
Application of Machine Learning Algorithms and SHAP for Prediction and Feature Analysis of Tempered Martensite Hardness in Low-Alloy Steels



Abstract
:1. Introduction
2. Data Collection
3. Machine Learning Training
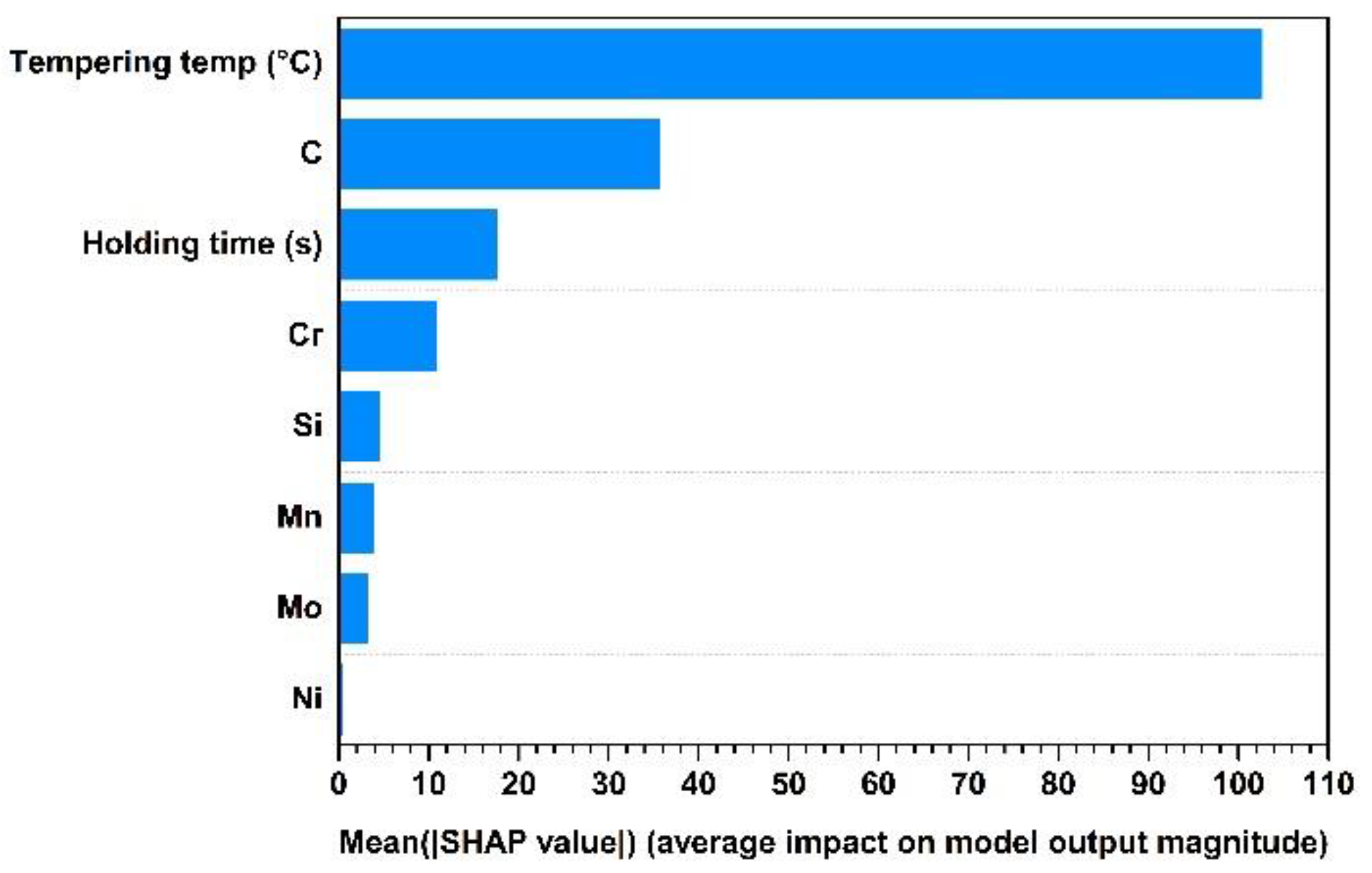
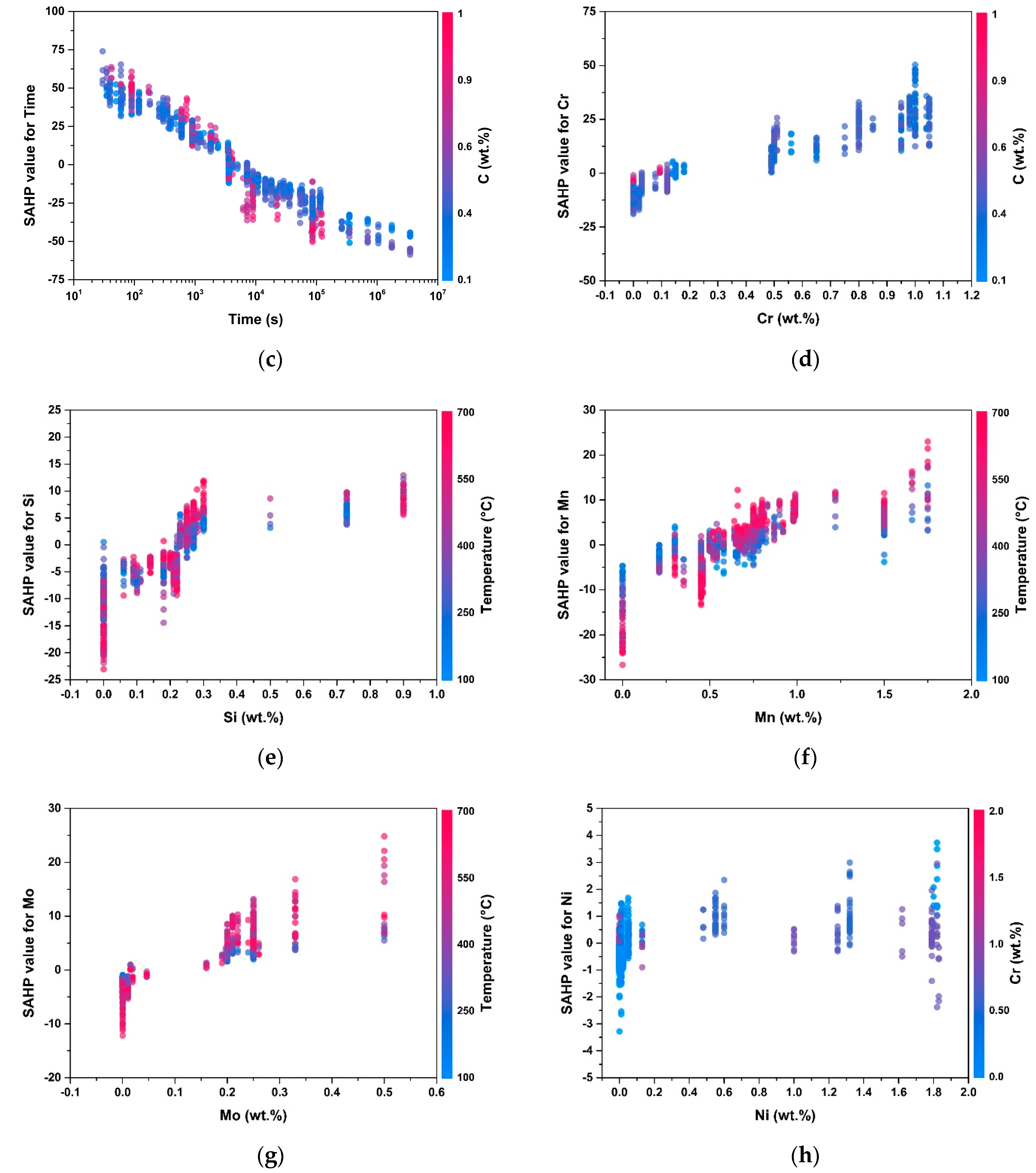
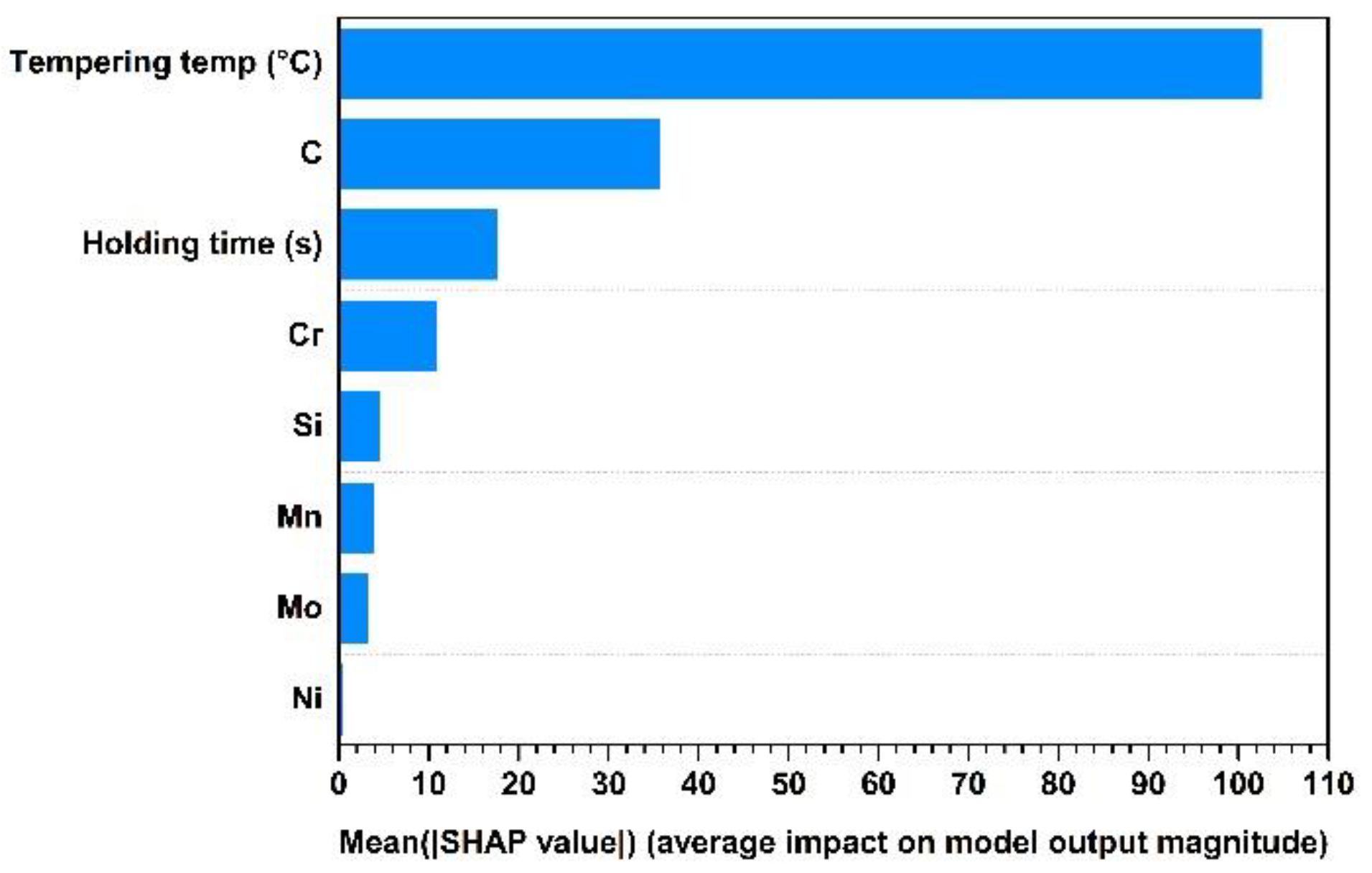
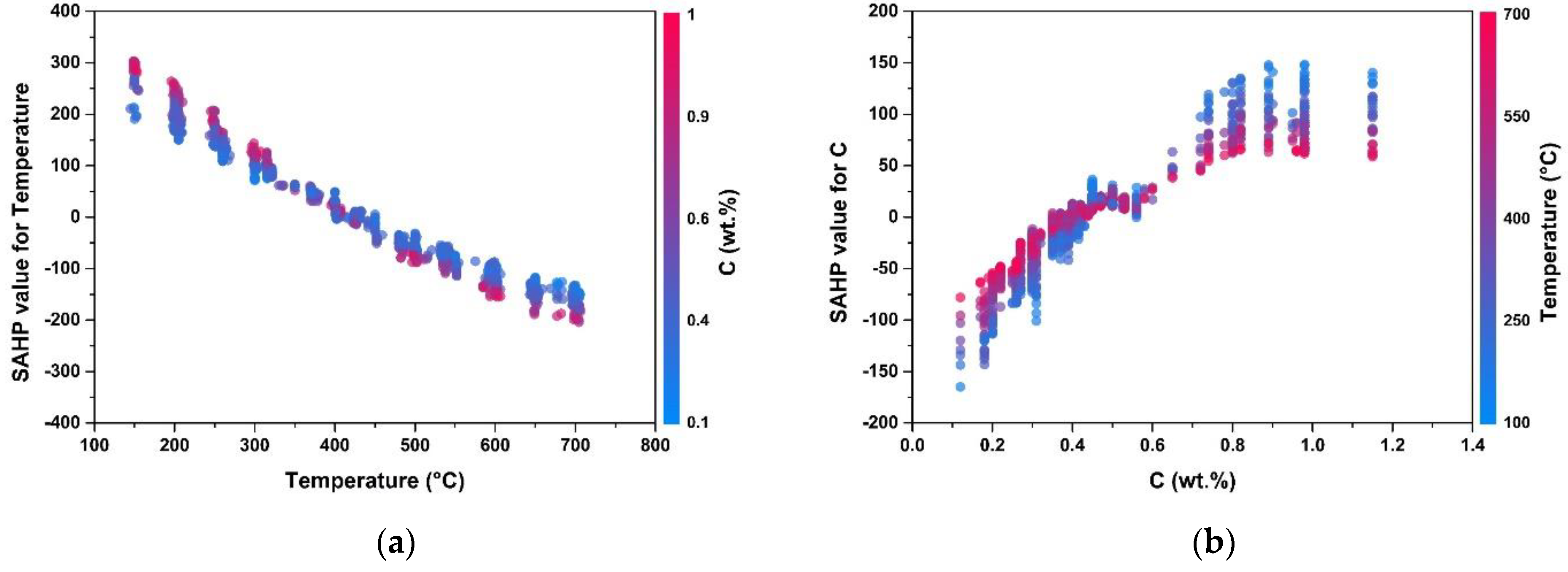
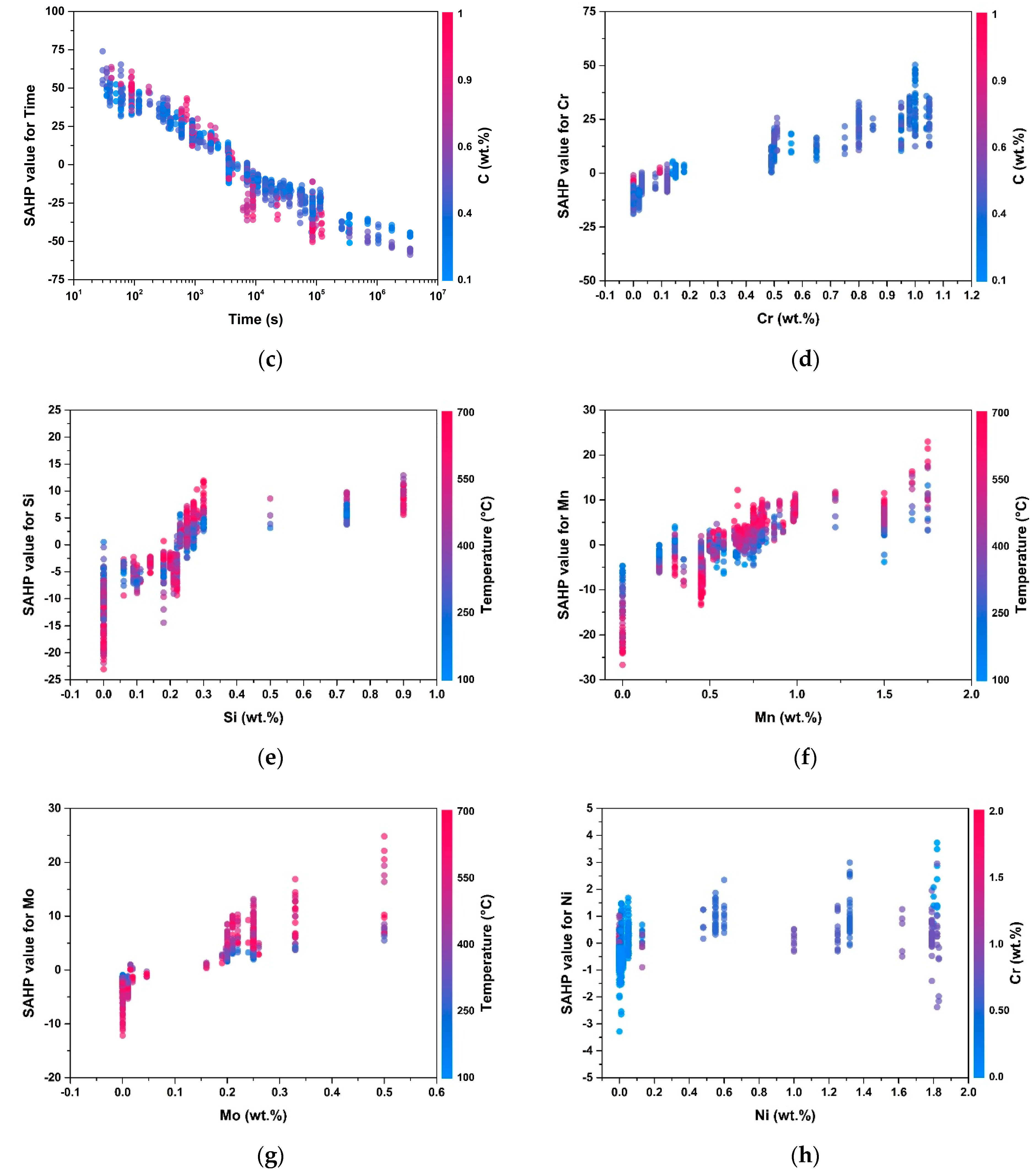
4. SHAP Method
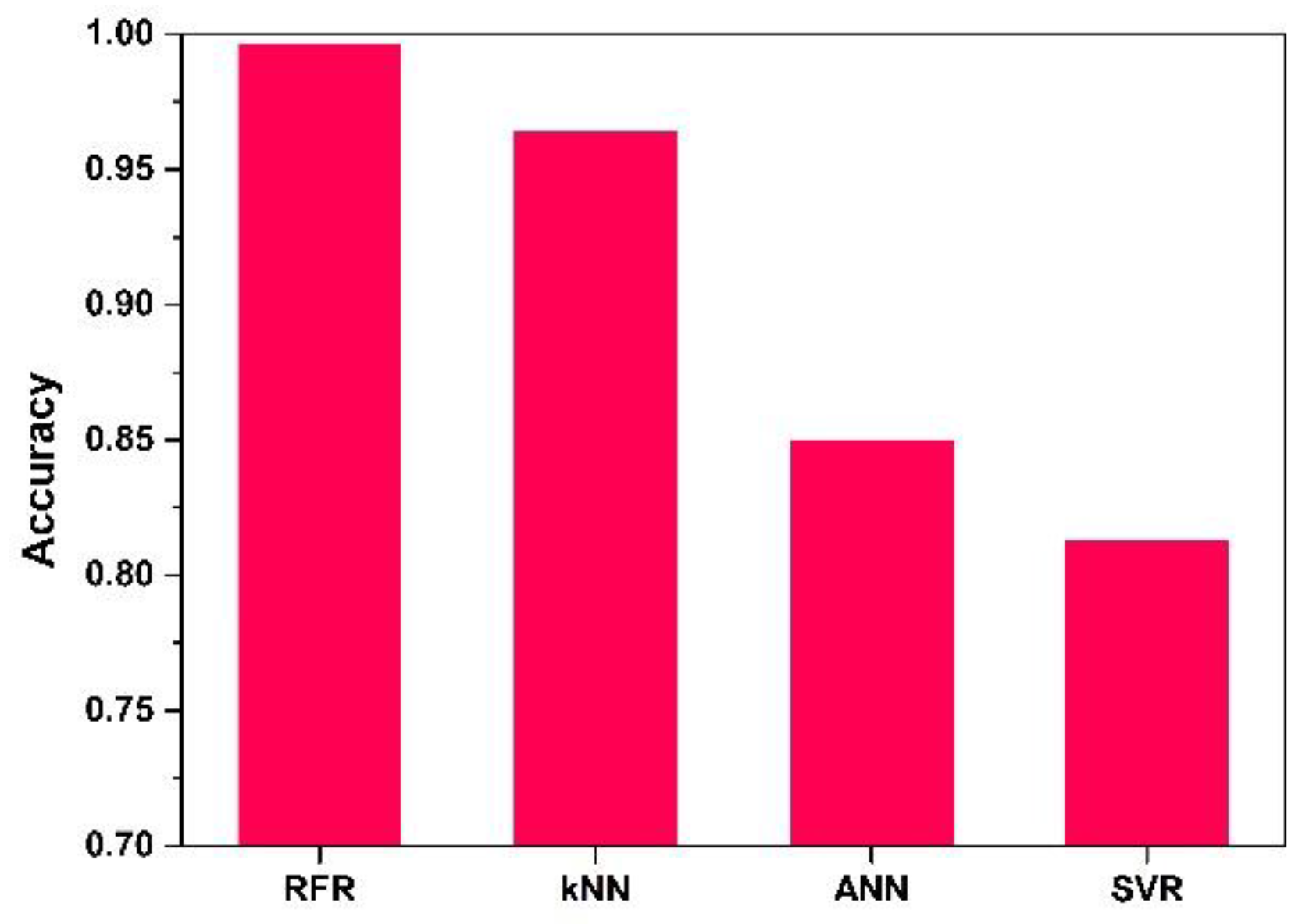
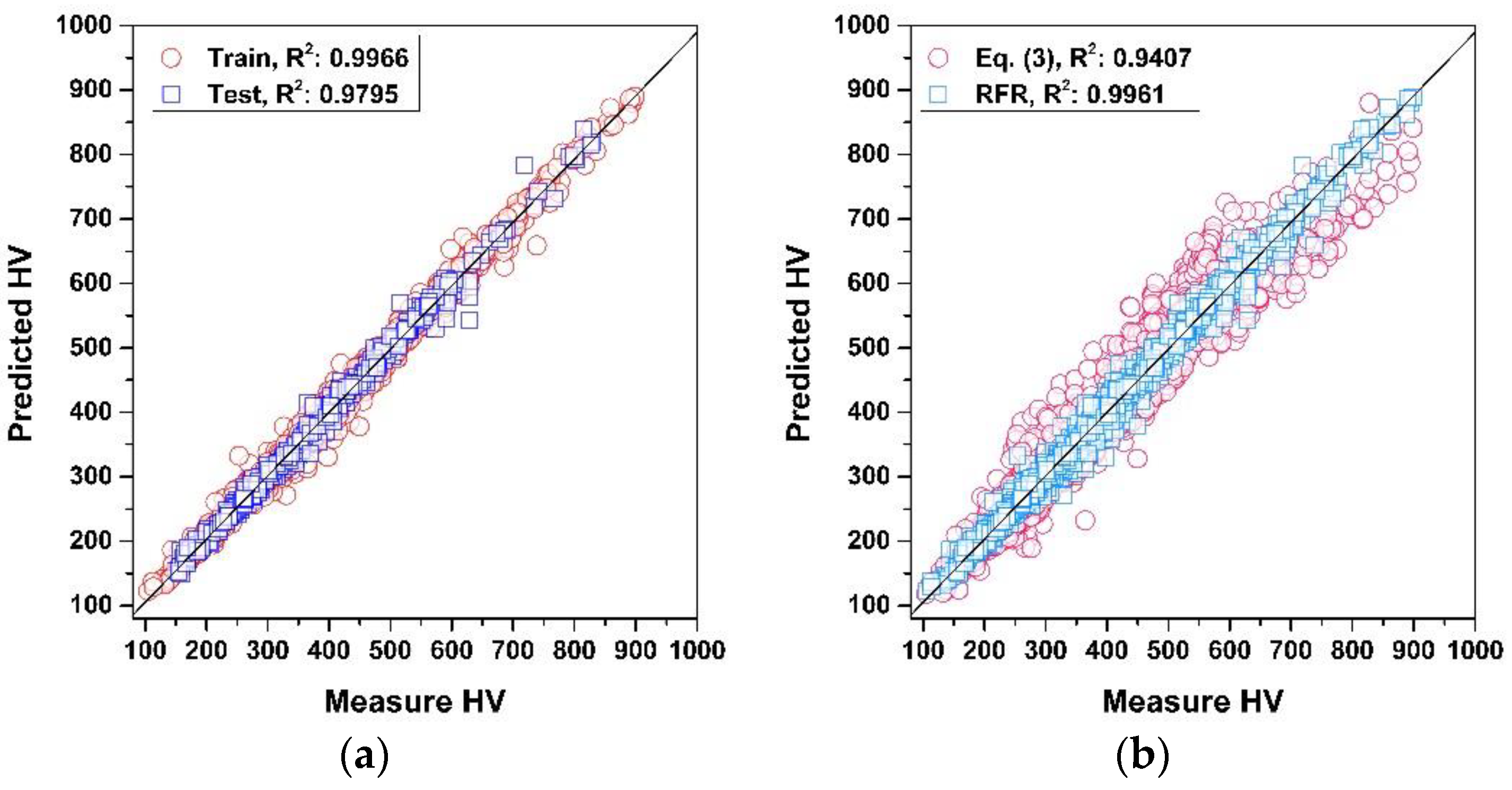
5. Results and Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hollomon, J.H.; Jaffe, L.D. Time-temperature relations in tempering steel. Trans. AIME 1945, 162, 223–249. [Google Scholar]
- Kang, S.; Lee, S.-J. Prediction of Tempered Martensite Hardness Incorporating the Composition-Dependent Tempering Parameter in Low Alloy Steels. Mater. Trans. 2014, 55, 1069–1072. [Google Scholar] [CrossRef] [Green Version]
- Grange, R.A.; Hribal, C.R.; Porter, L.F. Hardness of Tempered Martensite in Carbon and Low-Alloy Steels. Metall. Trans. A 1977, 8A, 1775–1785. [Google Scholar] [CrossRef]
- Materkowski, J.P.; Krauss, G. Tempered Martensite Embrittlement in SAE 4340 Steel. Matall. Trans. A 1979, 10A, 1643–1651. [Google Scholar] [CrossRef]
- Speich, G.R.; Leslie, W.C. Tempering of Steel. Metall. Trans. 1972, 3, 1043–1054. [Google Scholar] [CrossRef]
- Bhadeshia, H.; Honeycombe, R. Steels: Microstructure and Properties, 3rd ed.; Butterworth-Heinemann: Oxford, UK, 2006; pp. 231–262. [Google Scholar]
- Zhang, L.; Qian, K.; Schuller, B.W.; Shibuta, Y. Prediction on Mechanical Properties of Non-Equiatomic High-Entropy Alloy by Atomistic Simulation and Machine Learning. Metals 2021, 11, 922. [Google Scholar] [CrossRef]
- Narayana, P.L.; Kim, J.H.; Maurya, A.K.; Park, C.H.; Hong, J.-K.; Yeom, J.-T.; Reddy, N.S. Modeling Mechanical Properties of 25Cr-20Ni-0.4C Steels over a Wide Range of Temperatures by Neural Networks. Metals 2020, 10, 256. [Google Scholar] [CrossRef] [Green Version]
- Maurya, A.K.; Narayana, P.L.; Kim, H.I.; Reddy, N.S. Correlation of Sintering Parameters with Density and Hardness of Nano-sized Titanium Nitride reinforced Titanium Alloys using Neural Networks. J. Korean Powder Metall. Inst. 2020, 27, 1–8. [Google Scholar] [CrossRef]
- Jeon, J.; Seo, N.; Kim, H.-J.; Lee, M.-H.; Lim, H.-K.; Son, S.B.; Lee, S.-J. Inverse Design of Fe-based Bulk Metallic Glasses Using Machine Learning. Metals 2021, 11, 729. [Google Scholar] [CrossRef]
- Zhang, Y.; Xu, X. Lattice Misfit Predictions via the Gaussian Process Regression for Ni-Based Single Crystal Superalloys. Met. Mater. Int. 2021, 27, 235–253. [Google Scholar] [CrossRef]
- Park, C.H.; Cha, D.; Kim, M.; Reddy, N.S.; Yeom, J.-T. Neural Network Approach to Construct a Processing Map from a Non-linear Stress-Temperature Relationship. Met. Mater. Int. 2019, 25, 768–778. [Google Scholar] [CrossRef]
- Lee, W.; Lee, S.-J. Prediction of Jominy Curve using Artificial Neural Network. J. Korean Soc. Heat Treat. 2018, 31, 1–5. [Google Scholar]
- Schmidt, J.; Marques, M.R.G.; Botti, S.; Marques, M.A.L. Recent advances and applications of machine learning in solid-state materials science. Comput. Mater. 2019, 5, 1. [Google Scholar]
- Yan, L.; Diao, Y.; Lang, Z.; Gao, K. Corrosion rate prediction and influencing factors evaluation of low-alloy steels in marine atmosphere using machine learning approach. Sci. Technol. Adv. Mat. 2020, 21, 359–370. [Google Scholar] [CrossRef] [Green Version]
- Parsa, A.B.; Movahedi, A.; Taghipour, H.; Derrible, S.; Mohammadian, A. Toward safer highways, application of XGBoost and SHAP for real-time accident detection and feature analysis. Accid. Anal. Prev. 2020, 136, 105405. [Google Scholar] [CrossRef] [PubMed]
- Lundberg, S.M.; Nair, B.; Vavilala, M.S.; Horibe, M.; Eisses, M.J.; Adams, T.; Liston, D.E.; Low, D.K.-W.; Newman, S.-F.; Kim, J.; et al. Explainable machine-learning predictions for the prevention of hypoxaemia during surgery. Nat. Biomed. Eng. 2018, 2, 749–760. [Google Scholar] [CrossRef] [PubMed]
- Asgharzadeh, A.; Asgharzadeh, H.; Simchi, A. Role of Grain Size and Oxide Dispersion Nanopaticles on the Hot Deformation Behavior of AA6063: Experimental and Artificial Neural Network Modeling Investigations. Mat. Mater. Int. 2021, 29. [Google Scholar] [CrossRef]
- Smola, A.J.; Schölkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199. [Google Scholar] [CrossRef] [Green Version]
- Cover, T.; Hart, P. Nearest Neighbor Pattern Classification. IEEE Trans. Inf. Theory 1967, 13, 21. [Google Scholar] [CrossRef]
- Murthy, S.K.; Kasif, S.; Salzberg, S. A System for Induction of Oblique Decision Trees. J. Artif. Intell. Res. 1994, 2, 1. [Google Scholar] [CrossRef]
- Wang, Q.R.; Suen, C.Y. Analysis and Design of a Decision Tree Based on Entropy Reduction and Its Application to Large Character Set Recognition. IEEE Trans. Inf. Theory 1984, 6, 406. [Google Scholar] [CrossRef] [PubMed]
- Lundberg, S.M.; Lee, S.-I. A Unified Approach to Interpreting Model Predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4 December 2017; pp. 4768–4777. [Google Scholar]
- Shapley, L.S. Notes on the N-Person Game II: The Value of an N-Person Game; Technical Report for U.S. Air Force; Rand Corporation: Santa Monica, CA, USA, August 1951. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Minimum | Maximum | Average | Deviation | |
|---|---|---|---|---|
| C | 0.12 | 1.15 | 0.45 | 0.21 |
| Mn | 0.00 | 1.75 | 0.65 | 0.32 |
| Si | 0.00 | 0.90 | 0.24 | 0.17 |
| Ni | 0.00 | 3.50 | 0.26 | 0.71 |
| Cr | 0.00 | 2.00 | 0.20 | 0.38 |
| Mo | 0.00 | 0.50 | 0.06 | 0.11 |
| Tempering temperature | 145 | 716 | 444 | 160 |
| Holding time | 30 | 3,500,000 | 68,665 | 344,146 |
| Hardness (HV) | 105 | 899 | 395 | 144 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jeon, J.; Seo, N.; Son, S.B.; Lee, S.-J.; Jung, M. Application of Machine Learning Algorithms and SHAP for Prediction and Feature Analysis of Tempered Martensite Hardness in Low-Alloy Steels. Metals 2021, 11, 1159. https://doi.org/10.3390/met11081159
Jeon J, Seo N, Son SB, Lee S-J, Jung M. Application of Machine Learning Algorithms and SHAP for Prediction and Feature Analysis of Tempered Martensite Hardness in Low-Alloy Steels. Metals. 2021; 11(8):1159. https://doi.org/10.3390/met11081159
Chicago/Turabian StyleJeon, Junhyub, Namhyuk Seo, Seung Bae Son, Seok-Jae Lee, and Minsu Jung. 2021. "Application of Machine Learning Algorithms and SHAP for Prediction and Feature Analysis of Tempered Martensite Hardness in Low-Alloy Steels" Metals 11, no. 8: 1159. https://doi.org/10.3390/met11081159
APA StyleJeon, J., Seo, N., Son, S. B., Lee, S.-J., & Jung, M. (2021). Application of Machine Learning Algorithms and SHAP for Prediction and Feature Analysis of Tempered Martensite Hardness in Low-Alloy Steels. Metals, 11(8), 1159. https://doi.org/10.3390/met11081159