Classification of Planetary Nebulae through Deep Transfer Learning

 ,
,  , , ,
, , ,
Abstract
1. Introduction
Given a source domain and its learning task , a target domain and its learning task , transfer aims to help improve the learning of the target predictive function learning in from and , where or . consist the source domain data; , where is the image data instance and is its corresponding class label. Likewise, the target domain data , where is the input image data instance and is its corresponding output class label. Most often .
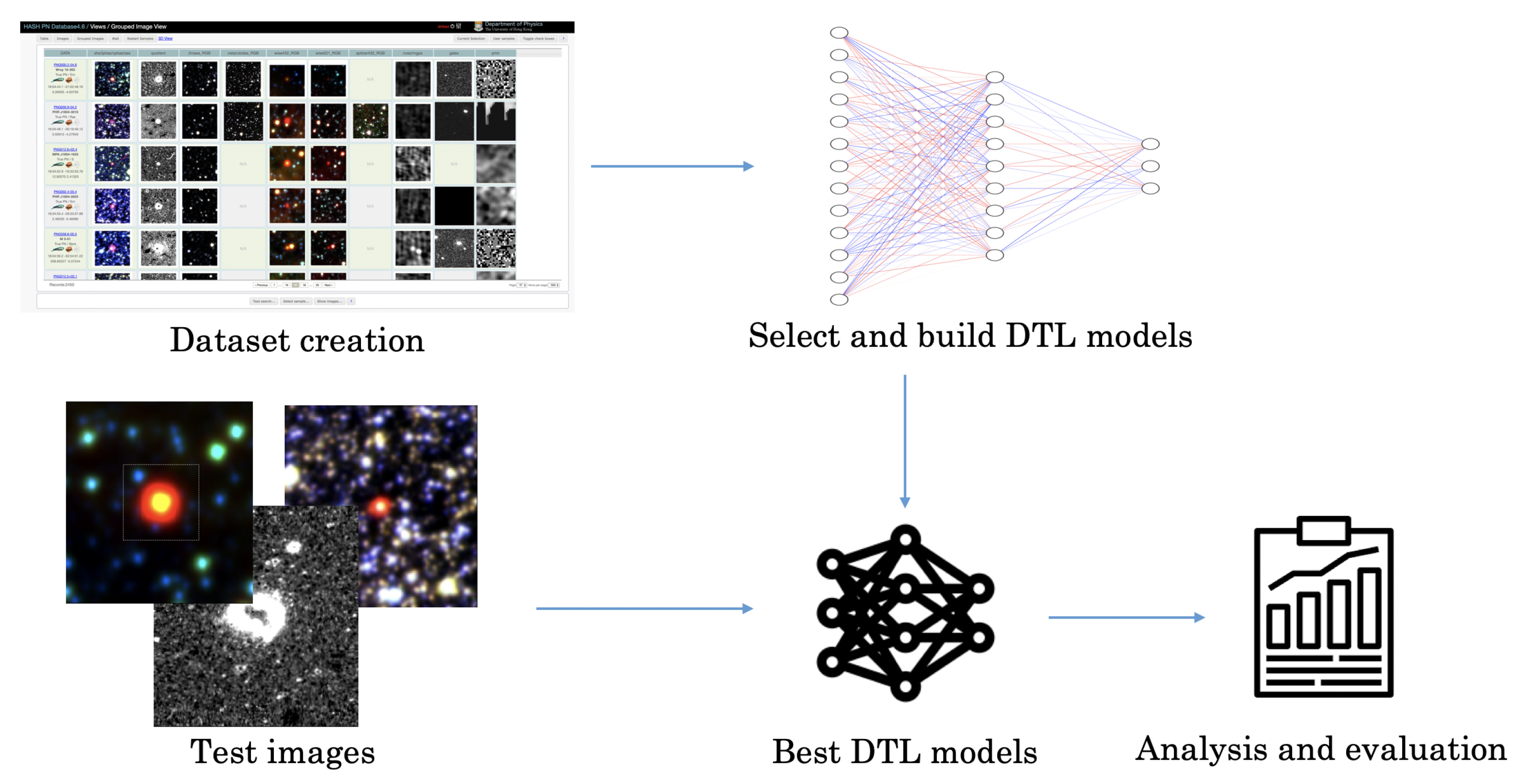
2. Materials and Methods
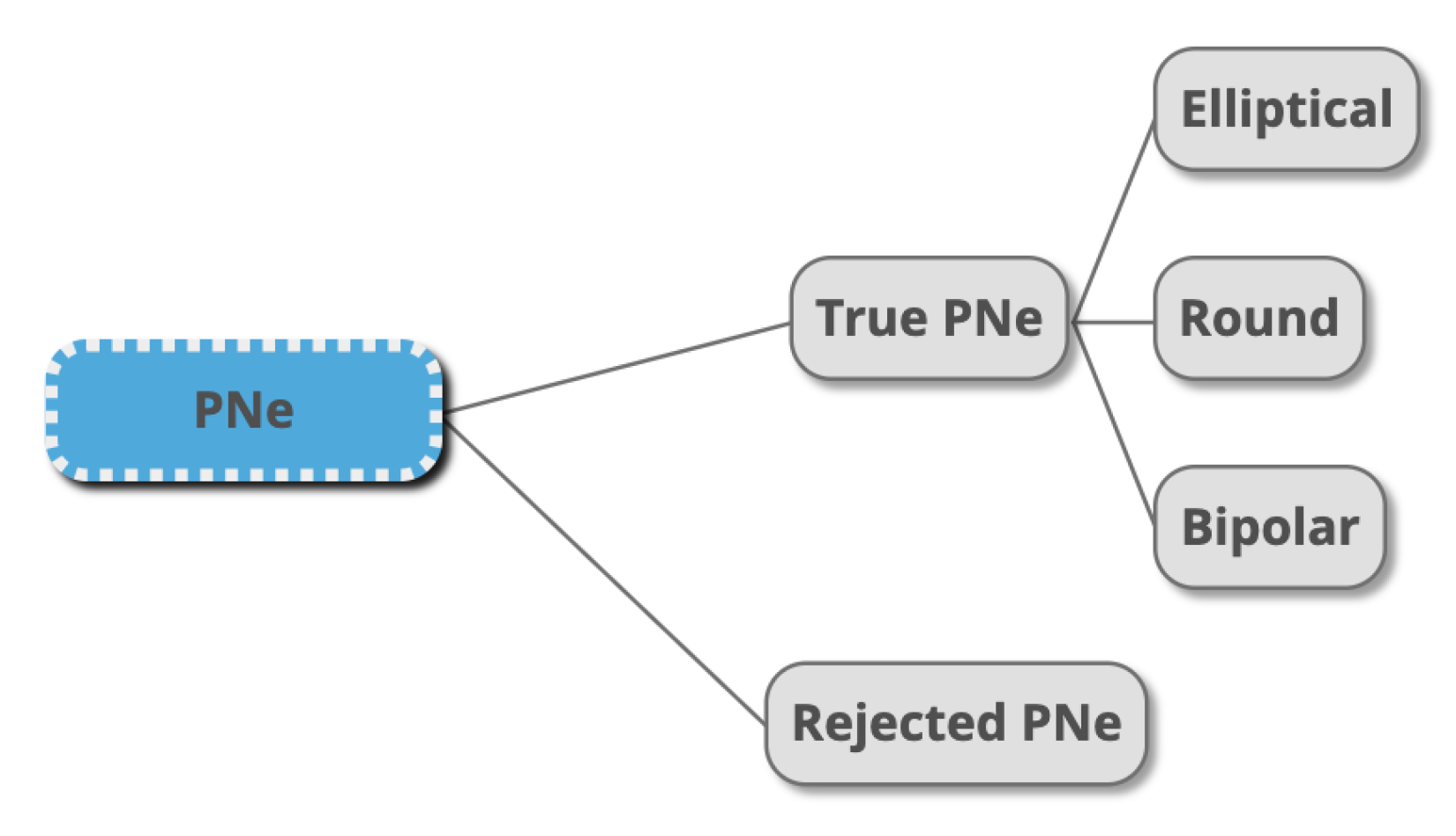
2.1. Dataset Creation and Pre-Processing: HASH DB
2.2. Dataset Creation and Pre-Processing: Pan-STARRS
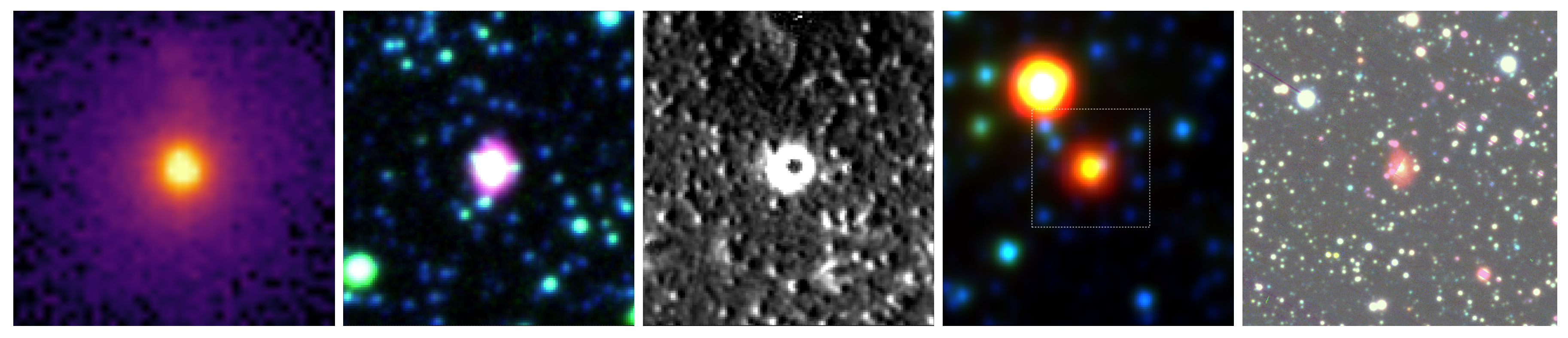
2.2.1. Sample Selection for True PNe and Rejected Classification
2.2.2. Sample Selection for PNe Morphological Classification
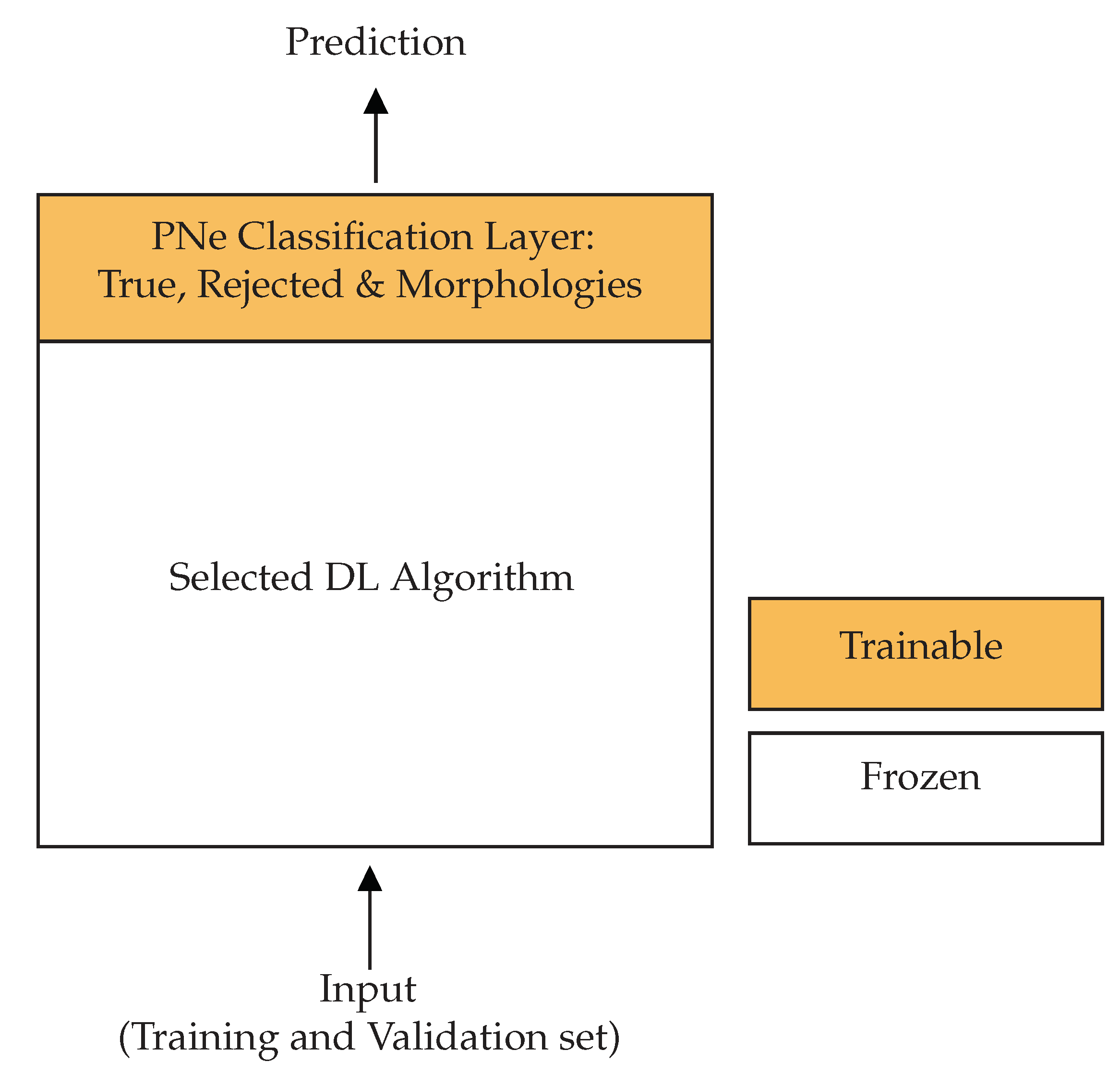
2.3. Deep Transfer Learning Algorithm Selection
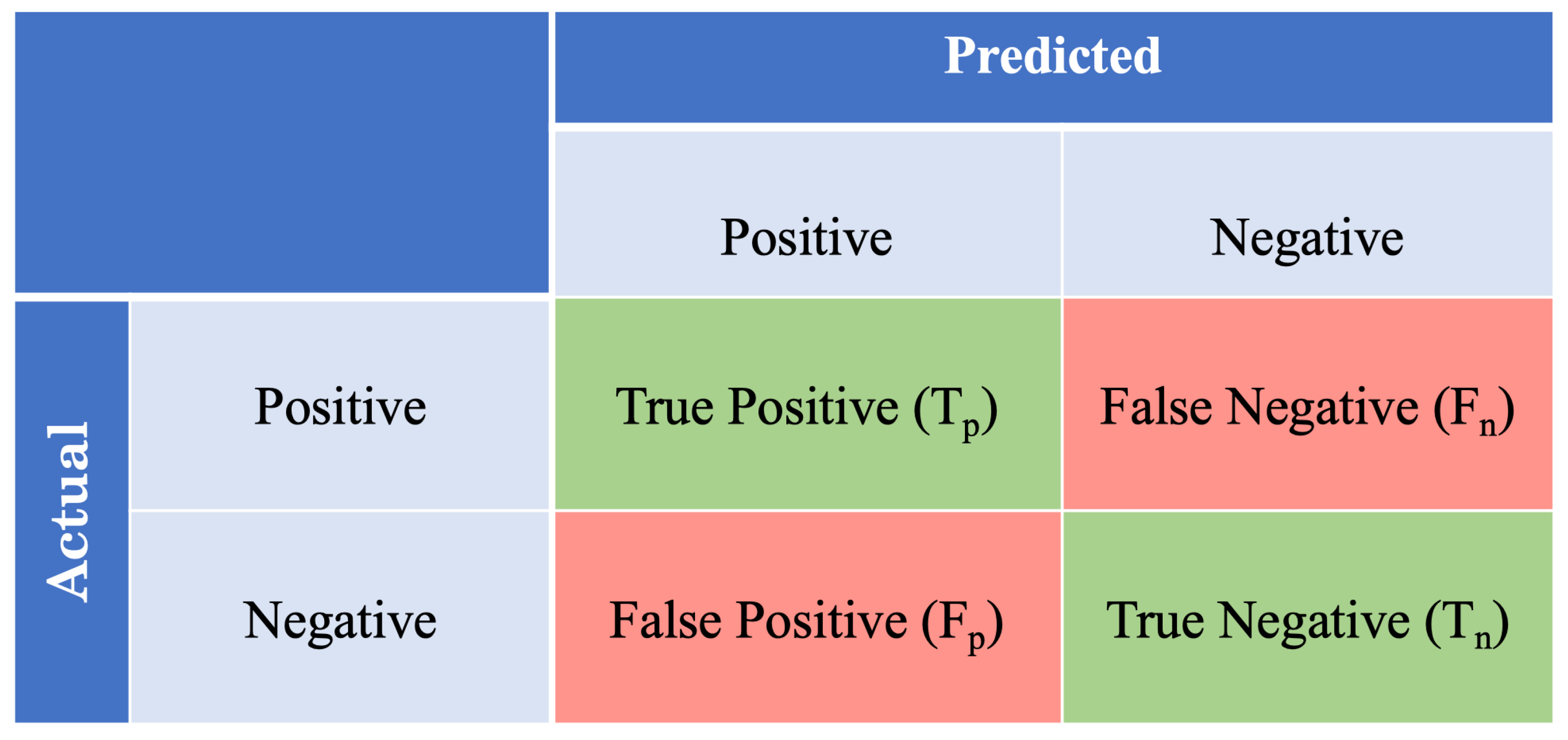
2.4. Evaluation Metrics
3. Results
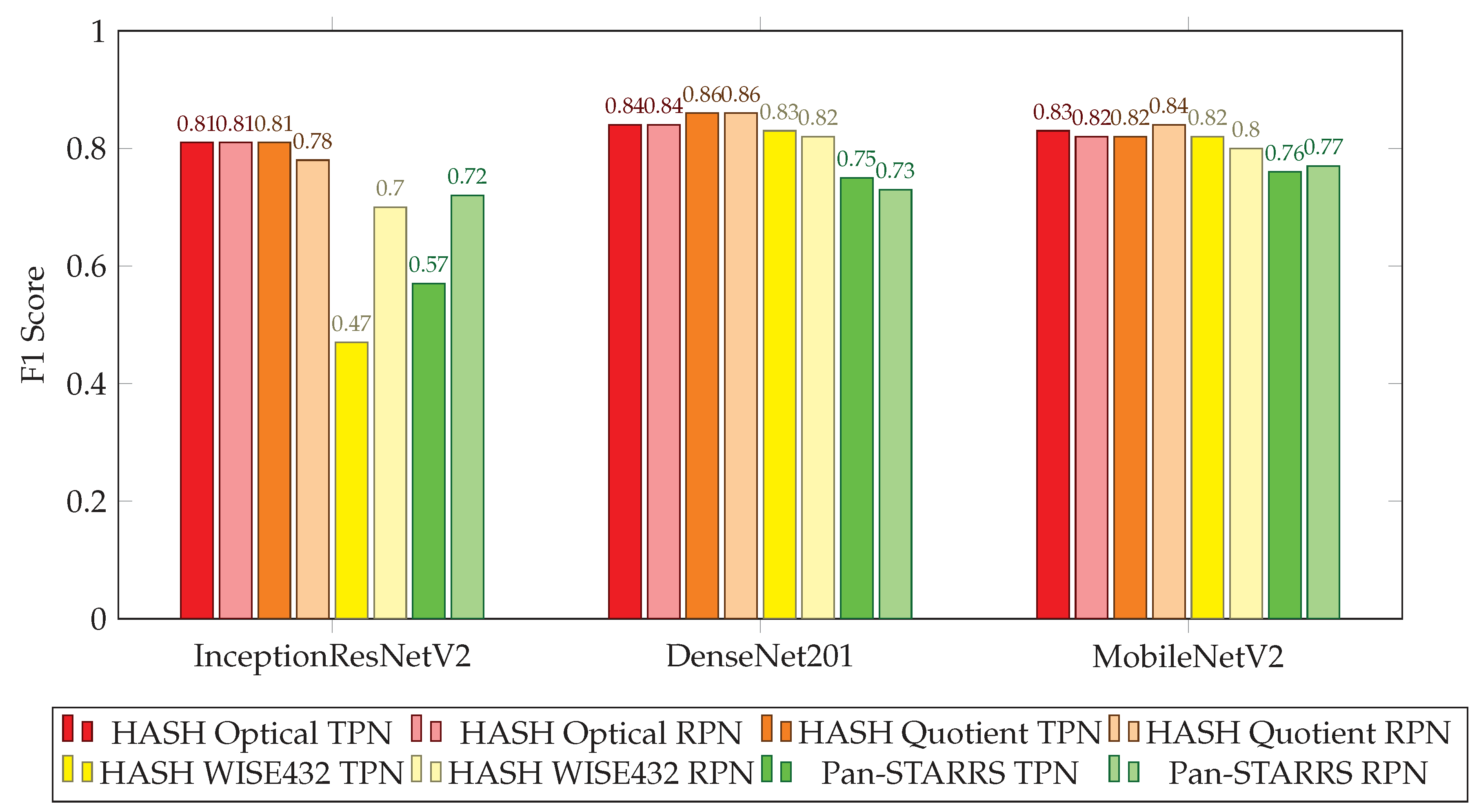
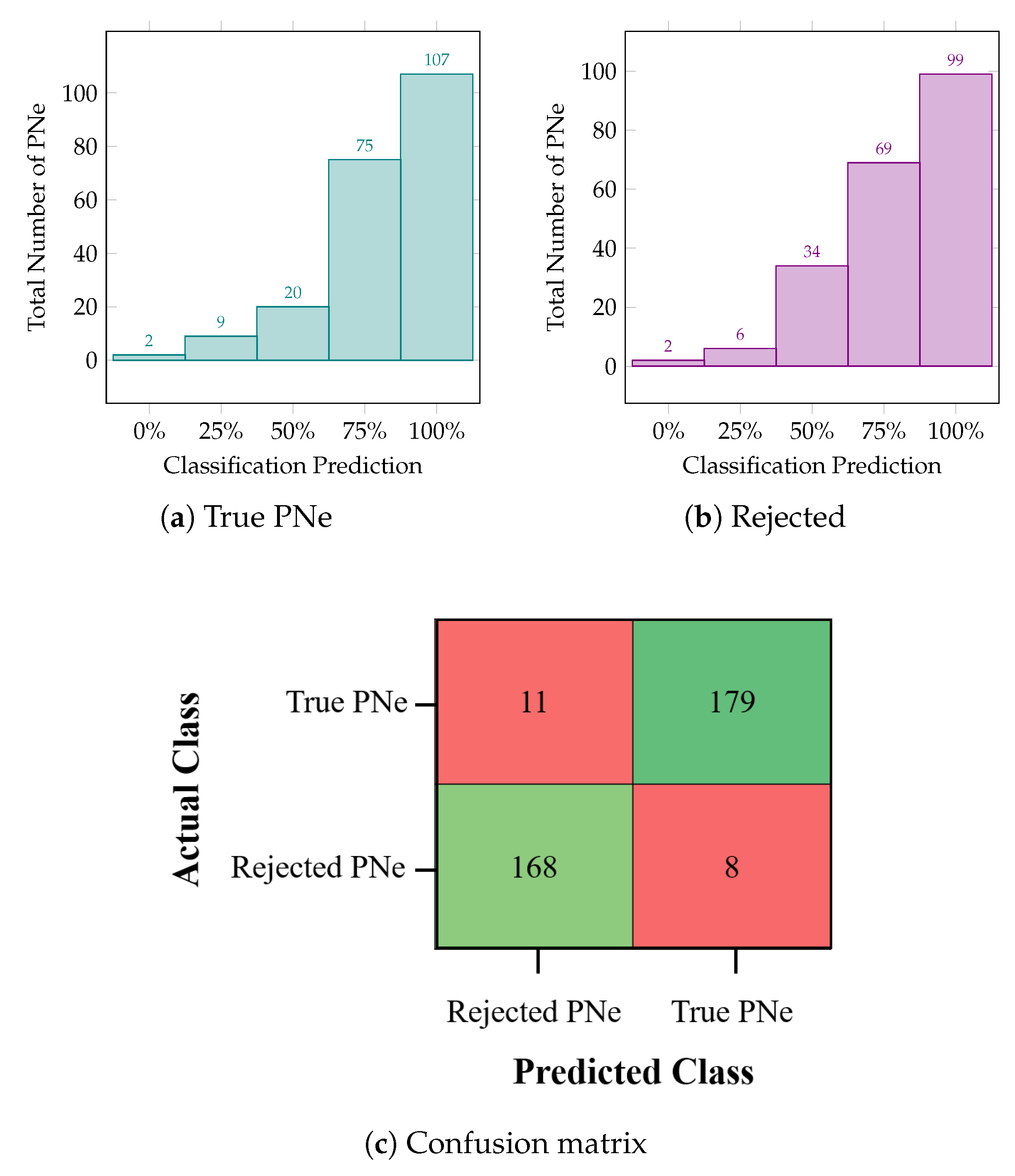
3.1. Planetary Nebulae True vs. Rejected Classification
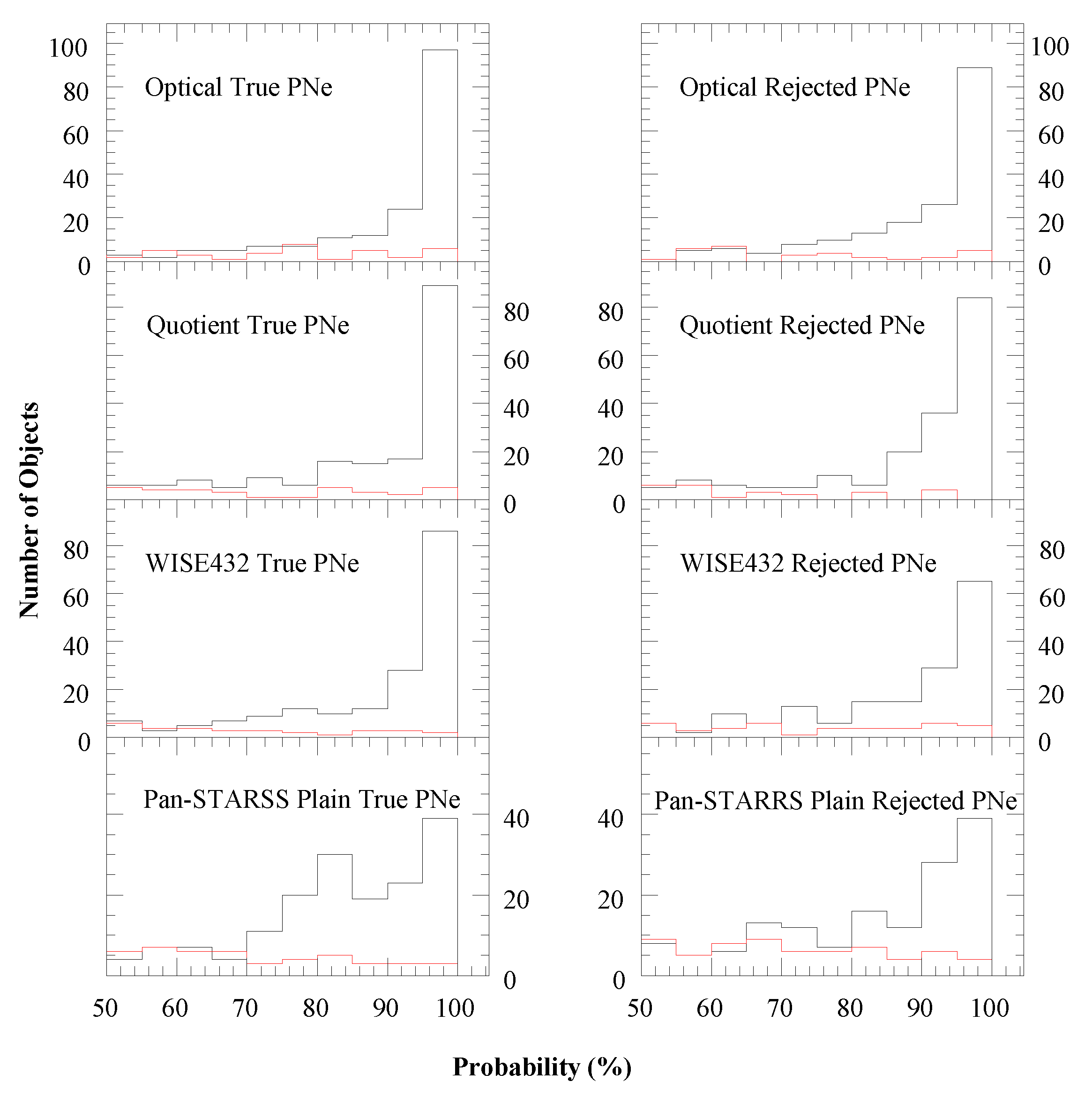
3.2. Prediction
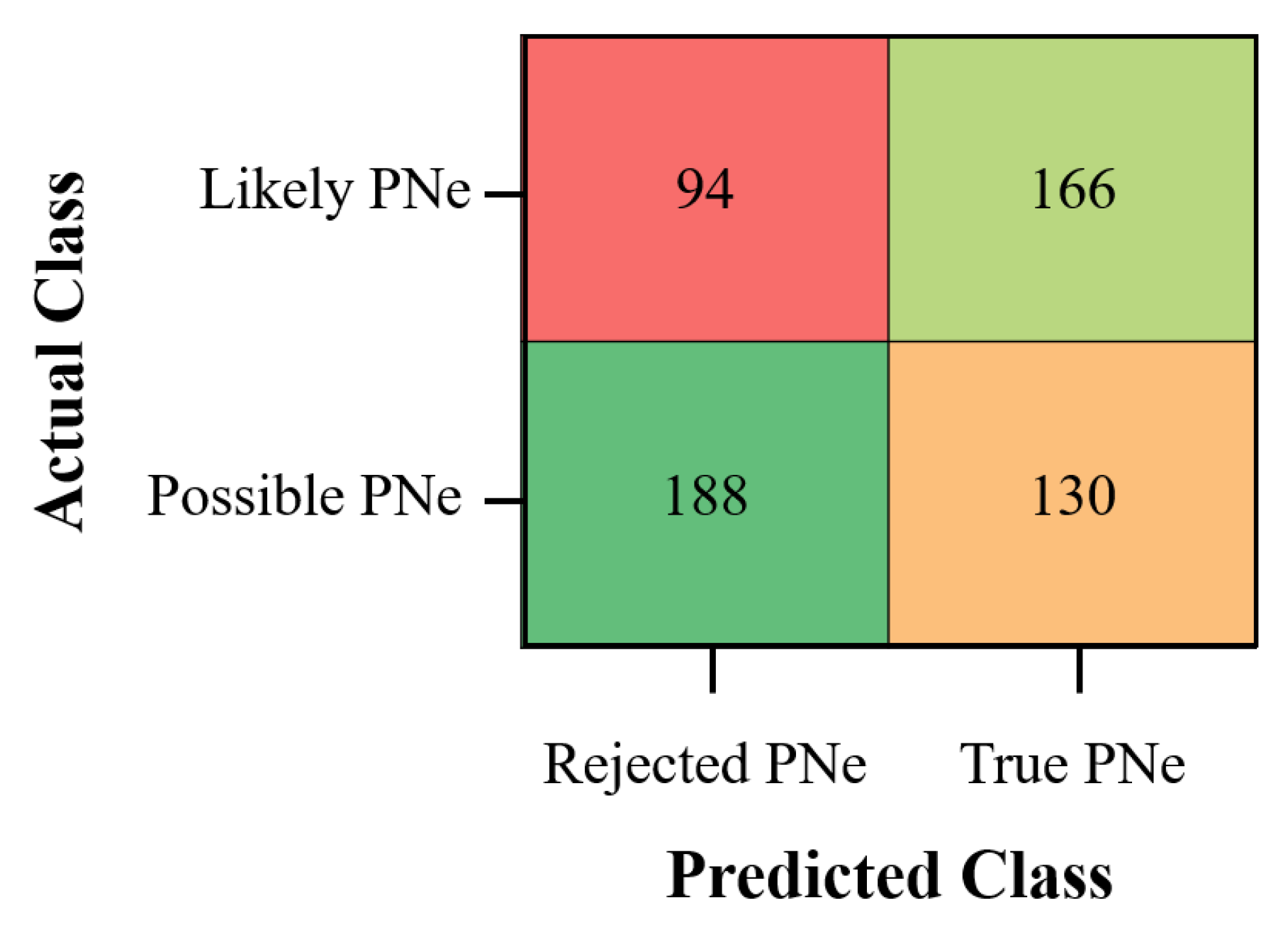
3.3. Possible and Likely Planetary Nebulae Classification
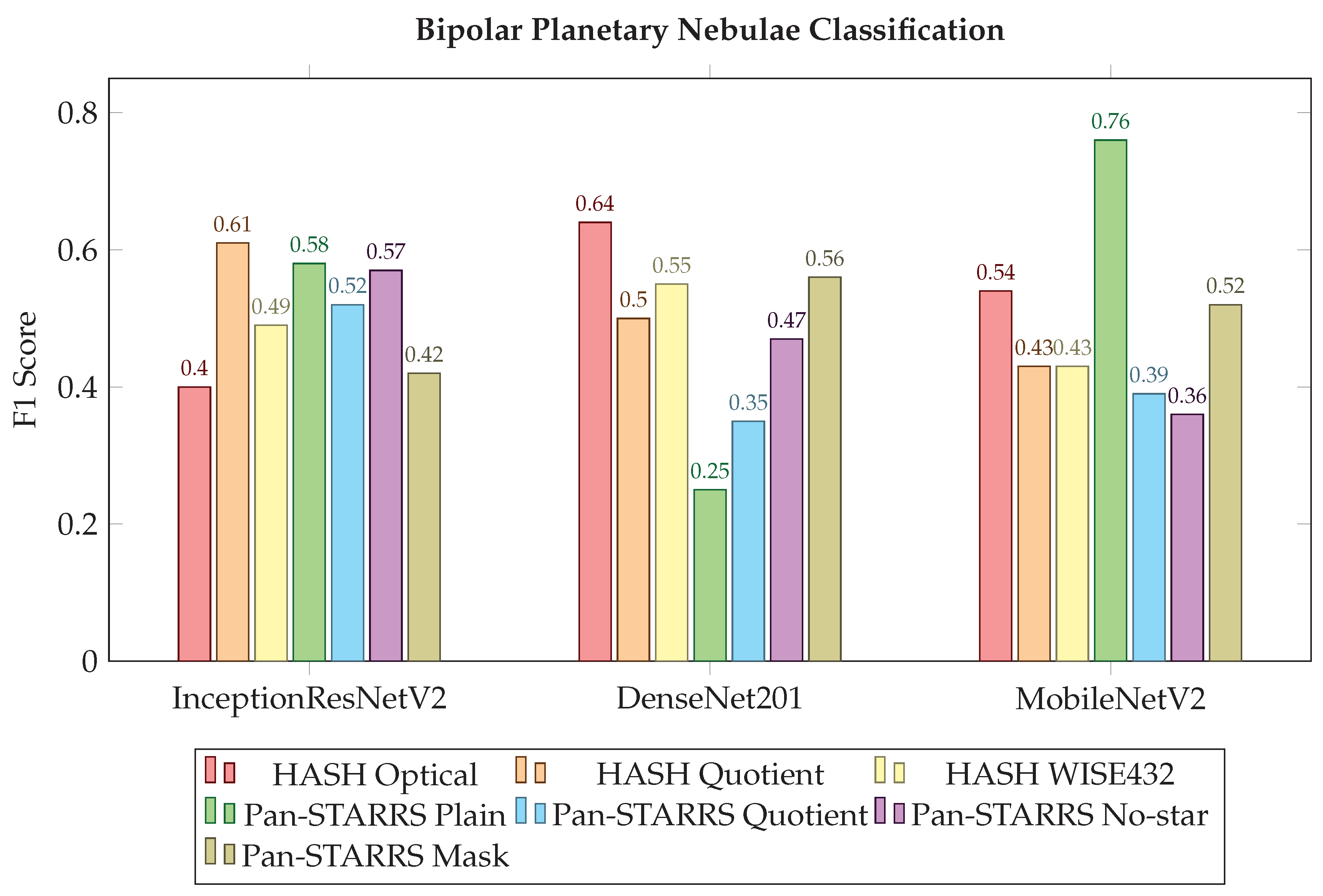
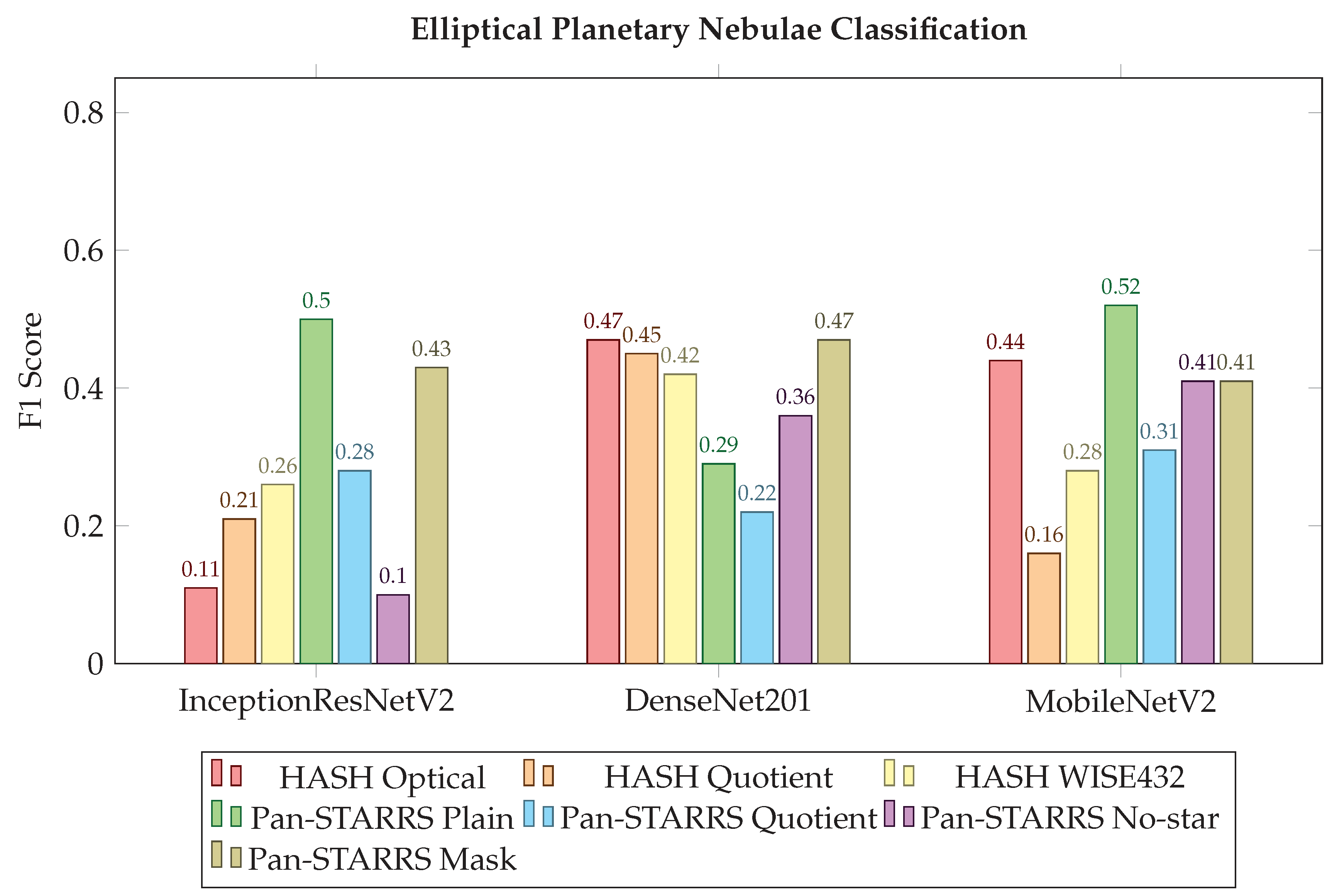
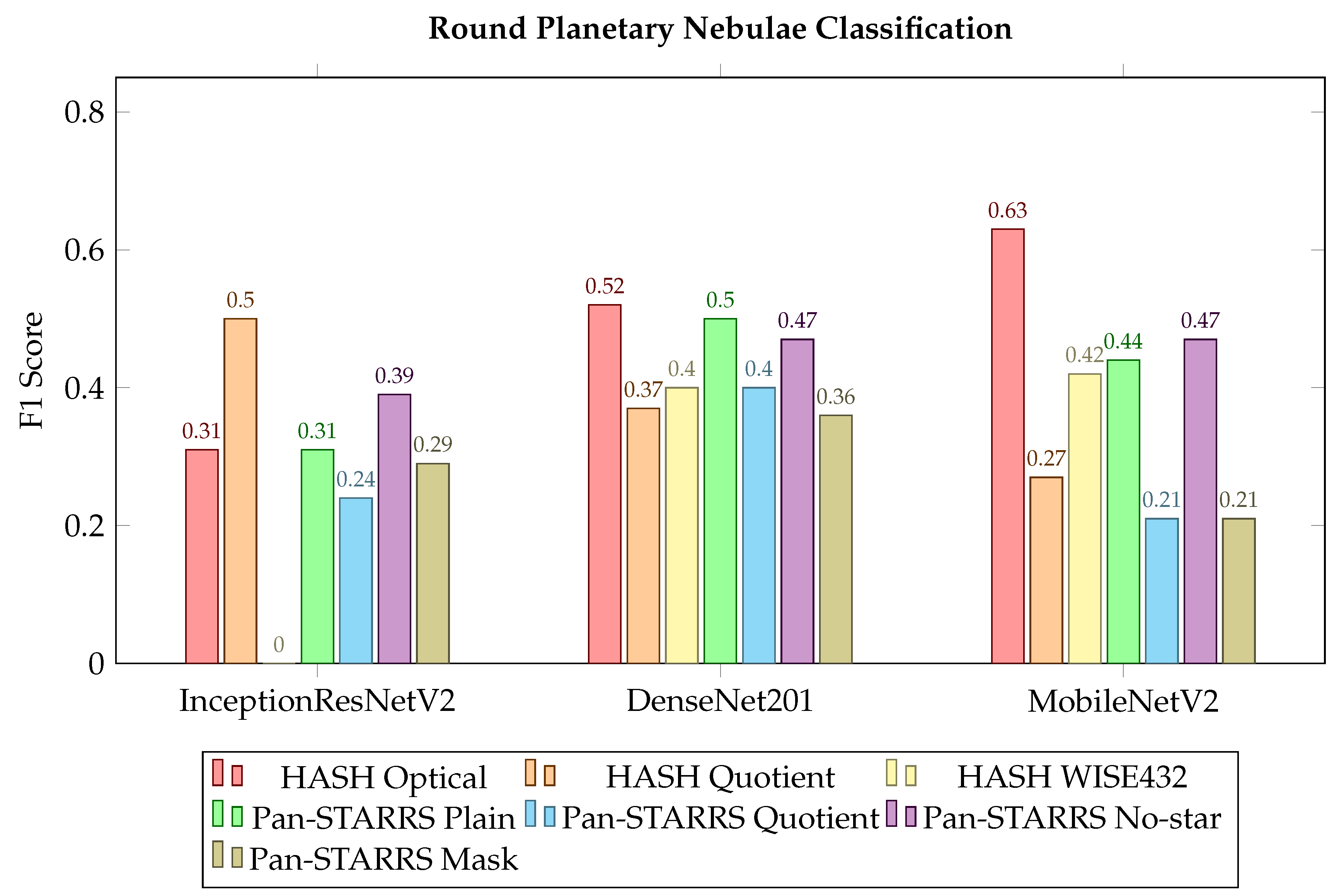
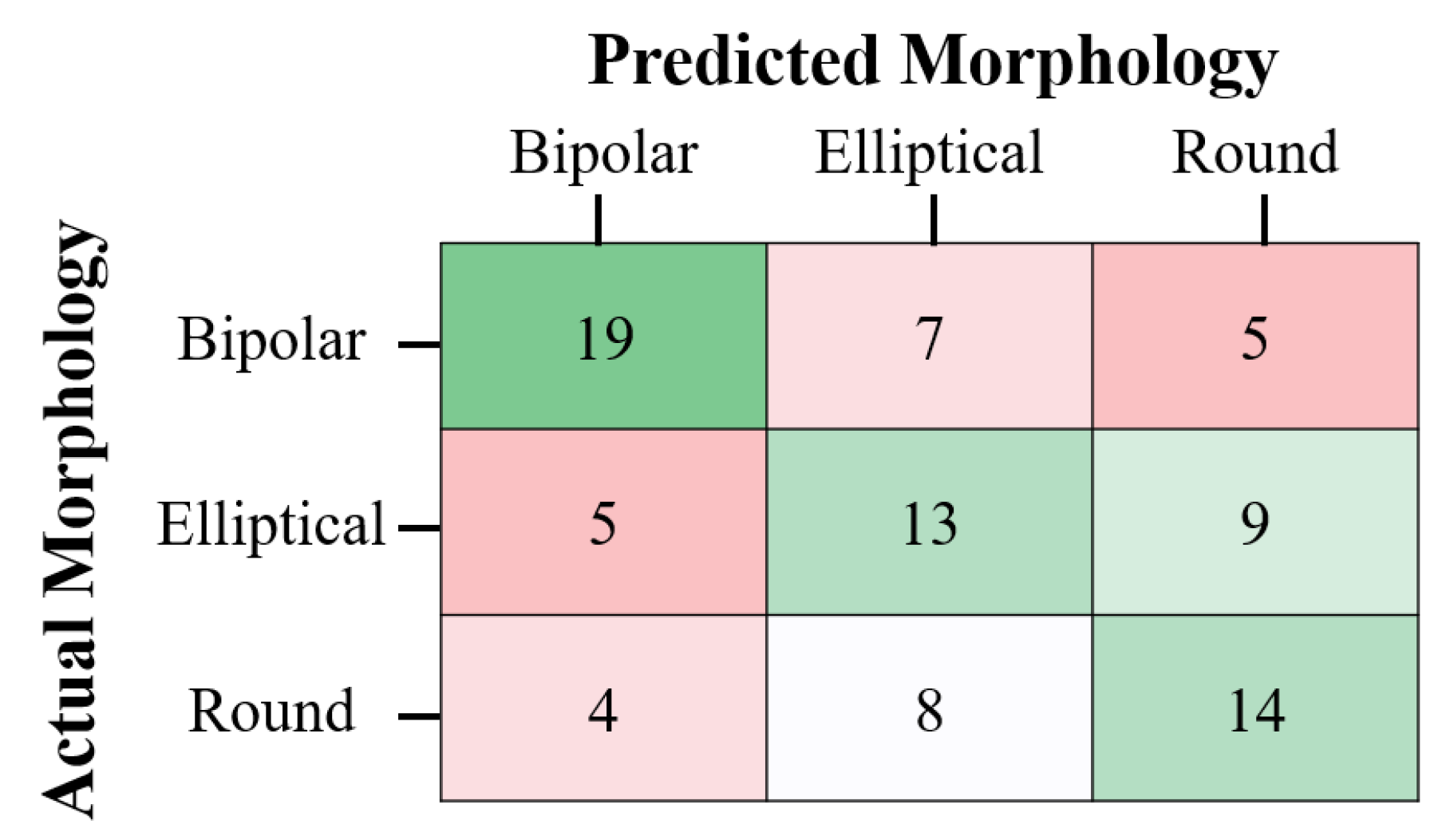
3.4. Planetary Nebulae Morphology Classification
Classification Accuracy of Bipolar, Round and Elliptical Planetary Nebulae
3.5. Prediction of Morphologies
4. Discussion
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. HASH DB Query

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Select Sample Options | True PNe | Rejected PNe and Other Objects |
|---|---|---|
| Status | True PN | Check all except True PN, Likely PN, Possible PN and New Candidates |
| Morphology | Check all | Uncheck all |
| Galaxy | Galactic PNe | Check all except Galactic PNe |
| Catalogs | Uncheck all | Uncheck all |
| Origin | Uncheck all | Uncheck all |
| Spectra | Uncheck all | Uncheck all |
| Checks | Uncheck all | Uncheck all |
| User Samples | Uncheck all | Uncheck all |
References
- Parker, Q.A. Planetary Nebulae and How to Find Them: A Review. arXiv 2020, arXiv:2012.05621. [Google Scholar]
- Parker, Q.A.; Bojičić, I.S.; Frew, D.J. HASH: The Hong Kong/AAO/Strasbourg Hα Planetary Nebula Database. J. Phys. Conf. Ser. 2016, 728, 032008. [Google Scholar] [CrossRef]
- Balick, B.; Frank, A. Shapes and Shaping of Planetary Nebulae. Annu. Rev. Astron. Astrophys. 2002, 40, 439–486. [Google Scholar] [CrossRef]
- Shaw, R.A. Shape, Structure, and Morphology in Planetary Nebulae. Proc. Int. Astron. Union 2011, 7, 156–163. [Google Scholar] [CrossRef]
- Kwok, S. On the Origin of Morphological Structures of Planetary Nebulae. Galaxies 2018, 6, 66. [Google Scholar] [CrossRef]
- Flewelling, H.A.; Magnier, E.A.; Chambers, K.C.; Heasley, J.N.; Holmberg, C.; Huber, M.E.; Sweeney, W.; Waters, C.Z.; Calamida, A.; Casertano, S.; et al. The Pan-STARRS1 Database and Data Products. arXiv 2016, arXiv:1612.05243. [Google Scholar]
- Chambers, K.C.; Magnier, E.A.; Metcalfe, N.; Flewelling, H.A.; Huber, M.E.; Waters, C.Z.; Denneau, L.; Draper, P.W.; Farrow, D.; Finkbeiner, D.P.; et al. The Pan-STARRS1 Surveys. arXiv 2019, arXiv:astro-ph.IM/1612.05560. [Google Scholar]
- Faundez-Abans, M.; Ormeno, M.I.; de Oliveira-Abans, M. Classification of Planetary Nebulae by Cluster analysis and Artificial Neural Networks. Astron. Astrophys. Suppl. Ser. 1996, 116, 395–402. [Google Scholar] [CrossRef][Green Version]
- Akras, S.; Guzman-Ramirez, L.; Gonçalves, D.R. Compact Planetary Nebulae: Improved IR Diagnostic Criteria Based on Classification Tree Modelling. Mon. Not. R. Astron. Soc. 2019, 488, 3238–3250. [Google Scholar] [CrossRef]
- Fluke, C.J.; Jacobs, C. Surveying the Reach and Maturity of Machine Learning and Artificial Intelligence in Astronomy. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2020, 10, e1349. [Google Scholar] [CrossRef]
- Barchi, P.; de Carvalho, R.; Rosa, R.; Sautter, R.; Soares-Santos, M.; Marques, B.; Clua, E.; Gonçalves, T.; de Sá-Freitas, C.; Moura, T. Machine and Deep Learning Applied to Galaxy Morphology-A Comparative Study. Astron. Comput. 2020, 30, 100334. [Google Scholar] [CrossRef]
- Beckwith, S.V.W.; Stiavelli, M.; Koekemoer, A.M.; Caldwell, J.A.R.; Ferguson, H.C.; Hook, R.; Lucas, R.A.; Bergeron, L.E.; Corbin, M.; Jogee, S.; et al. The Hubble Ultra Deep Field. Astron. J. 2006, 132, 1729–1755. [Google Scholar] [CrossRef]
- Gavali, P.; Banu, J.S. Chapter 6—Deep Convolutional Neural Network for Image Classification on CUDA Platform. In Deep Learning and Parallel Computing Environment for Bioengineering Systems; Arun, K.S., Ed.; Academic Press: Cambridge, MA, USA, 2019; pp. 99–122. [Google Scholar]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Hambly, N.C.; MacGillivray, H.T.; Read, M.A.; Tritton, S.B.; Thomson, E.B.; Kelly, B.D.; Morgan, D.H.; Smith, R.E.; Driver, S.P.; Williamson, J.; et al. The SuperCOSMOS Sky Survey-I. Introduction and description. Mon. Not. R. Astron. Soc. 2001, 326, 1279–1294. [Google Scholar] [CrossRef]
- Parker, Q.A.; Phillipps, S.; Pierce, M.J.; Hartley, M.; Hambly, N.C.; Read, M.A.; MacGillivray, H.T.; Tritton, S.B.; Cass, C.P.; Cannon, R.D.; et al. The AAO/UKST SuperCOSMOS Hα survey. Mon. Not. R. Astron. Soc. 2005, 362, 689–710. [Google Scholar] [CrossRef]
- Drew, J.E.; Gonzalez-Solares, E.; Greimel, R.; Irwin, M.J.; Küpcü Yoldas, A.; Lewis, J.; Barentsen, G.; Eislöffel, J.; Farnhill, H.J.; Martin, W.E.; et al. The VST Photometric Hα Survey of the Southern Galactic Plane and Bulge (VPHAS+). Mon. Not. R. Astron. Soc. 2014, 440, 2036–2058. [Google Scholar] [CrossRef]
- Wright, E.L.; Eisenhardt, P.R.M.; Mainzer, A.K.; Ressler, M.E.; Cutri, R.M.; Jarrett, T.; Kirkpatrick, J.D.; Padgett, D.; McMillan, R.S.; Skrutskie, M.; et al. The Wide-field Infrared Survey Explorer (WISE): Mission Description and Initial On-orbit Performance. Astron. J. 2010, 140, 1868–1881. [Google Scholar] [CrossRef]
- Feder, R.M.; Portillo, S.K.N.; Daylan, T.; Finkbeiner, D. Multiband Probabilistic Cataloging: A Joint Fitting Approach to Point-source Detection and Deblending. Astron. J. 2020, 159, 163. [Google Scholar] [CrossRef]
- Ritter, A.; Parker, Q.A. A Preferred Orientation Angle for Bipolar Planetary Nebulae. Galaxies 2020, 8, 34. [Google Scholar] [CrossRef]
- Corradi, R.L.M.; Schwarz, H.E. Morphological Populations of Planetary Nebulae: Which Progenitors? I. Comparative properties of bipolar nebulae. Astron. Astrophys. 1995, 293, 871–888. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Keras. Keras Applications. Available online: https://keras.io/api/applications/ (accessed on 20 May 2020).
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems-Volume 1, Lake Tahoe, NV, USA, 3–8 December 2012; Curran Associates Inc.: Red Hook, NY, USA, 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning Transferable Architectures for Scalable Image Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8697–8710. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; AAAI Press: Palo Alto, CA, USA, 2017; pp. 4278–4284. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Carneiro, T.; Medeiros Da NóBrega, R.V.; Nepomuceno, T.; Bian, G.; De Albuquerque, V.H.C.; Filho, P.P.R. Performance Analysis of Google Colaboratory as a Tool for Accelerating Deep Learning Applications. IEEE Access 2018, 6, 61677–61685. [Google Scholar] [CrossRef]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems, 2015. Software Available from tensorflow.org. Available online: https://arxiv.org/pdf/1603.04467.pdf (accessed on 15 January 2020).
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Baeza-Yates, R.A.; Ribeiro-Neto, B. Modern Information Retrieval; Addison-Wesley Longman Publishing Co., Inc.: Boston, MA, USA, 1999. [Google Scholar]
- Zhu, W.W.; Berndsen, A.; Madsen, E.C.; Tan, M.; Stairs, I.H.; Brazier, A.; Lazarus, P.; Lynch, R.; Scholz, P.; Stovall, K.; et al. Searching for Pulsars Using Image Pattern Recognition. Astrophys. J. 2014, 781, 117. [Google Scholar] [CrossRef]
- Cohen, M.; Parker, Q.A.; Green, A.J.; Miszalski, B.; Frew, D.; Murphy, T. Multiwavelength diagnostic properties of Galactic planetary nebulae detected by the GLIMPSE-I. Mon. Not. R. Astron. Soc. 2011, 413, 514–542. [Google Scholar] [CrossRef]
- Fragkou, V.; Parker, Q.A.; Bojičić, I.S.; Aksaker, N. New Galactic Planetary nebulae selected by radio and multiwavelength characteristics. Mon. Not. R. Astron. Soc. 2018, 480, 2916–2928. [Google Scholar] [CrossRef]
| 1. |














| Class | Total # PNe | Total # Images | Optical | Quotient | WISE432 | Pan-STARRS |
|---|---|---|---|---|---|---|
| True PNe | 2450 | 17,612 | 2443 | 2101 | 2441 | 1508 |
| Rejected PNe/Other Objects | 2741 | 18,507 | 2696 | 2159 | 2694 | 1768 |
| Possible PNe | 368 | 2630 | 367 | 330 | 368 | 216 |
| Likely PNe | 313 | 2287 | 311 | 282 | 312 | 242 |
| Grand Total | 5872 | 41,036 | 5817 | 4872 | 5815 | 3734 |
| Dataset | Percentage | HASH DB | Pan-STARRS |
|---|---|---|---|
| HASH DB/Pan-STARSS | Number of Images | Number of Images | |
| Training | 80%/77% | 1680 | 1200 |
| Validation | 10%/10% | 210 | 150 |
| Test | 10%/13% | 210 | 210 |
| Total number of images for each image resource | 2100 | 1560 | |
| Total number of images for each PNe class | 6300 | 1560 | |
| Total number of images used for True and Rejected PNe Classification | 12,600 | 3120 | |
| Morphology | Total Number of PNe | Total Number of Images | Optical | Quotient | WISE432 | Pan-STARRS |
|---|---|---|---|---|---|---|
| Asymmetric | 9 | 69 | 9 | 8 | 9 | N/A |
| Bipolar | 543 | 3857 | 542 | 464 | 540 | 161 |
| Elliptical/oval | 1017 | 9764 | 1010 | 861 | 1012 | 390 |
| Irregular | 18 | 135 | 18 | 15 | 18 | N/A |
| Quasi-Stellar | 374 | 2829 | 370 | 350 | 372 | N/A |
| Round | 489 | 3408 | 489 | 397 | 487 | 200 |
| Grand Total | 2450 | 20,062 | 2438 | 2095 | 2438 | 751 |
| Dataset | Percentage | HASH DB | Pan-STARRS |
|---|---|---|---|
| Number of Images | Number of Images | ||
| Training | 80% | 224 | 128 |
| Validation | 10% | 28 | 16 |
| Test | 10% | 28 | 16 |
| Total number of images for each morphology | 280 | 160 | |
| Total number of images for each image resource | 840 | 640 | |
| Total number of images used for PNe Morphology Classification | 2520 | 1920 | |
| Selected DL Algorithms | Top-1 Accuracy [23] |
|---|---|
| InceptionResNetV2 (2016) [28] | 0.803 |
| DenseNet201 (2017) [29] | 0.773 |
| ResNet50 (2015) [26] | 0.749 |
| NASNetMobile (2017) [27] | 0.744 |
| VGG-16 (2105) [25] | 0.713 |
| VGG-19 (2105) [25] | 0.713 |
| MobileNetV2 (2018) [30] | 0.713 |
| AlexNet (2012) [24] | 0.633 |
| Model | Image Size | STEM |
|---|---|---|
| InceptionResNetV2 | 299 | Total parameters: 66,920,163 |
| Trainable parameters: 66,859,619 | ||
| Non-trainable parameters: 60,544 | ||
| DenseNet201 | 224 | Total parameters: 30,364,739 |
| Trainable parameters: 30,135,683 | ||
| Non-trainable parameters: 229,056 | ||
| MobileNetV2 | 224 | Total parameters: 2,260,546 |
| Trainable parameters: 2562 | ||
| Non-trainable parameters: 2,257,984 |
| DTL Models | Training Set | Accuracy | Test Set | Recall | |
|---|---|---|---|---|---|
| Accuracy | Precision | ||||
| HASH Optical | InceptionResNetV2 | 0.80 | 0.81 | 0.78 | 0.78 |
| DenseNet201 | 0.86 | 0.84 | 0.85 | 0.82 | |
| MobileNetV2 | 0.83 | 0.83 | 0.83 | 0.82 | |
| HASH Quotient | InceptionResNetV2 | 0.77 | 0.80 | 0.81 | 0.75 |
| DenseNet201 | 0.88 | 0.86 | 0.88 | 0.84 | |
| MobileNetV2 | 0.84 | 0.83 | 0.79 | 0.86 | |
| HASH WISE432 | InceptionResNetV2 | 0.62 | 0.61 | 0.61 | 0.62 |
| DenseNet201 | 0.81 | 0.82 | 0.81 | 0.85 | |
| MobileNetV2 | 0.84 | 0.81 | 0.86 | 0.78 | |
| Pan-STARRS Plain | InceptionResNetV2 | 0.62 | 0.66 | 0.66 | 0.63 |
| DenseNet201 | 0.81 | 0.74 | 0.72 | 0.78 | |
| MobileNetV2 | 0.77 | 0.76 | 0.74 | 0.78 |
| DTL Models | Training Set | Accuracy | Test Set | Recall | |
|---|---|---|---|---|---|
| Accuracy | Precision | ||||
| HASH Optical | InceptionResNetV2 | 1.00 | 0.15 | 0.17 | 0.15 |
| DenseNet201 | 0.93 | 0.70 | 0.54 | 0.55 | |
| MobileNetV2 | 0.86 | 0.70 | 0.56 | 0.55 | |
| HASH Quotient | InceptionResNetV2 | 0.86 | 0.47 | 0.46 | 0.39 |
| DenseNet201 | 0.91 | 0.63 | 0.45 | 0.44 | |
| MobileNetV2 | 0.86 | 0.52 | 0.30 | 0.28 | |
| HASH WISE432 | InceptionResNetV2 | 0.41 | 0.34 | 0.37 | 0.30 |
| DenseNet201 | 0.95 | 0.64 | 0.47 | 0.45 | |
| MobileNetV2 | 0.86 | 0.59 | 0.38 | 0.38 | |
| Pan-STARRS Plain | InceptionResNetV2 | 1.00 | 0.48 | 0.49 | 0.44 |
| DenseNet201 | 0.97 | 0.58 | 0.37 | 0.38 | |
| MobileNetV2 | 0.98 | 0.71 | 0.59 | 0.56 | |
| Pan-STARRS Quotient | InceptionResNetV2 | 1.00 | 0.38 | 0.45 | 0.39 |
| DenseNet201 | 0.98 | 0.55 | 0.32 | 0.34 | |
| MobileNetV2 | 0.90 | 0.54 | 0.30 | 0.31 | |
| Pan-STARRS No-star | InceptionResNetV2 | 0.97 | 0.38 | 0.40 | 0.39 |
| DenseNet201 | 0.98 | 0.63 | 0.44 | 0.44 | |
| MobileNetV2 | 0.96 | 0.61 | 0.42 | 0.42 | |
| Pan-STARRS Mask | InceptionResNetV2 | 0.84 | 0.38 | 0.39 | 0.31 |
| DenseNet201 | 0.98 | 0.65 | 0.47 | 0.47 | |
| MobileNetV2 | 0.82 | 0.59 | 0.38 | 0.39 |
| PNG Number | Name | Visual Inspection |
|---|---|---|
| 359.0+02.8 | Al 2-G | p |
| 001.0−02.6 | Sa 3-104 | p |
| 002.5−02.6 | MPA 1802−2803 | n |
| 001.8−05.3 | PM 1-216 | n |
| 002.4+01.4 | [DSH2001] 520-9 | n |
| 018.6-02.7 | PN PM 1-243 | n |
| 003.0−02.8 | PHR J1803−2748 | p |
| 140.0+01.7 | IPHASX J031434.2+594856 | n |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Awang Iskandar, D.N.F.; Zijlstra, A.A.; McDonald, I.; Abdullah, R.; Fuller, G.A.; Fauzi, A.H.; Abdullah, J. Classification of Planetary Nebulae through Deep Transfer Learning. Galaxies 2020, 8, 88. https://doi.org/10.3390/galaxies8040088
Awang Iskandar DNF, Zijlstra AA, McDonald I, Abdullah R, Fuller GA, Fauzi AH, Abdullah J. Classification of Planetary Nebulae through Deep Transfer Learning. Galaxies. 2020; 8(4):88. https://doi.org/10.3390/galaxies8040088
Chicago/Turabian StyleAwang Iskandar, Dayang N. F., Albert A. Zijlstra, Iain McDonald, Rosni Abdullah, Gary A. Fuller, Ahmad H. Fauzi, and Johari Abdullah. 2020. "Classification of Planetary Nebulae through Deep Transfer Learning" Galaxies 8, no. 4: 88. https://doi.org/10.3390/galaxies8040088
APA StyleAwang Iskandar, D. N. F., Zijlstra, A. A., McDonald, I., Abdullah, R., Fuller, G. A., Fauzi, A. H., & Abdullah, J. (2020). Classification of Planetary Nebulae through Deep Transfer Learning. Galaxies, 8(4), 88. https://doi.org/10.3390/galaxies8040088