Legacy Data: How Decades of Seabed Sampling Can Produce Robust Predictions and Versatile Products



Abstract
:1. Introduction
2. Materials and Methods
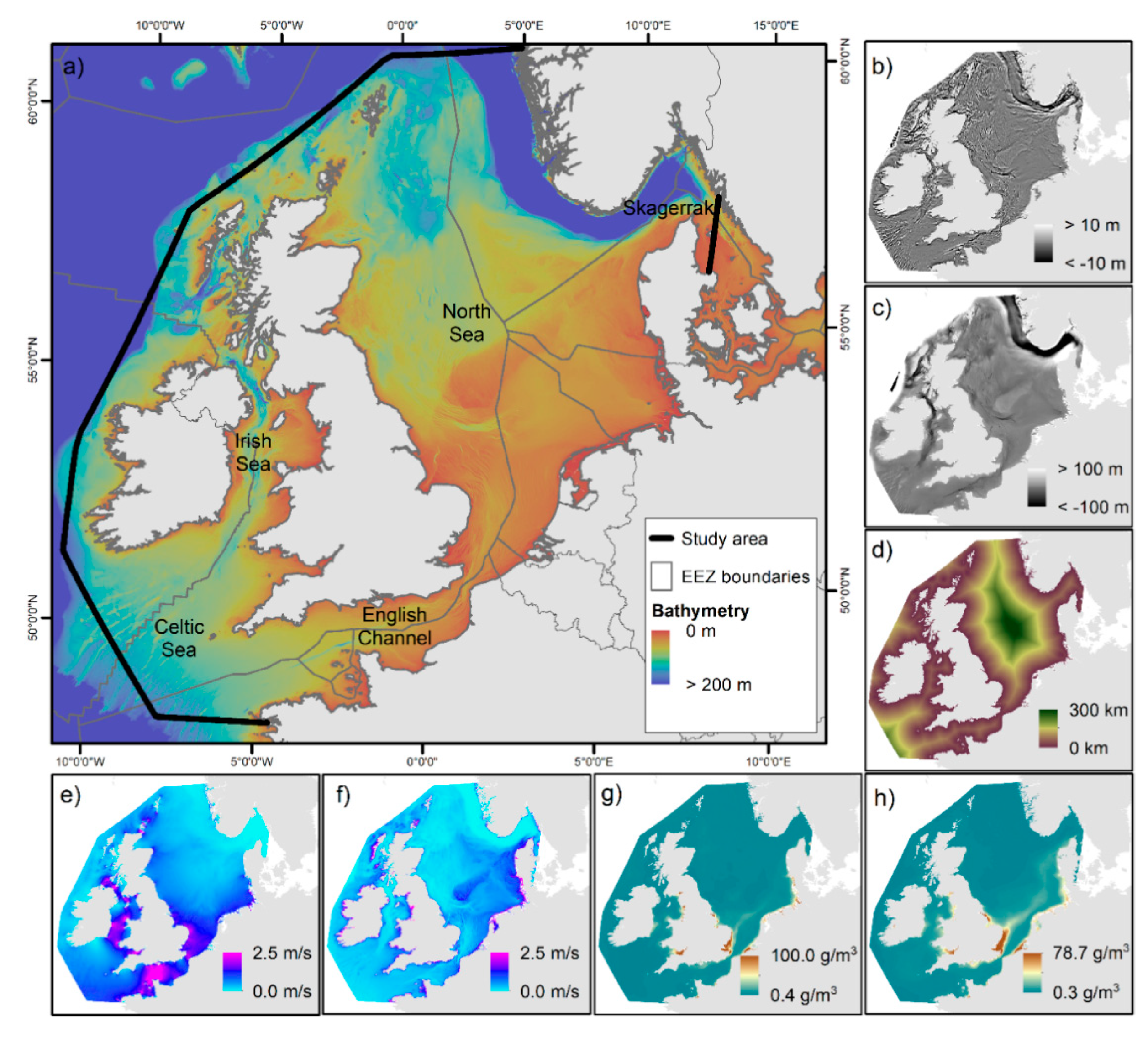
2.1. Study Area
2.2. Substrate Observations
2.3. Predictor Variables
2.4. Modelling
2.5. Model Validation
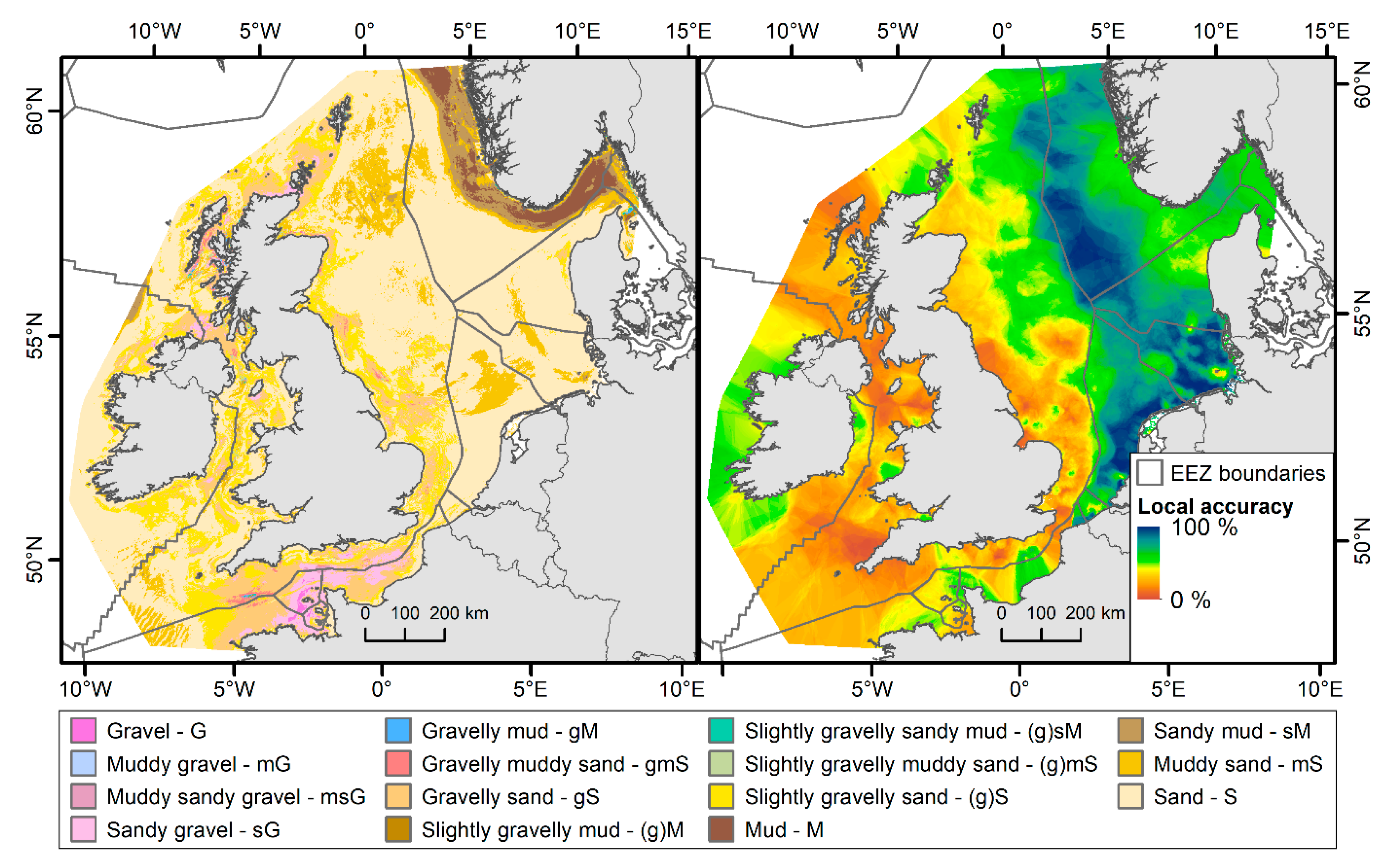
3. Results
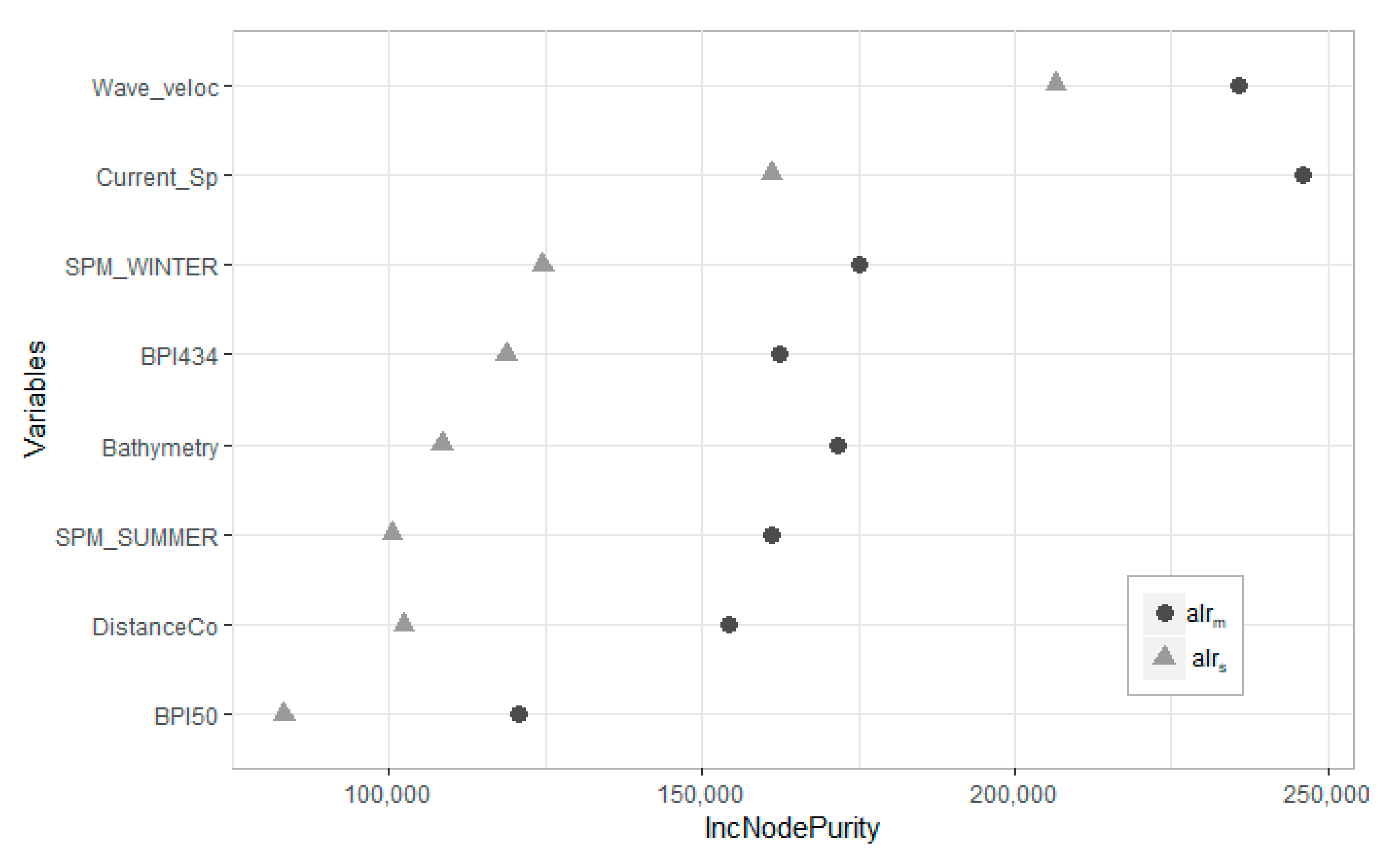
3.1. Features Importance
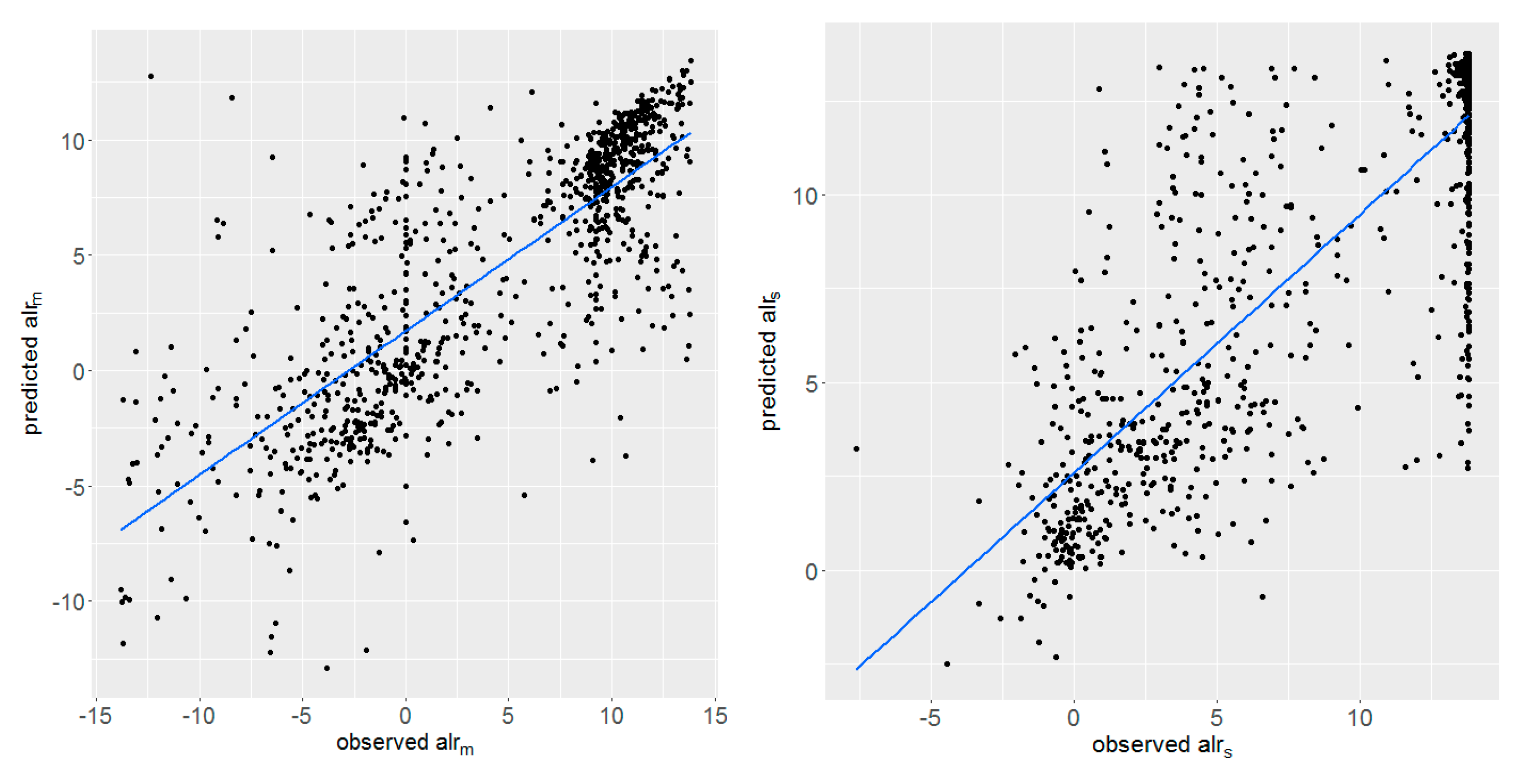
3.2. Model Validation
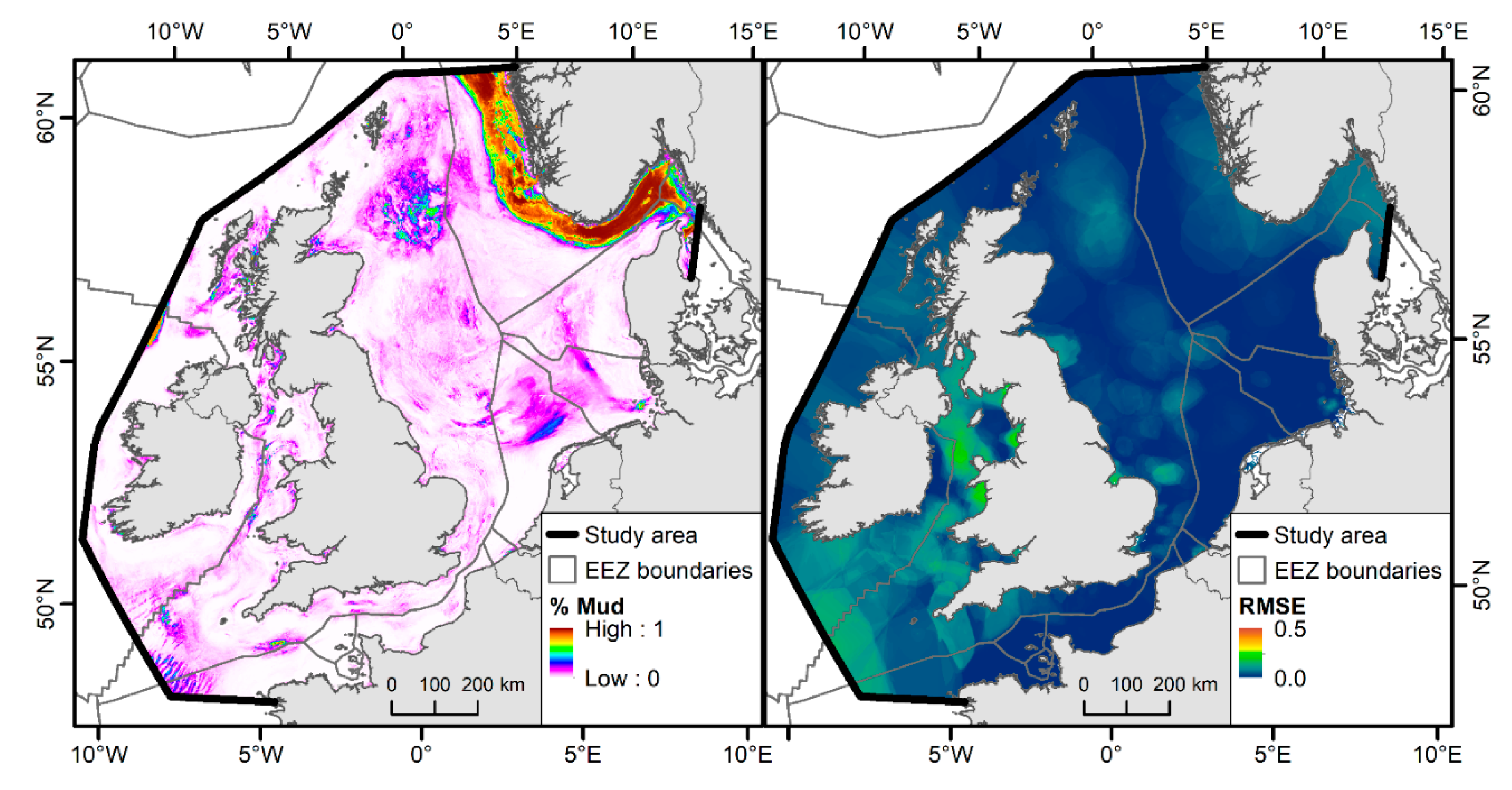
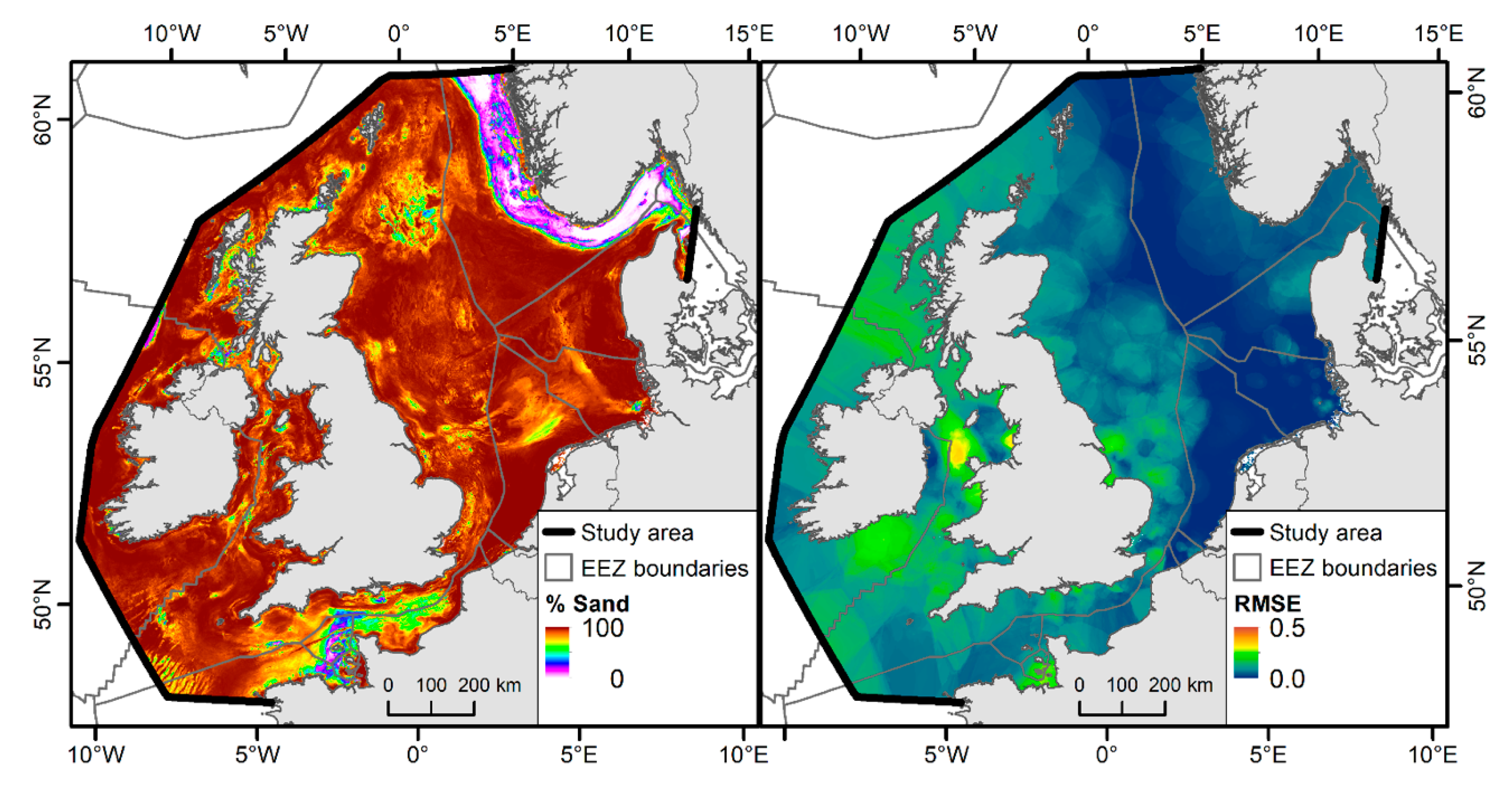
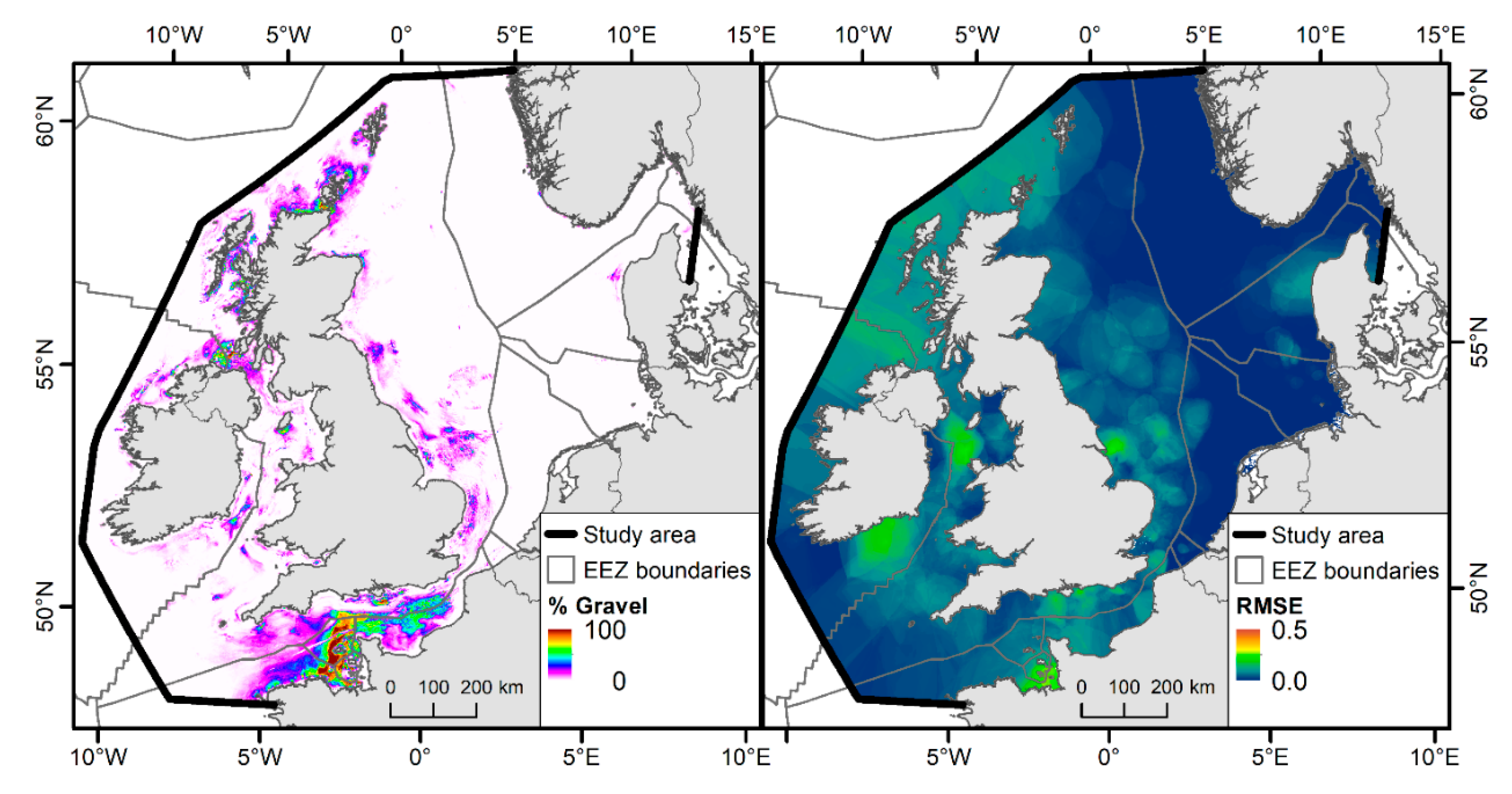
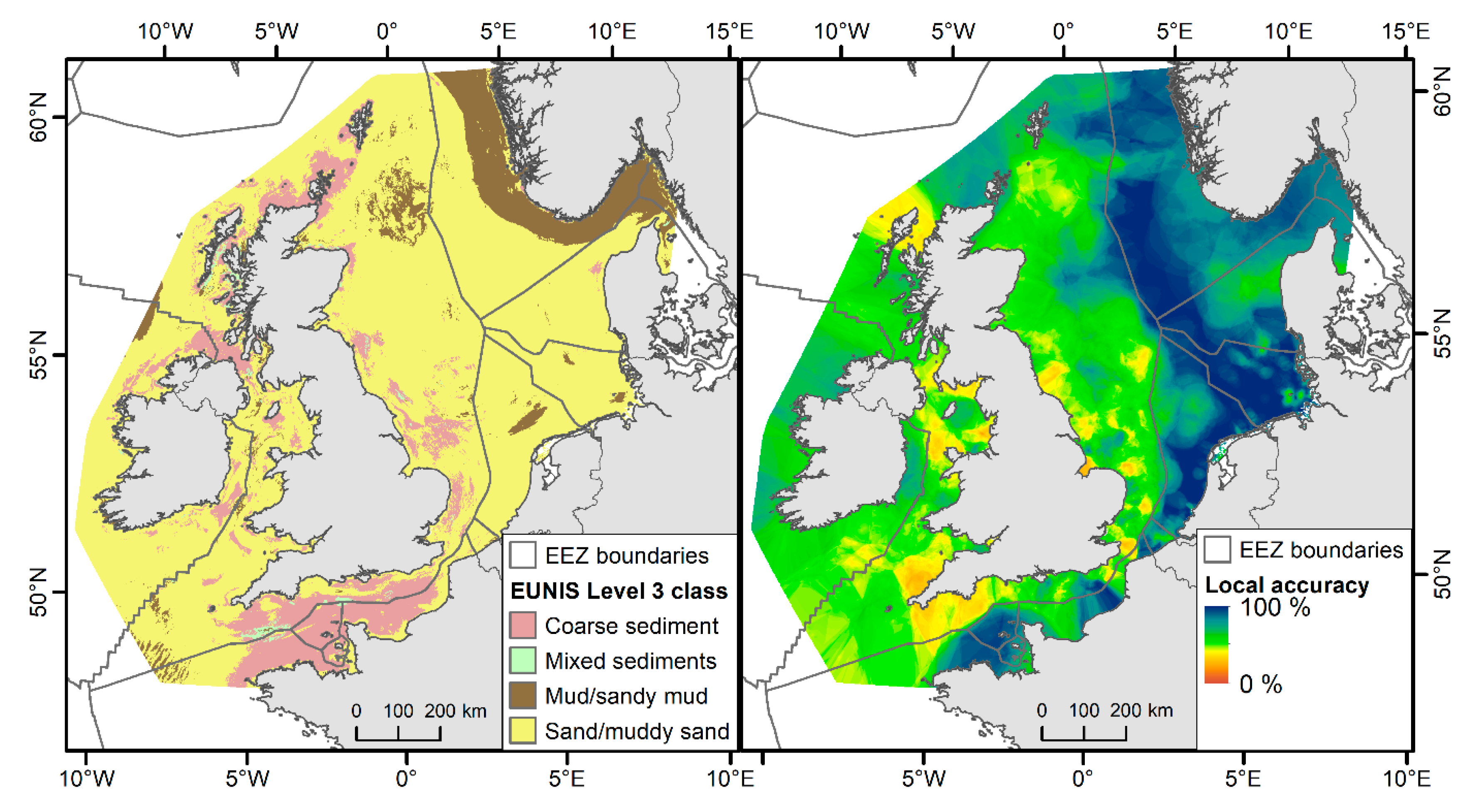
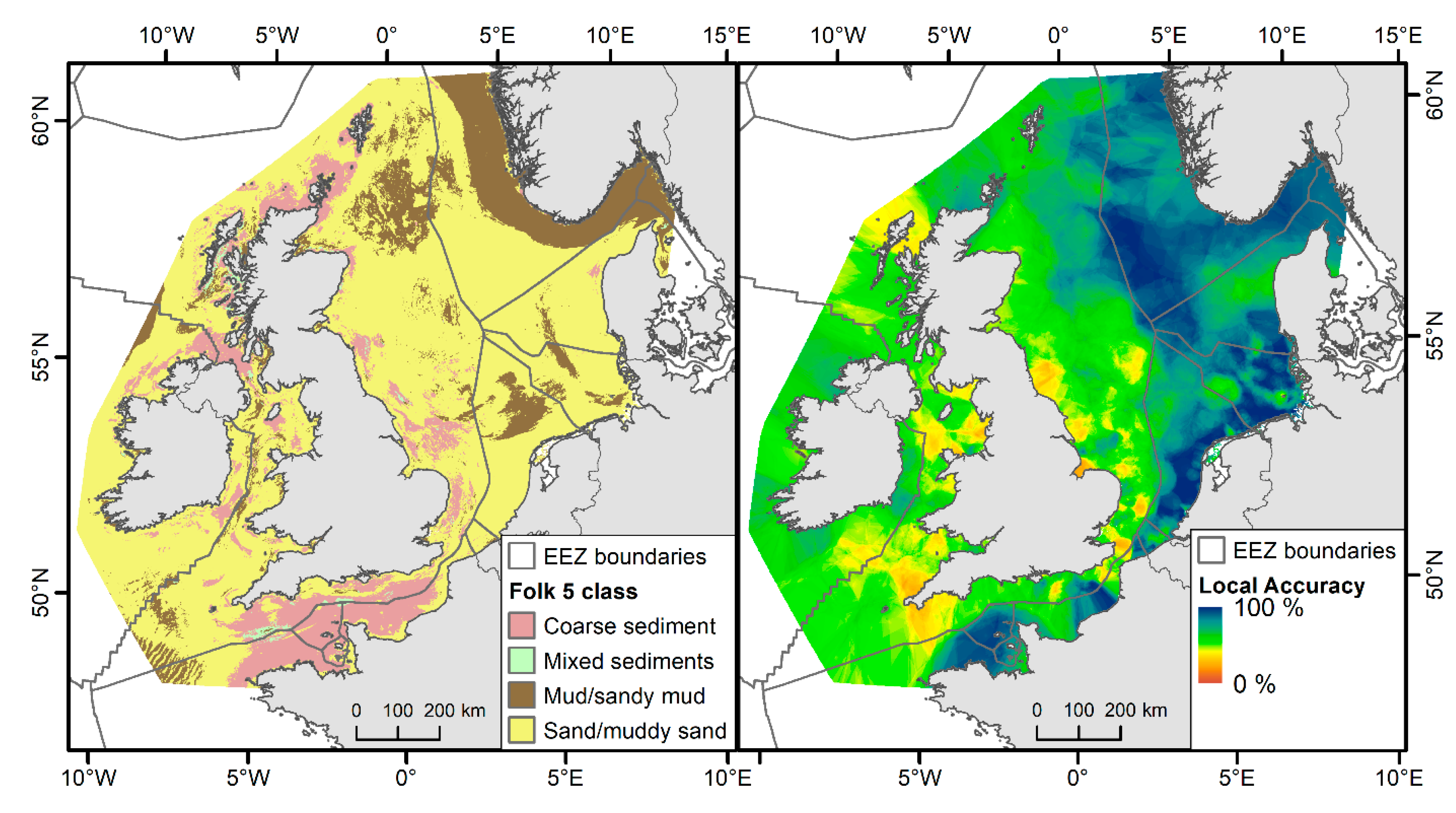
3.3. Sediment Composition
4. Discussion
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Data Availability
References
- Harris, P.T.; Macmillan-Lawler, M.; Rupp, J.; Baker, E.K. Geomorphology of the oceans. Mar. Geol. 2014, 352, 4–24. [Google Scholar] [CrossRef]
- Bauer, J.E.; Cai, W.-J.; Raymond, P.A.; Bianchi, T.S.; Hopkinson, C.S.; Regnier, P.A.G. The changing carbon cycle of the coastal ocean. Nature 2013, 504, 61–70. [Google Scholar] [CrossRef]
- Halpern, B.S.; Walbridge, S.; Selkoe, K.A.; Kappel, C.V.; Micheli, F.; D’Agrosa, C.; Bruno, J.F.; Casey, K.S.; Ebert, C.; Fox, H.E.; et al. A global map of human impact on marine ecosystems. Science 2008, 319, 948–952. [Google Scholar] [CrossRef]
- Kaskela, A.M.; Kotilainen, A.T.; Alanen, U.; Cooper, R.; Green, S.; Guinan, J.; Van Heteren, S.; Kihlman, S.; Van Lancker, V.; Stevenson, A.; et al. Picking up the pieces—Harmonising and collating seabed substrate data for European maritime areas. Geosciences 2019, 9, 84. [Google Scholar] [CrossRef]
- Folk, R.L. The distinction between grain size and mineral composition in sedimentary-rock nomenclature. J. Geol. 1954, 62, 344–359. [Google Scholar] [CrossRef]
- Long, D. BGS Detailed Explanation of Seabed Sediment Modified Folk Classification; MESH report; Joint Nature Conservation Committee: Peterborough, UK, 2006.
- Parry, M.E. Marine Habitat Classification for Britain and Ireland: Overview of User Issues; JNCC Report No. 529; Joint Nature Conservation Committee: Peterborough, UK, 2014.
- Cooper, K.M.; Bolam, S.G.; Downie, A.-L.; Barry, J. Biological-based habitat classification approaches promote cost-efficient monitoring: An example using seabed assemblages. J. Appl. Ecol. 2019. [Google Scholar] [CrossRef]
- Lark, R.M.; Dove, D.; Green, S.L.; Richardson, A.E.; Stewart, H.A.; Stevenson, A. Spatial prediction of seabed sediment texture classes by cokriging from a legacy database of point observations. Sediment. Geol. 2012, 281, 35–49. [Google Scholar] [CrossRef]
- Stephens, D.; Diesing, M. Towards quantitative spatial models of seabed sediment composition. PLoS ONE 2015. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Diesing, M. Case Study: Quantitative Spatial Prediction of Seabed Sediment Composition; Cefas: Lowestoft, UK, 2015. [Google Scholar]
- Diesing, M.; Kröger, S.; Parker, R.; Jenkins, C.M.; Mason, C.; Weston, K. Predicting the standing stock of organic carbon in surface sediments of the North–West European continental shelf. Biogeochemistry 2017, 135, 183–200. [Google Scholar] [CrossRef]
- Luisetti, T.; Turner, R.K.; Andrews, J.E.; Jickells, T.D.; Kröger, S.; Diesing, M.; Paltriguera, L.; Johnson, M.T.; Parker, E.R.; Bakker, D.C.E.; et al. Quantifying and valuing carbon flows and stores in coastal and shelf ecosystems in the UK. Ecosyst. Serv. 2019, 35, 67–76. [Google Scholar] [CrossRef]
- Silburn, B.; Kröger, S.; Parker, E.R.; Sivyer, D.B.; Hicks, N.; Powell, C.F.; Johnson, M.; Greenwood, N. Benthic pH gradients across a range of shelf sea sediment types linked to sediment characteristics and seasonal variability. Biogeochemistry 2017, 135, 69–88. [Google Scholar] [CrossRef]
- van der Reijden, K.J.; Hintzen, N.T.; Govers, L.L.; Rijnsdorp, A.D.; Olff, H. North Sea demersal fisheries prefer specific benthic habitats. PLoS ONE 2018, 13, e0208338. [Google Scholar] [CrossRef]
- Wilson, R.J.; Speirs, D.C.; Sabatino, A.; Heath, M.R. A synthetic map of the northwest European Shelf sedimentary environment for applications in marine science. Earth Syst. Sci. Data Discuss. 2018, 10, 109–130. [Google Scholar] [CrossRef]
- Aitchison, J. The Statistical Analysis of Compositional Data; Chapman and Hall: London, UK, 1986; Volume 44, ISBN 00359246. [Google Scholar]
- Lucieer, V.L.; Lucieer, A. Fuzzy clustering for seafloor classification. Mar. Geol. 2009, 264, 230–241. [Google Scholar] [CrossRef]
- Foody, G.M. Local characterization of thematic classification accuracy through spatially constrained confusion matrices. Int. J. Remote Sens. 2005, 26, 1217–1228. [Google Scholar] [CrossRef]
- Mitchell, P.J.; Downie, A.-L.; Diesing, M. How good is my map? A tool for semi-automated thematic mapping and spatially explicit confidence assessment. Env. Model. Softw. 2018, 108, 111–122. [Google Scholar] [CrossRef]
- Comber, A.J.; Fisher, P.F.; Brunsdon, C.; Khmag, A. Spatial analysis of remote sensing image classification accuracy. Remote Sens. Environ. 2012, 127, 237–246. [Google Scholar] [CrossRef]
- Foody, G.M. Status of land cover classification accuracy assessment. Remote Sens. Environ. 2002, 80, 185–201. [Google Scholar] [CrossRef]
- Diesing, M.; Mitchell, P.J.; Stephens, D. Image-based seabed classification: What can we learn from terrestrial remote sensing? ICES J. Mar. Sci. 2016, 73, 2425–2441. [Google Scholar] [CrossRef]
- Pawlowsky-Glahn, V.; Olea, R.A. Geostatistical Analysis of Compositional Data; Oxford University Press: New York, NY, USA, 2004. [Google Scholar]
- EMODnet Bathymetry Consortium. EMODnet Digital Bathymetry (DTM 2016). Available online: http://portal.emodnet-bathymetry.eu/ (accessed on 30 March 2018).
- Lundblad, E.R.; Wright, D.J.; Miller, J.; Larkin, E.M.; Rinehart, R.; Naar, D.F.; Donahue, B.T.; Anderson, S.M.; Battista, T.A. A Benthic terrain classification scheme for American Samoa. Mar. Geod. 2006, 29, 89–111. [Google Scholar] [CrossRef]
- Soulsby, R.L. Simplified Calculation of Wave Orbital Velocities; HR Wallingford Ltd.: Wallingford, Oxfordshire, UK, 2006. [Google Scholar]
- Gohin, F.; Bryère, P.; Griffiths, J.W. The exceptional surface turbidity of the North-West European shelf seas during the stormy 2013-2014 winter: Consequences for the initiation of the phytoplankton blooms? J. Mar. Syst. 2015, 148, 70–85. [Google Scholar] [CrossRef]
- Zhi, H.; Siwabessy, P.J.W.; Nichol, S.L.; Brooke, B.P. Predictive mapping of seabed substrata using high-resolution multibeam sonar data: A case study from a shelf with complex geomorphology. Mar. Geol. 2014, 357, 37–52. [Google Scholar] [CrossRef]
- Hasan, R.C.; Ierodiaconou, D.; Laurenson, L.; Schimel, A.C.G. Integrating multibeam backscatter angular response, mosaic and bathymetry data for benthic habitat mapping. PLoS ONE 2014, 9, e97339. [Google Scholar]
- Liaw, A.; Wiener, M. Breiman and Cutler’s Random Forests for Classification and Regression, R package version 4.6–14. 2015; 29.
- R Development Team R. A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2017. [Google Scholar]
- Populus, J.; Vasquez, M.; Albrecht, J.; Manca, E.; Agnesi, S.; Al Hamdani, Z.; Andersen, J.; Annunziatellis, A.; Bekkby, T.; Bruschi, A.; et al. EUSeaMap, a European Broad-Scale Seabed Habitat Map, EMODnet. 2017.
- Lacharité, M.; Brown, C.J.; Gazzola, V. Multisource multibeam backscatter data: Developing a strategy for the production of benthic habitat maps using semi-automated seafloor classification methods. Mar. Geophys. Res. 2017, 39, 307–322. [Google Scholar] [CrossRef]
- Cooper, K.M.; Barry, J. A big data approach to macrofaunal baseline assessment, monitoring and sustainable exploitation of the seabed. Sci. Rep. 2017, 7, 12431. [Google Scholar] [CrossRef]
- Valerius, J.; van Lancker, V.; van Heteren, S.; Leth, J.; Zeiler, M. Trans-National Database of North Sea Sediment Data; Federal Maritime and Hydrographic Agency (Germany): Hamburg, Germany; Royal Belgian Institute of Natural Sciences (Belgium): Brussels, Belgium; TNO (Netherlands): The Hague, The Netherlands; Geological Survey of Denmark and Greenland (Denmark): Copenhagen, Denmark, 2014. [Google Scholar]
- Mason, C. NMBAQC’s Best Practice Guidance. Particle Size Analysis (PSA) for Supporting Biological Analysis; National Marine Biological AQC Coordinating Committee, 2016. [Google Scholar]
- Konert, M.; Vandenberghe, J. Comparison of laser grain size analysis with pipette and sieve analysis: A solution for the underestimation of the clay fraction. Sedimentology 1997, 44, 523–535. [Google Scholar] [CrossRef]
- Mitchell, P.J.; Monk, J.; Laurenson, L. Sensitivity of fine-scale species distribution models to locational uncertainty in occurrence data across multiple sample sizes. Methods Ecol. Evol. 2017, 8, 12–21. [Google Scholar] [CrossRef]
- Blaschke, T. Object based image analysis for remote sensing. ISPRS J. Photogramm. Remote Sens. 2010, 65, 2–16. [Google Scholar] [CrossRef]
- Diesing, M.; Green, S.L.; Stephens, D.; Cooper, R.; Mellett, C.L.L. Semi-Automated Mapping of Rock in the English Channel and Celtic Sea; JNCC: Peterborough, UK, 2015; Volume 569.
- Downie, A.L.; Dove, D.; Westhead, R.K.; Diesing, M.; Green, S.L.; Cooper, R. Semi-Automated Mapping of Rock in the North Sea; JNCC: Peterborough, UK, 2016.
- Brown, L.S.; Green, S.L.; Stewart, H.A.; Diesing, M.; Downie, A.-L.; Cooper, R.; Lillis, H. Semi-Automated Mapping of Rock in the Irish Sea, Minches, Western Scotland and Scottish Continental Shelf; JNCC Report; JNCC: Peterborough, UK, 2017; p. 609.
- Hengl, T.; Nussbaum, M.; Wright, M.N.; Heuvelink, G.B.M.; Gräler, B. Random forest as a generic framework for predictive modeling of spatial and spatio-temporal variables. PeerJ 2018, 6, e5518. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Description | Unit | Initial Resolution | Source |
|---|---|---|---|---|
| Bathymetry | Bathymetry (water depth). | m | 7.5” | http://www.emodnet-bathymetry.eu/ [26] |
| BPI50 | Bathymetric position index at 50—pixel radii. | m | 7.5” | Calculated from bathymetry |
| BPI434 | Bathymetric position index at 434—pixel radii (approximately 100 km). | m | 7.5” | Calculated from bathymetry |
| Distance from coast | Euclidean distance to coast. | m | 7.5” | Calculated |
| Current Speed | Mean tidal current velocity. | m/s | 0.5–10 km | Supplement S2 |
| Orbital velocity at the seabed | Peak orbital velocity of waves at the seabed. | m/s | 11 km | Supplement S2 |
| Suspended inorganic particulate matter-Summer | Satellite derived estimate of the amount of inorganic particulate matter suspended in the water column. Mean of from the months of June, July and August. | g/m3 | 4 km | http://marine.copernicus.eu/ |
| Suspended inorganic particulate matter—Winter | Satellite derived estimate of the amount of inorganic particulate matter suspended in the water column. Mean of from the months of December, January and February. | g/m3 | 4 km | http://marine.copernicus.eu/ |
| alrm | alrs | |
|---|---|---|
| Cross validation (OOB) | ||
| MSE | 17.86 | 10.91 |
| Variance explained | 63.31% | 68.09% |
| Test set | ||
| MSE | 18.19 | 10.93 |
| Variance explained | 62.98% | 68.00% |
| (a) EUNIS Level 3 | Observed | User’s Accuracy | |||||||||||||||
| Coarse sediment | Mixed sediments | Mud/sandy mud | Sand/muddy sand | ||||||||||||||
| Predicted | Coarse sediment | 1871 | 312 | 40 | 386 | 71.7% | |||||||||||
| Mixed sediments | 36 | 63 | 13 | 15 | 49.6% | ||||||||||||
| Mud/sandy mud | 15 | 36 | 533 | 124 | 75.3% | ||||||||||||
| Sand/muddy sand | 1197 | 350 | 913 | 9377 | 79.2% | ||||||||||||
| Producer’s Accuracy | 60.0% | 8.3% | 35.6% | 94.6% | Overall 77.5% | ||||||||||||
| (b) Folk 5 | Observed | User’s Accuracy | |||||||||||||||
| Coarse sediment | Mixed sediments | Mud/sandy mud | Sand/muddy sand | ||||||||||||||
| Predicted | Coarse sediment | 1871 | 312 | 70 | 356 | 71.7% | |||||||||||
| Mixed sediments | 36 | 63 | 18 | 10 | 49.6% | ||||||||||||
| Mud/sandy mud | 60 | 80 | 1186 | 317 | 72.2% | ||||||||||||
| Sand/muddy sand | 1152 | 306 | 1247 | 8197 | 75.2% | ||||||||||||
| Producer’s Accuracy | 60.0% | 8.3% | 47.0% | 92.3% | Overall 74.1% | ||||||||||||
| (c) Folk 16 | Observed | ||||||||||||||||
| Gravel | Gravelly mud | Gravelly muddy sand | Gravelly sand | Mud | Muddy gravel | Muddy sand | Muddy sandy gravel | Sand | Sandy gravel | Sandy mud | Slightly gravelly mud | Slightly gravelly muddy sand | Slightly gravelly sand | Slightly gravelly sandy mud | User’s Accuracy | ||
| Predicted | Gravel | 10 | - | - | 1 | - | 1 | - | - | - | 20 | - | - | - | - | - | 31.3% |
| Gravelly mud | - | - | - | - | - | 1 | 1 | - | - | - | - | - | - | - | - | 0.0% | |
| Gravelly muddy sand | 1 | 9 | 13 | 10 | 2 | 4 | 4 | 27 | 4 | 14 | 3 | - | 5 | 5 | 2 | 12.6% | |
| Gravelly sand | 64 | 10 | 83 | 442 | 3 | 9 | 33 | 126 | 162 | 673 | 4 | - | 22 | 159 | 3 | 24.7% | |
| Mud | - | - | 2 | - | 69 | - | 4 | - | 1 | - | 7 | 2 | - | - | 3 | 78.4% | |
| Muddy gravel | - | - | - | - | - | 1 | - | 1 | - | 1 | - | - | 1 | - | - | 25.0% | |
| Muddy sand | 5 | 11 | 24 | 24 | 34 | 5 | 730 | 11 | 276 | 14 | 184 | - | 27 | 16 | 2 | 53.6% | |
| Muddy sandy gravel | 2 | - | 1 | 1 | - | - | - | 6 | 1 | 7 | - | - | - | - | - | 33.3% | |
| Sand | 22 | 25 | 69 | 380 | 42 | 13 | 836 | 48 | 7155 | 183 | 165 | - | 54 | 480 | 22 | 75.4% | |
| Sandy gravel | 70 | 1 | 9 | 122 | - | 5 | 1 | 68 | 9 | 469 | 1 | - | 2 | 26 | 1 | 59.8% | |
| Sandy mud | 1 | 1 | 5 | - | 25 | 2 | 16 | 2 | 6 | 1 | 57 | 1 | 1 | 1 | 2 | 47.1% | |
| Slightly gravelly mud | - | 4 | 8 | 7 | 1 | - | 4 | 3 | 13 | 8 | 11 | - | 3 | 4 | 1 | 0.0% | |
| Slightly gravelly muddy sand | 20 | 14 | 69 | 314 | 6 | 9 | 65 | 59 | 339 | 233 | 25 | - | 31 | 223 | 1 | 2.2% | |
| Slightly gravelly sand | - | - | - | - | 1 | 2 | - | - | - | - | 1 | - | - | - | - | 0.0% | |
| Slightly gravelly sandy mud | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | NA | |
| Producer’s Accuracy | 5.1% | 0.0% | 4.6% | 34.0% | 37.7% | 1.9% | 43.1% | 1.7% | 89.8% | 28.9% | 12.4% | 0.0% | 21.2% | 0.0% | 0.0% | Overall Accuracy 58.8% | |
| Total number of samples | 195 | 75 | 283 | 1301 | 183 | 52 | 1694 | 351 | 7966 | 1623 | 458 | 3 | 146 | 914 | 37 | ||
| High Resolution | Sum | Within Class Agreement | |||||
|---|---|---|---|---|---|---|---|
| Coarse Sediment | Mixed Sediments | Mud/Sandy Mud | Sand/Muddy Sand | ||||
| Stephens and Diesing [10] | Coarse sediment | 25,894 | 1446 | 1072 | 36,560 | 64,972 | 40.0% |
| Mixed sediments | 366 | 67 | 5 | 725 | 1163 | 5.8% | |
| Mud/sandy mud | 858 | 1210 | 9479 | 14,210 | 25,757 | 36.8% | |
| Sand/muddy sand | 11,408 | 948 | 2992 | 221,143 | 236,491 | 93.5% | |
| Sum | 38,526 | 3671 | 13,548 | 272,638 | Overall Agreement 78.1% | ||
| Within class agreement | 67.2% | 1.8% | 70.0% | 81.1% | |||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mitchell, P.J.; Aldridge, J.; Diesing, M. Legacy Data: How Decades of Seabed Sampling Can Produce Robust Predictions and Versatile Products. Geosciences 2019, 9, 182. https://doi.org/10.3390/geosciences9040182
Mitchell PJ, Aldridge J, Diesing M. Legacy Data: How Decades of Seabed Sampling Can Produce Robust Predictions and Versatile Products. Geosciences. 2019; 9(4):182. https://doi.org/10.3390/geosciences9040182
Chicago/Turabian StyleMitchell, Peter J, John Aldridge, and Markus Diesing. 2019. "Legacy Data: How Decades of Seabed Sampling Can Produce Robust Predictions and Versatile Products" Geosciences 9, no. 4: 182. https://doi.org/10.3390/geosciences9040182
APA StyleMitchell, P. J., Aldridge, J., & Diesing, M. (2019). Legacy Data: How Decades of Seabed Sampling Can Produce Robust Predictions and Versatile Products. Geosciences, 9(4), 182. https://doi.org/10.3390/geosciences9040182