1. Introduction
Undoubtedly, the analysis of the spread of communicable diseases has become an extremely promising area of research. This is attributed to its significant contributions in recent years to the development of vaccines, prevention techniques, and health response plans [
1,
2]. In the last two decades, we have witnessed the spread of numerous communicable diseases among different countries. Recent studies, including Prabu’s work [
3], elaborate that these diseases have been directly transmitted by bacteria, viruses, and other pathogens.
According to the International Federation of Red Cross and Red Crescent Societies (IFRC) and the World Health Organization (WHO), the most contagious diseases globally include tropical diseases such as tuberculosis, malaria, coronavirus, dengue, hepatitis, measles, and HIV/AIDS [
4]. These diseases pose significant global public health challenges due to their capacity to spread and their impact on the affected populations. A notable instance of the spread of communicable diseases is the MERS-CoV virus, which has caused severe respiratory infections in more than 2468 people, resulting in over 851 deaths in 27 countries since 2012 [
5].
In 2009, the swine flu virus (H1N1) emerged, spreading to 214 countries and causing more than 18,449 confirmed deaths, as reported by the WHO [
6]. However, this was not the only case of this nature during the aforementioned period. Between 2003 and 2019, the avian influenza virus (H5N1) emerged, infecting 861 people worldwide [
7]. Another virus of significant spread and relevance was the severe acute respiratory syndrome (SARS) pandemic, which originated at the end of 2002 and extended to 29 countries. SARS caused 8096 cases of infection and resulted in 774 deaths. More recently, the COVID-19 virus, likely originating in Wuhan, China, in 2019, caused a global epidemic that has severely affected numerous countries [
8]. According to the WHO [
9], COVID-19 has affected 770 million people, with 6 million lives lost due to this disease.
In the case of Ecuador, more than one million people have been diagnosed with COVID-19, and over 36,000 people have lost their lives [
10]. However, it is crucial to note that a significant vaccination campaign has been conducted in the country. According to data from the Ministry of Health of Ecuador [
11], nearly 39 million doses of vaccines have been administered to the population.
Research in this field is of vital importance, especially in the context of the coronavirus disease. Disease spread is a matter of the utmost significance due to the unpredictable evolution and mutation of viruses globally [
12]. This is particularly relevant in Ecuador, a country characterized by unique climatic diversity, which could be conducive to the development of various mutations.
A relevant work on this topic is Rui Wang’s study [
13], which identified and analyzed the positions, frequencies, and encoded proteins of SARS-CoV-2 mutations globally. The primary objective of this study was to isolate the SARS-CoV-2 genome and quantify the number of mutations present using the genotyping technique. The results were considered satisfactory, as they identified a total of 13,402 unique mutations. Additionally, the study revealed that 51.4% of the SARS-CoV-2 mutations corresponded to the
type.
Wang [
14] identified rapidly proliferating mutations in the receptor-binding domain (RBD) and analyzed the evolutionary trend of SARS-CoV-2. The primary goal was to examine a genomic dataset of SARS-CoV-2 recorded in the Mutation Tracker using a deep learning method. The results are highly encouraging, highlighting 6945 unique mutations and 2,194,305 non-unique mutations in the SARS-CoV-2 S gene worldwide. Furthermore, the authors determined that the majority of mutations in SARS-CoV-2 corresponded to the
,
, and
types. They also indicated that approximately 70% of these mutations can weaken the efficacy of known antibodies.
Thanh [
15] undertook a comprehensive analysis of genomic mutations in the coding regions of SARS-CoV-2, exploring the potential secondary structure of the resulting proteins. The central objective of this study was to assess all point mutations recorded to date in SARS-CoV-2. This study further identified different mutation patterns using various deep-learning models. A total of 3089 mutations were found in the S protein of SARS-CoV-2. Lucy Van Dorp [
16] analyzed mutations associated with SARS-CoV-2 virus transmission with the aim of quantifying the number of offspring that inherited a specific allele compared to those who did not. The phylogenetic index was employed for the data analysis in this study. The results revealed a total of 12,706
-type mutations. However, the study concluded that none of these mutations were associated with a significant increase in virus transmission.
Pachetti et al. [
17] conducted an analysis and evaluation of the distribution of SARS-CoV-2 mutations in various geographical areas (Asia, Oceania, Europe, and North America) using the Clustal Omega method. This study relied on randomly collected data from the GISAID database. The work produced significant findings, identifying a total of 14,408 mutations in the P to L proteins. Furthermore, the authors demonstrated that some of these mutations could lead to resistance to certain drugs.
Rozhgar [
18] identified and analyzed the genomic mutations of SARS-CoV-2. The primary objective was to determine the most common SARS-CoV-2 mutations using bioinformatics programs. The study analyzed 95 complete SARS-CoV-2 genome sequences available at the GenBank National Microbiology Data Center (NMDC). The results showed 116 mutations corresponding to the ORF1ab gene, ORF8, and the N gene. Ahmad [
19] analyzed the whole-genome mutations of SARS-CoV-2. The primary objective of this study was to determine the possible mutations and evolution of COVID-19. The study utilized BioEdit software version 7.2 to conduct genomic alignments and determined that there were 596 mutations across all genes.
Lastly, Abdel-Rahman [
20] analyzed the sequential mutations present in the SARS-CoV-2 genome and determined the various mutation patterns manifested in infected Egyptian patients. The author utilized the Pangolin and Nextstrain lineage declassification methods with the primary objective of determining the optimal classification of SARS-CoV-2 genomes. The results revealed the existence of a total of 1115 unique mutations. Further, approximately 60.5% of these mutations were located in the ORF1ab polyprotein.
Thus, the central objective of the present investigation is to analyze both the biological information of viral variants and the clinical data of patients infected with COVID-19 in Ecuador. This analysis encompasses variables such as age, gender, and geographic location, among others. The goal is to identify the most relevant variables and to comprehend the evolution of virus mutations, as well as their geographic distributions in various provinces of Ecuador. Through these data analyses, we aim to pinpoint the most vulnerable population groups based on their clinical characteristics, such as age, gender, and geographic location, concerning the diverse mutations and variants of SARS-CoV-2. This approach will foster a more profound understanding of the disease dynamics and enable more informed decision-making in terms of public health.
This paper is structured as follows.
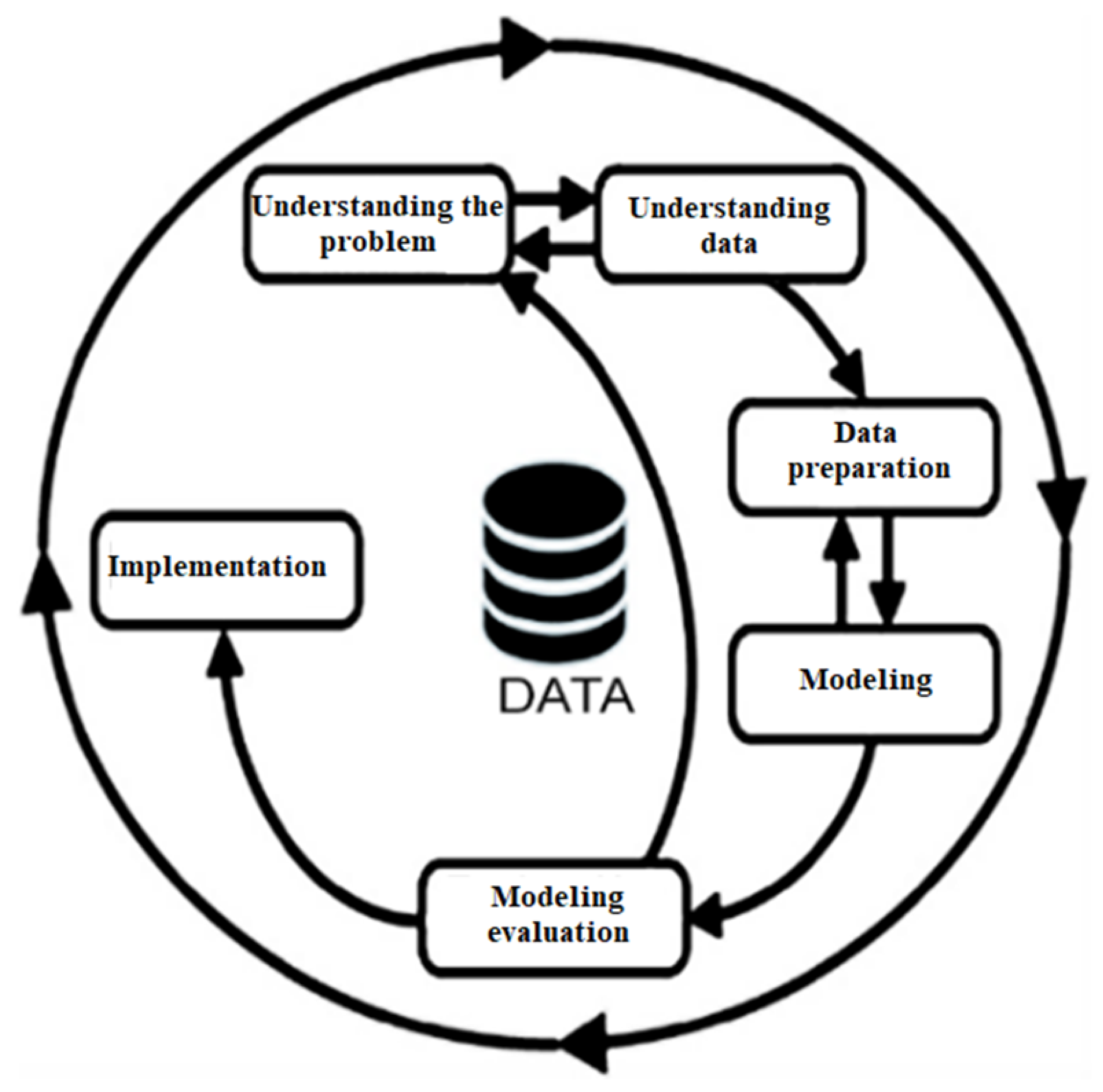
Section 2 details the methods and materials used to conduct the research.
Section 3 focuses on the phases of data preprocessing and the application of technological tools to the information.
Section 4 discusses the analysis of the data obtained, encompassing information related to variants of viruses, as well as patient profiles extracted from the database. The discussion is further enriched by incorporating perspectives and findings from other authors in the field. Finally, in
Section 5, conclusions derived from the findings are presented, and possible directions for future work are discussed.
4. COVID-19 Data Analysis and Results
This section presents data analysis related to COVID-19 patients in Ecuador post-data preprocessing. To conduct this analysis, Python, Matplotlib, Geopandas, and Seaborn libraries were employed to visualize the processed information. These libraries facilitated the generation of statistical diagrams and variable correlations, thereby easing the examination of each graph.
Table 5 presents the total number and infection rate of SARS-CoV-2 variants in different provinces of Ecuador.
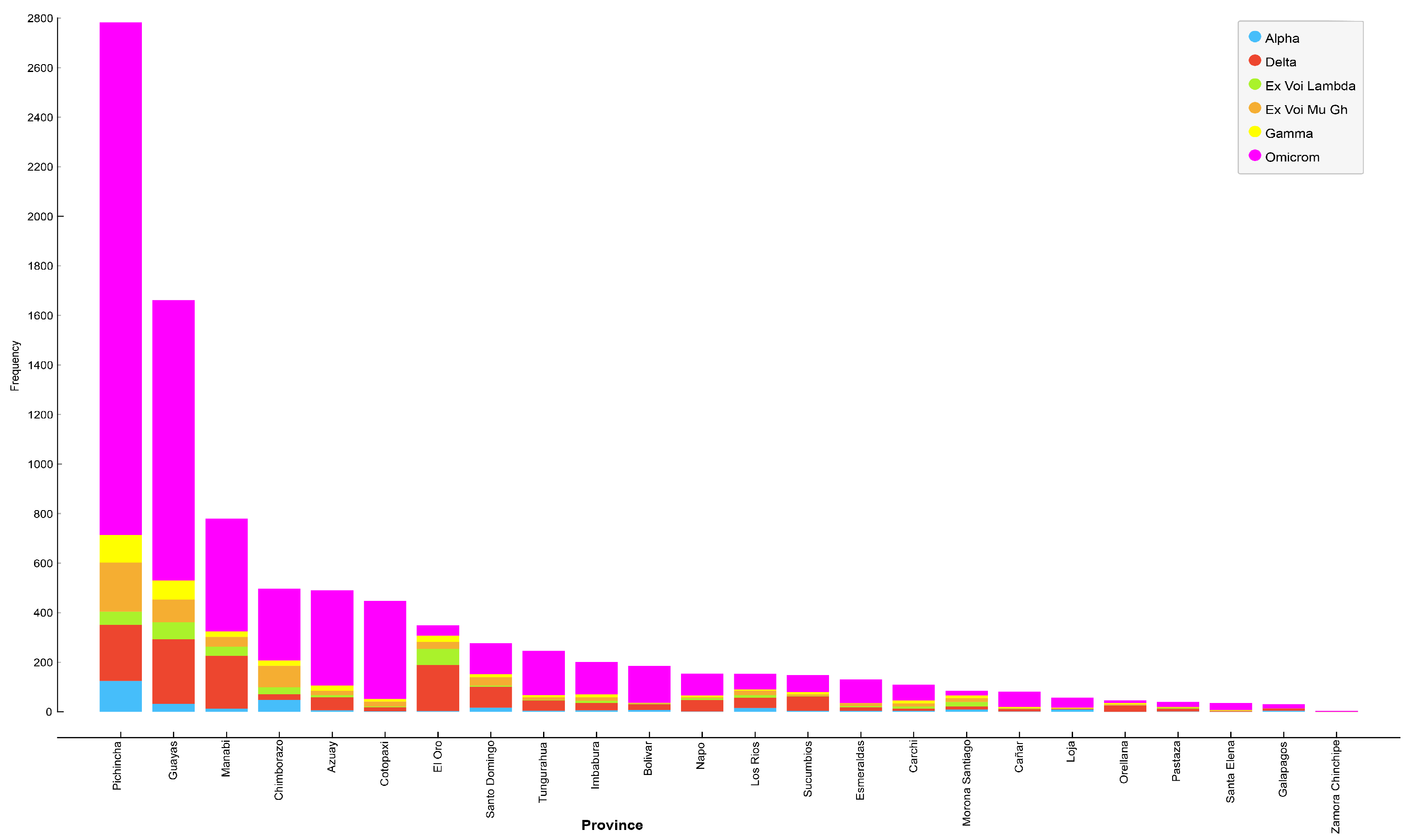
Table 6 illustrates the correlation between the provinces most impacted by various variants of SARS-CoV-2, along with the corresponding infection percentages. The data highlighted Pichincha, Guayas, and, to a lesser extent, Chimborazo as the provinces experiencing the highest infection percentages linked to different variants of SARS-CoV-2.
Figure 2 depicts the distribution of various SARS-CoV-2 variants across the provinces of Ecuador. Provinces with the six highest infection rates include Pichincha, Guayas, Manabí, Chimborazo, Azuay, and Cotopaxi. Moreover, the most prevalent variant in each province is Omicron, followed by Delta, Mu Gh, Gamma, Lambda, and, lastly, the Alpha variant (
Table 6).
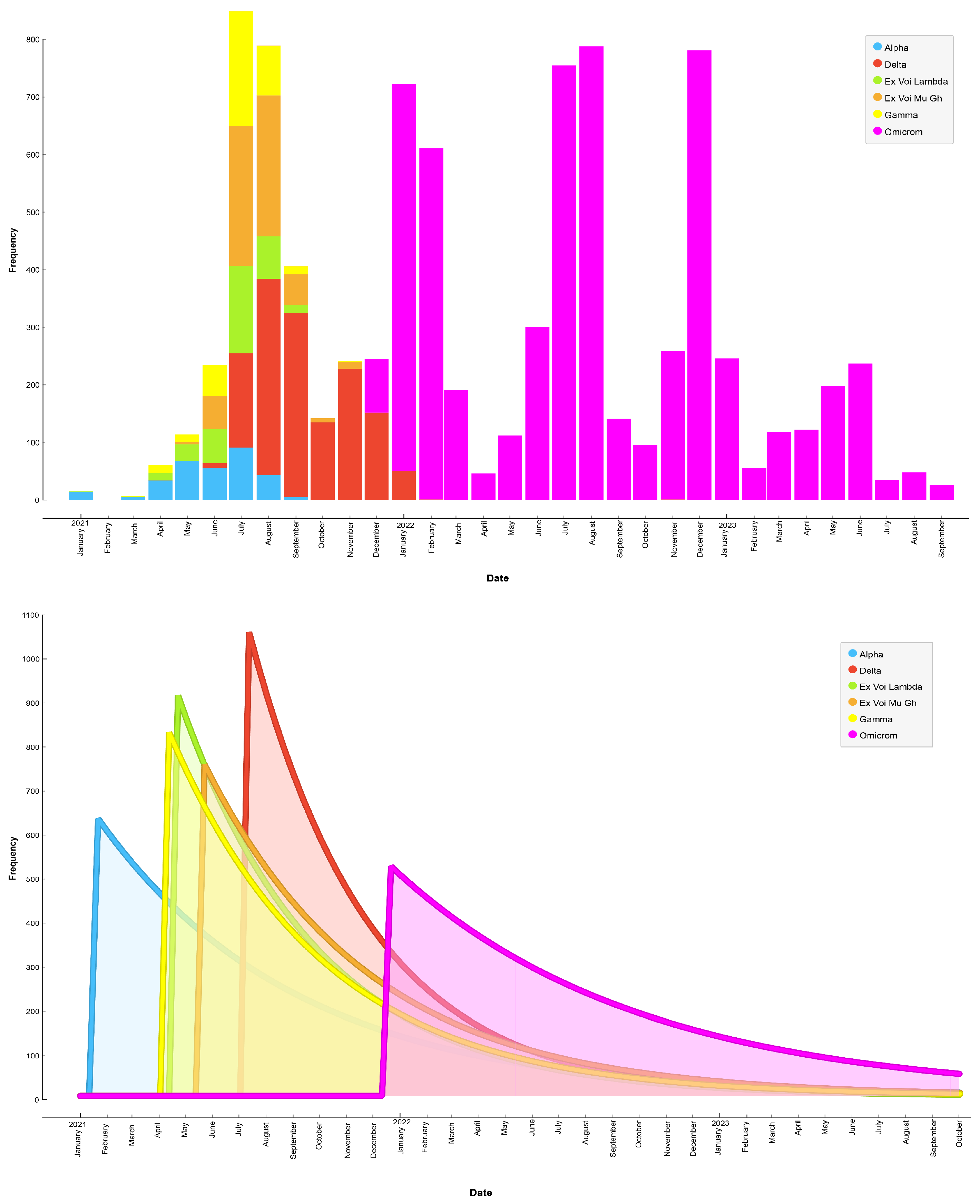
Figure 3 presents a plot illustrating the chronology of SARS-CoV-2 contagion by variant from January 2021 to October 2023. The results showed that the Alpha variant was predominant until July 2021, followed by the Delta variant from July 2021 to January 2021. However, the variant that consistently remained predominant in Ecuador is Omicron, which began spreading from December 2021 to October 2023.
Figure 4 illustrates the quantitative distribution of SARS-CoV-2 variants according to patient gender. We observed that female patients were highly affected by the Omicron variant, representing 69.17% of the cases, followed by the Delta variant, which was detected in 14.88% of cases. Conversely, male patients were preferrently affected by the Omicron variant, constituting 61.72% of the cases, followed by the Delta variant in 16.46% of cases. These findings underscore significant differences in SARS-CoV-2 variant prevalence between genders.
Figure 5 presents a quantitative distribution concerning individuals infected by SARS-CoV-2, categorized by gender and province. It illustrates that female COVID-19 patients were observed predominately in the provinces of Pichincha (30.97%), Guayas (19.36%), and Manabí (8.75%). Similarly, male patients showed a high incidence in the provinces of Pichincha (30.91%), Guayas (17.36%), and Manabí (8.55%). These findings indicate that the provinces of Pichincha, Guayas, and Manabí were the most affected by the COVID-19 pandemic, significantly impacting both female and male patients.
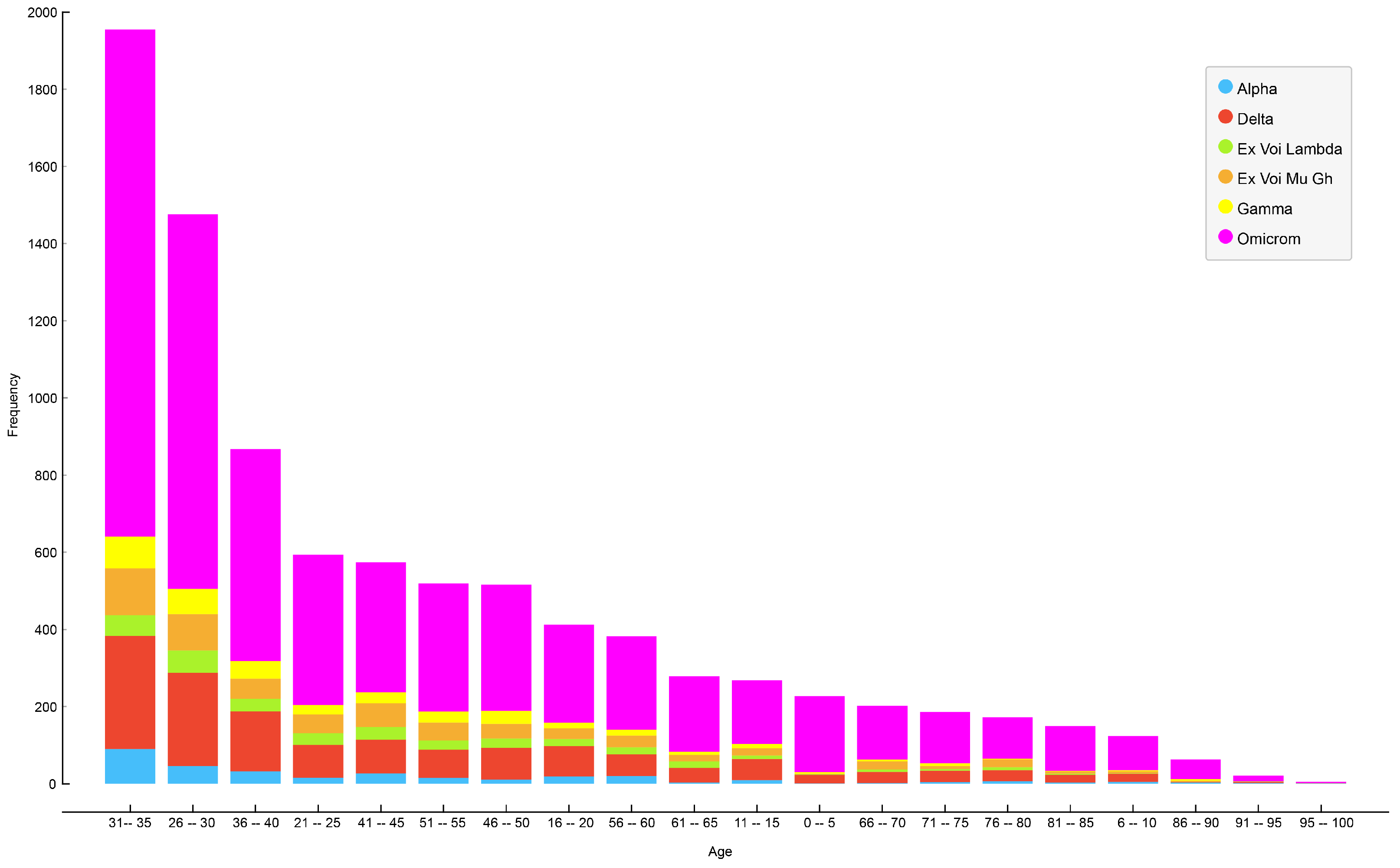
Figure 6 illustrates the age distribution of patients for each variant of SARS-CoV-2 in Ecuador, revealing that the most affected group consisted of patients between 31 and 35 years of age, followed by patients aged 26–30, and, in third place, patients aged 36–40.
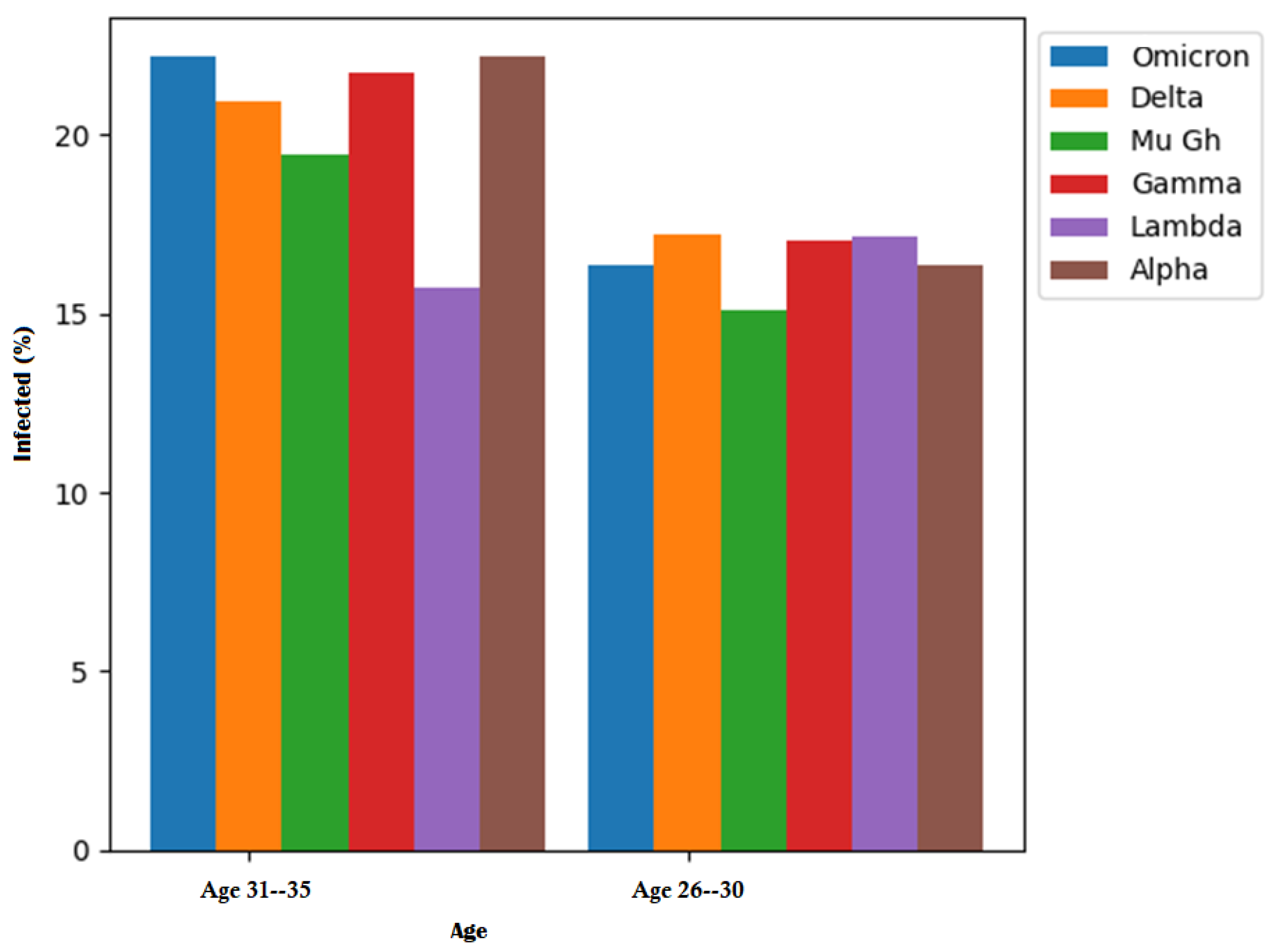
Figure 7 illustrates the primary distribution of infected patients by age and SARS-CoV-2 variant.
Table 7 provides a detailed breakdown of the ages affected by each COVID-19 variant. In the case of individuals aged 31–35 years, the Omicron variant accounted for 22.17%, the Delta variant for 20.93%, the Mu Gh variant for 19.45%, and the Gamma variant for 21.73% of cases. The Lambda variant showed a higher impact on patients aged 26–30 years, with 17.15%, while the Alpha variant affected 22.17% of patients.
Discussion
The analysis of the biological information of the virus specifically focused on the spike protein, which, as observed in prior studies, such as those by Wang [
14] and Thanh [
15], exhibits the highest number of mutations. As shown in
Table 8, the majority of amino acids with two mutations belong to the spike protein (S) chain. Mutations in this protein chain may impact transmissibility, the ability to evade the immune system, and vaccine efficacy. Notably, 98% of amino acids generating two mutations are associated with the spike protein, while the remaining 2% lack a defined protein chain.
The “Mutations” column delineates the type of genetic change occurring at a specific location in the genomic sequence. The “Protein” column identifies the protein linked to that mutation. The “Position” column specifies the precise location within the genomic sequence where the mutation is recorded. The “Original Sequence” column displays the reference genetic sequence at the affected location, while the “Mutated Sequence” column illustrates the genetic alteration. In instances where no specific protein is assigned to the sequences, informations on the original sequence and the mutated sequence are unavailable.
Table 9 displays the amino acids most significantly affected by mutations, offering crucial details such as the associated protein chain, the specific position within the sequence, the original amino acid sequence, and the resulting amino acid sequence following the mutation. The findings reveal that the predominant portion of amino acids affected by mutations is within the spike protein (S), accounting for 68.29% of cases. Additionally, 14.63% of intances are associated with the nucleocapsid (N) protein, 14.63% with the non-structural protein (nsp2), and 2.45% with the non-structural protein (nsp1).
Table 10 illustrates the amino acids that harbor two mutations in various variants. The most noteworthy are E484A and P681R. Amino acid E484A has been linked to a decrease in antibody effectiveness. Furthermore, the presence of the P681R amino acid in the spike protein of the virus may impact its ability to enter human cells.
Table 11 presents a comprehensive overview of the amino acids that have undergone mutation in various variants, specifying the protein chain to which they belong. The most frequently altered amino acids among variants are D614G, N501Y, and P681H. Amino acid D614G has been linked to enhanced virus transmission capability. Moreover, amino acid N501Y has been associated with a potential increase in virus binding to host cells. Lastly, amino acid P681H, similar to the P681R mutation, affects virus infectivity by influencing its ability to enter human cells. These amino acids, as listed in
Table 11, are particularly noteworthy due to their potential impact on transmission dynamics and the virus’s interaction with host cells.
The results obtained from the analysis of COVID-19 in Ecuador exhibit similarities with those reported by Wang [
14] and Thanh [
15], who indicated that the majority of mutations are associated with the spike protein (S). Conversely, Rozhgar’s findings [
18] align with our results, establishing that the affected protein chain includes nucleocapsid (N). Furthermore, Pachetti et al.’s study [
16], similar to our study, identified a set of affected amino acids, specifically those located in the protein sequence from “P” to “L”. Notably, mutations P1000L and P2046L within this sequence were prominent, being present in a high percentage of infected patients across the Omicron, Delta, Mu GH, and Alpha variants. These specific amino acids (P1000L and P2046L) underwent two significant mutations, emphasizing their association with the aforementioned virus variants and their recurrent presence in a substantial number of infected patients.
The literature review did not identify any comparable studies with the epidemiological data of COVID-19 from Ecuador.
5. Conclusions and Future Work
In this study, an in-depth analysis of COVID-19 data from Ecuador was conducted. This involved examining both the biological information from the viral variants and patient-related epidemiological data obtained through the GISAID initiative. Throughout the research, diverse data preprocessing and statistical analysis techniques were applied, including Pearson’s correlation, the chi-square test, and analysis of variance (ANOVA). Furthermore, statistical diagrams and graphs were utilized to enhance the visualization of the results.
The CRISP-DM methodology is utilized in numerous data mining projects yet exhibits notable limitations. First, it primarily focuses on the initial stages of a project, as a comprehensive grasp of the research domain is imperative for progressing to subsequent phases. Second, it lacks a robust emphasis on validating the obtained results. However, a vital advantage of the CRISP-DM methodology is its adaptability to meet the specific requirements of each project. This flexibility facilitates the integration of additional techniques, such as protein alignment and the transformation of proteins into amino acid chains, along with strategies to identify the most relevant mutations in our study. Consequently, this integration enhances both the procedural aspects and the outcomes obtained.
Clearly, this study generated significant findings by analyzing the geographic distribution of COVID-19-related variables in various provinces of Ecuador. We observed that the Omicron variant was more prevalent in a large part of the Ecuadorian territory, closely followed by the Delta variant, while the Lambda variant was present in some specific regions. In this context, we found that the Omicron, Delta, and Lambda variants affected more than 50% of female patients, while the Mu GH and Gamma variants affected more than 50% of male patients. A higher incidence of COVID-19 was observed in female patients in the provinces of Pichincha with 30.97%, Guayas with 19.36%, and Manabí with 8.75% of cases.
A high incidence among male patients was reported in the provinces of Pichincha (30.91%), Guayas (17.36%), and Manabí (8.55%), indicating that these provinces were the most affected by the disease. The findings further revealed that the age group of 26 to 35 years was the most affected by all variants, with the Delta variant being more noticeable in patients aged 31 to 35 years, while the Mu GH variant had a relevant impact on patients aged 31 to 35 years and 41 to 45 years. We also found that from January 2021 to the end of November 2021, the predominant variants in infections were Mu GH, Gamma, and Delta. However, from the beginning of December 2021 until 2023, the most prevalent variant was Omicron.
In addition, highly relevant genomic information highlighting the relationship between variants and amino acids was discovered, including the fact that amino acids associated with the S protein, nucleocapsid (N), and non-structural protein chains (nsp1) and (nsp2) were most affected by the mutations. Specifically, amino acids D614G, N501Y, P681H, E484A, and P681R were observed to have significant effects on virus transmissibility, its ability to bind to host cells, and its ability to evade the immune response. These findings underscore the importance of understanding and monitoring these mutations to develop effective strategies for both the treatment and prevention of virus infection. With this patient-related epidemiological information approach and variant data, public health institutions in Ecuador can improve their understanding of disease dynamics, comprehend the importance of disease monitoring, and formulate health safety policies to prevent the recurrence of dangerous SARS-CoV-2 variants.
For future research, we propose incorporating more information from different reputable free databases to enhance the analysis and make comparisons with existing data. This may include integrating genomic and epidemiological information from various countries to identify global or specific patterns. We also suggest considering the inclusion of additional variables, such as environmental factors and the underlying medical conditions of the patients, to achieve a deeper and more holistic understanding of the infection.
Another crucial aspect would be to conduct a detailed analysis of the mutations identified in key amino acids. This would enable the evaluation of their individual impact on the virus’s interaction with host cells, their replicative capacity, and their influence on the immune response. The use of predictive models or machine learning algorithms to forecast the evolution of variants and their impact could also offer accurate early insight into possible disease scenarios.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}