



Learning Pose Dynamical System for Contact Tasks under Human Interaction

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- (1)
- Learning pose state-dependent and time-invariant DS is proposed to achieve fast online planning of trajectory for the contact task;
- (2)
- We provide a contact task skills learning framework for the position-controlled robot to reproduce both the trajectory and the force of the human skills and achieve interaction with the human compliantly during the robot operation.
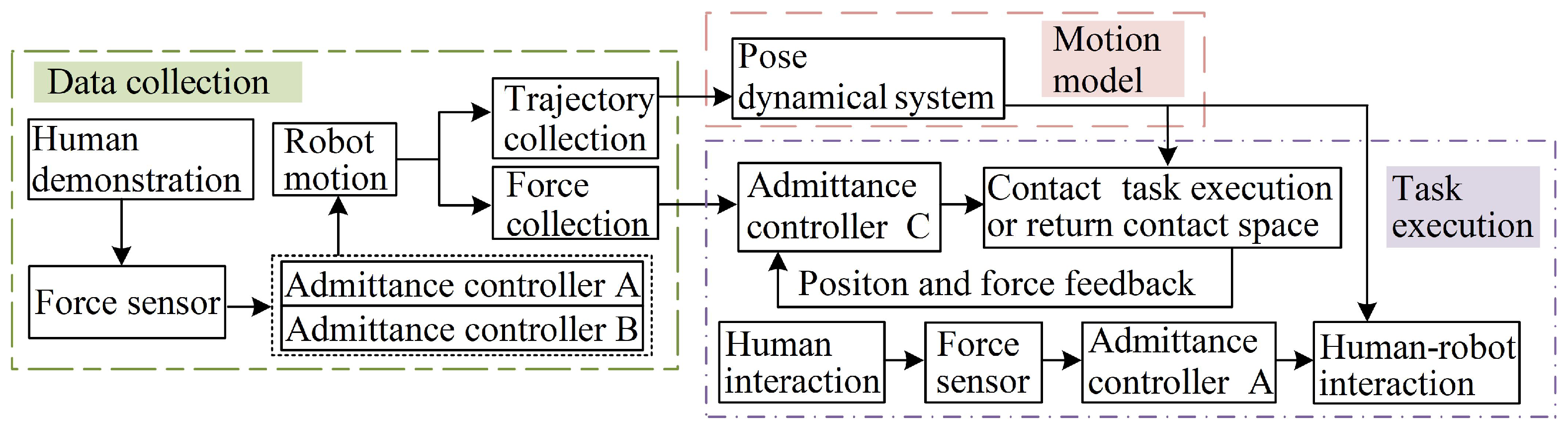
2. Methodology
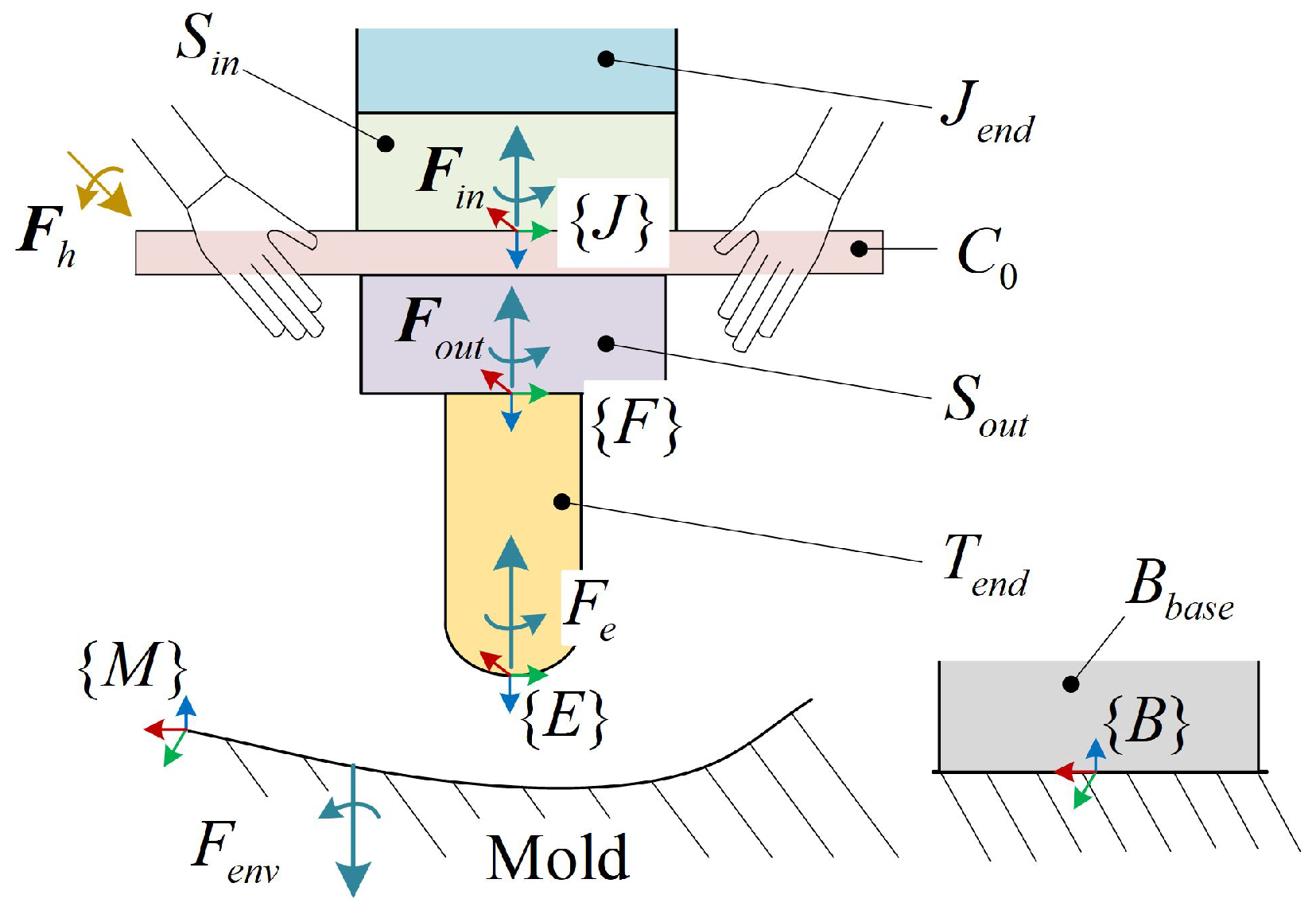
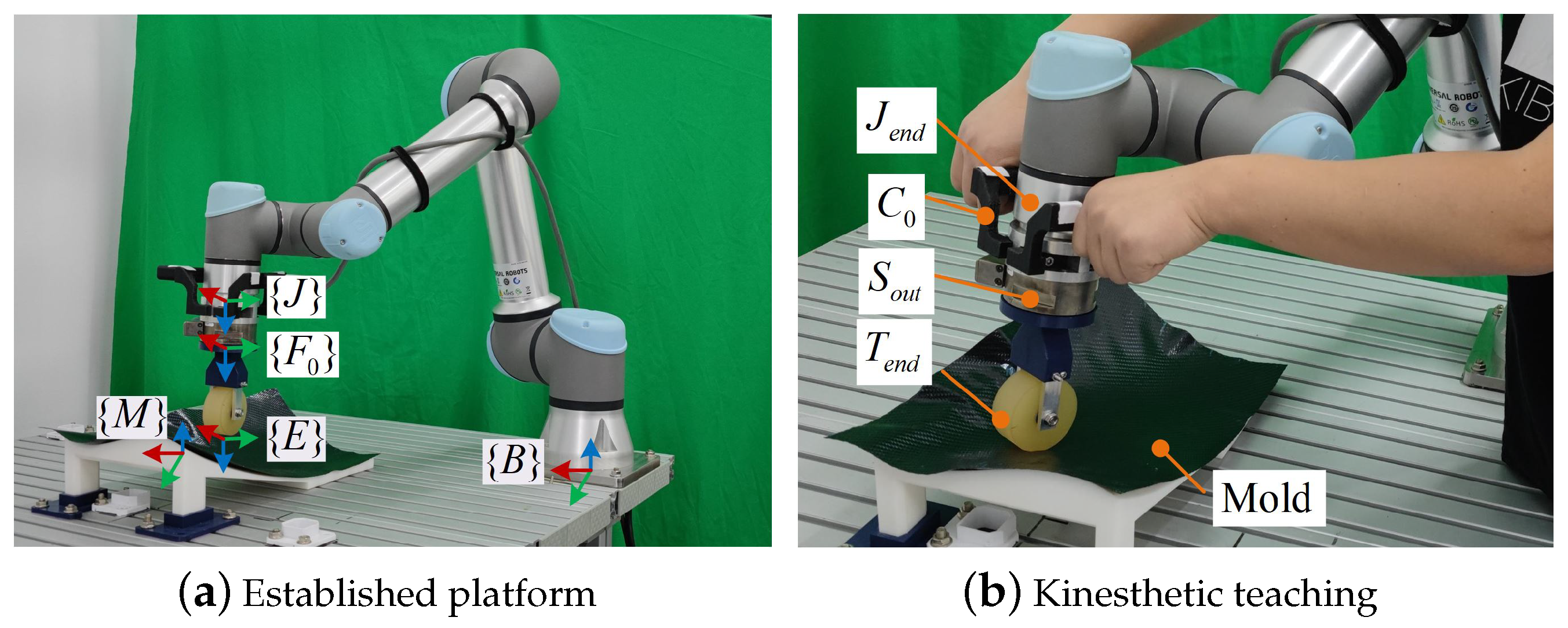
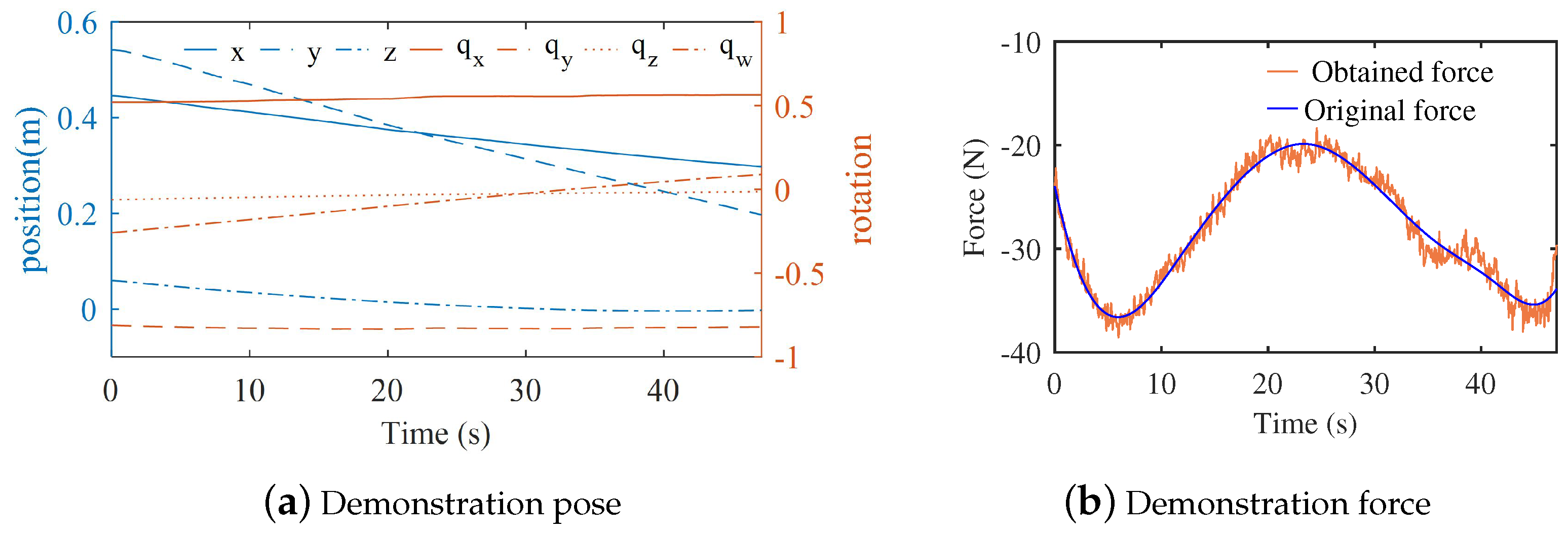
2.1. Human Demonstration
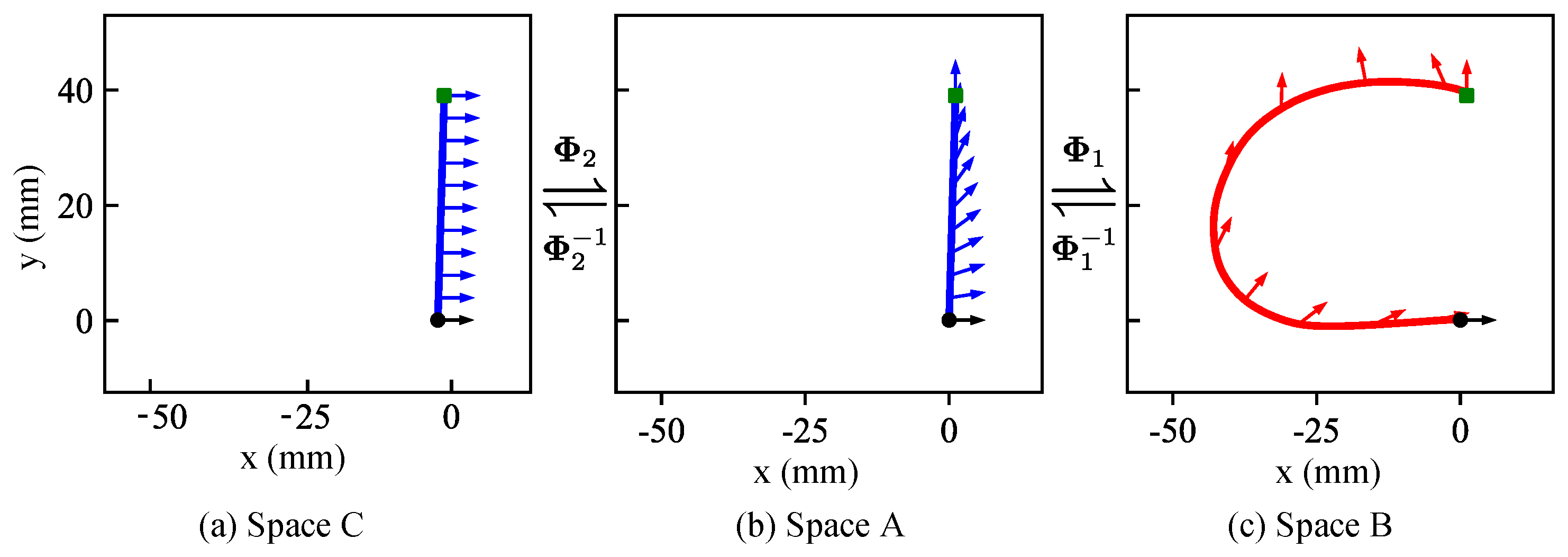
2.2. Pose DS Establishment
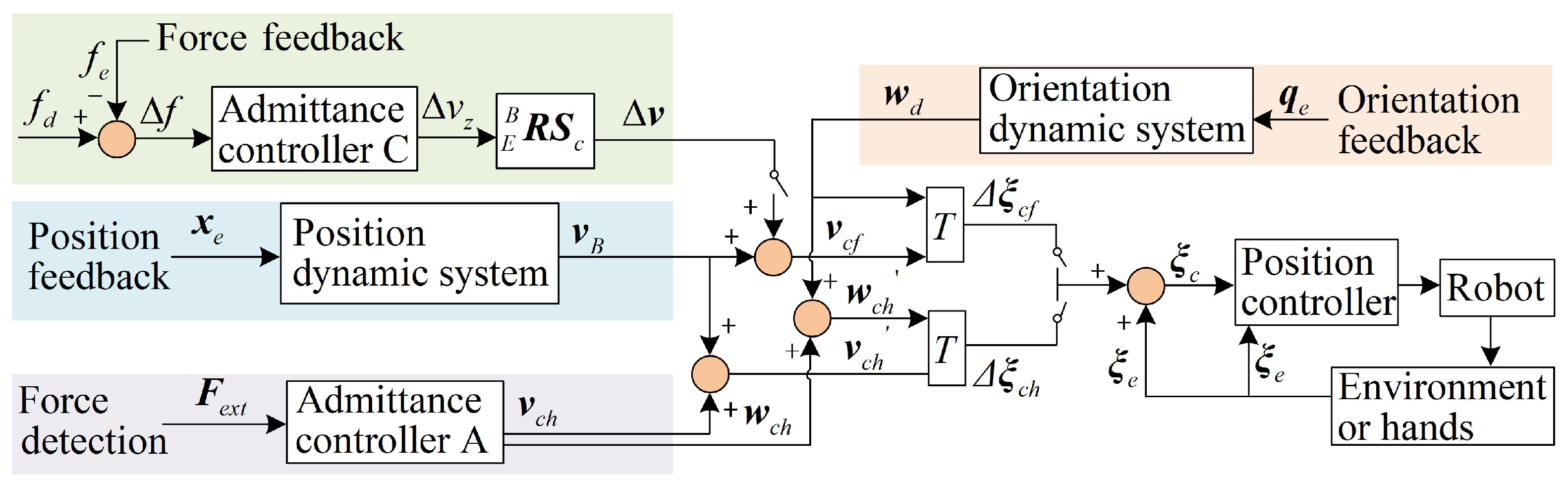
2.3. Motion Controllers for Reproducing
3. Experiment
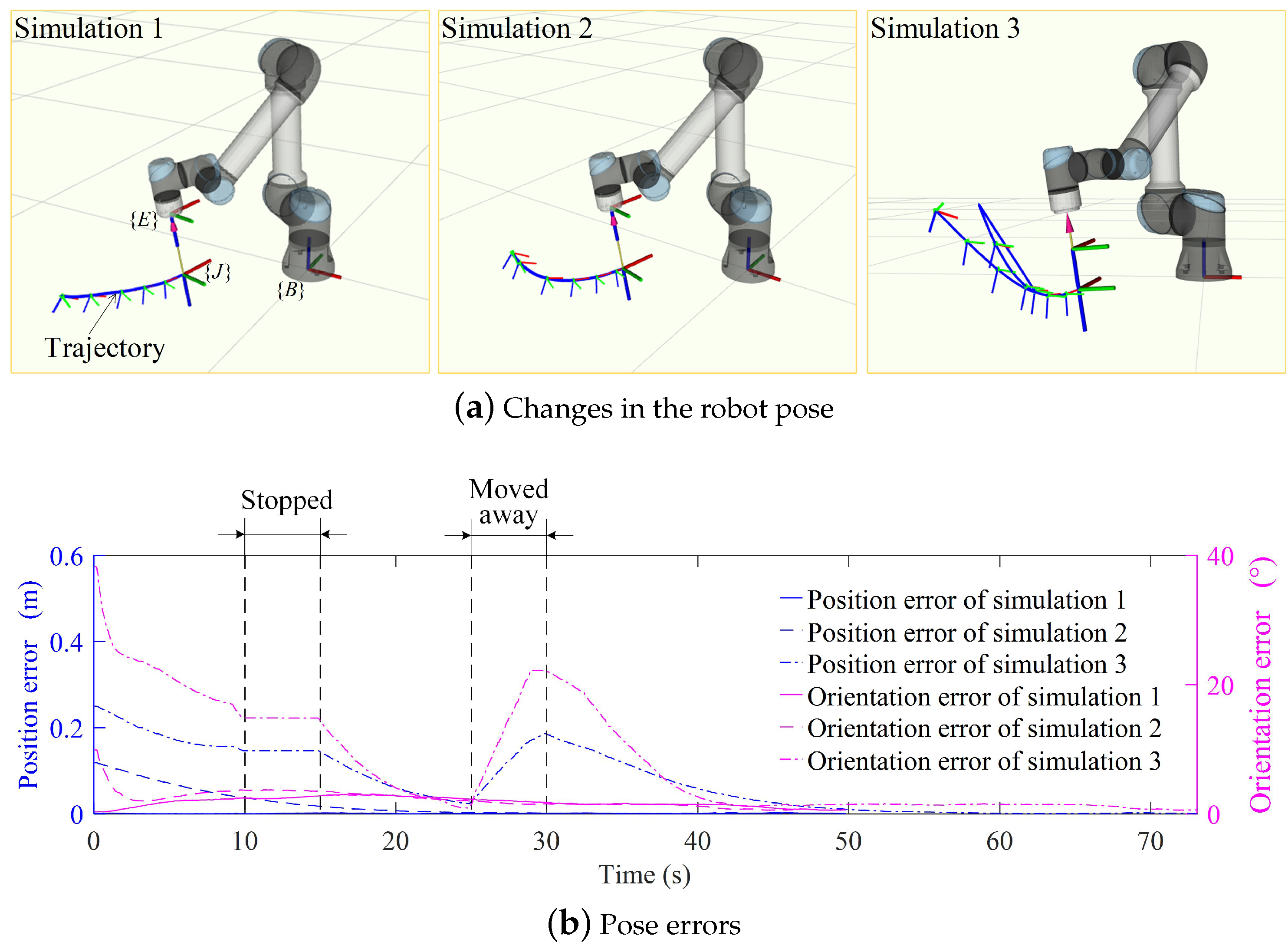
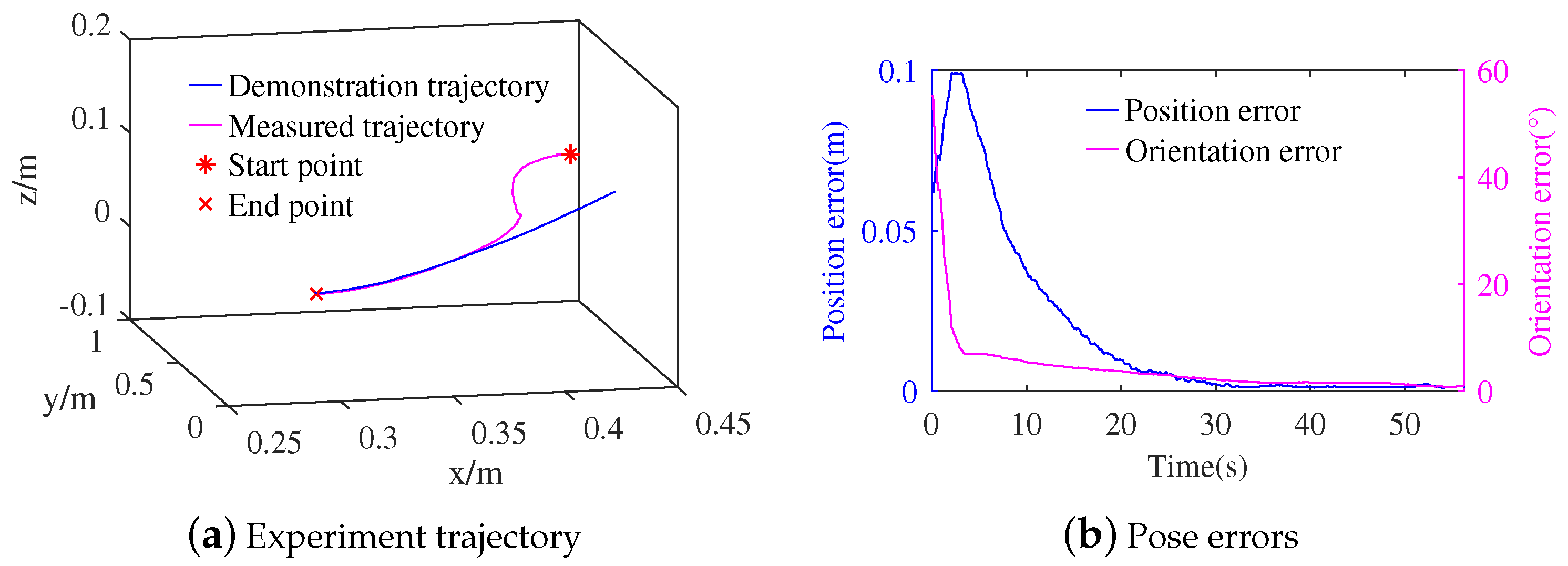
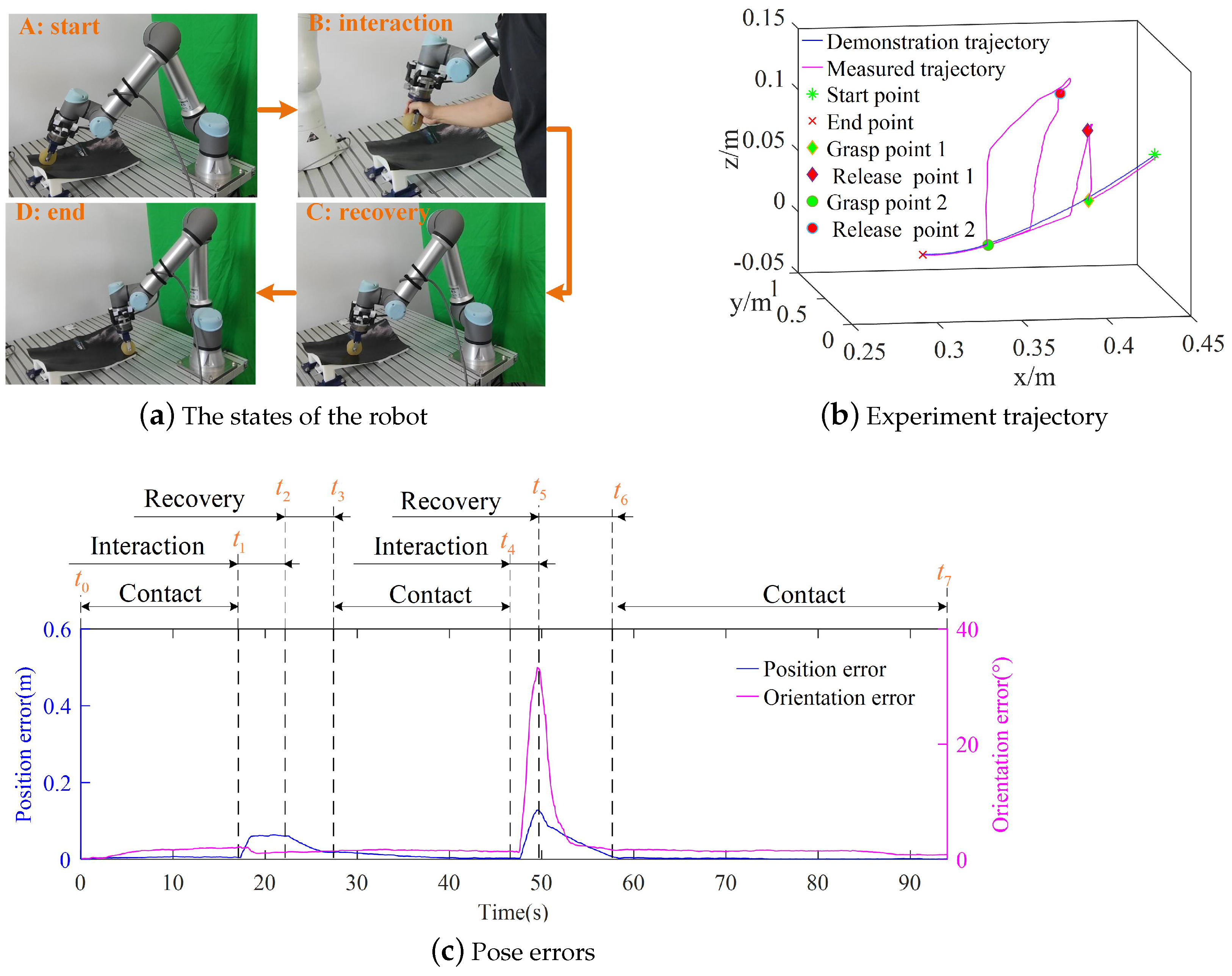
3.1. Contact Task Demonstration and Simulation
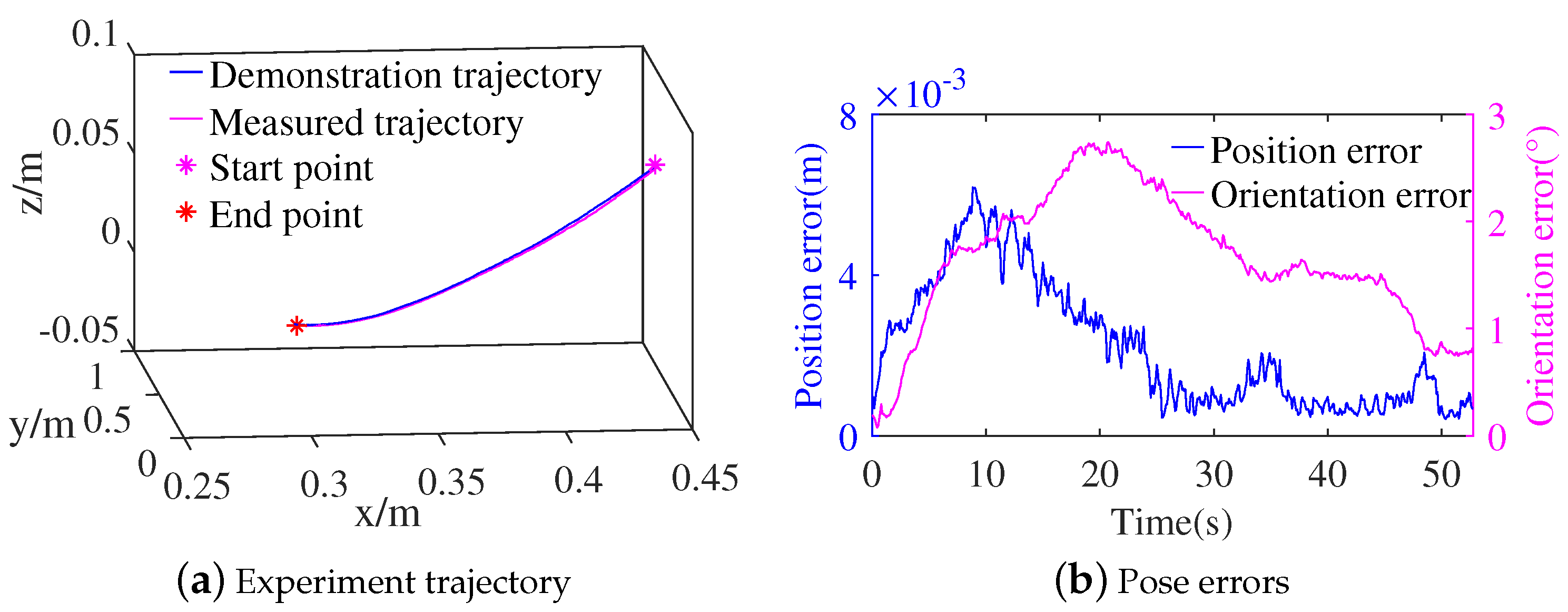
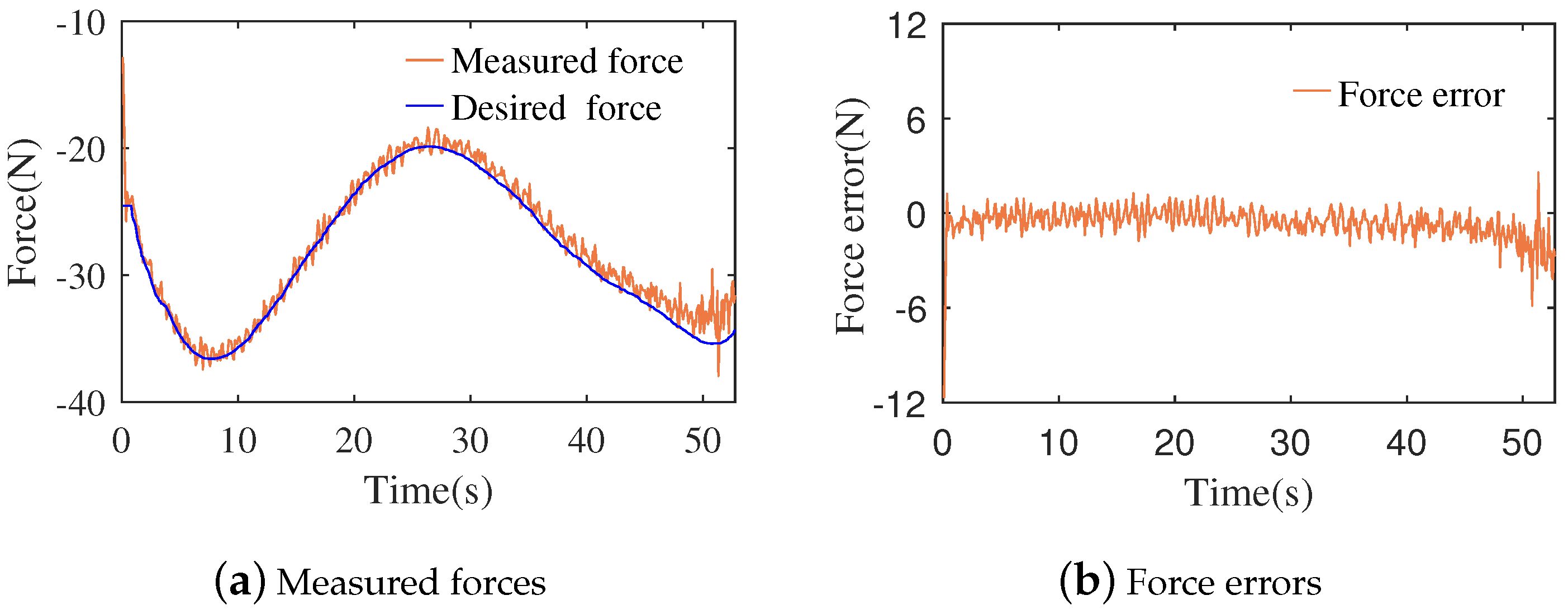
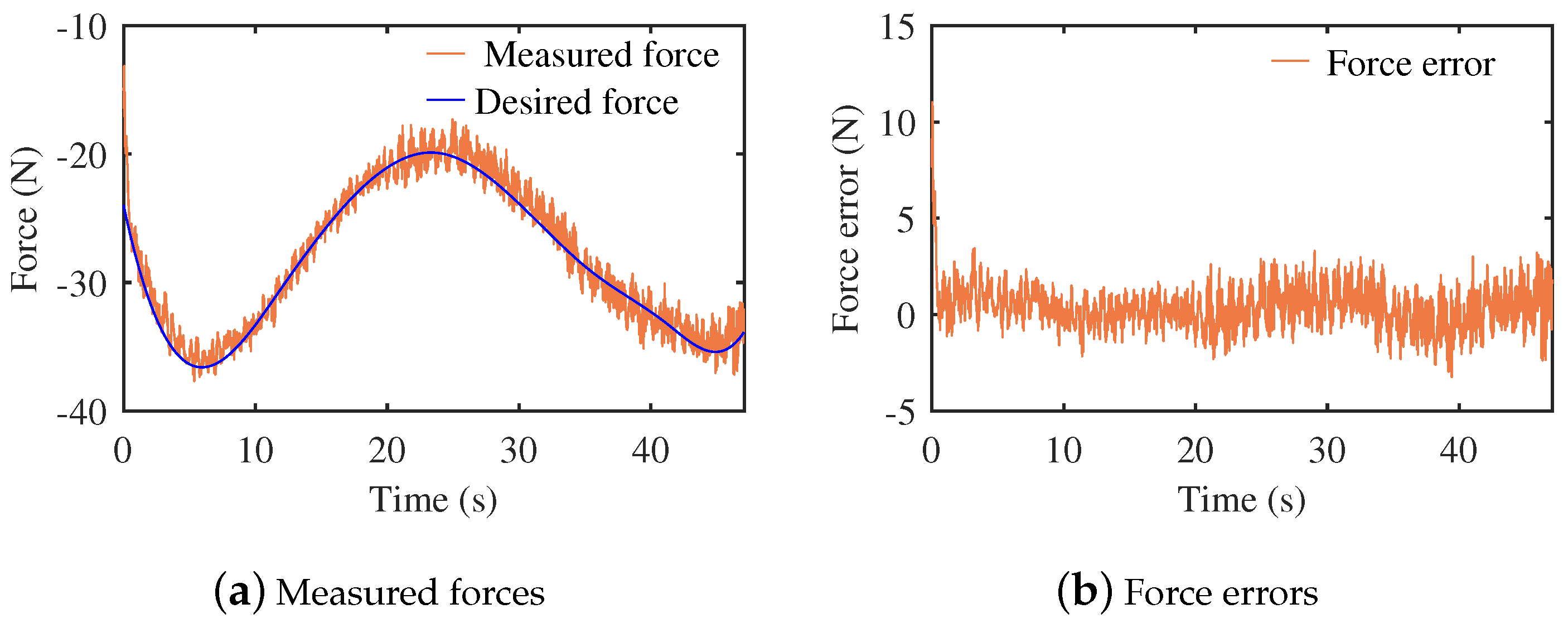
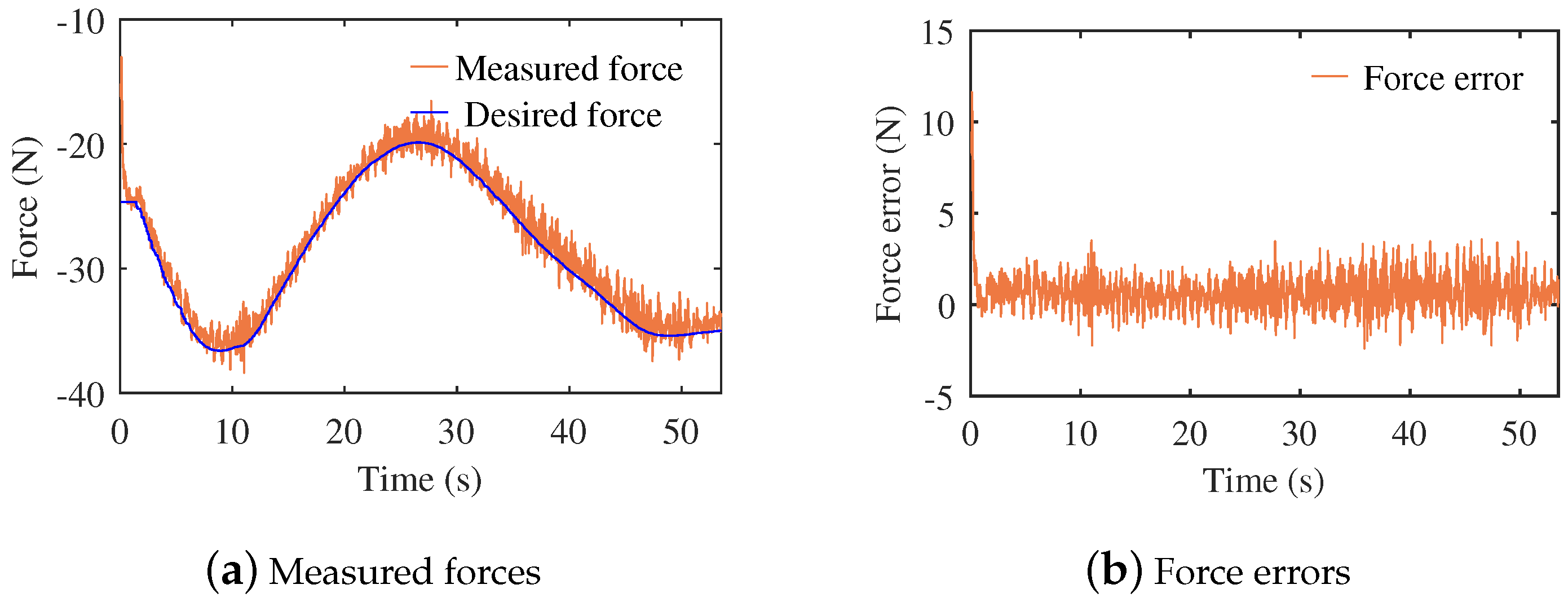
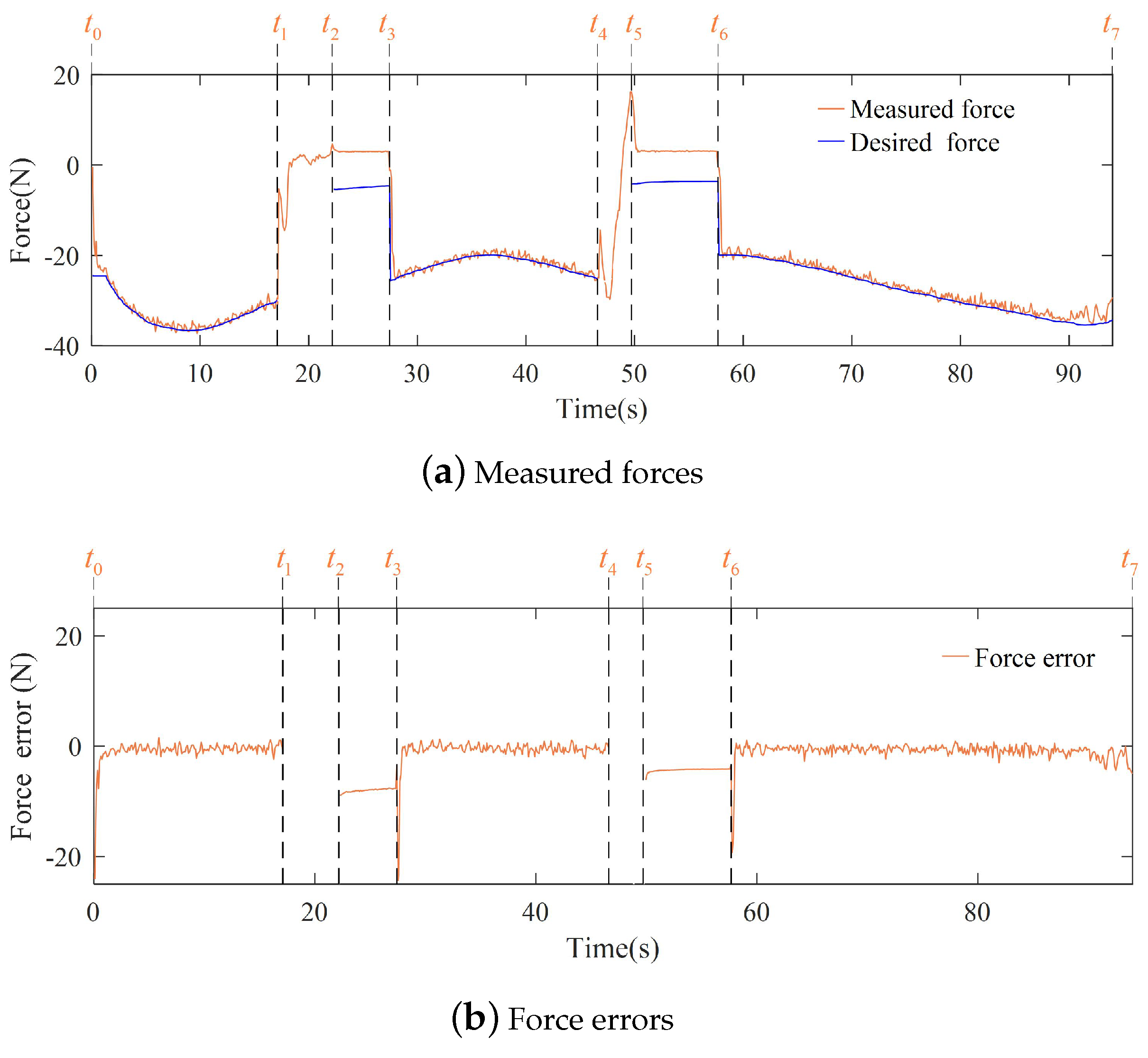
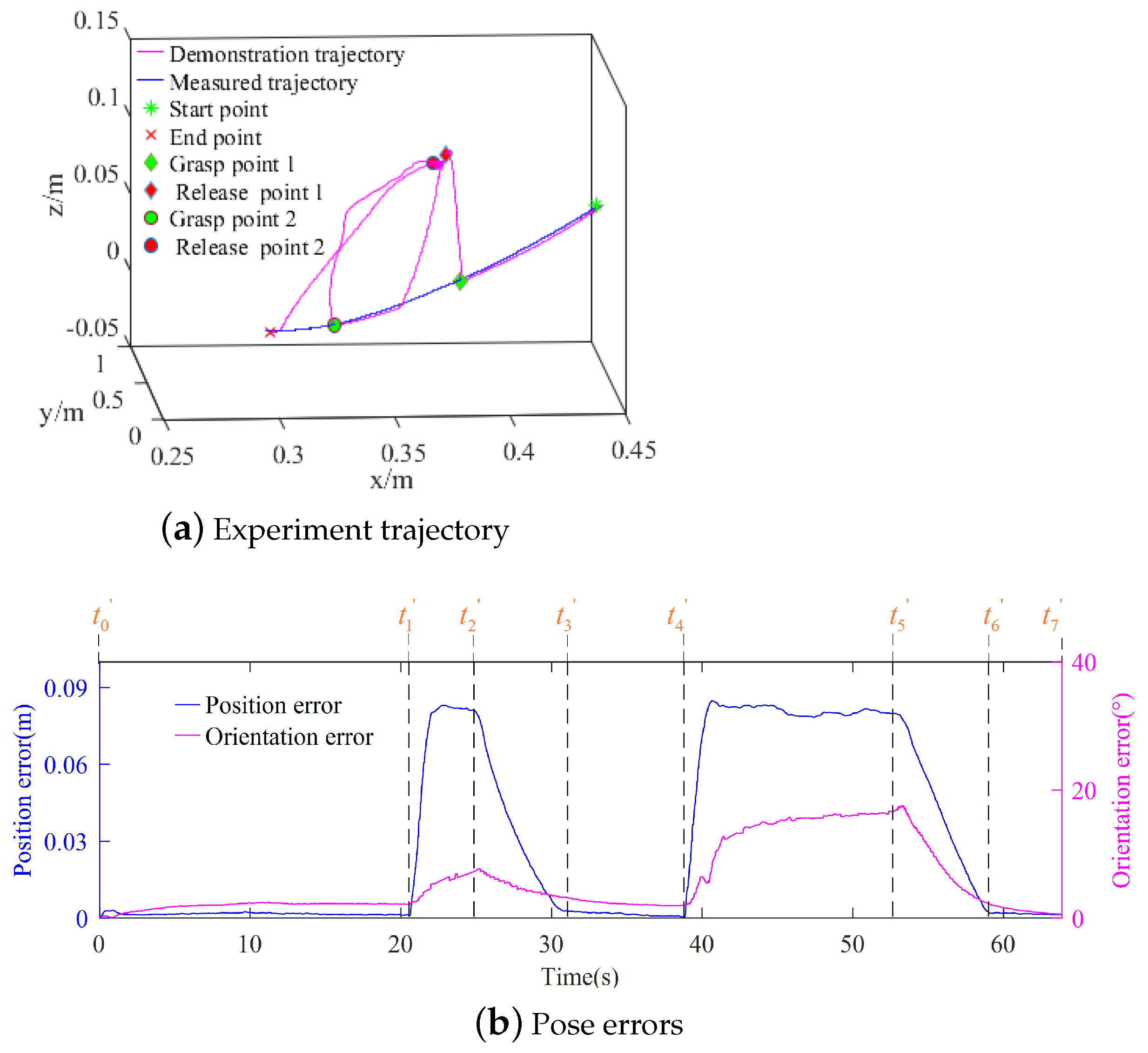
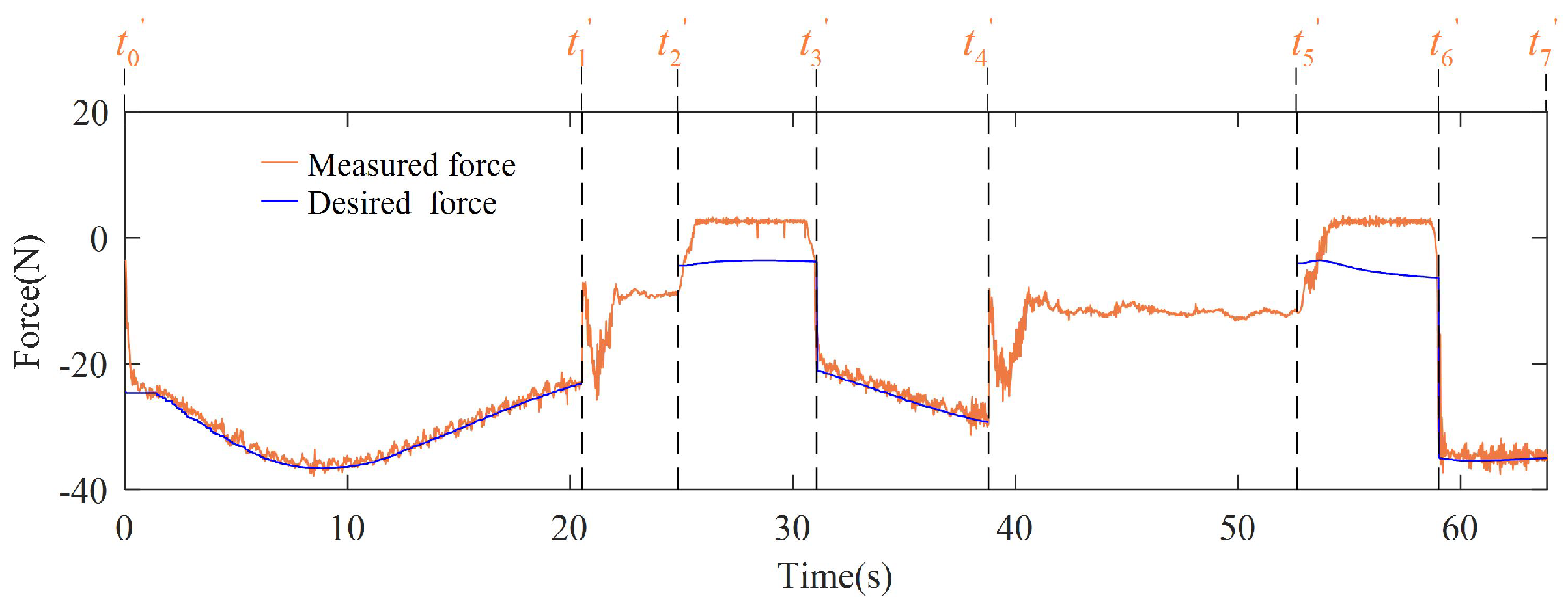
3.2. Experiments of the Contact Task
3.3. Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gao, X.; Ling, J.; Xiao, X.; Li, M. Learning force-relevant skills from human demonstration. Complexity 2019, 2019, 5262859. [Google Scholar] [CrossRef]
- Malhan, R.K.; Shembekar, A.V.; Kabir, A.M.; Bhatt, P.M.; Shah, B.; Zanio, S.; Nutt, S.; Gupta, S.K. Automated planning for robotic layup of composite prepreg. Robot. Comput. Integr. Manuf. 2021, 67, 102020. [Google Scholar] [CrossRef]
- Amanhoud, W.; Khoramshahi, M.; Bonnesoeur, M.; Billard, A. Force adaptation in contact tasks with dynamical systems. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; IEEE: New York, NY, USA, 2020; pp. 6841–6847. [Google Scholar]
- Huang, B.; Ye, M.; Lee, S.L.; Yang, G.Z. A vision-guided multi-robot cooperation framework for learning-by-demonstration and task reproduction. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; IEEE: New York, NY, USA, 2017; pp. 4797–4804. [Google Scholar]
- Kramberger, A. A comparison of learning-by-demonstration methods for force-based robot skills. In Proceedings of the 2014 23rd International Conference on Robotics in Alpe-Adria-Danube Region (RAAD), Smolenice, Slovakia, 3–5 September 2014; IEEE: New York, NY, USA, 2014; pp. 1–6. [Google Scholar]
- Sakr, M.; Freeman, M.; Van der Loos, H.M.; Croft, E. Training human teacher to improve robot learning from demonstration: A pilot study on kinesthetic teaching. In Proceedings of the 2020 29th IEEE International Conference on Robot and Human Interactive Communication (RO-MAN), Naples, Italy, 31 August–4 September 2020; IEEE: New York, NY, USA, 2020; pp. 800–806. [Google Scholar]
- Kramberger, A.; Gams, A.; Nemec, B.; Chrysostomou, D.; Madsen, O.; Ude, A. Generalization of orientation trajectories and force-torque profiles for robotic assembly. Robot. Auton. Syst. 2017, 98, 333–346. [Google Scholar] [CrossRef]
- Koropouli, V.; Lee, D.; Hirche, S. Learning interaction control policies by demonstration. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25–30 September 2011; IEEE: New York, NY, USA, 2011; pp. 344–349. [Google Scholar]
- Montebelli, A.; Steinmetz, F.; Kyrki, V. On handing down our tools to robots: Single-phase kinesthetic teaching for dynamic in-contact tasks. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; IEEE: New York, NY, USA, 2015; pp. 5628–5634. [Google Scholar]
- Luo, R.; Berenson, D. A framework for unsupervised online human reaching motion recognition and early prediction. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–3 October 2015; IEEE: New York, NY, USA, 2015; pp. 2426–2433. [Google Scholar]
- Kulić, D.; Ott, C.; Lee, D.; Ishikawa, J.; Nakamura, Y. Incremental learning of full body motion primitives and their sequencing through human motion observation. Int. J. Robot. Res. 2012, 31, 330–345. [Google Scholar] [CrossRef]
- Ijspeert, A.J.; Nakanishi, J.; Hoffmann, H.; Pastor, P.; Schaal, S. Dynamical movement primitives: Learning attractor models for motor behaviors. Neural Comput. 2013, 25, 328–373. [Google Scholar] [CrossRef]
- Khansari-Zadeh, S.M.; Billard, A. Learning stable nonlinear dynamical systems with gaussian mixture models. IEEE Trans. Robot. 2011, 27, 943–957. [Google Scholar] [CrossRef]
- Paraschos, A.; Daniel, C.; Peters, J.R.; Neumann, G. Probabilistic movement primitives. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–8 December 2013; Curran Associates Inc.: Red Hook, NY, USA, 2013; Volume 2, pp. 2616–2642. [Google Scholar]
- Huang, Y.; Rozo, L.; Silvério, J.; Caldwell, D.G. Kernelized movement primitives. Int. J. Robot. Res. 2019, 38, 833–852. [Google Scholar] [CrossRef]
- Zhou, Y.; Gao, J.; Asfour, T. Learning via-point movement primitives with inter-and extrapolation capabilities. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; IEEE: New York, NY, USA, 2019; pp. 4301–4308. [Google Scholar]
- Neumann, K.; Steil, J.J. Learning robot motions with stable dynamical systems under diffeomorphic transformations. Robot. Auton. Syst. 2015, 70, 1–15. [Google Scholar] [CrossRef]
- Perrin, N.; Schlehuber-Caissier, P. Fast diffeomorphic matching to learn globally asymptotically stable nonlinear dynamical systems. Syst. Control Lett. 2016, 96, 51–59. [Google Scholar] [CrossRef]
- Steinmetz, F.; Montebelli, A.; Kyrki, V. Simultaneous kinesthetic teaching of positional and force requirements for sequential in-contact tasks. In Proceedings of the 2015 IEEE-RAS 15th International Conference on Humanoid Robots (Humanoids), Seoul, Republic of Korea, 3–5 November 2015; IEEE: New York, NY, USA, 2015; pp. 202–209. [Google Scholar]
- Zhang, R.; Hu, Y.; Zhao, K.; Cao, S. A Novel Dual Quaternion Based Dynamic Motion Primitives for Acrobatic Flight. In Proceedings of the 2021 5th International Conference on Robotics and Automation Sciences (ICRAS), Xi’an, China, 30 May–5 June 2021; IEEE: New York, NY, USA, 2021; pp. 165–171. [Google Scholar]
- Gao, X.; Li, M.; Xiao, X. Learning Dynamical System for Grasping Motion. arXiv 2021, arXiv:2108.06728. [Google Scholar]
- Pedersen, M.R.; Nalpantidis, L.; Andersen, R.S.; Schou, C.; Bøgh, S.; Krüger, V.; Madsen, O. Robot skills for manufacturing: From concept to industrial deployment. Robot. Comput. Integr. Manuf. 2016, 37, 282–291. [Google Scholar] [CrossRef]
- Steinmetz, F.; Nitsch, V.; Stulp, F. Intuitive task-level programming by demonstration through semantic skill recognition. IEEE Robot. Autom. Lett. 2019, 4, 3742–3749. [Google Scholar] [CrossRef]
- Abdo, N.; Kretzschmar, H.; Stachniss, C. From low-level trajectory demonstrations to symbolic actions for planning. In ICAPS Workshop on Combining Task and Motion Planning for Real-World App; Citeseer: State College, PA, USA, 2012; pp. 29–36. [Google Scholar]
- Si, W.; Wang, N.; Li, Q.; Yang, C. A Framework for Composite Layup Skill Learning and Generalizing Through Teleoperation. Front. Neurorobot. 2022, 16, 840240. [Google Scholar] [CrossRef]
- Han, L.; Kang, P.; Chen, Y.; Xu, W.; Li, B. Trajectory optimization and force control with modified dynamic movement primitives under curved surface constraints. In Proceedings of the 2019 IEEE International Conference on Robotics and Biomimetics (ROBIO), Dali, China, 6–8 December 2019; IEEE: New York, NY, USA, 2019; pp. 1065–1070. [Google Scholar]
- Wang, Y.; Beltran-Hernandez, C.C.; Wan, W.; Harada, K. An Adaptive Imitation Learning Framework for Robotic Complex Contact-Rich Insertion Tasks. Front. Robot. AI 2022, 8, 414. [Google Scholar] [CrossRef]
- Wang, N.; Chen, C.; Di Nuovo, A. A framework of hybrid force/motion skills learning for robots. IEEE Trans. Cogn. Dev. Syst. 2020, 13, 162–170. [Google Scholar] [CrossRef]
- Shahriari, E.; Kramberger, A.; Gams, A.; Ude, A.; Haddadin, S. Adapting to contacts: Energy tanks and task energy for passivity-based dynamic movement primitives. In Proceedings of the 2017 IEEE-RAS 17th International Conference on Humanoid Robotics (Humanoids), Birmingham, UK, 15–17 November 2017; IEEE: New York, NY, USA, 2017; pp. 136–142. [Google Scholar]
- Kramberger, A.; Shahriari, E.; Gams, A.; Nemec, B.; Ude, A.; Haddadin, S. Passivity based iterative learning of admittance-coupled dynamic movement primitives for interaction with changing environments. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; IEEE: New York, NY, USA, 2018; pp. 6023–6028. [Google Scholar]
- Gao, J.; Zhou, Y.; Asfour, T. Learning compliance adaptation in contact-rich manipulation. arXiv 2020, arXiv:2005.00227. [Google Scholar]
- Amanhoud, W.; Khoramshahi, M.; Billard, A. A dynamical system approach to motion and force generation in contact tasks. Robot. Sci. Syst. RSS 2019. [Google Scholar] [CrossRef]
- Duan, J.; Gan, Y.; Chen, M.; Dai, X. Adaptive variable impedance control for dynamic contact force tracking in uncertain environment. Robot. Auton. Syst. 2018, 102, 54–65. [Google Scholar] [CrossRef]
- Sola, J. Quaternion kinematics for the error-state Kalman filter. arXiv 2017, arXiv:1711.02508. [Google Scholar]
- Gao, X.; Silvério, J.; Pignat, E.; Calinon, S.; Li, M.; Xiao, X. Motion mappings for continuous bilateral teleoperation. IEEE Robot. Autom. Lett. 2021, 6, 5048–5055. [Google Scholar] [CrossRef]
- Park, D.H.; Hoffmann, H.; Pastor, P.; Schaal, S. Movement reproduction and obstacle avoidance with dynamic movement primitives and potential fields. In Proceedings of the Humanoids 2008-8th IEEE-RAS International Conference on Humanoid Robots, Daejeon, Republic of Korea, 1–3 December 2008; IEEE: New York, NY, USA, 2008; pp. 91–98. [Google Scholar]
- Deng, X.; Chen, Y.; Chen, F.; Li, M. Learning robotic ultrasound scanning skills via human demonstrations and guided explorations. In Proceedings of the 2021 IEEE International Conference on Robotics and Biomimetics (ROBIO), Sanya, China, 6–9 December 2021; IEEE: New York, NY, USA, 2021; pp. 372–378. [Google Scholar]
- Li, C.; Fahmy, A.; Li, S.; Sienz, J. An enhanced robot massage system in smart homes using force sensing and a dynamic movement primitive. Front. Neurorobot. 2020, 14, 30. [Google Scholar] [CrossRef] [PubMed]

















Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, S.; Gao, X.; Feng, Z.; Xiao, X. Learning Pose Dynamical System for Contact Tasks under Human Interaction. Actuators 2023, 12, 179. https://doi.org/10.3390/act12040179
Yang S, Gao X, Feng Z, Xiao X. Learning Pose Dynamical System for Contact Tasks under Human Interaction. Actuators. 2023; 12(4):179. https://doi.org/10.3390/act12040179
Chicago/Turabian StyleYang, Shangshang, Xiao Gao, Zhao Feng, and Xiaohui Xiao. 2023. "Learning Pose Dynamical System for Contact Tasks under Human Interaction" Actuators 12, no. 4: 179. https://doi.org/10.3390/act12040179
APA StyleYang, S., Gao, X., Feng, Z., & Xiao, X. (2023). Learning Pose Dynamical System for Contact Tasks under Human Interaction. Actuators, 12(4), 179. https://doi.org/10.3390/act12040179