
Comparison of Supervised and Unsupervised Approaches for the Generation of Synthetic CT from Cone-Beam CT


Abstract
1. Introduction
1.1. Background
1.2. Key Contributions of the Work
2. Materials and Methods
2.1. Dataset Description
2.2. Image Pre-Processing
2.3. Deep Convolutional Neural Network Models
2.4. Training Methods
2.5. Performance Metrics
2.6. Cross-Validation Analysis
2.7. Implementation Details
3. Results
3.1. Performance Metrics
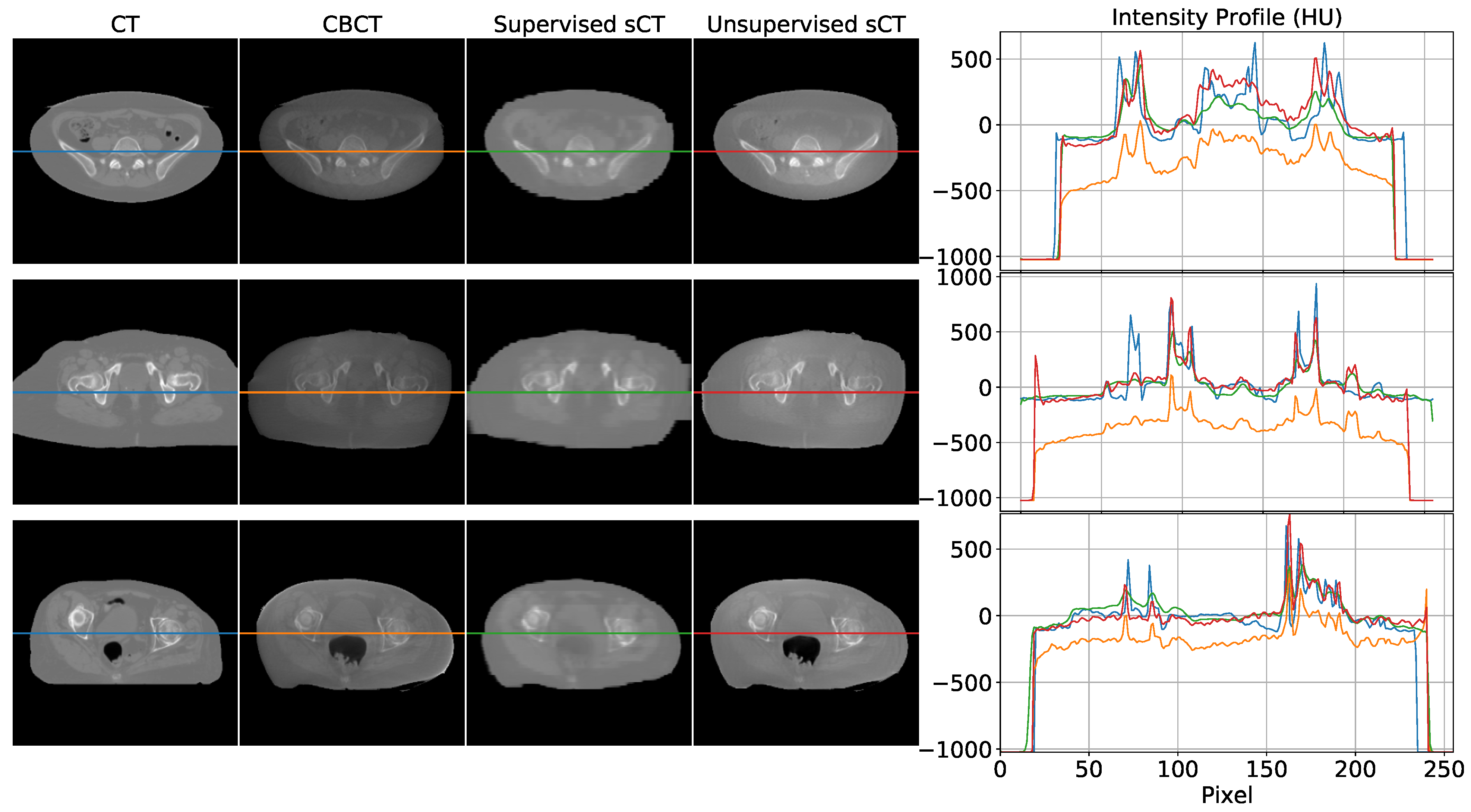
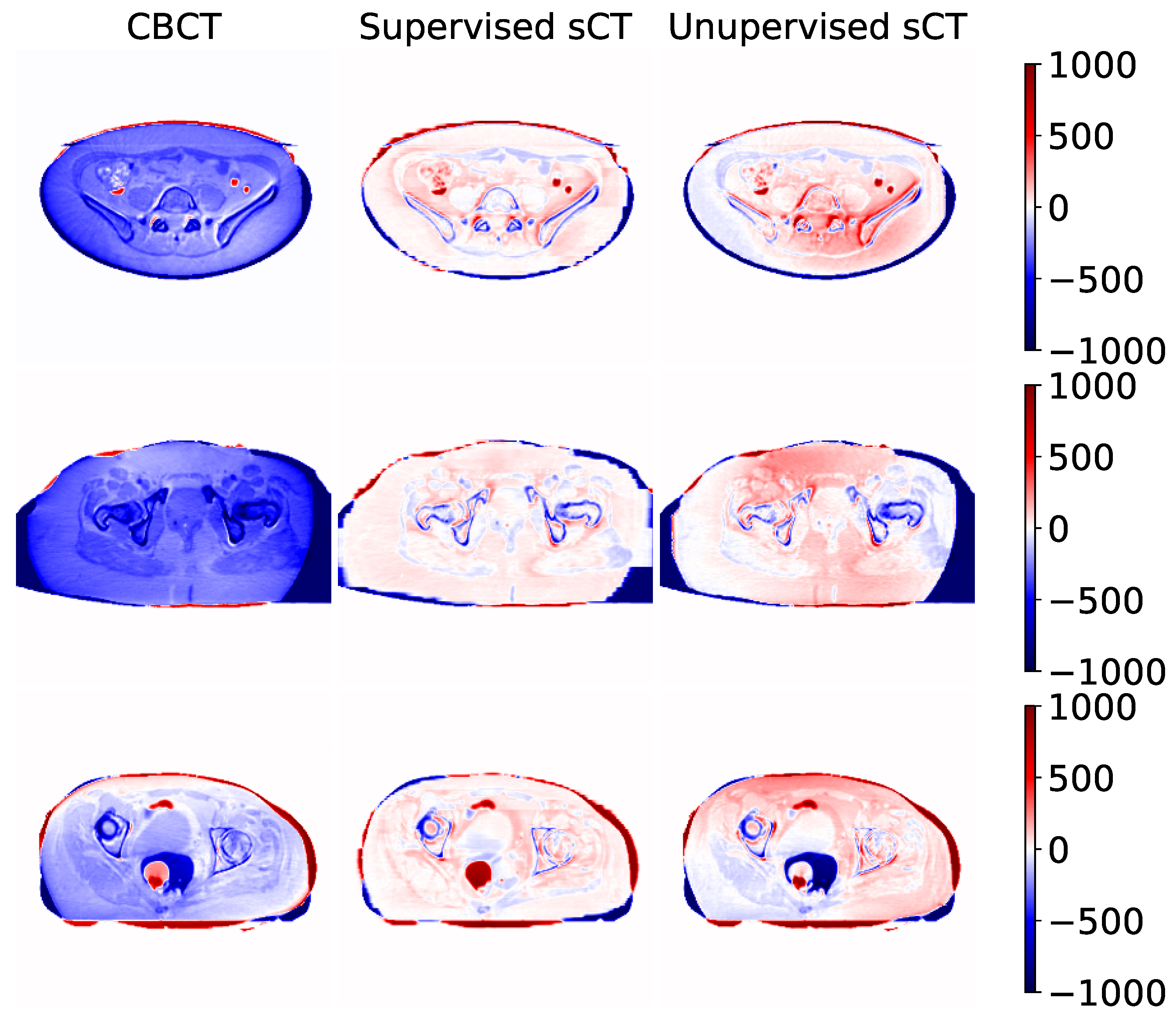
3.2. Qualitative Comparison
4. Discussion
4.1. Main Findings
4.2. Comparison with the Literature
4.3. Technical Challenges and Work Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CBCT | Cone-Beam Computed Tomography |
| cGAN | cycle Generative Adversarial Network |
| CNN | Convolutional Neural Network |
| CT | Computed Tomography |
| G | Generator CT |
| G | Generator CBCT |
| D | Discriminator CT |
| D | Discriminator CBCT |
| FOV | Field of View |
| MAE | Mean Absolute Error |
| MSE | Mean Squared Error |
| PRD | Pelvic Reference Dataset |
| PSNR | Peak Signal-to-Noise Ratio |
| SSIM | Structural Similarity Index Measure |
Appendix A
Loss Functions for Unsupervised Training
References
- Ding, G.X.; Duggan, D.M.; Coffey, C.W.; Deeley, M.; Hallahan, D.E.; Cmelak, A.; Malcolm, A. A study on adaptive IMRT treatment planning using kV cone-beam CT. Radiother. Oncol. 2007, 85, 116–125. [Google Scholar] [CrossRef] [PubMed]
- Niu, T.; Al-Basheer, A.; Zhu, L. Quantitative cone-beam CT imaging in radiation therapy using planning CT as a prior: First patient studies. Med. Phys. 2012, 39, 1991–2000. [Google Scholar] [CrossRef] [PubMed]
- Lei, T.; Wang, R.; Wan, Y.; Du, X.; Meng, H.; Nandi, A.K. Medical image segmentation using deep learning: A survey. arXiv 2020, arXiv:2009.13120. [Google Scholar]
- Saba, T. Recent advancement in cancer detection using machine learning: Systematic survey of decades, comparisons and challenges. J. Infect. Public Health 2020, 13, 1274–1289. [Google Scholar] [CrossRef]
- Albertini, F.; Matter, M.; Nenoff, L.; Zhang, Y.; Lomax, A. Online daily adaptive proton therapy. Br. J. Radiol. 2020, 93, 20190594. [Google Scholar] [CrossRef]
- Fattori, G.; Riboldi, M.; Pella, A.; Peroni, M.; Cerveri, P.; Desplanques, M.; Fontana, G.; Tagaste, B.; Valvo, F.; Orecchia, R.; et al. Image guided particle therapy in CNAO room 2: Implementation and clinical validation. Phys. Med. 2015, 31, 9–15. [Google Scholar] [CrossRef] [PubMed]
- Veiga, C.; Janssens, G.; Teng, C.L.; Baudier, T.; Hotoiu, L.; McClelland, J.R.; Royle, G.; Lin, L.; Yin, L.; Metz, J.; et al. First clinical investigation of Cone Beam Computed Tomography and deformable registration for adaptive proton therapy for lung cancer. Int. J. Radiat. Oncol. Biol. Phys. 2016, 95, 549–559. [Google Scholar] [CrossRef]
- Hua, C.; Yao, W.; Kidani, T.; Tomida, K.; Ozawa, S.; Nishimura, T.; Fujisawa, T.; Shinagawa, R.; Merchant, T.E. A robotic C-arm cone beam CT system for image-guided proton therapy: Design and performance. Br. J. Radiol. 2017, 90, 20170266. [Google Scholar] [CrossRef]
- Landry, G.; Hua, C.h. Current state and future applications of radiological image guidance for particle therapy. Med. Phys. 2018, 45, e1086–e1095. [Google Scholar] [CrossRef]
- Joseph, P.M.; Spital, R.D. The effects of scatter in x-ray computed tomography. Med. Phys. 1982, 9, 464–472. [Google Scholar] [CrossRef]
- Schulze, R.; Heil, U.; Groβ, D.; Bruellmann, D.D.; Dranischnikow, E.; Schwanecke, U.; Schoemer, E. Artefacts in CBCT: A review. Dentomaxillofac. Radiol. 2011, 40, 265–273. [Google Scholar] [CrossRef]
- Kurz, C.; Kamp, F.; Park, Y.K.; Zöllner, C.; Rit, S.; Hansen, D.; Podesta, M.; Sharp, G.C.; Li, M.; Reiner, M.; et al. Investigating deformable image registration and scatter correction for CBCT-based dose calculation in adaptive IMPT. Med. Phys. 2016, 43, 5635–5646. [Google Scholar] [CrossRef]
- Thing, R.S.; Bernchou, U.; Mainegra-Hing, E.; Hansen, O.; Brink, C. Hounsfield unit recovery in clinical cone beam CT images of the thorax acquired for image guided radiation therapy. Phys. Med. Biol. 2016, 61, 5781. [Google Scholar] [CrossRef]
- Giacometti, V.; Hounsell, A.R.; McGarry, C.K. A review of dose calculation approaches with cone beam CT in photon and proton therapy. Phys. Med. 2020, 76, 243–276. [Google Scholar] [CrossRef] [PubMed]
- Yorke, A.A.; McDonald, G.C.; Solis, D.; Guerrero, T. Pelvic Reference Data [Dataset]; Atlassian Confluence Open Source Project License: Sydney, Australia, 2019. [Google Scholar] [CrossRef]
- Siewerdsen, J.H.; Moseley, D.J.; Bakhtiar, B.; Richard, S.; Jaffray, D.A. The influence of antiscatter grids on soft-tissue detectability in cone-beam computed tomography with flat-panel detectors. Med. Phys. 2004, 31, 3506–3520. [Google Scholar] [CrossRef]
- Zhu, L.; Xie, Y.; Wang, J.; Xing, L. Scatter correction for cone-beam CT in radiation therapy. Med. Phys. 2009, 36, 2258–2268. [Google Scholar] [CrossRef] [PubMed]
- Sun, M.; Star-Lack, J.M. Improved scatter correction using adaptive scatter kernel superposition. Phys. Med. Biol. 2010, 55, 6695–6720. [Google Scholar] [CrossRef] [PubMed]
- Sisniega, A.; Zbijewski, W.; Badal, A.; Kyprianou, I.S.; Stayman, J.W.; Vaquero, J.J.; Siewerdsen, J.H. Monte Carlo study of the effects of system geometry and antiscatter grids on cone-beam CT scatter distributions. Med. Phys. 2013, 40, 051915. [Google Scholar] [CrossRef]
- Stankovic, U.; Ploeger, L.S.; van Herk, M.; Sonke, J.J. Optimal combination of anti-scatter grids and software correction for CBCT imaging. Med. Phys. 2017, 44, 4437–4451. [Google Scholar] [CrossRef] [PubMed]
- Harms, J.; Lei, Y.; Wang, T.; Zhang, R.; Zhou, J.; Tang, X.; Curran, W.J.; Liu, T.; Yang, X. Paired cycle-GAN-based image correction for quantitative cone-beam computed tomography. Med. Phys. 2019, 46, 3998–4009. [Google Scholar] [CrossRef] [PubMed]
- Zöllner, C.; Rit, S.; Kurz, C.; Vilches-Freixas, G.; Kamp, F.; Dedes, G.; Belka, C.; Parodi, K.; Landry, G. Decomposing a prior-CT-based cone-beam CT projection correction algorithm into scatter and beam hardening components. Phys. Imaging Radiat. Oncol. 2017, 3, 49–52. [Google Scholar] [CrossRef]
- Abe, T.; Tateoka, K.; Saito, Y.; Nakazawa, T.; Yano, M.; Nakata, K.; Someya, M.; Hori, M.; Sakata, K. Method for converting Cone-Beam CT values into Hounsfield Units for radiation treatment planning. Int. J. Med. Phys. Clin. Eng. Radiat. Oncol. 2017, 6, 361–375. [Google Scholar] [CrossRef]
- Kidar, H.S.; Azizi, H. Enhancement of Hounsfield unit distribution in cone-beam CT images for adaptive radiation therapy: Evaluation of a hybrid correction approach. Phys. Med. 2020, 69, 269–274. [Google Scholar] [CrossRef]
- Niu, T.; Sun, M.; Star-Lack, J.; Gao, H.; Fan, Q.; Zhu, L. Shading correction for on-board cone-beam CT in radiation therapy using planning MDCT images. Med. Phys. 2010, 37, 5395–5406. [Google Scholar] [CrossRef] [PubMed]
- Zbijewski, W.; Beekman, F.J. Efficient Monte Carlo based scatter artifact reduction in cone-beam micro-CT. IEEE Trans. Med. Imaging 2006, 25, 817–827. [Google Scholar] [CrossRef] [PubMed]
- Bootsma, G.J.; Verhaegen, F.; Jaffray, D.A. Efficient scatter distribution estimation and correction in CBCT using concurrent Monte Carlo fitting. Med. Phys. 2014, 42, 54–68. [Google Scholar] [CrossRef]
- Xu, Y.; Bai, T.; Yan, H.; Ouyang, L.; Pompos, A.; Wang, J.; Zhou, L.; Jiang, S.B.; Jia, X. A practical cone-beam CT scatter correction method with optimized Monte Carlo simulations for image-guided radiation therapy. Phys. Med. Biol. 2015, 60, 3567–3587. [Google Scholar] [CrossRef]
- Zhao, W.; Vernekohl, D.; Zhu, J.; Wang, L.; Xing, L. A model-based scatter artifacts correction for cone beam CT. Med. Phys. 2016, 43, 1736–1753. [Google Scholar] [CrossRef] [PubMed]
- Hansen, D.C.; Landry, G.; Kamp, F.; Li, M.; Belka, C.; Parodi, K.; Kurz, C. ScatterNet: A convolutional neural network for cone-beam CT intensity correction. Med. Phys. 2018, 45, 4916–4926. [Google Scholar] [CrossRef]
- Maier, J.; Eulig, E.; Vöth, T.; Knaup, M.; Kuntz, J.; Sawall, S.; Kachelrieß, M. Real-time scatter estimation for medical CT using the deep scatter estimation: Method and robustness analysis with respect to different anatomies, dose levels, tube voltages, and data truncation. Med. Phys. 2019, 46, 238–249. [Google Scholar] [CrossRef]
- Kida, S.; Nakamoto, T.; Nakano, M.; Nawa, K.; Haga, A.; Kotoku, J.; Yamashita, H.; Nakagawa, K. Cone Beam Computed Tomography image quality improvement using a deep convolutional neural network. Cureus 2018, 10, e2548. [Google Scholar] [CrossRef] [PubMed]
- Landry, G.; Hansen, D.; Kamp, F.; Li, M.; Hoyle, B.; Weller, J.; Parodi, K.; Belka, C.; Kurz, C. Comparing Unet training with three different datasets to correct CBCT images for prostate radiotherapy dose calculations. Phys. Med. Biol. 2019, 64, 035011. [Google Scholar] [CrossRef] [PubMed]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-To-Image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Liang, X.; Chen, L.; Nguyen, D.; Zhou, Z.; Gu, X.; Yang, M.; Wang, J.; Jiang, S. Generating synthesized computed tomography (CT) from cone-beam computed tomography (CBCT) using CycleGAN for adaptive radiation therapy. Phys. Med. Biol. 2019, 64, 125002. [Google Scholar] [CrossRef]
- Kurz, C.; Maspero, M.; Savenije, M.H.F.; Landry, G.; Kamp, F.; Pinto, M.; Li, M.; Parodi, K.; Belka, C.; van den Berg, C.A.T. CBCT correction using a cycle-consistent generative adversarial network and unpaired training to enable photon and proton dose calculation. Phys. Med. Biol. 2019, 64, 225004. [Google Scholar] [CrossRef]
- Kida, S.; Kaji, S.; Nawa, K.; Imae, T.; Nakamoto, T.; Ozaki, S.; Ohta, T.; Nozawa, Y.; Nakagawa, K. Visual enhancement of Cone-beam CT by use of CycleGAN. Med. Phys. 2020, 47, 998–1010. [Google Scholar] [CrossRef]
- Tien, H.J.; Yang, H.C.; Shueng, P.W.; Chen, J.C. Cone-beam CT image quality improvement using cycle-deblur consistent adversarial networks (cycle-deblur GAN) for chest CT imaging in breast cancer patients. Sci. Rep. 2021, 11, 1133. [Google Scholar] [CrossRef]
- Nie, D.; Trullo, R.; Lian, J.; Petitjean, C.; Ruan, S.; Wang, Q.; Shen, D. Medical image synthesis with context-aware generative adversarial networks. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2017, Quebec City, QC, Canada, 11–13 September 2017; pp. 417–425. [Google Scholar] [CrossRef]
- Li, Y.; Li, W.; Xiong, J.; Xia, J.; Xie, Y. Comparison of supervised and unsupervised deep learning methods for medical image synthesis between Computed Tomography and Magnetic Resonance images. BioMed Res. Int. 2020, 2020, 5193707. [Google Scholar] [CrossRef]
- Dong, X.; Lei, Y.; Wang, T.; Higgins, K.; Liu, T.; Curran, W.J.; Mao, H.; Nye, J.A.; Yang, X. Deep learning-based attenuation correction in the absence of structural information for whole-body positron emission tomography imaging. Phys. Med. Biol. 2020, 65, 055011. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of theInternational Conference on Medical Image Computing And Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Instance normalization: The missing ingredient for fast stylization. arXiv 2016, arXiv:1607.08022. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Hore, A.; Ziou, D. Image quality metrics: PSNR vs. SSIM. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Chollet, F. Keras. 2015. Available online: https://keras.io (accessed on 21 February 2021).
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: tensorflow.org (accessed on 21 February 2021).
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Chen, G.H.; Yang, C.L.; Xie, S.L. Gradient-based structural similarity for image quality assessment. In Proceedings of the 2006 International Conference on Image Processing, Atlanta, GA, USA, 8–11 October 2006. [Google Scholar] [CrossRef]
- Li, C.; Bovik, A.C. Content-partitioned structural similarity index for image quality assessment. Signal Process. Image Commun. 2010, 25, 517–526. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SSIM [A.U.] | PSNR [dB] | MAE [HU] | |
|---|---|---|---|
| CBCT | 0.887 (0.048) | 26.70 (3.36) | 93.30 (59.60) |
| Supervised sCT | 0.912 (0.030) | 30.89 (2.66) | 35.14 (13.19) |
| Unsupervised sCT | 0.898 (0.046) | 29.00 (3.38) | 46.38 (24.86) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rossi, M.; Cerveri, P. Comparison of Supervised and Unsupervised Approaches for the Generation of Synthetic CT from Cone-Beam CT. Diagnostics 2021, 11, 1435. https://doi.org/10.3390/diagnostics11081435
Rossi M, Cerveri P. Comparison of Supervised and Unsupervised Approaches for the Generation of Synthetic CT from Cone-Beam CT. Diagnostics. 2021; 11(8):1435. https://doi.org/10.3390/diagnostics11081435
Chicago/Turabian StyleRossi, Matteo, and Pietro Cerveri. 2021. "Comparison of Supervised and Unsupervised Approaches for the Generation of Synthetic CT from Cone-Beam CT" Diagnostics 11, no. 8: 1435. https://doi.org/10.3390/diagnostics11081435
APA StyleRossi, M., & Cerveri, P. (2021). Comparison of Supervised and Unsupervised Approaches for the Generation of Synthetic CT from Cone-Beam CT. Diagnostics, 11(8), 1435. https://doi.org/10.3390/diagnostics11081435