Recent Progress of Machine Learning Algorithms for the Oil and Lubricant Industry



Abstract
1. Introduction
2. Machine Learning
2.1. Machine Learning Types and Processes
2.2. Machine Learning Algorithms
2.3. Explored Machine Learning Algorithms
2.3.1. Linear Regression
2.3.2. Logistic Regression
2.3.3. Support Vector Machines (SVM)
2.3.4. Discriminant Analysis
2.3.5. Naïve Bayes
- is the probability that a hypothesis is true, irrespective of the data;
- is the prior, the overall probability of the data being observed irrespective of the hypothesis;
- is the probability that the data will be observed if the hypothesis is true;
- is the probability that the hypothesis is true, given the data being observed (posterior).
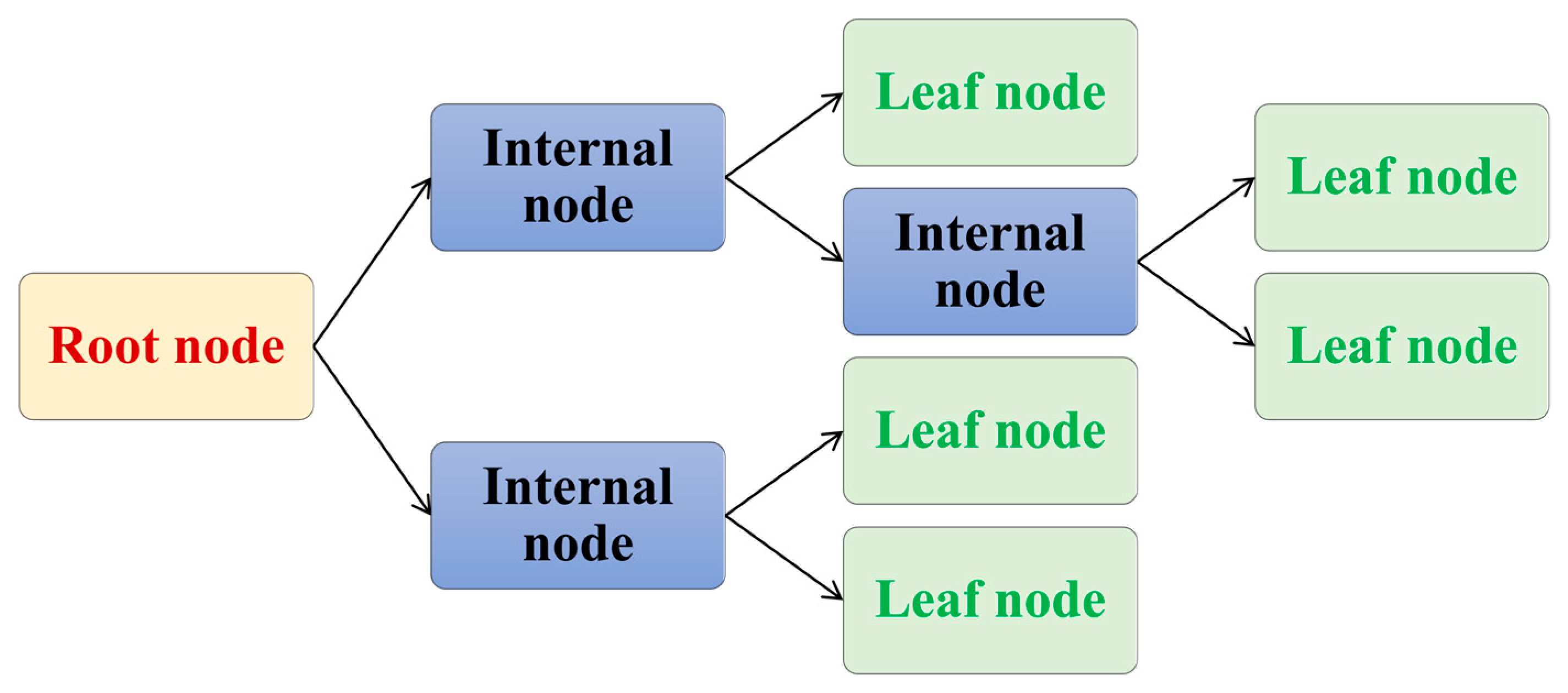
2.3.6. Decision Trees
2.3.7. Artificial Neural Network (ANN)
3. Application of Machine Learning Algorithms for the Lubricant Industry
- Predicting experimental parameters;
- Predicting film thickness;
- Predicting COF and wear;
- Lubricant condition monitoring.
3.1. Predicting Experimental Parameters
3.2. Predicting Film Thickness
3.3. Predicting COF and Wear
3.4. Lubricant Condition Monitoring
4. Future of ML in the Lubrication Industry
5. Conclusions
- ML techniques are being increasingly utilized in the lubrication research and lubrication industry to enhance lubricant design and optimization and predict maintenance needs;
- Various ML algorithms, such as artificial neural networks, support vector machines, and decision trees, have been successfully applied to predict lubricant properties, such as viscosity, COF, and wear, under different operating conditions;
- ML can assist in identifying correlations between lubricant properties and performance, enabling the optimization of lubrication solutions for specific applications;
- From the literature studies, it was observed that SVM, linear regression, and Bayesian regression have been utilized several times, whereas the number of studies involving artificial neural networks is significant. The ANN algorithm has been improvised for all four aspects discussed with significant accuracy;
- The future of ML in the lubrication industry holds great promise, including advancements in lubricant design, predictive maintenance, environmental sustainability, and optimization of manufacturing processes;
- Lubricant condition monitoring is being improved through the use of ML, allowing for real-time analysis of lubricant parameters and early detection of potential issues in lubrication systems;
- By leveraging ML, companies can make data-driven decisions, reduce costs, improve efficiency, and minimize the environmental impact of lubrication processes;
- For experimental condition prediction or lubricant film estimation, ANN showed significant advantages. Moreover, for COF, wear prediction, and lubricant condition monitoring, researchers relied mostly on ANN. It is because of the built-in feature of neural networks, where the input and output layers are separated by various intermediate layers as per the designers’ requirements. Therefore, the future of the lubricant industry’s prediction ability will depend largely on how efficiently tribologists can develop efficient neural networks that can take tribo-informatics to the next level.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Spikes, H. Friction modifier additives. Tribol. Lett. 2015, 60, 5. [Google Scholar] [CrossRef]
- Tzanakis, I.; Hadfield, M.; Thomas, B.; Noya, S.; Henshaw, I.; Austen, S. Future perspectives on sustainable tribology. Renew. Sustain. Energy Rev. 2012, 16, 4126–4140. [Google Scholar] [CrossRef]
- Matczak, L.; Johanning, C.; Gil, E.; Guo, H.; Smith, T.W.; Schertzer, M.; Iglesias, P. Effect of cation nature on the lubricating and physicochemical properties of three ionic liquids. Tribol. Int. 2018, 124, 23–33. [Google Scholar] [CrossRef]
- Stern, D.I. Energy and economic growth in the USA: A multivariate approach. Energy Econ. 1993, 15, 137–150. [Google Scholar] [CrossRef]
- Scharf, T.; Prasad, S. Solid lubricants: A review. J. Mater. Sci. 2013, 48, 511–531. [Google Scholar] [CrossRef]
- Ingole, S.P.; Menezes, P.L.; Nosonovsky, M.; Lovell, M.R.; Kailas, S.V. Tribology for Scientists and Engineers: From Basics to Advanced Concepts; Springer: New York, NY, USA, 2013. [Google Scholar]
- Mortier, R.M.; Orszulik, S.T.; Fox, M.F. Chemistry and Technology of Lubricants; Springer: Dordrecht, The Netherlands; Berlin/Heidelberg, Germany; London, UK; New York, NY, USA, 2010; Volume 107115. [Google Scholar]
- Kasar, A.K.; Siddaiah, A.; Menezes, P.L. Multifunctional Bio-Based Lubricants: Synthesis, Properties and Applications; IOP Publishing: Bristol, UK, 2023. [Google Scholar]
- Cai, M.; Yu, Q.; Liu, W.; Zhou, F. Ionic liquid lubricants: When chemistry meets tribology. Chem. Soc. Rev. 2020, 49, 7753–7818. [Google Scholar] [CrossRef]
- Reeves, C.J.; Siddaiah, A.; Menezes, P.L. Ionic liquids: A plausible future of bio-lubricants. J. Bio-Tribo-Corros. 2017, 3, 18. [Google Scholar] [CrossRef]
- Rahman, M.H.; Warneke, H.; Webbert, H.; Rodriguez, J.; Austin, E.; Tokunaga, K.; Rajak, D.K.; Menezes, P.L. Water-Based Lubricants: Development, Properties, and Performances. Lubricants 2021, 9, 73. [Google Scholar] [CrossRef]
- Sikdar, S.; Rahman, M.H.; Menezes, P.L. Synergistic study of solid lubricant nano-additives incorporated in canola oil for enhancing energy efficiency and sustainability. Sustainability 2021, 14, 290. [Google Scholar] [CrossRef]
- Syahir, A.; Zulkifli, N.; Masjuki, H.; Kalam, M.; Alabdulkarem, A.; Gulzar, M.; Khuong, L.; Harith, M. A review on bio-based lubricants and their applications. J. Clean Prod. 2017, 168, 997–1016. [Google Scholar] [CrossRef]
- Rahman, M.H.; Liu, T.; Macias, T.; Misra, M.; Patel, M.; Martini, A.; Menezes, P.L. Physicochemical and tribological comparison of bio-and halogen-based ionic liquid lubricants. J. Mol. Liq. 2023, 369, 120918. [Google Scholar] [CrossRef]
- Rosenkranz, A.; Marian, M.; Profito, F.J.; Aragon, N.; Shah, R. The Use of Artificial Intelligence in Tribology—A Perspective. Lubricants 2021, 9, 2. [Google Scholar] [CrossRef]
- Shram, V.; Agafonov, E.; Lysyannikov, N.; Lysyannikov, A.; Kovaleva, M. Prediction life of lubricants on the analysis of experimental data on their optical density. J. Phys. Conf. Ser. 2019, 1399, 55009. [Google Scholar] [CrossRef]
- Ghaffari, M.A.; Zhang, Y.; Xiao, S. Multiscale modeling and simulation of rolling contact fatigue. Int. J. Fatigue 2018, 108, 9–17. [Google Scholar] [CrossRef]
- Wolak, A. Statistical analysis of HTHS viscosity rating of present-day engine oils. Tribol. Trans. 2019, 62, 34–41. [Google Scholar] [CrossRef]
- Zhu, Y.; Zhao, T.; Jiao, J.; Chen, Z. The lifetime prediction of epoxy resin adhesive based on small-sample data. Eng. Fail. Anal. 2019, 102, 111–122. [Google Scholar] [CrossRef]
- Randerson. Machine Learning Simplified. Available online: https://randerson112358.medium.com/machine-learning-simplified-407caa414386 (accessed on 26 February 2021).
- Wakiru, J.M.; Pintelon, L.; Muchiri, P.N.; Chemweno, P.K. A review on lubricant condition monitoring information analysis for maintenance decision support. Mech. Syst. Signal Process. 2019, 118, 108–132. [Google Scholar] [CrossRef]
- Mitchell, T.M. Machine Learning; Springer Nature: Berlin/Heidelberg, Germany, 1997. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Machine learning basics. Deep Learn. 2016, 1, 98–164. [Google Scholar]
- Mathworks. Machine Learning in MATLAB. Available online: https://in.mathworks.com/help/stats/machine-learning-in-matlab.html?w.mathworks.com (accessed on 26 February 2021).
- Kang, J.; Niu, Y.; Zhou, Y.; Fan, Y.; Ma, G. Wear Resistance Prediction of AlCoCrFeNi-X (Ti, Cu) High-Entropy Alloy Coatings Based on Machine Learning. Metals 2023, 13, 939. [Google Scholar] [CrossRef]
- Bien, D.X. Predictive modeling of surface roughness in hard turning with rotary cutting tool based on multiple regression analysis, artificial neural network, and genetic programing methods. Proc. Inst. Mech. Eng. Part B J. Eng. Manuf. 2023, 09544054231157112. [Google Scholar] [CrossRef]
- Suresh, P.; Rao, P.V.; Deshmukh, S. A genetic algorithmic approach for optimization of surface roughness prediction model. Int. J. Mach. Tools Manuf. 2002, 42, 675–680. [Google Scholar] [CrossRef]
- Zhao, D.; Yan, J. Performance prediction methodology based on pattern recognition. Signal Process. 2011, 91, 2194–2203. [Google Scholar] [CrossRef]
- Montgomery, D.C.; Peck, E.A.; Vining, G.G. Introduction to Linear Regression Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2021. [Google Scholar]
- Andrews, D.F. A robust method for multiple linear regression. Technometrics 1974, 16, 523–531. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Moder, J.; Bergmann, P.; Grün, F. Lubrication Regime Classification of Hydrodynamic Journal Bearings by Machine Learning Using Torque Data. Lubricants 2018, 6, 108. [Google Scholar] [CrossRef]
- Nelder, J.A.; Wedderburn, R.W. Generalized linear models. J. R. Stat. Soc. Ser. A 1972, 135, 370–384. [Google Scholar] [CrossRef]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]
- Ben-Hur, A.; Horn, D.; Siegelmann, H.T.; Vapnik, V. Support vector clustering. J. Mach. Learn. Res. 2001, 2, 125–137. [Google Scholar] [CrossRef]
- Li, H.; Liang, Y.; Xu, Q. Support vector machines and its applications in chemistry. Chemom. Intell. Lab. Syst. 2009, 95, 188–198. [Google Scholar] [CrossRef]
- Ccoicca, Y. Applications of support vector machines in the exploratory phase of petroleum and natural gas: A survey. Int. J. Eng. Technol. 2013, 2, 113. [Google Scholar] [CrossRef]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A training algorithm for optimal margin classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PN, USA, 27–29 June 1992; pp. 144–152. [Google Scholar]
- Burges, C.J. A tutorial on support vector machines for pattern recognition. Data Min. Knowl. Discov. 1998, 2, 121–167. [Google Scholar] [CrossRef]
- Klecka, W.R.; Iversen, G.R.; Klecka, W.R. Discriminant Analysis; Sage: Newcastle upon Tyne, UK, 1980; Volume 19. [Google Scholar]
- Kim, Y.; Kim, N.Y.; Park, S.Y.; Lee, D.-k.; Lee, J.H. Classification and individualization of used engine oils using elemental composition and discriminant analysis. Forensic Sci. Int. 2013, 230, 58–67. [Google Scholar] [CrossRef]
- Webb, G.I.; Keogh, E.; Miikkulainen, R. Naïve Bayes. Encycl. Mach. Learn. 2010, 15, 713–714. [Google Scholar]
- Sreenath, P.; Praveen Kumare, G.; Pravin, S.; Vikram, K.; Saimurugan, M. Automobile gearbox fault diagnosis using Naive Bayes and decision tree algorithm. Appl. Mech. Mater. 2015, 813, 943–948. [Google Scholar] [CrossRef]
- Ide, D.; Ruike, A.; Kimura, M. Extraction of causalities and rules involved in wear of machinery from lubricating oil analysis data. In Proceedings of the Second International Conference on Digital Information Processing, Data Mining, and Wireless Communications (DIPDMWC2015), Dubai, United Arab Emirates, 28–30 January 2015; p. 16. [Google Scholar]
- Wakiru, J.M. A Decision Tree-Based Classification Framework for Used Oil Analysis Applying Random Forest Feature Selection. 2018. Available online: http://41.89.227.156:8080/xmlui/handle/123456789/748 (accessed on 5 July 2023).
- Li, D.; Lv, R.; Si, G.; You, Y. Hybrid neural network-based prediction model for tribological properties of polyamide6-based friction materials. Polym. Compos. 2017, 38, 1705–1711. [Google Scholar] [CrossRef]
- Hassoun, M.H. Fundamentals of Artificial Neural Networks; MIT Press: Cambridge, MA, USA, 1995. [Google Scholar]
- Sha, W.; Edwards, K. The use of artificial neural networks in materials science based research. Mater. Des. 2007, 28, 1747–1752. [Google Scholar] [CrossRef]
- Guo, Z.; Sha, W. Modelling the correlation between processing parameters and properties of maraging steels using artificial neural network. Comput. Mater. Sci. 2004, 29, 12–28. [Google Scholar] [CrossRef]
- Zhang, Z.; Friedrich, K. Artificial neural networks applied to polymer composites: A review. Compos. Sci. Technol. 2003, 63, 2029–2044. [Google Scholar] [CrossRef]
- Kalkat, M. Investigations on the effect of oil quality on gearboxes using neural network predictors. Ind. Lubr. Tribol. 2015, 67, 99–109. [Google Scholar] [CrossRef]
- Tomanik, E.; Jimenez-Reyes, A.J.; Tomanik, V.; Tormos, B. Machine-Learning-Based Digital Twins for Transient Vehicle Cycles and Their Potential for Predicting Fuel Consumption. Vehicles 2023, 5, 583–604. [Google Scholar] [CrossRef]
- Linnainmaa, S. The Representation of the Cumulative Rounding Error of an Algorithm as a Taylor Expansion of the Local Rounding Errors. Master’s Thesis, University of Helsinki, Helsinki, Finland, 1970. (In Finnish). [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning Internal Representations by Error Propagation; California University San Diego La Jolla Inst for Cognitive Science: La Jolla, CA, USA, 1985. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Sircar, A.; Yadav, K.; Rayavarapu, K.; Bist, N.; Oza, H. Application of machine learning and artificial intelligence in oil and gas industry. Pet. Res. 2021, 6, 379–391. [Google Scholar] [CrossRef]
- Gong, Y.; Wang, Y.; Ghanbarzadeh, A.; Wang, C.; Ishihara, A.; Tamura, Y.; Neville, A.; Morina, A. Experimental and numerical study on wear characteristics of steel surfaces involving the tribochemistry of a fully formulated oil. Part II: Computational modelling. Tribol. Int. 2023, 177, 107976. [Google Scholar] [CrossRef]
- Baboukani, B.S.; Ye, Z.; Reyes, K.G.; Nalam, P.C. Prediction of Nanoscale Friction for Two-Dimensional Materials Using a Machine Learning Approach. Tribol. Lett. 2020, 68, 57. [Google Scholar] [CrossRef]
- Umeda, A.; Sugimura, J.; Yamamoto, Y. Characterization of wear particles and their relations with sliding conditions. Wear 1998, 216, 220–228. [Google Scholar] [CrossRef]
- Peng, Z.; Kirk, T. Automatic wear-particle classification using neural networks. Tribol. Lett. 1998, 5, 249–257. [Google Scholar] [CrossRef]
- Yu, T.; Yin, P.; Zhang, W.; Song, Y.; Zhang, X. A compounding-model comprising back propagation neural network and genetic algorithm for performance prediction of bio-based lubricant blending with functional additives. Ind. Lubr. Tribol. 2020, 73, 246–252. [Google Scholar] [CrossRef]
- Ali, Y.H.; Abd Rahman, R.; Hamzah, R.I.R. Artificial neural network model for monitoring oil film regime in spur gear based on acoustic emission data. Shock Vib. 2015, 2015, 106945. [Google Scholar] [CrossRef]
- Hamel, M.; Addali, A.; Mba, D. Monitoring oil film regimes with acoustic emission. Proc. Inst. Mech. Eng. Part J J. Eng. Tribol. 2014, 228, 223–231. [Google Scholar] [CrossRef]
- Hamrock, B.J.; Dowson, D. Ball Bearing Lubrication: The Elastohydrodynamics of Elliptical Contacts; ASME: New York, NY, USA, 1981. [Google Scholar]
- Menezes, P.L.; Kailas, S.V. Effect of roughness parameter and grinding angle on coefficient of friction when sliding of Al–Mg alloy over EN8 steel. J. Tribol. 2006, 128, 697–704. [Google Scholar] [CrossRef]
- Sreepradha, C.; Kumari, A.K.; Perumal, A.E.; Panda, R.C.; Harshabardhan, K.; Aribalagan, M. Neural network model for condition monitoring of wear and film thickness in a gearbox. Neural Comput. Appl. 2014, 24, 1943–1952. [Google Scholar] [CrossRef]
- Katsaros, K.P.; Nikolakopoulos, P.G. On the tilting-pad thrust bearings hydrodynamic lubrication under combined numerical and machine learning techniques. Lubr. Sci. 2021, 33, 153–170. [Google Scholar] [CrossRef]
- Bonchev, D. Information Theoretic Indices for Characterization of Chemical Structures; Research Studies Press: Baldock, UK, 1983. [Google Scholar]
- Balaban, A.T. Highly discriminating distance-based topological index. Chem. Phys. Lett. 1982, 89, 399–404. [Google Scholar] [CrossRef]
- Müller, W.; Szymanski, K.; Knop, J.; Trinajstić, N. An algorithm for construction of the molecular distance matrix. J. Comput. Chem. 1987, 8, 170–173. [Google Scholar] [CrossRef]
- Gao, X.; Dai, K.; Wang, Z.; Wang, T.; He, J. Establishing quantitative structure tribo-ability relationship model using Bayesian regularization neural network. Friction 2016, 4, 105–115. [Google Scholar] [CrossRef]
- Jia, D.; Duan, H.; Zhan, S.; Jin, Y.; Cheng, B.; Li, J. Design and development of lubricating material database and research on performance prediction method of machine learning. Sci. Rep. 2019, 9, 20277. [Google Scholar] [CrossRef]
- Si, C. The analysis of the effects of surface texture on the capability of load carriage of journal bearings using neural network. Ind. Lubr. Tribol. 2005, 57, 28–40. [Google Scholar]
- Echávarri Otero, J.; De La Guerra Ochoa, E.; Chacón Tanarro, E.; Lafont Morgado, P.; Díaz Lantada, A.; Munoz-Guijosa, J.; Muñoz Sanz, J. Artificial neural network approach to predict the lubricated friction coefficient. Lubr. Sci. 2014, 26, 141–162. [Google Scholar] [CrossRef]
- Bharadwaj, P.V.; Jeevan, T.; Suvin, P.; Jayaram, S. Prediction of Surface Roughness and Coefficient of Friction Using Artificial Neural Network in Tribotesting of Bio-Lubricants. Appl. Mech. Mater. 2019, 895, 52–57. [Google Scholar] [CrossRef]
- Durak, E.; Salman, Ö.; Kurbanoğlu, C. Analysis of effects of oil additive into friction coefficient variations on journal bearing using artificial neural network. Ind. Lubr. Tribol. 2008, 60, 309–316. [Google Scholar] [CrossRef]
- Dawczyk, J.; Morgan, N.; Russo, J.; Spikes, H. Film thickness and friction of ZDDP tribofilms. Tribol. Lett. 2019, 67, 34. [Google Scholar] [CrossRef]
- Kanazawa, Y.; Sayles, R.S.; Kadiric, A. Film formation and friction in grease lubricated rolling-sliding non-conformal contacts. Tribol. Int. 2017, 109, 505–518. [Google Scholar] [CrossRef]
- Taylor, R.I.; Sherrington, I. A simplified approach to the prediction of mixed and boundary friction. Tribol. Int. 2022, 175, 107836. [Google Scholar] [CrossRef]
- Manghai, A.; Jegadeeshwaran, R.; Sugumaran, V. Brake Fault Diagnosis Through Machine Learning Approaches—A Review. Struct. Durab. Health Monit. 2017, 11, 43. [Google Scholar]
- Ljubas, D.; Krpan, H.; Matanović, I. Influence of engine oils dilution by fuels on their viscosity, flash point and fire point. Naft. Explor. Prod. Process. Petrochem. 2010, 61, 73–79. [Google Scholar]
- Afrand, M.; Najafabadi, K.N.; Sina, N.; Safaei, M.R.; Kherbeet, A.S.; Wongwises, S.; Dahari, M. Prediction of dynamic viscosity of a hybrid nano-lubricant by an optimal artificial neural network. Int. Commun. Heat Mass Transf. 2016, 76, 209–214. [Google Scholar] [CrossRef]
- Kocsis, M.C.; Briggs, T.; Anderson, G. The impact of lubricant volatility, viscosity and detergent chemistry on low speed pre-ignition behavior. SAE Int. J. Engines 2017, 10, 1019–1035. [Google Scholar] [CrossRef]
- Vališ, D.; Žák, L. Oil additives used as indicator and input for preventive maintenance optimisation. In Proceedings of the International Conference on Military Technologies (ICMT) 2015, Brno, Czech Republic, 19–21 May 2015; pp. 1–6. [Google Scholar]
- Dave, V.S.; Popielarczyk, M.; Boyce, H.; Al-Achi, A.; Ike-Amaechi, E.; Hoag, S.W.; Haware, R.V. Lubricant-sensitivity assessment of SPRESS® B820 by near-infrared spectroscopy: A comparison of multivariate methods. J. Pharm. Sci. 2017, 106, 537–545. [Google Scholar] [CrossRef]
- Barker, J.; Cook, S.; Richards, P. Sodium contamination of diesel fuel, its interaction with fuel additives and the resultant effects on filter plugging and injector fouling. SAE Int. J. Fuels Lubr. 2013, 6, 826–838. [Google Scholar] [CrossRef]
- George, S.; Balla, S.; Gautam, V.; Gautam, M. Effect of diesel soot on lubricant oil viscosity. Tribol. Int. 2007, 40, 809–818. [Google Scholar] [CrossRef]
- Prabhakaran, A.; Jagga, C. Condition monitoring of steam turbine-generator through contamination analysis of used lubricating oil. Tribol. Int. 1999, 32, 145–152. [Google Scholar] [CrossRef]
- Kumar, M.; Mukherjee, P.S.; Misra, N.M. Advancement and current status of wear debris analysis for machine condition monitoring: A review. Ind. Lubr. Tribol. 2013, 65, 3–11. [Google Scholar] [CrossRef]
- Cao, W.; Wang, W.J.; Wang, R. Wear trend prediction of gearbox based on oil monitoring technology. Adv. Mater. Res. 2012, 411, 576–579. [Google Scholar] [CrossRef]
- Fan, B.; Li, B.; Feng, S.; Mao, J.; Xie, Y.-B. Modeling and experimental investigations on the relationship between wear debris concentration and wear rate in lubrication systems. Tribol. Int. 2017, 109, 114–123. [Google Scholar] [CrossRef]
- Hu, Y.; Wang, L.; Politis, D.; Masen, M. Development of an interactive friction model for the prediction of lubricant breakdown behaviour during sliding wear. Tribol. Int. 2017, 110, 370–377. [Google Scholar] [CrossRef]
- SKF. Vibration Analysis and Diagnostics. Available online: https://www.skf.com/us/services/condition-based-maintenance/vibration-analysis-and-diagnostics (accessed on 22 June 2023).
- Schaeffler. Schaeffler OPTIME Condition Monitoring. Available online: https://www.schaeffler.com/ (accessed on 22 June 2023).
- Söffker, D.; Rothe, S. New Approaches for Supervision of Systems with Sliding Wear: Fundamental Problems and Experimental Results Using Different Approaches. Appl. Sci. 2017, 7, 843. [Google Scholar] [CrossRef]
- Alambeigi, F.; Khadem, S.M.; Khorsand, H.; Hasan, E.M.S. A comparison of performance of artificial intelligence methods in prediction of dry sliding wear behavior. Int. J. Adv. Manuf. Technol. 2016, 84, 1981–1994. [Google Scholar] [CrossRef]
- Azzam, B.; Schelenz, R.; Jacobs, G. Sensor Screening Methodology for Virtually Sensing Transmission Input Loads of a Wind Turbine Using Machine Learning Techniques and Drivetrain Simulations. Sensors 2022, 22, 3659. [Google Scholar] [CrossRef]
- Sinha, A.; Mukherjee, P.; De, A. Assessment of useful life of lubricants using artificial neural network. Ind. Lubr. Tribol. 2000, 52, 105–109. [Google Scholar] [CrossRef]
- Liu, X.; Azzam, B.; Harzendorf, F.; Kolb, J.; Schelenz, R.; Hameyer, K.; Jacobs, G. Early stage white etching crack identification using artificial neural networks. Forsch. Ing. 2021, 85, 153–163. [Google Scholar] [CrossRef]
- Coronado, D.; Wenske, J. Monitoring the oil of wind-turbine gearboxes: Main degradation indicators and detection methods. Machines 2018, 6, 25. [Google Scholar] [CrossRef]
- Yang, L. Prediction of Surface Texture Parameters Using Machine Learning in Laser Surface Texturing; Rutgers University-School of Graduate Studies: New Brunswick, NJ, USA, 2020. [Google Scholar]
- Marin, F.; Solomon, C.; Marin, M. Bearing failure prediction using audio signal analysis based on SVM algorithms. In Proceedings of the IOP Conference Series: Materials Science and Engineering, Galati, Romania, 11–13 October 2018; p. 012012. [Google Scholar]
- Kalkat, M.; Yıldırım, Ş.; Erkaya, S. Oils quality and performance analysis of vehicle’s engines using radial basis neural networks. Ind. Lubr. Tribol. 2009, 61, 301–310. [Google Scholar] [CrossRef]
- Canbulut, F.; Sinanoğlu, C.; Yildirim, Ş. Neural network analysis of leakage oil quantity in the design of partially hydrostatic slipper bearings. Ind. Lubr. Tribol. 2004, 56, 231–243. [Google Scholar] [CrossRef]
- Tysoe, W.T.; Spencer, N.D. Designing lubricants by artificial intelligence-the sequel. Tribol. Lubr. Technol. 2020, 76, 68–70. [Google Scholar]
- Hasan, M.S.; Kordijazi, A.; Rohatgi, P.K.; Nosonovsky, M. Triboinformatic modeling of dry friction and wear of aluminum base alloys using machine learning algorithms. Tribol. Int. 2021, 161, 107065. [Google Scholar] [CrossRef]
- Hasan, M.S.; Kordijazi, A.; Rohatgi, P.K.; Nosonovsky, M. Triboinformatics approach for friction and wear prediction of Al-graphite composites using machine learning methods. J. Tribol. 2022, 144, 11701. [Google Scholar] [CrossRef]
- Desai, P.S.; Granja, V.; Higgs, C.F., III. Lifetime prediction using a tribology-aware, deep learning-based digital twin of ball bearing-like tribosystems in oil and gas. Processes 2021, 9, 922. [Google Scholar] [CrossRef]
- Zhang, Y.; Xu, X. Machine learning decomposition onset temperature of lubricant additives. J. Mater. Eng. Perform. 2020, 29, 6605–6616. [Google Scholar] [CrossRef]
- Urban, A.; Zhe, J. A microsensor array for diesel engine lubricant monitoring using deep learning with stochastic global optimization. Sens. Actuators A Phys. 2022, 343, 113671. [Google Scholar] [CrossRef]
- Paturi, U.M.R.; Palakurthy, S.T.; Reddy, N. The role of machine learning in tribology: A systematic review. Arch. Comput. Methods Eng. 2023, 30, 1345–1397. [Google Scholar] [CrossRef]
- Paolanti, M.; Romeo, L.; Felicetti, A.; Mancini, A.; Frontoni, E.; Loncarski, J. Machine learning approach for predictive maintenance in industry 4.0. In Proceedings of the 2018 14th IEEE/ASME International Conference on Mechatronic and Embedded Systems and Applications (MESA), Oulu, Finland, 2–4 July 2018; pp. 1–6. [Google Scholar]
- Kasar, A.K.; Hill, P.; Sikdar, S.; Menezes, P.L. Machine learning to develop lubrication strategies. In Multifunctional Bio-Based Lubricants: Synthesis, Properties and Applications; IOP Publishing: Bristol, UK, 2023; pp. 5-1–5-16. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Applied Algorithm | Input Parameters/Descriptors | Involved Lubricants | Remarks | Ref. |
|---|---|---|---|---|
| Multilayer neural network | Four particle descriptors were used-
|
| Data was taken from pin-on-disk experiments under 58.8 N and 176 N loads. The wear particle features observed from the microscopic images were analyzed using ML to predict the unknown experimental conditions. | [61] |
| Fuzzy kohonen neural network, multi-layer perception with backpropagation | Six types of wear particles were analyzed: rubbing, cutting, spherical, laminar, fatigue chunk, and severe sliding. Wear particles were characterized based on: Area, length, roundness, fiber dimension, fractal dimension, Height aspect ratio (HAR), Average roughness (Ra), RMS roughness (Rq), and spectral moment analysis (γ2). | N/A | Six common types of metallic wear were studied using three-dimensional images obtained from laser scanning confocal microscopy. This study showed a way that a neural network could be effectively implemented to classify wear particles. | [62] |
| Discriminant analysis | Two types of markers were used-
|
| Six common automobile gasoline and diesel engine oils were collected from seventy-six sources, analyzed using inductively coupled plasma-optical emission spectrometry (ICP-OES), and then statistically compared. Brand of oil, engine type, and source vehicle type were predicted using ML with 92.1%, 82.9%, and 92.1% accuracy, respectively. This oil analysis would be beneficial for forensic analysis. | [41] |
| Bayesian modeling and transfer learning approach | Descriptors were selected based on the physical models for estimating dissipation in 2D materials-
|
| Five experimental data sets (from the literature) and ten molecular dynamic simulation data sets of the maximum energy barrier (MEB) of the potential surface energy were obtained. MEB is correlated to intrinsic friction (friction for a crystalline material with no defects) obtained from ten different 2D materials. Less than an 8% difference was observed in MEB values as predicted via the ML model and the PES profiles obtained from the MD simulation. | [60] |
| Back propagation neural network (BPNN), Generic algorithm (GA) | Content of additives for 25 combinations |
| A four-ball test was carried out to compare the results from the experiment and modeling. The content of the three functional additives varied between 0 and 0.7 wt.%, with a total additive wt.% of 1% in the bio-based base lubricant. The content of those additives was used as the input variable for the algorithm. The model was developed by combining the BPNN with GA and provided theoretical guidance for compounding optimization of lubricant additives. The predicted output matched above 90% of the experimental values. | [63] |
| Applied Algorithm | Input Parameters/Descriptors | Involved Lubricants | Remarks | Ref. |
|---|---|---|---|---|
| Neural Network and logistic regression | Six variables in this study were-
| Hydrodynamic journal-bearing data was used | A total of 888 high-speed torque measurements were taken in different experiments. Those experiments were carried out on a journal-bearing test rig. Up to 99.25% accuracy was observed for predicting lubricant regime class using an artificial neural network and logistic regression. | [32] |
| Feed-forward algorithm, Recurrent Elman neural network algorithm, Levenberg-Marquardt back-propagation algorithm | The following information was given as inputs from previous works-
| Mobil MOBILGEAR 636 | MATLAB Simulink was used to run the algorithms to monitor the oil film thickness and detect the lubrication regime for the gearbox. Levenberg–Marquardt’s back-propagation algorithm was used to reduce the error. | [64] |
| Artificial neural network | Loading conditions were utilized, such as-
| Any | The condition of wear and film thickness were predicted using ANN for a gearbox. MATLAB was used to create the simulation model. Hammock–Dowson’s equation was utilized in the model’s development. | [68] |
| Applied Algorithm | Input Parameters/Descriptors | Involved Lubricants | Remarks | Ref. |
|---|---|---|---|---|
| Simple, multivariable, linear, polynomial, and support vector machine regression | The following parameters were calculated under multiple experimental conditions and used as inputs for training the models-
|
| The operating condition was predicted for a thrust bearing with three lubricants. The ASW 100 biolubricant exhibited the lowest friction and better load-carrying capabilities among the three lubricants. The friction prediction using different algorithms varied between 70 and 93%. For example, simple linear regression (79%), simple 2nd order polynomial regression (93%), multivariable linear regression (83%), multivariable 2nd order polynomial regression (93%), and quadratic SVM regression (90%) successfully predict the friction values. | [69] |
| Bayesian regularization neural network | Molecular connectivity indices were used as the descriptors of 2D BRNN–QSTR models. The descriptors were categorized as: quantum descriptors, 3D descriptors, 2D topological descriptors. Some of the important descriptors were- | Thirty-six compounds were tested as additives. Such as- benzoxazole, benzimidazole, benzothiazole, dihydrothiazole piperazine, and piperidine were used as lubricant additives, and their tribological data were examined. | The authors concluded that elements S and P in the lubricant significantly improved tribological properties. Also, minimal carbon chain length is needed in the case of additives. However, extending the carbon chain length might not always be beneficial; rather, there could be a threshold number of carbons in the chain that would facilitate the lowest wear. | [73] |
| Linear regression |
| Thirty-six lubricant data were used for wear estimation. Among them, 29 groups were used for training purposes whereas 7 groups were used to perform the prediction. | For COF and wear estimation, a standard four-ball tester was used at 1450 rpm over 30 min. A linear regression algorithm was used to predict the wear and COF of seven test lubricants. The database was established in the MySQL database. | [74] |
| Artificial neural network | Neural network predictor consisted of: one input neuron, ten hidden layer of neurons, and three output neurons with non-linear activation function | Mobil 0W-40 | The load-carrying capacity of the journal bearing was investigated with a steel shaft with varying surface textures. The developed neural network was able to learn quickly and predict the load-carrying capacity. | [75] |
| Feed forward artificial neural network | Four dimensional inputs were- average velocity: 1 to 4 m/s, slide roll ratio (SRR): 2–200%, bath temperature: 40–100 °C contact load: 5–28 N | PAO-6 | The experiments were carried out on the tribological testing equipment named a mini-traction machine (MTM) using the ball-on-disk method. The friction coefficient was predicted using the feed-forward artificial neural network, which was simulated in MATLAB software. | [76] |
| Artificial neural network | Seven inputs from the lubricant properties were:
Inputs taken from the machining conditions were:
| Jatropha, Pongam, Neem, Mahua, and mineral oil (Servocut 945) | A tool-chip tribometer was used to simulate a similar aspect of a metal-cutting operation with a pool of oil samples. The prediction was made on the surface roughness and COF using artificial neural network for bio-lubricants. | [77] |
| Artificial neural network | Loading conditions were utilized, such as- Vibration, Temperature torque | - | The condition of wear and film thickness were predicted using ANN for a gearbox. MATLAB was used to create the simulation model. Hammock–Dowson’s equation was utilized in the model’s development. | [68] |
| Feed forward back propagation algorithm, Artificial neural network | Load, velocity and additive oil rate | Lubricant (Mineral oil, SAE 20W50) with polytetrafluoroethylene (PTFE) based additives at 1, 3, 5, 10, and 15% concentration | Two loads were implemented (153 and 253 N) for rotational speeds of 30, 60, 120, 180, 240, 300, 360, 420, 480, 540, 600, 660, 720, 780, 840, 900, 960, 1020, 1080, 1140, and 1200 rpm. The average COF from three tests was used to train the algorithm, and the artificial neural network reproduced the COF outputs with 98% accuracy. | [78] |
| Logistic curve | λ ratio | SAE 10 W-40 XHVI 5.2 Few other oil data from the literature [79,80] | A new equation: Is proposed that enables the simple calculation of the proportion of mixed/boundary friction in a contact as a function of λ ratio. When the X is plotted against λ, it represents a logistic or sigmoid curve. For a varied λ, this curve could be useful to predict friction under boundary and mixed lubrication regimes. | [81] |
| Class | Parameter | Refs. |
|---|---|---|
| Physical | Viscosity at 40 °C and 100 °C, Thermal stability, Temperature, Density, Vibration | [83,84,85] |
| Chemical | Total Base Number (TBN), Total Acid Number (TAN), Flashpoint | [83,84,85] |
| Additives | Barium(Ba), Boron (B), Calcium (Ca), Magnesium (Mg), Molybdenum (Mo), Phosphorus (P), Sodium (Na), Silicon (Si), Zinc (Zn) | [86,87] |
| Contamination | Boron (B), Coolant, Soot/carbon, Potassium (K), Silicon (Si), Sodium (Na), Vanadium (V), Water (H2O) | [88,89,90] |
| Elemental | Aluminum (Al), Chromium (Cr), Copper (Cu), Iron (Fe), Lead (Pb), Nickel (Ni), Silver (Ag), Titanium (Ti), Tin (Sn), Vanadium (V) | [91,92,93,94] |
| Applied Algorithm | Input Parameters/Descriptors | Involved Lubricants | Remarks | Ref. |
|---|---|---|---|---|
| Artificial neural network | - | Solid lubricants | Solid lubricant performance was studied using the artificial neural network technique. | [46] |
| Artificial neural networks (ANNs) | Vibration signals extracted from rotating parts were utilized to investigate the effect of oil quality on gearboxes. | Energol® GR-XP SyntHetiC (SHC) SPARTAN EP gear oils Gravis SP series Omala Oil 320 EP gear oil | ANN was employed to predict the vibration parameters of the experimental test rig. The wavelet features were extracted from the vibration data of the gearbox, and the gear fault was classified. The results suggest that the proposed RBNN is more predictive than the MNN. On the other hand, the Omala oil 320 was predicted to be reliable for such gearbox applications compared to other oils. | [51] |
| Short Time Fourier Transform (STFT), Fuzzy-based classification algorithm | Hardness Normal force Lubricant Lubrication interval | Applicable for any lubricant | STFT was used to extract relevant frequencies. Relationship prediction was possible between the physical failure mode and the calculated characteristics. | [97] |
| Artificial neural networks (ANNs), adaptive neural-based fuzzy inference systems (ANFIS), and fuzzy clustering method (FCM) | Sliding distance (m) Type Load (N) Cooling rate (°C/s) Volume loss (cm3) | Dry condition | Three cooling rates (0.5, 2, and 3 °C/s) were applied on six specimens made from pre-alloyed Astaloy 85 Mo and Distaloy AB powders through the powder metallurgy (PM) method. | [98] |
| Decision tree, Naïve Bayes | Statistical features were given as the inputs | No lubricant was considered | The vibration signal was monitored from the actual gearbox of the automobile, with simulated fault conditions within the gear and bearings. The fault detection was performed using two algorithms, and classification accuracy was observed at more than 80% for all cases. | [43] |
| Random Forest (RF) | Gearbox input load moment and force measurement, torque arm displacement and angular misalignment, wind direction and speed, generator mount displacement, generator rotational speed, and blade pitch angle | None | The authors highlight the need for machine learning in wind turbine drivetrain load monitoring. A RF model is employed to determine sensor positions that significantly influence the accuracy of virtual load sensing in wind turbine transmission. | [99] |
| Artificial neural network | Lubricant properties were used as inputs. Data were observed and feed based after a certain life interval | - | The remaining utilizable life of the lubricants (RULL) was predicted using ANN. | [100] |
| Artificial Neural Network (ANN) | Bearing shaft temperature, axial load, rotational speed, lubricant volume flow rate Bearing and resistor voltage, temperature and pressure of storage container, and temperature of chamber input | Not disclosed | The authors used the Long Short-Term Memory (LSTM, a variation of ANN) autoencoders to reconstruct time series data without the white etching cracks (WEC) in order to identify the anomalies in the new unseen data based on the reconstruction error. | [101] |
| ML technique was not used | Oil samples were analyzed by dint of: Viscosity Viscosity index Element analysis Total acid number (TAN) | Poly alfa olefin (PAO) Mineral oil | Wind turbine gearbox oil was monitored, and the degradation was studied. | [102] |
| Backpropagation feed-forward neural network algorithm | Input parameters were- Laser power Scanning velocity and energy density | The lubricant was not used, rather surface texturing was studied where the output parameters were average roughness (Sa), RMS roughness (Sq), Skewness (Ssk), Kurtosis (Sku) | Surface roughness parameters were predicted using a neural network. Laser surface processing parameters were used to evaluate the obtained surface properties. | [103] |
| Support Vector Machine (SVM), Real-time audio signal analysis, | The acoustic emission pattern was filtered and used for training the algorithm | CAW33 type 22,205 bearings were used for the experimental tests. | Bearing failure prediction plays an important role in safety. The SVM classifier provided at least 92% mean accuracy. | [104] |
| Back propagation neural network, Modular neural network, Radial basis neural network | A wide range of inputs was used for each of the three algorithms | Used and unused engine oils | Two types of vehicle engines were used for the analysis of oil quality and performance. The input layer consisted of 1 neuron, whereas the hidden layer consisted of 10 neurons and the output layer consisted of 4 neurons. This research provided helpful information for industrial applications for vehicle oil analysis and fault detection. | [105] |
| Artificial neural network | Leakage oil quantity and some other parameters were involved | - | The effect of slippers (which enhance the efficiency of axial piston pumps and motors) on lubrication was studied under different surface roughnesses and conditions). | [106] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rahman, M.H.; Shahriar, S.; Menezes, P.L. Recent Progress of Machine Learning Algorithms for the Oil and Lubricant Industry. Lubricants 2023, 11, 289. https://doi.org/10.3390/lubricants11070289
Rahman MH, Shahriar S, Menezes PL. Recent Progress of Machine Learning Algorithms for the Oil and Lubricant Industry. Lubricants. 2023; 11(7):289. https://doi.org/10.3390/lubricants11070289
Chicago/Turabian StyleRahman, Md Hafizur, Sadat Shahriar, and Pradeep L. Menezes. 2023. "Recent Progress of Machine Learning Algorithms for the Oil and Lubricant Industry" Lubricants 11, no. 7: 289. https://doi.org/10.3390/lubricants11070289
APA StyleRahman, M. H., Shahriar, S., & Menezes, P. L. (2023). Recent Progress of Machine Learning Algorithms for the Oil and Lubricant Industry. Lubricants, 11(7), 289. https://doi.org/10.3390/lubricants11070289