






On the Use of a Convolutional Block Attention Module in Deep Learning-Based Human Activity Recognition with Motion Sensors


Abstract
1. Introduction
- Although the effect of using attention with some deep learning architectures has been investigated in related studies, we are interested in exploring how an already good-performing deep model, DeepConvLSTM, can benefit from channel, spatial, or both attention methods.
- We performed an extensive set of experiments to explore how different reduction ratios and kernel sizes of attention and the application of attention at different depths of the deep architecture impact the performance of recognition on two different datasets where multiple body positions were involved with a large set of activities. In Section 5, we present a comparison with studies that utilize attention on the same datasets and show that we could achieve higher scores using the combination of CBAM and DeepConvLSTM.
- We also found that adding attention did not significantly increase the number of additional model parameters. Although we did not run these models on a mobile or wearable device in this work, having less complex models is important for future work when these models are ported to mobile or edge devices where computational resources are limited compared to a server or a cloud environment [37].
2. Related Work
3. Methodology
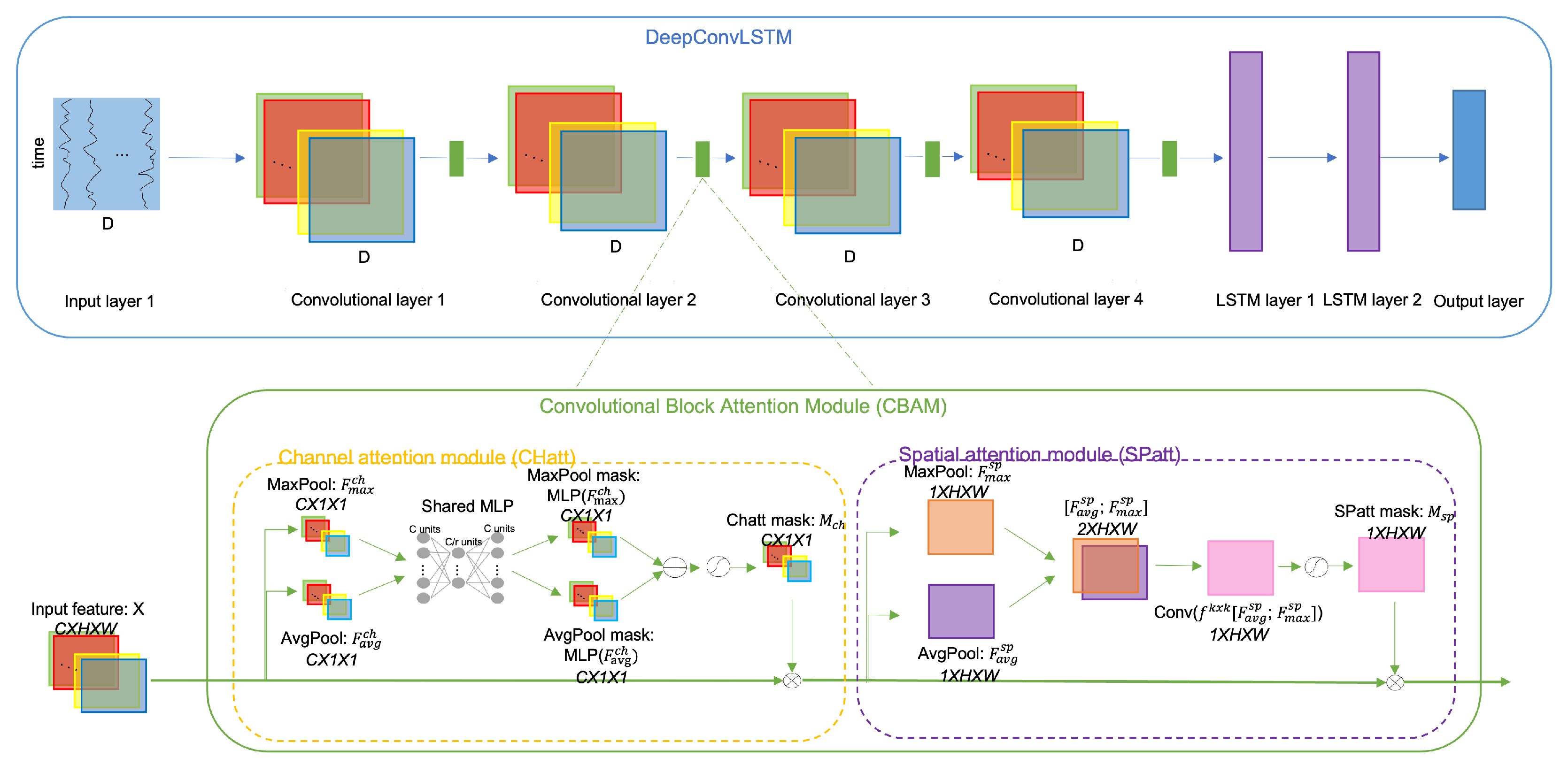
3.1. Convolutional Block Attention Module
3.2. DeepConvLSTM
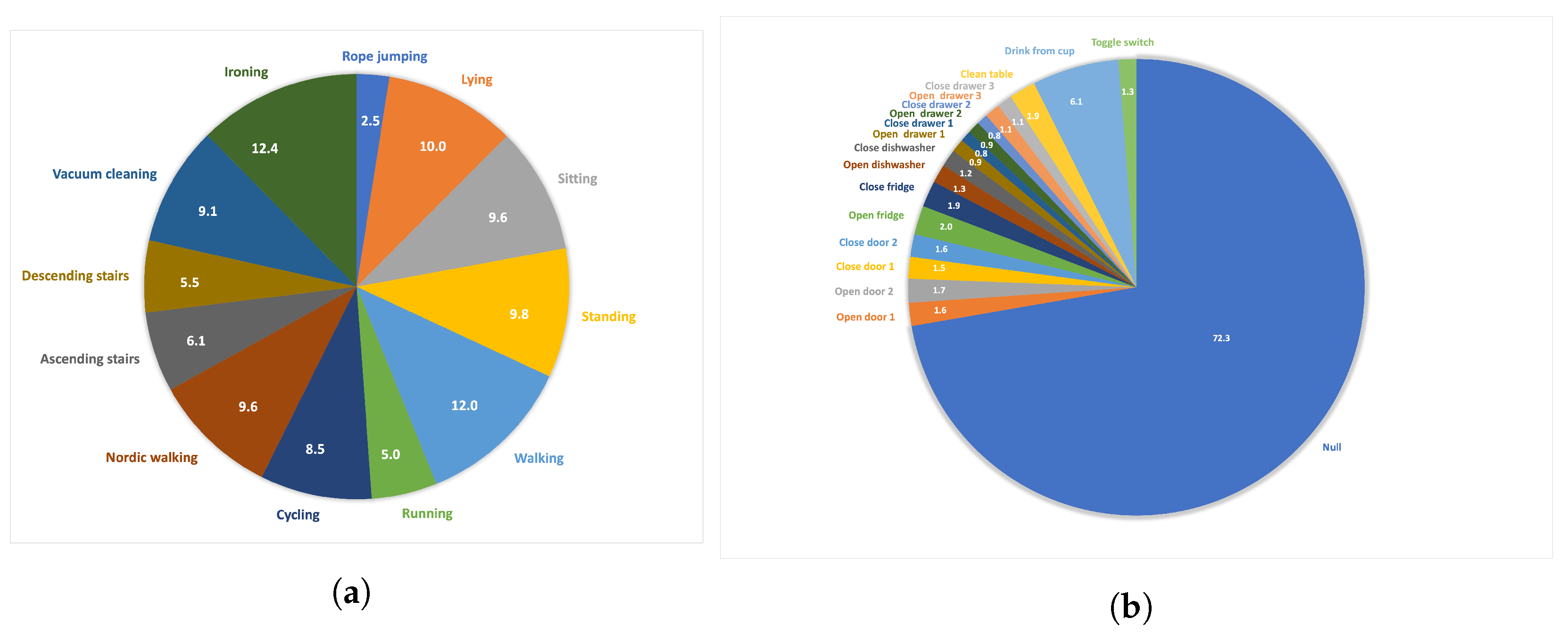
3.3. Datasets
3.4. Implementation Details
4. Results
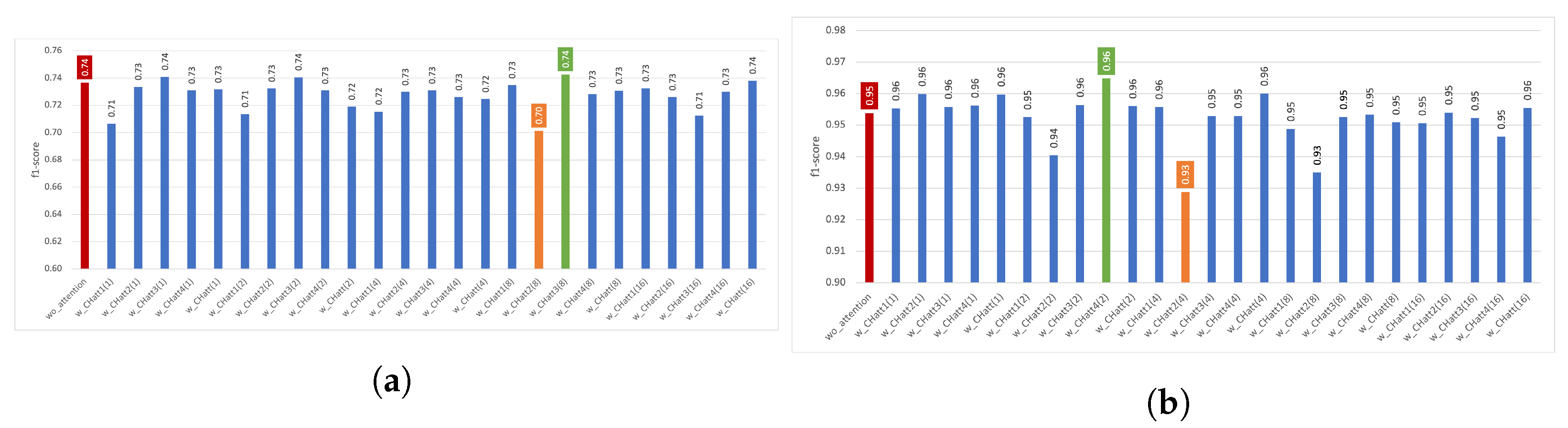
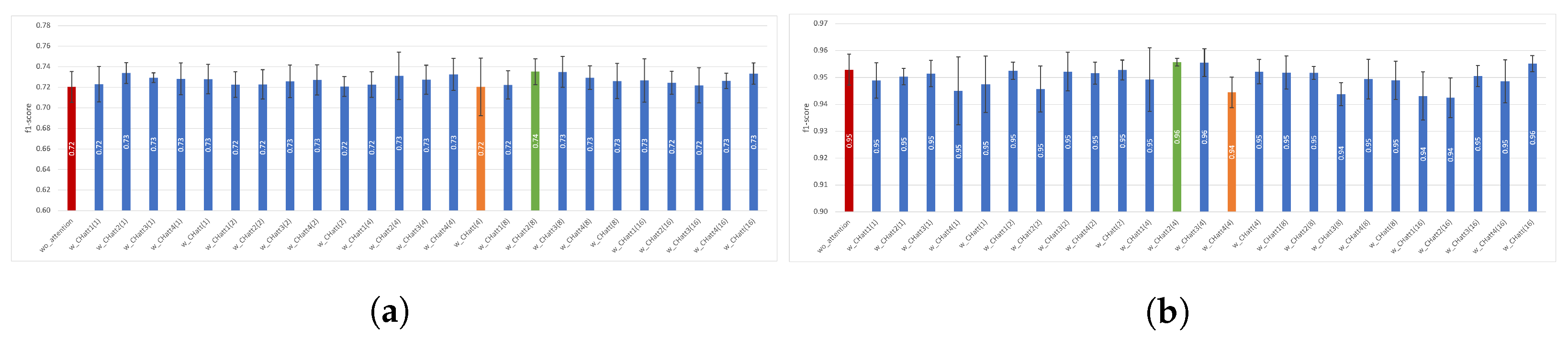
4.1. Experiments with Channel Attention
4.1.1. Results Using the Train–Test Split
4.1.2. Results Using Five-Fold Cross Validation
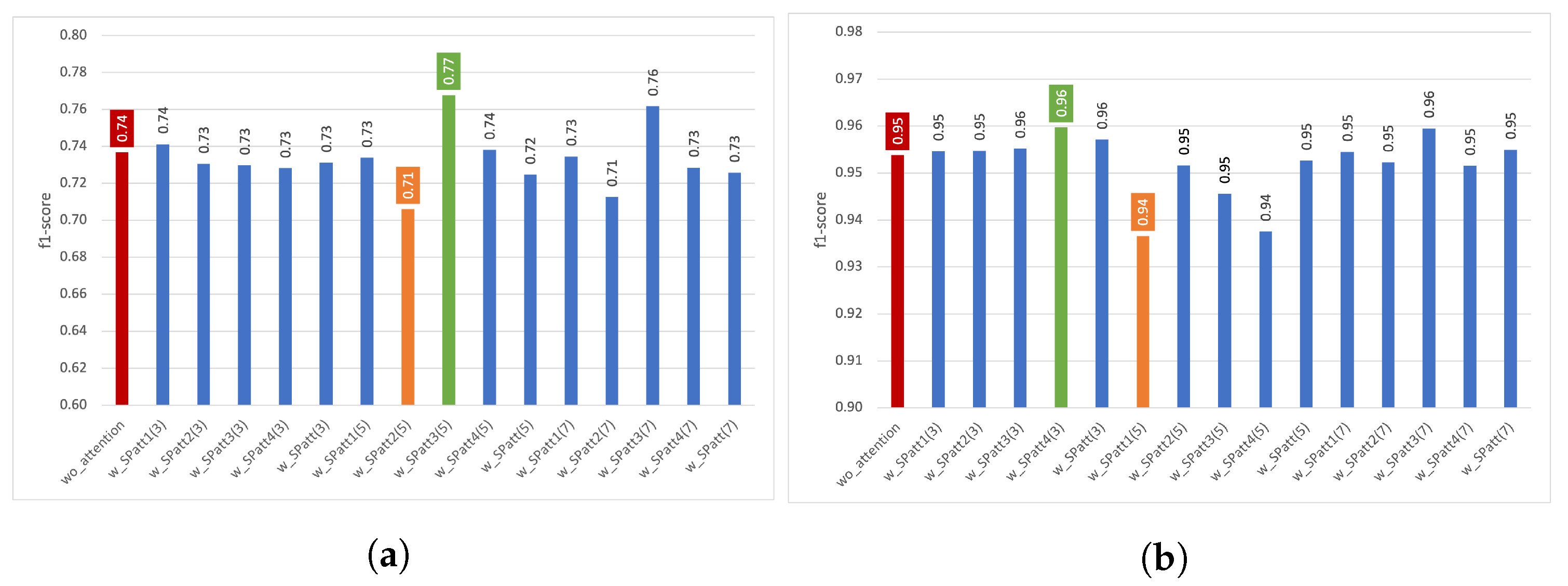
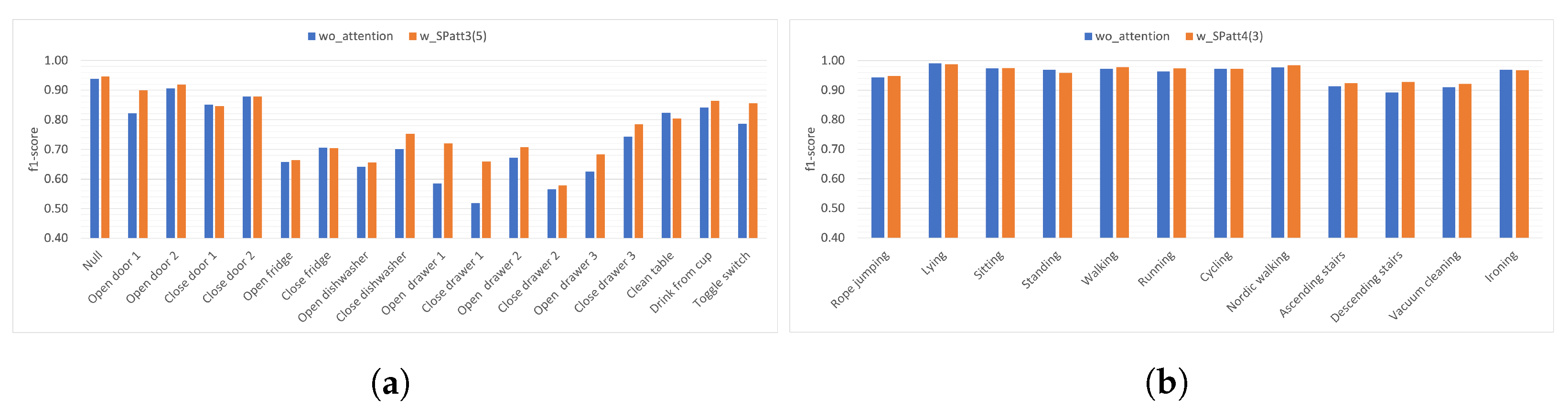
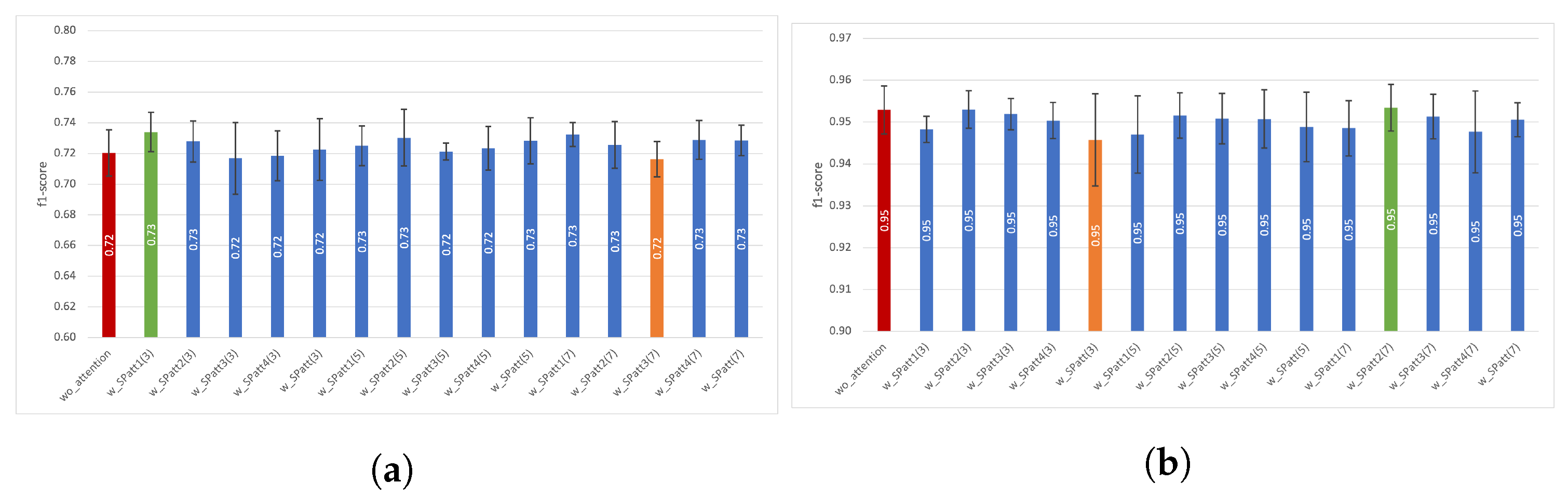
4.2. Experiments with Spatial Attention
4.2.1. Results Using Train–Test Split
4.2.2. Results Using Five-Fold Cross Validation
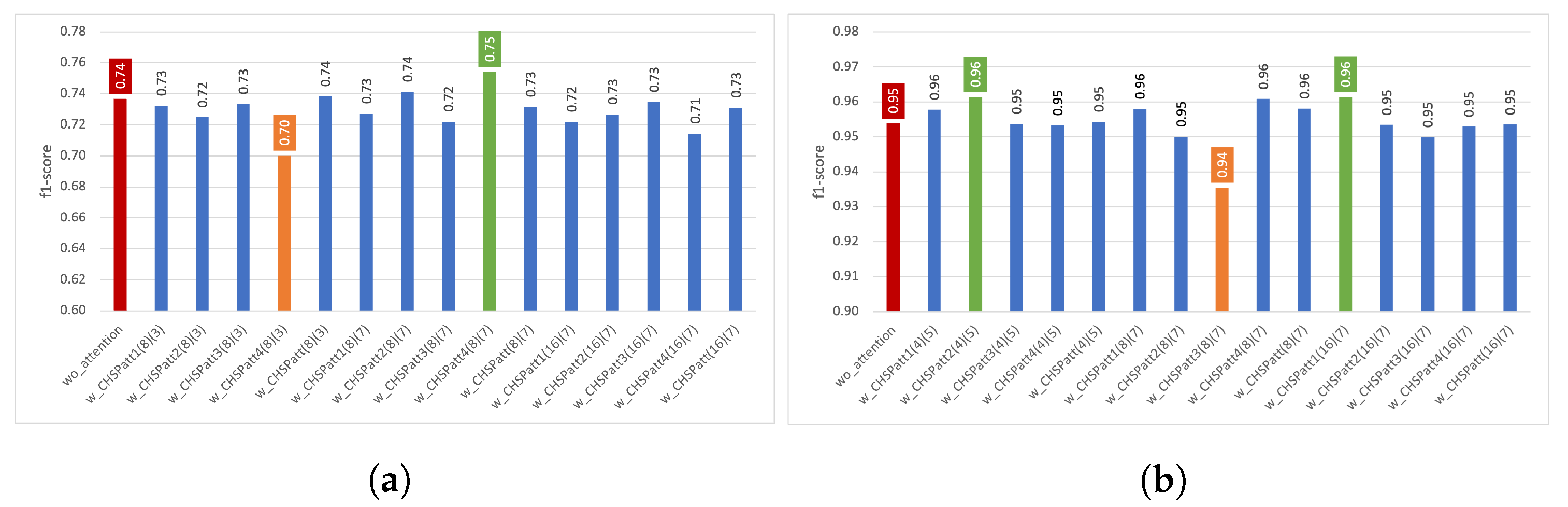
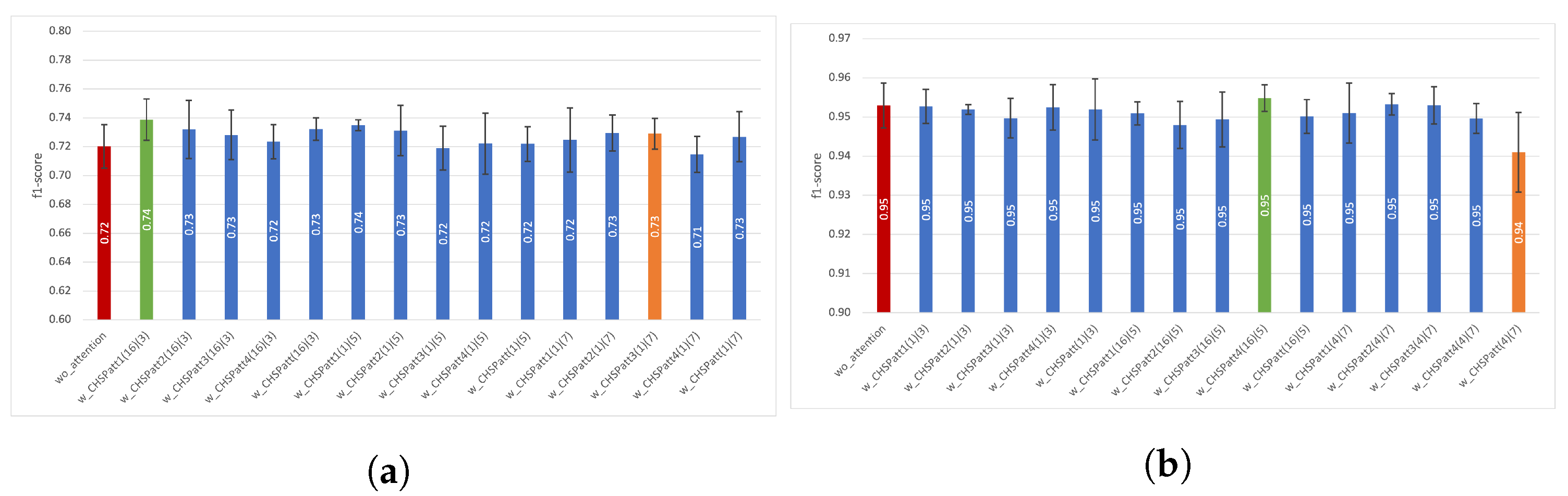
4.3. Experiments with Channel–Spatial Attention
4.3.1. Results Using Train–Test Split
4.3.2. Results Using Five-Fold Cross Validation
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
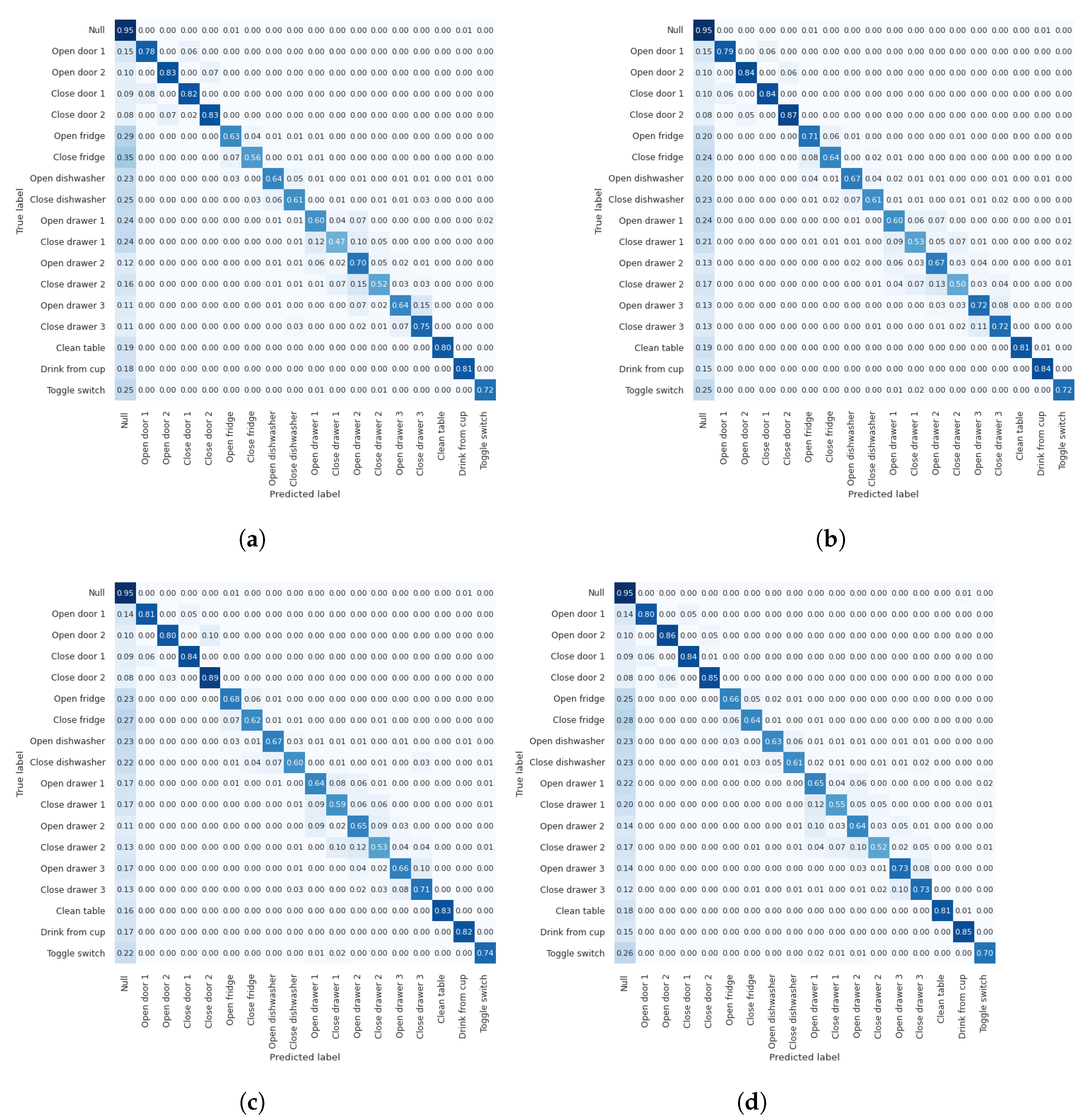
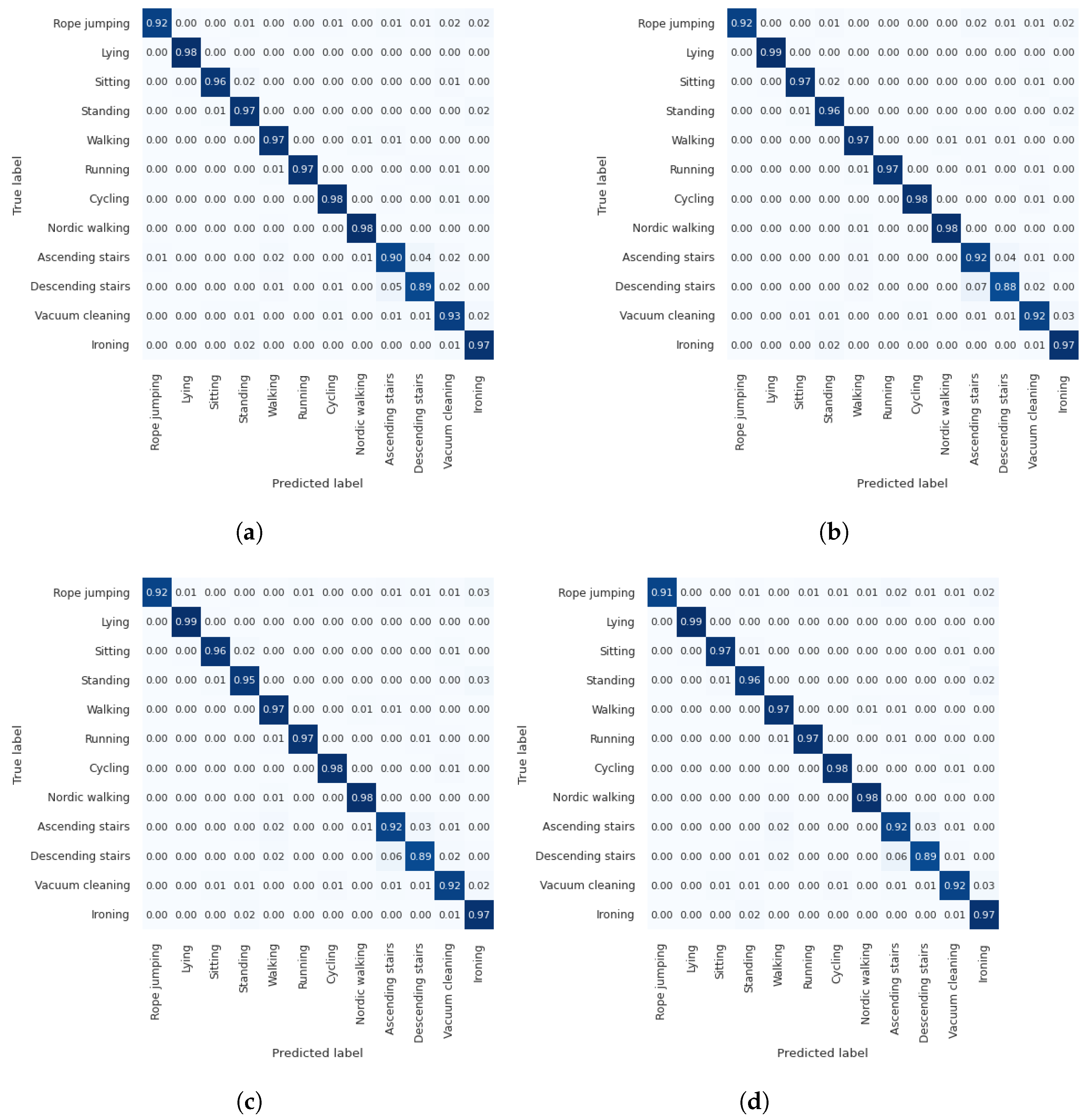
Appendix A. Additional Results

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Opportunity | Pamap2 | (Continue) | Opportunity | Pamap2 | |
|---|---|---|---|---|---|
| wo_attention | 0.74 | 0.95 | |||
| w_CHSPatt1(1)(3) | 0.72 | 0.95 | w_CHSPatt1(8)(5) | 0.71 | 0.95 |
| w_CHSPatt2(1)(3) | 0.73 | 0.95 | w_CHSPatt2(8)(5) | 0.73 | 0.96 |
| w_CHSPatt3(1)(3) | 0.73 | 0.96 | w_CHSPatt3(8)(5) | 0.73 | 0.95 |
| w_CHSPatt4(1)(3) | 0.73 | 0.96 | w_CHSPatt4(8)(5) | 0.74 | 0.95 |
| w_CHSPatt(1)(3) | 0.73 | 0.95 | w_CHSPatt(8)(5) | 0.72 | 0.96 |
| w_CHSPatt1(2)(3) | 0.73 | 0.96 | w_CHSPatt1(16)(5) | 0.72 | 0.96 |
| w_CHSPatt2(2)(3) | 0.73 | 0.95 | w_CHSPatt2(16)(5) | 0.71 | 0.96 |
| w_CHSPatt3(2)(3) | 0.72 | 0.96 | w_CHSPatt3(16)(5) | 0.73 | 0.95 |
| w_CHSPatt4(2)(3) | 0.73 | 0.95 | w_CHSPatt4(16)(5) | 0.75 | 0.96 |
| w_CHSPatt(2)(3) | 0.73 | 0.94 | w_CHSPatt(16)(5) | 0.72 | 0.95 |
| w_CHSPatt1(4)(3) | 0.75 | 0.96 | w_CHSPatt1(1)(7) | 0.74 | 0.96 |
| w_CHSPatt2(4)(3) | 0.73 | 0.96 | w_CHSPatt2(1)(7) | 0.72 | 0.95 |
| w_CHSPatt3(4)(3) | 0.72 | 0.96 | w_CHSPatt3(1)(7) | 0.73 | 0.95 |
| w_CHSPatt4(4)(3) | 0.73 | 0.95 | w_CHSPatt4(1)(7) | 0.72 | 0.95 |
| w_CHSPatt(4)(3) | 0.72 | 0.96 | w_CHSPatt(1)(7) | 0.71 | 0.95 |
| w_CHSPatt1(8)(3) | 0.73 | 0.95 | w_CHSPatt1(2)(7) | 0.73 | 0.96 |
| w_CHSPatt2(8)(3) | 0.72 | 0.95 | w_CHSPatt2(2)(7) | 0.70 | 0.96 |
| w_CHSPatt3(8)(3) | 0.73 | 0.96 | w_CHSPatt3(2)(7) | 0.73 | 0.94 |
| w_CHSPatt4(8)(3) | 0.70 | 0.95 | w_CHSPatt4(2)(7) | 0.73 | 0.96 |
| w_CHSPatt(8)(3) | 0.74 | 0.95 | w_CHSPatt(2)(7) | 0.73 | 0.96 |
| w_CHSPatt1(16)(3) | 0.73 | 0.95 | w_CHSPatt1(4)(7) | 0.72 | 0.94 |
| w_CHSPatt2(16)(3) | 0.71 | 0.95 | w_CHSPatt2(4)(7) | 0.71 | 0.96 |
| w_CHSPatt3(16)(3) | 0.73 | 0.96 | w_CHSPatt3(4)(7) | 0.75 | 0.95 |
| w_CHSPatt4(16)(3) | 0.74 | 0.96 | w_CHSPatt4(4)(7) | 0.73 | 0.95 |
| w_CHSPatt(16)(3) | 0.72 | 0.95 | w_CHSPatt(4)(7) | 0.73 | 0.96 |
| w_CHSPatt1(1)(5) | 0.73 | 0.95 | w_CHSPatt1(8)(7) | 0.73 | 0.96 |
| w_CHSPatt2(1)(5) | 0.73 | 0.94 | w_CHSPatt2(8)(7) | 0.74 | 0.95 |
| w_CHSPatt3(1)(5) | 0.73 | 0.95 | w_CHSPatt3(8)(7) | 0.72 | 0.94 |
| w_CHSPatt4(1)(5) | 0.75 | 0.96 | w_CHSPatt4(8)(7) | 0.75 | 0.96 |
| w_CHSPatt(1)(5) | 0.72 | 0.96 | w_CHSPatt(8)(7) | 0.73 | 0.96 |
| w_CHSPatt1(2)(5) | 0.73 | 0.96 | w_CHSPatt1(16)(7) | 0.72 | 0.96 |
| w_CHSPatt2(2)(5) | 0.73 | 0.96 | w_CHSPatt2(16)(7) | 0.73 | 0.95 |
| w_CHSPatt3(2)(5) | 0.72 | 0.96 | w_CHSPatt3(16)(7) | 0.73 | 0.95 |
| w_CHSPatt4(2)(5) | 0.72 | 0.96 | w_CHSPatt4(16)(7) | 0.71 | 0.95 |
| w_CHSPatt(2)(5) | 0.73 | 0.95 | w_CHSPatt(16)(7) | 0.73 | 0.95 |
| w_CHSPatt1(4)(5) | 0.71 | 0.96 | |||
| w_CHSPatt2(4)(5) | 0.73 | 0.96 | |||
| w_CHSPatt3(4)(5) | 0.73 | 0.95 | |||
| w_CHSPatt4(4)(5) | 0.75 | 0.95 | |||
| w_CHSPatt(4)(5) | 0.72 | 0.95 |
References
- Shoaib, M.; Bosch, S.; Incel, O.D.; Scholten, H.; Havinga, P.J. A survey of online activity recognition using mobile phones. Sensors 2015, 15, 2059–2085. [Google Scholar] [CrossRef]
- Khan, N.S.; Ghani, M.S. A survey of deep learning based models for human activity recognition. Wirel. Pers. Commun. 2021, 120, 1593–1635. [Google Scholar] [CrossRef]
- Zhang, S.; Li, Y.; Zhang, S.; Shahabi, F.; Xia, S.; Deng, Y.; Alshurafa, N. Deep learning in human activity recognition with wearable sensors: A review on advances. Sensors 2022, 22, 1476. [Google Scholar] [CrossRef]
- Hussain, A.; Zafar, K.; Baig, A.R.; Almakki, R.; AlSuwaidan, L.; Khan, S. Sensor-Based Gym Physical Exercise Recognition: Data Acquisition and Experiments. Sensors 2022, 22, 2489. [Google Scholar] [CrossRef]
- Vavoulas, G.; Chatzaki, C.; Malliotakis, T.; Pediaditis, M.; Tsiknakis, M. The mobiact dataset: Recognition of activities of daily living using smartphones. In Proceedings of the International Conference on Information and Communication Technologies for Ageing Well and e-Health, Rome, Italy, 1 January 2016; Volume 2, pp. 143–151. [Google Scholar]
- Reyes-Ortiz, J.L.; Oneto, L.; Samà, A.; Parra, X.; Anguita, D. Transition-aware human activity recognition using smartphones. Neurocomputing 2016, 171, 754–767. [Google Scholar] [CrossRef]
- Gravina, R.; Alinia, P.; Ghasemzadeh, H.; Fortino, G. Multi-sensor fusion in body sensor networks: State-of-the-art and research challenges. Inf. Fusion 2017, 35, 68–80. [Google Scholar] [CrossRef]
- Chen, Y.; Xue, Y. A deep learning approach to human activity recognition based on single accelerometer. In Proceedings of the 2015 IEEE International Conference on Systems, Man, and Cybernetics, Hong Kong, China, 9–12 October 2015; pp. 1488–1492. [Google Scholar]
- Grzeszick, R.; Lenk, J.M.; Rueda, F.M.; Fink, G.A.; Feldhorst, S.; ten Hompel, M. Deep neural network based human activity recognition for the order picking process. In Proceedings of the 4th International Workshop on Sensor-Based Activity Recognition and Interaction, Rostock, Germany, 21–22 September 2017; pp. 1–6. [Google Scholar]
- Abedin, A.; Ehsanpour, M.; Shi, Q.; Rezatofighi, H.; Ranasinghe, D.C. Attend and Discriminate: Beyond the State-of-the-Art for Human Activity Recognition Using Wearable Sensors. Proc. ACM Interactive Mobile Wearable Ubiquitous Technol. 2021, 5, 1–22. [Google Scholar] [CrossRef]
- Huynh-The, T.; Hua, C.H.; Tu, N.A.; Kim, D.S. Physical activity recognition with statistical-deep fusion model using multiple sensory data for smart health. IEEE Internet Things J. 2020, 8, 1533–1543. [Google Scholar] [CrossRef]
- Hanif, M.A.; Akram, T.; Shahzad, A.; Khan, M.A.; Tariq, U.; Choi, J.I.; Nam, Y.; Zulfiqar, Z. Smart Devices Based Multisensory Approach for Complex Human Activity Recognition. Comput. Mater. Contin. 2022, 70, 3221–3234. [Google Scholar] [CrossRef]
- Pires, I.M.; Pombo, N.; Garcia, N.M.; Flórez-Revuelta, F. Multi-Sensor Mobile Platform for the Recognition of Activities of Daily Living and their Environments based on Artificial Neural Networks. In Proceedings of the International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 5850–5852. [Google Scholar]
- Sena, J.; Barreto, J.; Caetano, C.; Cramer, G.; Schwartz, W.R. Human activity recognition based on smartphone and wearable sensors using multiscale DCNN ensemble. Neurocomputing 2021, 444, 226–243. [Google Scholar] [CrossRef]
- Yadav, S.K.; Tiwari, K.; Pandey, H.M.; Akbar, S.A. A review of multimodal human activity recognition with special emphasis on classification, applications, challenges and future directions. Knowl.-Based Syst. 2021, 223, 106970. [Google Scholar] [CrossRef]
- Qi, J.; Yang, P.; Waraich, A.; Deng, Z.; Zhao, Y.; Yang, Y. Examining sensor-based physical activity recognition and monitoring for healthcare using Internet of Things: A systematic review. J. Biomed. Inform. 2018, 87, 138–153. [Google Scholar] [CrossRef]
- Chen, K.; Zhang, D.; Yao, L.; Guo, B.; Yu, Z.; Liu, Y. Deep learning for sensor-based human activity recognition: Overview, challenges, and opportunities. ACM Comput. Surv. (CSUR) 2021, 54, 1–40. [Google Scholar] [CrossRef]
- Ramanujam, E.; Perumal, T.; Padmavathi, S. Human activity recognition with smartphone and wearable sensors using deep learning techniques: A review. IEEE Sens. J. 2021, 21, 13029–13040. [Google Scholar] [CrossRef]
- Murahari, V.S.; Plötz, T. On attention models for human activity recognition. In Proceedings of the 2018 ACM International Symposium on Wearable Computers, Singapore, 8–12 October 2018; ACM: New York, NY, USA, 2018; pp. 100–103. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Shen, T.; Zhou, T.; Long, G.; Jiang, J.; Pan, S.; Zhang, C. Disan: Directional self-attention network for rnn/cnn-free language understanding. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–3 February 2018; Volume 32. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. arXiv 2016, arXiv:1612.03928. [Google Scholar]
- Qiu, S.; Zhao, H.; Jiang, N.; Wang, Z.; Liu, L.; An, Y.; Zhao, H.; Miao, X.; Liu, R.; Fortino, G. Multi-sensor information fusion based on machine learning for real applications in human activity recognition: State-of-the-art and research challenges. Inf. Fusion 2022, 80, 241–265. [Google Scholar] [CrossRef]
- Tao, W.; Chen, H.; Moniruzzaman, M.; Leu, M.C.; Yi, Z.; Qin, R. Attention-Based Sensor Fusion for Human Activity Recognition Using IMU Signals. arXiv 2021, arXiv:2112.11224. [Google Scholar]
- Tang, Y.; Zhang, L.; Teng, Q.; Min, F.; Song, A. Triple Cross-Domain Attention on Human Activity Recognition Using Wearable Sensors. IEEE Trans. Emerg. Top. Comput. Intell. 2022, 6, 1167–1176. [Google Scholar] [CrossRef]
- Chen, K.; Yao, L.; Zhang, D.; Wang, X.; Chang, X.; Nie, F. A semisupervised recurrent convolutional attention model for human activity recognition. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 1747–1756. [Google Scholar] [CrossRef]
- Gao, W.; Zhang, L.; Teng, Q.; He, J.; Wu, H. DanHAR: Dual attention network for multimodal human activity recognition using wearable sensors. Appl. Soft Comput. 2021, 111, 107728. [Google Scholar] [CrossRef]
- Khaertdinov, B.; Ghaleb, E.; Asteriadis, S. Deep triplet networks with attention for sensor-based human activity recognition. In Proceedings of the 2021 IEEE International Conference on Pervasive Computing and Communications (PerCom), Kassel, Germany, 22–26 March 2021; pp. 1–10. [Google Scholar]
- Zeng, M.; Gao, H.; Yu, T.; Mengshoel, O.J.; Langseth, H.; Lane, I.; Liu, X. Understanding and improving recurrent networks for human activity recognition by continuous attention. In Proceedings of the 2018 ACM International Symposium on Wearable Computers, Singapore, 8–12 October 2018; ACM: New York, NY, USA, 2018; pp. 56–63. [Google Scholar]
- Ordóñez, F.J.; Roggen, D. Deep convolutional and lstm recurrent neural networks for multimodal wearable activity recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Reiss, A.; Stricker, D. Introducing a new benchmarked dataset for activity monitoring. In Proceedings of the 2012 16th International Symposium on Wearable Computers, Newcastle, UK, 16–22 June 2012; pp. 108–109. [Google Scholar]
- Chavarriaga, R.; Sagha, H.; Calatroni, A.; Digumarti, S.T.; Tröster, G.; Millán, J.d.R.; Roggen, D. The Opportunity challenge: A benchmark database for on-body sensor-based activity recognition. Pattern Recognit. Lett. 2013, 34, 2033–2042. [Google Scholar] [CrossRef]
- Ma, H.; Li, W.; Zhang, X.; Gao, S.; Lu, S. AttnSense: Multi-level Attention Mechanism For Multimodal Human Activity Recognition. In Proceedings of the International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; AAAI Press: Menlo Park, CA, USA, 2019; pp. 3109–3115. [Google Scholar]
- Wang, K.; He, J.; Zhang, L. Attention-based convolutional neural network for weakly labeled human activities’ recognition with wearable sensors. IEEE Sens. J. 2019, 19, 7598–7604. [Google Scholar] [CrossRef]
- Liu, S.; Yao, S.; Li, J.; Liu, D.; Wang, T.; Shao, H.; Abdelzaher, T. Globalfusion: A global attentional deep learning framework for multisensor information fusion. Proc. ACM Interactive Mobile Wearable Ubiquitous Technol. 2020, 4, 1–27. [Google Scholar]
- Incel, O.D.; Bursa, S.O. On-Device Deep Learning for Mobile and Wearable Sensing Applications: A Review. IEEE Sens. J. 2023. [Google Scholar] [CrossRef]
- Yao, S.; Zhao, Y.; Shao, H.; Liu, D.; Liu, S.; Hao, Y.; Piao, A.; Hu, S.; Lu, S.; Abdelzaher, T.F. Sadeepsense: Self-attention deep learning framework for heterogeneous on-device sensors in internet of things applications. In Proceedings of the IEEE INFOCOM 2019-IEEE Conference on Computer Communications, Paris, France, 29 April–2 May 2019; pp. 1243–1251. [Google Scholar]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 27.
- Park, J.; Woo, S.; Lee, J.Y.; Kweon, I.S. A simple and light-weight attention module for convolutional neural networks. Int. J. Comput. Vis. 2020, 128, 783–798. [Google Scholar] [CrossRef]
- Huang, J.; Lin, S.; Wang, N.; Dai, G.; Xie, Y.; Zhou, J. TSE-CNN: A two-stage end-to-end CNN for human activity recognition. IEEE J. Biomed. Health Inform. 2019, 24, 292–299. [Google Scholar] [CrossRef]
- Stiefmeier, T.; Roggen, D.; Ogris, G.; Lukowicz, P.; Tröster, G. Wearable activity tracking in car manufacturing. IEEE Pervasive Comput. 2008, 7, 42–50. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images; Technical Report; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Bock, M.; Hölzemann, A.; Moeller, M.; Van Laerhoven, K. Improving Deep Learning for HAR with Shallow LSTMs. In Proceedings of the 2021 International Symposium on Wearable Computers, New York, NY, USA, 21–26 September 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 7–12. [Google Scholar]
- Wang, J.; Chen, Y.; Hao, S.; Peng, X.; Hu, L. Deep learning for sensor-based activity recognition: A survey. Pattern Recognit. Lett. 2019, 119, 3–11. [Google Scholar] [CrossRef]
- Guo, M.H.; Xu, T.X.; Liu, J.J.; Liu, Z.N.; Jiang, P.T.; Mu, T.J.; Zhang, S.H.; Martin, R.R.; Cheng, M.M.; Hu, S.M. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems, 2015. Software available from tensorflow.org. arXiv 2015, arXiv:1603.04467. [Google Scholar]
- Google. Google Colaboratory. n.d. Available online: https://colab.research.google.com/ (accessed on 23 February 2023).












| Abbreviation | Description |
|---|---|
| w | With |
| wo | Without |
| CHattx(r) | Channel attention module applied to convolutional layer with a reduction ratio r |
| CHatt(r) | Channel attention modules applied to all four convolutional layers with a reduction ratio r |
| SPattx(k) | Spatial attention module applied to convolutional layer with a kernel size k |
| SPatt(k) | Spatial attention modules applied to all four convolutional layers with a kernel size k |
| CHSPattx(r)(k) | First channel and then spatial attention module (CHSPatt or CBAM) applied to convolutional layer with a reduction ratio r and kernel size k for channel and spatial attention, respectively |
| CHSPatt(r)(k) | First channel and then spatial attention module (CHSPatt or CBAM) applied to all four convolutional layers with a reduction ratio r and kernel size k for channel and spatial attention, respectively |
Reduction Ratio (r) | Kernel Size (k) | # of Additional Parameters | |
|---|---|---|---|
| 1 | 8320 | ||
| 2 | 4192 | ||
| w_CHattx(r) | 4 | 2128 | |
| 8 | 1096 | ||
| 16 | 580 | ||
| 3 | 18 | ||
| w_SPattx(k) | 5 | 50 | |
| 7 | 98 | ||
| 3 | 8338 | ||
| 1 | 5 | 8370 | |
| 7 | 8418 | ||
| 3 | 4210 | ||
| 2 | 5 | 4242 | |
| 7 | 4290 | ||
| 3 | 2146 | ||
| w_CHSPatt(r)(k) | 4 | 5 | 2178 |
| 7 | 2226 | ||
| 3 | 1114 | ||
| 8 | 5 | 1146 | |
| 7 | 1194 | ||
| 3 | 598 | ||
| 16 | 5 | 630 | |
| 7 | 678 |
| Opportunity | Pamap2 | ||||
|---|---|---|---|---|---|
| Performance Result | # of Parameters | Performance Result | # of Parameters | ||
| This study | DeepConvLSTM | 0.74 of f1-score | 0.82 M | 0.95 of f1-score | 1.42 M |
| DeepConvLSTM + CBAM Attention | 0.77 of f1-score | 0.82 M | 0.96 of f1-score | 1.42 M | |
| [19] | DeepConvLSTM | 0.67 of f1-score | 0.75 of f1-score | ||
| DeepConvLSTM + Temporal Attention in LSTM | 0.71 of f1-score | 0.87 of f1-score | |||
| [27] | CNN | 0.78 of accuracy | 1.15 M | 0.91 of accuracy | 2.73 M |
| CNN + BlockAttention | 0.80 of accuracy | 1.17 M | 0.92 of accuracy | 2.75 M | |
| [25] | CNN | 0.91 of f1 score | 0.86 M | ||
| CNN + Temporal, Channel, Spatial | 0.92 of f1 score | 0.86 M | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Agac, S.; Durmaz Incel, O. On the Use of a Convolutional Block Attention Module in Deep Learning-Based Human Activity Recognition with Motion Sensors. Diagnostics 2023, 13, 1861. https://doi.org/10.3390/diagnostics13111861
Agac S, Durmaz Incel O. On the Use of a Convolutional Block Attention Module in Deep Learning-Based Human Activity Recognition with Motion Sensors. Diagnostics. 2023; 13(11):1861. https://doi.org/10.3390/diagnostics13111861
Chicago/Turabian StyleAgac, Sumeyye, and Ozlem Durmaz Incel. 2023. "On the Use of a Convolutional Block Attention Module in Deep Learning-Based Human Activity Recognition with Motion Sensors" Diagnostics 13, no. 11: 1861. https://doi.org/10.3390/diagnostics13111861
APA StyleAgac, S., & Durmaz Incel, O. (2023). On the Use of a Convolutional Block Attention Module in Deep Learning-Based Human Activity Recognition with Motion Sensors. Diagnostics, 13(11), 1861. https://doi.org/10.3390/diagnostics13111861