1. Introduction
In recent years, deep learning methods have been applied to a variety of problems with promising results. From speech recognition [
1] and autonomous driving [
2] to image-based cancer detection [
3], deep neural networks (DNNs) have often outperformed traditional machine learning methods [
4,
5,
6]. In 2019, Esteva and Topol outlined the transformative potential of AI for skin cancer diagnosis [
7]. Furthermore, Google recently announced an AI tool for dermatological diagnosis, which proves that this subject is quite topical [
8,
9].
Higher predictive accuracy comes at a cost, however, as these models are often black boxes [
10]. The lack of model interpretability means that domain experts cannot check the underlying reasoning of a predictive model. In particular, it is often difficult to determine whether a model is a so-called “Clever Hans” predictor [
11]: producing seemingly correct results during training which rely on spurious correlations in the training data and not does not rely on any relevant rule. Those learned “shortcuts” [
12] might work well on standard benchmark datasets but usually fail to transfer to real world data. Shortcut learning can, therefore, cause incorrect performance estimates. As concluded by Geirhos et al. [
12], “we must not confuse performance on a dataset with the acquisition of an underlying ability”. It is known that various artefacts can be present in dermoscopy images [
13], increasing the risk of shortcut learning. For example, surgical skin markings in images can adversely impact skin cancer classification performance [
14]. Moreover, the widely used dataset for skin cancer classification from the International Skin Imaging Collaboration (ISIC) [
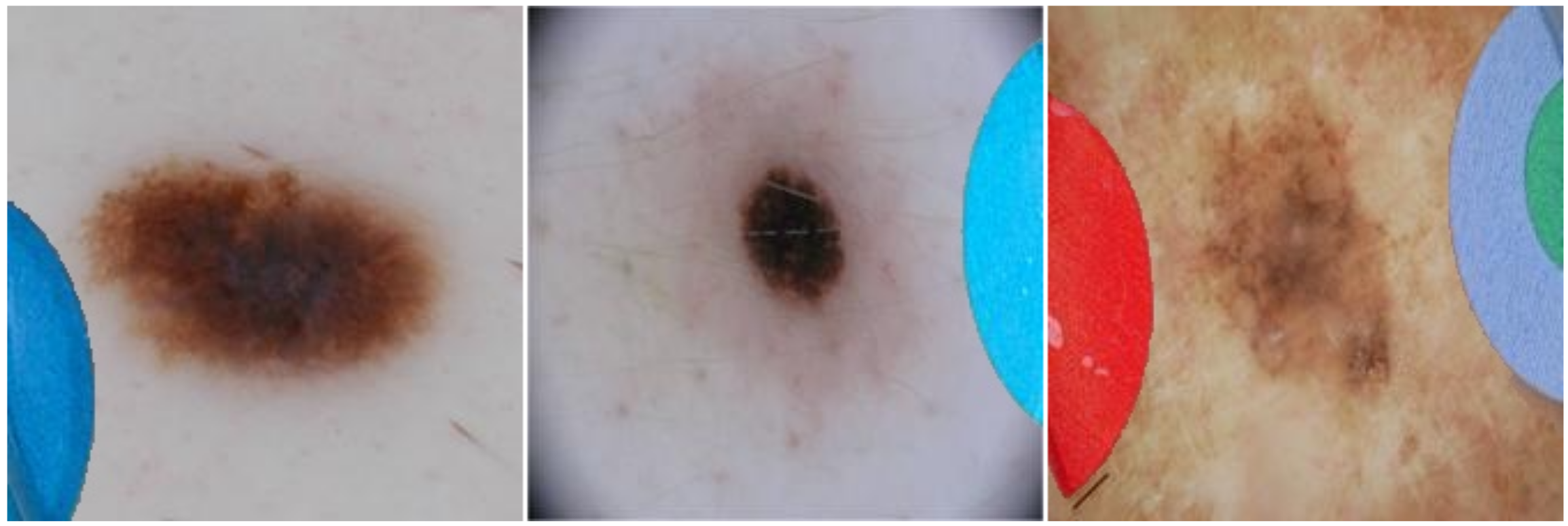
15] contains artefacts: Half of the images of benign lesions contain elliptical, coloured patches (colour calibration charts [
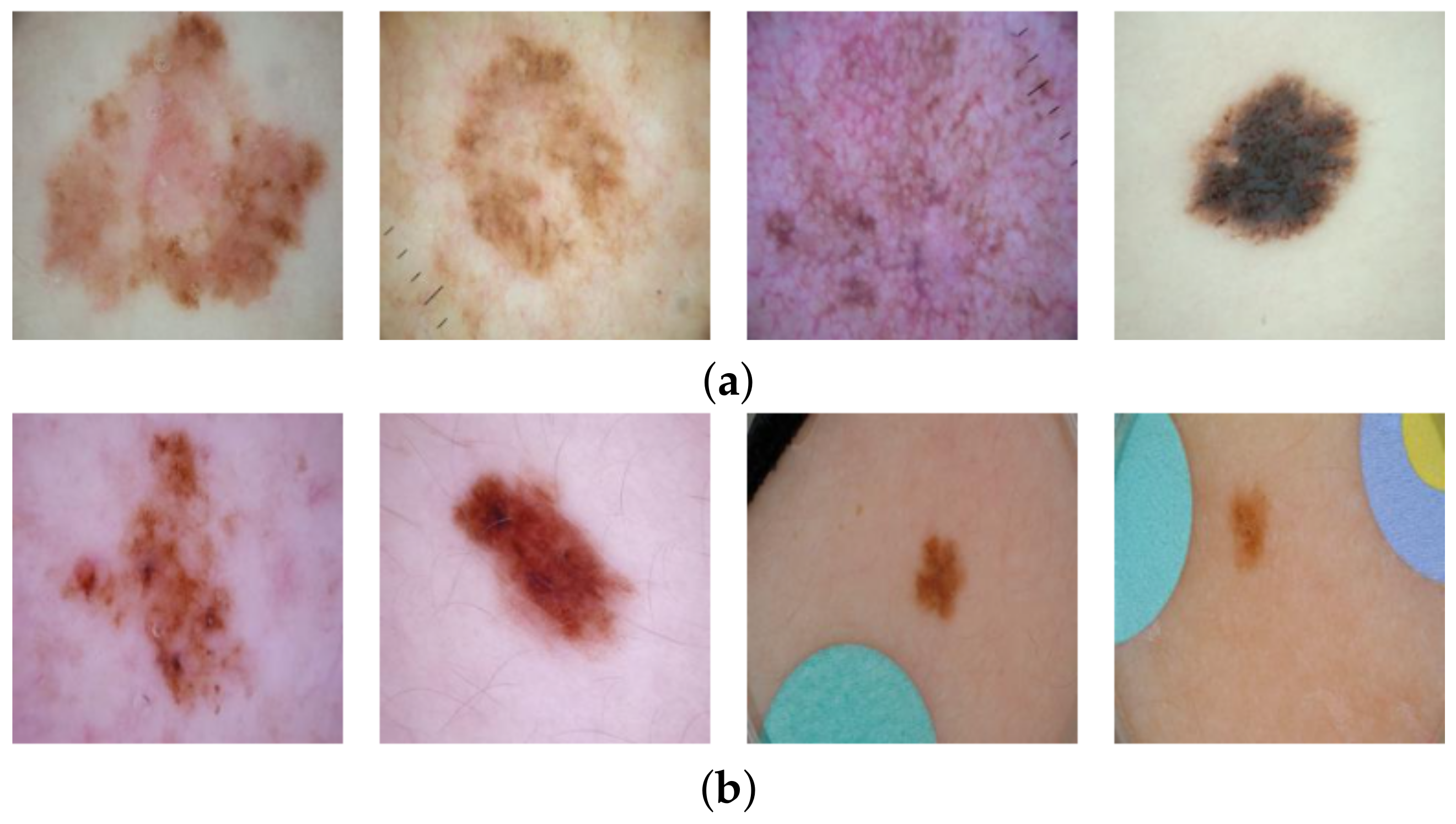
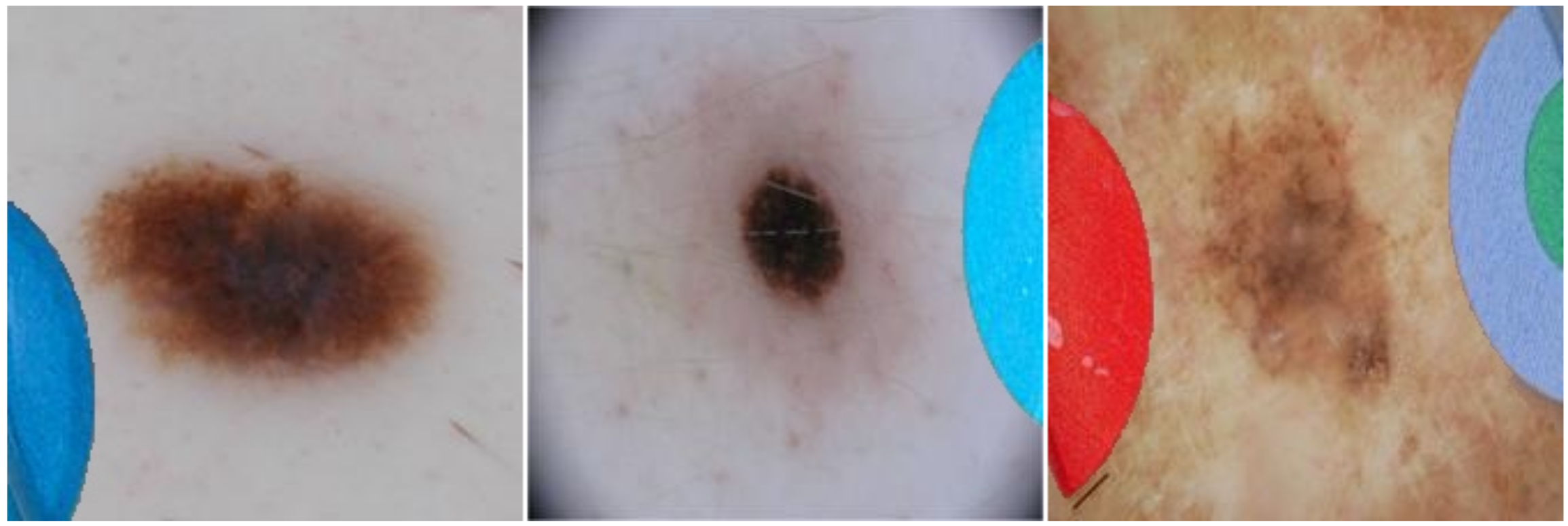
13]), whereas the malignant lesion images contain none (cf.
Figure 1). Hence, a deep learning model could learn to associate a coloured patch with a benign lesion and exploit this spurious correlation to achieve an artificially high prediction accuracy. Thus, in the first instance, the reported accuracy of such a shortcut model is higher than what would be expected when patches are no longer available. Furthermore, if a malignant lesion appears “in the wild” alongside a coloured patch (for example, when the diagnosis is not known a priori), then the model may base its decision on the patch, resulting in an incorrect diagnosis. It is, therefore, essential that biases are unearthed to avoid unexpected outcomes after deployment.
In this work, we examine how often a standard classification model for diagnosing skin cancer learns shortcuts. We present a methodology to measure and quantify shortcut learning in an already trained model and present a method to remove this confounding bias. More specifically, we will study the following research questions:
- RQ1:
To what extent is a standard skin cancer classifier taking shortcuts by using the coloured patches in the ISIC dataset for prediction?
- RQ2:
To what extent can the undesired usage of artefacts be removed by replacing the patches in the ISIC dataset with automatic inpainting and retraining the classifier?
In order to address these research questions, we apply automatic inpainting techniques. Image inpainting, also known as image completion, is the task of reconstructing missing regions in an image by estimating suitable pixel values. By masking the coloured patches in the ISIC data and letting an inpainting model automatically fill these masks, coloured patches are replaced by skin-coloured pixels. We then compare the difference in predictions of a classifier on the original benign images and on the images where those patches were replaced with benign skin to analyse to what extent the classifier relies on coloured patches. Similarly, we insert coloured patches into images with malignant skin lesions and subsequently compare the predictions of the classifier on the original and altered images to assess the risk that a malignant image with a coloured patch will be misclassified as benign. These analyses constitute our answers to RQ1. We emphasise that we do not change the training procedure of the original classifier but only pass original or modified images through a trained classifier to evaluate to what extent the classifier relies on shortcuts. This makes our approach model agnostic.
We further investigate to what extent we can remedy the undesired behaviour of the classifier by automatically inpainting all patches in the training data with benign skin and re-training the classifier on this de-biased dataset (RQ2). Since our approach removes artefacts from the data, it is classifier agnostic and can, therefore, be applied to other model architectures as well.
In summary, the contributions of this paper are as follows:
We propose a model-agnostic method to quantify the extent to which a classifier relies on artefacts present in the training data (“shortcuts”) by using inpainting methods.
We apply and validate the method on the ISIC skin cancer dataset.
By removing the artefacts with in-distribution inpainted images, we show that we can train an unbiased classifier.
The rest of the paper is organised as follows. The subsequent section details the background and related work on interpreting deep learning models and uncovering biases.
Section 3 describes the dataset and introduces our methodology to evaluate and quantify shortcut learning. Results are presented in
Section 4, and they are then discussed in
Section 5. In
Section 6, we draw conclusions from the main findings.
2. Related Work
Common deep learning models are nowadays black boxes by nature. Assessing and understanding the reasoning of models is the focus of research in explainable artificial intelligence (X-AI) [
16]. Explainability is especially important when algorithms are applied for medical diagnosis in order to establish trust among the medical community [
17]. Notably, in 2014, Zeiler and Fergus [
18] published a seminal paper explaining the predictions of convolutional neural networks (CNNs). One of their methods involves systematically occluding sections of the input images with grey boxes and assessing the change in predicted probabilities. Bazzani et al. [
19] also used occluded images with grey boxes for unsupervised object localisation. Issues may arise with this method, however, as regions of grey pixels have not been observed by CNN during training and such occluded images may, therefore, be out-of-distribution, raising questions about the reliability of the results [
20].
The approach by Fong and Vedaldi [
21] was to introduce blur and noise to parts of the image and again assess the change in predictions. The authors noted that this method could introduce artefacts, thus producing nonsensical results if the CNN has not observed examples of blur during training. Unexpected results from “fooling” neural networks has been studied by, e.g., Nguyen et al. [
22], who found that CNNs sometimes believe with high confidence that images of pure static are recognisable objects. Chang et al. [
23] and Burns et al. [
20] addressed this issue. Instead of grey boxes or image perturbations, both of these studies used inpainting to replace sections of an image, i.e., pixel patterns that fit with the rest of the image, in order to understand what the most important features were for a specific model prediction. We also apply inpainting, but rather than assessing important features for individual images (local explanations [
16]), we seek to identify across the full training dataset whether a CNN is using spurious correlations in order to uncover shortcut learning on a global level.
Rieger et al. [
24] studied confounders in the ISIC dataset, namely the presence of coloured patches in benign skin images. Where Bissoto et al. [
25] already found that skin lesion classifiers rely on these patches by occluding images with black patches, Rieger et al. [
24] proposed a method to solve this shortcut learning by lowering the importance of the patch regions during training. By defining a preferred region of interest and penalising the classifier for focusing on the patch regions, it optimises the model towards paying attention to the lesion and not to artefacts. Moreover, follow-up work by Bissoto et al. [
26] aimed to de-bias the machine learning model. In contrast, we propose an alternative method of training a shortcut-free classifier by adapting the dataset instead of the classifier or its training procedure. This means that our methodology is model-agnostic and is not tied to any specific machine learning model or architecture. Moreover, we can assess a classification model after it has already been trained by presenting a method to measure and quantify the amount of shortcut learning by a trained model. This means that existing models that might already be operational in clinical practice can be tested for shortcut learning.
3. Materials and Methods
3.1. Data Set and Classifier
We retrieved skin lesion images from the ISIC Archive Dataset [
15] using the code provided by Rieger et al. [
24]. In total, 2506 images labelled as cancerous (malignant) and 19,298 non-cancer (benign) images were retrieved. Coloured patches were present in 8973 (46%) of the benign images but none were present in malignant images. Example images are shown in
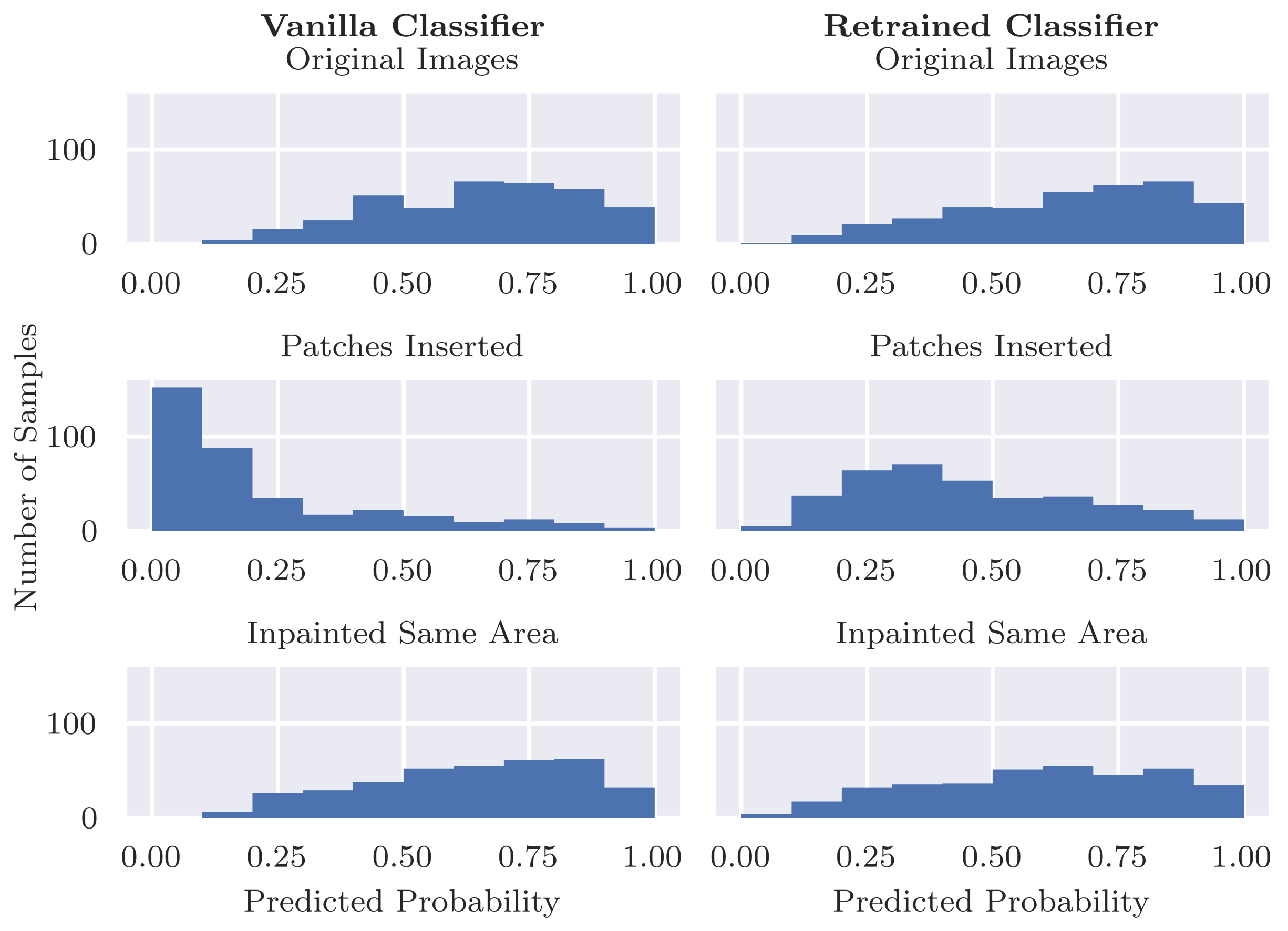
Figure 1. We randomly split the data set into training (80%) and test set (20%) and used the same splits for training the inpainting model and the classification model.
In order to analyse shortcut learning in classifiers for diagnosing skin cancer, we first train a neural network to distinguish between benign and malignant lesions. We emphasize that our goal is not to train a new, state-of-the-art classifier but instead to analyse the impact of shortcut learning in a widely used classification model. We followed the methodology by Rieger et al. [
24], which allows us to compare with the results of that study. We used VGG16 [
27] as the classifier, a standard neural network architecture which is also previously used for skin cancer diagnosis [
28,
29]. VGG16 consists of a feature extractor with 13 convolutional and pooling layers and 3 fully connected layers for the classification. The output layer has two nodes: one for predicting the probability that an image contains a malignant lesion and one for predicting benign. For details regarding this architecture, we refer to the original publication [
27] or to a discussion on neural networks for melanoma detection [
28]. We applied a standard training strategy by using a pre-trained VGG16 from Pytorch [
30], freezing the weights for the feature extraction layers and only adapting the final classification layers to our data set (the source code for our methodology is available at
https://github.com/adubowski/shortcuts-skin-cancer, accessed on 17 November 2021). We chose the same hyperparameters as Rieger et al. [
24] by relying on the associated source code (
https://github.com/laura-rieger/deep-explanation-penalization, accessed on 17 November 2021): training with SGD for 10 epochs with a learning rate of 0.00001 and momentum of 0.9.
The raw images of the ISIC dataset have differing resolutions. We resize all images to
, which is the standard image resolution for VGG16 [
27,
29,
31], and this allows us to use pre-trained weights for the VGG16 model. (Note that Rieger et al. [
24] used the non-standard resolution of
. For completeness, we also trained a VGG16 model on the non-standard
size but we found no significant differences in classification accuracy compared to the standard
).
3.2. Removal of Coloured Patches for Benign Cases
For automatic inpainting, we used the Generative Multi-column Convolutional Neural Network (GMCNN) model by Wang et al. [
32]. This inpainting model requires a masked image as input, after which it is trained with reconstruction loss to predict suitable pixel values to fill in the hole in the image. We set the hyperparameters of the inpainting model as the authors proposed it in their source code (
https://github.com/shepnerd/inpainting_gmcnn, accessed on 17 November 2021). The model, which had been pretrained on celebrity faces with rectangular masks, was finetuned on our dataset for 25 epochs, since the authors of the inpainting model advise finetuning for 20–40 epochs on a relatively small dataset size similar to ours. Better inpainting results may have been possible after training longer than 25 epochs, but we were limited in computing resources.
Inpainting models require binary masks indicating the regions the model should fill. In order to train the inpainting model on our dataset, we created random elliptical masks close to the boundaries of the images. Randomness was introduced to the locations, sizes and shapes of these masks, but they conformed roughly to the shapes of the observed coloured patches. Only images without patches were used for training to ensure that the model learns to inpaint skin only.
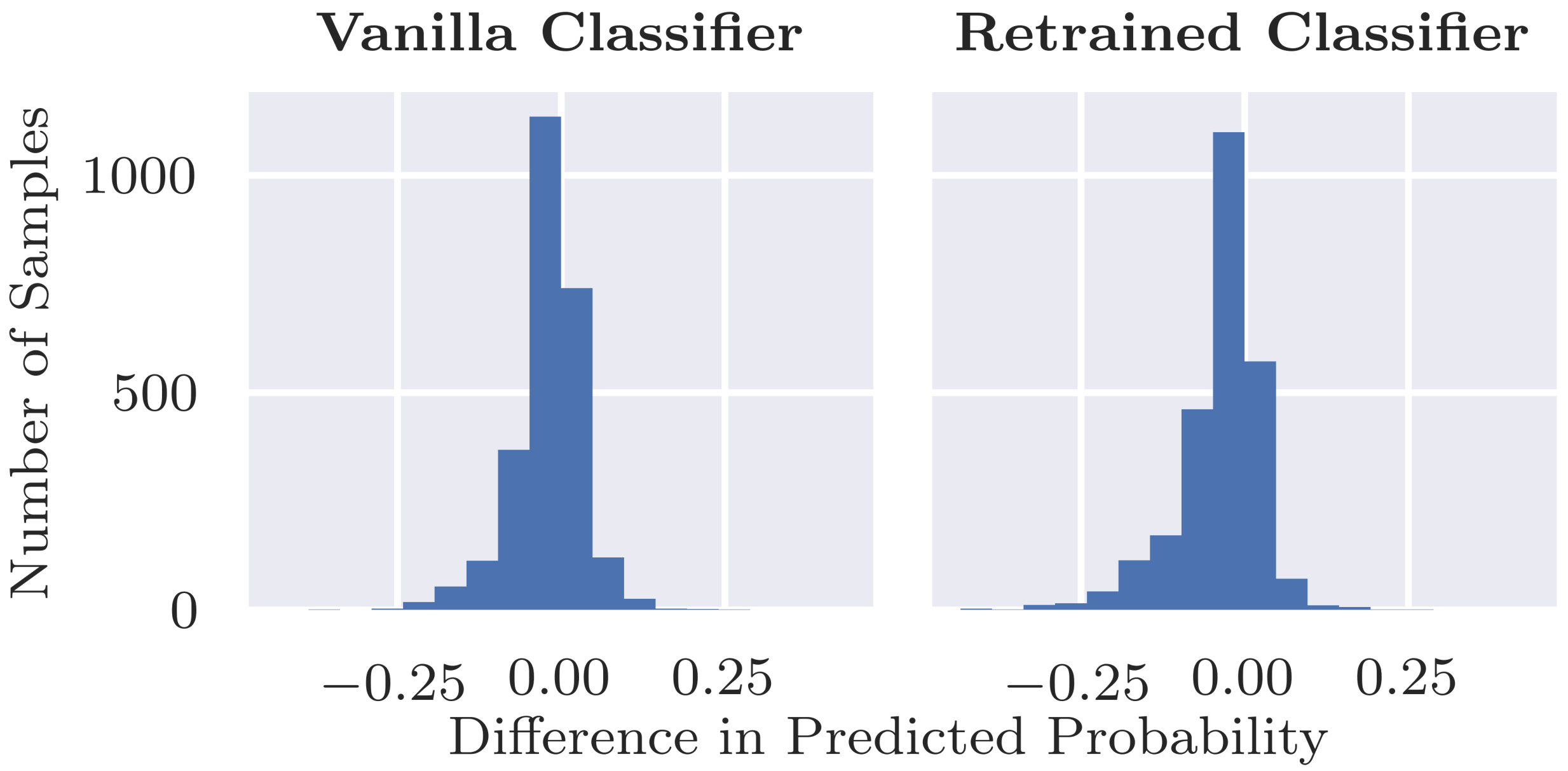
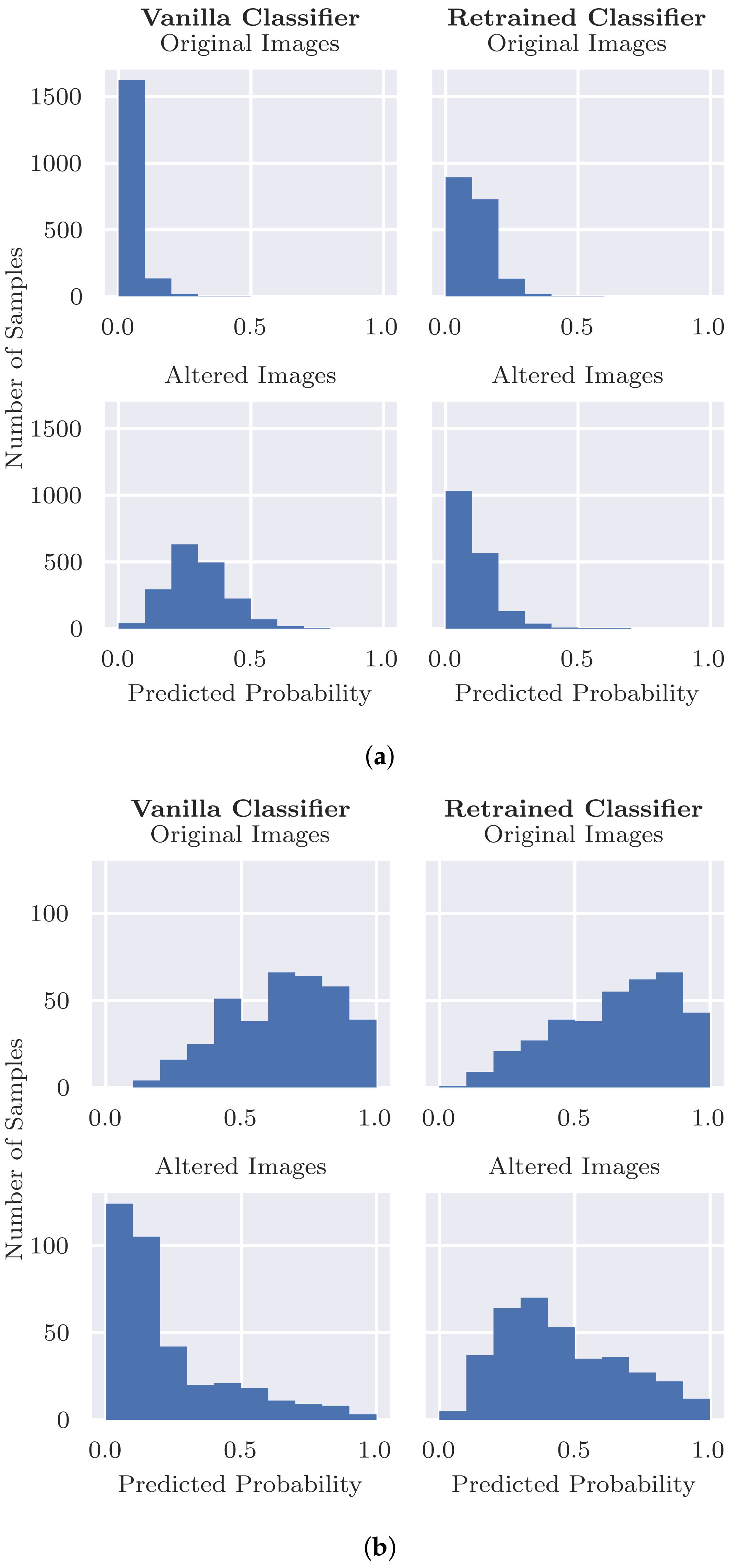
Validity Check. In order to evaluate inpainting quality and validate that the presence of inpainted pixels does not result in unexpected output of the classifier, we applied two validity checks. As the basis for these checks, we take the images
without coloured patches in the test set and use the GMCNN model to automatically inpaint random elliptical sections in the image. The first check calculates the structural similarity index measure (SSIM) [
33] between each original image and its corresponding randomly inpainted image. An SSIM of exactly 1 would indicate perfect inpainting. We use the implementation in scikit-image [
34] with parameters set to match the implementation of Wang et al. [
33]. Secondly, we analyse the behaviour of the classifier on these inpainted images by assessing the changes in output probability. This validity check evaluates whether inpainting results in a distribution shift for the classifier. If the predictions for each original image and inpainted image are similar, we can conclude that the inpainting model works reasonably well and that the inpainted regions are indeed “uninformative” [
20] replacements.
Patch Removal. In order to mask the coloured patches present in some images in the dataset, we need to know the exact location of these patches. As described by Rieger et al. [
24], the coloured patches can be segmented using the SLIC image-segmentation algorithm [
35] and splitting the segments based on the difference in RGB and HSV values to an average skin tone. Since Rieger et al. have publicly shared masks from their study, these have been re-used for the current study. However, we found that these masks did not always completely cover the coloured patches. Since this might lead the inpainting model to take the remaining pixels of the coloured patch and fill the hole with the original colour of the patch, thereby “repairing” the patch instead of removing it, we additionally dilated the masks before inpainting. For this, we used an elliptical structuring element of size
pixels such that the coloured patch was covered by the mask while not drastically increasing the mask size. Dilation was implemented using OpenCV [
36].
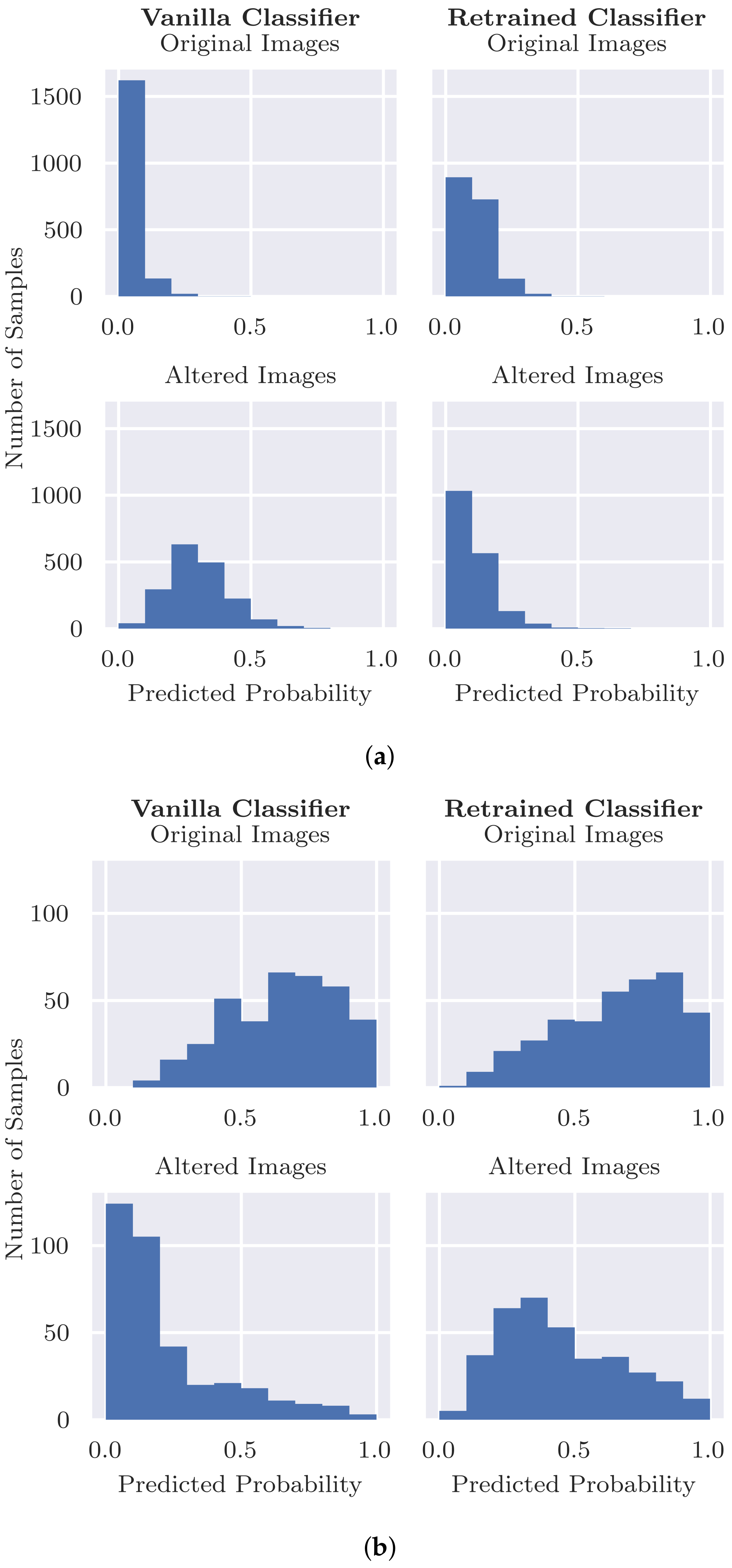
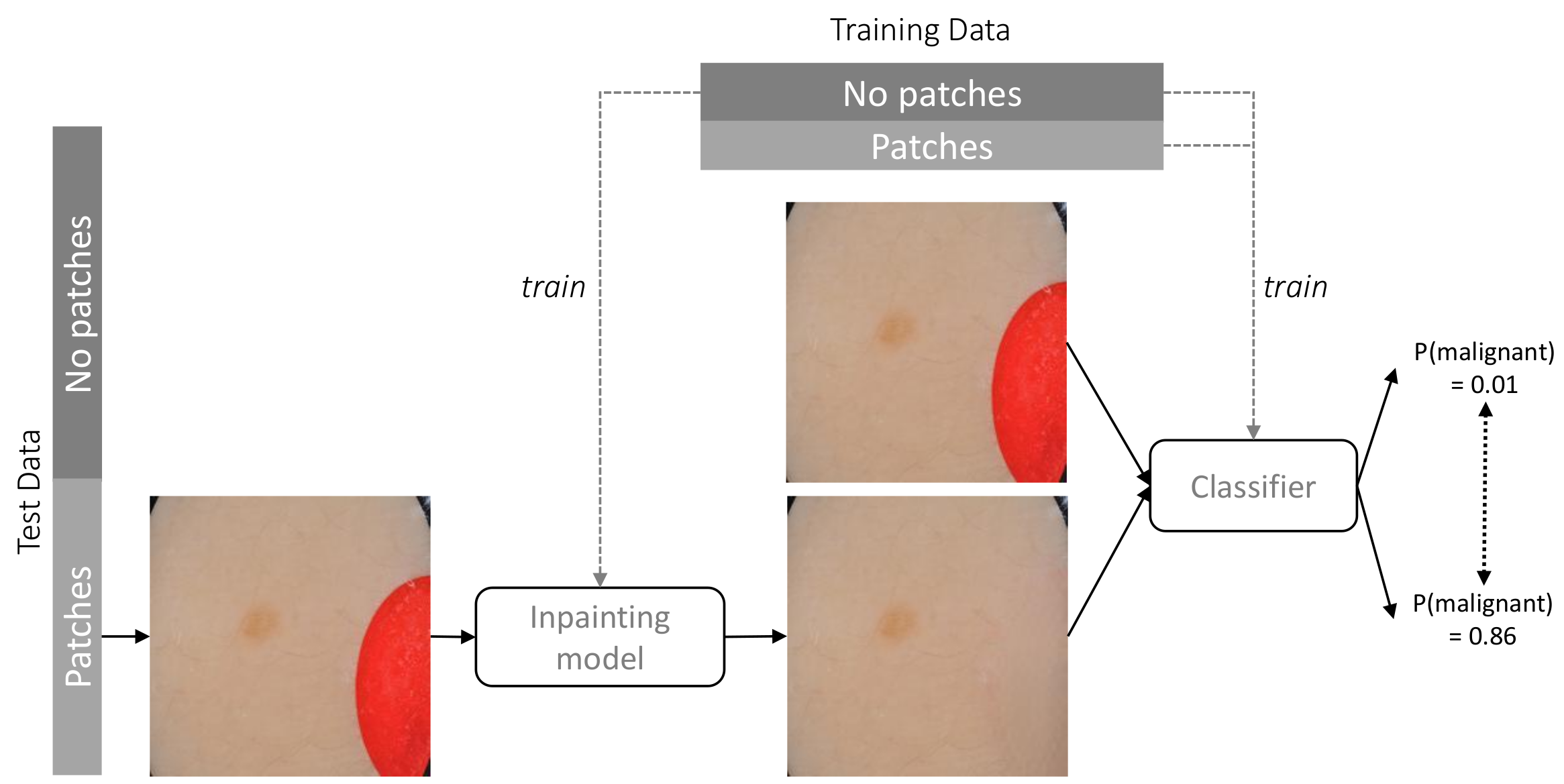
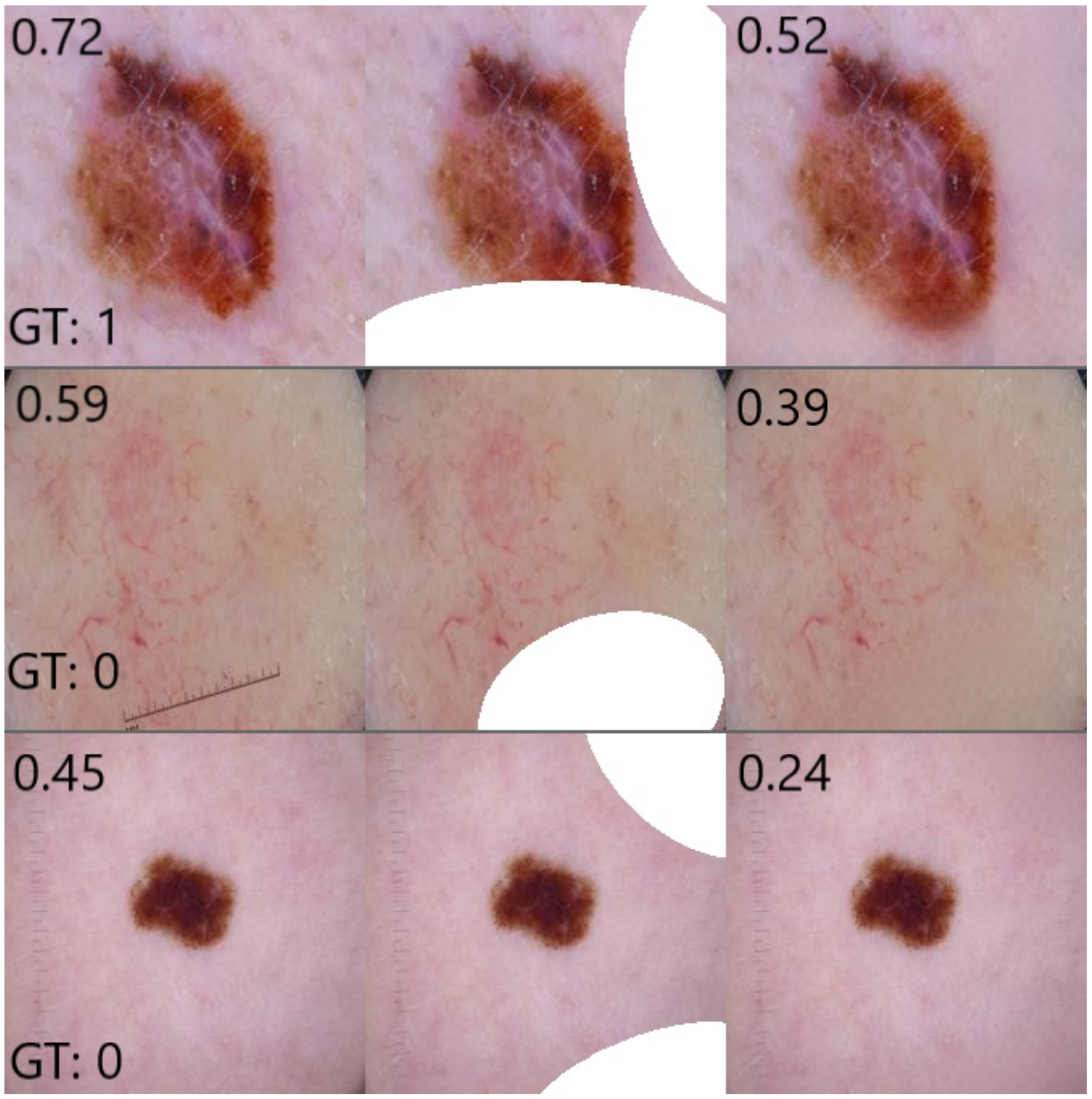
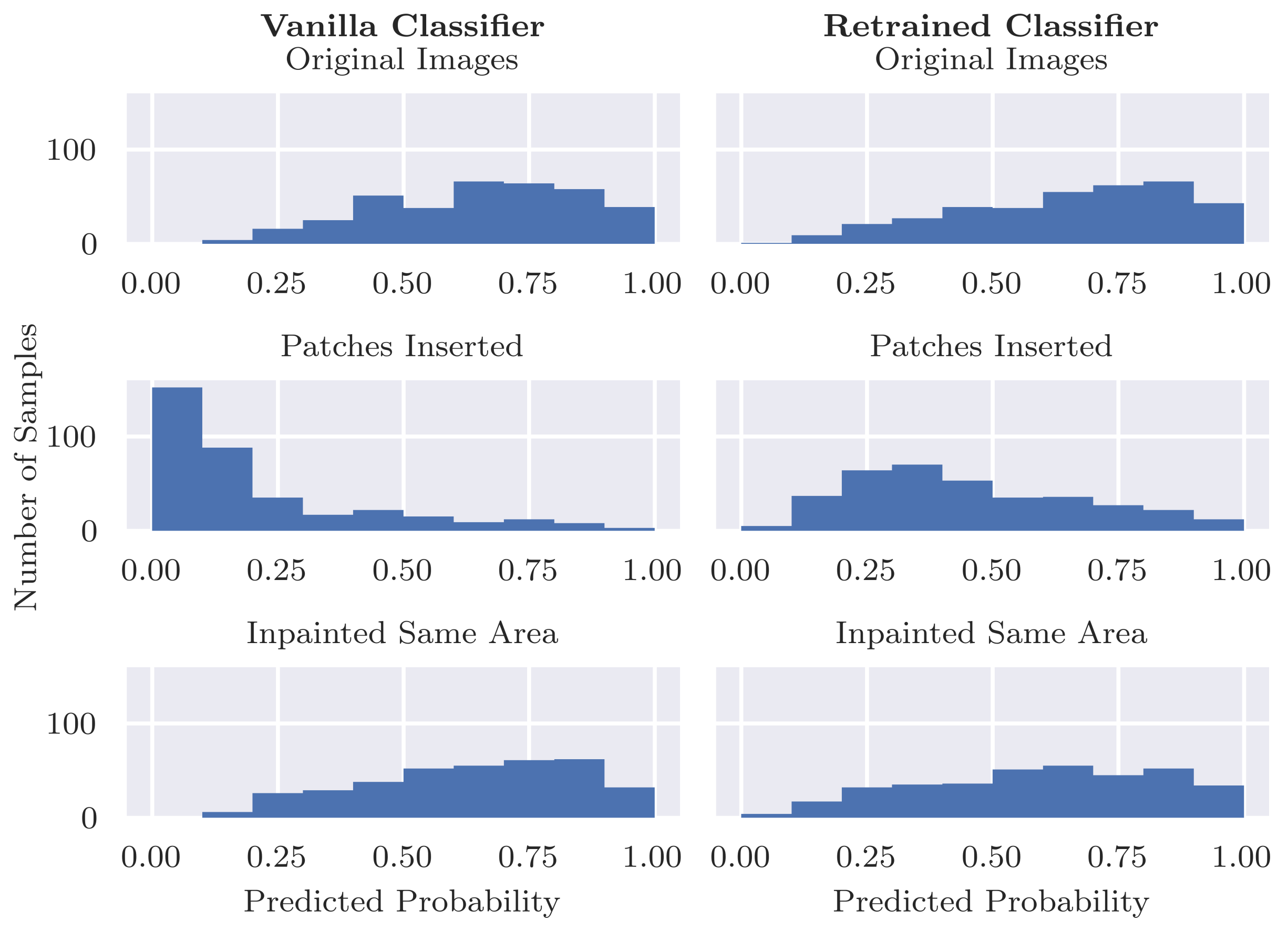
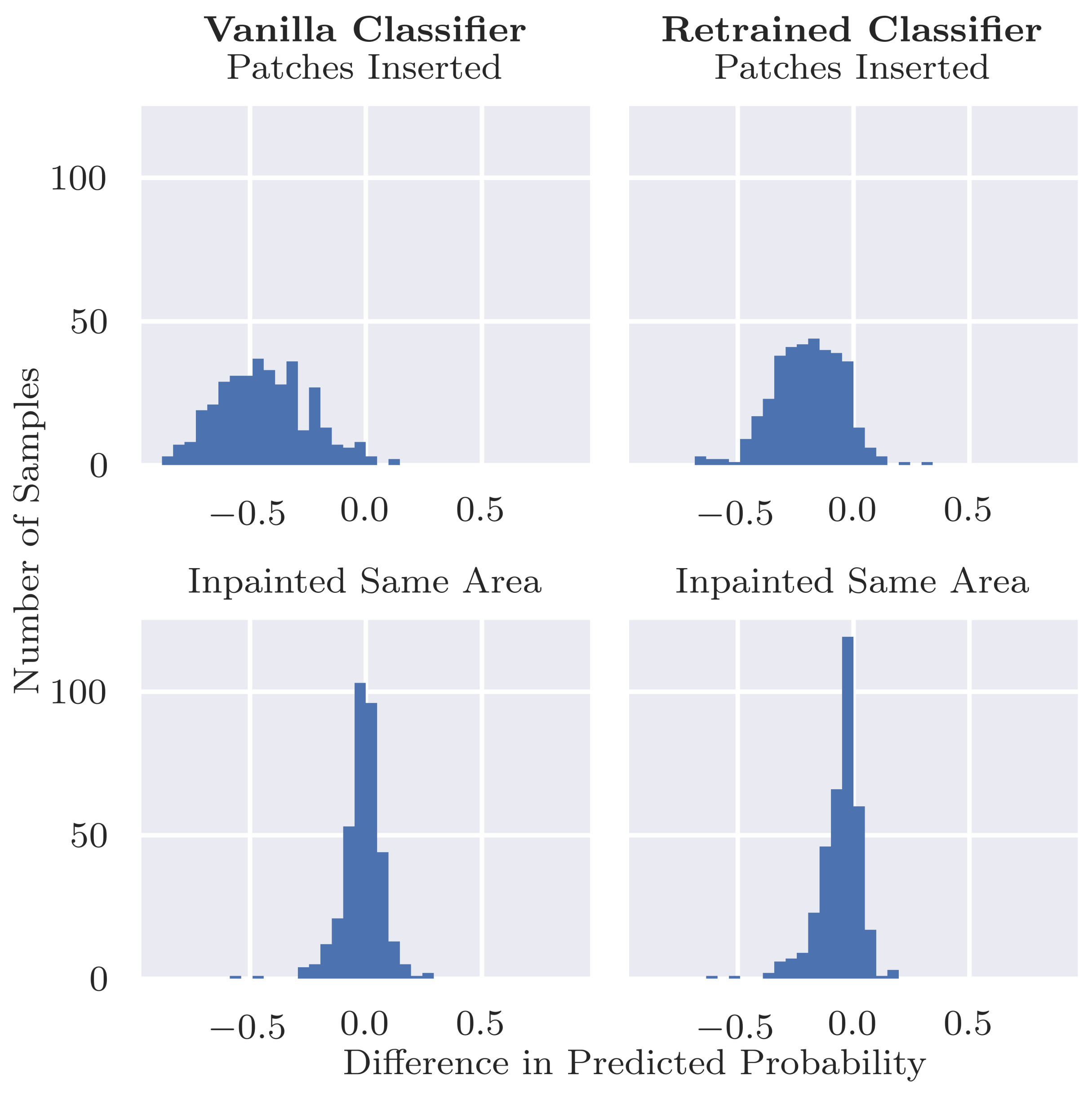
In order to assess the extent to which the classifier relies on coloured patches for predicting a benign case, we apply the trained inpainting model to the subset of test set images containing coloured patches. The trained inpainting model replaces these patches with artificially generated skin, after which these altered images are forwarded through the classifier. By comparing the difference between the prediction for the original image with patch and the prediction for the inpainted image without patch, we can measure how much the classifier relies on the coloured patch for each image. By aggregating over all test images with a patch, we can quantify the extent to which the classifier bases its decisions on those artefacts.
Figure 2 shows an overview of this approach. Similarly to the inpainting validity check above, we calculate the Structural Similarity Index Measure (SSIM) in order to evaluate the difference between the altered images and their original counterparts.
3.3. Inserting Coloured Patches to Malignant Cases
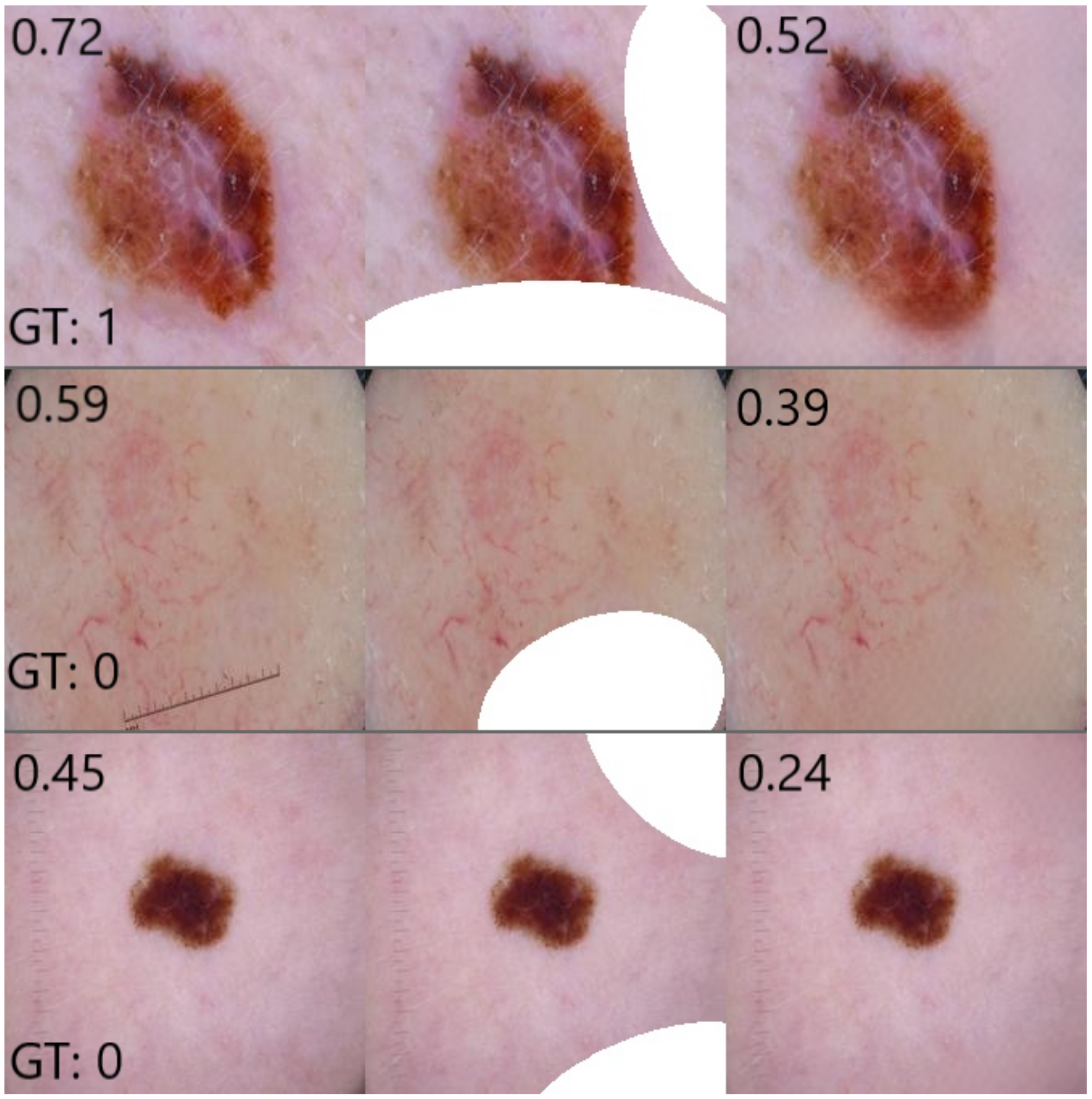
In order to assess the risk of classifying a malignant image as benign due to the presence of coloured patches, we add such patches to malignant images. We used the same segmentation approach as described in the previous section (
Section 3.2) to extract patches from benign images and inserted them into images of malignant lesions, as shown in
Figure 3. Again, class probabilities were obtained from the classifier and were compared for the original malignant images vs. the altered versions including patches. We observed that in some cases the inserted coloured patches overlapped part of the lesions, which may affect classifier results. We manually removed these images to obtain 361 (73%) of the 492 malignant images in the test set for evaluation. For completeness, we compared the results when using all malignant images in the set and observed no significant differences.
Additionally, we again calculate SSIM between the original image and the modified image. This indicates how much the insertion of patches changes the images, which can be compared with the changes in predictions by the classifier.
3.4. Quantifying the Classifier’s Dependency on Coloured Patches
By passing both the original test images as well as the altered test images (either with patches inserted or removed) through the classifier, two sets of predictions can be compared. We emphasise that we do not train the classifier at this step but forward the images through the already trained model to collect its predictions. In order to quantify how much the classifier relies upon the absence or presence of the coloured patches (the “shortcut”), we calculate the Mean Absolute Deviation (). This metric indicates how much, on average, modifying the image (i.e., inserting or removing a patch) affects the predicted class probability by the classifier.
When passing an input image
with label
through classifier
C (in our case a VGG16 model),
C outputs probability
and probability
, which sum up to 1. We denote with
an image containing a coloured patch, and
is an image without a coloured patch in the original dataset. We denote with
an altered version of
where a coloured patch was initially absent but was artificially inserted. Similarly,
is an image where a coloured patch was initially present but was removed with inpainting. In order to quantify how much classifier
C relies on the coloured patches to correctly classify a benign lesion, we calculate the following:
where
denotes the set of benign images with coloured patches (i.e.,
) in the test set. In order to quantify how much the model relies on the coloured patches when classifying malignant images with coloured patches, we calculate the following:
where
denotes the set of malignant images without coloured patches (i.e.,
) in the test set.
The MAD score does not contain information on the direction of change. We wish to assess for what fraction of benign images the predicted probability of being benign decreases and for what fraction of malignant images the predicted probability of being malignant decreases (denoted as %), respectively. Therefore, we additionally take the non-absolute deviation into account and calculate the fraction of images with respect to for which the deviation was negative and report the mean negative deviation () for this fraction. Lastly, we calculate the fraction of images with respect to for which their predictions crossed the decision boundary and, hence, where the modification would have resulted in a different classification. This score indicates the risk that a malignant image with a coloured patch would be classified as benign.
3.5. Inpainting to Create a Dataset without Artefacts
In addition to quantifying shortcut learning, it is desirable to fix shortcut learning and thereby remove the impact of unwanted confounders. Hence, for our second research question
RQ2, we address this issue by replacing the confounders in the training dataset (in our case the coloured patches in the ISIC data) with inpainting and retrain the classifier on this de-biased dataset. Specifically, we first train the classification model as described in
Section 3.1 on the unaltered training data (“Vanilla Classifier”). We then finetune the inpainting model on this training set, excluding images with patches. In this manner, the inpainting model is trained to generate skin-coloured segments without coloured patches. This approach is similar to the evaluation methodology presented before (cf.
Section 3.2), but instead of applying it to the test set only, we augment the
training dataset by replacing the coloured patches with their inpainted counterparts. In this manner, a classifier cannot learn a relationship between coloured patches and benign lesions and might generalise better in the real world. We train a classifier with the same architecture as before on this altered training data (“Retrained Classifier”). We apply the same three experiments as described in
Section 3.2 and
Section 3.3: a validity check for the inpainting model, quantifying shortcut learning of the classifier when coloured patches are removed and quantifying shortcut learning when coloured patches are inserted.
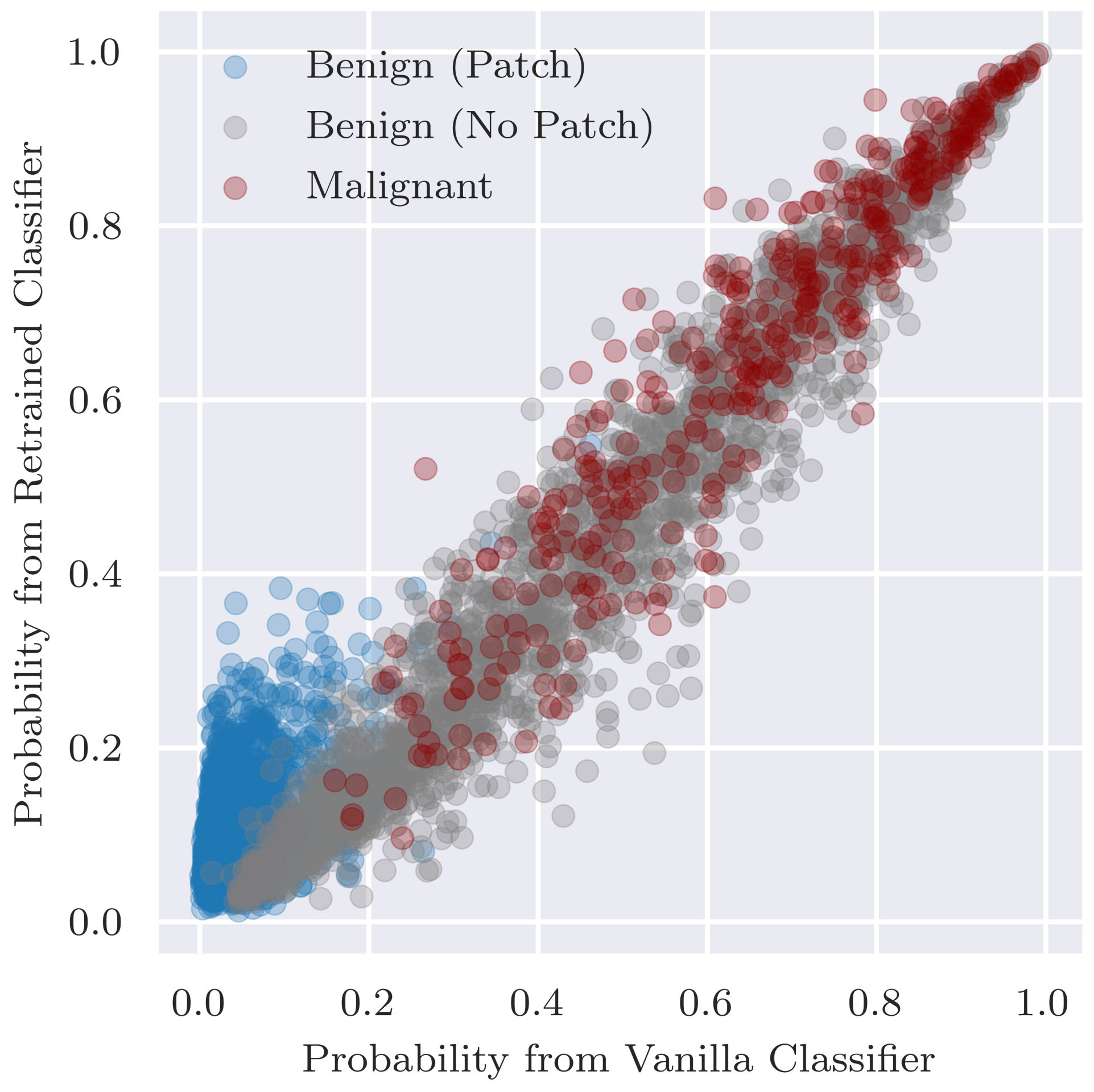
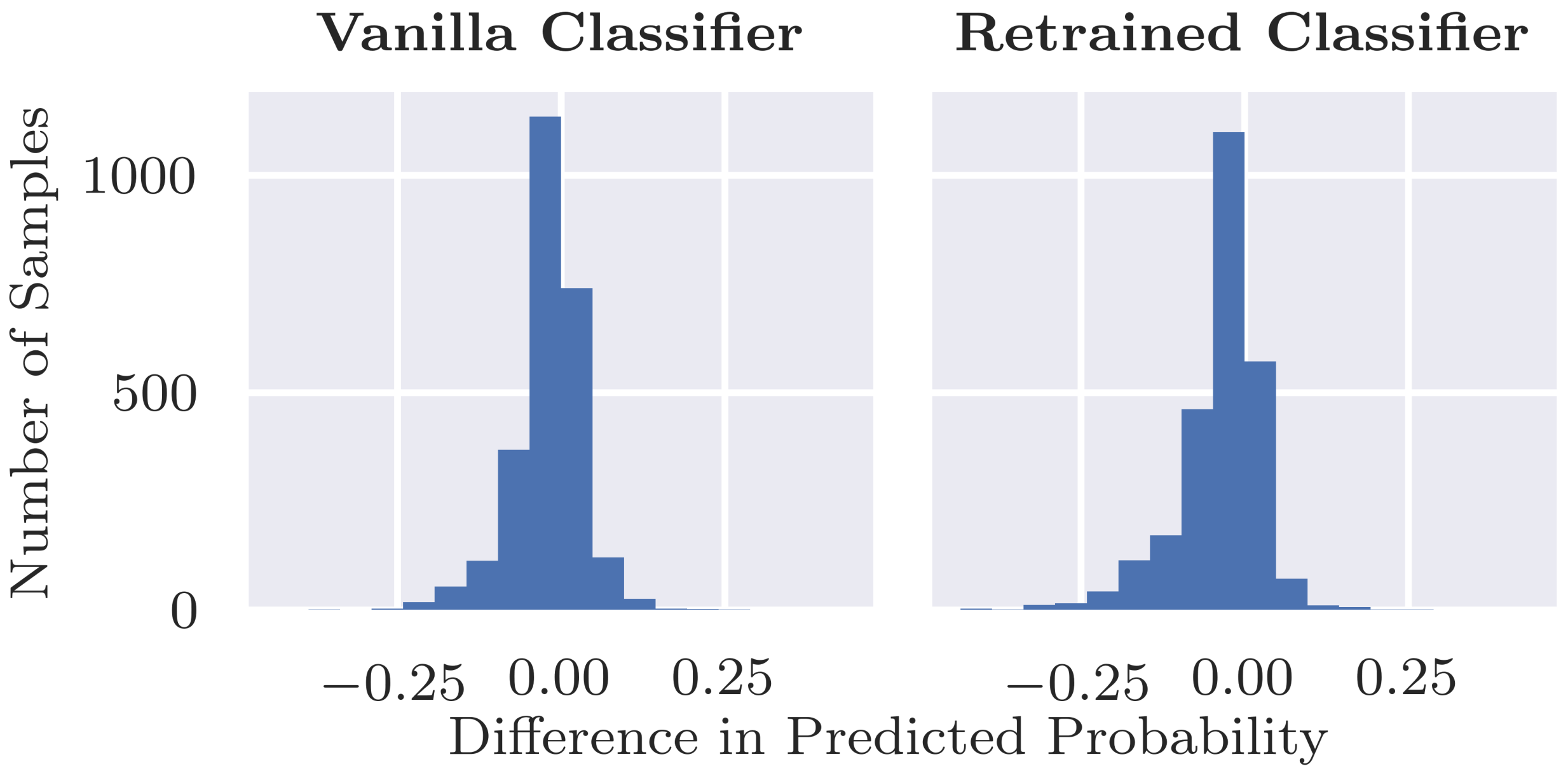
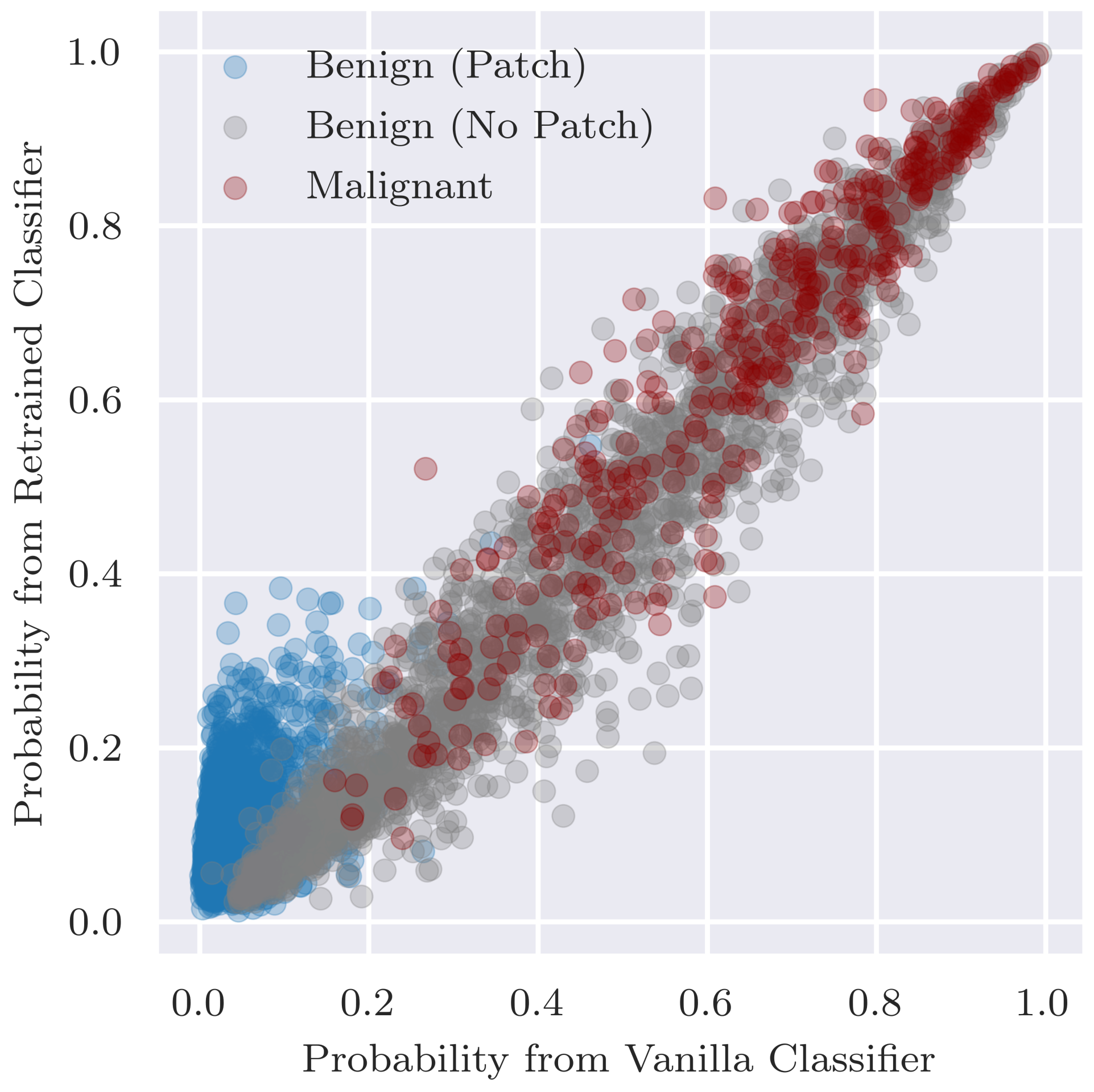
Additionally, we assess the overall classification performance of the retrained classifier since ideally the retraining does not result in a decrease in performance. In addition to comparing performance, we want to ensure that there are no major changes in predictions between the retrained classifier and original vanilla classifier. Thus, to assess the fidelity in predictions between the two classifiers, we visualise the predicted probabilities for individual examples as a scatterplot and calculate Pearson’s correlation coefficient between the two sets of predicted probabilities.
5. Discussion
Quantifying the classifier’s reliance on artefacts (RQ1): Our results show that our standard classifier is using patches as shortcuts when making predictions for skin cancer. We first evaluated how much the model relies on these patches to correctly predict benign lesions. Even when the patches are removed, the model is able to use other information in these images to correctly predict benign lesions in many cases, albeit with a drop in specificity as the model becomes less confident. Thus, in many cases we can say that the model is “right for the right reasons”. However, when we compare the specificity for images with patches vs. those with no patches in the original test set, we see a big difference both for the unaltered images and inpainted versions. Thus, it is possible that patches tend to occur more frequently in “easier” images, i.e., those that are more clearly benign. If the patches occurred instead in more difficult cases, then we might expect a heavier reliance on the patches to predict benign lesions.
The converse and arguably more serious case is examined by our second evaluation on inserting patches into malignant images. While patches occur only in benign images in this pre-labelled dataset, there is no guarantee that this will be the case in future clinical practice. Our results showed the potentially dangerous nature of the bias, where the presence of a coloured patch alongside a malignant lesion (
Figure 3) resulted in a sizeable drop in sensitivity from 0.886 to 0.191. As shown in
Table 3, this means that 69.5% of malignant lesions pictured next to a coloured patch may be misdiagnosed as benign because of the bias in training data and the shortcuts learned by the classifier. When such a shortcut model would be used in clinical practice, this can result in missed treatment opportunities and potentially fatal outcomes.
Can inpainting be used to remedy the undesired usage of artefacts in the training set (RQ2): Adjusting the training set by replacing the coloured patches with inpainted skin pixels certainly reduces the bias of the model. Particularly promising is the retrained classifier’s ability to correctly classify benign images with patches regardless of whether the patch has been inpainted or not. From the validity check that randomly inpaints images that have no patches, it does not seem that the model is associating the presence of inpainted pixels with the benign class. Although the predicted probability is more likely to decrease than increase with inpainting, the results were similar for the vanilla classifier for which larger decreases in probability tended to be caused by the inpainting covering part of the lesion or some other salient information.
However, the issue with misdiagnosed malignant lesions alongside coloured patches was not fully resolved by the retrained model. The sensitivity dropped from 0.839 to 0.512 when patches were inserted, which, although not as severe as for the original vanilla classifier, is still significant. A potential cause of this behaviour is that the patches are “out-of-distribution” with respect to the training data, resulting in unreliable predictions by the classifier. Further analysis could help to shed more light on the cause, e.g., using class activation maps or analysing the types of patches that result in the largest changes.
We note that we may just be replacing one confounder in the data, the coloured patches, with another artifact in the form of inpainted regions, and the model could detect inpainted patterns and learn to associate them with benign lesions. There is little evidence of this behaviour in the current study, as when we compared predictions of inpainted test images vs. the original unaltered images, no strong bias was observed from the retrained classifier. This might change, however, with a more sophisticated classification model. If the problem arose, then a possible solution would be to include randomly inpainted versions of images during training.
Limitations and Practical Implications: Inpainting proved to be a useful technique for understanding model predictions, and this work builds on the existing results in this area [
20,
23]. The main difference in the current study is to use predefined masks for inpainting which replace specific biases, rather than previous studies which inpaint different sections of the image to detect the most salient regions. The main benefit of our approach is that this allows the overall effect of specific biases to be assessed easily without having to examine many saliency maps for individual images. In particular, our quantitative metrics are useful for summarizing the extent of shortcut learning across a dataset. The main limitation with this, however, is that the bias in the data needs to be easily identifiable and able to be segmented from the images.
The method of reducing bias proposed in the current study by retraining on inpainted results is applied to the data only and is independent of classification models. Thus, it has the advantage that it is not restricted to specific neural network architectures or even other machine learning methods in contrast to many existing methods [
24,
37,
38]. It does, however, have the extra burden of training an inpainting model for replacing the bias and this may not work for every problem and dataset.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}