
Increased Accuracy of Genomic Prediction Using Preselected SNPs from GWAS with Imputed Whole-Genome Sequence Data in Pigs
 , , ,
, , ,
Abstract
:Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Ethics Statement
2.2. Pig Population
2.3. Phenotypic Data
2.4. Genotype Data
2.5. Genetic Parameter Estimation
2.6. Genome-Wide Association Study
2.7. SNP Preselection Based on the GWAS Results
2.8. Genomic Prediction Models
2.9. Prediction Accuracy
3. Results
3.1. Descriptive Statistics of Phenotypes and Heritability
3.2. SNP Preselection Based on the GWAS Results
3.3. Genomic Prediction
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Samorè, A.B.; Fontanesi, L. Genomic Selection in Pigs: State of the Art and Perspectives. Ital. J. Anim. Sci. 2016, 15, 211–232. [Google Scholar] [CrossRef]
- Meuwissen, T.H.E.; Hayes, B.J.; Goddard, M.E. Prediction of Total Genetic Value Using Genome-Wide Dense Marker Maps. Genetics 2001, 157, 1819–1829. [Google Scholar] [CrossRef] [PubMed]
- Goddard, M.E.; Hayes, B.J. Genomic Selection: Genomic Selection. J. Anim. Breed. Genet. 2007, 124, 323–330. [Google Scholar] [CrossRef] [PubMed]
- Pszczola, M.; Calus, M.P.L. Updating the Reference Population to Achieve Constant Genomic Prediction Reliability across Generations. Animal 2016, 10, 1018–1024. [Google Scholar] [CrossRef]
- VanRaden, P.M.; Van Tassell, C.P.; Wiggans, G.R.; Sonstegard, T.S.; Schnabel, R.D.; Taylor, J.F.; Schenkel, F.S. Invited Review: Reliability of Genomic Predictions for North American Holstein Bulls. J. Dairy Sci. 2009, 92, 16–24. [Google Scholar] [CrossRef]
- Christensen, O.F.; Madsen, P.; Nielsen, B.; Ostersen, T.; Su, G. Single-Step Methods for Genomic Evaluation in Pigs. Animal 2012, 6, 1565–1571. [Google Scholar] [CrossRef]
- Sanchez, M.-P.; Govignon-Gion, A.; Croiseau, P.; Fritz, S.; Hozé, C.; Miranda, G.; Martin, P.; Barbat-Leterrier, A.; Letaïef, R.; Rocha, D.; et al. Within-Breed and Multi-Breed GWAS on Imputed Whole-Genome Sequence Variants Reveal Candidate Mutations Affecting Milk Protein Composition in Dairy Cattle. Genet. Sel. Evol. 2017, 49, 68. [Google Scholar] [CrossRef] [PubMed]
- Song, H.; Ye, S.; Jiang, Y.; Zhang, Z.; Zhang, Q.; Ding, X. Using Imputation-Based Whole-Genome Sequencing Data to Improve the Accuracy of Genomic Prediction for Combined Populations in Pigs. Genet. Sel. Evol. 2019, 51, 58. [Google Scholar] [CrossRef]
- Pérez-Enciso, M.; Rincón, J.C.; Legarra, A. Sequence- vs. Chip-Assisted Genomic Selection: Accurate Biological Information Is Advised. Genet. Sel. Evol. 2015, 47, 43. [Google Scholar] [CrossRef]
- Larmer, S.G.; Sargolzaei, M.; Brito, L.F.; Ventura, R.V.; Schenkel, F.S. Novel Methods for Genotype Imputation to Whole-Genome Sequence and a Simple Linear Model to Predict Imputation Accuracy. BMC Genet. 2017, 18, 120. [Google Scholar] [CrossRef]
- Heidaritabar, M.; Calus, M.P.L.; Megens, H.-J.; Vereijken, A.; Groenen, M.A.M.; Bastiaansen, J.W.M. Accuracy of Genomic Prediction Using Imputed Whole-Genome Sequence Data in White Layers. J. Anim. Breed. Genet. 2016, 133, 167–179. [Google Scholar] [CrossRef]
- Ni, G.; Cavero, D.; Fangmann, A.; Erbe, M.; Simianer, H. Whole-Genome Sequence-Based Genomic Prediction in Laying Chickens with Different Genomic Relationship Matrices to Account for Genetic Architecture. Genet. Sel. Evol. 2017, 49, 8. [Google Scholar] [CrossRef]
- Yan, G.; Qiao, R.; Zhang, F.; Xin, W.; Xiao, S.; Huang, T.; Zhang, Z.; Huang, L. Imputation-Based Whole-Genome Sequence Association Study Rediscovered the Missing QTL for Lumbar Number in Sutai Pigs. Sci. Rep. 2017, 7, 615. [Google Scholar] [CrossRef]
- Druet, T.; Macleod, I.M.; Hayes, B.J. Toward Genomic Prediction from Whole-Genome Sequence Data: Impact of Sequencing Design on Genotype Imputation and Accuracy of Predictions. Heredity 2014, 112, 39–47. [Google Scholar] [CrossRef]
- Van Binsbergen, R.; Calus, M.P.L.; Bink, M.C.A.M.; Van Eeuwijk, F.A.; Schrooten, C.; Veerkamp, R.F. Genomic Prediction Using Imputed Whole-Genome Sequence Data in Holstein Friesian Cattle. Genet. Sel. Evol. 2015, 47, 71. [Google Scholar] [CrossRef]
- Ye, S.; Gao, N.; Zheng, R.; Chen, Z.; Teng, J.; Yuan, X.; Zhang, H.; Chen, Z.; Zhang, X.; Li, J.; et al. Strategies for Obtaining and Pruning Imputed Whole-Genome Sequence Data for Genomic Prediction. Front. Genet. 2019, 10, 673. [Google Scholar] [CrossRef]
- Brøndum, R.F. Quantitative Trait Loci Markers Derived from Whole Genome Sequence Data Increases the Reliability of Genomic Prediction. J. Dairy Sci. 2015, 98, 4107–4116. [Google Scholar] [CrossRef]
- Veerkamp, R.F.; Bouwman, A.C.; Schrooten, C.; Calus, M.P.L. Genomic Prediction Using Preselected DNA Variants from a GWAS with Whole-Genome Sequence Data in Holstein–Friesian Cattle. Genet. Sel. Evol. 2016, 48, 95. [Google Scholar] [CrossRef]
- Zhang, Z.; Ober, U.; Erbe, M.; Zhang, H.; Gao, N.; He, J.; Li, J.; Simianer, H. Improving the Accuracy of Whole Genome Prediction for Complex Traits Using the Results of Genome Wide Association Studies. PLoS ONE 2014, 9, e93017. [Google Scholar] [CrossRef]
- Gebreyesus, G.; Bovenhuis, H.; Lund, M.S.; Poulsen, N.A.; Sun, D.; Buitenhuis, B. Reliability of Genomic Prediction for Milk Fatty Acid Composition by Using a Multi-Population Reference and Incorporating GWAS Results. Genet. Sel. Evol. 2019, 51, 16. [Google Scholar] [CrossRef]
- Warburton, C.L.; Engle, B.N.; Ross, E.M.; Costilla, R.; Moore, S.S.; Corbet, N.J.; Allen, J.M.; Laing, A.R.; Fordyce, G.; Lyons, R.E.; et al. Use of Whole-Genome Sequence Data and Novel Genomic Selection Strategies to Improve Selection for Age at Puberty in Tropically-Adapted Beef Heifers. Genet. Sel. Evol. 2020, 52, 28. [Google Scholar] [CrossRef]
- Edwards, S.M.; Sørensen, I.F.; Sarup, P.; Mackay, T.F.C.; Sørensen, P. Genomic Prediction for Quantitative Traits Is Improved by Mapping Variants to Gene Ontology Categories in Drosophila melanogaster. Genetics 2016, 203, 1871–1883. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Zhuang, Z.; Yang, M.; Ding, R.; Quan, J.; Zhou, S.; Gu, T.; Xu, Z.; Zheng, E.; Cai, G.; et al. Genome-Wide Detection of Genetic Loci and Candidate Genes for Body Conformation Traits in Duroc × Landrace × Yorkshire Crossbred Pigs. Front. Genet. 2021, 12, 664343. [Google Scholar] [CrossRef] [PubMed]
- Misztal, I.; Lourenco, D.; Aguilar, I.; Legarra, A.; Vitezica, Z. Manual for BLUPF90 Family of Programs; University of Georgia: Athens, GA, USA, 2014. [Google Scholar]
- Wang, Y.; Ding, X.; Tan, Z.; Ning, C.; Xing, K.; Yang, T.; Pan, Y.; Sun, D.; Wang, C. Genome-Wide Association Study of Piglet Uniformity and Farrowing Interval. Front. Genet. 2017, 8, 194. [Google Scholar] [CrossRef] [PubMed]
- Chang, C.C.; Chow, C.C.; Tellier, L.C.; Vattikuti, S.; Purcell, S.M.; Lee, J.J. Second-Generation PLINK: Rising to the Challenge of Larger and Richer Datasets. Gigascience 2015, 4, 7. [Google Scholar] [CrossRef] [PubMed]
- Ding, R.; Savegnago, R.; Liu, J.; Long, N.; Tan, C.; Cai, G.; Zhuang, Z.; Wu, J.; Yang, M.; Qiu, Y.; et al. The SWine IMputation (SWIM) Haplotype Reference Panel Enables Nucleotide Resolution Genetic Mapping in Pigs. Commun. Biol. 2023, 6, 577. [Google Scholar] [CrossRef]
- Yang, J.; Benyamin, B.; McEvoy, B.P.; Gordon, S.; Henders, A.K.; Nyholt, D.R.; Madden, P.A.; Heath, A.C.; Martin, N.G.; Montgomery, G.W.; et al. Common SNPs Explain a Large Proportion of the Heritability for Human Height. Nat. Genet. 2010, 42, 565–569. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Lee, S.H.; Goddard, M.E.; Visscher, P.M. GCTA: A Tool for Genome-Wide Complex Trait Analysis. Am. J. Hum. Genet. 2011, 88, 76–82. [Google Scholar] [CrossRef]
- Yin, L.; Zhang, H.; Tang, Z.; Yin, D.; Fu, Y.; Yuan, X.; Li, X.; Liu, X.; Zhao, S. HIBLUP: An Integration of Statistical Models on the BLUP Framework for Efficient Genetic Evaluation Using Big Genomic Data. Nucleic Acids Res. 2023, 51, 3501–3512. [Google Scholar] [CrossRef]
- Su, G.; Christensen, O.F.; Janss, L.; Lund, M.S. Comparison of Genomic Predictions Using Genomic Relationship Matrices Built with Different Weighting Factors to Account for Locus-Specific Variances. J. Dairy Sci. 2014, 97, 6547–6559. [Google Scholar] [CrossRef]
- De Las Heras-Saldana, S.; Lopez, B.I.; Moghaddar, N.; Park, W.; Park, J.; Chung, K.Y.; Lim, D.; Lee, S.H.; Shin, D.; Van Der Werf, J.H.J. Use of Gene Expression and Whole-Genome Sequence Information to Improve the Accuracy of Genomic Prediction for Carcass Traits in Hanwoo Cattle. Genet. Sel. Evol. 2020, 52, 54. [Google Scholar] [CrossRef] [PubMed]
- Ye, S.; Li, J.; Zhang, Z. Multi-Omics-Data-Assisted Genomic Feature Markers Preselection Improves the Accuracy of Genomic Prediction. J. Anim. Sci. Biotechnol. 2020, 11, 109. [Google Scholar] [CrossRef] [PubMed]
- MacLeod, I.M.; Bowman, P.J.; Vander Jagt, C.J.; Haile-Mariam, M.; Kemper, K.E.; Chamberlain, A.J.; Schrooten, C.; Hayes, B.J.; Goddard, M.E. Exploiting Biological Priors and Sequence Variants Enhances QTL Discovery and Genomic Prediction of Complex Traits. BMC Genom. 2016, 17, 144. [Google Scholar] [CrossRef] [PubMed]
- Moghaddar, N.; Khansefid, M.; van der Werf, J.H.J.; Bolormaa, S.; Duijvesteijn, N.; Clark, S.A.; Swan, A.A.; Daetwyler, H.D.; MacLeod, I.M. Genomic Prediction Based on Selected Variants from Imputed Whole-Genome Sequence Data in Australian Sheep Populations. Genet. Sel. Evol. 2019, 51, 72. [Google Scholar] [CrossRef]
- Lopez, B.I.M.; An, N.; Srikanth, K.; Lee, S.; Oh, J.-D.; Shin, D.-H.; Park, W.; Chai, H.-H.; Park, J.-E.; Lim, D. Genomic Prediction Based on SNP Functional Annotation Using Imputed Whole-Genome Sequence Data in Korean Hanwoo Cattle. Front. Genet. 2021, 11, 603822. [Google Scholar] [CrossRef]
- Song, H.; Hu, H. Strategies to Improve the Accuracy and Reduce Costs of Genomic Prediction in Aquaculture Species. Evol. Appl. 2022, 15, 578–590. [Google Scholar] [CrossRef]
- Zhang, C.; Kemp, R.A.; Stothard, P.; Wang, Z.; Boddicker, N.; Krivushin, K.; Dekkers, J.; Plastow, G. Genomic Evaluation of Feed Efficiency Component Traits in Duroc Pigs Using 80K, 650K and Whole-Genome Sequence Variants. Genet. Sel. Evol. 2018, 50, 14. [Google Scholar] [CrossRef]

{kind=link}
| Trait | Unit | Mean (±SD) 3 | Min 4 | Max 5 | C.V./% 6 | h2 (±SE) 7 |
|---|---|---|---|---|---|---|
| BFT 1 | mm | 11.49 ± 3.27 | 5.50 | 25.58 | 25.48 | 0.35 ± 0.08 |
| LMA 2 | cm2 | 40.44 ± 7.39 | 20.25 | 64.63 | 18.28 | 0.34 ± 0.08 |
| Trait | Unit | Mean (±SD) 3 | Min 4 | Max 5 | C.V./% 6 | h2 (±SE) 7 |
|---|---|---|---|---|---|---|
| BFT 1 | mm | 11.85 ± 2.43 | 5.93 | 23.23 | 20.54 | 0.45 ± 0.06 |
| LMA 2 | cm2 | 40.34 ± 4.93 | 24.25 | 54.67 | 12.21 | 0.45 ± 0.07 |
| p-Value | BFT | LMA | ||
|---|---|---|---|---|
| Number of SNPs in GWAS 1 | Number of SNPs in Gf 2 | Number of SNPs in GWAS 1 | Number of SNPs in Gf 2 | |
| <0.05 | 731,061 | 517,173 | 720,230 | 515,502 |
| <0.005 | 66,867 | 47,987 | 81,028 | 57,767 |
| <0.0005 | 4399 | 2819 | 8020 | 6357 |
| <0.00005 | 262 | 171 | 478 | 341 |
| Model | p-Value | Accuracy (Mean ± SE 4) | |
|---|---|---|---|
| BFT | LMA | ||
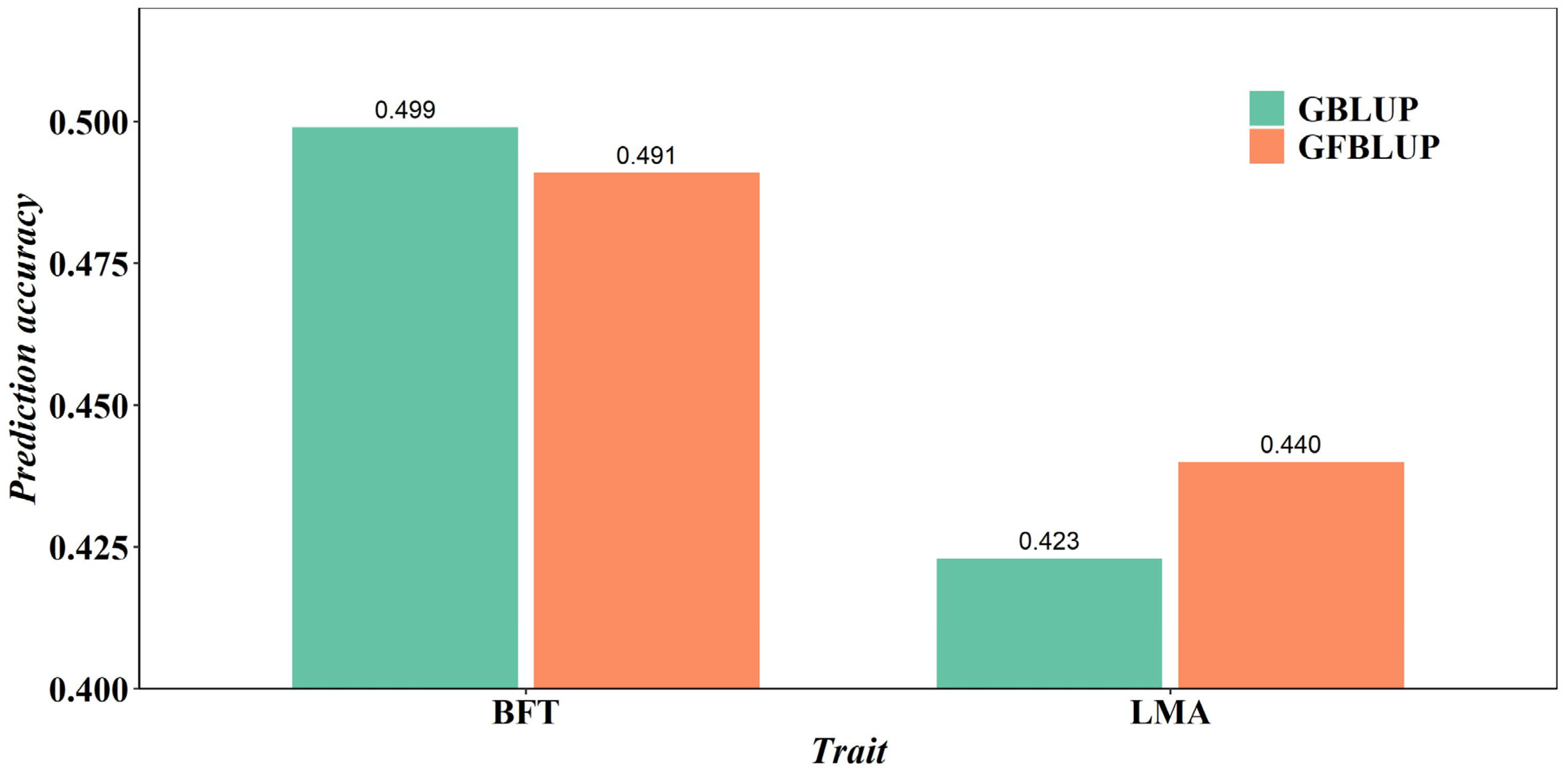
| GBLUP 1 | All 3 | 0.499 ± 0.016 | 0.423 ± 0.010 |
| GFBLUP 2 | <0.05 | 0.488 ± 0.017 | 0.440 ± 0.011 |
| <0.005 | 0.487 ± 0.017 | 0.420 ± 0.011 | |
| <0.0005 | 0.487 ± 0.016 | 0.417 ± 0.010 | |
| <0.00005 | 0.491 ± 0.016 | 0.423 ± 0.010 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Zhang, Y.; Zhou, F.; Yao, Z.; Zhan, Y.; Fan, Z.; Meng, X.; Zhang, Z.; Liu, L.; Yang, J.; et al. Increased Accuracy of Genomic Prediction Using Preselected SNPs from GWAS with Imputed Whole-Genome Sequence Data in Pigs. Animals 2023, 13, 3871. https://doi.org/10.3390/ani13243871
Liu Y, Zhang Y, Zhou F, Yao Z, Zhan Y, Fan Z, Meng X, Zhang Z, Liu L, Yang J, et al. Increased Accuracy of Genomic Prediction Using Preselected SNPs from GWAS with Imputed Whole-Genome Sequence Data in Pigs. Animals. 2023; 13(24):3871. https://doi.org/10.3390/ani13243871
Chicago/Turabian StyleLiu, Yiyi, Yuling Zhang, Fuchen Zhou, Zekai Yao, Yuexin Zhan, Zhenfei Fan, Xianglun Meng, Zebin Zhang, Langqing Liu, Jie Yang, and et al. 2023. "Increased Accuracy of Genomic Prediction Using Preselected SNPs from GWAS with Imputed Whole-Genome Sequence Data in Pigs" Animals 13, no. 24: 3871. https://doi.org/10.3390/ani13243871
APA StyleLiu, Y., Zhang, Y., Zhou, F., Yao, Z., Zhan, Y., Fan, Z., Meng, X., Zhang, Z., Liu, L., Yang, J., Wu, Z., Cai, G., & Zheng, E. (2023). Increased Accuracy of Genomic Prediction Using Preselected SNPs from GWAS with Imputed Whole-Genome Sequence Data in Pigs. Animals, 13(24), 3871. https://doi.org/10.3390/ani13243871