiency activities to more business-centric activities. Their efforts to engage the public with food-related activities met with greater receptivity and, hence, was the first work stream that attracted greater investment in time and effort from the team. When read against this context, the third frequency cluster of ‘project’, ‘food’, and ‘work’ became intelligible: The food projects were already requiring work by the staff team and were, to some degree, also ‘working’ insofar as they were being picked up by the local community. A food hub was an early developmental milestone, various food network models were being examined, and the efforts to start a food forum drawing on the participation of local food and drink producers and retailers was already gathering steam.
The point being that, for the frequency clusters summarized in
Table 3, there was a coherence or a salience that can account for the underlying structure revealed in the patterns of usage frequency. To interrogate these structures further, we turn now to topic modeling using the latent Dirichlet Allocation (LDA) to fit the topic model to explore some of the underlying structures in more detail (
Blei et al. 2003). The five LDA topic models are illustrated in
Figure 1. It will be remembered from the earlier discussion that the selection of 5 as the k means was predicated on there being five documents and applying LDA modeling to these documents revealed some of the salient topics in each.
In looking at these images, it was immediately apparent that there was a convergence between the prevailing patterns of the coupled terms ‘peopl’ and ‘know’, which were found to occur frequently and which were discussed above. It is also clear that ‘peopl’ is a dominant theme in all cases except those in topic 4, where it was exceeded by ‘know’. Examining topic 4 in more detail also shows that words like ‘transit’ (or transition, as per transition town), ‘time’, ‘work’, and ‘volunt’ (as in volunteers and volunteering) are also common—almost as common as ‘peopl’ in this instance. The topic appeared then to orient around themes of engaging the local transition town chapter and other volunteers, getting objectives done through work against a backdrop of time and possible deadlines.
In topic 1, however, the most common words were ‘project’, ‘time’, ‘event’, and ‘use’, again suggesting a preoccupation with a focus on activities, engagement events, and making use of available resources and opportunities. Topic 2 shifted emphasis slightly, showing that words like ‘capac’ (as in capacity) became more common, followed closely by ‘food’, ‘busi’ (as in business), ‘map’, ‘meet’, and ‘look’. These might be understood with reference to the project’s engagement with food businesses and the development of a free promotional map identifying the location of various producers and retailers of local food and drink. Again, in topic 3, ‘food’ was common, as was ‘time’, a pattern that was shared in topic 5 with the cluster of ‘food’, ‘time’, ‘work’, and ‘project’. However, in topic 5, for the first time, words like ‘energi’ and ‘group’ emerged as common, and this may be accounted for by the slower start, when compared with the food-related activities, to forming a business group concerned with energy efficiency.
The foregoing presented the findings from a naïve or simplistic term frequency weighting. In this type of analysis, only the most frequently occurring terms are considered. While this is interesting and facilitates insight into the underlying structure of the text and statistical patterns, TF weighting also lends itself to generating a lot of ‘noise’ insofar as the relative distribution of frequently occurring terms is overlooked, such that terms that occur frequently across all five documents were significant but obscured those terms that only occurred within one or two documents and which may, as a result, be considered even more significant in their import. In the next section, the term frequency-inverse document frequency (Tf-Idf) weighting is applied.
5.2. Term Frequency-Inverse Document Frequency (Tf-Idf) Analysis
The idea behind using Tf-Idf weighting in text mining is to reveal important terms within the context of the corpus. This is achieved through decreasing the weight of commonly used terms while increasing the weight for those terms that are not commonly used across the corpus. Applying the Tf-Idf weighting means that those terms that approach zero in frequency occur in many of the documents in the corpus, while those that are further from zero occur in fewer of the documents.
Table 3 summarizes the first 20 of these terms according to descending Tf-Idf weighting rounded up to four decimal points.
When applying the Tf-Idf weighting, it is apparent how different the word frequencies are when
Table 3 and
Table 4 are compared. In the former, we saw a preponderance of terms such as ‘peopl’ ‘know’, ‘time’, ‘project’, ’food’, and ‘work’, whereas with the latter we see an emphasis on databases, cooperatives and cooperation, legislative concerns, the truncated name of the local food hub (‘edibl’), ‘percentag’, feasibility, and risks. Such terms suggest themes more closely related to business activities, to project management, to planning and evaluating impacts and change, and the evidence for these. Within the context of this small sample of 20 terms, the Tf-Idf weighting shows that the term ‘databas’ occurs across more documents at 0.0062 than does ‘prize’ at 0.0027. Indeed, analyzing the corpus using this weighting affords a degree of granularity that the more blunt TF weighting did not and helps the analyst to review some of the concerns that were important, but not necessarily so frequently expressed to become ubiquitous.
The next step of the analysis is to see what terms tend to cluster together with respect to similarity. While the LDA topic modeling, discussed in
Section 5.1, used the number of documents to determine the k means, in the context of this discussion we will analyze the statistically optimal value of k.
Figure 2 shows the elbow at which the optimum value is derived and, as a consequence, for the calculation of the hierarchical clustering, the k means equals 3.
Using the foregoing k means value,
Figure 3 illustrates the hierarchical clustering of the first 20 terms derived through the Tf-Idf weighting, as summarized in
Table 4. The model can be seen in
Figure 3. There are three clusters, as per
Figure 2, and these are asymmetrical, with the α cluster converging the highest number of leaves overall. In this first cluster, we see two primary clades that comprise, from left to right, a set of three leaves, a set of two leaves, and then a subclustering of similar terms, which will be discussed in greater detail.
In the first subcluster on the left, the terms are ‘prize’, ‘red’, and ‘percent’, which agglomerate at very small distances, suggesting a strong association among these terms. While the use of ‘prize’ remains ambiguous, the grouping of ‘red’ and ‘percent’ is intelligible with reference to evaluation metrics in which certain targets—measured by the percent to which they are completed—are considered to be ‘red’ or not yet met. The second clade is more complex to interpret, however. The first of this multi-clade cluster converges ‘desk’ and ‘logo’ as demonstrating a strong similarity. However, it is reasonable to consider each of the members of this clade as broadly similar given their position relative to the x-axis. Hence, we see couplets of ‘blog’ and ‘brand’, ‘val’ and ‘visitor’, which also attract terms such as ‘gap’ and ‘amber’, the latter referring once again to the evaluation of activity relative to a target, perhaps as a ‘gap’ in being able to satisfy an objective. The term ‘val’ refers to the local volunteer center, and one can convincingly argue that establishing a blog online is associated with the development of a brand identity for the project. Overall, the salience of the α cluster appears to converge around establishing an identity, recruiting volunteers, and a concern about meeting targets.
The second, or β, cluster is smaller, comprising two bifolious pairings of four leaves, each of which agglomerates at very slight distances, suggesting similarity among these terms. The first clade appears to concern the evaluation of risk and feasibility, which are understandable from the perspective of the project actors who are engaged in planning particular activities and who need to evaluate the risk and feasibility associated with committing themselves to particular courses of action. The second clade concerns activities that are also connected to evaluations, but this time specifically with the quantification of evidence, that is, measuring and counting.
The final cluster, designated γ, concerns several discontinuous leaves. Reading this cluster from the right, the leaves ‘edibl’ and ‘legisl’ reflect a focus on the legal and legislative implications of starting a local food cooperative business, where ‘edibl’ is the truncated form of the name of the enterprise. This is substantiated by the next leaf to the left of this subcluster, ‘coop’, and these three leaves are quite similar with respect to their convergence around the start-up food business. The fourth and fifth leaves, i.e., ‘percentag’ and ‘databas’, respectively, suggest a concern with counting and measuring, although their specific relevance here is not clear. Nevertheless, the substantive convergence of the third clade suggests a concern to do with the formation and development of a local food business and its legality, along with a suggestion about evaluation metrics and data capture.
From the foregoing, one can reasonably advance that the α cluster appears to converge terms associated with a broader mechanics of a new project: developing a brand and a logo, identifying gaps, and concerns with not meeting targets (‘red’) or only partially being successful (‘amber’), as well as recruiting support (‘val’, pertaining to the local volunteer agency) and public engagement opportunities. In contrast, the β cluster appears to be far more closely focused on project management concerns, raising issues pertaining to risks and feasibility studies, and how to monitor and record performance along the way. The final cluster suggests the establishment of a legal cooperative business, and although the inclusion of terms like ‘databas’ and ‘percentag’ are not clear, it is probable that these refer to methods for recording performance against project objectives and may be related to identifying how the business will help further project objectives and ways of managing relevant data.
To summarize then, from the hierarchical cluster analysis of the 20 most frequent terms as per the Tf-Idf weighting method, three emergent themes were described and interpreted. These are, from left to right, that cluster α appears to depict a group of terms that refer to project management concerns, identity and branding, and performance evaluation. The second, or β, cluster also appears to be grouped around the project’s performance, although here the terms lend themselves to interpretations favoring decision-making and forward-looking strategies, such as measures of risk, identifying the feasibility of options, and what data is to be measured and counted (as well as perhaps the validity of the data collected, as in whether such data counts or holds merit). The final cluster closely agglomerates the food business and its legislative framework, its activity and identity as a cooperative, and, at a greater distance away, considerations about one or more databases.
From this review of the three clusters, project stakeholders appear to be discussing themes around data collection (what is valid data, how it is stored, how is it measured), performance evaluations (meeting targets and the status of these—red or amber—and relative percentages), identity (brand and logo), about stakeholders (volunteers and visitors), and forward-looking decision making and strategizing (risk, feasibility, measurements). Overall, the terms appear to describe an organization concerned with its identity and performance, that determines and evaluates strategic ways forward that are oriented to agreed targets, and that deliberates about regulatory frameworks governing the establishment of a food enterprise. These interpretations are summarized in
Table 5.
5.3. Concluding the Textual Analysis
The foregoing paragraphs have reported on the first of this two-stage study. The stage recruited a text-mining approach, treating the five-document corpus as a ‘bag of words’, which, when transposed to a document term matrix (DTM), permits the text to be treated statistically. Given the very small sample in this study, doing more elaborate quantitative analysis would be excessive and economies of scale will rapidly adhere. Moreover, as the study is interested in how STP staff learn about and understand what they do when they are organizing projects to support the local area to engage in transitions toward sustainability, the present study was concerned with the exploration of potential themes. Consequently, three analytic methods were applied to the corpus, these being term frequency (using both simple term frequency (TF) and term frequency inverse document frequency (Tf-Idf) weightings), LDA modeling, and hierarchical agglomerative clustering of the 20 most frequently used terms (using Tf-Idf weighting) into themes grouped by similarity.
The application of these three methods led, firstly, to an analysis of term use frequencies. Using the TF weighting, we explored the topic modeling across the five documents and noted some of the emergent themes from the reflective conversations among the STP team. Of particular interest here was the prevalence of terms referring to ‘people’ and to ‘know’ (knowing, knowledge, etc.), and the query was raised about how these terms, which, while both frequent, might be structurally related or coupled. To explore this further required the use of corpus linguistic methods, such as concordance analysis, but as this exceeded the present study, this line of inquiry was not pursued.
The second variation of term frequency analysis adopted the Tf-Idf weighting and this revealed terms that were significant but not ubiquitous. Applying this weighting method, we analyzed the hierarchical clustering of the 20 most frequent terms, and the three clusters were then interpreted according to themes, or descriptors, related to different aspects of the STP’s operation, i.e., performance, strategy, and governance. These descriptors offer some broad, and provisional, parameters with which to understand the different domains through which the STP realizes its task to facilitate the transition of the local community toward sustainability and to meet the outcomes and objectives with which success is defined according to their funding agreements.
Even though these themes align well with what would be expected to emerge from reflective conversations with project team members about how they go about doing what they have been tasked to do, one of the limitations of a text analytic method is that, because it purposively transforms sentences into a ‘bag of words’, it is unable to surface the layered contexts of meaning and signification. These are emergent and constitutive characteristics associated with the way that words are combined in usage and, therefore, exceeded the scope of text-mining applications. Accounts and reflections tend to be expressed in narrative form. Answers to questions are given shaped by the contexts in which the questions were asked, including reference to shared, albeit, unspoken assumptions about meaning and reference and, as a result, the meanings of the reflections are not measurable via a textual analysis when this method is used alone. Nevertheless, what a textual analysis does offer is a way of identifying terms with potential salience and the associations among them, and these can become the basis for a deeper, more qualitative investigation. Therefore, to further explore the meanings STP staff attribute to their experiences, we turn now to consider the same corpus, but from an alternate perspective, one which maintains the qualitative character of each meeting as a set of narratives attributing meaning to the participants’ experience as members of a STP group.
6. Findings from Thematic Coding Analysis
The second part of this study recruited the well-established qualitative research method of thematic analysis (
Braun and Clarke 2006). As this is a method with which it is assumed most will be familiar, it is presumably only necessary to introduce it by noting that the basic idea underpinning the method is that, through a succession of close readings of the textual material, the analyst generates a set of codes that are constructs for summarizing the ‘essence’ of a phrase or specific use of word in a form of shorthand, which is then used to iteratively assemble clusters of similar ideas into themes of increasing degrees of abstraction, as in more distant from the specificity of the data.
Coding was conducted using the R package RQDA (
Chandra and Shang 2017;
Huang 2014). Several attempts were undertaken to arrive at a suitable coding dictionary that fit the source data most appropriately and, following repeated iterations of reviewing the text until the point of saturation, the resulting collection of codes was grouped together into ‘categories’ or themes. As a result of this process, 23 codes were generated, which could be grouped into five categories, and these findings are summarized in
Table 6. Codes are given in the left-hand column along with their descriptive key in the second column, and the emergent theme is in the third.
In total, 836 segments of text were coded, and the emergent themes are rank-ordered by the number of times the theme was coded in the text, as per
Table 7.
As
Table 7 shows, the theme around ‘delivery’ tended to be the most frequently discussed when analyzing the transcripts of the action research meetings. When this was considered in greater detail, to understand how these results were arrived at,
Table 8 summarizes the most frequently applied codes and the theme that these support.
Of the five themes, ‘delivery’ was the most frequently coded theme in the text. This is understandable considering that the main concern of the STP team was about how the project was delivered. From the nature of the question, prompts used by the facilitator of these meetings, which asked team members to reflect on activities and successes and challenges, but also from the focal concern of the STP team themselves on getting things done, an emphasis on ‘delivery’ as a recurring theme makes sense.
Examples of some of the text coded as delivery-related include the following:
“Starting to work with (social housing provider partner) on retrofitting other local homes”;
(2 August 2014)
“(STP) has a wide programme of activities relative to other CLS projects”;
(23 July 2014)
“(STP) team has the right amount of resource available to tackle each of the projects”;
(23 July 2014)
“more projects going on than (the STP) have left on reserve to do”;
(17 December 2014)
“everyone felt the pressure to get out more and do more things”;
(17 December 2014)
and
“(STP) supports the ‘best interests of the town’”
(27 March 2015)
In addition to the ‘delivery’ theme, codes associated with ‘learning’ were also common, followed quite closely by discussions around engaging local community actors as part of the process of delivering on the project activities.
Although only briefly described here, the findings generated through the thematic analysis strongly oriented toward a common focus in the transcribed action research conversations around delivery. One might anticipate this emphasis, given the stage of the project relative to its funding cycle. Having started in early 2013, much of the emphasis given to delivery for any new project was likely to be around how to get on and deliver what it is funded to deliver. One might already anticipate that conversations at this stage would concern identifying how to interpret what needed to be done to meet targets, what resources were already available to deliver on such outcomes, and lining up specific tasks consistent with the project’s activities.
Moreover, considering the relative coding frequencies summarized in
Table 6, it seems reasonable to link what was to be delivered with discussions around the networks with which the project was to work, be this individual organizations and agencies, as well as an appreciation of which members of the community were network hubs, gatekeepers, brokers, bridges, and the other roles played by members of the local community with whom the project team was becoming familiar. As a consequence, I am confident that the relative preponderance of themes surfaced in a qualitative analysis of the transcribed action research meeting conversations were consistent with the response of a small, project-based organization finding its feet in a largely unknown community context, making sense of what needed to be done and with whom.
In the following, and last, section of this paper, the findings derived from the thematic analysis, as presented here, are synthesized with those from the preceding section and discussed relative to Mode-2 organizational learning and knowledge production within the context of community-based sustainability transition projects that operate at the front line of one of the most compelling and pressing wicked problems threatening human existence.
7. Discussion and Conclusions
Language—its usage and its ubiquity as a source for knowledge extraction—has come to the fore increasingly over the last few decades. Much of this recent blossoming of attention is the result of the widely available and cheap computer processing power along with user-friendly software programs that enable statistically robust analysis of both written and transcribed texts (
Potts et al. 2015). Over the last two to three decades, for example, there has been a proliferation of interest in what an analysis of language might reveal about how participants in an organization think (
Oliver and Brittain 2001;
Thibodeau and Boroditsky 2011). Areas of research interest have concerned how an organization and its (knowledge-based) assets are constructed and maintained, negotiated and navigated through language, and even how language and managerial sciences might be related (
Crilly et al. 2016;
Ford 1999;
Ford and Ford 1995;
Robichaud et al. 2004;
Steen 2011). Here, the organizational form of a funded, community-based sustainability transition project was considered through the analysis of five transcribed conversations generated through independently facilitated action research meetings with members of the project team. These texts were analyzed using two distinct methods. The first was a quantitative treatment of the texts as a ‘bag of words’ and investigated frequencies of term occurrences, using two weighting methods, analyzed the documents for emergent topics, and graphed the hierarchical clustering of frequent terms according to similarity. The second approach took these same five transcripts and iteratively analyzed these using a bottom-up generation of codes, which were then grouped together to yield a handful of recurring themes.
The subject matter for the present analysis is quite rare in the organizational learning and knowledge management literature. This is not only because funded, community-based, and nonprofit project-based organizations tend not to attract the attention that profit-oriented corporate organizations do, but also because the study of sustainability transition projects are, as yet, an understudied sector despite cutting across both organizational development and learning theory along with Mode 2 knowledge production theory. Consequently, the current paper is of an apparently limited literature, which converges a quantitative and a qualitative analysis of language under the auspice of project-based organizational learning and development research. Here, STPs were identified as project-based forms of organization (
Koskinen 2010;
Koskinen et al. 2003) that strategically and tactically converge around an intent, common to participant members, to address wicked problems of social-economic sustainability and resilience, given the existential threats of climate change and the Anthropocene.
In light of the blunt challenges posed to humanity’s future well-being and welfare (
Field et al. 2014;
Hamilton 2015;
Ripple et al. 2019;
Spratt and Sutton 2008), such project-based organizations potentially offer significant insights into how these wicked problems might be meaningfully addressed. While the present case study is not held up as an example of having come up with a magical solution, a ‘silver bullet’, nevertheless this paper offers the analysis of transcribed action research meetings with the case study STP as an initial step toward trying to make sense of how such front-line organizations position themselves relative to the challenges that they face in order to induce outcomes commensurate with both their funded objectives and with a vision of what might constitute resilient, adaptive transitions toward a more sustainable future. Of particular interest was how the case study STP reflects]ed on itself as an organized entity and made sense of its objectives, it resources, and the processes involved in delivering against its funded outcomes.
Over the preceding pages, the transcribed audio recordings of five action research meetings were interrogated using the quantitative approach of text mining, supplemented by the qualitative method of thematic analysis. What is apparent from this mixed-methods analytic approach to the conversations-as-text is the degree to which the findings converge around common idioms. In the text mining of the transcribed action research conversations, the relative frequencies of terms referring to the project itself were returned, suggesting a self-reflective tendency among the project team members to position the project itself as an entity to objectify in its own right. Even a preliminary consideration provided strong evidence by the findings generated by the term frequency and cluster analyses that the primary concern of the case study STP members was actually itself as a group tasked to deliver key objectives, with an emphasis on branding and identity, performance, evaluations, and issues of governance. Such self-reflective assessments and concerns with identity are common within processes of organizational development (
Fenton and Langley 2011;
Leclercq-Vandelannoitte 2011).
As a self-referential entity, the STP distinguished itself as an autonomous entity (
Kay 2001;
Maturana and Varela 1992;
von Krogh and Roos 1995b); it defined for itself an identity. In
Ran and Duimering’s (
2007, p. 179) terms, it “define[s] boundaries and internal structures of identity categories in ways that suit the interests of the organization”. While they continue by emphasizing the crucial role language plays in defining the identity of an organization, they also offer the critical observation that “[i]dentity claims also use action categories to construct identity with respect to what [the organization] does—its activities and its interactions with categories of other social actors or objects” (p. 179). We can find evidence of those processes here: Not only does the STP reflect on itself, distinguishing itself as an autonomous entity, particularly with respect to how it will be evaluated, how it legitimizes itself relative to targets and objectives, it also concerns itself with what it does and how it interacts with the community actors in its operational space. In such ways, the text-mining and thematic analyses converge in supporting the conclusion that at this early stage of development, the case study project is primarily concerned with matters around the formation and establishment of its own identity, corresponding to the ‘birth phase’ as described by
Miller and Friesen (
1984).
While Miller and Friesen, and many others who posit theories of organizational life cycles, often depict change as a linear process, moving from one stage to the next, by adopting the language of autopoietic theory, the organization can instead be argued to continuously produce itself (from ‘autopoiesis’, meaning self-producing) and the conditions that maintain its viability (
Maturana 2002;
Maturana and Varela 1992;
Mingers 1995;
Zeleny 1997). It accomplishes this through constituting its own boundaries and perceiving its medium (or domain of operations) according to its own structures, that is, the organization is structure determined. The operational domain, or ‘environment’, is not ‘out there’, but is actively constituted by the organization through the same processes whereby it constitutes itself. Therefore, to learn about the organization itself, an observer—here the action research facilitator—begins to develop an understanding of how members of the project organization reference, distinguish, and articulate values with respect to their operational domain. In other words, to understand the organization itself, one might usefully attend to the distinguished structures in the domain within which the organization realizes and maintains itself, because the organization only distinguishes those aspects of its world that make sense to it. One need only review the focus of conversations to see what structures are of key importance to the project actors (e.g., its own role relative to other actors, its performance evaluations, its logo and brand, its risk and feasibility assessments of planned activities, etc.). What is absent are references to the local council or even the county council, the transition town network, homeowners (given that advancing domestic energy efficiency was no longer viable, the attention had switched to businesses), transport infrastructure, and even the local biodiversity. From an observer’s perspective, each of these would be wider-scale actors and yet do not receive the degree of attention, as determined by the manner in which these conversations were quantitatively analyzed, that one might expect because, from the perspective of the organization, these are largely irrelevant, at least at the time these conversations took place.
Therefore, what is distinguished as relevant by the STP pertains to the project’s own structure, which concerns those parameters it was intended to address as targets and outcomes, and this is reflected in the language used by the project. Nevertheless, it should be borne in mind that the data for this study were generated within the first two years of a five-year lifespan for the project. As a result, how the conversational focus of the organization may have changed in the remaining period of funding is not known and would be an interesting research venture to explore. Similarly, if detailed transcriptions of the reflective conversations from other STPs could be analyzed for comparison, that, too, would offer a greater breadth of insight into this area.
The analysis of how language was used by the project team during the context of facilitated action research meetings revealed some interesting, even provocative, insights into how the project team positions itself as an organization and acquires learning with respect to fulfilling its funded objectives. By undertaking an analysis of this nature, three findings can be shown to have emerged, two of which concern the methods used. These are briefly discussed below in conclusion.
7.1. Text Mining as a Valid Mode of Investigation
The amount of usable information and insights made possible by the statistical analysis of language helps make the case in favor of this method as a practical approach to surfacing structures and associations within language that would be difficult for the analyst to observe without the application of statistical processing. While mere word frequencies were interesting, as noted previously, this is a blunt tool and can overlook salience, especially if a critical concept is only used once or if a range of synonyms are used to refer to a term that is, itself, rarely used. Nevertheless, even taking this caveat into account, by reducing the amount of noise-to-signal ratio by eliminating function words, punctuation, and numbers and by stemming terms, the claim common to text mining and corpus linguistics that what is important to the language will be referred to relatively frequently. One obtains an ‘aboutness’ about the text (
Gablasova et al. 2017). The caveat can be addressed through key word searches, for example, or through comparing the focal corpus with a reference corpus to identify those terms that are statistically more significant in the focal text. Neither of these options were deployed in this study and this limitation will be addressed in future research. Furthermore, analyzing similarity in terms of cluster analysis offered insights into how words tend to be associated in use and this proved to be useful information with which to understand the underlying structure of the language used by the project team.
7.2. Thematic Analysis Supplements Text Mining
While text mining is an explicitly quantitative form of analysis, in this study this statistical treatment that stripped words of their meaning was counterbalanced through a qualitative approach that coded segments of text to explore the underlying patterns of meaning. When the codes were combined, these generated themes that helped give a different perspective on the content and general ‘flavor’ of what had been said within the context of the conversation. While quite time-intensive in application, it was felt that this approach complemented the blunt analysis of text mining and returned a little richness to the text. Going forward, use of the two approaches in a mixed-methods study, therefore, seems to be indicated wherever feasible.
7.3. Language Use Reflects the Processes of Learning
The focus of the present study was to explore the processes of learning engaged in the doing of sustainability through the language used by project team members in reflecting upon their practices, challenges, decisions, and understandings. To some extent, this was successful. The study was able to identify key priorities of concern for the team, the resources they selected with which to deliver these priorities, and the actors and agents with which they would need to work to realize these priorities. The analysis also helped to surface the project team’s understanding of what it was that they were doing in the doing of eliciting community-scale transitions toward sustainability, and these were discussed in terms of ‘delivery’, ‘networks’, ‘governance’, ‘learning’, and ‘challenges’. The discussion particularly emphasized the formation of an organizational identity as the focal point with which themes pertaining to delivery, etc. were to be achieved and as a means through which to define itself relative to other salient community actors.
It is apparent that community-based STPs have the potential to generate Mode-2 knowing. As per the earlier discussion on this mode of knowledge, the learning generated by the case study STP is both germane to the context of its own operation as well as practical with respect to its operational options and parameters within that domain. The preceding pages developed the basis for the claim that the knowledge generated by the STP team was done within the same context to which it was applied. The knowledge produced concerned organizational identity and reflexivity, performance and quality control, and also issues pertaining to accountability, both social in terms of legitimacy and potential impacts and also legal accountability and reflections on matters of governance. The knowledge generated by the STP was clearly experiential, practical, and transdisciplinary, and as knowledge actors they are wholly immersed in their research to identify what does and does not work to facilitate shifts toward sustainability.
It is evident that, in addition to primary concerns to do with identity and defining itself relative to other actors, the members of the organization were occupied with defining key deliverables and opportunities for developing viable networks through which to deliver objectives, along with dealing with matters pertaining to identifying key actors within the community with whom they could work collaboratively to achieve mutually beneficial outcomes. Indeed, from one perspective, these are likely to be fairly obvious tasks and could reasonably be anticipated. However, the contribution of this paper is not only the confirmation of these assumptions through complementary analytic methods, but more so that the specifics, the details, of how these tasks are approached, how project team members make sense of these tasks and how to enact them, and how the STP team maps out and navigates its operational domain each offer unique insight into the ‘inner’ workings of such an organization. It is these latter considerations that constitute the content of the Mode-2 learning processes.
This paper also confirmed that working with language has the potential to lever significant insights into organizational learning and knowledge production, although it is also true to note that this paper has barely begun to scratch the surface of this exciting and rich seam of understanding. This leads into a reflection of the limits to this study. First, only five transcriptions were used, representing the first two years of the project’s lifespan. These do not allow for a meaningful distribution analysis to be undertaken to track the dynamics of themes and areas of concern for the members of the project team. Second, there is a very limited literature exploring the application of language analysis to organizational learning and knowledge management in noncorporate, not-for-profit sectors and even fewer that concern themselves with community-based sustainability projects. As a result, there is little that the present study can be compared with to evaluate similarity of findings. To be fair, this limitation is also one of the contributions this paper hopes to make. It begins to map out the trajectory for possible future studies. Finally, the third limitation is that the amount of information generated through both text-mining and thematic analyses is significant. Selecting the limits to what would and would not be included in this paper was a difficult decision to reach, and different analysts may well agree or disagree with the decisions made. Again, further studies in this field, using similar methods, will help develop some preliminary protocols to inform such studies.
As noted earlier, within the organizational learning discipline, STPs are significantly underrepresented. Part of this may be because not-for-profit projects have been overlooked in favor of corporate bodies, but it may also be because funded and accessible STPs are themselves quite rare. Many projects exist on a time-limited basis, often lacking funding, and researchers may not even be aware of their existence. Addressing these issues requires that such initiatives receive proper funding and, until such time as they do, research into this sector will remain problematic. Nevertheless, should such initiatives be amenable to study, future research should ideally involve the facilitation of action research-oriented conversations with key stakeholders, the transcripts of which can then be analyzed using the mixed (statistical and qualitative) methods as outlined in this paper. Once a corpus of themes (e.g., LDA topics, hierarchical clusters, and qualitative thematics) has been generated using multiple STPs as source data, this corpus can then be interrogated systematically to identify crosscutting issues and points of commonality and difference, in order to surface a synthesis of meta-analytic literature that can be used as an empirical evidence base for policy and decision makers to draw upon to inform strategic responses to the existential challenges of the Anthropocene.
Nonetheless, the intention motivating this paper has been fulfilled and the combination of the statistical approach to language together with the qualitative examination of emergent meanings and themes appears to offer a fertile methodology. More importantly, however, approaching STPs as learning organizations, trafficking in Mode-2 knowledge generation about responding to the wicked problem of sustainability, has been shown to be worthwhile in terms of deriving insight into how such organizations encounter and engage with their operational domains in terms of making sense of what it is that they do. Moreover, it also extends the scope of organizational learning literature further to include a sector that has hitherto been overlooked in the research literature. It is hoped that this paper contributes to changing that oversight by inspiring future research work into this important area of human endeavor.





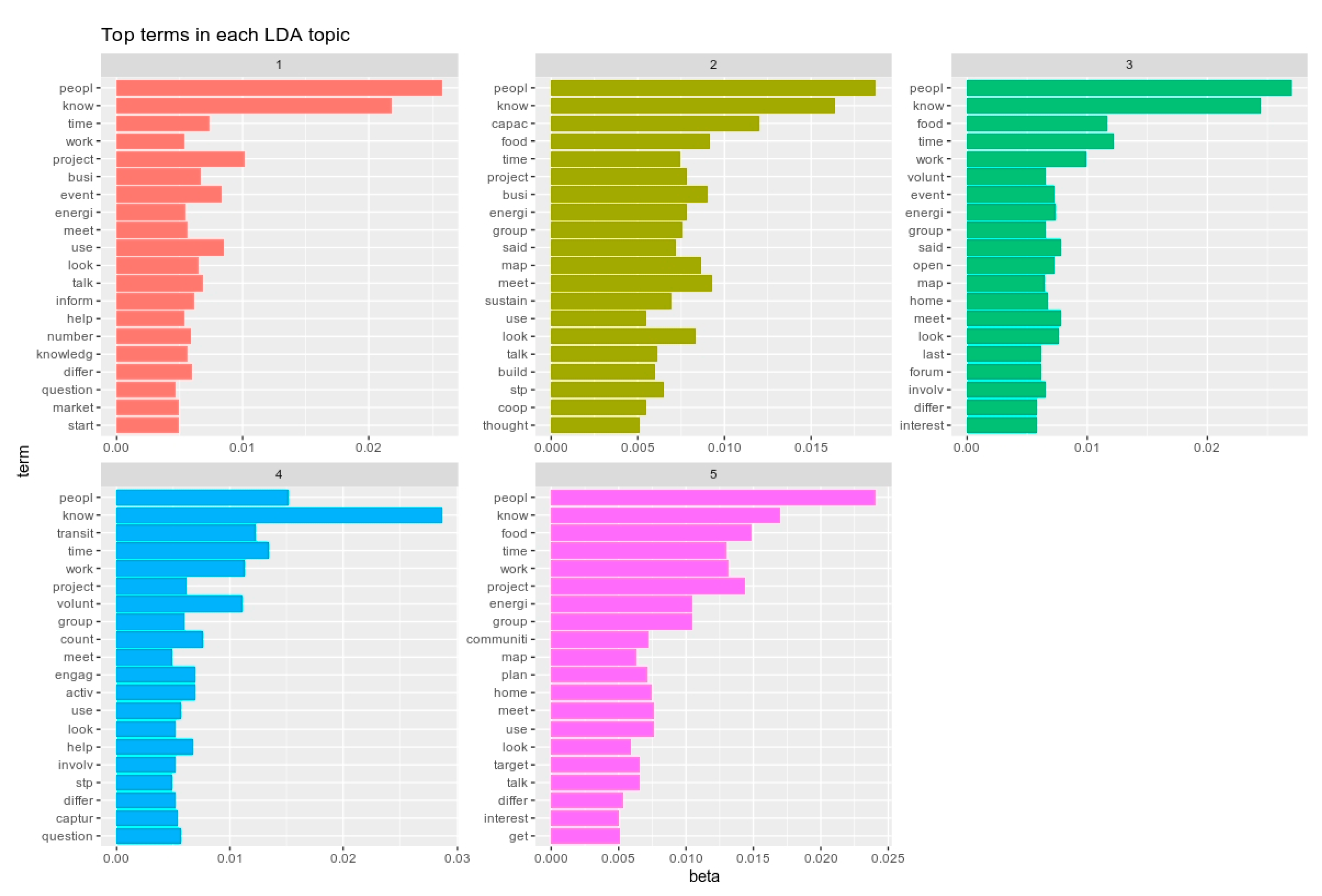{kind=link}
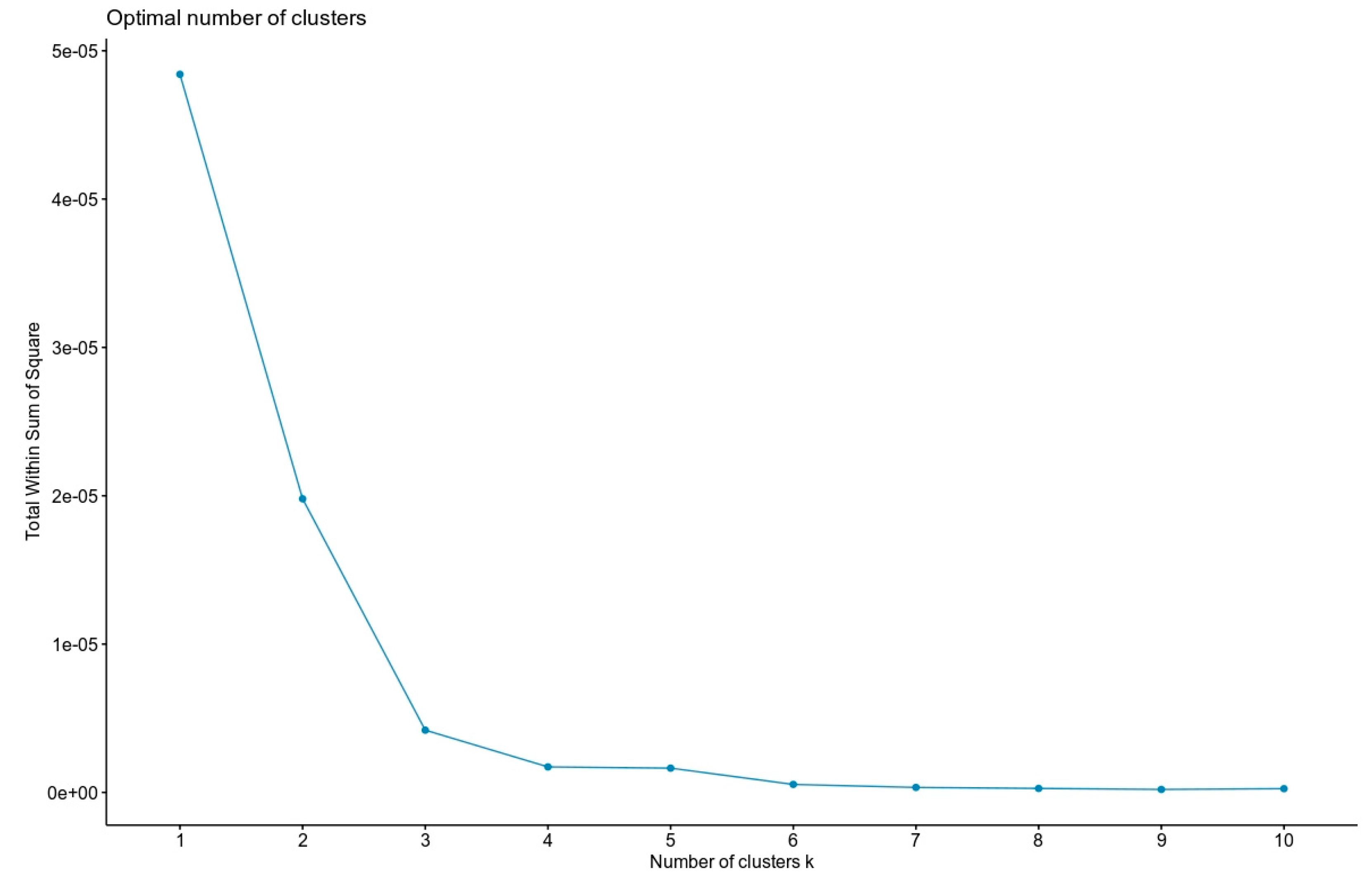{kind=link}
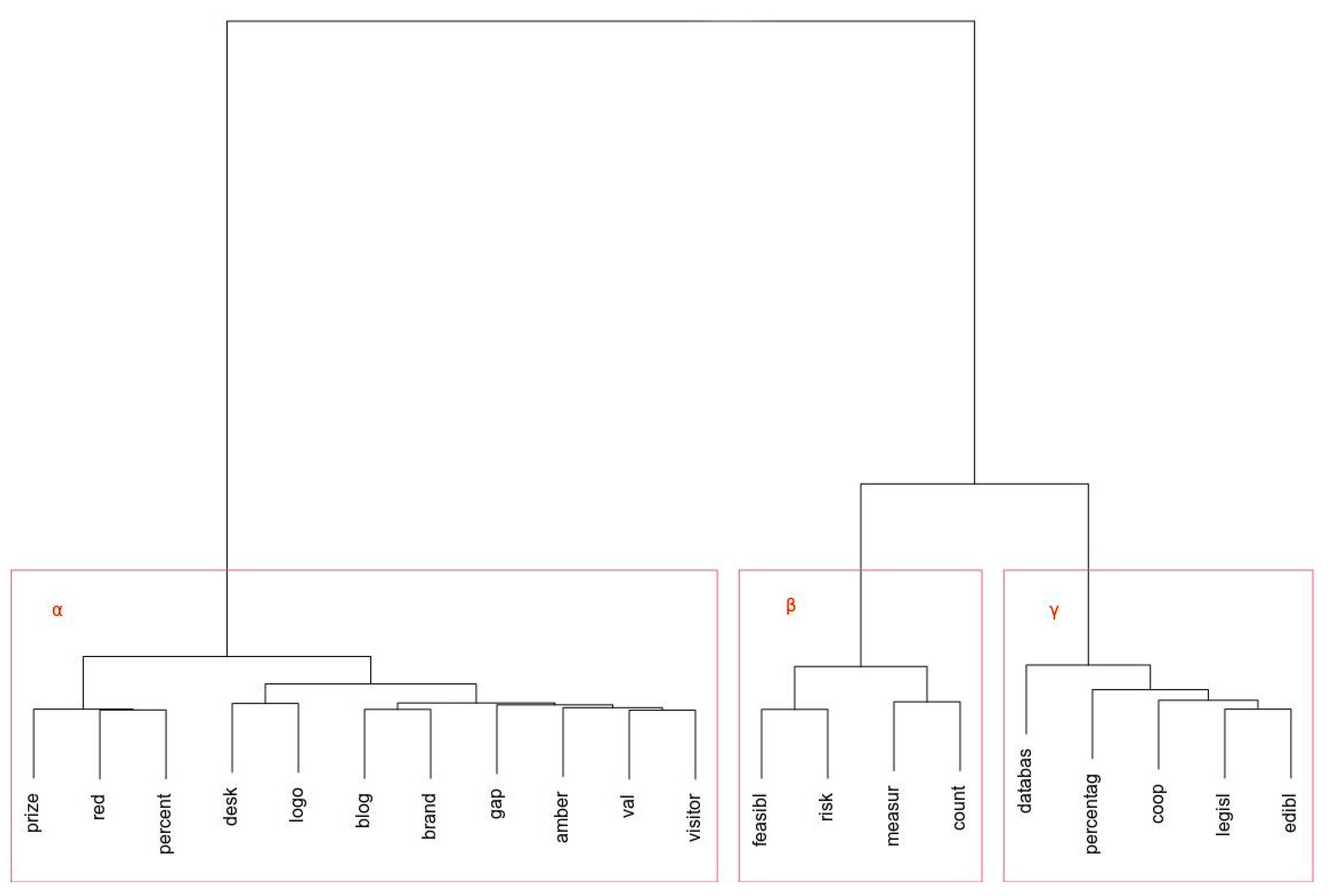{kind=link}