Abstract
Background: Rare diseases represent a significant research challenge due to the limited availability of data, small patient cohorts, and heterogeneous phenotypes. Data augmentation and synthetic data generation are increasingly adopted to mitigate these limitations. Methods: This scoping review maps the application of data augmentation and synthetic data generation methods as strategies to address these limitations. A total of 118 studies published between 2018 and 2025 were identified through PubMed, Scopus, and Electronics Engineers (IEEE) Xplore. Results: Imaging data headed the field, followed by clinical and omics datasets. Classical augmentation, mainly geometric and photometric transformations, emerged as the most frequent approach, while deep generative models have rapidly expanded since 2021. Rule- and model-based methods were less common but demonstrated high interpretability in small datasets. Conclusions: Overall, these techniques enabled dataset expansion and improved model robustness. However, both approaches require rigorous validation to confirm biological plausibility. Together, these methods can transform data scarcity from a barrier into a driver of methodological innovation, enabling more inclusive rare disease research.
1. Introduction
Rare diseases are conditions that affect a relatively small number of individuals compared to the general population [1], and their rarity presents specific challenges and issues, affecting over 350 million patients worldwide with approximately 7000 distinct conditions. Access to highly specialized, quality care faces two main obstacles: late diagnosis and limited therapeutic development [2]. The diagnostic pathway for patients with rare diseases is extremely challenging. On average, it takes six years from the onset of symptoms to receive an accurate pathological diagnosis due to several factors, including the low prevalence of these diseases, insufficient numbers of specialists with the necessary scientific expertise, limited access to specialist care, and inadequate research infrastructure [3]. In addition, the development of targeted therapies is hindered by data scarcity and small patient cohorts, which limit the research into pathophysiological mechanisms and therapeutic options. Meanwhile, rare diseases are now increasingly recognized as a critical public health issue, leading to international networks to raise awareness and drive research progress in the field [4]. At the same time, artificial intelligence (AI) has been progressively adopted to address these challenges [5,6] though its success relies on access to large datasets, which is challenging in the context of rare diseases. Small sample sizes, heterogeneous phenotypes, and fragmented data collections increase the risk of model overfitting and poor generalizability [7]. Therefore, insufficient data is one of the most significant limitations of data-driven approaches in rare disease research [8,9]. Promising strategies to address this limitation are data augmentation and synthetic data generation, which involve methods that artificially expand or enrich datasets either through the modification of existing samples or through the creation of new synthetic ones. Originally prevalent in computer vision, these techniques have more recently been applied to temporal [10], biomedical [11,12], and multi-omic data [13]. More recently, nonlinear and hybrid generative architectures have been proposed, including the integration of deep learning techniques with tensor decomposition frameworks for advanced neuroimaging analysis [14]. Such approaches enable greater robustness, generalisation, and resilience in downstream predictive models.
In the field of rare diseases, where recruiting patients and acquiring data is resource-intensive, augmentation can help to overcome small sample size issues, together with class imbalance, and restricted variability in clinical and biological data [15]. Furthermore, the generation of synthetic data may facilitate the simulation of disease progression, accelerate biomarker discovery, and support the design of clinical trials [16,17,18]. Despite their potential, augmentation and synthetic data generation are rarely used in rare disease research, with approaches often borrowed from other fields and hardly validated under the unique constraints of rare and ultra-rare conditions. Questions remain regarding the biological plausibility of augmented and synthetic data, how it can be integrated into clinical pipelines, and how its impact on model performance can be evaluated. The purpose of this review is to map the state of the art on data augmentation and synthesis within the context of rare diseases. Our objectives are to (1) describe the range of augmentation and synthetic data generation techniques adopted to date, (2) clarify their purposes and areas of application, and (3) discuss existing limitations and unresolved methodological issues. Bringing together the available evidence, we intend to provide both biomedical researchers and data scientists with guidance on how these approaches can help overcome one of the major obstacles in rare disease research: the limited availability of robust and representative datasets.
2. Materials and Methods
This review was performed in accordance with the PRISMA (Preferred Reporting Items for Systematic Reviews and Meta-Analyses) guidelines [19]. In particular, the following five-stage methodological framework was employed [20]: (1) Identify research questions, (2) Identify relevant studies, (3) Study selection, (4) Data Charting, (5) Collate and report results. This meta-analysis has been registered in PROSPERO (registration number CRD420251179956). The study protocol can be found on the same registry.
2.1. Literature Search and Selection
We comprehensively searched three databases, PubMed, Electronics Engineers (IEEE) Xplore, and Scopus, for candidate articles. Eligible records had to meet the following criteria: (1) focused on data augmentation or synthetic data in the context of rare diseases, (2) published or made publicly available between 1 January 2010, and 31 August 2025, (3) written in English. The general search strategy combined terms related to “data augmentation” or “synthetic data” with “rare disease”. For PubMed, the major repository of life science and biomedical publications, we also paired 9784 individual rare disease names from the Orphanet database (Table S1) with the terms “data augmentation” and “synthetic data”. To evaluate the robustness of this approach, the results were compared against a set of known relevant articles identified during preliminary screening. The initial search was conducted in August 2025, and the search strings for each database are reported in Table 1. In total, 2864 candidate articles were retrieved.

Table 1.
Database-specific search strings.
Once all the candidate articles were obtained, we screened titles, abstracts, and full texts. Citation management and initial screening were conducted using Rayann [21]. Exclusion criteria were: (1) not published in a peer-reviewed journal or conference proceeding, (2) not original research (e.g., editorials, reviews), (3) not involving human subjects, (4) not addressing data augmentation, synthetic data, and rare diseases. These exclusion criteria were applied to ensure the inclusion of relevant and original studies. Non-peer-reviewed and non-original research works were excluded to guarantee scientific reliability, to avoid duplication of evidence, and to focus on primary data. Studies not involving human subjects were excluded to maintain consistency with the clinical and translational scope of the review. Papers not addressing data augmentation, synthetic data, or rare diseases were excluded as they fell outside the main research question. Each publication’s title and abstract were independently screened by a minimum of two researchers. Any discrepancies or ambiguities were resolved through collegial discussion and consensus among all researchers.
2.2. Full-Text Analysis and Metadata Extraction
After the initial screening of abstracts, 150 publications were identified as relevant to the aim of this scoping review and were selected for further analysis based on their full texts. However, 148 publications were selected, as one article was retracted from the public record and the other was not available online, with no response received from the authors. A minimum of two researchers independently screened each of the 148 publications. During this process, the main data elements included (1) publication year, (2) study focus, (3) rare diseases, (4) data type, (5) data size (before), (6) data size (after), (7) method. Table 2 summarizes the metadata elements.
Table 2.
Metadata extracted from each article.
3. Results
The article selection process was performed in accordance with the PRISMA Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) flow diagram guidelines, as illustrated in Figure 1. Of the 2776 articles initially identified after deduplication, 148 were subject to full-text screening. The rigorous application of the inclusion criteria, coupled with a detailed examination of each publication, resulted in 118 publications being included in this scoping review. Articles were excluded for the following reasons: (1) Lack of direct application to rare disease data; (2) Absence of data augmentation or generation; (3) Insufficient methodological detail regarding the use of augmentation or synthetic data generation; (4) Methodological or conceptual inapplicability (framework-oriented papers not relevant to real-world rare disease data augmentation); and (5) Failed augmentation methods (reported unsuccessful or unreliable attempts). The titles and authors of the included publications are provided in Table S2, which summarizes the main characteristics of each study, including data type, study focus, rare disease investigated, and the augmentation or generation methods applied.
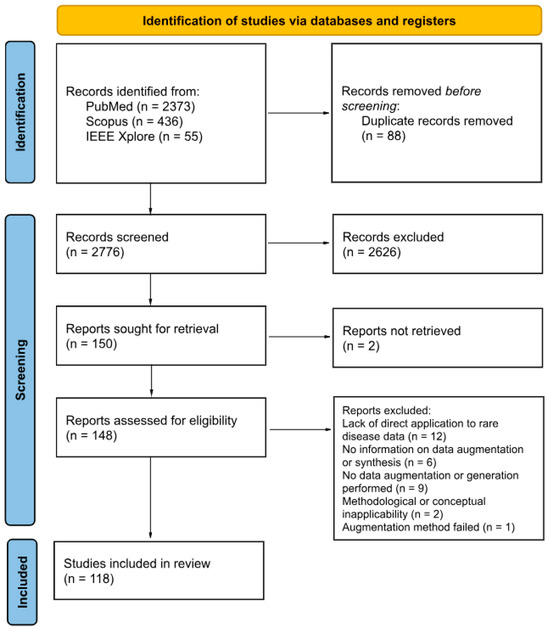
Figure 1.
PRISMA 2020 flow diagram for systematic reviews based on the publications on this topic.
3.1. Temporal Trends of Publication
Figure 2A shows the yearly evolution of the included publications. Although our search covered the period from 2010 onwards, no relevant articles to this scoping review were retrieved before 2018. The absence of augmentation and synthetic data techniques in the biomedical domain is not surprising, given that these techniques have only recently been adopted from computer vision and other data-rich fields. The first 2 publications appeared in 2018 (1.7%), followed by a gradual increase: 3 in 2019 (2.5%), 12 in 2020 (10.2%), and 15 in 2021 (12.7%). After a short decline in 2022 with only 9 articles published (7.6%), interest grew exponentially, reaching 24 in 2023 (20.3%), 26 in 2024 (22.0%), and 27 in 2025 (22.9%).
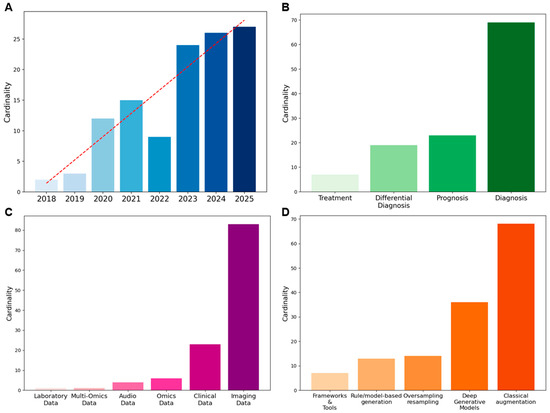
Figure 2.
Overview of metadata: (A) Temporal trend of publications, (B) Distribution of study focus, (C) Data types employed, (D) Methods applied for data augmentation/synthetic data generation.
3.2. Study Focus
Among the 118 articles, several analytical tasks are represented (see Figure 2B). Of these, 69 (58.5%) focus on diagnosis, 23 (19.5%) on prognosis, 19 (16.1%) on differential diagnosis, and 7 (5.9%) on treatment. Overall, diagnosis is the most frequent focus of studies in augmentation and synthetic data generation for rare diseases.
3.3. Rare Diseases Classification
Data augmentation and synthesis techniques have been applied to more than eighty rare diseases identified in the reviewed literature. The most represented domain includes hematological malignancies, particularly acute lymphoblastic leukemia, acute myeloid leukemia, and acute promyelocytic leukemia, which collectively account for the largest share of studies. Hepatic and oncological disorders, such as hepatocellular carcinoma and cholangiocarcinoma, also appear frequently, reflecting the widespread use of imaging data in these contexts. Genetic and metabolic diseases represent another substantial group, comprehending conditions like cystic fibrosis, Duchenne muscular dystrophy, and sickle cell disease, which are often explored in multi-disease or cross-cohort frameworks. Neurological and neuro-oncological conditions, including glioblastoma, meningioma, and craniosynostosis, are discussed in several contributions, together with systemic or autoimmune disorders such as systemic lupus erythematosus, systemic sclerosis, and Kawasaki disease. A smaller but noteworthy portion of studies addresses ophthalmological and endocrine diseases, including retinopathy of prematurity and thyroid carcinomas. However, the process of clear-cut classification remains challenging, as many rare conditions span multiple organ systems or etiological groups.
3.4. Data Type and Data Size
As illustrated in Figure 2C, the majority of the studies used imaging data, which covered 70.3% of the total, followed by clinical data (19.5%). Omics data accounted for 5.1%, while audio data represented 3.4%. Less frequent categories included multi-omics (0.8%) and laboratory data (0.8%). Quantitative information on dataset size before and after augmentation, when available, is detailed in Table S2. However, only 57% of the reviewed papers reported explicit numerical values for either the initial or augmented dataset, and less than one-third provided both. Where reported, imaging datasets increased on average about threefold, while non-imaging data showed broader variability. The remaining studies did not specify the number of samples generated, confirming a general lack of standardized reporting in this area.
3.5. Method
In this review, methods were categorized according to their data transformation principle. This conceptual distinction was adopted to ensure terminological consistency across studies, where definitions sometimes overlapped or were inconsistently applied. Classical augmentation methods, primarily geometric and photometric transformations, emerged as the most frequently applied strategies (49.3%), followed by deep generative models (DGMs) (26.1%). Rule/model-based synthetic data generation approaches accounted for 9.4%, while oversampling and resampling methods represented 10.1%. Frameworks and tools were less common, comprising 5.1% of the applications. The distribution of methods is displayed in Figure 2D. To provide an overview, Table 3 summarizes the main methodological differences between data augmentation and synthetic data generation, highlighting their typical scales of dataset expansion, main techniques, strengths, and limitations.
Table 3.
Comparison between data augmentation and synthetic data generation methods.
4. Discussion
This scoping review highlights the rapid increase in the use of data augmentation and synthesis in rare disease research over the past five years. Distinct patterns and challenges emerge when the distribution of methods is mapped across different data types, disease categories, and research focuses.
4.1. Data Augmentation
The main data augmentation approaches include classical augmentations and oversampling/resampling methods (Figure 3).
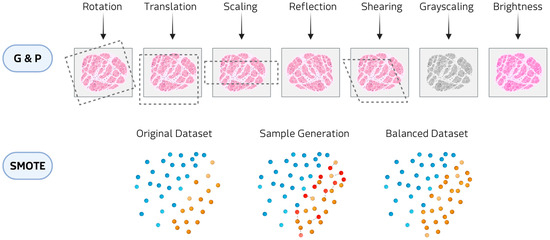
Figure 3.
Examples of data augmentation methods: Geometric and photometric transformations (G&P) at the top and SMOTE at the bottom.
In classical augmentation, geometric and photometric transformations constitute the most widely employed class in biomedical imaging, applied in almost 48% of the reviewed studies. Geometric transformations (e.g., rotations, translations, reflection, and shearing) modify the spatial configuration of the image, thereby simulating variability in patient positioning, tissue orientation, or magnification during acquisition. Photometric transformations (e.g., adjustments of brightness and contrast, and color perturbations) alter the pixel intensity distribution to mimic differences in staining protocols, illumination conditions, or scanner settings. These approaches have been reported to be applied in hematological diseases, where digital histopathology slides are expanded to reduce class imbalance [22,23,24,25,26,27,28,29,30,31,32]. Within classical augmentation, patch-based resampling methods are augmentation techniques that split medical images into smaller units, either as overlapping 3D cubes or slice-wise stacks. These approaches have been applied in rare tumor imaging [33,34] and rare neurological diseases [35]. This strategy allows models to focus on localized structural and textural features, reducing memory constraints associated with full-volume data.
Oversampling techniques, such as Synthetic Minority Over-sampling Technique (SMOTE) and Adaptive Synthetic Sampling (ADASYN), are widely applied to clinical imaging and omics data. SMOTE generates artificial samples by selecting a minority-class instance and interpolating new points along the line segments connecting it to its nearest minority-class neighbors. ADASYN builds on this principle by adaptively concentrating the generation of synthetic samples in regions of the feature space where class imbalance is more pronounced or classification is more challenging. In hematological malignancies, these methods have been employed to counteract imbalanced patient cohorts and improve predictive modeling [36]. In oncological contexts, SMOTE has been used to generate balanced datasets for imaging studies [37,38,39]. Beyond cancer, oversampling strategies have also been applied to metabolic and inherited disorders, where the scarcity of cases and controls poses major challenges [40,41]. In audio and signal processing domains, oversampling augmentations have been employed to enrich datasets for speech-related and movement disorders [42,43,44]. These transformations alter the temporal or frequency characteristics of the signals in ways that mimic natural variability in voice production, sensor noise, or recording conditions. Although technically lightweight, they are effective at enlarging small cohorts.
4.2. Synthetic Data Generation
Although less common than classical augmentation, the generation of synthetic data has received considerable attention since 2021, largely due to advances in DGMs. DGMs (Figure 4) allow realistic yet innovative samples to be generated that retain essential patterns and correlations, while introducing sufficient variability to enrich training sets [45].
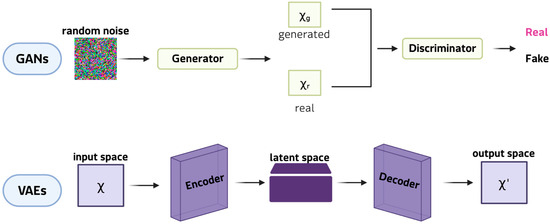
Figure 4.
Examples of DGMs: GANs at the top and VAEs at the bottom.
This ability is particularly valuable in the study of rare diseases, where a lack of patient data often restricts the reliability of subsequent analyses. Among DGMs, generative adversarial networks (GANs) are the most innovative and widely adopted framework for synthetic data generation. In their classic formulation, a GAN comprises two neural networks: the generator, which learns to produce synthetic samples from random noise vectors, and the discriminator, which determines whether a given sample is genuine or artificial. Through this antagonistic training cycle, the generator progressively captures the statistical properties of the original dataset, enabling the creation of new data points that closely resemble real observations [46]. This mechanism makes GANs particularly well-suited to expanding limited datasets, as they can model complex, high-dimensional distributions and reproduce subtle patterns that simpler augmentation strategies often lose. Key extensions include conditional GANs, which generate class-specific images; CycleGANs, which are effective in cross-modal translation (e.g., Magnetic resonance imaging (MRI) and computed tomography (CT) scans, and histopathological staining); and StyleGANs, which separate global and local features to produce realistic, detailed results [47]. These models can synthesise entirely new images that capture complex pathological heterogeneity, thereby expanding datasets beyond the scope of simple transformations. For instance, GAN-generated retinal scans of rare ophthalmic diseases [48] have doubled the size of training sets and enhanced the performance of classification in diagnostic pipelines. Applications also include the generation of MRI scans for small glioblastoma cohorts [49]. Variational autoencoders (VAEs), on the other hand, are used to generate synthetic patient records for clinical and tabular data. VAEs are particularly promising in omics research because their probabilistic latent space provides a structured and continuous representation of high-dimensional data. VAEs learn to reconstruct input data by compressing it into a lower-dimensional latent space and then sampling from this distribution. This framework enables smooth interpolation between samples, making VAEs ideal for modelling disease progression or transitions between phenotypic states. For instance, VAEs have been employed to simulate transcriptomic profiles of Niemann-Pick disease [40], generating virtual cohorts for comparing biomarker discovery workflows and testing analytical robustness. Rule- and model-based approaches, which generate synthetic data by explicitly modeling probabilistic dependencies between variables, represent a smaller class of generation methods. These include Bayesian networks and, in particular, dynamic Bayesian models that capture temporal relationships among clinical variables to simulate virtual patient trajectories. Recent applications to amyotrophic lateral sclerosis (ALS) have demonstrated that dynamic Bayesian networks can generate realistic longitudinal data, preserving conditional dependencies over time and enhancing downstream predictive modeling when combined with transfer learning [50,51]. Compared with deep generative models, these approaches offer higher interpretability and reliability on small datasets, although they reproduce a limited range of variability. This strategic use of data generation is particularly pertinent for bioinformatics applications in rare tumors, a field where molecular insights are often limited by data sparsity and feature instability. While current rare cancer bioinformatics studies [52,53] have successfully developed robust models by focusing on refined feature selection and deep learning architectures to mitigate these intrinsic data issues, generative strategies offer a complementary solution.
4.3. Advantages and Limitations
Data augmentation and synthetic data generation both address the challenge of small and imbalanced datasets in rare disease research; however, they differ in their technical scope, strengths, and limitations. Data augmentation is generally simpler, computationally inexpensive, and easier to validate. It works well when the data structure lends itself to transformations that do not compromise its meaning, for instance, rotating or scaling an MRI slice does not change the underlying pathology. This explains why data augmentation is prevalent in diseases where the use of images for diagnosis and prognosis is essential, such as hematological diseases and tumors. With simple transformations, it is therefore possible to expand datasets and balance small clinical cohorts without requiring specialist infrastructure or expertise. In terms of clinical feasibility, classical augmentation has high interpretability; the resulting data’s source is clear, which significantly increases clinician trust and simplifies integration into existing diagnostic workflows. This accessibility explains why classical augmentation continues to dominate the field. However, data augmentation can only modify what is already available, and if the original data are biased or incomplete, the resulting dataset will simply reproduce those shortcomings on a larger scale. It is also important to note that augmentation is unable to generate truly novel, unobserved patient phenotypes, thus limiting its capacity to comprehensively capture the heterogeneity that characterises numerous rare diseases.
Synthetic data generation, on the other hand, opens possibilities that augmentation alone cannot offer. Beyond technical utility, it also offers a practical advantage because it can produce artificial yet realistic patient records for clinical trials, potentially accelerating discovery when recruiting real patients is difficult. At the same time, synthetic data carries important limitations, since it is more powerful but technically demanding. Technical applicability is a major challenge for DGMs, which often suffer from instability, require significant computational power (GPU clusters) for training on complex datasets, and demand sophisticated hyperparameter tuning [54]. They also risk generating biologically implausible outputs [55]. Despite the consistent improvement of downstream models that incorporate DGM-generated data, few studies provided explicit technical validation of the generated samples themselves. In most studies, augmented or synthetic data were evaluated only by improvements in model performance, while independent clinical assessment or external benchmarking is limited. To improve clinical feasibility, validation needs to move beyond performance metrics to include measures of clinical utility, such as fidelity (how closely synthetic data matches the real data distribution) and diversity (the extent of novel, yet plausible, data generated). An additional limitation emerging from this review concerns the inconsistent quantitative reporting of dataset size before and after augmentation. Despite the inclusion of this information in our metadata extraction, more than 40% of the publications did not provide sufficient detail to compare expansion rates properly, limiting the comparability and reproducibility of reported results. Moreover, ethical and regulatory issues remain, especially regarding whether and how synthetic data can be accepted in diagnostic workflows or clinical research pipelines. A key step toward the adoption of these methods is the development of reliable validation frameworks that can ensure the clinical value of augmented and synthetic datasets. Validation should not be restricted to numerical performance metrics but should also include contextual evaluation to assess the coherence of generated data with disease mechanisms and clinical manifestations.
Cross-source comparisons and collaborative benchmarking are essential for identifying biases and verifying reproducibility. This approach aligns with the latest regulatory science for transparent synthetic health data usage. For example, the FDA’s internal programs addressing synthetic data and generative AI in medical device evaluation [56], EMA’s roadmap for ethical data sharing [18], and IRDiRC’s emphasis on data standardization and sharing in rare disease projects [57].
5. Conclusions
This review provides the first overview of how data augmentation and synthetic data generation are being applied across different rare disease domains. The proposed framework can help biomedical and computational scientists to select suitable techniques, to prioritize validation efforts, and to define benchmarks for reproducible and interpretable models in rare disease studies. Methodological innovation, combined with careful evaluation, can transform data scarcity into a catalyst for more robust and inclusive research. The increasing use of augmentation and generative strategies highlights the commitment to overcoming the limitations of small and imbalanced datasets. While classical augmentation provides accessibility and stability, synthetic approaches offer unprecedented opportunities to simulate biological variability. In the future, the impact of these methods will depend on rigorous validation, transparent reporting, and alignment with ethical and regulatory frameworks. Closer collaboration among data scientists, clinicians, and regulators, together with open and interoperable infrastructures, will be essential to ensure that models and datasets align with biological and clinical priorities. Furthermore, the widespread inconsistencies identified in this review highlight the urgent need for a common reporting framework for augmentation and synthesis studies. To enhance reproducibility and comparability, such a framework must, at a minimum, require transparent reporting of the following: (1) the size and composition of the initial dataset, including class distribution; (2) the size of the final dataset after augmentation/synthesis, with the expansion rate specified per class; (3) the precise details of the algorithm(s) used; and (4) the metrics used to validate the quality, diversity and biological plausibility of the generated data beyond model performance alone.
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/medsci13040260/s1, Table S1: Supplementary data 1; Table S2: Supplementary data 2.
Author Contributions
Conceptualization, B.R., R.F. and A.V.; methodology, B.R., R.F. and A.V.; software, B.R., R.F. and A.V.; validation, B.R., R.F. and A.V.; formal analysis, B.R., R.F. and A.V.; investigation, B.R., R.F. and A.V.; resources, B.R., R.F. and A.V.; data curation, B.R., R.F. and A.V.; writing—original draft preparation, B.R., R.F. and A.V.; writing—review and editing, A.S. and O.S.; visualization, B.R., R.F. and A.V.; supervision, A.S.; project administration, A.S.; funding acquisition, A.S., O.S. and A.V. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in this study are included in the article/Supplementary Material. Further inquiries can be directed to the corresponding authors.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| GANs | Generative adversarial networks |
| VAEs | Variational autoencoders |
| AI | Artificial intelligence |
| IEEE | Electronics Engineers |
| SMOTE | Synthetic Minority Over-sampling Technique |
| ADASYN | Adaptive Synthetic Sampling |
| G&P | Geometric and photometric transformations |
| DGMs | Deep generative models |
| MRI | Magnetic resonance imaging |
| CT | Computed tomography |
References
- Schieppati, A.; Henter, J.-I.; Daina, E.; Aperia, A. Why Rare Diseases Are an Important Medical and Social Issue. Lancet 2008, 371, 2039–2041. [Google Scholar] [CrossRef]
- Vickers, P.J. Challenges and Opportunities in the Treatment of Rare Diseases. Drug Discov. World 2013, 14, 9–16. [Google Scholar]
- Ferreira, C.R. The Burden of Rare Diseases. Am. J. Med. Genet. A 2019, 179, 885–892. [Google Scholar] [CrossRef]
- Austin, C.P.; Cutillo, C.M.; Lau, L.P.L.; Jonker, A.H.; Rath, A.; Julkowska, D.; Thomson, D.; Terry, S.F.; de Montleau, B.; Ardigò, D.; et al. Future of Rare Diseases Research 2017–2027: An IRDiRC Perspective. Clin. Transl. Sci. 2018, 11, 21–27. [Google Scholar] [CrossRef]
- Hurvitz, N.; Azmanov, H.; Kesler, A.; Ilan, Y. Establishing a Second-Generation Artificial Intelligence-Based System for Improving Diagnosis, Treatment, and Monitoring of Patients with Rare Diseases. Eur. J. Hum. Genet. 2021, 29, 1485–1490. [Google Scholar] [CrossRef]
- Al-Hussaini, I.; White, B.; Varmeziar, A.; Mehra, N.; Sanchez, M.; Lee, J.; DeGroote, N.P.; Miller, T.P.; Mitchell, C.S. An Interpretable Machine Learning Framework for Rare Disease: A Case Study to Stratify Infection Risk in Pediatric Leukemia. J. Clin. Med. 2024, 13, 1788. [Google Scholar] [CrossRef]
- Visibelli, A.; Roncaglia, B.; Spiga, O.; Santucci, A. The Impact of Artificial Intelligence in the Odyssey of Rare Diseases. Biomedicines 2023, 11, 887. [Google Scholar] [CrossRef] [PubMed]
- Ilan, Y. Second-Generation Digital Health Platforms: Placing the Patient at the Center and Focusing on Clinical Outcomes. Front. Digit. Health 2020, 2, 569178. [Google Scholar] [CrossRef] [PubMed]
- Dou, B.; Zhu, Z.; Merkurjev, E.; Ke, L.; Chen, L.; Jiang, J.; Zhu, Y.; Liu, J.; Zhang, B.; Wei, G.-W. Machine Learning Methods for Small Data Challenges in Molecular Science. Chem. Rev. 2023, 123, 8736–8780. [Google Scholar] [CrossRef]
- Halmich, C.; Höschler, L.; Schranz, C.; Borgelt, C. Data Augmentation of Time-Series Data in Human Movement Biomechanics: A Scoping Review. PLoS ONE 2025, 20, e0327038. [Google Scholar] [CrossRef] [PubMed]
- Goceri, E. Medical Image Data Augmentation: Techniques, Comparisons and Interpretations. Artif. Intell. Rev. 2023, 56, 12561–12605. [Google Scholar] [CrossRef]
- Lo, J.; Cardinell, J.; Costanzo, A.; Sussman, D. Medical Augmentation (Med-Aug) for Optimal Data Augmentation in Medical Deep Learning Networks. Sensors 2021, 21, 7018. [Google Scholar] [CrossRef] [PubMed]
- Baião, A.R.; Cai, Z.; Poulos, R.C.; Robinson, P.J.; Reddel, R.R.; Zhong, Q.; Vinga, S.; Gonçalves, E. A Technical Review of Multi-Omics Data Integration Methods: From Classical Statistical to Deep Generative Approaches. Brief. Bioinform. 2025, 26, bbaf355. [Google Scholar] [CrossRef]
- Wang, F.; Ke, H.; Tang, Y. Fusion of Generative Adversarial Networks and Non-Negative Tensor Decomposition for Depression fMRI Data Analysis. Inf. Process. Manag. 2025, 62, 103961. [Google Scholar] [CrossRef]
- Mahmud, M.; Kaiser, M.S.; McGinnity, T.M.; Hussain, A. Deep Learning in Mining Biological Data. Cogn. Comput. 2021, 13, 1–33. [Google Scholar] [CrossRef]
- Gonzales, A.; Guruswamy, G.; Smith, S.R. Synthetic Data in Health Care: A Narrative Review. PLoS Digit. Health 2023, 2, e0000082. [Google Scholar] [CrossRef] [PubMed]
- Jacobs, F.; D’Amico, S.; Benvenuti, C.; Gaudio, M.; Saltalamacchia, G.; Miggiano, C.; De Sanctis, R.; Della Porta, M.G.; Santoro, A.; Zambelli, A. Opportunities and Challenges of Synthetic Data Generation in Oncology. JCO Clin. Cancer Inform. 2023, 7, e2300045. [Google Scholar] [CrossRef] [PubMed]
- Pasculli, G.; Virgolin, M.; Myles, P.; Vidovszky, A.; Fisher, C.; Biasin, E.; Mourby, M.; Pappalardo, F.; D’Amico, S.; Torchia, M.; et al. Synthetic Data in Healthcare and Drug Development: Definitions, Regulatory Frameworks, Issues. CPT Pharmacomet. Syst. Pharmacol. 2025, 14, 840–852. [Google Scholar] [CrossRef]
- Tricco, A.C.; Lillie, E.; Zarin, W.; O’Brien, K.K.; Colquhoun, H.; Levac, D.; Moher, D.; Peters, M.D.; Horsley, T.; Weeks, L.; et al. PRISMA Extension for Scoping Reviews (PRISMA-ScR): Checklist and Explanation. Ann. Intern. Med. 2018, 169, 467–473. [Google Scholar] [CrossRef]
- Arksey, H.; O’Malley, L. Scoping Studies: Towards a Methodological Framework. Int. J. Soc. Res. Methodol. 2005, 8, 19–32. [Google Scholar] [CrossRef]
- Ouzzani, M.; Hammady, H.; Fedorowicz, Z.; Elmagarmid, A. Rayyan—A Web and Mobile App for Systematic Reviews. Syst. Rev. 2016, 5, 210. [Google Scholar] [CrossRef] [PubMed]
- Anwar, S.; Alam, A. A Convolutional Neural Network–Based Learning Approach to Acute Lymphoblastic Leukaemia Detection with Automated Feature Extraction. Med. Biol. Eng. Comput. 2020, 58, 3113–3121. [Google Scholar] [CrossRef]
- Atteia, G.; Alhussan, A.A.; Samee, N.A. BO-ALLCNN: Bayesian-Based Optimized CNN for Acute Lymphoblastic Leukemia Detection in Microscopic Blood Smear Images. Sensors 2022, 22, 5520. [Google Scholar] [CrossRef] [PubMed]
- Elrefaie, R.M.; Mohamed, M.A.; Marzouk, E.A.; Ata, M.M. A Robust Classification of Acute Lymphocytic Leukemia-Based Microscopic Images with Supervised Hilbert-Huang Transform. Microsc. Res. Tech. 2024, 87, 191–204. [Google Scholar] [CrossRef]
- Jammal, F.; Dahab, M.; Bayahya, A.Y. Neuro-Bridge-X: A Neuro-Symbolic Vision Transformer with Meta-XAI for Interpretable Leukemia Diagnosis from Peripheral Blood Smears. Diagnostics 2025, 15, 2040. [Google Scholar] [CrossRef]
- Kasani, P.H.; Park, S.-W.; Jang, J.-W. An Aggregated-Based Deep Learning Method for Leukemic B-Lymphoblast Classification. Diagnostics 2020, 10, 1064. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, P.; Zhang, J.; Liu, N.; Liu, Y. Weakly Supervised Ternary Stream Data Augmentation Fine-Grained Classification Network for Identifying Acute Lymphoblastic Leukemia. Diagnostics 2022, 12, 16. [Google Scholar] [CrossRef]
- Makem, M.; Tamas, L.; Bușoniu, L. A Reliable Approach for Identifying Acute Lymphoblastic Leukemia in Microscopic Imaging. Front. Artif. Intell. 2025, 8, 1620252. [Google Scholar] [CrossRef]
- Paing, M.P.; Sento, A.; Bui, T.H.; Pintavirooj, C. Instance Segmentation of Multiple Myeloma Cells Using Deep-Wise Data Augmentation and Mask R-CNN. Entropy 2022, 24, 134. [Google Scholar] [CrossRef] [PubMed]
- Shafique, S.; Tehsin, S. Acute Lymphoblastic Leukemia Detection and Classification of Its Subtypes Using Pretrained Deep Convolutional Neural Networks. Technol. Cancer Res. Treat. 2018, 17, 1533033818802789. [Google Scholar] [CrossRef]
- She, Z.; Marzullo, A.; Destito, M.; Spadea, M.F.; Leone, R.; Anzalone, N.; Steffanoni, S.; Erbella, F.; Ferreri, A.J.; Ferrigno, G.; et al. Deep Learning-Based Overall Survival Prediction Model in Patients with Rare Cancer: A Case Study for Primary Central Nervous System Lymphoma. Int. J. CARS 2023, 18, 1849–1856. [Google Scholar] [CrossRef]
- Elhassan, T.; Osman, A.H.; Mohd Rahim, M.S.; Mohd Hashim, S.Z.; Ali, A.; Elhassan, E.; Elkamali, Y.; Aljurf, M. CAE-ResVGG FusionNet: A Feature Extraction Framework Integrating Convolutional Autoencoders and Transfer Learning for Immature White Blood Cells in Acute Myeloid Leukemia. Heliyon 2024, 10, e37745. [Google Scholar] [CrossRef]
- Gu, D.; Guo, D.; Yuan, C.; Wei, J.; Wang, Z.; Zheng, H.; Tian, J. Multi-Scale Patches Convolutional Neural Network Predicting the Histological Grade of Hepatocellular Carcinoma. In Proceedings of the 2021 43rd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Virtual, 1–5 November 2021; pp. 2584–2587. [Google Scholar] [CrossRef]
- Zhou, W.; Jian, W.; Cen, X.; Zhang, L.; Guo, H.; Liu, Z.; Liang, C.; Wang, G. Prediction of Microvascular Invasion of Hepatocellular Carcinoma Based on Contrast-Enhanced MR and 3D Convolutional Neural Networks. Front. Oncol. 2021, 11, 588010. [Google Scholar] [CrossRef]
- Jang, W.; Lee, J.; Kim, Y.; Lee, J.; Kim, J.J.; Choi, J.Y. Slice-Wise Augmentation for Multi-Task Learning to Predict Neuropsychological Outcomes after Traumatic Brain Injury. Stud. Health Technol. Inform. 2025, 329, 1764–1765. [Google Scholar] [CrossRef] [PubMed]
- Carlier, T.; Frécon, G.; Mateus, D.; Rizkallah, M.; Kraeber-Bodéré, F.; Kanoun, S.; Blanc-Durand, P.; Itti, E.; Le Gouill, S.; Casasnovas, R.O.; et al. Prognostic Value of 18F-FDG PET Radiomics Features at Baseline in PET-Guided Consolidation Strategy in Diffuse Large B-Cell Lymphoma: A Machine-Learning Analysis from the GAINED Study. J. Nucl. Med. 2024, 65, 156–162. [Google Scholar] [CrossRef]
- Cai, Z.; Wong, L.M.; Wong, Y.H.; Lee, H.L.; Li, K.Y.; So, T.Y. Dual-Level Augmentation Radiomics Analysis for Multisequence MRI Meningioma Grading. Cancers 2023, 15, 5459. [Google Scholar] [CrossRef]
- Feng, Z.; Zhang, L.; Qi, Z.; Shen, Q.; Hu, Z.; Chen, F. Identifying BAP1 Mutations in Clear-Cell Renal Cell Carcinoma by CT Radiomics: Preliminary Findings. Front. Oncol. 2020, 10, 279. [Google Scholar] [CrossRef] [PubMed]
- Pereira, H.M.; Leite Duarte, M.E.; Ribeiro Damasceno, I.; de Oliveira Moura Santos, L.A.; Nogueira-Barbosa, M.H. Machine Learning-Based CT Radiomics Features for the Prediction of Pulmonary Metastasis in Osteosarcoma. Br. J. Radiol. 2021, 94, 20201391. [Google Scholar] [CrossRef]
- Moreno-Barea, F.J.; Franco, L.; Elizondo, D.; Grootveld, M. Application of Data Augmentation Techniques towards Metabolomics. Comput. Biol. Med. 2022, 148, 105916. [Google Scholar] [CrossRef] [PubMed]
- Moreno-Barea, F.J.; Franco, L.; Elizondo, D.; Grootveld, M. Data Augmentation Techniques to Improve Metabolomic Analysis in Niemann-Pick Type C Disease. In Proceedings of the Computational Science—ICCS 2022: 22nd International Conference, London, UK, 21–23 June 2022; Proceedings, Part III. Springer: Berlin/Heidelberg, Germany, 2022; pp. 78–91. [Google Scholar] [CrossRef]
- Fernández-Ruiz, R.; Núñez-Vidal, E.; Hidalgo-Delaguía, I.; Garayzábal-Heinze, E.; Álvarez-Marquina, A.; Martínez-Olalla, R.; Palacios-Alonso, D. Identification of Smith-Magenis Syndrome Cases through an Experimental Evaluation of Machine Learning Methods. Front. Comput. Neurosci. 2024, 18, 1357607. [Google Scholar] [CrossRef]
- Núñez-Vidal, E.; Fernández-Ruiz, R.; Álvarez-Marquina, A.; Hidalgo-delaGuía, I.; Garayzábal-Heinze, E.; Hristov-Kalamov, N.; Domínguez-Mateos, F.; Conde, C.; Martínez-Olalla, R. Noninvasive Deep Learning Analysis for Smith–Magenis Syndrome Classification. Appl. Sci. 2024, 14, 9747. [Google Scholar] [CrossRef]
- Revathi, R.; Ramachandran, T. Experimental Evaluation of Amyotrophic Lateral Sclerosis (ALS) Disease Prediction Based on Improved Deep Learning Mechanism. In Proceedings of the International Conference on Advances in Intelligent Systems (ICAISS), Trichy, India, 21–23 May 2025; pp. 1707–1713. [Google Scholar] [CrossRef]
- Harshvardhan, G.; Gourisaria, M.K.; Pandey, M.; Rautaray, S.S. A Comprehensive Survey and Analysis of Generative Models in Machine Learning. Comput. Sci. Rev. 2020, 38, 100285. [Google Scholar] [CrossRef]
- Figueira, A.; Vaz, B. Survey on Synthetic Data Generation, Evaluation Methods and GANs. Mathematics 2022, 10, 2733. [Google Scholar] [CrossRef]
- Jaffri, Z.A.; Chen, M.; Bao, S.; Ahmad, Z. Understanding GANs: Fundamentals, Variants, Training Challenges, Applications, and Open Problems. Multimed. Tools Appl. 2025, 84, 10347–10423. [Google Scholar] [CrossRef]
- Yoo, T.K.; Choi, J.Y.; Kim, H.K. Feasibility Study to Improve Deep Learning in OCT Diagnosis of Rare Retinal Diseases with Few-Shot Classification. Med. Biol. Eng. Comput. 2021, 59, 401–415. [Google Scholar] [CrossRef]
- Asadi, F.; Angsuwatanakul, T.; O’Reilly, J.A. Evaluating Synthetic Neuroimaging Data Augmentation for Automatic Brain Tumour Segmentation with a Deep Fully-Convolutional Network. IBRO Neurosci. Rep. 2023, 16, 57–66. [Google Scholar] [CrossRef] [PubMed]
- Longato, E.; Tavazzi, E.; Chiò, A.; Sparacino, G.; Di Camillo, B. Dynamic Bayesian Networks and Transfer Learning Enable the Development of Deep Sequence-Based Models on Small-Sample Data. In Proceedings of the GNB 2023—Gruppo Nazionale di Bioingegneria Conference, Padova, Italy, 21–23 June 2023. [Google Scholar]
- Longato, E.; Tavazzi, E.; Sparacino, G.; Di Camillo, B. Dynamic Bayesian Networks for Rare Disease Modeling. In Computational Methods for Biomedical Data Analysis; Springer: Cham, Switzerland, 2023; pp. 1–15. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, C.; Li, K.; Deng, J.; Liu, H.; Lai, G.; Xie, B.; Zhong, X. Identification of Molecular Subtypes and Prognostic Characteristics of Adrenocortical Carcinoma Based on Unsupervised Clustering. Int. J. Mol. Sci. 2023, 24, 15465. [Google Scholar] [CrossRef]
- Lai, G.; Liu, H.; Deng, J.; Li, K.; Zhang, C.; Zhong, X.; Xie, B. The Characteristics of Tumor Microenvironment Predict Survival and Response to Immunotherapy in Adrenocortical Carcinomas. Cells 2023, 12, 755. [Google Scholar] [CrossRef]
- Zhu, J. Synthetic data generation by diffusion models. Natl. Sci. Rev. 2024, 11, nwae276. [Google Scholar] [CrossRef]
- Sordo, Z.; Chagnon, E.; Hu, Z.; Donatelli, J.J.; Andeer, P.; Nico, P.S.; Northen, T.; Ushizima, D. Synthetic Scientific Image Generation with VAE, GAN, and Diffusion Model Architectures. J. Imaging 2025, 11, 252. [Google Scholar] [CrossRef]
- U.S. Food & Drug Administration; Center for Devices & Radiological Health. Executive Summary for the Digital Health Advisory Committee Meeting: Total Product Lifecycle Considerations for Generative AI-Enabled Devices; U.S. Food & Drug Administration: Silver Spring, MD, USA, 2024. Available online: https://www.fda.gov/media/182871/download (accessed on 13 October 2025).
- Southall, N.; Natarajan, M.; Lau, L.P.L.; Jonker, A.H.; Deprez, B.; Guilliams, T.; Hunter, L.; Rademaker, C.M.; Hivert, V.; Ardigò, D. The use or generation of biomedical data and existing medicines to discover and establish new treatments for patients with rare diseases—Recommendations of the IRDiRC Data Mining and Repurposing Task Force. Orphanet J. Rare Dis. 2019, 14, 225. [Google Scholar] [CrossRef] [PubMed]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).