1. Introduction
As a critical component in the manufacturing industry, the operational state of a compressor directly affects production efficiency. Diagnosing and maintaining compressor faults poses significant challenges in equipment management. When a compressor malfunctions, it typically provides faulty information and displays an alarm code. However, this information is often limited to basic system or electrical data, lacking comprehensive diagnostics, especially for specific system faults.
Compressor failures can be categorized into two types: mechanical system failures and electrical system failures. These failures are interrelated and require a comprehensive analysis to accurately determine the root cause [
1]. Over the years, factory floors have accumulated extensive compressor diagnostic and maintenance cases, primarily stored as unstructured text data. This discrete knowledge of compressor fault diagnosis is not effectively integrated or utilized, hindering the sharing of maintenance expertise among personnel. These issues lead to inefficiencies in fault diagnosis and slow progress in diagnostic capabilities.
Effectively leveraging the vast amount of unstructured expert text data to assess a compressor’s operational state is crucial for manufacturing. Doing so can reduce reliance on specialized knowledge, assist operators in making informed decisions, and minimize economic losses due to faults. This paper aims to integrate unstructured data, extract valuable information, and construct a knowledge graph, thereby laying the groundwork for the application of knowledge graphs in air compressor fault diagnosis.
A knowledge graph is an advanced form of graphical knowledge representation that evolved from directed graphs. The modern concept of the knowledge graph originated with Google’s announcement in 2012. It is widely used in applications such as search engines, question-answering systems, decision-making processes, and artificial intelligence reasoning.
A knowledge graph consists of nodes and directed edges, where each node represents an entity. Unlike traditional knowledge bases, knowledge graphs are superior and more complex because they utilize inference engines to generate new knowledge and integrate multiple information sources. They also feature custom query languages and specialized databases, making them highly adaptable for search, query, and decision-making tasks.
Knowledge graphs can be categorized into two types: domain knowledge graphs, which focus on specific fields of expertise, and enterprise knowledge graphs, which are tailored for organizational uses [
2]. Domain knowledge graphs have garnered significant attention from both industry and academia. Various domain-specific knowledge graphs have been developed in fields such as medicine, finance, social media, and energy. Existing review articles have provided detailed summaries of the development and applications of knowledge graphs [
2,
3]. These graphs offer concise and intuitive representations of complex concepts, where edges depict the relationships between entities derived from unstructured data.
Similarly, air compressor failure knowledge can be extracted from air compressor maintenance text data and stored in a knowledge base through knowledge graph technology. We identify the entities from the air compressor operation and maintenance text, extract the relationship between the entities to form the triples, and then import the triples into the graph database to form the knowledge graph of air compressor faults. The nodes in the knowledge graph represent various entities in the air compressor domain, including Equipment, Fault, Cause, Solution, and Request. The edges in the knowledge graph represent the relationships between entities, including Contain, Relate, etc. The conversion of unstructured text data to structured data is realized.
The knowledge graph of air compressor failure not only reflects its high-quality knowledge information but also is the premise of intelligent semantic understanding in the field of air compressor failure diagnosis, which can provide theoretical data support for the subsequent knowledge reasoning of equipment failure. The air compressor equipment fault knowledge graph realizes the query and visualization of equipment fault knowledge. On the one hand, it can help operation and maintenance personnel to efficiently learn relevant fault knowledge, improve safety awareness, and promote safe production; on the other hand, it can help the staff’s relative lack of experience. According to the fault situation on site, it provides previous fault records and possible causes of faults as a reference, assisting O&M personnel to more quickly and accurately determine the fault situation of the equipment on site, solve accidents and faults, and ensure the safe operation of the equipment.
However, due to the air compressor fault diagnosis field of Chinese entities and the existence of ambiguity, tautology, entity nesting (as shown in
Figure 1), data distribution imbalance, and other problems, the accuracy of Chinese entity recognition and relationship extraction needs to be improved. Otherwise, the application of Chinese knowledge graph in the field of air compressor fault diagnosis will be seriously affected.
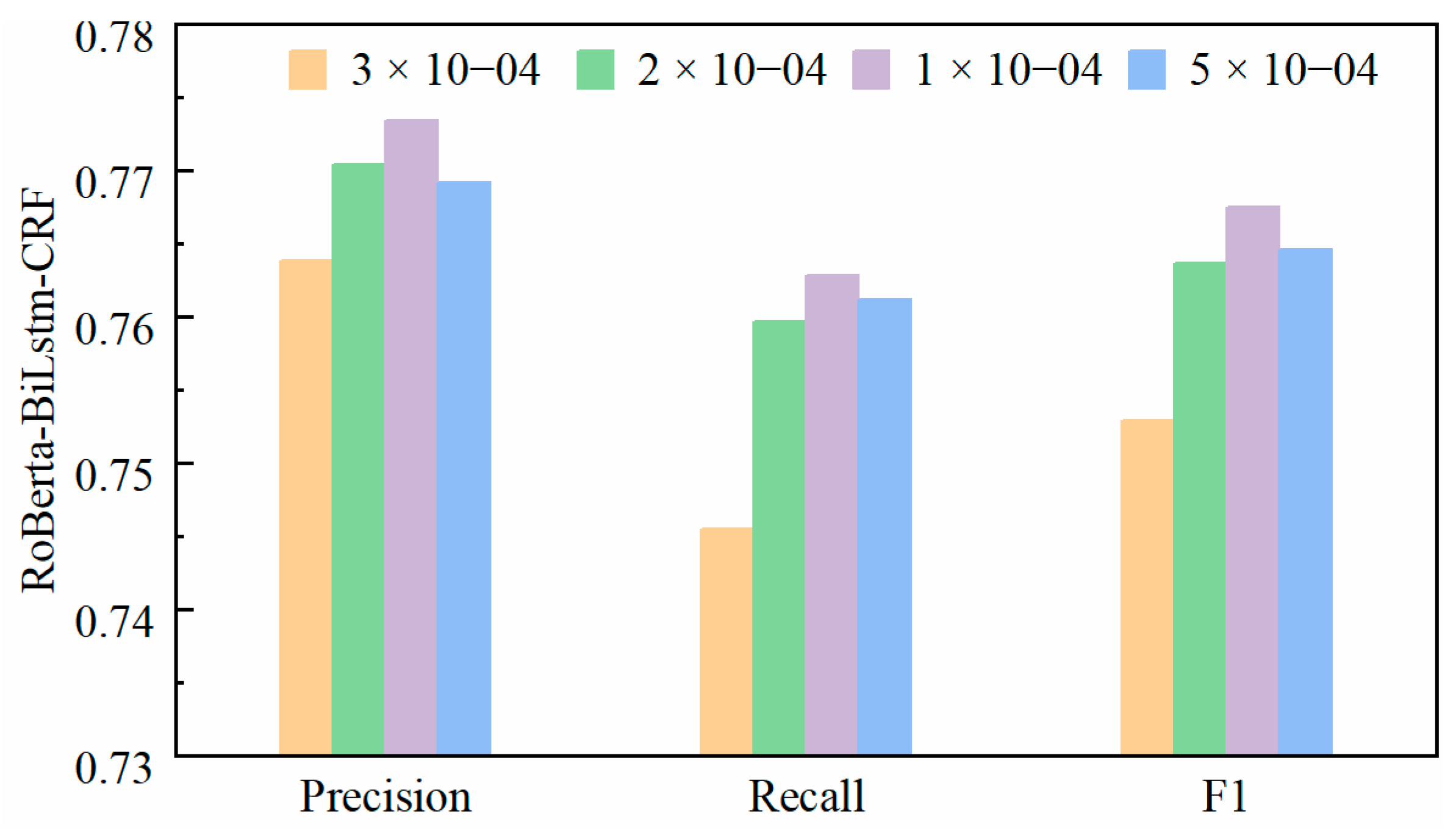
In view of the above problems, this paper proposes the following solutions when constructing the knowledge map of air compressor fault diagnosis: RoBERTa’s pre-trained model, which is more suitable for Chinese entity naming and recognition than Bert, is used to complete the entity extraction task. This model not only inherits the advantages of the BERT model but also presents the input sentence as the sum of the word vector, sentence vector, and position vector, and improves the BERT model in terms of model structure and data. A larger number of single training samples and more data were used to train the model, and the Next Sentence Prediction (NSP) objective function was removed, and a longer sequence length was used for training. In the pre-training stage, Chinese word masking technology (WWM) was adopted, and the LTP of HIT was used as a word segmentation tool. The semantic representation generated by the pre-training model contains word information and covers all the Chinese characters composed of the same word. At the same time, the model uses a dynamic mask mechanism to learn different language representations to avoid the influence of word segmentation errors [
4]. Then, in the training process, feature fusion is carried out to connect RoBERTa’s output with BiLSTM’s output. The BERT model can learn more global context information, while BiLSTM can learn local sequence information, so as to enrich the model’s representation ability for input sentences. At the same time, the training monitoring index and the evaluation index are unified into the F1 value at the entity level, and the learning rate attenuation strategy is adopted to monitor the F1 value in real time. When the F1 value no longer increases, the learning rate will automatically decrease to improve the performance of the model. In addition, a new entity identification process is proposed, in which the faulty equipment entities in the CFDK dataset are stored in a separate BIO file, and the remaining four fault knowledge annotation data are combined in a BIO file. The RoBERTa-BiLSTM-CRF model was used to classify the trained entity labeling. This process solves the problem of entity nesting of faulty equipment well. Moreover, Focal LOSS classifies entity samples and reduces the loss contribution of a large number of entity samples, so that the model pays more attention to the entity categories that were difficult to identify.
The rest of this paper is organized as follows: In the second part, the development of the knowledge graph and its research in the field of fault diagnosis are summarized. The third part mainly introduces the overall framework of the model and provides detailed descriptions of its key components. In the fourth part, we discuss the model’s evaluation metrics and parameter settings, compare and analyze its performance, and present the constructed knowledge graph. The fifth part concludes the paper and outlines prospects for future work.
2. Related Work
MIT, Massachusetts, USA developed the ConceptNet [
5] common sense graph using data from multiple sources, utilizing a non-formal, near-natural language description. Wikipedia, a multilingual collaborative encyclopedia, is the largest knowledge resource on the Internet. Consequently, many knowledge graphs are based on Wikipedia, such as DBpedia [
6], YAGO [
7,
8], and Freebase [
9]. DBpedia extracts structured knowledge from Wikipedia, standardizing entries in the form of ontologies. YAGO, developed by the Max Planck Institute in Germany, is a multilingual knowledge base that integrates data from Wikipedia, WordNet, and GeoNames, featuring a rich entity classification system. Freebase also extracts structured data from Wikipedia to form Resource Description Framework (RDF), storing this structured data in a graph database. Google released its Knowledge Graph in 2012. Unlike traditional search engines, which simply find all pages containing keywords, the Google Knowledge Graph uses entity recognition and linking to disambiguate search queries. It understands user intent through semantic parsing, providing more accurate search results.
With increasing attention from academia and industry, research on knowledge graphs for fault diagnosis has gradually grown. Wang et al. [
10] extracted semi-structured and unstructured fault knowledge from CNC machine tool fault cases, maintenance manuals, and on-site logs. They used a comprehensive system to integrate this interrelated fault diagnosis knowledge, achieving a structured application for CNC machine tool fault diagnosis. Xue et al. [
11] focused on the control rod drive mechanism (CRDM) of the liquid-fueled thorium molten salt reactor (TMSR-LF1), proposing a fault diagnosis system based on a knowledge graph and Bayesian inference algorithm. Chen et al. [
12] proposed a semi-supervised self-tuning graph neural network (SSGNN) for fault diagnosis, which can effectively extract features from vibration signals and generate a graph structure representation of fault knowledge. The SSGNNs proposed in this study play an important role in the construction, extension, and application of knowledge graphs. Cai et al. [
13] proposed a multilevel KG construction method to provide data support for FD, followed by a method based on multilevel KG and Bayesian theory to detect the system state, combined with relational path-based KG inference to locate the fault source, utilizing the relationship between the structures of rotating mechanical equipment for fault cause inference, and using KG as a knowledge base for reasoning using machine learning, which effectively solves the problem of low diagnostic accuracy.
In the field of power equipment fault diagnosis, Meng et al. [
14] employed the BERT-BiLSTM-CRF model to identify and extract power equipment entities from pre-processed Chinese technical literature. They then used dependency analysis relationship classification to extract semantic relationships between entities. The resulting knowledge was stored in the Neo4j database as triples and visualized as graphs.
Hu [
15] introduced knowledge graphs into automobile fault diagnosis. He enhanced the traditional construction process by adding text pre-classification and entity reorganization, effectively addressing issues with nested and discontinuous entities in the text.
In the field of air compressor fault diagnosis knowledge graphs, the complexity, diversity, and criticality of air compressor systems in industry make them ideal cases for validating and testing our proposed feature fusion RoBERTa-WWM-BiLSTM-CRF model. By applying it to air compressor fault diagnosis, we are able to demonstrate the effectiveness of our modeling approach in handling complex textual data and improving the accuracy and robustness of fault diagnosis, as well as demonstrating the potential of the approach to be applied to a wider range of industrial domains. Chen et al. [
16] proposed a benchmark dataset and baseline model for mining fault diagnosis knowledge from compressor maintenance logs using sequence labeling (SL) and named entity recognition (NER) technologies. Qin et al. [
17] developed a compressor fault knowledge mining model based on a large language model. This model can quickly and accurately extract structured compressor fault knowledge triples from unstructured fault text data, forming a comprehensive compressor fault knowledge graph.
Based on the reviewed studies, it is evident that there is a scarcity of research focusing on constructing knowledge graphs tailored to the characteristics of air compressor fault text data. While knowledge graph applications have enhanced efficiency and correlation performance in other equipment fault diagnosis fields, current methods primarily rely on models like Bert-BiLSTM-CRF to directly identify named entities in fault text data, often overlooking nested entity complexities specific to air compressor faults.
Moreover, with rapid advancements in pre-training models, such as the RoBERTa model optimized for Chinese text data logic, there is an opportunity to address these challenges effectively. This paper proposes a method tailored for constructing a fault knowledge graph specific to air compressors. The approach involves labeling fault equipment location entities nested within other entities separately within the dataset. Subsequently, entity identification tasks for fault equipment locations and other entities are performed using the RoBERTa-BiLSTM-CRF model optimized for air compressor fault diagnosis datasets. Experimental results validate the effectiveness of this optimized approach.
In summary, the main contributions of this paper include:
- (1)
This paper enhances the traditional sequence annotation model by replacing the Bert-BiLSTM-CRF model with the more advanced RoBERTa pre-trained model. This upgrade significantly boosts the accuracy and efficiency of entity recognition tasks. Furthermore, we optimized the model structure to better suit the data characteristics. The RoBERTa-BiLSTM-CRF model was further enhanced through feature fusion technology, learning rate attenuation, and Whole Word Masking (WWM), achieving superior performance in entity recognition tasks.
- (2)
We propose a novel method for constructing a knowledge graph from air compressor fault text. Specifically, we extract faulty equipment entities separately from other maintenance knowledge entities that may be nested within them. This approach effectively resolves issues related to entity nesting.
- (3)
The paper constructs a domain-specific knowledge graph for air compressor fault diagnosis, laying a foundational framework for utilizing knowledge graphs in air compressor fault diagnosis. This work also offers valuable insights for applying knowledge graphs to other engineering domains.
3. Construction of the Knowledge Graph
3.1. Framework of Construction
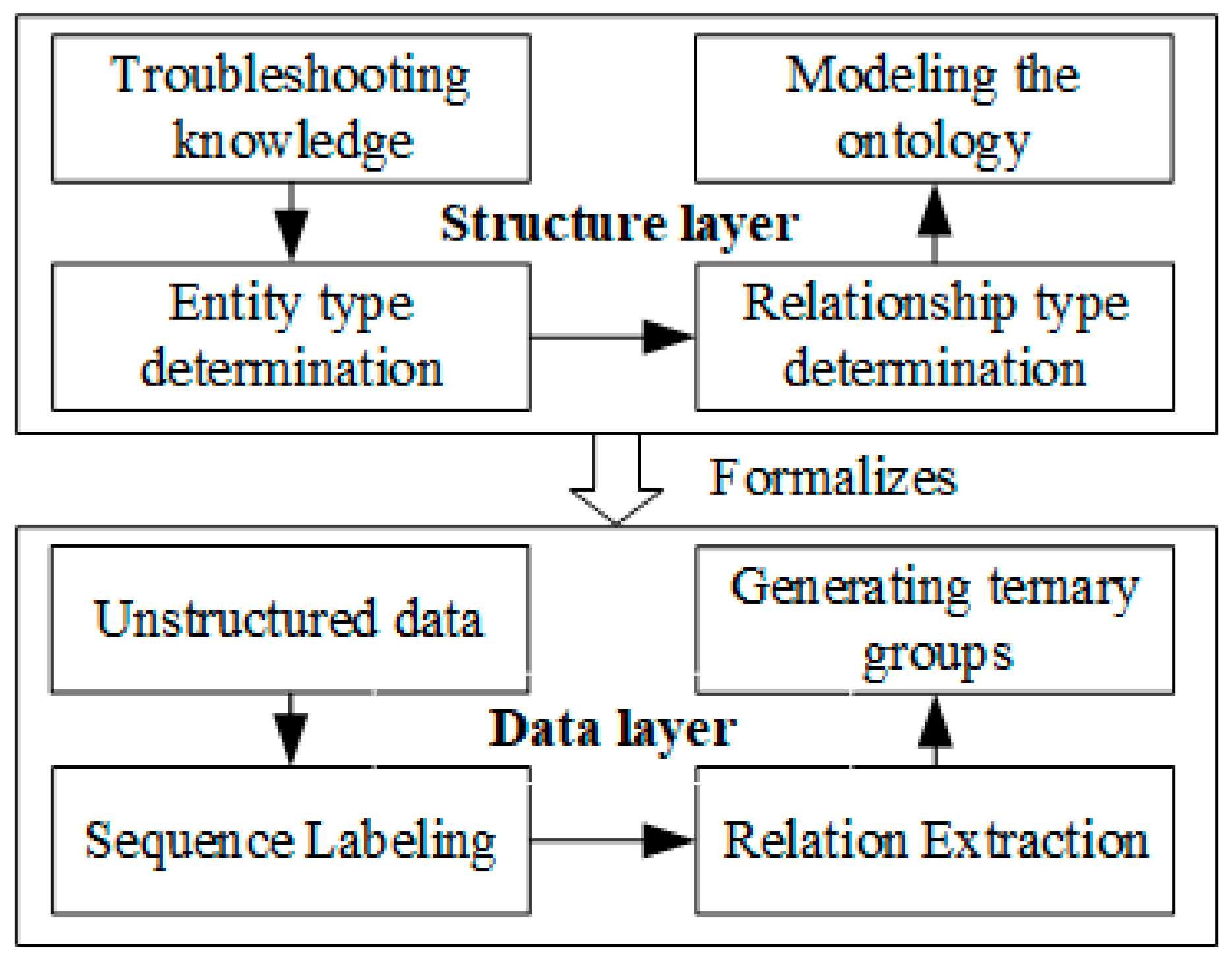
There are two approaches to constructing a knowledge graph: top–down and bottom–up. Bottom–up construction involves completing knowledge extraction before defining ontology information. In contrast, the top–down method defines ontology information first and then extracts knowledge from the data. The fault knowledge graph of an air compressor falls under the category of a vertical domain knowledge graph.
Vertical domain knowledge graphs differ from open domain knowledge graphs in two main aspects. Firstly, entities in vertical domain knowledge graphs are constrained within a specific domain compared to the broader scope of open domain graphs. Secondly, vertical domain knowledge graphs typically require higher precision and quality to meet the specialized needs of users within that domain.
Therefore, this paper adopts the top-down construction method for building the air compressor fault knowledge graph. The construction framework is illustrated in
Figure 2.
3.2. Ontology Construction
Ontology [
18] originates from philosophy and holds significant theoretical importance for artificial intelligence, web research, semantic web development, knowledge management, information retrieval, and human–computer interaction. In the context of AI and web research, ontology is defined as a document or file that formally specifies the relationships between terms [
19]. Various research groups globally have proposed diverse methods to guide ontology construction, such as the skeleton method, enterprise modeling, cyclic acquisition, METHONTOLOGY, IDEF-5, Bemem, et al., and virtual domain ontology construction [
20]. As a result, numerous ontology construction tools have emerged, including Ontosaurus, Ontolingua, webonto, WebODE, Protege, OntoEdit, OILEd, and OntoBuilder. The primary goal of ontology modeling is to clearly conceptualize domain knowledge. Before constructing the knowledge graph for air compressor fault diagnosis, it is essential to define knowledge concepts and their relationships within the ontology model. This framework provides specifications for extracting subsequent entities and relationships.
Knowledge related to air compressor fault diagnosis can be categorized into two types. Firstly, there is machine tool fact knowledge, such as the type and model of the air compressor, which remains unaffected by whether a fault occurs or not. Secondly, there is fault occurrence knowledge, directly associated with faults when they arise, encompassing fault phenomena, solutions, causes, and more. These two types of knowledge are intertwined to form the air compressor fault diagnosis knowledge model.
The next section will briefly introduce ontology editing methods and tools, followed by their application in ontology modeling for air compressor fault diagnosis knowledge.
Currently, one of the most widely used tools for ontology construction is Protege, a Java-based software for ontology editing and knowledge acquisition developed by the academic community. Protege features a user-friendly graphical interface and provides functions for constructing ontology concepts, classes, relationships, attributes, and instances.
Given the advantages mentioned above, Protege is selected in this section to construct the ontology for the air compressor fault diagnosis knowledge graph. The specific logic process for ontology construction is outlined as follows:
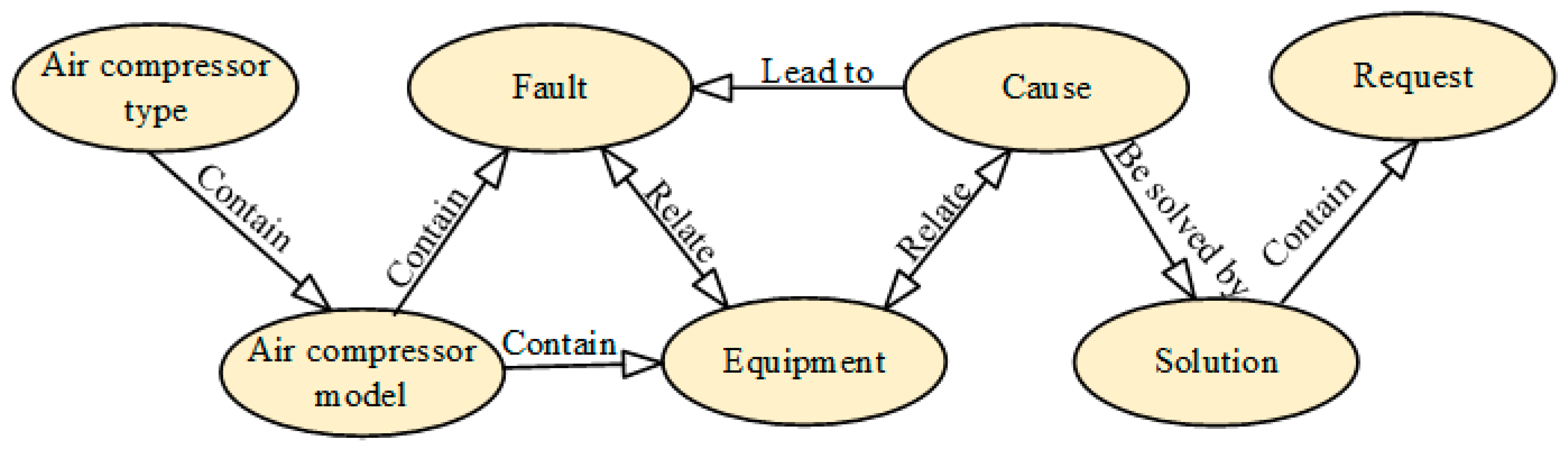
Air Compressor Ontology Construction: Upon reviewing air compressor fault diagnosis cases, it is evident that crucial information pertains to the model and type of air compressors. Therefore, two entity classes are defined: air compressor model number and air compressor type.
Construction of Air Compressor Fault Ontology: The air compressor fault ontology forms the foundational knowledge for air compressor fault diagnosis. Given that fault diagnosis typically involves fault causes, fault phenomena, maintenance plans, and maintenance requirements, four entity classes are defined: air compressor fault cause, fault phenomenon, maintenance plan, and maintenance demand. Additionally, due to the close relationship between air compressor faults and the components within them, a fault location class is also defined.
Defining Relationships Between Entity Classes: Based on logical relationships between entity classes, six types of relationships are defined: fault position–fault cause, fault phenomenon–fault cause, fault phenomenon–maintenance plan, fault phenomenon–air compressor model number, maintenance plan–maintenance demand, and air compressor type–air compressor model number. Each of the above entity classes exhibits pairwise mutual exclusion, meaning an entity cannot belong to two entity classes simultaneously.
Using the Protege ontology building tool, a total of seven entities and eight relationships are defined. These are detailed in
Table 1 below.
Figure 3 illustrates the ontology model for air compressor fault diagnosis domain knowledge created using the Protege ontology editing tool. This model integrates both machine tool fact knowledge and fault occurrence knowledge, highlighting their interconnectedness. This ontology model forms the foundational layer of the air compressor fault diagnosis knowledge graph.
3.3. Construction of Sequence Labeling Model and NER Model
3.3.1. Construction of Feature-Fusion RoBERTa-BiLSTM-CRF Model
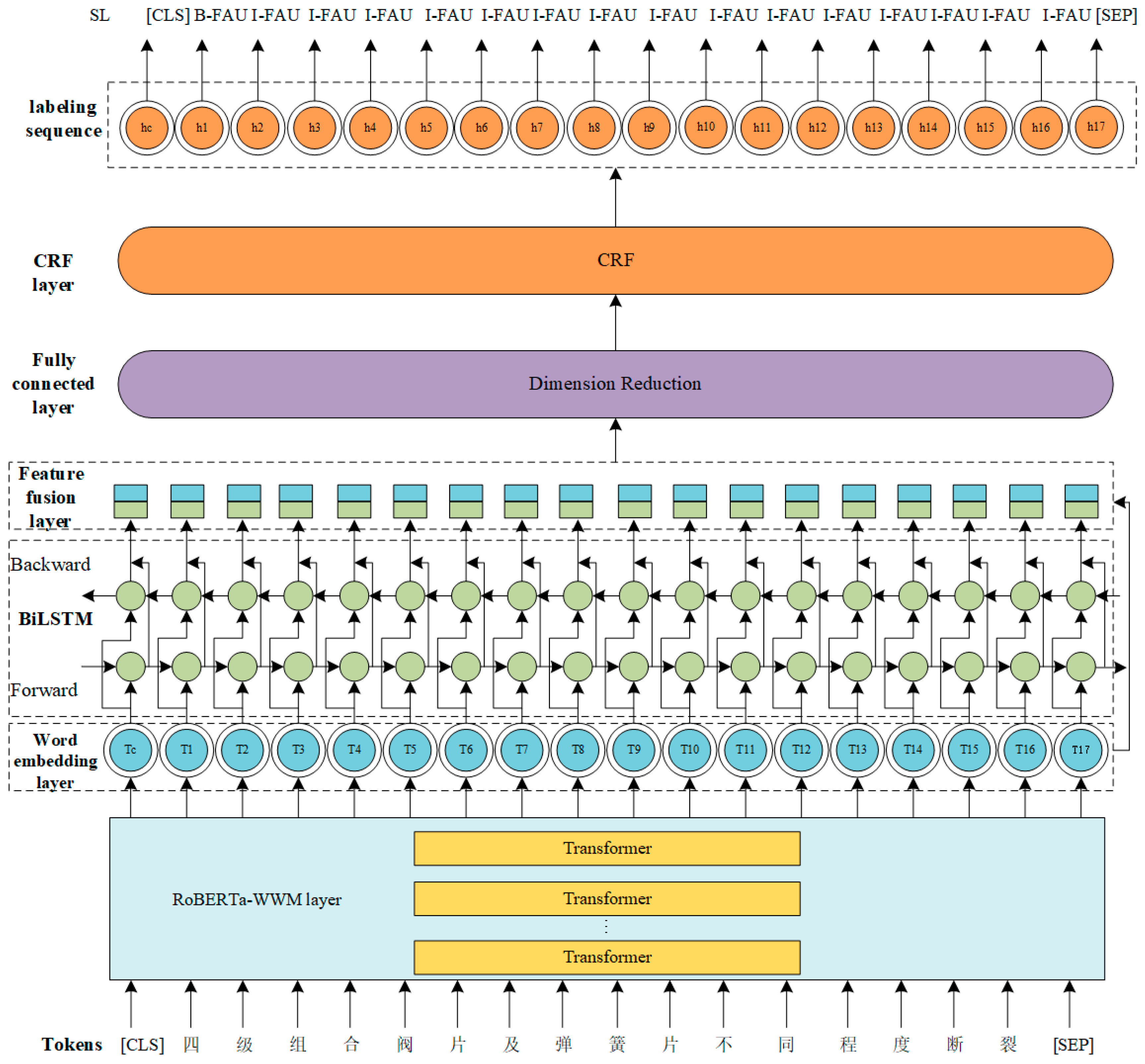
The RoBERTa-BiLSTM-CRF model used for marking fault knowledge sequences in air compressors employs RoBERTa as the pre-trained language model. It integrates a BiLSTM-CRF architecture to sequentially label fault phenomena, causes, and solutions in air compressor texts. RoBERTa initially converts each word in the text into a vector, which serves as input for the subsequent BiLSTM-CRF structure model. The model outputs a vector representation combined with contextual information. The overall structure of the RoBERTa-BiLSTM-CRF model, depicted in
Figure 4, consists of five layers: The first layer is the preprocessing RoBERTa layer, which converts every word in the sentence into a low-dimensional vector. The second layer is the BiLSTM layer, and the vector output from the RoBERTa layer is used as the input of this layer to automatically extract semantic and temporal features from the context. The third layer is the feature fusion layer, which connects the output of ROBERTA and BILSTM to combine the features of different levels. After the feature fusion layer is the fully connected layer, and the output undergoes dimensionality reduction through the fully connected layer. This step helps the model effectively learn important features and mitigates overfitting issues associated with high-dimensional features. The final layer is the CRF layer, which considers the order relationship between labels and solves the dependency between output labels to obtain the global optimal labeling sequence.
3.3.2. RoBERTa Pre-Trained Language Model
Bert (Bidirectional Encoder Representations from Transformers) [
21] is an unsupervised deep bidirectional language representation model trained using masked language modeling (MLM) [
21] and the next sentence prediction (NSP) [
21] mechanism to understand language. RoBERTa [
22], an upgraded version of BERT, undergoes longer training with more training data, resulting in improved performance. Both models share a similar structure consisting of 12 Transformer layers [
23]. The key difference lies in the masking strategy. BERT employs a static mask where parts of the input sequence are randomly replaced with special mask tokens (typically [MASK]) or random words from the vocabulary. The model predicts these mask tokens. This static approach means the mask remains fixed throughout training, with each masked position replaced consistently by the same special token.
In contrast, RoBERTa utilizes a dynamic masking strategy. Each time a sequence is inputted into the model, different tokens are randomly masked. This dynamic approach involves randomly selecting mask positions for each batch, allowing the model to adapt to varying masking strategies during training. This adaptation enhances RoBERTa’s ability to effectively model input sequences.
Additionally, RoBERTa eliminates the NSP module, which is unnecessary for identifying faulty entities in air compressors. Instead, RoBERTa adopts the FULL-SENTENCES training method, concatenating multiple consecutive sentences until reaching a maximum length of 512 tokens, which is twice the maximum character length of 256 tokens used in BERT [
22,
24,
25].
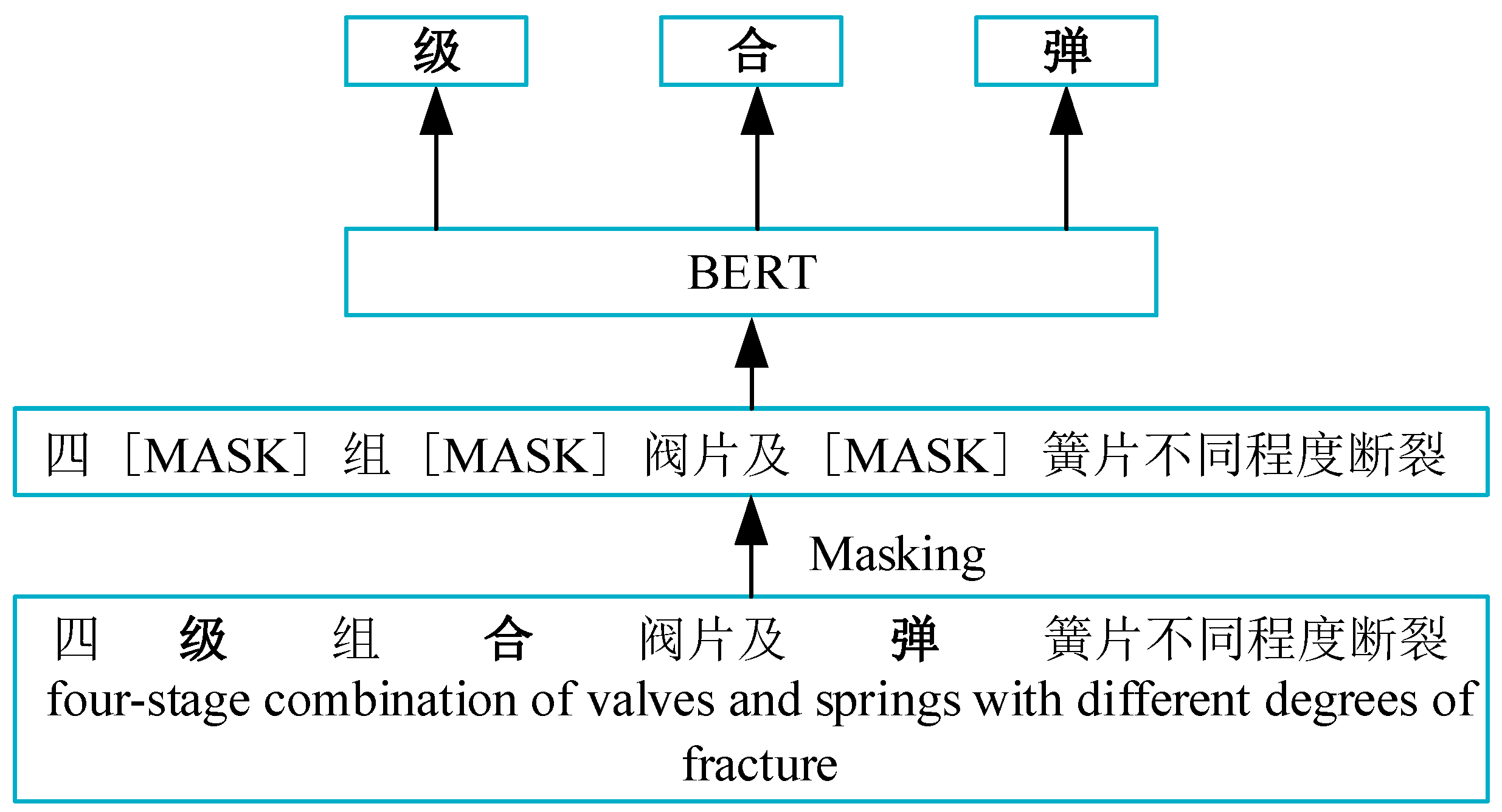
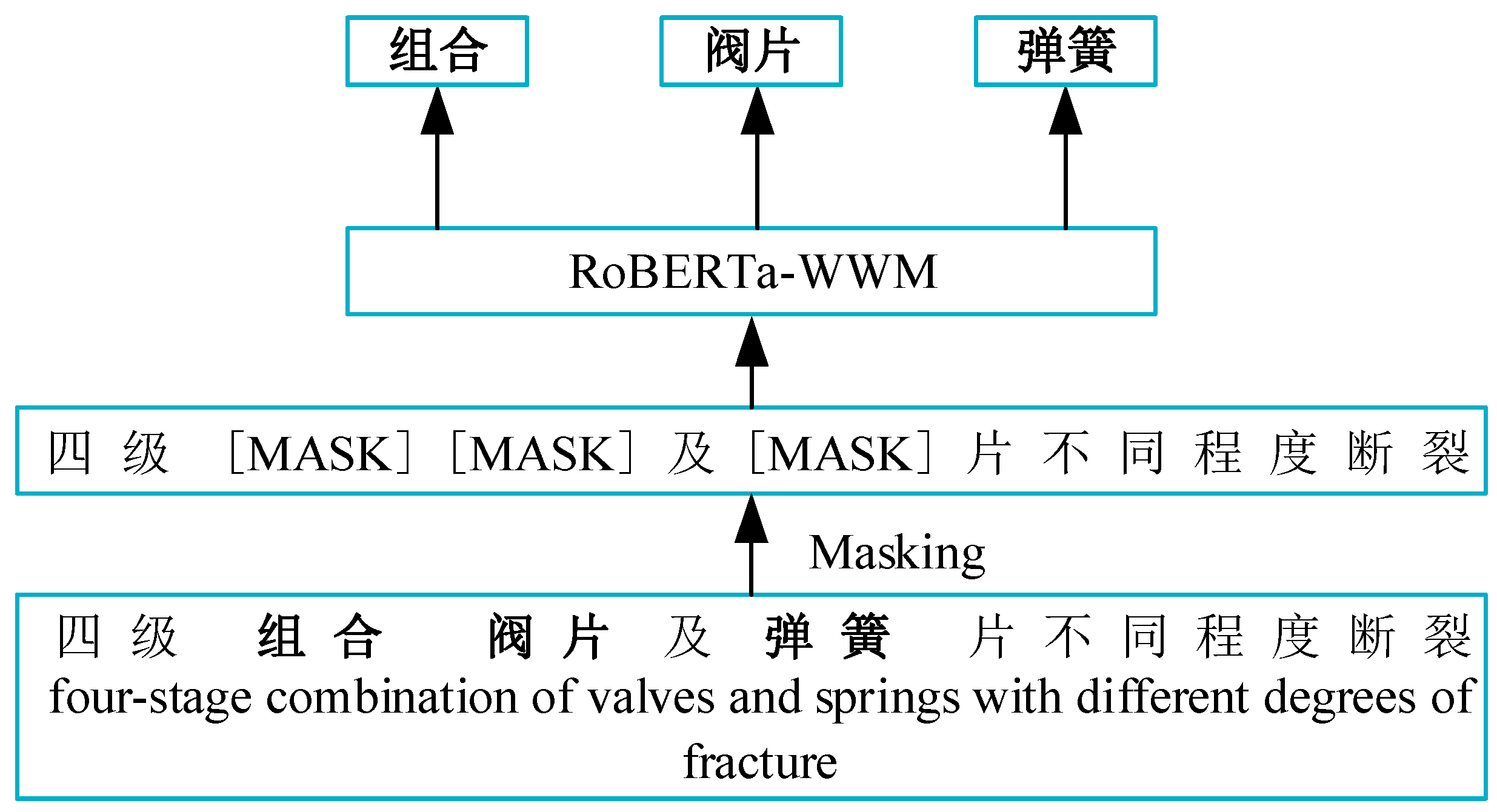
WWM (Whole Word Masking) is a masking strategy utilized in the BERT pre-training process. In contrast to BERT’s standard practice of randomly masking some subwords within a single word, WWM masks the entire word as a unit. When a word is selected for masking in WWM, the entire word is masked, rather than masking individual subwords separately.
To illustrate these two masking methods, consider the example “four-stage combined valve disc and spring disc with different degrees of breakage”. In
Figure 5 and
Figure 6, the model diagrams depict the differences between these masking strategies.
The primary advantage of the WWM strategy lies in its ability to preserve the integrity and original meaning of proper nouns or technical terms by masking them as whole units rather than breaking them down into sub-words. This feature is particularly beneficial when processing texts in specialized domains like air compressor fault diagnosis, where maintaining the accuracy and context of such terms is crucial.
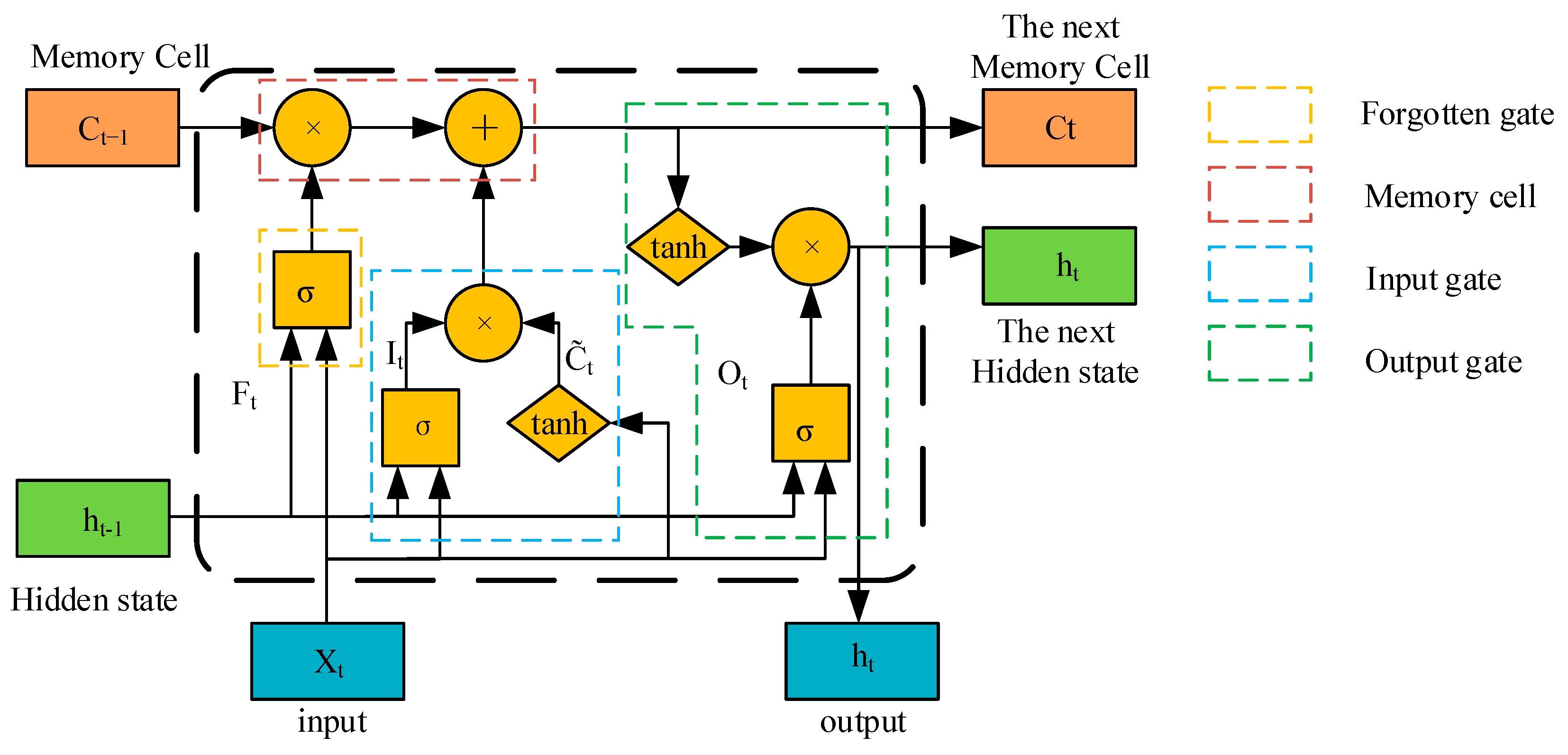
3.3.3. BiLSTM Layer Model Structure
The BiLSTM layer is an improvement of the LSTM model, and the LSTM model itself is an improved version of the traditional RNN model. The LSTM model is good at capturing remote dependencies in text data, thereby alleviating the problem [
25]. The structure of the LSTM unit is shown in
Figure 7.
BiLSTM combines forward LSTM and backward LSTM. It concatenates the output vector obtained from forward LSTM and the output vector obtained from backward LSTM as output. The model structure of BiLSTM is shown in
Figure 4.
3.3.4. CRF Layer
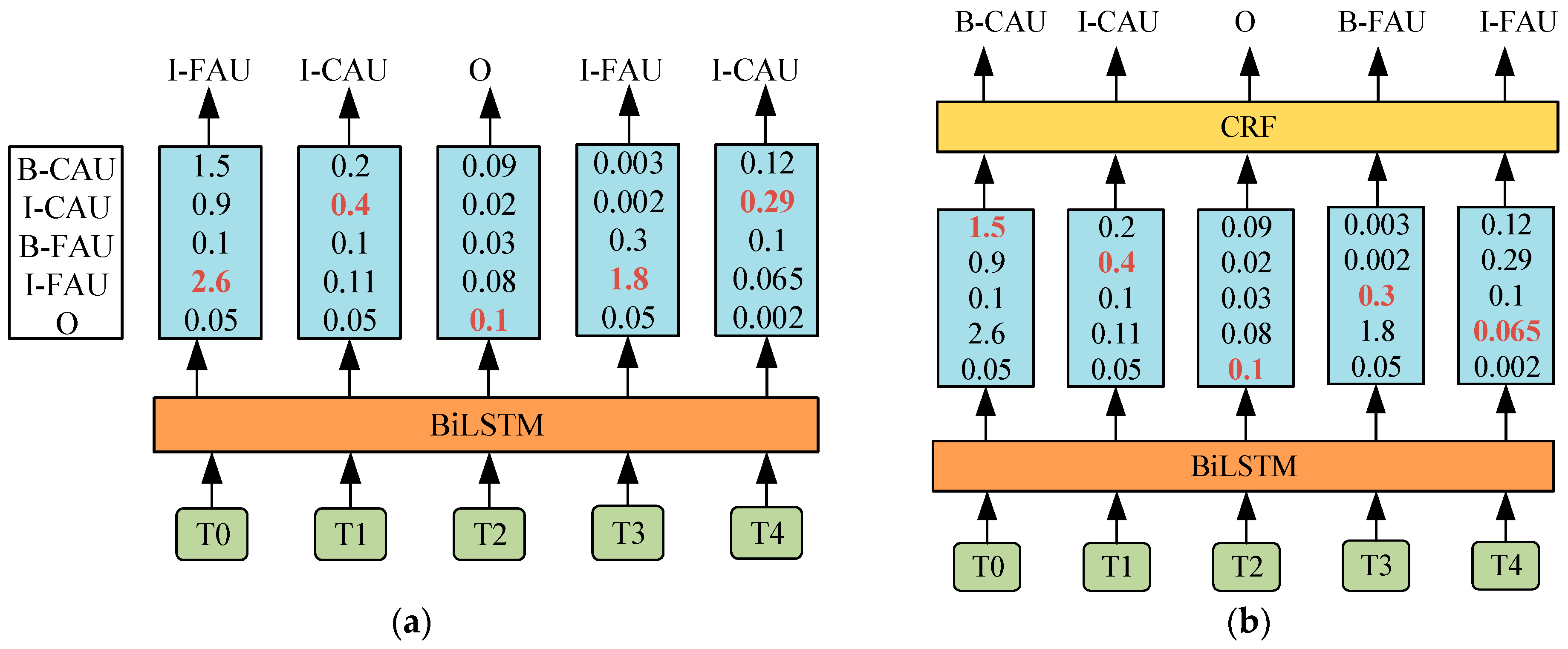
The RoBERTa-WWM model excels in capturing contextual information and feature representations. However, it generates labels independently for each case, without fully considering the global relationships between labels. For instance, entity recognition tasks like identifying equipment names (I-EQU) should logically be followed by the beginning of new equipment names (B-EQU). To address this, incorporating Conditional Random Fields (CRFs) is essential [
26]. The potential recognition outcomes influenced by the presence of CRF are illustrated in
Figure 8.
In
Figure 8a without CRF, the labeling model assigns labels based on the highest score principle, leading to nonsensical label sequences such as “I-FAU” (internal part of the fault phenomenon sequence) for T0 and “I-CAU” (internal part of the fault cause sequence) for T1. This contradicts the common understanding of fault diagnosis.
In
Figure 8b, with the application of CRF, the model’s labeling decision considers the transition probability between labels. For instance, despite “I-FAU” having the highest score (2.6 points), the CRF model selects “B-CAU” (the beginning part of the fault cause sequence), which had the second highest score, as the label for T0. Moreover, the labels for T3 and T4 are corrected to “B-FAU” (the beginning part of the fault phenomenon sequence) and “I-FAU” (the internal part of the fault phenomenon sequence), with scores of 0.3 and 0.065, respectively.
The introduction of CRF significantly reduces the occurrence of incorrect labels. By considering the probability of transitions between labels, CRF effectively corrects unreasonable labeling that arises from disregarding sequence dependencies based solely on score maximization.
The CRF model is calculated as follows: take the output sequence
of the BiLSTM layer and assume that
is the output score matrix of the BiLSTM layer of size
, where n is the number of words, k is the number of labels, and
denotes the score of the jth label of the ith word. For the prediction sequence
, the score function is shown in Formula (1) [
27].
In the above formula,
represents the transfer fraction matrix,
represents the fraction of label
transferred to label
, and
has a magnitude of k + 2. The probability that the predicted sequence Y produces is shown [
27].
The real labeled sequence is represented in the above formula.
represents all possible annotation sequences. When decoding, use the Viterbi algorithm to find the
with the highest score of all
s, as shown below [
27].
The with the highest score is the globally optimal annotated sequence.
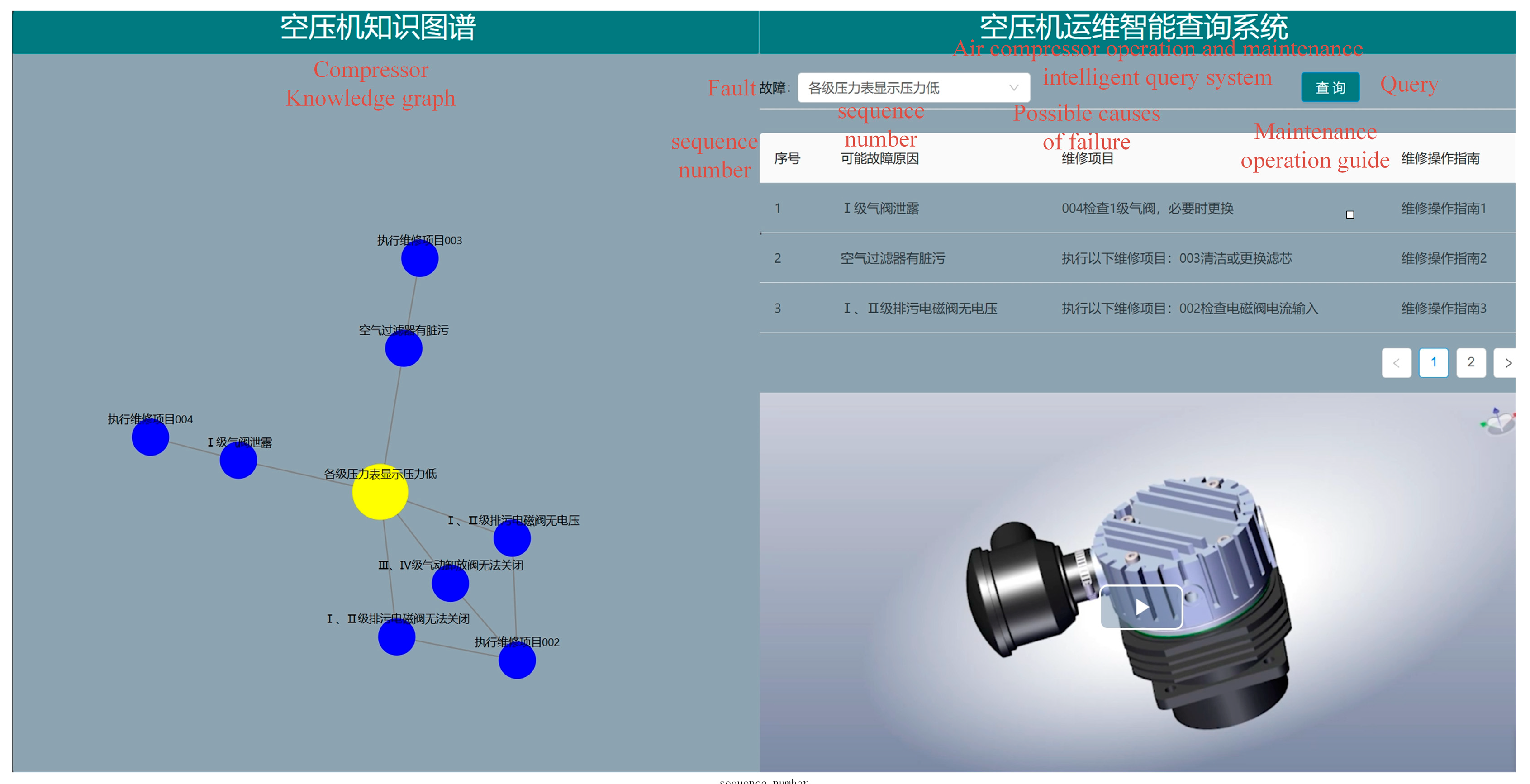
3.4. Knowledge Storage and Visualization
In practical applications, querying and processing knowledge graph data exhibit two notable characteristics. Firstly, queries typically involve a very small subset of triples within the knowledge base. Secondly, these operations often focus on retrieving specific entities and their immediate relationships. Additionally, the operations require numerous joint operations due to the fragmented nature of knowledge graph data representation.
Historically, knowledge graph data were stored as triples in relational databases, which presented challenges such as inefficient querying, scalability issues with large datasets, high I/O overhead during data updates, and costly index maintenance. With the rise of big data, there has been a growing demand for storage technologies capable of efficiently managing massive and complex relational data. Graph databases have emerged as a favored solution due to their ability to handle intricate relationships. They offer several advantages in typical knowledge graph applications:
Graphical Representation: Entities and their relationships are visually represented, enhancing clarity and ease of manipulation.
Scalability: Graph databases can effectively manage large-scale knowledge graphs comprising hundreds of millions of data points.
Efficient Query Execution: They execute relational queries efficiently, minimizing I/O operations and memory consumption compared to traditional relational databases’ join operations.
Support for Algorithms and Visualization: Many graph databases provide built-in algorithms and visualization tools, facilitating deeper analysis and intuitive knowledge of graph displays.
Given these benefits, graph databases have increasingly become the preferred choice for storing the data layer of knowledge graphs. Neo4j, a widely adopted graph database, structures knowledge graphs using nodes and relationships, making it particularly suitable for both storage and visualization in this study.
5. Conclusions
This study presents a method for constructing a knowledge graph specifically for air compressor fault diagnosis. We employ an optimized RoBERTa-BiLSTM-CRF model to identify knowledge entities related to air compressor fault maintenance and fine-tuning model parameters to enhance the quality of the knowledge graph. RoBERTa generates context-rich feature representations, while the CRF and BiLSTM layers optimize the capture of global context and sequence information, respectively. The feature fusion layer integrates the outputs from RoBERTa and BiLSTM, further boosting overall model performance.
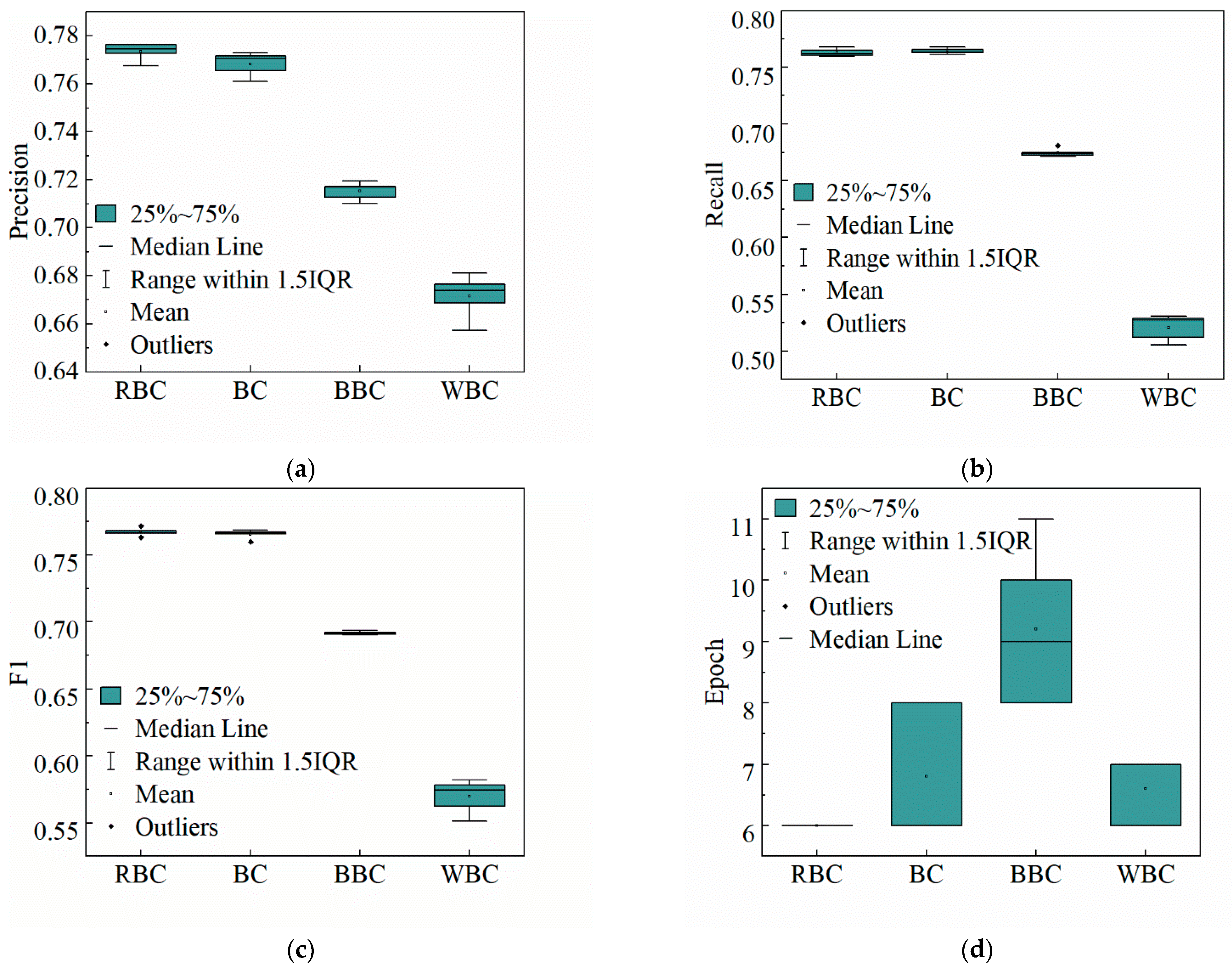
Comparative experiments demonstrate our model’s superiority over the baseline model by Chen et al., achieving higher precision, recall, and F1 scores across various metrics, with the F1 score showing a 5.11% improvement. By addressing challenges like entity nesting and data imbalance in air compressor fault maintenance logs, our model enhances training efficiency and improves the accuracy of fault diagnosis knowledge extraction.
Integrating this knowledge graph can significantly enhance the operational efficiency of air compressor fault diagnosis systems, enabling the visualization and analysis of complex fault relationships. This comprehensive approach surpasses isolated data-driven models in providing a more holistic view of fault diagnosis.
In conclusion, our research not only represents a substantial technological advancement in air compressor fault diagnosis but also introduces novel ideas and methods applicable to fields like natural language processing and intelligent operation and maintenance. This work has the potential to drive significant progress in more complex fields and cross-industry applications in the future. Future work will focus on expanding the graph with more comprehensive data sources and refining entity recognition models to handle diverse inputs effectively.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}