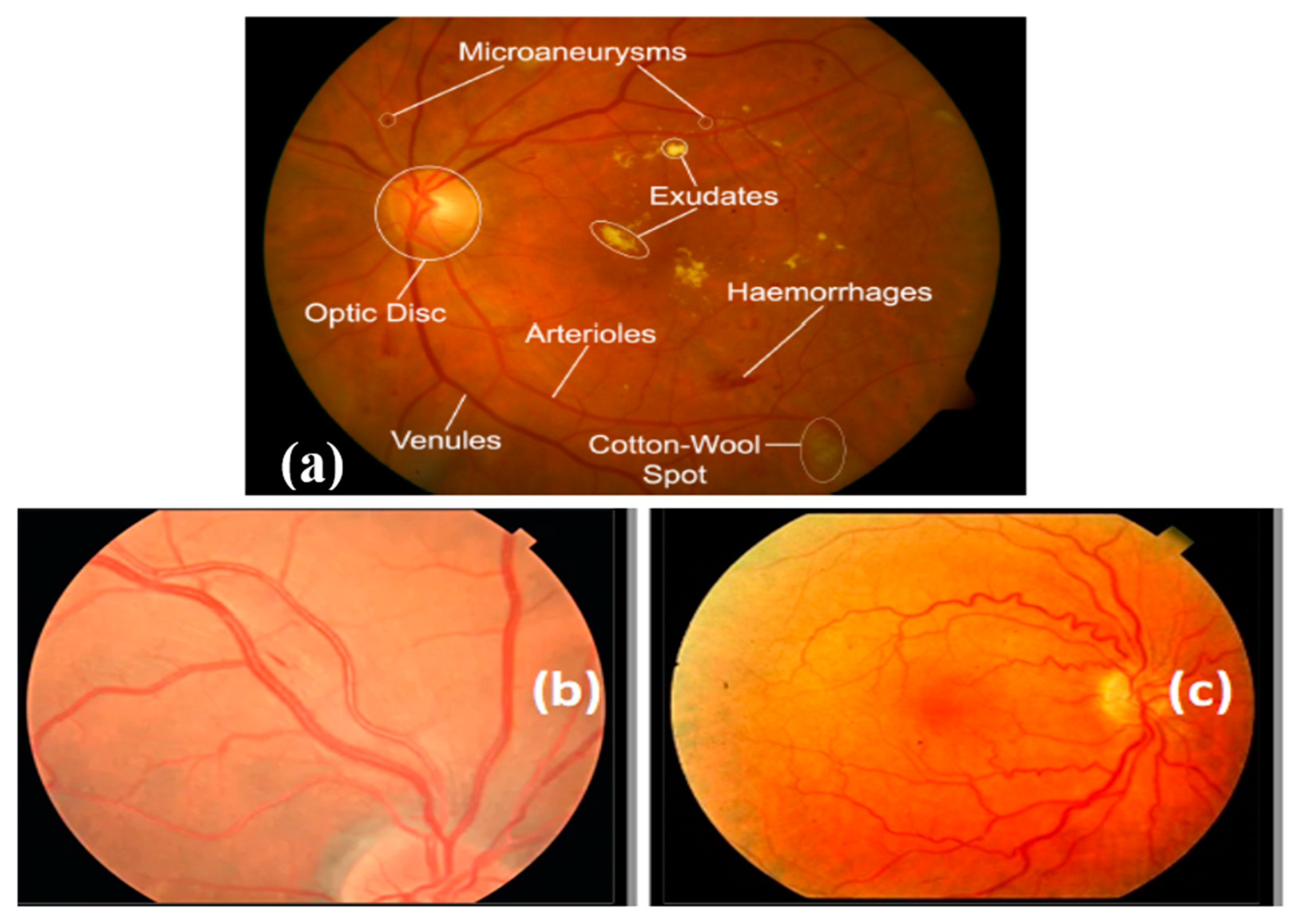
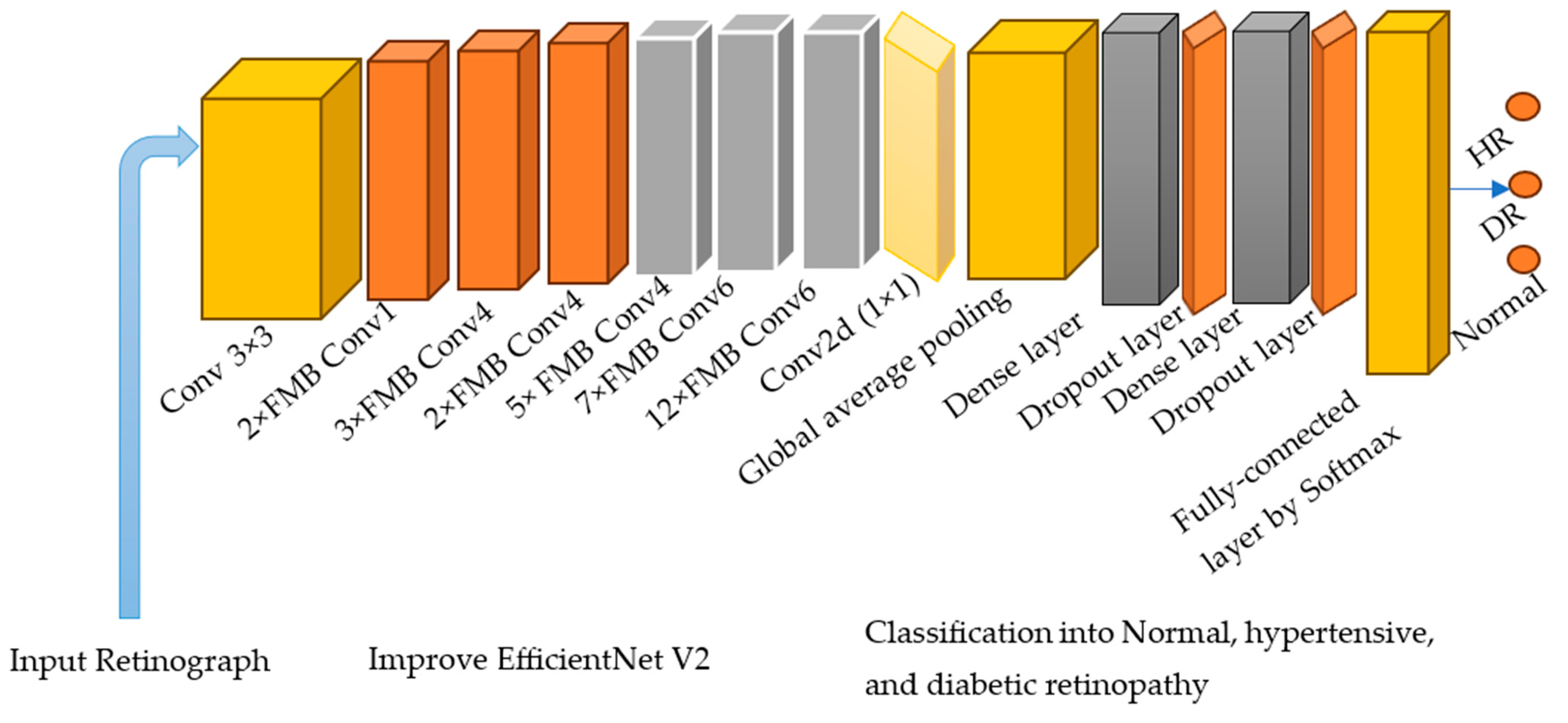
In this section, we provide a description of the experimental setup for all tests, including a concise explanation of the performance metrics used. Furthermore, we showcase the outcomes of the conducted experiments and offer an analysis of these results.
5.3. Model Evaluation Metrics
In this study, a specific dataset was utilized for the purpose of classifying instances into nine distinct categories. To comprehensively evaluate the classification results, a range of performance metrics were employed, encompassing the confusion matrix, accuracy, precision, recall, F1 score, and the Matthews correlation coefficient (MCC).
The confusion matrix serves as a detailed breakdown of the predicted and actual class assignments, capturing a variety of possible outcomes. It specifically includes true positive (TP) and true negative (TN) values, signifying the instances correctly identified as belonging to the HR and DR classes, respectively. Conversely, false positive (FP) and false negative (FN) values indicate instances inaccurately classified as HR, DR, or normal, respectively. For a comprehensive assessment of the model’s performance, the accuracy, recall, and F-measure were calculated using the macro-average technique for each of the nine classification classes. The macro-average approach treats all classes equally when calculating these metrics, offering a holistic perspective across all categories. Additionally, the Matthews correlation coefficient (MCC) was employed, as it is a robust metric capable of delivering a balanced evaluation even when classes vary significantly in size. The MCC accounts for true positives, true negatives, false positives, and false negatives, allowing for a comprehensive understanding of the model’s effectiveness.
Collectively, these metrics provide a comprehensive framework for assessing the classification model’s performance and offer valuable insights into its efficacy across diverse categories. This approach ensures a thorough evaluation of the model’s capabilities and its ability to accurately classify instances within each specific category.
Following is how these metrics are calculated:
5.4. Results Analysis
We conducted experiments using several powerful CNN models, including VGG16, AlexNet, InceptionV3, GoogleNet, Xception, MobileNet, SqueezeNet, and SqueezeNet-Light, to recognize multiclass scenarios. Additionally, we compared our results with state-of-the-art (SOTA) techniques. To assess the effectiveness of these approaches, we utilized both validation and testing splits. The proposed HDR-EfficientNet model accuracy versus loss validation curves is shown in
Figure 6. The testing data were obtained from separate sources, while the validation split was created using the same sources as the training data. This differentiation allows us to evaluate the models’ performance on unseen data and verify their generalization capabilities.
We examined various scenarios, including two-class and three-class classifications. For all experiments, we employed a 10-fold cross-validation technique, where the dataset was divided into ten subsets of roughly equal size. Each subset was used as a validation set once, while the remaining nine subsets were used for training. This approach helped to ensure a robust evaluation by considering different combinations of training and validation data. To assess the models’ efficacy, we calculated performance measures such as the accuracy, precision, recall, F1 score, and Matthew’s correlation coefficient (MCC) for each fold in the cross-validation process. The means of these metrics were then calculated and reported in the subsequent sections of this study, allowing us to evaluate the overall performance of the models across different classification scenarios. By employing these evaluation techniques, we aim to gain insights into the effectiveness of the CNN models and compare their performance in various multiclass scenarios.
With VGG16 serving as the core architecture for training, accuracy, and validation, along with a training loss and a validation loss function, we start testing our suggested HDR-EfficientNet model on the various datasets.
Figure 7 demonstrates the effectiveness of our suggested HDR-EfficientNet approach. To obtain a training accuracy and validation accuracy of above 96%, the training and validation procedures only needed to be iterated a total of 10 times. In addition, we were able to obtain a loss function below 0.1 for both training and validation data, further demonstrating the efficacy of our proposed method. The confusion matrix must first be gathered to appropriately evaluate detection performance.
5.5. Computational Cost
HDR-EfficientNet is a family of EfficientNet models that are designed to achieve state-of-the-art performance while maintaining a high level of efficiency in terms of computational complexity. The models in the EfficientNet family are scaled versions of a base architecture, where the scaling is performed uniformly across multiple dimensions, including depth, width, and resolution. The computational complexity of EfficientNet models can be characterized by two main aspects: Floating-point operations (FLOPs) and the number of parameters, which measure the number of floating-point operations required for the model to make predictions. EfficientNet models typically have a lower number of FLOPs compared to other deep neural network architectures of similar performance. This reduction in FLOPs is achieved by carefully balancing the model’s depth, width, and resolution during the scaling process.
Number of parameters: The number of parameters in a model reflects its memory requirements and affects both the model’s training time and inference time. EfficientNet models strike a balance between model size and performance by scaling the number of parameters appropriately based on the desired level of efficiency. EfficientNet models achieve a good trade-off between computational complexity and performance by employing a compound scaling method that optimizes the depth, width, and resolution simultaneously. This allows EfficientNet models to provide high accuracy while being computationally efficient, making them suitable for a wide range of applications, especially in resource-constrained environments such as mobile devices or edge computing platforms.
Let us consider HDR-EfficientNet, which is the smallest and least computationally complex variant of the EfficientNet family. The FLOPs and number of parameters for HDR-EfficientNet are as follows:
FLOPs: Approximately 0.39 billion (390 million) FLOPs. This indicates the number of floating-point operations required to process a single input image through the network.
Number of parameters: Approximately 5.3 million parameters. This represents the number of learnable weights in the model, which are adjusted during the training process. Compared to larger models such as EfficientNet-B7, which have significantly higher FLOPs and parameters, HDR-EfficientNet offers a less computationally intensive option while still achieving reasonable performance.
It is important to note that these numbers are approximate and can vary depending on the specific implementation and framework used. Additionally, the computational requirements can vary across different layers and operations within the network. HDR-EfficientNet models are designed to provide an efficient balance between computational complexity and performance, allowing for effective deployment on a range of devices and platforms. The computational parameters are mentioned in
Table 7.
One of the advantages of HDR-EfficientNet is its ability to reduce the number of parameters in the network, leading to a smaller model size. This reduction in parameters was achieved in part by using separable transfer networks.
Table 8 provides a comparison of the parameter count in the convolutional layers of various CNN models, including VGG16, AlexNet, InceptionV3, GoogleNet, Xception, MobileNet, SqueezeNet, and the proposed HDR-EfficientNet. The results revealed that the suggested model significantly reduced the number of parameters in the convolutional layer. Importantly, the reduction in parameters did not result in degenerate models but rather improved network generalization. In other words, the suggested model maintained its performance while being more efficient in terms of parameter utilization. In conclusion, the suggested HDR-EfficientNet model demonstrates superior performance, particularly when applied to large datasets, and establishes a solid foundation for its utilization in differentiation between HR and DR eye-related diseases. Furthermore, its faster running speed compared to certain other conventional models makes it a promising choice for real-time applications.
5.6. Performance Analysis
In the hyperparameter tuning process for the HDR-EfficientNet system, we aimed to optimize the learning rate, a crucial parameter affecting the training of the model. Using a grid search approach, we examined a range of learning rates, such as 0.001, 0.01, and 0.1. For each learning rate and batch size, we built the HDR-EfficientNet architecture, trained it on retinograph images, and evaluated its performance on a validation dataset. The learning rate that resulted in the highest validation accuracy was chosen as the optimal one. This process ensures that the model converges effectively during training, leading to better classification results.
In the context of performance analysis, the selection of dropout values and initial learning rates for the EfficientNet model during training was carried out randomly to mitigate the impact of manual parameter tuning. To reduce the influence of human bias, the network was trained to autonomously determine the optimal EfficientNet architecture. The dropout rate varied from 0.2 to 0.6, and the model incorporated batch normalization layers, enabling the use of higher initial learning rates ranging from 102 to 104. Training was performed using the Adam optimization technique with random choices of initial learning rates and dropout values under batch sizes of 32, 64, and 128. Each network for diverse training batches encompassed 30 distinct initial sequence parameters. A maximum of 10,000 training sessions was allowed per network with combined parameters, but training ceased if the verification set loss reached a plateau within ten sessions. To evaluate the system’s performance, various metrics including accuracy (ACC), specificity (SP), sensitivity (SE), precision (PR), recall (RL), F1-score, and Matthews correlation coefficient (MCC) were computed using statistical analysis. These metrics facilitated performance assessment and comparison with pre-trained transfer learning algorithms. The assessment spanned multiple experiments that gauged accuracy across different convolutional layers of various models such as VGG16, AlexNet, InceptionV3, GoogleNet, Xception, MobileNet, SqueezeNet, and the proposed HDR-EfficientNet model. Additionally, the area under the receiver operating curve (AUC) was used to demonstrate the efficacy of the training and validation datasets through 10-fold cross-validation tests.
Figure 6,
Figure 7 and
Figure 8 visually present the optimal plot loss, accuracy, AUC, and recall achieved during training and validation with data augmentation, conducted for 40 epochs, specifically for the HDR-EfficientNet model.
The model’s label for each category remains unmuddied even with a limited dataset training sample. The two groups have been categorized accurately.
Figure 6 shows that there is less uncertainty when using our recommended model, HDR-EfficientNet, for detection. The training phase is complete in multiple CNN and VGG19 architectures with eight to sixteen stages and pre-processing to improve contrast to compare the retinal fundus datasets.
Table 8 provides an illustration of the results. It is crucial to remember that the same number of epochs were used to train each of the CNN and VGG16 deep learning models. By employing the top-performing network to train an identical classic convolutional network, we obtained a 59% improvement in validation accuracy. The sensitivity, specificity, accuracy, and area under the curve (AUC) measurements were used to evaluate the proposed CAD performance in comparison to that of standard CNN, DRL, trained-CNN, and trained-DRL models. For the trained-CNN models on this dataset, the average values for SE, SP, ACC, and AUC were 81.5%, 83.2%, 81.5%, and 0.85, respectively. In contrast, the SE, SP, ACC, and AUC metrics values for the HDR-EfficientNet model were 94%, 96%, 95%, and 0.96, respectively. By combining the abilities of HDR-EfficientNet on four annotated fundus sets that are not prone to overfitting issues, the developed DR and HR system produced results as shown in
Table 9 that were superior to those of deep-learning models.
Table 8.
Metrics are used to evaluate the HDR system’s performance.
Table 8.
Metrics are used to evaluate the HDR system’s performance.
| Retinopathy Type | 1 SE | 2 SP | 3 ACC | 4 AUC | 5 MCC |
|---|
| Diabetic Hypertension (HR) | 93% | 96% | 94% | 0.95 | 0.76 |
| Diabetic Retinopathy (DR) | 95% | 96% | 95% | 0.96 | 0.67 |
| Normal | 93% | 96% | 94% | 0.95 | 0.76 |
| Average Result | 94% | 96% | 95% | 0.96 | 0.60 |
Figure 8.
Plot of AUC where class 0 represents the hypertension and class 1 shows the diabetes without data augmentations with 10-fold cross validation. Whereas the figure (
a) shows the dataset obtained from (Kaggle-Dataset [
32], IDRiD [
33], MESSIDOR [
34]), and (
b) shows the datasets obtained from (Kaggle-Dataset [
32], IDRiD [
33], MESSIDOR [
34], e-ophtha [
35], HRF [
36], and EYEPACS [
37]). In this experiment, we used 600 retinograph images of equal size of each category (DR, HR and normal).
Figure 8.
Plot of AUC where class 0 represents the hypertension and class 1 shows the diabetes without data augmentations with 10-fold cross validation. Whereas the figure (
a) shows the dataset obtained from (Kaggle-Dataset [
32], IDRiD [
33], MESSIDOR [
34]), and (
b) shows the datasets obtained from (Kaggle-Dataset [
32], IDRiD [
33], MESSIDOR [
34], e-ophtha [
35], HRF [
36], and EYEPACS [
37]). In this experiment, we used 600 retinograph images of equal size of each category (DR, HR and normal).
Experiment 1: In this section of the paper, we compare the proposed work to previous DL approaches and show how its superiority over those approaches may be demonstrated. A number of well-known deep learning frameworks, such as VGG16 [
20], VGG19 [
21], MobileNet [
22], ResNet50 [
23], and DenseNet-101 [
24], were proposed for this purpose. We were able to evaluate various DL architectures from the perspectives of model structure and performance by comparing the total number of model parameters and accuracy. The evaluation’s findings are displayed in
Table 9 of the report. The numbers show that, in comparison to previous DL frameworks, our technique is both successful and efficient. Apparently, this study has the fewest model parameters—11 million. The VGG19 model is more expensive in terms of model structure with a total of 1.96 million parameters. ResNet50 achieved the worst performance result in terms of model correctness, scoring 73.75%. MobileNet has the second-worst performance rating with a score of 78.84%. With an accuracy score of 93.93%, the DenseNet technique performs better, but its 40 million parameters and intricate network topology make it difficult to implement. In contrast, our method works well, scoring 98.12% accurate and using 11 million model parameters. Obviously, our model’s score is 98.12%, whereas the average for similar techniques is 83.92%. As a result, we have seen an increase in performance of 14.20%, which amply demonstrates the effectiveness of our strategy.
Experiment 2: In our evaluation, we adopted a robust 10-fold cross-validation testing strategy to comprehensively compare the statistical metrics obtained from our developed HDR-EfficientNet model with various other transfer learning (TL) algorithms. These included established models like VGG16, AlexNet, InceptionV3, GoogleNet, Xception, MobileNet, SqueezeNet, and our own SqueezeNet-Light. We assessed the classification outcomes of these pretrained deep learning (DL) models across different batch sizes, namely 16, 32, and 64, and presented the results in
Table 10,
Figure 9, and
Table 11, respectively. Interestingly, the performance of our HDR-EfficientNet model remained consistent across all batch sizes, with an identical classification outcome. However, the impact of batch size was evident in terms of the number of model parameters and computational time. This finding contrasted with the other pre-trained TL algorithms, where the classification results held steady irrespective of batch size. Our developed approach exhibited impressive results, boasting a sensitivity (SE) of 94%, specificity (SP) of 96%, accuracy (ACC) of 95.6%, precision (PR) of 94.12%, F1-score of 95.2, and Matthews correlation coefficient (MCC) of 96.7. Notably, the system also demonstrated low training error (0.76) in accurately identifying various classes of eye-related diseases within a multiclass framework. These findings underscore the efficacy and robustness of our approach in classification tasks pertaining to eye-related diseases.
The other techniques’ fairly complicated model structures, which lead to problems with model overfitting, are mostly to blame for these higher model classification outcomes. Comparatively, our strategy is more flexible and better equipped to address the overfitting problem. Additionally, our approach incorporates layers at the end of the network structure and leverages pixel and channel attention throughout the feature computation step, which aids in better recognizing the meaningful set of image characteristics and improves the cataloguing score. Therefore, it can be stated that we have offered a system that is both efficient and effective for memorizing the several categories of illnesses impacting HR and DR eye-related sickness.
Experiment 3: In this experiment, we focused on investigating the influence of different optimization techniques on classification performance. To build an efficient SqueezeNet-Light model, we employed various optimizers. Among these, adaptive algorithms like Adam exhibit rapid convergence, whereas stochastic gradient descent (SGD) optimizers demonstrate better generalization, particularly when presented with new data. In an effort to merge the strengths of both optimizer types, AdaBelief was previously developed to manage the loss function. AdaBelief is specifically designed to handle cases characterized by “large gradient, small curvature,” an aspect that Adam might struggle with.
Within the context of the same 10-fold training data setup,
Figure 10 offers a comparative analysis of optimizers, including the weighted variant. We compared the AdaBelief optimizer, which incorporates the learning rate, weight decay, and momentum settings of 1 × 10
−5, 1 × 10
−8, and 0.9, respectively, with other optimization methods. When utilizing the AdaBelief optimizer with momentum, we extended the epoch number to 40. This decision was informed by earlier experiments that demonstrated the loss function’s value continuing to decrease beyond the 30th epoch, implying a lack of convergence by the 30th epoch’s conclusion. It is important to note that for the purposes of this study, we maintained a consistent epoch number of 40 across all optimizers to ensure a fair comparison.
Table 8 consolidates the numeric outcomes of these experiments. Notably, when the AdaBelief optimizer was employed, the sensitivity (SE) value exhibited a notable increase, reaching 94%. Consequently, based on these findings, we identify the AdaBelief optimizer as the optimal choice for the optimization method in these experiments.
Experiment 4: In this particular experiment, we delved into the evaluation of various loss functions and their impact on classification performance. The outcomes highlighted the efficacy of the weighted-cross entropy loss function in enhancing classification accuracy by addressing class imbalance issues. Notably, when compared to the regular cross entropy loss, the weighted-cross entropy loss consistently yielded better results. Specifically, for different metrics, the cross-entropy loss values were 82.2 (SE), 97.8 (SP), 96.9 (ACC), 76 (PR), 79 (F1-score), and 82.2 (MCC), while the corresponding values for the weighted-cross entropy loss were significantly improved at 94 (SE), 96 (SP), 95.6 (ACC), 94.12 (PR), 95.2 (F1-score), and 96.7 (MCC). Based on these results, it becomes evident that the weighted-cross entropy loss function is more effective in enhancing classification performance. For a comprehensive overview of these outcomes,
Figure 11 presents the detailed results derived from this experiment, showcasing the superior performance achieved through the use of the weighted-cross entropy loss function.
Figure 12 presents a visual representation of the outcomes achieved through our proposed HDR-EfficientNet classifier, specifically in the context of identifying healthy retina (HR) and diabetic retinopathy (DR). While the testing splits for other disease classes were collected from diverse sources, our focus was on assessing various pre-trained transfer learning (TL) convolutional neural network (CNN) architectures. The architectures evaluated included VGG16, AlexNet, InceptionV3, GoogleNet, Xception, MobileNet, and SqueezeNet techniques. This comprehensive evaluation aimed to distinguish between different eye-related diseases across various scenarios. In order to circumvent the challenge of requiring extensive labeled data for CNN architectures, we employed data augmentation techniques. The findings of our experiments revealed that our proposed model outperformed these CNN architectures in the task of disease classification. Notably, our suggested HDR-EfficientNet architecture achieved an accuracy rate of 95.6% in effectively recognizing and classifying various types of retinograph images within a multiclass framework. This result highlights the potency of our approach and the HDR-EfficientNet model in addressing the complexities of eye-related disease identification.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}