
Complementing but Not Replacing: Comparing the Impacts of GPT-4 and Native-Speaker Interaction on Chinese L2 Writing Outcomes


Abstract
1. Introduction
2. Literature Review
2.1. Large Language Models in Language Learning and Teaching
2.2. Interactive Collaboration in L2 Writing
2.3. Topic Familiarity, Writing Confidence, and Perceived Difficulty in L2 Writing
3. Methodology
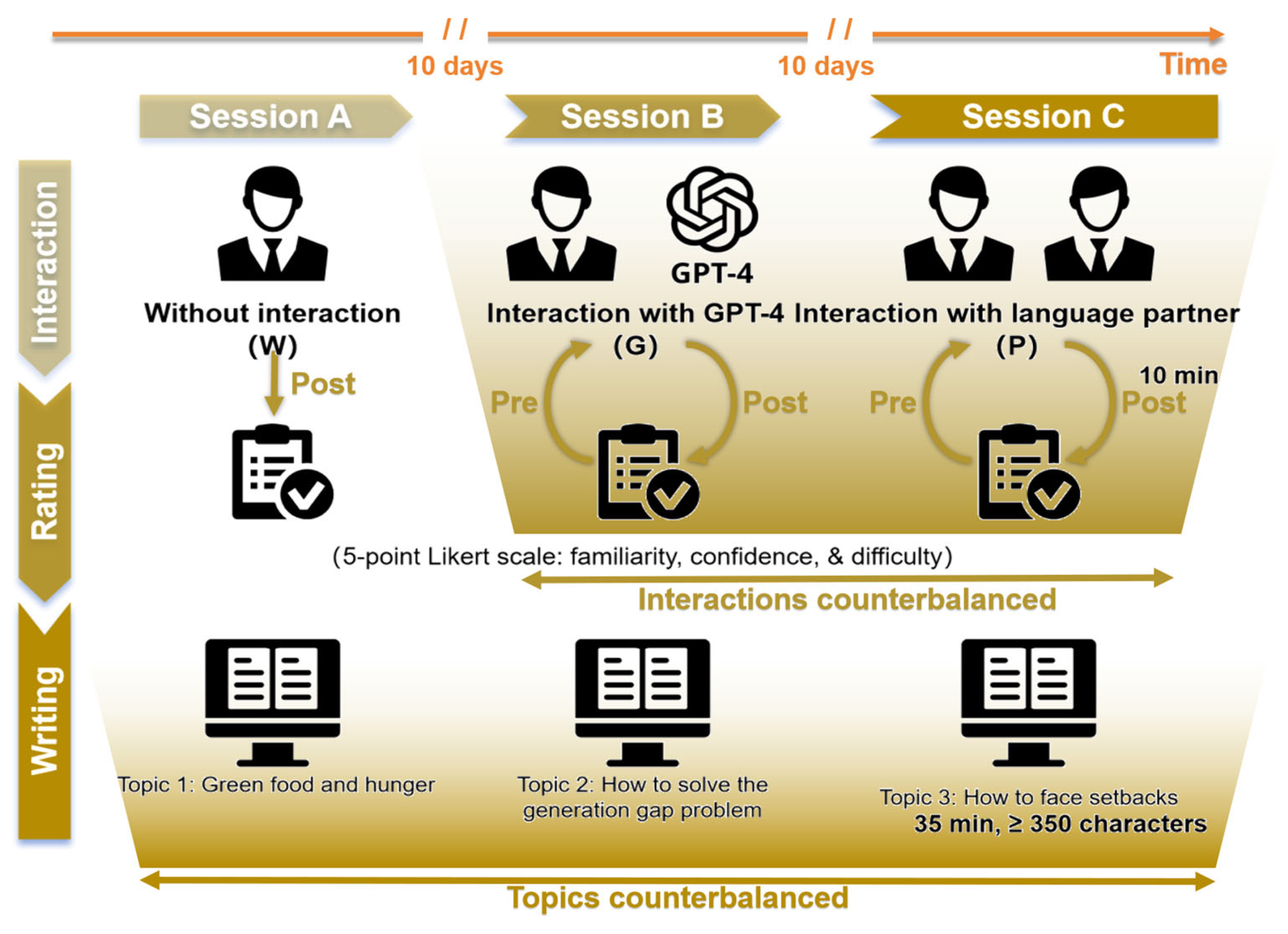
3.1. Overview
3.2. Research Questions
3.3. Methods
3.4. Participants
3.5. Materials and Procedures
“Please play the role of a Chinese language partner and help the international student you are conversing with to complete a 350-character argumentative essay. Before starting the conversation, you need to ask about their Chinese proficiency level and the essay topic that they need to write about. During the conversation, you should not provide a reference essay directly but instead assist them by asking questions and offering prompts to help them gradually develop and refine their essay. At the same time, you should pay attention to the accuracy of their Chinese language expression. Ensure that each exchange feels like a real conversation, guiding them step by step through the writing process.”
3.6. L2 Writing Assessment Criteria
“Please take on the role of an expert in Chinese essay evaluation, following the HSK exam’s scoring standards to assess the students’ essays. Begin with an overall analysis of the submitted text and then evaluate it across four dimensions: content, organization, language, and vocabulary. During the evaluation, pay special attention to the essay’s thematic coherence, grammatical accuracy, and lexical diversity. Instead of directly assigning a score, provide constructive feedback by identifying issues and offering suggestions. Ensure that the assessment process strictly adheres to the HSK scoring criteria to maintain fairness and consistency.”
3.7. Data Analyses
4. Results
4.1. Consistency in Writing Scores
4.2. Differences in Writing Scores
4.3. Differences in the Rating Scores
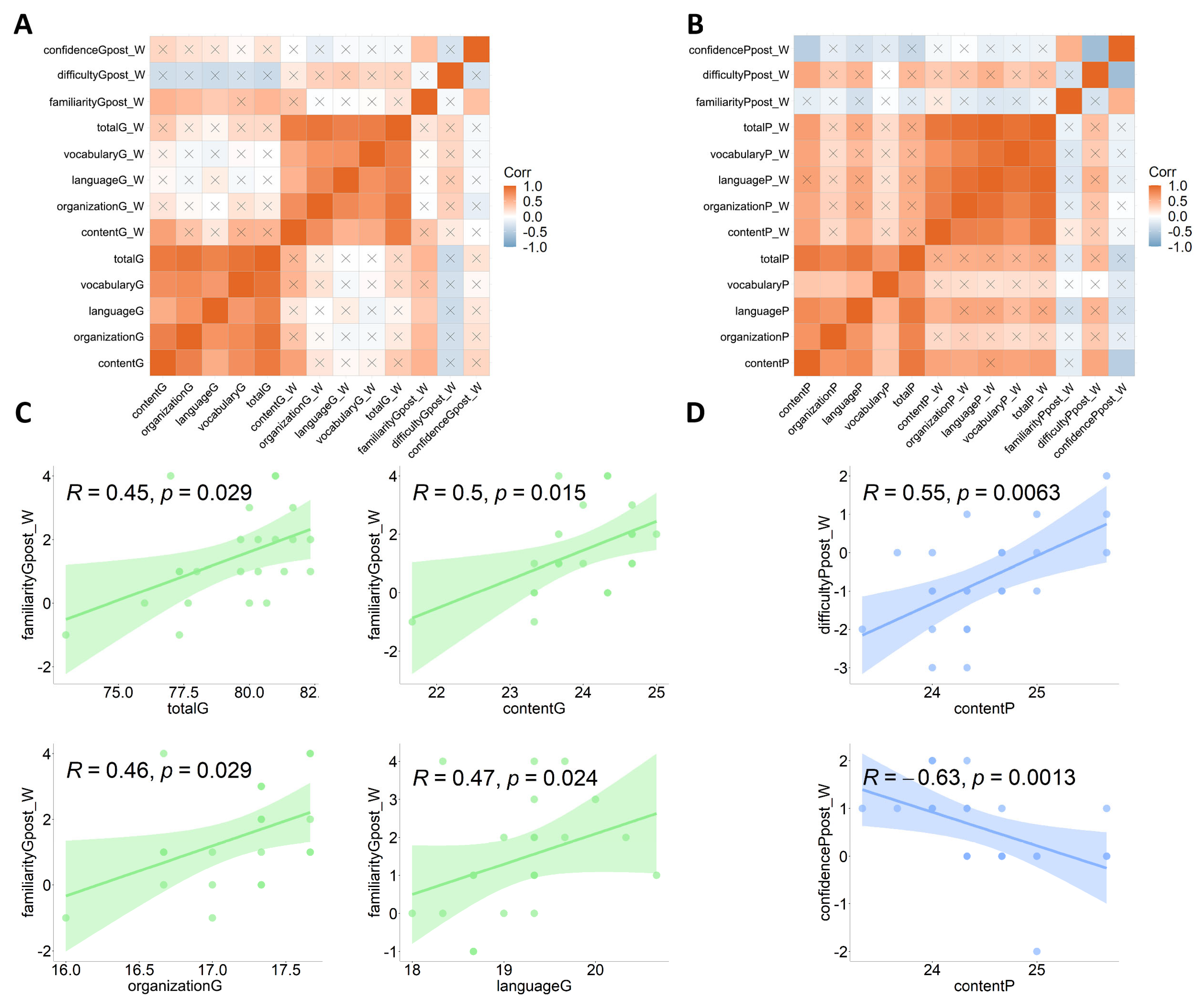
4.4. Correlations Between Writing and Rating Scores
5. Discussion
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dimension of Comparison | Language Partner | GPT-4 |
|---|---|---|
| Topic Introduction | Heuristic introduction: encourages students to think actively through specific questions. | Direct introduction: quickly asks core topic questions. |
| Content Support | Significantly personalized: adjusts content based on students’ background and specific questions. | Strong structure: provides a clear framework. |
| Emotional Support | Strong emotional resonance: increases students’ confidence with encouragement and affirmation. | More positive feedback: enhances confidence with encouraging phrases but lacks personalized interaction. |
| Language and Expression | Moderate complexity: adjusts expression difficulty based on students’ language levels. | Formal expression: uses more advanced written language, suitable for advanced learners. |
| Interaction Mode | Cooperative interaction: collaboratively discusses and forms content. | Supportive interaction: affirms students’ answers through feedback. |
References
- Abdi Tabari, M., Bui, G., & Wang, Y. (2024). The effects of topic familiarity on emotionality and linguistic complexity in EAP writing. Language Teaching Research, 28(4), 1616–1634. [Google Scholar] [CrossRef]
- Agustini, N. P. O. (2023). Examining the role of ChatGPT as a learning tool in promoting students’ English language learning autonomy relevant to Kurikulum Merdeka Belajar. Edukasia: Jurnal Pendidikan Dan Pembelajaran, 4(2), 921–934. [Google Scholar] [CrossRef]
- Albdrani, R. N., & Al-Shargabi, A. A. (2023). Investigating the effectiveness of ChatGPT for providing personalized learning experience: A case study. International Journal of Advanced Computer Science & Applications, 14(11), 1208. [Google Scholar]
- Alqahtani, T., Badreldin, H. A., Alrashed, M., Alshaya, A. I., Alghamdi, S. S., Bin Saleh, K., Alowais, S. A., Alshaya, O. A., Rahman, I., Al Yami, M. S., & Albekairy, A. M. (2023). The emergent role of artificial intelligence, natural learning processing, and large language models in higher education and research. Research in Social and Administrative Pharmacy, 19(8), 1236–1242. [Google Scholar] [CrossRef]
- Arques, A. C., & Ferrero, C. L. (2023). Peer-feedback of an occluded genre in the Spanish language classroom: A case study. Assessing Writing, 57, 100756. [Google Scholar] [CrossRef]
- Austin, J., Benas, K., Caicedo, S., Imiolek, E., Piekutowski, A., & Ghanim, I. (2025). Perceptions of artificial intelligence and ChatGPT by speech-language pathologists and students. American Journal of Speech-Language Pathology, 34(1), 174–200. [Google Scholar] [CrossRef]
- Ayeni, O. O., Al Hamad, N. M., Chisom, O. N., Osawaru, B., & Adewusi, O. E. (2024). AI in education: A review of personalized learning and educational technology. GSC Advanced Research and Reviews, 18(2), 261–271. [Google Scholar] [CrossRef]
- Bandura, A. (1986). Social foundations of thought and action (pp. 23–28). Prentice Hall. [Google Scholar]
- Bouzar, A., EL Idrissi, K., & Ghourdou, T. (2024). ChatGPT and academic writing self-efficacy: Unveiling correlations and technological dependency among postgraduate students. Arab World English Journal, 4, 225–236. [Google Scholar] [CrossRef]
- Braun, V., & Clarke, V. (2006). Using thematic analysis in psychology. Qualitative Research in Psychology, 3(2), 77–101. [Google Scholar] [CrossRef]
- Bruning, R., Dempsey, M., Kauffman, D. F., McKim, C., & Zumbrunn, S. (2013). Examining dimensions of self-efficacy for writing. Journal of Educational Psychology, 105(1), 25. [Google Scholar] [CrossRef]
- Bui, G., & Luo, X. (2021). Topic familiarity and story continuation in young English as a foreign language learners’ writing tasks. Studies in Second Language Learning and Teaching, 11(3), 377–400. [Google Scholar] [CrossRef]
- Busse, V., Graham, S., Müller, N., & Utesch, T. (2023). Understanding the interplay between text quality, writing self-efficacy and writing anxiety in learners with and without migration background. Frontiers in Psychology, 14, 1130149. [Google Scholar] [CrossRef]
- Chang, Y., Wang, X., Wang, J., Wu, Y., Yang, L., Zhu, K., Chen, H., Yi, X., Wang, C., Wang, Y., Ye, W., Zhang, Y., Chang, Y., Yu, P. S., Yang, Q., & Xie, X. (2024). A survey on evaluation of large language models. ACM Transactions on Intelligent Systems and Technology, 15(3), 1–45. [Google Scholar] [CrossRef]
- Chen, C., & Gong, Y. (2025). The role of AI-assisted learning in academic writing: A mixed-methods study on Chinese as a second language students. Education Sciences, 15(2), 141. [Google Scholar] [CrossRef]
- Chen, J., Liu, Z., Huang, X., Wu, C., Liu, Q., Jiang, G., Pu, Y., Lei, Y., Chen, X., Wang, X., Zheng, K., Lian, D., & Chen, E. (2024). When large language models meet personalization: Perspectives of challenges and opportunities. World Wide Web, 27(4), 42. [Google Scholar] [CrossRef]
- Cho, M. (2018). Task complexity and modality: Exploring learners’ experience from the perspective of flow. The Modern Language Journal, 102(1), 162–180. [Google Scholar] [CrossRef]
- Chowdhury, T. A. (2021). Fostering learner autonomy through cooperative and collaborative learning. Shanlax International Journal of Education, 10(1), 89–95. [Google Scholar] [CrossRef]
- Cumming, A. (2001). Learning to write in a second language: Two decades of research. International Journal of English Studies, 1(2), 1–23. [Google Scholar]
- Da Silva, D. C. A., de Mello, C. E., & Garcia, A. C. B. (2024). Analysis of the effectiveness of large language models in assessing argumentative writing and generating feedback. ICAART, 2, 573–582. [Google Scholar]
- Deng, Q. Z. (2024). Generative AI like ChatGPT empowering Chinese as a second language teaching: Opportunities and challenges. China Educational Informatization, 30(3), 121–128. [Google Scholar]
- Dergaa, I., Chamari, K., Zmijewski, P., & Saad, H. B. (2023). From human writing to artificial intelligence generated text: Examining the prospects and potential threats of ChatGPT in academic writing. Biology of Sport, 40(2), 615–622. [Google Scholar] [CrossRef] [PubMed]
- Dong, L. (2024). brave new world or not?: A mixed-methods study of the relationship between second language writing learners’ perceptions of ChatGPT, behaviors of using ChatGPT, and writing proficiency. Current Psychology, 43(21), 19481–19495. [Google Scholar] [CrossRef]
- Eryılmaz, A., & Başal, A. (2024). Rational AIs with emotional deficits: ChatGPT vs. counselors in providing emotional reflections. Current Psychology, 43, 34962–34977. [Google Scholar] [CrossRef]
- Fan, C., & Wang, J. (2024). Configurational impact of self-regulated writing strategy, writing anxiety, and perceived writing difficulty on EFL writing performance: An fsQCA approach. Scientific Reports, 14(1), 11125. [Google Scholar] [CrossRef] [PubMed]
- Fan, Y., & Xu, J. (2020). Exploring student engagement with peer feedback on L2 writing. Journal of Second Language Writing, 50, 100775. [Google Scholar] [CrossRef]
- Fernández-Dobao, A. (2020). Collaborative writing in mixed classes: What do heritage and second language learners think? Foreign Language Annals, 53(1), 48–68. [Google Scholar] [CrossRef]
- Golparvar, S. E., & Khafi, A. (2021). The role of L2 writing self-efficacy in integrated writing strategy use and performance. Assessing Writing, 47, 100504. [Google Scholar] [CrossRef]
- Gu, L. (2023). A study of the impact of ChatGPT on the training of international Chinese-language teachers and relevant coping strategies. Journal of Yunnan Normal University: Teaching and Research on Chinese as a Foreign Language Edition, 21(3), 63–70. [Google Scholar]
- Gu, Q. Y., & Jin, X. F. (2021). Cognitive load in production tasks among Chinese EFL learners: The effects of output modality and topic familiarity. Foreign Language World, (3), 73–81. [Google Scholar]
- Guo, X. (2024). Facilitator or thinking inhibitor: Understanding the role of ChatGPT-generated written corrective feedback in language learning. Interactive Learning Environments, 1–19. [Google Scholar] [CrossRef]
- Han, Z. (2024). Chatgpt in and for second language acquisition: A call for systematic research. Studies in Second Language Acquisition, 46(2), 301–306. [Google Scholar] [CrossRef]
- Haneda, M. (2005). Investing in foreign-language writing: A study of two multicultural learners. Journal of Language, Identity, and Education, 4(4), 269–290. [Google Scholar] [CrossRef]
- Hayes, J. R., & Flower, L. S. (1980). Writing as problem solving. Visible Language, 14(4). [Google Scholar]
- Hong, W. C. H. (2023). The impact of ChatGPT on foreign language teaching and learning: Opportunities in education and research. Journal of Educational Technology and Innovation, 5(1), 37–45. [Google Scholar] [CrossRef]
- Jacobs, H. L., Zinkgraf, S. A., Wormuth, D. R., Hartfiel, V. F., & Hughey, J. B. (1981). Testing ESLcomposition: A practical approach. Newbury House. [Google Scholar]
- Janesarvatan, F., & Asoodar, M. (2024). Constructive peer-feedback to improve language and communication skills in medical education. Innovation in Language Learning and Teaching, 18(5), 387–401. [Google Scholar] [CrossRef]
- Jeon, J., & Lee, S. (2023). Large language models in education: A focus on the complementary relationship between human teachers and ChatGPT. Education and Information Technologies, 28(12), 15873–15892. [Google Scholar] [CrossRef]
- Jian, M. J. K. O. (2023). Personalized learning through AI. Advances in Engineering Innovation, 5(1). [Google Scholar] [CrossRef]
- Kang, J. G., & Pyo, S. Y. (2024). College students’ writing self-efficacy in reflective writing classes utilizing ChatGPT. Journal of Practical Engineering Education, 16(4), 471–479. [Google Scholar]
- Kasneci, E., Seßler, K., Küchemann, S., Bannert, M., Dementieva, D., Fischer, F., Gasser, U., Groh, G., Günnemann, S., Hüllermeier, E., Krusche, S., Kutyniok, G., Michaeli, T., Nerdel, C., Pfeffer, J., Poquet, O., Sailer, M., Schmidt, A., Seidel, T., … Kasneci, G. (2023). ChatGPT for good? On opportunities and challenges of large language models for education. Learning and Individual Differences, 103, 102274. [Google Scholar] [CrossRef]
- Kessler, M., Ma, W., & Solheim, I. (2022). The effects of topic familiarity on text quality, complexity, accuracy, and fluency: A conceptual replication. Tesol Quarterly, 56(4), 1163–1190. [Google Scholar] [CrossRef]
- Krashen, S. D. (1981). Bilingual education and second language acquisition theory. Schooling and language minority students: A theoretical framework (pp. 51–79). Evaluation, Dissemination and Assessment Center, California State University. [Google Scholar]
- Kurt, G., & Kurt, Y. (2024). Enhancing L2 writing skills: ChatGPT as an automated feedback tool. Journal of Information Technology Education: Research, 23, 024. [Google Scholar] [CrossRef] [PubMed]
- Landrieu, Y., De Smedt, F., Van Keer, H., & De Wever, B. (2024). Argumentation in collaboration: The impact of explicit instruction and collaborative writing on secondary school students’ argumentative writing. Reading and Writing, 37(6), 1407–1434. [Google Scholar] [CrossRef]
- Lelepary, H. L., Rachmawati, R., Zani, B. N., & Maharjan, K. (2023). ChatGPT: Opportunities and challenges in the learning process of Arabic language in higher education. Journal International of Lingua and Technology, 2(1), 11–23. [Google Scholar]
- Li, D., & Zhang, L. (2022). Contextualizing feedback in L2 writing: The role of teacher scaffolding. Language Awareness, 31(3), 328–350. [Google Scholar] [CrossRef]
- Li, Q., & He, Z. H. (2017). On length approach in teaching Chinese writing as a foreign language under the pattern of flipped classroom. Journal of Hengyang Normal University, 38(2), 154–157. [Google Scholar]
- Li, X., Li, B., & Cho, S. J. (2023). Empowering Chinese language learners from low-income families to improve their Chinese writing with ChatGPT’s assistance afterschool. Languages, 8(4), 238. [Google Scholar] [CrossRef]
- Lin, S. (2024). Evaluating LLMs’ grammatical error correction performance in learner Chinese. PLoS ONE, 19(10), e0312881. [Google Scholar] [CrossRef]
- Lingard, L. (2023). Writing with ChatGPT: An illustration of its capacity, limitations & implications for academic writers. Perspectives on Medical Education, 12(1), 261. [Google Scholar]
- Liu, G. L., Darvin, R., & Ma, C. (2024). Exploring AI-mediated informal digital learning of English (AI-IDLE): A mixed-method investigation of Chinese EFL learners’ AI adoption and experiences. Computer Assisted Language Learning, 1–29. [Google Scholar] [CrossRef]
- Liu, M., Wu, Z. M., & Liao, J. (2023). Educational applications of large language models: Principles, status and challenges—From light-weight BERT to conversational ChatGPT. Modern Educational Technology, 33(8), 19–28. [Google Scholar]
- Lo, C. K., Yu, P. L. H., Xu, S., Ng, D. T. K., & Jong, M. S. Y. (2024). Exploring the application of ChatGPT in ESL/EFL education and related research issues: A systematic review of empirical studies. Smart Learning Environments, 11(1), 50. [Google Scholar] [CrossRef]
- Mah, C., Walker, H., Phalen, L., Levine, S., Beck, S. W., & Pittman, J. (2024). Beyond CheatBots: Examining tensions in teachers’ and students’ perceptions of cheating and learning with ChatGPT. Education Sciences, 14(5), 500. [Google Scholar] [CrossRef]
- Malagoli, C., Zanobini, M., Chiorri, C., & Bigozzi, L. (2021). Difficulty in writing perceived by university students: A comparison of inaccurate writers with and without diagnostic certification. Children, 8(2), 88. [Google Scholar] [CrossRef] [PubMed]
- Malt, B. C., & Sloman, S. A. (2003). Linguistic diversity and object naming by non-native speakers of English. Bilingualism: Language and Cognition, 6(1), 47–67. [Google Scholar] [CrossRef]
- Miao, J., Chang, J., & Ma, L. (2022). Teacher–student interaction, student–student interaction and social presence: Their impacts on learning engagement in online learning environments. The Journal of Genetic Psychology, 183(6), 514–526. [Google Scholar] [CrossRef] [PubMed]
- Miles, M. B., Huberman, A. M., & Saldana, J. (2014). Qualitative data analysis: A methods sourcebook (3rd ed.). Sage. [Google Scholar]
- Mitchell, K. M., Zumbrunn, S., Berry, D. N., & Demczuk, L. (2023). Writing self-efficacy in postsecondary students: A scoping review. Educational Psychology Review, 35(3), 82. [Google Scholar] [CrossRef]
- Naz, I., & Robertson, R. (2024). Exploring the feasibility and efficacy of ChatGPT3 for personalized feedback in teaching. Electronic Journal of e-Learning, 22(2), 98–111. [Google Scholar] [CrossRef]
- Nguyen, L. Q., Le, H. V., & Nguyen, P. T. (2024). A mixed-methods study on the use of chatgpt in the pre-writing stage: EFL learners’ utilization patterns, affective engagement, and writing performance. Education and Information Technologies, 1–24. [Google Scholar] [CrossRef]
- Pack, A., Barrett, A., & Escalante, J. (2024). Large language models and automated essay scoring of English language learner writing: Insights into validity and reliability. Computers and Education: Artificial Intelligence, 6, 100234. [Google Scholar] [CrossRef]
- Pajares, F., & Johnson, M. J. (1994). Confidence and competence in writing: The role of self-efficacy, outcome expectancy, and apprehension. Research in the Teaching of English, 28(3), 313–331. [Google Scholar] [CrossRef]
- Prat-Sala, M., & Redford, P. (2012). Writing essays: Does self-efficacy matter? The relationship between self-efficacy in reading and in writing and undergraduate students’ performance in essay writing. Educational Psychology, 32(1), 9–20. [Google Scholar] [CrossRef]
- Qian, J., & Li, D. (2025). Toward a better understanding of student engagement with peer feedback: A longitudinal study. International Review of Applied Linguistics in Language Teaching, 63(1), 709–734. [Google Scholar] [CrossRef]
- Qureshi, M. A., Khaskheli, A., Qureshi, J. A., Raza, S. A., & Yousufi, S. Q. (2023). Factors affecting students’ learning performance through collaborative learning and engagement. Interactive Learning Environments, 31(4), 2371–2391. [Google Scholar] [CrossRef]
- Rahimi, M., & Fathi, J. (2022). Exploring the impact of wiki-mediated collaborative writing on EFL students’ writing performance, writing self-regulation, and writing self-efficacy: A mixed methods study. Computer Assisted Language Learning, 35(9), 2627–2674. [Google Scholar] [CrossRef]
- Robinson, P. (2011). Task-based language learning: A review of issues. LanguageLearning, 61(1), 1–36. [Google Scholar] [CrossRef]
- Sasayama, S. (2016). Is a ‘complex’ task really complex? Validating the assumption of cognitive task complexity. The Modern Language Journal, 100(1), 231–254. [Google Scholar] [CrossRef]
- Schmidt-Rinehart, B. C. (1994). The effects of topic familiarity on second language listening comprehension. The Modern Language Journal, 78(2), 179–189. [Google Scholar] [CrossRef]
- Shi, H., Chai, C. S., Zhou, S., & Aubrey, S. (2025). Comparing the effects of ChatGPT and automated writing evaluation on students’ writing and ideal L2 writing self. Computer Assisted Language Learning, 1–28. [Google Scholar] [CrossRef]
- Shoufan, A. (2023). Exploring students’ perceptions of ChatGPT: Thematic analysis and follow-up survey. IEEE Access, 11, 38805–38818. [Google Scholar] [CrossRef]
- Shu, J. B. (2024). Effectiveness of peer feedback in teaching academic Chinese writing for CSL students. International Journal of Chinese Language Teaching, 6(1), 137–154. [Google Scholar]
- Song, Y., Zhu, Q., Wang, H., & Zheng, Q. (2024). Automated essay scoring and revising based on open-source large language models. IEEE Transactions on Learning Technologies, 17, 1880–1890. [Google Scholar] [CrossRef]
- Su, Y., Lin, Y., & Lai, C. (2023). Collaborating with ChatGPT in argumentative writing classrooms. Assessing Writing, 57, 100752. [Google Scholar] [CrossRef]
- Sun, T., Wang, C., Lambert, R. G., & Liu, L. (2021). Relationship between second language English writing self-efficacy and achievement: A meta-regression analysis. Journal of Second Language Writing, 53, 100817. [Google Scholar] [CrossRef]
- Tabone, W., & De Winter, J. (2023). Using ChatGPT for human–computer interaction research: A primer. Royal Society Open Science, 10(9), 231053. [Google Scholar] [CrossRef] [PubMed]
- Tam, A. C. F. (2025). Interacting with ChatGPT for internal feedback and factors affecting feedback quality. Assessment & Evaluation in Higher Education, 50(2), 219–235. [Google Scholar]
- Tang, X., Chen, H., Lin, D., & Li, K. (2024). Harnessing LLMs for multi-dimensional writing assessment: Reliability and alignment with human judgments. Heliyon, 10(14), 1–18. [Google Scholar] [CrossRef]
- Trafimow, D., Sheeran, P., Conner, M., & Finlay, K. A. (2002). Evidence that perceived behavioural control is a multidimensional construct: Perceived control and perceived difficulty. British Journal of Social Psychology, 41(1), 101–121. [Google Scholar] [CrossRef]
- Truckenmiller, A., Shen, M., & Sweet, L. E. (2021). The role of vocabulary and syntax in informational written composition in middle school. Reading and Writing, 34(4), 911–943. [Google Scholar] [CrossRef]
- Tsai, C. Y., Lin, Y. T., & Brown, I. K. (2024). Impacts of ChatGPT-assisted writing for EFL English majors: Feasibility and challenges. Education and Information Technologies, 29, 22427–22445. [Google Scholar] [CrossRef]
- Vygotsky, L. S. (1978). Mind in society: The development of higher psychological processes. Harvard University Press. [Google Scholar]
- Warsah, I., Morganna, R., Uyun, M., Afandi, M., & Hamengkubuwono, H. (2021). The impact of collaborative learning on learners’ critical thinking skills. International Journal of Instruction, 14(2), 443–460. [Google Scholar] [CrossRef]
- Wei, S., & Li, L. Y. (2023). Artificial intelligence-assisted second language writing feedback: A case study of ChatGPT. Foreign Languages in China, 20(3), 33–40. [Google Scholar]
- Wei, X. (2024). The Use of large language models for translating Buddhist texts from classical Chinese to modern English: An analysis and evaluation with ChatGPT 4, ERNIE Bot 4, and Gemini advanced. Religions, 15(12), 1559. [Google Scholar] [CrossRef]
- Wei, X., Zhang, L. J., & Zhang, W. (2020). Associations of L1-to-L2 rhetorical transfer with L2 writers’ perception of L2 writing difficulty and L2 writing proficiency. Journal of English for Academic Purposes, 47, 100907. [Google Scholar] [CrossRef]
- Wen, Q. M., & Zhang, X. W. (2022). The application of interactive collaboration in teaching Chinese as a second language writing. Journal of Mudanjiang College of Education, 3, 73–76. [Google Scholar]
- Wu, S. J. R. (2003). A comparison of learners’ beliefs about writing in their first and second language: Taiwanese junior college business-major students studying English. The University of Texas at Austin. [Google Scholar]
- Yan, D. (2023). Impact of ChatGPT on learners in a L2 writing practicum: An exploratory investigation. Education and Information Technologies, 28(11), 13943–13967. [Google Scholar] [CrossRef]
- Yan, L., Sha, L., Zhao, L., Li, Y., Martinez-Maldonado, R., Chen, G., Li, X., Jin, Y., & Gašević, D. (2024). Practical and ethical challenges of large language models in education: A systematic scoping review. British Journal of Educational Technology, 55(1), 90–112. [Google Scholar] [CrossRef]
- Yang, W., & Kim, Y. (2020). The effect of topic familiarity on the complexity, accuracy, and fluency of second language writing. Applied Linguistics Review, 11(1), 79–108. [Google Scholar] [CrossRef]
- Yuan, X., & Wu, Y. H. (2023). The opportunities, risks, and coping strategies of ChatGPT plus for international Chinese-language education. Journal of Yunnan Normal University: Teaching and Research on Chinese as a Foreign Language Edition, 21(3), 53–62. [Google Scholar]
- Zhang, X. (2023). Exploring L2 students’ experiences with an integrated teacher written and spoken feedback strategy. International Journal of Applied Linguistics, 33(2), 362–381. [Google Scholar] [CrossRef]
- Zhang, Z., & Huang, X. (2024). The impact of chatbots based on large language models on second language vocabulary acquisition. Heliyon, 10(3), e25370. [Google Scholar] [CrossRef]
- Zheng, Y. B., Zhou, Y. X., Chen, X. D., & Ye, X. D. (2025). The influence of large language models as collaborative dialogue partners on EFL English oral proficiency and foreign language anxiety. Computer Assisted Language Learning, 1–27. [Google Scholar] [CrossRef]
- Zou, M., & Huang, L. (2024). The impact of ChatGPT on L2 writing and expected responses: Voice from doctoral students. Education and Information Technologies, 29(11), 13201–13219. [Google Scholar] [CrossRef]
- Zou, S., Guo, K., Wang, J., & Liu, Y. (2024). Investigating students’ uptake of teacher-and ChatGPT-generated feedback in EFL writing: A comparison study. Computer Assisted Language Learning, 1–30. [Google Scholar] [CrossRef]
- Zubiri-Esnaola, H., Vidu, A., Rios-Gonzalez, O., & Morla-Folch, T. (2020). Inclusivity, participation and collaboration: Learning in interactive groups. Educational Research, 62(2), 162–180. [Google Scholar] [CrossRef]
- Zuckerman, M., Flood, R., Tan, R. J., Kelp, N., Ecker, D. J., Menke, J., & Lockspeiser, T. (2023). ChatGPT for assessment writing. Medical Teacher, 45(11), 1224–1227. [Google Scholar] [CrossRef]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shan, Z.; Song, Z.; Jiang, X.; Chen, W.; Chen, L. Complementing but Not Replacing: Comparing the Impacts of GPT-4 and Native-Speaker Interaction on Chinese L2 Writing Outcomes. Behav. Sci. 2025, 15, 540. https://doi.org/10.3390/bs15040540
Shan Z, Song Z, Jiang X, Chen W, Chen L. Complementing but Not Replacing: Comparing the Impacts of GPT-4 and Native-Speaker Interaction on Chinese L2 Writing Outcomes. Behavioral Sciences. 2025; 15(4):540. https://doi.org/10.3390/bs15040540
Chicago/Turabian StyleShan, Zhaoyang, Zhangyuan Song, Xu Jiang, Wen Chen, and Luyao Chen. 2025. "Complementing but Not Replacing: Comparing the Impacts of GPT-4 and Native-Speaker Interaction on Chinese L2 Writing Outcomes" Behavioral Sciences 15, no. 4: 540. https://doi.org/10.3390/bs15040540
APA StyleShan, Z., Song, Z., Jiang, X., Chen, W., & Chen, L. (2025). Complementing but Not Replacing: Comparing the Impacts of GPT-4 and Native-Speaker Interaction on Chinese L2 Writing Outcomes. Behavioral Sciences, 15(4), 540. https://doi.org/10.3390/bs15040540