Abstract
Mineral prospecting from vast geological text corpora is impeded by challenges in domain-specific semantic interpretation and knowledge synthesis. General-purpose Large Language Models (LLMs) struggle to parse the complex lexicon and relational semantics of geological texts, limiting their utility for constructing precise knowledge graphs (KGs). Our novel framework addresses this gap by integrating a domain-specific LLM, GeoGPT, with a lightweight retrieval-augmented generation architecture, LightRAG. Within this framework, GeoGPT automates the construction of a high-quality mineral-prospecting KG by performing ontology definition, entity recognition, and relation extraction. The LightRAG component then leverages this KG to power a specialized geological question-answering (Q&A) system featuring a dual-layer retrieval mechanism for enhanced precision and an incremental update capability for dynamic knowledge incorporation. The results indicate that the proposed method achieves a mean F1-score of 0.835 for entity extraction, representing a 17% to 25% performance improvement over general-purpose large models using generic prompts. Furthermore, the geological Q&A model, built upon the LightRAG framework with GeoGPT as its core, demonstrates a superior win rate against the DeepSeek-V3 and Qwen2.5-72B general-purpose large models by 8–29% in the geochemistry domain and 53–78% in the remote sensing geology domain. This study establishes an effective and scalable methodology for intelligent geological text analysis, enabling lightweight, high-performance Q&A systems that accelerate knowledge discovery in mineral exploration.
1. Introduction
The synthesis and interpretation of multi-source, heterogeneous geological data present considerable obstacles to applications such as mineral prospecting [1]. These difficulties are exacerbated by the inherent semantic complexity and the absence of a unified ontological framework within geological texts [2,3]. Consequently, establishing a robust semantic foundation for the deep integration and intelligent analysis of this data constitutes a primary obstacle to advancements in the geosciences [4].
While foundational Large Language Models (LLMs) have demonstrated remarkable capabilities in data extraction and reasoning, their direct application to specialized domains like geology is met with significant limitations. Without sufficient fine-tuning on domain-specific corpora, these models exhibit a propensity for factual inaccuracies and “hallucinations,” which pose substantial risks to high-stakes geological decision-making [5]. Although developing a specialized model through extensive pre-training can enhance domain proficiency, this approach is frequently impeded by prohibitive data acquisition costs, high computational overhead, and persistent scalability and iterative refinement challenges [6].
Retrieval-Augmented Generation (RAG) integrated with domain-specific Knowledge Graphs (KGs) has emerged as a viable approach for deploying LLMs in specialized fields [7,8]. However, this strategy confronts two principal bottlenecks. First, knowledge acquisition for constructing high-quality KGs presents a critical trade-off: manual curation is labor-intensive and costly, whereas automated construction by general-purpose LLMs often lacks the requisite precision [9]. Second, knowledge application is hampered by the need for efficient retrieval and cost-effective operationalization. Advanced frameworks like GraphRAG, while powerful, often incur substantial computational and maintenance overheads [9,10]. This juxtaposition reveals a critical research gap: the need for a unified methodology that ensures both high-fidelity knowledge extraction and its economically viable deployment.
To address this gap, this paper introduces and validates a novel framework that integrates a geology-specific LLM, GeoGPT, with a lightweight retrieval architecture, LightRAG. Our approach first utilizes GeoGPT’s intrinsic domain knowledge for the automated, high-quality construction of a mineral prospecting KG. This KG then forms the knowledge foundation of the LightRAG framework, underpinning an effective and precise question-answering (Q&A) system. Ultimately, this study delivers a practical and scalable solution for the intelligent analysis of geological text, bridging the gap between the theoretical potential of LLMs and the practical demands of data-driven mineral exploration.
2. Basic Notions
2.1. GeoGPT: A Domain-Specific Large Language Model for Geoscience
GeoGPT, developed by Zhejiang Lab, is a large language model tailored to the geoscience domain, featuring a pluggable modular architecture [11]. This design mitigates dependency on a single foundation model, enhancing system flexibility and scalability. Adaptations have been developed from prominent base model families—including Llama-3, Qwen-2, DeepSeek, and Mistral—with released versions such as Llama3.1-70B-GeoGPT and Qwen2.5-72B-GeoGPT comprising tens of billions of parameters.
GeoGPT’s domain-specific performance is primarily attributed to its extensive, high-quality training data. At its core is a 23.22-billion-token pre-training corpus for the geosciences, comprising three main tiers: (1) Academic Literature: integrating approximately 288,000 Open Access scientific papers from 12 major publishers; (2) Web Text: including geoscience-related documents mined from the Common Crawl dataset using topic modeling, alongside approximately 980,000 high-quality documents curated from over 3.54 million webpages; and (3) Expert Knowledge: an instruction-tuning dataset collaboratively constructed by hundreds of global geoscientists, containing nearly 100,000 highly specialized question-answer pairs.
To effectively leverage this data, GeoGPT’s training employs a multi-stage, incremental strategy. This strategy consists of three core phases: (1) Continual Pre-training, where the general-purpose base model ingests the vast professional corpus to master the specialized vocabulary, conceptual frameworks, and knowledge structures of the geosciences. (2) Supervised Fine-tuning (SFT), where the model learns to follow instructions and perform specific geoscience tasks by training on the expert-curated Q&A pairs. (3) Preference Alignment, a phase that utilizes techniques analogous to Reinforcement Learning from Human Feedback (RLHF) to optimize the model using preference-ranking data from domain experts. This ensures its generated content aligns more closely with professional standards of scientific accuracy, logical coherence, and idiomatic expression.
2.2. LightRAG: A Lightweight Retrieval-Augmented Generation Framework
While Graph-Augmented Generation (GraphRAG) frameworks can effectively capture complex textual relationships, they are constrained by significant limitations, including a reliance on complex community summarization for graph construction and the need for global reconstruction during knowledge updates. These factors lead to high computational costs and insufficient scalability. To address these challenges, the innovative Lightweight Retrieval-Augmented Generation (LightRAG) framework was introduced (Figure 1). The framework’s core innovation lies in constructing a knowledge graph (KG) that directly indexes entities and relationships, thereby replacing the complex community aggregation model. This design achieves significant improvements in both retrieval performance and the update process.
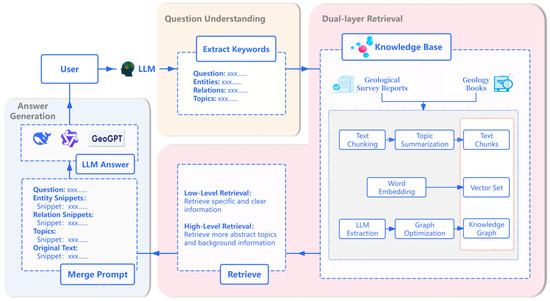
Figure 1.
Geological Q&A System based on LightRAG Technology.
To achieve a comprehensive understanding of user queries, LightRAG employs a dual-layer retrieval mechanism that processes information at different granularities in parallel. For a given user query, the system first utilizes an LLM to extract two types of keywords: low-level keywords () pointing to specific entities, and high-level keywords () referring to broader concepts. Subsequently, the system initiates a parallel retrieval process: the low-level retrieval performs precise matching of against entity nodes in a vector database, while the high-level retrieval matches against graph indices describing relationships or themes. Following this initial recall, the system expands the retrieval scope to include the one-hop neighbors of all matched elements to construct a contextual subgraph. Finally, this fused information is synthesized by the model to generate the final answer.
The architectural design of LightRAG ensures low computational cost and high scalability. In a study by Guo et al. [12], on the Legal dataset, which contains 94 documents and over 5 million tokens, LightRAG consumed fewer than 100 tokens and required only a single API call per KG query. In contrast, GraphRAG consumed over 610,000 tokens and necessitated hundreds of API calls. Furthermore, the framework’s high scalability is attributed to its incremental update algorithm. When new data is introduced, the system only needs to perform the graph indexing process once for the new data and integrate it incrementally into the existing graph. This approach avoids the costly global reconstruction required by GraphRAG, ensuring the framework’s timeliness and efficiency in dynamic data environments.
3. State of the Art
The proliferation of artificial intelligence (AI) has catalyzed a paradigm shift in the geosciences, enabling the analysis of vast, multi-source datasets at unprecedented scales. As comprehensively reviewed by scholars such as Zhu et al. [13] and Yang et al. [14], AI applications are becoming indispensable for modern geological research, with remarkable progress in areas like remote sensing and geophysical data processing. A significant frontier in this domain is the development of Geoscience Foundation Models, which aim to create general-purpose AI systems for a wide array of geological tasks [15]. However, within this broader context, a persistent and central challenge remains the precise extraction and application of domain-specific knowledge from enormous volumes of unstructured text, such as geological reports and academic literature, which are not readily processed by conventional AI models.
The quest to integrate and formalize complex geological data is a long-standing challenge. Traditional approaches have excelled at integrating quantitative data sources through sophisticated modeling. For instance, the works of Eppelbaum et al. [16] demonstrate mature methodologies for combining diverse geophysical and geothermal potential fields to construct detailed geological models. Conceptually, early efforts such as the informational approach proposed by Eppelbaum et al. [17] for integrating geological investigations also laid the groundwork for structured data analysis. While powerful, these methods primarily handle numerical data, leaving a gap in the systematic integration of the qualitative knowledge locked within textual documents. In recent years, the conventional paradigm for KG construction in specialized fields, as reviewed by Hogan et al. [18], is predicated on expert-defined ontologies [19]. This approach typically employs deep learning models like BERT-BiLSTM-CRF [20] and BERT-BiGRU-Attention-CRF [21] for instance-level entity recognition [22,23]. Although this paradigm provides a clear framework, its efficacy is contingent on large-scale, high-quality annotated corpora—a prerequisite entailing significant costs, protracted development cycles, and low operational efficiency [24]. For instance, a study by Feng et al. [25] on a carbonatite-type rare earth ore KG highlights this bottleneck: performance was severely constrained by a sparse annotated dataset (5% of the corpus), which yielded suboptimal relation extraction and compromised the model’s scalability.
In contrast, recent research has shifted toward automated KG construction using general-purpose LLMs [10]. Studies have demonstrated the potential of LLMs across the entire KG lifecycle, from extraction (e.g., RAKG [26]) to evaluation (e.g., Graph Judger [27]). However, when applied to a highly specialized domain such as geology, these models encounter fundamental challenges in domain adaptation. Their accuracy in recognizing technical terminology is limited by insufficient exposure to specialized corpora during pre-training [28]. Furthermore, their propensity for “hallucinations” and factual errors during inference critically undermines the trustworthiness and veracity of the resulting knowledge base [29].
Once a geological KG is constructed, its utility depends on its effective integration with an LLM for precise Q&A, a task for which RAG is a foundational technology [30]. Early RAG techniques, while improving precision, utilized flat data structures that were inadequate for modeling complex entity relationships [31]. To overcome this deficiency, advanced techniques such as GraphRAG were developed; by incorporating graph embeddings and multi-hop retrieval, these methods significantly enhance the model’s perception of complex relations and its capacity for multi-step reasoning [32,33]. Although this approach represents a significant advancement, its substantial computational costs and maintenance overheads restrict its practical application, particularly in resource-constrained settings [9,33]. As an alternative, Guo et al. [12] proposed LightRAG, a lightweight framework that achieves notable cost and efficiency optimizations via novel graph indexing and a dual-layer retrieval mechanism. This presents a compelling technical alternative, yet its efficacy introduces a new prerequisite: reliance on a pre-existing, high-quality knowledge base.
In summary, the preceding analysis reveals a fundamental dilemma rooted in two trade-offs: one between quality and efficiency in knowledge acquisition, and another between performance and cost in knowledge application. This study aims to resolve this central challenge by developing a methodology for the effective, low-cost construction and retrieval of KGs while ensuring the fidelity of geological knowledge. Motivated by this analysis, we propose a unified framework that combines a domain-specific large model with a lightweight retrieval architecture, designed to resolve these persistent bottlenecks through synergistic integration.
4. Methods
The methodological framework advanced in this study is designed to construct a geological Q&A system by integrating deep domain knowledge with effective retrieval technology (Figure 2). The framework consists of two primary modules: (1) the automated construction and dynamic updating of a high-fidelity Knowledge Graph (KG), facilitated by the GeoGPT large model; (2) the integration of this KG with the LightRAG framework to realize a highly effective and precise Q&A system.
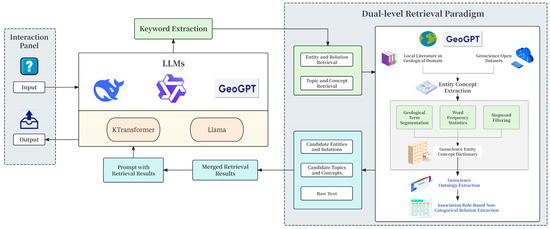
Figure 2.
Technical framework of the geological Q&A system based on GeoGPT and LightRAG.
4.1. Knowledge Graph Construction and Optimization
To circumvent the bottlenecks of conventional KG construction—namely, high manual costs and protracted update cycles—this module employs the advanced semantic parsing capabilities of GeoGPT. This process enables automated knowledge extraction and subsequently builds a high-quality, dynamic knowledge base through a dedicated post-processing and incremental update pipeline (Figure 3).
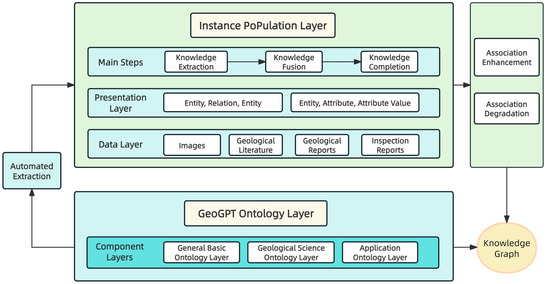
Figure 3.
Technical Framework of Automated Geological Domain Knowledge Graph Construction based on GeoGPT.
4.1.1. Automated Knowledge Extraction via GeoGPT
The construction of the knowledge graph proceeds in two principal stages: ontology construction and instance population.
The conventional approach to ontology construction is a labor-intensive knowledge engineering process, relying on domain experts for the manual curation, definition, and validation of concepts. This approach is characterized by protracted development cycles and substantial costs. In contrast, the large-scale geological model, GeoGPT, facilitates a semi-automated, human-in-the-loop construction paradigm. By leveraging its advanced capabilities in Natural Language Understanding (NLU) and Knowledge Extraction, GeoGPT automates the identification of key concepts and their complex semantic relationships from unstructured geological literature. This model-driven methodology significantly shortens the KG construction lifecycle and enhances overall efficiency.
The ontology layer of the mineral prospecting knowledge graph follows a bottom-up design, comprising three primary tiers: a General Basic Ontology Layer, a Geological Science Ontology Layer, and an Application Ontology Layer. In this study, the GeoGPT model is employed to autonomously extract knowledge from authoritative sources, including geological dictionaries, Chinese geological thesauri, and literature on ore deposit science. To ensure the ontological integrity and quality, this automated process is subsequently subjected to rigorous expert-driven evaluation and refinement.
The instance population stage is executed Via a three-step process, governed by structured task prompts, to achieve end-to-end knowledge extraction directly from unstructured geological texts:
- Knowledge Extraction: This initial step involves GeoGPT analyzing the source text to perform simultaneous entity recognition and relation extraction. The objective is to identify key geological entities (e.g., ore deposits, strata, structures) and their associations, thereby forming a preliminary set of knowledge triples.
- Knowledge Fusion: This step harmonizes and de-duplicates the initially extracted knowledge to resolve inconsistencies. It involves entity alignment to unify disparate textual expressions referring to the same real-world entity (e.g., “Ordovician lower Honghuayuan Formation” and “Honghuayuan Formation stratum”). The attributes of these aligned entities are then consolidated to ensure knowledge consistency.
- Knowledge Completion: This final step augments the graph’s density and semantic completeness. By leveraging the existing graph structure and semantics, GeoGPT performs logical reasoning to infer and incorporate missing entities or relationships that are implicitly present but not explicitly stated in the text. This process enriches the KG, providing a more comprehensive foundation for downstream applications.
4.1.2. Prompt Engineering
To ensure standardized, accurate, and reproducible knowledge extraction, we employed systematic prompt engineering to guide GeoGPT. This approach is grounded in a formalized schema designed specifically for the mineral prospecting knowledge graph.
The schema defines a knowledge graph architecture of nodes (geological entities) and edges (relationships).
- Nodes (Entities): Nodes represent distinct geological entities, each defined by three primary attributes:
- name: A unique identifier for the entity.
- type: The entity’s category, predefined for this study as “Tectonic Structure,” “Age,” “Mineral,” “Ore Deposit,” or “Rock.”
- description: A detailed explanation of the entity’s attributes and characteristics.
- Edges (Relations): Edges connect pairs of nodes to represent specific associations and include five attributes:
- source entity and target entity: The pair of nodes linked by the edge.
- relation description: A natural-language explanation of the association.
- relation keyword: A high-level summary of the relationship’s nature.
- relation strength: A metric quantifying the association’s strength.
Based on this schema, we engineered an ‘Entity and Relation Extraction’ prompt to instruct GeoGPT in the precise extraction of structured knowledge. The prompt consists of three principal sections.
- Objective: The prompt first defines the primary objective: to identify all entities and their interrelationships within a given geological text, consistent with the predefined schema.
- Procedural Decomposition: The prompt deconstructs the extraction task into three sequential steps:
- Entity Extraction: The model first identifies all entities matching the predefined categories and extracts their name, type, and description in a specified format.
- Relation Extraction: The model then identifies explicit relationships between the extracted entities, extracting their source entity, target entity, relation description, relation keyword, and relation strength.
- Global Keyword Extraction: Finally, the model extracts high-level keywords summarizing the document’s primary themes.
- Output Formatting and Exemplars: The prompt enforces a structured, machine-readable output by specifying a tuple delimiter “<|>” and a record delimiter “##”. Furthermore, to enhance accuracy and consistency, the prompt incorporates a few-shot learning strategy by providing high-quality input-output exemplars (e.g., the Dexing Copper Mine, gold deposits of the North China Craton). These exemplars offer concrete precedents, constraining the model’s output to the desired format and style.
This formal prompt engineering methodology converts the abstract task of knowledge graph construction into precise, machine-executable instructions, enabling GeoGPT to operate with high fidelity. The process thus facilitates the efficient, automated transformation of unstructured geological text into structured knowledge, establishing a robust data foundation for subsequent graph optimization and downstream applications.
4.1.3. Knowledge Graph Post-Processing and Optimization
The raw graph generated may contain weakly associated entities or erroneously extracted nodes. To refine its quality, the graph undergoes a two-stage post-processing protocol comprising Association Enhancement and Association Degradation.
Association Enhancement
To quantify the strength of relationships, we introduce a composite metric, termed Association Strength, which integrates both semantic similarity and topological proximity.
- First, to measure semantic consistency, the cosine similarity, , is computed between the vector representations of entities and :
- Second, the Jaccard similarity coefficient is employed to quantify the structural proximity between nodes and :where denotes the set of neighboring nodes for node .
These metrics are then combined into the final association strength Via a weighted sum:
where is a hyperparameter balancing the contributions of semantic and structural information. An edge is subsequently established between the nodes if their association strength exceeds a predefined threshold, :
Association Degradation
This operation prunes irrelevant or isolated nodes that may have resulted from incorrect extraction. Any isolated entity with a node degree of zero is removed:
Hyperparameter Optimization
To optimize the performance of the proposed association enhancement method, we systematically tuned its key hyperparameters: the association strength weight, , and the association threshold, . A subset of the geological dataset was reserved for validation, and a grid search-based sensitivity analysis was conducted for both hyperparameters using the F1-score as the primary performance metric.
First, we optimized the weight parameter , which balances the contributions of semantic similarity and graph-based structural proximity. For this experiment, the association threshold was held constant at = 0.75 while was varied from 0.1 to 0.9. The results (Figure 4a) show a nonlinear relationship between and the F1-score. The F1-score increased from 0.8112 to a peak of 0.8346 as was raised from 0.1 to 0.5, highlighting the importance of semantic information for identifying latent entity associations. Further increases in , however, led to a performance decline. This trend is attributed to an over-reliance on semantic similarity, which can introduce structurally irrelevant links.
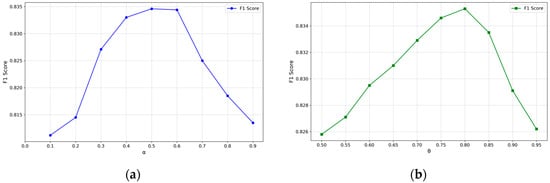
Figure 4.
(a) Effect of the weight parameter on extraction performance with 75; (b) Effect of the association threshold θ on extraction performance with .
With set to its optimal value of 0.5, the association threshold, , was subsequently optimized over the interval [0.5, 0.95]. This threshold controls the precision-recall trade-off for establishing entity connections. As depicted in Figure 4b, increasing from 0.5 to 0.8 steadily improved the F1-score from 0.8258 to 0.8353. This enhancement stems from the stricter threshold effectively pruning low-confidence, erroneous links and thereby increasing precision. However, increasing the threshold beyond 0.8 resulted in a performance drop, as the stricter criterion omitted valid but weaker associations and thus reduced recall.
Based on these empirical results, we selected the optimal hyperparameter combination of = 0.5 and = 0.8. This configuration ensures that the knowledge graph post-processing module effectively constructs high-quality associations between entities.
4.1.4. Incremental Update Mechanism
To ensure the knowledge base remains current with the latest exploration findings, an incremental update mechanism, an intrinsic feature of the LightRAG framework, is implemented. When new geological documents become available, the automated extraction and optimization pipeline is re-invoked to generate new entities () and relations (). These are subsequently merged with the existing KG () to produce an updated graph (), a process formally expressed as:
4.2. Geological Q&A Model Based on LightRAG
To address the demand for knowledge question answering for complex problems in the geoscience domain, this paper proposes an intelligent response model that integrates a domain knowledge graph with a large language model. This model utilizes the LightRAG framework as its core retrieval engine, whose general architecture and technical advantages have been described in Section 2.2. This section focuses on the specific application workflow of the framework within a geological prospecting scenario and the optimizations implemented to enhance its domain adaptability.
For an incoming natural language query in the geoscience domain, the system first activates the retrieval function of LightRAG to perform its signature two-stage retrieval on the geological knowledge graph constructed in Section 4.1. This process is designed to initially retrieve a set of contextual information comprising relevant entities, relationships, and their corresponding textual evidence. However, to ensure the precision of the final generated answer, the initially retrieved knowledge set must be refined by a crucial re-ranking module. This module employs the BM25 algorithm to score and rank the candidate documents from the initial retrieval for relevance. Its scoring function is shown in Equation (7):
where is the inverse document frequency of the query term ; is the term frequency of in document ; is the term frequency saturation parameter; controls document length normalization; is the document length; and is the average document length for the corpus. To optimize its performance on geological texts, the hyperparameters and are empirically tuned to enhance sensitivity to key geological terms and improve performance on lengthy documents. The efficacy of this integrated framework is evaluated using the quantitative metrics and qualitative analyses detailed in the subsequent section.
To illustrate this core retrieval process, consider the user query, “In which strata are the fluorite deposits of southeastern Chongqing primarily hosted?” as an example. The key to parsing this query lies in differentiating the semantic roles of its keywords: low-level keywords are used to locate known, specific entities within the query, serving as “anchors” for retrieval; in contrast, high-level keywords define the category of the unknown information being sought and the relationship patterns between entities, acting as a “query template.” In this query, the system extracts the low-level keywords [“Fluorite,” “southeastern Chongqing”] and the high-level keywords [“deposits,” “hosted in,” “strata”].
After the keywords are extracted, the two-stage retrieval mechanism returns a comprehensive result set from the geological knowledge graph. Its core components are as follows:
- Core Entities: Precisely located by the low-level retrieval based on keywords like “Fluorite.” Examples include [Entity: Fluorite], [Entity: Southeastern Chongqing], and [Entity: Yangjiashan Fluorite Mine].
- Key Relationships: Retrieved by the high-level retrieval based on relationship patterns like “hosted in.” An example is (Head Entity: Southeastern Chongqing Fluorite Mine, Relation: hosted in, Tail Entity: Lower Ordovician Honghuayuan Formation).
- Extended Context: Obtained through a one-hop neighbor expansion of the above results. For instance, expanding from [Entity: Lower Ordovician Honghuayuan Formation] yields background knowledge such as [Entity: Limestone] (its lithology).
This result set is ultimately integrated into a comprehensive, structured knowledge context. After being optimized by the re-ranking module, this context is fed into the GeoGPT model, which serves as the generator, along with the original user query. This is performed to synthesize a final answer that is logically rigorous and adheres to professional expression conventions.
5. Result Analysis and Discussion
This section presents a systematic evaluation of the experimental results. The assessment begins with a qualitative and quantitative comparison of the KGs constructed by GeoGPT versus general-purpose LLMs, and concludes with a performance evaluation of the proposed Q&A system.
5.1. Qualitative Comparison of Knowledge Graphs
To visually assess the differences in graph construction capabilities, KGs were generated from the “Southeast Chongqing Fluorite-Barite Symbiotic Ore” dataset using both DeepSeek-V3 and GeoGPT (Figure 5).
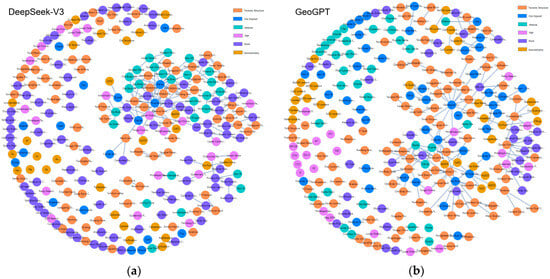
Figure 5.
(a) Global rendering of the knowledge graph constructed by DeepSeek-V3; (b) Global rendering of the knowledge graph constructed by GeoGPT. Node colors represent entity types as per the legend: orange for Tectonic Structure, blue for Ore Deposit, cyan for Mineral, lilac for Age, purple for Rock, and gold for Geochemistry.
Although the models extracted a comparable number of entities, our analysis reveals a significant disparity in the structural quality and semantic richness of the resulting KGs. Notably, the graph generated by GeoGPT exhibited a superior degree of network connectivity, with over 50% of its entities being interrelated, compared to approximately 30% for the DeepSeek-V3 graph. This dense relational network more effectively captures the intrinsic complexity among geological entities (e.g., rocks, minerals, structures), thereby providing a more robust foundation for deep relational analysis.
A detailed comparison of the local details in Figure 6 more clearly reveals that the graph structure constructed by DeepSeek-V3 is loosely structured, exhibiting a “hub-and-spoke” pattern. A large number of nodes are connected only to a few core entities, and the graph lacks lateral cross-connections between nodes. This exposes the limitations of the general-purpose model in knowledge extraction: namely, while it can identify key entities within the text, its lack of geological background knowledge prevents it from comprehending the complex intrinsic relationships between these entities. Consequently, it can only establish the most direct and superficial associations, resulting in a fragmented graph topology. In contrast, the GeoGPT-constructed graph demonstrated a more sophisticated and refined mesh-like topology. Its nodes were labeled with greater geological specificity (e.g., “Lower Ordovician Fenxiang Formation”), and it exhibited a superior capability to establish meaningful connections, such as linking “fluorite” to its chemical formula “CaF2,” its formation environment “structural fissures,” its co-occurring mineral “barite,” and its host stratum “Lower Ordovician Honghuayuan Formation.” This focus on establishing geologically salient relationships yields a data foundation of superior quality, which is essential for powering an advanced intelligent Q&A system. This capability stems from the fact that GeoGPT, during its pre-training on a massive corpus of geoscience literature, has already internalized the conceptual systems and knowledge structures of geology. Therefore, it is not merely “recognizing” words in the text but is “understanding” the geological logic behind them, enabling it to extract and construct multi-dimensional, multi-level associations that reflect true geological principles.
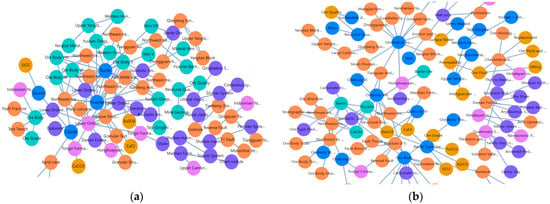
Figure 6.
(a) Local rendering of the knowledge graph constructed by DeepSeek-V3; (b) Local rendering of the knowledge graph constructed by GeoGPT. Node colors represent entity types as per the legend: orange for Tectonic Structure, blue for Ore Deposit, cyan for Mineral, lilac for Age, purple for Rock, and gold for Geochemistry.
In summary, this qualitative structural difference is not just a matter of visual appearance but a fundamental distinction in the semantic understanding depth between the two models. GeoGPT, leveraging its profound domain knowledge, is capable of constructing a knowledge graph that is more structurally sound, richer in relationships, and more logically coherent. This high-quality knowledge graph not only more closely approximates the cognition of a geological expert but also lays a solid and reliable data foundation for subsequent intelligent question answering on deep and complex problems.
5.2. Quantitative Analysis of Knowledge Graphs
To systematically validate the effectiveness of each core component in the proposed geological knowledge graph construction method, this section details an ablation study designed and conducted on a sample text dataset of 60,000 tokens. The study is aimed at quantitatively isolating and evaluating the independent contributions of two critical factors—GeoGPT and the geology-specific prompting strategy—to the final entity extraction performance.
5.2.1. Experiments
This ablation study was conducted on a unified geological prospecting text dataset, using the overall F1-score for entity extraction as the primary evaluation metric. We established the following three core experimental configurations:
- The Proposed Method: Utilizes GeoGPT as the base model in conjunction with the geology-specific prompting strategy for knowledge extraction. This configuration represents the full implementation of the method proposed in this paper.
- Ablating the Domain-Specific Model: The base model is replaced with a general-purpose large model (Qwen2.5-72B or Deepseek-V3), while still employing the geology-specific prompting strategy. By comparing this with “The Proposed Method,” this setup is used to measure the performance gain attributed to GeoGPT’s domain-specific pre-training and fine-tuning.
- Ablating the Prompting Strategy: GeoGPT is retained as the base model, but the prompting strategy is reverted to using generic prompts. The comparison with “The Proposed Method” is used to evaluate the effectiveness of the optimization provided by the domain-specific prompting strategy.
5.2.2. Results and Analysis
The quantitative results of the ablation study are presented in Table 1, from which the following conclusions can be drawn:

Table 1.
Comparison of entity extraction performance under different base models and prompting strategies.
First, the domain-specific prompting strategy provides a universal and significant boost to entity extraction performance. The experimental data show that for all models—GeoGPT, Qwen2.5-72B, and Deepseek-V3—the mean F1-score for entity extraction is markedly higher when using “Geology-specific Prompts” compared to the corresponding results with “Generic Prompts.” Specifically, GeoGPT’s F1-score increased from 0.7680 to 0.8353 (an 8.8% improvement); Qwen2.5-72B’s F1-score rose from 0.7117 to 0.7853 (a 10.3% improvement); and Deepseek-V3’s F1-score improved from 0.6675 to 0.7291 (a 9.2% improvement). These consistent results indicate that a well-designed prompting strategy that embeds domain knowledge can more effectively guide large models to understand and execute complex, specialized information extraction tasks.
Second, the native domain capability of GeoGPT is the core factor in achieving optimal performance. When comparing the different base models under the same optimal “Geology-specific Prompts” strategy, GeoGPT’s mean F1-score reaches 0.8353, significantly outperforming the 0.7853 of Qwen2.5-72B and the 0.7291 of Deepseek-V3. This phenomenon reveals that while domain-specific prompts can enhance the performance of general-purpose large models, their role is more akin to “external guidance.” In contrast, GeoGPT, through its extensive pre-training and fine-tuning on a massive geoscience corpus, has already formed a deep “internalized understanding” of geological concepts, terminology, and relationships. The optimal extraction performance is achieved only when this internalized domain knowledge is combined with the externalized prompting strategy.
In conclusion, this ablation study powerfully demonstrates the necessity and effectiveness of the two core components of our proposed method. The results show that the domain-specific large model, GeoGPT, and the domain-specific prompting strategy are complementary. Their synergistic combination is key to achieving the automated construction of high-precision geological knowledge graphs.
5.3. Performance Evaluation of the Geological Knowledge Q&A Model
To quantitatively evaluate the Q&A performance of the model proposed in this paper, a comparative experiment focusing on complex questions was designed. The experiment utilized geoscience textbooks and geological survey reports from the Chongqing region to construct four datasets in the domains of geophysics, geochemistry, remote sensing geology, and geological exploration and survey [30]. The geoscience textbook portion contains 200,000 tokens, while the geological survey reports, primarily consisting of survey and exploration data on fluorite and barite deposits in southeastern Chongqing, contain 30,000 tokens.
The performance of Q&A models constructed using GeoGPT, DeepSeek-V3, and Qwen2.5-72B within the LightRAG technical framework was compared across all datasets. The specific experimental workflow was as follows:
- Question Generation Phase: For each dataset, six virtual user personas and four tasks they might perform with the data were conceptualized. Subsequently, for each of the 24 “user-task” pairs, the Gemini 2.5 Pro large model was used to generate six questions that require a high-level, holistic understanding of the entire corpus to answer, resulting in a total of 144 (6 × 4 × 6) test questions. This approach was designed to ensure the generated questions were both diverse and highly relevant to real-world application scenarios.
- Geological Knowledge Graph Construction Phase: A single, unified geological knowledge graph, constructed using GeoGPT, was employed for all experimental configurations to ensure consistency.
- Retrieval and Answering Phase: The LightRAG-based knowledge Q&A models built with GeoGPT, DeepSeek-V3, and Qwen2.5-72B were tested to generate answers for the test questions.
- Automated Evaluation Phase: To ensure the evaluation of the generated answers was objective, fair, and reproducible, the state-of-the-art “Model-as-a-Judge” approach was adopted. We selected the high-performance Gemini 2.5 Pro model to act as a third-party “expert evaluator” to perform pairwise comparative judgments on the answers generated by the different models for the same question. To precisely control the evaluation process, we designed a detailed prompt engineering scheme to guide the evaluator model. This prompt first assigned the evaluator model the role of a “rigorous and objective AI response evaluation expert.” It then defined three core evaluation criteria:
- Comprehensiveness: To assess whether the answer covers all core aspects of the question.
- Diversity: To assess whether the answer provides multiple perspectives and pieces of information.
- Empowerment: To assess whether the answer effectively helps the user understand the topic and inspires further thought.
At the execution level, the prompt required the evaluator model to strictly adhere to a comparative evaluation process. Specifically, for each criterion, it had to make a “forced-choice” selection of the superior answer between the two candidates and articulate the specific reasons for its decision, thereby precluding ambiguous conclusions such as a “tie.” Finally, after completing the item-by-item comparison across the three dimensions, the model was required to make a holistic assessment to select the “Overall” best answer. All evaluation results were then output in a standardized JSON format to facilitate subsequent quantitative statistics and analysis. The detailed results are presented in Table 2.
Table 2.
Win rate comparison (%) of different models in geological Q&A tasks.
The results indicate that, compared to the general-purpose large models DeepSeek-V3 and Qwen2.5-72B, the GeoGPT-based Q&A model exhibits a clear advantage across all evaluation criteria. In terms of comprehensiveness, diversity, empowerment, and overall quality, the GeoGPT model demonstrates a significant lead in Q&A tasks across the different geological sub-domains.
Specifically, compared to the DeepSeek-V3 model, GeoGPT achieved an average win rate of 71.96% across the four domains. Its win rate was higher by 63–78% in the remote sensing geology domain and by 26–29% in the geochemistry domain. In the comparison against the Qwen2.5-72B model, GeoGPT had an average win rate of 65.63%, with its advantage being 53–68% in remote sensing geology and 8–21% in geochemistry.
In summary, these comparative tests demonstrate that the performance of the GeoGPT model is outstanding in the geoscience domain. Its advantage is particularly pronounced in the highly specialized, knowledge-dependent domain of geological exploration and survey when compared to general-purpose large models. This illustrates that domain-specific training for large models plays a crucial role in enhancing the quality of specialized Q&A, thereby validating that the approach of utilizing a domain-specific geological large model combined with the LightRAG framework to build a vertical-domain Q&A model is both effective and reliable.
6. Conclusions
This study addresses the limitations of applying general-purpose LLMs to specialized scientific domains by introducing and validating a framework that integrates a domain-specific LLM, GeoGPT, with a lightweight retrieval architecture, LightRAG. The principal contributions are threefold:
- We propose an automated method for constructing high-quality geological KGs using a domain-specific LLM. This approach leverages the deep geological prior knowledge embedded in GeoGPT and an optimized prompting strategy to automate the workflow from ontology definition to relationship extraction. A post-processing step integrating semantic and graph-structural information improves semantic association accuracy. Ablation studies confirmed that our method achieved a mean F1-score of 0.8353 for entity extraction, a 17–25% performance improvement over general-purpose LLMs (DeepSeek-V3, Qwen2.5-72B). This approach resolves the trade-off between the high cost of traditional methods and the lower accuracy of general-purpose models, making specialized KG construction more accessible.
- We developed and validated an efficient geological Q&A model based on the LightRAG framework. The model utilizes LightRAG’s two-stage retrieval function to precisely interpret complex geological queries, while its incremental update mechanism ensures the knowledge base can be dynamically expanded with low cost and high performance. This design avoids the significant resource consumption of frameworks like GraphRAG, enabling the effective deployment and iteration of geological Q&A systems.
- We evaluated the GeoGPT-based Q&A model, which significantly outperformed its general-purpose counterparts, achieving average win rates of 71.96% and 65.63% against DeepSeek-V3 and Qwen2.5-72B, respectively. Its dominance was particularly pronounced in specialized sub-domains, with win rates 53–78% higher in remote sensing geology and 8–29% higher in geochemistry.
In conclusion, this study establishes an effective and precise methodology for building geological KGs and intelligent Q&A systems by integrating a domain-specific LLM with a lightweight retrieval framework, providing a valuable blueprint for the advanced analysis of massive geological text data.
Despite these promising results, this study has several limitations. (1) Generalization Capability: The model was validated on data for a specific mineral type (fluorite-barite) in one region. Its generalization to other geological units or mineral deposits requires rigorous testing on more diverse datasets. (2) Multi-modal Data Integration: Geological literature is inherently multi-modal. The current model is limited to textual data, ignoring crucial information in maps, cross-sections, and geochemical charts, which introduces a bias in knowledge acquisition. (3) Knowledge Update Complexity: Although LightRAG supports incremental updates, the current method lacks robust mechanisms for knowledge correction, conflict resolution, or provenance tracking. (4) Evaluation Objectivity: We employed a “Model-as-a-Judge” approach with a single evaluator (Gemini 2.5 Pro), which may introduce systemic bias. Time and API cost constraints precluded the use of a more robust multi-model judging panel.
Future research will focus on enhancing the method’s practical utility and technical robustness. First, we will improve model generalization and knowledge base comprehensiveness by incorporating more diverse geological datasets and integrating multi-modal information. Second, we will extend the model’s application from Q&A to complex decision-support tasks, such as mineral resource assessment and intelligent prospecting target prediction. Finally, to ensure research rigor, we will adopt more robust evaluation systems, such as a multi-model “judging panel,” to provide more reliable decision support for geological exploration.
Author Contributions
Conceptualization, B.Z. and K.L.; methodology, B.Z.; software, B.Z.; validation, K.L.; formal analysis, B.Z.; investigation, K.L.; resources, B.Z.; data curation, B.Z.; writing—original draft preparation, B.Z.; writing—review and editing, K.L.; visualization, K.L.; supervision, K.L.; project administration, K.L.; funding acquisition, B.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Chongqing Bureau of Geology and Minerals Exploration grant number DKJ-2024-DKC-B-006. And the APC was funded by Chongqing Bureau of Geology and Minerals Exploration Geological Team 107.
Data Availability Statement
The original contributions presented in the study are included in the article, further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Sellars, S.L. ‘Grand challenges’ in big data and the earth sciences. Bull. Am. Meteorol. Soc. 2018, 99, ES95–ES98. [Google Scholar] [CrossRef]
- Linphrachaya, N.; Gómez-Méndez, I.; Siripatana, A. Geological inference from textual data using word embeddings. arXiv 2025, arXiv:2504.07490. [Google Scholar] [CrossRef]
- Harris, J.R.; Grunsky, E.; Behnia, P.; Corrigan, D. Data- and knowledge-driven mineral prospectivity maps for Canada’s north. Ore Geol. Rev. 2015, 71, 788–803. [Google Scholar] [CrossRef]
- Mantovani, A.; Piana, F.; Lombardo, V. Ontology-driven representation of knowledge for geological maps. Comput. Geosci. 2020, 139, 104446. [Google Scholar] [CrossRef]
- Ji, Z.; Lee, N.; Frieske, R.; Yu, T.; Su, D.; Xu, Y.; Ishii, E.; Bang, Y.J.; Madotto, A.; Fung, P. Survey of hallucination in natural language generation. ACM Comput. Surv. 2023, 55, 248. [Google Scholar] [CrossRef]
- Taylor, R.; Kardas, M.; Cucurull, G.; Scialom, T.; Hartshorn, A.; Saravia, E.; Poulton, A.; Kerkez, V.; Stojnic, R. Galactica: A large language model for science. arXiv 2022, arXiv:2211.09085. [Google Scholar] [CrossRef]
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.T.; Rocktäschel, T.; et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Adv. Neural Inf. Process. Syst. 2020, 33, 9459–9474. [Google Scholar]
- Lissandrini, M.; Hose, K.; Pedersen, T.B. Example-driven exploratory analytics over knowledge graphs. In Proceedings of the 26th International Conference on Extending Database Technology, EDBT 2023, Ioannina, Greece, 28–31 March 2023; pp. 105–117. [Google Scholar]
- Wadhwa, S.; Amir, S.; Wallace, B.C. Revisiting relation extraction in the era of large language models. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, Toronto, ON, Canada, 9–14 July 2023; pp. 15566–15581. [Google Scholar]
- Choi, S.; Jung, Y. Knowledge graph construction: Extraction, learning, and evaluation. Appl. Sci. 2025, 15, 3727. [Google Scholar] [CrossRef]
- Lin, Z.; Deng, C.; Zhou, L.; Zhang, T.; Xu, Y.; Xu, Y.; He, Z.; Shi, Y.; Dai, B.; Song, Y.; et al. Geogalactica: A scientific large language model in geoscience. arXiv 2023, arXiv:2401.00434. [Google Scholar]
- Guo, Z.; Xia, L.; Yu, Y.; Ao, T.; Huang, C. LightRAG: Simple and fast retrieval-augmented generation. arXiv 2024, arXiv:2410.05779. [Google Scholar]
- Zhao, T.; Wang, S.; Ouyang, C.; Chen, M.; Liu, C.; Zhang, J.; Yu, L.; Wang, F.; Xie, Y.; Li, J.; et al. Artificial intelligence for geoscience: Progress, challenges, and perspectives. Innovation 2024, 5, 100657. [Google Scholar] [CrossRef]
- Yang, L.; Driscol, J.; Sarigai, S.; Wu, Q.; Chen, H.; Lippitt, C.D. Google Earth Engine and artificial intelligence (AI): A comprehensive review. Remote Sens. 2022, 14, 3253. [Google Scholar] [CrossRef]
- Zhang, H.; Xu, J.J.; Cui, H.W.; Li, L.; Yang, Y.; Tang, C.S.; Boers, N. When Geoscience Meets Foundation Models: Toward a general geoscience artificial intelligence system. IEEE Geosci. Remote Sens. Mag. 2024, 2–41. [Google Scholar] [CrossRef]
- Eppelbaum, L. Geophysical Potential Fields: Geological and Environmental Applications; Elsevier: Amsterdam, The Netherlands, 2019; Volume 2. [Google Scholar]
- Eppelbaum, L.; Eppelbaum, V.; Ben-Avraham, Z. Formalization and Estimation of Integrated Geological Investigations: An Informational Approach. Geoinformatics 2003, 14, 233–240. [Google Scholar] [CrossRef]
- Hogan, A.; Blomqvist, E.; Cochez, M.; d’Amato, C.; De Melo, G.; Gutierrez, C.; Kirrane, S.; Labra Gayo, J.E.; Navigli, R.; Neumaier, S.; et al. Knowledge graphs. ACM Comput. Surv. 2021, 54, 71. [Google Scholar] [CrossRef]
- Niu, F.; Zhang, B.; Chen, S. Review and perspective of earth science knowledge graph in big data era. Acta Seismol. Sin. 2024, 46, 353–376. [Google Scholar]
- Liu, Y.; Wei, S.; Huang, H.; Lai, Q.; Li, M.; Guan, L. Naming entity recognition of citrus pests and diseases based on the BERT-BiLSTM-CRF model. Expert Syst. Appl. 2023, 234, 121103. [Google Scholar] [CrossRef]
- Qiu, Q.; Tian, M.; Wu, Q.; Chen, J.; Zhu, Y.; Chen, Z.; Xie, Z. Construction and application of geological knowledge graph based on multi-source heterogeneous data. Earth Sci. Front. 2024, 31, 1–17. [Google Scholar]
- Zhu, Y.; Sun, K.; Hu, X.; Lyu, H.; Wang, X.; Yang, J.; Wang, S.; Li, W.; Song, J.; Su, N.; et al. Research and practice on the framework for the construction, sharing, and application of large-scale geoscience knowledge graphs. J. Geo-Inf. Sci. 2023, 25, 1215–1227. [Google Scholar]
- Li, T.; Chen, R.; Duan, Y.; Yao, H.; Li, S.; Li, X. HGeoKG: A hierarchical geographic knowledge graph for geographic knowledge reasoning. ISPRS Int. J. Geo-Inf. 2025, 14, 18. [Google Scholar] [CrossRef]
- Tanon, T.P.; Weikum, G.; Suchanek, F.M. YAGO 4: A reason-able knowledge base. Semant. Web 2020, 11, 583–596. [Google Scholar]
- Feng, T.; Cai, S.; Zhang, Z. Mining elements of carbonatite-type rare earth ore mineralization based on knowledge map. Earth Sci. Front. 2025, 32, 1–24. [Google Scholar]
- Zhang, H.; Si, J.; Yan, G.; Qi, B.; Cai, P.; Mao, S.; Wang, D.; Shi, B. RAKG: Document-level retrieval augmented knowledge graph construction. arXiv 2025, arXiv:2504.09823. [Google Scholar]
- Huang, H.; Chen, C.; Sheng, Z.; Li, Y.; Zhang, W. Can LLMs be good graph judger for knowledge graph construction? arXiv 2025, arXiv:2411.17388. [Google Scholar]
- Zuo, J.; Niu, J. Construction of journal knowledge graph based on deep learning and LLM. Electronics 2025, 14, 1728. [Google Scholar] [CrossRef]
- Yang, F.; Zuo, R.; Kreuzer, O.P. Artificial intelligence for mineral exploration: A review and perspectives on future directions from data science. Earth-Sci. Rev. 2024, 258, 104941. [Google Scholar] [CrossRef]
- Arslan, M.; Ghanem, H.; Munawar, S.; Christophe, C. A survey on RAG with LLMs. Procedia Comput. Sci. 2024, 246, 3781–3790. [Google Scholar] [CrossRef]
- Zhang, Q.; Chen, S.; Bei, Y.; Yuan, Z.; Zhou, H.; Hong, Z.; Dong, J.; Chen, H.; Chang, Y.; Huang, X. A survey of graph retrieval-augmented generation for customized large language models. arXiv 2025, arXiv:2501.13958. [Google Scholar]
- Tang, Y.; Yang, Y. MultiHop-RAG: Benchmarking retrieval-augmented generation for multi-hop queries. arXiv 2024, arXiv:2401.15391. [Google Scholar]
- Edge, D.; Trinh, H.; Cheng, N.; Bradley, J.; Chao, A.; Mody, A.; Truitt, S.; Metropolitansky, D.; Ness, R.O.; Larson, J. From local to global: A graph RAG approach to query-focused summarization. arXiv 2025, arXiv:2404.16130. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).