
One-Year-Old Precocious Chinese Mitten Crab Identification Algorithm Based on Task Alignment


Abstract
Simple Summary
Abstract
1. Introduction
- (1)
- Introducing ResNeXt as the backbone network, embedding a CBAM in the residual block, and using variable convolution in the last residual block to enhance feature extraction for sexually precocious Chinese mitten crabs.
- (2)
- Combining the ASFF module with the traditional FPN for integrated training to solve feature fusion mismatches and reduce the loss of small-target information.
- (3)
- Conducting experiments on the anchor alignment metric formula to optimize the values of p and q, improving accuracy by adjusting the proportion of s.
2. Materials and Methods
2.1. Data Acquisition
2.1.1. Crab Dataset
2.1.2. Data Preprocessing
2.1.3. Data Augmentation
2.2. Experimental Environment
2.3. Overview of TOOD Framework
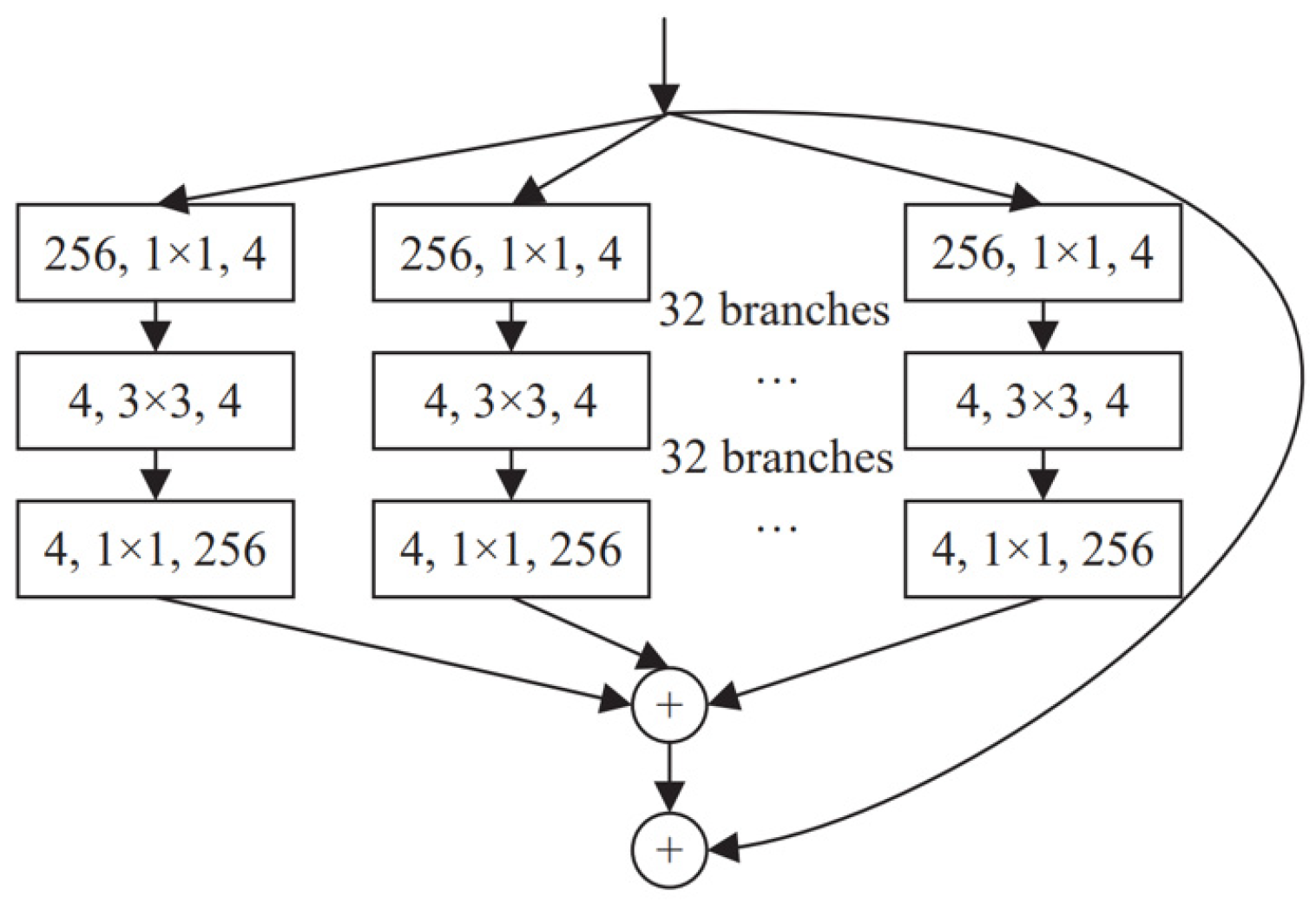
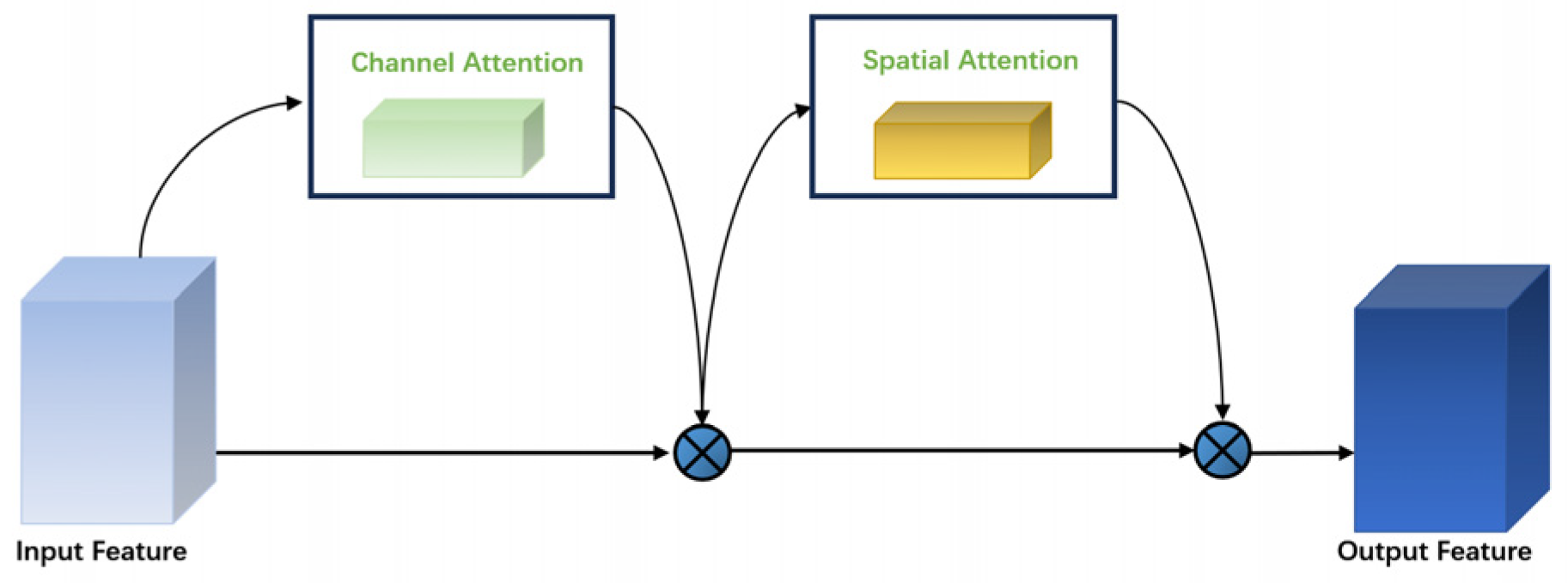
2.4. Improvement of Feature Extraction Network
2.4.1. ResNeXt Network
2.4.2. Convolutional Block Attention Module
2.4.3. Deformable Convolutional Networks
2.5. Improvement of Feature Fusion Module
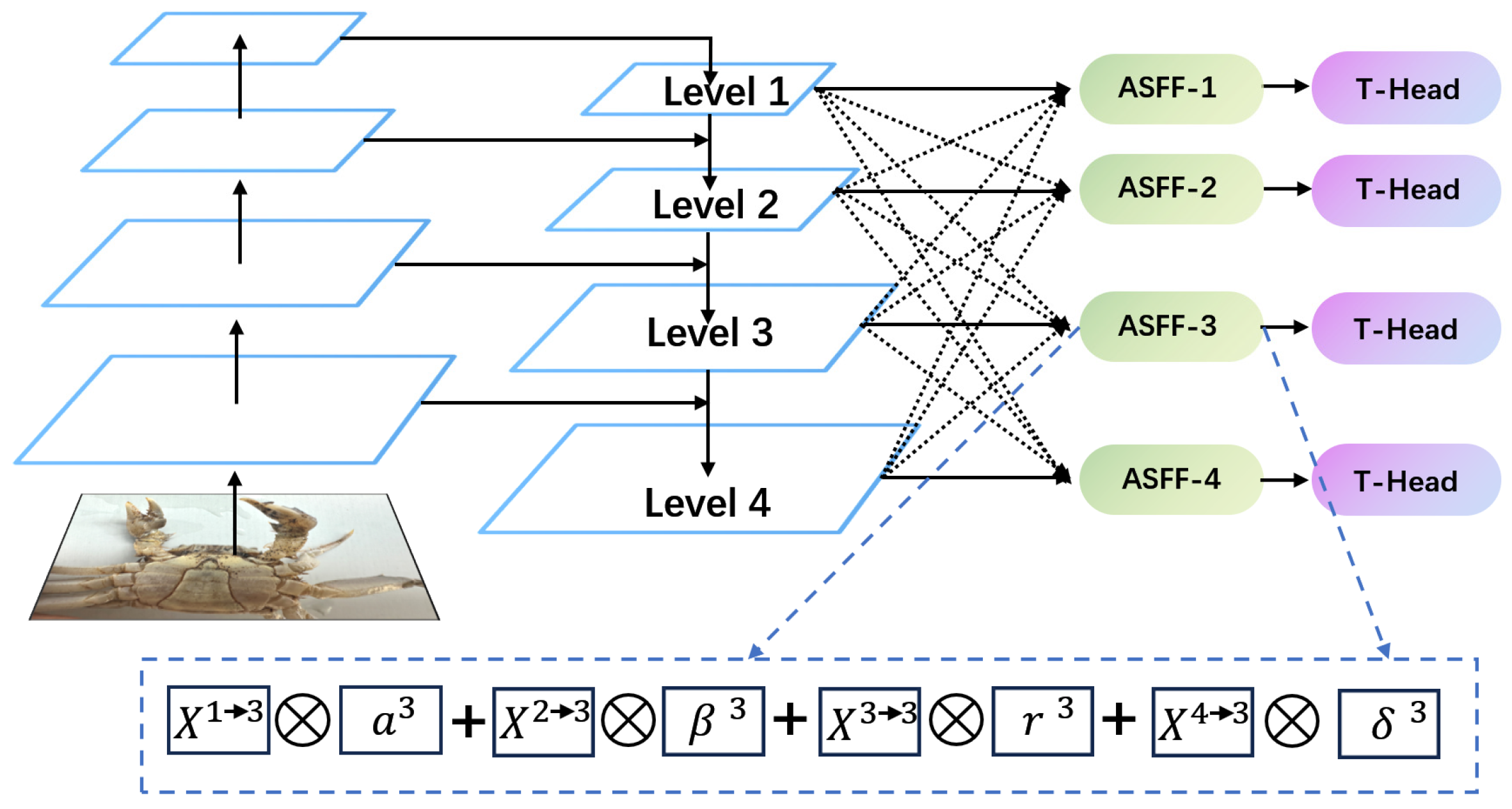
2.5.1. ASFPN
2.5.2. Principle of ASFF Module
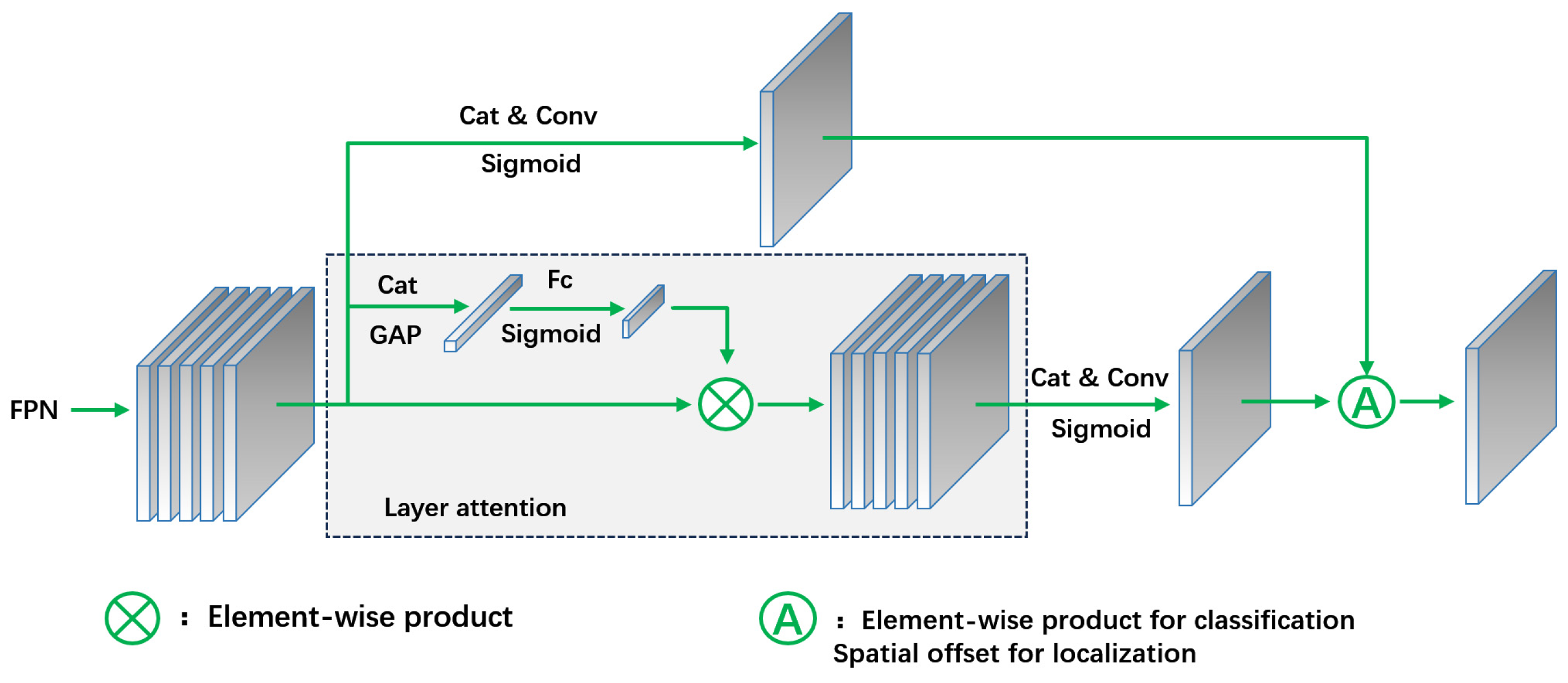
2.6. Improvement of Head Detection
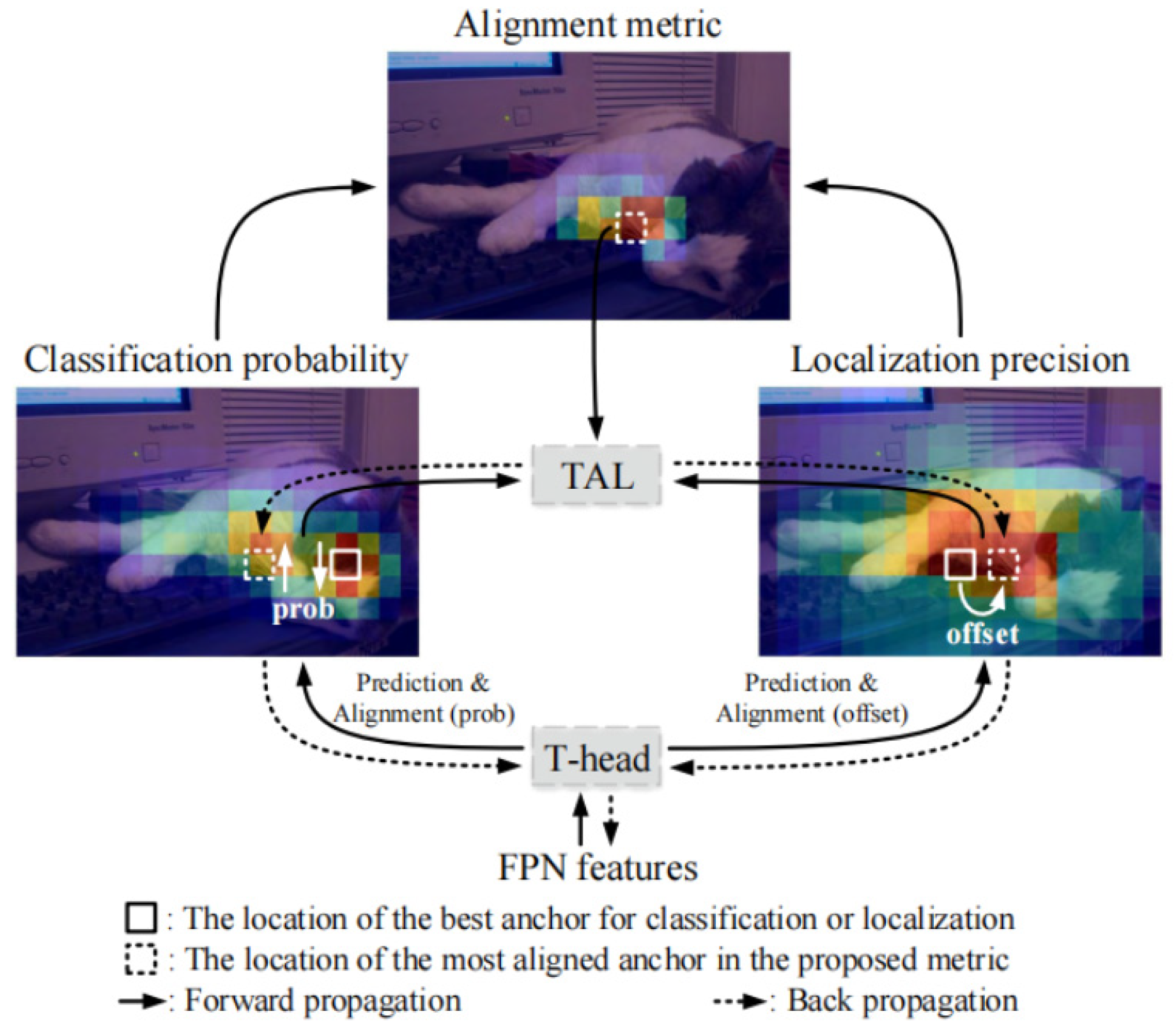
2.6.1. T-Head Feature Alignment
2.6.2. Anchor Alignment Metric
2.7. Evaluation Indicators
3. Results and Analysis
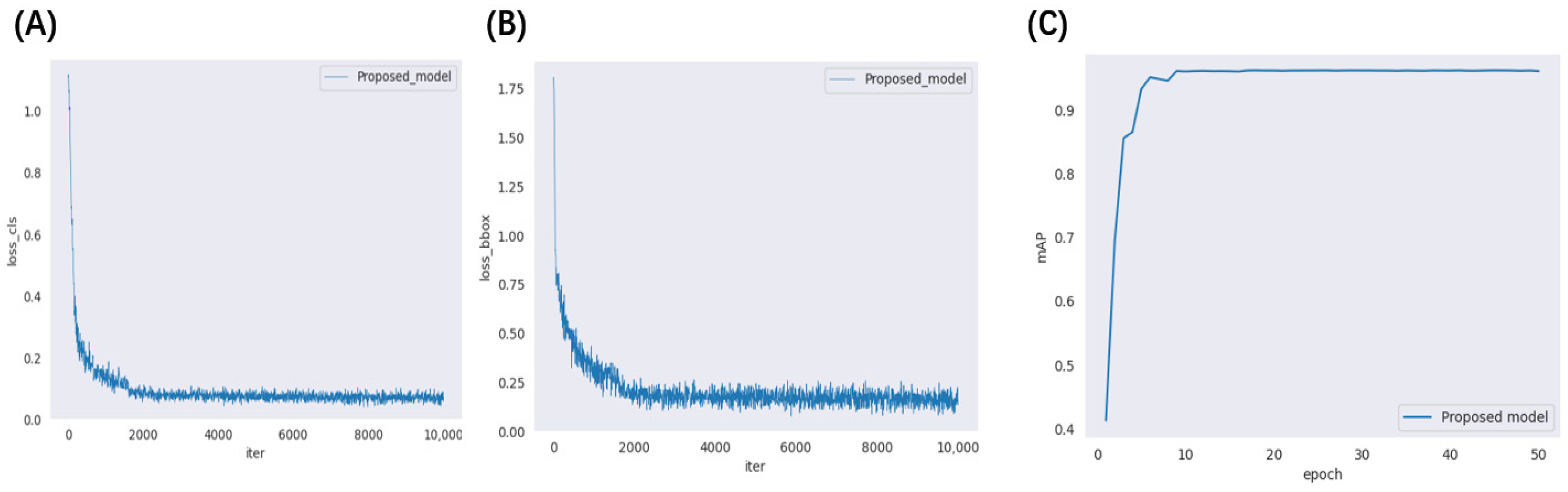
3.1. Model Training and Results
3.2. Ablation Experiment
3.2.1. Comparison of Different Feature Extraction Network Modules
3.2.2. Comparison of Different Feature Fusion Network Modules
3.3. Comparative Analysis with Other Models
3.4. Model Visualization Analysis
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, G.; Jiang, X.; Zhou, W.; Chen, W.; Levy, T.; Wu, X. Stocking density affects culture performance and economic profit of adult all-female Chinese mitten crabs (Eriocheir sinensis) reared in earthen ponds. Aquaculture 2024, 581–594, 740352. [Google Scholar] [CrossRef]
- Pan, Y.; Liu, C.; Hong, Y.; Li, Y.; Yang, H.; Lin, B.; Dong, Z.; Lou, Y.; Fu, S. Natural versus artificial seawater: Impacts on antioxidant capacity, muscle quality and gut microbiota of Acanthopagrus schlegelii during temporary rearing. Aquaculture 2024, 585–591, 740699. [Google Scholar] [CrossRef]
- Zeng, J.; Tian, J.; Kan, D.; Han, C.; Fei, X.; Ma, X.; Wang, Z.; Shen, W.; Yang, J.; Ge, J. Study of filtration, digestion and absorption of Chlorella pyrenoidosa by juvenile Chinese mitten crab (Eriocheir sinensis). Aquaculture 2023, 575, 739–772. [Google Scholar] [CrossRef]
- Chang, G.; Wu, X.; Cheng, Y.; Zeng, C.; Yu, Z. Reproductive performance, offspring quality, proximate and fatty acid composition of normal and precocious Chinese mitten crab Eriocheir sinensis. Aquaculture 2017, 469, 137–143. [Google Scholar] [CrossRef]
- Wu, X.; He, J.; Jiang, X.; Liu, Q.; Gao, F.; Cheng, Y. Does the wild-caught Chinese mitten crab megalopae perform better than the hatchery-produced seed during the juvenile culture? Aquac. Res. 2018, 49, 2042–2050. [Google Scholar] [CrossRef]
- Wang, L.; Gao, J.; Cao, X.; Du, J.; Cao, L.; Nie, Z.; Xu, G.; Dong, Z. Integrated analysis of transcriptomics and metabolomics unveil the novel insight of one-year-old precocious mechanism in the Chinese mitten crab, Eriocheir sinensis. Int. J. Mol. Sci. 2023, 24, 11171. [Google Scholar] [CrossRef] [PubMed]
- Wu, H.; Ge, M.; Zhou, X.; Jiang, S.; Lin, L.; Lu, J. Nutritional qualities of normal and precocious adult male Chinese mitten crabs (Eriocheir sinensis). Aquac. Res. 2019, 50, 2267–2275. [Google Scholar] [CrossRef]
- Cheng, H.; Wu, H.; Liang, F.; Ge, M.; Jiang, S.; Lin, L.; Lu, J. Comparison of the nutritional quality of three edible tissues from precocious and normal adult female Chinese mitten crabs (Eriocheir sinensis). J. Aquat. Food Prod. Technol. 2021, 30, 49–61. [Google Scholar] [CrossRef]
- Fu, C.; Li, F.; Wang, L.; Wang, A.; Yu, J.; Wang, H. Comparative transcriptology reveals effects of circadian rhythm in the nervous system on precocious puberty of the female Chinese mitten crab. Comp. Biochem. Physiol. Part D Gen. Proteomics 2019, 29, 67–73. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Guo, L.; Zhang, W.; Peng, J.; Chen, Q.; Cao, F.; Zhang, Z.; Guo, M.; Zhang, H.; Mu, S.; et al. Transcriptome and proteome reveal abnormal spermatozoa in precocious Chinese mitten crab, Eriocheir sinensis. Aquac. Rep. 2022, 27, 101–132. [Google Scholar] [CrossRef]
- Zhang, Z.; Xiao, J.; Wang, W.; Zielinska, M.; Wang, S.; Liu, Z.; Zheng, Z. Automated grading of angelica sinensis using computer vision and machine learning techniques. Agriculture 2024, 14, 507. [Google Scholar] [CrossRef]
- Chaurasia, D.; Patro, B.D.K. Detection of objects in satellite and aerial imagery using channel and spatially attentive YOLO-CSL for surveillance. Image Vis. Comput. 2024, 147–154, 105070. [Google Scholar] [CrossRef]
- Zhao, D.; Liu, X.; Sun, Y.; Wu, R.; Hong, J.; Ruan, C. Detection of underwater crabs based on machine vision. Trans. Chin. Soci. Agric. Mach. 2019, 50, 151–158. [Google Scholar]
- Zhao, D.; Cao, S.; Sun, Y.; Qi, H.; Ruan, C. Small-sized efficient detector for underwater freely live crabs based on compound scaling neural network. Trans. Chin. Soci. Agric. Mach. 2020, 51, 163–174. [Google Scholar]
- Cui, Y.; Pan, T.; Chen, S.; Zou, X. A gender classification method for Chinese mitten crab using deep convolutional neural network. Mult. Tools Appl. 2020, 79, 7669–7684. [Google Scholar] [CrossRef]
- Wei, T.; Zheng, X.; Li, T.; Wang, R. Multi-group convolutional neural network for gender recognition of Portunus tritubereulatus. South China Fish. Sci. 2024, 20, 89–98. [Google Scholar]
- Cao, Y.; Ren, K.; Chen, Q. Template matching based on convolution neural network for UAV visual localization. Optik 2023, 283, 170920. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, Y.; Li, D.; Duan, Q. Chinese mitten crab detection and gender classification method based on GMNet-YOLOv4. Comput. Electron. Agric. 2023, 214, 108318. [Google Scholar] [CrossRef]
- Gu, H.; Chen, M.; Gan, D. Gender identification of Chinese mitten crab juveniles based on improved Faster R-CNN. Appl. Sci. 2024, 14, 908. [Google Scholar] [CrossRef]
- Ahmed, A.; Imran, A.S.; Manaf, A.; Kastrati, Z.; Daudpota, S.M. Enhancing wrist abnormality detection with YOLO: Analysis of state-of-the-art single-stage detection models. Biomed. Signal Process. Control 2024, 93, 106–144. [Google Scholar]
- Liu, H.; Wang, X.; Zhao, F.; Yu, F.; Lin, P.; Gan, Y.; Ren, X.; Chen, Y.; Tu, J. Upgrading swin-B transformer-based model for accurately identifying ripe strawberries by coupling task-aligned one-stage object detection mechanism. Comput. Electron. Agric. 2024, 218, 108–674. [Google Scholar] [CrossRef]
- Safdar, M.; Li, Y.F.; El Haddad, R.; Zimmermann, M.; Wood, G.; Lamouche, G.; Wanjara, P.; Zhao, Y.F. Accelerated semantic segmentation of additively manufactured metal matrix composites: Generating datasets, evaluating convolutional and transformer models, and developing the MicroSegQ+ Tool. Expert. Syst. Appl. 2024, 251, 123–132. [Google Scholar] [CrossRef]
- Torralba, A.; Russell, B.C.; Yuen, J. LabelMe: Online image annotation and applications. Proc. IEEE 2010, 98, 1467–1484. [Google Scholar] [CrossRef]
- Yang, N.; Zhao, Y.; Chen, J.; Wang, F. Real-time classification for Φ-OTDR vibration events in the case of small sample size datasets. Opt. Fiber Technol. 2023, 76, 103–217. [Google Scholar] [CrossRef]
- Pu, H.; Xu, K.; Zhang, D.; Liu, L.; Liu, L.; Wang, D. TA-BiDet: Task-aligned binary object detector. Neurocomputing 2022, 511, 337–352. [Google Scholar] [CrossRef]
- Wang, H.; Ying, J.; Liu, J.; Yu, T.; Huang, D. Harnessing ResNet50 and SENet for enhanced ankle fracture identification. BMC Musculoskel. Disord. 2024, 25, 250. [Google Scholar] [CrossRef] [PubMed]
- Guo, X.; Guo, X.; Zou, Q.; Wulamu, A.; Yang, M.; Zheng, H.; Guo, X.; Zhang, T. FE-trans-net: Feature enhancement based single branch deep learning model for surface roughness detection. J. Manuf. Processes 2023, 105, 324–337. [Google Scholar] [CrossRef]
- Gaur, A.; Pant, G.; Jalal, A.S. Comparative assessment of artificial intelligence (AI)-based algorithms for detection of harmful bloom-forming algae: An eco-environmental approach toward sustainability. Appl. Water Sci. 2023, 13, 115. [Google Scholar] [CrossRef]
- Sangeetha, S.; Indumathi, N.; Grover, R.; Singh, R.; Mavi, R. IoT based wireless communication system for smart irrigation and rice leaf disease prediction using ResNeXt-50. Inter. J. Artif. Intell. Tools 2024, 33, 245–251. [Google Scholar] [CrossRef]
- Tie, J.; Wu, W.; Zheng, L.; Wu, L.; Chen, T. Improving walnut images segmentation using modified UNet3+ algorithm. Agriculture 2024, 14, 149. [Google Scholar] [CrossRef]
- Shin, Y.; Shin, H.; Ok, J.; Back, M.; Youn, J.; Kim, S. DCEF2-YOLO: Aerial detection YOLO with deformable convolution–efficient feature fusion for small target detection. Remote Sens. 2024, 16, 1071. [Google Scholar] [CrossRef]
- Li, H.; Ma, Z.; Xiong, S.-H.; Sun, Q.; Chen, Z.-S. Image-based fire detection using an attention mechanism and pruned dense network transfer learning. Inf. Sci. 2024, 670, 120–124. [Google Scholar] [CrossRef]
- Xu, Y.; Li, J.; Zhang, L.; Liu, H.; Zhang, F. CNTCB-YOLOv7: An effective forest fire detection model based on ConvNeXtV2 and CBAM. Fire 2024, 7, 54. [Google Scholar] [CrossRef]
- Zeng, W.; He, M. Rice disease segmentation method based on CBAM-CARAFE-DeepLabv3+. Crop Prot. 2024, 180, 106–665. [Google Scholar] [CrossRef]
- Michopoulos, J.G.; Iliopoulos, A.P.; Farhat, C.; Avery, P.; Daeninck, G.; Steuben, J.C.; Apetre, N.A. Bottom-up hierarchical and categorical metacomputing for automating composition and deployment of directly computable multiphysics models. J. Comput. Sci. 2024, 79, 102–295. [Google Scholar] [CrossRef]
- Luo, Q.; Shao, J.; Dang, W.; Wang, C.; Cao, L.; Zhang, T. An efficient feature pyramid attention network for person re-identification. Image Vis. Comput. 2024, 145, 104–163. [Google Scholar] [CrossRef]
- Shaheema, S.B.; Muppalaneni, N.B. Explainability based panoptic brain tumor segmentation using a hybrid PA-NET with GCNN-ResNet50. Biomed. Signal Process. Control 2024, 94, 106–334. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Original Number | Number after Expansion | Training Set | Test Set |
|---|---|---|---|---|
| Image/piece | 700 | 3928 | 3535 | 393 |
| Male/piece | 846 | 6465 | 5818 | 647 |
| Female/piece | 928 | 6322 | 5689 | 633 |
| Backbone Network | mAP (%) | mAP50 (%) | mAP75 (%) |
|---|---|---|---|
| ResNet50 | 78.43 | 83.45 | 80.22 |
| ResNeXt + CBAM | 79.98 | 85.56 | 82.79 |
| ResNeXt + CBAM + DCN | 81.11 | 86.86 | 84.34 |
| Algorithm | Backbone | mAP (%) | mAP50 (%) | mAP75 (%) | F1-Score (%) |
|---|---|---|---|---|---|
| Faster R-CNN | ResNet-50 + BiFPN | 84.88 | 89.29 | 91.45 | 94.79 |
| SSD | SSDVGG + FPN | 78.19 | 85.59 | 83.64 | 92.45 |
| YOLOv7 | ResNet-101 + PAFPN | 84.61 | 91.19 | 87.97 | 96.12 |
| Cascade-RCNN | ResNet-101 + FPN | 82.36 | 90.71 | 85.67 | 95.24 |
| R-TNET | ResNeXt + ASFPN | 88.78 | 96.14 | 92.56 | 97.89 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gu, H.; Gan, D.; Chen, M.; Feng, G. One-Year-Old Precocious Chinese Mitten Crab Identification Algorithm Based on Task Alignment. Animals 2024, 14, 2128. https://doi.org/10.3390/ani14142128
Gu H, Gan D, Chen M, Feng G. One-Year-Old Precocious Chinese Mitten Crab Identification Algorithm Based on Task Alignment. Animals. 2024; 14(14):2128. https://doi.org/10.3390/ani14142128
Chicago/Turabian StyleGu, Hao, Dongmei Gan, Ming Chen, and Guofu Feng. 2024. "One-Year-Old Precocious Chinese Mitten Crab Identification Algorithm Based on Task Alignment" Animals 14, no. 14: 2128. https://doi.org/10.3390/ani14142128
APA StyleGu, H., Gan, D., Chen, M., & Feng, G. (2024). One-Year-Old Precocious Chinese Mitten Crab Identification Algorithm Based on Task Alignment. Animals, 14(14), 2128. https://doi.org/10.3390/ani14142128