

LAD-RCNN: A Powerful Tool for Livestock Face Detection and Normalization
 , ,
, ,
Abstract
Simple Summary
Abstract
1. Introduction
- (1)
- A lightweight angle detection and region-based convolutional network (LAD-RCNN) was proposed in this study, which can handle arbitrary directions of livestock faces. LAD-RCNN was evaluated in multiple datasets. The average precision was more than 97%, and the average angle difference between the detection angle and the ground-truth angle was within 6.42°.
- (2)
- A rotation angle coding method was proposed in this study, which could deal with the angle discontinuity problem.
- (3)
- A lightweight backbone for LAD-RCNN was proposed in this study, which is faster than the widely used backbone MobileNetV2, ResNet50, and VGG16 with no significant accuracy reduction. The average detection speed of LAD-RCNN reaches 13.7 ms per image tested on a single GeForce RTX 2080 Ti GPU.
- (4)
- To adapt to livestock research, a dual dataset model for LAD-RCNN was designed in this study so that the dataset without angle data can also be used to train LAD-RCNN, which facilitates the use of various datasets. In addition, LAD-RCNN has a lot of built-in data amplification methods to support the use of small datasets.
- (5)
- The code of LAD-RCNN is open source. The code is available at https://github.com/SheepBreedingLab-HZAU/LAD-RCNN/ (accessed on 19 April 2023). Peers of livestock face recognition research can directly employ LAD-RCNN in their study to realize face detection and normalization with little modification.
2. Related Work
2.1. Object Detection
2.2. Angle-Based Rotated Object Detection
3. Method
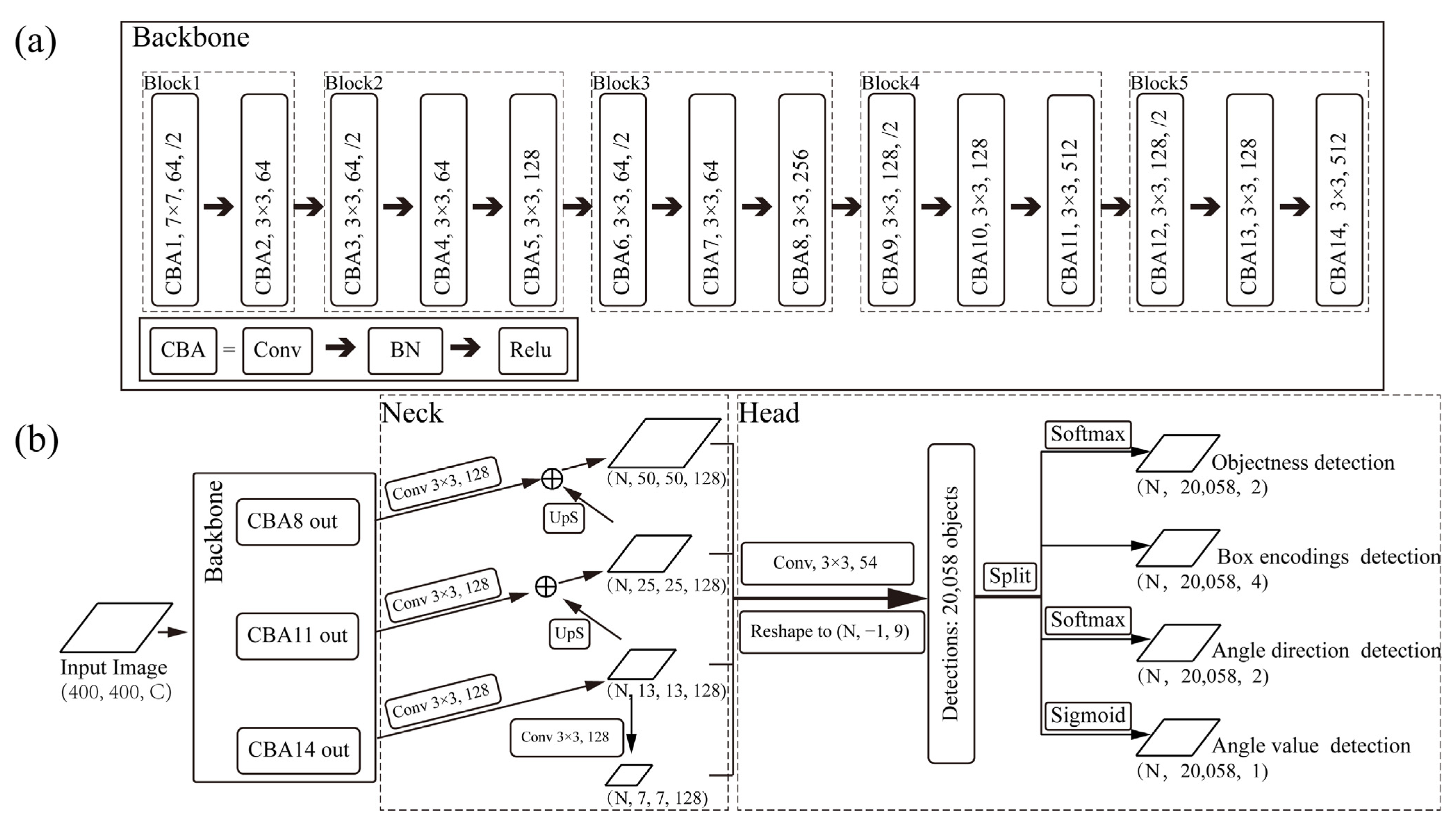
3.1. Model
3.1.1. Anchors
3.1.2. Overall Structure
3.1.3. Backbone
3.1.4. Rotation Angle
3.1.5. Angle Discontinuity Problem
3.1.6. Head Network
3.2. Training
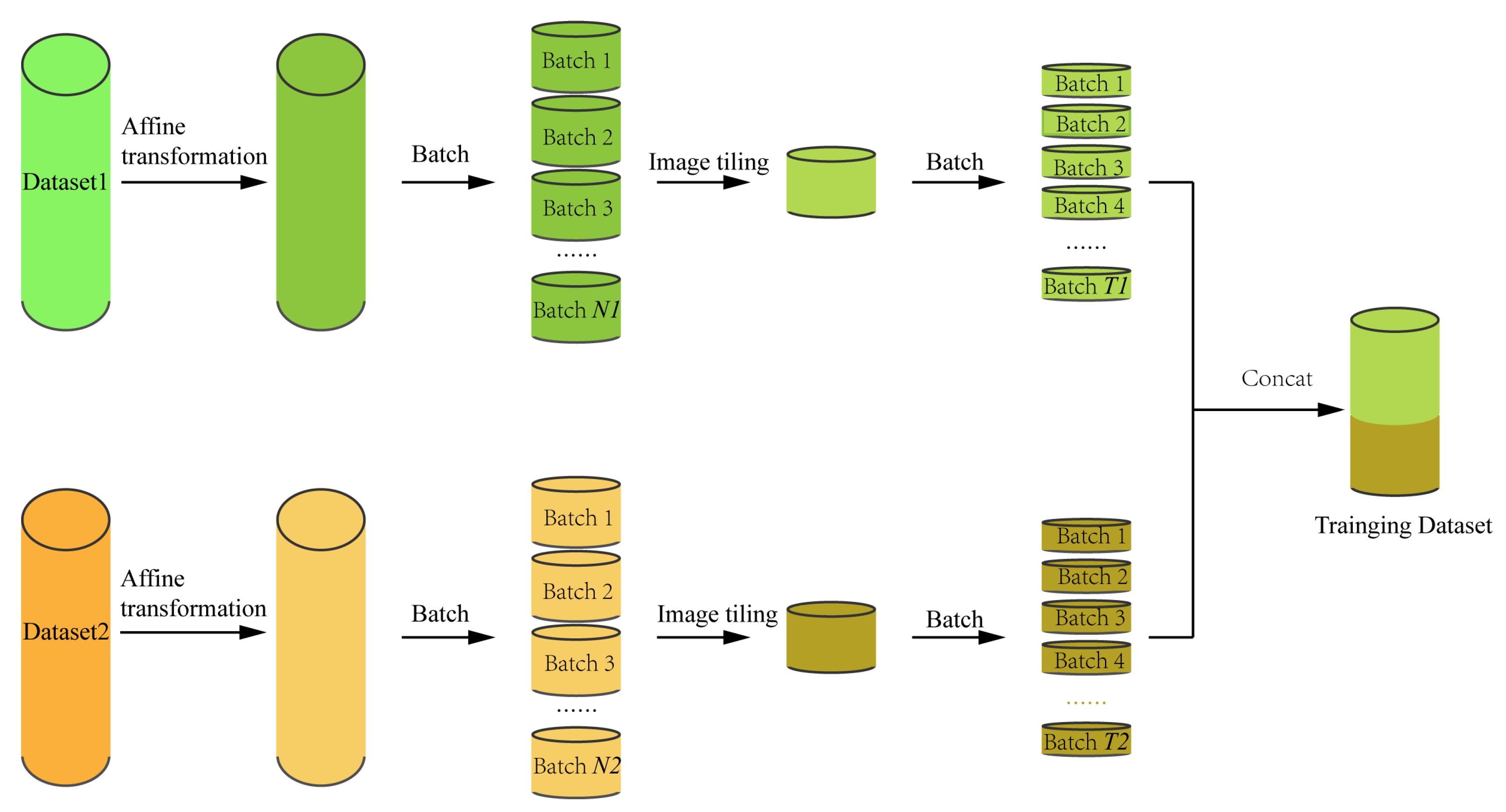
3.2.1. Dual Dataset Training
3.2.2. Loss Function
3.2.3. Data Augmentation
3.3. Evaluation Metrics
4. Evaluation Result
4.1. Backbone Evaluation
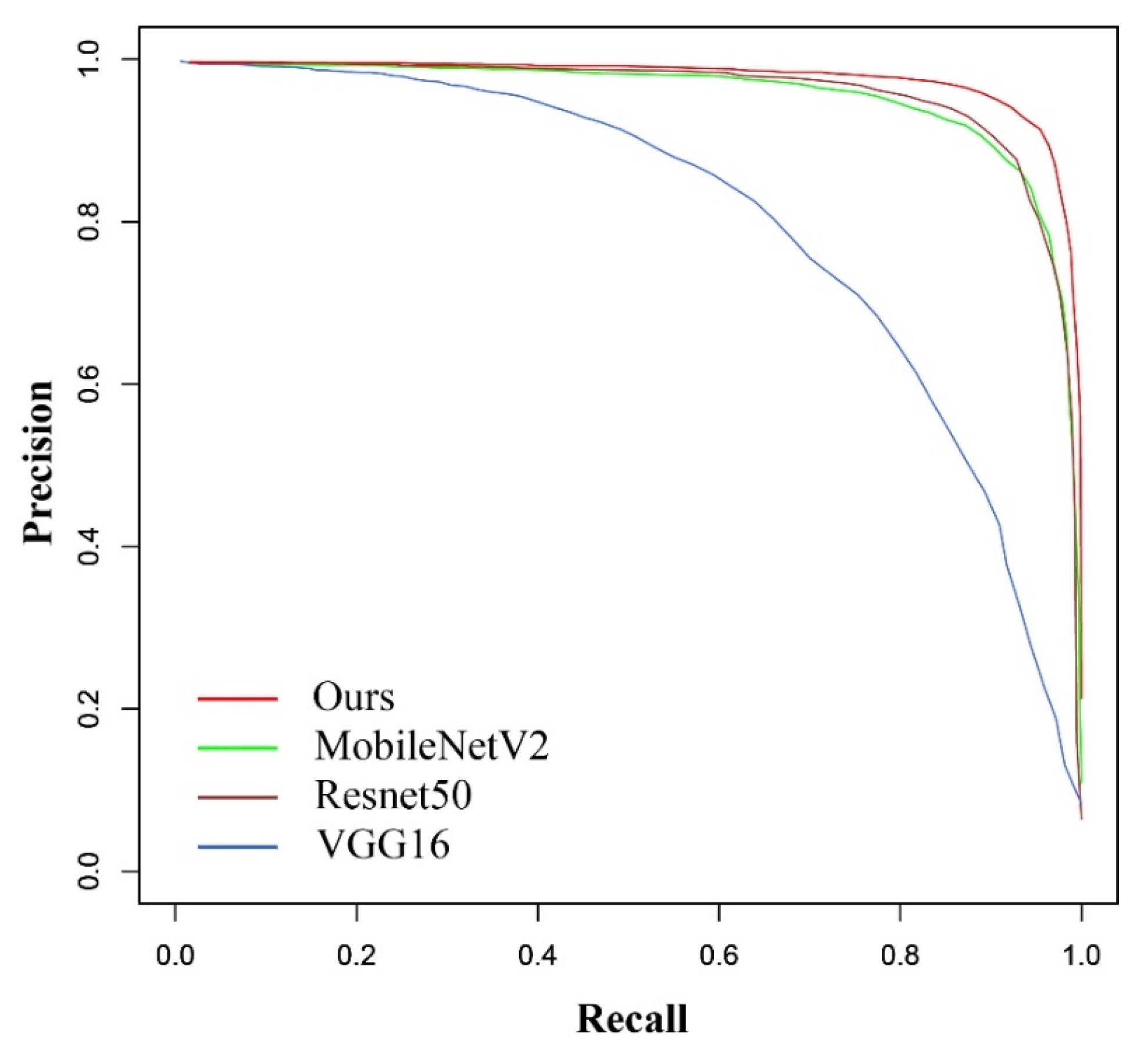
4.2. Experiments on Goat Dataset
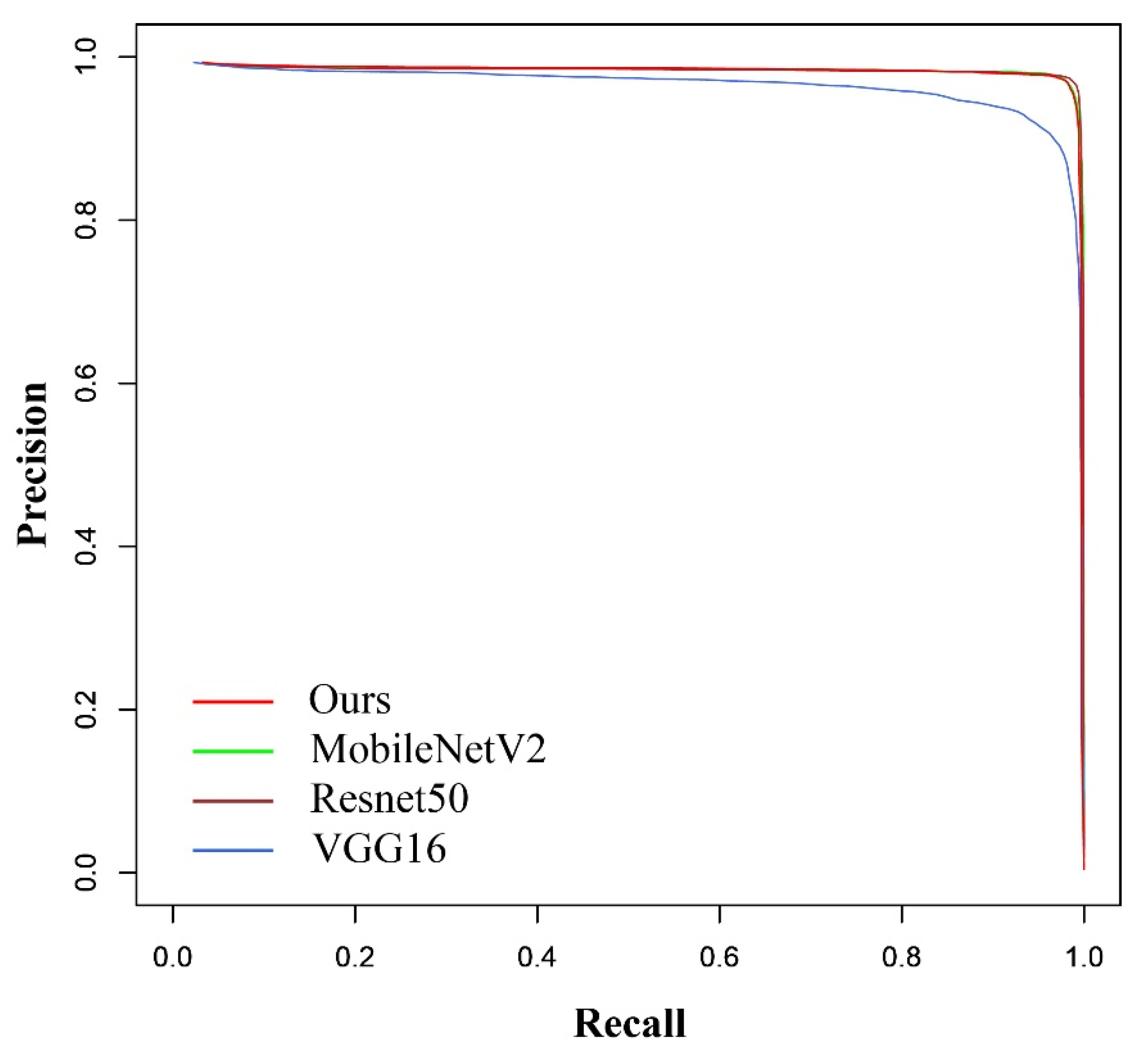
4.3. Experiments on Goat Infrared Image Dataset
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hansen, M.E.; Smith, M.L.; Smith, L.N.; Salter, M.G.; Baxter, E.M.; Farish, M.; Grieve, B. Towards on-farm pig face recognition using convolutional neural networks. Comput. Ind. 2018, 98, 145–152. [Google Scholar] [CrossRef]
- Maselyne, J.; Saeys, W.; De Ketelaere, B.; Mertens, K.; Vangeyte, J.; Hessel, E.F.; Millet, S.; Van Nuffel, A. Validation of a High Frequency Radio Frequency Identification (HF RFID) system for registering feeding patterns of growing-finishing pigs. Comput. Electron. Agric. 2014, 102, 10–18. [Google Scholar] [CrossRef]
- Bao, J.; Xie, Q.J. Artificial intelligence in animal farming: A systematic literature review. J. Clean. Prod. 2022, 331, 129956. [Google Scholar] [CrossRef]
- Billah, M.; Wang, X.H.; Yu, J.T.; Jiang, Y. Real-time goat face recognition using convolutional neural network. Comput. Electron. Agric. 2022, 194, 106730. [Google Scholar] [CrossRef]
- Xu, B.B.; Wang, W.S.; Guo, L.F.; Chen, G.P.; Li, Y.F.; Cao, Z.; Wu, S.S. CattleFaceNet: A cattle face identification approach based on RetinaFace and ArcFace loss. Comput. Electron. Agric. 2022, 193, 106675. [Google Scholar] [CrossRef]
- Wang, M.; Deng, W. Deep face recognition: A survey. Neurocomputing 2021, 429, 215–244. [Google Scholar] [CrossRef]
- Gogic, I.; Ahlberg, J.; Pandzic, I.S. Regression-based methods for face alignment: A survey. Signal Process 2021, 178, 107755. [Google Scholar] [CrossRef]
- Song, S.; Liu, T.; Wang, H.; Hasi, B.; Yuan, C.; Gao, F.; Shi, H. Using Pruning-Based YOLOv3 Deep Learning Algorithm for Accurate Detection of Sheep Face. Animals 2022, 12, 1465. [Google Scholar] [CrossRef]
- Hitelman, A.; Edan, Y.; Godo, A.; Berenstein, R.; Lepar, J.; Halachmi, I. Biometric identification of sheep via a machine-vision system. Comput. Electron. Agric. 2022, 194, 106713. [Google Scholar] [CrossRef]
- Wang, Z.Y.; Liu, T.H. Two-stage method based on triplet margin loss for pig face recognition. Comput. Electron. Agric. 2022, 194, 106737. [Google Scholar] [CrossRef]
- He, M.; Zhang, J.; Shan, S.; Kan, M.; Chen, X. Deformable face net for pose invariant face recognition. Pattern. Recognit. 2020, 100, 107113. [Google Scholar] [CrossRef]
- Zhang, K.P.; Zhang, Z.P.; Li, Z.F.; Qiao, Y. Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks. IEEE Signal Proc. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef]
- King, D. Dlib-Models. Available online: https://github.com/davisking/dlib-models (accessed on 10 August 2022).
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern. Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Lecture Notes in Computer Science, Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016; Part I; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. Scaled-YOLOv4: Scaling Cross Stage Partial Network. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13024–13033. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Advances in neural information processing systems. In Proceedings of the Thirty-first Conference on Neural Information Processing Systems, NeurIPS 2017, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Lecture Notes in Computer Science, Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer: Cham, Switzerland, 2020; Part I; pp. 213–229. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 9992–10002. [Google Scholar]
- Zhou, Q.; Yu, C.H. Point RCNN: An Angle-Free Framework for Rotated Object Detection. Remote Sens. 2022, 14, 2605. [Google Scholar] [CrossRef]
- Ma, J.Q.; Shao, W.Y.; Ye, H.; Wang, L.; Wang, H.; Zheng, Y.B.; Xue, X.Y. Arbitrary-Oriented Scene Text Detection via Rotation Proposals. IEEE Trans. Multimed. 2018, 20, 3111–3122. [Google Scholar] [CrossRef]
- Liu, Z.K.; Hu, J.G.; Weng, L.B.; Yang, Y.P. Rotated Region Based Cnn for Ship Detection. In Proceedings of the International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 900–904. [Google Scholar] [CrossRef]
- Qin, R.; Liu, Q.J.; Gao, G.S.; Huang, D.; Wang, Y.H. MRDet: A Multihead Network for Accurate Rotated Object Detection in Aerial Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5608412. [Google Scholar] [CrossRef]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.B.; Datcu, M.; Pelillo, M.; Zhang, L.P. DOTA: A Large-scale Dataset for Object Detection in Aerial Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar] [CrossRef]
- Zhang, Z.H.; Guo, W.W.; Zhu, S.N.; Yu, W.X. Toward Arbitrary-Oriented Ship Detection with Rotated Region Proposal and Discrimination Networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1745–1749. [Google Scholar] [CrossRef]
- Yang, X.; Yang, J.R.; Yan, J.C.; Zhang, Y.; Zhang, T.F.; Guo, Z.; Sun, X.; Fu, K. SCRDet: Towards More Robust Detection for Small, Cluttered and Rotated Objects. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV 2019), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8231–8240. [Google Scholar] [CrossRef]
- Yang, X.; Yan, J. Arbitrary-oriented object detection with circular smooth label. In Lecture Notes in Computer Science, Proceedings of the European Conference on Computer Vision, ECCV–2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer: Cham, Switzerland, 2020; Part VIII; pp. 677–694. [Google Scholar]
- Han, J.M.; Ding, J.; Xue, N.; Xia, G.S. ReDet: A Rotation-equivariant Detector for Aerial Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR, Nashville, TN, USA, 20–25 June 2021; pp. 2785–2794. [Google Scholar] [CrossRef]
- Xie, X.; Cheng, G.; Wang, J.; Yao, X.; Han, J. Oriented R-CNN for Object Detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 3500–3509. [Google Scholar]
- Yang, X.; Yan, J.; Liao, W.; Yang, X.; Tang, J.; He, T. SCRDet++: Detecting Small, Cluttered and Rotated Objects via Instance-Level Feature Denoising and Rotation Loss Smoothing. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 2384–2399. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Padilla, R.; Netto, S.L.; da Silva, E.A.B. A Survey on Performance Metrics for Object-Detection Algorithms. In Proceedings of the International Conference on Systems, Signals and Image Processing (IWSSIP), Niteroi, Brazil, 1–3 July 2020; pp. 237–242. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.L.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the Conference on Computer Vision and Pattern Recognition (Cvpr), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef]
- Chen, S.B.; Dai, B.M.; Tang, J.; Luo, B.; Wang, W.Q.; Lv, K. A Refined Single-Stage Detector with Feature Enhancement and Alignment for Oriented Objects. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 8898–8908. [Google Scholar] [CrossRef]
- McManus, C.; Tanure, C.B.; Peripolli, V.; Seixas, L.; Fischer, V.; Gabbi, A.M.; Menegassi, S.R.O.; Stumpf, M.T.; Kolling, G.J.; Dias, E.; et al. Infrared thermography in animal production: An overview. Comput. Electron. Agric. 2016, 123, 10–16. [Google Scholar] [CrossRef]
- Mota-Rojas, D.; Wang, D.; Titto, C.G.; Gomez-Prado, J.; Carvajal-de la Fuente, V.; Ghezzi, M.; Boscato-Funes, L.; Barrios-Garcia, H.; Torres-Bernal, F.; Casas-Alvarado, A.; et al. Pathophysiology of Fever and Application of Infrared Thermography (IRT) in the Detection of Sick Domestic Animals: Recent Advances. Animals 2021, 11, 2316. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.; Xiao, D.; Yang, Q.; Wen, Z.; Lv, L. Review: Application of Infrared Thermography in Livestock Monitoring. Trans. Asabe 2020, 63, 389–399. [Google Scholar] [CrossRef]
- He, Y.Z.; Deng, B.Y.; Wang, H.J.; Cheng, L.; Zhou, K.; Cai, S.Y.; Ciampa, F. Infrared machine vision and infrared thermography with deep learning: A review. Infrared Phys. Techn. 2021, 116, 103754. [Google Scholar] [CrossRef]
- Zhang, X.D.; Kang, X.; Feng, N.N.; Liu, G. Automatic recognition of dairy cow mastitis from thermal images by a deep learning detector. Comput. Electron. Agric. 2020, 178, 105754. [Google Scholar] [CrossRef]
- Xu, F.; Gao, J.; Pan, X. Cow Face Recognition for a Small Sample Based on Siamese DB Capsule Network. IEEE Access 2022, 10, 63189–63198. [Google Scholar] [CrossRef]
- Matkowski, W.M.; Kong, A.W.K.; Su, H.; Chen, P.; Hou, R.; Zhang, Z.H. Giant Panda Face Recognition Using Small Dataset. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1680–1684. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Backbone | Input Resolution | Parameters | FPS |
|---|---|---|---|
| Ours | 400 × 400 | 2.82 M | 72.74 |
| MobileNetV2 | 400 × 400 | 2.26 M | 53.37 |
| VGG16 | 400 × 400 | 14.71 M | 55.04 |
| ResNet50 | 400 × 400 | 23.59 M | 44.32 |
| Data Augmentation Operation | Probabilities in Dataset 1 | Probabilities in Dataset 2 |
|---|---|---|
| Counterclockwise rotation by 90° | 0.5 | 0 |
| Horizontally flipping | 0.5 | 0.5 |
| Vertically flipping | 0.5 | 0.5 |
| Image tiling 2 × 2 | 0.8 | 0.8 |
| Backbone | Precision | Recall | F1 Score | AP | AAD |
|---|---|---|---|---|---|
| Ours | 95.02% | 90.70% | 92.81% | 97.55% | 6.42° |
| MobileNetV2 | 89.23% | 90.30% | 89.76% | 95.25% | 4.98° |
| VGG16 | 64.89% | 79.67% | 71.52% | 79.80% | 9.08° |
| ResNet50 | 88.99% | 91.64% | 90.30% | 95.62% | 6.12° |
| Data Augmentation Operation | Probabilities in Dataset 1 | Probabilities in Dataset 2 |
|---|---|---|
| Counterclockwise rotation by 90° | 0.5 | 0 |
| Horizontally flipping | 0.5 | 0.5 |
| Vertically flipping | 0.55 | 0 |
| Image tiling 2 × 2 | 0.8 | 0.8 |
| Backbone | Precision | Recall | F1 Score | AP | AAD |
|---|---|---|---|---|---|
| Ours | 96.43% | 98.39% | 97.40% | 98.19% | 4.62° |
| MobileNetV2 | 97.20% | 97.66% | 97.43% | 98.35% | 4.96° |
| VGG16 | 89.95% | 96.69% | 93.20% | 96.30% | 5.94° |
| ResNet50 | 96.93% | 98.83% | 97.87% | 98.29% | 4.48° |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, L.; Liu, G.; Yang, H.; Jiang, X.; Liu, J.; Wang, X.; Yang, H.; Yang, S. LAD-RCNN: A Powerful Tool for Livestock Face Detection and Normalization. Animals 2023, 13, 1446. https://doi.org/10.3390/ani13091446
Sun L, Liu G, Yang H, Jiang X, Liu J, Wang X, Yang H, Yang S. LAD-RCNN: A Powerful Tool for Livestock Face Detection and Normalization. Animals. 2023; 13(9):1446. https://doi.org/10.3390/ani13091446
Chicago/Turabian StyleSun, Ling, Guiqiong Liu, Huiguo Yang, Xunping Jiang, Junrui Liu, Xu Wang, Han Yang, and Shiping Yang. 2023. "LAD-RCNN: A Powerful Tool for Livestock Face Detection and Normalization" Animals 13, no. 9: 1446. https://doi.org/10.3390/ani13091446
APA StyleSun, L., Liu, G., Yang, H., Jiang, X., Liu, J., Wang, X., Yang, H., & Yang, S. (2023). LAD-RCNN: A Powerful Tool for Livestock Face Detection and Normalization. Animals, 13(9), 1446. https://doi.org/10.3390/ani13091446