
Diagnostic Performance of Publicly Available Large Language Models in Corneal Diseases: A Comparison with Human Specialists

 ,
,  , , ,
, , ,  ,
,
Abstract
1. Introduction
2. Materials and Methods
2.1. Case Collection
2.2. Large Language Model Selection
2.3. Diagnosis
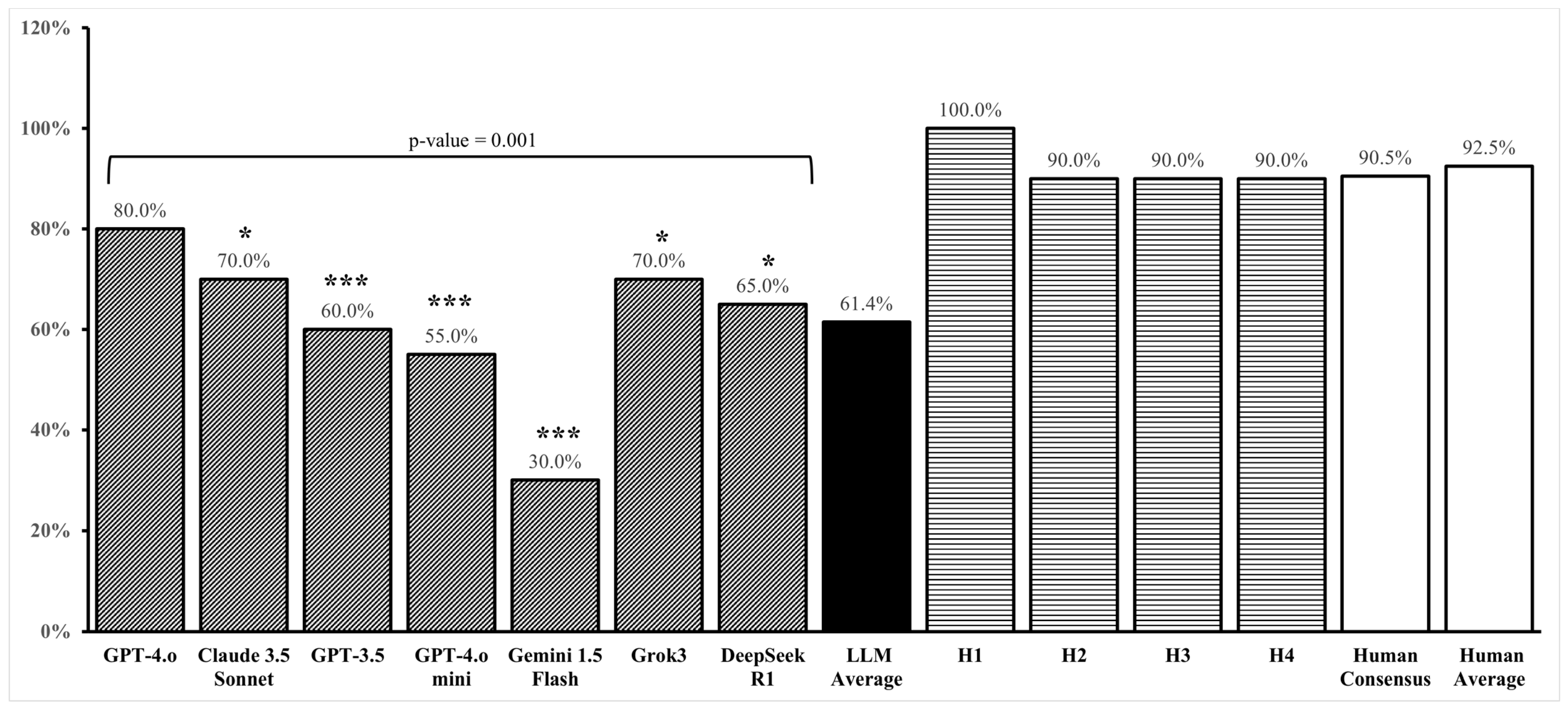
3. Results
4. Discussion
4.1. Theoretical Implications
4.2. Practical Implications
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | artificial intelligence |
| LLM | large language model |
| OKAP | Ophthalmic Knowledge Assessment Program |
| AAO | American Academy of Ophthalmology |
| BCSC | Basic and Clinical Science Course |
| FECD | Fuch’s endothelial corneal dystrophy |
| PPCD | posterior polymorphous corneal dystrophy |
| SND | Salzmann’s nodular degeneration |
| OCP | ocular cicatricial pemphigoid |
| PUK | peripheral ulcerative keratitis |
| HSK | herpes simplex keratitis |
| HSV | herpes simplex virus |
| ICK | infectious crystalline keratopathy |
| ABMD | anterior basement membrane dystrophy |
| OPMD | oculopharyngeal muscular dystrophy |
| PDLM | pupil dilation with lens movement |
| IOL | intraocular lens |
| CHED | congenital hereditary endothelial dystrophy |
| PBK | pseudophakic bullous keratopathy |
| RLHF | reinforced learning from human feedback |
References
- Wang, E.Y.; Kong, X.; Wolle, M.; Gasquet, N.; Ssekasanvu, J.; Mariotti, S.P.; Bourne, R.; Taylor, H.; Resnikoff, S.; West, S. Global trends in blindness and vision impairment resulting from corneal opacity 1984–2020: A meta-analysis. Ophthalmology 2023, 130, 863–871. [Google Scholar] [CrossRef] [PubMed]
- Erukulla, R.; Soleimani, M.; Woodward, M.; Karnik, N.; Joslin, C.; McMahon, T.; Scanzera, A.; Shorter, E.; Yoon, H.; Cortina, M. Socioeconomic and Demographic Disparities in Keratoconus Treatment. Am. J. Ophthalmol. 2025, 271, 424–435. [Google Scholar] [CrossRef] [PubMed]
- Bourne, R.; Steinmetz, J.D.; Flaxman, S.; Briant, P.S.; Taylor, H.R.; Resnikoff, S.; Casson, R.J.; Abdoli, A.; Abu-Gharbieh, E.; Afshin, A. Trends in prevalence of blindness and distance and near vision impairment over 30 years: An analysis for the Global Burden of Disease Study. Lancet Glob. Health 2021, 9, e130–e143. [Google Scholar] [CrossRef] [PubMed]
- De Fauw, J.; Ledsam, J.R.; Romera-Paredes, B.; Nikolov, S.; Tomasev, N.; Blackwell, S.; Askham, H.; Glorot, X.; O’Donoghue, B.; Visentin, D. Clinically applicable deep learning for diagnosis and referral in retinal disease. Nat. Med. 2018, 24, 1342–1350. [Google Scholar] [CrossRef]
- Ting, D.S.W.; Cheung, C.Y.-L.; Lim, G.; Tan, G.S.W.; Quang, N.D.; Gan, A.; Hamzah, H.; Garcia-Franco, R.; San Yeo, I.Y.; Lee, S.Y. Development and validation of a deep learning system for diabetic retinopathy and related eye diseases using retinal images from multiethnic populations with diabetes. JAMA 2017, 318, 2211–2223. [Google Scholar] [CrossRef]
- Gulshan, V.; Peng, L.; Coram, M.; Stumpe, M.C.; Wu, D.; Narayanaswamy, A.; Venugopalan, S.; Widner, K.; Madams, T.; Cuadros, J. Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. JAMA 2016, 316, 2402–2410. [Google Scholar] [CrossRef]
- Abràmoff, M.D.; Lavin, P.T.; Birch, M.; Shah, N.; Folk, J.C. Pivotal trial of an autonomous AI-based diagnostic system for detection of diabetic retinopathy in primary care offices. NPJ Digit. Med. 2018, 1, 39. [Google Scholar] [CrossRef]
- Soleimani, M.; Cheraqpour, K.; Sadeghi, R.; Pezeshgi, S.; Koganti, R.; Djalilian, A.R. Artificial intelligence and infectious keratitis: Where are we now? Life 2023, 13, 2117. [Google Scholar] [CrossRef]
- Cao, K.; Verspoor, K.; Sahebjada, S.; Baird, P.N. Evaluating the performance of various machine learning algorithms to detect subclinical keratoconus. Transl. Vis. Sci. Technol. 2020, 9, 24. [Google Scholar] [CrossRef]
- Heidari, Z.; Hashemi, H.; Sotude, D.; Ebrahimi-Besheli, K.; Khabazkhoob, M.; Soleimani, M.; Djalilian, A.R.; Yousefi, S. Applications of Artificial Intelligence in Diagnosis of Dry Eye Disease: A Systematic Review and Meta-Analysis. Cornea 2024, 43, 1310–1318. [Google Scholar] [CrossRef]
- Shilpashree, P.S.; Suresh, K.V.; Sudhir, R.R.; Srinivas, S.P. Automated image segmentation of the corneal endothelium in patients with Fuchs dystrophy. Transl. Vis. Sci. Technol. 2021, 10, 27. [Google Scholar] [CrossRef] [PubMed]
- Soleimani, M.; Najafabadi, S.J.; Razavi, A.; Tabatabaei, S.A.; Mirmoosavi, S.; Asadigandomani, H. Clinical characteristics, predisposing factors, and management of moraxella keratitis in a tertiary eye hospital. J. Ophthalmic Inflamm. Infect. 2024, 14, 36. [Google Scholar] [CrossRef]
- Soleimani, M.; Tabatabaei, S.A.; Bahadorifar, S.; Mohammadi, A.; Asadigandomani, H. Unveiling the landscape of post-keratoplasty keratitis: A comprehensive epidemiological analysis in a tertiary center. Int. Ophthalmol. 2024, 44, 230. [Google Scholar] [CrossRef] [PubMed]
- Soleimani, M.; Baharnoori, S.M.; Massoumi, H.; Cheraqpour, K.; Asadigandomani, H.; Mirzaei, A.; Ashraf, M.J.; Koganti, R.; Chaudhuri, M.; Ghassemi, M. A deep dive into radiation keratopathy; going beyond the current frontierss. Exp. Eye Res. 2025, 251, 110234. [Google Scholar] [CrossRef]
- Shareef, O.; Soleimani, M.; Tu, E.; Jacobs, D.S.; Ciolino, J.B.; Rahdar, A.; Cheraqpour, K.; Ashraf, M.; Habib, N.B.; Greenfield, J. A novel artificial intelligence model for diagnosing Acanthamoeba keratitis through confocal microscopy. Ocul. Surf. 2024, 34, 159–164. [Google Scholar] [CrossRef]
- Hayati, A.; Abdol Homayuni, M.R.; Sadeghi, R.; Asadigandomani, H.; Dashtkoohi, M.; Eslami, S.; Soleimani, M. Advancing Diabetic Retinopathy Screening: A Systematic Review of Artificial Intelligence and Optical Coherence Tomography Angiography Innovations. Diagnostics 2025, 15, 737. [Google Scholar] [CrossRef]
- Soleimani, M.; Hashemi, H.; Mehravaran, S.; Khabazkhoob, M.; Emamian, M.H.; Shariati, M.; Fotouhi, A. Comparison of anterior segment measurements using rotating Scheimpflug imaging and partial coherence interferometry. Int. J. Ophthalmol. 2013, 6, 510. [Google Scholar] [PubMed]
- Thirunavukarasu, A.J.; Ting, D.S.J.; Elangovan, K.; Gutierrez, L.; Tan, T.F.; Ting, D.S.W. Large language models in medicine. Nat. Med. 2023, 29, 1930–1940. [Google Scholar] [CrossRef]
- Bélisle-Pipon, J.-C. Why we need to be careful with LLMs in medicine. Front. Med. 2024, 11, 1495582. [Google Scholar] [CrossRef]
- Antaki, F.; Touma, S.; Milad, D.; El-Khoury, J.; Duval, R. Evaluating the performance of ChatGPT in ophthalmology: An analysis of its successes and shortcomings. Ophthalmol. Sci. 2023, 3, 100324. [Google Scholar] [CrossRef]
- Taloni, A.; Borselli, M.; Scarsi, V.; Rossi, C.; Coco, G.; Scorcia, V.; Giannaccare, G. Comparative performance of humans versus GPT-4.0 and GPT-3.5 in the self-assessment program of American Academy of Ophthalmology. Sci. Rep. 2023, 13, 18562. [Google Scholar] [CrossRef] [PubMed]
- Delsoz, M.; Madadi, Y.; Raja, H.; Munir, W.M.; Tamm, B.; Mehravaran, S.; Soleimani, M.; Djalilian, A.; Yousefi, S. Performance of ChatGPT in diagnosis of corneal eye diseases. Cornea 2024, 43, 664–670. [Google Scholar] [CrossRef] [PubMed]
- Team, G.; Anil, R.; Borgeaud, S.; Alayrac, J.-B.; Yu, J.; Soricut, R.; Schalkwyk, J.; Dai, A.M.; Hauth, A.; Millican, K. Gemini: A family of highly capable multimodal models. arXiv 2023, arXiv:2312.11805. [Google Scholar]
- GPT-4o vs. Gemini 1.5 Pro vs. Claude 3 Opus: Multimodal AI Model Comparison. Available online: https://encord.com/blog/gpt-4o-vs-gemini-vs-claude-3-opus/ (accessed on 28 December 2024).
- Introducing the Next Generation of Claude. 2024. Available online: https://www.anthropic.com/news/claude-3-family (accessed on 28 December 2024).
- EyeRounds. Case Reports, Tutorials, Videos, Images from Univ of Iowa Dept of Ophthalmology. Available online: https://eyerounds.org/#gsc.tab=0 (accessed on 28 December 2024).
- Wornow, M.; Xu, Y.; Thapa, R.; Patel, B.; Steinberg, E.; Fleming, S.; Pfeffer, M.A.; Fries, J.; Shah, N.H. The shaky foundations of large language models and foundation models for electronic health records. npj Digit. Med. 2023, 6, 135. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.S.; Reddy, A.J.; Al-Sharif, E.; Shoji, M.K.; Kalaw, F.G.P.; Eslani, M.; Lang, P.Z.; Arya, M.; Koretz, Z.A.; Bolo, K.A. Analysis of ChatGPT responses to ophthalmic cases: Can ChatGPT think like an ophthalmologist? Ophthalmol. Sci. 2025, 5, 100600. [Google Scholar] [CrossRef]
- Mihalache, A.; Grad, J.; Patil, N.S.; Huang, R.S.; Popovic, M.M.; Mallipatna, A.; Kertes, P.J.; Muni, R.H. Google Gemini and Bard artificial intelligence chatbot performance in ophthalmology knowledge assessment. Eye 2024, 38, 2530–2535. [Google Scholar] [CrossRef]
- Cai, L.Z.; Shaheen, A.; Jin, A.; Fukui, R.; Yi, J.S.; Yannuzzi, N.; Alabiad, C. Performance of Generative Large Language Models on Ophthalmology Board-Style Questions. Am. J. Ophthalmol. 2023, 254, 141–149. [Google Scholar] [CrossRef]
- Bernstein, I.A.; Zhang, Y.; Govil, D.; Majid, I.; Chang, R.T.; Sun, Y.; Shue, A.; Chou, J.C.; Schehlein, E.; Christopher, K.L.; et al. Comparison of Ophthalmologist and Large Language Model Chatbot Responses to Online Patient Eye Care Questions. JAMA Netw. Open 2023, 6, e2330320. [Google Scholar] [CrossRef]
- Holmes, J.; Peng, R.; Li, Y.; Hu, J.; Liu, Z.; Wu, Z.; Zhao, H.; Jiang, X.; Liu, W.; Wei, H. Evaluating multiple large language models in pediatric ophthalmology. arXiv 2023, arXiv:2311.04368. [Google Scholar]
- Huang, A.S.; Hirabayashi, K.; Barna, L.; Parikh, D.; Pasquale, L.R. Assessment of a Large Language Model’s Responses to Questions and Cases About Glaucoma and Retina Management. JAMA Ophthalmol. 2024, 142, 371–375. [Google Scholar] [CrossRef]
- Kreso, A.; Boban, Z.; Kabic, S.; Rada, F.; Batistic, D.; Barun, I.; Znaor, L.; Kumric, M.; Bozic, J.; Vrdoljak, J. Using large language models as decision support tools in emergency ophthalmology. Int. J. Med. Inform. 2025, 199, 105886. [Google Scholar] [CrossRef]
- Mihalache, A.; Huang, R.S.; Popovic, M.M.; Muni, R.H. Performance of an upgraded artificial intelligence chatbot for ophthalmic knowledge assessment. JAMA Ophthalmol. 2023, 141, 798–800. [Google Scholar] [CrossRef]
- Jiao, C.; Edupuganti, N.R.; Patel, P.A.; Bui, T.; Sheth, V. Evaluating the artificial intelligence performance growth in ophthalmic knowledge. Cureus 2023, 15, e45700. [Google Scholar] [CrossRef] [PubMed]
- Vithanage, D.; Deng, C.; Wang, L.; Yin, M.; Alkhalaf, M.; Zhang, Z.; Zhu, Y.; Soewargo, A.C.; Yu, P. Evaluating approaches of training a generative large language model for multi-label classification of unstructured electronic health records. medRxiv 2024. [Google Scholar] [CrossRef]
- Xu, T.; Zhao, Y.; Liu, X. Dual Generative Network with Discriminative Information for Generalized Zero-Shot Learning. Complexity 2021, 2021, 6656797. [Google Scholar] [CrossRef]
- Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S. Gpt-4 technical report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Bai, Y.; Jones, A.; Ndousse, K.; Askell, A.; Chen, A.; DasSarma, N.; Drain, D.; Fort, S.; Ganguli, D.; Henighan, T. Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv 2022, arXiv:2204.05862. [Google Scholar]
- Hatem, R.; Simmons, B.; Thornton, J.E. A call to address AI “hallucinations” and how healthcare professionals can mitigate their risks. Cureus 2023, 15, e44720. [Google Scholar] [CrossRef]
- Soleimani, M.; Esmaili, K.; Rahdar, A.; Aminizadeh, M.; Cheraqpour, K.; Tabatabaei, S.A.; Mirshahi, R.; Bibak, Z.; Mohammadi, S.F.; Koganti, R. From the diagnosis of infectious keratitis to discriminating fungal subtypes; a deep learning-based study. Sci. Rep. 2023, 13, 22200. [Google Scholar] [CrossRef]
- Hussain, Z.S.; Delsoz, M.; Elahi, M.; Jerkins, B.; Kanner, E.; Wright, C.; Munir, W.M.; Soleimani, M.; Djalilian, A.; Lao, P.A. Performance of DeepSeek, Qwen 2.5 MAX, and ChatGPT Assisting in Diagnosis of Corneal Eye Diseases, Glaucoma, and Neuro-Ophthalmology Diseases Based on Clinical Case Reports. medRxiv 2025. [Google Scholar] [CrossRef]
- Soleimani, M.; Cheung, A.Y.; Rahdar, A.; Kirakosyan, A.; Tomaras, N.; Lee, I.; De Alba, M.; Aminizade, M.; Esmaili, K.; Quiroz-Casian, N. Diagnosis of microbial keratitis using smartphone-captured images; a deep-learning model. J. Ophthalmic Inflamm. Infect. 2025, 15, 8. [Google Scholar] [CrossRef] [PubMed]
- Ferrara, E. Should chatgpt be biased? challenges and risks of bias in large language models. arXiv 2023, arXiv:2304.03738. [Google Scholar]
- Rosenfeld, A.; Lazebnik, T. Whose LLM is it anyway? Linguistic comparison and LLM attribution for GPT-3.5, GPT-4 and bard. arXiv 2024, arXiv:2402.14533. [Google Scholar]
- Brown, N.B. Enhancing trust in llms: Algorithms for comparing and interpreting llms. arXiv 2024, arXiv:2406.01943. [Google Scholar]


{kind=link}
{kind=link}
| Disease Category | Number of Cases | Percentage |
| Congenital | 6 | 30% |
| Degenerative | 6 | 30% |
| Infectious | 3 | 15% |
| Inflammatory | 5 | 25% |
| Age Group | Number of Cases | Percentage |
| 0–17 | 4 | 20% |
| 18–35 | 2 | 10% |
| 36–55 | 6 | 30% |
| 56–70 | 4 | 20% |
| >70 | 4 | 20% |
| Gender | Number of Cases | Percentage |
| Male | 9 | 45% |
| Female | 11 | 55% |
| Case | Corneal Eye Disease | Type | GPT 3.5 | GPT 4.o Mini | GPT 4.o | Gemini 1.5 Flash | Claude 3.5 Sonnet | Grok3 | DeepSeek R1 | Human Expert |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Acanthamoeba Keratitis | Infectious | Acanthamoeba Keratitis | Acanthamoeba Keratitis | Acanthamoeba Keratitis | Acanthamoeba Keratitis | Acanthamoeba Keratitis | Acanthamoeba Keratitis | Acanthamoeba Keratitis | H1: Acanthamoeba Keratitis H2: Acanthamoeba Keratitis H3: Acanthamoeba Keratitis H4: Acanthamoeba Keratitis |
| 2 | Acute Corneal Hydrops | Degeneration | Acute Corneal Hydrops | Corneal Hydrops | Acute Hydrops | Keratoconus | Acute Hydrops | Acute Corneal Hydrops | Acute Corneal Hydrops | H1: Acute Corneal Hydrops H2: Acute Corneal Hydrops H3: Acute Corneal Hydrops H4: Acute Corneal Hydrops |
| 3 | Atopic Keratoconjunctivitis | Inflammatory | Ocular Cicatricial Pemphigoid | Ocular Cicatricial Pemphigoid | Ocular Cicatricial Pemphigoid | Stevens-Johnson Syndrome | Atopic Keratoconjunctivitis | Ocular Cicatricial Pemphigoid | Ocular Cicatricial Pemphigoid | H1: Atopic Keratoconjunctivitis H2: Atopic Keratoconjunctivitis H3: Ocular Cicatricial Pemphigoid H4: Allergic Keratoconjunctivitis |
| 4 | Calcific Band Keratopathy | Degeneration | Superficial Corneal Scar | Band Keratopathy | Band Keratopathy | Schnyder’s Corneal Dystrophy | Calcific Band Keratopathy | Band Keratopathy | Band Keratopathy | H1: Calcific Band Keratopathy H2: Calcific Band Keratopathy H3: Calcific Band Keratopathy H4: Calcific Band Keratopathy |
| 5 | Cogan’s Syndrome | Inflammatory | Ocular Rosacea | Peripheral Ulcerative Keratitis | Scleritis | Granulomatous Anterior Uveitis | Anterior Scleritis | Scleritis | Episcleritis | H1: Cogan Syndrome H2: Episcleritis H3: Cogan Syndrome H4: Episcleritis |
| 6 | Corneal Marginal Ulcer | Inflammatory | Corneal Marginal Ulcer | Bacterial Keratitis | Herpes Simplex Keratitis | Microbial Keratitis | Peripheral Ulcerative Keratitis | Corneal Ulcer | Microbial Keratitis | H1: Corneal Marginal Ulcer H2: Corneal Marginal Ulcer H3: Mooren Ulcer H4: Corneal Marginal Ulcer |
| 7 | Cystinosis | Congenital | Cystinosis | Wilson Disease with Corneal Involvement | Cystinosis | Fabry Disease | Cystinosis | Cystinosis | Cystinosis | H1: Cystinosis H2: Cystinosis H3: Cystinosis H4: Cystinosis |
| 8 | Cytarabine Induced Keratoconjunctivitis | Inflammatory | Cytarabine-Induced Keratoconjunctivitis | Cytarabine-Induced Keratopathy | Cytarabine-Induced Keratopathy | Chemotherapy-Induced Dry Eye | Cytarabine-Induced Keratopathy | Cytarabine-Induced Keratoconjunctivitis | Cytarabine-Induced Keratoconjunctivitis | H1: Cytarabine-Induced Keratoconjunctivitis H2: Cytarabine-Induced Keratoconjunctivitis H3: Cytarabine-Induced Keratoconjunctivitis H4: Cytarabine-Induced Keratoconjunctivitis |
| 9 | Exposure Keratopathy | Degeneration | Exposure Keratopathy | Exposure Keratopathy | Exposure Keratopathy | Exposure Keratitis | Exposure Keratopathy | Exposure Keratopathy | Exposure Keratopathy | H1: Exposure Keratopathy H2: Exposure Keratopathy H3: Exposure Keratopathy H4: Exposure Keratopathy |
| 10 | Fabry Disease | Congenital | Fabry Disease | Fabry Disease | Fabry Disease | Fabry Disease | Fabry Disease | Fabry Disease | Fabry Disease | H1: Fabry Disease H2: Fabry Disease H3: Fabry Disease H4: Fabry Disease |
| 11 | Fuchs Endothelial Corneal Dystrophy (FECD) | Congenital | Fuchs Endothelial Corneal Dystrophy | Keratoconus | Fuchs’ Endothelial Corneal Dystrophy | Corneal Endothelial Dystrophy | Posterior Polymorphous Corneal Dystrophy | Fuchs’ Endothelial Corneal Dystrophy | Fuchs’ Endothelial Corneal Dystrophy | H1: FECD H2: FECD H3: FECD H4: FECD |
| 12 | Herpes Simplex Virus Keratitis | Infectious | Herpes Simplex Virus Keratitis | Herpes Simplex Keratitis | Herpes Simplex Epithelial Keratitis | Herpes Simplex Virus Keratitis | Herpes Simplex Keratitis | Herpes Simplex Virus Keratitis | Herpes Simplex Virus Keratitis | H1: Herpes Simplex Viral Keratitis H2: Herpes Simplex Viral Keratitis H3: Herpes Simplex Viral Keratitis H4: Herpes Simplex Viral Keratitis |
| 13 | Infectious Crystaline Keratopathy | Infectious | Recurrent Herpes Simplex Virus Keratitis | Recurrent Herpes Simplex Virus Keratitis | Infectious Crystaline Keratopathy | Recurrent Herpes Simplex Virus Keratitis | Candida Keratitis | Crystalline Keratopathy | Herpes Simplex Virus Keratitis | H1: ICK H2: ICK H3: ICK H4: ICK |
| 14 | Lattice Corneal Dystrophy Type II (Mertetoja’s Syndrome) | Congenital | Meesmann’s Corneal Dystrophy | Anterior Basement Membrane Dystrophy | Lattice Corneal Dystrophy | Meesmann’s Corneal Dystrophy | Oculopharyngeal Muscular Dystrophy | Meesmann’s Corneal Dystrophy | Corneal Dystrophy | H1: Lattice Corneal Dystrophy Type II H2: Lattice Corneal Dystrophy Type II H3: Lattice Corneal Dystrophy Type II H4: Lattice Corneal Dystrophy Type II |
| 15 | Megalocornea | Congenital | Positional Pseudo Phacodonesis | Pseudo Phacodonesis with IOL Instability | Pseudo Phacodonesis with IOL Instability | Pupil Dilation with Lens Movement | Megalocornea with Pseudo Phacodonesis | Pseudophacodonesis | Pseudophacodonesis | H1: Megalocornea H2: Megalocornea H3: Megalocornea H4: Megalocornea |
| 16 | Peripheral Ulcerative Keratitis | Inflammatory | Peripheral Ulcerative Keratitis | Peripheral Ulcerative Keratitis | Peripheral Ulcerative Keratitis | Neurotrophic Keratitis | Peripheral Ulcerative Keratitis | Peripheral Ulcerative Keratitis | Peripheral Ulcerative Keratitis | H1: PUK H2: PUK H3: PUK H4: PUK |
| 17 | Posterior Polymorphous Corneal Dystrophy (PPCD) | Congenital | Congenital Hereditary Endothelial Dystrophy | Posterior Polymorphous Corneal Dystrophy | Posterior Polymorphous Corneal Dystrophy | Guttata Keratopathy | Posterior Stromal Punctate Dystrophy (Posterior Crocodile Shagreen) | Posterior Stromal Corneal Dystrophy | Granular Corneal Dystrophy | H1: PPCD H2: Granular Corneal Dystrophy H3: PPCD H4: PPCD |
| 18 | Pseudophakic Bullous Keratopathy | Degeneration | Fuchs Endothelial Corneal Dystrophy | Bullous Keratopathy | Bullous Keratopathy | Corneal Endothelial Dystrophy | Pseudophakic Bullous Keratopathy | Corneal Decompensation Secondary to Endothelial Dysfunction | PBK | H1: PBK H2: PBK H3: PBK H4: PBK |
| 19 | Salzmann’s Nodular Degeneration (SND) | Degeneration | Salzmann’s Nodular Degeneration | Pterygium with Secondary Corneal Changes | Salzmann’s Nodular Degeneration | Iron Line Corneal Dystrophy | Salzmann’s Nodular Degeneration | Salzmann Nodular Degeneration | SND | H1: SND H2: SND H3: SND H4: SND |
| 20 | Amiodaron-Induced Corneal Deposits (Corneal Verticillata) | Degeneration | Amiodaron-Induced Corneal Deposits | Amiodarone-Related Corneal Deposits | Amiodaron-Induced Corneal Deposits | Amiodaron-Indued Corneal Dystrophy | Amiodarone-Induced Corneal Verticillata | Amiodarone-Induced Corneal Deposits | Amiodarone-Induced Corneal Deposits | H1: Amiodarone-induced corneal deposits H2: Amiodarone-induced corneal deposits H3: Amiodarone-induced corneal deposits H4: Amiodarone-induced corneal deposits |
| GPT 4.o | Claude 3.5 Sonnet | GPT 3.5 | GPT 4.o Mini | Gemini 1.5 Flash | Grok3 | DeepSeek R1 | |
|---|---|---|---|---|---|---|---|
| Interobserver Agreement H1 | 80% (16/20) | 60% (12/20) | 60% (12/20) | 55% (11/20) | 80% (16/20) | 60% (12/20) | 65% (13/20) |
| Interobserver Agreement H2 | 75% (15/20) | 60% (12/20) | 60% (12/20) | 50% (10/20) | 75% (15/20) | 65% (13/20) | 75% (15/20) |
| Interobserver Agreement H3 | 85% (17/20) | 60% (12/20) | 60% (12/20) | 60% (12/20) | 85% (17/20) | 65% (13/20) | 70% (14/20) |
| Interobserver Agreement H4 | 80% (16/20) | 65% (13/20) | 60% (12/20) | 65% (13/20) | 80% (16/20) | 65% (13/20) | 70% (14/20) |
| Kappa Agreement with Human Expert Consensus | 0.348 | 0.219 | 0.146 | 0.121 | 0.044 | 0.219 | 0.178 |
| Kappa p-Value | 0.04 | 0.117 | 0.209 | 0.257 | 0.502 | 0.117 | 0.162 |
| Model | Degenerative | Inflammatory | Congenital | Infectious |
|---|---|---|---|---|
| GPT 4.o | 100.0% (6/6) | 40.0% (2/5) | 83.3% (5/6) | 100.0% (3/3) |
| Claude 3.5 Sonnet | 100.0% (6/6) | 60.0% (3/5) | 50.0% (3/6) | 66.7% (2/3) |
| GPT 3.5 | 66.7% (4/6) | 60.0% (3/5) | 50.0% (3/6) | 66.7% (2/3) |
| GPT 4.o mini | 83.3% (5/6) | 40.0% (2/5) | 33.3 (2/6) | 66.7% (2/3) |
| Gemini 1.5 Flash | 33.3% (2/6) | 0.0% (0/5) | 33.3% (2/6) | 66.7% (2/3) |
| Grok3 | 83.3% (5/6) | 40% (2/5) | 66.7% (4/6) | 100% (3/3) |
| DeepSeek R1 | 100% (6/6) | 40% (2/5) | 50% (3/6) | 66.7% (2/3) |
| Author (Year) | Study Focus | LLMs Evaluated | Key Findings |
|---|---|---|---|
| Antaki et al. [20] | ChatGPT performance on OKAP-style questions | ChatGPT Legacy, ChatGPT Plus | Moderate accuracy (42.7–59.4%), performance influenced by question difficulty and subspecialty. |
| Chen et al. [28] | ChatGPT performance on ophthalmic case assessments | ChatGPT | 88.2% (15 of 17) diagnostic accuracy. |
| Mihalache et al. [29] | Gemini and Bard performance on board questions | Google Gemini, Bard | 71% accuracy (across 150 text-based multiple-choice questions); minor country-based performance variability. |
| Cai et al. [30] | Generative LLMs on board-style questions | ChatGPT-3.5, ChatGPT-4.0, Bing Chat | GPT-4.0 (71.6%) and Bing Chat (71.2%) near human performance (72.2%); hallucination rates: GPT-3.5 (42.4%) > Bing Chat (25.6%) > GPT-4.0 (18.0%). |
| Delsoz et al. [22] | LLM diagnosis of corneal diseases | ChatGPT-3.5, ChatGPT-4.0 | GPT-4.0 achieved 85% (17 of 20 cases) vs. 60% (12 of 20 cases) for GPT-3.5; high agreement of GPT-4.0 with cornea specialists. |
| Taloni et al. [21] | Performance on AAO self-assessment questions | ChatGPT-3.5, ChatGPT-4.0 | GPT-4.0 outperformed humans (82.4% vs. 75.7%), and GPT-3.5 had less accurate answers (65.9%). Both GPT-4.0 and GPT-3.5 showed the worst results in surgery-related questions (74.6% and 57.0%, respectively) |
| Bernstein et al. [31] | Comparison of LLM vs. ophthalmologists on patient question and answer | ChatGPT | Similar quality, appropriateness, and safety in AI and human responses—difficult to distinguish by experts. |
| Holmes et al. [32] | LLMs in pediatric ophthalmology education | ChatGPT-3.5, GPT-4, PaLM2 | GPT-4 matched attending physicians; GPT-3.5 > students; GPT-4 showed most consistency/confidence. |
| Huang et al. [33] | LLM performance in glaucoma and retina management | GPT-4 | GPT-4 outperformed glaucoma specialists and matched retina experts in diagnostic and treatment accuracy. |
| Kreso et al. [34] | LLMs in emergency ophthalmology | GPT-4, GPT-4o, Llama-3-70b | GPT-4 (score = 3.52) and Llama-3-70b (score = 3.48) performed similarly to experts (score = 3.72); GPT-4o underperformed. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiao, C.; Rosas, E.; Asadigandomani, H.; Delsoz, M.; Madadi, Y.; Raja, H.; Munir, W.M.; Tamm, B.; Mehravaran, S.; Djalilian, A.R.; et al. Diagnostic Performance of Publicly Available Large Language Models in Corneal Diseases: A Comparison with Human Specialists. Diagnostics 2025, 15, 1221. https://doi.org/10.3390/diagnostics15101221
Jiao C, Rosas E, Asadigandomani H, Delsoz M, Madadi Y, Raja H, Munir WM, Tamm B, Mehravaran S, Djalilian AR, et al. Diagnostic Performance of Publicly Available Large Language Models in Corneal Diseases: A Comparison with Human Specialists. Diagnostics. 2025; 15(10):1221. https://doi.org/10.3390/diagnostics15101221
Chicago/Turabian StyleJiao, Cheng, Erik Rosas, Hassan Asadigandomani, Mohammad Delsoz, Yeganeh Madadi, Hina Raja, Wuqaas M. Munir, Brendan Tamm, Shiva Mehravaran, Ali R. Djalilian, and et al. 2025. "Diagnostic Performance of Publicly Available Large Language Models in Corneal Diseases: A Comparison with Human Specialists" Diagnostics 15, no. 10: 1221. https://doi.org/10.3390/diagnostics15101221
APA StyleJiao, C., Rosas, E., Asadigandomani, H., Delsoz, M., Madadi, Y., Raja, H., Munir, W. M., Tamm, B., Mehravaran, S., Djalilian, A. R., Yousefi, S., & Soleimani, M. (2025). Diagnostic Performance of Publicly Available Large Language Models in Corneal Diseases: A Comparison with Human Specialists. Diagnostics, 15(10), 1221. https://doi.org/10.3390/diagnostics15101221