
Constrained Path Planning for Unmanned Aerial Vehicle in 3D Terrain Using Modified Multi-Objective Particle Swarm Optimization

Abstract
:1. Introduction
2. Related Work
2.1. Basic MOPSO
| Algorithm 1. The structure of MOPSO | |||
| /*Initialization*/ | |||
| Set the iteration count t = 1. | |||
| Initialize the location xi and velocities vi of particles randomly, i = 1,2,…,NP. | |||
| /*Establish archives*/ | |||
| Non-dominated sorting and save non-dominated solutions to archives A. | |||
| /*Iteration computation*/ | |||
| while t < tmax do | |||
| for each particle i do | |||
| Update the velocity vi and position xi by Equations (1) and (2). | |||
| Update the personal best position xpbest,i. | |||
| end for | |||
| /*Update archives*/ | |||
| |||
| |||
| |||
| t = t + 1. | |||
| end while | |||
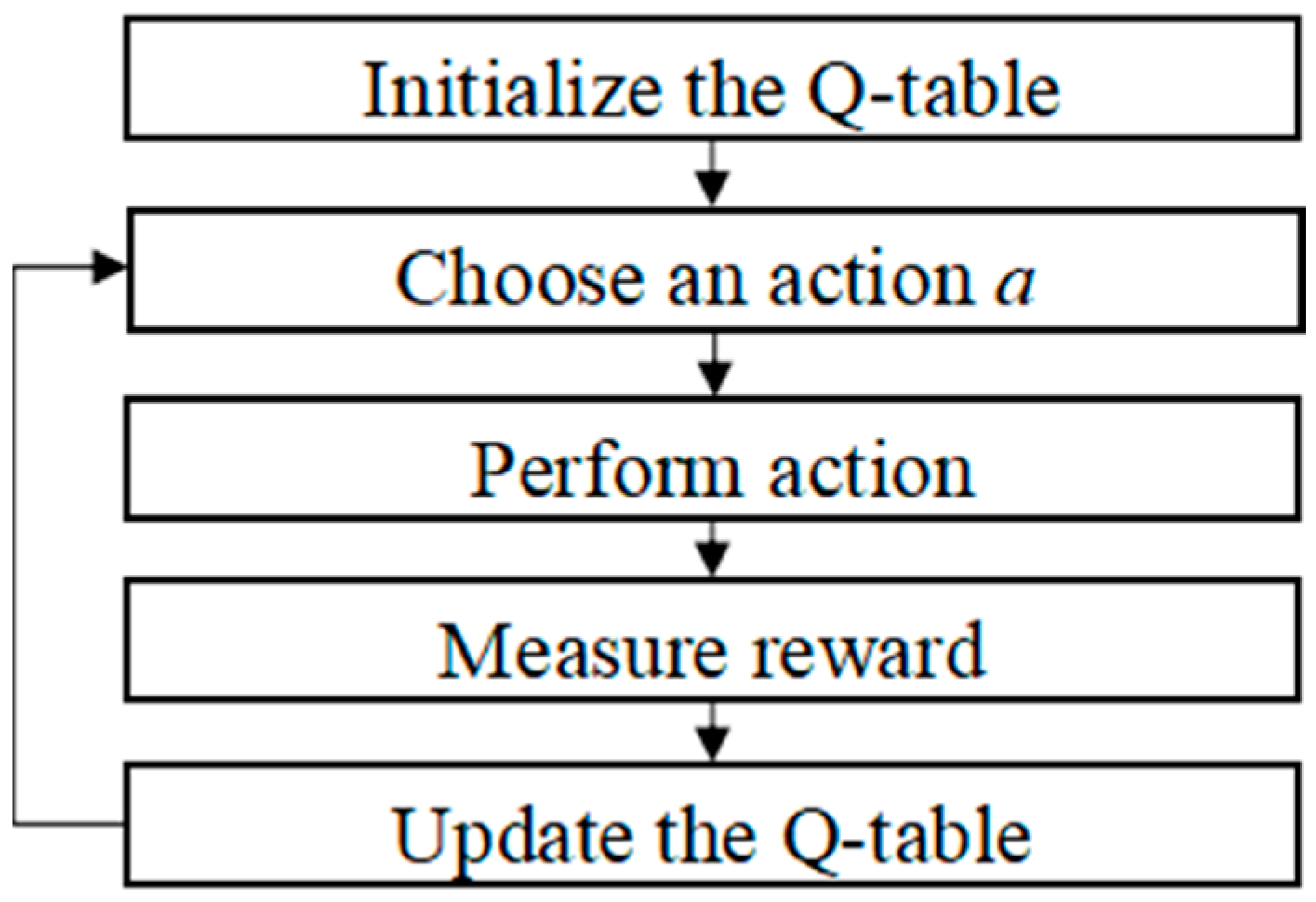
2.2. Q-Learning
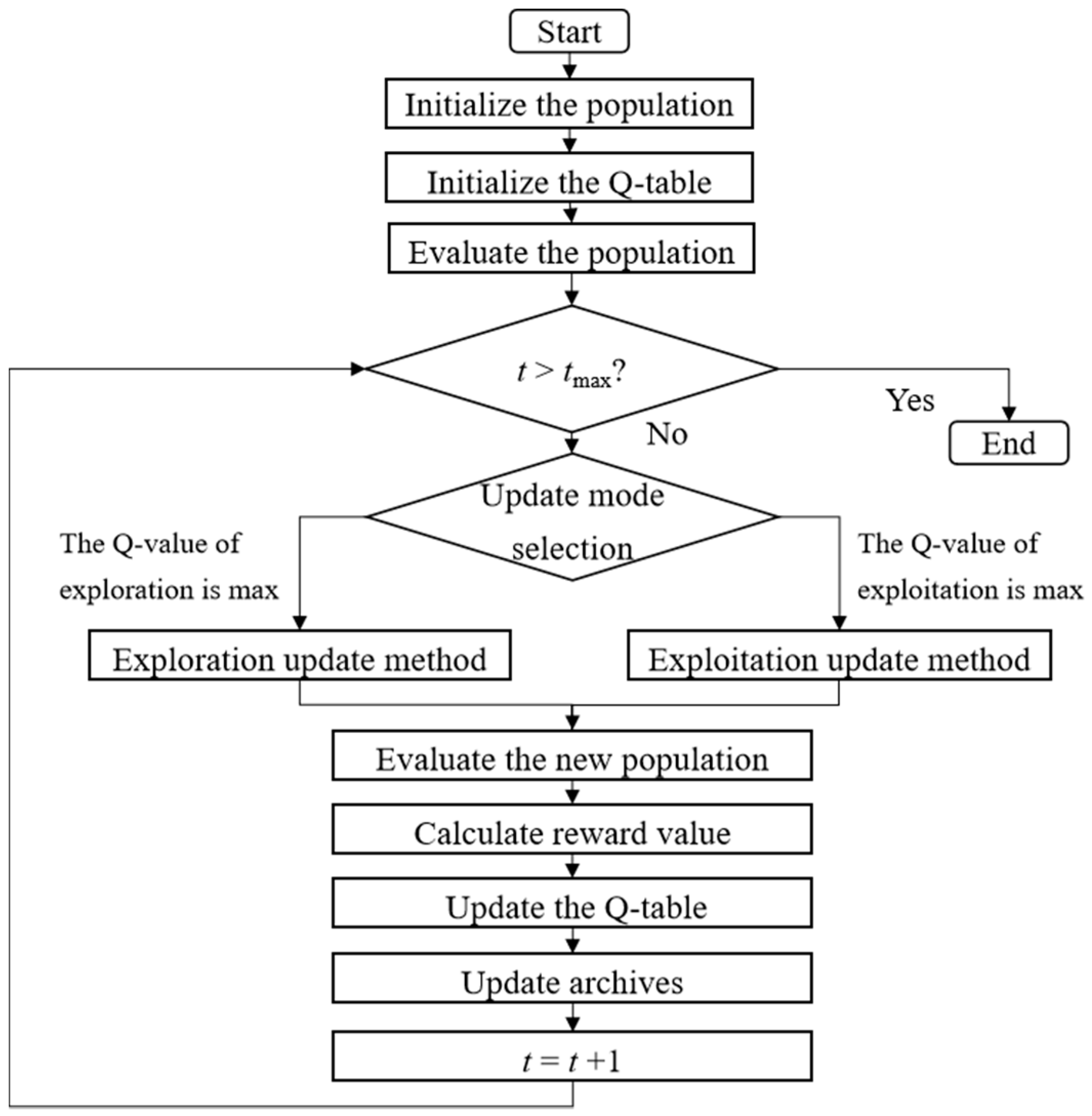
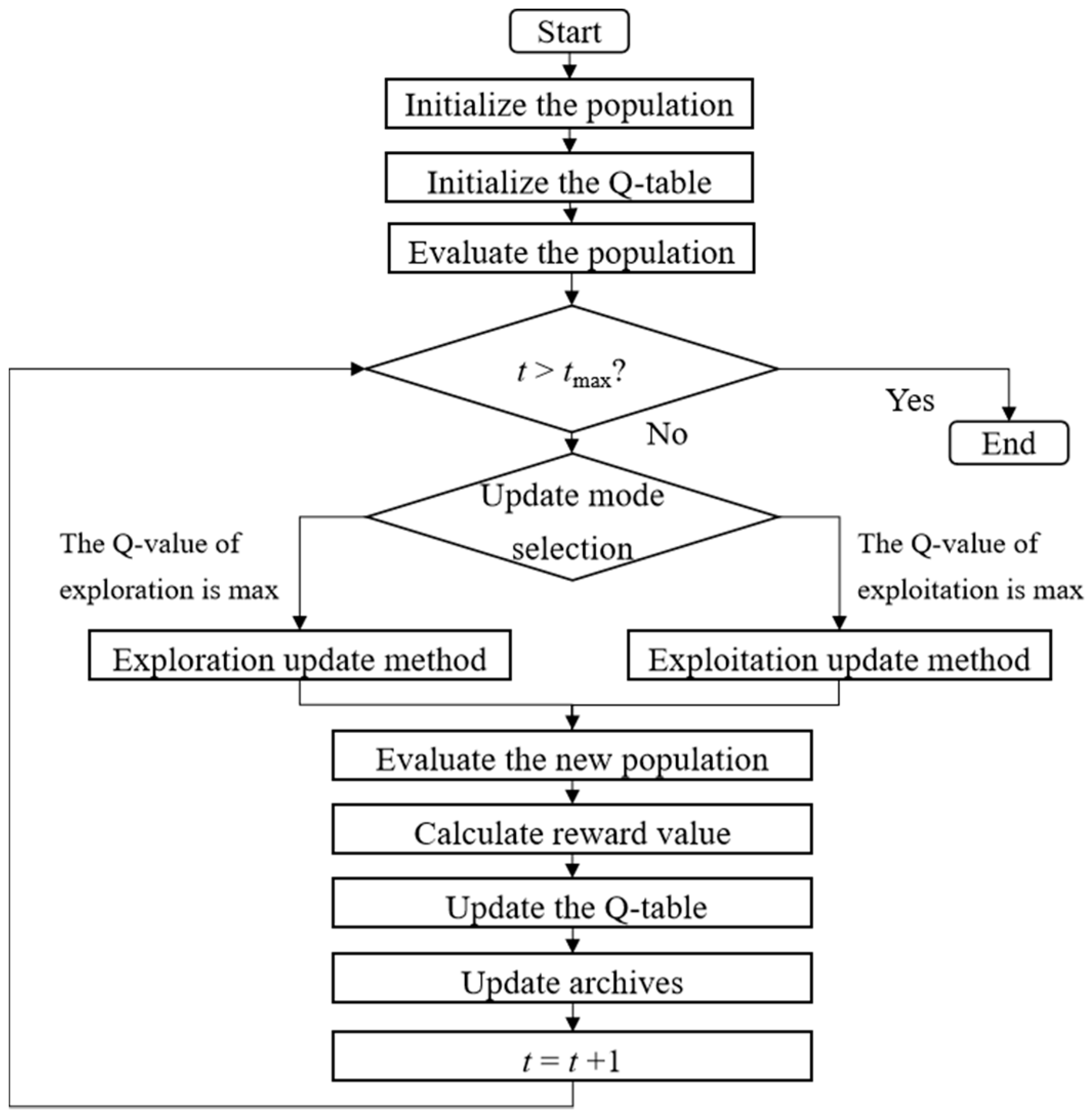
3. Proposed Modified Algorithm
3.1. Gaussian Based Exploration and Exploitation Update Modes
3.2. Q-Learning Based Mode Selection
3.3. Updating Archives
| Algorithm 2. Steps of updating external archives | ||||
| /*Input parameters*/ | ||||
| The current capacity of external archives m, the maximum capacity of external archives M | ||||
| /*Update Archives*/ | ||||
| For each particle in current population xi do | ||||
| For each particle in the archives xj do | ||||
| If xi dominates xj do | ||||
| Delete xj from the archives | ||||
| End if | ||||
| End for | ||||
| If xi is not dominated by any solution in the archives do | ||||
| Place xi in the archives. | ||||
| End if | ||||
| End for | ||||
| If m > Mdo | ||||
| Calculate the crowding distance of all solutions in the archives and arrange them in descending order. | ||||
| Delete the solutions with the smaller crowding distance until m = M. | ||||
| End if | ||||
3.4. Framework of GMOPSO-QL
3.5. Computing Complexity
4. Path Planning Based on GMOPSO-QL
4.1. Problem Modelling
4.2. GMOPSO-QL for Path Planning
| Algorithm 3. GMOPSO-QL based path planning | |||||
| /*Input for GMOPSO-QL*/ | |||||
| Set maximum iteration number tmax, the number of control points n and parameters λinitial, λfinal, ω, γ. | |||||
| /*Initialization*/ | |||||
| Set the generation number t = 1. | |||||
| Set the initial Q-table: Q(s,a) = 0. | |||||
| Initialize the location xi and velocities vi of particles randomly, i = 1,2,...,NP. | |||||
| /*Evaluation*/ | |||||
| Generate the smooth trajectory Path = {p0, p1, p2, …, pN, pN + 1}. | |||||
| Evaluate flight path performance indicators by Equation (8). | |||||
| /*Establish archives*/ | |||||
| Non-dominated sorting and save non-dominated solutions to archives A. | |||||
| /*Iteration computation*/ | |||||
| while t < tmax do | |||||
| Calculate the learning rate λ by Equation (6). | |||||
| for each particle i do | |||||
| Choose the best a for the current s from Q-table. | |||||
| switch action | |||||
| case 1: Exploration update mode | |||||
| Update the velocity vi and position xi by Equations (2) and (4) with c11 = 1.5 and c21 = 0.4. | |||||
| case 2: Exploitation update mode | |||||
| Update the velocity vi and position xi by Equations (2) and (5) with c12 = 0.4 and c22 = 1.5. | |||||
| end switch | |||||
| for each dimension j do | |||||
| if the velocity vi or position xi out of bounds, then limit them by and | |||||
| end for | |||||
| Update the personal best position xpbest,i. | |||||
| Calculate the reward r by Equation (7). | |||||
| end for | |||||
| Update the Q-table by Equation (3). | |||||
| Update the archives A | |||||
| t = t +1. | |||||
| end while | |||||
| /*Output*/ | |||||
| Output the best path for UAV. | |||||
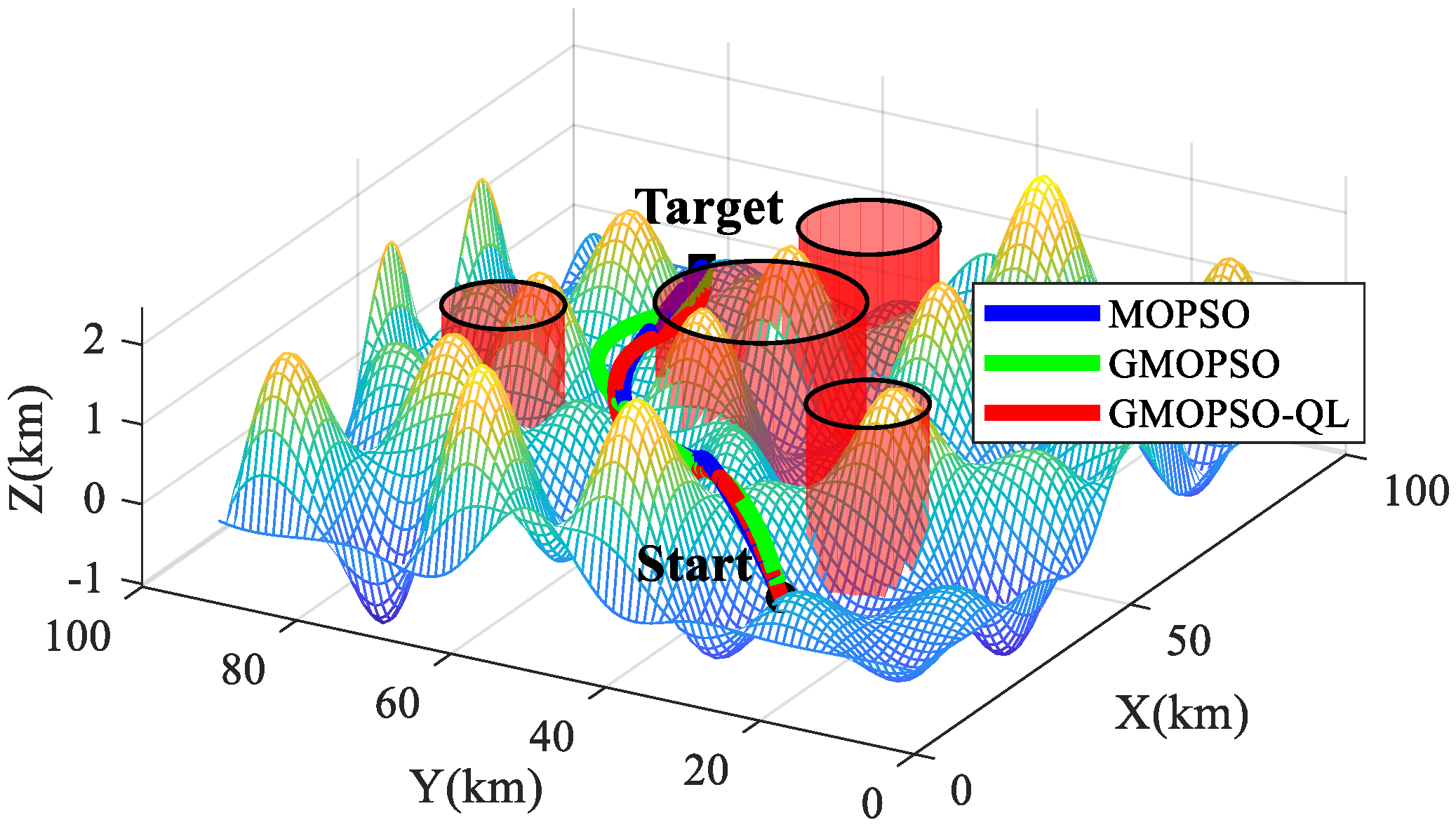
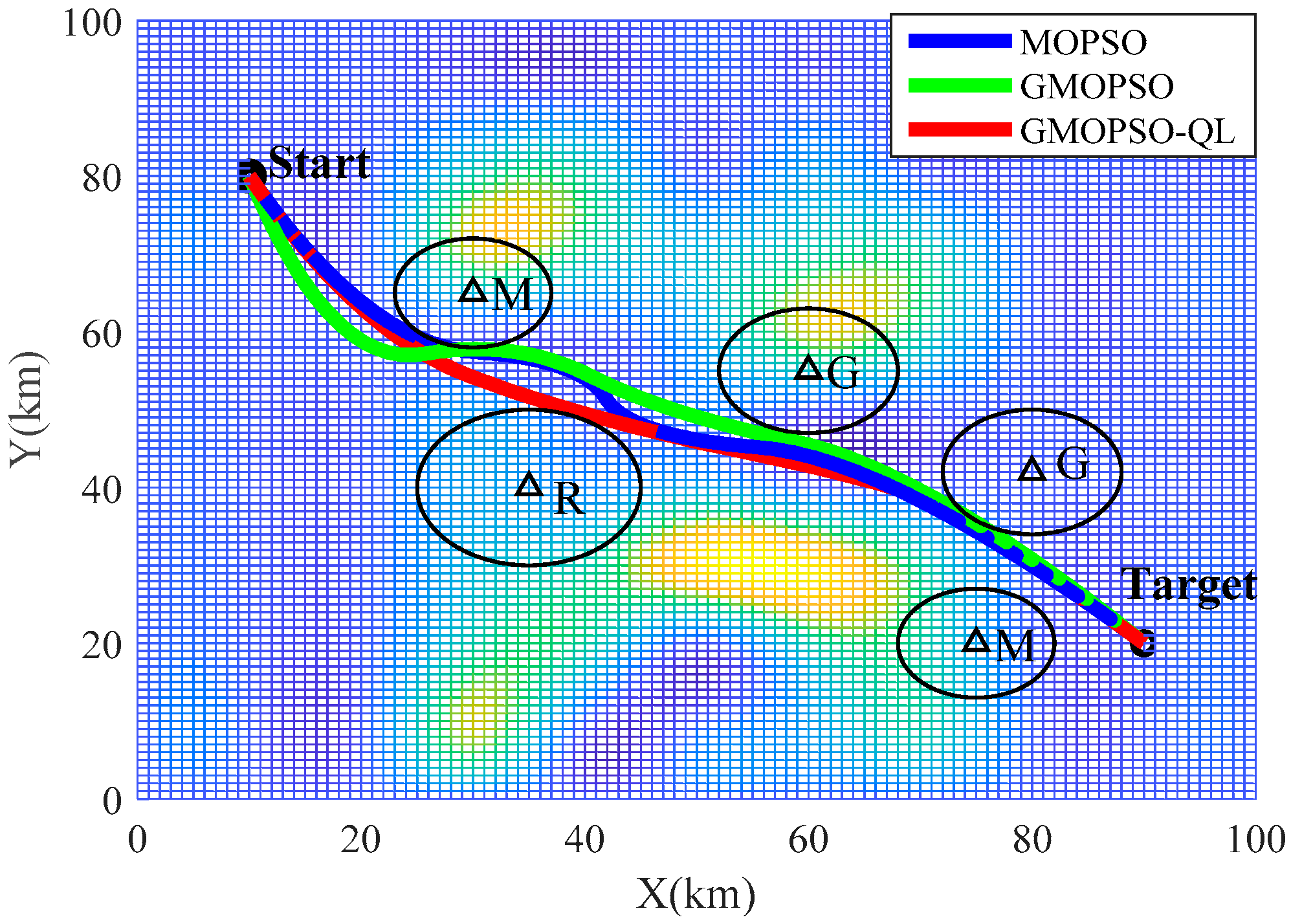
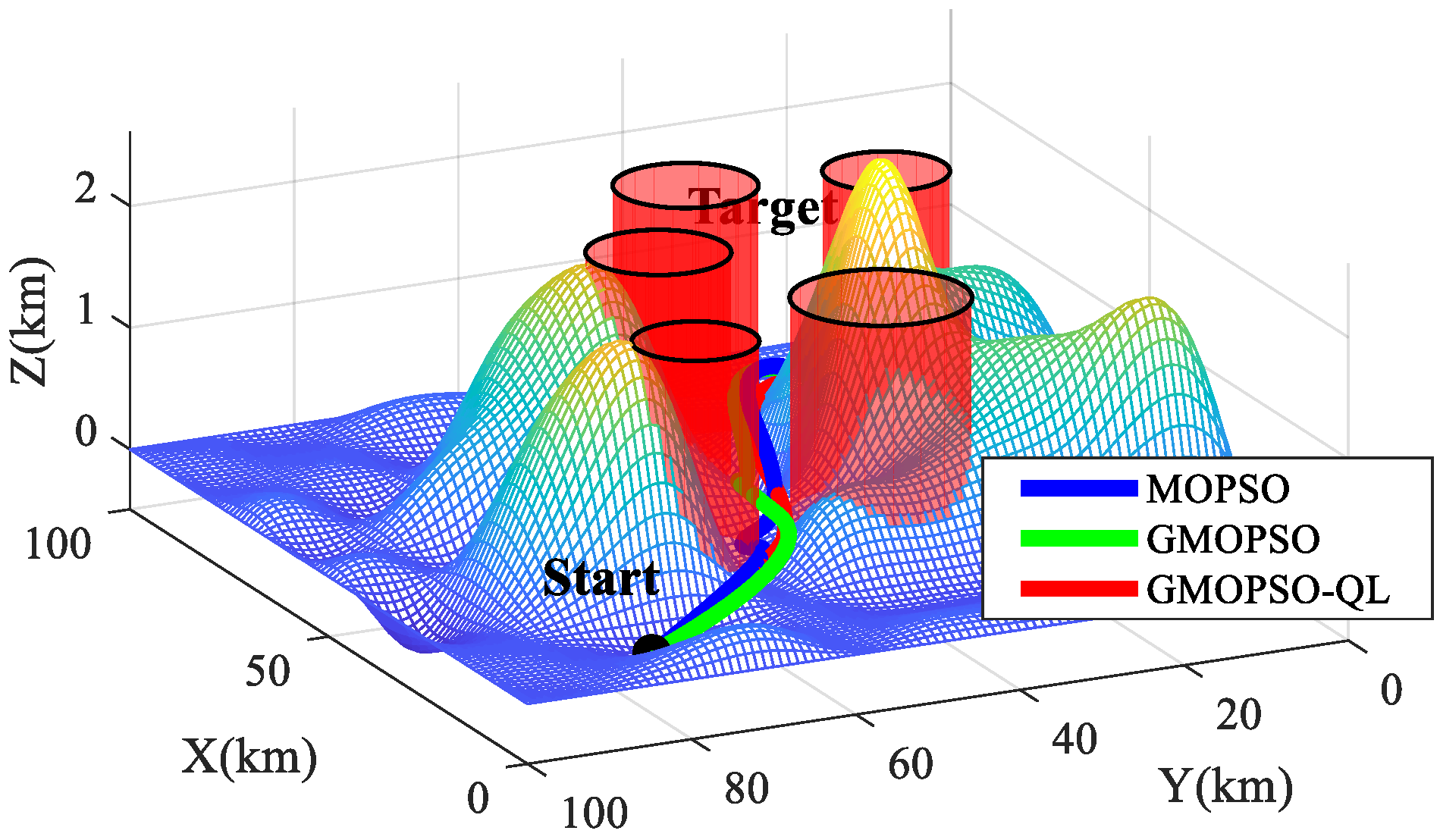
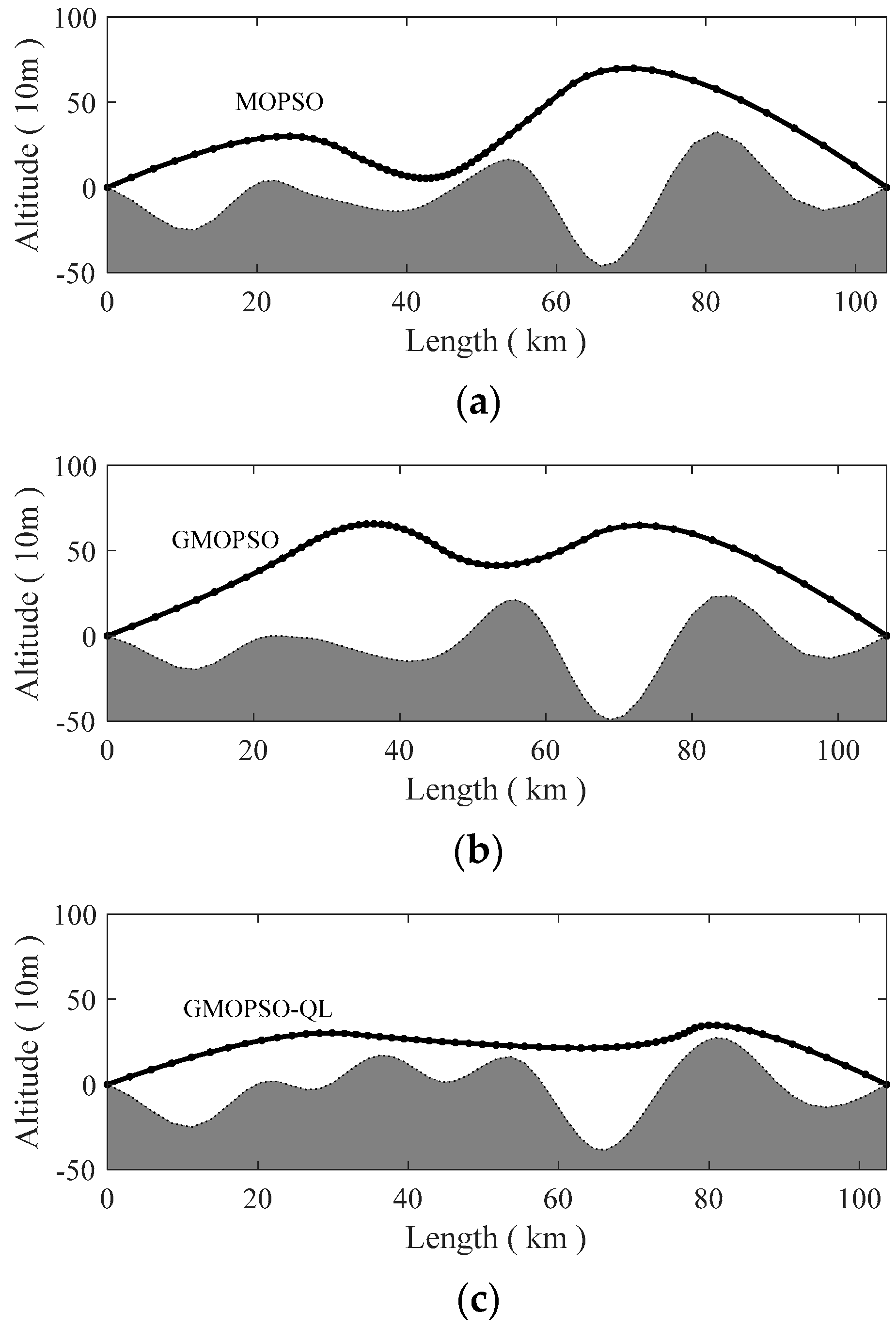
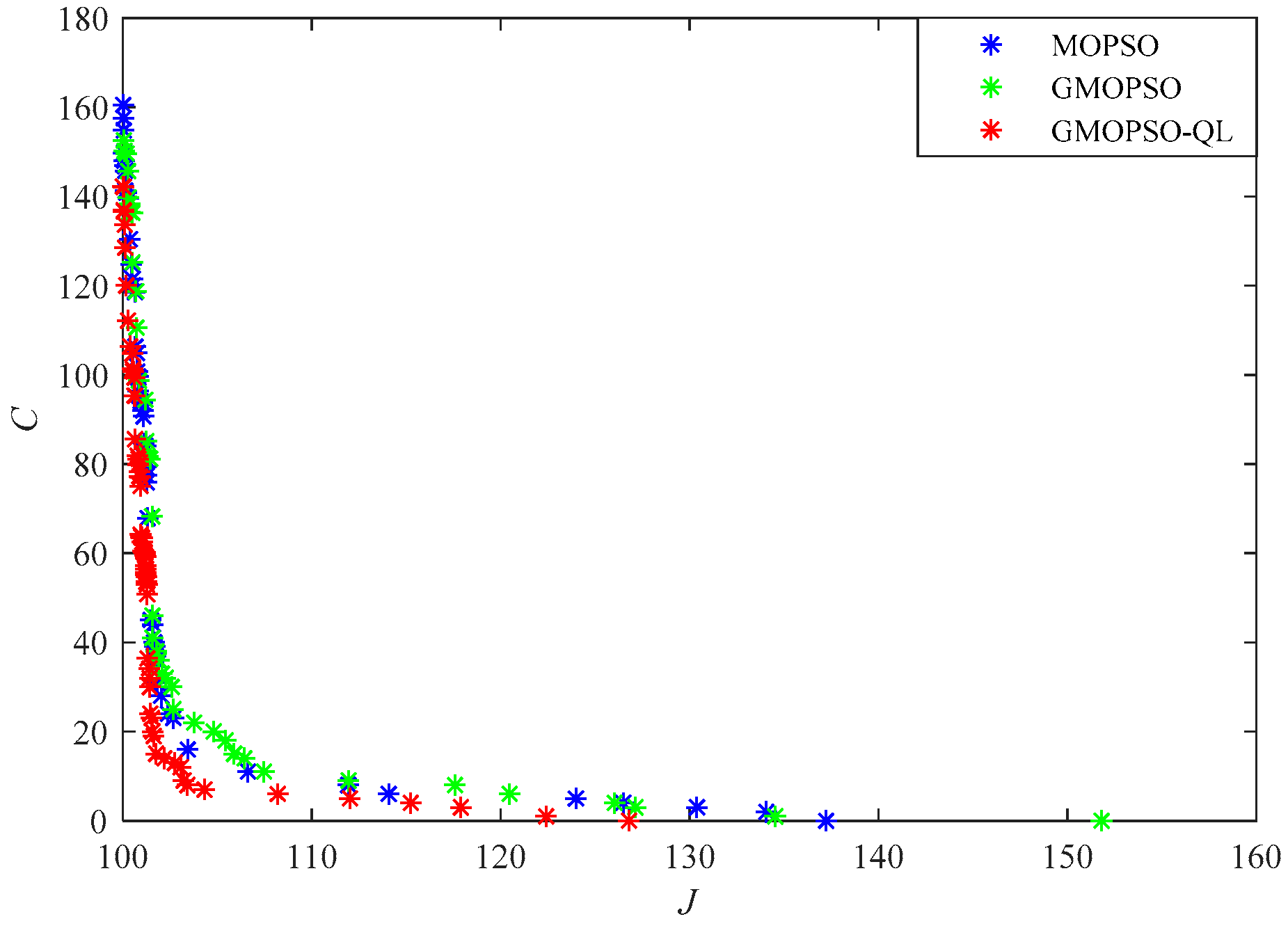
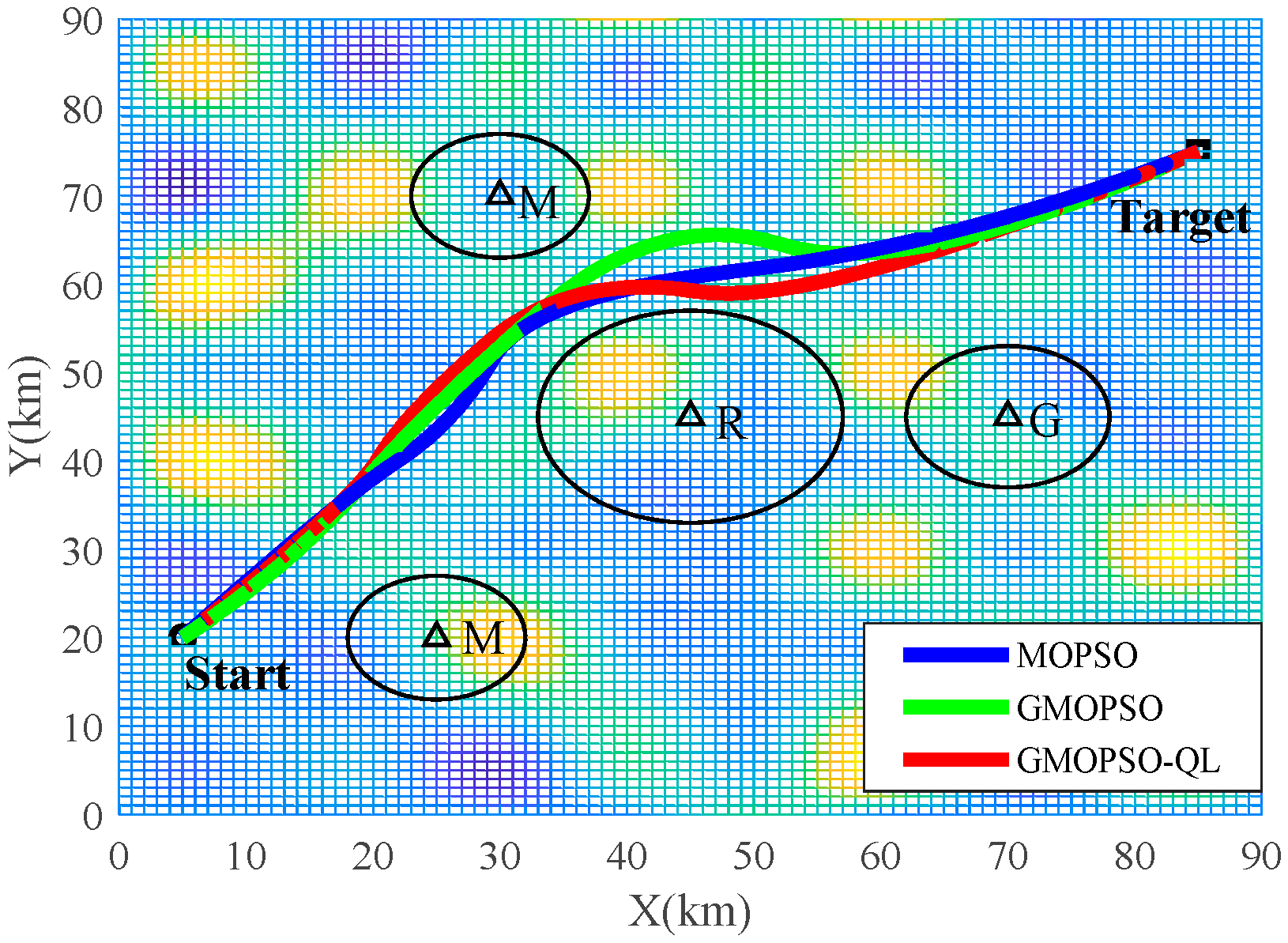
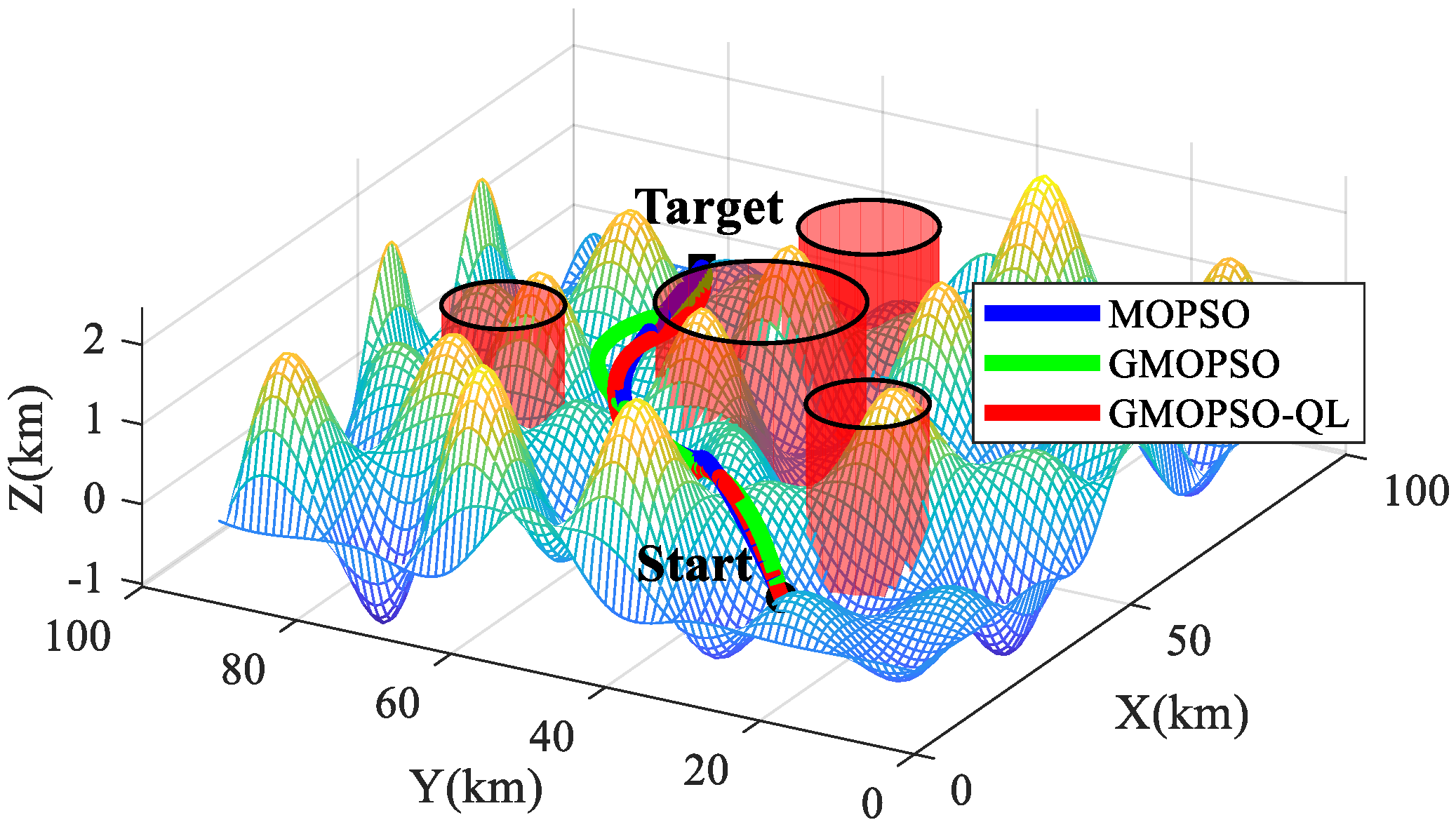
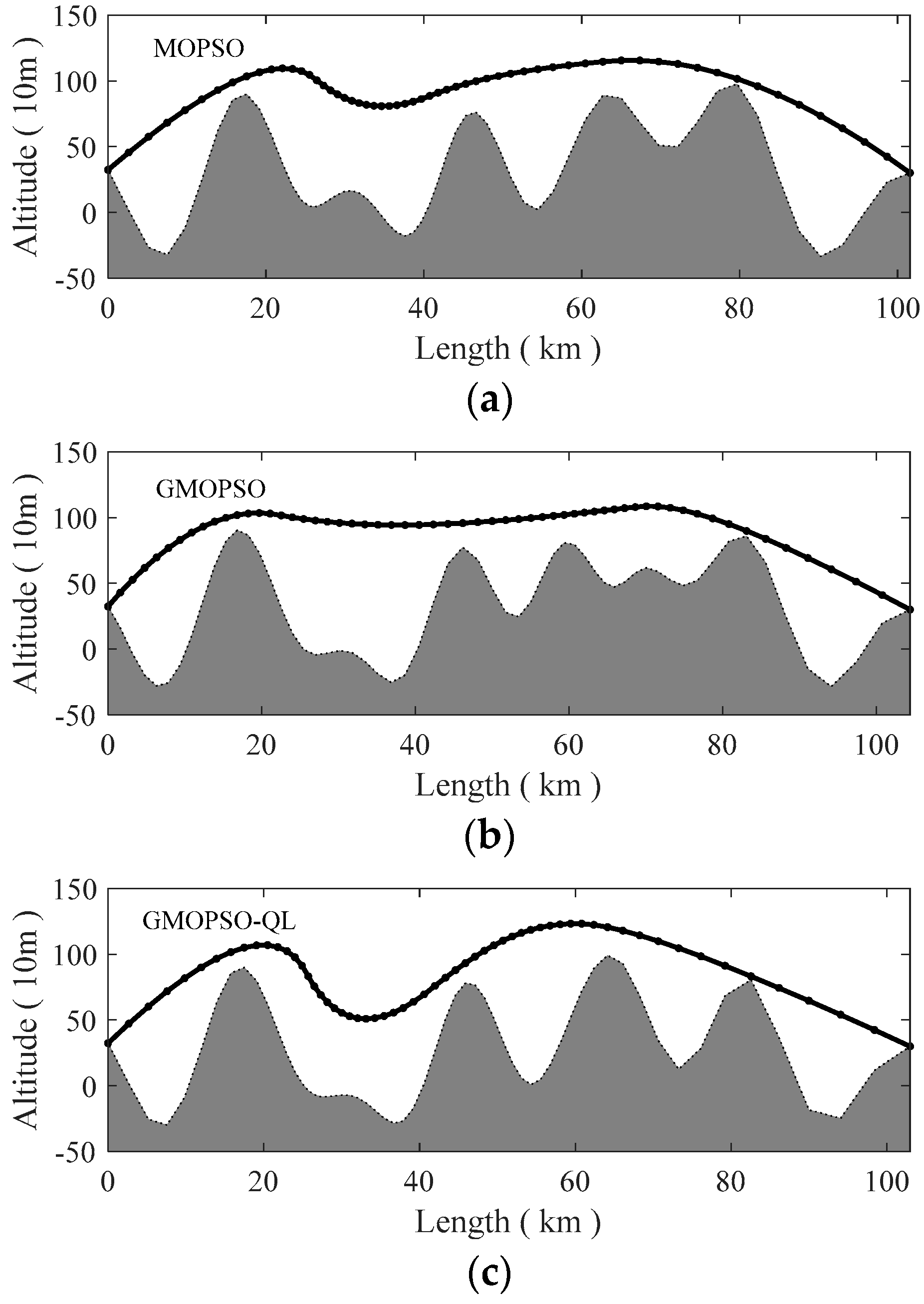
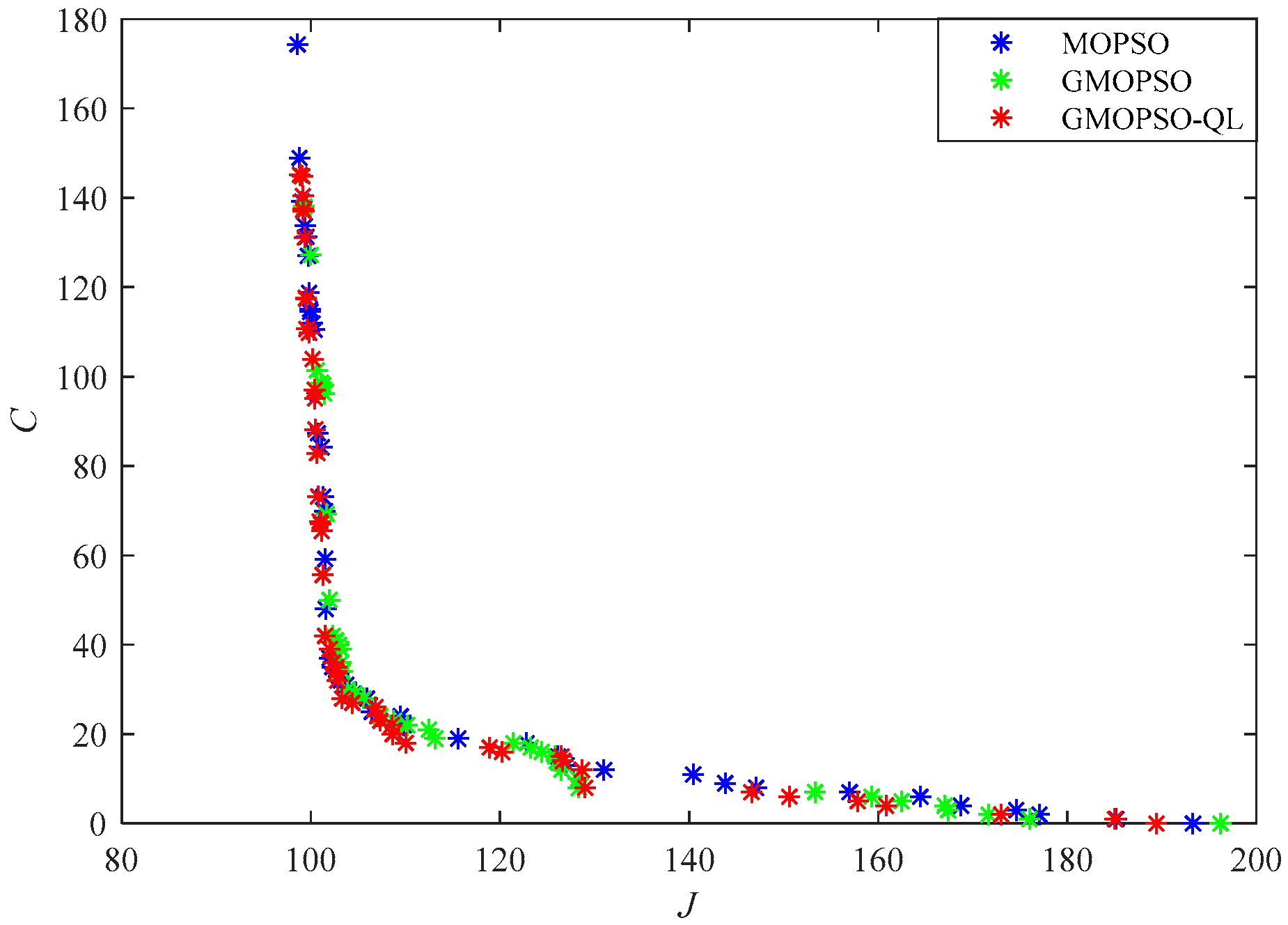
5. Simulation Results
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Shi, K.M.; Zhang, X.Y.; Xia, S. Multiple swarm fruit fly optimization algorithm based path planning method for multi-UAVs. Appl. Sci. 2020, 10, 2822. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Y.J.; Zheng, Z.; Liu, Y. Survey on computational-intelligence-based UAV path planning. Knowl.-Based Syst. 2018, 158, 54–64. [Google Scholar] [CrossRef]
- Lin, K.P.; Hung, K.C. An efficient fuzzy weighted average algorithm for the military UAV selecting under group decision-making. Knowl.-Based Syst. 2011, 24, 877–889. [Google Scholar] [CrossRef]
- Qu, C.Z.; Gai, W.D.; Zhang, J.; Zhong, M.Y. A novel hybrid grey wolf optimizer algorithm for unmanned aerial vehicle (UAV) path planning. Knowl.-Based Syst. 2020, 194, 105530. [Google Scholar] [CrossRef]
- Zhang, X.Y.; Duan, H.B. An improved constrained differential evolution algorithm for unmanned aerial vehicle global route planning. Appl. Soft Comput. 2015, 26, 270–284. [Google Scholar] [CrossRef]
- Park, C.; Kee, S.C. Online Local Path Planning on the Campus Environment for Autonomous Driving Considering Road Constraints and Multiple Obstacles. Appl. Sci. 2021, 11, 3909. [Google Scholar] [CrossRef]
- Yu, X.B.; Li, C.L.; Zhou, J.F. A constrained differential evolution algorithm to solve UAV path planning in disaster scenarios. Knowl.-Based Syst. 2020, 204, 106209. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, X.J.; Zhang, Y.; Guan, X.M. Collision free 4D path planning for multiple UAVs based on spatial refined voting mechanism and PSO approach. Chin. J. Aeronaut. 2019, 32, 1504–1519. [Google Scholar] [CrossRef]
- Maw, A.A.; Tyan, M.; Nguyen, T.A.; Lee, J.W. iADA*-RL: Anytime Graph-Based Path Planning with Deep Reinforcement Learning for an Autonomous UAV. Appl. Sci. 2021, 11, 3948. [Google Scholar] [CrossRef]
- Homaifar, A.; Lai, S.; Qi, X. Constrained optimization via genetic algorithms. Simulation 1994, 62, 242–254. [Google Scholar] [CrossRef]
- Saha, A.; Datta, R.; Deb, K. Hybrid gradient projection based genetic algorithms for constrained optimization. In Proceedings of the 2010 IEEE Congress on Evolutionary Computation, Barcelona, Spain, 18–29 July 2010; pp. 1–8. [Google Scholar]
- Wang, Y.; Cai, Z. Combining multiobjective optimization with differential evolution to solve constrained optimization problems. IEEE Trans. Evol. Comput. 2012, 16, 117–134. [Google Scholar] [CrossRef]
- Zhao, M.; Liu, R.; Li, W.; Liu, H. Multi-objective optimization based differential evolution constrained optimization algorithm. In Proceedings of the 2010 Second WRI Global Congress on Intelligent Systems, Wuhan, China, 16–17 December 2010; pp. 320–326. [Google Scholar]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the IEEE International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; pp. 1942–1948. [Google Scholar]
- Zhang, D.F.; Duan, H.B. Social-class pigeon-inspired optimization and time stamp segmentation for multi-UAV cooperative path planning. Neurocomputing 2018, 313, 229–246. [Google Scholar] [CrossRef]
- Yang, Y.K.; Liu, J.C.; Tan, S.B.; Liu, Y.C. A multi-objective differential evolution algorithm based on domination and constraint-handling switching. Inform. Sci. 2021, 579, 796–813. [Google Scholar] [CrossRef]
- Ma, Y.N.; Gong, Y.J.; Xiao, C.F.; Gao, Y.; Zhang, J. Path Planning for Autonomous Underwater Vehicles: An Ant Colony Algorithm Incorporating Alarm Pheromone. IEEE Trans. Veh. Technol. 2019, 68, 141–154. [Google Scholar] [CrossRef]
- Zhang, X.Y.; Jia, S.M.; Li, X.Z.; Jian, M. Design of the fruit fly optimization algorithm based path planner for UAV in 3D environments. In Proceedings of the 2017 IEEE International Conference on Mechatronics and Automation, Takamatsu, Japan, 6–9 August 2017; pp. 381–386. [Google Scholar]
- Pham, M.; Zhang, D.; Koh, C.S. Multi-guider and cross-searching approach in multi-objective particle swarm optimization for electromagnetic problems. IEEE Trans. Magn. 2012, 48, 539–542. [Google Scholar] [CrossRef]
- Xu, W.; Wang, W.; He, Q.; Liu, C.; Zhuang, J. An improved multi-objective particle swarm optimization algorithm and its application in vehicle scheduling. In Proceedings of the 2017 Chinese Automation Congress, Jinan, China, 20–22 October 2017; pp. 4230–4235. [Google Scholar]
- Sheikholeslami, F.; Navimipour, N.J. Service allocation in the cloud environments using multi-objective particle swarm optimization algorithm based on crowding distance. Swarm Evol. Comput. 2017, 35, 53–64. [Google Scholar] [CrossRef]
- Wang, B.F.; Li, S.; Guo, J.; Chen, Q.W. Car-like mobile robot path planning in rough terrain using multi-objective particle swarm optimization algorithm. Neurocomputing 2018, 282, 42–51. [Google Scholar] [CrossRef]
- Li, Z.H.; Shi, L.; Yue, C.T.; Shang, Z.G.; Qu, B.Y. Differential evolution based on reinforcement learning with fitness ranking for solving multimodal multiobjective problems. Swarm Evol. Comput. 2019, 49, 234–244. [Google Scholar] [CrossRef]
- Chen, Z.Q.; Qin, B.B.; Sun, M.W.; Sun, Q.L. Q-Learning-based parameters adaptive algorithm for active disturbance rejection control and its application to ship course control. Neurocomputing 2019, 408, 51–63. [Google Scholar] [CrossRef]
- Coello, C.A.; Lechuga, M.S. MOPSO: A proposal for multiple objective particle swarm optimization. In Proceedings of the 2002 Congress on Evolutionary Computation, Honolulu, HI, USA, 12–17 May 2002; pp. 1051–1056. [Google Scholar]
- Coelho, L. Novel Gaussian quantum-behaved particle swarm optimiser applied to electromagnetic design. IET Sci. Meas. Technol. 2007, 1, 290–294. [Google Scholar] [CrossRef]
- Qu, C.Z.; Gai, W.D.; Zhong, M.Y.; Zhang, J. A novel reinforcement learning based grey wolf optimizer algorithm for unmanned aerial vehicles (UAVs) path planning. Appl. Soft Comput. 2020, 89, 106099. [Google Scholar] [CrossRef]
- Zhang, X.Y.; Lu, X.Y.; Jia, S.M.; Li, X.Z. A novel phase angle-encoded fruit fly optimization algorithm with mutation adaptation mechanism applied to UAV path planning. Appl. Soft Comput. 2018, 70, 371–388. [Google Scholar] [CrossRef]
- Coelho, L.; Ayala, H.V.H.; Alotto, P. A multiobjective Gaussian particle swarm approach applied to electromagnetic optimization. IEEE Trans. Magn. 2010, 46, 3289–3292. [Google Scholar] [CrossRef]
- Aguilar, M.E.B.; Coury, D.V.; Reginatto, R.; Monaro, R.M. Multi-objective PSO applied to PI control of DFIG wind turbine under electrical fault conditions. Electr. Power Syst. Res. 2020, 180, 106081. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Best | Median | Mean | Worst | Std. | FR(%) | AT (s) | |
|---|---|---|---|---|---|---|---|
| MOPSO | 137.22 | 169.16 | 176.38 | 293.92 | 34.13 | 70 | 69.38 |
| GMOPSO | 151.80 | 194.68 | 215.12 | 399.84 | 50.53 | 96 | 70.54 |
| GMOPSO-QL | 126.78 | 160.74 | 172.22 | 350.96 | 44.85 | 100 | 69.40 |
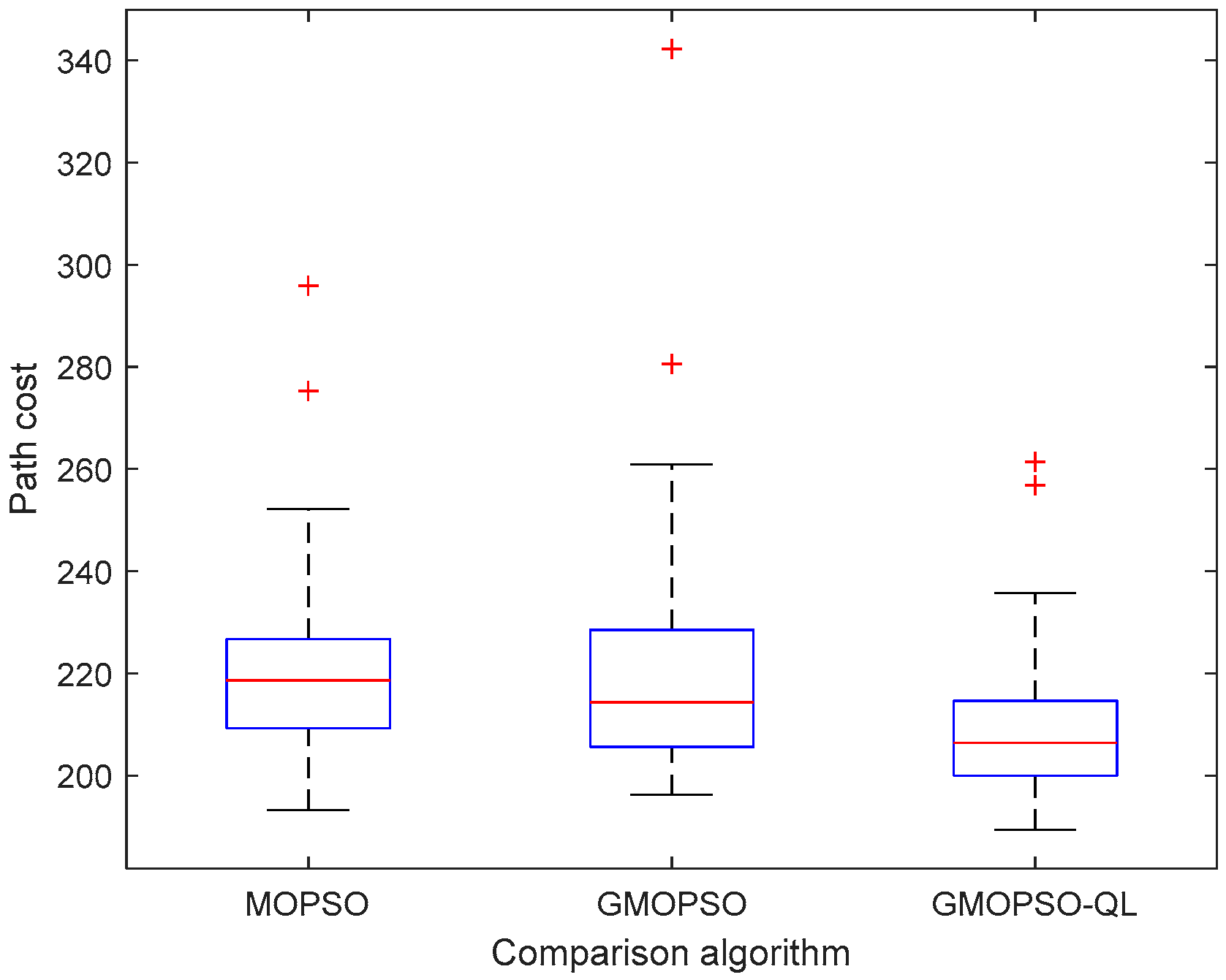
| Best | Median | Mean | Worst | Std. | FR(%) | AT (s) | |
|---|---|---|---|---|---|---|---|
| MOPSO | 193.28 | 218.57 | 219.65 | 295.92 | 19.72 | 82 | 55.43 |
| GMOPSO | 196.21 | 214.34 | 221.02 | 342.23 | 24.47 | 98 | 58.86 |
| GMOPSO-QL | 189.41 | 206.35 | 210.09 | 261.35 | 14.77 | 98 | 55.02 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xia, S.; Zhang, X. Constrained Path Planning for Unmanned Aerial Vehicle in 3D Terrain Using Modified Multi-Objective Particle Swarm Optimization. Actuators 2021, 10, 255. https://doi.org/10.3390/act10100255
Xia S, Zhang X. Constrained Path Planning for Unmanned Aerial Vehicle in 3D Terrain Using Modified Multi-Objective Particle Swarm Optimization. Actuators. 2021; 10(10):255. https://doi.org/10.3390/act10100255
Chicago/Turabian StyleXia, Shuang, and Xiangyin Zhang. 2021. "Constrained Path Planning for Unmanned Aerial Vehicle in 3D Terrain Using Modified Multi-Objective Particle Swarm Optimization" Actuators 10, no. 10: 255. https://doi.org/10.3390/act10100255
APA StyleXia, S., & Zhang, X. (2021). Constrained Path Planning for Unmanned Aerial Vehicle in 3D Terrain Using Modified Multi-Objective Particle Swarm Optimization. Actuators, 10(10), 255. https://doi.org/10.3390/act10100255