Are Danes’ Immigration Policy Preferences Based on Accurate Stereotypes?


Abstract
1. Introduction
2. Data and Questionnaire Design
2.1. Survey Design
- Overall, how are Muslims treated in Denmark in comparison to non-Muslims? 1–7 Likert scale from ‘much better’ to ‘much worse’.
- On a scale of 1–7 (Likert agreement), how much do you agree with the following statement: Denmark should only allow immigrants who do not harm the public budget.
- On a scale of 1–7 (Likert agreement), how much do you agree with the following statement: Currently, non-Western immigrants pay on average more in tax than they receive in form of social benefits.
2.2. Other Data
3. Analyses
3.1. Aggregate Stereotypes
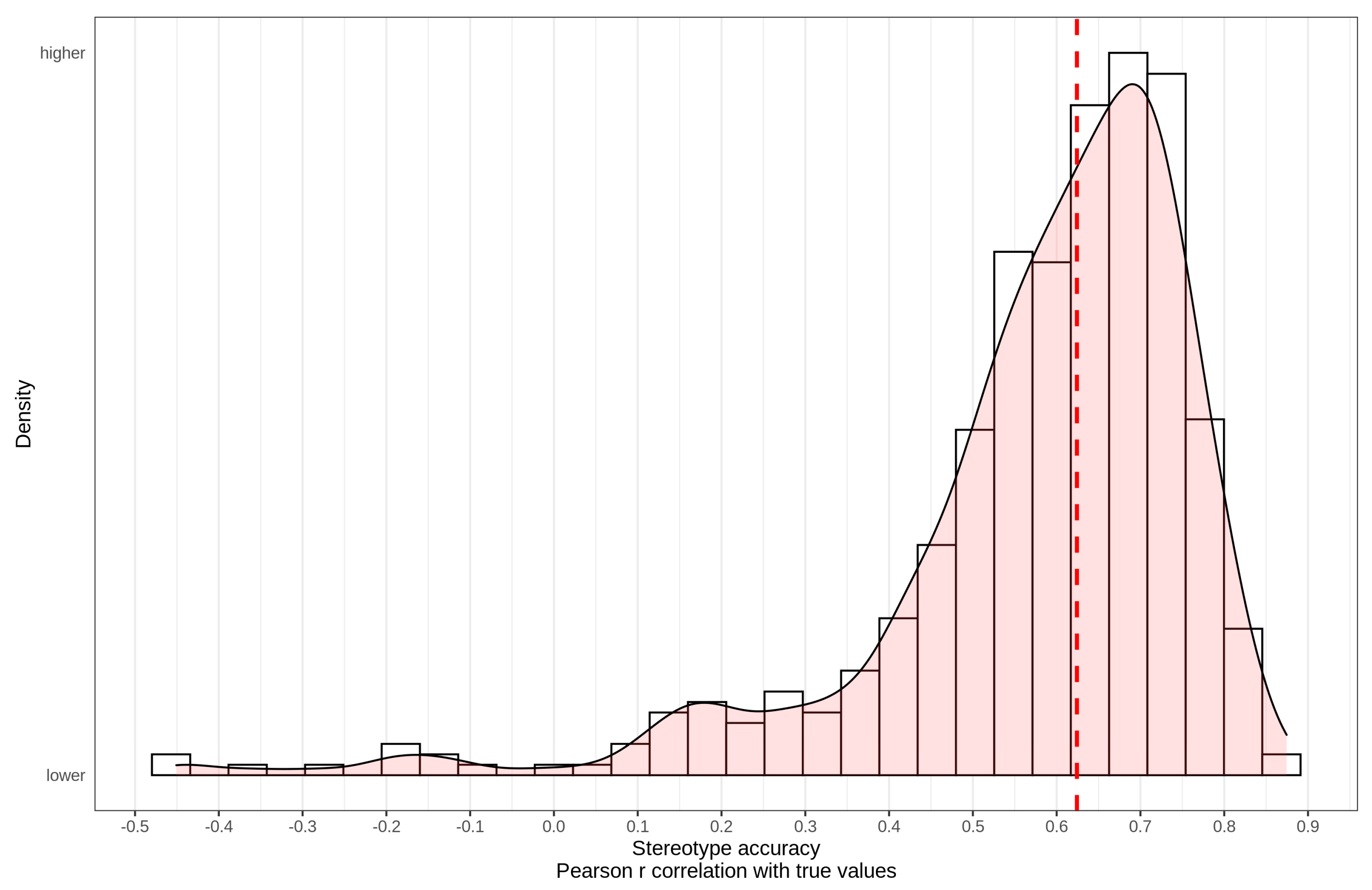
3.1.1. Accuracy
3.1.2. Muslim Bias in Stereotypes
3.1.3. Stereotypes and Preferred Immigration Policy
3.1.4. Comparison with Results from the Study of the United Kingdom
3.2. Individual Stereotypes
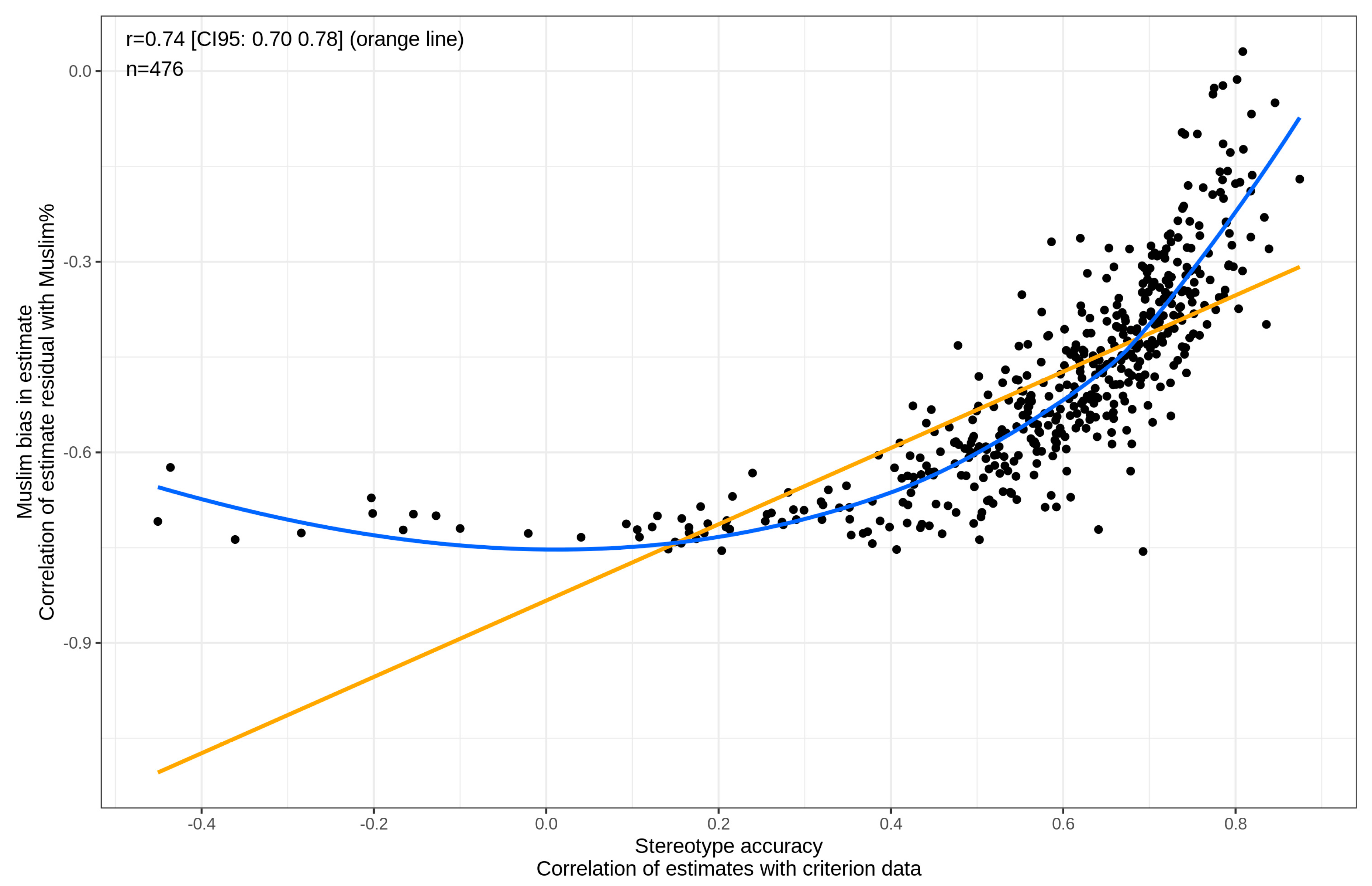
3.2.1. Accuracy
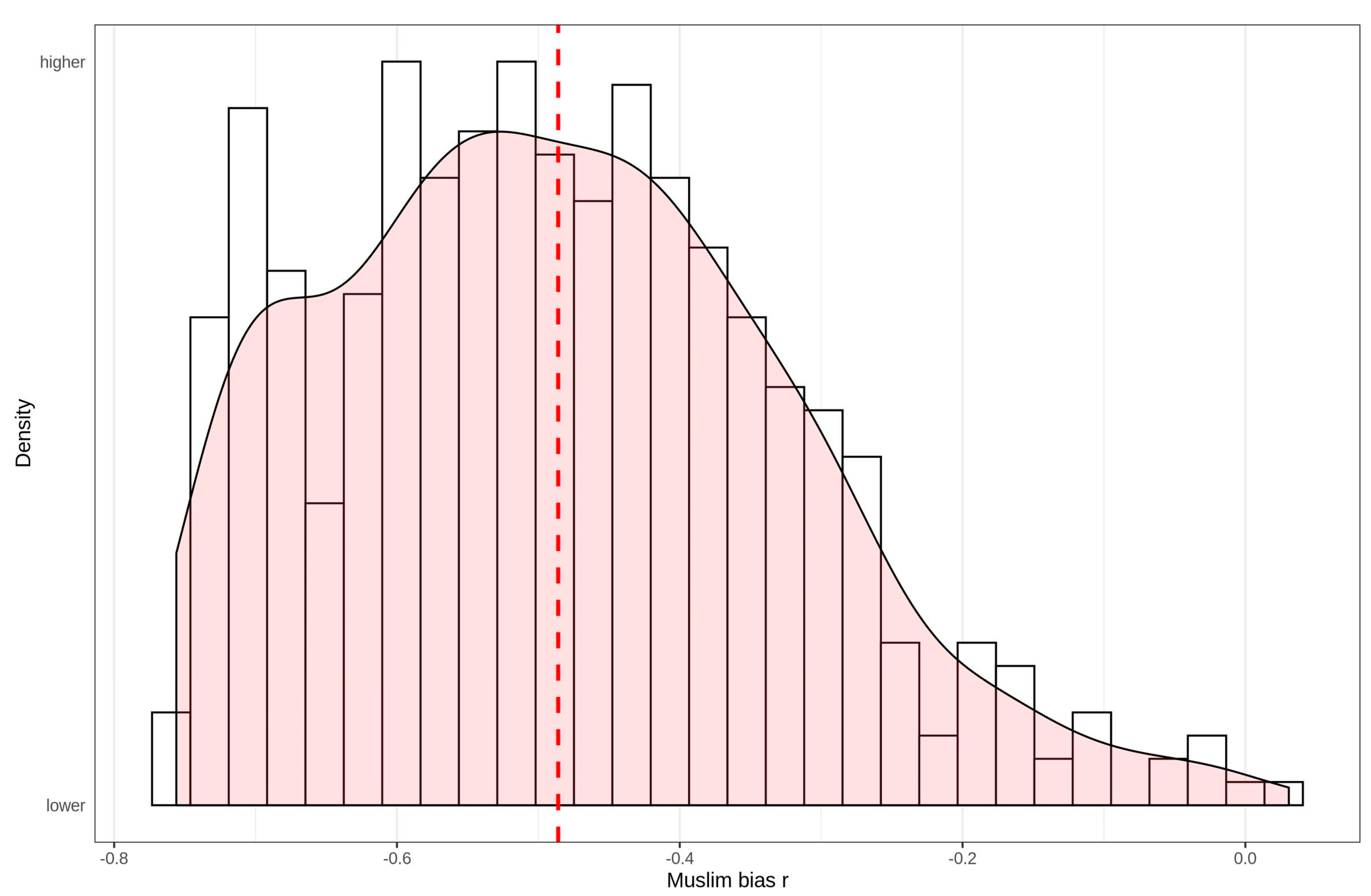
3.2.2. Muslim Bias in Stereotypes
3.2.3. Muslim Preferences
3.2.4. Predictors of Stereotype Accuracy, Muslim Bias and Muslim Preference
4. Discussion and Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Bansak, K.; Hainmueller, J.; Hangartner, D. How economic, humanitarian, and religious concerns shape European attitudes toward asylum seekers. Science 2016, 354, 217–222. [Google Scholar] [CrossRef] [PubMed]
- Goodwin, M.J.; Raines, T.; Cutts, D. What do Europeans Think about Muslim Immigration? Chatham House. Available online: https://www.chathamhouse.org//node/27756 (accessed on 1 March 2017).
- De Rooij, E.A.; Goodwin, M.J.; Pickup, M. A Research Note: The Differential Impact of Threats on Ethnic Prejudice Toward Three Minority Groups in Britain. Politi Sci. Res. Methods 2017, 6, 837–845. [Google Scholar] [CrossRef]
- Valentino, N.A.; Soroka, S.N.; Iyengar, S.; Aalberg, T.; Duch, R.; Fraile, M.; Hahn, K.S.; Hansen, K.M.; Harell, A.; Helbling, M.; et al. Economic and Cultural Drivers of Immigrant Support Worldwide. Br. J. Politi- Sci. 2017, 49, 1201–1226. [Google Scholar] [CrossRef]
- Carl, N. Net opposition to immigrants of different nationalities correlates strongly with their arrest rates in the UK. Open Quant. Sociol. Politi- Sci. 2016. [Google Scholar] [CrossRef]
- Kirkegaard, E.O.W.; Bjerrekær, J.D. Country of origin and use of social benefits: A large, preregistered study of stereotype accuracy in Denmark. Open Differ. Psychol. 2016. [Google Scholar] [CrossRef]
- Heine, S.J.; Buchtel, E.E.; Norenzayan, A. What Do Cross-National Comparisons of Personality Traits Tell Us? The Case of Conscientiousness. Psychol. Sci. 2008, 19, 309–313. [Google Scholar] [CrossRef]
- Jussim, L. Social Perception and Social Reality; Oxford University Press (OUP): Oxford, UK, 2012. [Google Scholar]
- Jussim, L.; Crawford, J.T.; Rubinstein, R.S. Stereotype (In)Accuracy in Perceptions of Groups and Individuals. Curr. Dir. Psychol. Sci. 2015, 24, 490–497. [Google Scholar] [CrossRef]
- Landy, D.; Guay, B.; Marghetis, T. Bias and ignorance in demographic perception. Psychon. Bull. Rev. 2017, 25, 1606–1618. [Google Scholar] [CrossRef]
- Naegele, K.D.; Merton, R.K. Social Theory and Social Structure. Am. Sociol. Rev. 1957, 22, 759. [Google Scholar] [CrossRef]
- Fernández-Kelly, P. Fixing the cultural fallacy. Ethn. Racial Stud. 2016, 39, 1–7. [Google Scholar] [CrossRef]
- Tubadji, A.; Gheasi, M.; Nijkamp, P.; Ziderman, A.; Lange, T. Immigrants’ socio-economic achievements and cultural diversity. Int. J. Manpow. 2017, 38, 712–728. [Google Scholar] [CrossRef]
- Shewach, O.R.; Sackett, P.R.; Quint, S. Stereotype threat effects in settings with features likely versus unlikely in operational test settings: A meta-analysis. J. Appl. Psychol. 2019, 104, 1514–1534. [Google Scholar] [CrossRef] [PubMed]
- Neve, A.F. Time Favors Them not: Some Migrant Groups Have Low Employment Rates even after 25+ Years of Residence. Medium. Available online: https://medium.com/@afn/time-favors-them-not-some-migrant-groups-have-low-employment-rates-even-after-25-years-of-3c3e36094108 (accessed on 28 August 2017).
- Borjas, G.J. We Wanted Workers: Unraveling the Immigration Narrative; W. W. Norton & Company: New York, NY, USA, 2016. [Google Scholar]
- Hendricks, L.; Schoellman, T. Human Capital and Development Accounting: New Evidence from Wage Gains at Migration. Q. J. Econ. 2017, 133, 665–700. [Google Scholar] [CrossRef]
- Carl, N. Immigrant Groups That Are more Skill-Selected Have Higher Average Incomes. Medium. Available online: https://medium.com/@NoahCarl/immigrant-groups-that-are-more-skill-selected-have-higher-average-incomes-b97f09b2bbe2 (accessed on 14 January 2017).
- Jussim, L. Précis of Social Perception and Social Reality: Why accuracy dominates bias and self-fulfilling prophecy. Behav. Brain Sci. 2017, 40, e1. [Google Scholar] [CrossRef] [PubMed]
- Spitz, H.H. Beleaguered Pygmalion: A History of the Controversy Over Claims that Teacher Expectancy Raises Intelligence. Intelligence 1999, 27, 199–234. [Google Scholar] [CrossRef]
- Calin-Jageman, R. We’ve Been Here Before: The Replication Crisis over the Pygmalion Effect. Introduction to the New Statistics. Available online: https://thenewstatistics.com/itns/2018/04/03/weve-been-here-before-the-replication-crisis-over-the-pygmalion-effect/ (accessed on 3 April 2018).
- Finansministeriet. Økonomisk Analyse: Indvandreres Nettobidrag til de Offentlige Finanser. Finansministeriet. Available online: https://www.fm.dk/oekonomi-og-tal/oekonomisk-analyse/2017/indvandreres-nettobidrag-til-offentlige-finanser (accessed on 1 November 2017).
- Statistics Denmark. FOLK1A. Population at the First Day of the Quarter by Region, Sex, Age and Marital Status. Statistics Denmark. 2017. Available online: https://www.statbank.dk/statbank5a/SelectVarVal/Define.asp?MainTable=FOLK1A&PLanguage=1 / (accessed on 1 September 2017).
- Statistics Denmark. HFUDD10. Educational Attainment (15-69 Years) by Region, Ancestry, Highest Education Completed, Age and Sex. Statistics Denmark. 2017. Available online: https://www.statbank.dk/statbank5a/SelectVarVal/Define.asp?MainTable=HFUDD10&PLanguage=1. / (accessed on 1 September 2017).
- Wikipedia. Opinion Polling for the 2019 Danish General Election. Wikipedia. Available online: https://en.wiki. (accessed on 1 May 2019).
- Pew Research Center. Table: Muslim Population by Country. Pew Research Center. Available online: http://www.pewforum.org/2011/01/27/table-muslim-population-by-country/ (accessed on 27 January 2011).
- Koopmans, R. Religious Fundamentalism and Hostility against Out-groups: A Comparison of Muslims and Christians in Western Europe. J. Ethn. Migr. Stud. 2014, 41, 33–57. [Google Scholar] [CrossRef]
- Wagenmakers, E.-J.; Wetzels, R.; Borsboom, D.; Van Der Maas, H.L.J.; Kievit, R.A. An Agenda for Purely Confirmatory Research. Perspect. Psychol. Sci. 2012, 7, 632–638. [Google Scholar] [CrossRef]
- Wicherts, J.M.; Veldkamp, C.L.S.; Augusteijn, H.E.M.; Bakker, M.; Van Aert, R.C.M.; Van Assen, M.A.L.M. Degrees of Freedom in Planning, Running, Analyzing, and Reporting Psychological Studies: A Checklist to Avoid p-Hacking. Front. Psychol. 2016, 7, 108. [Google Scholar] [CrossRef]
- Velicer, W.F.; Cumming, G.; Fava, J.L.; Rossi, J.S.; Prochaska, J.O.; Johnson, J. Theory Testing Using Quantitative Predictions of Effect Size. Appl. Psychol. 2008, 57, 589–608. [Google Scholar] [CrossRef]
- Ashton, M.C.; Esses, V.M. Stereotype Accuracy: Estimating the Academic Performance of Ethnic Groups. Pers. Soc. Psychol. Bull. 1999, 25, 225–236. [Google Scholar] [CrossRef]
- Jussim, L.; Stevens, S.T.; Honeycutt, N. The Accuracy of Demographic Stereotypes. Available online: https://psyarxiv.com/beaq3/ (accessed on 1 February 2018).
- Statistics Denmark. FOLK1C. Population at the First Day of the Quarter by Time and Country of Origin. Statistics Denmark. 2018. Available online: http://www.statistikbanken.dk/statbank5a/SelectVarVal/Define.asp?Maintable=FOLK1C&PLanguage=1. / (accessed on 1 September 2018).
- Tingley, D.; Yamamoto, T.; Hirose, K.; Keele, L.; Imai, K. mediation: R Package for Causal Mediation Analysis. J. Stat. Softw. 2014, 59, 1–36. [Google Scholar] [CrossRef]
- Carabana, J. Why Do the Results of Immigrant Students Depend So Much on Their Country of Origin and so Little on Their Country of Destination? In Pisa Under Examination; Springer Science and Business Media LLC: Berlin, Germany, 2011; Volume 11, pp. 207–221. [Google Scholar]
- Kirkegaard, E.O.W. Crime, income, educational attainment and employment among immigrant groups in Norway and Finland. Open Differ. Psychol. 2014, 10, 1–13. [Google Scholar] [CrossRef]
- Skardhamar, T.; Aaltonen, M.; Lehti, M. Immigrant crime in Norway and Finland. J. Scand. Stud. Criminol. Crime Prev. 2014, 15, 107–127. [Google Scholar] [CrossRef]
- Kirkegaard, E.O.W. Employment Rates for 11 Country of Origin Groups in Scandinavia. Mank. Q. 2017, 58, 312–323. [Google Scholar]
- Royston, P.; Altman, U.G.; Sauerbrei, W. Dichotomizing continuous predictors in multiple regression: a bad idea. Stat. Med. 2005, 25, 127–141. [Google Scholar] [CrossRef] [PubMed]
- Westfall, J.; Yarkoni, T. Statistically Controlling for Confounding Constructs Is Harder than You Think. PLOS ONE 2016, 11, e0152719. [Google Scholar] [CrossRef] [PubMed]
- Uebersax, J.S. Introduction to the Tetrachoric and Polychoric Correlation Coefficients. Available online: http://john-uebersax.com/stat/tetra.htm. (accessed on 1 September 2017).
- Revelle, W. psych: Procedures for Psychological, Psychometric, and Personality Research (Version 1.7.8). Available online: https://cran.r-project.org/web/packages/psych/index.html (accessed on 1 September 2017).
- Lovakov, A.; Agadullina, E. Empirically Derived Guidelines for Interpreting Effect Size in Social Psychology. Available online: https://doi.org/10.17605/OSF.IO/2EPC4 (accessed on 1 September 2017).
- Richard, D.; Bond, C.F.; Stokes-Zoota, J.J. One Hundred Years of Social Psychology Quantitatively Described. Rev. Gen. Psychol. 2003, 7, 331–363. [Google Scholar] [CrossRef]
- Hunter, J.E.; Schmidt, F.L. Methods of Meta-Analysis Correcting Error and Bias in Research Findings. Thousand Oaks, CA: Sage. Available online: http://site.ebrary.com/id/10387875 (accessed on 1 September 2017).
- Cole, D.A.; Preacher, K.J. Manifest variable path analysis: Potentially serious and misleading consequences due to uncorrected measurement error. Psychol. Methods 2014, 19, 300–315. [Google Scholar] [CrossRef]
- Lick, D.J.; Alter, A.L.; Freeman, J.B. Superior pattern detectors efficiently learn, activate, apply, and update social stereotypes. J. Exp. Psychol. Gen. 2018, 147, 209–227. [Google Scholar] [CrossRef]
- Fraley, R.C.; Vazire, S. The N-Pact Factor: Evaluating the Quality of Empirical Journals with Respect to Sample Size and Statistical Power. PLOS ONE 2014, 9, e109019. [Google Scholar] [CrossRef]
- Henrich, J.; Heine, S.J.; Norenzayan, A. The weirdest people in the world? Behav. Brain Sci. 2010, 33, 61–83. [Google Scholar] [CrossRef] [PubMed]
- Gelman, A.; Loken, E. The Garden of Forking Paths: Why Multiple Comparisons Can Be a Problem, Even When There Is no Fishing Expedition’’ or p-hacking’’ and the Research Hypothesis Was Posited ahead of Time. Available online: http://www.stat.columbia.edu/~gelman/research/unpublished/ (accessed on 1 September 2017).
- Rubin, M. An Evaluation of Four Solutions to the Forking Paths Problem: Adjusted Alpha, Preregistration, Sensitivity Analyses, and Abandoning the Neyman-Pearson Approach. Rev. Gen. Psychol. 2017, 21, 321–329. [Google Scholar] [CrossRef]
- Alexander, S. Noisy Poll Results and Reptilian Muslim Climatologists from Mars. Available online: from: http://slatestarcodex.com/2013/04/12/noisy-poll-results-and-reptilian-muslim-climatologists-from-mars/ (accessed on 12 April 2013).
- Chang, S.-J.; Van Witteloostuijn, A.; Eden, L. From the Editors: Common method variance in international business research. J. Int. Bus. Stud. 2010, 41, 178–184. [Google Scholar] [CrossRef]
- Jakobsen, M.; Jensen, R. Common Method Bias in Public Management Studies. Int. Public Manag. J. 2014, 18, 3–30. [Google Scholar] [CrossRef]
- Caplan, B. The Myth of the Rational Voter: Why Democracies Choose Bad Policies; Princeton University Press: Princeton, NJ, USA, 2007; pp. 1–296. [Google Scholar]
- Nardelli, A.; Arnett, G. Today’s Key Fact: You Are Probably Wrong about almost Everything. Guardian Datablog. Available online: https://www.theguardian.com/news/datablog/2014/oct/29/todays-key-fact-you-are-probably-wrong-about-almost-everything (accessed on 29 October 2014).
- Sohoni, D.; Sohoni, T.W.P. Perceptions of Immigrant Criminality: Crime and Social Boundaries. Sociol. Q. 2014, 55, 49–71. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Muslim Resid r | Muslim Elevation Error | Muslim Error r | |
|---|---|---|---|
| Muslim resid r | 1 | ||
| Muslim elevation error | 0.71 | 1 | |
| Muslim error r | 0.65 | 0.96 | 1 |
| Data | n | Metric | Value |
|---|---|---|---|
| New | 32 | Muslim resid r | −0.25 [−0.55, 0.11] |
| Old | 32 | Muslim resid r | −0.11 [−0.44, 0.25] |
| Old | 70 | Muslim resid r | −0.27 [−0.48, −0.04] |
| Old | 32 | Muslim error r | −0.39 [−0.65, −0.05] |
| Old | 70 | Muslim error r | −0.34 [−0.53, −0.12] |
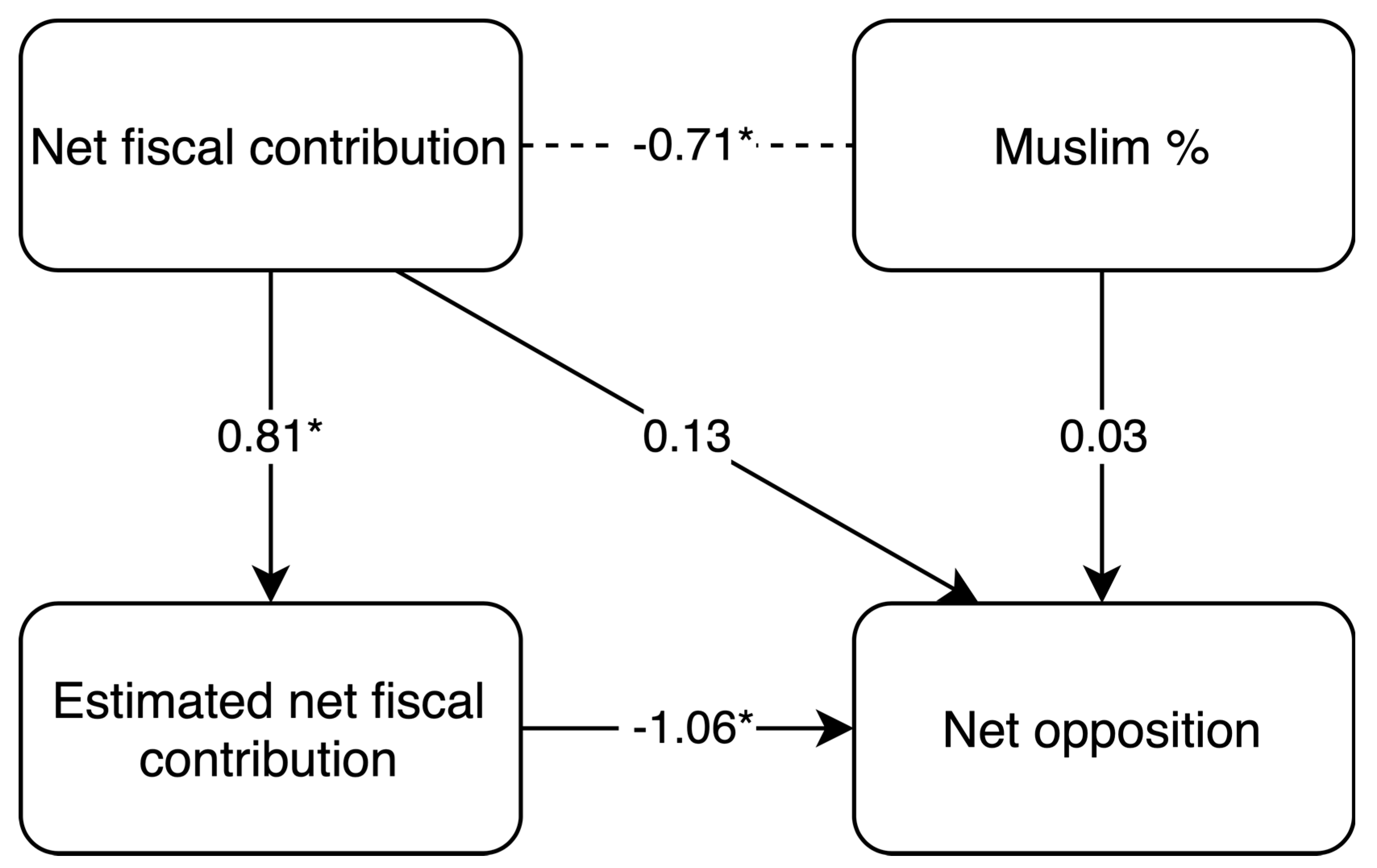
| Net fiscal Contribution | Mean Estimate | Muslim Population (%) | Net Opposition | |
|---|---|---|---|---|
| Net fiscal contribution | 1 | |||
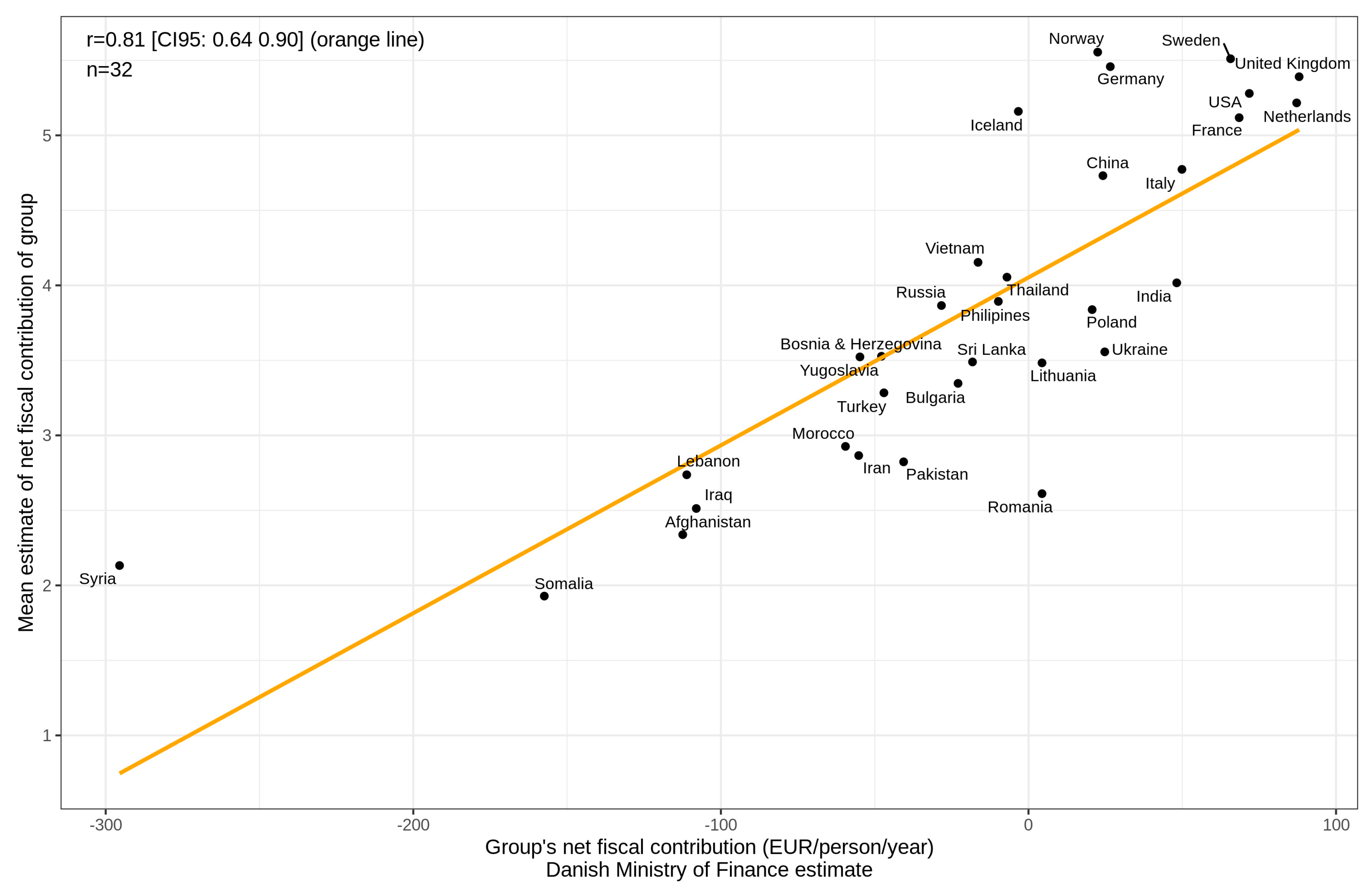
| Mean estimate | 0.81 [0.64, 0.90] | 1 | ||
| Muslim population (%) | −0.73 [−0.86, −0.51] | −0.72 [−0.86, −0.50] | 1 | |
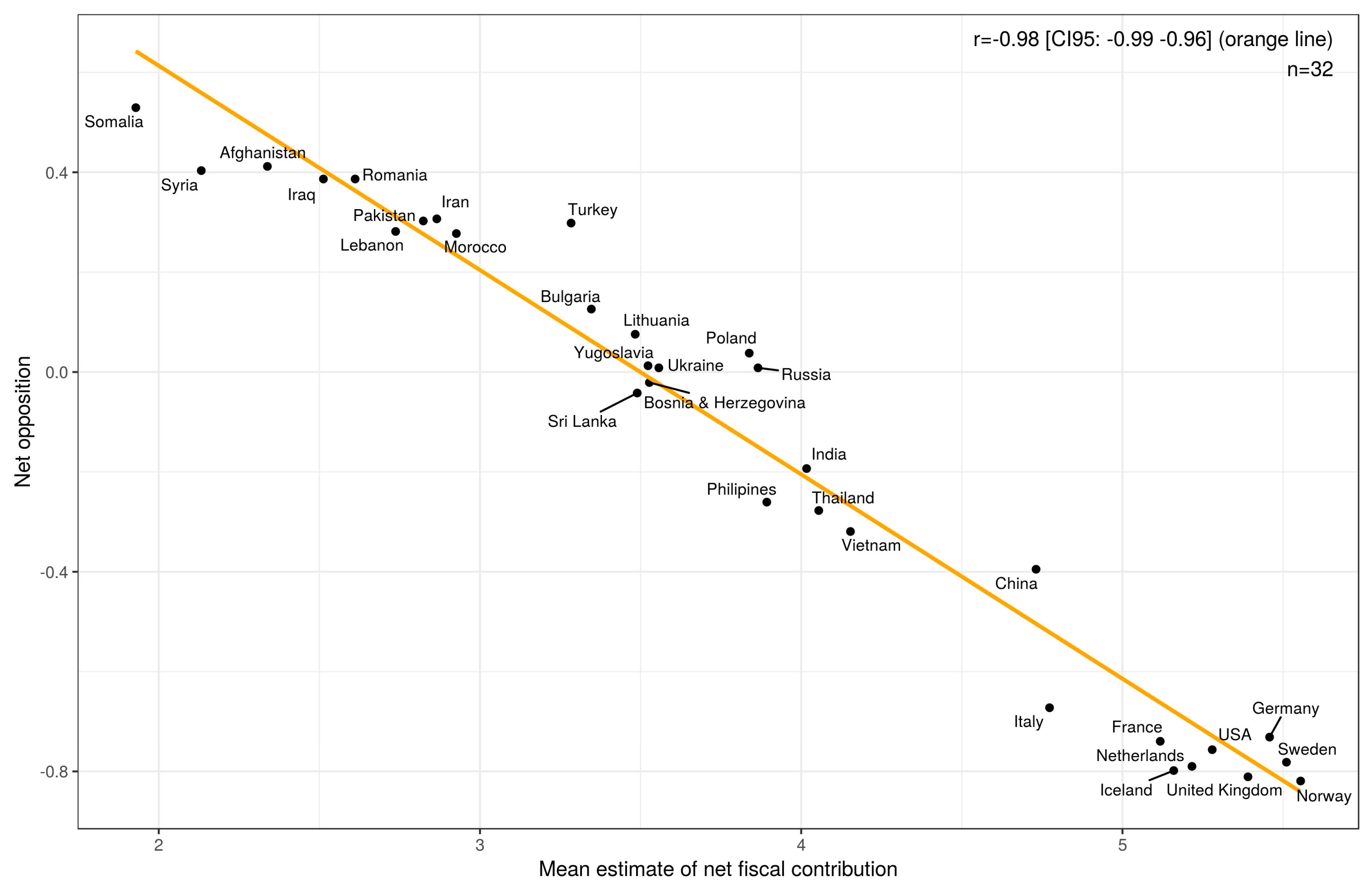
| Net opposition | −0.75 [−0.87, −0.55] | −0.98 [−0.99, −0.96] | 0.70 [0.47, 0.85] | 1 |
| DK: Benefits Ue | DK: Net Fiscal Contribution | UK: Crime Rate | DK: Mean Estimate Benefits | DK: Mean Estimate Fiscal | DK: Net Opposition | UK: Net Opposition | Muslim Population (%) | |
|---|---|---|---|---|---|---|---|---|
| DK: benefits use | 1 | |||||||
| DK: net fiscal contribution | −0.89 | 1 | ||||||
| UK: crime rate | 0.51 | −0.41 | 1 | |||||
| DK: mean estimate benefits | 0.70 | −0.89 | 0.70 | 1 | ||||
| DK: mean estimate fiscal | −0.72 | 0.81 | −0.70 | −0.94 | 1 | |||
| DK: Net opposition | 0.68 | −0.75 | 0.73 | 0.90 | −0.98 | 1 | ||
| UK: Net opposition | 0.60 | −0.85 | 0.68 | 0.85 | −0.95 | 0.97 | 1 | |
| Muslim population (%) | 0.68 | −0.73 | 0.42 | 0.70 | −0.72 | 0.70 | 0.58 | 1 |
| Stereotype Accuracy | Muslim Bias r | Muslim Preference | Age | Muslims are Treated Well | Admit Only Net Positive Immigrants | Non-Westerns are Net Positive | |
|---|---|---|---|---|---|---|---|
| Stereotype accuracy | 1 | ||||||
| Muslim bias r | 0.74 | 1 | |||||
| Muslim preference | −0.04 | −0.05 | 1 | ||||
| Age | 0.14 | 0.09 | −0.12 | 1 | |||
| Muslims are treated well | 0.09 | 0.10 | −0.19 | 0.13 | 1 | ||
| Admit only net positive immigrants | 0.15 | 0.18 | −0.32 | 0.10 | 0.49 | 1 | |
| Non-westerns are net positive | −0.12 | −0.16 | 0.09 | −0.11 | −0.19 | −0.21 | 1 |
| Model 1 | Model 2 | Model 3 | Model 4 | Model 5 | Model 6 | |
|---|---|---|---|---|---|---|
| Intercept | 0.12 (0.063) | 0.20 ** (0.071) | 0.22 *** (0.078) | 0.29 *** (0.086) | 0.10 (0.119) | 0.21 (0.133) |
| Age | 0.13 *** (0.045) | 0.13 ** (0.051) | 0.13** (0.045) | 0.13 * (0.051) | 0.15 *** (0.047) | 0.12 * (0.054) |
| Female | −0.24 ** (0.091) | -0.19 (0.098) | -0.21* (0.092) | −0.15 (0.102) | −0.19 * (0.093) | −0.16 (0.105) |
| Education | 0.15 *** (0.049) | 0.16 *** (0.049) | 0.16 *** (0.053) | |||
| Left-wing block | −0.20 * (0.098) | −0.20 (0.108) | ||||
| Vote blank | −0.24 (0.164) | −0.22 (0.173) | ||||
| Would not vote | −0.23 (0.218) | −0.10 (0.240) | ||||
| Alternativet | −0.13 (0.217) | −0.27 (0.257) | ||||
| Dansk Folkeparti | −0.08 (0.154) | 0.09 (0.168) | ||||
| Enhedslisten | −0.11 (0.198) | −0.19 (0.204) | ||||
| Konservative Folkeparti | 0.43 (0.317) | 0.03 (0.486) | ||||
| Kristendemokraterne | 0.37 (0.416) | 0.19 (0.384) | ||||
| Liberal Alliance | 0.37 (0.218) | 0.23 (0.248) | ||||
| Nye Borgerlige | −0.09 (0.241) | −0.10 (0.265) | ||||
| Radikale Venstre | −0.05 (0.215) | −0.28 (0.232) | ||||
| Socialistisk Folkeparti | −0.25 (0.205) | 0.00 (0.239) | ||||
| Venstre | 0.27 (0.176) | 0.07 (0.193) | ||||
| Vote blank | −0.11 (0.186) | −0.14 (0.196) | ||||
| Would not vote | −0.11 (0.234) | −0.02 (0.257) | ||||
| R2 adj. | 0.030 | 0.063 | 0.035 | 0.066 | 0.038 | 0.048 |
| N | 476 | 276 | 476 | 276 | 476 | 276 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kirkegaard, E.O.W.; Carl, N.; Bjerrekær, J.D. Are Danes’ Immigration Policy Preferences Based on Accurate Stereotypes? Societies 2020, 10, 29. https://doi.org/10.3390/soc10020029
Kirkegaard EOW, Carl N, Bjerrekær JD. Are Danes’ Immigration Policy Preferences Based on Accurate Stereotypes? Societies. 2020; 10(2):29. https://doi.org/10.3390/soc10020029
Chicago/Turabian StyleKirkegaard, Emil O. W., Noah Carl, and Julius D. Bjerrekær. 2020. "Are Danes’ Immigration Policy Preferences Based on Accurate Stereotypes?" Societies 10, no. 2: 29. https://doi.org/10.3390/soc10020029
APA StyleKirkegaard, E. O. W., Carl, N., & Bjerrekær, J. D. (2020). Are Danes’ Immigration Policy Preferences Based on Accurate Stereotypes? Societies, 10(2), 29. https://doi.org/10.3390/soc10020029