
An Integrated Goat Head Detection and Automatic Counting Method Based on Deep Learning

 ,
,
Abstract
:Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Data Acquisition
2.2. Data Preprocessing
2.3. Rand Augment
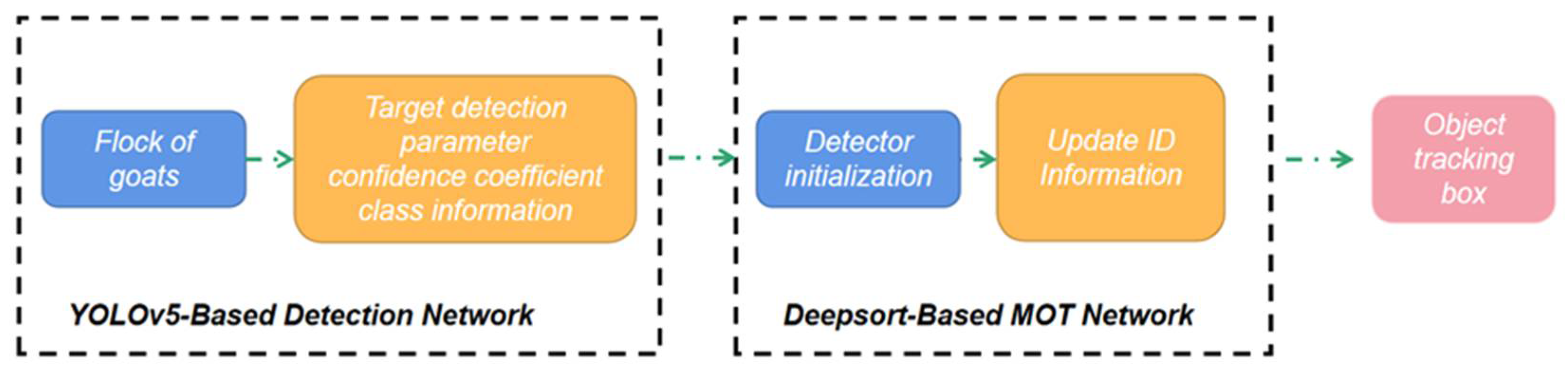
2.4. Object Detection
2.5. Our Improved YOLOV5-Based Detection Network for Chengdu Ma Goat
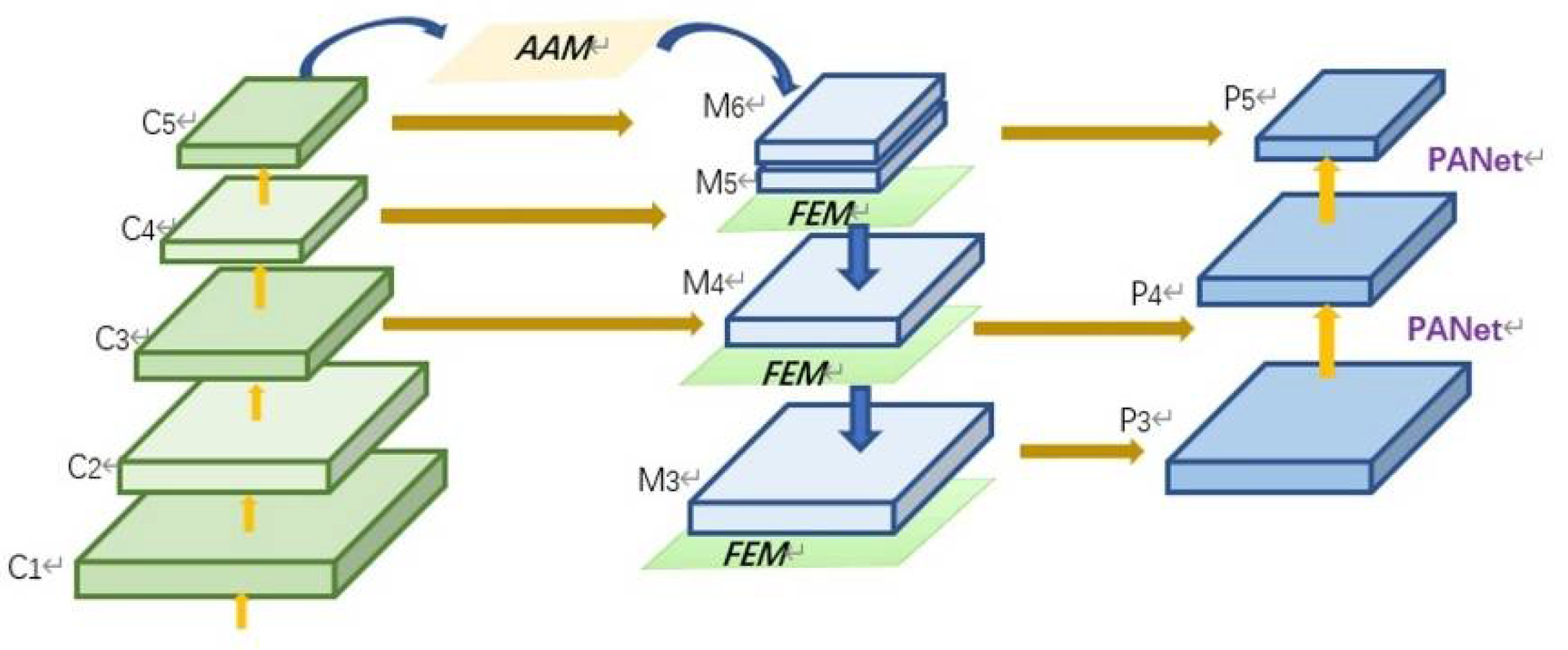
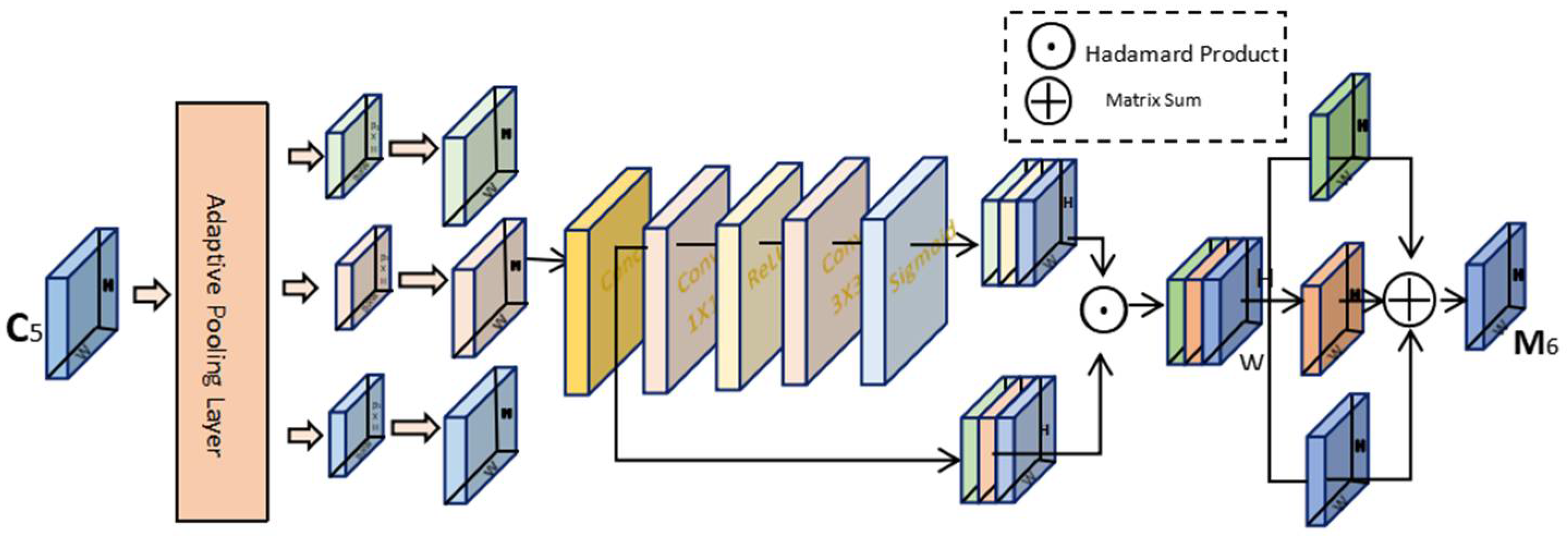
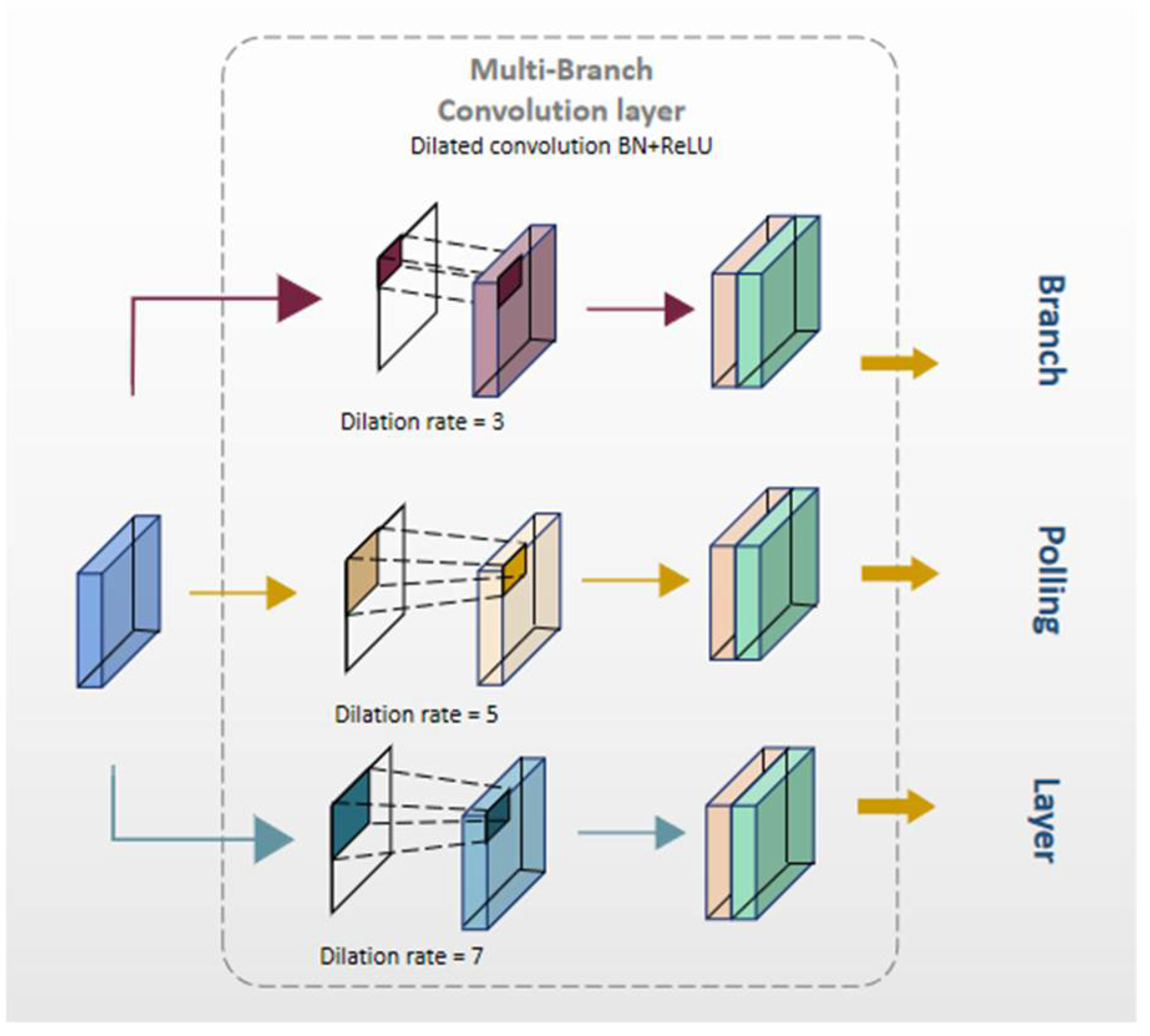
2.5.1. AF-FPN
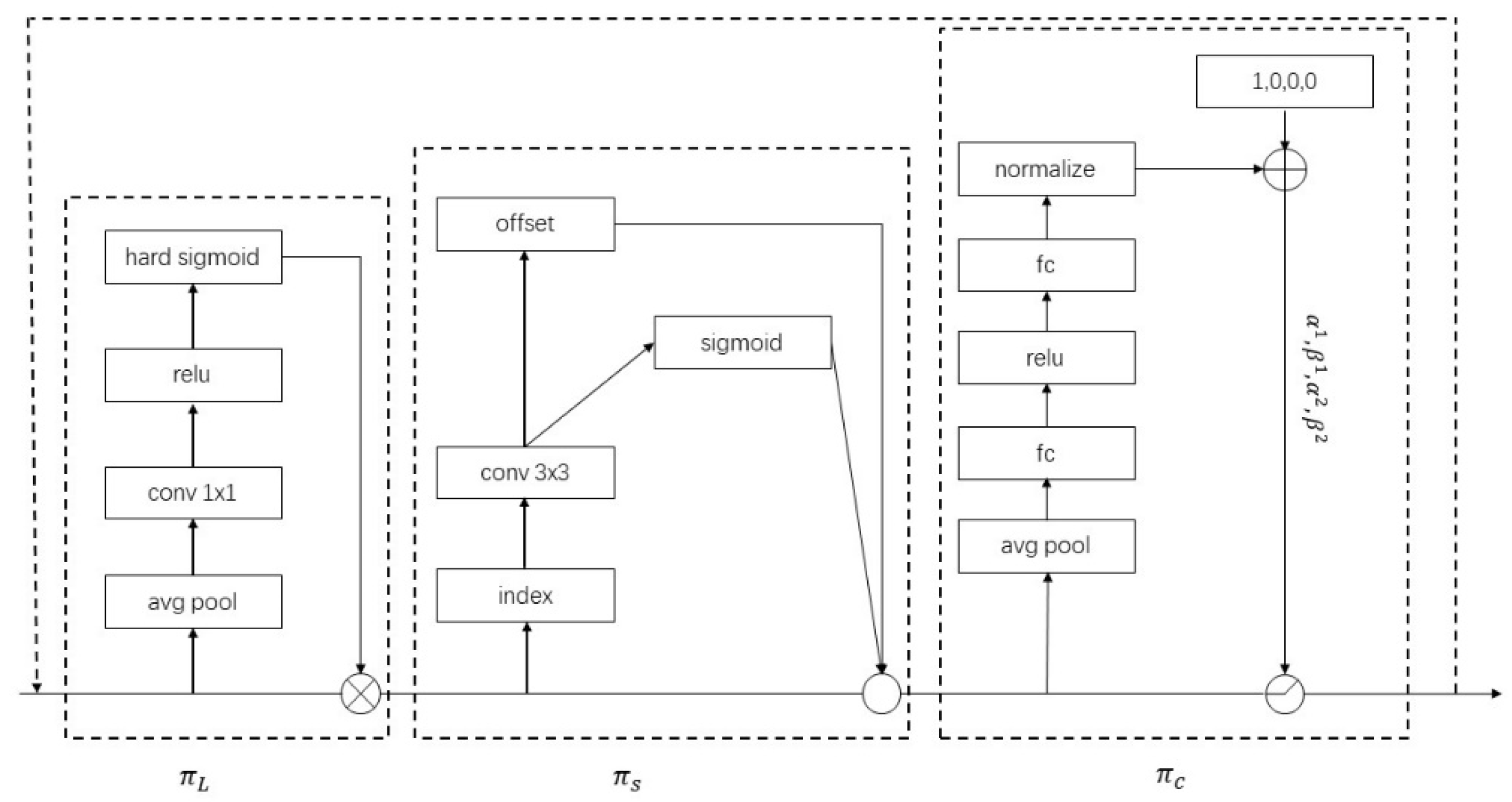
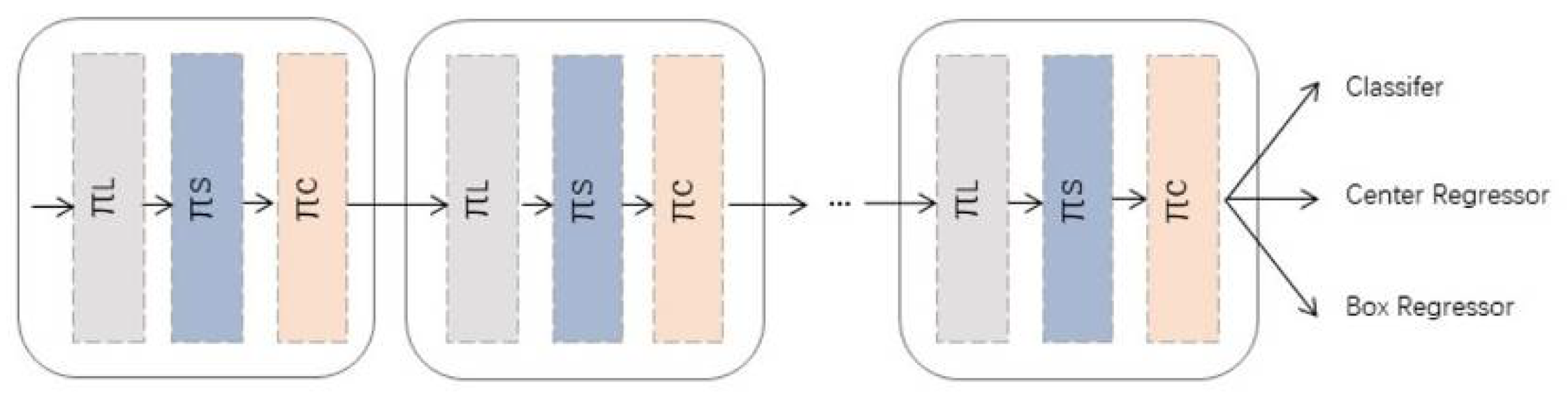
2.5.2. Dynamic Head
- Scale-aware attention (level-wise) : Different levels of feature maps correspond to different object scales, so increasing attention level-wise enhances the scale awareness of the object detector.
- Spatial-aware attention (spatial-wise) : Different spatial locations correspond to geometric transformations of the object, so adding attention spatial-wise enhances the spatial location perception of the object detector.
- Task-aware attention (channel-wise) : Different channels correspond to different tasks, so adding attention to the channel dimension can enhance the perception of object detector for different tasks.
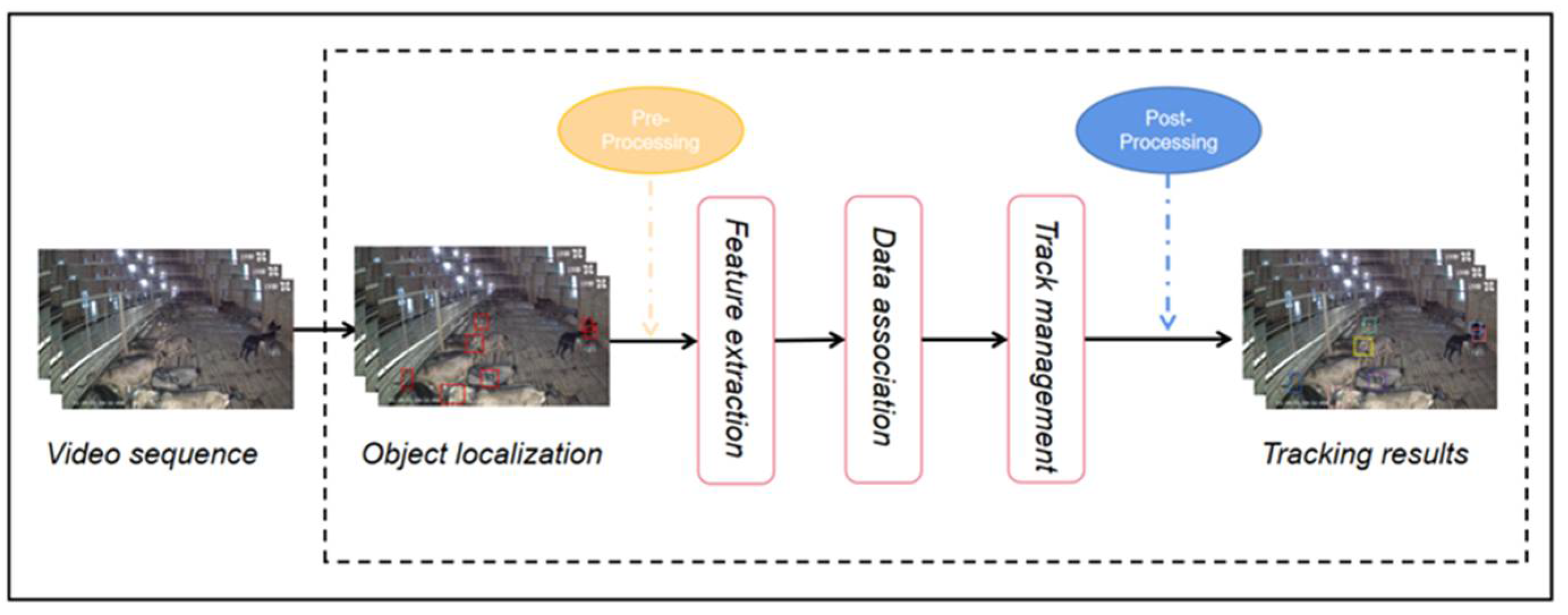
2.6. Object Tracking
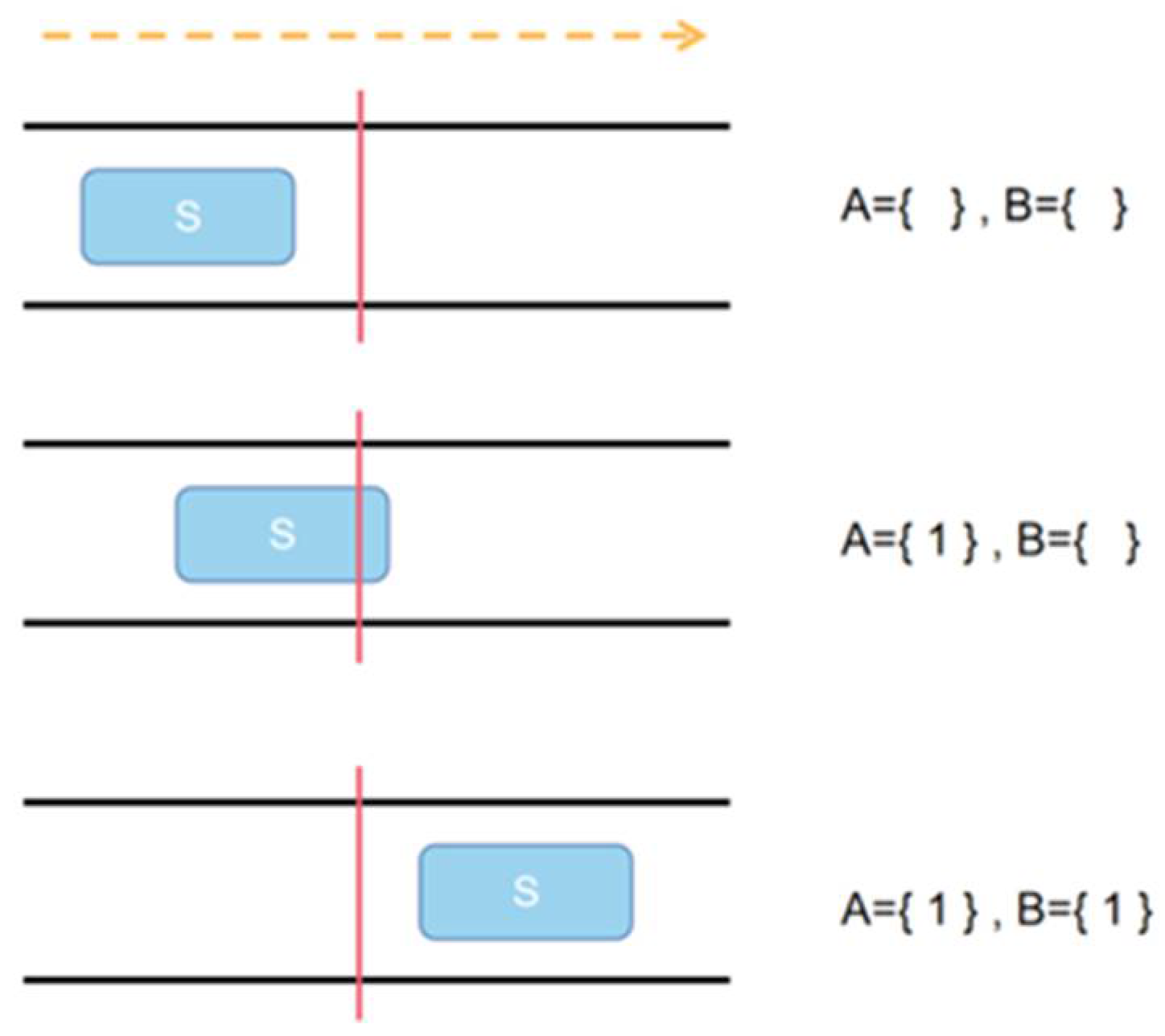
2.7. DeepSORT-Based MOT Network for Automatic Countering
2.8. Evaluation Methods
2.8.1. Precision
2.8.2. Recall
2.8.3. mAP
2.8.4. Average Overlap Rate
2.8.5. Mean Center Position Error
3. Results
3.1. Experimental Effect Analysis of Object Detection Model
3.2. Experimental Effect Analysis of Object Tracking and Automatic Counting Model
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhou, G. The Development of Sheep Industry in Sichuan. Sichuan Anim. Husb. Vet. 2018, 45, 6–7. [Google Scholar]
- Tian, M.; Guo, H.; Chen, H.; Wang, Q.; Long, C.; Ma, Y. Automated pig counting using deep learning. Comput. Electron. Agric. 2019, 163, 104840. [Google Scholar] [CrossRef]
- Xu, J.; Yu, L.; Zhang, J.; Wu, Q. Automatic Sheep Counting by Multi-object Tracking. In Proceedings of the 2020 IEEE International Conference on Visual Communications and Image Processing (VCIP), Macau, China, 1–4 December 2020; IEEE: Piscataway, NJ, USA, 2020; p. 257. [Google Scholar]
- Huang, E.; Mao, A.; Gan, H.; Ceballos, M.C.; Parsons, T.D.; Xue, Y.; Liu, K. Center clustering network improves piglet counting under occlusion. Comput. Electron. Agric. 2021, 189, 106417. [Google Scholar] [CrossRef]
- Jensen, D.B.; Pedersen, L.J. Automatic counting and positioning of slaughter pigs within the pen using a convolutional neural network and video images. Comput. Electron. Agric. 2021, 188, 106296. [Google Scholar] [CrossRef]
- Liu, C.; Su, J.; Wang, L.; Lu, S.; Li, L. LA-DeepLab V3+: A Novel Counting Network for Pigs. Agriculture 2022, 12, 284. [Google Scholar] [CrossRef]
- Kim, J.; Suh, Y.; Lee, J.; Chae, H.; Ahn, H.; Chung, Y.; Park, D. EmbeddedPigCount: Pig Counting with Video Object Detection and Tracking on an Embedded Board. Sensors 2022, 22, 2689. [Google Scholar] [CrossRef] [PubMed]
- Huang, X.; Hu, Z.; Qiao, Y.; Sukkarieh, S. Deep Learning-Based Cow Tail Detection and Tracking for Precision Livestock Farming. IEEE/ASME Trans. Mechatron. 2022, 1–9. [Google Scholar] [CrossRef]
- Brown, J.; Qiao, Y.; Clark, C.; Lomax, S.; Rafique, K.; Sukkarieh, S. Automated aerial animal detection when spatial resolution conditions are varied. Comput. Electron. Agric. 2022, 193, 106689. [Google Scholar] [CrossRef]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE international Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 3645–3649. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Mikołajczyk, A.; Grochowski, M. Data augmentation for improving deep learning in image classification problem. In Proceedings of the 2018 International Interdisciplinary PhD Workshop (IIPhDW), Swinoujscie, Poland, 9–12 May 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 117–122. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Shlens, J.; Le, Q.V. Randaugment: Practical automated data augmentation with a reduced search space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 702–703. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Li, A. Improvement of Yolov5 Algorithm and Its Practical Application. Master’s Thesis, North University of China, Taiyuan, China, 2021. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Wang, J.; Chen, Y.; Gao, M.; Dong, Z. Improved YOLOv5 network for real-time multi-scale traffic sign detection. arXiv 2021, arXiv:2112.08782. [Google Scholar]
- Dai, X.; Chen, Y.; Xiao, B.; Chen, D.; Liu, M.; Yuan, L.; Zhang, L. Dynamic head: Unifying object detection heads with attentions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Montreal, QC, Canada, 20–25 June 2021; pp. 7373–7382. [Google Scholar]
- Zhang, Y.; Wang, T.; Liu, K.; Zhang, B.; Chen, L. Recent advances of single-object tracking methods: A brief survey. Neurocomputing 2021, 455, 1–11. [Google Scholar] [CrossRef]
- Luo, W.; Xing, J.; Milan, A.; Zhang, X.; Liu, W.; Kim, T.K. Multiple object tracking: A literature review. Artif. Intell. 2021, 293, 103448. [Google Scholar] [CrossRef]
- Li, X. The Multi-Object Tracking Method Based on Re-identification. Master’s Thesis, University of Electronic Science and Technology of China, Chengdu, China, 2021. [Google Scholar]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 3464–3468. [Google Scholar]
- Zhang, Y. Design of Sheep Counting System Based on Embedded AI. Master’s Thesis, Inner Mongolia University of Science & Technology, Baotou, China, 2021. [Google Scholar]
- Wu, T. Individual Identification and Counting of Grassland Sheep Herd Based on Improved SSD Algorithm. Ph.D. Thesis, Inner Mongolia Agricultural University, Hohhot, China, 2021. [Google Scholar]
- Sarwar, F.; Griffin, A.; Periasamy, P.; Portas, K.; Law, J. Detecting and counting sheep with a convolutional neural network. In Proceedings of the 2018 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Auckland, New Zealand, 27–30 November 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–6. [Google Scholar]
- Shao, W.; Kawakami, R.; Yoshihashi, R.; You, S.; Kawase, H.; Naemura, T. Cattle detection and counting in UAV images based on convolutional neural networks. Int. J. Remote Sens. 2019, 41, 31–52. [Google Scholar] [CrossRef] [Green Version]
- Pu, J.; Yu, C.; Chen, X.; Zhang, Y.; Yang, X.; Li, J. Research on Chengdu Ma Goat Recognition Based on Computer Vison. Animals 2022, 12, 1746. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | mAP@0.5 (%) |
|---|---|
| YOLOv5 | 82.97 |
| YOLOv5 + Mixup | 83.32 |
| YOLOv5 + Mosaic | 83.87 |
| YOLOv5 + Mixup + Mosaic | 84.26 |
| YOLOv5 + RandAugment | 85.13 |
| YOLOv5 + Mixup + Mosaic + RandAugment | 85.35 |
| Methods | mAP@0.5 (%) | Inference Time (ms) |
|---|---|---|
| YOLOv5 | 84.26 | 23.3 |
| YOLOv5 + AF-FPN | 86.62 | 22.4 |
| YOLOv5 + DyHead | 88.21 | 26.7 |
| YOLOv5 + RandAugment | 85.13 | 23.7 |
| YOLOv5 + AF-FPN + DyHead + RandAugment | 92.19 | 25.6 |
| Methods | Average Overlap Rate (%) | Mean Center Position Error |
|---|---|---|
| YOLOv5 + DeepSORT | 82.78 | 8.56 |
| Ours | 89.69 | 5.92 |
| The Time Interval | 1~15 s | 16~30 s | 31~45 s | 46~60 s |
|---|---|---|---|---|
| Quantity in reality/goat | 7 | 11 | 17 | 26 |
| Quantity calculated by the model/goat | 7 | 11 | 17 | 25 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Yu, C.; Liu, H.; Chen, X.; Lei, Y.; Pang, T.; Zhang, J. An Integrated Goat Head Detection and Automatic Counting Method Based on Deep Learning. Animals 2022, 12, 1810. https://doi.org/10.3390/ani12141810
Zhang Y, Yu C, Liu H, Chen X, Lei Y, Pang T, Zhang J. An Integrated Goat Head Detection and Automatic Counting Method Based on Deep Learning. Animals. 2022; 12(14):1810. https://doi.org/10.3390/ani12141810
Chicago/Turabian StyleZhang, Yu, Chengjun Yu, Hui Liu, Xiaoyan Chen, Yujie Lei, Tao Pang, and Jie Zhang. 2022. "An Integrated Goat Head Detection and Automatic Counting Method Based on Deep Learning" Animals 12, no. 14: 1810. https://doi.org/10.3390/ani12141810
APA StyleZhang, Y., Yu, C., Liu, H., Chen, X., Lei, Y., Pang, T., & Zhang, J. (2022). An Integrated Goat Head Detection and Automatic Counting Method Based on Deep Learning. Animals, 12(14), 1810. https://doi.org/10.3390/ani12141810