
MAGnitude-Image-to-Complex K-space (MAGIC-K) Net: A Data Augmentation Network for Image Reconstruction



Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Acquisition
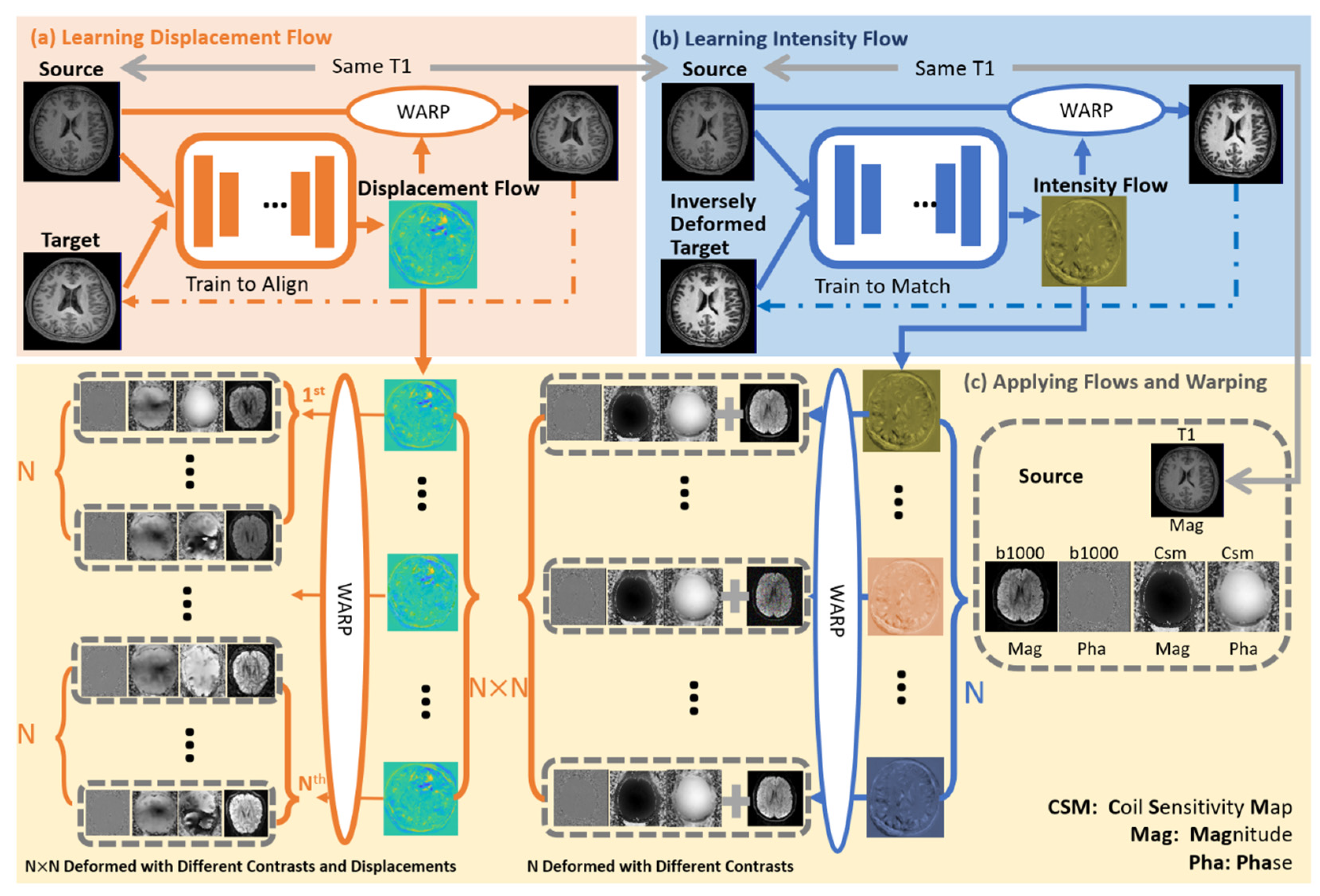
2.2. MAGIC-K Net Architecture
2.2.1. MAGIC-K Net Training
2.2.2. MAGIC-K Net Application
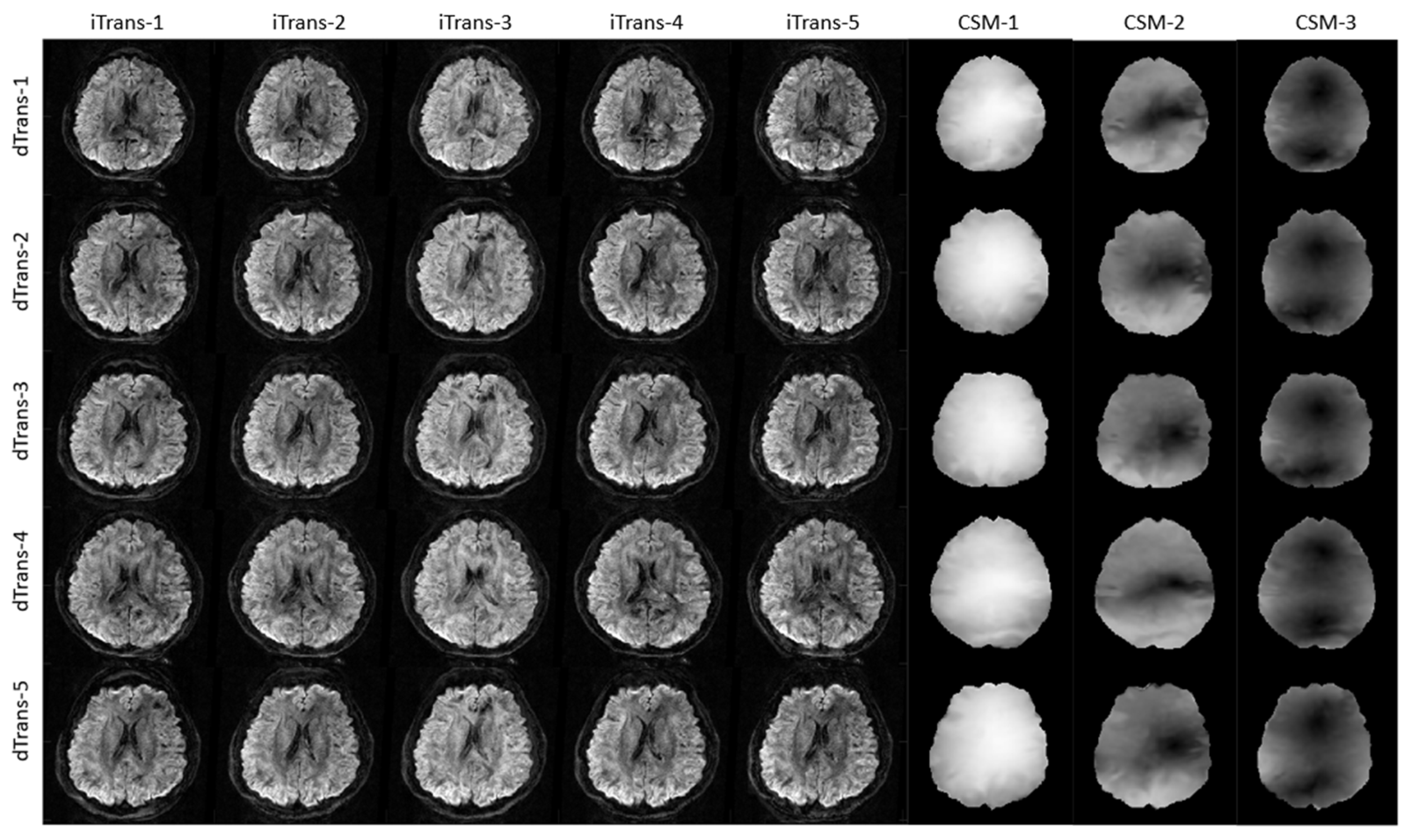
2.3. Training Data Augmentation
- shearing by 5%, 10%, −5%, and −10%;
- rotations of 20°, 40°, 60°, 80°, 100°, 120°, 140°, and 160°;
- translations along the x and y axes with 12, −12, 24, and −24 pixels;
- brightness with 5 scales (i.e., 0.8, 0.9, 1, 1.1, and 1.2 times of the average image intensity);
- MAGIC-K Net with displacement deformations (26 geometries) only;
- MAGIC-K Net with intensity variations (26 contrasts) and 4 scales (0.8, 0.9, 1.1, and 1.2).
- (s) BASIC: 4 (A) × 5 (D) = 20;
- (r) BASIC: 8 (B) × 5 (D) = 40;
- (t) BASIC: 16 (C) × 5 (D) = 80;
- (s + r + t) BASIC: 4 (A) × 8 (B) × 16 (C) × 5 (D) = 2560;
- (d) MAGIC-K: 26 (E) × 5 (D) ×16 (C) = 2080;
- (d + i) MAGIC-K: 26 (E) × 26 × 4 (F) = 2730.
2.4. Deep Learning Reconstruction
2.5. Performance Assessments
2.5.1. Evaluation Metrics
2.5.2. Apparent Diffusion Coefficient (ADC) Fitting
2.6. Model Implementation
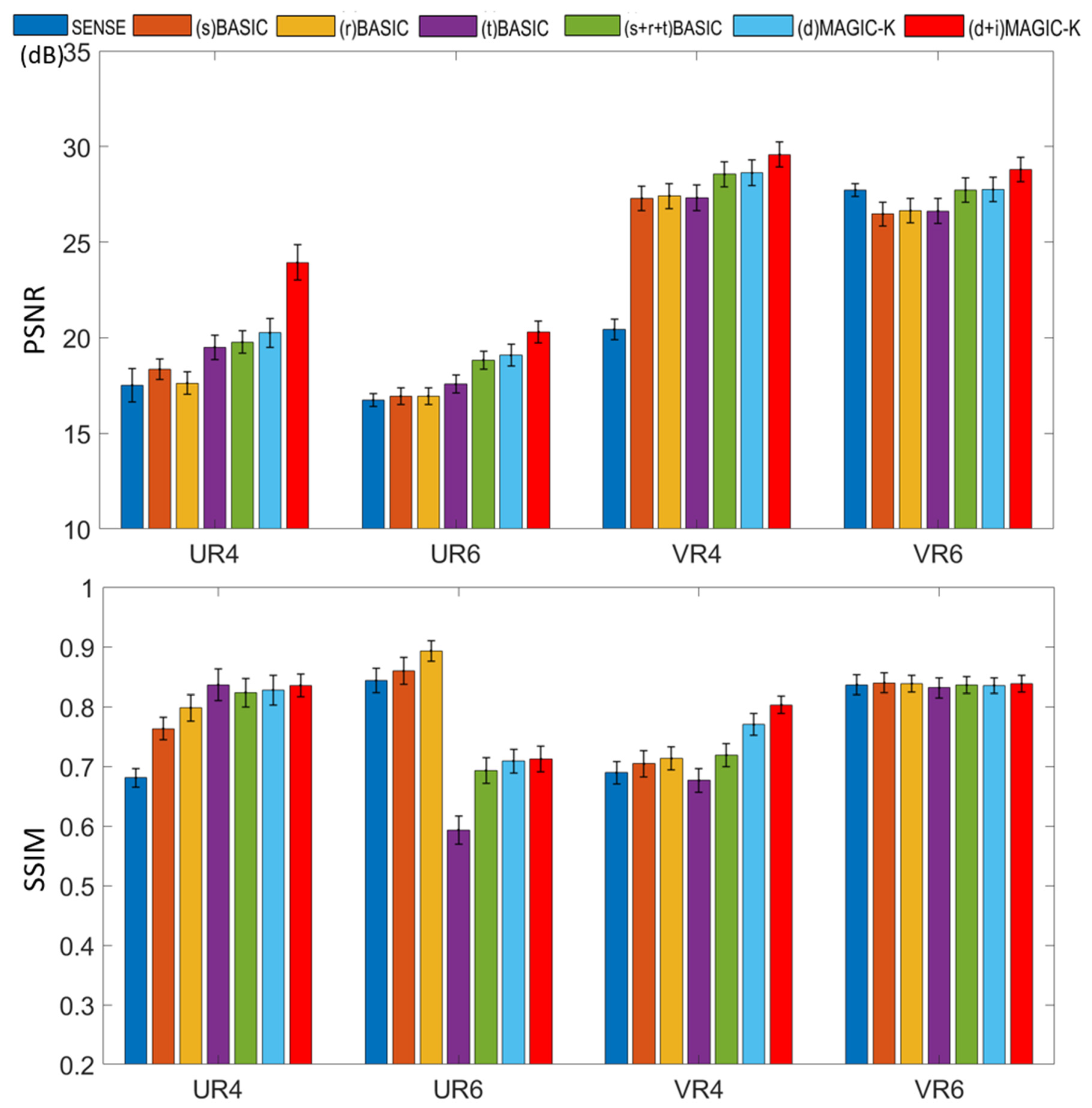
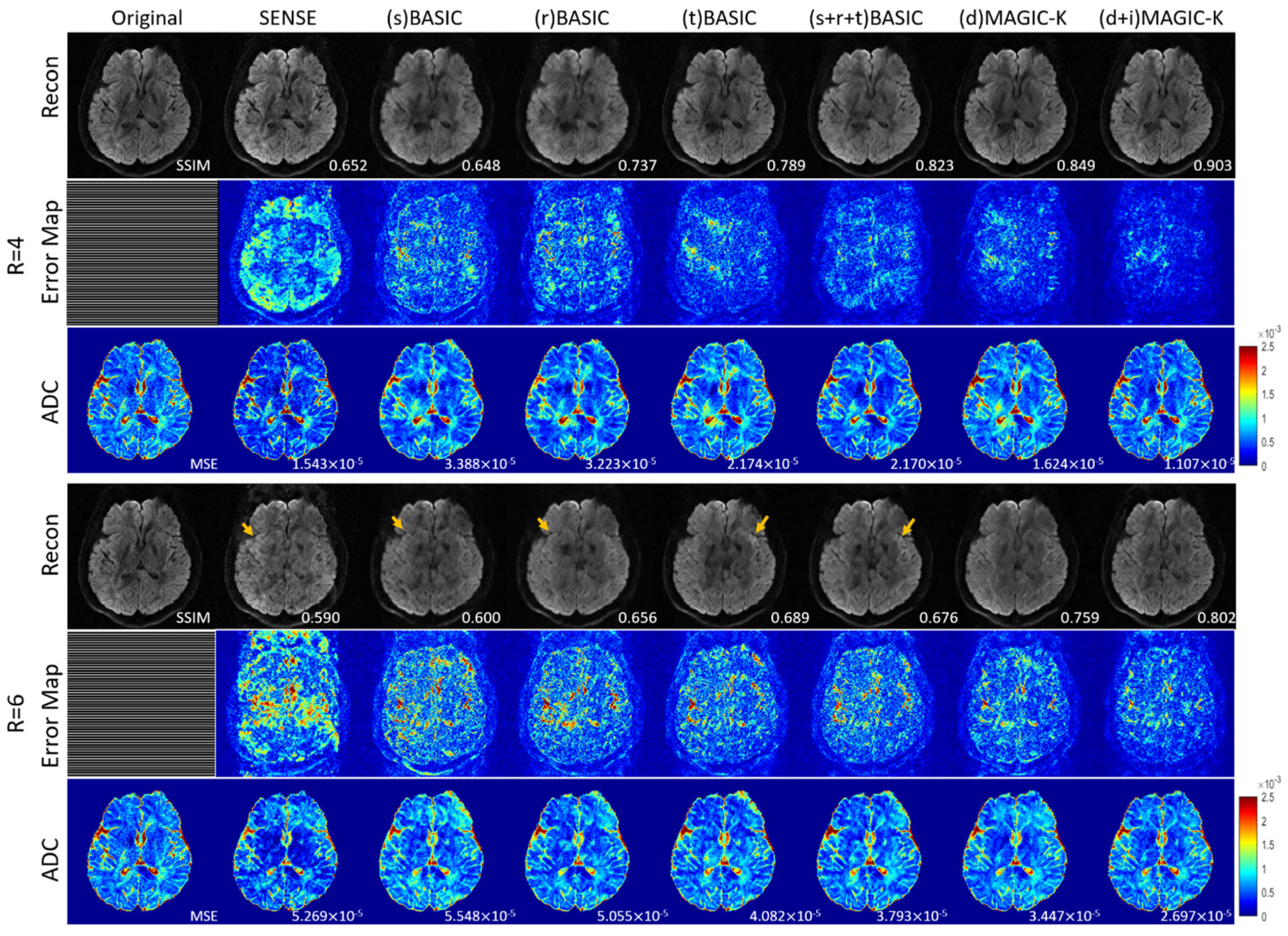
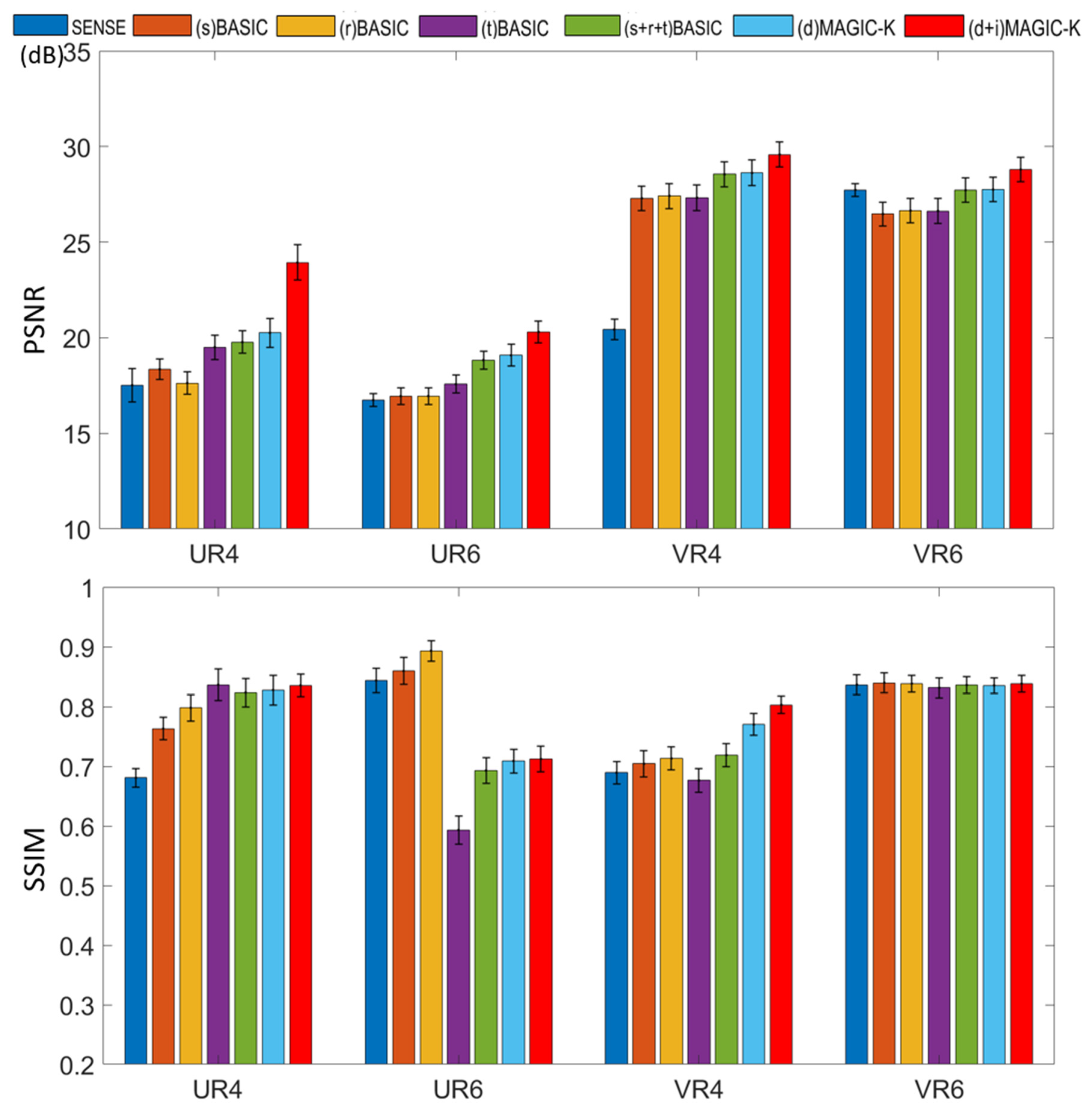
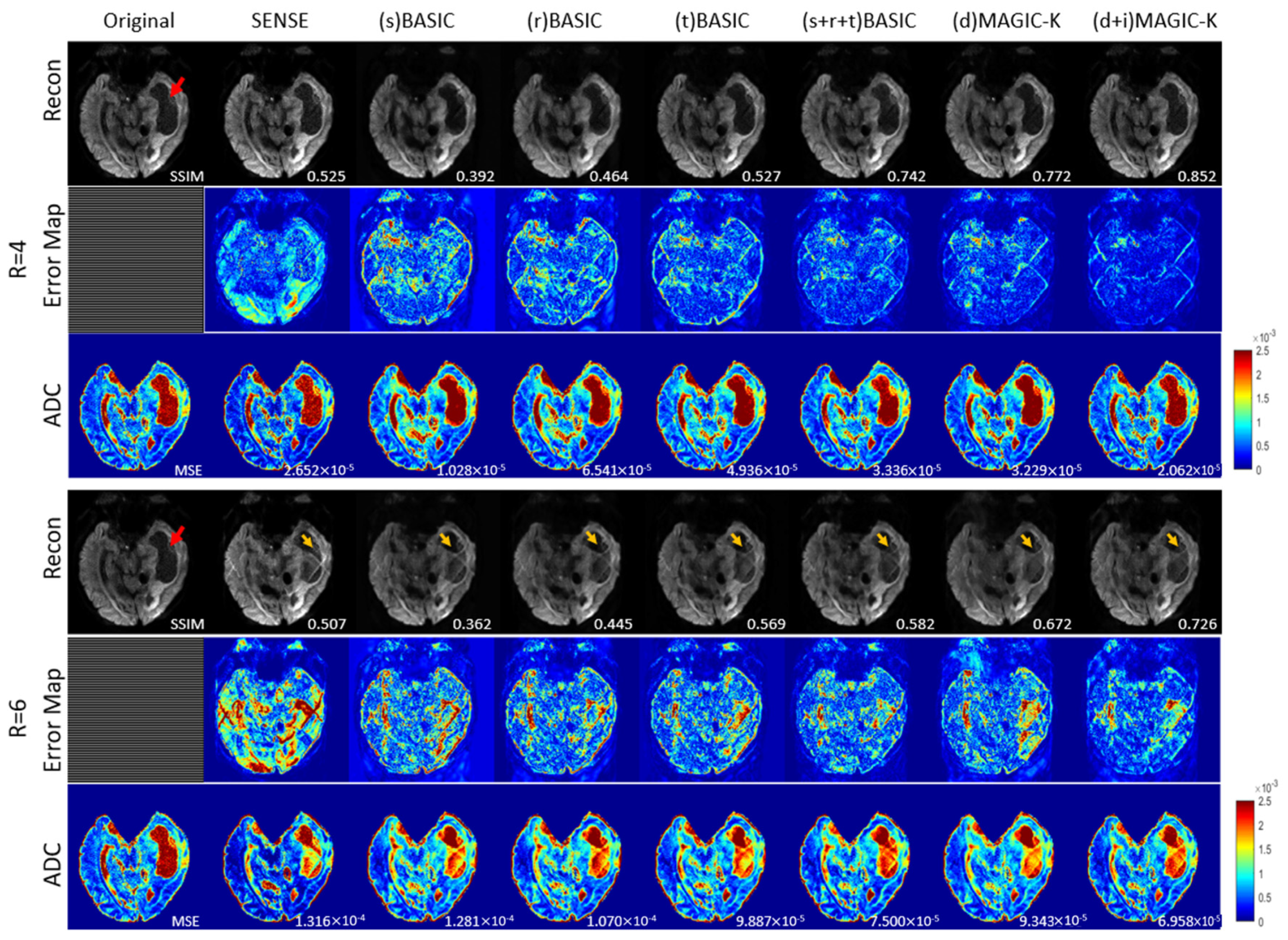
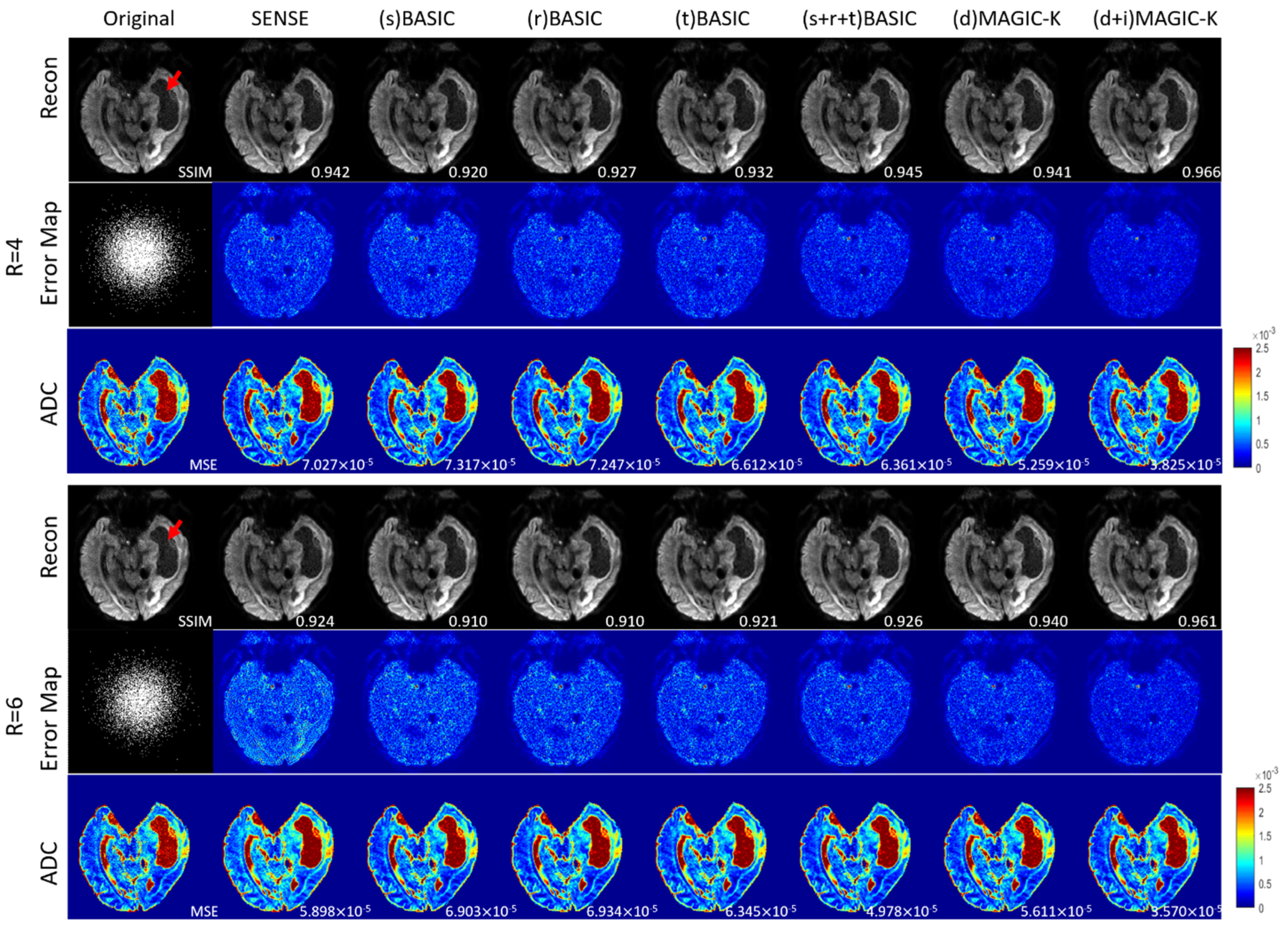
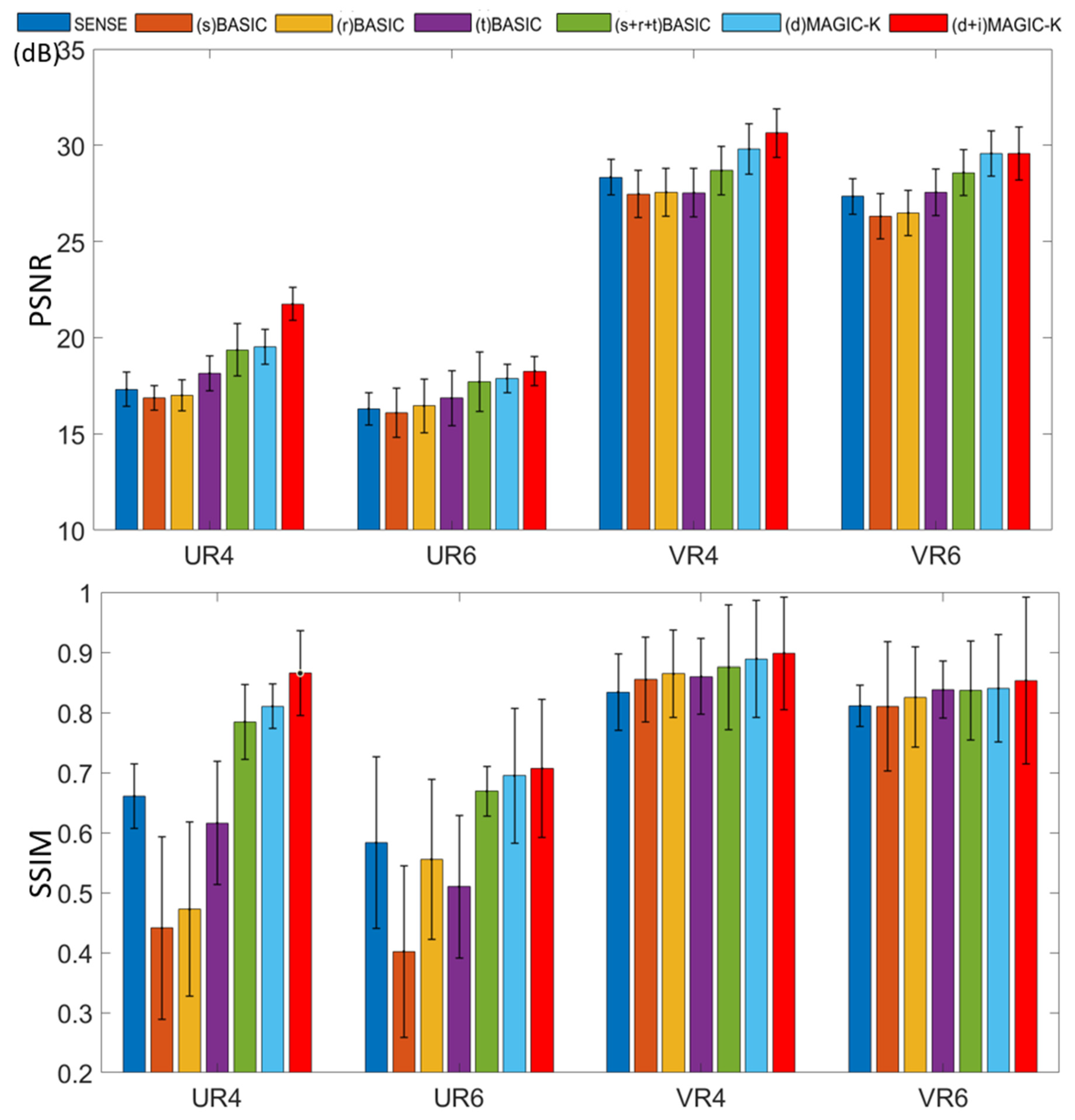
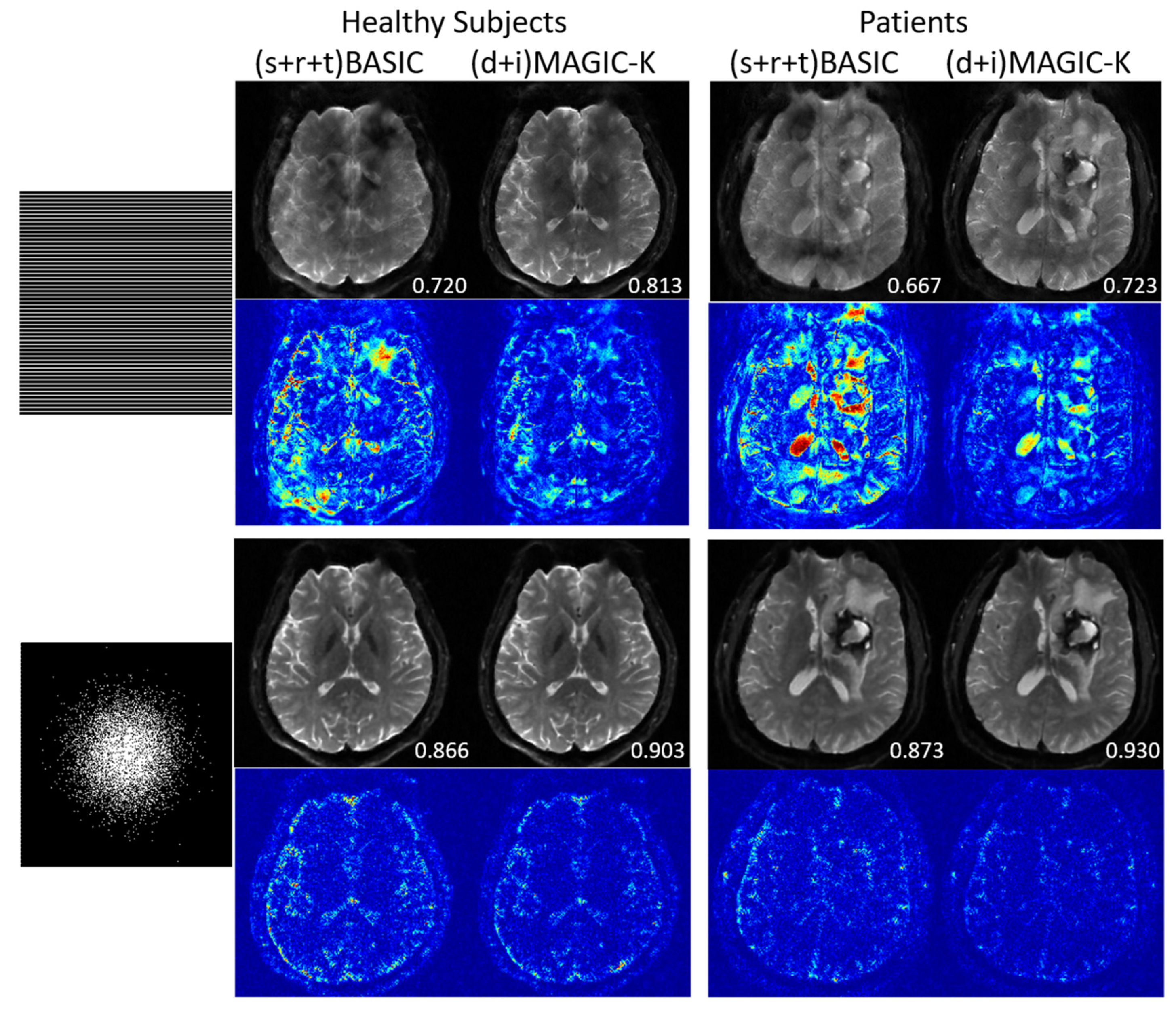
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Brown, R.W.; Cheng, Y.-C.N.; Haacke, E.M.; Thompson, M.R.; Venkatesan, R. Magnetic Resonance Imaging: Physical Principles and Sequence Design; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Pruessmann, K.P.; Weiger, M.; Scheidegger, M.B.; Boesiger, P. SENSE: Sensitivity encoding for fast MRI. Magn. Reson. Med. Off. J. Int. Soc. Magn. Reson. Med. 1999, 42, 952–962. [Google Scholar] [CrossRef]
- Griswold, M.A.; Jakob, P.M.; Heidemann, R.M.; Nittka, M.; Jellus, V.; Wang, J.; Kiefer, B.; Haase, A. Generalized autocalibrating partially parallel acquisitions (GRAPPA). Magn. Reson. Med. Off. J. Int. Soc. Magn. Reson. Med. 2002, 47, 1202–1210. [Google Scholar] [CrossRef] [Green Version]
- Knoll, F.; Hammernik, K.; Zhang, C.; Moeller, S.; Pock, T.; Sodickson, D.K.; Akcakaya, M. Deep-learning methods for parallel magnetic resonance imaging reconstruction: A survey of the current approaches, trends, and issues. IEEE Signal Process. Mag. 2020, 37, 128–140. [Google Scholar] [CrossRef]
- Ravishankar, S.; Bresler, Y. MR image reconstruction from highly undersampled k-space data by dictionary learning. IEEE Trans. Med. Imaging 2010, 30, 1028–1041. [Google Scholar] [CrossRef]
- Zhu, B.; Liu, J.Z.; Cauley, S.F.; Rosen, B.R.; Rosen, M.S. Image reconstruction by domain-transform manifold learning. Nature 2018, 555, 487–492. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Su, Z.; Ying, L.; Peng, X.; Zhu, S.; Liang, F.; Feng, D.; Liang, D. Accelerating Magnetic Resonance Imaging Via Deep Learning. In Proceedings of the 2016 IEEE 13th International Symposium on Biomedical Imaging (ISBI), Prague, Czech Republic, 13–16 April 2016; pp. 514–517. [Google Scholar]
- Hyun, C.M.; Kim, H.P.; Lee, S.M.; Lee, S.; Seo, J.K. Deep learning for undersampled MRI reconstruction. Phys. Med. Biol. 2018, 63, 135007. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Conventional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical image computing and Computer-Assisted intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Lee, D.; Yoo, J.; Tak, S.; Ye, J.C. Deep Residual Learning for Accelerated MRI Using Magnitude and Phase Networks. IEEE Trans. Biomed. Eng. 2018, 65, 1985–1995. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, G.; Yu, S.; Dong, H.; Slabaugh, G.; Dragotti, P.L.; Ye, X.; Liu, F.; Arridge, S.; Keegan, J.; Guo, Y. DAGAN: Deep de-aliasing generative adversarial networks for fast compressed sensing MRI reconstruction. IEEE Trans. Med. Imaging 2017, 37, 1310–1321. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Hammernik, K.; Klatzer, T.; Kobler, E.; Recht, M.P.; Sodickson, D.K.; Pock, T.; Knoll, F. Learning a variational network for reconstruction of accelerated MRI data. Magn. Reson. Med. 2018, 79, 3055–3071. [Google Scholar] [CrossRef]
- Tewari, A.; Zollhofer, M.; Kim, H.; Garrido, P.; Bernard, F.; Perez, P.; Theobalt, C. Mofa: Model-based deep convolutional face autoencoder for unsupervised monocular reconstruction. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 1274–1283. [Google Scholar]
- Aggarwal, H.K.; Mani, M.P.; Jacob, M. MoDL: Model-based deep learning architecture for inverse problems. IEEE Trans. Med. Imaging 2018, 38, 394–405. [Google Scholar] [CrossRef] [PubMed]
- Duan, J.; Schlemper, J.; Qin, C.; Ouyang, C.; Bai, W.; Biffi, C.; Bello, G.; Statton, B.; O’Regan, D.P.; Rueckert, D. VS-Net: Variable Splitting Network for Accelerated Parallel MRI Reconstruction. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019; pp. 713–722. [Google Scholar]
- Lv, J.; Wang, C.; Yang, G. PIC-GAN: A Parallel Imaging Coupled Generative Adversarial Network for Accelerated Multi-Channel MRI Reconstruction. Diagnostics 2021, 11, 61. [Google Scholar] [CrossRef]
- Ding, J.; Li, X.; Gudivada, V.N. Augmentation and evaluation of training data for deep learning. In Proceedings of the 2017 IEEE International Conference on Big Data (Big Data), Orlando, FL, USA, 6–10 November 2017; pp. 2603–2611. [Google Scholar]
- Nalepa, J.; Marcinkiewicz, M.; Kawulok, M. Data augmentation for brain-tumor segmentation: A review. Front. Comput. Neurosci. 2019, 13, 83. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Frid-Adar, M.; Diamant, I.; Klang, E.; Amitai, M.; Goldberger, J.; Greenspan, H. GAN-based synthetic medical image augmentation for increased CNN performance in liver lesion classification. Neurocomputing 2018, 321, 321–331. [Google Scholar] [CrossRef] [Green Version]
- Zhang, C.; Tavanapong, W.; Wong, J.; de Groen, P.C.; Oh, J. Real data augmentation for medical image classification. In Intravascular Imaging and Computer Assisted Stenting, and Large-Scale Annotation of Biomedical Data and Expert Label Synthesis; Springer: Berlin/Heidelberg, Germany, 2017; pp. 67–76. [Google Scholar]
- Zhao, A.; Balakrishnan, G.; Durand, F.; Guttag, J.V.; Dalca, A.V. Data Augmentation Using Learned Transformations for One-Shot Medical Image Segmentation. In Proceedings of the Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 8543–8553. [Google Scholar]
- Shin, H.-C.; Tenenholtz, N.A.; Rogers, J.K.; Schwarz, C.G.; Senjem, M.L.; Gunter, J.L.; Andriole, K.P.; Michalski, M. Medical image synthesis for data augmentation and anonymization using generative adversarial networks. In Proceedings of the International Workshop on Simulation and Synthesis in Medical Imaging, Granada, Spain, 16 September 2018; pp. 1–11. [Google Scholar]
- Rusak, F.; Santa Cruz, R.; Bourgeat, P.; Fookes, C.; Fripp, J.; Bradley, A.; Salvado, O. 3D Brain MRI GAN-Based Synthesis Conditioned on Partial Volume Maps. In Proceedings of the International Workshop on Simulation and Synthesis in Medical Imaging, Lima, Peru, 4 October 2020; pp. 11–20. [Google Scholar]
- Uzunova, H.; Wilms, M.; Handels, H.; Ehrhardt, J. Training CNNs for image registration from few samples with model-based data augmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Quebec City, QC, Canada, 11–13 September 2017; pp. 223–231. [Google Scholar]
- Chaitanya, K.; Karani, N.; Baumgartner, C.F.; Becker, A.; Donati, O.; Konukoglu, E. Semi-supervised and task-driven data augmentation. In Proceedings of the International Conference on Information Processing in Medical Imaging, Hong Kong, China, 2–7 June 2019; pp. 29–41. [Google Scholar]
- Abolvardi, A.A.; Hamey, L.; Ho-Shon, K. Registration Based Data Augmentation for Multiple Sclerosis Lesion Segmentation. In Proceedings of the 2019 Digital Image Computing: Techniques and Applications (DICTA), Perth, Australia, 2–4 December 2019; pp. 1–5. [Google Scholar]
- Chen, N.K.; Guidon, A.; Chang, H.C.; Song, A.W. A robust multi-shot scan strategy for high-resolution diffusion weighted MRI enabled by multiplexed sensitivity-encoding (MUSE). NeuroImage 2013, 72, 41–47. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Uecker, M.; Lai, P.; Murphy, M.J.; Virtue, P.; Elad, M.; Pauly, J.M.; Vasanawala, S.S.; Lustig, M. ESPIRiT—an eigenvalue approach to autocalibrating parallel MRI: Where SENSE meets GRAPPA. Magn. Reson. Med. 2014, 71, 990–1001. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Balakrishnan, G.; Zhao, A.; Sabuncu, M.R.; Guttag, J.; Dalca, A.V. VoxelMorph: A Learning Framework for Deformable Medical Image Registration. IEEE Trans. Med. Imaging 2019, 38, 1788–1800. [Google Scholar] [CrossRef] [Green Version]
- Hore, A.; Ziou, D. Image quality metrics: PSNR vs. SSIM. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2366–2369. [Google Scholar]
- Stejskal, E.O.; Tanner, J.E. Spin diffusion measurements: Spin echoes in the presence of a time-dependent field gradient. J. Chem. Phys. 1965, 42, 288–292. [Google Scholar] [CrossRef] [Green Version]
- Smith, S.M. Fast robust automated brain extraction. Hum. Brain Mapp. 2002, 17, 143–155. [Google Scholar] [CrossRef]
- Penny, W.; Friston, K.; Ashburner, J.; Kiebel, S.; Nichols, T. Statistical Parametric Mapping: The Analysis of Functional Brain Images; Elsevier: Amsterdam, The Netherlands, 2007. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M. Tensorflow: A system for large-scale machine learning. In Proceedings of the 12th Symposium on Operating Systems Design and Implementation (OSDI), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Zbontar, J.; Knoll, F.; Sriram, A.; Murrell, T.; Huang, Z.; Muckley, M.J.; Defazio, A.; Stern, R.; Johnson, P.; Bruno, M. fastMRI: An open dataset and benchmarks for accelerated MRI. arXiv 2018, arXiv:1811.08839. [Google Scholar]
- Knoll, F.; Zbontar, J.; Sriram, A.; Muckley, M.J.; Bruno, M.; Defazio, A.; Parente, M.; Geras, K.J.; Katsnelson, J.; Chandarana, H. fastMRI: A publicly available raw k-space and DICOM dataset of knee images for accelerated MR image reconstruction using machine learning. Radiol. Artif. Intell. 2020, 2, e190007. [Google Scholar] [CrossRef] [PubMed]
- Zuo, L.; Dewey, B.E.; Carass, A.; He, Y.; Shao, M.; Reinhold, J.C.; Prince, J.L. Synthesizing Realistic Brain MR Images with Noise Control. In Proceedings of the International Workshop on Simulation and Synthesis in Medical Imaging, Lima, Peru, 4 October 2020; pp. 21–31. [Google Scholar]
- Watts, R.; Wang, Y. k-space interpretation of the Rose Model: Noise limitation on the detectable resolution in MRI. Magn. Reson. Med. Off. J. Int. Soc. Magn. Reson. Med. 2002, 48, 550–554. [Google Scholar] [CrossRef]
- Shaw, R.; Sudre, C.H.; Varsavsky, T.; Ourselin, S.; Cardoso, M.J. A k-space model of movement artefacts: Application to segmentation augmentation and artefact removal. IEEE Trans. Med. Imaging 2020, 39, 2881–2892. [Google Scholar] [CrossRef]
- Lv, J.; Li, G.; Tong, X.; Chen, W.; Huang, J.; Wang, C.; Yang, G. Transfer Learning Enhanced Generative Adversarial Networks for Multi-Channel MRI Reconstruction. Comput. Biol. Med. 2021, 134, 104504. [Google Scholar] [CrossRef] [PubMed]
- Biswas, S.; Aggarwal, H.K.; Jacob, M. Dynamic MRI using model-based deep learning and SToRM priors: MoDL-SToRM. Magn. Reson. Med. 2019, 82, 485–494. [Google Scholar] [CrossRef] [PubMed]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Uniform Undersampling with R = 6. | PSNR (dB) | SSIM | |
| Healthy Subjects | (s + r + t) BASIC | 21.093 | 0.694 0.044 |
| (d + i) MAGIC-K | 23.901 0.632 | 0.764 0.043 | |
| Patients | (s + r + t) BASIC | 19.234 0.734 | 0.683 0.031 |
| (d + i) MAGIC-K | 21.417 0.693 | 0.715 0.043 | |
| Variable Density Undersampling with R = 6 | PSNR (dB) | SSIM | |
| Healthy Subjects | (s + r + t) BASIC | 30.432 0.453 | 0.859 0.033 |
| (d + i) MAGIC-K | 32.954 0.581 | 0.903 0.028 | |
| Patients | (s + r + t) BASIC | 29.043 0.734 | 0.844 0.031 |
| (d + i) MAGIC-K | 31.890 0.843 | 0.913 0.024 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, F.; Zhang, H.; Dai, F.; Chen, W.; Wang, C.; Wang, H. MAGnitude-Image-to-Complex K-space (MAGIC-K) Net: A Data Augmentation Network for Image Reconstruction. Diagnostics 2021, 11, 1935. https://doi.org/10.3390/diagnostics11101935
Wang F, Zhang H, Dai F, Chen W, Wang C, Wang H. MAGnitude-Image-to-Complex K-space (MAGIC-K) Net: A Data Augmentation Network for Image Reconstruction. Diagnostics. 2021; 11(10):1935. https://doi.org/10.3390/diagnostics11101935
Chicago/Turabian StyleWang, Fanwen, Hui Zhang, Fei Dai, Weibo Chen, Chengyan Wang, and He Wang. 2021. "MAGnitude-Image-to-Complex K-space (MAGIC-K) Net: A Data Augmentation Network for Image Reconstruction" Diagnostics 11, no. 10: 1935. https://doi.org/10.3390/diagnostics11101935
APA StyleWang, F., Zhang, H., Dai, F., Chen, W., Wang, C., & Wang, H. (2021). MAGnitude-Image-to-Complex K-space (MAGIC-K) Net: A Data Augmentation Network for Image Reconstruction. Diagnostics, 11(10), 1935. https://doi.org/10.3390/diagnostics11101935