
Artificial Intelligence-Based Opportunities in Liver Pathology—A Systematic Review

 , and
, and 
Abstract
1. Introduction
1.1. Introduction to AI
1.2. Principles of Deep Neural Networks Algorithms
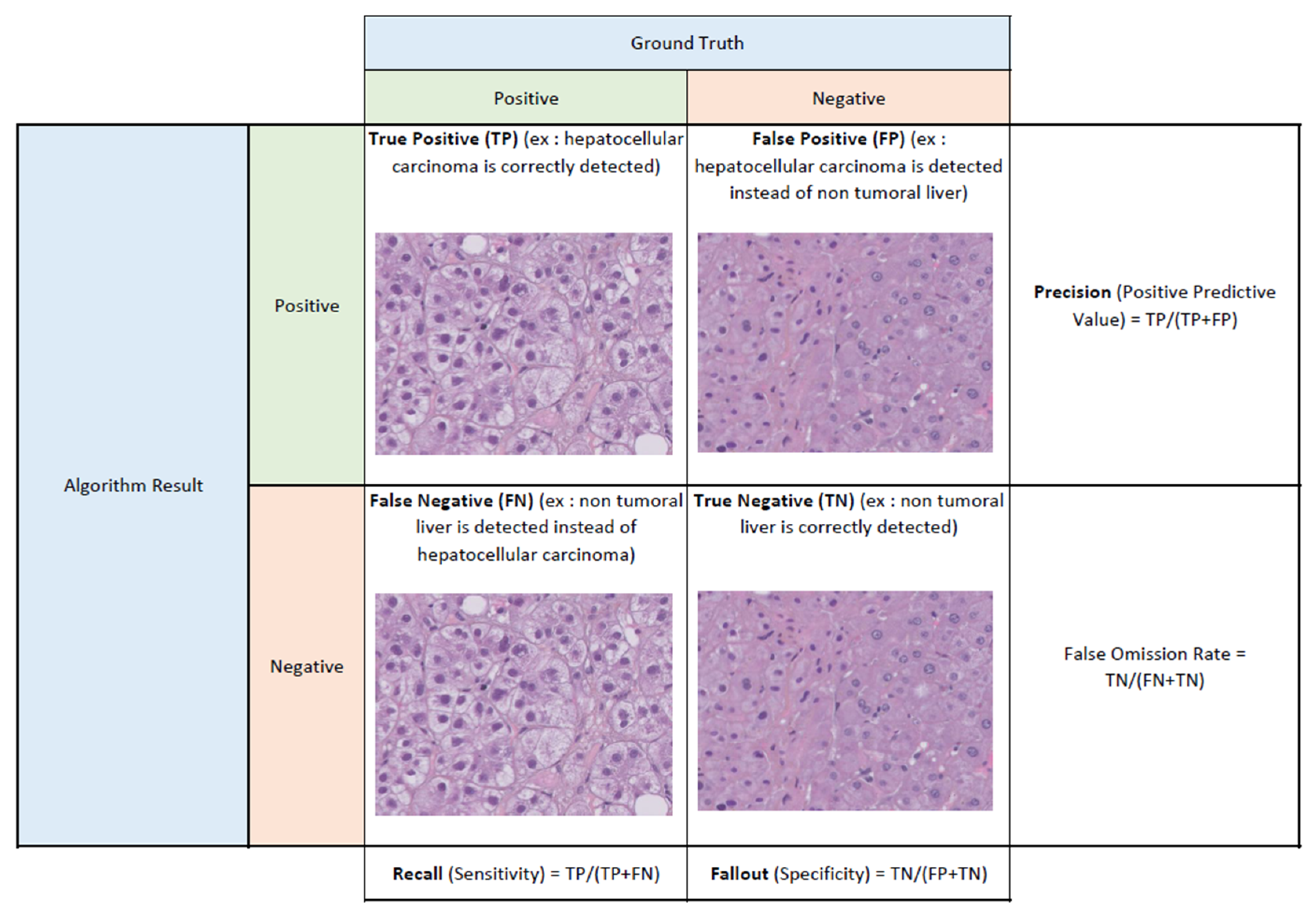
1.3. Evaluation of Algorithms by Performance Metrics
1.4. Aim of the Present Review
2. Materials and Methods
2.1. Inclusion and Exclusion Criteria
2.2. Online Registration Information
2.3. Data Sources and Literature Search Strategy
2.4. Studies Selection and Data Extraction
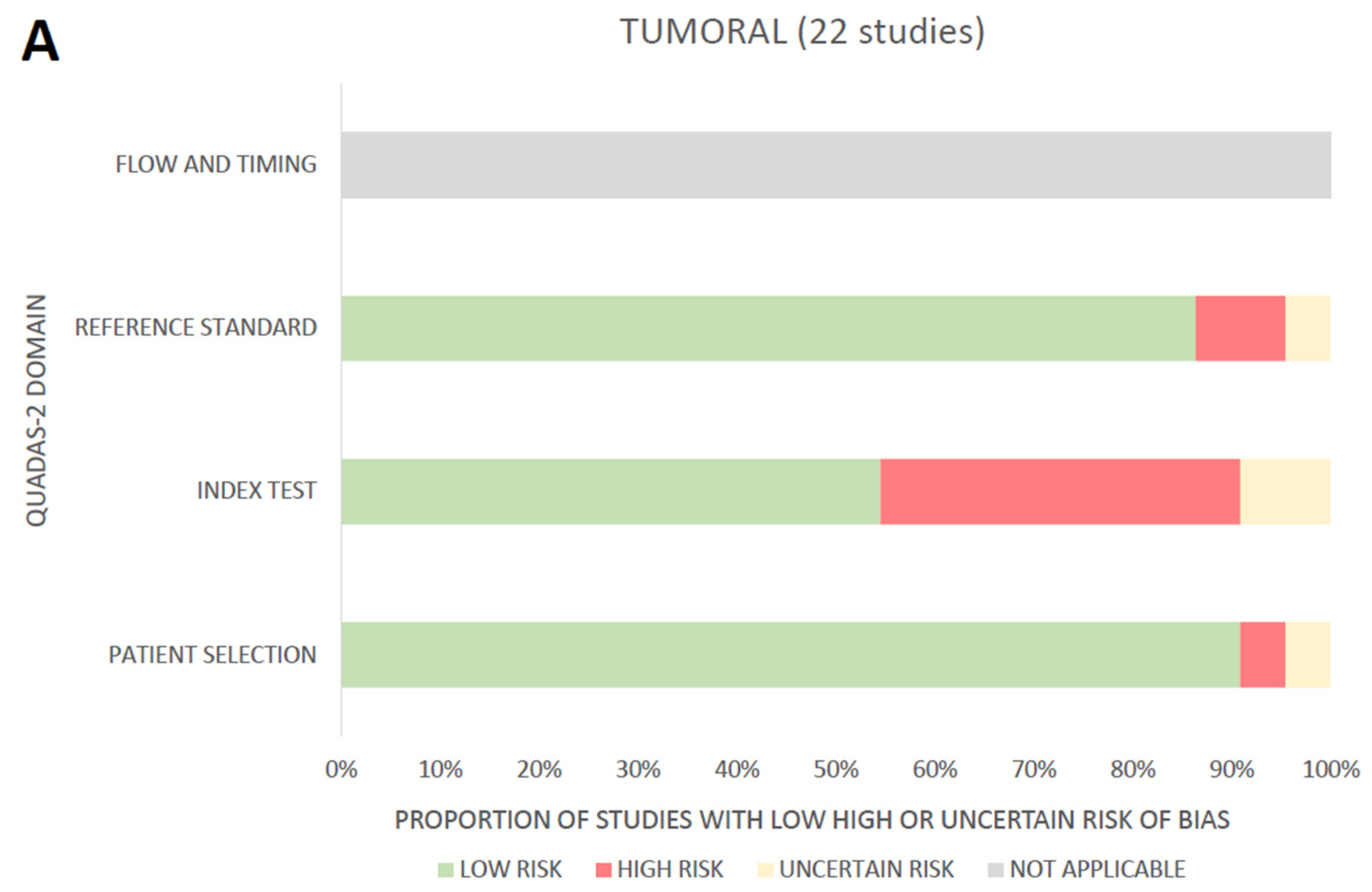
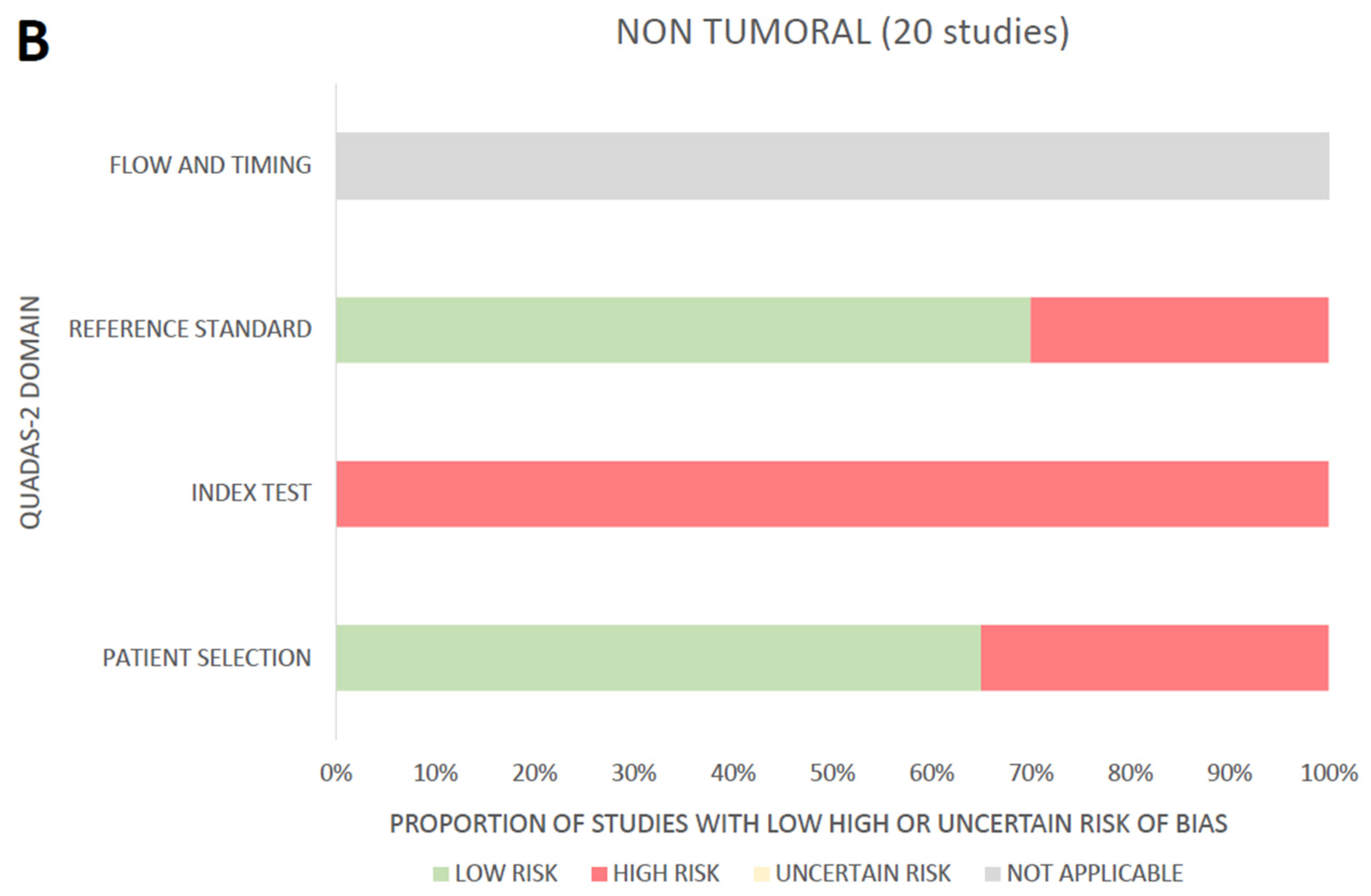
2.5. Assessment of the Risk of Bias and Applicability
3. Results
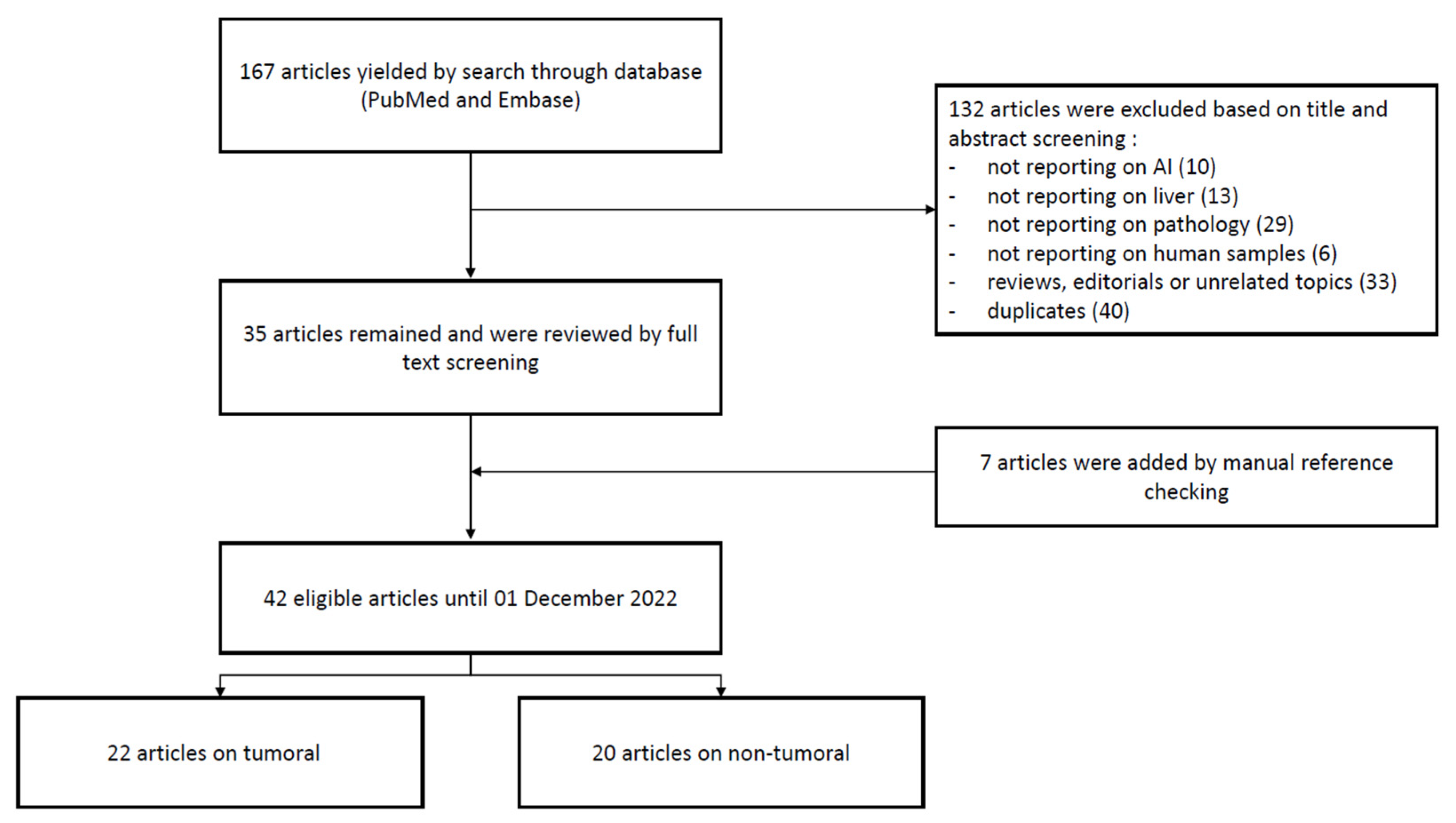
3.1. Search Results
3.2. Tumoral

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors (Year) [Reference] | Country | Algorithm Goal | Development Dataset | External Validation Dataset | Performance Metrics |
|---|---|---|---|---|---|
| Feng Y. et al. (2021) [11] | France | segmentation (HCC) | 60 WSI | 40 WSI | Jaccard score 0.90 F1 score 0.47 |
| Cancian P. et al. (2021) [12] | Italy | segmentation (LM) | 303 WSI | no | Jaccard score 0.89 |
| Roy M. et al. (2021) [13] | USA | segmentation (HCC) | 60 WSI | 40 WSI | F1 score 0.94 |
| Wang X. et al. (2021) [14] | China | segmentation (HCC) | 60 WSI | 40 WSI | Jaccard score 0.797 |
| Feng S. et al. (2021) [15] | China | segmentation (HCC) | 592 WSI | 157 WSI (TCGA) | Accuracy 0.88 |
| Yang TL. et al. (2022) [16] | Taiwan | segmentation (HCC) | 46 WSI | no | Jaccard score 0.89 |
| Li S. et al. (2017) [17] | China | segmentation (HCC) | 127 WSI | not provided | Accuracy 0.97 F1 score 0.94 |
| Kiani A. et al. (2020) [18] | USA | classification (HCC and CCK) | 70 WSI | 80 WSI | Accuracy 0.84 |
| Schau GF. et al. (2020) [19] | USA | classification (LM) | 257 WSI | no | F1 score 0.77 |
| Ercan C. et al. (2022) [20] | Switzerland | classification (HCC) | 98 WSI | no | Accuracy 0.84 F1 score 0.91 |
| Diao S. et al. (2022) [21] | China | classification (HCC) | 100 WSI (TCGA) | no | AUC 0.92 |
| Cheng N. et al. (2022) [22] | China | classification (HCC) | 649 WSI | 234 WSI | AUC 0.94 |
| Chen M. et al. (2020) [23] | China | prediction (HCC) | 387 WSI | 101 WSI | AUC 0.71 |
| Liao H. et al. (2020) [24] | China | prediction (HCC) | not provided | not provided | AUC 0.89 |
| Saillard C. et al. (2020) [25] | France | prediction (HCC) | 390 WSI | 342 WSI (TCGA) | c-index 0.70 |
| Yamashita et al. (2021) [26] | USA | prediction (HCC) | 299 WSI (TCGA) | 198 WSI | c-index 0.67 |
| Saito A. et al. (2021) [27] | Japan | prediction (HCC) | 158 WSI | no | Accuracy 0.90 |
| Xiao C. et al. (2022) [28] | China | prediction (LM) | 611 WSI | no | AUC 0.85 |
| Chen Q. et al. (2022) [29] | China | prediction (HCC) | 2917 WSI | 504 WSI | AUC 0.87 |
| Zeng Q. et al. (2022) [30] | France | prediction (HCC) | 349 WSI (TCGA) | 139 WSI | AUC 0.92 |
| Qu WF. et al. (2022) [31] | China | prediction (HCC) | 576 WSI | 147 WSI (TCGA) | c-index 0.71 |
| Xie J. et al. (2022) [32] | China | prediction (CCK) | 766 WSI | no | AUC 0.68 |
3.3. Non-Tumoral
| Authors (Year) [Reference] | Country | Algorithm Goal | Development Dataset | External Validation Dataset | Performance Metrics |
|---|---|---|---|---|---|
| Guo X. et al. (2018) [34] | USA | segmentation (steatosis) | 451 WSI | no | Jaccard score 0.77 F1 score 0.66 |
| Jirik M. et al. (2020) [35] | Czech Republic | segmentation (intra vs. extralobular) | 33 WSI | no | Accuracy 0.91 |
| Roy M. et al. (2020) [36] | USA | segmentation (steatosis) | 36 WSI | no | F1 score 0.94 |
| Yu H. et al. (2022) [37] | USA | segmentation (portal tracts) | 53 WSI | no | Jaccard score 0.80 F1 score 0.89 |
| Vanderbeck S. et al. (2014) [38] | USA | classification (steatosis, bile ducts, vascular structures) | 47 WSI | no | AUC 0.83 |
| Vanderbeck S. et al. (2015) [39] | USA | classification (NASH) | 59 WSI | no | AUC 0.98 |
| Wang TH et al. (2015) [40] | Taiwan | classification (fibrosis) | 175 WSI | no | AUC 0.82 |
| Munsterman I. et al. (2019) [41] | Netherlands | classification (NASH) | 79 WSI | no | AUC 0.97 |
| Klimov S. et al. (2019) [42] | USA | classification (fibrosis) | 115 WSI | no | AUC 0.70 |
| Puri M. (2020) [43] | USA | classification (DILI) | 1277 WSI | no | Accuracy 0.99 |
| Forlano et al. (2020) [44] | UK | classification (NASH) | 246 WSI | no | AUC 0.80 |
| Teramoto T. et al. (2020) [45] | Japan | classification (NASH) | 79 WSI | no | AUC 0.85 |
| Salvi M. et al. (2020) [46] | Italy | classification (steatosis) | 385 WSI | no | Accuracy 0.97 |
| Gawrieh S. et al. (2020) [47] | USA | classification (NASH) | 18 WSI | no | AUC 0.79 |
| Perez-Sans F. et al. (2021) [48] | Spain | classification (steatosis) | 20 WSI | no | AUC 0.98 |
| Marti-Aguado D. et al. (2021) [49] | Spain | Classification (chronic hepatitis) | 156 WSI | no | AUC 0.75 (NASH) AUC 0.99 (Chronic Hepatitis model) |
| Sjöblom N. et al. (2021) [50] | Finland | classification (chronic cholestatis) | 210 WSI | no | Accuracy 0.93 |
| Ramkissoon R. et al. (2022) [51] | USA | classification (NASH) | 97 WSI | no | AUC 0.96 |
| Heinemann F. et al. (2022) [52] | USA | classification (NASH) | 467 WSI | no | F1 score 0.37 to 0.85 |
| Constantinescu C. et al. (2022) [53] | Romania | prediction (liver surgery complications) | 500 WSI | no | AUC 0.97 |
3.4. Assessment of the Risk of Bias and Applicability through the QUADAS-2 Tool
4. Discussion
4.1. AI in Tumoral Liver Pathology: What to Remember
4.2. AI in Non-Tumoral Liver Pathology: What to Remember
4.3. Persistent Limitations to the Implementation of AI in Daily Practice
4.4. Present Review’s Limitations
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Su, T.H.; Wu, C.H.; Kao, J.H. Artificial intelligence in precision medicine in hepatology. J. Gastroenterol. Hepatol. 2021, 36, 569–580. [Google Scholar] [CrossRef]
- Balsano, C.; Alisi, A.; Brunetto, M.R.; Invernizzi, P.; Burra, P.; Piscaglia, F. The application of artificial intelligence in hepatology: A systematic review. Dig. Liver Dis. 2022, 54, 299–308. [Google Scholar] [CrossRef]
- Calderaro, J.; Kather, J.N. Artificial intelligence-based pathology for gastrointestinal and hepatobiliary cancers. Gut 2021, 70, 1183–1193. [Google Scholar] [CrossRef]
- Lee, H.W.; Sung, J.J.Y.; Ahn, S.H. Artificial intelligence in liver disease. J. Gastroenterol. Hepatol. 2021, 36, 539–542. [Google Scholar] [CrossRef] [PubMed]
- Le Berre, C.; Sandborn, W.J.; Aridhi, S.; Devignes, M.-D.; Fournier, L.; Smaïl-Tabbone, M.; Danese, S.; Peyrin-Biroulet, L. Application of Artificial Intelligence to Gastroenterology and Hepatology. Gastroenterology 2020, 158, 76–94.e2. [Google Scholar] [CrossRef] [PubMed]
- Christou, C.D.; Tsoulfas, G. Challenges and opportunities in the application of artificial intelligence in gastroenterology and hepatology. World J. Gastroenterol. 2021, 27, 6191–6223. [Google Scholar] [CrossRef] [PubMed]
- Cao, J.-S.; Lu, Z.-Y.; Chen, M.-Y.; Zhang, B.; Juengpanich, S.; Hu, J.-H.; Li, S.-J.; Topatana, W.; Zhou, X.-Y.; Feng, X.; et al. Artificial intelligence in gastroenterology and hepatology: Status and challenges. World J. Gastroenterol. 2021, 27, 1664–1690. [Google Scholar] [CrossRef]
- Ahn, J.C.; Connell, A.; Simonetto, D.A.; Hughes, C.; Shah, V.H. Application of Artificial Intelligence for the Diagnosis and Treatment of Liver Diseases. Hepatology 2021, 73, 2546–2563. [Google Scholar] [CrossRef]
- Liberati, A.; Altman, D.G.; Tetzlaff, J.; Mulrow, C.; Gøtzsche, P.C.; Ioannidis, J.P.A.; Clarke, M.; Devereaux, P.J.; Kleijnen, J.; Moher, D. The PRISMA statement for reporting systematic reviews and meta-analyses of studies that evaluate healthcare interventions: Explanation and elaboration. BMJ 2009, 339, b2700. [Google Scholar] [CrossRef]
- Bristol U of. QUADAS-2. University of Bristol. Available online: https://www.bristol.ac.uk/population-health-sciences/projects/quadas/quadas-2/ (accessed on 29 December 2022).
- Feng, Y.; Hafiane, A.; Laurent, H. A deep learning based multiscale approach to segment the areas of interest in whole slide images. Comput. Med. Imaging Graph. 2021, 90, 101923. [Google Scholar] [CrossRef]
- Cancian, P.; Cortese, N.; Donadon, M.; Di Maio, M.; Soldani, C.; Marchesi, F.; Savevski, V.; Santambrogio, M.D.; Cerina, L.; Laino, M.E.; et al. Development of a Deep-Learning Pipeline to Recognize and Characterize Macrophages in Colo-Rectal Liver Metastasis. Cancers 2021, 13, 3313. [Google Scholar] [CrossRef]
- Roy, M.; Kong, J.; Kashyap, S.; Pastore, V.P.; Wang, F.; Wong, K.C.L.; Mukherjee, V. Convolutional autoencoder based model HistoCAE for segmentation of viable tumor regions in liver whole-slide images. Sci. Rep. 2021, 11, 139. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Fang, Y.; Yang, S.; Zhu, D.; Wang, M.; Zhang, J.; Tong, K.; Han, X. A hybrid network for automatic hepatocellular carcinoma segmentation in H&E-stained whole slide images. Med. Image Anal. 2021, 68, 101914. [Google Scholar] [PubMed]
- Feng, S.; Yu, X.; Liang, W.; Li, X.; Zhong, W.; Hu, W.; Zhang, H.; Feng, Z.; Song, M.; Zhang, J.; et al. Development of a Deep Learning Model to Assist With Diagnosis of Hepatocellular Carcinoma. Front Oncol. 2021, 11, 762733. [Google Scholar] [CrossRef]
- Yang, T.-L.; Tsai, H.-W.; Huang, W.-C.; Lin, J.-C.; Liao, J.-B.; Chow, N.-H.; Chung, P.-C. Pathologic liver tumor detection using feature aligned multi-scale convolutional network. Artif. Intell. Med. 2022, 125, 102244. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Jiang, H.; Pang, W. Joint multiple fully connected convolutional neural network with extreme learning machine for hepatocellular carcinoma nuclei grading. Comput. Biol. Med. 2017, 84, 156–167. [Google Scholar] [CrossRef] [PubMed]
- Kiani, A.; Uyumazturk, B.; Rajpurkar, P.; Wang, A.; Gao, R.; Jones, E.; Yu, Y.; Langlotz, C.P.; Ball, R.L.; Montine, T.J.; et al. Impact of a deep learning assistant on the histopathologic classification of liver cancer. NPJ Digit. Med. 2020, 3, 23. [Google Scholar] [CrossRef]
- Schau, G.F.; Burlingame, E.A.; Thibault, G.; Anekpuritanang, T.; Wang, Y.; Gray, J.W.; Corless, C.; Chang, Y.H. Predicting primary site of secondary liver cancer with a neural estimator of metastatic origin. J. Med. Imaging 2020, 7, 012706. [Google Scholar] [CrossRef]
- Ercan, C.; Coto-Llerena, M.; Piscuoglio, S.; Terracciano, L.M. Establishing quantitative image analysis methods for tumor microenviroment evaluation. J. Hepatol. 2022, 77, S660–S661. [Google Scholar] [CrossRef]
- Diao, S.; Tian, Y.; Hu, W.; Hou, J.; Lambo, R.; Zhang, Z.; Xie, Y.; Nie, X.; Zhang, F.; Racoceanu, D.; et al. Weakly Supervised Framework for Cancer Region Detection of Hepatocellular Carcinoma in Whole-Slide Pathologic Images Based on Multiscale Attention Convolutional Neural Network. Am. J. Pathol. 2022, 192, 553–563. [Google Scholar] [CrossRef]
- Cheng, N.; Ren, Y.; Zhou, J.; Zhang, Y.; Wang, D.; Zhang, X.; Chen, B.; Liu, F.; Lv, J.; Cao, Q.; et al. Deep Learning-Based Classification of Hepatocellular Nodular Lesions on Whole-Slide Histopathologic Images. Gastroenterology 2022, 162, 1948–1961.e7. [Google Scholar] [CrossRef]
- Chen, M.; Zhang, B.; Topatana, W.; Cao, J.; Zhu, H.; Juengpanich, S.; Mao, Q.; Yu, H.; Cai, X. Classification and mutation prediction based on histopathology H&E images in liver cancer using deep learning. NPJ Precis. Oncol. 2020, 4, 14. [Google Scholar] [PubMed]
- Liao, H.; Xiong, T.; Peng, J.; Xu, L.; Liao, M.; Zhang, Z.; Wu, Z.; Yuan, K.; Zeng, Y. Classification and Prognosis Prediction from Histopathological Images of Hepatocellular Carcinoma by a Fully Automated Pipeline Based on Machine Learning. Ann. Surg. Oncol. 2020, 27, 2359–2369. [Google Scholar] [CrossRef] [PubMed]
- Saillard, C.; Schmauch, B.; Laifa, O.; Moarii, M.; Toldo, S.; Zaslavskiy, M.; Pronier, E.; Laurent, A.; Amaddeo, G.; Regnault, H.; et al. Predicting Survival After Hepatocellular Carcinoma Resection Using Deep Learning on Histological Slides. Hepatology 2020, 72, 2000–2013. [Google Scholar] [CrossRef] [PubMed]
- Yamashita, R.; Long, J.; Saleem, A.; Rubin, D.L.; Shen, J. Deep learning predicts postsurgical recurrence of hepatocellular carcinoma from digital histopathologic images. Sci. Rep. 2021, 11, 2047. [Google Scholar] [CrossRef]
- Saito, A.; Toyoda, H.; Kobayashi, M.; Koiwa, Y.; Fujii, H.; Fujita, K.; Maeda, A.; Kaneoka, Y.; Hazama, S.; Nagano, H.; et al. Prediction of early recurrence of hepatocellular carcinoma after resection using digital pathology images assessed by machine learning. Mod. Pathol. 2021, 34, 417–425. [Google Scholar] [CrossRef]
- Xiao, C.; Zhou, M.; Yang, X.; Wang, H.; Tang, Z.; Zhou, Z.; Tian, Z.; Liu, Q.; Li, X.; Jiang, W.; et al. Accurate Prediction of Metachronous Liver Metastasis in Stage I–III Colorectal Cancer Patients Using Deep Learning with Digital Pathological Images. Front. Oncol. 2022, 12, 67. [Google Scholar] [CrossRef]
- Chen, Q.; Xiao, H.; Gu, Y.; Weng, Z.; Wei, L.; Li, B.; Liao, B.; Li, J.; Lin, J.; Hei, M.; et al. Deep learning for evaluation of microvascular invasion in hepatocellular carcinoma from tumor areas of histology images. Hepatol. Int. 2022, 16, 590–602. [Google Scholar] [CrossRef]
- Zeng, Q.; Klein, C.; Caruso, S.; Maille, P.; Laleh, N.G.; Sommacale, D.; Laurent, A.; Amaddeo, G.; Gentien, D.; Rapinat, A.; et al. Artificial intelligence predicts immune and inflammatory gene signatures directly from hepatocellular carcinoma histology. J. Hepatol. 2022, 77, 116–127. [Google Scholar] [CrossRef]
- Qu, W.-F.; Tian, M.-X.; Qiu, J.-T.; Guo, Y.-C.; Tao, C.-Y.; Liu, W.-R.; Tang, Z.; Qian, K.; Wang, Z.-X.; Li, X.-Y.; et al. Exploring pathological signatures for predicting the recurrence of early-stage hepatocellular carcinoma based on deep learning. Front. Oncol. 2022, 12, 968202. [Google Scholar] [CrossRef]
- Xie, J.; Pu, X.; He, J.; Qiu, Y.; Lu, C.; Gao, W.; Wang, X.; Lu, H.; Shi, J.; Xu, Y.; et al. Survival prediction on intrahepatic cholangiocarcinoma with histomorphological analysis on the whole slide images. Comput. Biol. Med. 2022, 146, 105520. [Google Scholar] [CrossRef] [PubMed]
- PAIP 2019—Grand Challenge. Available online: https://paip2019.grand-challenge.org/ (accessed on 28 December 2022).
- Guo, X.; Wang, F.; Teodoro, G.; Farris, A.B.; Kong, J. Liver steatosis segmentation with deep learning methods. Proc. IEEE Int. Symp. Biomed Imaging 2019, 2019, 24–27. [Google Scholar] [PubMed]
- Jirik, M.; Gruber, I.; Moulisova, V.; Schindler, C.; Cervenkova, L.; Palek, R.; Rosendorf, J.; Arlt, J.; Bolek, L.; Dejmek, J.; et al. Semantic Segmentation of Intralobular and Extralobular Tissue from Liver Scaffold H&E Images. Sensors 2020, 20, 7063. [Google Scholar]
- Roy, M.; Wang, F.; Vo, H.; Teng, D.; Teodoro, G.; Farris, A.B.; Castillo-Leon, E.; Vos, M.B.; Kong, J. Deep-learning-based accurate hepatic steatosis quantification for histological assessment of liver biopsies. Lab. Investig. 2020, 100, 1367–1383. [Google Scholar] [CrossRef] [PubMed]
- Yu, H.; Sharifai, N.; Jiang, K.; Wang, F.; Teodoro, G.; Farris, A.B.; Kong, J. Artificial intelligence based liver portal tract region identification and quantification with transplant biopsy whole-slide images. Comput. Biol. Med. 2022, 150, 106089. [Google Scholar] [CrossRef] [PubMed]
- Vanderbeck, S.; Bockhorst, J.; Komorowski, R.; Kleiner, D.E.; Gawrieh, S. Automatic classification of white regions in liver biopsies by supervised machine learning. Hum. Pathol. 2014, 45, 785–792. [Google Scholar] [CrossRef]
- Vanderbeck, S.; Bockhorst, J.; Kleiner, D.; Komorowski, R.; Chalasani, N.; Gawrieh, S. Automatic quantification of lobular inflammation and hepatocyte ballooning in nonalcoholic fatty liver disease liver biopsies. Hum. Pathol. 2015, 46, 767–775. [Google Scholar] [CrossRef]
- Wang, T.H.; Chen, T.C.; Teng, X.; Liang, K.H.; Yeh, C.T. Automated biphasic morphological assessment of hepatitis B-related liver fibrosis using second harmonic generation microscopy. Sci. Rep. 2015, 5, 12962. [Google Scholar] [CrossRef]
- Munsterman, I.D.; van Erp, M.; Weijers, G.; Bronkhorst, C.; de Korte, C.L.; Drenth, J.P.H.; van der Laak, J.A.W.M.; Tjwa, E.T.T.L. A Novel Automatic Digital Algorithm that Accurately Quantifies Steatosis in NAFLD on Histopathological Whole-Slide Images. Cytometry B Clin. Cytom. 2019, 96, 521–528. [Google Scholar] [CrossRef]
- Klimov, S.; Farris, A.; Chen, H.; Chen, Y.; Jiang, Y. THU-083-Predicting advanced liver fibrosis using deep learning based biopsy image analysis. J. Hepatol. 2019, 70, e196. [Google Scholar] [CrossRef]
- Puri, M. Automated Machine Learning Diagnostic Support System as a Computational Biomarker for Detecting Drug-Induced Liver Injury Patterns in Whole Slide Liver Pathology Images. Assay Drug Dev. Technol. 2020, 18, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Forlano, R.; Mullish, B.H.; Giannakeas, N.; Maurice, J.B.; Angkathunyakul, N.; Lloyd, J.; Tzallas, A.T.; Tsipouras, M.; Yee, M.; Thursz, M.R.; et al. High-Throughput, Machine Learning-Based Quantification of Steatosis, Inflammation, Ballooning, and Fibrosis in Biopsies from Patients with Nonalcoholic Fatty Liver Disease. Clin. Gastroenterol. Hepatol. 2020, 18, 2081–2090.e9. [Google Scholar] [CrossRef] [PubMed]
- Teramoto, T.; Shinohara, T.; Takiyama, A. Computer-aided classification of hepatocellular ballooning in liver biopsies from patients with NASH using persistent homology. Comput. Methods Programs Biomed. 2020, 195, 105614. [Google Scholar] [CrossRef] [PubMed]
- Salvi, M.; Molinaro, L.; Metovic, J.; Patrono, D.; Romagnoli, R.; Papotti, M.; Molinari, F. Fully automated quantitative assessment of hepatic steatosis in liver transplants. Comput. Biol. Med. 2020, 123, 103836. [Google Scholar] [CrossRef] [PubMed]
- Gawrieh, S.; Sethunath, D.; Cummings, O.W.; Kleiner, D.E.; Vuppalanchi, R.; Chalasani, N.; Tuceryan, M. Automated quantification architectural pattern detection of hepatic fibrosis in, N.A.F.L.D. Ann. Diagn. Pathol. 2020, 47, 151518. [Google Scholar] [CrossRef]
- Pérez-Sanz, F.; Riquelme-Pérez, M.; Martínez-Barba, E.; de la Peña-Moral, J.; Salazar Nicolás, A.; Carpes-Ruiz, M.; Esteban-Gil, A.; Legaz-García, M.D.C.; Parreño-González, M.A.; Ramírez, P.; et al. Efficiency of Machine Learning Algorithms for the Determination of Macrovesicular Steatosis in Frozen Sections Stained with Sudan to Evaluate the Quality of the Graft in Liver Transplantation. Sensors 2021, 21, 1993. [Google Scholar] [CrossRef]
- Marti-Aguado, D.; Fernández-Patón, M.; Alfaro-Cervello, C.; Mestre-Alagarda, C.; Bauza, M.; Gallen-Peris, A.; Merino, V.; Benlloch, S.; Pérez-Rojas, J.; Ferrández, A.; et al. Digital Pathology Enables Automated and Quantitative Assessment of Inflammatory Activity in Patients with Chronic Liver Disease. Biomolecules 2021, 11, 1808. [Google Scholar] [CrossRef]
- Sjöblom, N.; Boyd, S.; Manninen, A.; Knuuttila, A.; Blom, S.; Färkkilä, M.; Arola, J. Chronic cholestasis detection by a novel tool: Automated analysis of cytokeratin 7-stained liver specimens. Diagn. Pathol. 2021, 16, 41. [Google Scholar] [CrossRef]
- Ramkissoon, R.; Ahn, J.; Noh, Y.-K.; Yeon, Y.; Meroueh, C.; Thanneeru, P.; Das, A.; Hipp, J.; Allen, A.; Simonetto, D.; et al. Application of machine learning algorithms to classify steatohepatitis on liver biopsy. J. Hepatol. 2022, 77, S138–S139. [Google Scholar] [CrossRef]
- Heinemann, F.; Birk, G.; Stierstorfer, B. Deep learning enables pathologist-like scoring of NASH models. Sci. Rep. 2019, 9, 18454. [Google Scholar] [CrossRef]
- Constantinescu, C.; Udristoiu, A.; Gruionu, L.G.; Pirici, D.; Gruionu, G.; Iacob, A.V.; Udristoiu, S.; Surlin, V.; Ramboiu, S.; Saftoiu, A. Tu1315: Deep learning assessment of inflammation and angiogenesis in liver steatosis as an accurate predictor of liver surgery complications. Gastroenterology 2022, 162, S1272. [Google Scholar] [CrossRef]
- Song, Z.; Zou, S.; Zhou, W.; Huang, Y.; Shao, L.; Yuan, J.; Gou, X.; Jin, W.; Wang, Z.; Chen, X.; et al. Clinically applicable histopathological diagnosis system for gastric cancer detection using deep learning. Nat. Commun. 2020, 11, 4294. [Google Scholar] [CrossRef] [PubMed]
- Sakamoto, T.; Furukawa, T.; Lami, K.; Pham, H.H.N.; Uegami, W.; Kuroda, K.; Kawai, M.; Sakanashi, H.; Cooper, L.A.D.; Bychkov, A.; et al. A narrative review of digital pathology and artificial intelligence: Focusing on lung cancer. Transl. Lung Cancer Res. 2020, 9, 2255–2276. [Google Scholar] [CrossRef] [PubMed]
- De Logu, F.; Ugolini, F.; Maio, V.; Simi, S.; Cossu, A.; Massi, D.; Italian Association for Cancer Research (AIRC) Study Group; Nassini, R.; Laurino, M. Recognition of Cutaneous Melanoma on Digitized Histopathological Slides via Artificial Intelligence Algorithm. Front. Oncol. 2020, 10, 1559. [Google Scholar] [CrossRef] [PubMed]
- Ström, P.; Kartasalo, K.; Olsson, H.; Solorzano, L.; Delahunt, B.; Berney, D.M.; Bostwick, D.G.; Evans, A.J.; Grignon, D.J.; Humphrey, P.A.; et al. Artificial intelligence for diagnosis and grading of prostate cancer in biopsies: A population-based, diagnostic study. Lancet Oncol. 2020, 21, 222–232. [Google Scholar] [CrossRef]
- Massironi, S.; Pilla, L.; Elvevi, A.; Longarini, R.; Rossi, R.E.; Bidoli, P.; Invernizzi, P. New and Emerging Systemic Therapeutic Options for Advanced Cholangiocarcinoma. Cells 2020, 9, 688. Available online: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7140695/ (accessed on 16 February 2023). [CrossRef] [PubMed]
- Kabbara, K.W.; Cannon, T.; Winer, A.; Wadlow, R.C. Molecular Pathogenesis of Cholangiocarcinoma: Implications for Disease Classification and Therapy. Oncology 2022, 36, 492–498. [Google Scholar]
- Park, H.J.; Park, B.; Lee, S.S. Radiomics and Deep Learning: Hepatic Applications. Korean J. Radiol. 2020, 21, 387–401. [Google Scholar] [CrossRef]
- Wei, J.; Jiang, H.; Gu, D.; Niu, M.; Fu, F.; Han, Y.; Song, B.; Tian, J. Radiomics in liver diseases: Current progress and future opportunities. Liver Int. 2020, 40, 2050–2063. [Google Scholar] [CrossRef]
- Alvarez-Jimenez, C.; Sandino, A.A.; Prasanna, P.; Gupta, A.; Viswanath, S.E.; Romero, E. Identifying Cross-Scale Associations between Radiomic and Pathomic Signatures of Non-Small Cell Lung Cancer Subtypes: Preliminary Results. Cancers 2020, 12, 3663. [Google Scholar] [CrossRef]
- Zhang, Z.; Li, X.; Sun, H. Development of machine learning models integrating PET/CT radiomic and immunohistochemical pathomic features for treatment strategy choice of cervical cancer with negative pelvic lymph node by mediating COX-2 expression. Front. Physiol. 2022, 13, 994304. [Google Scholar] [CrossRef]
- Tran, W.T.; Jerzak, K.; Lu, F.-I.; Klein, J.; Tabbarah, S.; Lagree, A.; Wu, T.; Rosado-Mendez, I.; Law, E.; Saednia, K. Personalized Breast Cancer Treatments Using Artificial Intelligence in Radiomics and Pathomics. J. Med. Imaging Radiat. Sci. 2019, 50 (Suppl. 2), S32–S41. [Google Scholar] [CrossRef] [PubMed]
- Brancato, V.; Cavaliere, C.; Garbino, N.; Isgrò, F.; Salvatore, M.; Aiello, M. The relationship between radiomics and pathomics in Glioblastoma patients: Preliminary results from a cross-scale association study. Front. Oncol. 2022, 12, 1005805. [Google Scholar] [CrossRef] [PubMed]
- Castiglioni, I.; Rundo, L.; Codari, M.; Di Leo, G.; Salvatore, C.; Interlenghi, M.; Gallivanone, F.; Cozzi, A.; D’Amico, N.C.; Sardanelli, F. AI applications to medical images: From machine learning to deep learning. Phys. Med. 2021, 83, 9–24. [Google Scholar] [CrossRef]
- Davison, B.A.; Harrison, S.A.; Cotter, G.; Alkhouri, N.; Sanyal, A.; Edwards, C.; Colca, J.R.; Iwashita, J.; Koch, G.G.; Dittrich, H.C. Suboptimal reliability of liver biopsy evaluation has implications for randomized clinical trials. J. Hepatol. 2020, 73, 1322–1332. [Google Scholar] [CrossRef] [PubMed]
- Brunt, E.M.; Clouston, A.D.; Goodman, Z.; Guy, C.; Kleiner, D.E.; Lackner, C.; Tiniakos, D.G.; Wee, A.; Yeh, M.; Leow, W.Q.; et al. Complexity of ballooned hepatocyte feature recognition: Defining a training atlas for artificial intelligence-based imaging in NAFLD. J. Hepatol. 2022, 76, 1030–1041. [Google Scholar] [CrossRef] [PubMed]
- Car, J.; Sheikh, A.; Wicks, P.; Williams, M.S. Beyond the hype of big data and artificial intelligence: Building foundations for knowledge and wisdom. BMC Med. 2019, 17, 143. [Google Scholar] [CrossRef]
- Willemink, M.J.; Koszek, W.A.; Hardell, C.; Wu, J.; Fleischmann, D.; Harvey, H.; Folio, L.R.; Summers, R.M.; Rubin, D.L.; Lungren, M.P. Preparing Medical Imaging Data for Machine Learning. Radiology 2020, 295, 4–15. [Google Scholar] [CrossRef] [PubMed]
- Leslie, D.; Mazumder, A.; Peppin, A.; Wolters, M.K.; Hagerty, A. Does “AI” stand for augmenting inequality in the era of covid-19 healthcare? BMJ 2021, 372, n304. [Google Scholar] [CrossRef]
- Liu, X.; Faes, L.; Kale, A.U.; Wagner, S.K.; Fu, D.J.; Bruynseels, A.; Mahendiran, T.; Moraes, G.; Shamdas, M.; Kern, C.; et al. A comparison of deep learning performance against health-care professionals in detecting diseases from medical imaging: A systematic review and meta-analysis. Lancet Digit. Health 2019, 1, e271–e297. [Google Scholar] [CrossRef]
- Wilson, A.; Saeed, H.; Pringle, C.; Eleftheriou, I.; Bromiley, P.A.; Brass, A. Artificial intelligence projects in healthcare: 10 practical tips for success in a clinical environment. BMJ Health Care Inform. 2021, 28, e100323. [Google Scholar] [CrossRef] [PubMed]
- Sounderajah, V.; Ashrafian, H.; Rose, S.; Shah, N.H.; Ghassemi, M.; Golub, R.; Kahn, C.E.; Esteva, A.; Karthikesalingam, A.; Mateen, B.; et al. A quality assessment tool for artificial intelligence-centered diagnostic test accuracy studies: QUADAS-AI. Nat. Med. 2021, 27, 1663–1665. [Google Scholar] [CrossRef] [PubMed]
- Cabitza, F.; Campagner, A. The need to separate the wheat from the chaff in medical informatics: Introducing a comprehensive checklist for the (self)-assessment of medical AI studies. Int. J. Med. Inform. 2021, 153, 104510. [Google Scholar] [CrossRef] [PubMed]
- Cabitza, F.; Campagner, A. The IJMEDI Checklist for Assessment of Medical AI. 28 May 2021. Available online: https://zenodo.org/record/4835800 (accessed on 12 January 2023).




| Performance Metric | Rationnal | Interpretation | Key Concepts | Main Applications |
|---|---|---|---|---|
| Jaccard Index | Also known as the ratio of Intersection over Union (IoU) | 0 ≤ x ≤ 1 the closer to 1 the best | Very simple to use, the Jaccard index is a way of conceptualizing accuracy for object detection. It quantifies the similarity of the algorithm vision with those of the annotated ground truth | object/area segmentation (may also be employed for binary classification) |
| Accuracy | Number of correct predictions (true positives and true negatives) divided by the total number of predictions | 0 ≤ x ≤ 1 the closer to 1 the best | Very simple to use, accuracy quantifies the percentage of correct predictions by the algorithm. However, it is not adapted to imbalanced problems (where positive and negative proportions are greatly different) nor to problems where the “cost” of false positives/negatives must be taken into account (such as screening situations). Therefore, it may not be suited for evaluating algorithms in certain medical situations | classification/prediction |
| F1-score | Combines Precision (ratio of true positives/total positives predicted) and Recall (ratio of true positives/total positives in ground truth) | 0 ≤ x ≤ 1 the closer to 1 the best enhancing Precision OR Recall leads to a better score | Useful for evaluating performance in situations where Accuracy would be misleading (see above). It is adapted to unbalanced problems. It is, however, difficult to interpret when low: is it because of low Precision (too much false positives) or low Recall (not enough true positives)? | classification/prediction |
| AUROC (or AUC) | Combines Recall (ratio of true positives/total positives in ground truth) and Fallout (ratio of false positives/total negatives in ground truth) | 0 ≤ x≤1 the closer to 1 the best enhancing Precision OR diminishing Fallout leads to a better score | Useful for evaluating the diagnostic ability of a (binary) classifier, because it takes both true positives and true negatives into account. Therefore (and contrary to F1-score), diminishing the number of false negatives is taken into account (which is of importance in screening situations) | classification/prediction |
| c-index (concordance index) | Generalization of AUROC for assessing the correct ranking of events | 0 ≤ x ≤ 1 the closer to 1 the best | Adapted to datasets with censored data (survival studies, prediction of adverse events, etc.) | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Allaume, P.; Rabilloud, N.; Turlin, B.; Bardou-Jacquet, E.; Loréal, O.; Calderaro, J.; Khene, Z.-E.; Acosta, O.; De Crevoisier, R.; Rioux-Leclercq, N.; et al. Artificial Intelligence-Based Opportunities in Liver Pathology—A Systematic Review. Diagnostics 2023, 13, 1799. https://doi.org/10.3390/diagnostics13101799
Allaume P, Rabilloud N, Turlin B, Bardou-Jacquet E, Loréal O, Calderaro J, Khene Z-E, Acosta O, De Crevoisier R, Rioux-Leclercq N, et al. Artificial Intelligence-Based Opportunities in Liver Pathology—A Systematic Review. Diagnostics. 2023; 13(10):1799. https://doi.org/10.3390/diagnostics13101799
Chicago/Turabian StyleAllaume, Pierre, Noémie Rabilloud, Bruno Turlin, Edouard Bardou-Jacquet, Olivier Loréal, Julien Calderaro, Zine-Eddine Khene, Oscar Acosta, Renaud De Crevoisier, Nathalie Rioux-Leclercq, and et al. 2023. "Artificial Intelligence-Based Opportunities in Liver Pathology—A Systematic Review" Diagnostics 13, no. 10: 1799. https://doi.org/10.3390/diagnostics13101799
APA StyleAllaume, P., Rabilloud, N., Turlin, B., Bardou-Jacquet, E., Loréal, O., Calderaro, J., Khene, Z.-E., Acosta, O., De Crevoisier, R., Rioux-Leclercq, N., Pecot, T., & Kammerer-Jacquet, S.-F. (2023). Artificial Intelligence-Based Opportunities in Liver Pathology—A Systematic Review. Diagnostics, 13(10), 1799. https://doi.org/10.3390/diagnostics13101799