1. Introduction
According to researchers’ findings, there is a clear link between global warming and industrialization, as shown by the many ecological imbalances that have arisen in recent years and have led to several disasters, the most significant of which is flooding. Depending on their location, floods are divided into three categories: River Floods, Coastal Floods, and Flash Floods (FF). Due to their rapid occurrence, high speed, and destructive effect, FFs are among the world’s deadliest natural disasters [
1]. This also applies to Morocco, which has suffered from several FFs, the most significant of which are the Mohammadia flood [
2], the Oued Ourika FF [
3], the Guelmim region flood [
4,
5], and the Tetouan FF [
6].
One reason FFs are so hazardous is that they commonly happen in metropolitan areas, where there is a high concentration of impervious surfaces that contribute significantly to urban FFs [
7].
Impervious surfaces, slope, soil type, land use, rainfall intensity, and duration are among the major factors in FFs. Understanding the variables that affect the probability of FF occurrence in a given area is very important, and this can be done in several ways, including determining FF susceptibility. Prior studies have demonstrated the value of FF susceptibility mapping in disaster management. As time passed, different methods were developed in this sense, such as Dempster–Shafer [
8], frequency ratio [
9], weights of evidence (WofE) [
10], index of entropy [
11], the analytical hierarchy process [
12], fuzzy logic [
13], and the Machine learning and deep learning approach (ML and DL) [
14]. Because of their ability to process significant volumes of complicated data and recognize and predict future patterns, Machine Learning (ML) and Deep Learning (DL) techniques have recently demonstrated their effectiveness in accurately identifying and predicting FF susceptibility. Consequently, these approaches are considered the best for such modeling. Contrary to traditional methods that directly determine weights, ML and DL learn weights through the training process, enabling complex relationships to be found between FF risk and its influencing factors. This was the case in the study of Shreevastav et al. [
15], which adopted the same approach to assess flood risk modeling in the lower Bagmati river region of Eastern Terai, Nepal, using the ML model of MaxEnt. Moreover, Al-Areeq et al.’s [
16] research used a logistic model tree (LT), a Bagging ensemble (BE), k-nearest neighbors, and a kernel support vector machine to map Jeddah, Saudi Arabia’s flood vulnerability. In Karachi, Pakistan, by combining a novel set model of Multi-Layer Perceptron, Support Vector Machine, and Logistic Regression (LR), which additionally assesses influencing variables, Yaseen et al. [
17] created a flood susceptibility map.
It should be emphasized that mapping FF susceptibility using the ML approach requires two types of variables to feed the model, the dependent variable (1) and the independent variable (2):
(1): The dependent variable represents the FF and non-FF areas and can be collected using a variety of techniques, with field survey and satellite remote sensing techniques being the most useful. However, due to the conditions and flash occurrence of this phenomenon, it is not always possible to process a field survey. For this reason, many studies focus on remote sensing techniques to estimate the extent of FFs using satellite imagery, especially synthetic aperture radar SAR data [
18,
19,
20], with sensors able to pierce clouds and heavy rainfall during FFs and post-flood events [
19].
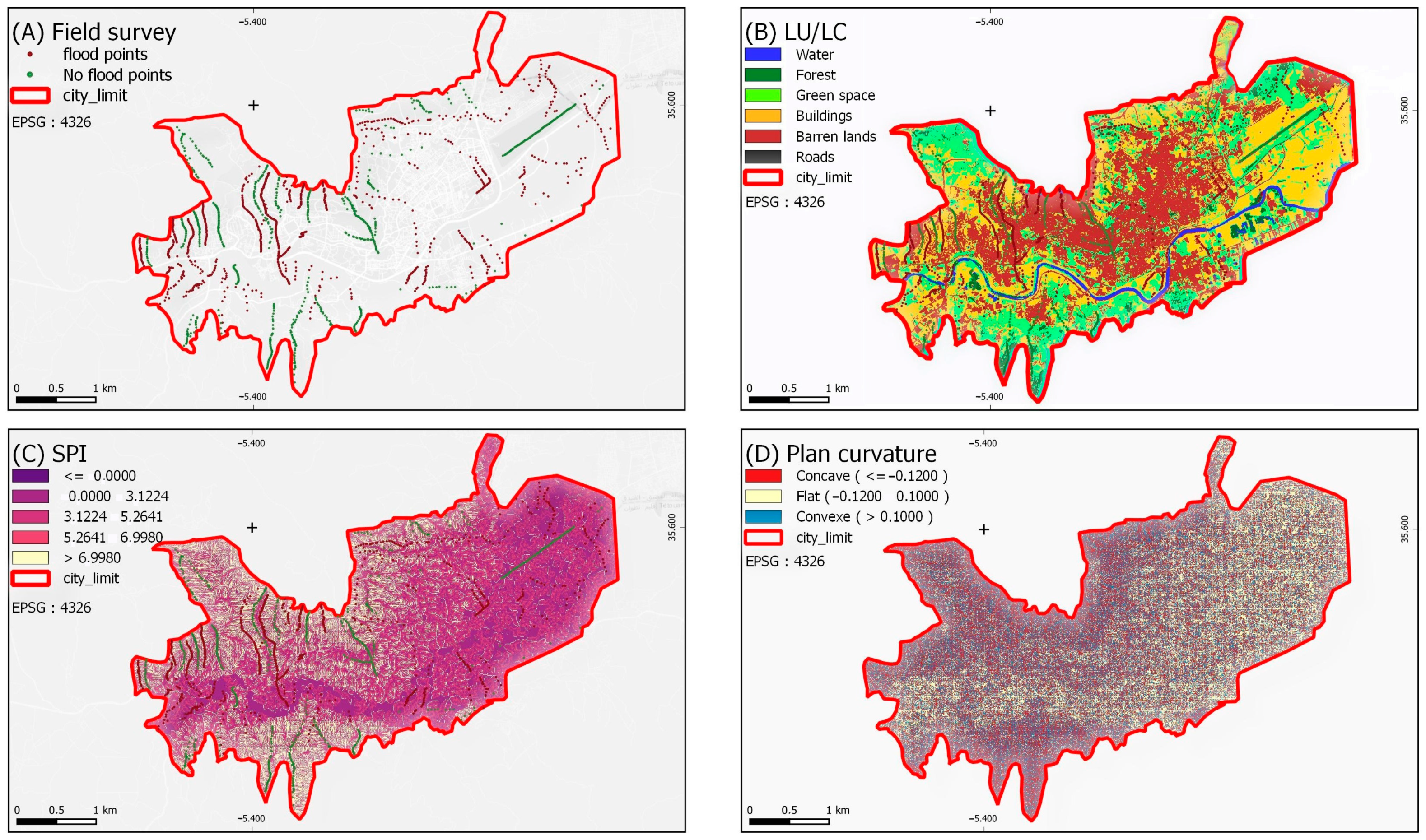
(2): The independent variable, on the other hand, indicates the climatic, hydrological, and geographical conditions that affect the event’s occurrence. Among these factors are the topographic wetness index (TWI), stream power index (SPI), flow accumulation (FA), plan curvature (PC), convergence index (CI), topographic position index (TPI), elevation, aspect, slope, and LULC. The last factor is the variable with the highest impact; hence, the correct mapping of LULC is extremely important.
Most studies in recent years have attempted to map LULC using cloud computing platforms such as GEE, which is considered an all-in-one cloud computing platform with an archive of petabytes of geospatial data freely available for visualization and analysis without having to download data or work on local software. It also enables quick selection of the best satellite imagery based on multiple criteria, the use of specific aggregation functions, and the comparison of different compositions to process the best classification. As an example, the research by Liu et al. [
21] employed time series data from GEE and a random forest model in Ganan Prefecture to generate LULC change. Similarly, Feizizadeh et al. [
22] employed ML techniques on GEE in Northern Iran to assess changes in LULC based on a time series image of Landsat. In addition, Nasiri et al.’s study [
23] compared two composition techniques using GEE for producing precise LULC maps over Tehran Province (Iran) using Sentinel-2 and Landsat-8. LULC is not only among the factors that contribute to FF susceptibility but is also considered a key element of FF exposure.
The FF is a localized flood that happens quickly and lasts for a short time (less than 6 h). It is caused by intense precipitation in a small watershed (often less than 100 km
2) [
24,
25]. This makes it difficult for authorities to respond effectively to the recovery processes. Determining exposure—the position, physical qualities, and cost of resources that are essential to communities (people, buildings, businesses, agriculture, etc.)—in a fast way is necessary. In response to the previous difficulty, several researchers have turned to the prospect of using GEE because it offers a viable solution concerning rapid analysis and data availability for rapid exposure determination, such as in the study of Shinde et al. [
18], which proposed a semi-automatic flood mapping system as a quick analysis method for impact analysis and damage assessment utilizing GEE. Pandey et al. [
20] employed the Synthetic Aperture Radar (SAR) Sentinel-1A at GEE to monitor widespread floods in the Ganga-Brahmaputra region in 2020 and to calculate the effects of flooding on agriculture and people. To our knowledge, most studies that have used GEE for flood and FF damage assessment use existing LULC datasets (e.g., Copernicus Global Land Cover Layers) rather than creating an accurate LULC map based on high-resolution satellite imagery of the region in question even though it can provide a higher level of identification and specificity, given that the accurate assessment of events requires accurate LULC mapping.
In addition, recent evidence has shown that using GEE to monitor flooding is practical, informative, and user-friendly for decision-makers [
26,
27,
28,
29,
30]. The availability of quickly accessible data is a factor that all researchers agree on. In the context of flooding, SAR data are most commonly used to determine their extent [
20]. However, it is not always available due to the temporal resolution of the satellites, especially in the case of FFs, which are characterized by their rapid occurrence. Therefore, the satellite may occasionally not reach the location of the event; it may take several days or even weeks before it returns to that location and collects new data. Therefore, in situations where SAR data are not available, ML models can be used as a valuable surrogate to determine the hazard of FFs based on other available data sources such as historical FF records as well as climatic, hydrological, and geographical data. However, even when SAR data are available, the use of ML to quantify FF susceptibility can help improve and validate the results obtained from SAR analysis. This is because SAR data only provide information on the extent and severity of flooding or FFs, whereas FF susceptibility models can provide additional information on fundamental variables that influence the occurrence of the event at a particular location. In addition, it is important to assess the damage caused by FFs, identify the most affected regions, and prioritize the allocation of resources for reconstruction and rehabilitation. The results of FF susceptibility or SAR data can help with these assessments by properly supporting details about the type of event and the locations affected.
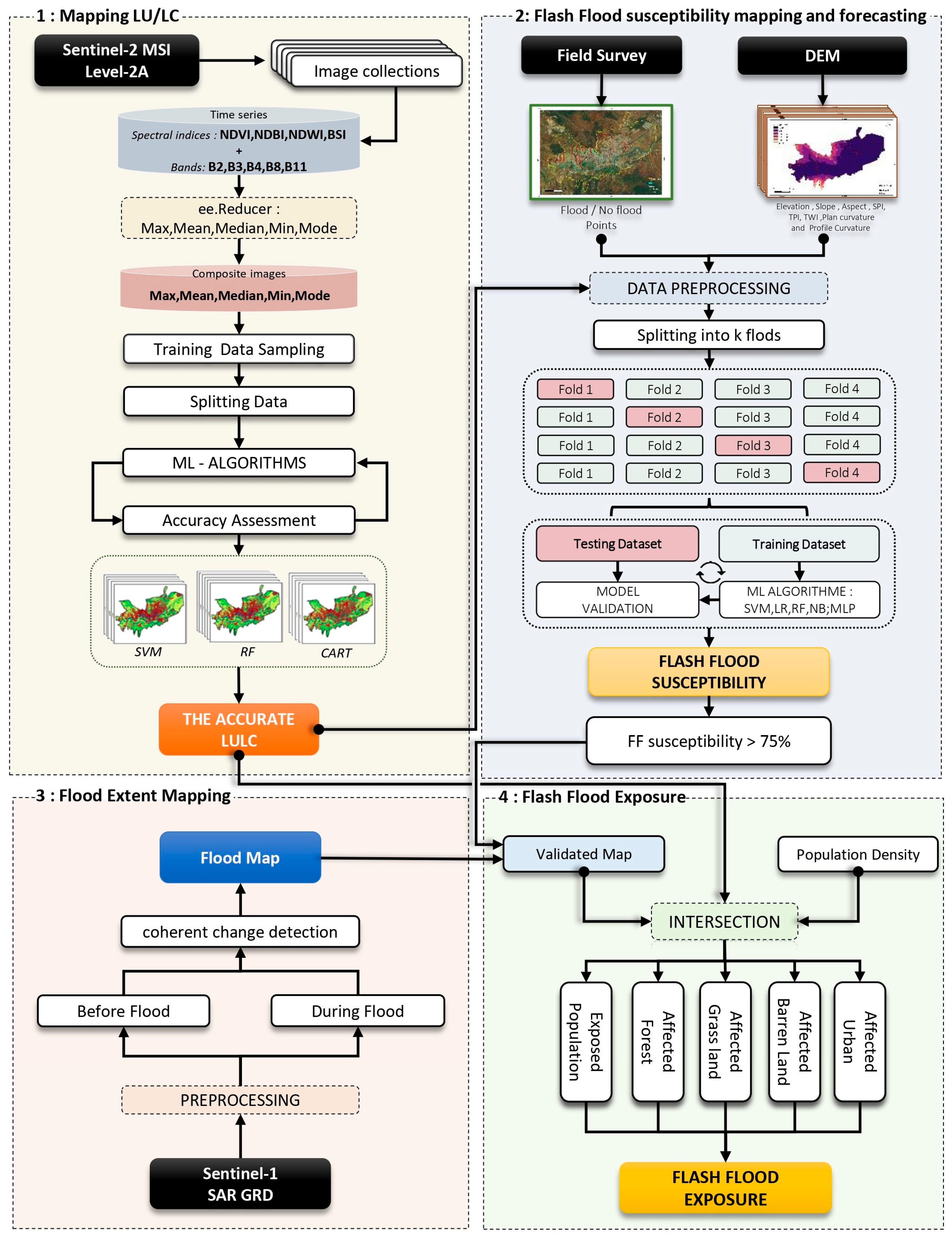
Motivated by recent challenges, a new initiative is proposed that breaks new ground in FF mapping by providing a comprehensive and rigorous framework that utilizes diverse datasets, explores a range of ML algorithms, and evaluates performance across multiple metrics. This study focuses on the major FF that occurred on 1 March 2021, in the northern Moroccan city of Tetouan and presents a precise strategy for detecting and mapping FF damage. Using a comparison of many composite methods (max, min, mean, and median) trained on different machine learning models (SVM, CART, and RF), the LULC will first be mapped. The accurately determined LULC will be one of the criteria for predicting FF susceptibility using several ML methods (SVM, RF, LR, NB, and MLP). The FF extent will also be extracted using SAR data, and the exposure assessment will be concluded by overlaying all obtained data.
4. Discussion
Over the past three years, Tetouan has been confronted with numerous FFs, with an average of one per year, causing major damage. This prompted us to try to understand and map the pattern of these FFs, taking the FF of 2021 as an example. Our main objective was to assess the damage during and after the event using remotely available data and utilizing a cloud computing platform (GEE) enhanced with ML algorithms.
Based on the initial results of this study, the effectiveness of the proposed methodology has been well demonstrated; however, the limitations and possible sources of uncertainty need to be addressed.
The first result obtained in this study is LULC. In that section, we aimed to evaluate several composites (Min, Max, Median, Mode, and Min) using three ML algorithms (SVM, RF, and NB) to determine those that can be used for the rest of our study. This assessment was based on Sentinel-2 imagery rather than Landsat imagery as the latter has been used by most researchers when using GEE [
48,
49]. Our decision was influenced by the study area’s morphology, which is made up of small condensed districts, and also by the diversity of land classes, which requires good spatial resolution (10 m in Sentinel 2 instead of 30 m in Landsat).
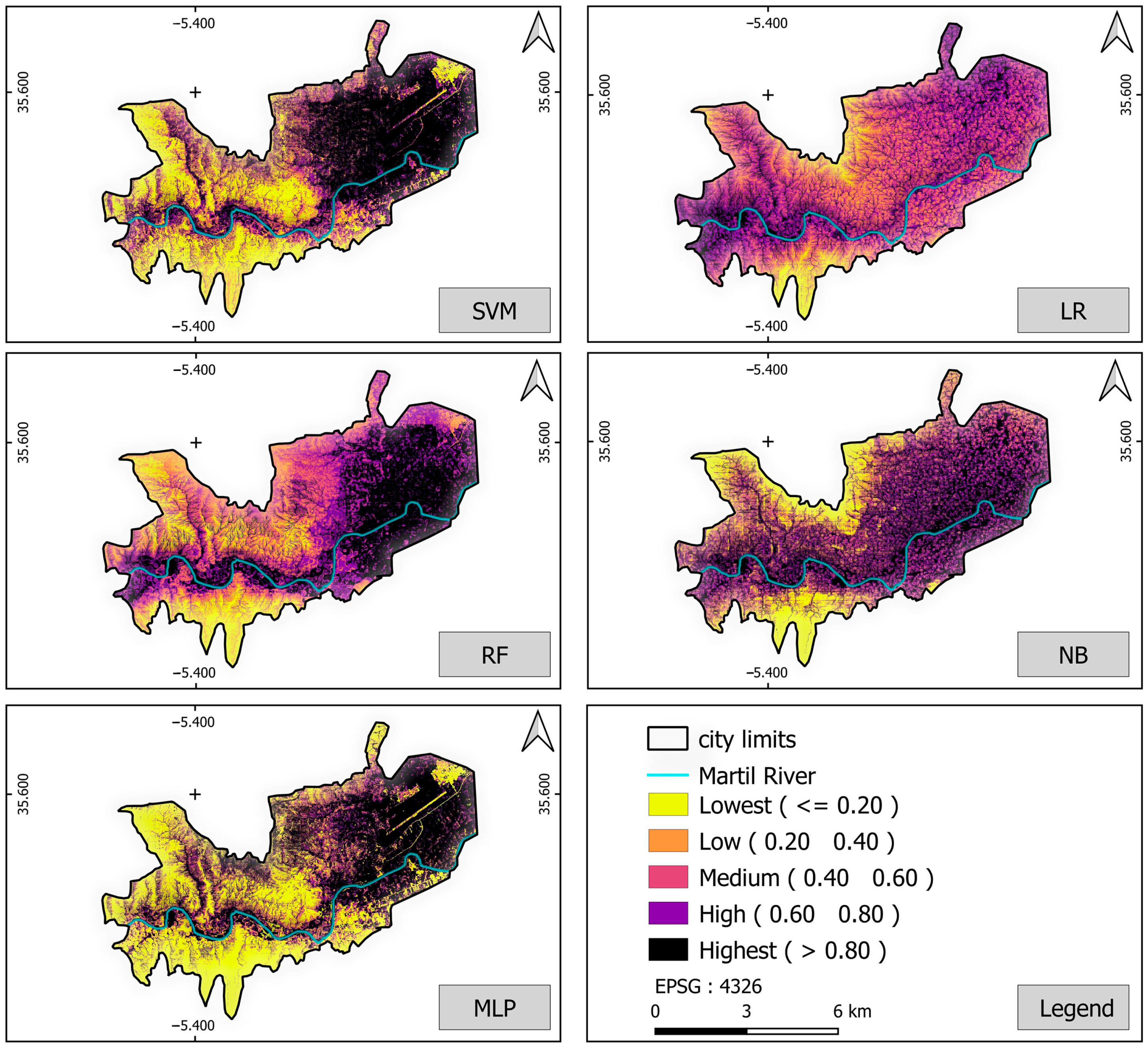
The fifteen maps produced were compared (
Figure 7). This comparison in terms of OA and Kappa index gave us reasonable results, according to the USGS and Gashaw et al. [
50], who recommended accuracies of 85% and 80%, respectively. The best classification threshold in our case was that of SVM; it performed best for all composites (except the Min composite). The results were confirmed by many researchers who chose to use SVM to map LULC [
51,
52,
53]. Our approach was not only about identifying the best classifiers but also about testing performance based on multiple composites. All composites created in our study are based on a collection of images from three seasons (summer, autumn, and spring). We excluded the winter season due to the large number of clouds. A comparison between the composites used also leads to the conclusion that the mean composite performed best out of all classifiers. This was confirmed by visual interpretation and can be explained by the fact that using a mean composite reduces temporal variations and atmospheric noise by taking the mean while also mitigating the effects of cloud cover. Nevertheless, the mean composite has a weakness in some cases as it is influenced by outliers. Therefore, in the literature, we have found that some authors use the median instead of the mean [
23,
54,
55]. The choice of the best composite between median and mean depends entirely on the morphology of the area studied, the data specificity, and the LULC generation objective. We have chosen to use a mean composite classified by SVM for the remainder of our study, but it should be mentioned that, despite the accuracy of the results obtained, they could be improved by introducing other topographical factors into the training part of our models, which has proved their effectiveness in several studies [
21,
34,
56].
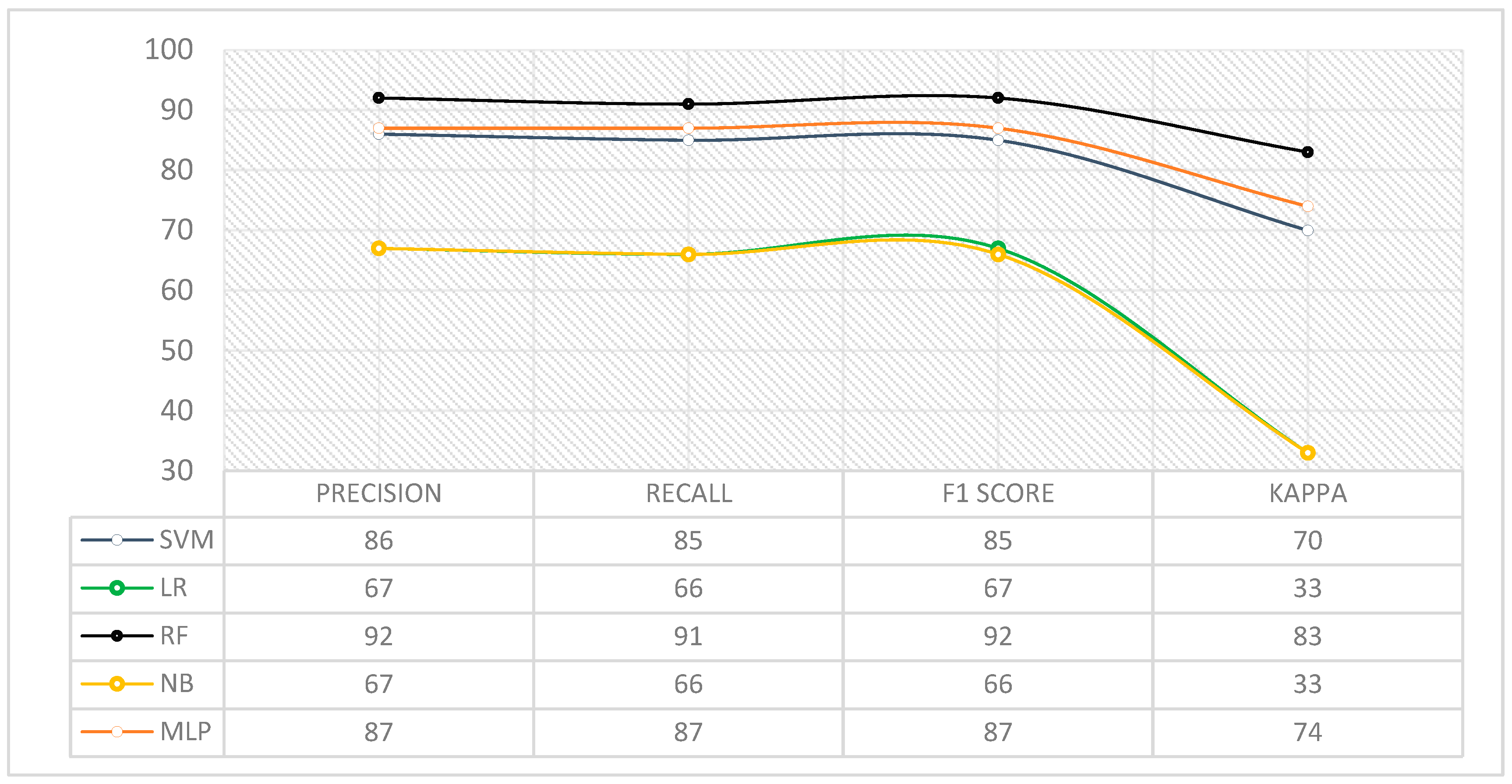
The second result generated is the FF susceptibility. For this purpose and to obtain an accurate result, we trained our models based on five ML algorithms (SVM, LR, LR, RF, NB, and MLP), with the conclusion that RF is the best classifier, which corresponds to previous studies [
57,
58,
59]. Therefore, we trained all our algorithms based on nine factors (topographic wetness index, LULC, profile curvature, topographic index, stream power index, plan curvature, elevation, aspect, and slope). Most studies with the same objective as ours have introduced rainfall as a factor directly influencing flooding [
60,
61,
62,
63]. Still, in our study, we neglected it because our region of interest is small and the same amount of precipitation is found all around it, so rainfall will have the same effect at any point in the region. This fact has been confirmed by numerous studies, of which the study by Shahabi et al. [
38] is the best example. Rainfall was introduced as a factor in the first part of the study but ultimately, it was confirmed that the relationship between rainfall and flooding is more complex than a simple correlation between the quantity of rainfall and flood intensity.
Based on the Pearson correlation analysis presented in
Figure 12, it is possible to understand the strength of the relationships between the different variables. In terms of TPI and plan curvature, TPI measures the relative elevation of a point while PC assesses the relative curvature of the terrain in the direction of the slope. Since higher elevations tend to have less curvature, it is logical that TPI and PC have a strong negative correlation. Concerning slope and DEM, areas with higher DEM values tend to have steeper slopes, which explains the strong positive correlation between these two variables. In the same way, TWI and FF occurrence show a strong positive correlation because areas with higher TWI values are more likely to experience flooding, while areas at lower elevations are more vulnerable to flooding, which explains the strong negative correlation between FF occurrence and DEM. Regarding TWI and slope, wetter areas are more likely to have flatter terrain, resulting in a moderate negative correlation between TWI and slope. TWI and DEM have a moderate negative correlation, as higher DEM values (higher elevations) tend to be drier, with water flowing downhill towards lower elevations. Plane curvature and profile curvature measure opposite aspects of the surface’s curvature. Therefore, it is logical that they have a moderately negative correlation. Lower TPI values and steeper slopes are linked to higher FF risk. This is because lower TPI values indicate lower elevations and steeper slopes create more runoff, possibly leading to flooding. LULC and the other variables in the dataset are not directly related to each other. For example, a change in LULC does not necessarily lead to a change in SPI, DEM, TPI, plan, or profile. This explains the weak correlations between LULC and all variables. Finally, SPI is a measure of a stream’s erosive power over time, while the other variables in the dataset are measures of various environmental characteristics at a specific location. This explains the relatively weak correlations between SPI and most variables. It should be noted that the previous studies did not all use the same variables; rather, different variables were used in each study. In essence, the decision depends on the morphology of the study area and the nature of the event; in fact, there is no precise consensus regarding the factors that must be taken into account, but in general, it is preferable to use more than six factors to minimize the production of reflective weights that are influenced by a single weight, leading to an overestimation of certain factors responsible for flooding [
64].
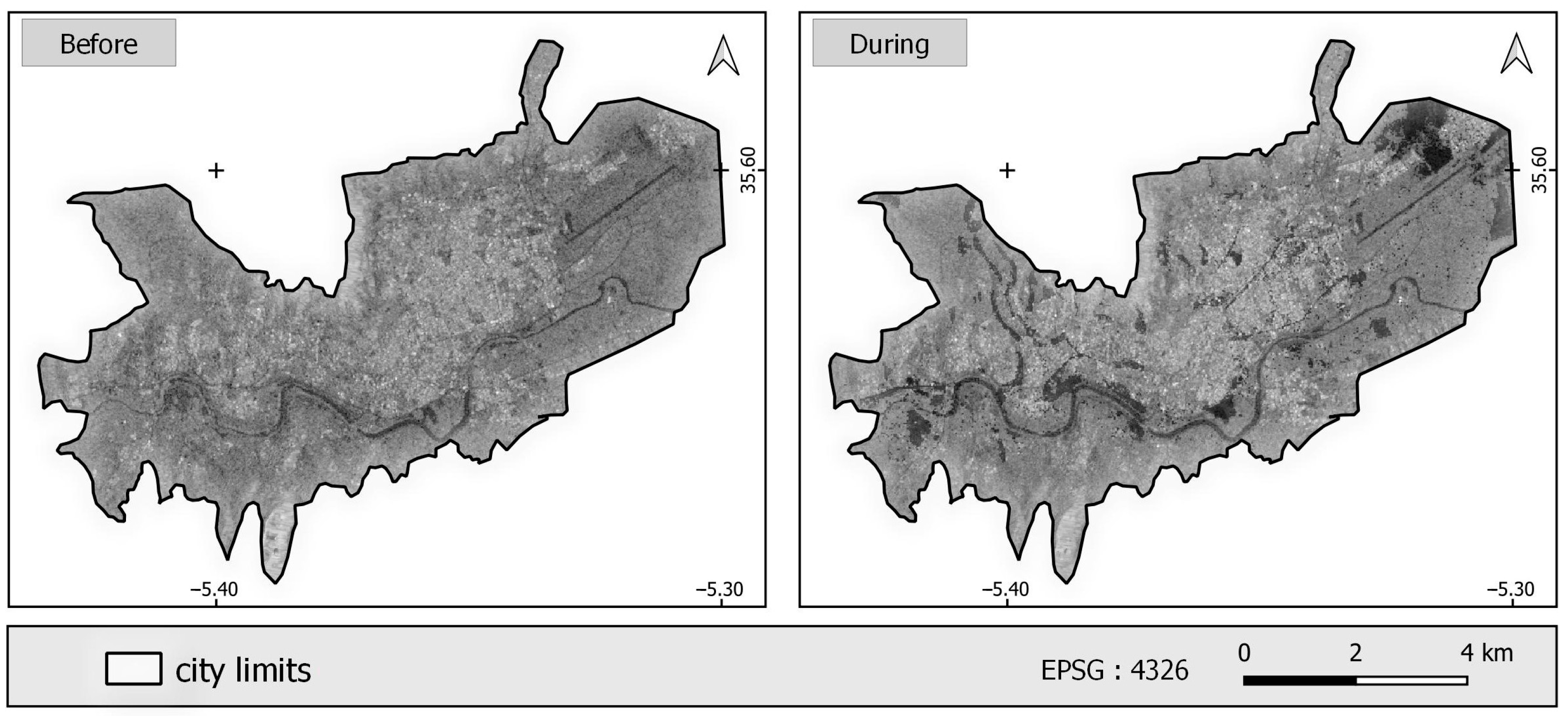
Instead of the previous result, which gives an overview of the basic variables that influence the occurrence of the event at each location with the degree of susceptibility to FFs, we needed to closely monitor FFs before and after to determine the extent and severity, and this was achieved by using Sentinel-1A SAR GRD data, which are considered a powerful backup that provides useful information for FF monitoring both during the day and at night, regardless of cloud cover. However, despite these advantages, it is not always possible to use these data due to their temporal resolution, which is usually 6–12 days, depending on where you are. This temporal resolution may not be sufficient to track the progression of flooding as the water changes rapidly. In addition, the spatial resolution of 10 m is not enough to determine the true FF extent in the small streets and neighborhoods, as was the case in the Old Town in our region. Our result was validated using high FF susceptibility and the field survey points with an accepted score.
The final level of analysis in our study was to determine exposure. The difficulty lies in the accuracy of the results we had to use: for LULC, we used the best results of the first outcome (
Section 3.3), for FF susceptibility, we used the precise result of the high-accuracy algorithm (
Section 3.3), and for the FF extent, we used the SAR data (
Section 3.4). To this end, we integrated these different data sets as well as field monitoring points (FF and non-FF points). The SAR data were used to identify potentially FF-prone areas, although their effectiveness in urban environments is limited. The identification of areas with high FF susceptibility (>75%) was used to localize areas at high risk of FFs. In addition, the overlay of field survey points was used to validate and improve exposure results. By overlaying these three results with LULC and population data, we were able to identify the types of land use likely to be exposed and extract the exposed population. It is important to note that areas with false positive results indicating the existence of FFs were filtered out and excluded. This procedure ensures that disaster preparedness strategies and mitigation measures are effectively targeted through the accurate extraction of data relating to actual FFs. The results of the intersectional study show that the region is located in a high disaster-risk zone and that rapid action is needed to limit the impact of the impending FF on people’s lives and economic situations.
Despite the high degree of accuracy achieved in our study, a visual interpretation of the final products shows some irregularities in certain areas, particularly those located in the condensed districts. This prompts us to think systematically about how to improve our final result. After analyzing our dataset, we concluded that improvements at this level are not possible, as all datasets used in our study are open-availability datasets with a 10 m spatial resolution. Therefore, advancements can be made in future research by using the same methodology, which has proven effective despite the use of low-resolution open data, but this time with commercial satellite data with high spatial resolution, such as data from Maxar (during major fatal natural disaster cases, it is often offered free of charge), Planet Labs, and Airbus Defense, or with government satellite imagery, as in the case of our study area, with the Moroccan satellites Mohammed 6 A and B. The latest commercial datasets proposed can be very important for accurate LULC mapping, with a spatial resolution of up to 30 cm. For DEM generation and FF mapping, we propose to use data from commercial SAR satellites, such as the Terra SARX radar satellite, with a spatial resolution of up to 25 cm. Furthermore, the use of LIDAR data is strongly advocated, and various studies have demonstrated their utility, particularly since the data can capture extreme features of a terrain [
65], which may help in the production of very accurate DEMs and therefore increase modeling accuracy. Another effective method is the use of UAVs (unmanned aerial vehicles) equipped with sensors that differ according to the type of use. This is also considered an effective method of pre- and post-event monitoring and has proven its worth in numerous disasters.
Faced with the explosion of the population in all of the cities in the world, climate change, and an increase in disasters, we are faced with the challenge of reducing disasters; in fact, we cannot stop them, but we can reduce their effect, and it is time for all management strategies to take resilience into account and try to make the city resilient to disasters. Resilience is not about stopping disasters from occurring but rather about reducing their impact.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}