
Adaptive Gait Generation for Hexapod Robots Based on Reinforcement Learning and Hierarchical Framework

Abstract
:1. Introduction
2. Robot Prototype and Hierarchical Framework
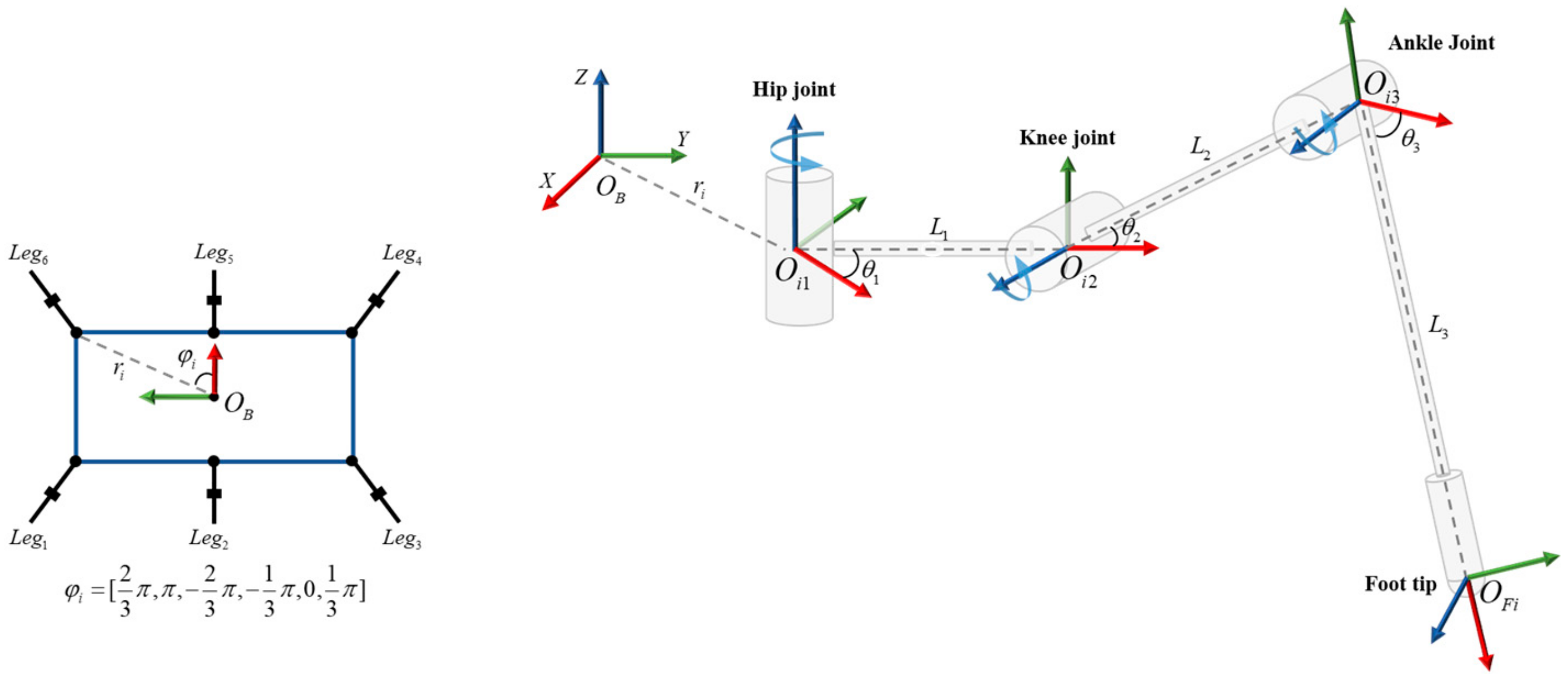
2.1. Hexapod Robot
2.2. Reinforcement Learning and Hierarchical Framework
- (a)
- Gait policy network
- (b)
- Gait modular
- (c)
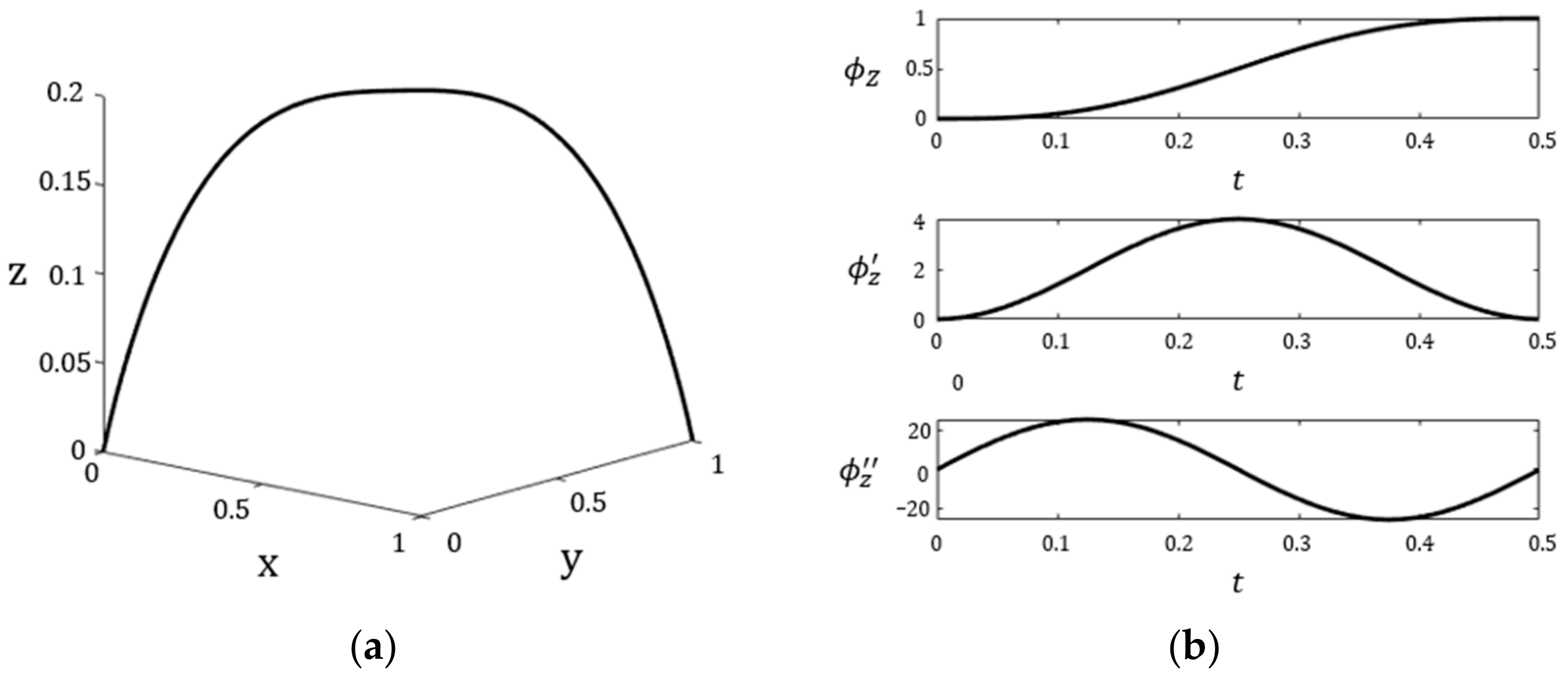
- Trajectory planner
- (d)
- Inverse Kinematics solver
- (e)
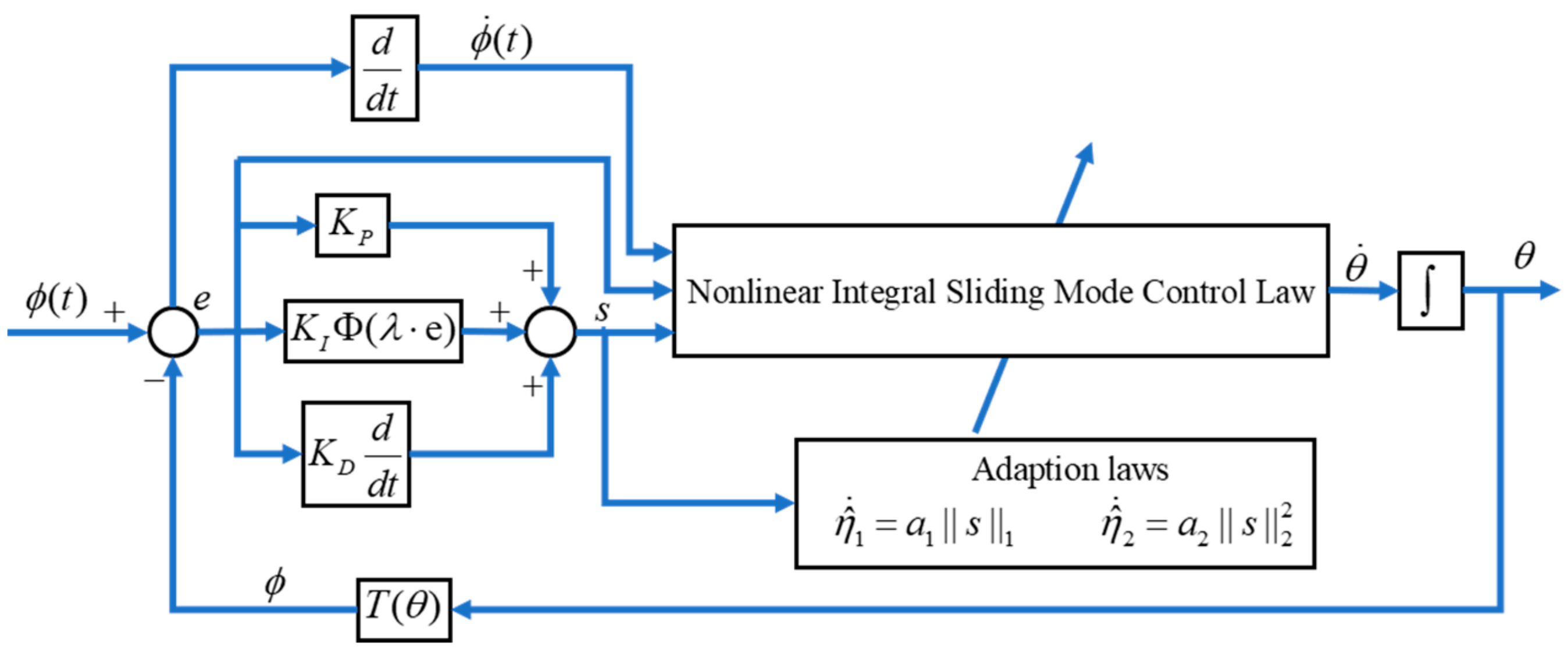
- Trajectory Tracking Controller
3. Learning Process
3.1. Markov Decision Process
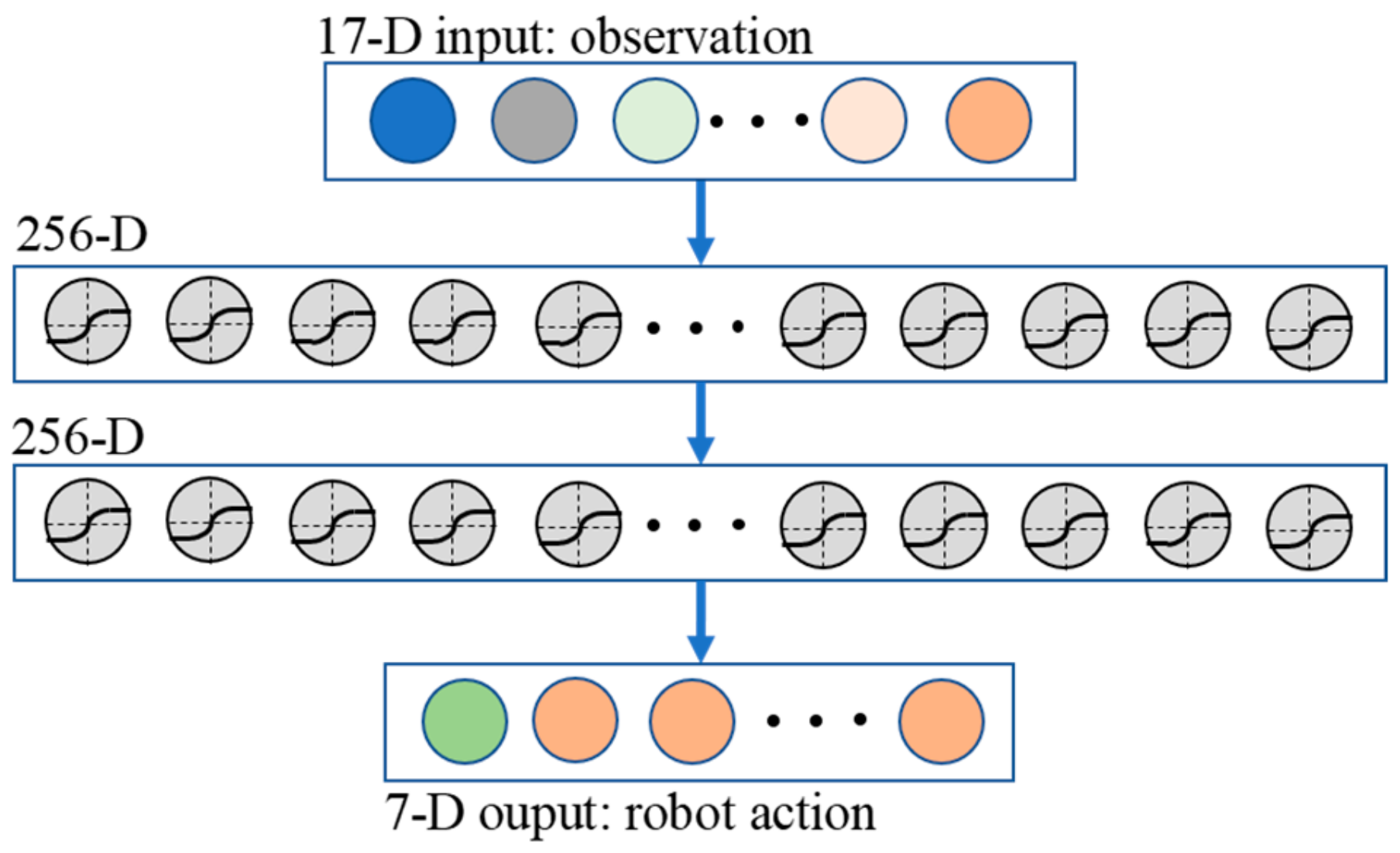
3.2. Action
- Gait duty factor (1D);
- Phase difference (5D);
- Step length s (1D).
3.3. Observation
- Current velocity of the VkHex (3D);
- Current angular velocity of the VkHex (3D);
- Body platform height H (1D);
- Last moment action (7D);
- Target velocity of the VkHex (3D).
3.4. Reward Function
- (i)
- In our study, the gait stability reward is the primary reward. The new generated gaits must be stable enough. Only when the hexapod robot reaches the target position without falling can it receive a positive reward. The functional expression of this reward is as follows:
- (ii)
- The learning task is that the hexapod robot can track speed commands and generate new RL-based gaits. The velocity tracking penalty forces the agent to move at the desired velocity:
- (iii)
- The energy consumption penalty is the penalty for gait motion efficiency and energy consumption. We used the cost of transportation (CoT) [35] as the penalty index. The expression is:
- (iv)
- The joint tracking penalty is the penalty for the joint tracking error, which aims to improve the joint tracking control accuracy under the premise of stable motion:
- (v)
- The roll and pitch penalty penalizes the roll-pitch-yaw angle of the body, which can further improve the stability of RL-based gait:
3.5. Termination Condition
- The robot is involved in a self-collision.
- The pitch or roll degree of the base exceeds the allowable range.
- The base height is less than the set threshold.
- Any link except the foot-tip collides with the ground.
3.6. Policy Training
| Algorithm 1: Soft Actor-Critic | |
| 1 | Initialize policy parameters , replay buffer , Soft Q-function parameters , Soft value function V parameters and Target critic function V′ parameters . |
| 2 | for iteration = 1, M do: |
| 3 | for environment step = 1, N-1 do: |
| 4 | |
| 5 | |
| 6 | |
| 7 | end |
| 8 | for gradient step = 1, T-1 do: |
| 9 | Update V via minimizing the squared residual error: |
| 10 | Update Q and Q′ via minimizing the soft Bellman residual: for |
| 11 | Update : |
| 12 | Update V′: |
| 13 | end |
| 14 | end |
4. Experiments and Results
4.1. Implementation Details
- (i)
- (ii)
- (iii)
- External disturbance: Applying random disturbance force has been shown to be effective in achieving sim-to-real transfer and virtual load simulation [17]. During training, the external force was applied to the body from a random direction for every certain number of steps. The disturbance force was generated randomly within and lasted for 0.5 s.
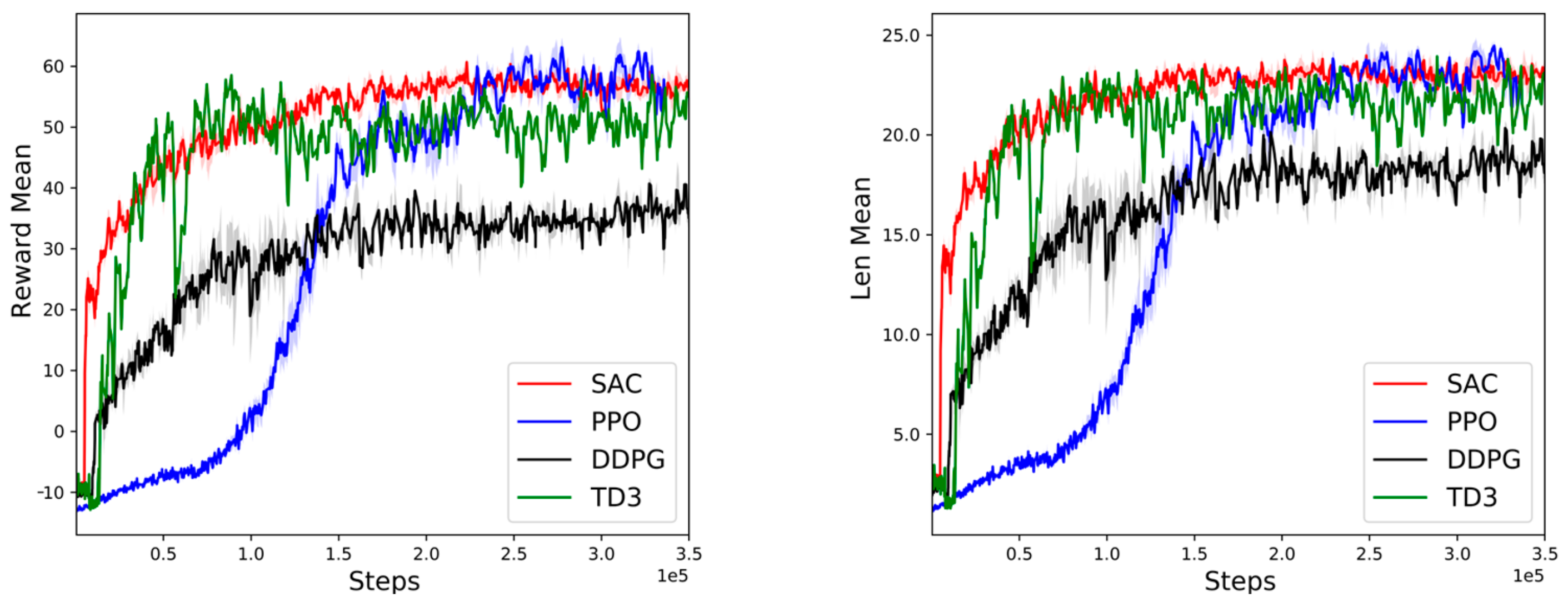
4.2. Training Result
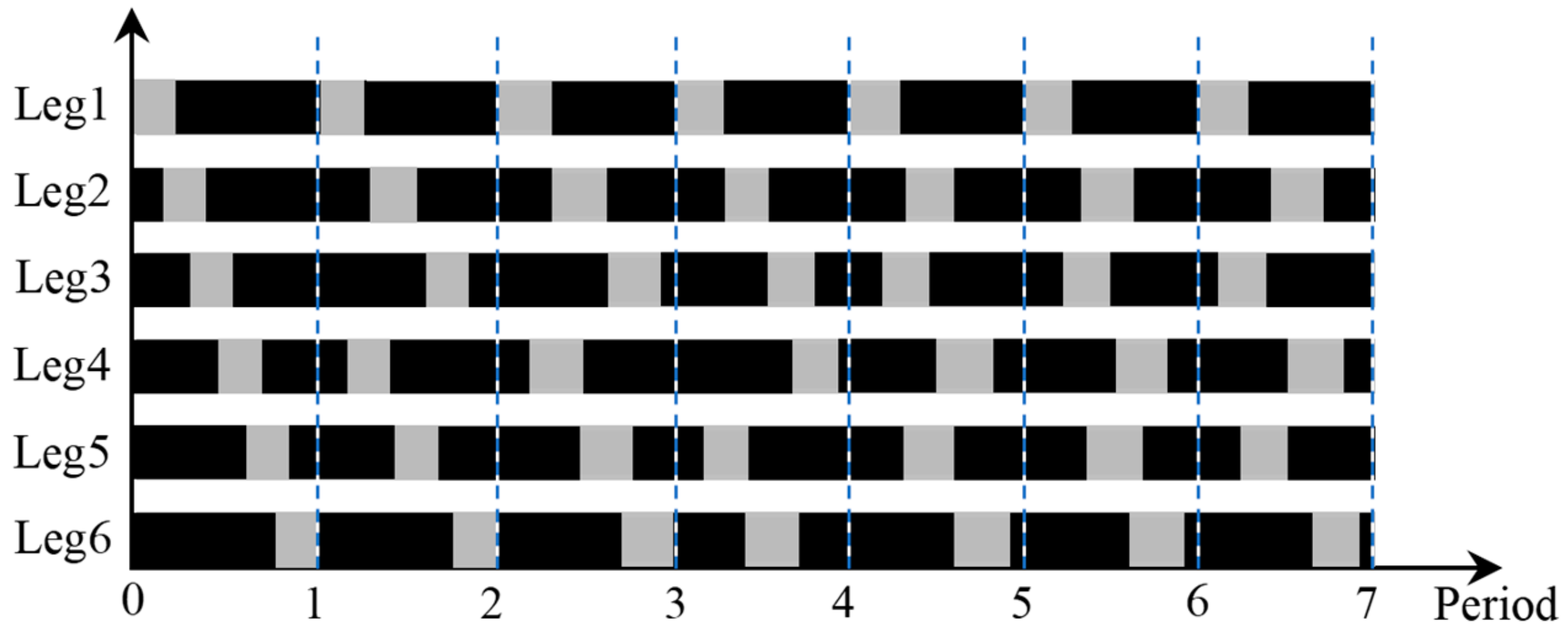
4.3. Motion Verification
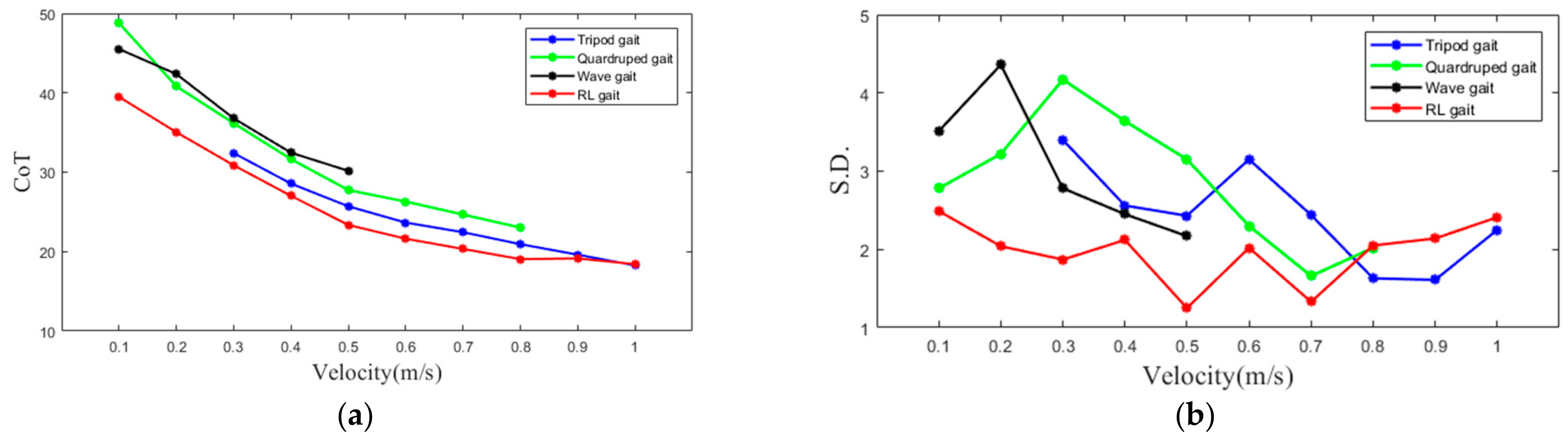
4.4. Motion Efficiency Comparison
4.5. Sim-to-Real
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Azayev, T.; Zimmerman, K. Blind hexapod locomotion in complex terrain with gait adaptation using deep reinforcement learning and classification. J. Intell. Robot. Syst. 2020, 99, 659–671. [Google Scholar] [CrossRef]
- Chen, Z.; Wang, S.; Wang, J.; Xu, K.; Lei, T.; Zhang, H.; Wang, X.; Liu, D.; Si, J. Control strategy of stable walking for a hexapod wheel-legged robot. ISA Trans. 2021, 108, 367–380. [Google Scholar] [CrossRef] [PubMed]
- Gao, Y.; Wei, W.; Wang, X.; Li, Y.; Wang, D.; Yu, Q. Feasibility, planning and control of ground-wall transition for a suctorial hexapod robot. Appl. Intell. 2021, 51, 5506–5524. [Google Scholar] [CrossRef]
- Sun, Q.; Gao, F.; Chen, X. Towards dynamic alternating tripod trotting of a pony-sized hexapod robot for disaster rescuing based on multi-modal impedance control. Robotica 2018, 36, 1048–1076. [Google Scholar] [CrossRef]
- Melenbrink, N.; Werfel, J.; Menges, A. On-site autonomous construction robots: Towards unsupervised building. Autom. Constr. 2020, 119, 103312. [Google Scholar] [CrossRef]
- Teixeira Vivaldini, K.C.; Franco Barbosa, G.; Santos, I.A.D.; Kim, P.H.C.; McMichael, G.; Guerra-Zubiaga, D.A. An intelligent hexapod robot for inspection of airframe components oriented by deep learning technique. J. Braz. Soc. Mech. Sci. Eng. 2021, 43, 494. [Google Scholar] [CrossRef]
- Deepa, T.; Angalaeswari, S.; Subbulekshmi, D.; Krithiga, S.; Sujeeth, S.; Kathiravan, R. Design and implementation of bio inspired hexapod for exploration applications. Mater. Today Proc. 2021, 37, 1603–1607. [Google Scholar] [CrossRef]
- Coelho, J.; Ribeiro, F.; Dias, B.; Lopes, G.; Flores, P. Trends in the Control of Hexapod Robots: A survey. Robotics 2021, 10, 100. [Google Scholar] [CrossRef]
- Schilling, M.; Konen, K.; Ohl, F.W.; Korthals, T. Decentralized deep reinforcement learning for a distributed and adaptive locomotion controller of a hexapod robot. In Proceedings of the IROS 2020-International Conference on Intelligent Robots and Systems, Las Vegas, NV, USA, 25–29 October 2020; pp. 5335–5342. [Google Scholar] [CrossRef]
- Flores, P. Modeling and Simulation of Frictional Contacts in Multi-rigid-Body Systems. In International Symposium on Multibody Systems and Mechatronics; Springer: Cham, Switzerland, 2021; pp. 77–84. [Google Scholar] [CrossRef]
- Gao, Y.; Wei, W.; Wang, X.; Wang, D.; Li, Y.; Yu, Q. Trajectory Tracking of Multi-Legged Robot Based on Model Predictive and Sliding Mode Control. Inf. Sci. 2022, 606, 489–511. [Google Scholar] [CrossRef]
- Cai, Z.; Gao, Y.; Wei, W.; Gao, T.; Xie, Z. Model design and gait planning of hexapod climbing robot. J. Phys. Conf. Ser. IOP Publ. 2021, 1754, 012157. [Google Scholar] [CrossRef]
- Ijspeert, A.J. Central pattern generators for locomotion control in animals and robots: A review. Neural Netw. 2008, 21, 642–653. [Google Scholar] [CrossRef] [PubMed]
- Fuchs, E.; Holmes, P.; Kiemel, T.; Ayali, A. Intersegmental coordination of cockroach locomotion: Adaptive control of centrally coupled pattern generator circuits. Front. Neural Circuits 2011, 4, 125. [Google Scholar] [CrossRef] [PubMed]
- Knüsel, J.; Crespi, A.; Cabelguen, J.M.; Lispeert, A.J.; Ryczko, D. Reproducing five motor behaviors in a salamander robot with virtual muscles and a distributed CPG controller regulated by drive signals and proprioceptive feedback. Front. Neurorobot. 2020, 14, 604426. [Google Scholar] [CrossRef] [PubMed]
- Schilling, M.; Melnik, A. An approach to hierarchical deep reinforcement learning for a decentralized walking control architecture. Biol. Inspired Cogn. Archit. Meet. 2018, 848, 272–282. [Google Scholar] [CrossRef]
- Schilling, M.; Hoinville, T.; Schmitz, J.; Cruse, H. Walknet, a bio-inspired controller for hexapod walking. Biol. Cybern. 2013, 107, 397–419. [Google Scholar] [CrossRef]
- Lee, J.; Hwangbo, J.; Wellhausen, L.; Koltun, V.; Hutter, M. Learning quadrupedal locomotion over challenging terrain. Sci. Robot. 2020, 5, eabc5986. [Google Scholar] [CrossRef]
- Peng, X.B.; Berseth, G.; Yin, K.K.; Panne, M.V.D. Deeploco: Dynamic locomotion skills using hierarchical deep reinforcement learning. ACM Trans. Graph. 2017, 36, 1–13. [Google Scholar] [CrossRef]
- Tan, J.; Zhang, T.; Coumans, E.; Iscen, A.; Bai, Y.; Hafner, D.; Bohez, S.; Vanhoucke, V. Sim-to-real: Learning agile locomotion for quadruped robots. arXiv 2018. [Google Scholar] [CrossRef]
- Tsounis, V.; Alge, M.; Lee, J.; Farshidian, F.; Hutter, M. Deepgait: Planning and control of quadrupedal gaits using deep reinforcement learning. IEEE Robot. Autom. Lett. 2020, 5, 3699–3706. [Google Scholar] [CrossRef]
- Fu, H.; Tang, K.; Li, P.; Zhang, W.; Wang, X.; Deng, G.; Wang, T.; Chen, C. Deep Reinforcement Learning for Multi-contact Motion Planning of Hexapod Robots. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 21 August 2021; pp. 2381–2388. [Google Scholar] [CrossRef]
- Thor, M.; Manoonpong, P. Versatile modular neural locomotion control with fast learning. Nat. Mach. Intell. 2022, 4, 169–179. [Google Scholar] [CrossRef]
- Miki, T.; Lee, J.; Hwangbo, J.; Wellhausen, L.; Koltun, V.; Hutter, M. Learning robust perceptive locomotion for quadrupedal robots in the wild. Sci. Robot. 2022, 7, eabk2822. [Google Scholar] [CrossRef] [PubMed]
- Lele, A.S.; Fang, Y.; Ting, J.; Raychowdhury, A. Learning to walk: Spike based reinforcement learning for hexapod robot central pattern generation. In Proceedings of the IEEE International Conference on Artificial Intelligence Circuits and Systems, Genoa, Italy, 31 August–4 September 2020; pp. 208–212. [Google Scholar] [CrossRef]
- Merel, J.; Botvinick, M.; Wayne, G. Hierarchical motor control in mammals and machines. Nat. Commun. 2019, 10, 5489. [Google Scholar] [CrossRef] [PubMed]
- Eppe, M.; Gumbsch, C.; Kerzel, M.; Butz, M.V.; Wermter, S. Intelligent problem-solving as integrated hierarchical reinforcement learning. Nat. Mach. Intell. 2022, 4, 11–20. [Google Scholar] [CrossRef]
- Panerati, J.; Zheng, H.; Zhou, S.Q.; Xu, J.; Prorok, A.; Schoellig, A.P. Learning to fly-a gym environment with pybullet physics for reinforcement learning of multi-agent quadcopter control. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Prague, Czech Republic, 27 September–1 October 2021; pp. 7512–7519. [Google Scholar] [CrossRef]
- Khera, P.; Kumar, N. Role of machine learning in gait analysis: A review. J. Med. Eng. Technol. 2020, 44, 441–467. [Google Scholar] [CrossRef] [PubMed]
- Shi, F.; Homberger, T.; Lee, J.; Miki, T.; Zhao, M. Circus anymal: A quadruped learning dexterous manipulation with its limbs. In Proceedings of the International Conference on Robotics and Automation, Xi’an, China, 30 May–5 June 2021; pp. 2316–2323. [Google Scholar] [CrossRef]
- Kim, J.; Ba, D.X.; Yeom, H.; Bae, J. Gait optimization of a quadruped robot using evolutionary computation. J. Bionic Eng. 2021, 18, 306–318. [Google Scholar] [CrossRef]
- Han, Y. Action Planning and Design of Humanoid Robot Based on Sports Analysis in Digital Economy Era. Int. J. Multimed. Comput. 2022, 3, 37–50. [Google Scholar] [CrossRef]
- He, J.; Gao, F. Mechanism, actuation, perception, and control of highly dynamic multilegged robots: A review. Chin. J. Mech. Eng. 2020, 33, 79. [Google Scholar] [CrossRef]
- Xu, P.; Ding, L.; Wang, Z.; Gao, H.; Zhou, R.; Gong, Z.; Liu, G. Contact sequence planning for hexapod robots in sparse foothold environment based on monte-carlo tree. IEEE Robot. Autom. Lett. 2021, 7, 826–833. [Google Scholar] [CrossRef]
- Owaki, D.; Ishiguro, A. A quadruped robot exhibiting spontaneous gait transitions from walking to trotting to galloping. Sci. Rep. 2017, 7, 277. [Google Scholar] [CrossRef]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. International conference on machine learning. Proc. Mach. Learn. Res. 2018, 80, 1861–1870. [Google Scholar] [CrossRef]
- Zhang, Z.; Luo, X.; Liu, T.; Xie, S.; Wang, J.; Wang, W.; Li, Y.; Peng, Y. Proximal policy optimization with mixed distributed training. In Proceedings of the 2019 IEEE 31st International Conference on Tools with Artificial Intelligence (ICTAI), Portland, OR, USA, 4–6 November 2019; pp. 1452–1456. [Google Scholar] [CrossRef]
- Hou, Y.; Liu, L.; Wei, Q.; Xu, X.; Chen, C. A novel DDPG method with prioritized experience replay. In Proceedings of the 2017 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Banff, AB, Canada, 5–8 October 2017; Volume 12, pp. 316–321. [Google Scholar] [CrossRef]
- Fujimoto, S.; Hoof, H.; Meger, D. Addressing function approximation error in actor-critic methods. International conference on machine learning. Proc. Mach. Learn. Res. 2018, 80, 1587–1596. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| Body dimensions | 0.3866 × 0.2232 × 0.0821 m | Robot weight | 10 kg |
| DoF | 18 | Hip link | 0.1179 m |
| Knee link | 0.1302 m | Ankle link | 0.3996 m |
| Servo size | 72 × 40 × 56 mm | Servo weight | 72 g |
| Servo parameters | 27.5 kg/cm 7.4V | Computing device | Nvidia Tx2 |
| 9-axis IMU | MPU9250 | Power | 7.4 V 8000 mAh |
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| Learning rate | 3 × 10−4 | Replay buffer size | 1× 105 |
| Discount factor | 0.99 | Entropy regularization | 0.005 |
| Policy network hidden layer nodes | [256,256] | Critic network hidden layer nodes | [400,300] |
| Parameter update frequency | 1 | Gradient update steps | 1 |
| Velocity tracking penalty factor | −0.1 | Energy consumption penalty factor | −0.3 |
| Joint tracking penalty factor | −0.1 | Roll and pitch penalty factor | −0.35 |
| Roll and pitch penalty coefficient | 2 | Joint tracking penalty coefficient | 1.5 |
| Parameter | Lower Bound | Upper Bound |
|---|---|---|
| Centroid position | −2 cm | 2 cm |
| Link mass | 0.04 kg | 0.06 kg |
| Rotational inertia | 80% | 120% |
| Joint max torque | 80% | 120% |
| Friction coefficient | 0.5 | 1.2 |
| Parameter | Sample Distribution |
|---|---|
| Joint position (rad) | |
| Joint velocity (rad/s) | |
| Joint torque (Nm) | |
| Body height (m) | |
| Body velocity (m/s) | |
| Body angular velocity (rad/s) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiu, Z.; Wei, W.; Liu, X. Adaptive Gait Generation for Hexapod Robots Based on Reinforcement Learning and Hierarchical Framework. Actuators 2023, 12, 75. https://doi.org/10.3390/act12020075
Qiu Z, Wei W, Liu X. Adaptive Gait Generation for Hexapod Robots Based on Reinforcement Learning and Hierarchical Framework. Actuators. 2023; 12(2):75. https://doi.org/10.3390/act12020075
Chicago/Turabian StyleQiu, Zhiying, Wu Wei, and Xiongding Liu. 2023. "Adaptive Gait Generation for Hexapod Robots Based on Reinforcement Learning and Hierarchical Framework" Actuators 12, no. 2: 75. https://doi.org/10.3390/act12020075
APA StyleQiu, Z., Wei, W., & Liu, X. (2023). Adaptive Gait Generation for Hexapod Robots Based on Reinforcement Learning and Hierarchical Framework. Actuators, 12(2), 75. https://doi.org/10.3390/act12020075