
Behavioral Dynamics Analysis in Language Education: Generative State Transitions and Attention Mechanisms

Abstract
1. Introduction
- Introduction of interactive attention mechanisms to optimize behavior analysis: This study applies interactive attention mechanisms to the field of Chinese learning behavior analysis, using deep learning models to capture students’ behavioral characteristics during digital cultural resource learning and dynamically adjust the system’s focus. This mechanism can flexibly allocate attention to the personalized needs of different learners, addressing the issue of real-time feedback.
- Utilizing digital cultural heritage resources to enhance the learning experience: Unlike traditional classroom teaching, this study introduces digital cultural heritage resources into Chinese language learning. By using rich virtual cultural resources, it provides an immersive learning experience. This not only helps students more intuitively understand Chinese culture but also promotes cross-cultural communication and language application skills development.
- Building a generative model for learning behavior prediction and feedback: This study innovatively constructs a generative learning behavior prediction model by collecting students’ learning logs and interaction data, predicting learning behaviors and emotional states. The model is optimized using a generative loss function, allowing the system to provide personalized learning path recommendations based on predictions.
- Spatial state transition equations for dynamic emotional and behavioral capture: In order to better understand students’ emotional and behavioral changes during the learning process, this study designs a spatial state transition equation to model the transition of students’ learning states. This equation describes the evolution of students from one learning state to another.
2. Related Work
2.1. Research on Traditional Teaching Methods
2.2. Current Applications of Artificial Intelligence in Education
2.3. AI-Based Student Behavior Analysis
3. Materials and Methods
3.1. Dataset Construction
3.1.1. Source of Experimental Data
3.1.2. Data Collection Process
3.1.3. Ethical Considerations and Data Source Compliance
3.1.4. Data Processing and Feature Extraction
3.2. Proposed Method
3.2.1. Overview
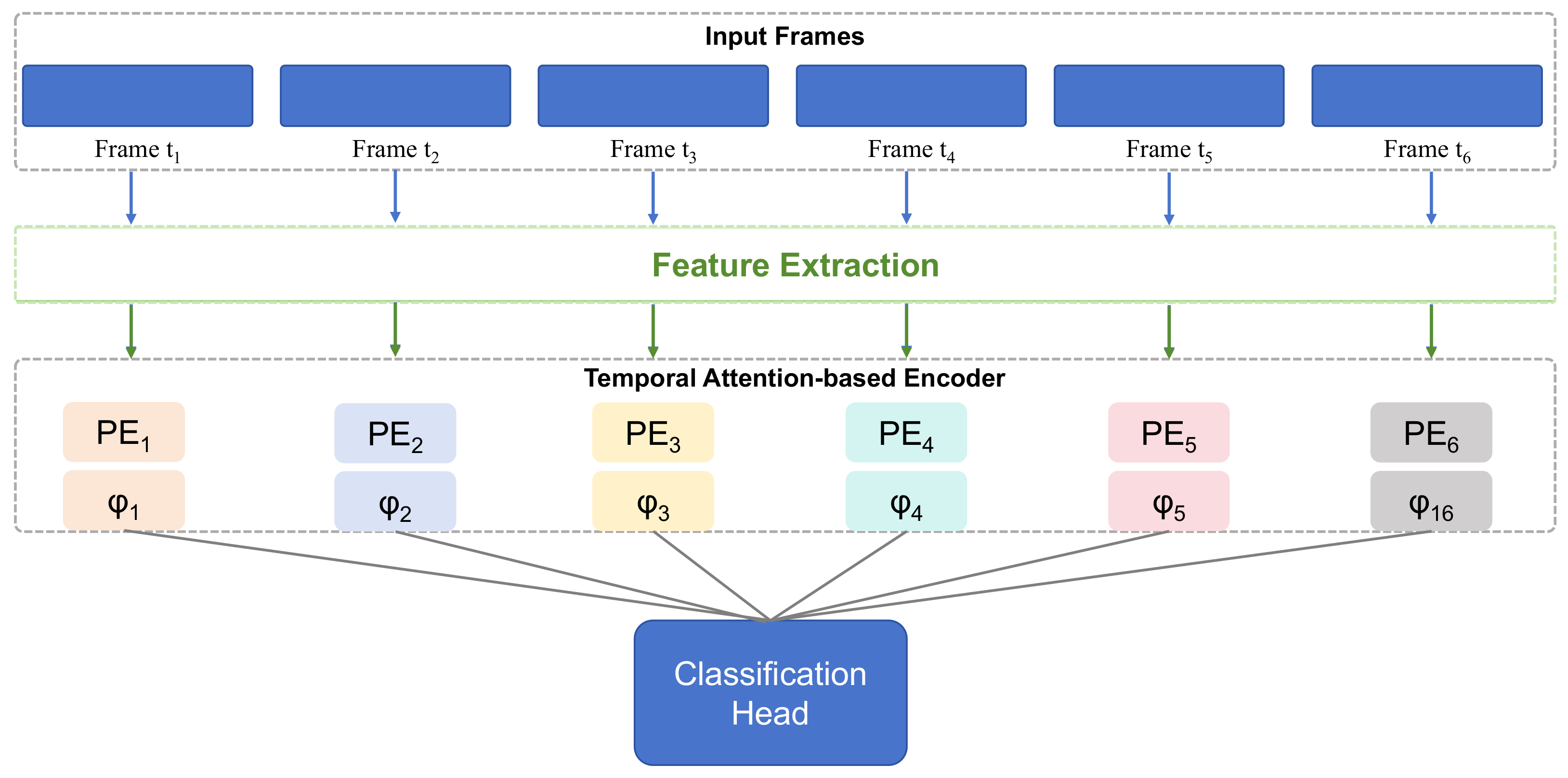
3.2.2. Generative Attention Mechanism
- Input Layer: The input layer receives the behavior features of the student during the learning process, such as study duration, classroom participation, emotional states, etc. These features are passed through an embedding layer to map the raw input into a higher-dimensional feature space.
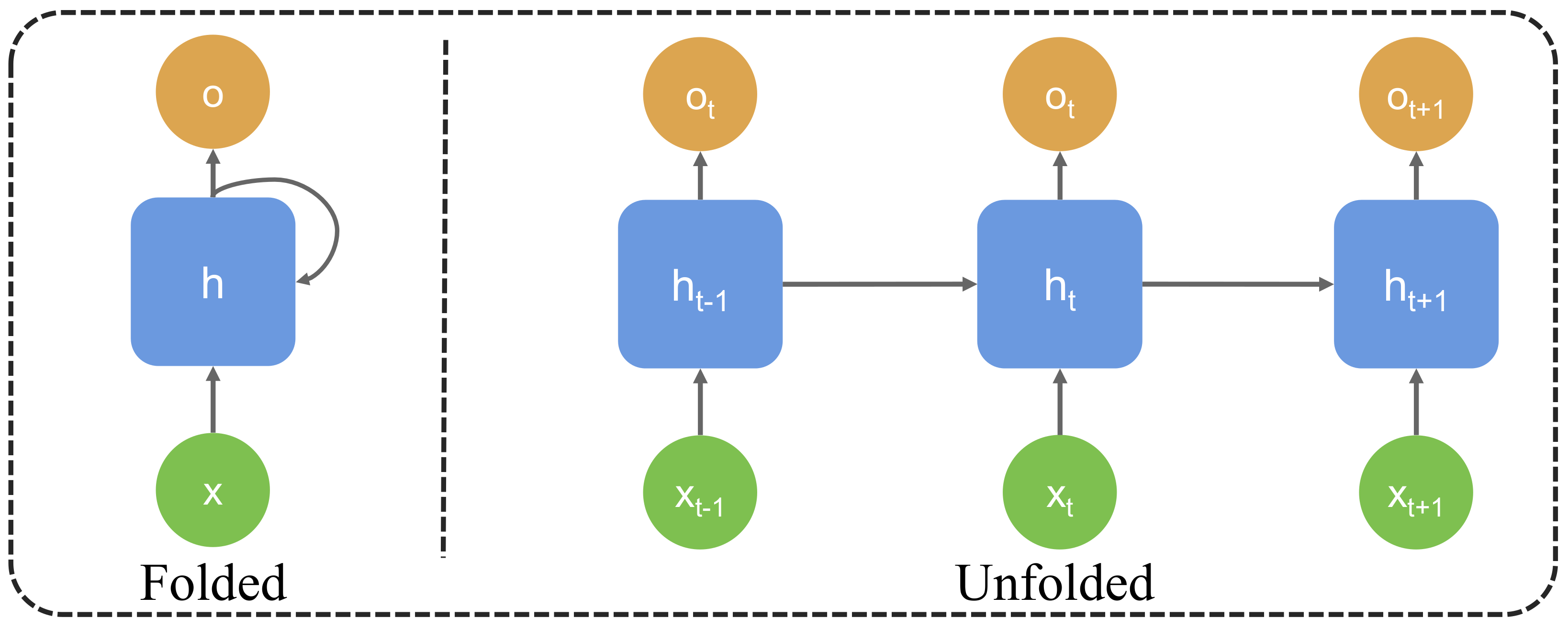
- Generative Module: An LSTM layer is used to capture the temporal features of student behavior. The LSTM layer, through memory cells and gating mechanisms, can effectively capture long-term dependencies in students’ learning processes, thereby generating attention weights at each time step.
- Attention Calculation Layer: The output of the generative module is used as a query vector, which is then used to compute the attention weights by performing attention operations with the key and value matrices from the input sequence.
- Output Layer: The output layer generates the final weighted feature representation, which is used for subsequent learning behavior prediction or emotional state analysis.
- Dynamic Adaptability: The generative attention mechanism dynamically adjusts attention weights based on the student’s current learning state, while traditional self-attention is static and cannot respond in real time to changes in student behavior. Students may experience different emotional fluctuations and behavioral changes during the learning process, such as declining interest or the onset of anxiety. The generative attention mechanism can adjust the attention distribution in real time based on these changes, providing more precise feedback.
- Personalized Learning Path: By dynamically generating attention weights, the generative attention mechanism can customize the learning path for each student. As students’ behavioral patterns and emotional states change with the progression of learning, the generative mechanism can adjust learning content and teaching strategies accordingly, thereby improving student engagement and learning outcomes.
- Long-Term Dependency Modeling: By incorporating generative models (such as LSTM), the generative attention mechanism can capture long-term dependencies in students’ learning processes, identifying their learning patterns and generating dynamic attention weights that adapt to these patterns. This is crucial for predicting long-term learning behaviors and capturing emotional fluctuations.
- Improved Emotional and Behavioral Prediction Accuracy: Traditional self-attention mechanisms can capture short-term learning behaviors, but due to the lack of emotional fluctuation detection, the prediction results may not be accurate. The generative attention mechanism, by combining generative models and deep learning techniques, can more accurately identify changes in students’ emotional states, improving the accuracy of both emotional and behavioral predictions.
3.2.3. Generative State Transition Equation
3.2.4. Generative Loss Function
3.2.5. Model Training and Optimization
4. Results
4.1. Experimental Setup and Comparison Models
4.1.1. Software and Hardware Configuration
4.1.2. Comparison Models and Parameter Settings
4.1.3. Evaluation Metrics
4.2. Behavior Prediction Results
4.3. Learning Experience Satisfaction Results
4.4. Sentiment Analysis and Behavioral Dynamics Capture Results
5. Discussion
5.1. Behavior Prediction Results Discussion
5.2. Learning Experience Satisfaction Results Discussion
5.3. Sentiment Analysis and Behavioral Dynamics Capture Results Discussion
5.4. Failure Case Analysis
5.5. Limitations and Potential Risks of the Proposed Approach
5.6. Future Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Abu-Ghuwaleh, M., & Saffaf, R. (2023). Integrating AI and NLP with project-based learning in STREAM education. Preprints. [Google Scholar] [CrossRef]
- Alenezi, M. (2023). Digital learning and digital institution in higher education. Education Sciences, 13(1), 88. [Google Scholar] [CrossRef]
- Barrett, A., Pack, A., Guo, Y., & Wang, N. (2023). Technology acceptance model and multi-user virtual reality learning environments for Chinese language education. Interactive Learning Environments, 31(3), 1665–1682. [Google Scholar] [CrossRef]
- Bernacki, M. L., Greene, M. J., & Lobczowski, N. G. (2021). A systematic review of research on personalized learning: Personalized by whom, to what, how, and for what purpose(s)? Educational Psychology Review, 33(4), 1675–1715. [Google Scholar] [CrossRef]
- Bernardes, R. C., Lima, M. A. P., Guedes, R. N. C., da Silva, C. B., & Martins, G. F. (2021). Ethoflow: Computer vision and artificial intelligence-based software for automatic behavior analysis. Sensors, 21(9), 3237. [Google Scholar] [CrossRef] [PubMed]
- Bilyalova, A. A., Salimova, D. A., & Zelenina, T. I. (2020). Digital transformation in education. In Integrated science in digital age: ICIS 2019 (pp. 265–276). Springer. [Google Scholar] [CrossRef]
- Camacho-Morles, J., Slemp, G. R., Pekrun, R., Loderer, K., Hou, H., & Oades, L. G. (2021). Activity achievement emotions and academic performance: A meta-analysis. Educational Psychology Review, 33(3), 1051–1095. [Google Scholar] [CrossRef]
- Chen, M., Chai, C.-S., Jong, M. S.-Y., & Jiang, M. Y.-C. (2021). Teachers’ conceptions of teaching Chinese descriptive composition with interactive spherical video-based virtual reality. Frontiers in Psychology, 12, 591708. [Google Scholar] [CrossRef]
- Chiu, T. K. F., & Chai, C. (2020). Sustainable curriculum planning for artificial intelligence education: A self-determination theory perspective. Sustainability, 12(14), 5568. [Google Scholar] [CrossRef]
- Clark, K., Luong, M.-T., Le, Q. V., & Manning, C. D. (2020). ELECTRA: Pre-training text encoders as discriminators rather than generators. arXiv, arXiv:2003.10555. [Google Scholar] [CrossRef]
- Devlin, J. (2018). BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv, arXiv:1810.04805. [Google Scholar] [CrossRef]
- Elimadi, I., Chafiq, N., & Ghazouani, M. (2024). Artificial intelligence in the context of digital learning environments (DLEs): Towards adaptive learning. In Engineering applications of artificial intelligence (pp. 95–111). Springer. [Google Scholar] [CrossRef]
- Ezzaim, A., Dahbi, A., Aqqal, A., & Haidine, A. (2024). AI-based learning style detection in adaptive learning systems: A systematic literature review. Journal of Computers in Education, 1–39. [Google Scholar] [CrossRef]
- Fan, M., & Antle, A. N. (2020, June 21–24). An English language learning study with rural Chinese children using an augmented reality app. IDC ’20: Interaction Design and Children (pp. 385–397), London, UK. [Google Scholar] [CrossRef]
- Floridi, L., & Chiriatti, M. (2020). GPT-3: Its nature, scope, limits, and consequences. Minds and Machines, 30(4), 681–694. [Google Scholar] [CrossRef]
- García-Martínez, I., Fernández-Batanero, J. M., Fernández-Cerero, J., & León, S. P. (2023). Analysing the impact of artificial intelligence and computational sciences on student performance: Systematic review and meta-analysis. Journal of New Approaches in Educational Research, 12(1), 171–197. [Google Scholar] [CrossRef]
- Guan, C., Mou, J., & Jiang, Z. (2020). Artificial intelligence innovation in education: A twenty-year data-driven historical analysis. International Journal of Innovation Studies, 4(4), 134–147. [Google Scholar] [CrossRef]
- Gulyamov, S., Zolea, S., Babaev, J., Akromov, A., & Ubaydullaeva, A. (2024). Administrative law in the era of digital technologies: New opportunities for the saving of cultural heritage and public education. International Journal of Law and Policy, 2(9), 49–70. [Google Scholar] [CrossRef]
- Guo, Y., Xu, J., & Chen, C. (2023). Measurement of engagement in the foreign language classroom and its effect on language achievement: The case of Chinese college EFL students. International Review of Applied Linguistics in Language Teaching, 61(3), 1225–1270. [Google Scholar] [CrossRef]
- Hein, G. E. (1991). Constructivist learning theory. Institute for Inquiry. [Google Scholar]
- Kalogiannakis, M., Papadakis, S., & Zourmpakis, A.-I. (2021). Gamification in science education. A systematic review of the literature. Education Sciences, 11(1), 22. [Google Scholar] [CrossRef]
- Li, Y., Zhong, Z., Zhang, F., & Zhao, X. (2022). Artificial intelligence-based human–computer interaction technology applied in consumer behavior analysis and experiential education. Frontiers in Psychology, 13, 784311. [Google Scholar] [CrossRef]
- Lian, Y., & Xie, J. (2024). The evolution of digital cultural heritage research: Identifying key trends, hotspots, and challenges through bibliometric analysis. Sustainability, 16(16), 7125. [Google Scholar] [CrossRef]
- Liu, S., & Wang, J. (2021). Ice and snow talent training based on construction and analysis of artificial intelligence education informatization teaching model. Journal of Intelligent & Fuzzy Systems, 40(2), 3421–3431. [Google Scholar] [CrossRef]
- Liu, Y., Ott, M., Goyal, M., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L., & Stoyanov, V. (2019). RoBERTa: A robustly optimized BERT pretraining approach. arXiv, arXiv:1907.11692. [Google Scholar] [CrossRef]
- Lu, X., Fan, S., Houghton, J., Wang, L., & Wang, X. (2023, April 23–28). ReadingQuizMaker: A human-NLP collaborative system that supports instructors to design high-quality reading quiz questions. CHI ’23: CHI Conference on Human Factors in Computing Systems (pp. 1–18), Hamburg, Germany. [Google Scholar] [CrossRef]
- Mariani, M. M., Perez-Vega, R., & Wirtz, J. (2022). AI in marketing, consumer research and psychology: A systematic literature review and research agenda. Psychology & Marketing, 39(4), 755–776. [Google Scholar] [CrossRef]
- Marín-Morales, J., Llinares, C., Guixeres, J., & Alcañiz, M. (2020). Emotion recognition in immersive virtual reality: From statistics to affective computing. Sensors, 20(18), 5163. [Google Scholar] [CrossRef] [PubMed]
- Meddah, A., & Benamara, K. (2024). The implementation of communicative language teaching in secondary school [PhD Thesis, Ibn Khaldoun University-Tiaret]. [Google Scholar]
- Munna, A. S., & Kalam, M. A. (2021). Teaching and learning process to enhance teaching effectiveness: A literature review. International Journal of Humanities and Innovation (IJHI), 4(1), 1–4. [Google Scholar] [CrossRef]
- Ottenbreit-Leftwich, A., Glazewski, K., Jeon, M., Jantaraweragul, K., Hmelo-Silver, C. E., Scribner, A., Lee, S., Mott, B., & Lester, J. (2023). Lessons learned for AI education with elementary students and teachers. International Journal of Artificial Intelligence in Education, 33(2), 267–289. [Google Scholar] [CrossRef]
- Ouyang, F., & Zhang, L. (2024). AI-driven learning analytics applications and tools in computer-supported collaborative learning: A systematic review. Educational Research Review, 44, 100616. [Google Scholar] [CrossRef]
- Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., & Liu, P. J. (2020). Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21(140), 1–67. [Google Scholar] [CrossRef]
- Roll, I., McNamara, D., Sosnovsky, S., Luckin, R., & Dimitrova, V. (2021). Artificial intelligence in education. Springer. [Google Scholar] [CrossRef]
- Safarov, F., Kutlimuratov, A., Abdusalomov, A. B., Nasimov, R., & Cho, Y. I. (2023). Deep learning recommendations of e-education based on clustering and sequence. Electronics, 12(4), 809. [Google Scholar] [CrossRef]
- Sanusi, I. T., Ayanwale, M. A., & Chiu, T. K. F. (2024). Investigating the moderating effects of social good and confidence on teachers’ intention to prepare school students for artificial intelligence education. Education and Information Technologies, 29(1), 273–295. [Google Scholar] [CrossRef]
- Sapci, A. H., & Sapci, H. A. (2020). Artificial intelligence education and tools for medical and health informatics students: Systematic review. JMIR Medical Education, 6(1), e19285. [Google Scholar] [CrossRef]
- Selwyn, N. (2024). Digital degrowth: Toward radically sustainable education technology. Learning, Media and Technology, 49(2), 186–199. [Google Scholar] [CrossRef]
- Sweller, J. (2011). Cognitive load theory. Springer. [Google Scholar] [CrossRef]
- Tahir, M., Tubaishat, A., Al-Obeidat, F., Shah, B., Halim, Z., & Waqas, M. (2022). A novel binary chaotic genetic algorithm for feature selection and its utility in affective computing and healthcare. Neural Computing and Applications, 34, 11453–11474. [Google Scholar] [CrossRef]
- Tlili, A., Wang, H., Gao, B., Shi, Y., Zhiying, N., Looi, C.-K., & Huang, R. (2023). Impact of cultural diversity on students’ learning behavioral patterns in open and online courses: A lag sequential analysis approach. Interactive Learning Environments, 31(6), 3951–3970. [Google Scholar] [CrossRef]
- Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., & Rodriguez, A. (2023). Llama: Open and efficient foundation language models. arXiv, arXiv:2302.13971. [Google Scholar] [CrossRef]
- Uiphanit, T., Unekontee, J., Wattanaprapa, N., Jankaweekool, P., & Rakbumrung, W. (2020). Using augmented reality (AR) for enhancing Chinese vocabulary learning. International Journal of Emerging Technologies in Learning (IJET), 15(17), 268–276. [Google Scholar] [CrossRef]
- Vu, T., Magis-Weinberg, L., Jansen, B. R. J., van Atteveldt, N., Janssen, T. W. P., Lee, N. C., van der Maas, H. L. J., Raijmakers, M. E. J., Sachisthal, M. S., & Meeter, M. (2022). Motivation-achievement cycles in learning: A literature review and research agenda. Educational Psychology Review, 34(1), 39–71. [Google Scholar] [CrossRef]
- Wang, X., & Reynolds, B. L. (2024). Beyond the books: Exploring factors shaping Chinese English learners’ engagement with large language models for vocabulary learning. Education Sciences, 14(5), 496. [Google Scholar] [CrossRef]
- Wong, G. K. W., Ma, X., Dillenbourg, P., & Huan, J. (2020). Broadening artificial intelligence education in K-12: Where to start? ACM Inroads, 11(1), 20–29. [Google Scholar] [CrossRef]
- Yang, W. (2022). Artificial intelligence education for young children: Why, what, and how in curriculum design and implementation. Computers and Education: Artificial Intelligence, 3, 100061. [Google Scholar] [CrossRef]
- Yang, Z., Dai, Z., Yang, Y., Carbonell, J., Salakhutdinov, R., & Le, Q. V. (2019). XLNet: Generalized autoregressive pretraining for language understanding. arXiv, arXiv:1906.08237. [Google Scholar] [CrossRef]
- Yu, T., Dai, J., & Wang, C. (2023). Adoption of blended learning: Chinese university students’ perspectives. Humanities and Social Sciences Communications, 10(1), 390. [Google Scholar] [CrossRef]
- Yu, Y.-T., & Tsuei, M. (2023). The effects of digital game-based learning on children’s Chinese language learning, attention and self-efficacy. Interactive Learning Environments, 31(10), 6113–6132. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
| Group | Sample Size | Mean | Std Dev | Skewness | Kurtosis | Kolmogorov–Smirnov Test | Shapiro–Wilk Test | ||
|---|---|---|---|---|---|---|---|---|---|
| Statistic | p-Value | Statistic | p-Value | ||||||
| A | 7 | 35.143 | 2.968 | 0.556 | −0.716 | 0.221 | 0.376 | 0.907 | 0.374 |
| B | 7 | 35.143 | 4.880 | −0.374 | 0.313 | 0.122 | 0.989 | 0.990 | 0.993 |
| Content | Group (Mean ± Std Dev) | t-Statistic | p-Value | |
|---|---|---|---|---|
| Group A | Group B | |||
| Predicted Performance | 35.14 ± 2.97 | 35.14 ± 4.88 | 0.000 | 1.000 |
| Group | Mean | Std Dev | Skewness | Kurtosis | Kolmogorov–Smirnov Test | Shapiro–Wilk Test | ||
|---|---|---|---|---|---|---|---|---|
| Statistic | p-Value | Statistic | p-Value | |||||
| Bronze and Porcelain Knowledge | ||||||||
| A | 9.714 | 2.138 | −0.772 | 0.263 | 0.267 | 0.136 | 0.894 | 0.294 |
| B | 8.571 | 2.225 | 0.249 | −0.944 | 0.173 | 0.762 | 0.992 | 0.482 |
| Bronze Craftsmanship Topic | ||||||||
| A | 15.143 | 2.116 | −1.442 | 2.080 | 0.229 | 0.326 | 0.854 | 0.133 |
| B | 17.571 | 1.618 | −0.674 | −1.151 | 0.240 | 0.258 | 0.864 | 0.163 |
| Porcelain Evaluation Topic | ||||||||
| A | 16.714 | 1.380 | 0.706 | −0.325 | 0.269 | 0.103 | 0.918 | 0.456 |
| B | 14.429 | 2.070 | −0.489 | −0.361 | 0.205 | 0.503 | 0.945 | 0.686 |
| Content | Group (Mean ± Std Dev) | t-Statistic | p-Value | |
|---|---|---|---|---|
| Group A | Group B | |||
| Basic Knowledge | 9.714 ± 2.138 | 8.571 ± 2.225 | 0.980 | 0.347 |
| Bronze Knowledge | −2.412 | 0.033 | ||
| Porcelain Knowledge | 2.431 | 0.032 | ||
| Interviewee | Experimental Group | Gender | Interview Date | Interview Location |
|---|---|---|---|---|
| Interviewee 1 | Group A | Male | 15 January 2024 16:00 | Tencent Meeting 207-219-815 |
| Interviewee 2 | Group A | Male | 16 January 2024 9:30 | Tencent Meeting 748-925-593 |
| Interviewee 3 | Group B | Female | 15 January 2024 20:00 | Tencent Meeting 599-892-029 |
| Interviewee 4 | Group B | Female | 16 January 2024 20:00 | Tencent Meeting 565-305-123 |
| Model | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|
| BERT | 82.4 | 81.8 | 80.5 | 81.1 |
| LLAMA | 84.2 | 83.7 | 82.9 | 83.3 |
| RoBERTa | 85.6 | 85.0 | 84.3 | 84.6 |
| GPT-3 | 87.8 | 87.0 | 86.4 | 86.7 |
| XLNet | 86.5 | 85.9 | 85.1 | 85.5 |
| T5 | 88.1 | 87.5 | 86.9 | 87.2 |
| ELECTRA | 85.9 | 85.2 | 84.6 | 84.9 |
| Self-Attention | 88.9 | 88.0 | 88.3 | 88.4 |
| CBAM Attention | 79.3 | 80.1 | 80.2 | 79.8 |
| Proposed Method | 90.3 | 89.7 | 89.0 | 89.4 |
| Model | Satisfaction Score | Std. Deviation | Positive Feedback (%) | Negative Feedback (%) |
|---|---|---|---|---|
| BERT | 76.5 | 5.4 | 82.1 | 17.9 |
| LLAMA | 78.3 | 4.8 | 83.5 | 16.5 |
| RoBERTa | 79.8 | 4.2 | 85.7 | 14.3 |
| GPT-3 | 81.5 | 3.9 | 87.3 | 12.7 |
| XLNet | 80.7 | 4.0 | 86.9 | 13.1 |
| T5 | 82.4 | 3.6 | 88.5 | 11.5 |
| ELECTRA | 79.1 | 4.5 | 85.2 | 14.8 |
| Self-Attention | 84.3 | 3.1 | 89.6 | 12.0 |
| CBAM Attention | 80.4 | 4.5 | 83.7 | 13.2 |
| Proposed Method | 89.2 | 2.8 | 94.3 | 5.7 |
| Model | Sentiment Accuracy (%) | Behavioral Recall (%) | Behavioral Precision (%) | F1-Score (%) |
|---|---|---|---|---|
| BERT | 78.5 | 75.4 | 76.2 | 75.8 |
| LLAMA | 81.3 | 78.5 | 79.1 | 78.8 |
| RoBERTa | 83.2 | 80.6 | 81.0 | 80.8 |
| GPT-3 | 85.7 | 83.1 | 84.3 | 83.7 |
| XLNet | 84.5 | 82.7 | 83.5 | 83.1 |
| T5 | 86.4 | 84.8 | 85.5 | 85.1 |
| ELECTRA | 82.9 | 80.3 | 81.2 | 80.7 |
| Self-Attention | 86.1 | 84.9 | 85.4 | 85.3 |
| CBAM Attention | 71.3 | 70.7 | 70.9 | 71.0 |
| Proposed Method | 90.6 | 88.4 | 89.3 | 88.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Q.; Qian, Y.; Gao, S.; Liu, Y.; Shen, X.; Jiang, Q. Behavioral Dynamics Analysis in Language Education: Generative State Transitions and Attention Mechanisms. Behav. Sci. 2025, 15, 326. https://doi.org/10.3390/bs15030326
Zhang Q, Qian Y, Gao S, Liu Y, Shen X, Jiang Q. Behavioral Dynamics Analysis in Language Education: Generative State Transitions and Attention Mechanisms. Behavioral Sciences. 2025; 15(3):326. https://doi.org/10.3390/bs15030326
Chicago/Turabian StyleZhang, Qi, Yiming Qian, Shumiao Gao, Yufei Liu, Xinyu Shen, and Qing Jiang. 2025. "Behavioral Dynamics Analysis in Language Education: Generative State Transitions and Attention Mechanisms" Behavioral Sciences 15, no. 3: 326. https://doi.org/10.3390/bs15030326
APA StyleZhang, Q., Qian, Y., Gao, S., Liu, Y., Shen, X., & Jiang, Q. (2025). Behavioral Dynamics Analysis in Language Education: Generative State Transitions and Attention Mechanisms. Behavioral Sciences, 15(3), 326. https://doi.org/10.3390/bs15030326