


Evaluating ChatGPT-4 Plus in Ophthalmology: Effect of Image Recognition and Domain-Specific Pretraining on Diagnostic Performance



Abstract
1. Introduction
2. Materials and Methods
3. Results
3.1. Baseline Characteristics of the Testing Sets
- Questions are categorized by difficulty: easy, moderate, and difficult.
- The presence of images in questions is noted as either with or without images.
3.2. Repeatability of ChatGPT Performance
3.3. Comparative Performance Analysis of ChatGPT Models and Average Test-Takers Across Examination Sections
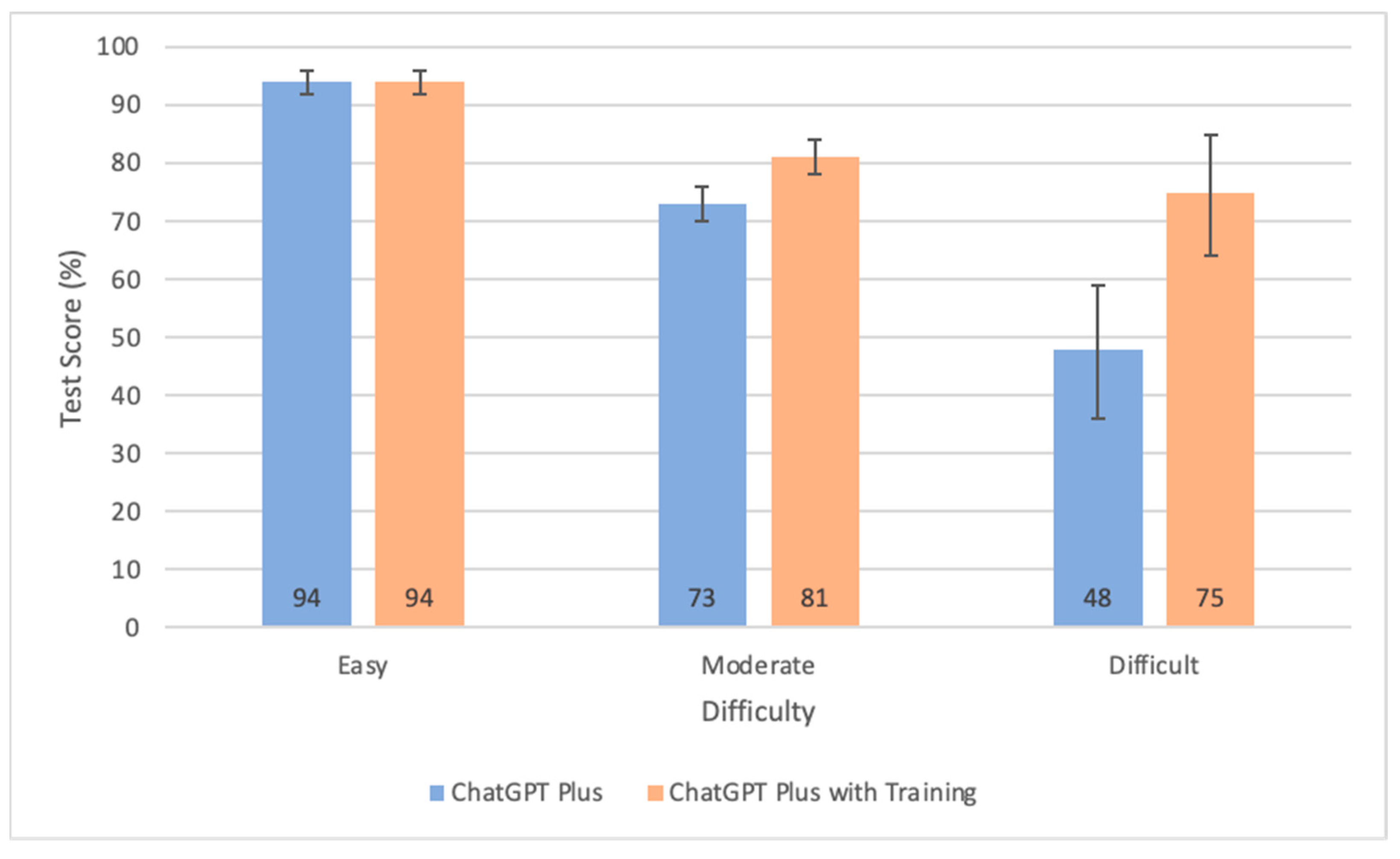
3.4. Performance Metrics Across Different Difficulty Levels
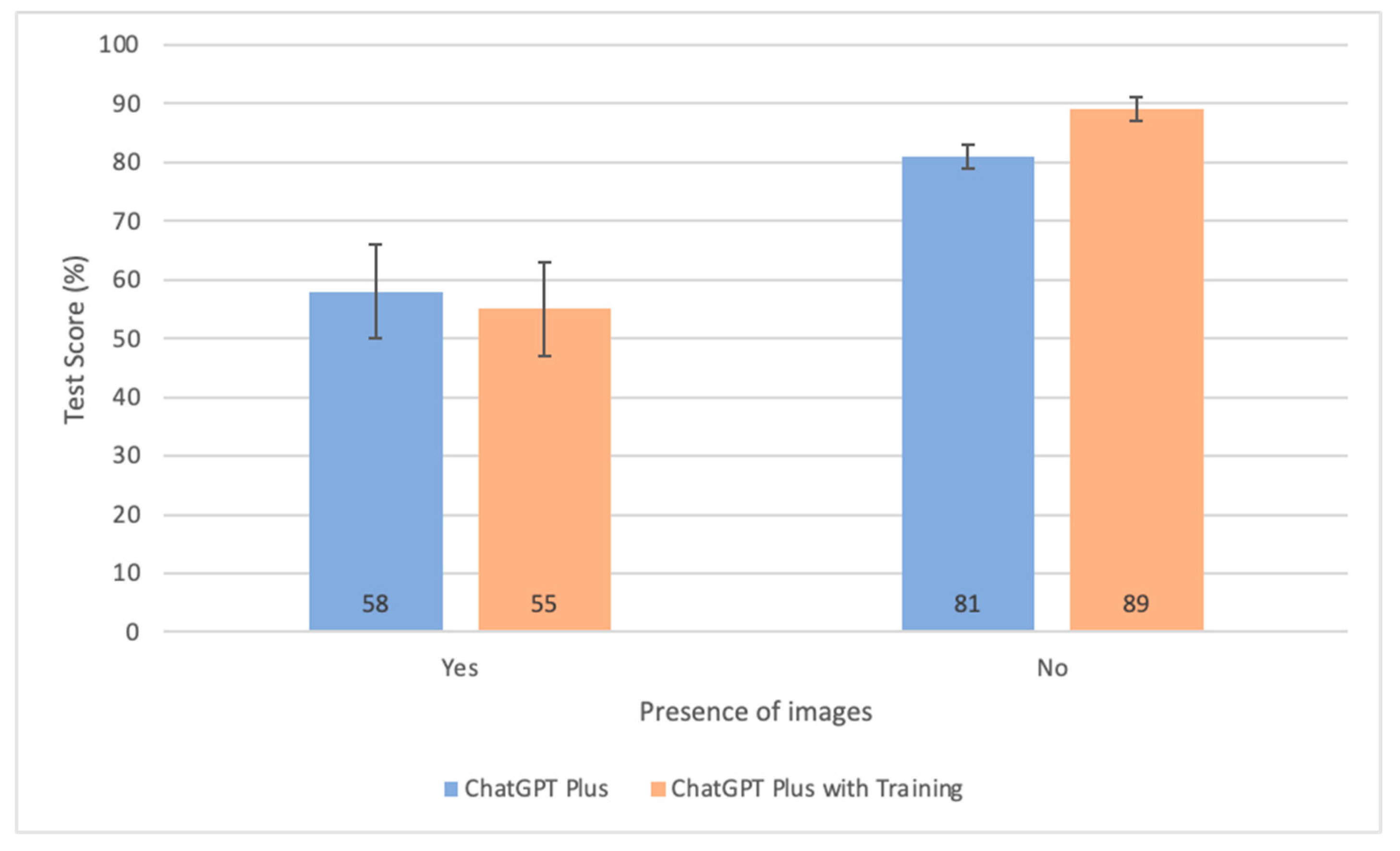
3.5. Comparative Analysis of Test Scores Based on the Presence of Images
4. Discussion
4.1. Comparative Review of ChatGPT’s Performance in Ophthalmology Assessments
4.2. Performance Across Subspecialties, Question Difficulties and Image Presence
4.3. Impact of Domain-Specific Pretraining
4.4. Repeatability and Consistency
4.5. ChatGPT-4 Plus’ Performance Against Average Test-Takers
4.6. Strengths and Limitations
5. Conclusions
- The ChatGPT Plus model demonstrated a superior performance, surpassing the average test-taker by a margin of 4%. When enhanced with domain-specific pretraining, this model further outshone the non-pretrained ChatGPT Plus variant by 7% and exceeded average test-taker scores by 11%.
- The benefits of domain-specific pretraining become increasingly significant as the difficulty of questions increases. However, this advantage does not extend to performance on image-based questions.
- The accuracy of ChatGPT-4’s responses is primarily influenced by the difficulty of questions, followed by the presence of images, and the specific exam section. ChatGPT scores higher on questions categorized as easy, those without images, and within certain sections, such as general medicine and fundamentals.
- The repeatability and consistency of ChatGPT-4 Plus’s responses are affirmed by kappa coefficients spanning from 0.79 to 0.95 across individual sections, indicating a range from substantial to nearly perfect concordance.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AAO | American Academy of Ophthalmology |
| AI | Artificial intelligence |
| BCSC | Basic and Clinical Science Course |
| CT | Computed tomography |
| LLM | Large language model |
| LR | Likelihood ratio |
| MRI | Magnetic resonance imaging |
| OCT | Optical coherence tomography |
| USMLE | United States Medical Licensing Examination |
Appendix A
Appendix A.1
- Observed Agreement (po):
- 2.
- Expected Agreement (pe):
Appendix A.2
References
- Aldoseri, A.; Al-Khalifa, K.N.; Hamouda, A.M. Re-Thinking Data Strategy and Integration for Artificial Intelligence: Concepts, Opportunities, and Challenges. Appl. Sci. 2023, 13, 7082. [Google Scholar] [CrossRef]
- Basu, K.; Sinha, R.; Ong, A.; Basu, T. Artificial Intelligence: How Is It Changing Medical Sciences and Its Future? Indian J. Dermatol. 2020, 65, 365–370. [Google Scholar] [CrossRef] [PubMed]
- Tolsgaard, M.G.; Pusic, M.V.; Sebok-Syer, S.S.; Gin, B.; Svendsen, M.B.; Syer, M.D.; Brydges, R.; Cuddy, M.M.; Boscardin, C.K. The Fundamentals of Artificial Intelligence in Medical Education Research: AMEE Guide No. 156. Med. Teach. 2023, 45, 565–573. [Google Scholar] [CrossRef] [PubMed]
- Ting, D.S.W.; Pasquale, L.R.; Peng, L.; Campbell, J.P.; Lee, A.Y.; Raman, R.; Tan, G.S.W.; Schmetterer, L.; Keane, P.A.; Wong, T.Y. Artificial Intelligence and Deep Learning in Ophthalmology. Br. J. Ophthalmol. 2019, 103, 167–175. [Google Scholar] [CrossRef]
- Li, Z.; Wang, L.; Wu, X.; Jiang, J.; Qiang, W.; Xie, H.; Zhou, H.; Wu, S.; Shao, Y.; Chen, W. Artificial Intelligence in Ophthalmology: The Path to the Real-World Clinic. Cell Rep. Med. 2023, 4, 101095. [Google Scholar] [CrossRef]
- Singh, S.; Djalilian, A.; Ali, M.J. ChatGPT and Ophthalmology: Exploring Its Potential with Discharge Summaries and Operative Notes. Semin. Ophthalmol. 2023, 38, 503–507. [Google Scholar] [CrossRef]
- Waisberg, E.; Ong, J.; Masalkhi, M.; Kamran, S.A.; Zaman, N.; Sarker, P.; Lee, A.G.; Tavakkoli, A. GPT-4 and Ophthalmology Operative Notes. Ann. Biomed. Eng. 2023, 51, 2353–2355. [Google Scholar] [CrossRef]
- Ray, P.P. ChatGPT: A Comprehensive Review on Background, Applications, Key Challenges, Bias, Ethics, Limitations and Future Scope. Internet Things Cyber-Phys. Syst. 2023, 3, 121–154. [Google Scholar] [CrossRef]
- OpenAI; Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; et al. GPT-4 Technical Report. arXiv. 2024. Available online: https://arxiv.org/abs/2303.08774 (accessed on 15 May 2024).
- Singh, S. ChatGPT Statistics 2025—DAU & MAU Data [Worldwide]. DemandSage. 2025. Available online: https://www.demandsage.com/chatgpt-statistics/ (accessed on 28 June 2025).
- ChatGPT in Ophthalmology: The Dawn of a New Era?|Eye. Available online: https://www.nature.com/articles/s41433-023-02619-4 (accessed on 27 March 2024).
- Dossantos, J.; An, J.; Javan, R. Eyes on AI: ChatGPT’s Transformative Potential Impact on Ophthalmology. Cureus 2023, 15, e40765. [Google Scholar] [CrossRef]
- Tan, T.F.; Thirunavukarasu, A.J.; Campbell, J.P.; Keane, P.A.; Pasquale, L.R.; Abramoff, M.D.; Kalpathy-Cramer, J.; Lum, F.; Kim, J.E.; Baxter, S.L.; et al. Generative Artificial Intelligence Through ChatGPT and Other Large Language Models in Ophthalmology: Clinical Applications and Challenges. Ophthalmol. Sci. 2023, 3, 100394. [Google Scholar] [CrossRef]
- Cappellani, F.; Card, K.R.; Shields, C.L.; Pulido, J.S.; Haller, J.A. Reliability and Accuracy of Artificial Intelligence ChatGPT in Providing Information on Ophthalmic Diseases and Management to Patients. Eye 2024, 38, 1368–1373. [Google Scholar] [CrossRef]
- Madadi, Y.; Delsoz, M.; Lao, P.A.; Fong, J.W.; Hollingsworth, T.J.; Kahook, M.Y.; Yousefi, S. ChatGPT Assisting Diagnosis of Neuro-Ophthalmology Diseases Based on Case Reports. Journal of Neuro-Ophthalmology 2024. [Google Scholar] [CrossRef]
- Delsoz, M.; Madadi, Y.; Munir, W.M.; Tamm, B.; Mehravaran, S.; Soleimani, M.; Djalilian, A.; Yousefi, S. Performance of ChatGPT in Diagnosis of Corneal Eye Diseases. Cornea 2024, 43, 664–670. [Google Scholar] [CrossRef]
- Shemer, A.; Cohen, M.; Altarescu, A.; Atar-Vardi, M.; Hecht, I.; Dubinsky-Pertzov, B.; Shoshany, N.; Zmujack, S.; Or, L.; Einan-Lifshitz, A.; et al. Diagnostic Capabilities of ChatGPT in Ophthalmology. Graefes Arch Clin Exp Ophthalmol 2024, 262, 2345–2352. [Google Scholar] [CrossRef] [PubMed]
- Haddad, F.; Saade, J.S. Performance of ChatGPT on Ophthalmology-Related Questions Across Various Examination Levels: Observational Study. JMIR Med. Educ. 2024, 10, e50842. [Google Scholar] [CrossRef] [PubMed]
- Sakai, D.; Maeda, T.; Ozaki, A.; Kanda, G.N.; Kurimoto, Y.; Takahashi, M. Performance of ChatGPT in Board Examinations for Specialists in the Japanese Ophthalmology Society. Cureus 2023, 15, e49903. [Google Scholar] [CrossRef] [PubMed]
- Antaki, F.; Touma, S.; Milad, D.; El-Khoury, J.; Duval, R. Evaluating the Performance of ChatGPT in Ophthalmology: An Analysis of Its Successes and Shortcomings. Ophthalmol. Sci. 2023, 3, 100324. [Google Scholar] [CrossRef]
- Mihalache, A.; Popovic, M.M.; Muni, R.H. Performance of an Artificial Intelligence Chatbot in Ophthalmic Knowledge Assessment. JAMA Ophthalmol. 2023, 141, 589–597. [Google Scholar] [CrossRef]
- Balci, A.S.; Yazar, Z.; Ozturk, B.T.; Altan, C. Performance of Chatgpt in Ophthalmology Exam; Human versus AI. Int. Ophthalmol. 2024, 44, 413. [Google Scholar] [CrossRef]
- Balas, M.; Mandelcorn, E.D.; Yan, P.; Ing, E.B.; Crawford, S.A.; Arjmand, P. ChatGPT and Retinal Disease: A Cross-Sectional Study on AI Comprehension of Clinical Guidelines. Can. J. Ophthalmol. 2025, 60, e117–e123. [Google Scholar] [CrossRef]
- Landis, J.R.; Koch, G.G. The Measurement of Observer Agreement for Categorical Data. Biometrics 1977, 33, 159–174. [Google Scholar] [CrossRef]
- Antaki, F.; Milad, D.; Chia, M.A.; Giguère, C.-É.; Touma, S.; El-Khoury, J.; Keane, P.A.; Duval, R. Capabilities of GPT-4 in Ophthalmology: An Analysis of Model Entropy and Progress towards Human-Level Medical Question Answering. Br. J. Ophthalmol. 2024, 108, 1371–1378. [Google Scholar] [CrossRef] [PubMed]
- Cai, L.Z.; Shaheen, A.; Jin, A.; Fukui, R.; Yi, J.S.; Yannuzzi, N.; Alabiad, C. Performance of Generative Large Language Models on Ophthalmology Board-Style Questions. Am. J. Ophthalmol. 2023, 254, 141–149. [Google Scholar] [CrossRef] [PubMed]
- Mihalache, A.; Huang, R.S.; Popovic, M.M.; Muni, R.H. Performance of an Upgraded Artificial Intelligence Chatbot for Ophthalmic Knowledge Assessment. JAMA Ophthalmol. 2023, 141, 798–800. [Google Scholar] [CrossRef] [PubMed]
- Teebagy, S.; Colwell, L.; Wood, E.; Yaghy, A.; Faustina, M. Improved Performance of ChatGPT-4 on the OKAP Examination: A Comparative Study with ChatGPT-3.5. J. Acad. Ophthalmol. (2017) 2023, 15, e184–e187. [Google Scholar] [CrossRef]
- Chen, L.; Zaharia, M.; Zou, J. How Is ChatGPT’s Behavior Changing over Time? Harv. Data Sci. Rev. 2024, 6. [Google Scholar] [CrossRef]
- Koga, S.; Du, W. From Text to Image: Challenges in Integrating Vision into ChatGPT for Medical Image Interpretation. Neural Regen. Res. 2025, 20, 487. [Google Scholar] [CrossRef]
- Roumeliotis, K.I.; Tselikas, N.D. ChatGPT and Open-AI Models: A Preliminary Review. Future Internet 2023, 15, 192. [Google Scholar] [CrossRef]
- Kumar, M. Understanding Tokens in ChatGPT. Medium. 2023. Available online: https://medium.com/@manav.kumar87/understanding-tokens-in-chatgpt-32845987858d (accessed on 26 April 2025).
- Zhou, Y.; Chia, M.A.; Wagner, S.K.; Ayhan, M.S.; Williamson, D.J.; Struyven, R.R.; Liu, T.; Xu, M.; Lozano, M.G.; Woodward-Court, P.; et al. A Foundation Model for Generalizable Disease Detection from Retinal Images. Nature 2023, 622, 156–163. [Google Scholar] [CrossRef]
- Wu, X.-K.; Chen, M.; Li, W.; Wang, R.; Lu, L.; Liu, J.; Hwang, K.; Hao, Y.; Pan, Y.; Meng, Q.; et al. LLM Fine-Tuning: Concepts, Opportunities, and Challenges. Big Data Cogn. Comput. 2025, 9, 87. [Google Scholar] [CrossRef]
- Kourounis, G.; Elmahmudi, A.A.; Thomson, B.; Hunter, J.; Ugail, H.; Wilson, C. Computer Image Analysis with Artificial Intelligence: A Practical Introduction to Convolutional Neural Networks for Medical Professionals. Postgrad. Med. J. 2023, 99, 1287–1294. [Google Scholar] [CrossRef]
- Mosqueira-Rey, E.; Hernández-Pereira, E.; Alonso-Ríos, D.; Bobes-Bascarán, J.; Fernández-Leal, Á. Human-in-the-Loop Machine Learning: A State of the Art. Artif. Intell. Rev. 2023, 56, 3005–3054. [Google Scholar] [CrossRef]
- Gu, Y.; Tinn, R.; Cheng, H.; Lucas, M.; Usuyama, N.; Liu, X.; Naumann, T.; Gao, J.; Poon, H. Domain-Specific Language Model Pretraining for Biomedical Natural Language Processing. ACM Trans. Comput. Healthc. 2022, 3, 1–23. [Google Scholar] [CrossRef]
- Pattam, A. Generative AI: Episode #9: The Rise of Domain-Specific Large Language Models. Medium. 2023. Available online: https://arunapattam.medium.com/generative-ai-the-rise-of-domain-specific-large-language-models-ec212290c8a2 (accessed on 28 March 2025).
- Chen, J.S.; Reddy, A.J.; Al-Sharif, E.; Shoji, M.K.; Kalaw, F.G.P.; Eslani, M.; Lang, P.Z.; Arya, M.; Koretz, Z.A.; Bolo, K.A.; et al. Analysis of ChatGPT Responses to Ophthalmic Cases: Can ChatGPT Think like an Ophthalmologist? Ophthalmol. Sci. 2024, 5, 100600. [Google Scholar] [CrossRef]
- Kassam, A.; Cowan, M.; Donnon, T. An Objective Structured Clinical Exam to Measure Intrinsic CanMEDS Roles. Med. Educ. Online 2016, 21, 31085. [Google Scholar] [CrossRef]
- Dave, T.; Athaluri, S.A.; Singh, S. ChatGPT in Medicine: An Overview of Its Applications, Advantages, Limitations, Future Prospects, and Ethical Considerations. Front. Artif. Intell. 2023, 6, 1169595. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| Difficulty Level | Presence of Images | ||||
|---|---|---|---|---|---|
| Easy | Moderate | Difficult | Without Images | With Images | |
| BCSC Overall (N = 1300) | 459 | 751 | 90 | 1148 | 152 |
| General Medicine (N = 100) | 49 | 43 | 8 | 99 | 1 |
| Fundamentals (N = 100) | 35 | 60 | 5 | 97 | 3 |
| Clinical Optics (N = 100) | 22 | 66 | 12 | 96 | 4 |
| Ophthalmic Pathology (N = 100) | 21 | 59 | 20 | 85 | 15 |
| Neuro-Ophthalmology (N = 100) | 40 | 55 | 5 | 83 | 17 |
| Pediatrics and Strabismus (N = 100) | 30 | 68 | 2 | 91 | 9 |
| Oculoplastics (N = 100) | 44 | 56 | 0 | 86 | 14 |
| Cornea (N = 100) | 58 | 41 | 1 | 70 | 30 |
| Uveitis (N = 100) | 30 | 59 | 11 | 90 | 10 |
| Glaucoma (N = 100) | 31 | 65 | 4 | 91 | 9 |
| Lens and Cataract (N = 100) | 36 | 58 | 6 | 86 | 14 |
| Retina and Vitreous (N = 100) | 26 | 64 | 10 | 82 | 18 |
| Refractive Surgery (N = 100) | 37 | 57 | 6 | 92 | 8 |
| Section | Cohen’s Kappa (κ) | 95% CI |
|---|---|---|
| General medicine | 0.9 | 0.83–0.97 |
| Fundamentals | 0.82 | 0.74–0.90 |
| Clinical optics | 0.8 | 0.71–0.89 |
| Ophthalmic pathology | 0.82 | 0.74–0.90 |
| Neuro-ophthalmology | 0.79 | 0.69–0.88 |
| Pediatrics and strabismus | 0.84 | 0.75–0.92 |
| Oculoplastics | 0.83 | 0.75–0.92 |
| Cornea | 0.87 | 0.79–0.94 |
| Uveitis | 0.95 | 0.90–0.99 |
| Glaucoma | 0.81 | 0.72–0.90 |
| Lens and cataracts | 0.88 | 0.80–0.95 |
| Retina and vitreous | 0.84 | 0.76–0.92 |
| Refractive surgery | 0.86 | 0.78–0.93 |
| Overall | 0.85 | 0.82–0.87 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, K.Y.; Qian, S.Y.; Marchand, M. Evaluating ChatGPT-4 Plus in Ophthalmology: Effect of Image Recognition and Domain-Specific Pretraining on Diagnostic Performance. Diagnostics 2025, 15, 1820. https://doi.org/10.3390/diagnostics15141820
Wu KY, Qian SY, Marchand M. Evaluating ChatGPT-4 Plus in Ophthalmology: Effect of Image Recognition and Domain-Specific Pretraining on Diagnostic Performance. Diagnostics. 2025; 15(14):1820. https://doi.org/10.3390/diagnostics15141820
Chicago/Turabian StyleWu, Kevin Y., Shu Yu Qian, and Michael Marchand. 2025. "Evaluating ChatGPT-4 Plus in Ophthalmology: Effect of Image Recognition and Domain-Specific Pretraining on Diagnostic Performance" Diagnostics 15, no. 14: 1820. https://doi.org/10.3390/diagnostics15141820
APA StyleWu, K. Y., Qian, S. Y., & Marchand, M. (2025). Evaluating ChatGPT-4 Plus in Ophthalmology: Effect of Image Recognition and Domain-Specific Pretraining on Diagnostic Performance. Diagnostics, 15(14), 1820. https://doi.org/10.3390/diagnostics15141820