1. Introduction
Brain computed tomography (CT) is a modality most commonly used for evaluating the cerebral condition [
1]. It is more widely available, fast, and cost-effective than is brain magnetic resonance imaging. Although brain CT was developed in the 1970s, its widespread clinical use became achievable only recently, after the introduction of rapid, large-coverage multidetector-row CT scanners. Key clinical applications for brain CT include the diagnoses of cerebral hemorrhage and ischemia neoplasm and evaluation of the mass effect after hemorrhage, neoplasm, and cerebral edema secondary to ischemia. However, immediate and highly accurate interpretation of emergent CT images remains time-consuming and laborious, even for skilled neuroradiologists [
2]. Lodwick described computer-aided diagnosis (CAD) for the first time. Since then, a wide variety of lesion detection systems have been reported [
3,
4]. The usefulness of CAD depends on the number of true- and false-positive markers. High-performance CAD systems are appreciated by radiologists in the screening practices [
5]. For nodule detection in chest X-ray, CAD can even outperform the diagnosis efficiency of the unexperienced radiologists [
6]. At present, some CAD systems have received approval from the U.S. Food and Drug Administration [
7,
8]. Compared with traditional CAD (which may be limited by detecting specific disease and requiring a work-alone station), deep learning can handle more complicated condition. With a relatively wide scope, deep learning delivers multiple answers. The software improvements over the last few decades have enabled not only a considerable amount of research on image processing algorithms and methodologies but also rapid, faultless identification and quantification of abnormalities in scanned regions [
9].
Deep learning, a well-employed network for medicine [
10,
11,
12], can outperform humans in diagnosis. Li et al. [
13] proposed a U-net based model to identify cerebral hemorrhage, which has many advantages over human expertise, but it demands much manpower and time for segmentation. We aimed at developing a simple model, like a CNN-based system, to classify the results of brain CT as red-dot systems. Training a conventional convolutional neural network (CNN) from scratch typically requires a considerable amount of data. Nevertheless, through transfer learning, a small amount of data can become sufficient for finetuning a pretrained model [
14]. For patients with preexisting cerebral changes, a final human check of the deep learning–based diagnosis is required to ensure credibility; nevertheless, it can improve the clinical decision-making of neuroradiologists [
15]. Owing to the wide variety commercial models available, understanding the mechanism underlying the “black box” in computer operation is difficult. Moreover, studies that defined a reference to hyperparameter adjustment in the various models in certain conditions have been limited.
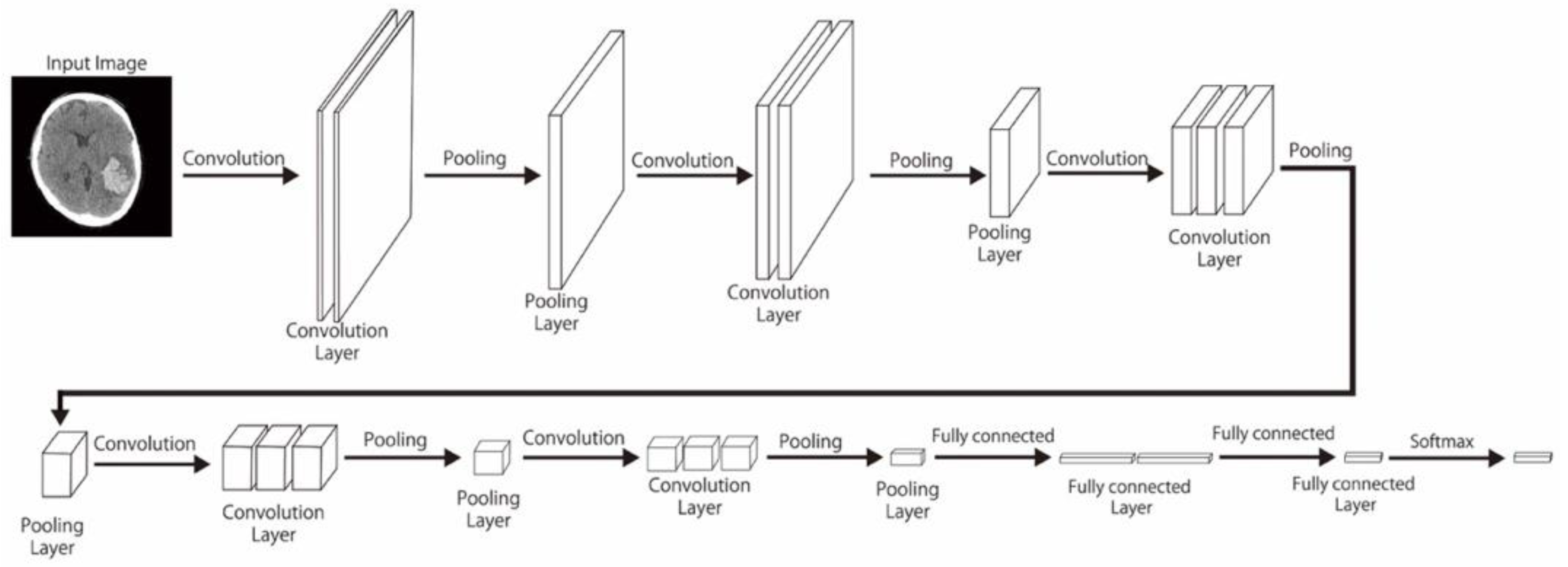
In this study, pretrained models including CNN-2, VGG-16, and ResNet-50—with varied data sizes, mini-batch sizes, and optimizers—were compared in terms of their performance in classifying unenhanced brain CT image findings into normal, acute or subacute hemorrhage, acute infarction, and other categories. We also reviewed other studies on deep learning–based diagnoses of hemorrhagic and ischemic stroke and compared their outcome with ours.
4. Discussion
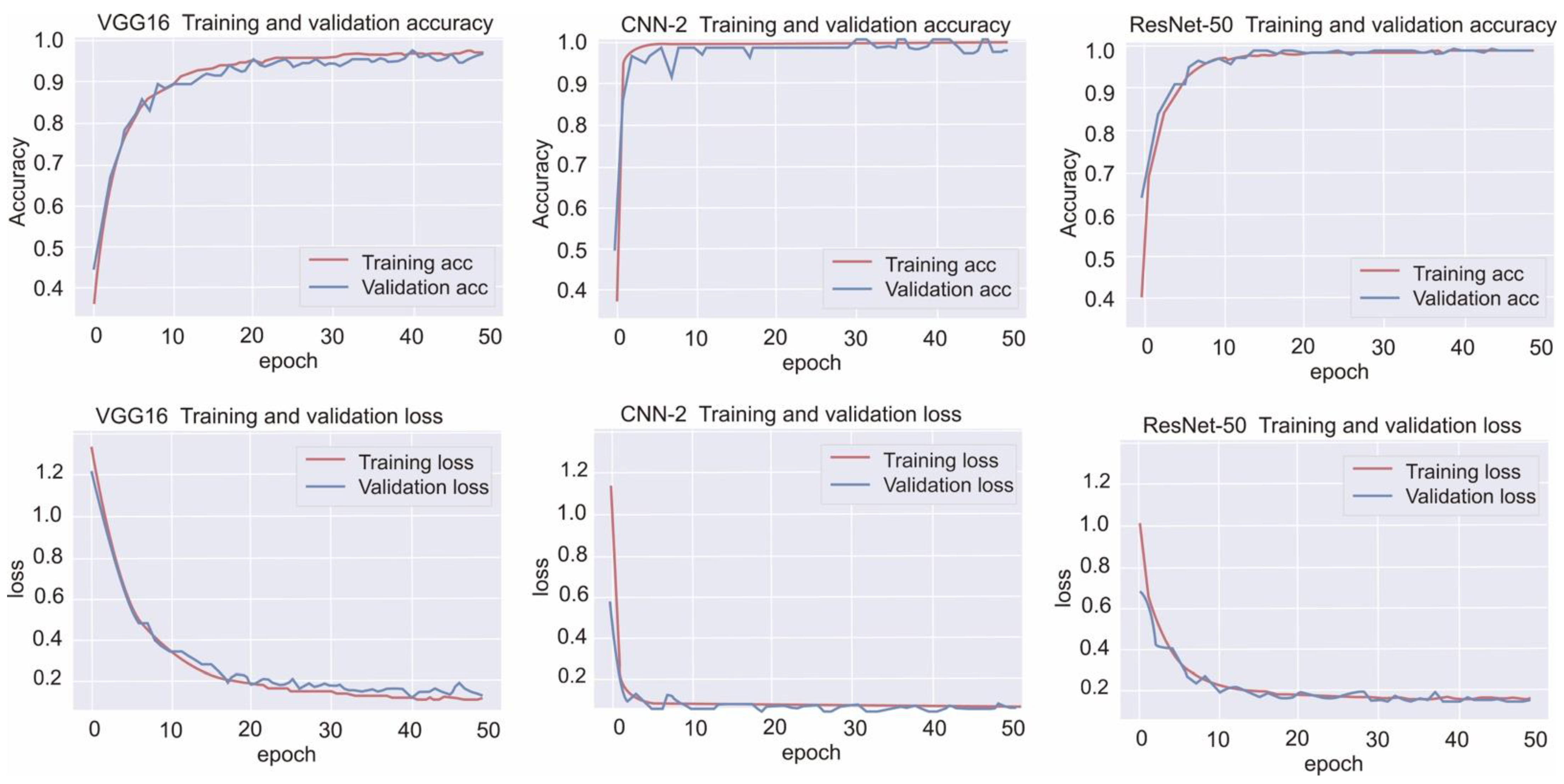
On the basis of the current results, CNN-based deep learning models can be used to detect strokes automatically and with high accuracy after hyperparameter optimization. We also compared the performance with different hyperparameters, regularizers, and data sizes.
Hemorrhagic stroke, a common and fatal disease, often presents symptoms similar to the more commonly diagnosed ischemic stroke. However, the treatment for hemorrhagic stroke is focused on controlling the bleeding from ruptured cerebral vasculatures or aneurysms, whereas that for ischemic stroke is focused on recannulating clot blockages in cerebral arteries. Misdiagnosis leading to the erroneous use of anticoagulant agents for treating a hemorrhagic stroke can cause death. Unenhanced brain CT is the most common and recommended test of choice to identify the two stroke types. Nevertheless, it is more difficult to make a diagnosis of subtle infarct only based on unenhanced CT. Schriger et al. [
26] claimed that in the absence of support from a radiologist, the accuracy of this interpretation is only 0.67 among emergency physicians treating patients with stroke.
Since the advent of deep learning, the use of brain CT images for accurate prediction of critical anomalies has received considerable attention. Several attempts have thus been made to develop a reliable diagnosis model using deep learning methods. Transfer learning has also been extensively used with the recent CNN-based networks [
27]. However, most of these methods have employed an imbalanced and limited amount of data, which has led to unsatisfactory results. In the current study, we developed a system that classifies hemorrhagic and ischemic strokes by using numerous brain CT images sampled uniformly from a patient population.
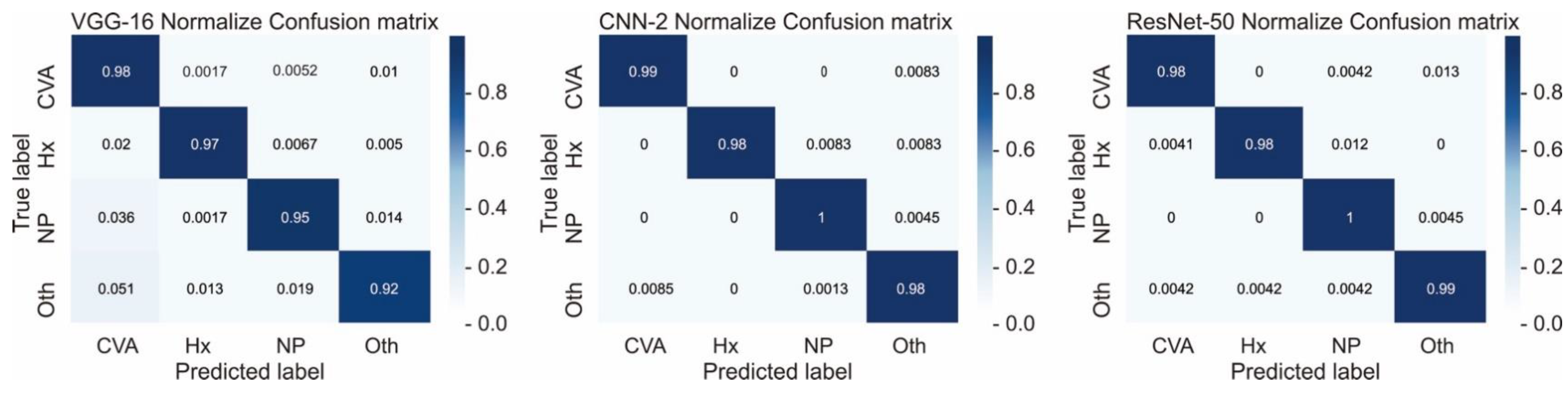
Here, we comprehensively evaluated the effectiveness of the three most efficient CNN models, namely CNN-2, VGG-16, and ResNet-50, in the classification of hemorrhagic and ischemic strokes from brain CT images after hyperparameter optimization. One of the most crucial hyperparameters considered in this study was the mini-batch size. We accordingly identified the mini-batch size that provided the highest validation accuracy for the CNN-2, VGG-16, and ResNet-50 with regard to classifying the brain CT images. Moreover, the best performing models in this study were found to be CNN-2 and ResNet-50 (highest accuracy = 0.9872). Grewal et al. [
28] developed an automatic intracranial hemorrhage detection model based on deep learning, with a sensitivity of 0.8864 and a precision of 0.8124 in a dataset of 77 brain CT images interpreted by three radiologists. However, the authors included a small dataset and detected only hemorrhagic stroke in their analysis. Moreover, Prevedello et al. [
29] assessed the performance of a deep learning algorithm to detect hemorrhage, mass effect, hydrocephalus, and suspected acute infarction by using a dataset of 50 brain CT images and reported AUCs of 0.91 for hemorrhage, mass effect, and hydrocephalus and only 0.81 for suspected acute infarction. In the current study, after optimization, all three models, trained with relatively more data, demonstrated outstanding performance, with F1 scores >0.95.
In addition to accuracy, efficiency is an important factor in medical image classification. In this study, the VGG-16 and CNN-2 required only about 2 and 8 min on average to provide the outcome, respectively, which is nearly 14 and 4 times faster than the time taken by the ResNet-50, respectively. We thus believe that this significant difference in time consumption occurs because of the relatively complicated structure of ResNet-50, with numerous hidden layers. If the data size is bigger, it costs several folds of time higher than ours, and the difference in time consumption is bigger.
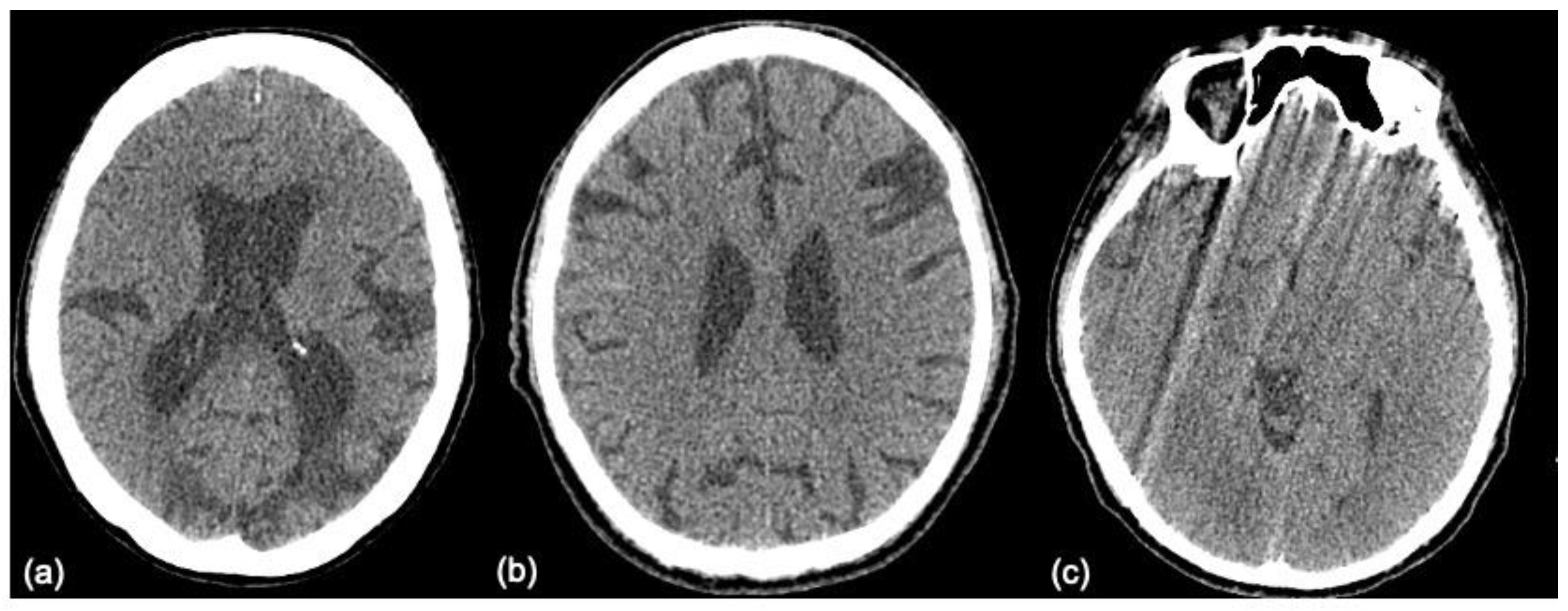
The images that are false positive are illustrated in
Figure 6. However, we cannot provide a clear explanation of why the classification failed, due to the mechanism underlying the “black box”. There is no relationship between size, laterality, location, or augmentation process. It is possible that an increase in data size will achieve better performance.
Tandel et al. [
30] reported that the simplest CNN-1 could classify benign and malignant gliomas with high efficiency from magnetic resonance images, with further high-efficiency subclassification into low- and high-grade malignant gliomas enabled by the CNN-2. Further segmentation of low-grade and high-grade malignant gliomas can be performed using the CNN-3 and CNN-4. They utilized artificial neural networks (ANNs) as feature extraction algorithms and a CNN as classifier, with high accuracy of 0.98. Despite the simple architecture of a CNN, it is effective in classifying gliomas from magnetic resonance images; hence, we considered it efficient to classify the four categories in our study.
Ioffe and Szegedy [
31] claimed that removing dropout as an optimizer from ResNet allows the network to achieve increased accuracy. We noted similar results for our brain CT images (
Table 3), even in different mini-batch sizes.
Activation function is key in deep learning architectures, and many types of nonlinear activation functions exist. Pedamonti [
24] reported that both ReLU and LeakyReLU are suitable activation functions for CNN-based models, particularly deeper neural networks. In the current study, we also compared the different activation functions on VGG-16 for stroke classification, and no apparent difference between ReLU and LeakyReLU was noted; nevertheless, their performance was better than that of the sigmoid activation function. However, considering the wide range of activation functions available, including ReLU, LeakyReLU, ELU, SELU, and sigmoid, the activation function most suitable for classifying stroke images warrants further investigation.
The clinical application of our result is mainly as a classifier for radiologists, who can quickly issue a warning to clinicians. Rather than a “red-dot system”, we will apply this result to further develop a system combined with the nature language process (NLP). Although understanding the mechanism underlying the “black box” in computer operation is difficult, we can supply many image inputs for NLP training through this classifier. We are committed to doing this in the future.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}