1. Introduction
In 2019, 6700 neonatal deaths occurred every day, and around 75% of these deaths occurred within the first 7 days after birth; this highlights the significance of expeditious diagnosis during the first few days of any neonate’s life. Several pathologies associated with a neonate’s mortality require invasive clinical tests and a high vigilance. Unfortunately, the regions that suffer the most from high newborn mortality rates are those deficient in the number of skilled health professionals. The World Health Organization (WHO) states that two-thirds of newborn deaths could be prevented if diagnosis and treatments took place before the second week of an infant’s life. Furthermore, in most cases of pathological studies, if the treatment is initiated expeditiously, the infant may completely heal if given the right treatments [
1].
As early as the 19th century, the cry of neonates was recognized as a cue in identifying morbidity [
2]. The acoustic characteristics of a cry may vary due to various factors such as air pressure, tension, length, thickness, and shape of the vocal cords and resonators [
3]. Experienced parents and caregivers may distinguish types of cries only by listening; however, even trained nurses could only reach an accuracy of around 33% by relying on their auditory system [
4]. Healthy newborns have a fundamental frequency of 400–600 Hz, with an average of 450 Hz [
5]; they also show a decreasing or increasing–decreasing melody shape with super imposed harmonics, and an average duration of 1–1.5 s [
6]. The cries of babies suffering from a specific pathology are associated with low punctuation; they reflect high irritability and the physiological persistency is low [
7]. Some of the features and attributes in infant cry signals can seldom be observed in healthy infants, though are commonly seen in pathologic ones [
8]. For example, hypothyroidism could result in low-pitched cries, a lower number of shifts, and a frequent observance of the glottal roll at the end of phonation. Cries marked with hypothyroidism have been marked as hoarse [
9]. This acoustic structure has enabled us to develop a Newborn Cry Diagnostic System (NCDS) and take a deeper look into the health status of neonates.
The study of newborn cry signals unveiled that they bear abundant helpful information about the neonate’s health conditions. Extensive research in this area has demanded an automatic approach and accurate analysis of the cry spectrographs; hence, newborn cry analysis systems were designed to overcome this challenge [
10,
11,
12,
13,
14,
15]. The study of newborn cry signals has multiple goals.
There are many interesting publications in the literature that analyze cry signals from aspects other than those used in this study. These studies range from the identification of the reason for crying, e.g., hunger, pain or boredom [
16,
17,
18]; emotion detection [
19]; detecting the cry in Neonatal Intensive Care Units (NICUs) and in surveillance systems [
20,
21]; segmenting the cry signal into its episodes [
22,
23]; diagnosis of specific pathologies [
24] or general identification of a pathologic infant [
25,
26,
27,
28], as well as studying how each factor would affect the cry characteristics. Some of these works have explored the roles of pain intensity [
29,
30,
31], gender [
32], gestational age [
33], and other similar factors in cry signals. This study focuses on a different type of application, which is diagnosing pathologies in newborns based on their cry signal. What this study tried to achieve was to exploit features that could reflect the alterations in the cry signal only as a result of being unhealthy and independent of other factors. We expected these features (and their fusion) to represent attributes in the cry signals that were not obvious in simple observations of spectrograms, and also were not affected by changes in etiological factors across newborns and the emotional state of the newborns.
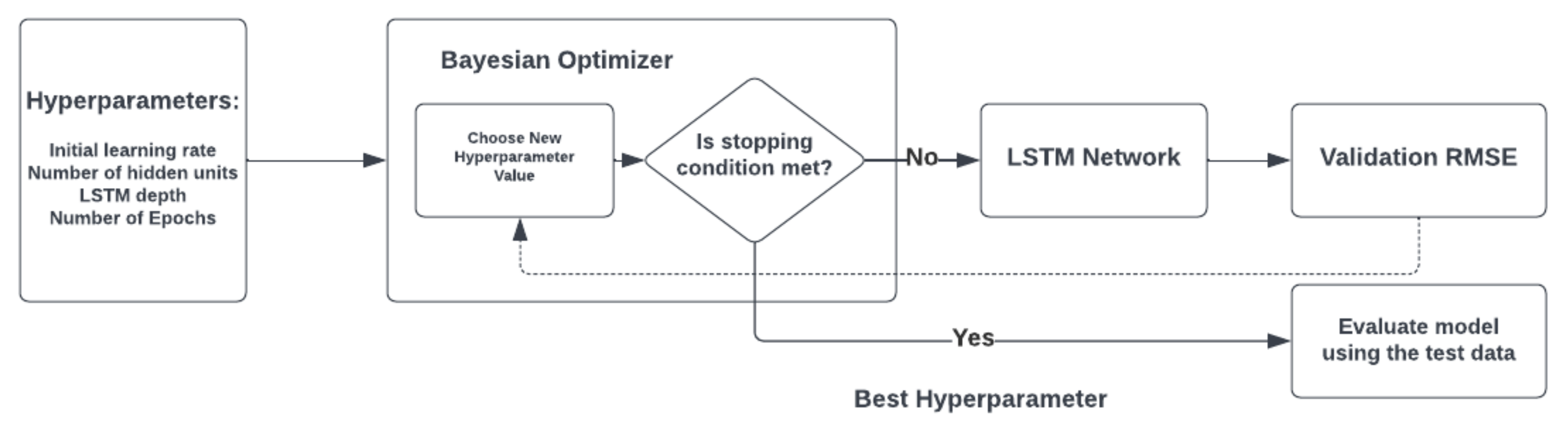
Every NCDS comprises three principal stages: pre-processing, feature extraction, and classification. In the pre-processing stage, the cry signal is pre-emphasized and framed; the pauses and silences are removed, filtered, and segmented to be ready for feature extraction. Following pre-processing is the feature extraction step. The features that are capable of discriminating the healthy cry signals from the pathologic ones are exploited in this stage. These features pass through dimensionality reduction techniques and are then fed as inputs into the classifier in the last stage of the NCDS. Finally, the class labels, which were predicted by the classifier, constitute the result.
The prominent features in the analysis of newborn cry signals include the Mel-frequency Cepstral Coefficients (MFCC), owing to their good performance in the diagnostic studies of cries. MFCCs are often employed as the baseline in many experiments concerning the neonate cry. The MFCC features aid the detection of multiple diseases, such as hypothyroidism, asphyxia [
34,
35], hyperbilirubinemia [
28], respiratory distress syndrome [
10], sepsis [
24,
36], and cleft palate [
37].
Gammatone Frequency features (GFCC) have been employed for the purpose of emotion recognition in the study of newborn cry signals [
19], where they have outperformed MFCCs. GFCCs have a wide range of applications in acoustic scene classification problems, the recognition of emotions in adult speech [
38], and speaker identification [
39]. GFCCs were also employed in recent research identifying septic newborns from those diagnosed with RDS based on their cry, which proved to be successful [
40]. Among the machine learning architectures used in infant cry analysis, Support Vector Machines (SVM) is one of the most prevalent approaches. A diversity of features such as temporal, prosodic, and cepstral have functioned successfully with SVMs [
41,
42,
43]. Onu et al. [
44] concluded that SVMs have a practical design for limited samples and data with high dimensionality, and are the most suitable for the study of asphyxiated neonates. Another classification approach employed in this work was the Long Short-term Memory (LSTM) neural network. LSTMs have been successfully paired with MFCC, GFCC, and their fusions; they showed promising performance in emotion and gender recognition applications [
45,
46]. However, their application has been limited in NCDS designs thus far [
47]. LSTMs are one of the best choices when it comes to sequential data, such as audio signals. Nevertheless, like any other deep learning framework, LSTMs encounter the challenge of fine-tuning hyperparameters (HP) [
48,
49]. HP tuning can enhance the performance of a Neural Network (NN) from medium to state-of-the-art. Although many researchers emphasized the vital role of Hyperparameter Optimization (HPO) in NN architectures, only a few works have been published that suggest which and how many HPs should be optimized [
50,
51,
52].
This study aimed to develop a comprehensive NCDS to distinguish between healthy and morbid infants as an early alert to medical staff and the guardians of the newborn. In order to obtain a comprehensive NCDS, the cry signals were analyzed regardless of cry stimulus, region, and gender. The proposed NCDS utilized both expiratory and inspiratory cry data sets. In this regard, the priority of this work was to study the role of acoustic features of the GFCC and MFCC in assessing the acoustic structure of the cry signals. Additionally, the GFCC and MFCC feature sets were combined by means of conventional and fusion methods. To the best of the authors’ knowledge, this is the first time that the Canonical Convolution Analysis (CCA) fusion of the employed feature sets has been introduced to the assessment of pathologic newborn cries. Furthermore, the discussed challenges are addressed for both classification methods through two HPO schemes, where both classifiers have been fine-tuned using the grid search and Bayesian Hyperparameter Optimization (BHPO) methods. The proposed frameworks were evaluated by several measures and the results for each one expounded and compared extensively.
This study was proposed to address multiple the challenges and shortcomings of previous studies, as represented in
Table A1. A majority of the NCDS designs focus on studying a certain pathology group, whereas the aim of our work is to design a comprehensive alert system to notify the guardians of the newborn and the health professionals that the infant should undergo more screening tests, as there is a high potential it might be diagnosed with one or more pathologies from the ensemble of pathologies. Furthermore, the highest infant mortality rates are unfortunately associated with lower-income countries, where the proper screening equipment is inadequate and not available to many newborns [
53]. This calls for the design of a non-complex, efficient NCDS that can perform early diagnosis so that the newborns are examined for an ensemble of pathologies and it can be determined if they are at risk of being unhealthy. As can be seen from
Table A1, the studies of newborn cries, undertaken for the purpose of differentiating between healthy and pathological infants, were either performed with a less inclusive set of pathologies or included less details on how HPO would assess enhancing the NCDS design.
There are an ever-growing number of designs that trade complexity for performance; however, this study proposes that employing proper feature fusion and HPO techniques could improve an NCDS from a moderate to a highly desirable state, where all the evaluation measures are relatively high and presented. The former studies present fewer measures for the evaluation; as an example, there are a very limited number of studies that have investigated the MCC measure.
Table A1 also shows that the use of HPO and fusion methods in the study of pathological newborn cry signals is inadequate. As an example, most of the presented studies employed the SVM classifier. However, the resulting values are far lower than those presented in this study (the same explanation applies to the LSTM classifier, where the results are around 10% lower without the use of HPO methods). The aim of this study is to highlight the effects and importance of HPO and fusion methods in all NCDS designs, by explaining run-times and comparing the results before and after fusion and employing HPO. The role of feature fusion and HP tuning could be crucial and shed light on many further applications that employ various modalities for developing a comprehensive system; thus, we tried to provide a detail-oriented study of how each step of the NCDS design contributed to enhancing or decrementing the final results, which distinguishes our study from other research in the field of cry-based diagnostic systems.
3. Evaluation
This study aimed to differentiate pathologic infants from healthy infants and employed the GFCC and MFCC features with the LSTM and SVM classifiers. A wide range of pathologies were included in these experiments in order to achieve a comprehensive NCDS, which is able to act as an early alert given the lack of medical experts and access to expensive and extensive laboratory experiments. Different experiments were conducted with the proposed feature vectors, their combination, and their CCA fusion. Following the feature extraction step is classification. There are two approaches to validating the classifier’s performance after training: holdout and cross-validation. The data were split into 70% training and 30% unseen testing data for both classifiers. For the SVM classifier, a 5-fold cross-validation was conducted on the training data, whereas for the LSTM classification, a holdout validation approach was chosen with 20% of the training data with a frequency of once every 10 iterations, because of the different natures of the classifiers. For the k-fold cross-validation, the data were split into k partitions, k−1 folds of which were used for training and one fold for testing in each iteration. This procedure was repeated up to the point at which each of the k folds was marked as the test fold. Finally, the results of grid search and BHPO for each architecture were compared.
The discriminatory performance of an NCDS in a binary problem can be represented by a contingency matrix, as shown in
Table 4. The task of the NCDS in our paper was to detect the pathological neonates amid the healthy. In order to appraise how well the system performed its role, the evaluation measures were introduced and computed. Practically, the most convenient evaluation measure is the accuracy, which is equivalent to the proportion of correctly predicted samples over all the observations. The accuracy measure benefits from both calculation and apprehension simplicity; however, the lack of informativeness as well as the fewer concessions towards the minority calls for the implementation of more evaluation measures [
75].
One solution is to evaluate the NCDS performance without considering the true negative case, which will introduce a measure named precision. Precision, or Positive Predictive Value (PPV), is the ratio of true pathologic cases among the samples predicted as healthy. Another measure is recall, or sensitivity, which refers to the probability of recognizing a truly pathologic case by NCDS. The F-score and Matthews’ Correlation Coefficient (MCC) were reported to be more instructive in binary classification problems. F-score is a function of both recall and precision, and indicates the inclusive performance of the system and is equal to the harmonic mean of precision and recall [
76]. The specificity measure denotes the true negative rate, and it indicates the true healthy samples correctly identified by the NCDS [
77].
The MCC is a highly informative evaluation measure when used in problems such as NCDS designs, since it accounts for all the information in a contingency matrix. The MCC, Equation (8), gives a value in the range of [−1, +1], where the misclassified performance results in negative values, and the higher values in the positive range signify better performance in terms of classification [
78,
79]. In this study, a high acceptance value of +0.50 was set to evaluate the classification.
4. Results
This section presents the results of evaluating different architectures with multiple measures in
Table 5,
Table 6,
Table 7,
Table 8,
Table 9,
Table 10,
Table 11 and
Table 12. Regarding the evaluation measures introduced, higher values for each measure translate into the better performance of the system. In this study, four sets of experiments were conducted: 1. Evaluate the NCDS performance with default/random search hyperparameter configuration of the classifiers. 2. Evaluate the NCDS performance with grid search HPO. 3. Evaluate the NCDS performance with BHPO. 4. Compare the performance of the system with different iterations of HPO for each method, ranging from 30 iterations to 100 iterations for SVM and different numbers of neurons for the LSTM.
Each of the feature vectors were evaluated with the SVM classifiers, which are shown in
Table 5,
Table 6,
Table 7 and
Table 8. In this step, the evaluation of system performance was undertaken by three different settings of the classifier: 1. Default settings. 2. Grid search optimization. 3. BHPO. The same procedure was repeated for the LSTM classifier, and 30 iterations of each HPO method were performed.
First, the results related to using the SVM classifier as a baseline to compare the results of the next steps are discussed.
Table 5 represents the results for the MFCC feature set for the INSV and EXP datasets. The use of HPO similarly increased the evaluation measures across both datasets. Moreover, BHPO achieved a very similar or better performance except for in the recall measure. The highest accuracy and F-score for the EXP dataset were 87.37% and 86.64%, respectively; both were obtained through BHPO. This experiment yielded a better performance with the INSV dataset, and yielded 89.05% for the accuracy measure, which was again achieved through BHPO. However, grid search had a slight superiority in terms of the F-score, and achieved 89.24%.
Table 6 presents the results of evaluating the GFCC feature set with the SVM classifier. By briefly looking at
Table 5 and
Table 6, it can be seen that the MFCC feature set outperformed the GFCC feature set across both datasets. Similar to all the other feature sets, the best results in terms of F-score and accuracy in relation to the EXP dataset for the GFCC feature set were achieved through BHPO. In a general sense, the combination of the GFCC with the SVM yielded better results with the INSV dataset compared to the EXP dataset. The GFCC features’ highest accuracy and F-score were 85.51% and 85.88%, respectively; both were achieved with BHPO and INSV dataset.
In the next step, the GFCC and MFCC feature sets were combined to evaluate the NCDS performance under these conditions. As for the EXP dataset, the concatenated feature set could increase the accuracy and F-score measures by 1% and 1.7%, respectively, compared to the best results of the last two feature sets. The highest results for the EXP dataset were 88.41% and 88.30% for accuracy and F-score, respectively. The performance of the NCDS with this configuration for the INSV dataset was very similar to that for the MFCC feature set used individually, and there was a slight improvement in the evaluation measures (
Table 7).
As a final experiment with the SVM classifier, the GFCC and MFCC feature sets—each containing 39 elements—were fused, and the feature vector was reduced to 60 elements, which was a more than 25% reduction in the size of the feature space. Since the size of the feature space was reduced, it might be expected that we see a rather small drop or a similar performance across the evaluation measures with this experiment compared to with the EXP dataset. However, as can be seen from
Table 8, not only were the overall best results in terms of accuracy and F-score maintained, but they were also increased by about 1%. The results for the INSV dataset show the new highest accuracy and F-score across all the experiments with the SVM classifier, with 89.96% and 90.27%, respectively. For the EXP dataset, compared to the best results in terms of accuracy and F-score in previous experiments, the fusion of the features decreased the performance of the NCDS by 0.7% and 0.35%, respectively.
After evaluating different aspects of the NCDS with the SVM classifier, the study proceeded to design an LSTM configuration to differentiate pathologic newborns from the healthy group. The same procedure of the experiments as with the SVM classifier was followed, and the system was evaluated with each feature configuration separately. The performances of all feature sets were improved considerably by using the LSTM classification method. The MFCC feature set achieved the highest accuracy and F-score of 99.03% and 99.05%, respectively, with the LSTM classifier for the INSV dataset, which is a nearly 10% improvement compared to the SVM method. As can be seen from
Table 9 and
Table 10, the performance of the GFCC feature set was slightly better than the MFCC feature set with the LSTM classifier for the EXP dataset, and vice versa for the INSV dataset. Both HPO methods worked marvellously with the LSTM classifier; however, they were not efficient in terms of run-time, which will be compared in the Discussion section.
The best accuracy and F-score achieved by the GFCC feature set were 99.45% and 99.44%, respectively, whereas the MFCC obtained 99.33% for both measures. The mentioned results were accomplished for the EXP dataset. It is noteworthy to mention that both feature sets attained 100.00% for specificity and precision measures. Moreover, the MCC measure has acquired a high value for the BHPO with EXP dataset for both feature sets, which indicates close to perfect classification quality (
Table 10).
Even though the state-of-the-art performance of both individual feature sets through HPO methods leaves little room for improvement, it is still beneficial to study the behavior of the system by the combination of the two feature vectors to assess their efficacy compared to the SVM classifier. As can be deduced from
Table 11, the performance of the NCDS was degraded by simply concatenating the feature sets, which may translate to lower uniformity of the feature space. The highest accuracy and F-score achieved with this experiment belonged to the INSV dataset, which reached 98.99% and 99.00%, respectively.
Table 12 constitutes the results of the next experiment with the LSTM classifier. The system’s performance was better than the concatenation framework since the CCA fusion removes the redundant features and helps improve the uniformity of feature space. This experiment showed the best performance in assessing the INSV dataset among all the previous experiments for all of the evaluation measures, specifically reaching 99.86% for both F-score and accuracy and 1.00 for the MCC measure. As for the EXP dataset, the GFCC feature set outperformed both combinational feature sets in terms of all evaluation measures.
In the previous section, the evaluation results regarding each feature set and classifier combination were extensively discussed; now, the discussion is undertaken from the perspective of the computational cost. For this matter, the run-time was selected as an indicator. It should be noted that in the case of the joint feature sets, namely, concatenation and CCA fusion, the given run-times include the process of concatenation and fusion, and not only the time corresponding to the HPO process. The elapsed times for the extraction of the GFCC and MFCC feature sets were 558.31 and 836.16 s, respectively, which suggests the GFCC feature set requires lower computational costs; other researchers have also mentioned the same results [
66].
Figure 4 compares the run-times of the grid search HPO and BHPO methods for different iterations of each one when applied to the SVM classifier.
The comparison between run-times regarding each feature set firstly confirms that the CCA fusion method results in a more homogenous feature space, and reduces run-times until they are lower than the run-time for the individual feature sets, which is consistent in both HPO methods. As can be seen, BHPO resulted in the higher performance of the system and required longer run-times. In order to better illustrate this comparison,
Figure 5 presents the average run-times of the two HPO methods for each NCDS configuration for a more detailed evaluation.
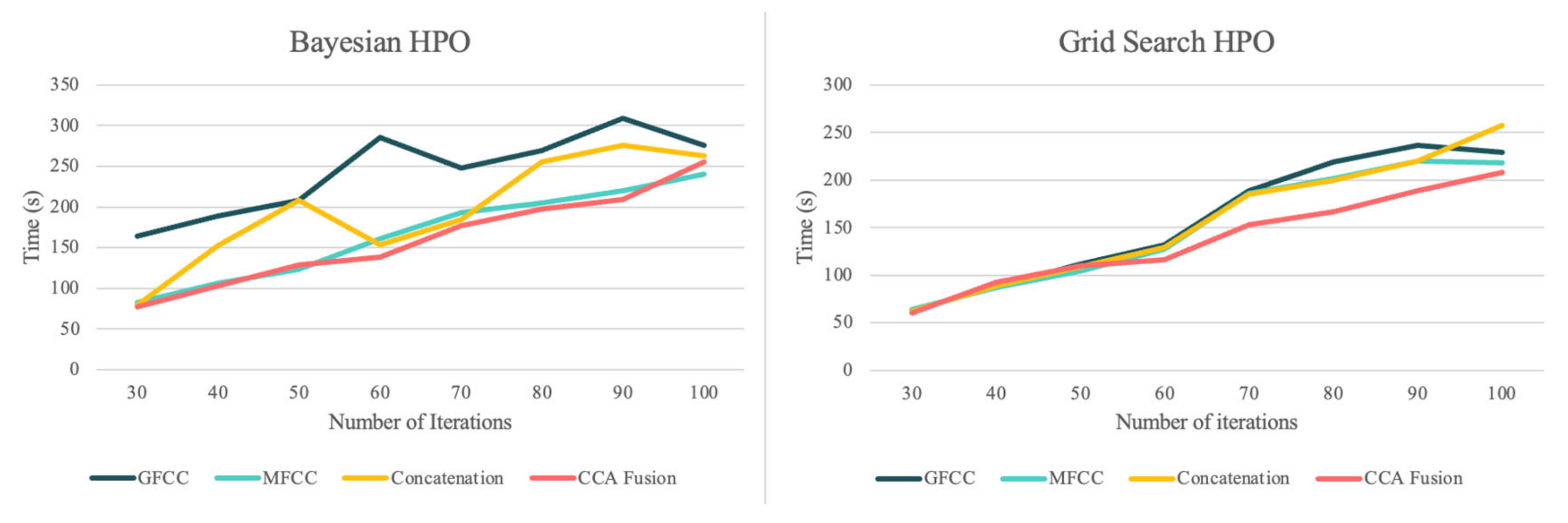
Figure 6 shows the elapsed times (in seconds) for the grid search and BHPO methods for the LSTM classifier. Since the process of HPO for the NNs is highly time-consuming compared to the machine learning models, only 30 iterations of HPO were performed for this experiment. The results show that CCA fusion requires the shortest run-time out of all other feature sets for the grid search HPO, similar to the SVM HPO methods; the run-times regarding the grid search method were lower than for BHPO. It should be noted that the number of trials for both methods was limited to 30; BHPO can achieve satisfactory results with this number of iterations, whereas grid search often requires a much greater number of trials. In summary, the proposed NCDS in this study accomplished desirable results across all the experiments in terms of performance and computational costs, and the longest elapsed time was less than 1700 s simultaneously.
5. Discussion
The design of the NCDS is a challenging problem for every researcher aiming to study newborn cry characteristics, regardless of the purpose the NCDS aims to serve. This challenge is even more significant regarding the sensitive subject of detecting pathologic newborns. The NCDS designs are not developed enough compared to the other acoustic scene recognition systems or speech analysis applications; there is still a need for further studies in this field, which is mainly due to the fact that datasets are very limited in terms of the number of samples. This is due to certain limitations, such as the fact that the chances of having a newborn diagnosed with a specific pathology in any given duration of conducting a clinical study are not predictable. Therefore, there may not be sufficient samples from each given pathology group; ensuring the ethical and technical standards required to collect and use the cry samples in a database calls for extreme measures. In this regard, by segmenting each cry recording into multiple expiratory and inspiratory episodes, two datasets of EXP and INSV were formed. As mentioned above, the areas of the world that suffer the most from infant mortality are less developed and lack a sufficient number of expert physicians. Thus, it is vital to keep the design as simple as possible so that expensive hardware would not be required to achieve high performance.
One other aspect of the proposed study is that by employing MFCC and GFCC features, the cry signal is investigated both from the speech processing and non-speech audio processing perspectives. As was previously discussed, MFCCs have proved to be powerful discriminators, especially in speech processing tasks, while GFCCs have shown even better performance and robustness in non-speech audio applications. For the first time in newborn cry analysis a CCA fusion at the feature level was performed in order to make the feature space homogenized and omit redundant information. By looking at the results of run-times in the previous section, it can be seen that CCA fusion homogenized the feature space in a way that the fused feature vectors required less time for optimization, even when compared to the single feature vector of GFCC. This shows that although the fused vector had 60 elements, it was still optimized faster than a 39-element feature vector, even with the time required for fusion included. This is rather an interesting finding that shows potential for many further applications with the inclusion of features from various modalities in this field. Not only were the HPO run-times reduced, but also, the results were improved by reducing the number of features by about one fourth.
Since the challenge is to detect a pathologic newborn and alert the newborn caregivers and medical experts, it is worth tolerating higher run-times in order to obtain a more accurate diagnosis and benefit from the HPO methods. The other important factor here is that the NCDS cannot afford to misdiagnose a pathologic newborn as a healthy one, so the focus should be on achieving a high hit rate (recall) and F-score measure, which are the indicators of a low miss rate. This study proposed two different designs with respect to the runtime and performance trade-off. Firstly, using the SVM classification method, a simplistic design was proposed, which requires minimal run-time and could work with commercial hardware. It was shown that by implementing the HPO methods, a similar performance to the complex state-of-the-art designs with up to 90% F-score for the SVM could be achieved. Moreover, our LSTM design, which only has a one-layer depth, was able to achieve better F-scores than similar or more complex works in the literature using the proper HPO, with improvements of 99.86% and 99.45% for INSV and EXP datasets, respectively. This study also offers an extensive evaluation of the HPO factors and methods in addition to the primary goal, achieving high diagnostic power. Additionally, the powerful discriminatory role of inspiratory cries, which are neglected in most NCDS studies, is highlighted here, as is the success of our design with the EXP dataset, which worked even better with this dataset.
Finally, the high number of pathology groups included in this study makes it a comprehensive framework capable of a more reliable diagnosis, since the medical staff could suggest that the newborn does not suffer from the given list of pathologies.
Figure 7 gives a visual summary of the best results achieved by each experiment in terms of F-score and accuracy. These results imply the similar performances of the NCDS in terms of both F-score and accuracy measures, which indicates that discussing the F-score measure alone would be sufficient.
In order to evaluate the results from another perspective and further explore the potential of both HPO methods and CCA fusion, another experiment was designed wherein the performance of the NCDS could be investigated with different HPO iterations of 30 to 100 (rising by steps of 10) on the EXP dataset. The average of all evaluations (eight experiments) across all measures is reported in
Table 13. As can be inferred from the results, both HPO methods enhanced the system performance in terms of accuracy, recall, F-score and MCC measures. Several patterns were observed when conducting these experiments. Firstly, the performance of the BHPO method was superior to that of the grid search method across all the measures, except for the recall measure. Even though the recall measure represented an exception to the mentioned pattern, the highest recall was achieved through the BHPO method with the fusion of features, which was 90.25%. Secondly, the best performance in terms of accuracy, MCC, and F-score was achieved using the CCA fusion framework. Finally, it can be deduced that although CCA fusion slenderized feature space, the performance of the NCDS was not considerably aggravated, and was even increased in terms of the F-score measure.
As was previously discussed in the Results section, the evaluation measures showed exceptional performance with the LSTM classifier. Therefore, to better demonstrate the power of LSTM in the NCDS design and validate the surprisingly high performance of the system, a final experiment was mapped out. In this experiment, the LSTM classifier was manually tuned for only one HP: the number of hidden neurons. For each feature set, the number of hidden neurons was changed from 2 neurons to half the size of each feature vector, e.g., 30 neurons for the fusion feature set with 60 elements for each sample.
Table 14 presents the average of each evaluation measure used in the successful attempts with manual search methods for each feature set. Therefore, if the only parameter being tuned is the number of hidden neurons, the system’s performance undergoes a bearable decline in exchange for lowering the computational costs. Moreover, as can be seen from the results, the best evaluation measures belonged to the CCA-fused feature set (except for the recall measure), which are 96.62% and 96.58% for accuracy and F-score, respectively. Therefore, by manually tuning only one HP, the system was capable of achieving up to a 96.58% average F-score, which translates to the high classification power of the LSTM classifier compared to the SVM, and the potential for an even better performance if other HPs are tuned as well.
So far, the experiments in this study have been discussed and compared in terms of performance, classification power, and run-times. There are various tools and frameworks for the study of audio signals, which have resulted in many different applications and publications. Among these frameworks, many different machine learning and deep learning methods have been explored. It is worthwhile to compare the performance of the proposed NCDS with other similar works or architectures that analyze either newborn cry signals or other audio signals. In a recent study [
80], environment sounds were classified through different models including SVM, LightGBM, XGBoost (XGB) nd CatBoost classification frameworks, employing time and frequency domain features and their combination. They were able to get 87.3% as their highest accuracy measure when using the LightGBM framework, and through the alteration of the gain factor, whereas their baseline classifiers yielded 66.7% for KNN, 67.5% for SVM, 72.7% for baseline Random Forest (RF), and 81.5% for their joint feature set with RF classifier. In another study [
81], speech signals were employed to diagnose Parkinson’s with the use of RF, Decision Tree (DT), KNN, XGB, and Naïve Bayes (NBC) classifiers. The results show that the classifiers’ performances ranked as follows: XGB achieved 96.61% for the accuracy measure, and KNN, RF, DT and NBC achieved accuracies of 94.91%, 88.13%, 86.44%, and 67.79%, respectively. The study of Singhal et al. [
82] classified music genres with Logistic Regression (LR), KNN, SVM, XGB, and RF classifiers. They also explored the effect of HPO on the RF classifier only, where the results were enhanced about 13% for accuracy and reached 98.8%. However, they did not discuss the HPO methods and trends. The highest result was achieved when using both RF and XGB classifiers—99.6% for both frameworks. The study of Kim et al. [
83] explored a very similar framework to the one presented in this study for the analysis of beehive sounds through MFCCs, a Mel spectrogram and constant-Q transform features, with RF, XGB, CNN, and SVM classifiers. The highest accuracy was achieved through the combination of MFCC features with the XGB classifier, reaching 87.36%. Their VGG-13 classification showed very promising results, with 96% for the F-score measure. Lahmiri et al. [
47] designed an NCDS for the purpose of detecting pathologic newborns with cepstrum features and multiple NN classifiers. By implementing LSTM classification, they were able to achieve an accuracy of 83.89% and 80.18% for the EXP and INSV datasets, respectively. Another work worth mentioning in this field is that by Matikolaei et al. [
84], wherein the proposed NCDS served the same purpose as in our study. The authors combined the MFCC with the auditory-inspired amplitude modulation features, and fed them into an SVM classifier; they attained 80.50% for the accuracy measure. Kumaran et al. [
45] focused on the recognition of emotions; they combined the GFCC with the MFCC feature sets and employed C-RNN classification. They used a different architecture of LSTM than in our study, with the addition of a convolutional network, and the highest F-score yielded by their design was 79%. In another emotion recognition study, the MFCC features were employed with a combined CNN-LSTM architecture, and the highest accuracy of 87.4% was reported with the use of HPO methods, wherein they tuned learning rate and batch size [
46]. Given the results of the mentioned studies, our NCDS designs proved to be successful and introduced novelty to the study of newborn cries with the purpose of detecting pathologic infants. Our study proposed a simplistic design using the SVM classifier that benefits from BHPO; we showed it could achieve results similar to (and even better than) the state-of-the-art of NCDS employing NNs, which in the literature reached 90.27% for the F-score measure. Our second framework of LSTM classification with BHPO obtained up to 99.86% for the F-score measure, which is remarkable in the study of pathologic newborn cry signals. However, our system was outperformed by a design that implements DFFNN, since it was able to achieve 100% for both datasets of EXP and INSV [
85].
In the design of the LSTM, the main concern was to prevent the model from becoming complex, and it employed only one hidden layer with a low number of hidden units. Both these achievements owe their success to the CCA fusion of the GFCC and MFCC feature sets, which not only enhances the overall performance, but also lowers the run-time by homogenizing the feature space and marks out the optimal feature set.
In summary, the presented results of this study suggest that a fusion of MFCC and GFCC features fed to deep and machine learning classifiers attains a higher performance compared to previous studies on detecting pathologic newborns. This framework is proposed as a non-invasive tool for aiding the expeditious detection of pathologic infants. There is still a vast ocean of unexplored ideas and architectures to be implemented in the study of pathological newborn cry signals, which is beyond the scope of this study. In future works, exploring more deep learning and machine learning designs such as DCNNs, and further exploring fusion techniques, especially at the decision level, such as the matching score method, would be of interest. Furthermore, studying more acoustic features and combining them with different classifiers would be worthwhile in order to highlight the efficacy of existing research on pathologic newborn cry signals.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






