
A Double-Teacher Model Capable of Exploiting Isomorphic and Heterogeneous Discrepancy Information for Medical Image Segmentation


Abstract
:1. Introduction
2. Related Work
2.1. Semi-Supervised Learning
2.2. Semi-Supervised Image Segmentation of Left Atrium
2.3. Uncertainty
3. Methods
3.1. Supervised Segmentation
3.2. Mean Teacher Framework with Two Teachers
4. Experimental Analysis
4.1. Dataset and Preprocessing
4.2. Experimental Details
4.3. Evaluation Metrics
4.4. Comparison with Other Methods
4.5. Ablation Experiments
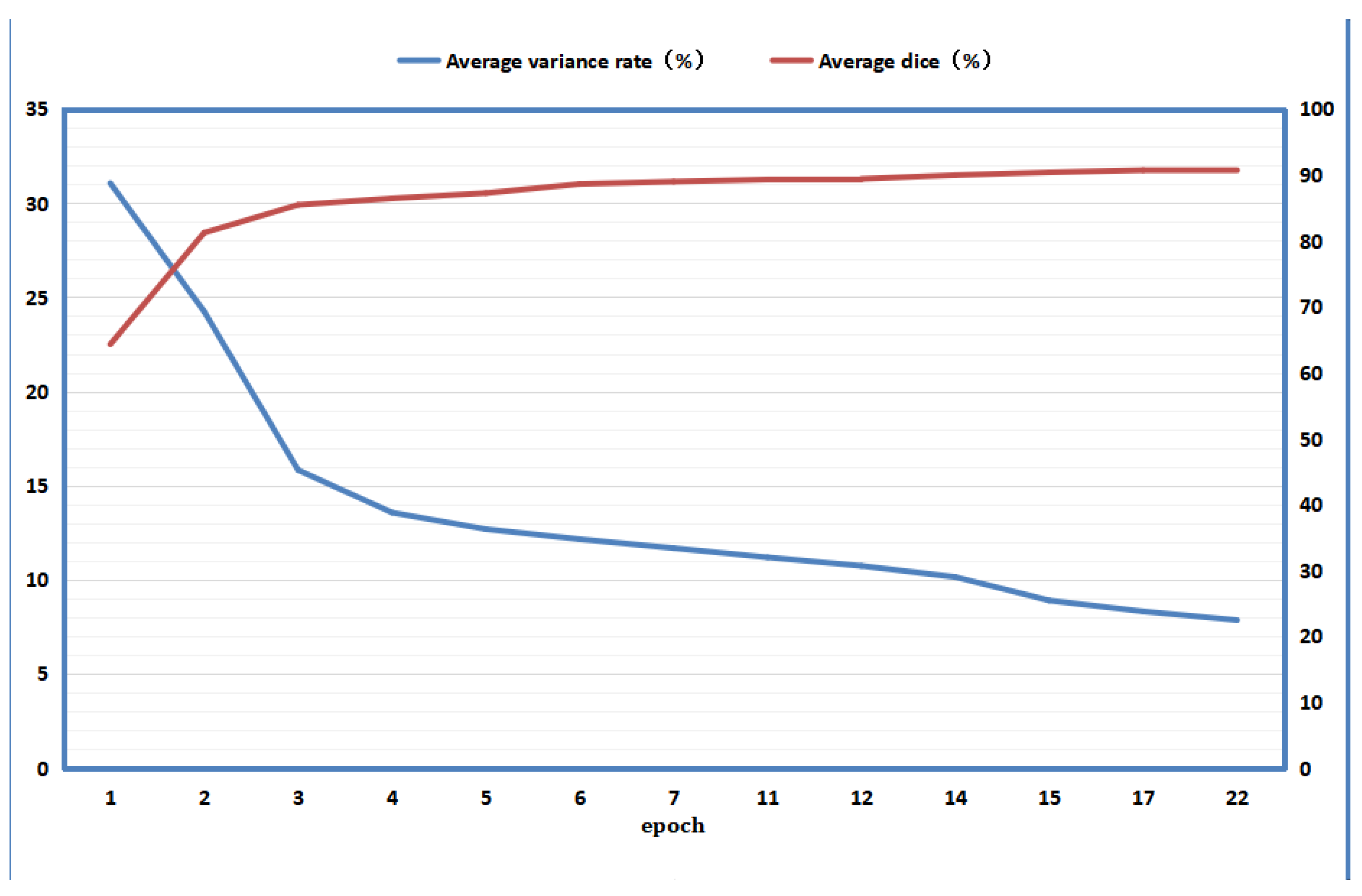
4.6. Relationship between Mean Discrepancy Rate and Mean Dice
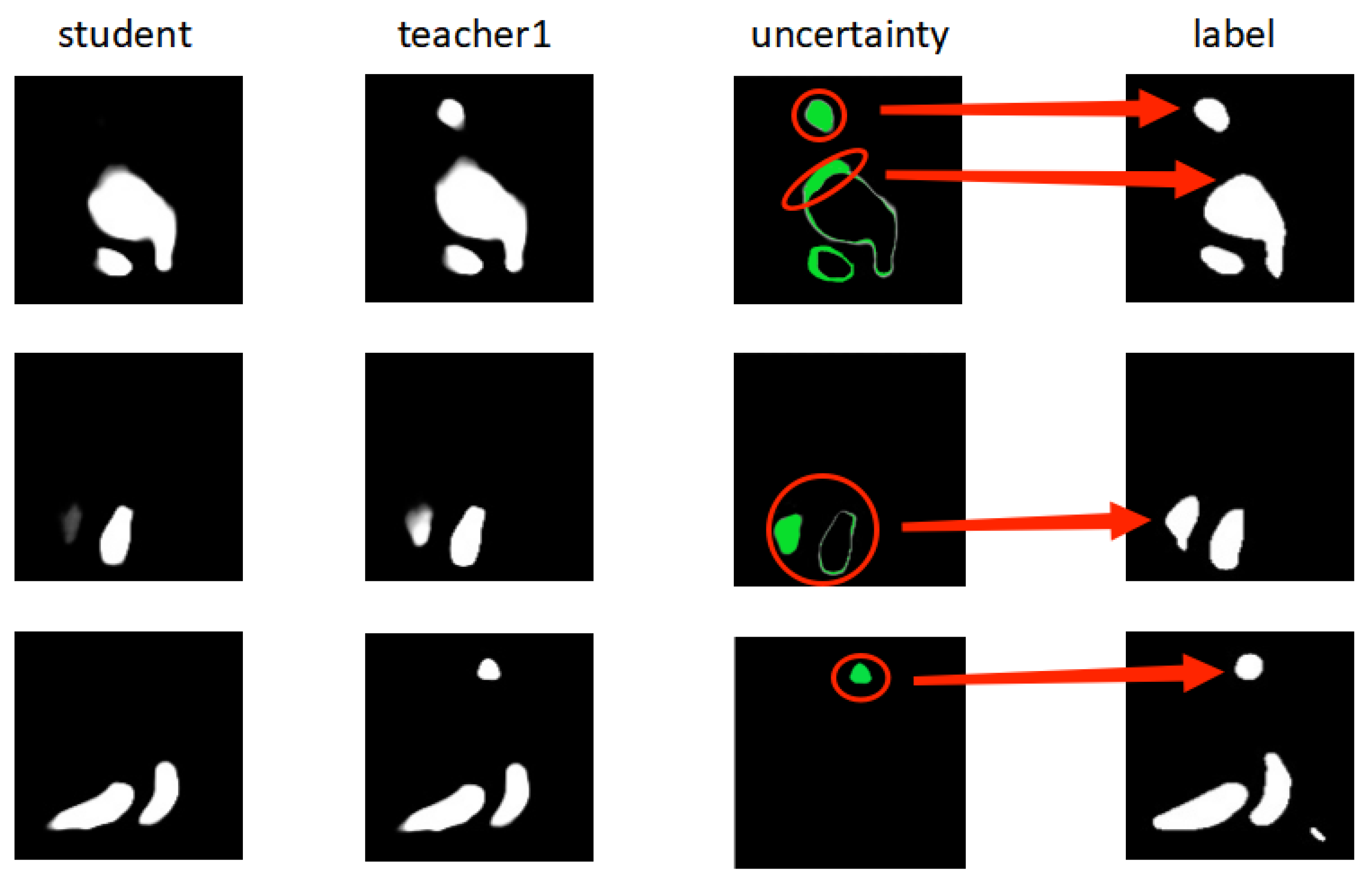
4.7. Importance of Uncertainty Derived from Discrepancy Information
4.8. Importance of Teacher Models That Can Handle Both 2D and 3D Information
4.9. Clinical Applications
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kendall, A.; Gal, Y. What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision? Adv. Neural Inf. Process. Syst. 2017, 30, 5580–5590. [Google Scholar]
- Yu, L.; Wang, S.; Li, X.; Fu, C.W.; Heng, P.A. Uncertainty-Aware Self-Ensembling Model for Semi-Supervised 3D Left Atrium Segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2019: 22nd International Conference, Shenzhen, China, 13–17 October 2019; pp. 605–613. [Google Scholar]
- Wu, Y.; Xu, M.; Ge, Z.; Cai, J.; Zhang, L. Semi-Supervised Left Atrium Segmentation with Mutual Consistency Training. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2021: 24th International Conference, Strasbourg, France, 27 September–1 October 2021; pp. 297–306. [Google Scholar]
- Woo, B.; Lee, M. Comparison of Tissue Segmentation Performance between 2D U-Net and 3D U-Net on Brain MR Images. In Proceedings of the 2021 International Conference on Electronics, Information, and Communication (ICEIC), Jeju, Republic of Korea, 31 January–3 February 2021; pp. 1–4. [Google Scholar]
- Portela, N.M.; Cavalcanti, G.; Ren, T.I. Semi-supervised clustering for MR brain image segmentation. Expert Syst. Appl. 2014, 41, 1492–1497. [Google Scholar] [CrossRef]
- You, X.; Peng, Q.; Yuan, Y.; Cheung, Y.M.; Lei, J. Segmentation of retinal blood vessels using the radial projection and semi-supervised approach. Pattern Recognit. 2011, 44, 2314–2324. [Google Scholar] [CrossRef]
- Kalluri, T.; Varma, G.; Chandrakar, M.; Jawahar, C.V. Universal Semi-Supervised Semantic Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5259–5270. [Google Scholar]
- Zhang, Y.; Yang, L.; Chen, J.; Fredericksen, M.; Hughes, D.P.; Chen, D.Z. Deep Adversarial Networks for Biomedical Image Segmentation Utilizing Unannotated Images. In Proceedings of the Medical Image Computing and Computer Assisted Intervention— MICCAI 2017: 20th International Conference, Quebec City, QC, Canada, 11–13 September 2017; pp. 408–416. [Google Scholar]
- Bai, W.; Oktay, O.; Sinclair, M.; Suzuki, H.; Rajchl, M.; Tarroni, G.; Glocker, B.; King, A.; Matthews, P.M.; Rueckert, D. Semi-Supervised Learning for Network-Based Cardiac MR Image Segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2017: 20th International Conference, Quebec City, QC, Canada, 11–13 September 2017; pp. 253–260. [Google Scholar]
- Krhenbühl, P.; Koltun, V. Efficient Inference in Fully Connected CRFs with Gaussian Edge Potentials. Adv. Neural Inf. Process. Syst. 2011, 24, 109–117. [Google Scholar]
- Rizve, M.N.; Duarte, K.; Rawat, Y.S.; Shah, M. In Defense of Pseudo-Labeling: An Uncertainty-Aware Pseudo-label Selection Framework for Semi-Supervised Learning. arXiv 2021, arXiv:2101.06329. [Google Scholar]
- Zhou, Y.; Wang, Y.; Tang, P.; Bai, S.; Yuille, A. Semi-Supervised 3D Abdominal Multi-Organ Segmentation Via Deep Multi-Planar Co-Training. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 7–11 January 2019; pp. 121–140. [Google Scholar]
- Wang, Y.; Huang, G.; Song, S.; Pan, X.; Xia, Y.; Wu, C. Regularizing Deep Networks with Semantic Data Augmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3733–3748. [Google Scholar] [CrossRef] [PubMed]
- Sajjadi, M.; Javanmardi, M.; Tasdizen, T. Regularization with Stochastic Transformations and Perturbations for Deep Semi-Supervised Learning. Adv. Neural Inf. Process. Syst. 2016, 29, 1171–1179. [Google Scholar]
- Li, X.; Yu, L.; Chen, H.; Fu, C.W.; Heng, P.A. Semi-supervised Skin Lesion Segmentation via Transformation Consistent Self-ensembling Model. arXiv 2018, arXiv:1808.03887. [Google Scholar]
- Xie, Y.; Zhang, J.; Liao, Z.; Verjans, J.; Shen, C.; Xia, Y. Pairwise Relation Learning for Semi-Supervised Gland Segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2020: 23rd International Conference, Lima, Peru, 4–8 October 2020; pp. 417–427. [Google Scholar]
- Luo, X.; Liao, W.; Chen, J.; Song, T.; Chen, Y.; Zhang, S.; Chen, N.; Wang, G.; Zhang, S. Efficient Semi-Supervised Gross Target Volume of Nasopharyngeal Carcinoma Segmentation via Uncertainty Rectified Pyramid Consistency. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, 27 September–1 October 2021; pp. 318–329. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. Adv. Neural Inf. Process. Syst. 2017, 30, 1195–1204. [Google Scholar]
- Li, X.; Yu, L.; Chen, H.; Fu, C.W.; Heng, P.A. Transformation-Consistent Self-Ensembling Model for Semisupervised Medical Image Segmentation. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 523–534. [Google Scholar] [CrossRef] [PubMed]
- Luo, X.; Chen, J.; Song, T.; Chen, Y.; Zhang, S. Semi-supervised Medical Image Segmentation through Dual-task Consistency. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; Volume 35, pp. 8801–8809. [Google Scholar]
- Li, S.; Zhang, C.; He, X. Shape-Aware Semi-Supervised 3D Semantic Segmentation for Medical Images. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2020: 23rd International Conference, Lima, Peru, 4–8 October 2020; pp. 552–561. [Google Scholar]
- Wang, Y.; Zhang, Y.; Tian, J.; Zhong, C.; Shi, Z.; Zhang, Y.; He, Z. Double-Uncertainty Weighted Method for Semi-Supervised Learning. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2020: 23rd International Conference, Lima, Peru, 4–8 October 2020; pp. 542–551. [Google Scholar]
- Li, S.; Zhao, Z.; Xu, K.; Zeng, Z.; Guan, C. Hierarchical Consistency Regularized Mean Teacher for Semi-Supervised 3D Left Atrium Segmentation. In Proceedings of the 2021 43rd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Guadalajara, Mexico, 1–5 November 2021; pp. 3395–3398. [Google Scholar]
- Lakshminarayanan, B.; Pritzel, A.; Blundell, C. Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles. Adv. Neural Inf. Process. Syst. 2017, 30, 6405–6416. [Google Scholar]
- Gal, Y.; Ghahramani, Z. Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 1050–1059. [Google Scholar]
- Sedai, S.; Antony, B.; Rai, R.; Jones, K.; Ishikawa, H.; Schuman, J.; Gadi, W.; Garnavi, R. Uncertainty Guided Semi-Supervised Segmentation of Retinal Layers in OCT Images. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2019: 22nd International Conference, Shenzhen, China, 13–17 October 2019; pp. 282–290. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Zhou, Y.; Huang, W.; Dong, P.; Xia, Y.; Wang, S. D-UNet: A Dimension-Fusion U Shape Network for Chronic Stroke Lesion Segmentation. IEEE/ACM Trans. Comput. Biol. Bioinform. 2019, 18, 940–950. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Laine, S.; Aila, T. Temporal Ensembling for Semi-Supervised Learning. arXiv 2016, arXiv:1610.02242. [Google Scholar]
- Han, K.; Liu, L.; Song, Y.; Liu, Y.; Qiu, C.; Tang, Y.; Teng, Q.; Liu, Z. An Effective Semi-Supervised Approach for Liver CT Image Segmentation. IEEE J. Biomed. Health Inform. 2022, 26, 3999–4007. [Google Scholar] [CrossRef] [PubMed]
- Xiong, Z.; Xia, Q.; Hu, Z.; Huang, N.; Zhao, J. A global benchmark of algorithms for segmenting the left atrium from late gadolinium-enhanced cardiac magnetic resonance imaging. Med. Image Anal. 2021, 67, 101832. [Google Scholar] [CrossRef] [PubMed]
- Hang, W.; Feng, W.; Liang, S.; Yu, L.; Wang, Q.; Choi, K.S.; Qin, J. Local and Global Structure-Aware Entropy Regularized Mean Teacher Model for 3D Left Atrium Segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2020: 23rd International Conference, Lima, Peru, 4–8 October 2020; pp. 562–571. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | # Scans Used | Metrics | ||||
|---|---|---|---|---|---|---|
| Labeled | Unlabeled | Dice | Jaccard | 95HD (v) | ASD (v) | |
| V-Net | 8 (10%) | 72 | 79.99% | 68.12% | 21.11 | 5.48 |
| UA-MT [2] | 8 (10%) | 72 | 84.25% | 73.48% | 13.84 | 3.36 |
| SASSNet [21] | 8 (10%) | 72 | 87.32% | 77.72% | 9.62 | 2.55 |
| DUWM [22] | 8 (10%) | 72 | 85.91% | 75.75% | 12.67 | 3.31 |
| LG-ER-MT [32] | 8 (10%) | 72 | 85.54% | 75.12% | 13.29 | 3.77 |
| DTC [20] | 8 (10%) | 72 | 86.57% | 76.55% | 14.47 | 3.74 |
| MC-Net [3] | 8 (10%) | 72 | 87.71% | 78.31% | 9.36 | 2.18 |
| ISO-MT (ours) | 8 (10%) | 72 | 87.93% | 78.85% | 7.93 | 2.07 |
| V-Net | 16 (20%) | 64 | 86.03% | 76.06% | 14.26 | 3.51 |
| UA-MT-UN [2] | 16 (20%) | 64 | 88.83% | 80.13% | 10.04 | 3.12 |
| UA-MT [2] | 16 (20%) | 64 | 88.88% | 80.21% | 7.32 | 2.26 |
| SASSNet [21] | 16 (20%) | 64 | 89.54% | 81.24% | 8.24 | 2.20 |
| DUWM [22] | 16 (20%) | 64 | 89.65% | 81.35% | 7.04 | 2.03 |
| LG-ER-MT [32] | 16 (20%) | 64 | 89.62% | 81.31% | 7.16 | 2.06 |
| DTC [20] | 16 (20%) | 64 | 89.42% | 80.98% | 7.32 | 2.10 |
| MC-Net [3] | 16 (20%) | 64 | 90.34% | 82.48% | 6.00 | 1.77 |
| ISO-MT (ours) | 16 (20%) | 64 | 90.85% | 83.38% | 5.23 | 1.55 |
| Method | # Scans Used | Metrics | ||||
|---|---|---|---|---|---|---|
| Labeled | Unlabeled | Dice | Jaccard | 95HD (v) | ASD (v) | |
| Teacher1 | 8 (10%) | 72 | 86.87% | 77.95% | 7.40 | 1.95 |
| Teacher1 + PO | 8 (10%) | 72 | 87.75% | 78.65% | 7.67 | 2.20 |
| Teacher1 + teacher2 | 8 (10%) | 72 | 87.70% | 78.63% | 7.66 | 1.96 |
| Teacher1 + P + Teacher2 | 8 (10%) | 72 | 87.93% | 78.85% | 7.93 | 2.07 |
| Teacher1 | 16 (20%) | 64 | 90.19% | 82.27% | 6.56 | 2.01 |
| Teacher1 + PO | 16 (20%) | 64 | 90.65% | 83.03% | 5.16 | 1.67 |
| Teacher1 + teacher2 | 16 (20%) | 64 | 90.44% | 82.84% | 5.19 | 1.63 |
| Teacher1 + PO + teacher2 | 16 (20%) | 64 | 90.85% | 83.38% | 5.23 | 1.55 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zou, J.; Wang, Z.; Du, X. A Double-Teacher Model Capable of Exploiting Isomorphic and Heterogeneous Discrepancy Information for Medical Image Segmentation. Diagnostics 2023, 13, 1971. https://doi.org/10.3390/diagnostics13111971
Zou J, Wang Z, Du X. A Double-Teacher Model Capable of Exploiting Isomorphic and Heterogeneous Discrepancy Information for Medical Image Segmentation. Diagnostics. 2023; 13(11):1971. https://doi.org/10.3390/diagnostics13111971
Chicago/Turabian StyleZou, Junguo, Zhaohe Wang, and Xiuquan Du. 2023. "A Double-Teacher Model Capable of Exploiting Isomorphic and Heterogeneous Discrepancy Information for Medical Image Segmentation" Diagnostics 13, no. 11: 1971. https://doi.org/10.3390/diagnostics13111971
APA StyleZou, J., Wang, Z., & Du, X. (2023). A Double-Teacher Model Capable of Exploiting Isomorphic and Heterogeneous Discrepancy Information for Medical Image Segmentation. Diagnostics, 13(11), 1971. https://doi.org/10.3390/diagnostics13111971