
Automatic Identification of Pangolin Behavior Using Deep Learning Based on Temporal Relative Attention Mechanism

Abstract
Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Data Collection
2.2. Data Set Annotation Definition
2.3. Data Set Making
2.4. Data Set Structure
2.5. Behavior Recognition Model Structure
2.5.1. Backbone
2.5.2. PBATn Head
2.5.3. PBATn Improvement
2.6. Network Workflow
2.7. Behavior Recognition Evaluation Metrics
3. Result
3.1. Model Training Process Analysis
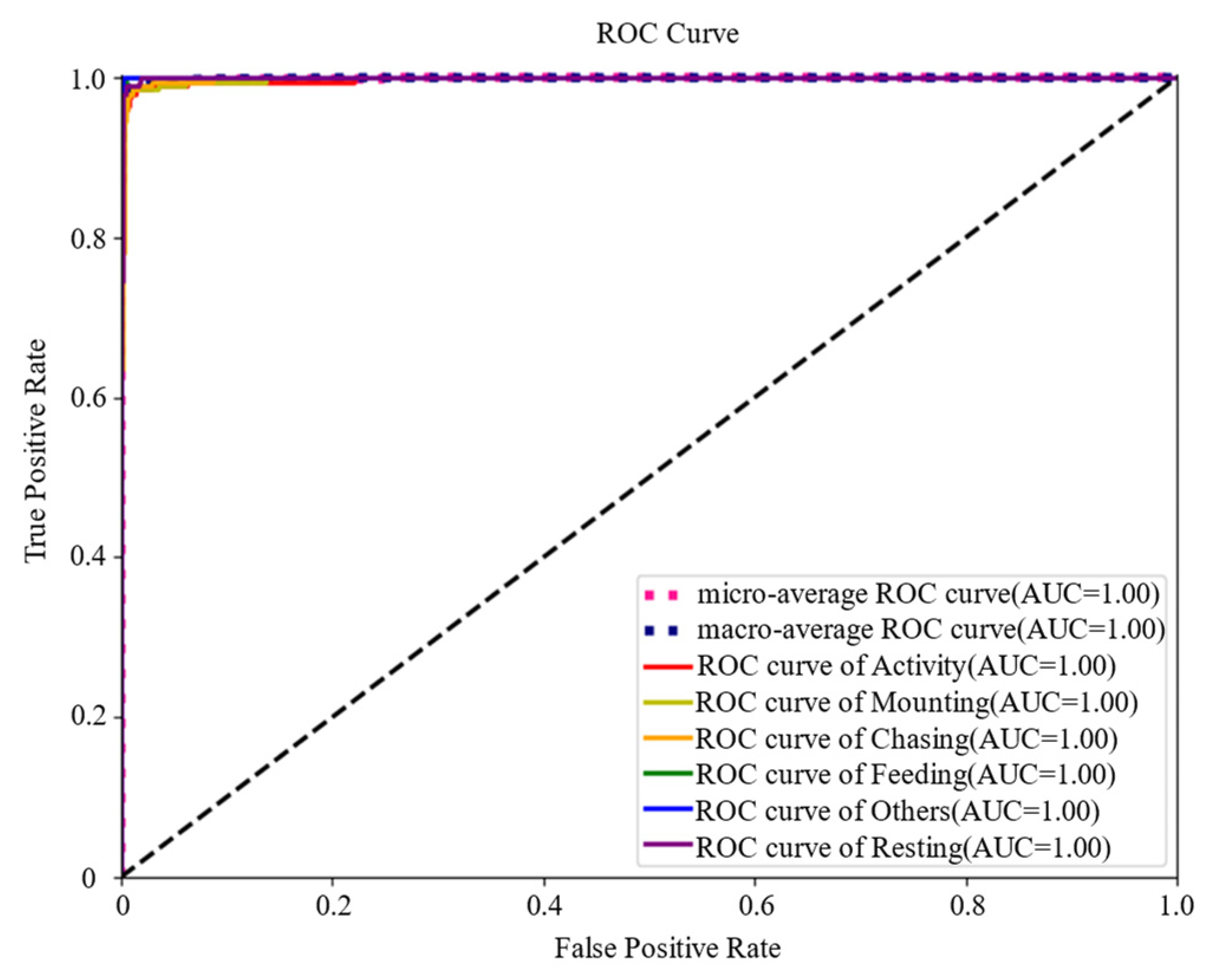
3.2. Identification Result of PBATn Network
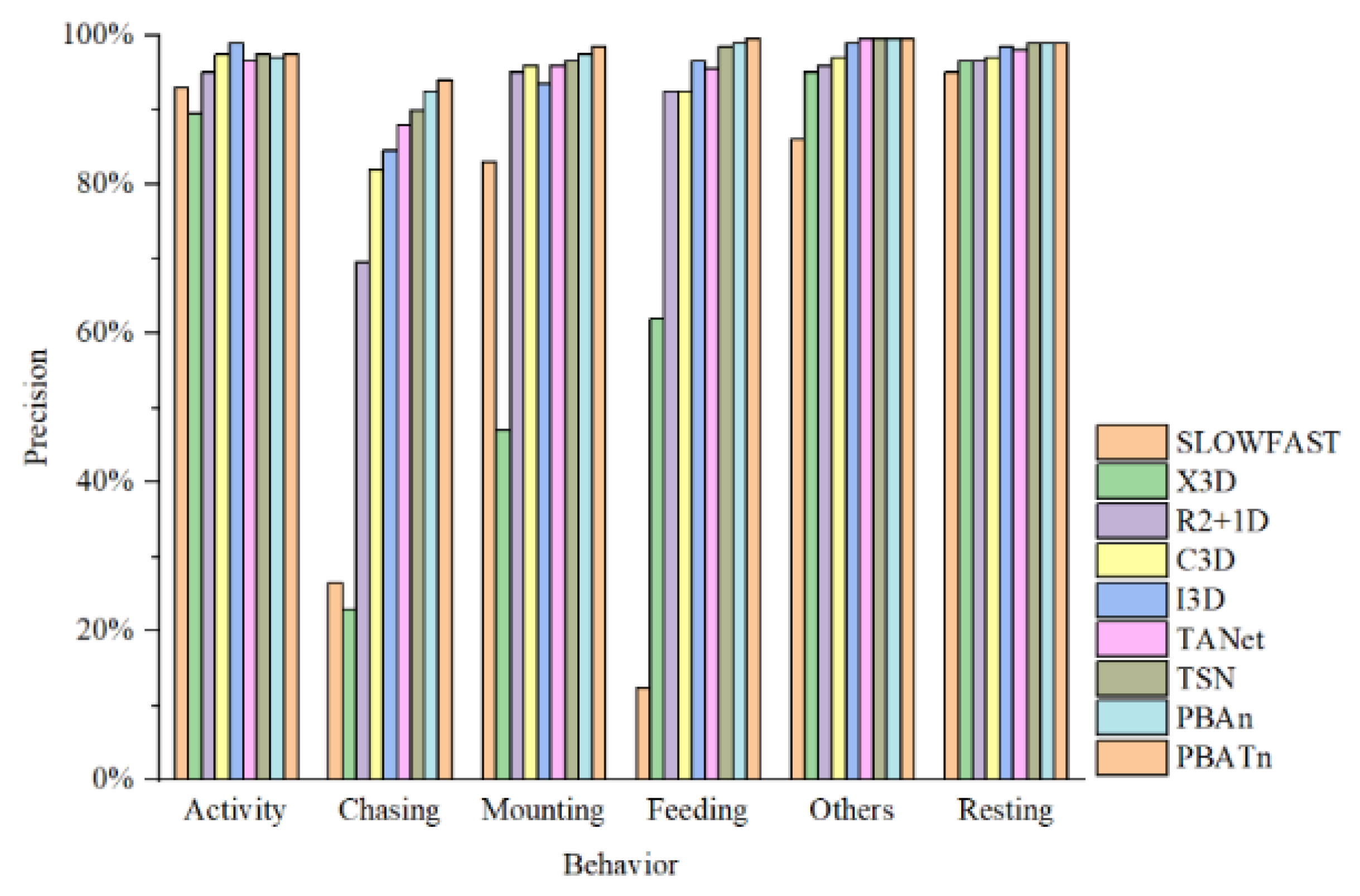
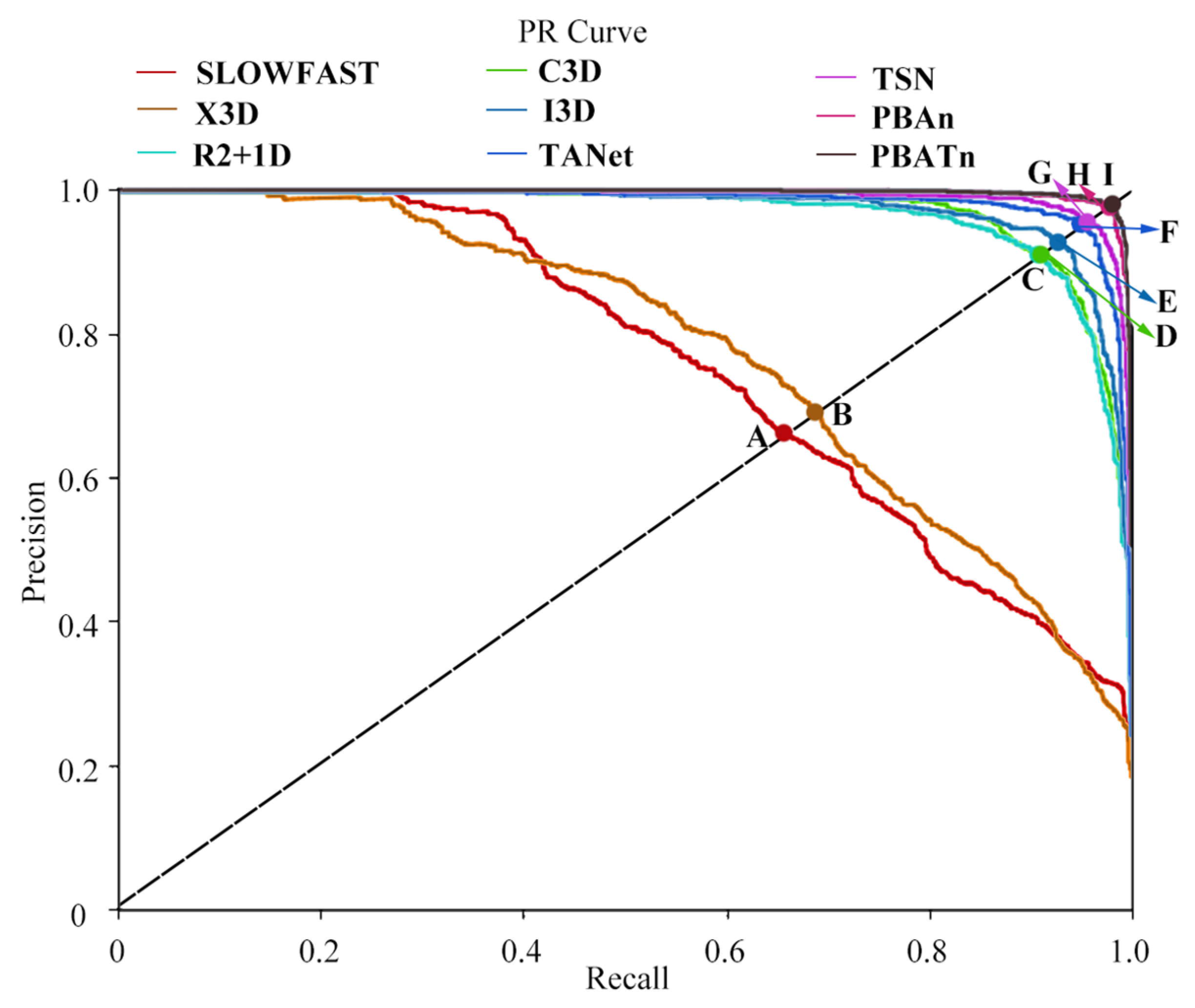
3.3. Comparison Results with Other Networks
4. Discussion
4.1. Discussion of Data Processing
4.2. Discussion of PBATn
4.3. Discussion of Different Networks
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Breck, S. Sampling Rare or Elusive Species: Concepts, Designs, and Techniques for Estimating Population Parameters, edited by William L. Thompson. Wildl. Soc. Bull. 2006, 34, 897–898. [Google Scholar] [CrossRef]
- Khwaja, H.; Buchan, C.; Wearn, O.R.; Bahaa-El-Din, L.; Bantlin, D.; Bernard, H.; Bitariho, R.; Bohm, T.; Borah, J.; Brodie, J.; et al. Pangolins in global camera trap data: Implications for ecological monitoring. Glob. Ecol. Conserv. 2019, 20, e00769. [Google Scholar] [CrossRef]
- Nash, H.C.; Wong, M.H.G.; Turvey, S.T. Using local ecological knowledge to determine status and threats of the Critically Endangered Chinese pangolin (Manis pentadactyla) in Hainan, China. Biol. Conserv. 2016, 196, 189–195. [Google Scholar] [CrossRef]
- Heinrich, S.; Wittmann, T.A.; Prowse, T.A.; Ross, J.V.; Delean, S.; Shepherd, C.R.; Cassey, P. Where did all the pangolins go? International CITES trade in pangolin species. Glob. Ecol. Conserv. 2016, 8, 241–253. [Google Scholar] [CrossRef]
- Wu, S.; Zhang, F.; Zou, C.; Wang, Q.; Li, S.; Sun, R. A note on captive breeding and reproductive parameters of the Chinese pangolin, Manis pentadactyla Linnaeus, 1758. ZooKeys 2016, 618, 129–144. [Google Scholar] [CrossRef] [PubMed]
- Sun, N.C.; Pei, K.J.; Wu, L.Y. Long term monitoring of the reproductive behavior of wild Chinese pangolin (Manis pentadactyla). Sci. Rep. 2021, 11, 18116. [Google Scholar] [CrossRef] [PubMed]
- Gaude, I.; Kempf, A.; Strüve, K.D.; Hoedemaker, M. Estrus signs in Holstein Friesian dairy cows and their reliability for ovulation detection in the context of visual estrus detection. Livest. Sci. 2021, 245, 104449. [Google Scholar] [CrossRef]
- Camerlink, I.; Proßegger, C.; Kubala, D.; Galunder, K.; Rault, J.L. Keeping littermates together instead of social mixing benefits pig social behavior and growth post-weaning. Appl. Anim. Behav. Sci. 2021, 235, 105230. [Google Scholar] [CrossRef]
- Weixing, Z.; Yong, W. Research on the recognition of pig behavior based on contour features. In Proceedings of the 2011 International Conference on Computers, Communications, Control and Automation Proceedings (CCCA 2011 V2), Hong Kong, China, 20–21 February 2011; pp. 198–201. [Google Scholar]
- Shao, B.; Xin, H. A real-time computer vision assessment and control of thermal comfort for group-housed pigs. Comput. Electron. Agric. 2007, 62, 15–21. [Google Scholar] [CrossRef]
- Zhu, W.X.; Guo, Y.Z.; Jiao, P.P.; Ma, C.H.; Chen, C. Recognition and drinking behavior analysis of individual pigs based on machine vision. Livest. Sci. 2017, 205, 129–136. [Google Scholar] [CrossRef]
- Kashiha, M.; Bahr, C.; Haredasht, S.A.; Ott, S.; Moons, C.P.; Niewold, T.A.; Ödberg, F.O.; Berckmans, D. The automatic monitoring of pigs water use by cameras. Comput. Electron. Agric. 2013, 90, 164–169. [Google Scholar] [CrossRef]
- Kashiha, M.A.; Bahr, C.; Ott, S.; Moons, C.P.; Niewold, T.A.; Tuyttens, F.; Berckmans, D. Automatic monitoring of pig locomotion using image analysis. Livest. Sci. 2014, 159, 141–148. [Google Scholar] [CrossRef]
- Nasirahmadi, A.; Edwards, S.A.; Matheson, S.M.; Sturm, B. Using automated image analysis in pig behavioral research: Assessment of the influence of enrichment substrate provision on lying behavior. Appl. Anim. Behav. Sci. 2017, 196, 30–35. [Google Scholar] [CrossRef]
- Yang, A.; Huang, H.; Yang, X.; Li, S.; Chen, C.; Gan, H.; Xue, Y. Automated video analysis of sow nursing behavior based on fully convolutional network and oriented optical flow. Comput. Electron. Agric. 2019, 167, 105048. [Google Scholar] [CrossRef]
- Guo, Y.; Zhang, Z.; He, D.; Niu, J.; Tan, Y. Detection of cow mounting behavior using region geometry and optical flow characteristics. Comput. Electron. Agric. 2019, 163, 104828. [Google Scholar] [CrossRef]
- Lee, J.; Jin, L.; Park, D.; Chung, Y. Automatic Recognition of Aggressive Behavior in Pigs Using a Kinect Depth Sensor. Sensors 2016, 16, 631. [Google Scholar] [CrossRef] [PubMed]
- Huang, W.; Zhu, W.; Ma, C.; Guo, Y.; Chen, C. Identification of group-housed pigs based on Gabor and Local Binary Pattern features. Biosyst. Eng. 2018, 166, 90–100. [Google Scholar] [CrossRef]
- Nasirahmadi, A.; Sturm, B.; Olsson, A.-C.; Jeppsson, K.-H.; Müller, S.; Edwards, S.; Hensel, O. Automatic scoring of lateral and sternal lying posture in grouped pigs using image processing and Support Vector Machine. Comput. Electron. Agric. 2019, 156, 475–481. [Google Scholar] [CrossRef]
- Fuentes, A.; Yoon, S.; Park, J.; Park, D.S. Deep learning-based hierarchical cattle behavior recognition with spatio-temporal information. Comput. Electron. Agric. 2020, 177, 105627. [Google Scholar] [CrossRef]
- Li, D.; Zhang, K.; Li, Z.; Chen, Y. A Spatiotemporal Convolutional Network for Multi-Behavior Recognition of Pigs. Sensors 2020, 20, 2381. [Google Scholar] [CrossRef] [PubMed]
- Wang, M.; Larsen, M.; Bayer, F.; Maschat, K.; Baumgartner, J.; Rault, J.L.; Norton, T. A PCA-based frame selection method for applying CNN and LSTM to classify postural behavior in sows. Comput. Electron. Agric. 2021, 189, 106351. [Google Scholar] [CrossRef]
- Qiumei, Y.; Deqin, X.; Jiahao, C. Pig mounting behavior recognition based on video spatial–temporal features. Biosyst. Eng. 2021, 206, 55–66. [Google Scholar]
- Wang, R.; Bai, Q.; Gao, R.; Li, Q.; Zhao, C.; Li, S.; Zhang, H. Oestrus detection in dairy cows by using atrous spatial pyramid and attention mechanism. Biosyst. Eng. 2022, 223, 259–276. [Google Scholar] [CrossRef]
- Gan, H.; Xu, C.; Hou, W.; Guo, J.; Liu, K.; Xue, Y. Spatiotemporal graph convolutional network for automated detection and analysis of social behaviors among pre-weaning piglets. Biosyst. Eng. 2022, 217, 102–114. [Google Scholar] [CrossRef]
- Yun, G.; Pengfei, H.; Jiajun, X.; Xuelin, X.; Bin, C.; Kang, L. Automatic Recognition Algorithm for Sika Deer Attacking Behaviors Based on Optical Current Attention Network. Trans. Chin. Soc. Agric. Mach. 2022, 53, 261–270. [Google Scholar]
- Gong, H.; Deng, M.; Li, S.; Hu, T.; Sun, Y.; Mu, Y.; Wang, Z.; Zhang, C.; Tyasi, T.L. Sika Deer Behavior Recognition Based on Machine Vision. Comput. Mater. Contin. 2022, 73. [Google Scholar] [CrossRef]
- Yunfei, W.; Rong, L.; Zheng, W.; Zhixin, H.; Yitao, J.; Yuanchao, D.; Huaibo, S. E3D: An efficient 3D CNN for the recognition of dairy cow’s basic motion behavior. Comput. Electron. Agric. 2023, 205, 107607. [Google Scholar]
- Zhou, B.; Andonian, A.; Oliva, A.; Torralba, A. Temporal Relational Reasoning in Videos. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 803–818. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 7132–7141. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006; p. 738. [Google Scholar]
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. Slowfast networks for video recognition. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6202–6211. [Google Scholar]
- Feichtenhofer, C. X3D: Expanding Architectures for Efficient Video Recognition. arXiv 2020, arXiv:2004.04730. [Google Scholar]
- Powers, D.M.W. Evaluation: From precision, recall and f-measure to roc, informedness, markedness & correlation. arXiv 2020, arXiv:2010.16061. [Google Scholar] [CrossRef]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features with 3D Convolutional Networks. arXiv 2014, arXiv:1412.0767. [Google Scholar]
- Tran, D.; Wang, H.; Torresani, L.; Ray, J.; LeCun, Y.; Paluri, M. A closer look at spatiotemporal convolutions for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2018, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6450–6459. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6299–6308. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, L.; Wu, W.; Qian, C.; Lu, T. TAM: Temporal Adaptive Module for Video Recognition. arXiv 2020, arXiv:2005.06803. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Van Gool, L. Temporal segment networks: Towards good practices for deep action recognition. In Computer Vision—ECCV 2016—Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2016; Volume 9912, pp. 20–36. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Batch | 18–19 Aug. 2021 | 16–18 Sept. 2021 | 07–10 Jan. 2022 | 02–07 Mar. 2022 | 17–21 Mar. 2022 |
|---|---|---|---|---|---|
| Pangolin id | Z1 | M5 | Z2, Z6 | Z2, Z6, Z9 | Z8, Z12, M13, M21 |
| Behavior Label | Number of Video Segments | Number of Video Frame |
|---|---|---|
| activity | 3367 | 106,981 |
| chasing | 544 | 17,190 |
| mounting | 2999 | 95,251 |
| feeding | 642 | 19,930 |
| resting | 3274 | 104,759 |
| other | 660 | 19,511 |
| total | 11,476 | 363,622 |
| DataSet | Number of Video Segments | Number of Video Frame | Total Time (min) |
|---|---|---|---|
| training set | 8221 | 260,480 | 4341.32 |
| validation set | 2055 | 65,120 | 1085.33 |
| test set | 1200 | 38,022 | 633.70 |
| total | 11,476 | 363,622 | 6060.35 |
| PBATn | Accuracy | Precision | Recall | Specificity | F1_Score |
|---|---|---|---|---|---|
| activity | 98.75 | 96.50 | 96.00 | 99.30 | 96.20 |
| chasing | 98.83 | 93.00 | 100.00 | 98.80 | 96.37 |
| mounting | 98.67 | 98.50 | 93.80 | 99.70 | 96.10 |
| feeding | 99.67 | 99.50 | 98.50 | 99.90 | 99.00 |
| resting | 99.75 | 99.00 | 99.50 | 99.80 | 99.20 |
| others | 99.33 | 98.50 | 97.50 | 99.70 | 98.00 |
| Average | 99.17 | 97.50 | 97.55 | 99.53 | 97.48 |
| Models | mAP/% | ms/Frame | Params/MB | Flops/G |
|---|---|---|---|---|
| SlowFast [34] | 66.00 | 526.31 | 33.57 | 49.42 |
| X3D [35] | 68.83 | 89.28 | 2.99 | 17.62 |
| R2 + 1D [36] | 90.75 | 800.00 | 63.56 | 286.19 |
| C3D [37] | 93.67 | 666.67 | 54.21 | 63.11 |
| I3D [38] | 95.17 | 202.02 | 27.24 | 58.58 |
| TANet [39] | 95.58 | 370.37 | 24.78 | 51.04 |
| TSN (improved) [40] | 96.83 | 142.86 | 23.52 | 51.03 |
| OUR (PBAn) | 97.00 | 66.01 | 31.51 | 40.62 |
| OUR (PBATn) | 97.50 | 11.79 | 22.70 | 40.62 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, K.; Hou, P.; Xu, X.; Gao, Y.; Chen, M.; Lai, B.; An, F.; Ren, Z.; Li, Y.; Jia, G.; et al. Automatic Identification of Pangolin Behavior Using Deep Learning Based on Temporal Relative Attention Mechanism. Animals 2024, 14, 1032. https://doi.org/10.3390/ani14071032
Wang K, Hou P, Xu X, Gao Y, Chen M, Lai B, An F, Ren Z, Li Y, Jia G, et al. Automatic Identification of Pangolin Behavior Using Deep Learning Based on Temporal Relative Attention Mechanism. Animals. 2024; 14(7):1032. https://doi.org/10.3390/ani14071032
Chicago/Turabian StyleWang, Kai, Pengfei Hou, Xuelin Xu, Yun Gao, Ming Chen, Binghua Lai, Fuyu An, Zhenyu Ren, Yongzheng Li, Guifeng Jia, and et al. 2024. "Automatic Identification of Pangolin Behavior Using Deep Learning Based on Temporal Relative Attention Mechanism" Animals 14, no. 7: 1032. https://doi.org/10.3390/ani14071032
APA StyleWang, K., Hou, P., Xu, X., Gao, Y., Chen, M., Lai, B., An, F., Ren, Z., Li, Y., Jia, G., & Hua, Y. (2024). Automatic Identification of Pangolin Behavior Using Deep Learning Based on Temporal Relative Attention Mechanism. Animals, 14(7), 1032. https://doi.org/10.3390/ani14071032