1. Introduction
Recently, the ‘Strengthening the screening of Lung Cancer in Europe’ (SOLACE) project has been established which has sparked a significant increase in chest CT examinations across Europe. However, various CT scanners represent CT images with heterogeneous slice thickness, and this discrepancy leads to significant challenges in accurate volumetric measurements of the lung nodules, as it is known that slice thickness is inversely proportional to the precision in lung nodule volumetric measurements [
1]. According to the Lung CT Screening Reporting and Data System version 2022 (Lung-RADS v2022) established by the American College of Radiology, lung nodules with volumes of 113 mm
3 or greater have an increased risk of developing into tumors [
2,
3]. Therefore, the precise measurement of lung nodule volume is critical for early detection and intervention before its progression to malignancy.
Recent advances in deep learning, particularly in super-resolution techniques, have shown notable improvements over traditional interpolation methods in image quality restoration. Dong et al. [
4] introduced one of the first super-resolution methods utilizing a three-layer convolutional neural network (CNN), outperforming classic interpolation methods. However, the shallow depth of layers limited its ability to faithfully restore high-frequency components in images. Building on this, Kim et al. [
5,
6] applied ideas from ResNet, using a 32-layer CNN with skip connections to address the vanishing gradient problem. The network with larger parameters enabled the restoration of high-frequency details. Zhang et al. [
7] further enhanced the network by introducing a residual-in-residual structure, achieving high peak signal-to-noise ratio (PSNR) and structural similarity index measure (SSIM).
Ledig et al. [
8] observed that relying solely on L1 loss functions resulted in blurry outputs, as they favor averaged pixel values and thus sacrifice high-frequency details. Moreover, PSNR and SSIM metrics do not always directly reflect perceived image quality. To address this, they introduced perceptual loss derived from pre-trained VGG network feature maps and employed a generative adversarial network (GAN) for training. In this framework, the generator produces super-resolved (SR) images from low-resolution (LR) inputs, while the discriminator attempts to distinguish between the SR images and high-resolution (HR) ground truths. Through adversarial training, the generator learns to produce images indistinguishable from HR images, a network they named SRGAN. Despite not achieving the highest PSNR and SSIM values, SRGAN produced images that were perceptually closer to HR images.
Following this, the enhanced SRGAN (ESRGAN) was developed by Wang et al. [
9], who deepened the network using residual-in-residual dense blocks without batch normalization, further improving image quality. Subsequently, Real-ESRGAN [
10] introduced additional degradations such as noise, blur, and JPEG compression during training, making the network more robust for real-world images.
In the medical imaging domain, researchers have actively adapted deep learning techniques to advance the field. Park et al. [
11,
12,
13] utilized residual networks to upsample in the z-direction and generate thin CT slices, leveraging this technology to explore radiomic features in chest CT. Yun et al. [
14,
15] generated thin CT slices to achieve higher quality orbital bone reconstructions. Other studies have employed slice generation for visualizing spine structures and early-stage lung adenocarcinomas [
16,
17,
18].
Given these advancements, we propose a DL-based 3D super-resolution method to generate thin-slice CT images from heterogeneous thick-slice inputs to improve consistency of lung nodule categorization.
The following are the main contributions of this paper:
To the best of our knowledge, modified ESRGAN to take in 3D inputs such as CT images has not been used to observe lung nodules by generating thin slices from thick-slice CT.
We show that slice generation on thick-slice CT images are essential for retaining lung nodule texture, accurate lung nodule volumetric measurement, and the corresponding categorization of lung nodules based on Lung-RADS v2022.
By enhancing the resolution in the depth direction, our approach improves the accuracy of lung nodule measurements and thus results in consistent lung nodule categorization. This will facilitate the more reliable, early detection of lung nodules, thereby supporting the process of lung cancer screening programs.
2. Materials and Methods
2.1. Training Dataset
For training the deep learning model, we utilized CT image data from the National Lung Screening Trial (NLST) open dataset. From hundreds of thousands of series, a total of 28,628 chest CT images with a slice thickness of 1.0 mm were selected. Among these images, 18,243 were acquired using Siemens Sensation 16 scanners (Erlangen, Germany), 2931 from Canon Aquilion scanners (Otawara, Japan), 2707 from GE LightSpeed 16 scanners (Chicago, IL, USA), and 4747 from Philips MX8000 scanners (Amsterdam, Netherlands) as shown in
Table 1.
2.2. Test Dataset
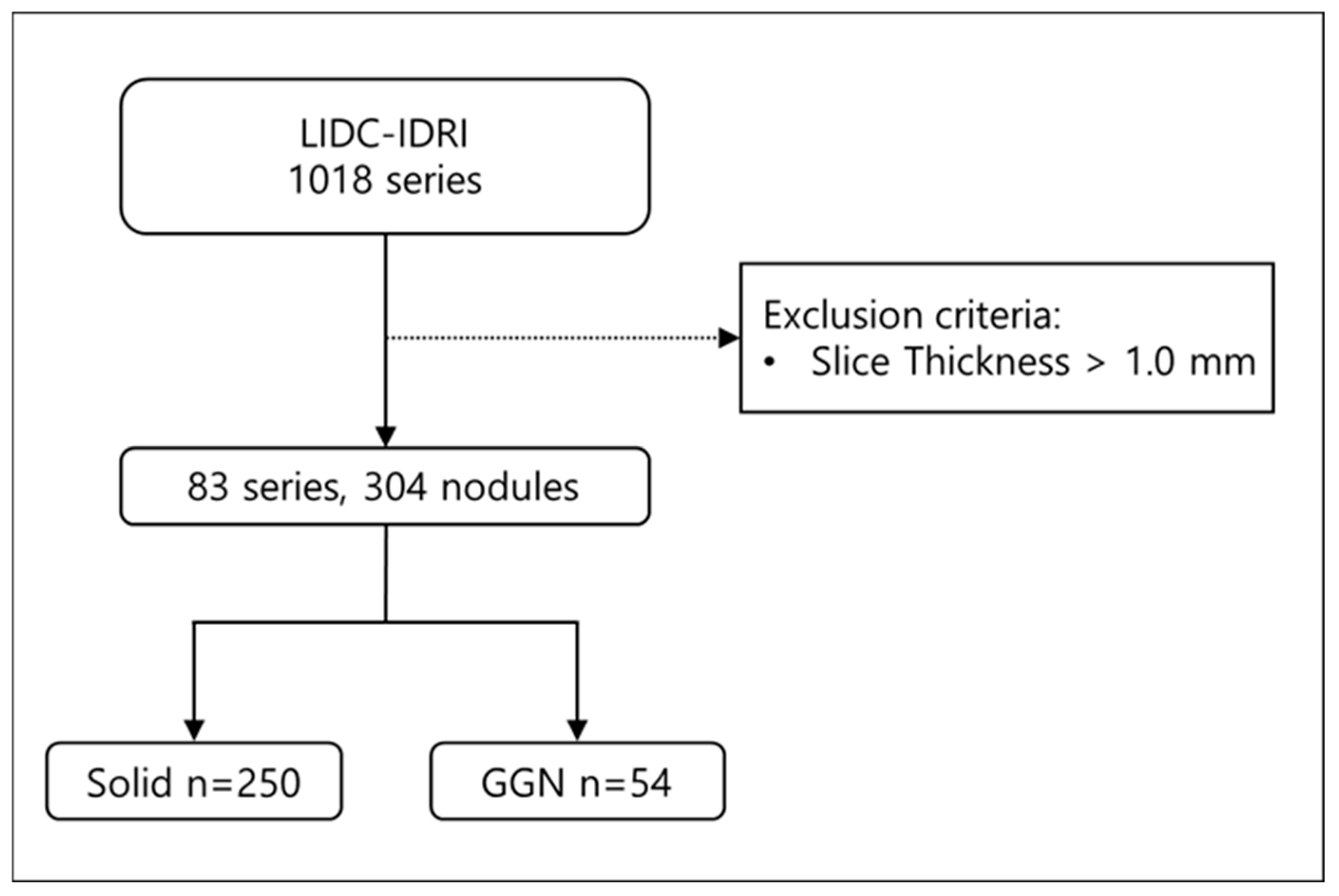
To evaluate the performance of the model, we employed the Lung Image Database Consortium and Image Database Resource Initiative (LIDC-IDRI) open dataset. LIDC-IDRI consists of diagnostic and lung cancer screening thoracic CT scans with annotated lung nodules. The dataset contains 1018 thoracic CT scans; among them, 55 scans had a slice thickness of 1.0 mm, and 28 scans had a slice thickness of 0.75 mm. We included CT scans with a slice thickness of 1.0 mm or less in this study to enable direct comparison of lung nodule characteristics between thick-slice, generated thin-slice, and thin-slice CT scans. From a total of 83 CT scans, 304 lung nodules were identified and manually segmented (
Figure 1), from which all of them were used for qualitative and quantitative analysis.
2.3. Model Architecture
We selected ESRGAN as the baseline model for our super-resolution method, making necessary modifications to adapt it for medical imaging. Unlike real-world images, CT image acquisition occurs under controlled environments, ensuring consistent image quality. Therefore, introducing degradations such as noise, blur, and JPEG compression, as performed in Real-ESRGAN [
9], was deemed unnecessary for our application.
Traditional super-resolution networks focus on single-image super-resolution. However, CT images are volumetric, necessitating modifications to handle three-dimensional data. We adapted the convolutions in the network to accept three-dimensional arrays, such as 512 × 512 × 16 volumes. Due to GPU memory limitations, CT images were partitioned into segments of 16 slices before being input into the network.
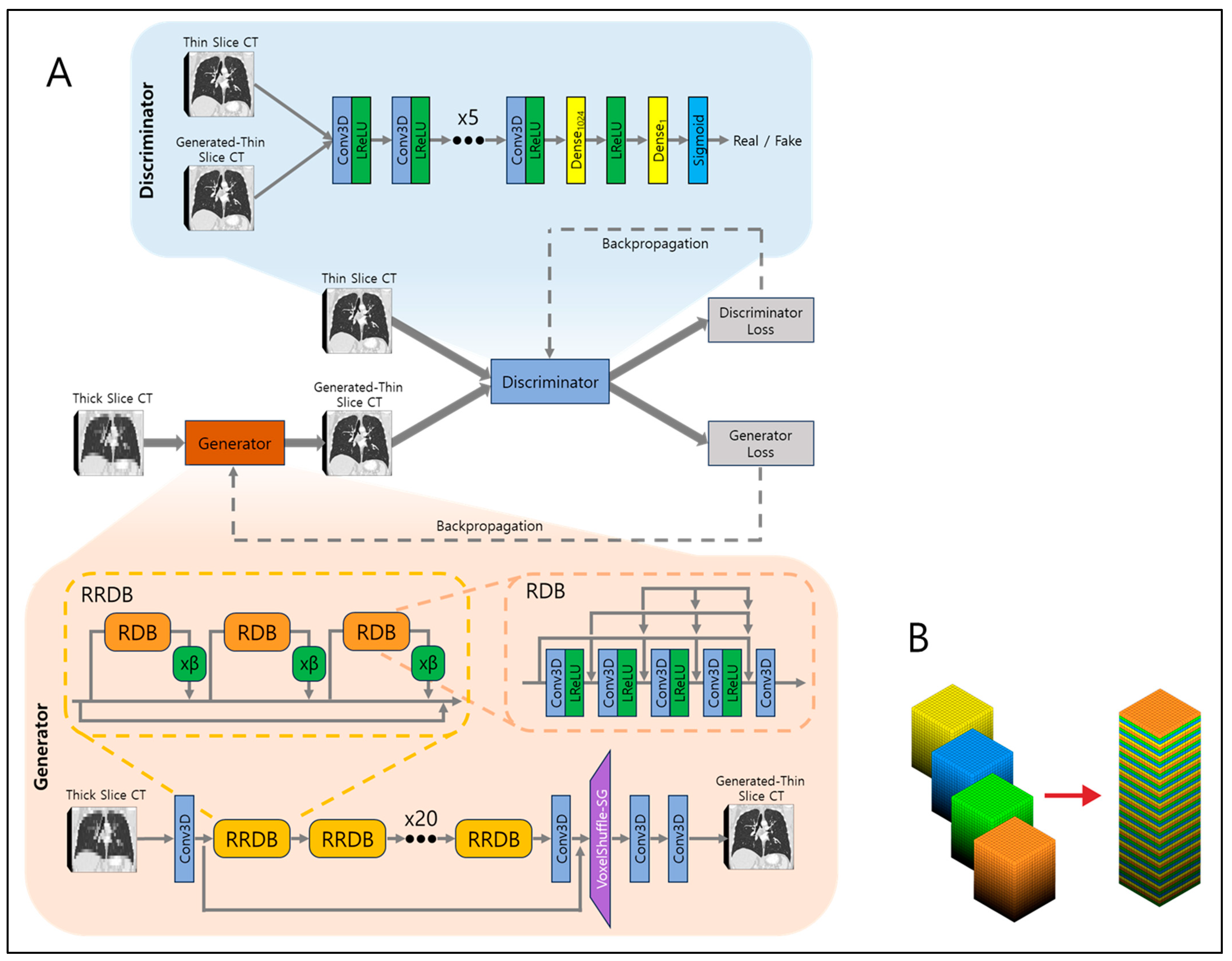
The network architecture is illustrated in
Figure 2A. At its core is the generator network, responsible for converting low-resolution (LR) inputs to super-resolved (SR) outputs. The generator employs 23 residual-in-residual dense blocks (RRDBs) as its fundamental building units. Each RRDB has a single skip connection running through the center and comprises three residual dense blocks (RDBs), each multiplied by β which is a residual scaling parameter, set to 0.2. RDB consists of alternating five 3D CNNs and four leaky rectified linear units (LReLUs), and in front of every 3D CNN, dense connections are present to allow residual flow. This design enhances the efficient flow of information and improves the network’s ability to learn complex features. Local residual connections within each RDB further stabilize the training process by mitigating the vanishing gradient problem, commonly encountered in deep networks. The global residual connection links the input of the first RDB to the output of the last RDB, creating a residual-in-residual structure. This dual-level residual design—both within each RDB and across the entire stack of RDBs—enhances the model’s capacity to capture and synthesize high-frequency details essential for producing high-resolution images with fine textures and sharp edges.
After processing through the RRDBs, the network applies another 3D CNN, followed by VoxelShuffle-Slice Generation (SG) module, depicted in
Figure 2B, to increase spatial resolution in the depth direction while preserving learned features. The VoxelShuffle-SG is a custom-made module which closely resembles the PixelShuffle module from PyTorch [
19], adapted for processing three-dimensional data. While PixelShuffle transfers tensors from the channel domain to the spatial domain in two dimensions, VoxelShuffle-SG extends this functionality to three-dimensional arrays, enabling tensor transfer from the channel domain to the depth dimension. For example, when input tensor of shape (batch, channel × r
2, height, width) enters PixelShuffle, the tensors are transferred from channel to dimension so that output tensor is of shape (batch, channel, height × r, width × r), where r represents scaling number. Similarly, when input tensor of shape (batch, channel × r, height, width, depth) enters VoxelShuffle-SG, the tensors are transferred from channel to depth so that output tensor is of shape (batch, channel, height, width, depth × r). Finally, two 3D CNNs are applied to output generated thin-slice CT images.
The output is then fed into the discriminator network along with the ground truth thin-slice CT images. The discriminator’s role is to discern generated thin-slice CT images (i.e., fake) and ground truth thin-slice CT images (i.e., real). Its network is composed of eight 3D CNN and LReLU pairs, one dense fully connected layer which outputs 1024 tensors, followed by another LReLU and another dense fully connected layer which output one tensor, and finally a sigmoid function. The output of one would represent the discriminator that assumes the input was ground truth thin-slice CT images and the output of zero would represent the discriminator that assumes the input was generated thin-slice CT images. The discriminator is trained adversarially against the generator, encouraging the generator to produce generated thin-slice CT images increasingly indistinguishable from the ground truth thin-slice CT images. In the ideal case, at the end of model training, the generator would produce generated thin-slice CT images which are perceived as almost identical to the ground truth thin-slice CT images, such that the discriminator cannot discern between the two.
2.4. CT Image Pre-Processing
To generate thin slices, CT images reconstructed in the axial plane were resliced into the coronal plane. This re-slicing allows the network to effectively utilize volumetric information by employing three-dimensional convolutions. Due to GPU memory constraints, only 16 slices of coronal images were input into the network at a time. The network outputs coronal images with four times more voxels in the depth dimension, effectively increasing the resolution. Subsequently, the coronal images are resliced back into the axial plane, resulting in axial images with slices that are four times thinner than the original thick slices. This process is illustrated in
Figure 3.
2.5. Training
For training, we used 23,816 chest CT images with a slice thickness of 1.0 mm. On average, each series contained approximately 300 slices. To simulate thick-slice CT images, every four consecutive slices were averaged to produce a single slice, reducing the number of slices from 300 to 75 per series and increasing the slice thickness from 1.0 mm to 4.0 mm. These low-resolution thick-slice CT images were input into the network to produce generated thin-slice images. The network was trained with the Adam optimizer by setting β1 = 0, β2 = 0.9, and learning rate of 1 × 10−4. It was implemented in Python 3.11 and PyTorch 2.4.0 with four Nvidia GeForce RTX 3090 graphics cards.
The original 1.0 mm thin-slice CT images and the generated 1.0 mm thin-slice images were compared using the following three loss functions: (1) mean squared error (MSE) loss, (2) perceptual loss, and (3) adversarial loss, with equations provided below, as follows:
where
r is scaling factor which is 4 for this study;
D is depth;
H is height;
W is width;
ILR is thick-slice CT image;
IGT is the thin-slice CT image;
Gθ is the generator function;
Dθ is the discriminator function;
φi,j is the feature map obtained after the
j-th convolution and before the
i-th max-pooling layer in the VGG network; and
Di,j,
Hi,j, and
Wi,j denote the dimensions of the respective feature maps.
The MSE is a pixel-wise metric that measures the average squared difference between the estimated values and the actual values, derived from the square of the Euclidean distance. While minimizing MSE reduces the overall difference in voxel values between predicted and actual images, relying solely on MSE can result in blurry textures due to the suppression of high-frequency details. To address this limitation, we introduced perceptual and adversarial losses.
The perceptual loss for SR was first proposed by Johnson et al. [
20] and extended usage in SRGAN and ESRGAN. The perceptual loss employs the pre-trained VGG19 network, a classification model used in the ImageNet dataset challenge. The MSE of the feature map of VGG between SR and HR is calculated and minimized. Since the VGG network is designed for natural two-dimensional images, we could not directly implement it on three-dimensional CT images. Therefore, we split the CT volumes into individual slices and sequentially fed them into the VGG network, calculating the loss by summing and averaging over all slices. By minimizing the Euclidean distance between the feature representations of the ground truth thin-slice CT images and the generated thin-slice CT images, the network produces images that are perceptually similar to each other.
The adversarial loss is derived from the discriminator, which simultaneously encourages the generator to produce images more similar to the ground truth thin-slice images and trains the discriminator to better distinguish between the ground truth and generated images. This adversarial training is carried out until the saturation of loss output, both in the training and validation dataset. The model with completed training fosters the generation of high-quality images that are indistinguishable from the real thin-slice CT images.
2.6. Evaluation Methods
For the qualitative evaluation, radiologist 1 and radiologist 2 were given a 5-point Likert scale to score based on the following criteria: visibility of fine lung structures, i.e., how visible are the overall lung structures, nodule margin delineation, i.e., how delineated are the solid nodule margins, and visibility of ground-glass nodule (GGN)/subsolid nodule components, i.e., how visible are the GGN and subsolid nodules. For the generated thin-slice CT images, an additional evaluation assessed the presence of any generated artifacts. This is because since the model architecture is based on GAN, there could be concern regarding fake nodule synthesis, and the evaluation presented the radiologists the choice of responding yes/no regarding the presence of generated artifacts. As for the rest of the evaluation criteria, the quality levels were defined as follows: 1—poor, 2—fair, 3—good, 4—very good, 5—excellent.
For the quantitative analysis, the lung nodules of thick-slice, generated thin-slice, and thin-slice CT images were manually segmented for the volume measurements. The segmentation process involved setting a region of interest (ROI) encompassing the nodule in all three axial, coronal, and sagittal views. The nodule was then separated from surrounding lung structures accordingly. If the nodule was present in only one or two slices in the axial plane, the separation was performed only in that plane. To verify the repeatability of lung nodule volume measurements, a single reference nodule was measured five times, yielding volumes of 133, 121, 146, 142, and 144 mm3 for the expert 1 and 137, 140, 133, 125, and 148 mm3 for the expert 2. For the expert 1, the average measurement was 137.2 mm3 with a standard deviation of 9.23 mm3, corresponding to a coefficient of variation of 6.73 percent., and for the expert 2, the average measurement was 136.6 mm3 with a standard deviation of 7.61 mm3, corresponding to a coefficient of variation of 5.57 percent. Since pixel spacing and slice thickness are known, voxel volume can be calculated, and total nodule volume can be found from the segmentations. A threshold value of −450 was used for separation between nodule types. If all voxels have a CT number above −450, the nodule is considered solid; if all voxels have a CT number equal to or below −450, the nodule is considered GGN; and if voxels have a CT number above and below −450, the nodule is considered sub-solid.
Finally, lung nodule categorization was performed based on the nodule volume measurements and in accordance with categorization criteria of Lung-RADS v2022. where it specifies categories (2—benign, 3—probably benign, 4a—suspicious and 4b—very suspicious), depending on nodule types and volume measurements. The category agreements between the lung nodules of the thick-slice–thin-slice CT pair and generated thin-slice–thin-slice CT pair were derived using confusion matrices where the category agreement of each pair was calculated by summing all the number of nodules present in the diagonal axes and dividing by the total number of nodules.
3. Results
3.1. Qualitative Analysis
The qualitative evaluation of 304 lung nodules in thick-slice, generated thin-slice and thin-slice CT images using a 5-point Likert scale is shown in
Table 2. In all criteria, both radiologists assigned higher scores to the generated thin-slice CT with respect to the thick-slice CT. No artifacts were observed in the generated thin-slice CT.
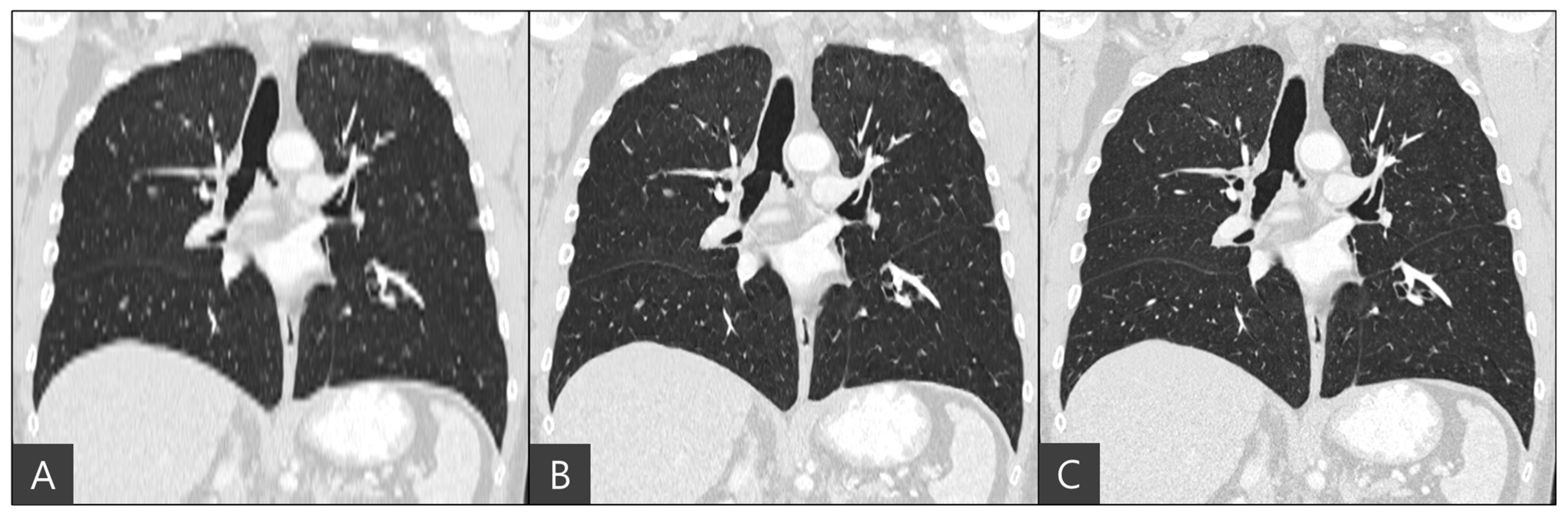
The representative coronal views of thick-slice, generated thin-slice, and ground truth thin-slice CT images are presented in
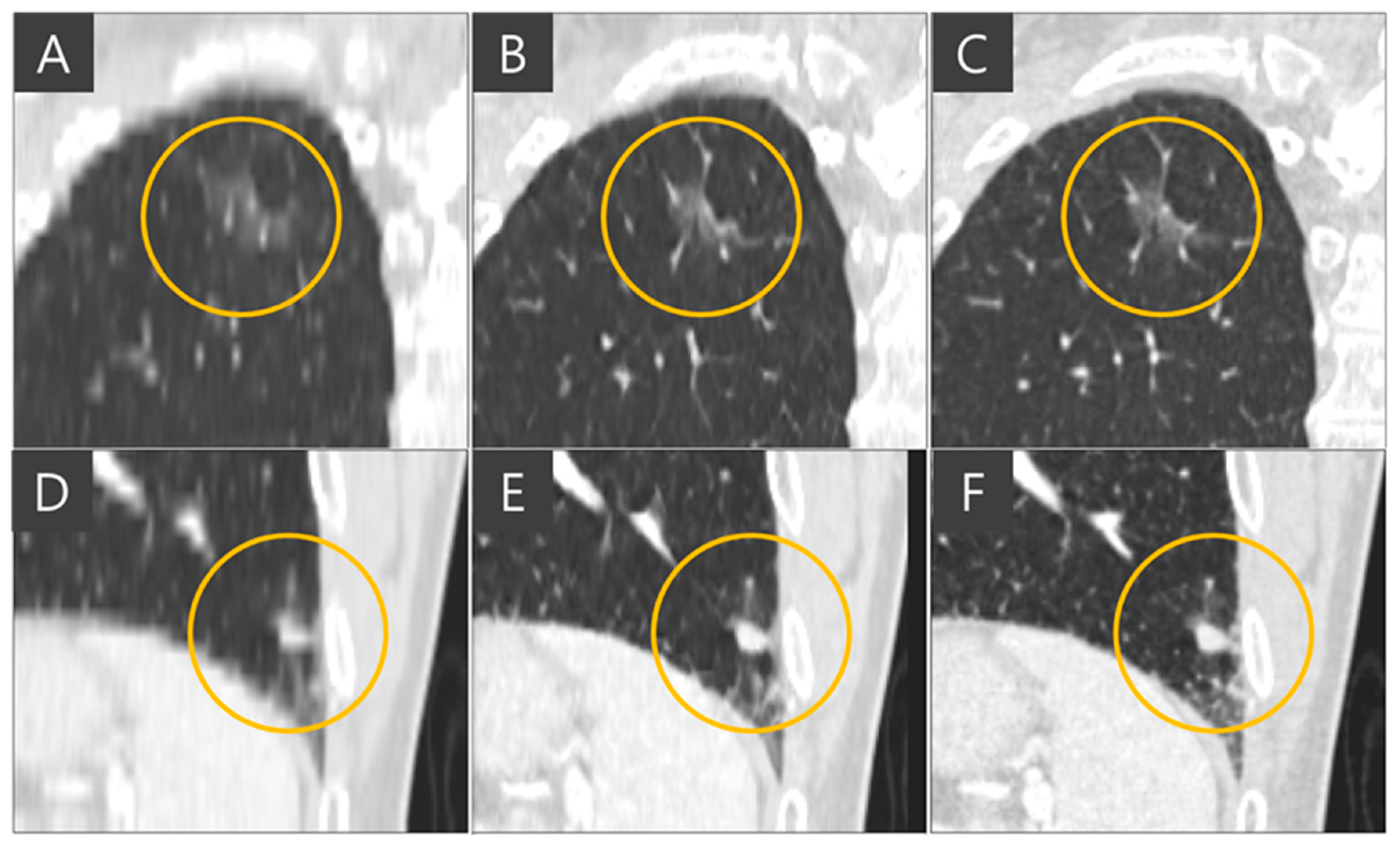
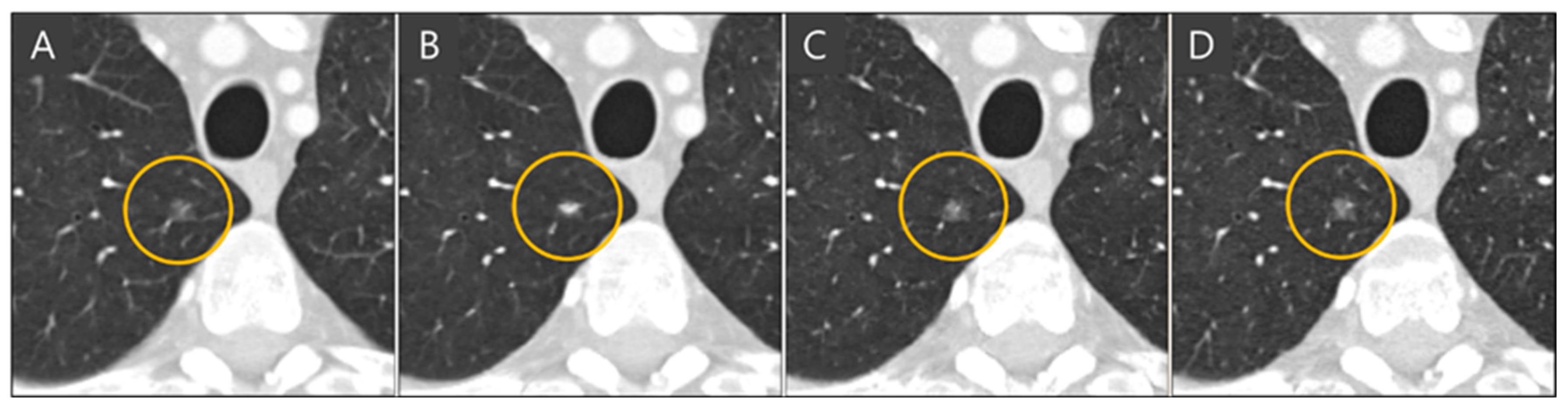
Figure 4. The thick-slice CT image exhibits staircase artifacts, unidentifiable fissures, and blurred lung vessels, whereas the generated thin-slice CT image quality is comparable to that of the ground truth thin-slice CT image. Visual inspection of GGN and solid nodules in each image type reveals clearer distinctions. In
Figure 5, the GGN in the thick slice CT image has indistinct boundaries, making accurate segmentation and volume estimation challenging. In contrast, the GGN in the generated thin-slice CT image closely resembles that in the ground truth thin-slice CT image, facilitating accurate assessment. The Likert scale scored 1, 4, 5 on the visibility of fine lung structures, 1, 4, 5 on nodule margin delineation, and 1, 4, 5 on visibility of GGN/subsolid nodule component for thick-slice, generated thin-slice, and thin-slice CT, respectively, by both radiologists. Similarly, for solid nodules, the thick-slice CT image lacks sufficient image quality for precise volume measurement, whereas the solid nodule in the generated thin-slice CT image exhibits adequate quality for accurate segmentation, mirroring the ground truth. The Likert scale scored 1, 4, 5 on the visibility of fine lung structures and 1, 4, 5 on nodule margin delineation for the thick-slice, generated thin-slice, and thin-slice CT, respectively, by both radiologists.
The importance of administration of multiple slices into the network for slice generation is demonstrated in
Figure 6. When single slices of coronal CT images are fed into the network, it focuses solely on coronal views and cannot accurately reconstruct images in the sagittal plane, resulting in inaccurate nodule representations when viewed axially. In the ground truth thin-slice CT image and the generated thin-slice CT image produced by the network using sixteen slices simultaneously, a lung vessel passing through a GGN is faithfully reconstructed, preserving both volume and texture. However, the network trained with single-slice inputs failed to accurately reproduce the GGN, resulting in an appearance resembling a subsolid nodule. This highlights the necessity of training the network with multiple slices to capture the full details of three-dimensional CT images.
3.2. Quantitative Analysis
Expert 1 and expert 2 each manually segmented 304 lung nodules from thick-slice, generated thin-slice, and thin-slice CT images and the calculated volumes derived from the two segmentations were averaged.
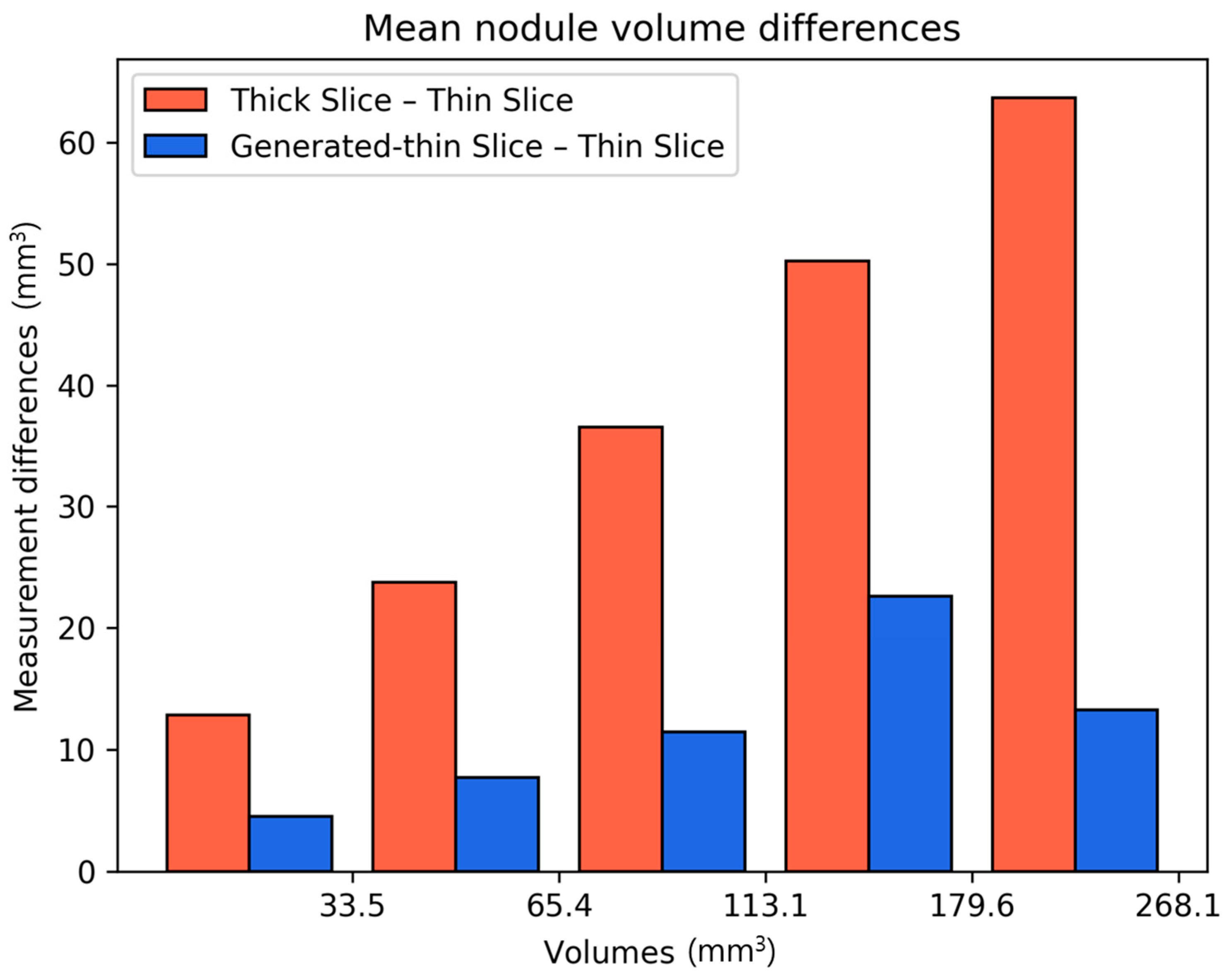
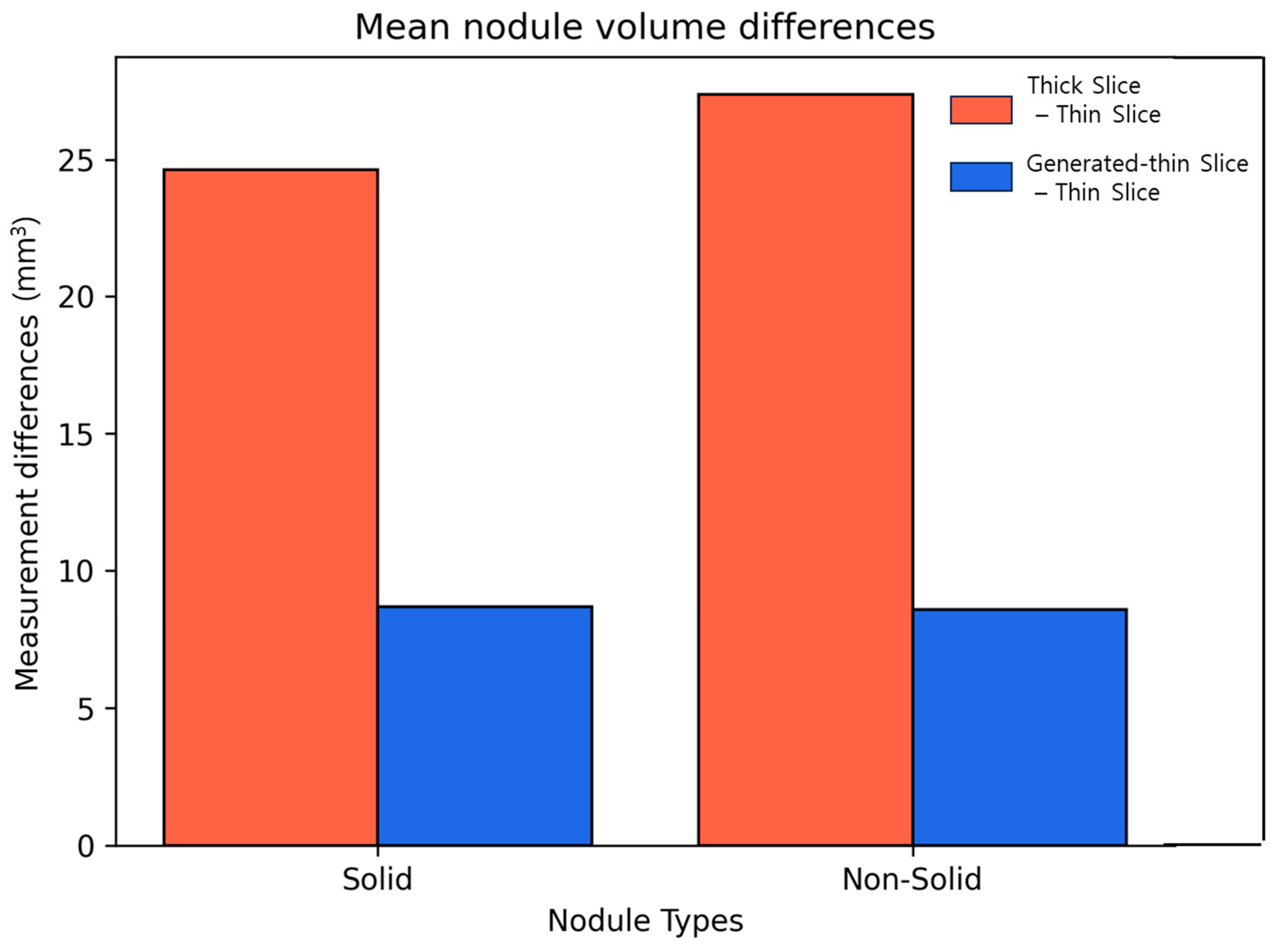
We calculated the differences in lung nodule volumes between thick-slice and thin-slice CT images, as well as between the generated thin-slice and thin-slice CT images. These differences were categorized by nodule volume (
Figure 7) and by nodule types (
Figure 8). The volume differences between the generated thin-slice and thin-slice CT images were significantly smaller than those between the thick-slice and thin-slice images in both categorizations.
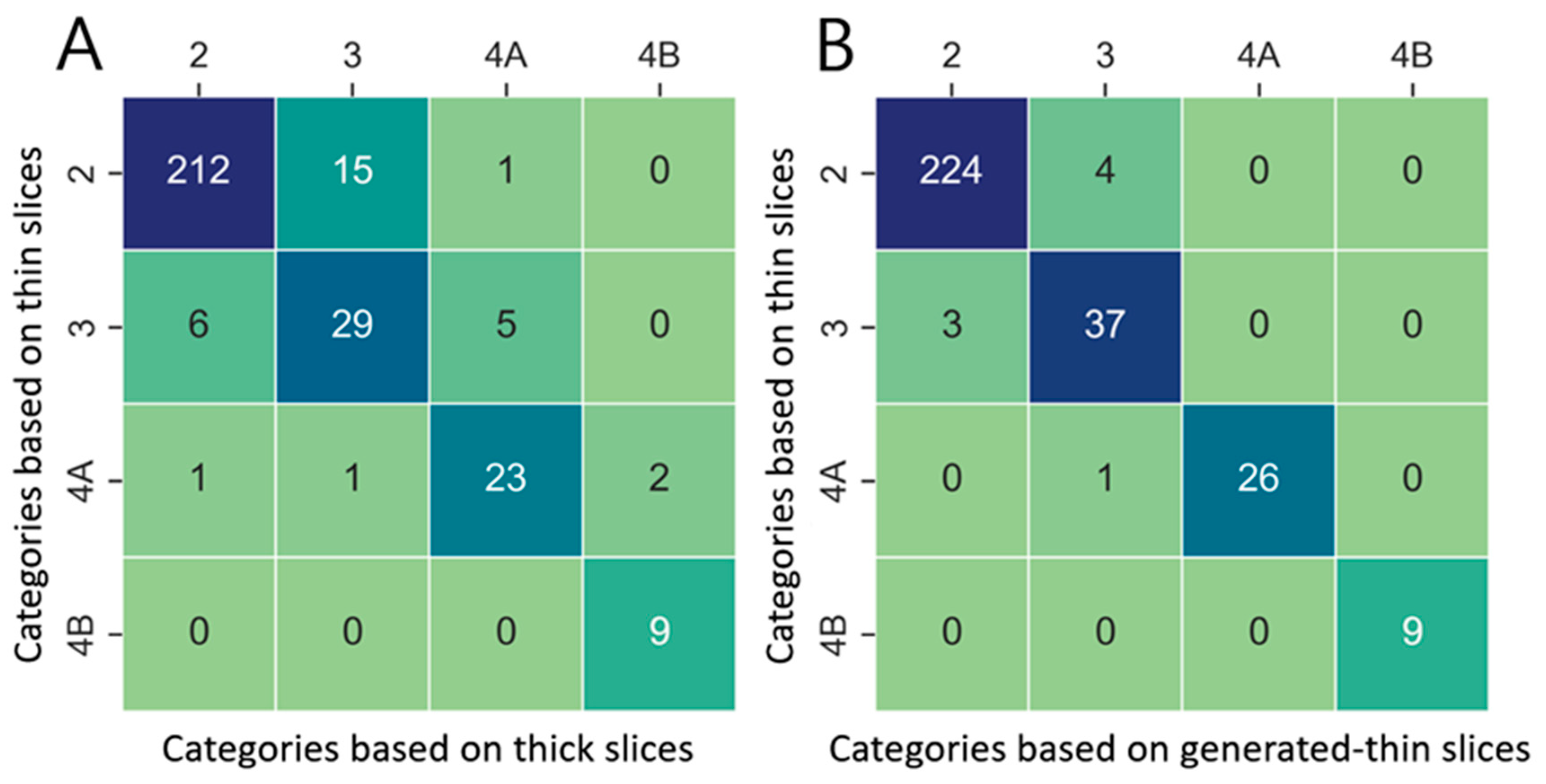
Lung nodule volumes measured in thick-slice, generated thin-slice, and thin-slice CT were categorized according to Lung-RADS v2022. Confusion matrices illustrating the classification outcomes and corresponding categorization definitions are presented in
Figure 9 and
Table 3, respectively. There were 31 misclassifications between the thick-slice and thin-slice CT, whereas only 8 misclassifications occurred between the generated thin-slice and thin-slice CT. Therefore, the agreement of lung nodule categorization with reference thin-slice CT images increased by 74 percent.
4. Discussion
The accurate measurement of the lung nodule volume is critical for proper categorization based on Lung-RADS v2022, particularly for solid nodules around 113 mm 3—the threshold between category 2 (benign) and category 3 (probably benign). Our results indicate that lung nodules from thick-slice CT images were misclassified 3.9 times more often than those from generated thin-slice CT images when compared to thin-slice CT images.
Older CT scanners typically produce images with slice thicknesses between 3 and 5 mm. Even with newer generation CT scanners, thick-slice images are often stored in Picture Archiving and Communication Systems (PACS) for storage efficiency. In both scenarios, the slice thickness is inadequate for precise nodule volume measurements, underscoring the necessity for methods to convert thick slices to thin slices.
Our deep learning model, based on ESRGAN, was modified to accommodate 3D CT images by adjusting the input channels and replacing the PixelShuffle module with the VoxelShuffle-SG module. While single-slice generation can recover nodule volume, it fails to accurately restore nodule texture. By extending the model to process three-dimensional data, both nodule volume and texture were faithfully recovered. Due to GPU memory constraints, we limited the input to 16 slices for slice generation. This proved sufficient, as the generated thin-slice CT images exhibited similar image quality to the ground truth thin-slice images, as observed by a radiologist, and demonstrated quantitatively similar volumes upon manual segmentation. This level of accuracy enables reliable lung nodule classification using Lung-RADS v2022, even from thick-slice CT images.
There are limitations to this study. Although training was conducted using data from four major CT vendors (Siemens – Erlangen, Germany, GE – Chicago, IL, USA, Canon – Otawara, Japan, and Philips – Amsterdam, Netherlands), all images were sourced from the NLST open dataset. Similarly, the test data originated from the LIDC-IDRI open dataset. Future work should include validating the model’s performance on CT images from other institutions and with various CT scanners to ensure generalizability.
5. Conclusions
Heterogeneous thick-slice CT images introduce inconsistency in the quality of lung nodule volumetric properties which is an essential factor in low-dose cancer screening programs. Therefore, a proper way to neutralize the effect of slice thickness is required, and in this research, we proposed a DL-based super-resolution method to convert heterogeneous slice thickness to thin-slice CT images. The resulting generated thin-slice and reference thin-slice CT image qualities were evaluated qualitatively and quantitatively. The qualitative evaluation was performed by the radiologist’s perceptual assessment using a 5-point Likert scale, and regarding the visibility of fine lung structures, the score increased from 1.28/1.3 to 4.02/3.71 for generated thin-slice CT which is on par with the score of 4.95/4.98 for thin-slice CT. The quantitative evaluation was performed with lung nodule volume measurement and lung nodule categorization. The average nodule volume difference between thick- and thin-slice CT was 52.2 which was reduced to 15.7 percent when compared between generated thin- and thin-slice CT. Lung nodule classification had 74 percent increased agreement between generated thin- and thin-slice CT. In all evaluation tools, generated thin-slice CT showed better performance than original thick-slice CT. In conclusion, when only thick-slice CT images are available, converting them to thin-slice CT images are crucial for reliable lung nodule classification, which would facilitate early lung nodule detection and appropriate follow-up clinical management.
Author Contributions
Conceptualization, D.K. and J.H.K.; methodology, D.K.; validation, D.K., J.H.P., C.H.L. and Y.-J.K., formal analysis, D.K., J.H.P., C.H.L. and Y.-J.K.; investigation, D.K. and J.H.K.; resources, D.K.; data curation, D.K.; writing—original draft preparation, D.K.; writing—review and editing, D.K. and J.H.K.; visualization, D.K., supervision, J.H.K.; project administration, J.H.K. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Ethical review and approval were waived since this study uses open dataset only. The study was conducted according to the relevant guidelines and regulations.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
Conflicts of Interest
J.H.K. is the CEO of ClariPi, and D.K. is an employee of ClariPi. The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as potential conflicts of interest.
References
- Petrou, M.; Quint, L.E.; Nan, B.; Baker, L.H. Pulmonary Nodule Volumetric Measurement Variability as a Function of CT Slice Thickness and Nodule Morphology. Am. J. Roentgenol. 2007, 188, 306–312. [Google Scholar] [CrossRef] [PubMed]
- MacMahon, H.; Naidich, D.P.; Goo, J.M.; Lee, K.S.; Leung, A.N.C.; Mayo, J.R.; Mehta, A.C.; Ohno, Y.; Powell, C.A.; Prokop, M.; et al. Guidelines for Management of Incidental Pulmonary Nodules Detected on CT Images: From the Fleischner Society 2017. Radiology 2017, 284, 228–243. [Google Scholar] [CrossRef] [PubMed]
- Martin, M.D.; Kanne, J.P.; Broderick, L.S.; Kazerooni, E.A.; Meyer, C.A. RadioGraphics Update: Lung-RADS 2022. RadioGraphics 2023, 43, e230037. [Google Scholar] [CrossRef] [PubMed]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks 2015. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate Image Super-Resolution Using Very Deep Convolutional Networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced Deep Residual Networks for Single Image Super-Resolution. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1132–1140. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image Super-Resolution Using Very Deep Residual Channel Attention Networks. In Computer Vision—ECCV 2018, Proceedings of the 15th European Conference, Munich, Germany, 8–14 September 2018; Lecture Notes in Computer Science; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; Volume 11211, pp. 294–310. ISBN 978-3-030-01233-5. [Google Scholar]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network 2017. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Loy, C.C. ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks. In Computer Vision—ECCV 2018 Workshops, Proceedings of the 15th European Conference, Munich, Germany, 8–14 September 2018; Leal-Taixé, L., Roth, S., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2019; Volume 11133, pp. 63–79. ISBN 978-3-030-11020-8. [Google Scholar]
- Wang, X.; Xie, L.; Dong, C.; Shan, Y. Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021; pp. 1905–1914. [Google Scholar]
- Goo, J.M. Deep Learning–Based Super-Resolution Algorithm: Potential in the Management of Subsolid Nodules. Radiology 2021, 299, 220–221. [Google Scholar] [CrossRef]
- Park, S.; Lee, S.M.; Kim, W.; Park, H.; Jung, K.-H.; Do, K.-H.; Seo, J.B. Computer-Aided Detection of Subsolid Nodules at Chest CT: Improved Performance with Deep Learning–Based CT Section Thickness Reduction. Radiology 2021, 299, 211–219. [Google Scholar] [CrossRef] [PubMed]
- Park, S.; Lee, S.M.; Do, K.-H.; Lee, J.-G.; Bae, W.; Park, H.; Jung, K.-H.; Seo, J.B. Deep Learning Algorithm for Reducing CT Slice Thickness: Effect on Reproducibility of Radiomic Features in Lung Cancer. Korean J. Radiol. 2019, 20, 1431. [Google Scholar] [CrossRef]
- Yun, H.R.; Lee, M.J.; Hong, H.; Shim, K.W.; Jeon, J. Improvement of Inter-Slice Resolution Based on 2D CNN with Thin Bone Structure-Aware on Head-and-Neck CT Images. In Proceedings of the Medical Imaging 2021: Image Processing, California, CA, USA, 15–20 February 2021; SPIE: Bellingham, WA, USA, 2021; Volume 11596, pp. 600–605. [Google Scholar]
- Yun, H.R.; Lee, M.J.; Hong, H.; Shim, K.W. Inter-Slice Resolution Improvement Using Convolutional Neural Network with Orbital Bone Edge-Aware in Facial CT Images. J. Digit. Imaging 2022, 36, 240–249. [Google Scholar] [CrossRef] [PubMed]
- Kudo, A.; Kitamura, Y.; Li, Y.; Iizuka, S.; Simo-Serra, E. Virtual Thin Slice: 3D Conditional GAN-Based Super-Resolution for CT Slice Interval. In Proceedings of the Machine Learning for Medical Image Reconstruction, Shenzhen, China, 17 October 2019. [Google Scholar]
- Nakamoto, A.; Hori, M.; Onishi, H.; Ota, T.; Fukui, H.; Ogawa, K.; Masumoto, J.; Kudo, A.; Kitamura, Y.; Kido, S.; et al. Three-Dimensional Conditional Generative Adversarial Network-Based Virtual Thin-Slice Technique for the Morphological Evaluation of the Spine. Sci. Rep. 2022, 12, 12176. [Google Scholar] [CrossRef] [PubMed]
- Iwano, S.; Kamiya, S.; Ito, R.; Kudo, A.; Kitamura, Y.; Nakamura, K.; Naganawa, S. Measurement of Solid Size in Early-Stage Lung Adenocarcinoma by Virtual 3D Thin-Section CT Applied Artificial Intelligence. Sci. Rep. 2023, 13, 21709. [Google Scholar] [CrossRef] [PubMed]
- PixelShuffle—PyTorch 2.5 Documentation. Available online: https://pytorch.org/docs/stable/generated/torch.nn.PixelShuffle.html (accessed on 12 December 2024).
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual Losses for Real-Time Style Transfer and Super-Resolution. In Computer Vision—ECCV 2016, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Lecture Notes in Computer Science; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; Volume 9906, pp. 694–711. ISBN 978-3-319-46474-9. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}