
Channel and Spatial Attention in Chest X-Ray Radiographs: Advancing Person Identification and Verification with Self-Residual Attention Network




Abstract
1. Introduction
- Advancements in Biometrics: This work demonstrates the potential of chest X-rays as a reliable biometric modality, enhancing the scope and precision of biometric identification in medical imaging.
- Development of a Biometric System: A novel system is proposed for human identification and verification using chest X-ray radiographs, leveraging distinctive radiographic features.
- Innovative Use of Siamese Networks: A novel approach utilizing Siamese networks is introduced, enabling the learning of highly discriminative features by comparing and contrasting pairs of images.
- Enhanced Discriminative Power with Triplet Loss: The incorporation of triplet loss further improves the model’s discriminative capability, driving the network to learn a feature space that maximizes the dissimilarity between different individuals.
- Establishing a New Benchmark: A new standard is established for person identification in chest X-ray imaging, setting a benchmark for future research in this area.
- Introduction of the Self-Residual Attention Network (SRAN): The paper introduces the SRAN architecture for chest X-ray image analysis, advancing the field with this attention-based approach.
2. Related Works
3. Materials and Methods
3.1. Datasets
3.1.1. NIH ChestX-ray14 Dataset
3.1.2. CheXpert Dataset
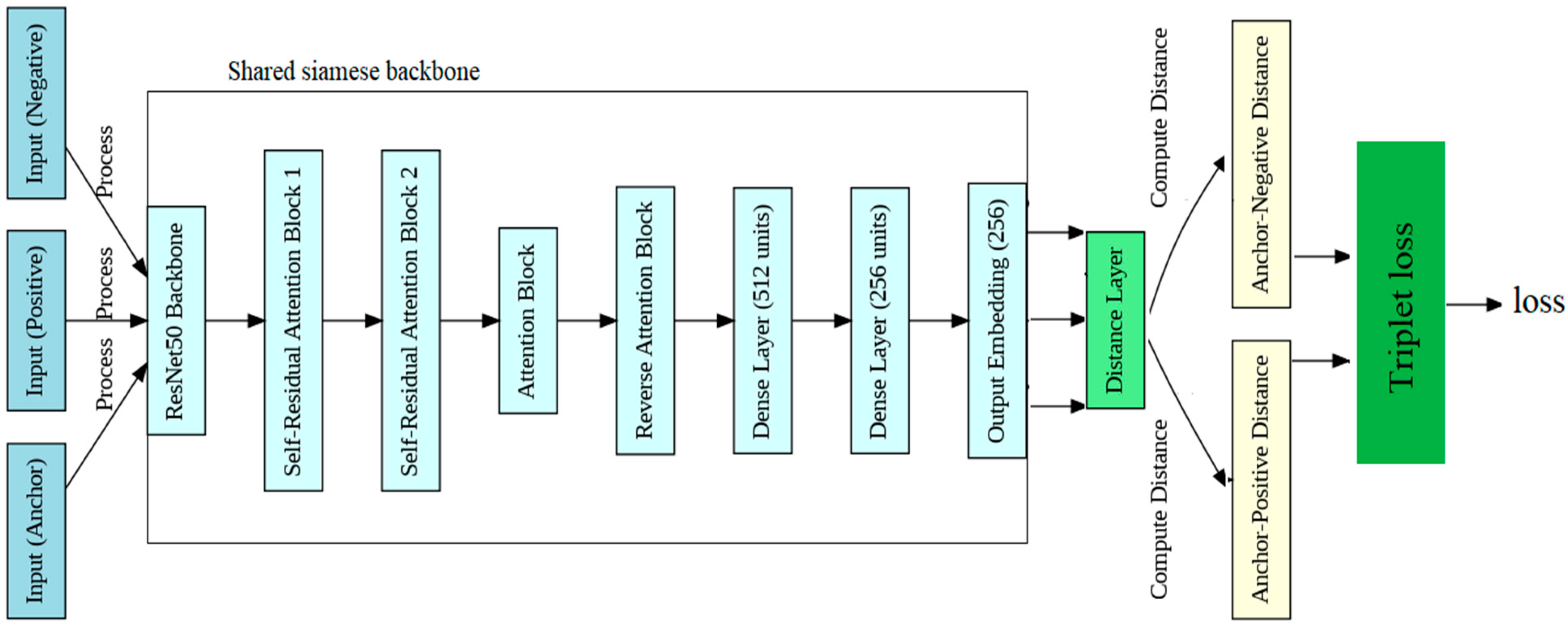
3.2. Proposed Method
3.2.1. Training Phase
ResNet50
Self-Residual Attention Block (SRAB)
- a.
- Channel Attention
- Global average pooling (GAP):
- Global max pooling (GMP):
- b.
- Spatial Attention
- Average pooling across channels:
- Max pooling across channels:
- c.
- Residual Connection:
Attention Block
- a.
- Channel Attention
- b.
- Spatial Attention
Reverse Attention Block
Reverse Channel Attention
Distance Layer
Triplet Loss
Data Preparation
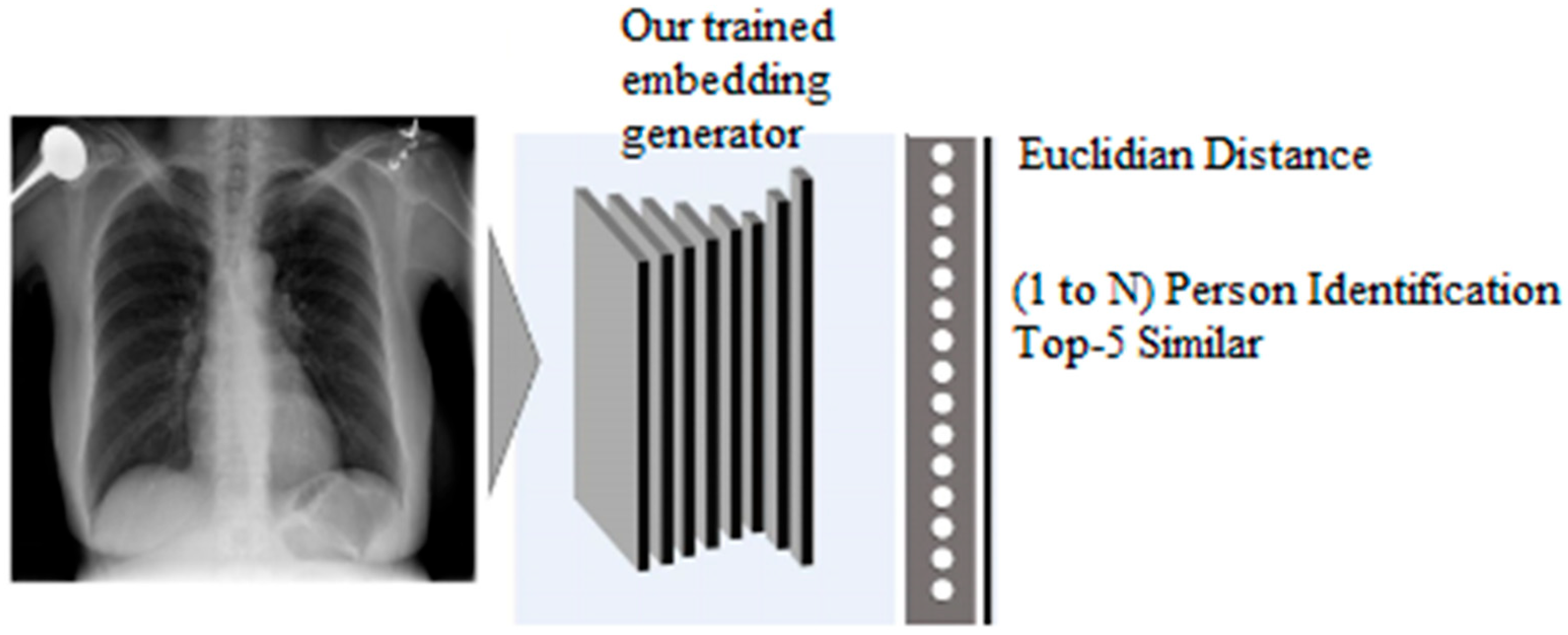
3.2.2. Testing Phase
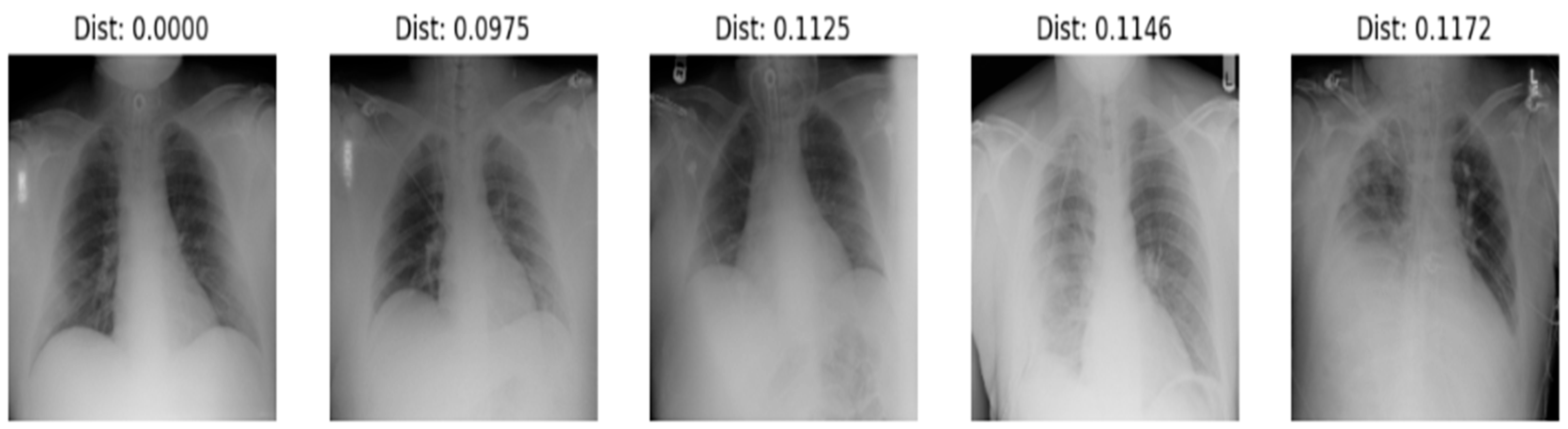
Identification
Verification
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Morishita, J.; Ueda, Y. New solutions for automated image recognition and identification: Challenges to radiologic technology and forensic pathology. Radiol. Phys. Technol. 2021, 14, 123–133. [Google Scholar] [CrossRef] [PubMed]
- Bennour, A.; Djeddi, C.; Gattal, A.; Siddiqi, I.; Mekhaznia, T. Handwriting based writer recognition using implicit shape codebook. Forensic Sci. Int. 2019, 301, 91–100. [Google Scholar] [CrossRef] [PubMed]
- Bennour, A. Automatic Handwriting Analysis for Writer Identification and Verification. In Proceedings of the 7th International Conference on Software Engineering and New Technologies, Hammamet, Tunisia, 26–28 December 2018; pp. 1–7. [Google Scholar]
- Raho, G.I.; Al-Ani, M.S.; Al-Alosi, A.A.K.; Mohammed, L.A. Signature recognition using discrete Fourier transform. Intl. J. Bus. ICT 2015, 1, 17–24. [Google Scholar]
- Thomas, P.A.; Preetha Mathew, K. A broad review on non-intrusive active user authentication in biometrics. J. Ambient. Intell. Humaniz. Comput. 2023, 14, 339–360. [Google Scholar] [CrossRef]
- Jain, A.K.; Ross, A. Bridging the gap: From biometrics to forensics. Philos. Trans. R. Soc. B Biol. Sci. 2015, 370, 20140254. [Google Scholar] [CrossRef]
- Saini, M.; Kapoor, A.K. Biometrics in forensic identification: Applications and challenges. J. Forensic Med. 2016, 1, 2. [Google Scholar] [CrossRef]
- Drahansky, M.; Dolezel, M.; Urbanek, J.; Brezinova, E.; Kim, T.H. Influence of skin diseases on fingerprint recognition. BioMed Res. Int. 2012, 2012, 626148. [Google Scholar] [CrossRef] [PubMed]
- Sarfraz, N. Adermatoglyphia: Barriers to Biometric Identification and the Need for a Standardized Alternative. Cureus 2019, 11, e4040. [Google Scholar] [CrossRef] [PubMed] [PubMed Central]
- Wells, J.D.; Linville, J.G. Biology/DNA/Entomology: Overview. Encycl. Forensic Sci. 2013, 387–393.–393. [Google Scholar]
- Emergency Care Research Institute: Patient Identification Errors. 2016. Available online: https://www.ecri.org/Resources/HIT/Patient%20ID/Patient_Identification_Evidence_Based_Literature_final.pdf (accessed on 28 September 2021).
- Morishita, J.; Katsuragawa, S.; Kondo, K.; Doi, K. An automated patient recognition method based on an image-matching technique using previous chest radiographs in the picture archiving and communication system environment. Med. Phys. 2001, 28, 1093–1097. [Google Scholar] [CrossRef] [PubMed]
- Danaher, L.A.; Howells, J.; Holmes, P.; Scally, P. Is it possible to eliminate patient identification errors in medical imaging? J. Am. Coll. Radiol. 2011, 8, 568–574. [Google Scholar] [CrossRef] [PubMed]
- Morishita, J.; Watanabe, H.; Katsuragawa, S.; Oda, N.; Sukenobu, Y.; Okazaki, H.; Nakata, H.; Doi, K. Investigation of misfiled cases in the PACS environment and a solution to prevent filing errors for chest radiographs1. Acad. Radiol. 2005, 12, 97–103. [Google Scholar] [CrossRef] [PubMed]
- Ueda, Y.; Morishita, J.; Kudomi, S.; Ueda, K. Usefulness of biological fingerprint in magnetic resonance imaging for patient verification. Med. Biol. Eng. Comput. 2016, 54, 1341–1351. [Google Scholar] [CrossRef] [PubMed]
- Murphy, W.A.; Spruill, F.G.; Gantner, G.E. Radiologic identification of unknown human remains. J. Forensic Sci. 1980, 25, 727–735. [Google Scholar] [CrossRef] [PubMed]
- Isa, M.I.; Hefner, J.T.; Markey, M.A. Application of the Stephan et al. Chest Radiograph Comparison Method to Decomposed Human Remains. J. Forensic Sci. 2017, 62, 1304–1307. [Google Scholar] [CrossRef]
- Strauch, H.; Wirth, I.; Reisinger, W. Human identification by comparison if skull roentgen image. Arch. Kriminol. 2002, 210, 101–111. [Google Scholar]
- Cho, H.; Zin, T.T.; Shinkawa, N.; Nishii, R.; Hama, H. Automatic Postmortem Human Identification using Collarbone of X-ray and CT Scan Images. In Proceedings of the 2018 IEEE 7th Global Conference on Consumer Electronics (GCCE), Nara, Japan, 9–12 October 2018; pp. 551–552. [Google Scholar]
- Singh, H. 101 Chest X-Ray Solutions; Jaypee Brothers Medical: New Delhi, India, 2013. [Google Scholar]
- Le-Phan, A.; Nguyen, X.P.-P.; Ly-Tu, N. Training Siamese Neural Network Using Triplet Loss with Augmented Facial Alignment Dataset. In Proceedings of the 2022 9th NAFOSTED Conference on Information and Computer Science (NICS), Ho Chi Minh, Vietnam, 31 October–1 November 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 281–286. [Google Scholar]
- Hazem, F.; Akram, B.; Mekhaznia, T.; Ghabban, F.; Alsaeedi, A.; Goyal, B. Beyond Traditional Biometrics: Harnessing Chest X-Ray Features for Robust Person Identification. Acta Inform. Pragensia 2024, 13, 234–250. [Google Scholar] [CrossRef]
- Hazem, F.; Akram, B.; Khalaf, O.I.; Sikder, R.; Algburi, S. X-ray insights: Innovative person identification through Siamese and Triplet networks. In Proceedings of the IET Conference CP870, Patna, India, 14–15 July 2023; The Institution of Engineering and Technology: Stevenage, UK, 2023; pp. 40–49. [Google Scholar] [CrossRef]
- Ishigami, R.; Zin, T.T.; Shinkawa, N.; Nishii, R. Human identification using X-Ray image matching. In Proceedings of the International Multi Conference of Engineers and Computer Scientists, Hong Kong, China, 15–17 March 2017; Volume 1. [Google Scholar]
- Cho, H.; Zin, T.T.; Shinkawa, N.; Nishii, R. Post-mortem human identification using chest X-ray and ct scan images. Int. J. Biomed. Soft Comput. Hum. Sci. 2018, 23, 51–57. [Google Scholar]
- Packhäuser, K.; Gündel, S.; Münster, N.; Syben, C.; Christlein, V.; Maier, A. Deep learning-based patient re-identification is able to exploit the biometric nature of medical chest X-ray data. Sci. Rep. 2022, 12, 14851. [Google Scholar] [CrossRef]
- Ueda, Y.; Morishita, J. Patient Identification Based on Deep Metric Learning for Preventing Human Errors in Follow-up X-Ray Examinations. J. Digit. Imaging 2023, 36, 1941–1953. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ling, H.; Wu, J.; Wu, L.; Huang, J.; Chen, J.; Li, P. Self residual attention network for deep face recognition. IEEE Access 2019, 7, 55159–55168. [Google Scholar] [CrossRef]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Wang, X.; Tang, X. Residual attention network for image classification. arXiv 2017, arXiv:1704.06904. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. arXiv 2017, arXiv:1709.01507. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Buades, A.; Coll, B.; Morel, J.-M. A Non-Local Algorithm for Image Denoising. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20 June 2005; Volume 2, pp. 60–65. [Google Scholar]
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-attention generative adversarial networks. arXiv 2018, arXiv:1805.08318. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. arXiv 2018, arXiv:1809.02983. [Google Scholar]
- Wang, X.; Peng, Y.; Lu, L.; Lu, Z.; Bagheri, M.; Summers, R.M. Chestx-ray8: Hospital-scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2097–2106. [Google Scholar]
- Irvin, J.; Rajpurkar, P.; Ko, M.; Yu, Y.; Ciurea-Ilcus, S.; Chute, C.; Marklund, H.; Haghgoo, B.; Ball, R.; Shpanskaya, K.; et al. Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison. AAAI Conf. Artif. Intell. 2019, 33, 590–597. [Google Scholar] [CrossRef]
- Hazem, F.; Akram, B.; Mekhaznia, T.; Ghabban, F.; Alsaeedi, A.; Goyal, B. X-Ray Insights: A Siamese with CNN and Spatial Attention Network for Innovative Person Identification. In Proceedings of the Fourth International Conference on Intelligent Systems and Pattern Recognition, ISPR-2024, Istanbul, Turkey, 26–28 June 2024. in press. [Google Scholar]
- Thapar, D.; Jaswal, G.; Nigam, A.; Kanhangad, V. PVSNet: Palm Vein Authentication Siamese Network Trained Using Triplet Loss and Adaptive Hard Mining by Learning Enforced Domain Specific Features. In Proceedings of the 2019 IEEE 5th International Conference on Identity, Security, and Behavior Analysis (ISBA), Hyderabad, India, 22–24 January 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–8. [Google Scholar]
- Kumar, C.R.; Saranya, N.; Priyadharshini, M.; Gilchrist, D. Face recognition using CNN and siamese network. Measurement. Sensors 2023, 27, 100800. [Google Scholar]
- Lai, S.C.; Lam, K.M. Deep Siamese Network for Low-Resolution Face Recognition. In Proceedings of the 2021 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Tokyo, Japan, 14–17 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1444–1449. [Google Scholar]
- Kumar, K.V.; Teja, K.A.; Bhargav, R.T.; Satpute, V.; Naveen, C.; Kamble, V. One-Shot Face Recognition. In Proceedings of the 2023 2nd International Conference on Paradigm Shifts in Communications Embedded Systems, Machine Learning and Signal Processing (PCEMS), Nagpur, India, 5–6 April 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–6. [Google Scholar]
- Wu, D.; Wang, C.; Wu, Y.; Wang, Q.C.; Huang, D.S. Attention deep model with multi-scale deep supervision for person re-identification. IEEE Trans. Emerg. Top. Comput. Intell. 2021, 5, 70–78. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Task | Accuracy (NIH Dataset) | Accuracy (CheXpert Dataset) |
|---|---|---|---|
| Identification | 98.3 | 96.1 | |
| Our trainable model | Verification | 91 | 90.8 |
| Identification | 56 | 61.2 | |
| The same architecture without training | Verification | 59 | 57 |
| Work | Application | Modality Used | Method | Dataset | Accuracy |
|---|---|---|---|---|---|
| [24] | Person identification | Chest X-ray | HOG BOW classifier Euclidean distance | collected from data stored in the database of Miyazaki University School of Medicine | 44.4 to 63.0 |
| [25] | Person identification | Chest X-ray | CLAHE Two-dimensional discrete Fourier transform (DFT) | collected from data stored in the database of Miyazaki University School of Medicine | 74.07 |
| [26] | Person reidentification | Chest X-ray | Siamese NN Contrastive loss ResNet50 | ChestX-ray8 dataset | 95.55 |
| [27] | Person identification | Chest X-ray | EfficientNet Cosine distance | NIH ChestX-ray14 dataset | 83.0 |
| [22] | Person identification | Chest X-ray | Siamese NN Triplet loss Transfer learning | NIH ChestX-ray14 dataset | 97 |
| [40] | Palm vein detection | Palm | Siamese network with triplet loss CED, adaptive margin-based hard negative mining Generative domain-specific features | ------ | ------ |
| [41] | Facial detection | Face | CNN for key point extraction KNN for classification Siamese network and triplet loss | ------ | ------ |
| [42] | Face recognition | Face | Triplet loss Deep Siamese network K-way face recognition network | LFW dataset | 94.8 |
| [43] | Face recognition | Face | Deep Siamese network Triplet loss | ------ | 91 |
| [44] | Face recognition | Face | Attention feature learning ResNet50 Triplet loss | Market-1501 dataset | 95.5 |
| [29] | Face recognition | Face | Self-residual attention N | CASIA-WebFace and MS-Celeb-1M | 98.3 |
| Our | Person identification | Chest X-ray | Siamese NN Self-residual attention N Triplet loss | ChestXray14 dataset and CheXpert | 98 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Farah, H.; Bennour, A.; Kurdi, N.A.; Hammami, S.; Al-Sarem, M. Channel and Spatial Attention in Chest X-Ray Radiographs: Advancing Person Identification and Verification with Self-Residual Attention Network. Diagnostics 2024, 14, 2655. https://doi.org/10.3390/diagnostics14232655
Farah H, Bennour A, Kurdi NA, Hammami S, Al-Sarem M. Channel and Spatial Attention in Chest X-Ray Radiographs: Advancing Person Identification and Verification with Self-Residual Attention Network. Diagnostics. 2024; 14(23):2655. https://doi.org/10.3390/diagnostics14232655
Chicago/Turabian StyleFarah, Hazem, Akram Bennour, Neesrin Ali Kurdi, Samir Hammami, and Mohammed Al-Sarem. 2024. "Channel and Spatial Attention in Chest X-Ray Radiographs: Advancing Person Identification and Verification with Self-Residual Attention Network" Diagnostics 14, no. 23: 2655. https://doi.org/10.3390/diagnostics14232655
APA StyleFarah, H., Bennour, A., Kurdi, N. A., Hammami, S., & Al-Sarem, M. (2024). Channel and Spatial Attention in Chest X-Ray Radiographs: Advancing Person Identification and Verification with Self-Residual Attention Network. Diagnostics, 14(23), 2655. https://doi.org/10.3390/diagnostics14232655