
An Efficient Method for Monitoring Birds Based on Object Detection and Multi-Object Tracking Networks

 , , , and
, , , and
Abstract
Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Data Acquisition
2.2. Data Preprocessing
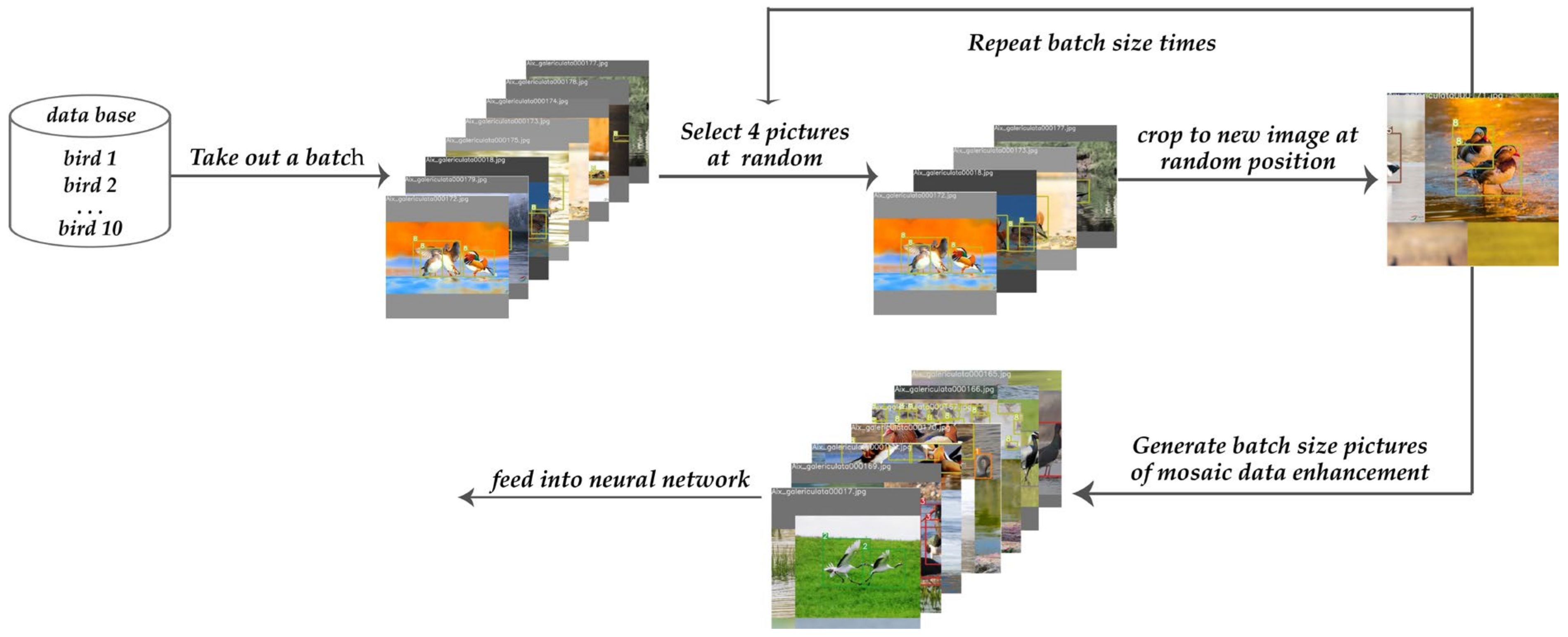
2.2.1. Mosaic Data Enhancement
2.2.2. Mixup Data Enhancement
2.2.3. HSV Data Enhancement
2.3. Related Networks
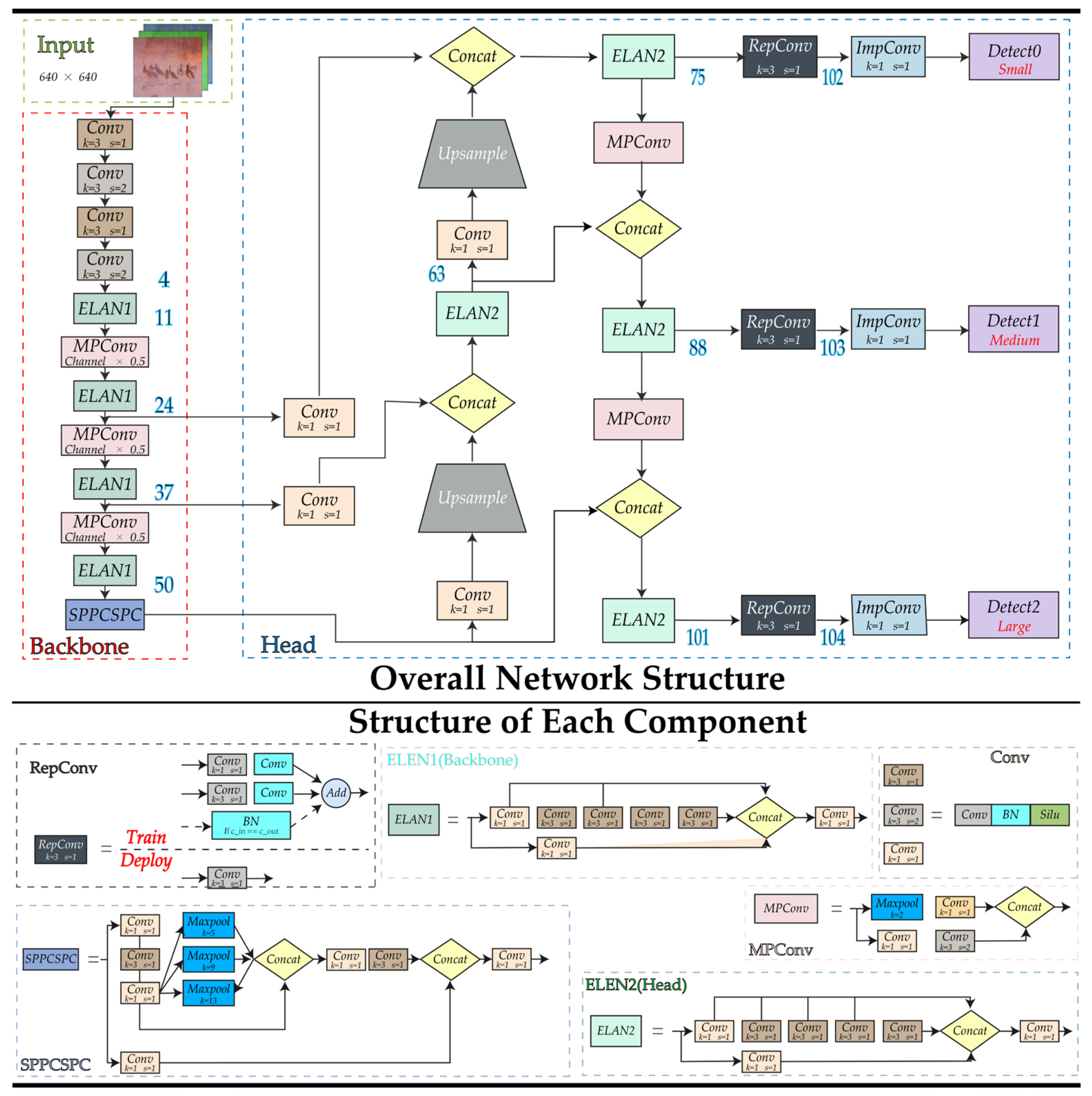
2.3.1. Object Detection: YOLOv7
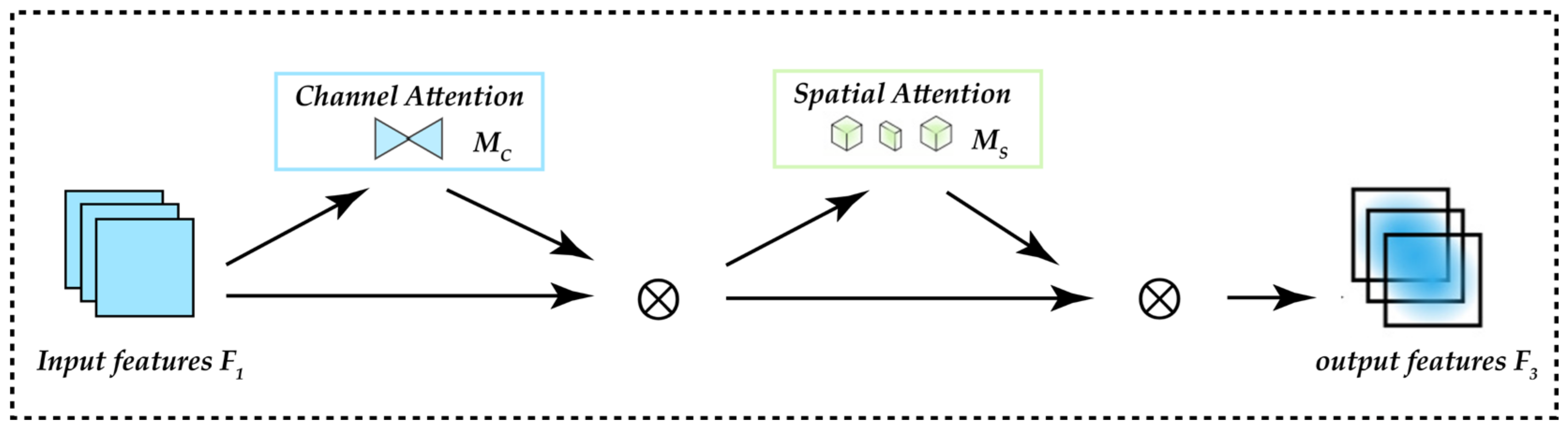
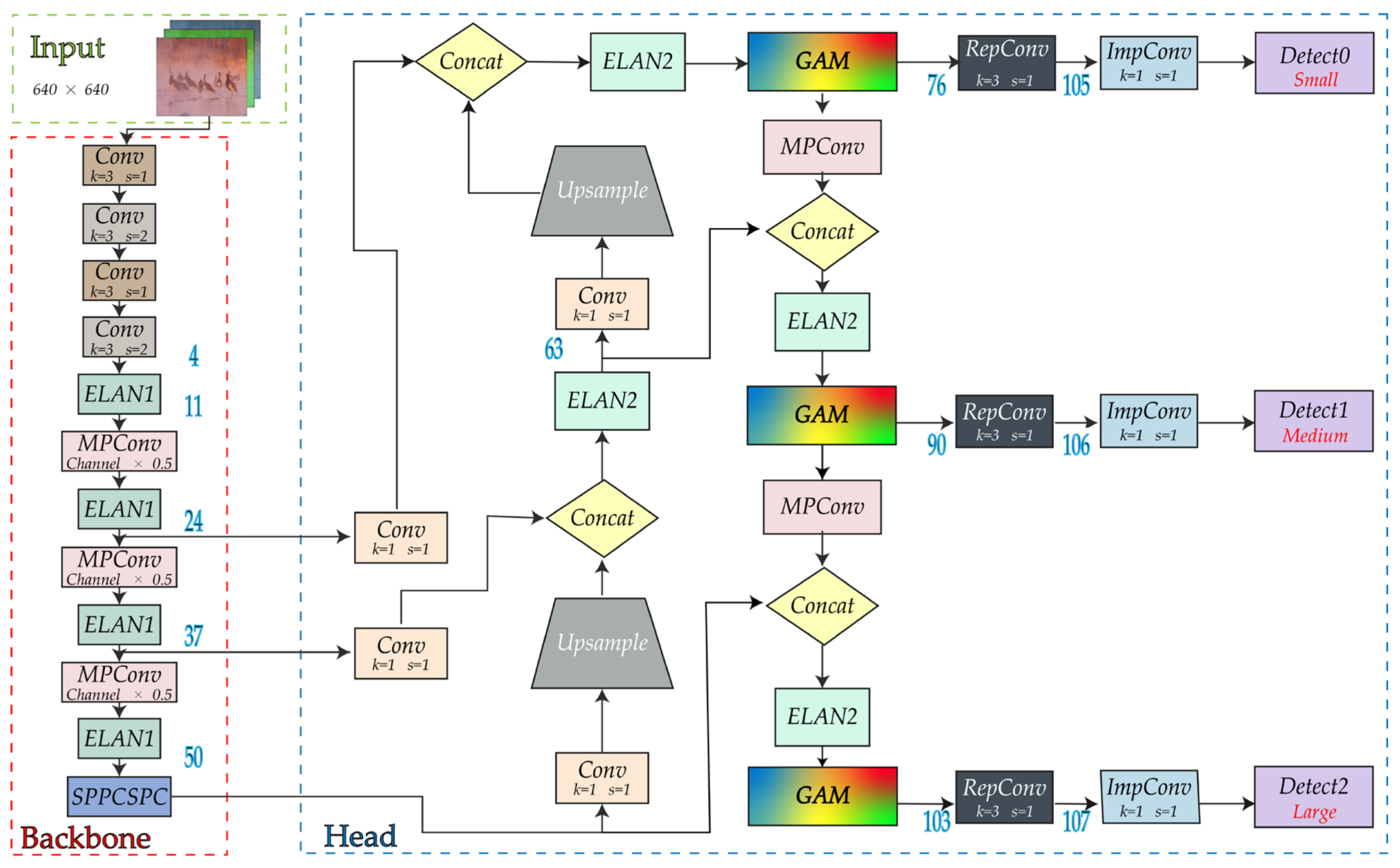
2.3.2. Introducing Attention Mechanism into YOLOv7: GAM
- Channel Attention Sub-module
- 2.
- Spatial Attention Sub-module
2.3.3. Introducing Alpha-IoU into YOLOv7
2.3.4. Multi-Object Tracking: DeepSORT
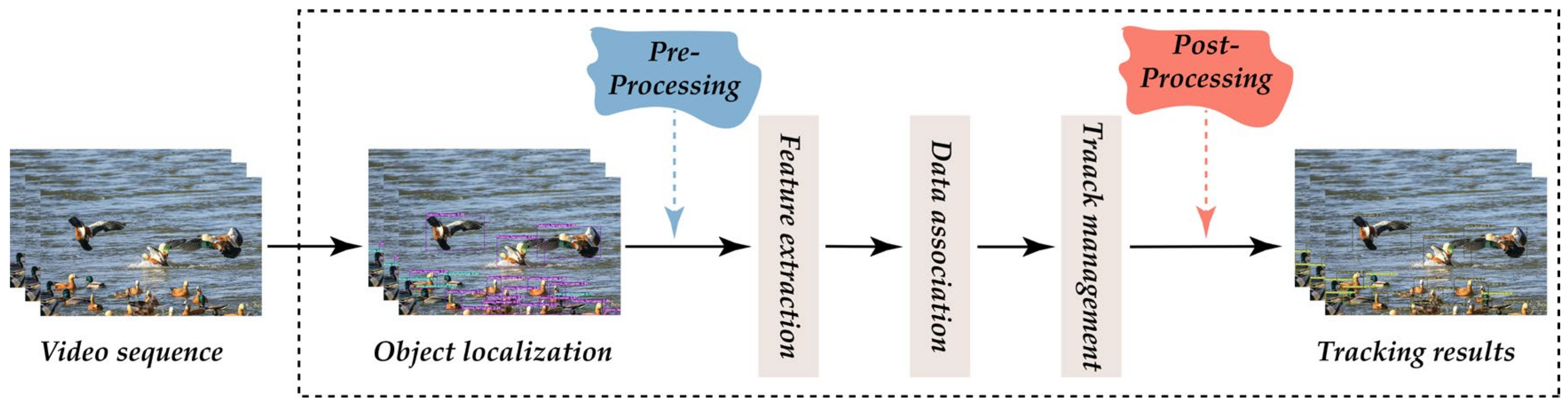
2.4. Monitoring Methods
2.4.1. Different Labelling Methods
2.4.2. Obtaining the Best Algorithmic Model
2.4.3. Multi-Object Tracking
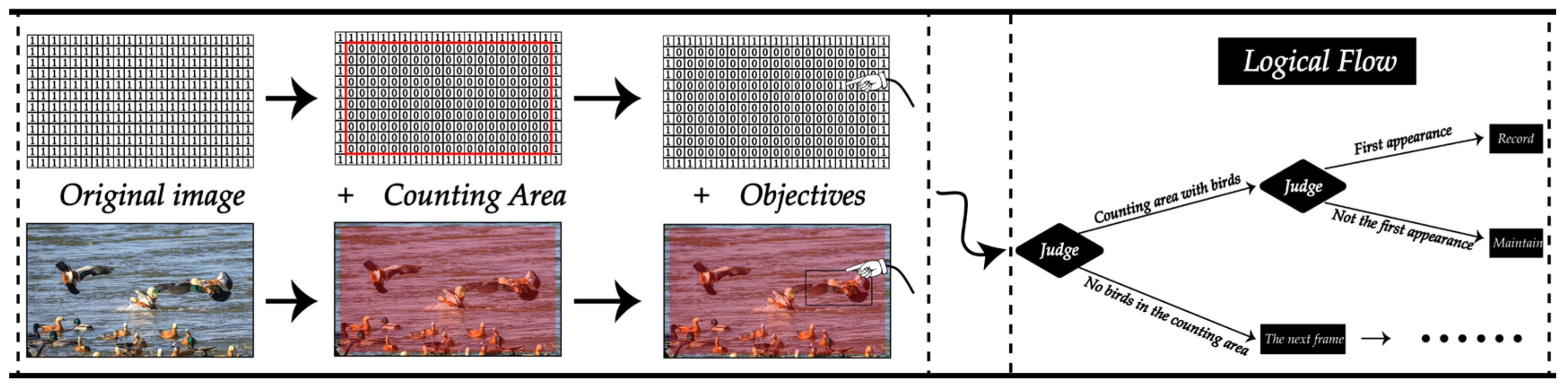
2.4.4. Implementation of the Counting Area
3. Results
3.1. Experimental Environment
3.2. Training Parameters
3.3. Evaluation Metrics
3.4. Experimental Results
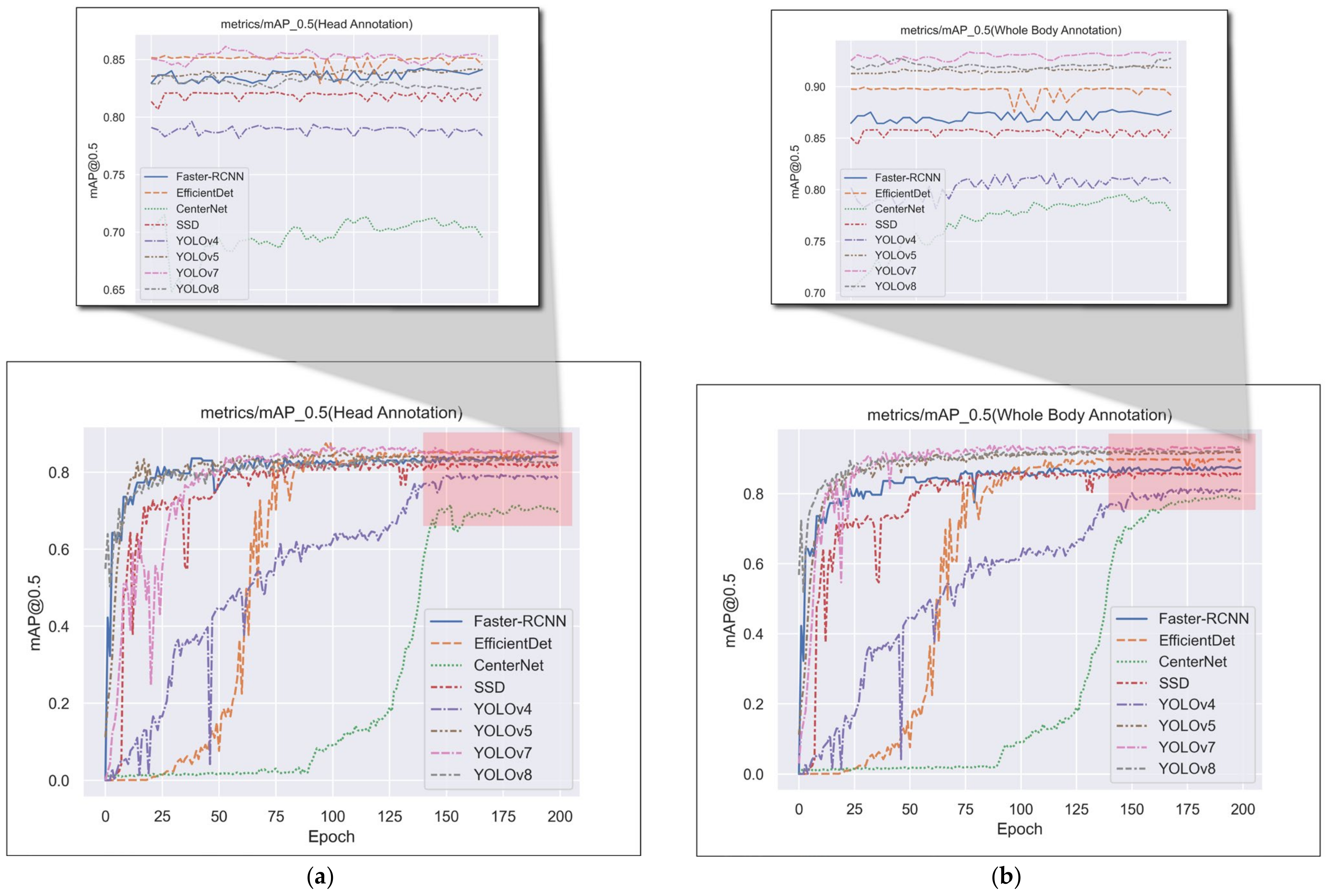
3.4.1. Comparison Experiments of the Most Advanced Methods for Object Detection under Different Labeling Methods
3.4.2. Ablation Experiment on Data Enhancement
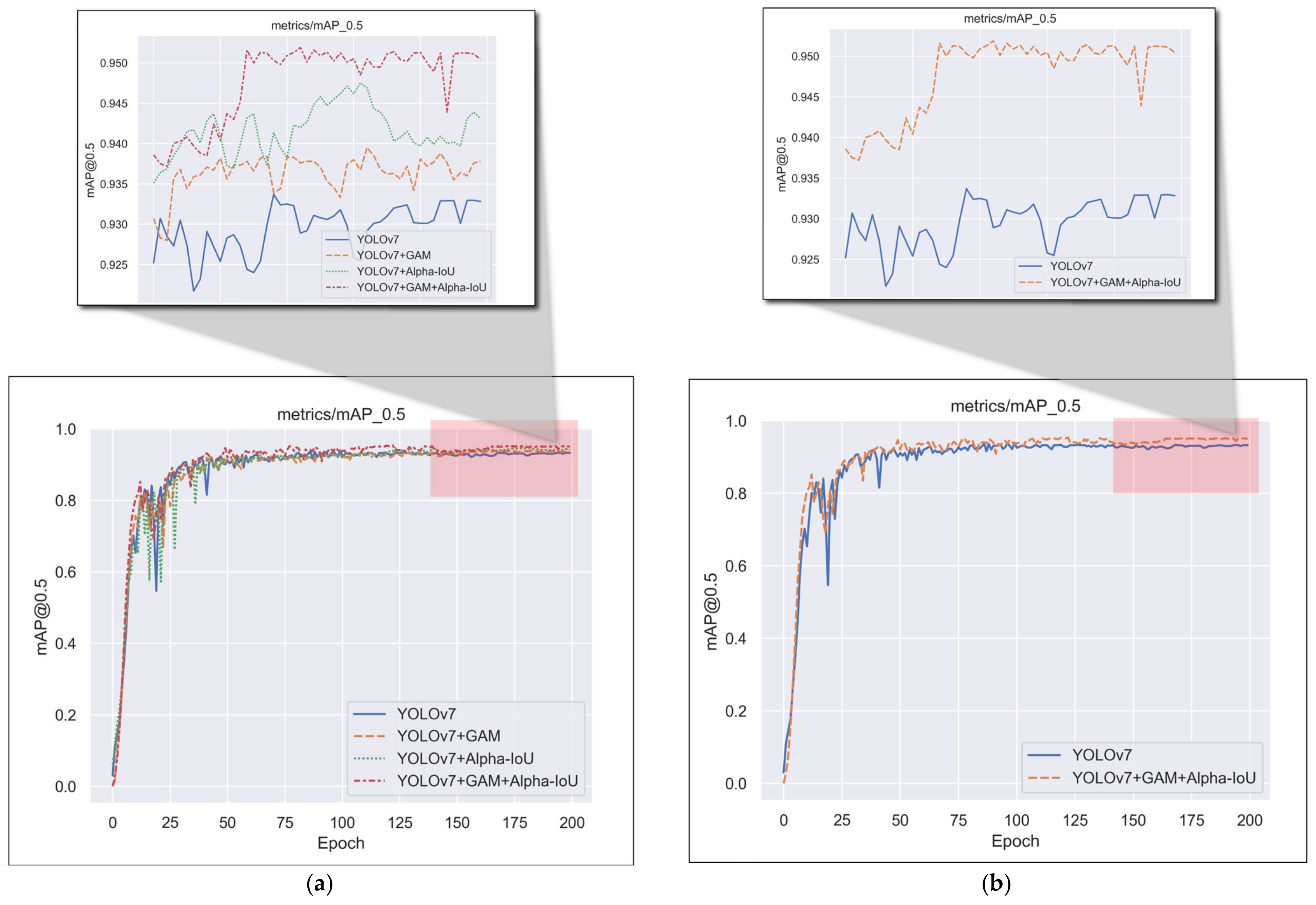
3.4.3. Ablation Experiment of Introducing a Series of Improved Strategies for YOLOv7
3.4.4. Manual Verification of Algorithm Effectiveness
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Almond, R.E.A.; Grooten, M.; Peterson, T. Living Planet Report 2020—Bending the Curve of Biodiversity Loss; World Wildlife Fund: Gland, Switzerland, 2020. [Google Scholar]
- Murali, G.; de Oliveira Caetano, G.H.; Barki, G.; Meiri, S.; Roll, U. Emphasizing Declining Populations in the Living Planet Report. Nature 2022, 601, E20–E24. [Google Scholar] [CrossRef] [PubMed]
- IUCN. The IUCN Red List of Threatened Species. Version 2022-2. 2022. Available online: https://www.iucnredlist.org (accessed on 17 April 2023).
- Sun, G.; Zeng, L.; Qian, F.; Jiang, Z. Current Status and Development Trend of Bird Diversity Monitoring Technology. Geomat. World 2022, 29, 26–29. Available online: https://chrk.cbpt.cnki.net/WKE2/WebPublication/paperDigest.aspx?paperID=8cfe8d55-8931-42f0-8cd9-0fe1011305e5# (accessed on 12 May 2023).
- Cui, P.; Xu, H.; Ding, H.; Wu, J.; Cao, M.; Chen, L. Status Quo, Problems and Countermeasures of Bird Monitoring in China. J. Ecol. Rural. Environ. 2013, 29, 403–408. [Google Scholar]
- Pugesek, B.H.; Stehn, T.V. The Utility of Census or Survey for Monitoring Whooping Cranes in Winter; University of Nebraska-Lincoln: Lincoln, NE, USA, 2016. [Google Scholar]
- Bibby, C.J.; Burgess, N.D.; Hillis, D.M.; Hill, D.A.; Mustoe, S. Bird Census Techniques; Elsevier: Amsterdam, The Netherlands, 2000. [Google Scholar]
- Gregory, R.D.; Gibbons, D.W.; Donald, P.F. Bird census and survey techniques. Bird Ecol. Conserv. 2004, 17–56. [Google Scholar] [CrossRef]
- Pacifici, K.; Simons, T.R.; Pollock, K.H. Effects of vegetation and background noise on the detection process in auditory avian point-count surveys. Auk 2008, 125, 600–607. [Google Scholar] [CrossRef]
- Zheng, F.; Guo, X.; Zhai, R.; Xian, S.; Huang, F. Analysis of the status and protection measures of birds in Xinying Mangrove National Wetland Park. Guizhou Sci. 2022, 40, 62–66. [Google Scholar]
- Sun, R.; Ma, H.; Yu, L.; Xu, Z.; Chen, G.; Pan, T.; Zhou, W.; Yan, L.; Sun, Z.; Peng, Z.; et al. A preliminary report on bird diversity and distribution in Dabie Mountains. J. Anhui Univ. 2021, 45, 85–102. [Google Scholar]
- Liu, J. Design of Bird Image Recognition System Based on DNN. Agric. Equip. Veh. Eng. 2019, 57, 113–116. [Google Scholar]
- Chabot, D.; Francis, C.M. Computer-Automated Bird Detection and Counts in High-Resolution Aerial Images: A Review. J. Field Ornithol. 2016, 87, 343–359. [Google Scholar] [CrossRef]
- Weissensteiner, M.H.; Poelstra, J.W.; Wolf, J.B.W. Low-Budget Ready-to-Fly Unmanned Aerial Vehicles: An Effective Tool for Evaluating the Nesting Status of Canopy-Breeding Bird Species. J. Avian Biol. 2015, 46, 425–430. [Google Scholar] [CrossRef]
- Chabot, D.; Craik, S.R.; Bird, D.M. Population Census of a Large Common Tern Colony with a Small Unmanned Aircraft. PLoS ONE 2015, 10, e0122588. [Google Scholar] [CrossRef]
- McClelland, G.; Bond, A.; Sardana, A.; Glass, T. Rapid Population Estimate of a Surface-Nesting Seabird on a Remote Island Using a Low-Cost Unmanned Aerial Vehicle. Mar. Ornithol. 2016, 44, 215–220. [Google Scholar]
- Hodgson, J.C.; Baylis, S.M.; Mott, R.; Herrod, A.; Clarke, R.H. Precision Wildlife Monitoring Using Unmanned Aerial Vehicles. Sci. Rep. 2016, 6, 22574. [Google Scholar] [CrossRef]
- Sardà-Palomera, F.; Bota, G.; Padilla, N.; Brotons, L.; Sardà, F. Unmanned Aircraft Systems to Unravel Spatial and Temporal Factors Affecting Dynamics of Colony Formation and Nesting Success in Birds. J. Avian Biol. 2017, 48, 1273–1280. [Google Scholar] [CrossRef]
- Wilson, A.M.; Barr, J.; Zagorski, M. The feasibility of counting songbirds using unmanned aerial vehicles. AUK A Q. J. Ornithol. 2017, 134, 350–362. [Google Scholar] [CrossRef]
- Xie, J.; Zhu, M. Acoustic Classification of Bird Species Using an Early Fusion of Deep Features. Birds 2023, 4, 11. [Google Scholar] [CrossRef]
- Bateman, H.L.; Riddle, S.B.; Cubley, E.S. Using Bioacoustics to Examine Vocal Phenology of Neotropical Migratory Birds on a Wild and Scenic River in Arizona. Birds 2021, 2, 19. [Google Scholar] [CrossRef]
- Yip, D.; Leston, L.; Bayne, E.; Sólymos, P.; Grover, A. Experimentally derived detection distances from audio recordings and human observers enable integrated analysis of point count data. Avian Conserv. Ecol. 2017, 12, 11. [Google Scholar] [CrossRef]
- Budka, M.; Kułaga, K.; Osiejuk, T.S. Evaluation of Accuracy and Precision of the Sound-Recorder-Based Point-Counts Applied in Forests and Open Areas in Two Locations Situated in a Temperate and Tropical Regions. Birds 2021, 2, 26. [Google Scholar] [CrossRef]
- Zhang, C.; Lu, Y. Study on Artificial Intelligence: The State of the Art and Future Prospects. J. Ind. Inf. Integr. 2021, 23, 100224. [Google Scholar] [CrossRef]
- Pan, Y. Heading toward Artificial Intelligence 2.0. Engineering 2016, 2, 409–413. [Google Scholar] [CrossRef]
- Berger-Wolf, T.Y.; Rubenstein, D.I.; Stewart, C.V.; Holmberg, J.A.; Parham, J.; Menon, S.; Crall, J.; Van Oast, J.; Kiciman, E.; Joppa, L. Wildbook: Crowdsourcing, Computer Vision, and Data Science for Conservation. arXiv 2017, arXiv:1710.08880. [Google Scholar]
- Tuia, D.; Kellenberger, B.; Beery, S.; Costelloe, B.R.; Zuffi, S.; Risse, B.; Mathis, A.; Mathis, M.W.; van Langevelde, F.; Burghardt, T.; et al. Perspectives in Machine Learning for Wildlife Conservation. Nat. Commun. 2022, 13, 792. [Google Scholar] [CrossRef] [PubMed]
- Niemi, J.; Tanttu, J.T. Deep Learning Case Study for Automatic Bird Identification. Appl. Sci. 2018, 8, 2089. [Google Scholar] [CrossRef]
- Ferreira, A.C.; Silva, L.R.; Renna, F.; Brandl, H.B.; Renoult, J.P.; Farine, D.R.; Covas, R.; Doutrelant, C. Deep Learning-Based Methods for Individual Recognition in Small Birds. Methods Ecol. Evol. 2020, 11, 1072–1085. [Google Scholar] [CrossRef]
- Lyu, X.; Chen, S. Location and identification of red-crowned cranes based on convolutional neural network. Electron. Meas. Technol. 2020, 43, 104–108. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. Mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Ghiasi, G.; Lin, T.Y.; Le, Q.V. Dropblock: A regularization method for convolutional networks. Adv. Neural Inf. Process. Syst. 2018. [Google Scholar] [CrossRef]
- Wickens, C. Attention: Theory, Principles, Models and Applications. Int. J. Hum. Comput. Interact. 2021, 37, 403–417. [Google Scholar] [CrossRef]
- Bidirectional Encoder Representations from Transformers—An Overview ScienceDirect Topics. Available online: https://www.sciencedirect.com/topics/computer-science/bidirectional-encoder-representations-from-transformers (accessed on 4 March 2023).
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training; OpenAI: San Francisco, CA, USA, 2018. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 9–14 September 2018; pp. 3–19. [Google Scholar]
- Park, J.; Woo, S.; Lee, J.Y.; Kweon, I.S. Bam: Bottleneck attention module. arXiv 2018, arXiv:1807.06514. [Google Scholar]
- Liu, Z.; Wang, L.; Wu, W.; Qian, C.; Lu, T. Tam: Temporal adaptive module for video recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 13708–13718. [Google Scholar]
- Liu, Y.; Shao, Z.; Hoffmann, N. Global attention mechanism: Retain information to enhance channel-spatial interactions. arXiv 2021, arXiv:2112.05561. [Google Scholar]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. Unitbox: An advanced object detection network. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 516–520. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.Y.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Zheng, Z.; Wang, P.; Ren, D.; Liu, W.; Ye, R.; Hu, Q.; Zuo, W. Enhancing geometric factors in model learning and inference for object detection and instance segmentation. IEEE Trans. Cybern. 2021, 52, 8574–8586. [Google Scholar] [CrossRef]
- He, J.; Erfani, S.; Ma, X.; Bailey, J.; Chi, Y.; Hua, X.S. α-IoU: A Family of Power Intersection over Union Losses for Bounding Box Regression. Adv. Neural Inf. Process. Syst. 2021, 34, 20230–20242. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 3645–3649. [Google Scholar]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 3464–3468. [Google Scholar]
- Basar, T. A New Approach to Linear Filtering and Prediction Problems. In Control Theory: Twenty-Five Seminal Papers (1932–1981); IEEE: Piscataway, NJ, USA, 2001; pp. 167–179. ISBN 978-0-470-54433-4. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. Int. J. Comput. Vis. 2020, 128, 336–359. [Google Scholar] [CrossRef]
- Dixon, A.P.; Baker, M.E.; Ellis, E.C. Agricultural landscape composition linked with acoustic measures of avian diversity. Land 2020, 9, 145. [Google Scholar] [CrossRef]
- Farina, A.; James, P.; Bobryk, C.; Pieretti, N.; Lattanzi, E.; McWilliam, J. Low cost (audio) recording (LCR) for advancing soundscape ecology towards the conservation of sonic complexity and biodiversity in natural and urban landscapes. Urban Ecosyst. 2014, 17, 923–944. [Google Scholar] [CrossRef]
- Nichols, J.D.; Williams, B.K. Monitoring for conservation. Trends Ecol. Evol. 2006, 21, 668–673. [Google Scholar] [CrossRef] [PubMed]
- MacKenzie, D.; Nichols, J.; Lachman, G.; Droege, G.S.; Royle, J.; Langtimm, C. Estimating site occupancy rates when detection probabilities are less than one. Ecology 2002, 83, 2248–2255. [Google Scholar] [CrossRef]
- Gu, W.; Swihart, R.K. Absent or undetected? Effects of non-detection of species occurrence on wildlife–habitat models. Biol. Conserv. 2003, 116, 195–203. [Google Scholar] [CrossRef]
- Sliwinski, M.; Powell, L.; Koper, N.; Giovanni, M.; Schacht, W. Research design considerations to ensure detection of all species in an avian community. Methods Ecol. Evol. 2016, 7, 456–462. [Google Scholar] [CrossRef]
- Dettmers, R.; Buehler, D.; Bartlett, J.; Klaus, N. Influence of point count length and repeated visits on habitat model performance. J. Wild Manag. 1999, 63, 815–823. [Google Scholar] [CrossRef]
- Budka, M.; Czyż, M.; Skierczyńska, A.; Skierczyński, M.; Osiejuk, T.S. Duration of survey changes interpretation of habitat preferences: An example of an endemic tropical songbird, the Bangwa Forest Warbler. Ostrich 2020, 91, 195–203. [Google Scholar] [CrossRef]
- Johnson, M.D. Measuring habitat quality: A review. Condor 2007, 109, 489–504. [Google Scholar] [CrossRef]
- Battin, J. When Good Animals Love Bad Habitats: Ecological Traps and the Conservation of Animal Populations. Conserv. Biol. 2004, 18, 1482–1491. [Google Scholar] [CrossRef]
- Zottesso, R.H.; Costa, Y.M.; Bertolini, D.; Oliveira, L.E. Bird species identification using spectrogram and dissimilarity approach. Ecol. Inform. 2018, 48, 187–197. [Google Scholar] [CrossRef]
- Zheng, H.; Fu, J.; Zha, Z.J.; Luo, J. Learning deep bilinear transformation for fine-grained image representation. Adv. Neural Inf. Process. Syst. 2019. [Google Scholar] [CrossRef]
- Ji, X.; Jiang, K.; Xie, J. LBP-based bird sound classification using improved feature selection algorithm. Int. J. Speech Technol. 2021, 24, 1033–1045. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Annotation Method | Name | Proportion | Number of Pictures | Number of Birds |
|---|---|---|---|---|
| Whole Body Annotation | training set | 85% | 3176 | 11,322 |
| validation set | 10% | 373 | 1543 | |
| test set | 5% | 188 | 863 | |
| Head Annotation | training set | 85% | 2782 | 10,085 |
| validation set | 10% | 327 | 1217 | |
| test set | 5% | 164 | 681 | |
| Total | Whole Body Annotation | 100% | 3737 | 13,728 |
| Head Annotation | 100% | 3273 | 11,983 |
| Partition Name | Proportion | Number of Pictures |
|---|---|---|
| training set | 85% | 9468 |
| validation set | 10% | 1114 |
| test set | 5% | 557 |
| Total | 100% | 11,139 |
| Name | Type/Version |
|---|---|
| Operating system | Ubuntu 20.04 |
| Python version | Python 3.8 |
| Versions of the library | Torch1.9.0 + cu111 |
| Integrated Development Environment | Pycharm 2021.3.3 |
| Central Processing Unit | AMD EPYC 7543 32-Core Processor |
| Graphics Processing Unit | A40(48 GB) × 2 |
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| Initial Learning Rate | 0.01 | Weight Decay | 0.0005 |
| Momentum | 0.937 | Batch Size | 32 |
| Image Size | 640 × 640 | Epochs | 200 |
| Confusion Matrix | Predicted Results | ||
|---|---|---|---|
| Positive | Negative | ||
| Real Results | True | ||
| False | |||
| Model | Class | Precision | Recall | F1 Score | mAP@0.5 | FPS |
|---|---|---|---|---|---|---|
| Faster-RCNN | All | 0.793 | 0.854 | 0.82 | 0.841 | 25 |
| Ruddy Shelduck | 0.697 | 0.874 | 0.78 | 0.855 | ||
| Whooper Swan | 0.686 | 0.802 | 0.74 | 0.775 | ||
| Red-crowned Crane | 0.639 | 0.860 | 0.73 | 0.825 | ||
| Black Stork | 0.806 | 0.847 | 0.83 | 0.824 | ||
| Little Grebe | 0.856 | 0.897 | 0.88 | 0.873 | ||
| Mallard | 0.879 | 0.855 | 0.87 | 0.861 | ||
| Pheasant-tailed Jacana | 0.868 | 0.869 | 0.87 | 0.859 | ||
| Demoiselle Crane | 0.921 | 0.818 | 0.87 | 0.854 | ||
| Mandarin Duck | 0.857 | 0.865 | 0.86 | 0.859 | ||
| Scaly-sided Merganser | 0.725 | 0.852 | 0.78 | 0.824 | ||
| EfficientDet | All | 0.873 | 0.832 | 0.85 | 0.851 | 12 |
| Ruddy Shelduck | 0.887 | 0.900 | 0.89 | 0.895 | ||
| Whooper Swan | 0.820 | 0.745 | 0.78 | 0.807 | ||
| Red-crowned Crane | 0.872 | 0.737 | 0.80 | 0.821 | ||
| Black Stork | 0.838 | 0.821 | 0.83 | 0.834 | ||
| Little Grebe | 0.913 | 0.892 | 0.90 | 0.899 | ||
| Mallard | 0.812 | 0.869 | 0.84 | 0.829 | ||
| Pheasant-tailed Jacana | 0.897 | 0.857 | 0.88 | 0.871 | ||
| Demoiselle Crane | 0.930 | 0.741 | 0.82 | 0.807 | ||
| Mandarin Duck | 0.911 | 0.883 | 0.90 | 0.891 | ||
| Scaly-sided Merganser | 0.854 | 0.874 | 0.86 | 0.861 | ||
| CenterNet | All | 0.828 | 0.611 | 0.70 | 0.712 | 59 |
| Ruddy Shelduck | 1.000 | 0.749 | 0.86 | 0.892 | ||
| Whooper Swan | 0.914 | 0.750 | 0.82 | 0.883 | ||
| Red-crowned Crane | 0.956 | 0.733 | 0.83 | 0.840 | ||
| Black Stork | 0.802 | 0.630 | 0.71 | 0.799 | ||
| Little Grebe | 0.644 | 0.793 | 0.71 | 0.636 | ||
| Mallard | 0.892 | 0.600 | 0.72 | 0.793 | ||
| Pheasant-tailed Jacana | 0.802 | 0.761 | 0.78 | 0.792 | ||
| Demoiselle Crane | 0.703 | 0.612 | 0.65 | 0.694 | ||
| Mandarin Duck | 0.802 | 0.393 | 0.53 | 0.611 | ||
| Scaly-sided Merganser | 0.762 | 0.093 | 0.17 | 0.181 | ||
| SSD | All | 0.861 | 0.768 | 0.81 | 0.821 | 63 |
| Ruddy Shelduck | 0.790 | 0.810 | 0.80 | 0.809 | ||
| Whooper Swan | 0.759 | 0.623 | 0.68 | 0.673 | ||
| Red-crowned Crane | 0.854 | 0.707 | 0.77 | 0.811 | ||
| Black Stork | 0.890 | 0.790 | 0.84 | 0.840 | ||
| Little Grebe | 0.934 | 0.885 | 0.91 | 0.892 | ||
| Mallard | 0.867 | 0.844 | 0.86 | 0.866 | ||
| Pheasant-tailed Jacana | 0.926 | 0.892 | 0.91 | 0.917 | ||
| Demoiselle Crane | 0.843 | 0.586 | 0.69 | 0.725 | ||
| Mandarin Duck | 0.859 | 0.722 | 0.78 | 0.796 | ||
| Scaly-sided Merganser | 0.893 | 0.821 | 0.86 | 0.878 | ||
| YOLOv4 | All | 0.907 | 0.679 | 0.76 | 0.790 | 40 |
| Ruddy Shelduck | 0.879 | 0.888 | 0.88 | 0.889 | ||
| Whooper Swan | 0.839 | 0.702 | 0.76 | 0.808 | ||
| Red-crowned Crane | 0.777 | 0.664 | 0.72 | 0.767 | ||
| Black Stork | 0.891 | 0.765 | 0.82 | 0.849 | ||
| Little Grebe | 0.962 | 0.839 | 0.90 | 0.933 | ||
| Mallard | 0.894 | 0.696 | 0.78 | 0.790 | ||
| Pheasant-tailed Jacana | 0.985 | 0.767 | 0.86 | 0.900 | ||
| Demoiselle Crane | 0.951 | 0.656 | 0.78 | 0.838 | ||
| Mandarin Duck | 0.906 | 0.556 | 0.69 | 0.801 | ||
| Scaly-sided Merganser | 0.985 | 0.254 | 0.40 | 0.329 | ||
| YOLOv5 | All | 0.923 | 0.847 | 0.88 | 0.841 | 88 |
| Ruddy Shelduck | 0.818 | 0.877 | 0.85 | 0.811 | ||
| Whooper Swan | 0.901 | 0.578 | 0.70 | 0.734 | ||
| Red-crowned Crane | 0.942 | 0.770 | 0.85 | 0.675 | ||
| Black Stork | 0.961 | 0.936 | 0.95 | 0.914 | ||
| Little Grebe | 0.855 | 0.946 | 0.90 | 0.876 | ||
| Mallard | 0.940 | 0.923 | 0.93 | 0.918 | ||
| Pheasant-tailed Jacana | 0.960 | 0.950 | 0.95 | 0.862 | ||
| Demoiselle Crane | 0.971 | 0.796 | 0.87 | 0.830 | ||
| Mandarin Duck | 0.917 | 0.924 | 0.92 | 0.914 | ||
| Scaly-sided Merganser | 0.967 | 0.771 | 0.86 | 0.878 | ||
| YOLOv7 | All | 0.850 | 0.836 | 0.84 | 0.862 | 81 |
| Ruddy Shelduck | 0.911 | 0.668 | 0.77 | 0.800 | ||
| Whooper Swan | 0.648 | 0.701 | 0.67 | 0.705 | ||
| Red-crowned Crane | 0.851 | 0.846 | 0.85 | 0.876 | ||
| Black Stork | 0.652 | 0.759 | 0.70 | 0.726 | ||
| Little Grebe | 0.968 | 0.902 | 0.93 | 0.968 | ||
| Mallard | 0.841 | 0.900 | 0.87 | 0.915 | ||
| Pheasant-tailed Jacana | 0.749 | 0.909 | 0.82 | 0.773 | ||
| Demoiselle Crane | 0.959 | 0.784 | 0.86 | 0.903 | ||
| Mandarin Duck | 0.960 | 0.958 | 0.96 | 0.989 | ||
| Scaly-sided Merganser | 0.962 | 0.934 | 0.95 | 0.966 | ||
| YOLOv8 | All | 0.846 | 0.800 | 0.82 | 0.835 | 91 |
| Ruddy Shelduck | 0.852 | 0.569 | 0.68 | 0.713 | ||
| Whooper Swan | 0.646 | 0.603 | 0.62 | 0.573 | ||
| Red-crowned Crane | 0.790 | 0.815 | 0.80 | 0.834 | ||
| Black Stork | 0.763 | 0.774 | 0.77 | 0.787 | ||
| Little Grebe | 0.954 | 0.961 | 0.96 | 0.970 | ||
| Mallard | 0.902 | 0.864 | 0.88 | 0.896 | ||
| Pheasant-tailed Jacana | 0.749 | 0.864 | 0.80 | 0.791 | ||
| Demoiselle Crane | 0.910 | 0.768 | 0.83 | 0.877 | ||
| Mandarin Duck | 0.961 | 0.881 | 0.92 | 0.938 | ||
| Scaly-sided Merganser | 0.932 | 0.898 | 0.91 | 0.970 |
| Model | Class | Precision | Recall | F1 Score | mAP@0.5 | FPS |
|---|---|---|---|---|---|---|
| Faster-RCNN | All | 0.831 | 0.892 | 0.86 | 0.879 | 26 |
| Ruddy Shelduck | 0.735 | 0.912 | 0.81 | 0.893 | ||
| Whooper Swan | 0.724 | 0.840 | 0.78 | 0.813 | ||
| Red-crowned Crane | 0.677 | 0.898 | 0.77 | 0.863 | ||
| Black Stork | 0.844 | 0.885 | 0.86 | 0.862 | ||
| Little Grebe | 0.894 | 0.935 | 0.91 | 0.911 | ||
| Mallard | 0.917 | 0.893 | 0.91 | 0.899 | ||
| Pheasant-tailed Jacana | 0.906 | 0.907 | 0.91 | 0.897 | ||
| Demoiselle Crane | 0.959 | 0.856 | 0.90 | 0.892 | ||
| Mandarin Duck | 0.895 | 0.903 | 0.90 | 0.897 | ||
| Scaly-sided Merganser | 0.763 | 0.890 | 0.82 | 0.862 | ||
| EfficientDet | All | 0.915 | 0.874 | 0.89 | 0.898 | 14 |
| Ruddy Shelduck | 0.932 | 0.955 | 0.94 | 0.945 | ||
| Whooper Swan | 0.860 | 0.785 | 0.82 | 0.857 | ||
| Red-crowned Crane | 0.912 | 0.777 | 0.84 | 0.867 | ||
| Black Stork | 0.893 | 0.866 | 0.88 | 0.884 | ||
| Little Grebe | 0.943 | 0.937 | 0.94 | 0.945 | ||
| Mallard | 0.867 | 0.899 | 0.88 | 0.875 | ||
| Pheasant-tailed Jacana | 0.927 | 0.912 | 0.92 | 0.917 | ||
| Demoiselle Crane | 0.985 | 0.771 | 0.86 | 0.853 | ||
| Mandarin Duck | 0.941 | 0.938 | 0.94 | 0.937 | ||
| Scaly-sided Merganser | 0.894 | 0.904 | 0.90 | 0.897 | ||
| CenterNet | All | 0.968 | 0.659 | 0.74 | 0.796 | 58 |
| Ruddy Shelduck | 1.000 | 0.977 | 0.99 | 0.998 | ||
| Whooper Swan | 0.984 | 0.750 | 0.85 | 0.783 | ||
| Red-crowned Crane | 0.973 | 0.750 | 0.85 | 0.840 | ||
| Black Stork | 1.000 | 0.851 | 0.92 | 0.881 | ||
| Little Grebe | 0.842 | 0.800 | 0.82 | 0.936 | ||
| Mallard | 0.909 | 0.517 | 0.66 | 0.740 | ||
| Pheasant-tailed Jacana | 1.000 | 0.778 | 0.88 | 0.906 | ||
| Demoiselle Crane | 0.971 | 0.810 | 0.88 | 0.862 | ||
| Mandarin Duck | 1.000 | 0.333 | 0.50 | 0.785 | ||
| Scaly-sided Merganser | 1.000 | 0.023 | 0.04 | 0.226 | ||
| SSD | All | 0.901 | 0.796 | 0.84 | 0.858 | 60 |
| Ruddy Shelduck | 0.838 | 0.838 | 0.84 | 0.857 | ||
| Whooper Swan | 0.784 | 0.661 | 0.72 | 0.696 | ||
| Red-crowned Crane | 0.892 | 0.745 | 0.81 | 0.849 | ||
| Black Stork | 0.909 | 0.805 | 0.85 | 0.878 | ||
| Little Grebe | 0.976 | 0.900 | 0.94 | 0.930 | ||
| Mallard | 0.882 | 0.882 | 0.88 | 0.904 | ||
| Pheasant-tailed Jacana | 0.968 | 0.930 | 0.95 | 0.955 | ||
| Demoiselle Crane | 0.910 | 0.601 | 0.72 | 0.763 | ||
| Mandarin Duck | 0.941 | 0.737 | 0.83 | 0.834 | ||
| Scaly-sided Merganser | 0.912 | 0.859 | 0.88 | 0.916 | ||
| YOLOv4 | All | 0.924 | 0.683 | 0.77 | 0.811 | 37 |
| Ruddy Shelduck | 0.848 | 0.907 | 0.88 | 0.944 | ||
| Whooper Swan | 0.877 | 0.713 | 0.79 | 0.846 | ||
| Red-crowned Crane | 0.769 | 0.625 | 0.69 | 0.782 | ||
| Black Stork | 0.929 | 0.776 | 0.85 | 0.887 | ||
| Little Grebe | 1.000 | 0.850 | 0.92 | 0.948 | ||
| Mallard | 0.932 | 0.707 | 0.80 | 0.805 | ||
| Pheasant-tailed Jacana | 1.000 | 0.778 | 0.88 | 0.892 | ||
| Demoiselle Crane | 0.966 | 0.667 | 0.79 | 0.853 | ||
| Mandarin Duck | 0.921 | 0.556 | 0.69 | 0.816 | ||
| Scaly-sided Merganser | 1.000 | 0.250 | 0.40 | 0.333 | ||
| YOLOv5 | All | 0.865 | 0.805 | 0.83 | 0.920 | 93 |
| Ruddy Shelduck | 0.808 | 0.824 | 0.82 | 0.911 | ||
| Whooper Swan | 0.897 | 0.678 | 0.77 | 0.734 | ||
| Red-crowned Crane | 0.875 | 0.477 | 0.62 | 0.875 | ||
| Black Stork | 0.911 | 0.874 | 0.89 | 0.984 | ||
| Little Grebe | 0.823 | 0.894 | 0.86 | 0.960 | ||
| Mallard | 0.914 | 0.909 | 0.91 | 0.978 | ||
| Pheasant-tailed Jacana | 0.769 | 0.912 | 0.83 | 0.992 | ||
| Demoiselle Crane | 0.873 | 0.774 | 0.82 | 0.910 | ||
| Mandarin Duck | 0.828 | 0.912 | 0.87 | 0.964 | ||
| Scaly-sided Merganser | 0.954 | 0.791 | 0.86 | 0.889 | ||
| YOLOv7 | All | 0.942 | 0.870 | 0.90 | 0.932 | 111 |
| Ruddy Shelduck | 0.766 | 0.896 | 0.83 | 0.921 | ||
| Whooper Swan | 0.929 | 0.601 | 0.73 | 0.760 | ||
| Red-crowned Crane | 0.975 | 0.809 | 0.88 | 0.915 | ||
| Black Stork | 0.984 | 0.947 | 0.97 | 0.980 | ||
| Little Grebe | 0.900 | 0.973 | 0.94 | 0.974 | ||
| Mallard | 0.951 | 0.939 | 0.95 | 0.978 | ||
| Pheasant-tailed Jacana | 1.000 | 0.987 | 0.99 | 0.996 | ||
| Demoiselle Crane | 0.983 | 0.830 | 0.90 | 0.915 | ||
| Mandarin Duck | 0.967 | 0.930 | 0.95 | 0.960 | ||
| Scaly-sided Merganser | 0.966 | 0.791 | 0.87 | 0.921 | ||
| YOLOv8 | All | 0.925 | 0.864 | 0.89 | 0.927 | 97 |
| Ruddy Shelduck | 0.846 | 0.900 | 0.87 | 0.929 | ||
| Whooper Swan | 0.892 | 0.597 | 0.72 | 0.759 | ||
| Red-crowned Crane | 0.971 | 0.799 | 0.88 | 0.899 | ||
| Black Stork | 0.953 | 0.947 | 0.95 | 0.976 | ||
| Little Grebe | 0.852 | 0.946 | 0.90 | 0.970 | ||
| Mallard | 0.946 | 0.937 | 0.94 | 0.971 | ||
| Pheasant-tailed Jacana | 1.000 | 0.975 | 0.99 | 0.995 | ||
| Demoiselle Crane | 0.975 | 0.859 | 0.91 | 0.947 | ||
| Mandarin Duck | 0.897 | 0.930 | 0.91 | 0.953 | ||
| Scaly-sided Merganser | 0.954 | 0.755 | 0.84 | 0.875 |
| Group | HSV | Mosaic | MixUp | FocalLoss | Precision | Recall | F1 Score | mAP@0.5 | mAP@0.5:0.95 | FPS |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 🗴 | 🗴 | 🗴 | 🗴 | 0.939 | 0.870 | 0.90 | 0.932 | 0.807 | 111 |
| 2 | ✓ | 🗴 | 🗴 | 🗴 | 0.914 | 0.885 | 0.90 | 0.930 | 0.801 | 92 |
| 3 | 🗴 | ✓ | 🗴 | 🗴 | 0.933 | 0.876 | 0.90 | 0.931 | 0.798 | 89 |
| 4 | 🗴 | 🗴 | ✓ | 🗴 | 0.929 | 0.878 | 0.90 | 0.929 | 0.798 | 91 |
| 5 | 🗴 | 🗴 | 🗴 | ✓ | 0.925 | 0.872 | 0.90 | 0.924 | 0.782 | 82 |
| 6 | ✓ | ✓ | 🗴 | 🗴 | 0.924 | 0.885 | 0.90 | 0.930 | 0.801 | 84 |
| 7 | ✓ | 🗴 | ✓ | 🗴 | 0.935 | 0.880 | 0.91 | 0.927 | 0.790 | 79 |
| 8 | ✓ | 🗴 | 🗴 | ✓ | 0.913 | 0.877 | 0.89 | 0.929 | 0.801 | 83 |
| 9 | 🗴 | ✓ | ✓ | 🗴 | 0.940 | 0.881 | 0.91 | 0.932 | 0.807 | 86 |
| 10 | 🗴 | ✓ | 🗴 | ✓ | 0.916 | 0.884 | 0.90 | 0.929 | 0.777 | 77 |
| 11 | 🗴 | 🗴 | ✓ | ✓ | 0.930 | 0.874 | 0.90 | 0.929 | 0.797 | 82 |
| 12 | ✓ | ✓ | ✓ | 🗴 | 0.942 | 0.888 | 0.91 | 0.933 | 0.809 | 85 |
| 13 | ✓ | ✓ | 🗴 | ✓ | 0.932 | 0.876 | 0.90 | 0.927 | 0.783 | 81 |
| 14 | ✓ | 🗴 | ✓ | ✓ | 0.933 | 0.879 | 0.91 | 0.927 | 0.789 | 81 |
| 15 | 🗴 | ✓ | ✓ | ✓ | 0.945 | 0.879 | 0.91 | 0.931 | 0.801 | 80 |
| 16 | ✓ | ✓ | ✓ | ✓ | 0.932 | 0.875 | 0.90 | 0.927 | 0.788 | 84 |
| Model | Class | Precision | Recall | F1 Score | mAP@0.5 | mAP@0.5:0.95 | FPS |
|---|---|---|---|---|---|---|---|
| YOLOv7 | All | 0.942 | 0.888 | 0.91 | 0.933 | 0.809 | 85 |
| Ruddy Shelduck | 0.766 | 0.912 | 0.83 | 0.921 | 0.804 | ||
| Whooper Swan | 0.931 | 0.669 | 0.78 | 0.770 | 0.536 | ||
| Red-crowned Crane | 0.975 | 0.819 | 0.89 | 0.915 | 0.757 | ||
| Black Stork | 0.984 | 0.956 | 0.97 | 0.980 | 0.864 | ||
| Little Grebe | 0.900 | 0.979 | 0.94 | 0.974 | 0.931 | ||
| Mallard | 0.951 | 0.939 | 0.94 | 0.978 | 0.878 | ||
| Pheasant-tailed Jacana | 1.000 | 0.957 | 0.98 | 0.996 | 0.912 | ||
| Demoiselle Crane | 0.983 | 0.883 | 0.93 | 0.915 | 0.760 | ||
| Mandarin Duck | 0.967 | 0.934 | 0.95 | 0.960 | 0.852 | ||
| Scaly-sided Merganser | 0.966 | 0.833 | 0.89 | 0.921 | 0.793 | ||
| YOLOv7 + GAM | All | 0.929 | 0.883 | 0.91 | 0.938 | 0.803 | 101 |
| Ruddy Shelduck | 0.750 | 0.890 | 0.81 | 0.917 | 0.792 | ||
| Whooper Swan | 0.920 | 0.649 | 0.76 | 0.780 | 0.538 | ||
| Red-crowned Crane | 0.972 | 0.834 | 0.90 | 0.922 | 0.754 | ||
| Black Stork | 0.956 | 0.962 | 0.96 | 0.979 | 0.849 | ||
| Little Grebe | 0.818 | 0.973 | 0.89 | 0.982 | 0.923 | ||
| Mallard | 0.947 | 0.961 | 0.95 | 0.977 | 0.884 | ||
| Pheasant-tailed Jacana | 1.000 | 0.987 | 0.99 | 0.996 | 0.889 | ||
| Demoiselle Crane | 0.983 | 0.834 | 0.90 | 0.921 | 0.752 | ||
| Mandarin Duck | 0.967 | 0.939 | 0.95 | 0.971 | 0.851 | ||
| Scaly-sided Merganser | 0.978 | 0.799 | 0.88 | 0.931 | 0.797 | ||
| YOLOv7 + Alpha-IoU | All | 0.945 | 0.887 | 0.92 | 0.947 | 0.809 | 92 |
| Ruddy Shelduck | 0.873 | 0.908 | 0.89 | 0.944 | 0.816 | ||
| Whooper Swan | 0.914 | 0.684 | 0.78 | 0.811 | 0.549 | ||
| Red-crowned Crane | 0.972 | 0.825 | 0.89 | 0.935 | 0.747 | ||
| Black Stork | 0.952 | 0.962 | 0.96 | 0.980 | 0.867 | ||
| Little Grebe | 0.885 | 0.973 | 0.93 | 0.989 | 0.906 | ||
| Mallard | 0.946 | 0.947 | 0.95 | 0.979 | 0.879 | ||
| Pheasant-tailed Jacana | 1.000 | 0.987 | 0.99 | 0.995 | 0.901 | ||
| Demoiselle Crane | 0.972 | 0.828 | 0.89 | 0.920 | 0.778 | ||
| Mandarin Duck | 0.968 | 0.943 | 0.96 | 0.978 | 0.854 | ||
| Scaly-sided Merganser | 0.971 | 0.817 | 0.89 | 0.940 | 0.793 | ||
| YOLOv7 GAM Alpha-IoU (YOLOv7Birds) | All | 0.945 | 0.898 | 0.92 | 0.951 | 0.815 | 82 |
| Ruddy Shelduck | 0.892 | 0.904 | 0.90 | 0.944 | 0.803 | ||
| Whooper Swan | 0.922 | 0.730 | 0.81 | 0.825 | 0.573 | ||
| Red-crowned Crane | 0.984 | 0.858 | 0.92 | 0.935 | 0.752 | ||
| Black Stork | 0.947 | 0.962 | 0.95 | 0.981 | 0.857 | ||
| Little Grebe | 0.817 | 0.973 | 0.89 | 0.990 | 0.919 | ||
| Mallard | 0.956 | 0.946 | 0.95 | 0.983 | 0.880 | ||
| Pheasant-tailed Jacana | 1.000 | 0.987 | 0.99 | 0.996 | 0.911 | ||
| Demoiselle Crane | 0.977 | 0.871 | 0.92 | 0.932 | 0.807 | ||
| Mandarin Duck | 0.975 | 0.943 | 0.96 | 0.985 | 0.847 | ||
| Scaly-sided Merganser | 0.977 | 0.808 | 0.88 | 0.937 | 0.797 |
| Interval of Time | 0–15 s | 16–30 s | 31–45 s | 46–60 s | |
|---|---|---|---|---|---|
| Results of manual count (“true count”) | Quantity | 36 | 44 | 65 | 72 |
| Counting Accuracy (%) | 100% | 100% | 100% | 100% | |
| Results of our algorithm | Quantity | 36 | 44 | 65 | 72 |
| Counting Accuracy (%) | 100% | 100% | 100% | 100% | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, X.; Pu, H.; He, Y.; Lai, M.; Zhang, D.; Chen, J.; Pu, H. An Efficient Method for Monitoring Birds Based on Object Detection and Multi-Object Tracking Networks. Animals 2023, 13, 1713. https://doi.org/10.3390/ani13101713
Chen X, Pu H, He Y, Lai M, Zhang D, Chen J, Pu H. An Efficient Method for Monitoring Birds Based on Object Detection and Multi-Object Tracking Networks. Animals. 2023; 13(10):1713. https://doi.org/10.3390/ani13101713
Chicago/Turabian StyleChen, Xian, Hongli Pu, Yihui He, Mengzhen Lai, Daike Zhang, Junyang Chen, and Haibo Pu. 2023. "An Efficient Method for Monitoring Birds Based on Object Detection and Multi-Object Tracking Networks" Animals 13, no. 10: 1713. https://doi.org/10.3390/ani13101713
APA StyleChen, X., Pu, H., He, Y., Lai, M., Zhang, D., Chen, J., & Pu, H. (2023). An Efficient Method for Monitoring Birds Based on Object Detection and Multi-Object Tracking Networks. Animals, 13(10), 1713. https://doi.org/10.3390/ani13101713