
Improving the Generalizability and Performance of an Ultrasound Deep Learning Model Using Limited Multicenter Data for Lung Sliding Artifact Identification

 , , , , , , , ,
, , , , , , , ,
Abstract
1. Introduction
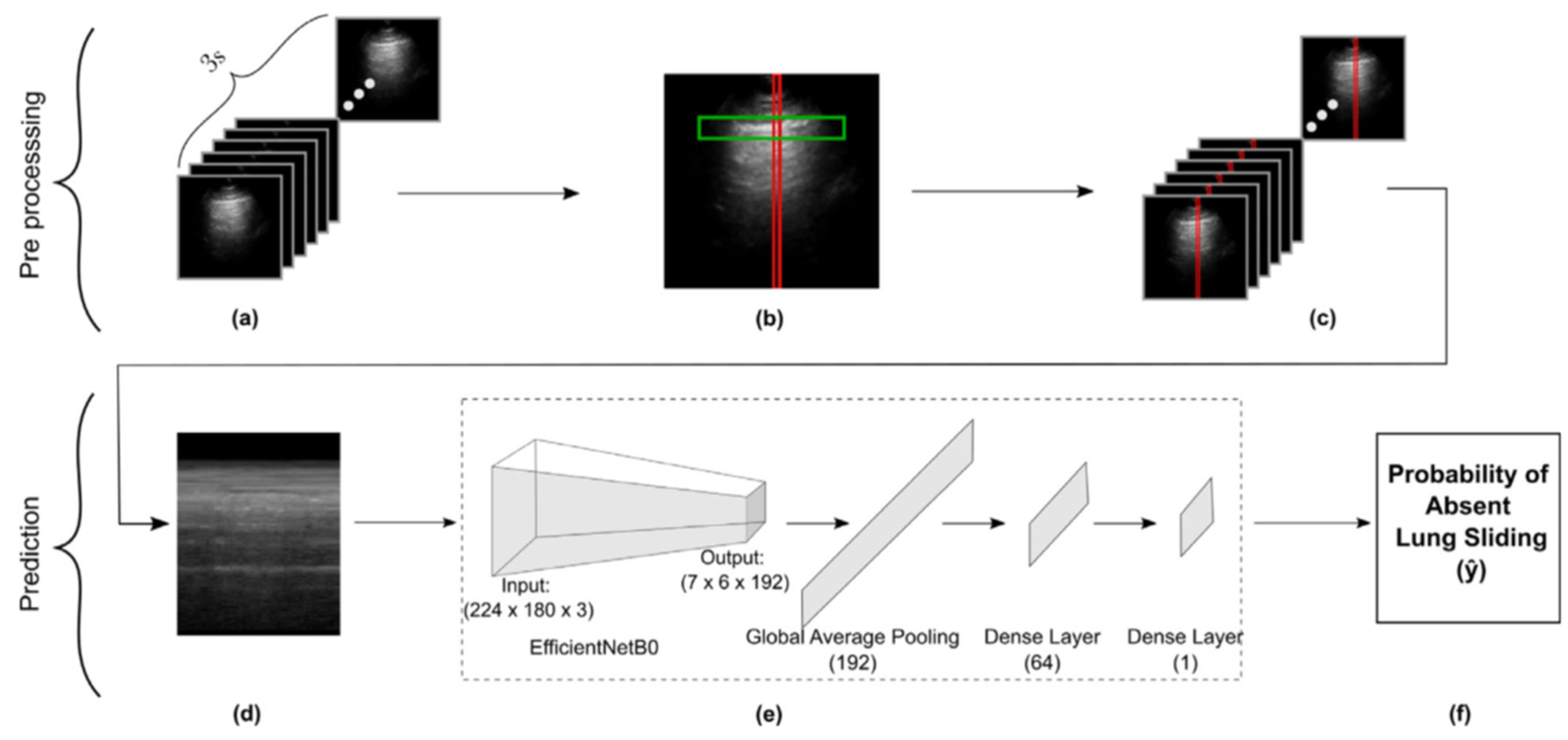
2. Materials and Methods
2.1. Dataset Description and Preparation
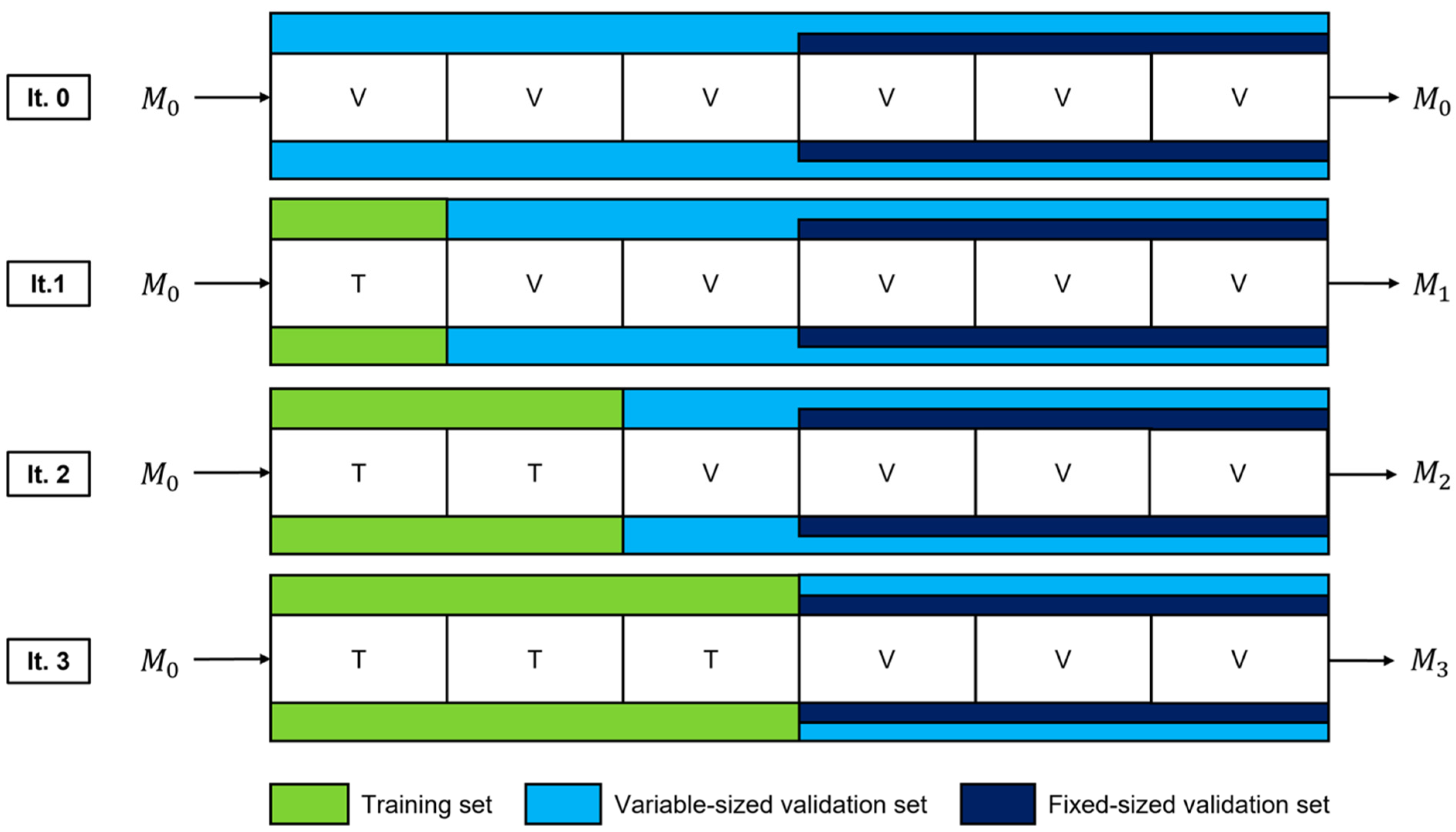
2.2. Model Fine-Tuning
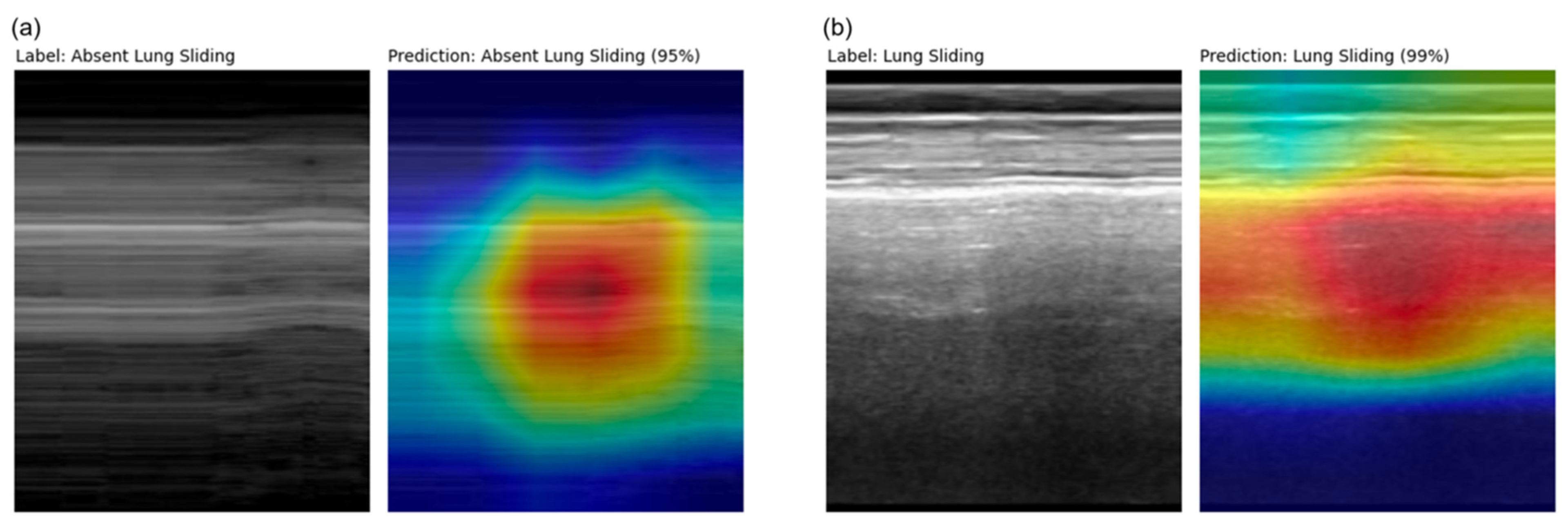
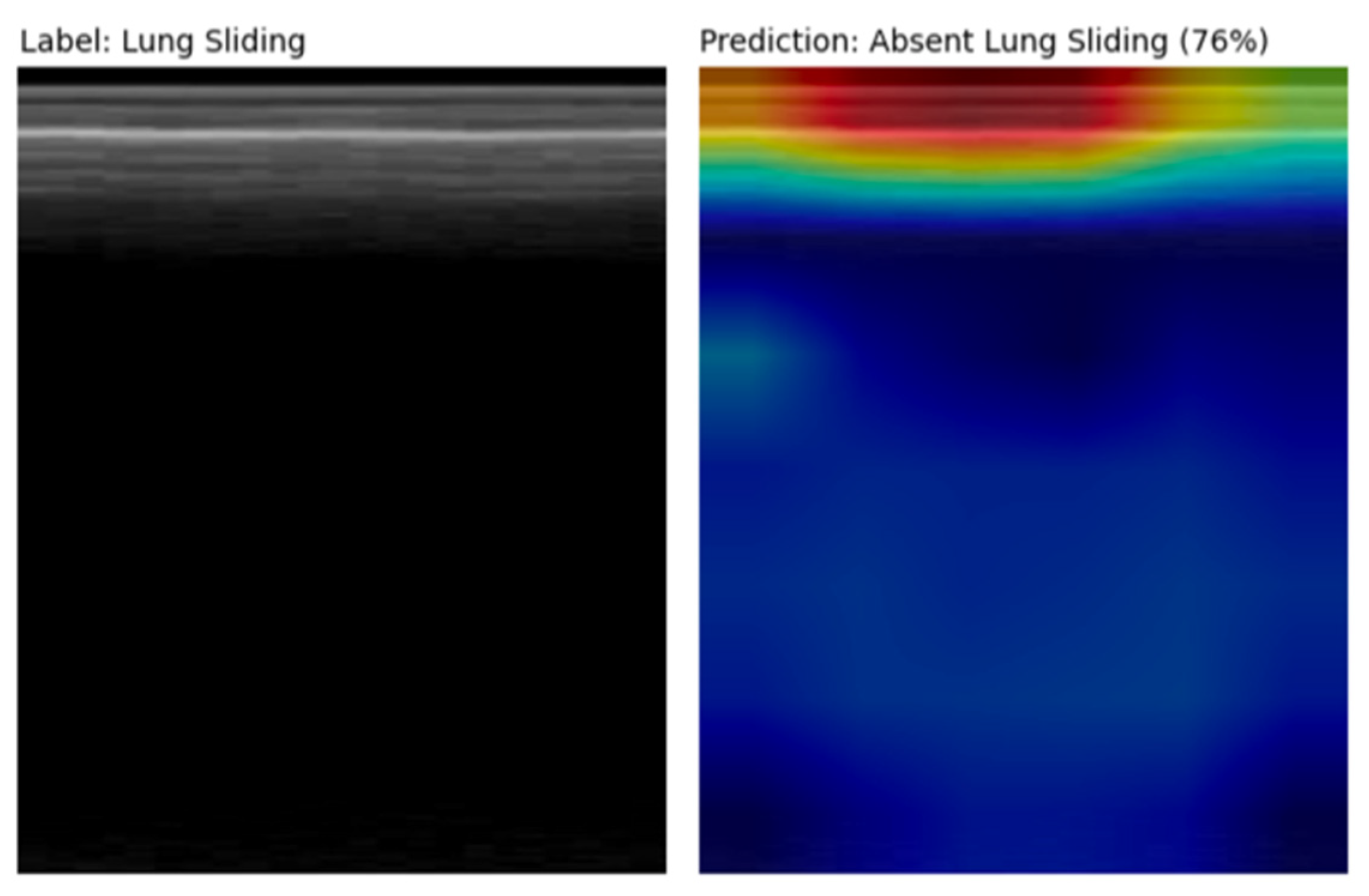
2.3. Explainability and Error Analysis
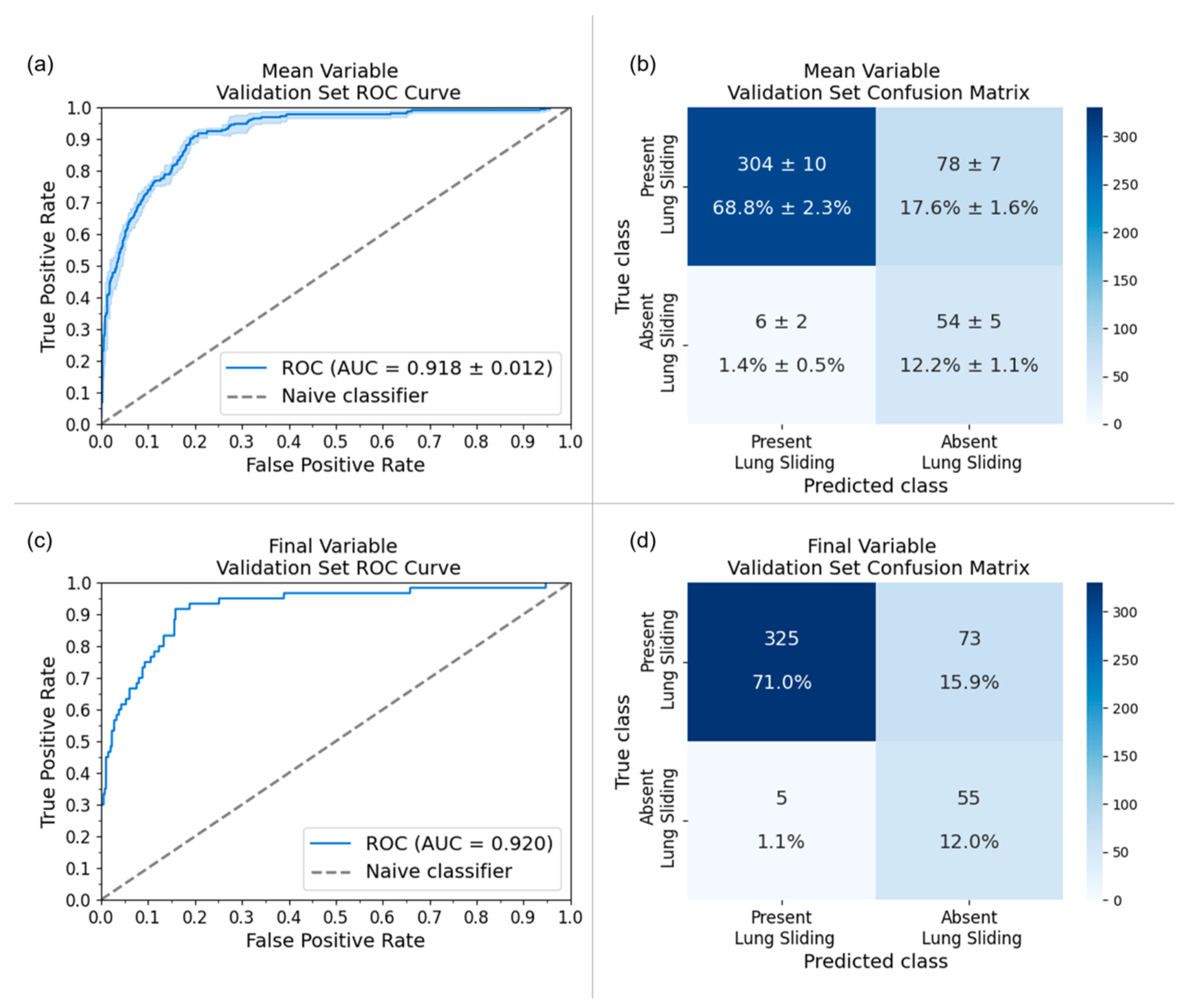
3. Results
4. Discussion
5. Limitations and Future Directions
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kim, J.; Hong, J.; Park, H. Prospects of deep learning for medical imaging. Precis. Future Med. 2018, 2, 37–52. [Google Scholar] [CrossRef]
- Shen, D.; Wu, G.; Suk, H. Deep Learning in Medical Image Analysis. Annu. Rev. Biomed. Eng. 2017, 21, 221–248. [Google Scholar] [CrossRef] [PubMed] [PubMed Central]
- Duran-Lopez, L.; Dominguez-Morales, J.P.; Corral-Jaime, J.; Diaz, S.V.; Linares-Barranco, A. Covid-xnet: A custom deep learning system to diagnose and locate COVID-19 in chest x-ray images. Appl. Sci. 2020, 10, 5683. [Google Scholar] [CrossRef]
- Ozdemir, O.; Russell, R.L.; Berlin, A.A. A 3D probabilistic deep learning system for detection and diagnosis of lung cancer using low-dose CT scans. IEEE Trans. Med. Imaging 2019, 39, 1419–1429. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Yang, X.; Cai, H.; Tan, W.; Jin, C.; Li, L. Discrimination of breast cancer with microcalcifications on mammography by deep learning. Sci. Rep. 2016, 6, 27327. [Google Scholar] [CrossRef] [PubMed]
- Xin, K.Z.; Li, D.; Yi, P.H. Limited generalizability of deep learning algorithm for pediatric pneumonia classification on external data. Emerg. Radiol. 2022, 29, 107–113. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Shen, L.; Xie, X.; Huang, S.; Xie, Z.; Hong, X.; Yu, J. Multi-resolution convolutional networks for chest x-ray radiograph based lung nodule detection. Artif. Intell. Med. 2020, 103, 101744. [Google Scholar] [CrossRef]
- Yun, J.; Park, J.E.; Lee, H.; Ham, S.; Kim, N.; Kim, H.S. Radiomic features and multilayer perceptron network classifier: A robust mri classification strategy for distinguishing glioblastoma from primary central nervous system lymphoma. Sci. Rep. 2019, 9, 5746. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Liang, G.; Zhang, Y.; Blanton, H.; Bessinger, Z.; Jacobs, N. Inconsistent performance of deep learning models on mammogram classification. J. Am. Coll. Radiol. 2020, 17, 796–803. [Google Scholar] [CrossRef]
- Spolaôr, N.; Lee, H.; Mendes, A.; Nogueira, C.; Parmezan, A.; Takaki, W.; Coy, C.S.R.; Wu, F.C.; Fonseca-Pinto, R. Fine-tuning pre-trained neural networks for medical image classification in small clinical datasets. Multimed. Tools Appl. 2024, 83, 27305–27329. [Google Scholar] [CrossRef]
- Deng, J.; Dong; Socher, R.; Li, L.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Blaivas, L.; Blaivas, M. Are convolutional neural networks trained on imagenet images wearing rose-colored glasses? A quantitative comparison of imagenet, computed tomographic, magnetic resonance, chest x-ray, and point-of-care ultrasound images for quality. J. Ultrasound Med. 2021, 40, 377–383. [Google Scholar] [CrossRef] [PubMed]
- Alzubaidi, L.; Al-Amidie, M.; Al-Asadi, A.; Humaidi, A.; Al-Shamma, O.; Fadhel, M.; Duan, Y. Novel transfer learning approach for medical imaging with limited labeled data. Cancers 2021, 13, 1590. [Google Scholar] [CrossRef]
- An, C.; Park, Y.W.; Ahn, S.S.; Han, K.; Kim, H.; Lee, S.K. Radiomics machine learning study with a small sample size: Single random training-test set split may lead to unreliable results. PLoS ONE 2021, 16, e0256152. [Google Scholar] [CrossRef] [PubMed]
- Anguita, D.; Ghelardoni, L.; Ghio, A.; Oneto, L.; Ridella, S. The’K’in K-fold Cross Validation. In ESANN 2012 Proceedings, Proceedings of the European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, Bruges, Belgium, 25–27 April 2012; ESANN: Bruges, Belgium, 2012; Volume 102, pp. 441–446. [Google Scholar]
- Vabalas, A.; Gowen, E.; Poliakoff, E.; Casson, A.J. Machine learning algorithm validation with a limited sample size. PLoS ONE 2019, 14, e0224365. [Google Scholar] [CrossRef] [PubMed]
- Arntfield, R.; Wu, D.; Tschirhart, J.; VanBerlo, B.; Ford, A.; Ho, J.; Cauley, J.M.; Wu, B.; Deglint, J.; Chaudhary, R.; et al. Automation of lung ultrasound interpretation via deep learning for the classification of normal versus abnormal lung parenchyma: A multicenter study. Diagnostics 2021, 11, 2049. [Google Scholar] [CrossRef] [PubMed]
- VanBerlo, B.; Wu, D.; Li, B.; Rahman, M.A.; Hogg, G.; VanBerlo, B.; Tschirhart, J.; Ford, A.; Ho, J.; McCauley, J.; et al. Accurate assessment of the lung sliding artefact on lung ultrasonography using a deep learning approach. Comput. Biol. Med. 2022, 148, 105953. [Google Scholar] [CrossRef] [PubMed]
- Mento, F.; Khan, U.; Faita, F.; Smargiassi, A.; Inchingolo, R.; Perrone, T.; Demi, L. State of the art in lung ultrasound, shifting from qualitative to quantitative analyses. Ultrasound Med. Biol. 2022, 48, 2398–2416. [Google Scholar] [CrossRef]
- Demi, L.; Wolfram, F.; Klersy, C.; De Silvestri, A.; Ferretti, V.V.; Muller, M.; Miller, D.; Feletti, F.; Welnicki, M.; Buda, N.; et al. New international guidelines and consensus on the use of lung ultrasound. J. Ultrasound Med. 2023, 42, 309–344. [Google Scholar] [CrossRef]
- Brady, A.K.; Spitzer, C.R.; Kelm, D.; Brosnahan, S.B.; Latifi, M.; Burkart, K.M. Pulmonary critical care fellows’ use of and self-reported barriers to learning bedside ultrasound during training: Results of a national survey. Chest 2021, 160, 231–237. [Google Scholar] [CrossRef]
- Lichtenstein, D.A.; Menu, Y. A bedside ultrasound sign ruling out pneumothorax in the critically iii: Lung sliding. Chest 1995, 108, 1345–1348. [Google Scholar] [CrossRef]
- Summers, S.M.; Chin, E.J.; April, M.D.; Grisell, R.D.; Lospinoso, J.A.; Kheirabadi, B.S.; Salinas, J.; Blackbourne, L.H. Diagnostic accuracy of a novel software technology for detecting pneumothorax in a porcine model. Am. J. Emerg. Med. 2017, 35, 1285–1290. [Google Scholar] [CrossRef] [PubMed]
- Lindsey, T.; Lee, R.; Grisell, R.; Vega, S.; Veazey, S. Automated pneumothorax diagnosis using deep neural networks. In Progress in Pattern Recognition, Image Analysis, Computer Vision, and Applications, Proceedings of the 23rd Iberoamerican Congress, CIARP 2018, Madrid, Spain, 19–22 November 2018; Proceedings; Springer: Berlin/Heidelberg, Germany, 2019; pp. 723–731. [Google Scholar]
- Ja, M.; Bundzel, M.; Mal, M.; Dzian, A.; Feren, N.; Babi, F. Detecting the absence of lung sliding in lung ultrasounds using deep learning. Appl. Sci. 2021, 11, 6976. [Google Scholar] [CrossRef]
- Abu-Zidan, F.M.; Hefny, A.F.; Corr, P. Clinical ultrasound physics. J. Emerg. Trauma Shock. 2011, 4, 501. [Google Scholar] [CrossRef] [PubMed]
- Tan, M.; Le, Q. EfficientNet: Rethinking model scaling for convolutional neural networks. In Proceedings of the 36th International Conference on Machine Learning Research, PMLR, Long Beach, CA, USA, 10–15 June 2019; Chaudhuri, K., Salakhutdinov, R., Eds.; Volume 97, pp. 6105–6114. Available online: https://proceedings.mlr.press/v97/tan19a.html (accessed on 10 November 2023).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.-C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 1314–1324. [Google Scholar]
- Chattopadhay, A.; Sarkar, A.; Howlader, P.; Balasubramanian, V.N. Grad-cam++: Generalized gradient-based visual explanations for deep convolutional networks. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 839–847. [Google Scholar]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; Van Der Laak, J.A.; Van Ginneken, B.; Sánchez, C.I. A survey on deep learning in medical image analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef] [PubMed]
- Roy, S.; Menapace, W.; Oei, S.; Luijten, B.; Fini, E.; Saltori, C.; Huijben, I.; Chennakeshava, N.; Mento, F.; Sentelli, A.; et al. Deep learning for classification and localization of COVID-19 markers in point-of-care lung ultrasound. IEEE Trans. Med. Imaging 2020, 39, 2676–2687. [Google Scholar] [CrossRef] [PubMed]
- Baloescu, C.; Toporek, G.; Kim, S.; McNamara, K.; Liu, R.; Shaw, M.M.; McNamara, R.L.; Raju, B.I.; Moore, C.L. Automated lung ultrasound b-line assessment using a deep learning algorithm. IEEE Trans. Ultrason. Ferroelectr. Freq. Control 2020, 67, 2312–2320. [Google Scholar] [CrossRef] [PubMed]
- La Salvia, M.; Secco, G.; Torti, E.; Florimbi, G.; Guido, L.; Lago, P.; Salinaro, F.; Perlini, S.; Leporati, F. Deep learning and lung ultrasound for COVID-19 pneumonia detection and severity classification. Comput. Biol. Med. 2021, 136, 104742. [Google Scholar] [CrossRef] [PubMed]
- Rajpurkar, P.; Irvin, J.; Ball, R.L.; Zhu, K.; Yang, B.; Mehta, H.; Duan, T.; Ding, D.; Bagul, A.; Langlotz, C.P.; et al. Deep learning for chest radio- graph diagnosis: A retrospective comparison of the chexnext algorithm to practicing radiologists. PLoS Med. 2018, 15, e1002686. [Google Scholar] [CrossRef] [PubMed]
- Kuo, W.; Hne, C.; Mukherjee, P.; Malik, J.; Yuh, E.L. Expert-level detection of acute intracranial hemorrhage on head computed tomography using deep learning. Proc. Natl. Acad. Sci. USA 2019, 116, 22737–22745. [Google Scholar] [CrossRef]
- Wu, N.; Phang, J.; Park, J.; Shen, Y.; Huang, Z.; Zorin, M.; Jastrzebski, S.; Févry, T.; Katsnelson, J.; Kim, E.; et al. Deep neural networks improve radiologists’ performance in breast cancer screening. IEEE Trans. Med. Imaging 2019, 39, 1184–1194. [Google Scholar] [CrossRef]
- Kim, D.W.; Jang, H.Y.; Kim, K.W.; Shin, Y.; Park, S.H. Design characteristics of studies reporting the performance of artificial intelligence algorithms for diagnostic analysis of medical images: Results from recently published papers. Korean J. Radiol. 2019, 20, 405–410. [Google Scholar] [CrossRef]
- Yao, A.D.; Cheng, D.L.; Pan, I.; Kitamura, F. Deep learning in neuroradiology: A systematic review of current algorithms and approaches for the new wave of imaging technology. Radiol. Artif. Intell. 2020, 2, e190026. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, A.V.; Blears, E.E.; Ross, E.; Lall, R.R.; Ortega-Barnett, J. Machine learning applications for the differentiation of primary central nervous system lymphoma from glioblastoma on imaging: A systematic review and meta-analysis. Neurosurg. Focus 2018, 45, E5. [Google Scholar] [CrossRef]
- Yu, A.C.; Mohajer, B.; Eng, J. External validation of deep learning algorithms for radiologic diagnosis: A systematic review. Radiol. Artif. Intell. 2022, 4, e210064. [Google Scholar] [CrossRef]
- Fernando, K.R.M.; Tsokos, C.P. Dynamically weighted balanced loss: Class imbalanced learning and confidence calibration of deep neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 2940–2951. [Google Scholar] [CrossRef] [PubMed]
- Kreuzberger, D.; Ku, N.; Hirschl, S. Machine learning operations (mlops): Overview, definition, and architecture. arXiv 2022, arXiv:2205.02302. [Google Scholar] [CrossRef]
- Leis, J.A.; Shojania, K.G. A primer on pdsa: Executing plan–do–study–act cycles in practice, not just in name. BMJ Qual. Saf. 2017, 26, 572–577. [Google Scholar] [CrossRef] [PubMed]
- Im, D.; Lee, S.; Lee, H.; Yoon, B.; So, F.; Jeong, J. A data-centric approach to design and analysis of a surface-inspection system based on deep learning in the plastic injection molding industry. Processes 2021, 9, 1895. [Google Scholar] [CrossRef]
- Tartarisco, G.; Cicceri, G.; Bruschetta, R.; Tonacci, A.; Campisi, S.; Vitabile, S.; Pioggia, G. An intelligent Medical Cyber–Physical System to support heart valve disease screening and diagnosis. Expert Syst. Appl. 2024, 238, 121772. [Google Scholar] [CrossRef]
- Song, I.; Yoon, J.; Kang, J.; Kim, M.; Jang, W.S.; Shin, N.-Y.; Yoo, Y. Design and implementation of a new wireless carotid neckband doppler system with wearable ultrasound sensors: Preliminary results. Appl. Sci. 2019, 9, 2202. [Google Scholar] [CrossRef]
- Steinberg, S.; Huang, A.; Ono, Y.; Rajan, S. Continuous artery monitoring using a flexible and wearable single-element ultrasonic sensor. IEEE Instrum. Meas. Mag. 2022, 25, 6–11. [Google Scholar] [CrossRef]
- Fatima, N.; Mento, F.; Zanforlin, A.; Smargiassi, A.; Torri, E.; Perrone, T.; Demi, L. Human-to-ai interrater agreement for lung ultrasound scoring in COVID-19 patients. J. Ultrasound Med. 2023, 42, 843–851. [Google Scholar] [CrossRef] [PubMed]
- VanBerlo, B.; Hoey, J.; Wong, A. A survey of the impact of self-supervised pretraining for diagnostic tasks in medical X-ray, CT, MRI, and ultrasound. BMC Med. Imaging 2024, 24, 79. [Google Scholar] [CrossRef] [PubMed]
- Vanberlo, B.; Li, B.; Hoey, J.; Wong, A. Self-Supervised Pretraining Improves Performance and Inference Efficiency in Multiple Lung Ultrasound Interpretation Tasks. IEEE Access 2023, 11, 135696–135707. [Google Scholar] [CrossRef]
- VanBerlo, B.; Li, B.; Wong, A.; Hoey, J.; Arntfield, R. Exploring the Utility of Self-Supervised Pretraining Strategies for the Detection of Absent Lung Sliding in M-Mode Lung Ultrasound. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 3076–3085. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Local Data | External Data | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| D462 | D117 | D62 | Dall | ||||||||
| Sliding | Absent | Sliding | Absent | Sliding | Absent | Sliding | Absent | Sliding | Absent | ||
| Patients | By source | 122 | 163 | 53 | 22 | 238 | |||||
| By class | 88 | 36 | 154 | 36 | 48 | 6 | 21 | 7 | 223 | 49 | |
| Sex | Male | 46 (37%) | 25 (20%) | 75 (39%) | 22 (12%) | 25 (46%) | 5 (9%) | 9 (32%) | 3 (11%) | 109 (40%) | 30 (11%) |
| Female | 42 (34%) | 11 (9%) | 47 (25%) | 12 (6%) | 23 (43%) | 1 (2%) | 9 (32%) | 2 (7%) | 79 (29%) | 15 (5%) | |
| Unavailable | 0 (0%) | 0 (0%) | 32 (17%) | 2 (1%) | 0 (0%) | 0 (0%) | 3 (10%) | 2 (7%) | 35 (13%) | 4 (1%) | |
| Age | Mean (std) | 60.0 (17.3%) | 64.9 (13.9%) | 56.4 (16.4%) | 58.5 (13.1%) | 55.9 (22.0%) | 43.3 (20.8%) | 56.8 (16.7%) | 50.5 (19.1%) | 56.3 (18.0%) | 55.5 (16.1%) |
| Unavailable | 0 (0%) | 0 (0%) | 32 (17%) | 2 (1%) | 0 (0%) | 0 (0%) | 2 (7%) | 2 (7%) | 34 (12%) | 4 (1%) | |
| Clips | By source | 540 | 462 | 117 | 62 | 641 | |||||
| By class | 402 (74%) | 138 (26%) | 404 (88%) | 58 (12%) | 107 (91%) | 10 (9%) | 46 (74%) | 16 (26%) | 557 (87%) | 84 (13%) | |
| Machine Vendors | Phillips | 0 (0%) | 2 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 24 (39%) | 9 (15%) | 24 (4%) | 9 (1%) |
| Sonosite | 395 (73%) | 96 (18%) | 398 (86%) | 58 (13%) | 0 (0%) | 0 (0%) | 13 (21%) | 0 (0%) | 411 (64%) | 58 (9%) | |
| Mindray | 7 (1%) | 40 (7%) | 0 (0%) | 0 (0%) | 107 (91%) | 10 (9%) | 6 (10%) | 5 (8%) | 113 (18%) | 16 (2%) | |
| Unavailable | 0 (0%) | 0 (0%) | 6 (1%) | 0 (0%) | 0 (0%) | 0 (0%) | 3 (5%) | 2 (3%) | 9 (1%) | 2 (0%) | |
| Probe | Phased Array | 366 (68%) | 118 (22%) | 337 (73%) | 52 (11%) | 65 (56%) | 3 (3%) | 20 (32%) | 1 (2%) | 422 (66%) | 56 (9%) |
| Curved Linear | 32 (6%) | 14 (3%) | 67 (15%) | 6 (1%) | 42 (36%) | 7 (6%) | 26 (42%) | 15 (24%) | 135 (21%) | 28 (4%) | |
| Location | ED | 122 (23%) | 12 (2%) | 0 (0%) | 0 (0%) | 107 (91%) | 10 (9%) | 24 (39%) | 13 (21%) | 131 (20%) | 23 (4%) |
| ICU | 274 (51%) | 124 (23%) | 401 (87%) | 58 (13%) | 0 (0%) | 0 (0%) | 19 (31%) | 1 (2%) | 420 (65%) | 59 (9%) | |
| Unavailable | 0 (0%) | 0 (0%) | 3 (1%) | 0 (0%) | 0 (0%) | 0 (0%) | 3 (5%) | 2 (3%) | 6 (1%) | 2 (0%) | |
| Imaging Preset | Abdominal | 373 (69%) | 104 (19%) | 194 (42%) | 21 (5%) | 45 (38%) | 4 (3%) | 20 (32%) | 13 (21%) | 259 (41%) | 38 (6%) |
| Cardiac | 14 (3%) | 4 (1%) | 23 (5%) | 0 (0%) | 20 (17%) | 2 (2%) | 4 (6%) | 0 (0%) | 47 (7%) | 2 (0%) | |
| Lung | 11 (2%) | 24 (4%) | 178 (39%) | 37 (8%) | 42 (36%) | 4 (3%) | 16 (26%) | 1 (2%) | 236 (37%) | 42 (7%) | |
| Unavailable | 0 (0%) | 0 (0%) | 9 (2%) | 0 (0%) | 0 (0%) | 0 (0%) | 6 (9%) | 2 (3%) | 15 (2%) | 2 (0%) | |
| Depth | <6 cm | 14 (3%) | 8 (1%) | 4 (1%) | 0 (0%) | 2 (2%) | 0 (0%) | 4 (6%) | 0 (0%) | 10 (2%) | 0 (0%) |
| 6–20 cm | 382 (71%) | 130 (24%) | 395 (85%) | 58 (13%) | 104 (89%) | 10 (9%) | 40 (65%) | 16 (26%) | 539 (84%) | 84 (13%) | |
| >20 cm | 6 (1%) | 0 (0%) | 5 (1%) | 0 (0%) | 1 (1%) | 0 (0%) | 2 (3%) | 0 (0%) | 8 (1%) | 0 (0%) | |
| Data | Fold 1 | Fold 2 | Fold 3 | Fold 4 | Fold 5 | Fold 6 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sliding | Absent | Sliding | Absent | Sliding | Absent | Sliding | Absent | Sliding | Absent | Sliding | Absent | ||
| (a) | Patients | 36 ± 3 (83 ± 5%) | 7 ± 2 (17 ± 5%) | 38 ± 3 (84 ± 2%) | 7 ± 1 (16 ± 2%) | 37 ± 2 (82 ± 3%) | 8 ± 2 (18 ± 3%) | 36 ± 3 (78 ± 4%) | 10 ± 3 (22 ± 4%) | 39 ± 4 (86 ± 2%) | 6 ± 2 (14 ± 2%) | 37 ± 2 (80 ± 4%) | 10 ± 2 (20 ± 4%) |
| Clips | 85 ± 6 (88 ± 5%) | 11 ± 5 (12 ± 5%) | 89 ± 6 (88 ± 4%) | 12 ± 5 (12 ± 4%) | 98 ± 8 (88 ± 3%) | 12 ± 4 (12 ± 3%) | 94 ± 6 (84 ± 5%) | 18 ± 7 (16 ± 5%) | 100 ± 15 (89 ± 2%) | 12 ± 4 (11 ± 2%) | 91 ± 8 (84 ± 5%) | 16 ± 5 (16 ± 5%) | |
| (b) | Patients | 30 (80%) | 9 (20%) | 37 (80%) | 9 (20%) | 42 (81%) | 10 (19%) | 35 (90%) | 4 (10%) | 36 (82%) | 8 (18%) | 38 (81%) | 9 (19%) |
| Clips | 92 (88%) | 13 (12%) | 67 (86%) | 11 (14%) | 108 (87%) | 16 (13%) | 71 (91%) | 7 (9%) | 106 (82%) | 24 (18%) | 113 (90%) | 13 (10%) | |
| Trial | Sensitivity | Specificity | AUC | Accuracy |
|---|---|---|---|---|
| 1 | 0.912 | 0.777 | 0.919 | 0.798 |
| 2 | 0.922 | 0.769 | 0.911 | 0.787 |
| 3 | 0.838 | 0.819 | 0.908 | 0.822 |
| 4 | 0.943 | 0.797 | 0.942 | 0.814 |
| 5 | 0.905 | 0.810 | 0.912 | 0.824 |
| Mean | 0.903 | 0.795 | 0.918 | 0.809 |
| (STD) | (0.035) | (0.019) | (0.012) | (0.014) |
| Dataset | Model | Sensitivity | Specificity | AUC | Accuracy |
|---|---|---|---|---|---|
| External Validation | Final | 0.917 | 0.817 | 0.920 | 0.830 |
| M0 | 0.919 | 0.761 | 0.914 | 0.782 | |
| Local Holdout | Final | 0.942 | 0.891 | 0.974 | 0.904 |
| M0 | 0.949 | 0.868 | 0.973 | 0.889 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, D.; Smith, D.; VanBerlo, B.; Roshankar, A.; Lee, H.; Li, B.; Ali, F.; Rahman, M.; Basmaji, J.; Tschirhart, J.; et al. Improving the Generalizability and Performance of an Ultrasound Deep Learning Model Using Limited Multicenter Data for Lung Sliding Artifact Identification. Diagnostics 2024, 14, 1081. https://doi.org/10.3390/diagnostics14111081
Wu D, Smith D, VanBerlo B, Roshankar A, Lee H, Li B, Ali F, Rahman M, Basmaji J, Tschirhart J, et al. Improving the Generalizability and Performance of an Ultrasound Deep Learning Model Using Limited Multicenter Data for Lung Sliding Artifact Identification. Diagnostics. 2024; 14(11):1081. https://doi.org/10.3390/diagnostics14111081
Chicago/Turabian StyleWu, Derek, Delaney Smith, Blake VanBerlo, Amir Roshankar, Hoseok Lee, Brian Li, Faraz Ali, Marwan Rahman, John Basmaji, Jared Tschirhart, and et al. 2024. "Improving the Generalizability and Performance of an Ultrasound Deep Learning Model Using Limited Multicenter Data for Lung Sliding Artifact Identification" Diagnostics 14, no. 11: 1081. https://doi.org/10.3390/diagnostics14111081
APA StyleWu, D., Smith, D., VanBerlo, B., Roshankar, A., Lee, H., Li, B., Ali, F., Rahman, M., Basmaji, J., Tschirhart, J., Ford, A., VanBerlo, B., Durvasula, A., Vannelli, C., Dave, C., Deglint, J., Ho, J., Chaudhary, R., Clausdorff, H., ... Arntfield, R. (2024). Improving the Generalizability and Performance of an Ultrasound Deep Learning Model Using Limited Multicenter Data for Lung Sliding Artifact Identification. Diagnostics, 14(11), 1081. https://doi.org/10.3390/diagnostics14111081