1. Introduction
Virulence factors (VFs) are essential for pathogenesis, enabling bacteria to adhere to and invade host cells, utilize host cell nutrients for survival and reproduction, evade host immune defenses, and secrete toxins that destroy host cells. Antibiotics remain the primary therapeutic agents for bacterial infections, exerting their effects by either killing bacteria or inhibiting their growth and reproduction. For example, this can be accomplished by disrupting the bacterial cell wall and cell membrane, inhibiting bacterial DNA/RNA and protein synthesis, and blocking folate synthesis [
1]. Since antibiotics directly suppress bacterial survival, large-scale antibiotic use accelerates the evolution of bacterial antibiotic resistance. Antibiotic resistance has become a significant global public health challenge [
2]. To relieve the pressure stemming from the rapid evolution of bacterial resistance, relevant research has proposed anti-virulence strategies aimed at achieving therapeutic effects by targeting VFs to suppress the manifestation of bacterial virulence. These strategies include inhibiting bacterial toxins’ gene expression and toxins transmission, disrupting bacterial adhesion capabilities, and interfering with bacterial communication [
3]. Therefore, identifying bacterial VFs and developing an in-depth understanding of their mechanisms of action provide potential targets for the development of anti-virulence therapeutic strategies.
Due to the importance of this problem, a large number of studies have emerged in the field of VF identification. Methods based on sequence similarity aim to obtain homologous sequences corresponding to a given query and determine the type of the given query based on the type of homologous sequences. However, due to the diversity of VFs, which are involved in various pathogenic processes such as adhesion, invasion, and toxicity, and exhibit species-specificity and host-specificity, many VFs may show only insignificant similarity to known protein sequences [
4]. Moreover, pathogens continuously adapt to the environment during the evolutionary process, and their VFs are prone to alterations. Therefore, traditional sequence alignment methods such as BLAST [
5] have limited performance in identifying diverse VFs and VFs with distant evolutionary relationships.
To address this challenge, methods based on predefined protein features have been proposed. These methods extract features such as protein sequences, physicochemical properties, and evolutionary information, and combine them with traditional machine learning models and deep learning models for VF identification. For example, VirulentPred [
6] takes amino acid composition (ACC), dipeptide composition (DPC), higher-order dipeptide composition, and position-specific scoring matrixes (PSSMs) as inputs for the first layer of a two-stage cascade support vector machine (SVM). The results from the first layer are then cascaded to the second-layer SVM classifier for training to generate the final classifier, which outperforms SVM classifiers based on single or multiple sequence features only in the first layer. MP3 [
4] uses AAC and DPC as inputs for SVM, while leveraging the hidden Markov model (HMM) to analyze domain information in a local MiniPfam database constructed based on the Pfam database. The results from SVM and HMM are integrated according to specific rules, providing a new and promising approach for predicting virulence proteins in large-scale genomic or metagenomic datasets. PBVF [
7] conducts relevant analysis and prediction of VFs by taking DPC and multiple sequence, similarity-based features as the inputs for SVM. Regarding the critical issue of negative dataset selection, this research adopts the NExIGO method based on Gene Ontology (GO) annotations to construct the negative dataset. The research results indicate that direct sequence similarity is crucial in the identification of VFs, and thus this characteristic should be fully utilized to improve the accuracy of analysis and prediction. DeepVF [
8] extracts features based on sequence, physicochemical properties, and evolutionary information as inputs for four classic traditional machine learning models. It maps protein sequences to numerical values in alphabetical order, generating 10-dimensional features based on different window lengths for three deep learning models. By employing a stacking strategy, DeepVF effectively combines these baseline models, significantly enhancing model performance, as well as providing an important reference for classification problems in bioinformatics. VF-Pred [
9] is based on sequence features and physicochemical properties and can successfully generate the sequence similarity features proposed in reference [
7]. Additionally, it introduces the sequence alignment feature, Seg-Alignment, to capture the percentage of the best sequence alignment with the negative and positive datasets. These features are input into traditional machine learning models, and various ensemble methods including stacking, voting, and boosting are used together to enhance the classification performance. Experimental results show that the sequence alignment feature significantly improves the accuracy of the adopted machine learning algorithms. Methods based on predefined protein features usually rely on the knowledge of domain experts for design, and thus have certain limitations in feature selection, especially for manually extracted sequence features, which makes it difficult to comprehensively cover the potential information of protein sequences. Since the selection of predefined features is crucial to model performance, the model performance often highly depends on the quality of feature engineering.
With the rapid development of deep learning, natural language processing (NLP) has provided a new research perspective for protein representation learning [
10,
11]. Essentially, protein sequences can be viewed as a kind of “language”. By leveraging the framework of language models, it is possible not only to capture the local patterns within the sequences but also to reveal their global connections. Compared with traditional manually extracted features, protein features extracted based on language models are more likely to unearth the deep semantic information and complex patterns of protein sequences. The DTVF method proposed in reference [
12] is based upon the protein sequence model ProtT5 [
13], which is pre-trained on large-scale protein sequence data, as a protein feature extractor. It adopts a dual-channel architecture model, combining the long short-term memory network (LSTM) module with the convolutional neural network (CNN) module, and it introduces a dot-product self-attention layer into each respective module. This model can enhance the accuracy and efficiency of VF identification. Another approach, GTAE-VF [
14], aided with a graph transformer autoencoder for VF identification, leverages the ESM-2 [
15] language model to obtain amino acid feature vectors, and is the first to utilize three-dimensional structural information of protein predicted by ESMFold, finally transforming VF identification into a graph-level prediction task. The encoder–decoder framework integrates graph convolutional networks (GNNs) and Transformer structures, effectively capturing long-range correlations, thereby further improving predictive performance. Methods based on language models for protein features indicate that the introduction of high-quality features may help models better capture the relationship between VFs and sequence patterns. The transition from methods based on predefined features to those based on language model features marks a shift in VF identification models from traditional manual feature extraction to data-driven automated representation learning.
Most relevant studies primarily focus on the properties of proteins, including sequences, physicochemical properties, evolutionary information, and structural characteristics, to identify VFs. However, protein–protein interaction (PPI) network information has also been demonstrated to have potential in VF prediction. Reference [
16] proposes a method to predict VFs based on the PPI network through the number, type, and interaction weight of neighbor nodes. Reference [
17] further enriches the direct interaction neighbors of proteins into KEGG pathways, calculates the pathway enrichment scores, and uses the random forest model for prediction. However, these methods only utilize direct protein interactions and explicit features, such as the number and labels of neighbors, as well as pathway enrichment scores, which are limited to shallow information within the direct neighborhood. They lack comprehensive modeling of broader contextual and deeper information on PPI networks and do not fully leverage the biological features of proteins themselves, such as sequence and structure. Moreover, explicit features rely on known protein functional annotations, and the models may be restricted by incomplete annotation information, making it difficult to comprehensively capture the implicit properties of unannotated proteins. Since the PPI network can be naturally modeled and mined using a graph structure, GNNs can be taken into account to address the above limitations.
GNNs can integrate and simultaneously deal with protein sequence features and interaction information, as well as effectively aggregate node information across network layers through message-passing mechanisms to capture deeper, non-linear features [
18]. Most GNNs are based on the homophily hypothesis [
19,
20,
21], which essentially reflects the principle that “birds of a feather flock together” [
22], meaning that interconnected nodes in a graph tend to belong to the same category. Under the homophily assumption, node representations will be smoothed through the aggregation process, with each node acquiring additional information from neighboring nodes that likely share the same label.
The natural distribution of proteins in bacterial systems exhibits an inherent imbalance between virulence and non-virulence proteins, with virulence proteins constituting a minority class. Traditional modeling approaches have attempted to address this imbalance through various sampling techniques. Under-sampling strategies are commonly employed for strain-specific datasets to reduce the number of non-virulence proteins moderately (such as maintaining a ratio of 1:5 between the size of the negative dataset and the positive dataset), thereby mitigating class imbalance effects. Balanced sampling is performed for multi-strain datasets by randomly selecting negative samples to match the number of positive samples to construct a balanced dataset. Additionally, repeated learning of virulence proteins is performed to enhance model performance. However, these sampling approaches may inadvertently compromise the inherent diversity of the training data, potentially limiting the model’s generalization capabilities. In imbalanced datasets, the majority class often dominates the learning process, causing the decision boundary to be biased towards the majority class. Self-supervised learning [
23] has emerged as a promising alternative, offering the ability to extract effective representations from unlabeled data. This approach has the potential to capture more comprehensive and generalizable information that is inherent in the data itself, regardless of the skewed label distribution, demonstrating particular promise in addressing imbalanced classification challenges [
24,
25]. Existing self-supervised graph learning methodologies can be categorized into three distinct paradigms [
26]. The generative approach leverages intrinsic graph information as self-supervised signals, focusing on reconstructing specific components of the input data to develop robust graph data representations [
27,
28,
29]. Contrastive methods emphasize the analysis of consistency between different views to extract essential features and structural patterns inherent in the data [
30,
31]. The predictive approach autonomously generates informative labels as supervision signals, addressing the relationships between data and their corresponding labels [
32,
33].
In the field of class-imbalanced node classification, multiple innovative, self-supervised learning methods have been applied to meet the challenges. INS-GNN [
34] implements generative, self-supervised pre-training to reconstruct the origin graph structure, effectively mitigating the inherent label bias present in imbalanced datasets. This method further incorporates self-training for pseudo-label assignment to unlabeled nodes and utilizes self-supervised edge enhancement to modify the structural characteristics of minority nodes, thereby amplifying their influence in the learning process. GraphMixup [
35] improves the class-imbalanced node classification on graphs based on predictive self-supervised learning. It conducts semantic-level feature mixing by building a semantic relationship space and mixing edges while using an edge predictor trained via two context-based self-supervised tasks. Existing self-supervised learning approaches for addressing class-imbalanced graph node classification have been predominantly validated in conventional graph domains, such as social networks and citation networks, yet with limited exploration beyond these traditional contexts. This constraint is particularly noteworthy in the domain of bioinformatics, where complex graph structures such as PPI networks present unique challenges and opportunities that remain largely unexplored within the current methodological framework.
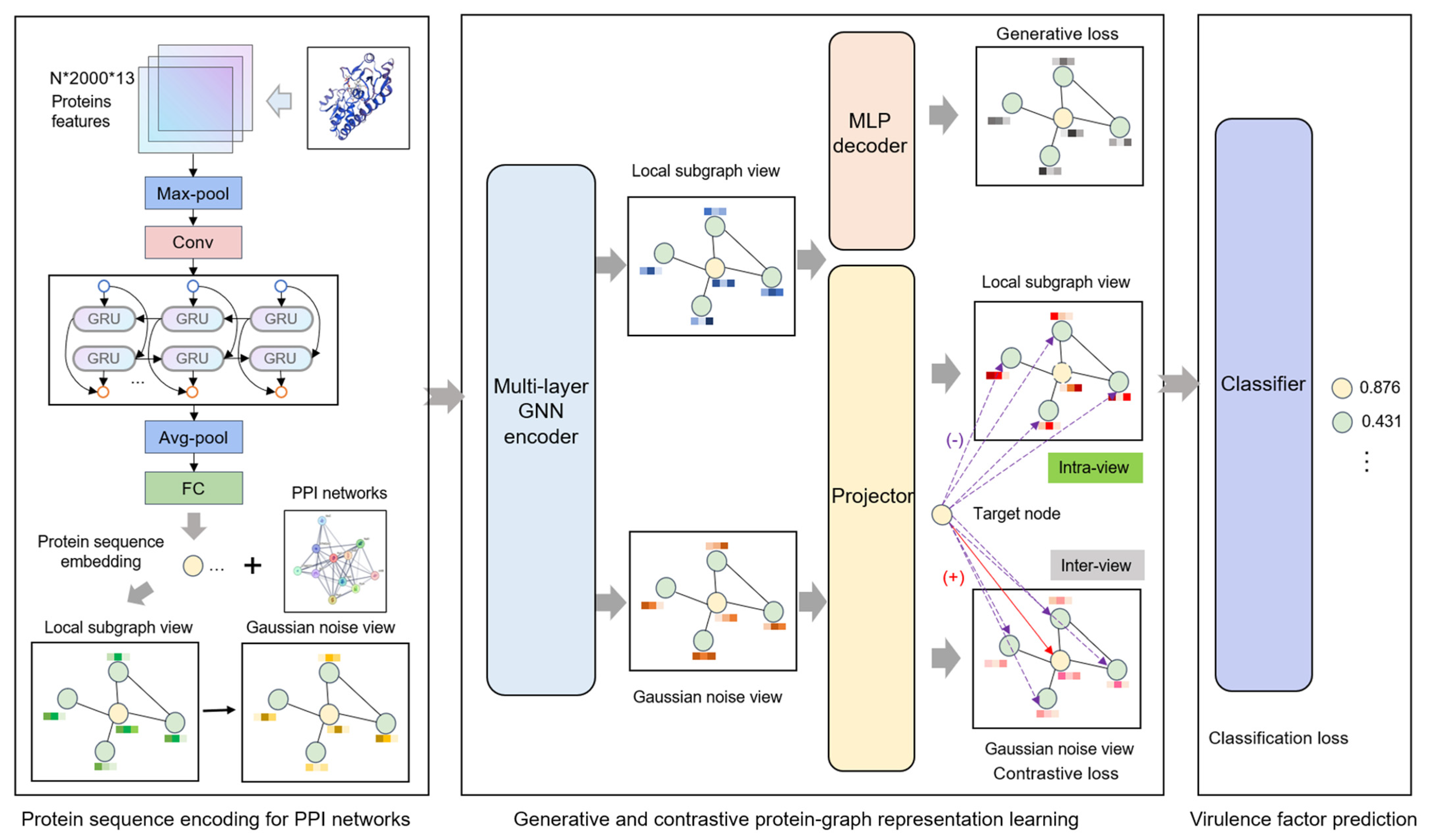
We present a novel framework for VF identification based on PPI networks, which integrates both generative and contrastive self-supervised learning strategies. Specifically, we construct local subgraphs centered on target proteins and generate multi-view representations through data augmentation strategies. These subgraph views are processed through GNNs to learn latent node representations. During the self-supervised learning phase, generative learning captures the inherent distributional characteristics of the data through node attribute reconstruction, while contrastive learning performs node-level comparisons between different views to effectively capture both local node features and contextual information. The learned latent representations are then utilized by a classifier for VF prediction.
The main objectives of this work are as follows:
To develop a GNN-based framework for VF identification that leverages both the topological information of PPI networks and protein sequence features, transforming VF identification into a class-imbalanced node classification problem within the graph domain.
To propose a novel self-supervised learning framework that combines generative and contrastive strategies, aiming to improve performance in imbalanced classification tasks through multi-view contrast and attribute reconstruction.
2. Materials and Methods
As illustrated in
Figure 1, the Generative and Contrastive self-supervised learning framework for Virulence Factor identification (GC-VF) framework’s overall architecture comprises three components: protein sequence encoding, generative and contrastive self-supervised learning, and VF probability prediction. During the protein sequence encoding phase, the model encodes amino acid sequence features through multiple layers of deep neural networks, transforming them into protein sequence representations that are conducive to subsequent tasks. Subsequently, leveraging PPI networks, the model employs a hierarchical sampling strategy to construct local subgraphs of target proteins. Through data augmentation techniques, multi-view features essential for contrastive learning are generated. These views undergo information aggregation via GNNs, which enhance node representations by capturing more effective features.
In the self-supervised learning module, generative learning captures the intrinsic feature distribution of proteins by node attribute reconstruction tasks, while contrastive learning focuses on optimizing discriminative features between nodes by minimizing feature distances between positive samples and maximizing those between negative samples. Combining these approaches enables the model to take account of both global distribution and local variations in the data. Node-level generative and contrastive objectives inhibit decision-making from being dominated by global structural patterns, thus more precisely capturing the inherent characteristics of individual nodes. Finally, the model inputs the learned node representations into a classifier and utilizes the optimized features for VF prediction.
2.1. Datasets
Since the proportion of VFs in most bacterial strains is relatively low, three species with a moderate proportion of VFs were selected for analysis:
Salmonella enterica serovar Typhimurium LT2,
Campylobacter jejuni NCTC 11168, and
Staphylococcus aureus NCTC 8325. Protein sequence data and PPI network data for these three strains were obtained from the STRING [
36] database while corresponding VFs’ information was retrieved from the VFDB database [
37]. Following the combined score threshold settings of the STRING database, only interaction relationships with a combined score greater than or equal to 0.4 were retained. To achieve a more comprehensive understanding of the characteristics inherent in each dataset, we calculated the basic properties of the PPI networks for these three strains and the class imbalance ratio (defined as the ratio of the number of samples in the largest class to that in the smallest class) [
38] for each dataset. The relevant data is summarized in
Table 1. Specifically, the numbers of VFs in the three strains are 156, 130, and 97, respectively. Furthermore, the class imbalance ratios in the selected datasets are 27.53, 11.48, and 31.72, respectively, all of which are notably high, indicating significant class imbalance. In this study, the class imbalance ratio is defined as the number of samples in the majority class divided by that in the minority class, a formulation that applies to binary classification settings.
2.2. Protein Sequence Encoding
Currently, significant advances have been achieved in extracting protein features from amino acid sequences through the application of protein language models [
39,
40]. In particular, the extraction method of amino acid embedding proposed in reference [
41] has demonstrated substantial improvements in PPI-related tasks. This method implemented a dual-component embedding representation, the first leveraged amino acid sequences to compute co-occurrence similarities via a pre-trained Skip-Gram model [
42], which was trained on the SHS148k dataset from the STRING database. Each protein sequence was treated as a sentence, and each amino acid as a token, allowing the model to learn contextual similarity by predicting surrounding amino acids (within a context window of 7) for each central amino acid, using negative sampling (size 5) to distinguish true co-occurrences from random noise. The second component employed one-hot encoding to capture electrostatic and hydrophobic similarities among amino acids [
43]. Extending this amino acid embedding framework, reference [
44] developed a multi-layer deep neural network architecture to generate protein feature representations optimized for PPI network input and achieved good predictive performance on PPI datasets using the same pre-trained embeddings from reference [
41]. This architecture combined four types of layers, namely convolutional layers (Conv1d), pooling layers, bidirectional gated recurrent units (BiGRU), and fully connected (FC) layers to produce 256-dimensional protein representations. In our present work, we utilize this combination of the amino acid embedding method and multi-layer deep neural network architecture with an additional dropout layer to generate node feature representations that effectively characterize both global and local protein sequence properties. These refined feature embeddings establish a robust foundation for subsequent graph learning processes that incorporate PPI networks.
2.3. Generative and Contrastive Protein Representation Learning
2.3.1. Graph View Establishment
Based upon the protein sequence encoding module, which is responsible for transforming protein sequences into node feature embeddings essential for GNNs, we employ a hierarchical neighborhood sampling method to construct local subgraphs [
21] to further mine the structural information within PPI networks. Specifically, within each batch iteration, we initially select target proteins as center nodes from the PPI network through sampling without replacement. Next, we construct local structures through a two-layer neighborhood sampling approach, which involved randomly sampling
nodes from first-order neighbors that have direct physical interactions with the center protein, and further sampling
second-order neighbor nodes for each selected first-order neighbor, thereby constructing an original view centered on the target protein. The first-order neighbors capture direct interaction relationships, while the incorporation of the second-order neighbors facilitates the detection of potential indirect interaction patterns. Then, we introduce Gaussian-distributed random noise into the protein features of the original view, forming an augmented view. Subsequently, both the original and augmented views are processed as dual-stream inputs through the GNNs, enabling the aggregation of multi-scale neighborhood information and facilitating the learning of contextual protein representations within the PPI network.
2.3.2. Generative Attribute Reconstruction
The basic principle of an autoencoder is to map the input data into a latent representation space through an encoder, followed by the reconstruction of the original input through a decoder. Within the context of graph data, this architecture not only facilitates the learning of latent node representations but also enables the capture of intrinsic association patterns between nodes through reconstruction tasks in an unsupervised manner.
For node attribute reconstruction, we implement a strategic approach by not employing target node anonymization (setting features to zero), instead enabling the original attributes of target nodes to participate directly in the information aggregation process. This decision stems from the consideration that virulence proteins do not manifest strong homophily in their interaction patterns. Therefore, the non-anonymized reconstruction approach facilitates the more precise capture of critical shared features between target nodes and their neighborhood nodes, while circumventing the introduction of irrelevant noise that might emerge from excessive reliance on neighborhood information.
The PPI network is formally defined as , where denotes the set of protein nodes and represents the set of interaction relationships. For each target node , views and are derived from sampling and feature augmentation procedures, respectively. Notably, the augmentation operation exclusively modifies node features while preserving structural consistency between the two views, yielding identical adjacency matrices.
The GNN architecture facilitates node representation updates through iterative neighbor information propagation, effectively mapping high-dimensional features onto a low-dimensional space. In the initial phase, the original subgraph
of target node
is processed through a multi-layer GNN encoder, which can be formally represented as
where
represents the latent embedding of node
at the
-th layer of the GNNs.
is the adjacency matrix of the subgraph sampled for node
. The
is a GNN encoder consisting of
layers. The multi-layer structure enables the gradual aggregation of node information from more distant neighbors and effectively captures the multi-level collaborative patterns among proteins. Each layer of the GNN is defined as follows:
where
represents the set of adjacent nodes in the subgraph sampled for node
. In particular, at the input stage,
, represents the initial encoded feature of the protein sequence of the node.
The architecture allows for various GNN implementations, including Graph Convolutional Network (GCN) [
19], Graph Attention Network (GAT) [
20], and Graph Isomorphism Network (GIN) [
45], each employing distinct neighbor aggregation strategies. In this study, we employ GraphSAGE [
21] as the backbone network due to its robust generalization capabilities, achieved mainly by training a set of aggregator functions rather than individual node embeddings. The specific formulation of GraphSAGE is as follows:
where
is the ReLU [
46] activation function,
represents the weight matrix, and
represents the weight of the edge between the node pair
. The incorporation of edge weights enables the model to differentiate varying interaction strengths between protein pairs, reflecting their distinct collaborative importance in biological processes. The model firstly performs weighted aggregation of features from all neighboring nodes of node
in the subgraph and then concatenates the aggregated information with the feature of node
at the
-th layer to obtain the latent representation at the
-th layer.
The decoder transforms the encoder-generated node embeddings back into original node features, guiding the encoder toward more significant node representations while continuing to capture latent structural graph relationships. The decoder utilizes a multi-layer perceptron (MLP) with an architecture matching the encoder in terms of layer count and parameters, which can be denoted as
where the MLP decoder implements two-layer architectures:
. Specifically, the decoder transforms the
-th layer node representation
into a reconstructed original encoded feature
through a series of non-linear transformations.
The generative self-supervised learning framework optimizes itself by minimizing the reconstruction error between decoder-generated and origin embeddings. The mean squared error (MSE) quantifies the reconstruction loss, which can be specifically written as
where
denotes the dimension of the original encoded feature
. Through minimization of reconstruction loss, the model learns to extract feature patterns shared between the target node and neighboring nodes during reconstruction.
2.3.3. Multi-View Local–Local Contrasting
Contrastive learning, an unsupervised learning method, facilitates the exploration of structural information and node relationships to learn feature similarities and differences, offering novel approaches for identifying potential virulence proteins. However, virulence proteins within PPI networks, compared to their non-virulence counterparts, typically struggle to form stable subgraph features. This characteristic presents significant challenges for graph-level contrastive learning in extracting positive sample features from heavily imbalanced virulence protein subgraphs. Pooling subgraph features as positive samples in contrastive learning may disproportionately reflect non-virulence protein patterns, potentially compromising virulence protein feature learning. To address this challenge, we implement a node-level (local–local) contrastive scheme enabling independent optimization of individual node features.
Specifically, the encoded features
from original view and
from augmented view of the target node
are processed through a shared GNN encoder
to generate node embeddings
and
. To enhance representation quality, we incorporate a projection head
, implementing a two-layer MLP that projects node features onto a new feature space. Within this space, positive sample pair features exhibit increased proximity while negative sample pairs maintain greater separation, thereby improving representation quality [
47]. This process is formalized as
During node-level contrastive instance sampling,
from the original view serves as the anchor, while
from the augmented view serves as the positive sample. For negative sample selection, inspired by GRACE [
48], we employ a mixed sampling strategy across and within views: node embeddings excluding node
in the original view are selected as negative samples to enhance intra-view relationship understanding, while nodes other than the positive sample in the augmented view are selected to improve inter-view discrimination capability.
The contrastive self-supervised learning objective simultaneously minimizes representation distance between similar samples while maximizing it between dissimilar samples. We employ InfoNCE [
47] to compute contrastive loss, maximizing mutual information between random events, which is a practical and powerful tool for extracting shared data information. The InfoNCE loss can be formulated as
where
denotes the cosine similarity between the node features of
and
, calculated as
. The temperature coefficient
modulates similarity distribution sharpness, with smaller values producing more concentrated distributions and larger values yielding smoother distributions.
represents negative sample contribution to the loss function, computed as
where the first term aggregates similarity contributions from original-view negative samples to the anchor node, while the second term computes augmented-view negative sample contributions. For a subgraph of size
, both terms use
negative samples.
2.4. VF Prediction
The protein embeddings optimized through self-supervised modules achieve an integration of protein sequences, physicochemical properties, as well as contextual information derived from the PPI network. These embeddings are subsequently processed through a classifier to predict VFs. The classifier architecture incorporates a FC layer and a dropout layer, the latter of which effectively mitigates overfitting. The final output is transformed into a probability value via the sigmoid activation function. The classifier can be mathematically expressed as
where
denotes the protein embedding of node
learned by the GNN,
represents the FC layer weight matrix,
is the bias term, and
represents the sigmoid activation function.
To address class imbalance in VF prediction, we implement focal loss [
49] for classification loss. The focal loss dynamically adjusts sample weights, diminishing easily classified sample contributions while amplifying difficult-to-classify sample importance, thereby enhancing minority class recognition capabilities. The focal loss calculation introduces an intermediate variable
, which is a combination of the true label and the predicted probability, and its specific definition is as follows:
where
represents the predicted probability, and
is the true label. The complete form of the focal loss can be formulated as
where
represents the class weight coefficient balancing positive and negative sample contributions, and
denotes the focusing parameter controlling attention distribution between easy and difficult samples.
The final loss function integrates three essential components: reconstruction loss
, contrastive loss
, and classification loss
. Self-supervised learning components are balanced by coefficients
and
as follows:
The overall workflow of the proposed GC-VF framework is shown in Algorithm 1. Firstly, we sample a batch of protein nodes from the PPI network. For each target node, we generate its original view and augmented view, then input these two views into the shared GNN encoder to extract the embeddings of the target node. After that, we decode and restore the target node embeddings in the original view and calculate the reconstruction loss. Next, we input the target node embeddings from the two views into the projection head and project them onto a new embedding space. Subsequently, we adopt a mixed sampling strategy between and within views for node-level contrastive learning and calculate the contrastive loss. Finally, we combine the generation, contrastive, and classification tasks, train the model through joint optimization of multiple objectives, and perform predictions on proteins.
| Algorithm 1. The key algorithm for the proposed GC-VF framework
|
, ,
,
- 1:
- 2:
. - 3:
- 4:
- 5:
, and by adding Gaussian noise to the features. - 6:
and
from the and , via Equation (3). - 7:
via Equation (4) to obtain . - 8:
using Equation (5) between . - 9:
Project the GNN-encoded target node embeddings from the by the projection head to obtain latent embeddings via Equation (6) and Equation (7), respectively. - 10:
to via Equation (8). - 11:
for VF prediction via Equation (12). - 12:
Update the model parameters by backpropagating the total loss via Equation (13). - 13:
end for - 14:
end for - 15:
end for - 16:
via Equation (11).
|
2.5. Experimental Settings and Evaluation Metrics
In experimental implementation, a two-layer GraphSAGE was employed as the GNN backbone, utilizing LSTM as the aggregation function. Given that the protein sequence encoding module generated embeddings of 256 dimensions, we configured the GNN architecture with hidden dimensions of 128 and 64 for the first and second layers, respectively. The noise hyperparameter was configured at 0.1, and the InfoNCE loss temperature hyperparameter was set to 0.03. For the composite loss function, we assigned a coefficient of 0.4 to the generative loss. As for the contrastive loss, its coefficient varied depending on the dataset, which was set to either 0.6 or 0.2. The focal loss hyperparameters and were set to 0.25 and 2. The subgraph sampling was established at a size of (6, 6), resulting in a subgraph with the size of 37 nodes for each target node.
For performance evaluation, we employed two primary metrics: the Area Under the Receiver Operating Characteristic Curve (AUROC) and the Area Under the Precision–Recall Curve (AUPRC). The AUROC provides a comprehensive assessment of the model’s discriminative capability between positive (majority) and negative (minority) samples, while the AUPRC specifically emphasizes performance on positive samples. To ensure a thorough evaluation, we incorporated additional supplementary metrics: sensitivity, specificity, F1-score, and Matthews Correlation Coefficient (MCC). Sensitivity is specifically utilized to evaluate positive sample identification capability, while specificity measures its discriminative ability for negative samples. The F1-score adeptly balances the accuracy and recall evaluations of positive class prediction, and the MCC comprehensively contemplates various prediction outcomes, rendering them particularly appropriate for the evaluation of imbalanced datasets.
Our model was trained using the Adam optimizer, with a learning rate of 0.001 and a weight decay coefficient of 0.0001. The datasets were partitioned into training, validation, and test sets in a 6:2:2 ratio. Throughout the training process, a total of 131 epochs were carried out, and the model’s performance was scrutinized on the validation set every 10 epochs. The optimal model was then selected and archived. During the testing phase, the model was subjected to 100 trials on the test set, and the average of the results was adopted as the final performance indicator. To expedite and optimize the training process, the batch size was set to 300. The GC-VF model was executed on a NVIDIA GeForce RTX 3080 GPU.
To comprehensively evaluate method performance in VF prediction, we conducted experiments on three representative bacterial strain datasets: S. enterica serovar Typhimurium LT2, C. jejuni NCTC 11168, and S. aureus NCTC 8325. These datasets exhibit VF ratios of 3.5%, 8.0%, and 3.1%, respectively, reflecting the characteristic class imbalance encountered in real-world applications.
For comparative analysis, we selected four representative baseline methods:
BLAST (2.16.0) [
5]: relies on sequence similarity; constructs a local database from training sequences and predicts test sequences based on the most similar match.
VirulentPred 2.0 [
50]: applies classical machine learning; evaluated using default parameters provided by its web platform.
DeepVF [
8]: combines traditional machine learning and deep learning; tested using default configurations from the official server.
DTVF [
12]: adopts a deep learning framework; uses ProtT5 to encode protein sequences and applies a pre-trained predictor for classification.
3. Results and Discussion
3.1. Structural and Biological Pre-Analysis for Applying GNNs on PPI Networks
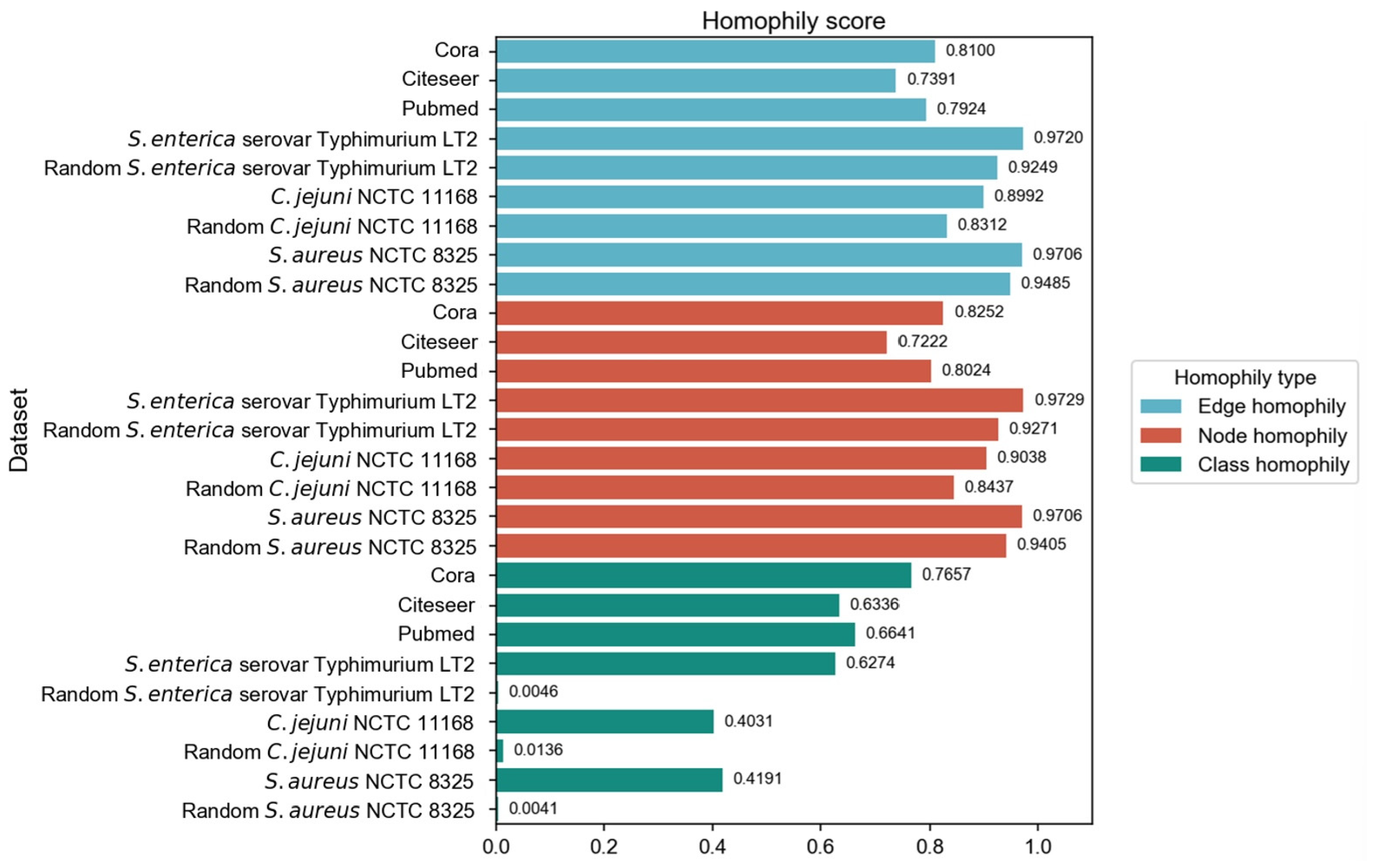
We have employed three commonly used homophily metrics—edge homophily [
51,
52], node homophily [
53], and class homophily [
21]—to evaluate the homophily of three PPI networks:
Salmonella enterica serovar Typhimurium LT2,
Campylobacter jejuni NCTC, and
Staphylococcus aureus NCTC 8325. In addition to comparing with three homophily graphs commonly used in node classification tasks, we also compared the homophily of PPI networks with the randomly generated networks. We ensured that the randomly generated networks are of the same size as the corresponding PPI networks, in order to eliminate the influence of network size differences and focus precisely on the homophily aspect during the comparison process. For each PPI network, 30 random graphs were generated with the same number of nodes and edges, as well as identical label distributions. We employed the Configuration Model to preserve the degree distribution while randomizing edge connections. The Configuration Model algorithm represents each node’s degree as a corresponding number of “stubs” (half-edges), then randomly pairs all stubs to form complete edges while avoiding self-loops and multi-edges. This randomization process maintains both the class proportions and the original degree distribution, allowing us to isolate the effect of class-based connectivity patterns on homophily while controlling for degree heterogeneity. The three homophily metrics were calculated and subjected to
t-tests (
p-values all less than 0.05). The results are shown in
Figure 2.
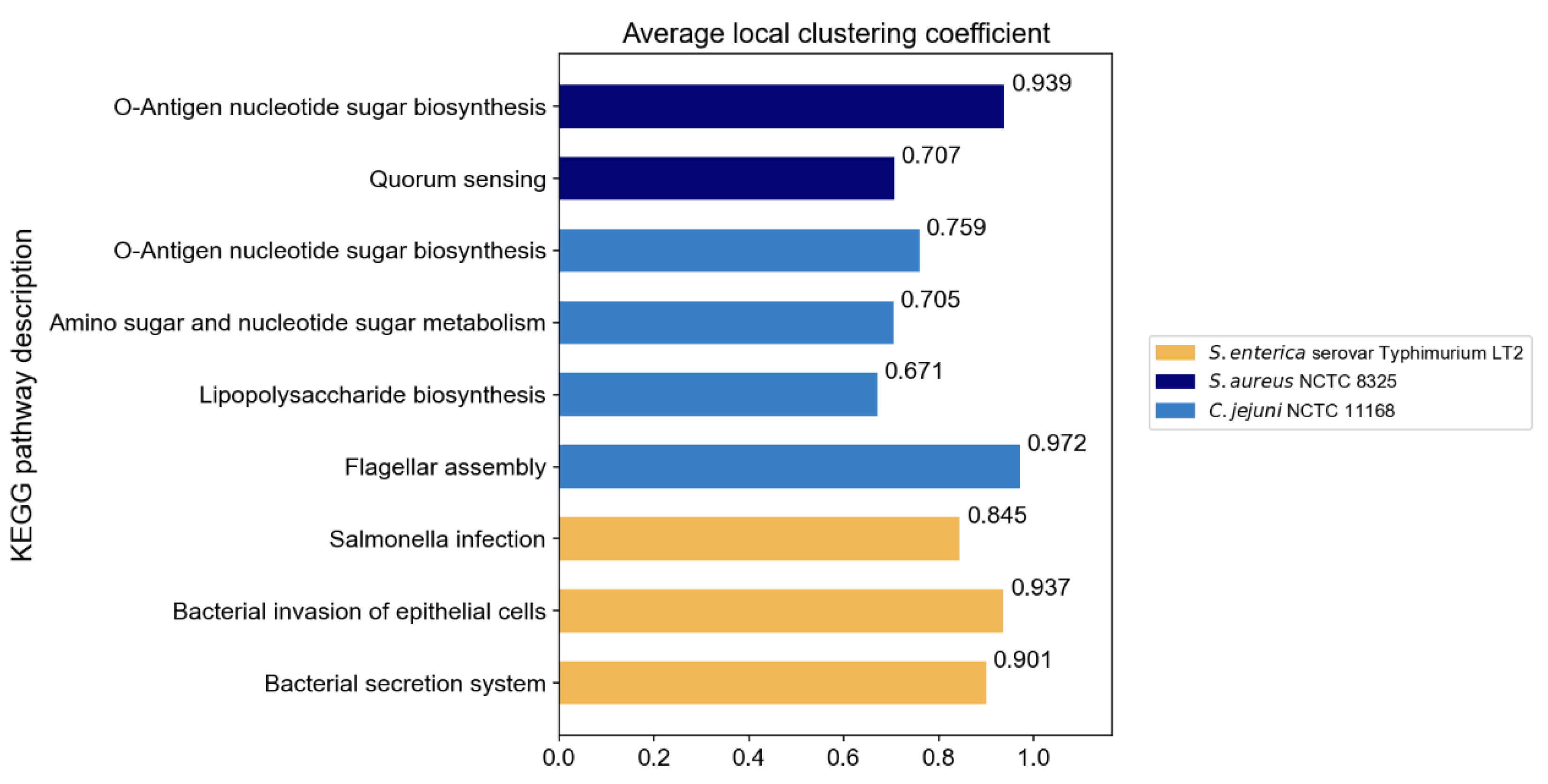
The original PPI networks exhibited higher node and edge homophily compared to commonly used homophily graphs for node classification tasks, although class homophily was relatively low. Overall, the homophily metrics of the original PPI networks were promising, suggesting that homophily-based GNNs are likely to effectively aggregate node information to obtain beneficial embeddings. Compared to random networks of the same scale, the original PPI networks showed superior performance across all homophily metrics. The high node and edge homophily observed in both original PPI networks and random networks of the same size may reflect the impact of class imbalance in PPI networks, where dominant class nodes enhance these two metrics. The numerical advantage of dominant class nodes increases the probability of connections between nodes within this class. The difference in class homophily between original PPI networks and random networks indicates significant collaborative relationships among minority class nodes (virulence proteins), suggesting their coordinated participation in pathogenesis-related biological processes. Furthermore, based on the STRING database, KEGG pathway enrichment analysis was performed on the interactions between virulence proteins, and the average local clustering coefficient among virulence proteins in these pathways was calculated, with results shown in
Figure 3. The high average local clustering coefficient indicates that virulence proteins cooperatively participate in pathogenesis-related biological activities through tight interactions, involving multiple aspects such as bacterial secretion regulation, bacterial invasion of host cells, synthesis and assembly of bacterial structural components, and coordination of quorum sensing. The intimate interactions of virulence proteins in PPI networks facilitate learning virulence protein features through message passing.
3.2. Baseline Methods Comparison
In performance evaluation, we employ multiple complementary metrics. The AUROC baseline of 0.5 represents random classifier performance, while AUPRC baselines vary with positive sample proportions, corresponding to 0.035, 0.08, and 0.031 for the three datasets, respectively. The experimental results presented in
Table 2 demonstrate that our proposed GC-VF method exhibited notable overall performance.
Analysis of experimental results revealed that while certain baseline methods achieved high accuracy on specific datasets, such apparent advantages may mask underlying classification limitations. These methods often exhibited high specificity, showing a tendency to classify samples into the majority negative class. In scenarios with substantial class imbalance, while this tendency might yield favorable accuracy and specificity metrics, the actual discriminative capability remains limited. Thus, comprehensive evaluation necessitates consideration of multiple metrics, particularly sensitivity and AUPRC.
Notably, we observed that some methods often struggled to maintain adequate specificity while attempting to enhance sensitivity. For instance, VirulentPred 2.0, despite demonstrating high sensitivity, achieved a low F1-score, indicating that increased recall came at the cost of precision, resulting in numerous false positive predictions. This observation underscores the importance of balancing various performance metrics in VF prediction and highlights the GC-VF framework’s capability in effectively harmonizing these competing objectives.
3.3. Analysis of Graph-Based Approaches
We conducted a comprehensive evaluation of various graph methods on three bacterial strain datasets, categorized into two primary classes: graph learning and graph construction. To ensure experimental validity, consistent datasets and hyperparameter settings were maintained across all methods.
Among the graph learning methods, we primarily evaluated three prominent GNN architectures: GraphSAGE, GCN, and GAT. GraphSAGE aims to train aggregator functions and has multiple aggregator architectures, including the Mean aggregator, LSTM aggregator, and Pooling aggregator. Moreover, GraphSAGE-GCN, a convolutional variant of GraphSAGE, is an extended inductive version of GCN.
In terms of graph construction methods, we explored several graph construction strategies: the PPI networks, the Cosine Similarity Graph (CSG), and the BLAST Similarity Graph (BSG). The CSG model computed the cosine similarity between protein feature vectors and constructed the graph using a threshold of 0.5. The BSG model, on the other hand, calculated protein sequence similarities via BLAST (2.16.0) and retained edges with an E-value below 20. In addition, we set a baseline method without using a graph structure (MLP-NS), which directly inputs the embeddings encoded from protein sequences into an MLP classifier. Notably, both the CSG and BSG models utilized GraphSAGE-LSTM for graph learning.
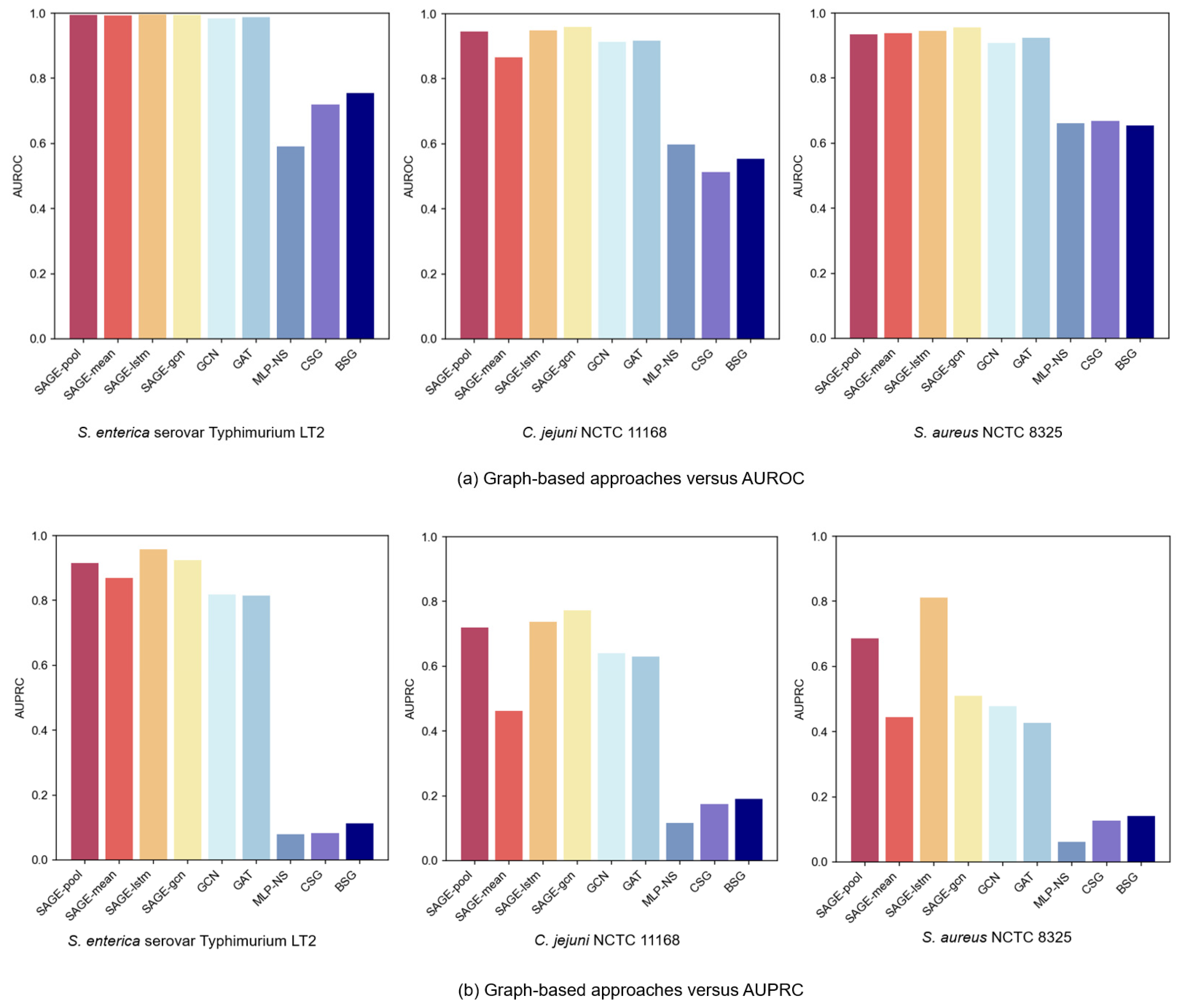
Figure 4a,b present comparative AUROC and AUPRC metrics across the three bacterial strain datasets. In the experiments’ PPI of the graph-based GNN variant, GraphSAGE models consistently outperformed GCN and GAT, with superior performance from LSTM and Pooling aggregators. The LSTM aggregator achieved optimal performance, primarily due to its distinctive sequence processing mechanism. By establishing continuous dependency chains between nodes, it effectively captured complex neighbor relationships, which might have enhanced the GNNs’ expressive capacity in neighbor feature aggregation, enabling more comprehensive node-dependency modeling. Meanwhile, the Pooling aggregator, by adaptively identifying key features from neighbors, focused attention on important information for VF prediction.
Experimental results revealed significant performance degradation when excluding the PPI network structure. While both CSG and BSG approaches based on sequence similarity captured certain protein relationships, they failed to adequately capture complex biological interactions. This characteristic underscores the PPI network’s advantage in capturing protein functional relationships: sequence similarity alone does not equate to functional similarity. For instance, proteins with similar sequences may not participate in identical biological pathways, whereas PPI graphs better reflect proteins’ synergistic effects through real biological interactions. Furthermore, even advanced sequence-based models (e.g., CNN, GRU) underperformed when employing graph-based methods. This suggests that graph structures have more potential to capture protein feature relationships, compensating for the limitations of sequence-only models.
3.4. Hyperparameter Study
We conducted comprehensive experiments to evaluate how various key hyperparameters influenced our proposed framework’s performance. The analysis focused on four critical hyperparameters: noise hyperparameter, temperature hyperparameter, subgraph sampling size, and loss function balance factors. Below we present our detailed findings.
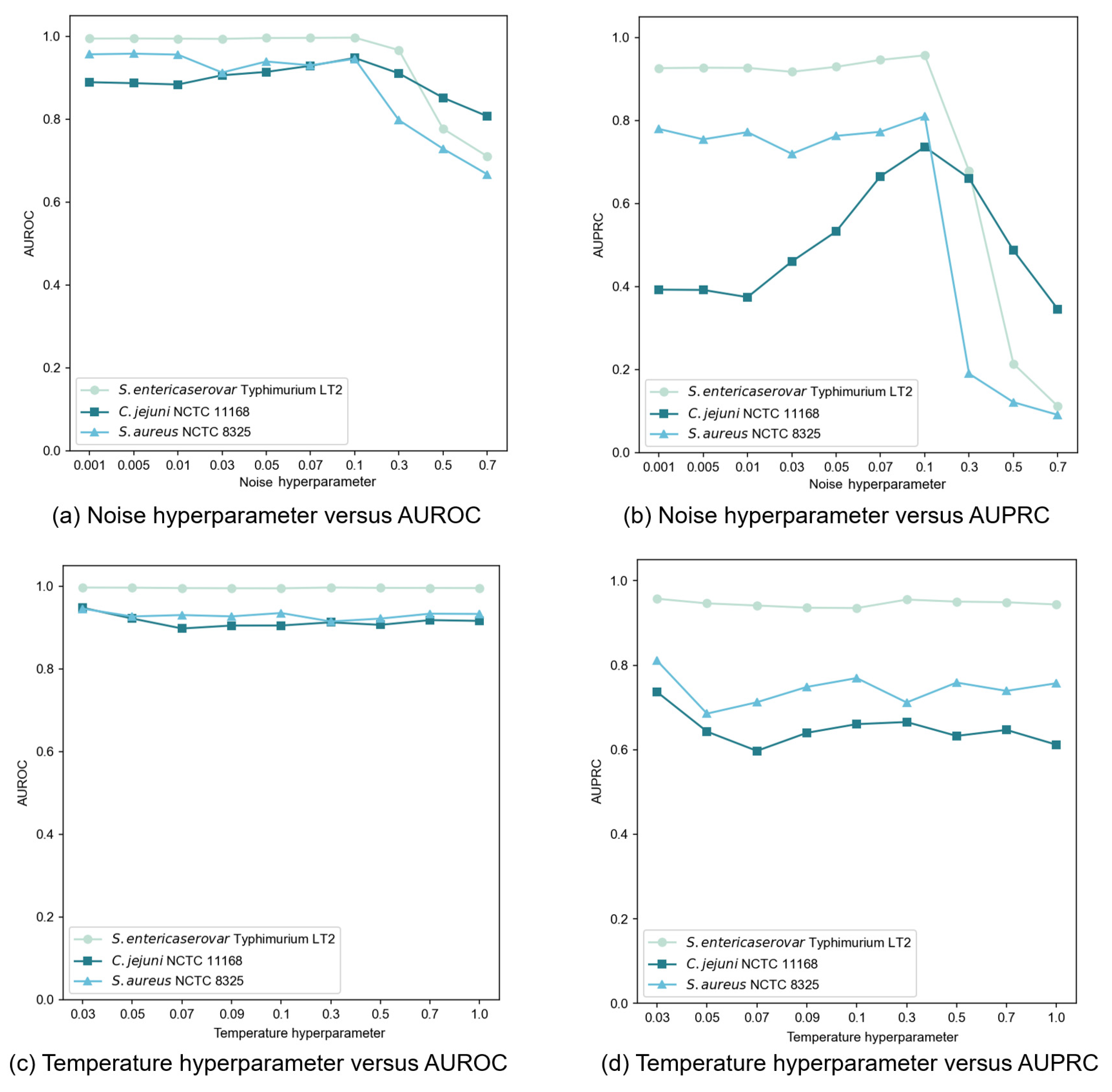
In our contrastive learning setup, we generated an augmented view by applying Gaussian noise to the original node features. The noise, following a standard normal distribution, was controlled by a hyperparameter that determined the perturbation magnitude. We tested noise hyperparameter values throughout the set {0.001, 0.005, 0.01, 0.03, 0.05, 0.07, 0.1, 0.3, 0.5, 0.7} and evaluated performances using AUROC and AUPRC, as illustrated in
Figure 5a,b. Our findings revealed that moderate noise levels improved model performance, though the effect varied from dataset to dataset. Excessive noise (above 0.1) significantly degraded performance by disrupting feature integrity. Through extensive testing, we determined that a noise hyperparameter of 0.1 provided an optimal balance between data diversity and stability across datasets.
The temperature hyperparameter
in the InfoNCE loss governs the model’s ability to distinguish between positive and negative samples. Our experiments, spanning
values within the set {0.03, 0.05, 0.07, 0.09, 0.1, 0.3, 0.5, 0.7, 1.0}, revealed dataset-specific sensitivities to this hyperparameter (
Figure 5c,d). When setting
= 0.01, an abnormal situation occurred where the model outputs NaN (Not a Number) values. This indicated that the selected value for this parameter was rather diminutive, failing to support stable operations of the model. Consequently, in subsequent experiments regarding the setting of this hyperparameter, we initiated the range from 0.03 to avoid such instabilities and further explored the optimal configuration. Based on extensive testing, we finally selected
= 0.03 as the optimal value, delivering consistent and superior performance across most datasets.
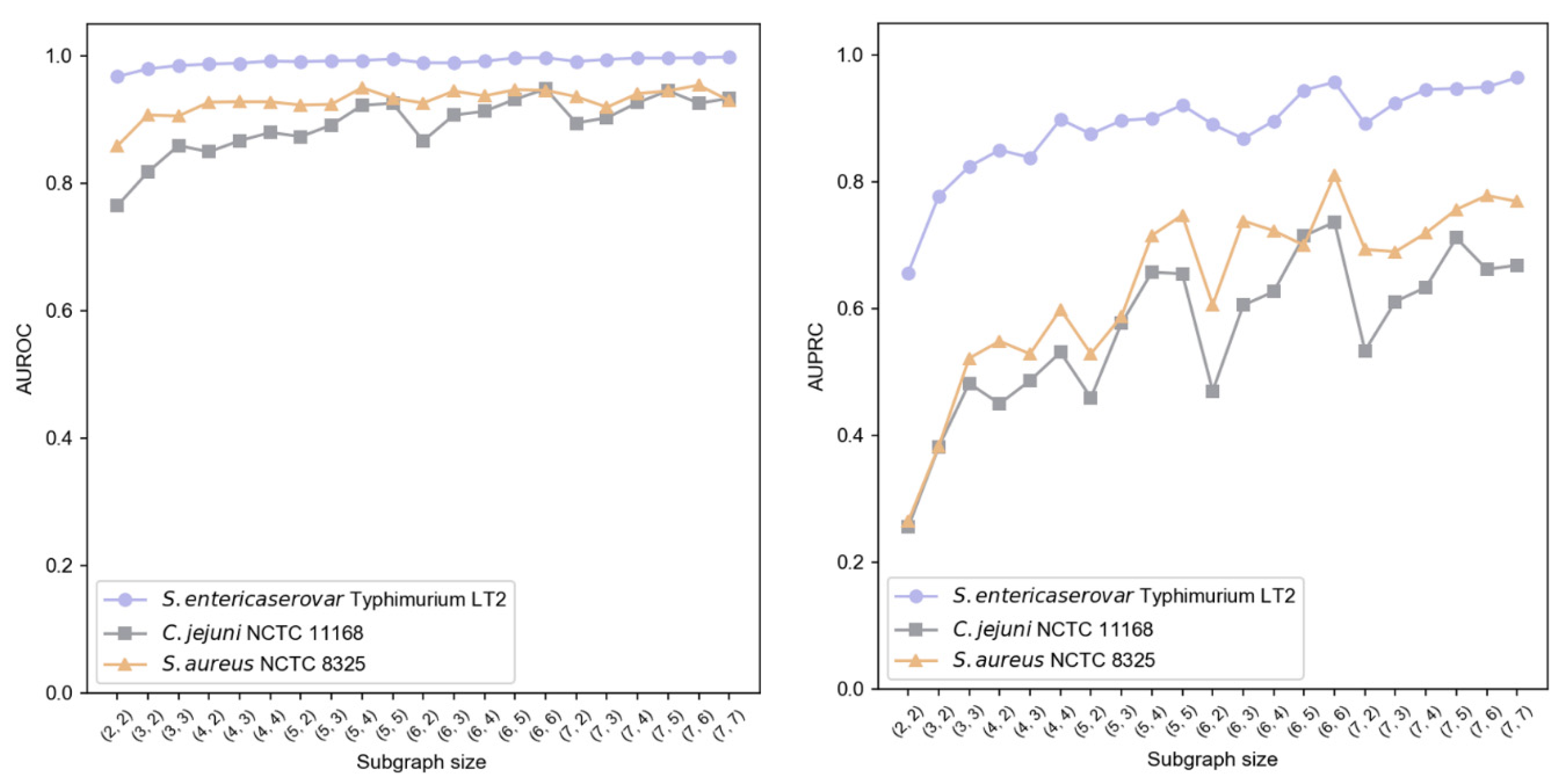
We implemented a two-layer subgraph sampling strategy, denoted as
, where
{2, 3, 4, 5, 6, 7} and
. Results shown in
Figure 6 indicate that subgraph size particularly affects AUPRC, while AUROC remains more stable. Larger first-layer sampling (
) generally enhanced performance, suggesting better capture of local information characteristics. Similarly, increased second-layer sampling (
) improved AUPRC, highlighting the importance of second-order neighborhood information in modeling contextual relationships. Balancing performance and computational efficiency, we established
= (6, 6) as optimal sampling hyperparameters.
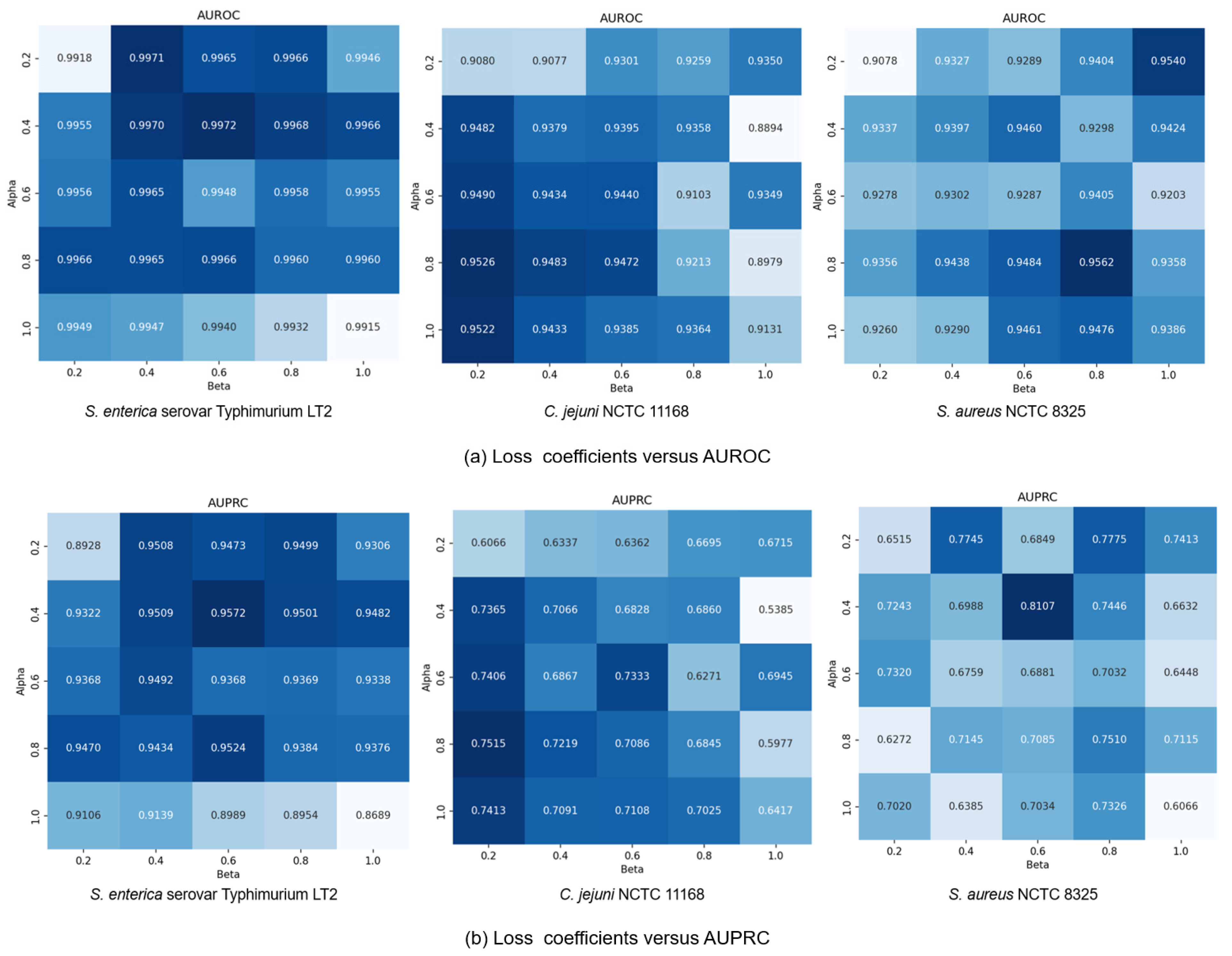
Finally, we explored how the coefficients
and
in loss function (13) affected model performance by modulating the influence of generative and contrastive self-supervised modules. Given that self-supervised learning serves an auxiliary role to classification, we constrained both
and
to (0, 1]. We set the coefficients in a range of {0.2, 0.4, 0.6, 0.8, 1.0} and conducted a comprehensive exploration of different combinations within this range. Results in
Figure 7 show that small coefficients (
= 0.2,
= 0.2) led to suboptimal performance due to insufficient feature learning, while large values (
= 1.0,
= 1.0) compromised classification capability by overemphasizing self-supervised tasks. The
C. jejuni NCTC 11168 dataset showed particular sensitivity to the generative loss coefficient
, performing best with high
and low
values (
= 0.2). Conversely, the
S. enterica serovar Typhimurium LT2 dataset exhibited performance degradation at
= 1.0, suggesting dataset-specific dependencies on different self-supervised learning modules. Based on these findings, we standardized
at 0.4 while allowing
to vary by dataset:
= 0.2 for
S. aureus NCTC 8325 and
= 0.6 for the other datasets, achieving optimal cross-dataset performance.
3.5. Ablation Study
To systematically evaluate the GC-VF framework’s key components, we conducted a series of ablation experiments. We tested several variant models by removing specific modules: the generative attribute reconstruction module (GC-VF w/o Gen), the local contrastive learning module (GC-VF w/o Con), and the self-supervised learning module (GC-VF w/o SL). Additionally, we evaluated variants of the GraphSAGE encoder without edge weights (GC-VF w/o EW) and with binary cross-entropy loss replacing focal loss (GC-VF w/BCE).
Table 3 presents the comparative results across all three datasets.
Our experiments revealed that the complete GC-VF model, incorporating both generative and contrastive learning for self-supervision, achieved notable performance across all datasets. The ablation studies demonstrated that removing any self-supervised module results in performance degradation. Notably, the combined implementation of both modules produced performance improvements exceeding their individual contributions, confirming positive and effective synergy between these self-supervised strategies. However, we observed distinct variations in module contributions across different datasets. For the S. enterica serovar Typhimurium LT2 and C. jejuni NCTC 11168 datasets, the removal of the generative module resulted in minimal impact, suggesting contrastive learning’s dominance in feature extraction. Conversely, for the S. aureus NCTC 8325 dataset, the attempt to remove the generative module significantly degraded performance across multiple metrics, underlining its crucial role in feature learning. These variations suggest that bacterial strain datasets possess unique feature distribution patterns, leading to differential responses to various self-supervised learning strategies.
The analysis of edge weights revealed their importance in model performance. Removing edge weights substantially degraded the results, primarily because traditional feature aggregation methods fail to capture the nuanced intensity differences in PPI networks. Our statistical analysis of PPIs across the three datasets revealed distinctive patterns in interaction strengths: virulence protein interactions averaged a combined score of 0.7556, virulence-to-non-virulence protein interactions averaged 0.6037, and non-virulence protein interactions averaged 0.6428. These findings indicate stronger interaction patterns between proteins of the same type, among which virulence proteins exhibit the strongest interaction patterns. This biological insight justifies our integration of edge weights into the framework. By incorporating these differentiated edge weights into the GNNs, our model effectively prioritizes strong interaction connections, particularly the high-intensity interactions between virulence proteins, during feature aggregation. This approach not only enhances the model’s prediction capabilities but also aligns with established biological characteristics of PPI networks.
Furthermore, the implementation of focal loss proved effective in addressing class imbalance, even with default hyperparameter settings. The comparative analysis showed that replacing focal loss with binary cross-entropy loss resulted in performance degradation, highlighting focal loss’s beneficial role in managing data imbalance challenges.
3.6. Training and Inference Efficiency
Training and inference runtimes are reported in
Table 4. The runtime measurements represent averaged results using optimal hyperparameters for each dataset and were executed on a NVIDIA GeForce RTX 3080 GPU. As expected, both training and inference times correlate positively with graph scale, as larger networks require more computational resources. Training time includes the complete 131-epoch process using the Adam optimizer (learning rate of 0.001, weight decay of 0.0001) and a batch size of 300, while inference time refers to the average duration of 100 test evaluations on the respective test sets.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}