
Machine Learning-Based Behavioral Diagnostic Tools for Depression: Advances, Challenges, and Future Directions




Abstract
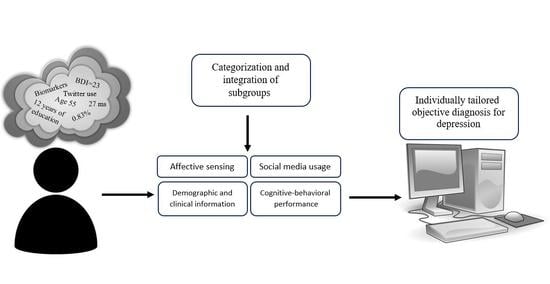
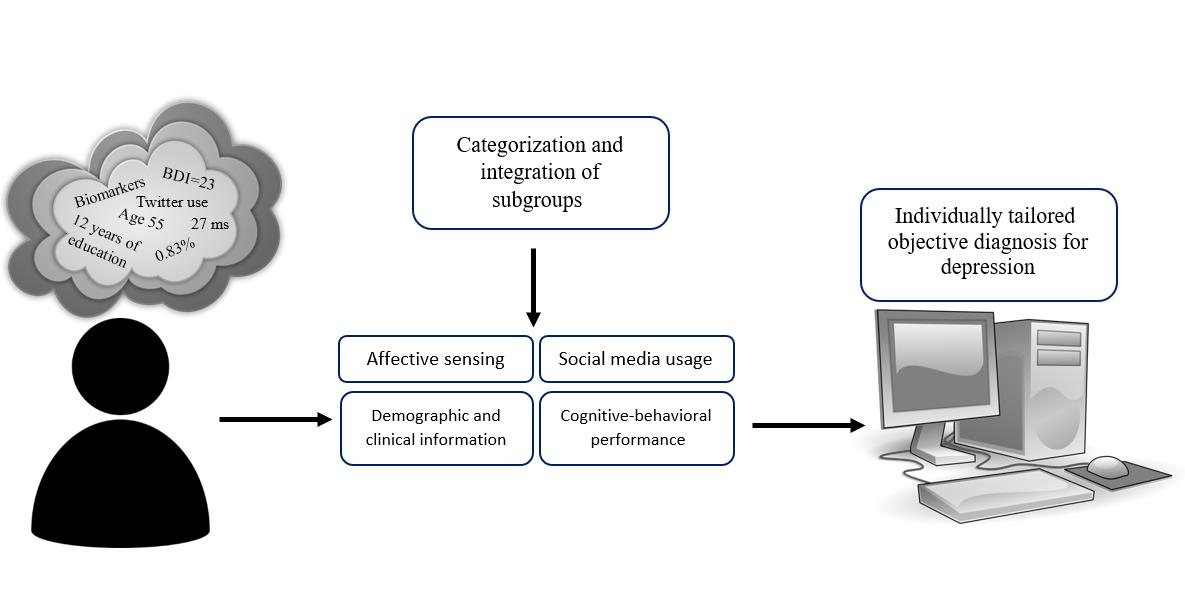
:
{kind=link}
1. Introduction
2. Machine Learning Analysis in Psychiatry
3. Machine Learning Analysis Based on Behavioral Assessment in Psychiatry
4. Laboratory-Based Assessments
5. Data Mining
5.1. Social Media Usage and Movement Sensors Data
5.2. Demographic and Clinical Information
6. Advances and Future Implementations of ML-Based Behavioral Diagnosis
7. Current Challenges of ML-Based Behavioral Diagnosis
8. Summary
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- James, S.L.; Abate, D.; Abate, K.H.; Abay, S.M.; Abbafati, C.; Abbasi, N.; Briggs, A.M. Global, regional, and national incidence, prevalence, and years lived with disability for 354 diseases and injuries for 195 countries and territories, 1990–2017: A systematic analysis for the Global Burden of Disease Study 2017. Lancet 2018, 392, 1789–1858. [Google Scholar] [CrossRef] [Green Version]
- World Health Organization. Depression and Other Common Mental Disorders: Global Health Estimates (No. WHO/MSD/MER/2017.2); World Health Organization: Geneva, Switzerland, 2018. [Google Scholar]
- Spinks, D.; Spinks, G. Serotonin reuptake inhibition: An update on current research strategies. Curr. Med. Chem. 2002, 9, 799–810. [Google Scholar] [CrossRef]
- Hunsley, J.; Elliott, K.; Therrien, Z. The Efficacy and Effectiveness of Psychological Treatments; Canadian Psychological Association: Ottawa, ON, Canada, 2013. [Google Scholar]
- Khan, A.; Faucett, J.; Lichtenberg, P.; Kirsch, I.; Brown, W.A. A Systematic Review of Comparative Efficacy of Treatments and Controls for Depression. PLoS ONE 2012, 7, e41778. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Groen, R.N.; Ryan, O.; Wigman, J.T.; Riese, H.; Penninx, B.W.; Giltay, E.J.; Hartman, C.A. Comorbidity between depression and anxiety: Assessing the role of bridge mental states in dynamic psychological networks. BMC Med. 2020, 18, 308. [Google Scholar] [CrossRef] [PubMed]
- Hofmann, S.G.; Hayes, S.C. Beyond the DSM: Toward a Process-Based Alternative for Diagnosis and Mental Health Treatment; Context Press/New Harbinger Publications: Oakland, CA, USA, 2020. [Google Scholar]
- Donaldson, S.I.; Grant-Vallone, E.J. Understanding self-report bias in organizational behavior research. J. Bus. Psychol. 2002, 17, 245–260. [Google Scholar] [CrossRef] [Green Version]
- Piedmont, R.L.; McCrae, R.R.; Riemann, R.; Angleitner, A. On the invalidity of validity scales: Evidence from self-reports and observer ratings in volunteer samples. J. Personal. Soc. Psychol. 2000, 78, 582. [Google Scholar] [CrossRef]
- Hunt, M.; Auriemma, J.; Cashaw, A.C. Self-report bias and underreporting of depression on the BDI-II. J. Personal. Assess. 2003, 80, 26–30. [Google Scholar] [CrossRef] [PubMed]
- Aboraya, A. The Reliability of Psychiatric Diagnoses: Point-Our psychiatric Diagnoses are Still Unreliable. Psychiatry 2007, 4, 22–25. [Google Scholar] [PubMed]
- Aboraya, A.; France, C.; Young, J.; Curci, K.; LePage, J. The validity of psychiatric diagnosis revisited: The clinician’s guide to improve the validity of psychiatric diagnosis. Psychiatry 2005, 2, 48. [Google Scholar]
- Skre, I.; Onstad, S.; Torgersen, S.; Kringlen, E. High interrater reliability for the Structured Clinical Interview for DSM-III-R Axis I (SCID-I). Acta Psychiatr. Scand. 1991, 84, 167–173. [Google Scholar] [CrossRef]
- Lovibond, S.H.; Lovibond, P.F. Manuals for the Depression Anxiety Stress Scales, 2nd ed.; Psychology Foundation of Australia: Sydney, NSW, Australia, 1995. [Google Scholar] [CrossRef]
- Van den Bergh, N.; Marchetti, I.; Koster, E.H. Bridges over troubled waters: Mapping the interplay between anxiety, depression and stress through network analysis of the DASS-21. Cognit. Ther. Res. 2020, 45, 46–60. [Google Scholar] [CrossRef]
- Finlay, W.M.; Lyons, E. Methodological issues in interviewing and using self-report questionnaires with people with mental retardation. Psychol. Assess. 2001, 13, 319. [Google Scholar] [CrossRef]
- Forbes, G.B. Clinical utility of the test of variables of attention (TOVA) in the diagnosis of attention-deficit/hyperactivity disorder. J. Clin. Psychol. 1998, 54, 461–476. [Google Scholar] [CrossRef]
- Bzdok, D.; Meyer-Lindenberg, A. Machine learning for precision psychiatry: Opportunities and challenges. Biol. Psychiatry Cogn. Neurosci. Neuroimaging 2018, 3, 223–230. [Google Scholar] [CrossRef] [Green Version]
- Kanchanatawan, B.; Thika, S.; Sirivichayakul, S.; Carvalho, A.; Geffard, M.; Maes, M. Schizophrenia, depression, anxiety, and physiosomatic symptoms are strongly related to psychotic symptoms and excitation, impairments in episodic memory, and increased production of neurotoxic tryptophan catabolites: A multivariate and machine learning study. Neurotox. Res. 2018, 33, 641–655. [Google Scholar]
- Shatte, A.B.; Hutchinson, D.M.; Teague, S.J. Machine learning in mental health: A scoping review of methods and applications. Psychol. Med. 2019, 49, 1426–1448. [Google Scholar] [CrossRef] [Green Version]
- Rubin-Falcone, H.; Zanderigo, F.; Thapa-Chhetry, B.; Lan, M.; Miller, J.M.; Sublette, M.E.; Mann, J.J. Pattern recognition of magnetic resonance imaging-based gray matter volume measurements classifies bipolar disorder and major depressive disorder. J. Affect. Disord. 2018, 227, 498–505. [Google Scholar] [CrossRef] [PubMed]
- Sato, J.R.; Biazoli, C.E., Jr.; Salum, G.A.; Gadelha, A.; Crossley, N.; Vieira, G.; Bressan, R.A. Association between abnormal brain functional connectivity in children and psychopathology: A study based on graph theory and machine learning. World J. Biol. Psychiatry 2018, 19, 119–129. [Google Scholar] [CrossRef] [PubMed]
- Rosa, M.J.; Portugal, L.; Hahn, T.; Fallgatter, A.J.; Garrido, M.I.; Shawe-Taylor, J.; Mourao-Miranda, J. Sparse network-based models for patient classification using fMRI. Neuroimage 2015, 105, 493–506. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Patel, M.J.; Khalaf, A.; Aizenstein, H.J. Studying depression using imaging and machine learning methods. NeuroImage Clin. 2016, 10, 115–123. [Google Scholar] [CrossRef] [Green Version]
- Gao, S.; Calhoun, V.D.; Sui, J. Machine learning in major depression: From classification to treatment outcome prediction. CNS Neurosci. Ther. 2018, 24, 1037–1052. [Google Scholar] [CrossRef] [Green Version]
- Joshi, J.; Goecke, R.; Alghowinem, S.; Dhall, A.; Wagner, M.; Epps, J.; Parker, G.; Breakspear, M. Multimodal assistive technologies for depression diagnosis and monitoring. J. Multimodal User Interfaces 2013, 7, 217–228. [Google Scholar] [CrossRef]
- McGinnis, R.S.; McGinnis, E.W.; Hruschak, J.; Lopez-Duran, N.L.; Fitzgerald, K.; Rosenblum, K.L.; Muzik, M. Rapid anxiety and depression diagnosis in young children enabled by wearable sensors and machine learning. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 17–21 July 2018; pp. 3983–3986. [Google Scholar]
- McGinnis, E.W.; Anderau, S.P.; Hruschak, J.; Gurchiek, R.D.; Lopez-Duran, N.L.; Fitzgerald, K.; Rosenblum, K.L.; Muzik, M.; McGinnis, R.S. Giving voice to vulnerable children: Machine learning analysis of speech detects anxiety and depression in early childhood. IEEE J. Biomed. Health. Inform. 2019, 23, 2294–2301. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Y.; Shang, Y.; Shao, Z.; Guo, G. Automated depression diagnosis based on deep networks to encode facial appearance and dynamics. IEEE Trans. Affect. Comput. 2017, 9, 578–584. [Google Scholar] [CrossRef]
- Kang, Y.; Jiang, X.; Yin, Y.; Shang, Y.; Zhou, X. Deep transformation learning for depression diagnosis from facial images. In Proceedings of the Chinese Conference on Biometric Recognition, Shenzhen, China, 28–29 October 2017; pp. 13–22. [Google Scholar]
- Maridaki, A.; Pampouchidou, A.; Marias, K.; Tsiknakis, M. Machine learning techniques for automatic depression assessment. In Proceedings of the 2018 41st International Conference on Telecommunications and Signal Processing (TSP), Athens, Greece, 4–6 July 2018; pp. 1–5. [Google Scholar]
- Victor, E.; Aghajan, Z.M.; Sewart, A.R.; Christian, R. Detecting depression using a framework combining deep multimodal neural networks with a purpose-built automated evaluation. Psychol. Assess. 2019, 31, 1019–1027. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Smith, M.; Dietrich, B.J.; Bai, E.W.; Bockholt, H.J. Vocal pattern detection of depression among older adults. Int. J. Ment. Health Nurs. 2020, 29, 440–449. [Google Scholar] [CrossRef]
- Miao, B.; Liu, X.; Zhu, T. Automatic mental health identification method based on natural gait pattern. PsyCh Journal. 2021, 10, 453–464. [Google Scholar] [CrossRef]
- Bot, M.; Chan, M.K.; Jansen, R.; Lamers, F.; Vogelzangs, N.; Steiner, J.; Leweke, F.M.; Rothermundt, M.; Cooper, J.; Bahn, S.; et al. Serum proteomic profiling of major depressive disorder. Transl. Psychiatry 2015, 5, e599. [Google Scholar] [CrossRef] [Green Version]
- Chalmers, J.A.; Quintana, D.S.; Abbott, M.J.; Kemp, A.H. Anxiety disorders are associated with reduced heart rate variability: A meta-analysis. Front. Psychiatry 2014, 5, 80. [Google Scholar] [CrossRef] [Green Version]
- Kim, E.Y.; Lee, M.Y.; Kim, S.H.; Ha, K.; Kim, K.P.; Ahn, Y.M. Diagnosis of major depressive disorder by combining multimodal information from heart rate dynamics and serum proteomics using machine-learning algorithm. Prog. Neuro-Psychopharmacol. Biol. Psychiatry 2017, 76, 65–71. [Google Scholar] [CrossRef]
- Dipnall, J.F.; Pasco, J.A.; Berk, M.; Williams, L.; Dodd, S.; Jacka, F.N.; Meyer, D. Fusing Data Mining, Machine Learning and Traditional Statistics to Detect Biomarkers Associated with Depression. PLoS ONE 2016, 11, e0148195. [Google Scholar] [CrossRef] [Green Version]
- Sharma, A.; Verbeke, W.J. Improving Diagnosis of Depression with XGBOOST Machine Learning Model and a Large Biomarkers Dutch Dataset (n = 11,081). Front. Big Data 2020, 3, 15. [Google Scholar] [CrossRef]
- Wollenhaupt-Aguiar, B.; Librenza-Garcia, D.; Bristot, G.; Przybylski, L.; Stertz, L.; Kubiachi Burque, R.; Ceresér, K.M.; Spanemberg, L.; Caldieraro, M.A.; Frey, B.N.; et al. Differential biomarker signatures in unipolar and bipolar depression: A machine learning approach. Aust. N. Z. J. Psychiatry 2020, 54, 393–401. [Google Scholar] [CrossRef]
- Tomasik, J.; Han, S.Y.S.; Barton-Owen, G.; Mirea, D.M.; Martin-Key, N.A.; Rustogi, N.; Lago, S.G.; Olmert, T.; Cooper, J.D.; Ozcan SEljasz, P. A machine learning algorithm to differentiate bipolar disorder from major depressive disorder using an online mental health questionnaire and blood biomarker data. Transl. Psychiatry 2021, 11, 41. [Google Scholar] [CrossRef]
- Mathews, A.; MacLeod, C. Cognitive vulnerability to emotional disorders. Annu. Rev. Clin. Psychol. 2005, 1, 167–195. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hallion, L.S.; Ruscio, A.M. A meta-analysis of the effect of cognitive bias modification on anxiety and depression. Psychol. Bull. 2011, 137, 940–958. [Google Scholar] [CrossRef] [PubMed]
- Hertel, P.T. Cognition in emotional disorders: An abundance of habit and a dearth of control. In Remembering: Attributions, Processes, and Control in Human Memory; Lindsay, D.S., Kelley, C.M., Yonelinas, A.P., Roediger, H.L., Eds.; Psychology Press: Hove, UK, 2015; pp. 322–335. [Google Scholar]
- Power, M.; Dalgleish, T. Cognition and Emotion: From Order to Disorder, 3rd ed.; Psychology Press: Hove, UK, 2015. [Google Scholar]
- Richter, T.; Fishbain, B.; Markus, A.; Richter-Levin, G.; Okon-Singer, H. Using machine learning-based analysis for behavioral differentiation between anxiety and depression. Sci. Rep. 2020, 10, 16381. [Google Scholar] [CrossRef] [PubMed]
- Richter, T.; Fishbain, B.; Fruchter, E.; Okon-Singer, H. Machine learning-based diagnosis support system for differentiating between clinical anxiety and depression disorders. J. Psychiatr. Res. 2021, in press. [Google Scholar] [CrossRef]
- Wawer, A.; Chojnicka, I.; Okruszek, L.; Sarzynska-Wawer, J. Single and cross-disorder detection for autism and schizophrenia. Cogn. Comput. 2021, 13. [Google Scholar] [CrossRef]
- Demetriou, E.A.; Park, S.H.; Ho, N.; Pepper, K.L.; Song, Y.J.; Naismith, S.L.; Guastella, A.J. Machine Learning for Differential Diagnosis Between Clinical Conditions With Social Difficulty: Autism Spectrum Disorder, Early Psychosis, and Social Anxiety Disorder. Front. Psychiatry 2020, 11, 545. [Google Scholar] [CrossRef]
- Reece, A.G.; Reagan, A.J.; Lix, K.L.; Dodds, P.S.; Danforth, C.M.; Langer, E.J. Forecasting the onset and course of mental illness with Twitter data. Sci. Rep. 2017, 7, 13006. [Google Scholar] [CrossRef]
- Guntuku, S.C.; Yaden, D.B.; Kern, M.L.; Ungar, L.H.; Eichstaedt, J.C. Detecting depression and mental illness on social media: An integrative review. Curr. Opin. Behav. Sci. 2017, 18, 43–49. [Google Scholar] [CrossRef]
- Hassan, A.U.; Hussain, J.; Hussain, M.; Sadiq, M.; Lee, S. Sentiment analysis of social networking sites (SNS) data using machine learning approach for the measurement of depression. In Proceedings of the 2017 International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Korea, 18–20 October 2017; pp. 138–140. [Google Scholar]
- De Choudhury, M.; Gamon, M.; Counts, S.; Horvitz, E. Predicting depression via social media. In Proceedings of the International AAAI Conference on Web and Social Media, Cambridge, MA, USA, 8–11 July 2013; Volume 7. [Google Scholar]
- Reece, A.G.; Danforth, C.M. Instagram photos reveal predictive markers of depression. EPJ Data Sci. 2017, 6, 15. [Google Scholar] [CrossRef] [Green Version]
- Tsugawa, S.; Kikuchi, Y.; Kishino, F.; Nakajima, K.; Itoh, Y.; Ohsaki, H. Recognizing depression from twitter activity. In Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems, Seoul, Korea, 18–23 April 2015; pp. 3187–3196. [Google Scholar]
- Chiong, R.; Budhi, G.S.; Dhakal, S.; Chiong, F. A textual-based featuring approach for depression detection using machine learning classifiers and social media texts. Comput. Biol. Med. 2021, 104499. [Google Scholar] [CrossRef]
- Razavi, R.; Gharipour, A.; Gharipour, M. Depression screening using mobile phone usage metadata: A machine learning approach. J. Am. Med Inform. Assoc. 2020, 27, 522–530. [Google Scholar] [CrossRef]
- Islam, M.R.; Kabir, M.A.; Ahmed, A.; Kamal, A.R.M.; Wang, H.; Ulhaq, A. Depression detection from social network data using machine learning techniques. Health Inf. Sci. Syst. 2018, 6, 8. [Google Scholar] [CrossRef]
- Hou, Y.; Xu, J.; Huang, Y.; Ma, X. A big data application to predict depression in the university based on the reading habits. In Proceedings of the 2016 3rd International Conference on Systems and Informatics (ICSAI), Shanghai, China, 19–21 November 2016; pp. 1085–1089. [Google Scholar]
- Mohr, D.C.; Zhang, M.; Schueller, S.M. Personal sensing: Understanding mental health using ubiquitous sensors and machine learning. Annu. Rev. Clin. Psychol. 2017, 13, 23–47. [Google Scholar] [CrossRef] [Green Version]
- Asare, K.O.; Terhorst, Y.; Vega, J.; Peltonen, E.; Lagerspetz, E.; Ferreira, D. Predicting Depression From Smartphone Behavioral Markers Using Machine Learning Methods, Hyperparameter Optimization, and Feature Importance Analysis: Exploratory Study. JMIR mHealth uHealth 2021, 9, e26540. [Google Scholar] [CrossRef]
- Kim, H.; Lee, S.; Lee, S.; Hong, S.; Kang, H.; Kim, N. Depression prediction by using ecological momentary assessment, actiwatch data, and machine learning: Observational study on older adults living alone. JMIR mHealth uHealth 2019, 7, e14149. [Google Scholar] [CrossRef] [Green Version]
- Tazawa, Y.; Liang, K.C.; Yoshimura, M.; Kitazawa, M.; Kaise, Y.; Takamiya, A.; Kishimoto, T. Evaluating depression with multimodal wristband-type wearable device: Screening and assessing patient severity utilizing machine-learning. Heliyon 2020, 6, e03274. [Google Scholar] [CrossRef]
- Sau, A.; Bhakta, I. Screening of anxiety and depression among seafarers using machine learning technology. Inform. Med. Unlocked 2019, 16, 100228. [Google Scholar] [CrossRef]
- Oh, J.; Yun, K.; Maoz, U.; Kim, T.S.; Chae, J.H. Identifying depression in the National Health and Nutrition Examination Survey data using a deep learning algorithm. J. Affect. Disord. 2019, 257, 623–631. [Google Scholar] [CrossRef]
- de Souza Filho, E.M.; Rey, H.C.V.; Frajtag, R.M.; Cook, D.M.A.; de Carvalho, L.N.D.; Ribeiro, A.L.P.; Amaral, J. Can machine learning be useful as a screening tool for depression in primary care? J. Psychiatr. Res. 2021, 132, 1–6. [Google Scholar] [CrossRef]
- Nemesure, M.D.; Heinz, M.V.; Huang, R.; Jacobson, N.C. Predictive modeling of depression and anxiety using electronic health records and a novel machine learning approach with artificial intelligence. Sci. Rep. 2021, 11, 1980. [Google Scholar] [CrossRef]
- Sau, A.; Bhakta, I. Predicting anxiety and depression in elderly patients using machine learning technology. Healthc. Technol. Lett. 2017, 4, 238–243. [Google Scholar] [CrossRef]
- Su, D.; Zhang, X.; He, K.; Chen, Y. Use of machine learning approach to predict depression in the elderly in China: A longitudinal study. J. Affect. Disord. 2021, 282, 289–298. [Google Scholar] [CrossRef]
- Hatton, C.M.; Paton, L.W.; McMillan, D.; Cussens, J.; Gilbody, S.; Tiffin, P.A. Predicting persistent depressive symptoms in older adults: A machine learning approach to personalised mental healthcare. J. Affect. Disord. 2019, 246, 857–860. [Google Scholar] [CrossRef] [Green Version]
- Hochman, E.; Feldman, B.; Weizman, A.; Krivoy, A.; Gur, S.; Barzilay, E.; Gabay, H.; Levy, J.; Levinkron, O.; Lawrence, G. Development and validation of a machine learning-based postpartum depression prediction model: A nationwide cohort study. Depress. Anxiety 2021, 38, 400–411. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, S.; Hermann, A.; Joly, R.; Pathak, J. Development and validation of a machine learning algorithm for predicting the risk of postpartum depression among pregnant women. J. Affect. Disord. 2021, 279, 1–8. [Google Scholar] [CrossRef]
- Wang, S.; Pathak, J.; Zhang, Y. Using electronic health records and machine learning to predict postpartum depression. In MEDINFO 2019: Health and Wellbeing e-Networks for All; IOS Press: Amsterdam, The Netherlands, 2019; pp. 888–892. [Google Scholar]
- Edgcomb, J.B.; Thiruvalluru, R.; Pathak, J.; Brooks, J.O., III. Machine learning to differentiate risk of suicide attempt and self-harm after general medical hospitalization of women with mental illness. Med. Care 2021, 59, S58–S64. [Google Scholar] [CrossRef]
- Zhou, L.; Baughman, A.W.; Lei, V.J.; Lai, K.H.; Navathe, A.S.; Chang, F.; Sordo, M.; Topaz, M.; Zhong, F.; Murrali, M.; et al. Identifying patients with depression using free-text clinical documents. In MEDINFO 2015: eHealth-enabled Health; IOS Press: Amsterdam, The Netherlands, 2015; pp. 629–633. [Google Scholar]
- Kraepelien, M.; Svanborg, C.; Lallerstedt, L.; Sennerstam, V.; Lindefors, N.; Kaldo, V. Individually tailored internet treatment in routine care: A feasibility study. Internet Interv. 2019, 18, 100263. [Google Scholar] [CrossRef]
- Kircher, S.; Arya, A.; Altmann, D.; Rolf, S.; Bollmann, A.; Sommer, P.; Dagres, N.; Richter, S.; Breithardt, O.A.; Dinov, B.; et al. Individually tailored vs. standardized substrate modification during radiofrequency catheter ablation for atrial fibrillation: A randomized study. Ep Eur. 2018, 20, 1766–1775. [Google Scholar] [CrossRef]
- Zilcha-Mano, S. Toward personalized psychotherapy: The importance of the trait-like/state-like distinction for understanding therapeutic change. Am. Psychol. 2020, 76, 516–528. [Google Scholar] [CrossRef]
- Hakamata, Y.; Lissek, S.; Bar-Haim, Y.; Britton, J.C.; Fox, N.A.; Leibenluft, E.; Ernst, M.; Pine, D.S. Attention bias modification treatment: A meta-analysis toward the establishment of novel treatment for anxiety. Biol. Psychiatry 2010, 68, 982–990. [Google Scholar] [CrossRef] [Green Version]
- Shani, R.; Tal, S.; Zilcha-Mano, S.; Okon-Smger, H. Can machine learning approaches lead toward personalized cognitive training? Front. Behav. Neurosci. 2019, 13, 64. [Google Scholar] [CrossRef] [Green Version]
- Chekroud, A.M.; Zotti, R.J.; Shehzad, Z.; Gueorguieva, R.; Johnson, M.K.; Trivedi, M.H.; Cannon, T.D.; Krystal, J.H.; Corlett, P.R. Cross-trial prediction oftreatment outcome in depression: A machine learning approach. Lancet Psychiatry 2016, 3, 243–250. [Google Scholar] [CrossRef]
- Moore, M.; Maclin, E.L.; Iordan, A.D.; Katsumi, Y.; Larsen, R.J.; Bagshaw, A.P.; Mayhew, S.; Shafer, A.T.; Sutton, B.P.; Fabiani, M.; et al. Proof-of-Concept Evidence for Trimodal Simultaneous Investigation of Human Brain Function; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2021. [Google Scholar]
- Zulfiker, M.S.; Kabir, N.; Biswas, A.A.; Nazneen, T.; Uddin, M.S. An in-depth analysis of machine learning approaches to predict depression. Curr. Res. Behav. Sci. 2021, 2, 100044. [Google Scholar] [CrossRef]
- Shani, R.; Tal, S.; Derakshan, N.; Cohen, N.; Enock, P.M.; McNally, R.J.; Mor, N.; Daches, S.; Williams, A.D.; Yiend, J.; et al. Personalized cognitive training: Protocol for individual-level meta-analysis implementing machine learning methods. J. Psychiatr. Res. 2021, 138, 342–348. [Google Scholar] [CrossRef]
- Kathol, R.G.; Mutgi, A.; Williams, J.W.; Clamon, G.; Noyes, R. Diagnosis of major depression in cancer patients according to four sets of criteria. Am. J. Psychiatry 1990, 147, 1021–1024. [Google Scholar]
- Angst, J.; Merikangas, K.R. Multi-dimensional criteria for the diagnosis of depression. J. Affect. Disord. 2001, 62, 7–15. [Google Scholar] [CrossRef]
- Arbabshirani, M.R.; Plis, S.; Sui, J.; Calhoun, V.D. Single subject prediction of brain disorders in neuroimaging: Promises and pitfalls. Neuroimage 2017, 145, 137–165. [Google Scholar] [CrossRef] [Green Version]
- Varoquaux, G. Cross-validation failure: Small sample sizes lead to large error bars. Neuroimage 2018, 180, 68–77. [Google Scholar] [CrossRef] [Green Version]
- Vabalas, A.; Gowen, E.; Poliakoff, E.; Casson, A.J. Machine learning algorithm validation with a limited sample size. PLoS ONE 2019, 14, e0224365. [Google Scholar] [CrossRef]
- Chakraborty, S.; Tomsett, R.; Raghavendra, R.; Harborne, D.; Alzantot, M.; Cerutti, F.; Gurram, P. Interpretability of deep learning models: A survey of results. In Proceedings of the 2017 IEEE Smartworld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computed, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation (Smartworld/SCALCOM/UIC/ATC/CBDcom/IOP/SCI), San Francisco Bay Area, CA, USA, 4–8 August 2017; pp. 1–6. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Richter, T.; Fishbain, B.; Richter-Levin, G.; Okon-Singer, H. Machine Learning-Based Behavioral Diagnostic Tools for Depression: Advances, Challenges, and Future Directions. J. Pers. Med. 2021, 11, 957. https://doi.org/10.3390/jpm11100957
Richter T, Fishbain B, Richter-Levin G, Okon-Singer H. Machine Learning-Based Behavioral Diagnostic Tools for Depression: Advances, Challenges, and Future Directions. Journal of Personalized Medicine. 2021; 11(10):957. https://doi.org/10.3390/jpm11100957
Chicago/Turabian StyleRichter, Thalia, Barak Fishbain, Gal Richter-Levin, and Hadas Okon-Singer. 2021. "Machine Learning-Based Behavioral Diagnostic Tools for Depression: Advances, Challenges, and Future Directions" Journal of Personalized Medicine 11, no. 10: 957. https://doi.org/10.3390/jpm11100957
APA StyleRichter, T., Fishbain, B., Richter-Levin, G., & Okon-Singer, H. (2021). Machine Learning-Based Behavioral Diagnostic Tools for Depression: Advances, Challenges, and Future Directions. Journal of Personalized Medicine, 11(10), 957. https://doi.org/10.3390/jpm11100957