
Deep Learning-Based Detection of Depression and Suicidal Tendencies in Social Media Data with Feature Selection



Abstract
1. Introduction
2. Literature Review
2.1. Deep Learning-Based Approaches
2.2. Explainable AI and Feature Engineering Approaches
2.3. Hybrid and Ensemble Learning Approaches
2.4. Real-Time and Interactive Models
2.5. Deficiencies in Prior Research
2.6. Novelties and Contributions
- For the first time, an ensemble of diverse pre-trained language models, including BERT, RoBERTa, ALBERT, ClinicalBERT, BioBERT, DistilBERT, ELECTRA, and XLNet, is integrated to extract contextual features from social media data. This ensemble-based strategy leverages the strengths of individual models to generate robust and comprehensive feature representations.
- While multiple pre-trained language models have been employed in previous studies for psychiatric disorder detection, our approach introduces several key advancements. First, we integrate a diverse set of models, ensuring robust contextual representation across different linguistic domains. Second, we implement Cumulative Weight-based Iterative Neighborhood Component Analysis (CWINCA) to optimize feature selection, eliminating redundant and less relevant features while enhancing interpretability. Third, our model utilizes an iterative majority voting strategy, aggregating predictions from different classifiers to improve overall accuracy and robustness. These innovations allow our framework to outperform existing approaches in terms of generalizability, efficiency, and real-time applicability.
- Cumulative Weight-based Iterative Neighborhood Component Analysis (CWINCA) is employed to identify meaningful and significant features from high-dimensional text data. This technique effectively eliminates redundant features, resulting in substantial improvements in classification performance.
- Predictions from different language models and classifiers are combined using an iterative majority voting method. This approach enhances the overall performance of the framework, significantly improving accuracy rates.
- The model’s generalizability and effectiveness are assessed across six diverse social media datasets: Suicidal Ideation Detection, Depression Detection from Reddit Posts, Mental Health Corpus, Twitter US Airline Sentiment, Suicide and Depression Detection, and Sentiment140. The comprehensive assessment revealed uniform performance across multiple problem areas.
3. Material
3.1. Dataset 1
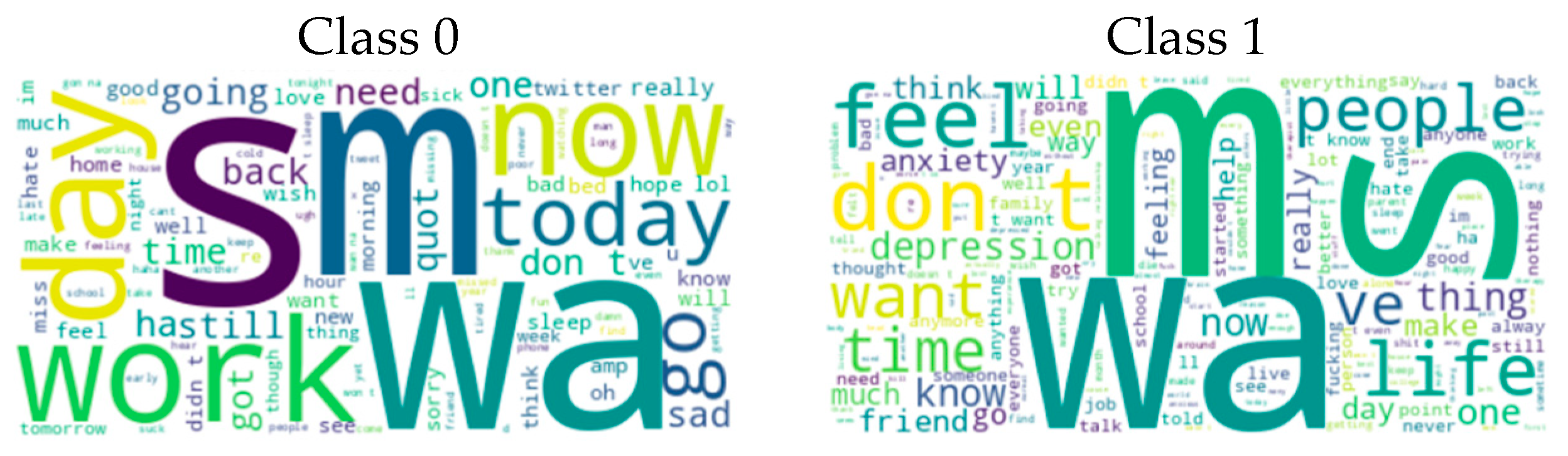
3.2. Dataset 2
3.3. Dataset 3
3.4. Dataset 4
3.5. Dataset 5
3.6. Dataset 6
4. Method
| Algorithm 1. Pseudocode of the Feature Selection Process. |
| Input: Extracted features (X) with the size of R × C, Actual outputs (y) Output: Selected feature vector (SV) |
| 00: Load X 01: for j = 1 to C do 02: //Normalize each column of X 03: X(:, j) = (X(:, j) − min(X(:, j)))/(max(X(:, j)) − min(X(:, j)) + epsilon) 04: end for 05://Train feature selector model 06: mdl = fscnca(X, y, ‘Solver’, ‘sgd’) 07: xx = mdl.FeatureWeights 08://Rank features by importance 09: index = sort(xx, ‘descend’) 10: cumulativeWeights = cumsum(xx(index))/sum(xx(index)) 11://Determine starting and stopping points 12: startIndex = find(cumulativeWeights >= 0.5, 1) 13: if isempty(startIndex) then 14: startIndex = 10 15: end if 16: stopIndex = find(cumulativeWeights >= 0.999, 1) 17: if isempty(stopIndex) then 18: stopIndex = size(X, 2) 19: end if 20://Perform feature selection iteratively 21: bestLoss = inf 22: for ts = 0 to stopIndex − startIndex do 23: for i = 1 to startIndex + ts do 24: poz(:, i) = X(:, index(i)) 25: end for 26: 27: //Train k-NN model and calculate cross-validation loss 28: mdl_knn = fitcknn(poz, y, ‘Distance’, ‘cityblock’, ‘NumNeighbors’, 1, ‘DistanceWeight’, ‘Equal’, ‘Standardize’, true, ‘ClassNames’, unique(y)’) 29: kk = crossval(mdl_knn, ‘KFold’, 10) 30: ll(ts + 1) = kfoldLoss(kk, ‘LossFun’, ‘ClassifError’) 31: 32: clear poz 33: end for 34://Select best features 35: [bestLoss, inde] = min(ll) 36: for i = 1 to startIndex + inde − 1 do 37: SV(:, i) = X(:, index(i)) 38: end for 39: Return SV |
Pre-Trained Language Models
5. Experimental Results
5.1. Experimental Setup
5.2. Classification Performance Across Models
5.3. Impact of Feature Selection (CWINCA)
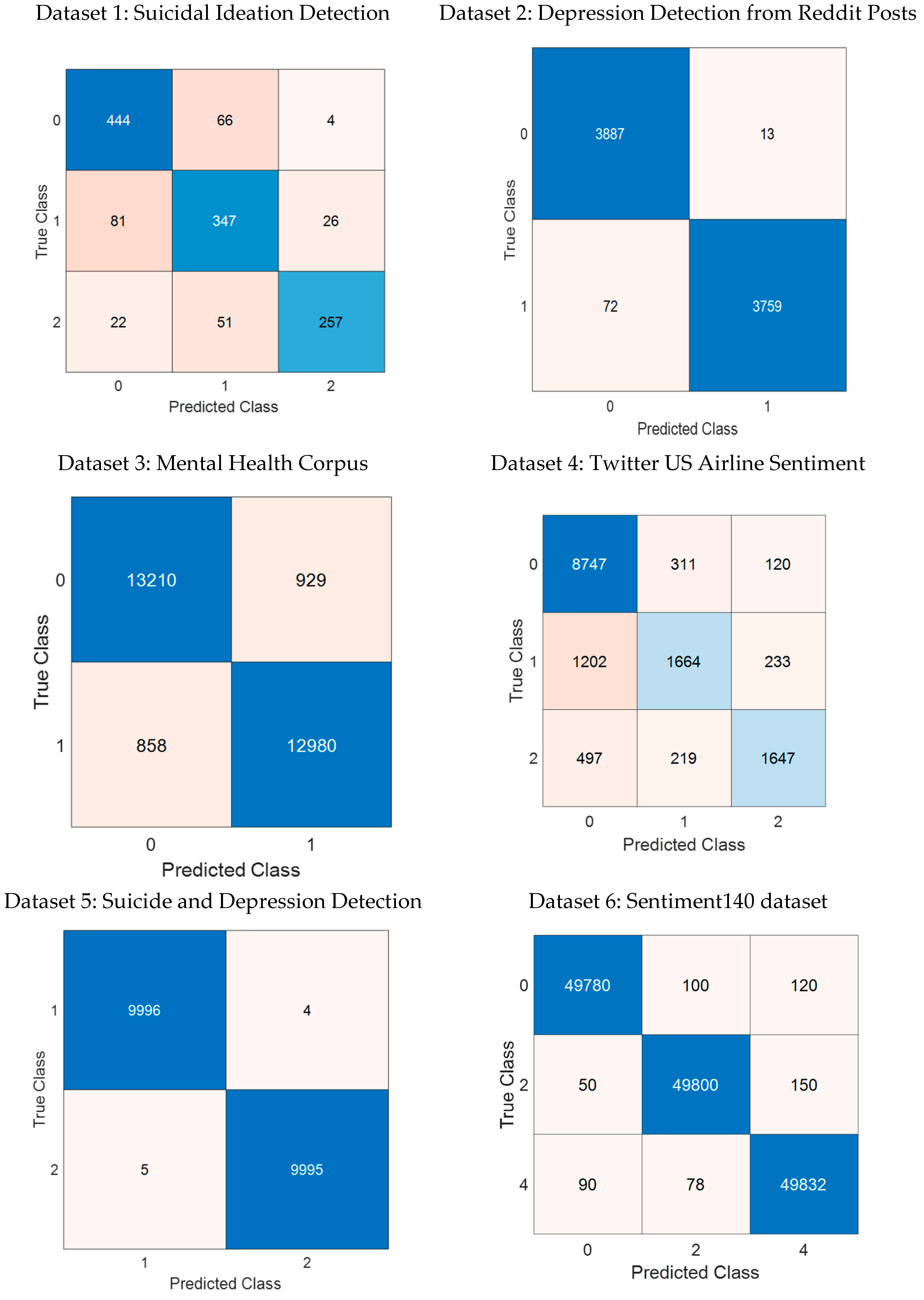
5.4. Performance Evaluation on Different Datasets
5.5. Effect of Ensemble Learning (IMV Method)
5.6. Discussion of Results and Key Findings
- SVM consistently outperformed other classifiers, achieving the highest accuracy in almost all datasets.
- Feature selection using CWINCA significantly improved model performance by eliminating redundant attributes.
- The ensemble-based approach (IMV) further enhanced classification robustness, particularly in datasets with high class imbalance.
- The model demonstrated superior performance compared to existing methods, achieving the highest accuracy on the Suicide and Depression Detection dataset (99.96%).
- Despite minor performance fluctuations in certain datasets (e.g., lower recall for specific classes in the Twitter Sentiment dataset), the model maintained strong overall accuracy.
6. Discussion
6.1. Comparison with Existing Methods
6.2. Detailed Analysis of Performance Differences Across Models
6.3. Key Contributions of the Proposed Method
6.4. Clinical and Psychological Implications
7. Conclusions
7.1. Limitations
7.2. Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Adoma, A. F., Henry, N.-M., & Chen, W. (2020, December 18–20). Comparative analyses of bert, roberta, distilbert, and xlnet for text-based emotion recognition. 2020 17th International Computer Conference on Wavelet Active Media Technology and Information Processing (ICCWAMTIP), Chengdu, China. [Google Scholar] [CrossRef]
- Ahmed, T., Ivan, S., Munir, A., & Ahmed, S. (2024). Decoding depression: Analyzing social network insights for depression severity assessment with transformers and explainable AI. Natural Language Processing Journal, 7, 100079. [Google Scholar] [CrossRef]
- Akintoye, O., Wei, N., & Liu, Q. (2024, January 26–28). Suicide detection in tweets using LSTM and transformers. 2024 4th Asia Conference on Information Engineering (ACIE), Singapore. [Google Scholar] [CrossRef]
- AlHamed, F., Ive, J., & Specia, L. (2022, July 14–15). Predicting moments of mood changes overtime from imbalanced social media data. Eighth Workshop on Computational Linguistics and Clinical Psychology, Seattle, WA, USA. [Google Scholar] [CrossRef]
- Balkin, J. M. (2017). Digital speech and democratic culture: A theory of freedom of expression for the information society. In Law and Society approaches to cyberspace (pp. 325–382). Routledge. [Google Scholar] [CrossRef]
- Bao, E., Pérez, A., & Parapar, J. (2024). Explainable depression symptom detection in social media. Health Information Science and Systems, 12(1), 47. [Google Scholar] [CrossRef] [PubMed]
- Basiri, M. E., Nemati, S., Abdar, M., Cambria, E., & Acharya, U. R. (2021). ABCDM: An attention-based bidirectional CNN-RNN deep model for sentiment analysis. Future Generation Computer Systems, 115, 279–294. [Google Scholar] [CrossRef]
- Bauer, B., Norel, R., Leow, A., Rached, Z. A., Wen, B., & Cecchi, G. (2024). Using large language models to understand suicidality in a social media–based taxonomy of mental health disorders: Linguistic analysis of reddit posts. JMIR Mental Health, 11, e57234. [Google Scholar] [CrossRef]
- Baydili, İ., Tasci, B., & Tasci, G. (2025). Artificial intelligence in psychiatry: A review of biological and behavioral data analyses. Diagnostics, 15(4), 434. [Google Scholar] [CrossRef]
- Bendebane, L., Laboudi, Z., Saighi, A., Al-Tarawneh, H., Ouannas, A., & Grassi, G. (2023). A multi-class deep learning approach for early detection of depressive and anxiety disorders using twitter data. Algorithms, 16(12), 543. [Google Scholar] [CrossRef]
- Bhaumik, R., Srivastava, V., Jalali, A., Ghosh, S., & Chandrasekharan, R. (2023). Mindwatch: A smart cloud-based ai solution for suicide ideation detection leveraging large language models. medRxiv. 2025.23296062. [Google Scholar] [CrossRef]
- Bhuiyan, M. I., Kamarudin, N. S., & Ismail, N. H. (2025). Enhanced Suicidal Ideation Detection from Social Media Using a CNN-BiLSTM Hybrid Model. arXiv, arXiv:2501.11094. [Google Scholar] [CrossRef]
- Bin Abdullah, T. B. A. (2023). The effectiveness of interactive communication channels in facilitating two-way communication between employees at STC. Egyptian Journal of Public Opinion Research, 22(3), 197–232. [Google Scholar] [CrossRef]
- Bingham, T., & Conner, M. (2010). The new social learning: A guide to transforming organizations through social media. Berrett-Koehler Publishers. [Google Scholar]
- Bokolo, B. G., & Liu, Q. (2023). Deep learning-based depression detection from social media: Comparative evaluation of ML and transformer techniques. Electronics, 12(21), 4396. [Google Scholar] [CrossRef]
- Boulouard, Z., Ouaissa, M., Ouaissa, M., Krichen, M., Almutiq, M., & Gasmi, K. (2022). Detecting hateful and offensive speech in arabic social media using transfer learning. Applied Sciences, 12(24), 12823. [Google Scholar] [CrossRef]
- Braghieri, L., Levy, R. E., & Makarin, A. (2022). Social media and mental health. American Economic Review, 112(11), 3660–3693. [Google Scholar] [CrossRef]
- Cambria, E., Zhang, X., Mao, R., Chen, M., & Kwok, K. (2024, June 29–July 4). SenticNet 8: Fusing emotion AI and commonsense AI for interpretable, trustworthy, and explainable affective computing. International Conference on Human-Computer Interaction (HCII), Washington, DC, USA. [Google Scholar]
- Choi, H., Kim, J., Joe, S., & Gwon, Y. (2021, January 10–15). Evaluation of bert and albert sentence embedding performance on downstream nlp tasks. 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy. [Google Scholar] [CrossRef]
- Clark, K. (2020). Electra: Pre-training text encoders as discriminators rather than generators. arXiv, arXiv:2003.10555. [Google Scholar] [CrossRef]
- Dahlgren, P. (2009). Media and political engagement: Citizens, communication and democracy. Cambridge University Press. [Google Scholar]
- Dai, Y., Liu, J., Cao, L., Xue, Y., Wang, X., Ding, Y., Tian, J., & Feng, L. (2024). Leveraging social media for real-time interpretable and amendable suicide risk prediction with human-in-the-loop. IEEE Transactions on Affective Computing, 1–18. [Google Scholar] [CrossRef]
- Devlin, J. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv, arXiv:1810.04805. [Google Scholar] [CrossRef]
- Farruque, N., Goebel, R., Sivapalan, S., & Zaïane, O. R. (2024). Depression symptoms modelling from social media text: An LLM driven semi-supervised learning approach. Language Resources and Evaluation, 58, 1013–1041. [Google Scholar] [CrossRef]
- Faruq, A., Lestandy, M., & Nugraha, A. (2024). Analyzing reddit data: Hybrid model for depression sentiment using FastText embedding. Jurnal RESTI (Rekayasa Sistem dan Teknologi Informasi), 8(2), 288–297. [Google Scholar] [CrossRef]
- Go, A., Bhayani, R., & Huang, L. (2009). Twitter sentiment classification using distant supervision. CS224N Project Report, Stanford, 1(12), 2009. [Google Scholar]
- Hammad, M. A., & Awed, H. S. (2023). Investigating the relationship between social media addiction and mental health. Nurture, 17(3), 149–156. [Google Scholar] [CrossRef]
- Hearst, M. A., Dumais, S. T., Osuna, E., Platt, J., & Scholkopf, B. (1998). Support vector machines. IEEE Intelligent Systems and Their Applications, 13(4), 18–28. [Google Scholar] [CrossRef]
- Huang, K., Altosaar, J., & Ranganath, R. (2019). Clinicalbert: Modeling clinical notes and predicting hospital readmission. arXiv, arXiv:1904.05342. [Google Scholar] [CrossRef]
- Ibtihaj, M. (2020). Suicidal-ideation-detection. Available online: https://github.com/M-Ibtihaj/Suicidal-ideation-detection (accessed on 14 December 2024).
- Ince, U., Talu, Y., Duz, A., Tas, S., Tanko, D., Tasci, I., Dogan, S., Hafeez Baig, A., Aydemir, E., & Tuncer, T. (2025). CubicPat: Investigations on the mental performance and stress detection using EEG signals. Diagnostics, 15(3), 363. [Google Scholar] [CrossRef] [PubMed]
- InFamousCoder. (2022). Depression: Reddit dataset (cleaned). Available online: https://www.kaggle.com/datasets/infamouscoder/depression-reddit-cleaned (accessed on 10 November 2024).
- Islam, M. R., Sakib, M. K. H., Prome, S. A., Wang, X., Ulhaq, A., Sanin, C., & Asirvatham, D. (2023, October 30–November 1). Machine learning with explainability for suicide ideation detection from social media data. 2023 10th International Conference on Behavioural and Social Computing (BESC), Larnaca, Cyprus. [Google Scholar] [CrossRef]
- Kaggle. (2020). Twitter US airline sentiment. Available online: https://www.kaggle.com/datasets/crowdflower/twitter-airline-sentiment (accessed on 25 November 2024).
- Kaplan, A. M., & Haenlein, M. (2010). Users of the world, unite! The challenges and opportunities of Social Media. Business Horizons, 53(1), 59–68. [Google Scholar] [CrossRef]
- Khowaja, S. A., Nkenyereye, L., Khuwaja, P., Al Hamadi, H., & Dev, K. (2024). Depression detection from social media posts using emotion aware encoders and fuzzy based contrastive networks. IEEE Transactions on Fuzzy Systems, 33(1), 43–53. [Google Scholar] [CrossRef]
- Kietzmann, J. H., Hermkens, K., McCarthy, I. P., & Silvestre, B. S. (2011). Social media? Get serious! Understanding the functional building blocks of social media. Business Horizons, 54(3), 241–251. [Google Scholar] [CrossRef]
- Komati, N. (2021). Suicide and depression detection. Available online: https://www.kaggle.com/datasets/nikhileswarkomati/suicide-watch (accessed on 25 October 2024).
- Lan, X., Cheng, Y., Sheng, L., Gao, C., & Li, Y. (2024). Depression detection on social media with large language models. arXiv, arXiv:2403.10750. [Google Scholar] [CrossRef]
- Lan, Z. (2019). Albert: A lite bert for self-supervised learning of language representations. arXiv, arXiv:1909.11942. [Google Scholar] [CrossRef]
- Lee, J., Yoon, W., Kim, S., Kim, D., Kim, S., So, C. H., & Kang, J. (2020). BioBERT: A pre-trained biomedical language representation model for biomedical text mining. Bioinformatics, 36(4), 1234–1240. [Google Scholar] [CrossRef]
- Lestandy, M. (2023). Exploring the impact of word embedding dimensions on depression data classification using BiLSTM model. Procedia Computer Science, 227, 298–306. [Google Scholar] [CrossRef]
- Li, Z., Zhou, J., An, Z., Cheng, W., & Hu, B. (2022). Deep hierarchical ensemble model for suicide detection on imbalanced social media data. Entropy, 24(4), 442. [Google Scholar] [CrossRef]
- Liu, J., Shi, M., & Jiang, H. (2022). Detecting suicidal ideation in social media: An ensemble method based on feature fusion. International Journal of Environmental Research and Public Health, 19(13), 8197. [Google Scholar] [CrossRef]
- Liu, Y. (2019). Roberta: A robustly optimized bert pretraining approach. arXiv, arXiv:1907.11692. [Google Scholar] [CrossRef]
- Malhotra, A., & Jindal, R. (2024). Xai transformer based approach for interpreting depressed and suicidal user behavior on online social networks. Cognitive Systems Research, 84, 101186. [Google Scholar] [CrossRef]
- Mansoor, M. A., & Ansari, K. H. (2024). Early detection of mental health crises through artifical-intelligence-powered social media analysis: A prospective observational study. Journal of Personalized Medicine, 14(9), 958. [Google Scholar] [CrossRef] [PubMed]
- Namdari, R. (2023). Mental health corpus. Available online: https://www.kaggle.com/datasets/reihanenamdari/mental-health-corpus (accessed on 20 November 2024).
- Onan, A. (2023). SRL-ACO: A text augmentation framework based on semantic role labeling and ant colony optimization. Journal of King Saud University-Computer and Information Sciences, 35(7), 101611. [Google Scholar] [CrossRef]
- Qorich, M., & El Ouazzani, R. (2024). Advanced deep learning and large language models for suicide ideation detection on social media. Progress in Artificial Intelligence, 13, 135–147. [Google Scholar] [CrossRef]
- Sanh, V. (2019). DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv, arXiv:1910.01108. [Google Scholar] [CrossRef]
- Sheldon, P., Rauschnabel, P., & Honeycutt, J. M. (2019). The dark side of social media: Psychological, managerial, and societal perspectives. Academic Press. [Google Scholar]
- Sun, L. (2023). Social media usage and students’ social anxiety, loneliness and well-being: Does digital mindfulness-based intervention effectively work? BMC Psychology, 11(1), 362. [Google Scholar] [CrossRef]
- Tan, K. L., Lee, C. P., & Lim, K. M. (2023). RoBERTa-GRU: A hybrid deep learning model for enhanced sentiment analysis. Applied Sciences, 13(6), 3915. [Google Scholar] [CrossRef]
- Tesfagergish, S. G., Kapočiūtė-Dzikienė, J., & Damaševičius, R. (2022). Zero-shot emotion detection for semi-supervised sentiment analysis using sentence transformers and ensemble learning. Applied Sciences, 12(17), 8662. [Google Scholar] [CrossRef]
- Tuncer, T., Dogan, S., Baygin, M., Tasci, I., Mungen, B., Tasci, B., Barua, P. D., & Acharya, U. R. (2024). Directed Lobish-based explainable feature engineering model with TTPat and CWINCA for EEG artifact classification. Knowledge-Based Systems, 305, 112555. [Google Scholar] [CrossRef]
- Van Dijck, J., & Poell, T. (2013). Understanding social media logic. Media and Communication, 1(1), 2–14. [Google Scholar] [CrossRef]
- Vaswani, A. (2017, December 4–9). Attention is all you need. Advances in Neural Information Processing Systems, Long Beach, CA, USA. [Google Scholar]
- Wang, L., Liu, H., & Zhou, T. (2020). A sequential emotion approach for diagnosing mental disorder on social media. Applied Sciences, 10(5), 1647. [Google Scholar] [CrossRef]
- We Are Social. (2024). Digital 2024 october global statshot report. Available online: https://wearesocial.com/id/blog/2024/10/digital-2024-october-global-statshot-report/ (accessed on 14 December 2024).
- Yang, Z. (2019). XLNet: Generalized autoregressive pretraining for language understanding. arXiv, arXiv:1906.08237. [Google Scholar]
- Yujie, Z., Al Imran Yasin, M., Alsagoff, S. A. B. S., & Hoon, A. L. (2022). The mediating role of new media engagement in this digital age. Frontiers in Public Health, 10, 879530. [Google Scholar] [CrossRef] [PubMed]
- Zhang, D., Zhou, L., Tao, J., Zhu, T., & Gao, G. (2024). KETCH: A knowledge-enhanced transformer-based approach to suicidal ideation detection from social media content. Information Systems Research. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SVM | kNN | Tree | Neural Network | Efficient Logistic Regression | Ensemble | |
|---|---|---|---|---|---|---|
| ALBERT | 77.27 | 72.49 | 68.56 | 75.8 | 68.01 | 75.42 |
| BERT | 79.96 | 75.88 | 70.64 | 77.5 | 70.72 | 77.42 |
| BioBERT | 77.04 | 71.8 | 67.79 | 75.42 | 57.24 | 76.65 |
| ClinicaBERT | 76.57 | 71.41 | 68.95 | 74.88 | 57.01 | 75.8 |
| DistilBERT | 79.5 | 72.65 | 70.41 | 77.96 | 67.71 | 76.88 |
| Electra | 75.34 | 70.33 | 68.25 | 74.49 | 69.55 | 69.95 |
| RoBERTa | 79.5 | 72.72 | 70.33 | 77.73 | 58.92 | 78.35 |
| XLNet | 76.19 | 70.33 | 66.4 | 75.88 | 59.36 | 74.57 |
| Combined | 79.27 | 73.34 | 66.94 | 78.27 | 69.64 | 77.11 |
| Class | Accuracy (%) | Precision (%) | Recall (%) | F1Score (%) | |
|---|---|---|---|---|---|
| Dataset 1 | Class 1(0) | 80.74 | 81.17 | 86.38 | 83.69 |
| Class 2(1) | 74.78 | 76.43 | 75.60 | ||
| Class 3(2) | 89.55 | 77.88 | 83.31 | ||
| Macro-Averaged | 81.83 | 80.23 | 80.87 | ||
| Dataset 2 | Class 1(0) | 98.90 | 98.18 | 99.67 | 98.92 |
| Class 2(1) | 99.66 | 98.12 | 98.88 | ||
| Macro-Averaged | 98.92 | 98.89 | 98.90 | ||
| Dataset 3 | Class 1(0) | 93.61 | 93.90 | 93.43 | 93.66 |
| Class 2(1) | 93.32 | 93.80 | 93.56 | ||
| Macro-Averaged | 93.61 | 93.61 | 93.61 | ||
| Dataset 4 | Class 1(0) | 82.36 | 83.74 | 95.30 | 89.15 |
| Class 2(1) | 75.84 | 53.69 | 62.88 | ||
| Class 3(2) | 82.35 | 69.70 | 75.50 | ||
| Macro-Averaged | 80.64 | 72.90 | 75.84 | ||
| Dataset 5 | Class 1(1) | 99.96 | 99.95 | 99.96 | 99.96 |
| Class 2(2) | 99.96 | 99.95 | 99.95 | ||
| Macro-Averaged | 99.96 | 99.96 | 99.95 | ||
| Dataset 6 | Class 1(0) | 99.61 | 99.72 | 99.56 | 99.64 |
| Class 2(2) | 99.64 | 99.6 | 99.62 | ||
| Class 3(4) | 99.46 | 99.66 | 99.56 | ||
| Macro-Averaged | 99.61 | 99.61 | 99.61 |
| Study | Method | Research Background and Objectives | Data Type Used | Number of Data | Limitations | Results |
|---|---|---|---|---|---|---|
| Faruq et al. (2024) | Combining BiLSTM and BiGRU with FastText embeddings for improved depression sentiment classification. | This study focuses on leveraging deep learning architectures to analyze depression-related Reddit posts and improve sentiment classification accuracy. | Reddit text data on depression and non-depression | 7731 instances | The dataset is limited to Reddit, which may not generalize well to other social media platforms or clinical settings. | Accuracy = 97.03%, F1 score = 97.02%. |
| Lestandy (2023) | Utilizing BiLSTM with Word2Vec and GloVe embeddings to enhance feature representation in depression classification. | This research investigates the impact of different word embedding dimensions on the accuracy of depression classification models. | Depression: Reddit Dataset (labeled as depressed and non-depressed) | 7731 instances; split as 75% training and 25% testing | The dataset lacks diversity and may be biased due to the informal language used on social media. Misclassification is possible due to contextual variations. | Accuracy = 96.22%, precision = 97.02%, recall = 95.30%, F1 score = 96.15%. |
| Cambria et al. (2024) | Implementing a neurosymbolic AI approach integrating hierarchical attention networks and commonsense knowledge representation. | The study introduces an interpretable AI model for sentiment analysis and suicidal ideation detection, emphasizing trustworthiness and explainability. | Sentiment140 (Twitter), First Impressions (personality), SuicideWatch (Reddit) | Polarity (1,440,144); personality (6000); suicide (138,479) | Interpretability of the models is limited. The use of SuicideWatch data raises ethical concerns regarding mental health predictions. | Accuracy = 99.34%. |
| Onan (2023) | Applying semantic role labeling (SRL) with ant colony optimization (ACO) for effective sentiment classification. | The research explores the effectiveness of semantic role labeling and ant colony optimization in improving sentiment classification models. | 7 datasets: SST-2, Senti140, Yelp, US Airline, Toxic, SemEval, Sarcasm | Before: 1,795,666 (total); after: 3,613,637 (augmented) | Text augmentation may enhance model performance but can also introduce synthetic errors, reducing real-world applicability. | SST-2 accuracy = 89.17%, toxic = 99.45%. |
| Bendebane et al. (2023) | Developing a hybrid CNN-BiGRU deep learning model for multi-class classification of mental health conditions. | The study aims to classify normal, depression, and anxiety cases in Twitter data, particularly during the COVID-19 pandemic, using deep learning. | Twitter data during COVID-19 | 3,178,570 tweets | The dataset is specific to the COVID-19 period, limiting its generalization to post-pandemic social contexts. | Accuracy = 93.38%. F1 scores: normal = 96%, depression = 91%, anxiety = 93%. |
| Tan et al. (2023) | Combining RoBERTa transformer and GRU for enhanced sentiment analysis in various datasets. | This study evaluates the performance of a RoBERTa-GRU hybrid model in sentiment classification across diverse datasets. | IMDb, Sentiment140, Twitter US Airline datasets | IMDb: 50,000 reviews; Sentiment140: 1.6M tweets; Twitter: 14,160 tweets | The model is optimized for specific datasets, and its effectiveness in broader applications remains uncertain. | IMDb accuracy = 94.63%, Sentiment140 accuracy = 89.59%, Twitter US Airline accuracy = 91.52%. |
| Tesfagergish et al. (2022) | Using a two-stage model incorporating a zero-shot sentence transformer and an ensemble learning classifier for emotion detection. | The research focuses on enhancing emotion detection and sentiment classification through a zero-shot learning approach combined with ensemble learning. | IMDB, Sentiment140, SemEval-2017 datasets | IMDB: 50K reviews; Sentiment140: 1.6M tweets; SemEval-2017: 2.3K samples | The model struggles with multi-class classification, and dataset imbalances may impact performance. | Binary accuracy = 87.3%, F1 = 88.4%; Three-class accuracy = 62.7%, F1 = 55.4%. |
| Wang et al. (2020) | Proposing a sequential emotion analysis (SEA) and bidimensional hash search (BHS) model for mental disorder prediction. | The study aims to predict mental disorder severity using sequential emotion analysis and bidimensional hash search techniques. | Sentiment140, Twitter data (diagnosed-oriented and occupation-oriented), psychology blogs | Sentiment140: 1.04M tweets; blogs: 125K+, diagnosed data: 167K tweets | Diagnosis relies solely on textual data, which may lack clinical validation and lead to unreliable classifications. | Accuracy for diagnosed mental disorders: Anxiety (90.76%), Bipolar (90.70%), Depression (90.66%), OCD (90.44%). |
| Basiri et al. (2021) | Leveraging an attention-based bidirectional CNN-RNN deep learning framework for sentiment classification. | This research investigates how an attention-based CNN-RNN deep learning approach can improve sentiment classification on Twitter data. | Sentiment140 (Twitter dataset) | 1.6M tweets (balanced positive/negative) | The model demonstrates relatively low accuracy, requiring further optimization for improved classification performance. | Accuracy: 81.82%, F1-Score (positive): 83.23%, F1-Score (negative): 80.76%. |
| Our Method | Integrating multiple pre-trained language models with Cumulative Weight-based Iterative Neighborhood Component Analysis (CWINCA) and iterative majority voting (IMV) for enhanced psychiatric disorder detection. | The study proposes a novel framework integrating deep learning and feature selection to enhance psychiatric disorder detection from social media data. | X (Twitter) and Reddit data (6 different datasets) | 6 datasets, totaling millions of data points | Accuracy Dataset 1 = 80.74 Dataset 2 = 98.90 Dataset 3 = 93.61 Dataset 4 = 82.36 Dataset 5 = 99.96 Dataset 6 = 99.61 |
| Model | First Layer | Middle Layer | Last Layer | Final Output (SVM) |
|---|---|---|---|---|
| BERT | 70.64 | 75.88 | 79.96 | 79.96 |
| RoBERTa | 70.33 | 72.72 | 79.50 | 79.50 |
| ALBERT | 68.56 | 72.49 | 77.27 | 77.27 |
| ClinicalBERT | 68.95 | 71.41 | 76.57 | 76.57 |
| DistilBERT | 70.50 | 76.50 | 79.50 | 79.50 |
| Electra | 68.25 | 70.33 | 75.34 | 75.34 |
| XLNet | 66.40 | 70.33 | 76.19 | 76.19 |
| BioBERT | 67.79 | 71.80 | 77.04 | 77.04 |
| Combined | 66.94 | 73.34 | 79.27 | 79.27 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Baydili, İ.; Tasci, B.; Tasci, G. Deep Learning-Based Detection of Depression and Suicidal Tendencies in Social Media Data with Feature Selection. Behav. Sci. 2025, 15, 352. https://doi.org/10.3390/bs15030352
Baydili İ, Tasci B, Tasci G. Deep Learning-Based Detection of Depression and Suicidal Tendencies in Social Media Data with Feature Selection. Behavioral Sciences. 2025; 15(3):352. https://doi.org/10.3390/bs15030352
Chicago/Turabian StyleBaydili, İsmail, Burak Tasci, and Gülay Tasci. 2025. "Deep Learning-Based Detection of Depression and Suicidal Tendencies in Social Media Data with Feature Selection" Behavioral Sciences 15, no. 3: 352. https://doi.org/10.3390/bs15030352
APA StyleBaydili, İ., Tasci, B., & Tasci, G. (2025). Deep Learning-Based Detection of Depression and Suicidal Tendencies in Social Media Data with Feature Selection. Behavioral Sciences, 15(3), 352. https://doi.org/10.3390/bs15030352