
Pulmonary Hypertension Detection Non-Invasively at Point-of-Care Using a Machine-Learned Algorithm

 ,
,
Abstract
1. Introduction
2. Materials and Methods
2.1. Clinical Studies & Population
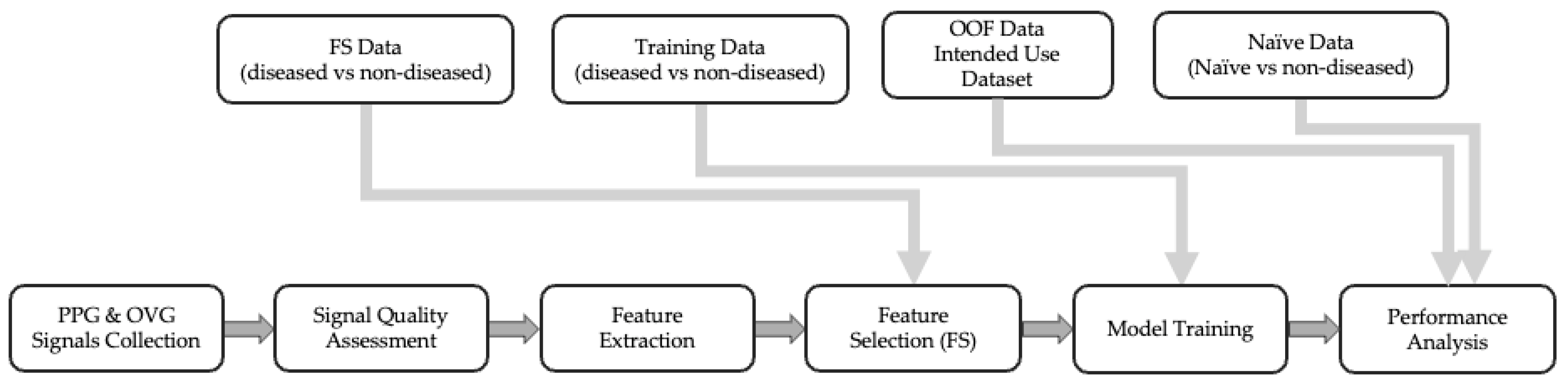
2.2. Overview of Model Development Process
2.3. Signal Collection, Quality Assessment and Feature Extraction
2.4. Dimensionality Reduction (Feature Selection)
2.5. Modeling
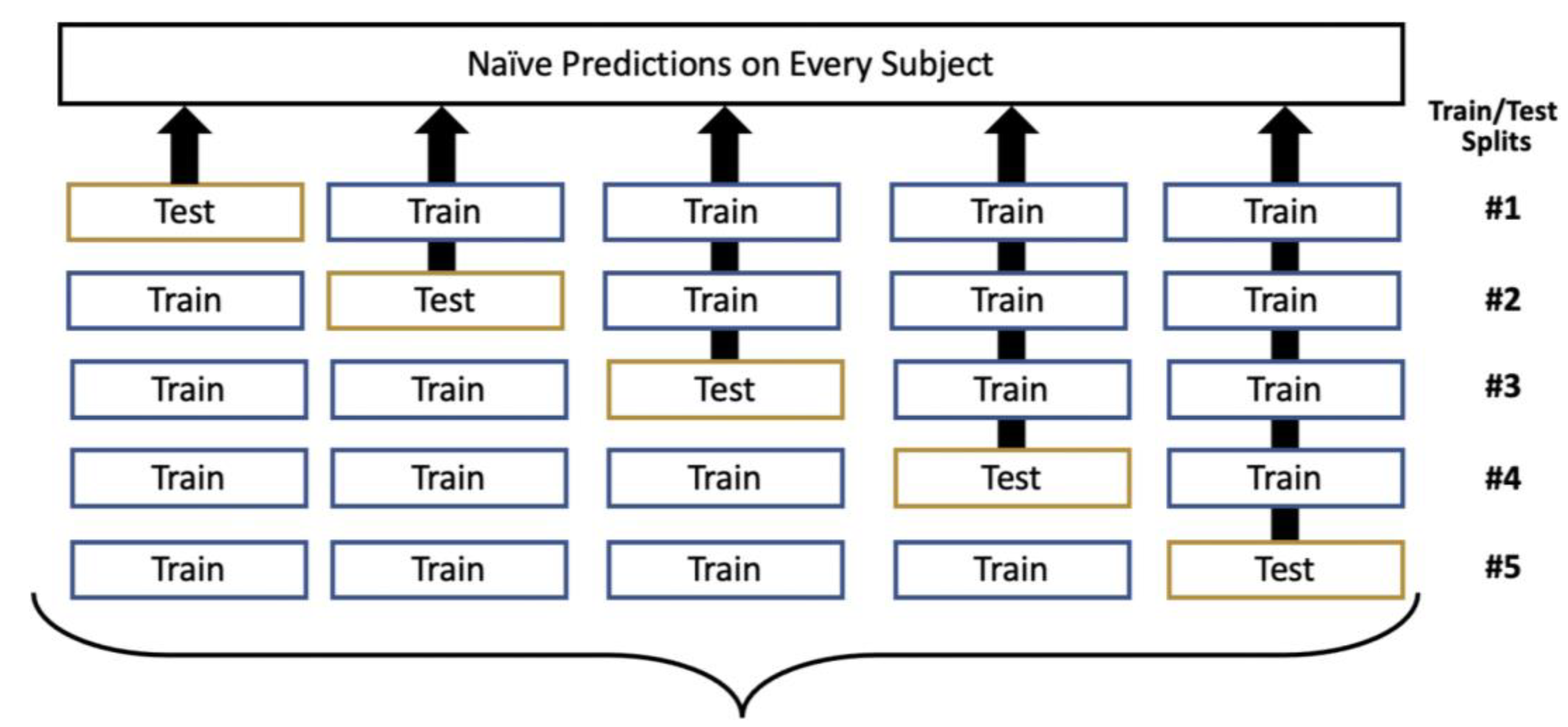
2.6. Performance Analysis
3. Results
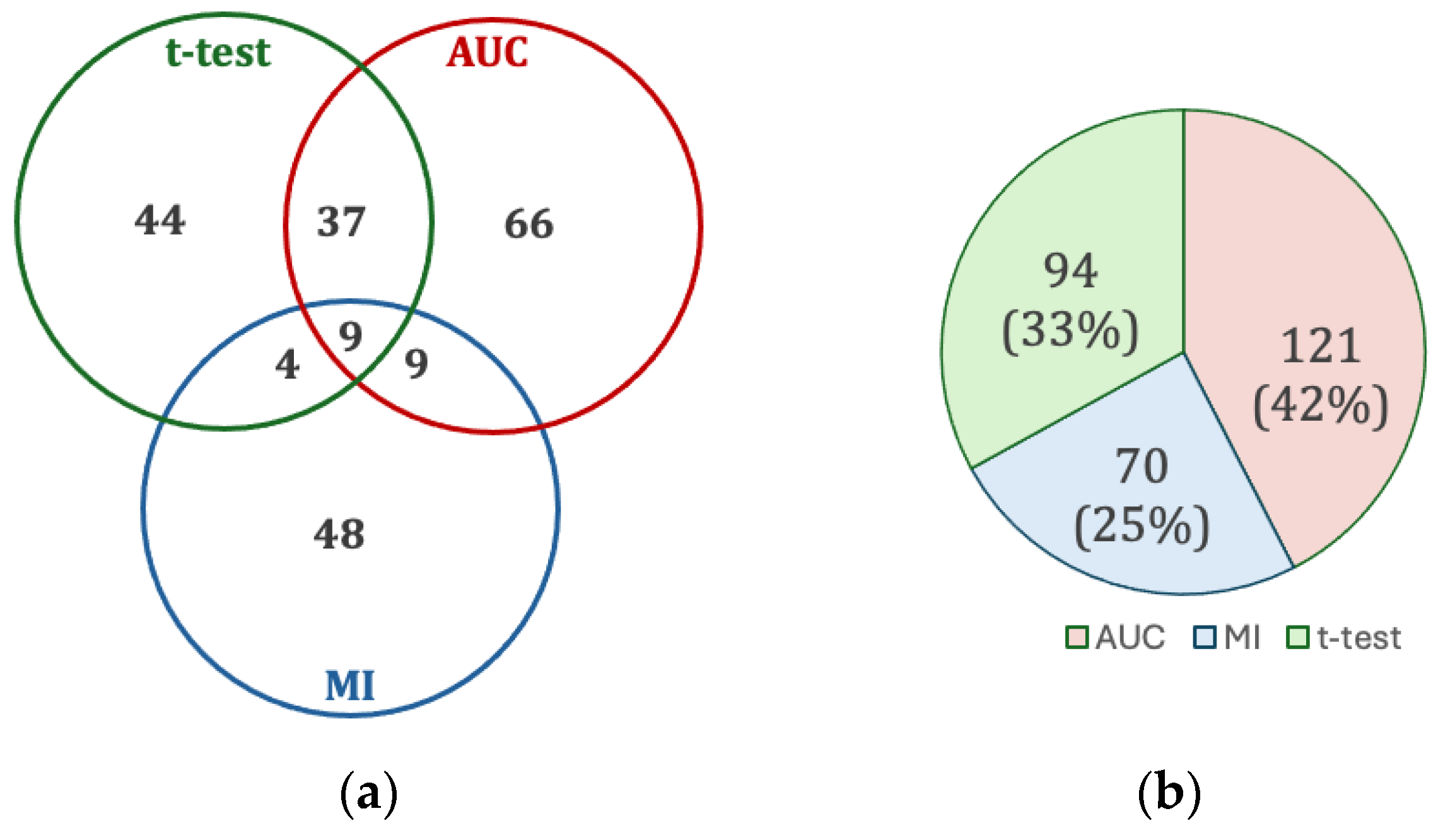
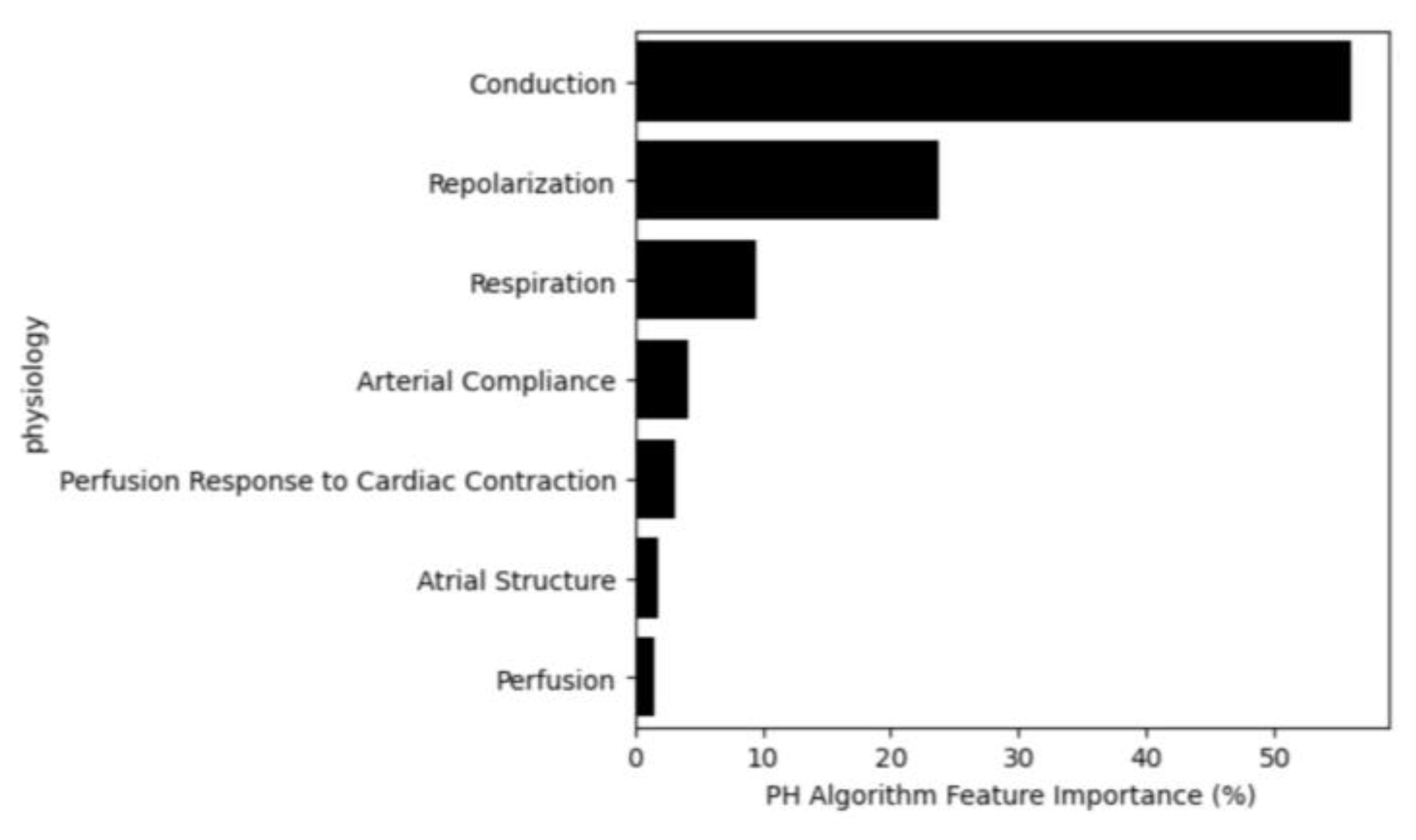
3.1. Selected Features
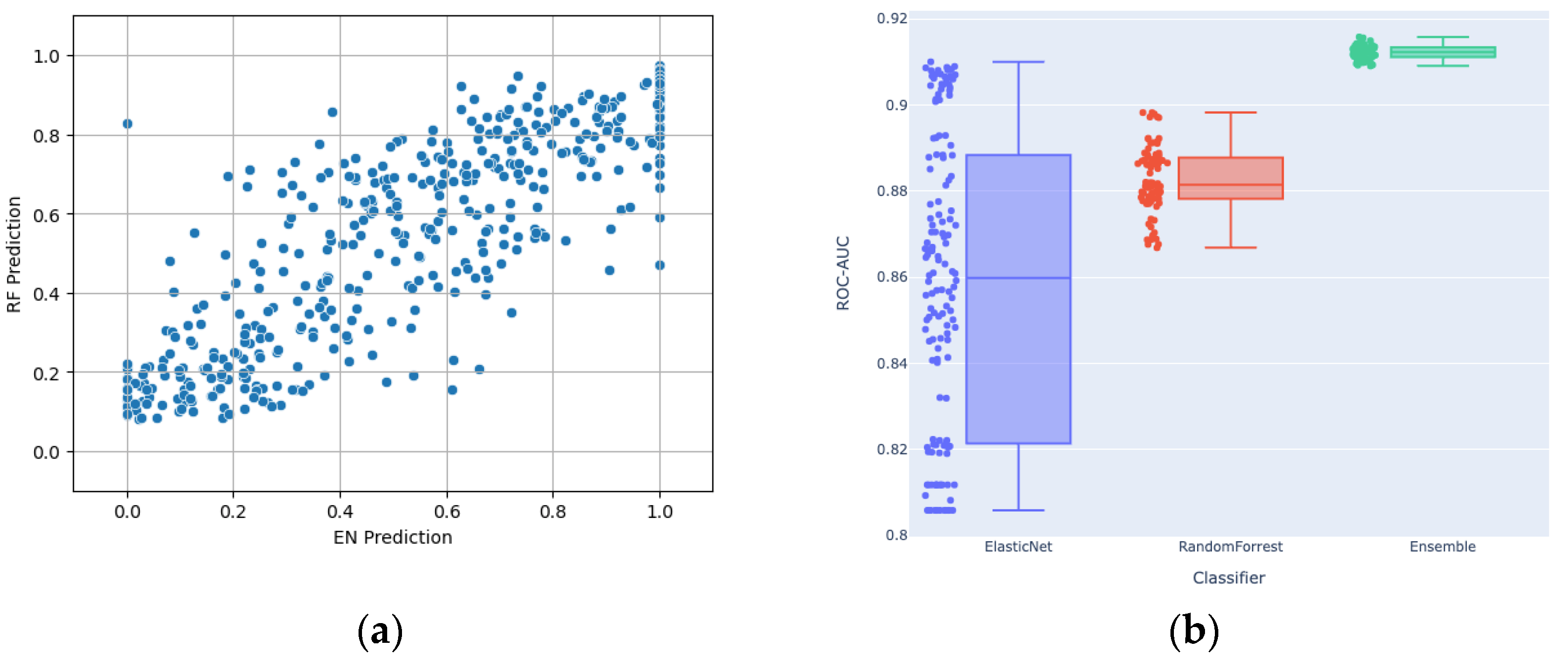
3.2. Relationship between EN and RF
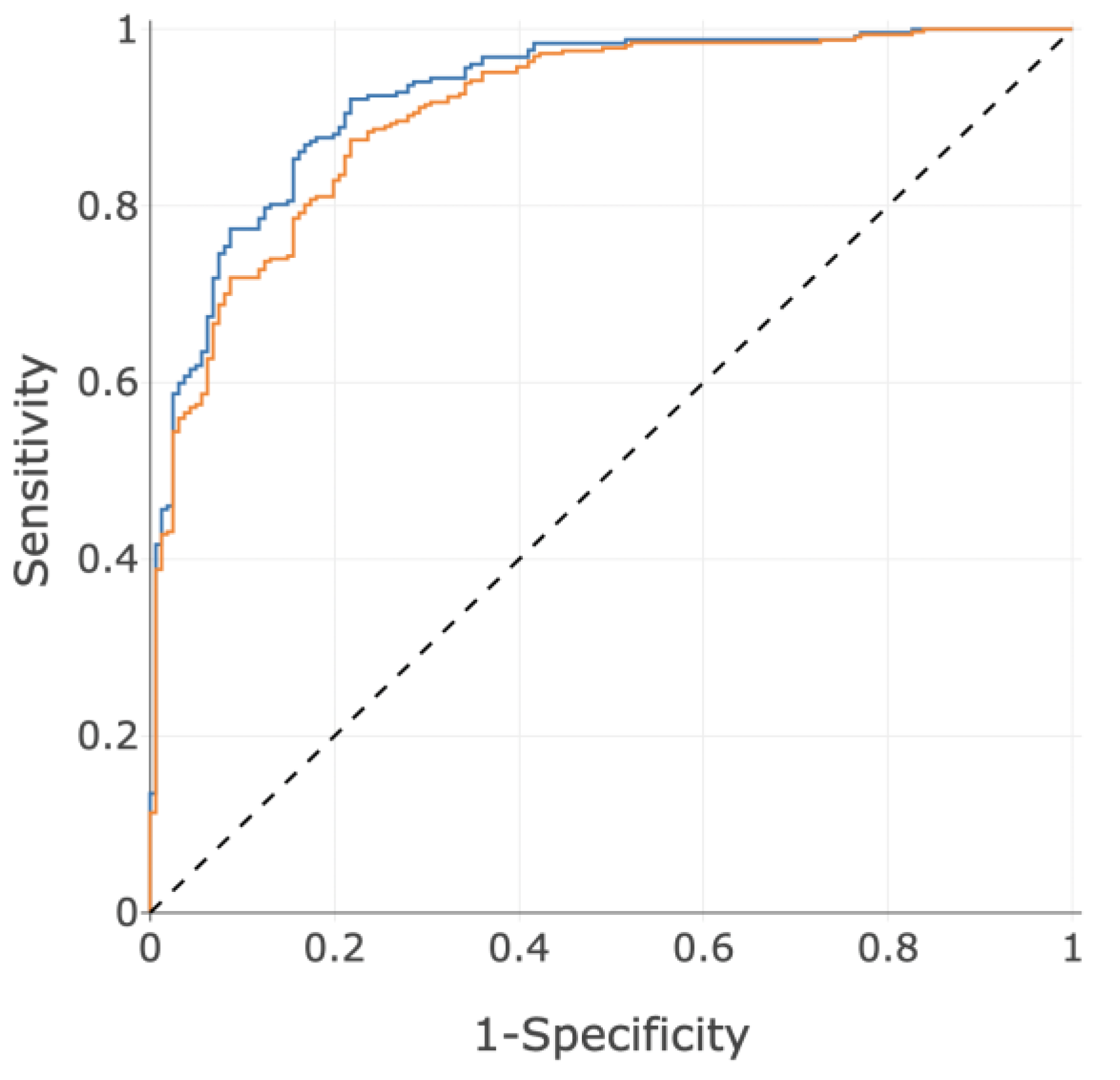
3.3. Performance
3.4. Feature Importance
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Galié, N.; Humbert, M.; Vachiéry, J.-L.; Gibbs, S.; Lang, I.; Torbicki, A.; Simonneau, G.; Peacock, A.; Noordegraaf, A.V.; Beghetti, M.; et al. 2015 ESC/ERS Guidelines for the diagnosis and treatment of pulmonary hypertension. Eur. Respir. J. 2015, 46, 903–975. [Google Scholar] [CrossRef] [PubMed]
- Humbert, M.; Kovacs, G.; Hoeper, M.M.; Badagliacca, R.; Berger, R.M.; Brida, M.; Carlsen, J.; Coats, A.J.S.; Escribano-Subias, P.; Ferrari, P.; et al. 2022 ESC/ERS Guidelines for the diagnosis and treatment of pulmonary hypertension: Developed by the task force for the diagnosis and treatment of pulmonary hypertension of the European Society of Cardiology (ESC) and the European Respiratory Society (ERS). Eur. Heart J. 2022, 43, 3618–3731. [Google Scholar] [CrossRef] [PubMed]
- Dunlap, B.; Weyer, G. Pulmonary Hypertension: Diagnosis and Treatment. Am. Acad. Fam. Physicians 2016, 94, 463–469. [Google Scholar]
- Guazzi, M.; Borlaug, B.A. Pulmonary hypertension due to left heart disease. Circulation 2012, 126, 975–990. [Google Scholar] [CrossRef] [PubMed]
- Vachiéry, J.-L.; Adir, Y.; Barberà, J.A.; Champion, H.; Coghlan, J.G.; Cottin, V.; De Marco, T.; Galiè, N.; Ghio, S.; Gibbs, J.S.R.; et al. Pulmonary hypertension due to left heart diseases. J. Am. Coll. Cardiol. 2013, 62, D109–D116. [Google Scholar] [CrossRef] [PubMed]
- Lam, C.S.; Borlaug, B.A.; Kane, G.C.; Enders, F.T.; Rodeheffer, R.J.; Redfield, M.M. Age-associated increases in pulmonary artery systolic pressure in the general population. Circulation 2009, 119, 2663–2670. [Google Scholar] [CrossRef] [PubMed]
- Galiè, N.; McLaughlin, V.V.; Rubin, L.J.; Simonneau, G. An overview of the 6th World Symposium on Pulmonary Hypertension. Eur. Respir. J. 2019, 53, 1802148. [Google Scholar] [CrossRef]
- Hoeper, M.M.; Humbert, M.; Souza, R.; Idrees, M.; Kawut, S.M.; Sliwa-Hahnle, K.; Jing, Z.-C.; Gibbs, J.S.R. A global view of pulmonary hypertension. Lancet Respir. Med. 2016, 4, 306–322. [Google Scholar] [CrossRef] [PubMed]
- Sikirica, M.; Iorga, S.R.; Bancroft, T.; Pot-ash, J. The economic burden of pulmonary arterial hypertension (PAH) in the US on payers and patients. BMC Health Serv. Res. 2014, 14, 676. [Google Scholar] [CrossRef]
- Janda, S.; Shahidi, N.; Gin, K.; Swiston, J. Diagnostic accuracy of echocardiography for pulmonary hypertension: A systematic review and meta-analysis. Heart 2011, 97, 612–622. [Google Scholar] [CrossRef]
- Ong, M.; Klann, J.G.; Lin, K.J.; Maron, B.A.; Murphy, S.N.; Natter, M.D.; Mandl, K.D. Claims-based algorithms for identifying patients with pulmonary hypertension: A comparison of decision rules and machine-learning approaches. J. Am. Heart Assoc. 2020, 9, e016648. [Google Scholar] [CrossRef] [PubMed]
- Burton, T.; Fathieh, F.; Nemati, N.; Gillins, H.R.; Shadforth, I.P.; Ramchandani, S.; Bridges, C.R. Development of a Non-Invasive Machine-Learned Point-of-Care Rule-Out Test for Coronary Artery Disease. Diagnostics 2024, 14, 719. [Google Scholar] [CrossRef] [PubMed]
- Fathieh, F.; Paak, M.; Khosousi, A.; Burton, T.; Sanders, W.E.; Doomra, A.; Lange, E.; Khedraki, R.; Bhavnani, S.; Ramchandani, S. Predicting cardiac disease from interactions of simultaneously-acquired hemodynamic and cardiac signals. Comput. Methods Programs Biomed. 2021, 202, 105970. [Google Scholar] [CrossRef] [PubMed]
- Nagueh, S.F.; Smiseth, O.A.; Appleton, C.P.; Byrd, B.F.; Dokainish, H.; Edvardsen, T.; Flachskampf, F.A.; Gillebert, T.C.; Klein, A.L.; Lancellotti, P.; et al. Recommendations for the evaluation of left ventricular diastolic function by echocardiography: An update from the American Society of Echocardiography and the European Association of Cardiovascular Imaging. Eur. J. Echocardiogr. 2016, 17, 1321–1360. [Google Scholar]
- Bhavnani, S.P.; Khedraki, R.; Cohoon, T.J.; Meine, F.J.; Stuckey, T.D.; McMinn, T.; Depta, J.P.; Bennett, B.; McGarry, T.; Carroll, W.; et al. Multicenter validation of a machine learning phase space electro-mechanical pulse wave analysis to predict elevated left ventricular end diastolic pressure at the point-of-care. PLoS ONE 2022, 17, e0277300. [Google Scholar] [CrossRef] [PubMed]
- Nemati, N.; Fathieh, F.; Burton, T.; Gillins, H.; Shadforth, I.; Ramchandani, S.; Bridges, C.R. Development of a Non-Ivasive Point-of-Care Rule-Out Test for Hearth Failure Using Machine Learning. J. Am. Coll. Cardiol. 2024, 83 (Suppl. S13). [Google Scholar] [CrossRef]
- Jia, W.; Sun, M.; Lian, J.; Hou, S. Feature dimensionality reduction: A review. Complex Intell. Syst. 2022, 8, 2663–2693. [Google Scholar] [CrossRef]
- Krittanawong, C.; Virk, H.U.H.; Bangalore, S.; Wang, Z.; Johnson, K.W.; Pinotti, R.; Zhang, H.; Kaplin, S.; Narasimhan, B.; Kitai, T.; et al. Machine learning prediction in cardiovascular diseases: A meta-analysis. Sci. Rep. 2020, 10, 16057. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. B Stat. Methodol. 2005, 67, 301–320. [Google Scholar] [CrossRef]
- Berrar, D. Encyclopedia of Bioinformatics and Computational Biology; Cross-Validation; Ranganathan, S., Gribskov, M., Nakai, K., Schönbach, C., Eds.; Academic Press: Oxford, UK, 2019; pp. 542–545. [Google Scholar]
- Breiman, L. Bagging Predictors; Technical Report TR-421; Department of Statistics, University of California Berkeley: Berkeley, CA, USA, 2019. [Google Scholar]
- Allgaier, J.; Mulansky, L.; Draelos, R.L.; Pryss, R. How does the model make predictions? A systematic literature review on the explainability power of machine learning in healthcare. Artif. Intell. Med. 2023, 143, 102616. [Google Scholar] [CrossRef] [PubMed]
- Zehir, R.; Karabay, C.Y.; Kalaycı, A.; Akgün, T.; Kılıçgedik, A.; Kırma, C. Evaluation of Tpe interval and Tpe/QT ratio in patients with slow coronary flow. Anatol. J. Cardiol. 2015, 15, 463. [Google Scholar] [CrossRef] [PubMed]
- Moraes, J.L.; Rocha, M.X.; Vasconcelos, G.G.; Vasconcelos Filho, J.E.; De Albuquerque, V.H.C.; Alexandria, A.R. Advances in photopletysmography signal analysis for biomedical applications. Sensors 2018, 18, 1894. [Google Scholar] [CrossRef] [PubMed]
- Platonov, P.G. P-wave morphology: Underlying mechanisms and clinical implications. Ann. Noninvasive Electrocardiol. 2012, 17, 161–169. [Google Scholar] [CrossRef] [PubMed]
- Elgendi, M. On the analysis of fingertip photoplethysmogram signals. Curr. Cardiol. Rev. 2012, 8, 14–25. [Google Scholar] [CrossRef] [PubMed]
- Hoeper, M.M.; Badesch, D.B.; Ghofrani, H.A.; Gibbs, J.S.R.; Gomberg-Maitland, M.; McLaughlin, V.V.; Preston, I.R.; Souza, R.; Waxman, A.B.; Grünig, E.; et al. Phase 3 trial of sotatercept for treatment of pulmonary arterial hypertension. N. Engl. J. Med. 2023, 388, 1478–1490. [Google Scholar] [CrossRef]
- Heidenreich, P.A.; Bozkurt, B.; Aguilar, D.; Allen, L.A.; Byun, J.J.; Colvin, M.M.; Deswal, A.; Drazner, M.H.; Dunlay, S.M.; Evers, L.R.; et al. 2022 AHA/ACC/HFSA guideline for the management of heart failure: Executive summary: A report of the American College of Cardiology/American Heart Association Joint Committee on Clinical Practice Guidelines. J. Am. Coll. Cardiol. 2022, 79, 1757–1780. [Google Scholar] [CrossRef] [PubMed]
- Ayano, Y.M.; Schwenker, F.; Dufera, B.D.; Debelee, T.G. Interpretable Machine Learning Techniques in ECG-Based Heart Disease Classification: A Systematic Review. Diagnostics 2023, 13, 111. [Google Scholar] [CrossRef] [PubMed]
- Allen, J. Photoplethysmography and its application in clinical physiological measurement. Physiol. Meas. 2007, 28, R1. [Google Scholar] [CrossRef]
- Pan, D.; Liu, R.; Ren, S.; Li, C.; Chang, Q. Prediction of Pulmonary Arterial Hypertension in Chronic Obstructive Lung Disease from Three-Dimensional Vectorcardiographic Parameters. Ann. Noninvasive Electrocardiol. 2016, 21, 280–286. [Google Scholar] [CrossRef]
- Rubulis, A.; Jensen, J.; Lundahl, G.; Tapanainen, J.; Wecke, L.; Bergfeldt, L. T vector and loop characteristics in coronary artery disease and during acute ischemia. Heart Rhythm. 2004, 1, 317–325. [Google Scholar] [CrossRef] [PubMed]
- Tereshchenko, L.G.; Waks, J.W.; Kabir, M.; Ghafoori, E.; Shvilkin, A.; Josephson, M.E. Analysis of speed, curvature, planarity and frequency characteristics of heart vector movement to evaluate the electrophysiological substrate associated with ventricular tachycardia. Comput. Biol. Med. 2015, 65, 150–160. [Google Scholar] [CrossRef] [PubMed]
- Sedaghat, G.; Ghafoori, E.; Waks, J.W.; Kabir, M.M.; Shvilkin, A.; Josephson, M.E.; Tereshchenko, L.G. Quantitative assessment of vectorcardiographic loop morphology. J. Electrocardiol. 2016, 49, 154–163. [Google Scholar] [CrossRef] [PubMed]
- Bansal, D.; Khan, M.; Salhan, A.K. A Review of Measurement and Analysis of Heart Rate Variability. In Proceedings of the 2009 International Conference on Computer and Automation Engineering, Bangkok, Thailand, 8–10 March 2009; pp. 243–246. [Google Scholar]
- Călburean, P.A.; Pannone, L.; Sorgente, A.; Gauthey, A.; Monaco, C.; Strazdas, A.; Almorad, A.; Bisignani, A.; Bala, G.; Ramak, R.; et al. Heart rate variability and microvolt T wave alternans changes during ajmaline test may predict prognosis in Brugada syndrome. Clin. Auton. Res. 2023, 33, 51–62. [Google Scholar] [CrossRef] [PubMed]
- Wang, T.; Lu, C.; Sun, Y.; Yang, M.; Liu, C.; Ou, C. Automatic ECG Classification Using Continuous Wavelet Transform and Convolutional Neural Network. Entropy 2021, 23, 119. [Google Scholar] [CrossRef] [PubMed]
- He, R.; Wang, K.; Zhao, N.; Liu, Y.; Yuan, Y.; Li, Q.; Zhang, H. Automatic detection of atrial fibrillation based on continuous wavelet transform and 2D convolutional neural networks. Front. Physiol. 2018, 9, 1206. [Google Scholar] [CrossRef] [PubMed]
- Lin, C.H. Frequency-domain features for ECG beat discrimination using grey relational analysisbased classifier. Comput. Math. Appl. 2008, 55, 680–690. [Google Scholar] [CrossRef]
- Madsen, H.M. Spectral Decomposition of Electrocardiograms for the Diagnosis of Pulmonary Hypertension and the Estimation of Invasively Measured Parameters. Master’s Thesis, College of BioEng., University of Colorado, Denver, CO, USA, 2017. [Google Scholar]
- Bhoi, A.K.; Sherpa, K.S.; Khandelwal, A.B. Ischemia and arrhythmia classification using timefrequency domain features of QRS complex. Procedia Comput. Sci. 2018, 132, 606613. [Google Scholar] [CrossRef]
- PCharlton, H.; Bonnici, T.; Tarassenko, L.; Clifton, D.A.; Beale, R.; Watkinson, P.J. An assessment of algorithms to estimate respiratory rate from the electrocardiogram and photoplethysmogram. Physiol. Meas. 2016, 37, 610–626. [Google Scholar] [CrossRef]
- Schumann, A.; Wessel, N.; Schirdewan, A.; Osterziel, K.J.; Voss, A. Potential of feature selection methods in heart rate variability analysis for the classification of different cardiovascular diseases. Stat. Med. 2002, 21, 2225–2242. [Google Scholar] [CrossRef]
- Witte, C.; Meyer Zur Heide Genannt Meyer-Arend, J.U.; Andrié, R.; Schrickel, J.W.; Hammerstingl, C.; Schwab, J.O.; Nickenig, G.; Skowasch, D.; Pizarro, C. Heart Rate Variability and Arrhythmic Burden in Pulmonary Hypertension. In Pulmonary Dysfunction and Disease. Advances in Experimental Medicine and Biology; Pokorski, M., Ed.; Springer: Cham, Switzerland, 2016; Volume 934. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 2015 ESC/ERS Guidelines | 2022 ESC/ERS Guidelines | WHO Groups | |
|---|---|---|---|
| Pre-Capillary PH | mPAP ≥ 25 mmHg PCWP ≤ 15 mmHg PVR > 3 WU | mPAP ≥ 21 mmHg PCWP ≤ 15 mmHg PVR > 2 WU | 1, 3, 4, 5 |
| (Isolated) Post-Capillary PH | mPAP ≥ 25 mmHg PCWP > 15 mmHg PVR ≤ 3 WU | mPAP ≥ 21 mmHg PCWP > 15 mmHg PVR ≤ 2 WU | 2, 5 |
| Combined Pre- & Post-Capillary PH | mPAP ≥ 25 mmHg PCWP > 15 mmHg PVR > 3 WU | mPAP ≥ 21 mmHg PCWP > 15 mmHg PVR > 2 WU | 2, 5 |
| Characteristic | PH− IDENTIFY Groups 3 & 4 | PH+ IDENTIFY PH | p-Value |
|---|---|---|---|
| Number of Subjects | 204 | 252 | |
| Age | |||
| Mean ± Std | 54.6 ± 12.2 | 64.7 ± 12.3 | <0.05 |
| Age ≥ 65 | 19.6% (40/204) | 53.6% (135/252) | <0.05 |
| Age < 65 | 80.4% (164/204) | 46.4% (117/252) | |
| Sex | 0.358 | ||
| Male | 48.0% (98/204) | 52.4% (132/252) | 0.397 |
| Female | 52.0% (106/204) | 47.6% (120/252) | |
| BMI | <0.05 | ||
| Mean ± Std | 31.3 ± 6.7 | 33.5 ± 9.2 | <0.05 |
| BMI ≥ 30 | 53.0% (108/204) | 58.7% (148/252) | 0.217 |
| BMI < 30 | 47.0% (96/204) | 40.9% (103/252) | |
| PH Subgroups * | |||
| Combined Pre- & Post-Capillary | 51 (20.2%) | ||
| Isolated Post-Capillary | 65 (25.8%) | ||
| Pre-Capillary | 40 (15.9%) |
| Status | Females | Males | Total | Threshold |
|---|---|---|---|---|
| Positive | 41 | 42 | 83 | mPaP ≥ 21 |
| Negative | 39 | 39 | 78 | mPaP ≤ 16 |
| Subgroup | Size | ROC-AUC (95% CI) | Sensitivity (95% CI) | Specificity (95% CI) |
|---|---|---|---|---|
| All Subjects | 413 | 0.93 (0.91–0.95) | 87% (84–90%) | 83% (79–87%) |
| Sex | ||||
| Males | 187 | 0.95 (0.92–0.98) | 89% (86–93%) | 87% (82–92%) |
| Females | 226 | 0.90 (0.86–0.94) | 85% (80–90%) | 80% (75–85%) |
| Age | ||||
| ≥65 | 162 | 0.89 (0.84–0.94) | 84% (78–90%) | 78% (72–84%) |
| <65 | 251 | 0.94 (0.91–0.97) | 91% (87–95%) | 84% (79–89%) |
| BMI | ||||
| ≥30 * | 233 | 0.90 (0.86–0.94) | 82% (77–87%) | 80% (75–85%) |
| <30 * | 179 | 0.96 (0.93–0.99) | 93% (89–97%) | 86% (81–91%) |
| PH Groups | ||||
| Combined Pre- & Post-capillary ** | 51 | 0.94 (0.87–1.00) | 86% (76–96%) | 83% (73–93%) |
| (Isolated) Post-capillary ** | 65 | 0.92 (0.85–0.99) | 88% (80–96%) | 83% (74–92%) |
| Pre-capillary ** | 40 | 0.95 (0.88–1.00) | 92% (84–100%) | 83% (71–95%) |
| Subgroup | Size | ROC-AUC (95% CI) | Sensitivity (95% CI) | Specificity (95% CI) |
|---|---|---|---|---|
| All Subjects | 488 | 0.91 (0.88–0.94) | 80% (76–84%) | 83% (80–86%) |
| Sex | ||||
| Males | 225 | 0.94 (0.91–0.97) | 83% (78–88%) | 87% (83–91%) |
| Females | 263 | 0.88 (0.84–0.92) | 78% (73–83%) | 80% (75–85%) |
| Age | ||||
| ≥65 | 205 | 0.87 (0.82–0.92) | 78% (72–84%) | 78% (72–84%) |
| <65 | 283 | 0.92 (0.89–0.95) | 83% (79–87%) | 84% (80–88%) |
| BMI | ||||
| ≥30 * | 271 | 0.89 (0.85–0.93) | 78% (73–83%) | 80% (75–85%) |
| <30 * | 216 | 0.93 (0.90–0.96) | 84% (79–89%) | 86% (81–91%) |
| PH Groups | ||||
| Combined Pre- & Post-capillary PH ** | 81 | 0.94 (0.89–0.99) | 89% (82–96%) | 83% (75–91%) |
| (Isolated) Post-capillary PH ** | 45 | 0.89 (0.80–0.98) | 76% (64–88%) | 83% (72–94%) |
| Pre-capillary PH ** | 74 | 0.94 (0.89–0.99) | 88% (81–95%) | 83% (74–92%) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nemati, N.; Burton, T.; Fathieh, F.; Gillins, H.R.; Shadforth, I.; Ramchandani, S.; Bridges, C.R. Pulmonary Hypertension Detection Non-Invasively at Point-of-Care Using a Machine-Learned Algorithm. Diagnostics 2024, 14, 897. https://doi.org/10.3390/diagnostics14090897
Nemati N, Burton T, Fathieh F, Gillins HR, Shadforth I, Ramchandani S, Bridges CR. Pulmonary Hypertension Detection Non-Invasively at Point-of-Care Using a Machine-Learned Algorithm. Diagnostics. 2024; 14(9):897. https://doi.org/10.3390/diagnostics14090897
Chicago/Turabian StyleNemati, Navid, Timothy Burton, Farhad Fathieh, Horace R. Gillins, Ian Shadforth, Shyam Ramchandani, and Charles R. Bridges. 2024. "Pulmonary Hypertension Detection Non-Invasively at Point-of-Care Using a Machine-Learned Algorithm" Diagnostics 14, no. 9: 897. https://doi.org/10.3390/diagnostics14090897
APA StyleNemati, N., Burton, T., Fathieh, F., Gillins, H. R., Shadforth, I., Ramchandani, S., & Bridges, C. R. (2024). Pulmonary Hypertension Detection Non-Invasively at Point-of-Care Using a Machine-Learned Algorithm. Diagnostics, 14(9), 897. https://doi.org/10.3390/diagnostics14090897