
Research on Sinter Quality Prediction System Based on Granger Causality Analysis and Stacking Integration Algorithm

Abstract
:1. Introduction
2. Data Foundation and Model Algorithm
2.1. Production Data
2.2. Data Processing
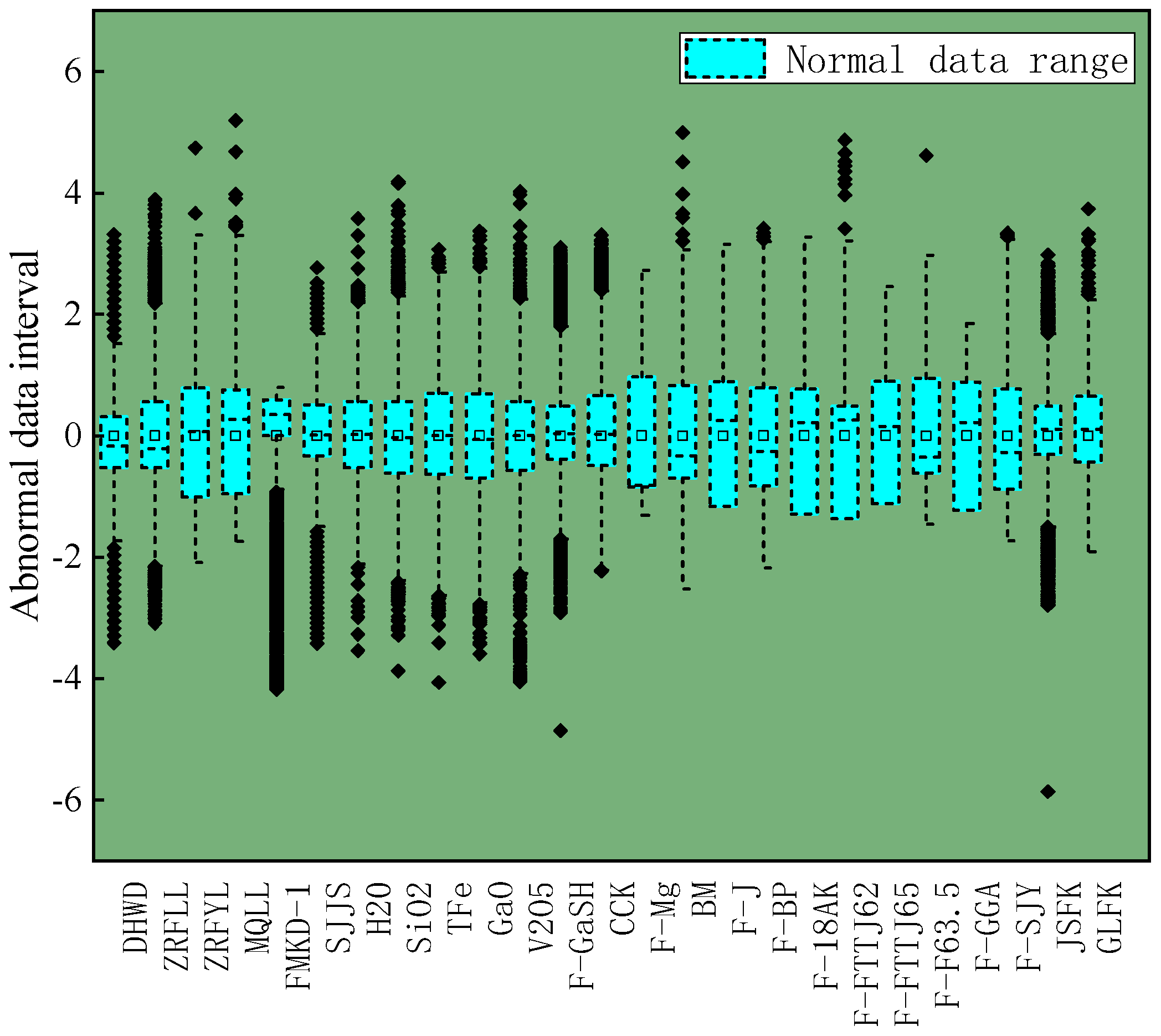
2.2.1. Abnormal Data Processing
Missing Data Values
Data Noise Value
Data Standardization
2.2.2. Data Frequency Unification
2.2.3. Data Derivation
2.3. Feature Selection
- (1)
- Regress the current y on all lags of y and whatever other variables (if such a variable exists), i.e., on the lags of , ,..., and other variables, but do not include the lag in this regression, which is a constrained regression. This regression then yields the constrained residual sum of squares RSSR.
- (2)
- Completing a regression with a lag term , i.e., adding the lag term to the previous regression equation, is an unconstrained regression, from which the regression yields the unconstrained residual sum of squares RSSUR.
- (3)
- The null hypothesis is that H0: = = … = = 0, i.e., the lag term is not part of this regression.
- (4)
- To test this hypothesis, an F-test was used.
- (5)
- The null hypothesis is rejected if the critical F value of F-value speculation is calculated at the selected level of significance , such that the lagged term belongs to this regression, indicating that is the cause of .
2.4. Model Principle
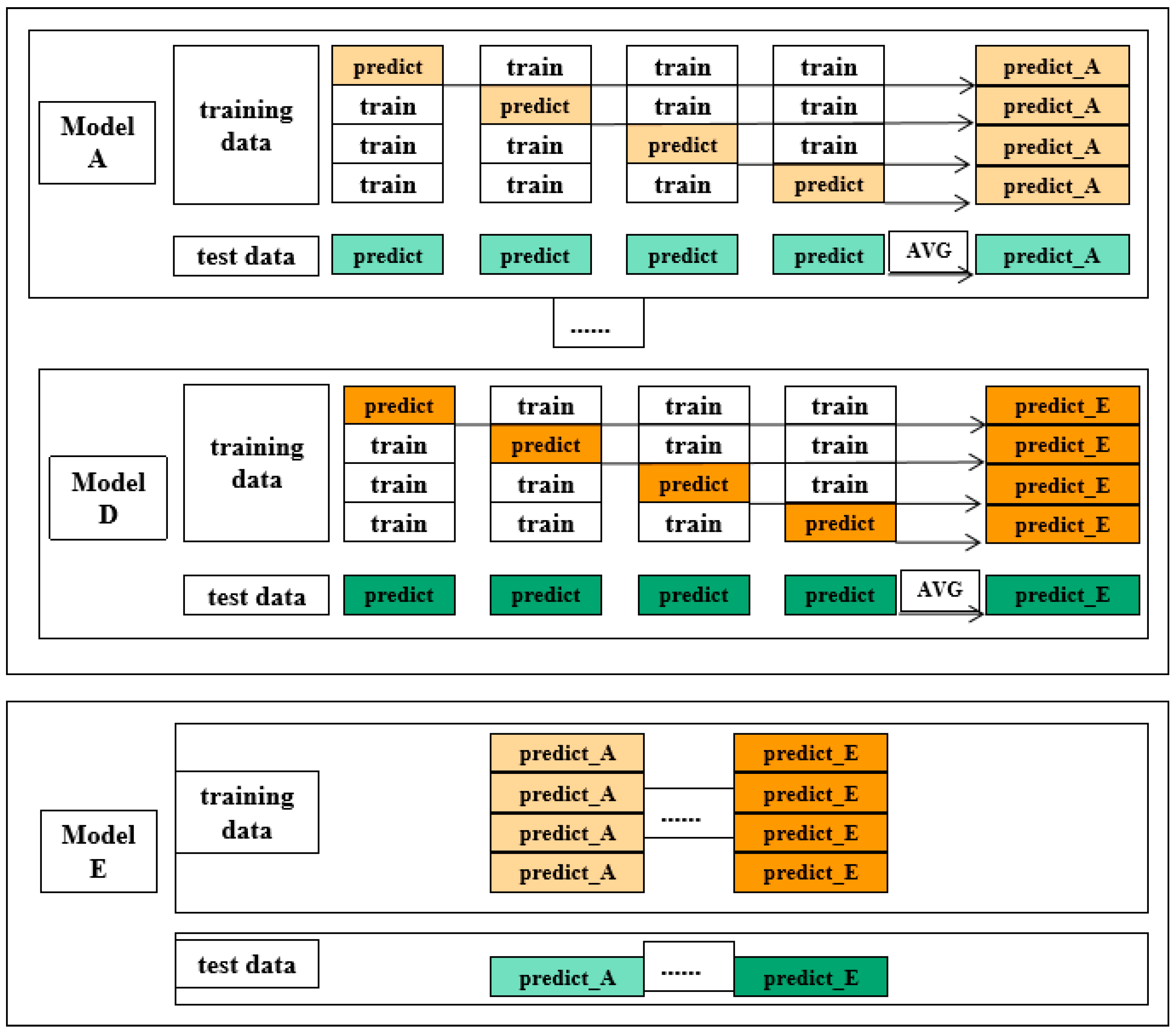
- (1)
- Divide the training set data into five parts; each part should include a validation set and a test set. Use one as the validation set and the rest as the training set.
- (2)
- Iterating through the five base models proposed will produce one prediction for each part of the test set; each sample will produce five prediction results, and the average of the five results can be taken. The prediction results of each model on the training set can be combined as the new features of the next layer.
- (3)
- The learning model can fit the dataset after combining new features and target parameters, and the learned model can be used for prediction tests to obtain the best results.
3. Model Building
3.1. Sintering State Division
3.2. Feature Selection Results
3.3. Evaluation Function
4. Prediction Model Results
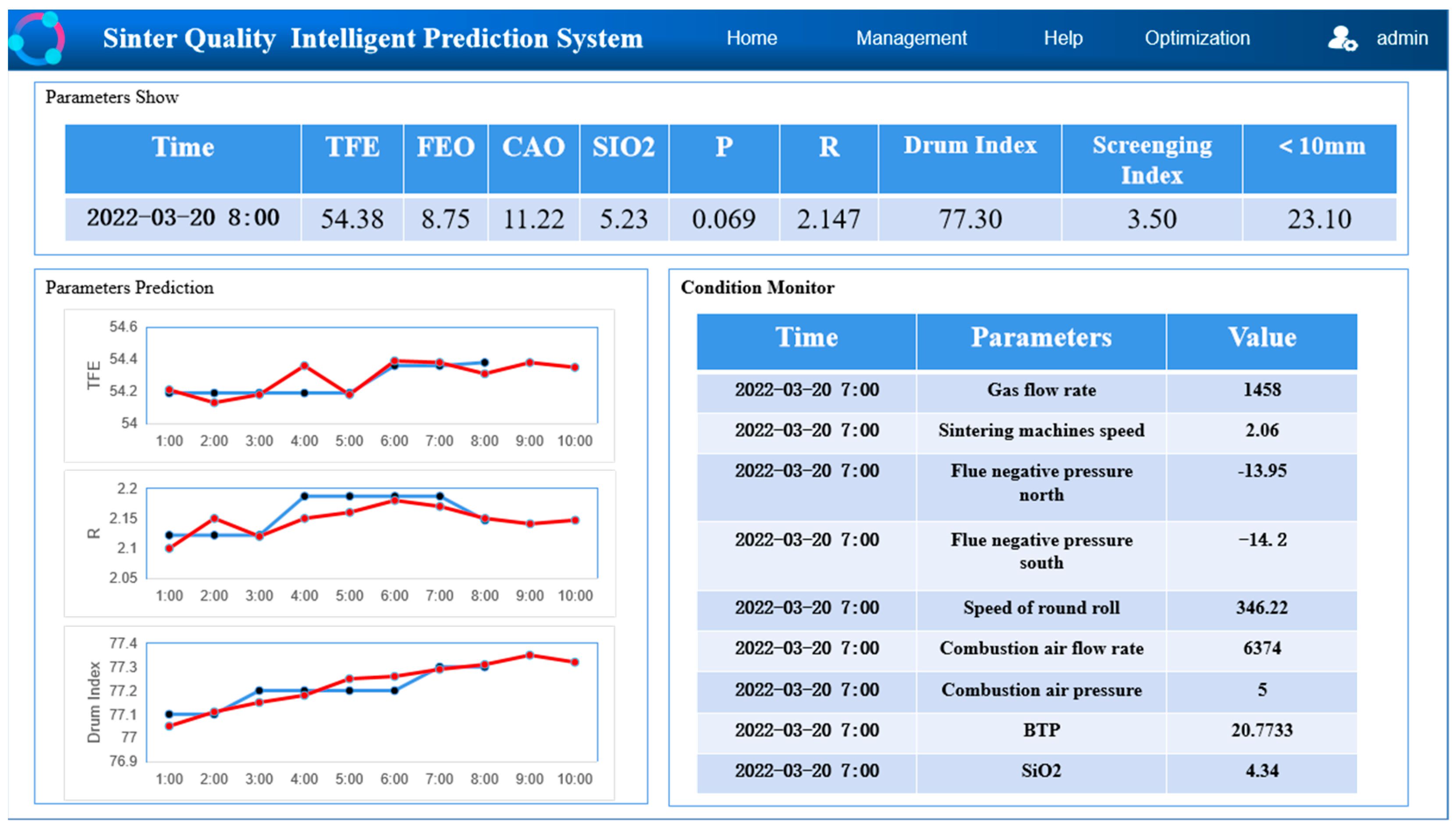
5. Sinter Quality Prediction System Implementation
- (1)
- Front-end design. The front-end page was developed using the react open-source framework released by Facebook, which helps to create an interactive UI. During the development phase, the framework supports many developers in receiving adequate technical support, and the design process components can be reused. Once the design is complete, if a panel needs to be added or deleted, it can be easily modified in a widget and indexed simply. The framework has sufficient superiority both from the design and maintenance points of view.
- (2)
- Back-end design. The back end is developed using an Express framework based on the Node platform. Using Express greatly reduces the number of code functions, and the logic is more concise, improving development efficiency and reducing engineering maintenance costs. The development process registers routes with web pages to provide path requests to different modules, avoiding the massive path problem. In addition, middleware modules developed for specific routes can be reused, solving the problem of interleaved references to complex logic. In front- and back-end interaction, we can combine redux to globally control the state in react and use ajax to read data from the server and store data in the action of redux
- (3)
- Database design. The database is MYSQL, where multiple tables, such as user tables, are connected by foreign keys, and suitable indexes are also created within the tables to speed up the table query process.
- (4)
- Deployment. The project is deployed on a Linux server; the front-end is deployed through the nginx proxy server while being able to ensure load balancing. The back end is deployed on the server by packaging the project into a jar package, so the front and back ends can be deployed separately.
6. Conclusions
- (1)
- To address the problems of different storage methods, large differences in scale levels and outliers in sintering data, data collection, extraction, integration, standardization, and outlier processing for the sintering system were completed by using a database, Excel, and Python language under the principles of close integration with the sintering process and ensuring data reliability, comprehensiveness, and timeliness. The data collection, extraction, integration, standardization, and outlier processing for the sintering system were completed by using a database, Excel, and Python language. The sintering sample set of Chenggang was constructed in a time-based and standardized format spanning 2 years.
- (2)
- The Pearson correlation coefficient, Spearman correlation coefficient, and Granger causality coefficient were used to analyze the correlation between the sinter ore quality and sintering process production parameters from different perspectives and realize the feature selection of the prediction model by combining the experience of sintering experts. The selected characteristic parameters are the actual data of the sintering process, including airbox exhaust gas temperatures, fuel ratio, Sintering machine speed, etc. And the selected input parameters can meet the requirements of online calculation of the prediction model.
- (3)
- A sinter quality prediction model was established using a stacking integrated learning algorithm, which could accurately predict the indices of TFe, R, and the drum index of sinter ore. The prediction errors of different parameters could meet the accuracy requirements for guiding production.
- (4)
- Based on Webstorm2021 and Xshell7 as the development environment, the sinter quality prediction system was built and tested online using the existing platform of the plant. The results showed that the operation status was stable during the test period, and the prediction results met the expected results.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, J.W.; Niu, L.Q. The practical exploration and enlightenment of Shougang Group’s green and low-carbon development in the century. N. Econ. Guide 2021, 2, 41. [Google Scholar]
- Wu, W.N.; Lu, Q.; Wan, X.Y. Effect of base characteristics of iron ore fines on the strength of sintering drums in Chengde Steel. Iron Steel 2013, 48, 12. [Google Scholar]
- Kawaguchi, T.; Yoshinaga, M. Development and application of an integrate simulation model for iron ore Sintering. Ironmak. Proceeding 1987, 12, 99–106. [Google Scholar]
- Hamada, K.; Matoba, Y.; Murai, T.; Ueno, Y.; Sato, K. Control system of chemical composition of iron ore sinter. Trans. Iron Steel Inst. Jpn. 1986, 84, 409–419. [Google Scholar]
- Peng, Q.K. Simulation Model of Sinter Bed Temperature Field and Experts System of Sinter Quality Optimization; Central South University: Changsha, China, 2011. [Google Scholar]
- Zhao, D.K.; Wang, J.; Wang, H. Control system of quality supervision and operating guidance in sintering production based on expert system. Metall. Ind. Autom. 2004, 2, 26–29. [Google Scholar]
- Wang, Q.Y. Research on Prediction Model of Tumbler Strength Based on the Online Inspection of Sinter Composition; Wuhan University of Science and Technology: Wuhan, China, 2017. [Google Scholar]
- Wang, Q.Y.; Liu, Q. Research on online prediction of sinter quality based on Elman Neural Network. Instrum. Tech. Sens. 2017, 98–100, 104. [Google Scholar]
- Xin, Z.C.; Li, J.; Liu, W.X. Forecast for low temperature reduction disintegration properties of vanadium-titanium sinter based on BP Neural Network. Iron Steel Vanadium Titan. 2017, 38, 94–99. [Google Scholar]
- Wang, D. Application Research Based on GA-FWA in Prediction of Sintering Burning through Point; Liaoning University of Science and Technology: Anshan, China, 2019. [Google Scholar]
- Li, H.Y.; Li, X.; Liu, X.J.; Bu, X.; Li, H.; Lyu, Q. Prediction of blast furnace parameters using feature engineering and Stacking algorithm. Ironmak. Steelmak. 2022, 49, 283–296. [Google Scholar] [CrossRef]
- Chen, S.; Jin, G.; Peng, S.; Zhang, L. Anomaly Detection Method Based on Granger Causality Modeling. In Proceedings of the International Conference on Wireless and Satellite Systems, Nanjing, China, 17–18 September 2020; Springer: Cham, Switzerland, 2021; pp. 145–151. [Google Scholar]
- Najjar, I.R.; Sadoun, A.M.; Fathy, A.; Abdallah, A.W.; Elaziz, M.A.; Elmahdy, M. Prediction of Tribological Properties of Alumina-Coated, Silver-Reinforced Copper Nanocomposites Using Long Short-Term Model Combined with Golden Jackal Optimization. Lubricants 2022, 10, 277. [Google Scholar] [CrossRef]
- Sadoun, A.M.; Najjar, I.M.R.; Fathy, A.; Abd Elaziz, M.; Al-qaness, M.A.; Abdallah, A.W.; Elmahdy, M. An enhanced Dendritic Neural Algorithm to predict the wear behavior of alumina coated silver reinforced copper nanocomposites. Alex. Eng. J. 2023, 65, 809–823. [Google Scholar] [CrossRef]
- Sadoun, A.M.; Wagih, A.; Fathy, A.; Essa, A.R.S. Effect of tool pin side area ratio on temperature distribution in friction stir welding. Results Phys. 2019, 15, 102814. [Google Scholar] [CrossRef]
- Cao, Y.F. A Comment on Granger Causality Test. J. Quant. Tech. Econ. 2006, 1, 155–160. [Google Scholar]
- Liu, J.; Zhao, H.Y.; Liu, J.C.; Pan, L.; Wang, K. Medium-term load forecasting based on cointegration-Granger causality test and seasonal decomposition. Autom. Electr. Power Syst. 2019, 43, 73–80. [Google Scholar] [CrossRef]
- Cui, G.Q. Feature Selection and Regression Prediction in Complex Dataset; Shanghai Jiao Tong University: Shanghai, China, 2017. [Google Scholar]
- Song, J.; Wang, W.L.; Li, D. Injection molding part size prediction method based on Stacking ensemble learning. J. South China Univ. Technol. (Nat. Sci. Ed.) 2022, 50, 19–26. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter Type | Parameter Name | Abbreviations | Parameter Name | Abbreviations |
|---|---|---|---|---|
| Raw material parameters | 63.5%Vanadium powder | VP63.5 | Calcium lime powder/(t·h−1) | GSHF |
| Steelmaking dust ash/(t·h−1) | SDA | Magnesium lime powder/(t·h−1) | MSHF | |
| Sintering return mines/(t·h−1) | SRM | Blast furnace return mines/(t·h−1) | BFRM | |
| Iron ore powder with vanadium_SiO2 | IOPV_SiO2 | Iron ore powder with vanadium_MgO | IOPV_MgO | |
| Mixes Composition parameters | Mixes_(water)/% | M-H2O | Mixes_(FeO)/% | M-FeO |
| Mixes_(SiO2)/% | M-SiO2 | Mixes_(CaO)/% | M-CaO | |
| Operating parameters | Trolley material thickness/mm | TMT | Coal gas pressure/kPa | CGP |
| Coal gas flow/(m3·h−1) | GGF | Ignition temperature/°C | IT | |
| Combustion air flow/(m3·h−1) | CAF | Combustion air pressure/kPa | CAP | |
| No. 1Damper opening/% | 1DO | No. 2Damper opening/% | 2DO | |
| Sintering machine speed/(m·min−1) | SMS | Ring cooler speed/(m·min−1) | RCS | |
| Exhaust gas temperature of north bellows/°C | EGTNB | Negative pressure of south pipe/kPa | NPSP | |
| No. 2Blast volume/(m3·h−1) | 2BV | Round roll speed | RRS | |
| Status Parameters | Burning through point/No. | BTP | Burn through temperature/°C | BTT |
| No. 1Airbox exhaust gas temperatures/°C | 1AEGT | No. 2Airbox exhaust gas temperatures/°C | 2AEGT | |
| No. 3Airbox exhaust gas temperatures/°C | 3AEGT | No. 5Airbox exhaust gas temperatures/°C | 5AEGT | |
| No. 7Airbox exhaust gas temperatures/°C | 7AEGT | No. 22Airbox exhaust gas temperatures/°C | 22AEGT | |
| No. 1Air box vacuum degree/kPa | 1ABVD | No. 2Air box vacuum degree/kPa | 3ABVD | |
| No. 3Air box vacuum degree/kPa | 3ABVD | No. 5Air box vacuum degree/kPa | 5ABVD | |
| No. 7Air box vacuum degree/kPa | 7ABVD | No. 22Air box vacuum degree/kPa | 22ABVD | |
| Sintered Ore Quality parameters | Drum index/% | DI | Screening index/% | SI |
| Particle size less than 10 mm/% | PSLT10mm | Fe/% | TFe | |
| FeO/% | FeO | Alkalinity | R | |
| SiO2/% | SiO2 | CaO/% | CaO |
| Definition | BTP | Sintering Temperature | Relationship |
|---|---|---|---|
| overburning | BTP < No. 20 | 360 °C < T | AND |
| normal | No. 20 ≤ BTP ≤ No. 21 | 320 °C ≤ T ≤ 360 °C | AND |
| underburning | No. 21 < BTP | T < 320 °C | OR |
| Data Volume Share of Drum Index | Drum Index Distribution Range | TFe Distribution Range | |
|---|---|---|---|
| Overburning | 7.25% | [75.7, 78.7] | [53.5, 56.5] |
| Normal | 86.30% | [76.8, 77.5] | [54.5, 55.8] |
| Underburning | 6.45% | [74.8, 78.5] | [54.5, 55.8] |
| NO. | Pearson | Value | Spearman | Value | Granger Causality | Value | |
|---|---|---|---|---|---|---|---|
| Drum Index | 1 | Screening index | −0.437 | Screening index | −0.500 | Blast volume | 0.621 |
| 2 | No. 1Air box vacuum degree | +0.287 | 1Air box vacuum degree | +0.344 | No. 5Air box vacuum degree | 0.589 | |
| 3 | CaO | +0.279 | Particle size less than 10 mm | −0.323 | Titanium iron concentrates | 0.531 | |
| 4 | BTP | −0.270 | Sintering return mines | +0.287 | No. 1Damper opening | 0.498 | |
| 5 | Magnesium lime powder | −0.270 | No. 5Air box vacuum degree | −0.278 | Vanadium titanium iron powder | 0.456 | |
| 6 | Mixed material CaO content | +0.255 | No. 11Air box vacuum degree | −0.278 | BTP | 0.448 | |
| 7 | No. 5Air box vacuum degree | −0.254 | Titanium iron concentrates | +0.278 | Sintering return mines | 0.431 | |
| 8 | No. 3Air box vacuum degree | +0.243 | BTP | −0.266 | Screening index | 0.402 | |
| 9 | lime powder | +0.243 | Mixed material CaO content | −0.265 | Lime powder | 0.387 | |
| 10 | Particle size less than 10 mm | −0.225 | No. 2Damper opening | 0.243 | Mixed material CaO content | 0.377 |
| TFe | Alkalinity | ||||||
|---|---|---|---|---|---|---|---|
| 1 | Mixes_(SiO2) | 7 | Mixed material SiO2 content | 1 | Trolley material thickness | 7 | Water addition rate of second mix |
| 2 | Mixes_(CaO) | 8 | Fuel ratio | 2 | Sintering machine speed | 8 | FeO |
| 3 | Mixes_(MgO) | 9 | No. 2Damper opening | 3 | Water addition rate of first mix | 9 | CaO |
| 4 | Mixes_(Al2O3) | 10 | Ring cooler speed | 4 | Mixture temperature | 10 | Coal powder proportion |
| 5 | Percentage of returned mine | 11 | Blast volume | 5 | Mixed material SiO2 content | 11 | BTP |
| 6 | BTP | 12 | Moisture rate | 6 | Mixed material CaO content | 12 | Blast volume |
| Sinter Quality Parameters | Evaluation Indicators | SVM | Random Forest | GBDT | Neural Network | Stacking |
|---|---|---|---|---|---|---|
| TFe | MSE | 0.332 | 0.075 | 0.368 | 0.068 | 0.038 |
| RMSE | 0.576 | 0.274 | 0.607 | 0.261 | 0.195 | |
| MAE | 0.447 | 0.177 | 0.470 | 0.168 | 0.058 | |
| R2 | 0.498 | 0.827 | 0.443 | 0.827 | 0.942 | |
| Test time/s | 13.866 | 20.145 | 28.508 | 8.387 | 35.138 | |
| Alkalinity | MSE | 0.003 | 0.002 | 0.003 | 0.002 | 0.001 |
| RMSE | 0.052 | 0.047 | 0.059 | 0.030 | 0.010 | |
| MAE | 0.046 | 0.032 | 0.035 | 0.021 | 0.002 | |
| R2 | 0.512 | 0.621 | 0.487 | 0.583 | 0.958 | |
| Test time/s | 2.221 | 5.095 | 1.445 | 0.154 | 6.081 | |
| Drum index | MSE | 0.170 | 0.007 | 0.065 | 0.012 | 0.003 |
| RMSE | 0.412 | 0.084 | 0.255 | 0.095 | 0.054 | |
| MAE | 0.277 | 0.031 | 0.198 | 0.045 | 0.005 | |
| R2 | 0.268 | 0.870 | 0.720 | 0.821 | 0.987 | |
| Test time/s | 16.969 | 14.326 | 5.077 | 6.016 | 34.441 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Liu, X.; Li, H.; Liu, R.; Zhang, Z.; Li, H.; Lyu, Q.; Wen, L. Research on Sinter Quality Prediction System Based on Granger Causality Analysis and Stacking Integration Algorithm. Metals 2023, 13, 419. https://doi.org/10.3390/met13020419
Li X, Liu X, Li H, Liu R, Zhang Z, Li H, Lyu Q, Wen L. Research on Sinter Quality Prediction System Based on Granger Causality Analysis and Stacking Integration Algorithm. Metals. 2023; 13(2):419. https://doi.org/10.3390/met13020419
Chicago/Turabian StyleLi, Xin, Xiaojie Liu, Hongyang Li, Ran Liu, Zhifeng Zhang, Hongwei Li, Qing Lyu, and Liangyixin Wen. 2023. "Research on Sinter Quality Prediction System Based on Granger Causality Analysis and Stacking Integration Algorithm" Metals 13, no. 2: 419. https://doi.org/10.3390/met13020419
APA StyleLi, X., Liu, X., Li, H., Liu, R., Zhang, Z., Li, H., Lyu, Q., & Wen, L. (2023). Research on Sinter Quality Prediction System Based on Granger Causality Analysis and Stacking Integration Algorithm. Metals, 13(2), 419. https://doi.org/10.3390/met13020419