
Sepsis Trajectory Prediction Using Privileged Information and Continuous Physiological Signals



Abstract
1. Introduction
2. Methods
2.1. Machine Learning
2.1.1. Support Vector Machine
2.1.2. Learning Using Privileged Information
2.2. Dataset
2.2.1. Cohort 1
2.2.2. Cohort 2
2.3. Signal Processing
2.3.1. Electrocardiogram Preprocessing
2.3.2. Feature Extraction in the Regular Space
2.3.3. Feature Extraction in the Privileged Space
3. Results
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| SOFA | Sequential Organ Failure Assessment |
| qSOFA | quick-SOFA |
| GCS | Glasgow Coma Scale |
| ICU | Intensive Care Unit |
| ECG | Electrocardiogram |
| EHR | Electronic Health Record |
| PI | Privileged Information |
| SVM | Support Vector Machine |
| AUROC | Area Under Receiver Operating Characteristic Curve |
| AUPRC | Area Under Precision-Recall Curve |
| LUPI | Learning Using Privileged Information |
| TS | Taut String |
| SD | Standard Deviation |
Appendix A

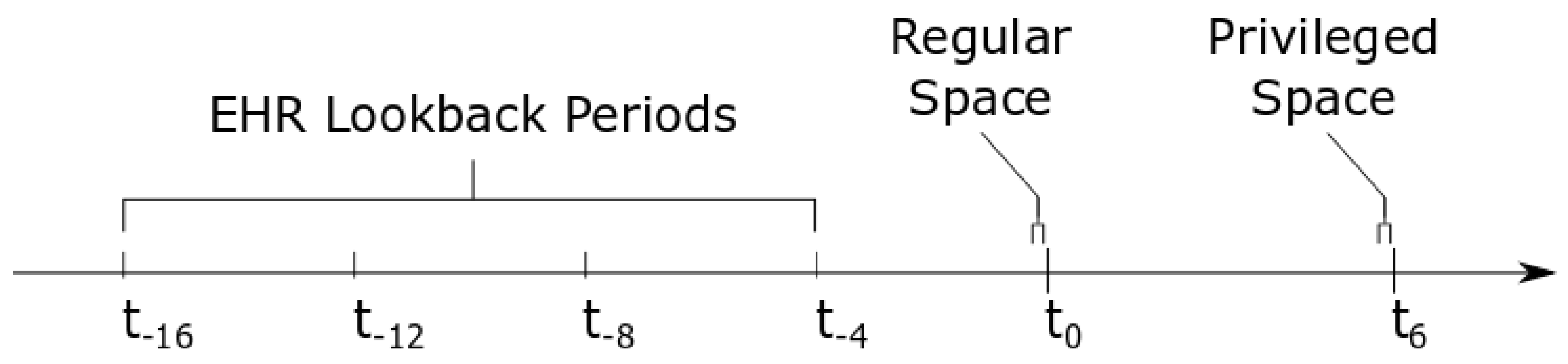
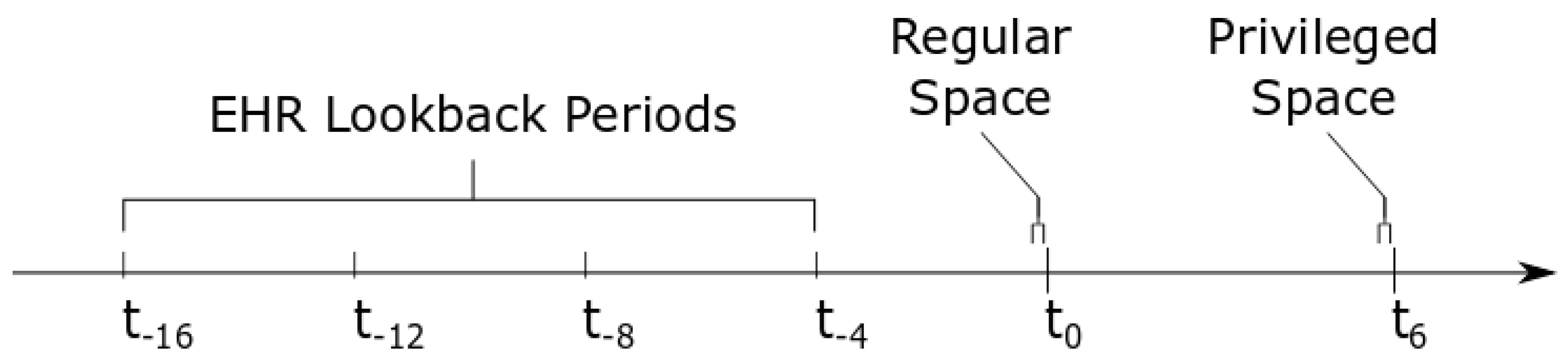{kind=link}
| Characteristic * | Full Cohort (N = 1803) | Cohort 1 (N = 105) | Cohort 2 (N = 434) | |
|---|---|---|---|---|
| Age, Mean (SD) | 58.9 (17.9) | 56.6 (17.2) | 56.2 (18.9) | |
| Sex, Female/Male | 866/937 | 48/57 | 221/213 | |
| Race and Ethnicity | Asian | 20 | 1 | 9 |
| Black or African-American | 198 | 13 | 54 | |
| Hispanic or Latine | 28 | 0 | 6 | |
| White | 1520 | 88 | 352 | |
| Other | 65 | 3 | 19 |
Appendix B
| Medication | 1 | 2 | 3 |
|---|---|---|---|
| Dobutamine | None Given | ≤2.0 g/kg/min | >2.0 g/kg/min |
| Dopamine | None Given | ≤2.5 g/kg/min | >2.5 g/kg/min |
| Epinephrine | None Given | ≤0.02 g/kg/min | >0.02 g/kg/min |
| Isoproterenol | None Given | ≤2.0 g/kg/min | >2.0 g/kg/min |
| Milrinone | None Given | ≤0.25 g/kg/min | >0.25 g/kg/min |
| Norepinephrine | None Given | ≤0.1 g/kg/min | >0.1 g/kg/min |
| Vasopressin | None Given | ≤2.0 g/kg/min | >2.0 g/kg/min |
Appendix C
| Lab Value | 1 | 2 | 3 | 4 | Unit |
|---|---|---|---|---|---|
| Creatinine, F | [0.5, 1.0] | <0.5 | (1.0, 2.0] | >2.0 | mg/dL |
| Creatinine, M | [0.7, 1.3] | <0.7 | (1.3, 2.0] | >2.0 | mg/dL |
| Glucose | [70, 180] | [40, 70) | >180 | <40 | mg/dL |
| Hematocrit, F | [36, 49) | ≥ 49 | [22, 36) | <22 | % |
| Hematocrit, M | [40, 51) | ≥ 51 | [22, 40) | <22 | % |
| Hemoglobin, F | (11.9, 16.0] | >16.0 | [7.0, 11.9] | <7.0 | g/dL |
| Hemoglobin, M | (13.4, 17.0] | >17.0 | [7.0, 13.4] | <7.0 | g/dL |
| INR * | [0.9, 1.2] | <0.9 | (1.2, 2.0] | >2.0 | |
| Lactate, Arterial | [0.5, 1.6] | <0.5 | (1.6, 4.0] | >4.0 | mmol/L |
| Lactate, Venous | [0.5, 2.2] | <0.5 | (2.2, 4.0] | >4.0 | mmol/L |
| Platelet Count | [150, 400] | >400 | [50, 150) | <50 | /L |
| Potassium | [3.5, 5.0] | (5.0, 6.0] | <3.5 | >6.0 | mmol/L |
| Sodium | [136, 146] | <136 | (146, 155] | >155 | mmol/L |
| WBC ** | [4, 10] | <4 | (10, 20] | >20 | /L |
Appendix D
References
- Singer, M.; Deutschman, C.S.; Seymour, C.W.; Shankar-Hari, M.; Annane, D.; Bauer, M.; Bellomo, R.; Bernard, G.R.; Chiche, J.D.; Coopersmith, C.M.; et al. The Third International Consensus Definitions for Sepsis and Septic Shock (Sepsis-3). JAMA 2016, 315, 801–810. [Google Scholar] [CrossRef] [PubMed]
- Paoli, C.J.; Reynolds, M.A.; Sinha, M.; Gitlin, M.; Crouser, E. Epidemiology and Costs of Sepsis in the United States-An Analysis Based on Timing of Diagnosis and Severity Level. Crit. Care Med. 2018, 46, 1889–1897. [Google Scholar] [CrossRef] [PubMed]
- Seymour, C.W.; Liu, V.X.; Iwashyna, T.J.; Brunkhorst, F.M.; Rea, T.D.; Scherag, A.; Rubenfeld, G.; Kahn, J.M.; Shankar-Hari, M.; Singer, M.; et al. Assessment of Clinical Criteria for Sepsis: For the Third International Consensus Definitions for Sepsis and Septic Shock (Sepsis-3). JAMA 2016, 315, 762. [Google Scholar] [CrossRef] [PubMed]
- Evans, L.; Rhodes, A.; Alhazzani, W.; Antonelli, M.; Coopersmith, C.M.; French, C.; Machado, F.R.; Mcintyre, L.; Ostermann, M.; Prescott, H.C.; et al. Surviving Sepsis Campaign: International Guidelines for Management of Sepsis and Septic Shock 2021. Crit. Care Med. 2021, 49, e1063–e1143. [Google Scholar] [CrossRef] [PubMed]
- Alge, O.P.; Pickard, J.; Zhang, W.; Cheng, S.; Derksen, H.; Omenn, G.S.; Gryak, J.; VanEpps, J.S.; Najarian, K. Continuous Sepsis Trajectory Prediction using Tensor-Reduced Physiological Signals. Sci. Rep. 2021; in review. [Google Scholar]
- Sabeti, E.; Drews, J.; Reamaroon, N.; Gryak, J.; Sjoding, M.; Najarian, K. Detection of Acute Respiratory Distress Syndrome by Incorporation of Label Uncertainty and Partially Available Privileged Information. In Proceedings of the 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 23–27 July 2019; pp. 1717–1720. [Google Scholar] [CrossRef]
- Sabeti, E.; Drews, J.; Reamaroon, N.; Warner, E.; Sjoding, M.W.; Gryak, J.; Najarian, K. Learning Using Partially Available Privileged Information and Label Uncertainty: Application in Detection of Acute Respiratory Distress Syndrome. IEEE J. Biomed. Health Inform. 2021, 25, 784–796. [Google Scholar] [CrossRef] [PubMed]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Fan, R.E.; Chen, P.H.; Lin, C.J. Working Set Selection Using Second Order Information for Training Support Vector Machines. J. Mach. Learn. Res. 2005, 6, 1889–1918. [Google Scholar]
- Li, W.; Dai, D.; Tan, M.; Xu, D.; Van Gool, L. Fast Algorithms for Linear and Kernel SVM+. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2258–2266. [Google Scholar] [CrossRef]
- Vapnik, V.; Vashist, A. A new learning paradigm: Learning using privileged information. Neural Netw. 2009, 22, 544–557. [Google Scholar] [CrossRef] [PubMed]
- Pierre, L.; Pasrija, D.; Keenaghan, M. Arterial Lines. In StatPearls; StatPearls Publishing: Treasure Island, FL, USA, 2023. [Google Scholar]
- Hernandez, L.; Kim, R.; Tokcan, N.; Derksen, H.; Biesterveld, B.E.; Croteau, A.; Williams, A.M.; Mathis, M.; Najarian, K.; Gryak, J. Multimodal tensor-based method for integrative and continuous patient monitoring during postoperative cardiac care. Artif. Intell. Med. 2021, 113, 102032. [Google Scholar] [CrossRef] [PubMed]
- Kim, R.B.; Alge, O.P.; Liu, G.; Biesterveld, B.E.; Wakam, G.; Williams, A.M.; Mathis, M.R.; Najarian, K.; Gryak, J. Prediction of postoperative cardiac events in multiple surgical cohorts using a multimodal and integrative decision support system. Sci. Rep. 2022, 12, 11347. [Google Scholar] [CrossRef] [PubMed]
- Davies, P.L.; Kovac, A. Local Extremes, Runs, Strings and Multiresolution. Ann. Stat. 2001, 29, 1–65. [Google Scholar] [CrossRef]
- Belle, A.; Ansari, S.; Spadafore, M.; Convertino, V.A.; Ward, K.R.; Derksen, H.; Najarian, K. A Signal Processing Approach for Detection of Hemodynamic Instability before Decompensation. PLoS ONE 2016, 11, e0148544. [Google Scholar] [CrossRef] [PubMed]
| Group | Feature | Time(s) Collected | Type |
|---|---|---|---|
| Taut String ECG Features | Number of Line Segments, | Numerical | |
| Number of Inflection Segments, | |||
| Total Variation of Noise, | |||
| Total Variation of Denoised Signal, | |||
| Power of Noise, | |||
| Power of Denoised Signal | |||
| EHR Vital Signs | Temperature, | , , , , | Numerical |
| SpO2, | |||
| Heart Rate, | |||
| Mean Arterial Pressure, | |||
| Respiratory Rate | |||
| EHR Fluid Output | Urine Output | , , , , | Numerical |
| EHR Lab Values | Creatinine, | , , , , | Ordinal |
| Glucose, | |||
| Hematocrit, | |||
| Hemoglobin, | |||
| INR *, | |||
| Lactate, | |||
| Platelet Count, | |||
| Potassium, | |||
| Sodium, | |||
| WBC ** | |||
| EHR CVIs *** | Dobutamine, | , , , , | Ordinal |
| Dopamine, | |||
| Epinephrine, | |||
| Isoproterenol, | |||
| Milrinone, | |||
| Norepinephrine, | |||
| Vasopressin |
| Group | Feature | Time(s) Collected | Type |
|---|---|---|---|
| Taut String ECG Features | Number of Line Segments, | Numerical | |
| Number of Inflection Segments, | |||
| Total Variation of Noise, | |||
| Total Variation of Denoised Signal, | |||
| Power of Noise, | |||
| Power of Denoised Signal | |||
| Statistical ECG Features | Mean, | Numerical | |
| Median, | |||
| Variance, | |||
| Kurtosis, | |||
| Skewness, | |||
| Shannon Entropy, | |||
| Absolute Value of FFT | |||
| EHR Vital Signs | Temperature, | Numerical | |
| SpO2, | |||
| Heart Rate, | |||
| Mean Arterial Pressure, | |||
| Respiratory Rate | |||
| EHR Fluid Output | Urine Output | Numerical | |
| EHR Lab Values | Creatinine, | Ordinal | |
| Glucose, | |||
| Hematocrit, | |||
| Hemoglobin, | |||
| INR *, | |||
| Lactate, | |||
| Platelet Count, | |||
| Potassium, | |||
| Sodium, | |||
| WBC ** | |||
| EHR CVIs *** | Dobutamine, | Ordinal | |
| Dopamine, | |||
| Epinephrine, | |||
| Isoproterenol, | |||
| Milrinone, | |||
| Norepinephrine, | |||
| Vasopressin |
| PI Type | F1 Score | Sensitivity | Specificity | AUROC | AUPRC |
|---|---|---|---|---|---|
| None | 0.71 (0.10) | 0.71 (0.16) | 0.65 (0.17) | 0.65 (0.13) | 0.66 (0.10) |
| TS-ECG | 0.70 (0.11) | 0.69 (0.16) | 0.69 (0.14) | 0.68 (0.12) | 0.68 (0.10) |
| SF-ECG | 0.70 (0.10) | 0.68 (0.15) | 0.68 (0.15) | 0.65 (0.12) | 0.67 (0.12) |
| EHR | 0.70 (0.12) | 0.70 (0.18) | 0.66 (0.15) | 0.65 (0.13) | 0.66 (0.11) |
| PI Type | F1 Score | Sensitivity | Specificity | AUROC | AUPRC |
|---|---|---|---|---|---|
| None | 0.51 (0.06) | 0.62 (0.10) | 0.63 (0.10) | 0.62 (0.07) | 0.42 (0.07) |
| TS-ECG | 0.48 (0.06) | 0.60 (0.11) | 0.59 (0.10) | 0.58 (0.07) | 0.39 (0.07) |
| SF-ECG | 0.50 (0.06) | 0.62 (0.10) | 0.58 (0.10) | 0.59 (0.07) | 0.39 (0.06) |
| EHR | 0.51 (0.07) | 0.64 (0.10) | 0.59 (0.09) | 0.61 (0.08) | 0.40 (0.08) |
| PI Type | F1 Score | Sensitivity | Specificity | AUROC | AUPRC |
|---|---|---|---|---|---|
| None | 0.69 (0.09) | 0.66 (0.13) | 0.71 (0.14) | 0.65 (0.11) | 0.66 (0.10) |
| TS-ECG | 0.69 (0.10) | 0.67 (0.15) | 0.70 (0.14) | 0.64 (0.12) | 0.65 (0.09) |
| SF-ECG | 0.68 (0.10) | 0.67 (0.15) | 0.67 (0.14) | 0.62 (0.12) | 0.65 (0.10) |
| EHR | 0.68 (0.11) | 0.66 (0.16) | 0.69 (0.16) | 0.63 (0.13) | 0.65 (0.10) |
| PI Type | F1 Score | Sensitivity | Specificity | AUROC | AUPRC |
|---|---|---|---|---|---|
| None | 0.60 (0.06) | 0.70 (0.09) | 0.69 (0.09) | 0.72 (0.05) | 0.54 (0.08) |
| TS-ECG | 0.58 (0.05) | 0.70 (0.09) | 0.67 (0.08) | 0.70 (0.06) | 0.50 (0.08) |
| SF-ECG | 0.58 (0.05) | 0.69 (0.08) | 0.68 (0.08) | 0.71 (0.05) | 0.51 (0.07) |
| EHR | 0.59 (0.05) | 0.70 (0.09) | 0.69 (0.08) | 0.72 (0.05) | 0.53 (0.06) |
| PI Type | F1 Score | Sensitivity | Specificity | AUROC | AUPRC |
|---|---|---|---|---|---|
| None | 0.59 (0.15) | 0.59 (0.21) | 0.61 (0.18) | 0.51 (0.13) | 0.55 (0.10) |
| TS-ECG | 0.59 (0.13) | 0.59 (0.19) | 0.58 (0.17) | 0.49 (0.12) | 0.54 (0.09) |
| SF-ECG | 0.62 (0.11) | 0.61 (0.17) | 0.60 (0.17) | 0.51 (0.12) | 0.56 (0.09) |
| EHR | 0.62 (0.12) | 0.59 (0.17) | 0.64 (0.17) | 0.54 (0.12) | 0.58 (0.09) |
| PI Type | F1 Score | Sensitivity | Specificity | AUROC | AUPRC |
|---|---|---|---|---|---|
| None | 0.59 (0.06) | 0.68 (0.09) | 0.71 (0.10) | 0.71 (0.06) | 0.55 (0.09) |
| TS-ECG | 0.55 (0.06) | 0.67 (0.10) | 0.65 (0.09) | 0.67 (0.07) | 0.47 (0.07) |
| SF-ECG | 0.56 (0.06) | 0.68 (0.09) | 0.66 (0.07) | 0.68 (0.06) | 0.49 (0.08) |
| EHR | 0.57 (0.06) | 0.66 (0.09) | 0.68 (0.10) | 0.68 (0.06) | 0.51 (0.08) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alge, O.P.; Gryak, J.; VanEpps, J.S.; Najarian, K. Sepsis Trajectory Prediction Using Privileged Information and Continuous Physiological Signals. Diagnostics 2024, 14, 234. https://doi.org/10.3390/diagnostics14030234
Alge OP, Gryak J, VanEpps JS, Najarian K. Sepsis Trajectory Prediction Using Privileged Information and Continuous Physiological Signals. Diagnostics. 2024; 14(3):234. https://doi.org/10.3390/diagnostics14030234
Chicago/Turabian StyleAlge, Olivia P., Jonathan Gryak, J. Scott VanEpps, and Kayvan Najarian. 2024. "Sepsis Trajectory Prediction Using Privileged Information and Continuous Physiological Signals" Diagnostics 14, no. 3: 234. https://doi.org/10.3390/diagnostics14030234
APA StyleAlge, O. P., Gryak, J., VanEpps, J. S., & Najarian, K. (2024). Sepsis Trajectory Prediction Using Privileged Information and Continuous Physiological Signals. Diagnostics, 14(3), 234. https://doi.org/10.3390/diagnostics14030234