1. Introduction
Research on synchronization of multi-agent systems (MASs) is inspired by certain collective animal behaviors, such as fish schooling, bird flocking, and bug swarming. The mechanism behind these behaviors can be found in crucial technological areas such as spacecraft formation flying [
1], cooperative adaptive cruise control (CACC) [
2], autonomous warehouse vehicles [
3], smart power grids [
4], robotics swarms [
5], and smart buildings [
6].
Prior to an explanation of the theory of synchronization of MASs, it is useful to give a definition of “agent”. The term “agent” appears in multiple disciplines in engineering and science; therefore, the term has been continuously revised. According to [
7], an agent consists of four basic elements: the sensor, the actuator, the information element, and the reasoning element. According to [
8], agents can be divided into three main categories: human agents, hardware agents, and software agents. Depending on the task, the software agent can be broken down into information agents, cooperation agents, and transaction agents. Information plays a crucial role in MASs: In centralized schemes, agents have access to global information, while in distributed schemes only access to the information from a few neighbors is possible [
9,
10].
In general, the study of synchronization has the objective of finding the coupling gains and/or the network topology that guarantee that the synchronization state error or the synchronization output error converges asymptotically to zero. Initial research on synchronization has been focusing on networks of identical agents, e.g., [
11]. However, it is well known that agents can have heterogeneous dynamics, which makes synchronization more challenging [
12]. Fixed coupling gains among the identical and non-identical agents that stabilize the synchronization error and guarantee the desired performance were proposed in [
13]. Due to large uncertainties in network systems and unknown parameters, many distributed adaptive approaches have been developed to synchronize the agents. The distributed adaptive synchronization of the unknown heterogeneous agents and bounded misjudgment error was discussed extensively in [
14]. In that work, synchronization was reached by using an extended form of state feedback model reference adaptive control (MRAC). Another approach based on the passification method was adopted to synchronize unknown heterogeneous MASs in [
15]. Hybrid dynamics in networks may arise from networked-induced constraints [
16] or from switching topologies.
In practice, the topology is not fixed and tends to change each time. An appropriate network structure or topology to achieve synchronous behavior was discussed in [
17]. By using the proposed control laws, the topology changes lead to a different controller structure. In order to prove the stability of the switched system, one can rely on multiple Lyapunov functions and the dwell time switching law [
18]. Novel model reference adaptive laws for uncertain switched linear systems to guarantee asymptotic and bounded stability were discussed in [
19,
20]. An open question pertains to how output synchronization can be achieved for heterogeneous agents with unknown dynamics in the presence of possibly switching topologies, and this question motivates this work.
The main contribution here is an extended adaptive synchronization law based on output- feedback MRAC for heterogeneous agents with unknown linear dynamics. It is to be noticed that our controller does not need any global information of the network. A Lyapunov-based approach is derived analytically to show that error converges asymptotically to zero. To address switching topologies, a novel switching adaptive controller is proposed in case some neighbor’s measurements cannot be accessed. Finally, numerical simulations are performed on a representative test case inspired by formation control of quadrotors.
The article is organized as follows:
Section 2 introduces multi-agent output-feedback synchronization based on the MRAC approach.
Section 3 includes switching communication topologies that handle the communication loss between agents.
Section 4 presents the simulation to validate theoretical findings. Finally,
Section 5 provides conclusions and proposes directions for further research.
Notation: The directed graph is a pair (), where is a set of nodes and is a set of edges. The edge’s weight is defined as , where . The represents the set of real numbers. The matrices are denoted by capital letters, e.g., P, and the notation indicates a symmetric positive definite matrix. The identity matrix of compatible dimensions is denoted by I, and diag represents a block-diagonal matrix. The function takes the sign •. The vectors are denoted by small letters, e.g., x. A vector signal belongs to the class; if , . A vector signal belongs to class; if max , .
2. Output-Feedback MRAC
The main task in this section is to find the control laws
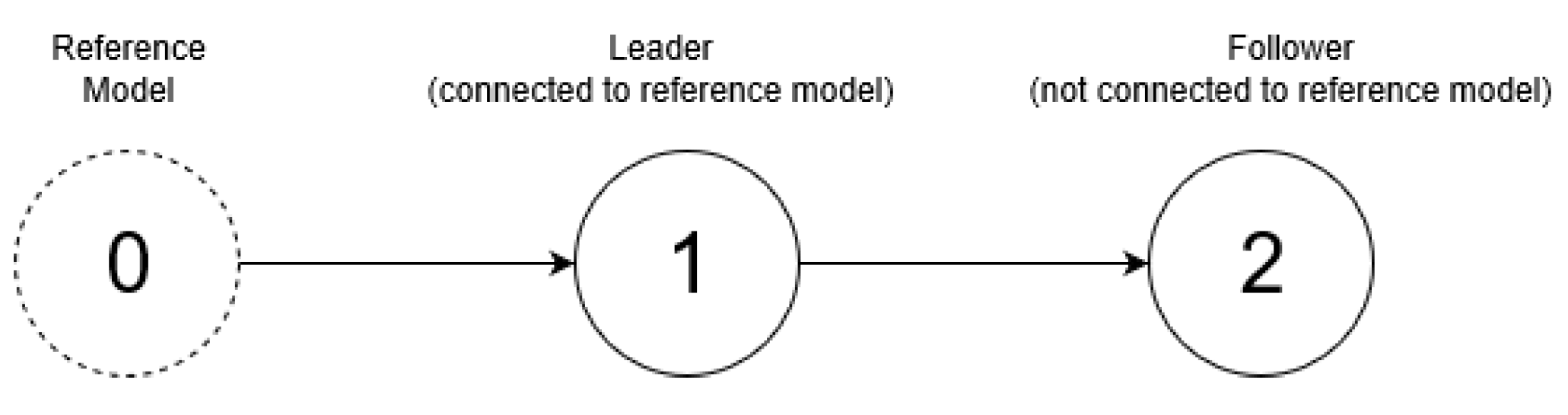
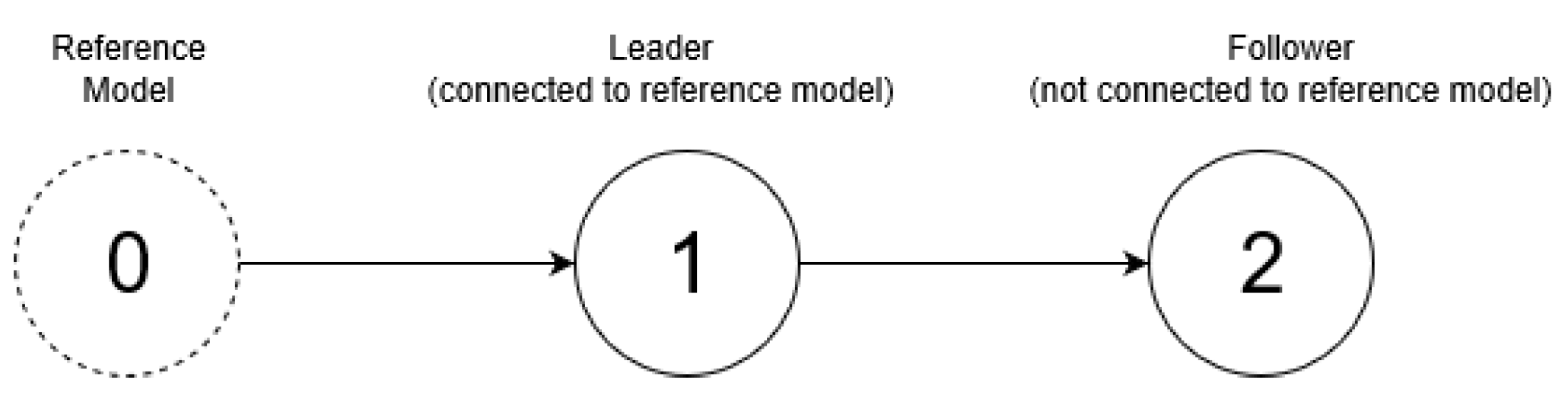
for each agent that guarantee synchronization of MASs with unknown linear dynamics by only using the input and the output of the neighbors. In order to facilitate the main result, let us assume that there are three agents denoted with subscripts 0, 1, and 2. Let us consider the network depicted in
Figure 1. Here, the purpose of Agent 1, the leader, is to follow Agent 0. At the same time, the purpose of Agent 2 is to follow Agent 1. Agent 0 is a reference model that is connected to Agent 1, satisfying the following dynamics:
where
and
are the reference input and the output of the reference model.
and
are known monic polynomials, and
is the high-frequency gain. Next, we have Agents 1 and 2, denoted with subscripts 1 and 2, respectively, and with dynamics expressed in the transfer function form as
where
,
, and
,
are the inputs and the outputs of two agents.
,
,
, and
are unknown monic polynomials, and
and
are constants referred to the high frequency gains. Note that, possibly,
and
(heterogeneous agents with unknown dynamics). We assume a directed connection from Agent 1 to Agent 2, i.e., the digraph is described by
,
. By using this configuration, Agent 2 can observe the measurement from Agent 1, but not vice versa.
The synchronization task between Agent 0 and Agent 1 is achieved when for . As the signal from the reference model is known to Agent 1 only, the purpose of Agent 2 is to follow Agent 1. In this case, the synchronization task is achieved when for . It is clear that, if both synchronization tasks are achieved, then we have also for . These tasks should be achieved for any bounded reference signal r.
Assumption 1. To achieve the synchronization objectives, we need the following assumptions for the reference model (R) and the agents (A):
- (R1)
and are monic Hurwitz polynomials, where the degree of is less than or equal to the relative degree of , n.
- (R2)
The relative degree of is the same as that of , .
- (A1)
are monic Hurwitz polynomials.
- (A2)
An upper bound n of the degree of , i.e., , is known.
- (A3)
The relative degree of , i.e., , is known, where m is the degree of the numerator. The relative degree of the agents and the reference should be the same.
- (A4)
The sign of the high frequency gains i.e., is known.
In the next subsection, the synchronization of Agent 1 to a reference model will be discussed.
2.1. Synchronization of a Leader to a Reference Model
As classical MRAC was used for the SISO plant in Chapter 5 of [
21], it is well known that the agents
i can be synchronized to the reference model by using the following control law:
where
is a Hurwitz monic polynomial and
are defined as
The consequence of Assumption 1 is that there are scalars , and that match the condition of agent i and the reference model such that
The matching conditions for Agent 1 to the reference model can be defined as follows, in line with Chapter 5 in [
21].
where
. Because the parameters of Agent 1 are unknown, the proposed control law (
3) cannot be used for Agent 1, and we can come up with
where the controller parameter vector
,
,
, and
are the estimates for
,
,
, and
, respectively. Let us assume the relative degree of 1 for simplicity. Adopting a state–space representation of the reference model and Agent 1, we obtain
It is well known that one can use the following adaptive law:
where
,
,
,
F,
d, and
defined as follows
Here the adaptive gain,
, is not taken as a scalar, as it is in most literature, but as a diagonal matrix:
where
are the positive real numbers to be designed. By using the control law
, one can achieve
for
. In this work, the Lyapunov-based approach is derived to show analytically the asymptotic convergence of the synchronization error. First, let us define the state–space representation of Agent 1 in the closed-loop form:
where
.
, and
are defined as
Obviously, Agent 1 can be matched to Agent 0 or it can be said that
. Therefore, the state–space representation of Agent 1 in the closed-loop form could be rewritten as follows:
where
. By defining the state tracking error
and the output error
, we obtain the error equation:
where
.
Proof. To show analytically the asymptotic convergence of the synchronization error between the leader and the model reference, let us define the following Lyapunov function:
where
such that
where
, and
. One can verify the time derivative of
:
Since
and
, we can delete the indefinite term by choosing
which leads to
From (
20), we obtain that
has a finite limit, so
. Because
and
, we have
. This implies
. From
and
, we have
. Therefore, all signals in the closed-loop system are bounded. From (
20), we can establish that
has a bounded integral, so we have
. Furthermore, using
, in (
15), we have
. This implies
for
, which concludes the proof. ☐
In relative degree 2 case (
), an extra filter is introduced to synchronize the agents with the model reference. The extra-filter and the new form of the control law are defined as follows:
where
is to be designed. Using similar Lyapunov arguments as before, one can prove
for
[
21]. The complexity of the methods increases with the relative degree
of the agent. In the next subsection, the synchronization of Agent 2 to a leader node will be discussed.
2.2. Synchronization of a Follower to a Neighbor
The control law (
3) and consequently the matching condition (
5) have two problems. The first problem is that the transfer function
of the agents is unknown, and we do not know the
, and
. The second problem is that, even if the transfer function were known, the control law (
3) would be implementable only for those agents connected to the reference model, Agent 0, and with access to
r. Therefore, we cannot implement the control law (
3) for Agent 2. In place of the matching condition between Agent 2 and Agent 0, we should formulate a matching condition between Agent 2 and Agent 1. The following proposition follows.
Proposition 1. There is an ideal control law that matches an agent to its neighbor in the form
Proof. In this proof, we want to formulate the matching conditions for Agent 2 to Agent 1 by using the proposed control law for Agent 2. First, let us rewrite the control law (
22) as follows:
Substitute the control law in (
23) to (
2) and use the following matching condition of Agent 2 to reference model
which leads to
Then (
25) can be written as follows:
where
, and
. This concludes the proof. ☐
The parameters of Agent 2 are unknown, but we can come up with
where the controller parameter vector
,
,
,
,
,
, and
are the estimates for
,
,
,
,
,
, and
, respectively. Let us define the adaptive laws and the designed parameters as follows
where
.
where
are the positive real numbers to be designed. By using the proposed control law
, one can achieve the following result.
Proposition 2. Consider the reference model (
1),
with heterogeneous agents with unknown dynamics (
2),
controllers (
7)
and (
27),
and adaptive laws (
9)
and (
28).
Then, all closed-loop signals are bounded and the errors converge asymptotically to zero. Proof. To show analytically the asymptotic converge of the synchronization error, the Lyapunov-based approach will be used. First let us consider Agent 2 with dynamics
The closed-loop form allows us to write
where
and
.
From Equation (
26), we already know that Agent 2 can match Agent 1 or it can be defined as
. Therefore, Agent 2 can match the reference model
. We can then take a non-nominal state–space representation of Agent 2:
where
. By defining the state tracking error
, and the output error
, let us define the following error dynamics:
where
. By taking the Lyapunov function,
where
and
such that (
17) holds. The time derivative (
35) along the trajectory of (
34) is given by
Since
and
, we can delete the indefinite term by choosing
which leads to
From (
38), we obtain that
has a finite limit, so
. Because
and
, we have
. This implies
. From
and
, we have
. Therefore, all signals in the closed-loop system are bounded. From (
38) we can establish that
has a bounded integral, so we have
. Furthermore, using
in (
34), we have
. This concludes the proof of the boundedness of all closed-loop signals and convergence
for
. ☐
2.3. Synchronization of a Follower to Two Neighbors
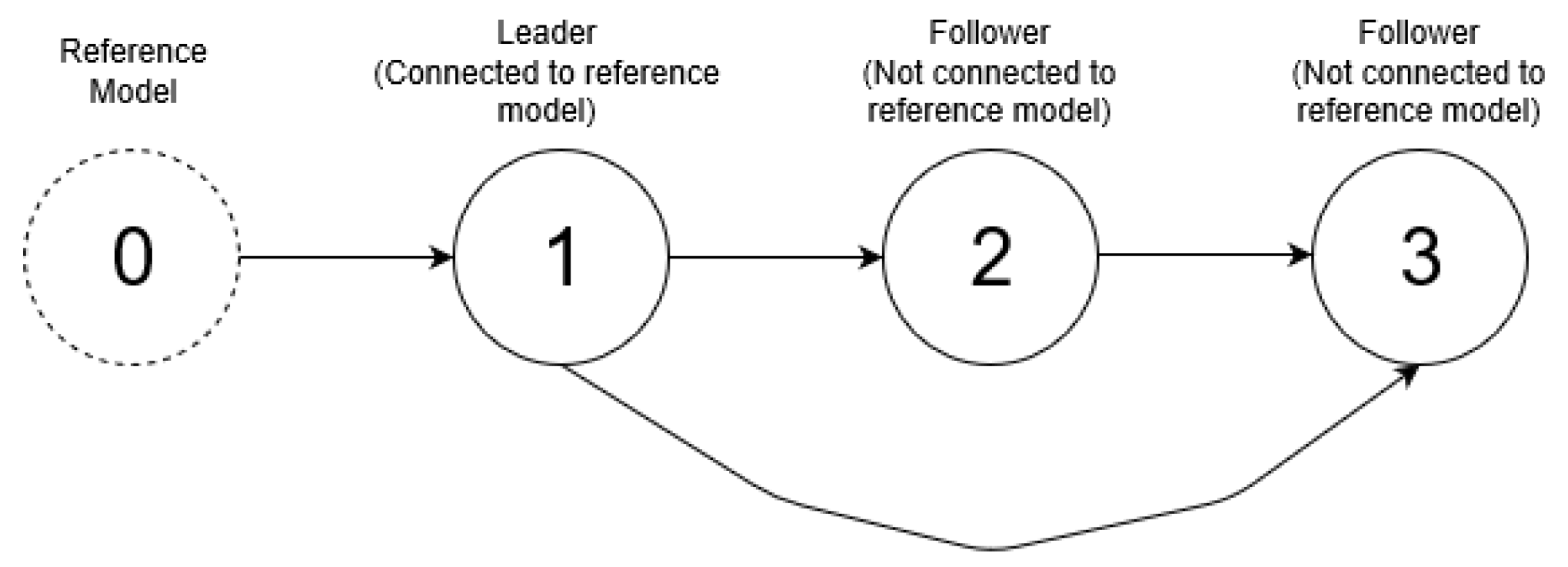
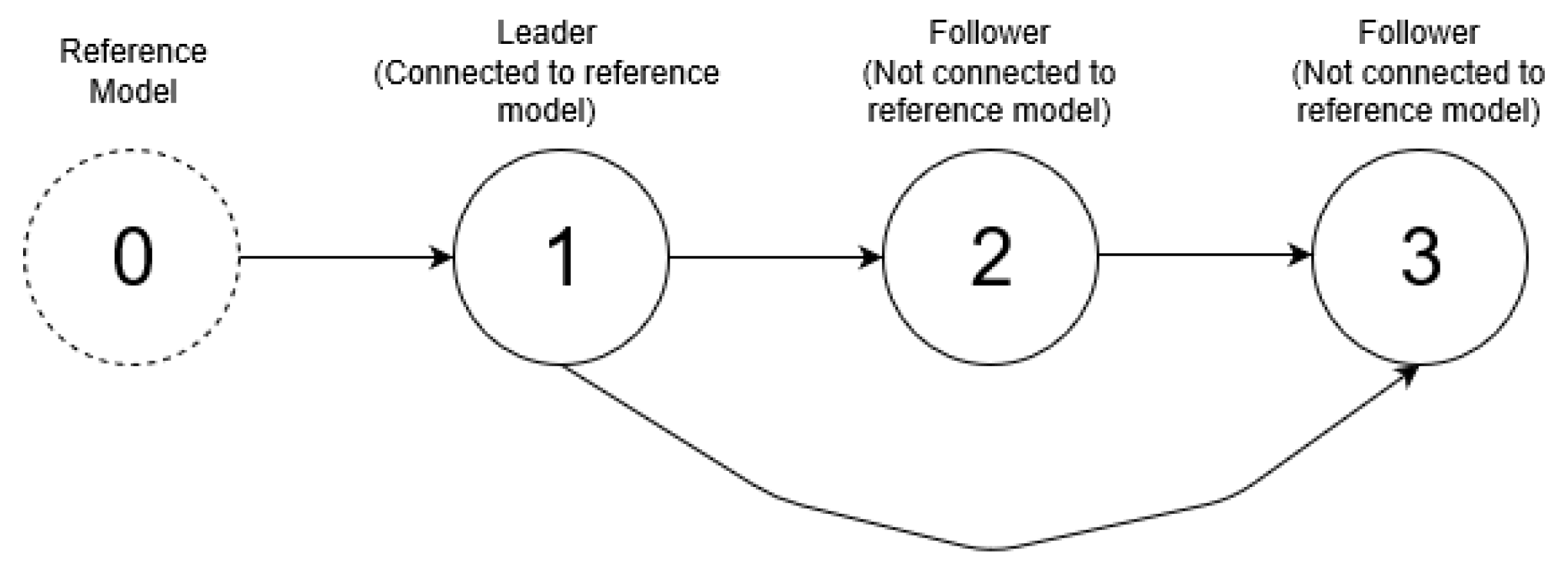
Before giving the main result, it is necessary to deal with the case in which a follower (called Agent 3) tries to synchronize two parent neighbors (called Agents 1 and 2). Let us assume a directed connection from 1 to 3 and from 2 to 3. The digraph is described by , .
Assumption 2. The communication graph is a directed acyclic graph (DAG), where the leader is the root node.
In addition, let us consider for simplicity an unweighted digraph, i.e.,
, and the edges’ weights are equal to 1. The network under the consideration is presented in
Figure 2.
We have Agent 3 denoted with subscript 3 and dynamics expressed in the transfer function form:
where
and
are the input and the output of Agent 3.
and
are unknown monic polynomials, and
is a constant referred to the high frequency gains. Note that, possibly,
,
, and
,
(heterogeneous agents with unknown dynamics). We assume a directed connection from Agent 1 to Agent 3 and a directed connection from Agent 2 to Agent 3. By using this configuration, Agent 3 can observe measurement from Agent 1 and Agent 2, respectively, but not vice versa. By following an approach similar to that taken in the previous subsection (cf. Proposition 2), the synchronization of Agent 3 to Agent 1 is possible via the controller.
and the synchronization of Agent 3 to Agent 2 is possible via the controller
where
and
, and the output error
,
. In a more compact form, the controller for Agent 3 can be defined as the addition of (
40) and (
41):
where
,
, and
. We then derive the adaptation law and the parameters to be designed for an agent with two parent neighbors as follows:
By using the proposed control law , the following result (which can be extended to general DAG) holds.
Proposition 3. Consider the reference model (
1),
with the heterogeneous agents with unknown dynamics (
2), (
39),
controllers (
7), (
27),
and (
42),
and adaptive laws (
9), (
28),
and (
43).
Then, all closed-loop signals are bounded and the errors converge asymptotically to zero. Using a similar approach as in [14], synchronization can be extended to any DAG. The derivation is not provided due to a lack of space. Proof. To show analytically the asymptotic convergence of the synchronization error, the Lyapunov-based approach will be used. Let us define the dynamics error
,
, and
. Following the same approach in the previous section, let us derive the dynamics error
:
where
,
,
, and
. One can take the Lyapunov function:
where
and
such that (
17) holds. The time derivative (
45) along (
44) is given by
Since
and
, we can delete the indefinite term by choosing
which leads to
From (
48), we obtain that
has a finite limit, so
. Because
,
,
,
, and
, we have
. This implies
. From
and
, we have
. Therefore, all signals in the closed-loop system are bounded. From (
48), we can establish that
has bounded integral, so we have
. Furthermore, using
in (
44), we have
. This concludes the proof of the boundedness of all closed-loop signals and convergence
for
. ☐
3. Switching Topology of Multi-Agent Systems
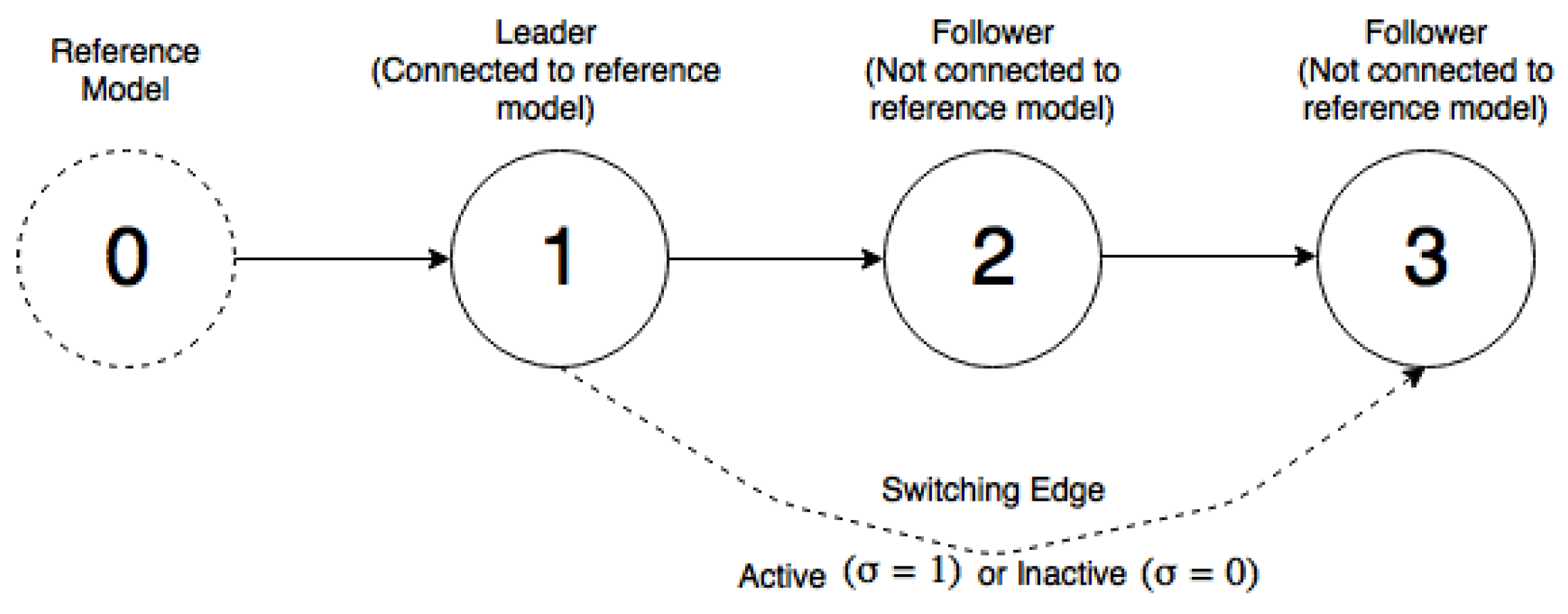
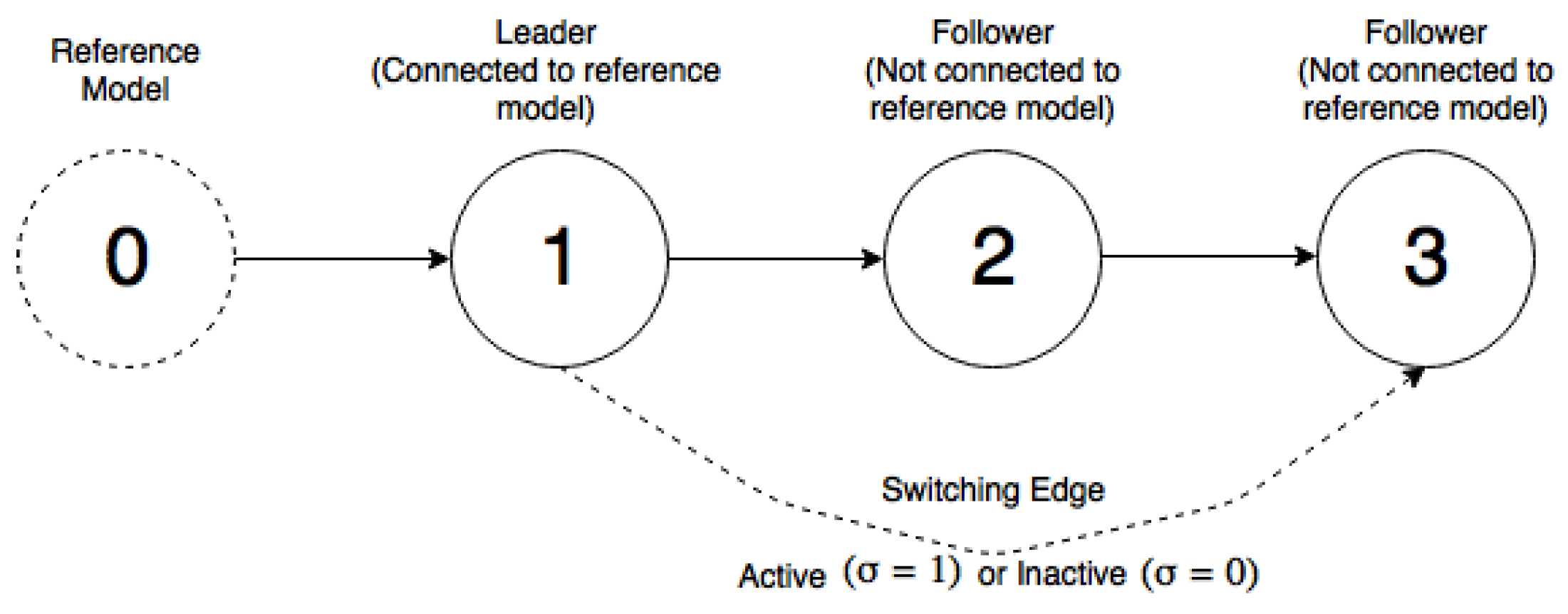
In practice, communication losses between agents may occur. Here, the communication loss is defined by a switching edge
. If the switching edge is equal to zero, it means there is no communication between Agent 1 and Agent 3, and vice versa. The time-varying communication between Agent 1 and Agent 3 can change the network topology, which leads to different control structures in the form (
42) or (
27). The network topology where communication loss may occur between Agent 1 and Agent 3 is shown in
Figure 3.
In order to prove the stability of the switched system, one can rely on the Lyapunov-based approach. In the case of Agent 3 with two parent neighbors, one can take the Lyapunov function as follows:
In the case of Agent 3 with one parent neighbor, one can take the Lyapunov function as follows:
where
and
such that (
17) holds. It is clear that the Lyapunov function is not common to (
49) and (
50). This is because the Lyapunov function is influenced by the switching topology. Using the result in [
19,
20], we know that there is a dwell time for which stability can be derived. However, such a dwell time is unknown in the output-feedback case. Therefore, we conclude this work by proposing an adaptive switching scheme and by evaluating its effectiveness in simulations. The switching scheme resembles the multiple model adaptive control, e.g., as discussed in [
22,
23,
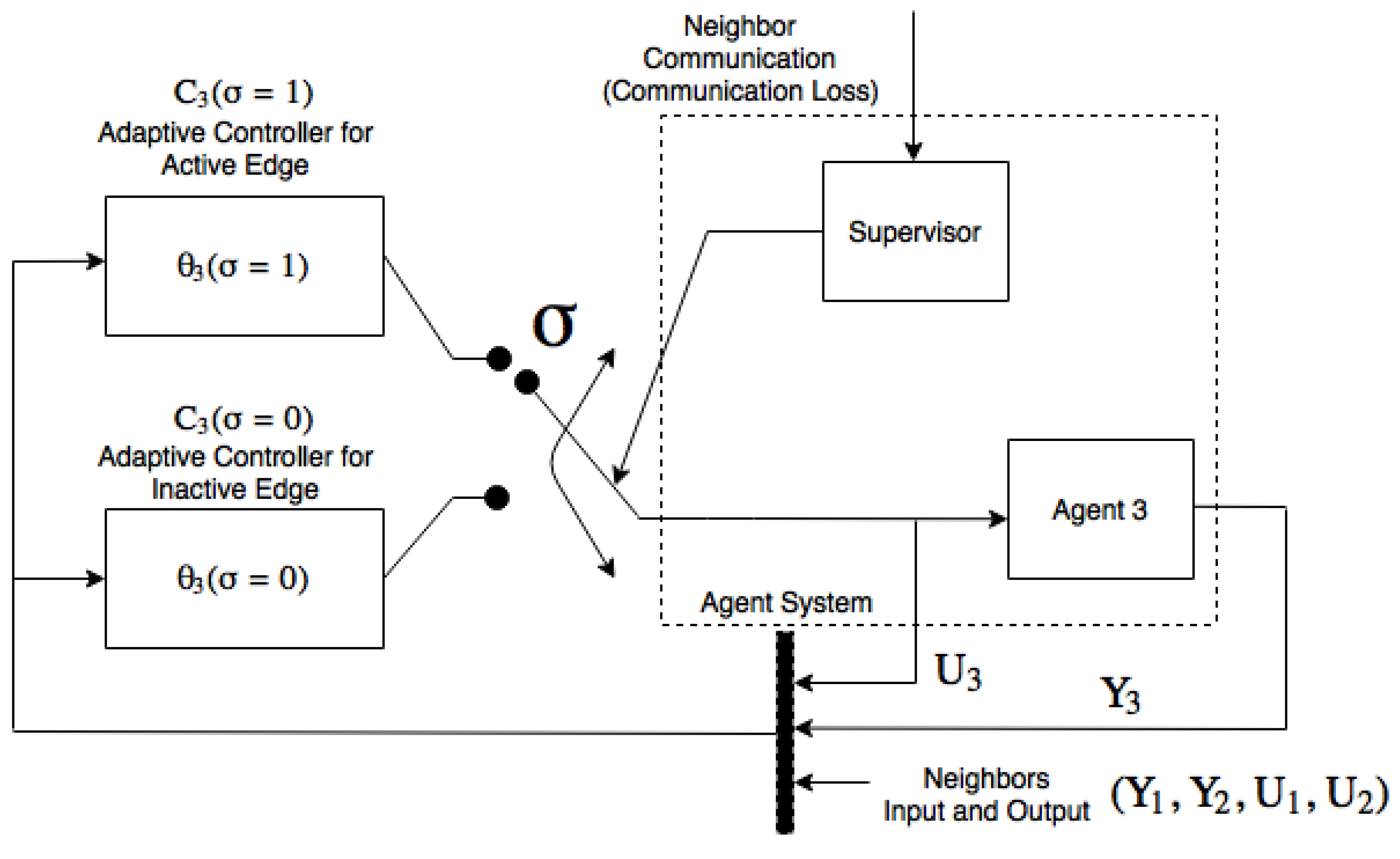
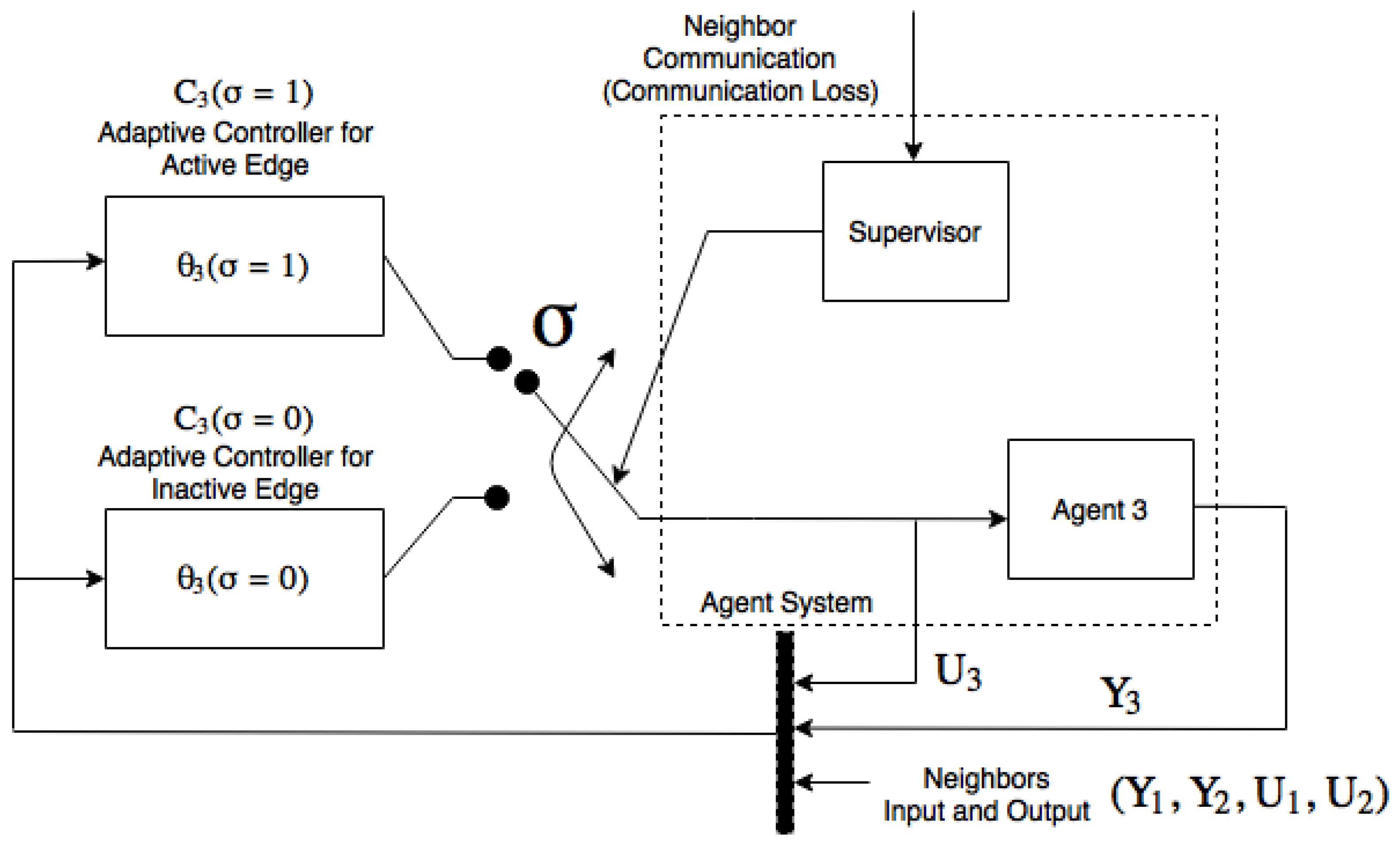
24]. The switching adaptive controller that will be applied in this work is shown in
Figure 4.
Here we have a free-running adaptive controller for an agent with one parent neighbor (Agent 2) and a reinitialized adaptive controller for an agent with two parent neighbors (Agent 1 and Agent 2). Then, let us define the adaptive controller parameter vectors and . Note that, if the switching edge is inactive, the value should be held at its last value until the switching edge is active. Note also that is not affected by the switching edge because it only depends on Agent 2. Consider that, if the switching edge is inactive, the measurement of the input and the output of Agent 1 by Agent 3 are equal to zero.
4. Numerical Simulation
In line with [
25,
26], some simplified quadcopter dynamics are used as a numerical example. The simplified quadcopter attitude dynamics is given as follows:
where
,
, and
are the yaw angle, the rotational moments of inertia on the y-axis, and the rotating torque on yaw angle, respectively. The yaw angle output will be utilized to synchronize the yaw angle for all the agents. The state–space representation of the quadcopter
i with attitude dynamics:
where the state vector,
, comprises the yaw angle and the yaw rate,
, where
N is the total number of the quadcopter. Note that (
52) has relative degree 2 (
). Index 1 indicates the leader quadcopter, which is the only quadcopter that has direct access to the reference model. The reference model is indicated as fictitious Agent 0, which can communicate the reference signal to Agent 1. The reference model dynamics in state–space formulation is given as follows:
where the model reference parameters are taken as:
, and the initial condition of the reference model
. Each quadcopter has different and unknown rotational moments of inertia
, and the initial state is also unknown. Therefore, the network is composed of heterogeneous and unknown agents.
Table 1 shows the parameters of each quadcopter that are used only to simulate the network.
In the next subsection, we will illustrate the synchronization of the MAS based on output-feedback MRAC with a fixed topology.
4.1. Multi-Agent Output-Feedback MRAC without Switching Topology
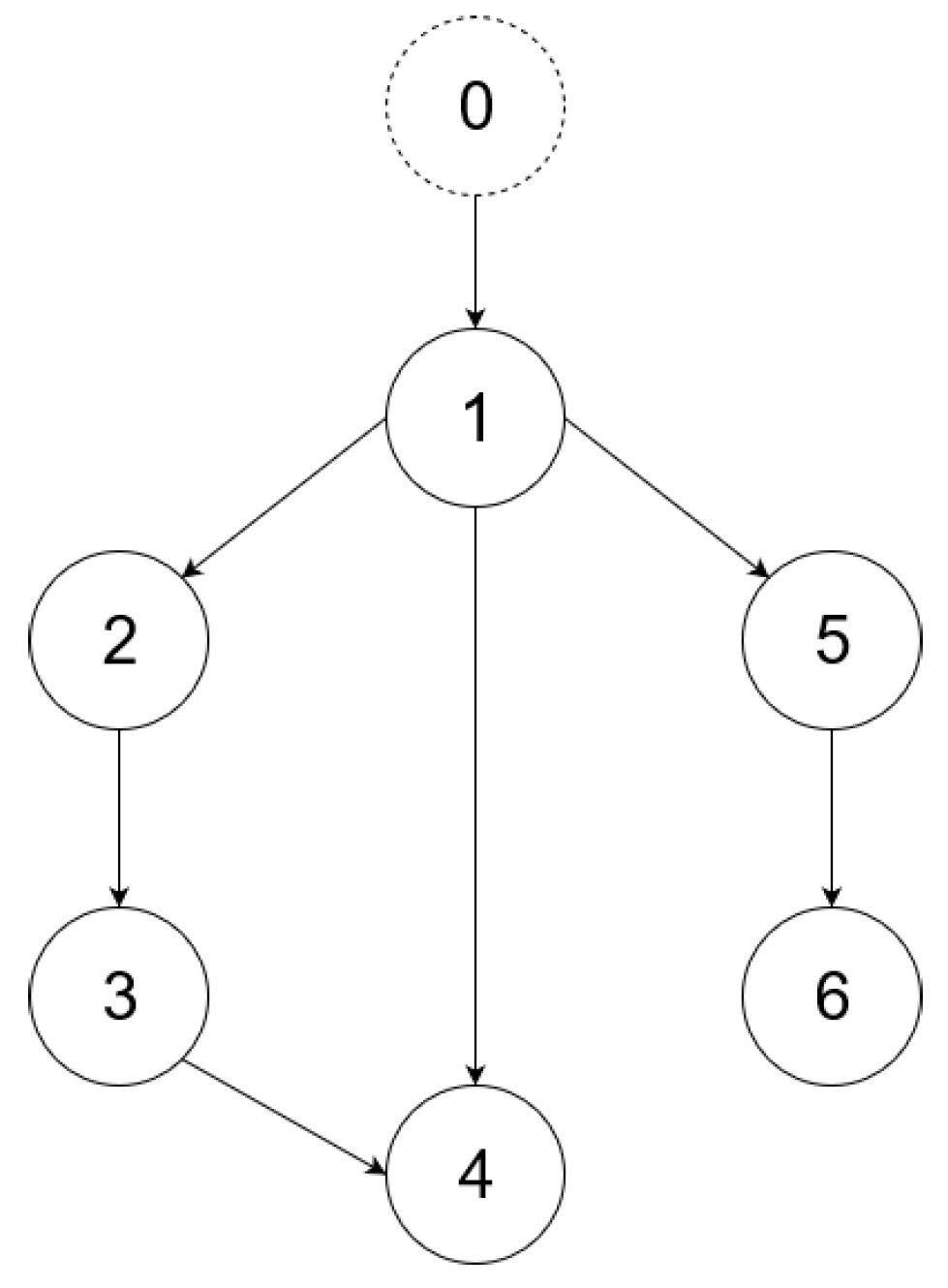
The simulations for multi-agent output-feedback MRAC with fixed topology are carried out on the directed graph shown in
Figure 5. The design parameters are taken as
, and all coupling vector gains are initialized to be 0. Let us define the adaptive gain
for each agent
i as follows:
have been selected to give a smooth response and acceptable input action where , , , and . In our case, two reference inputs are considered:
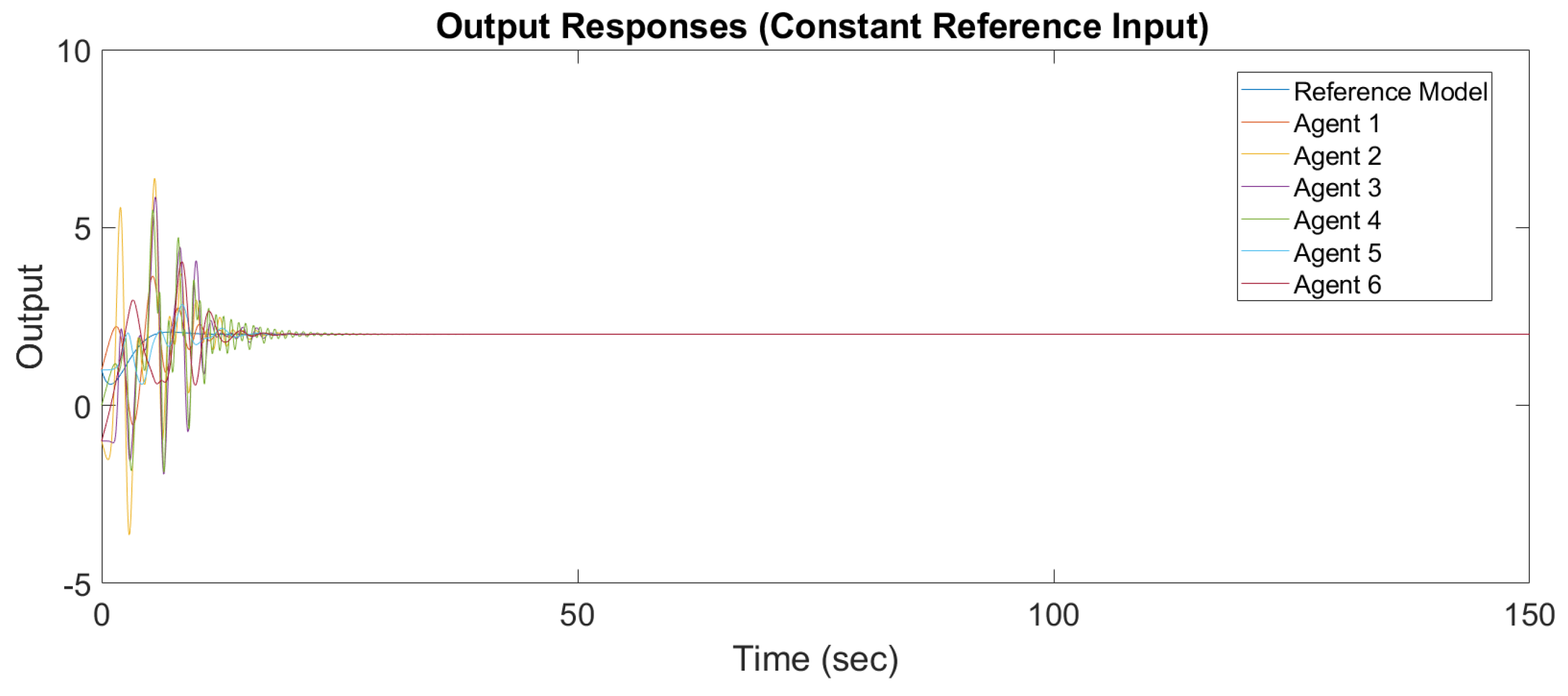
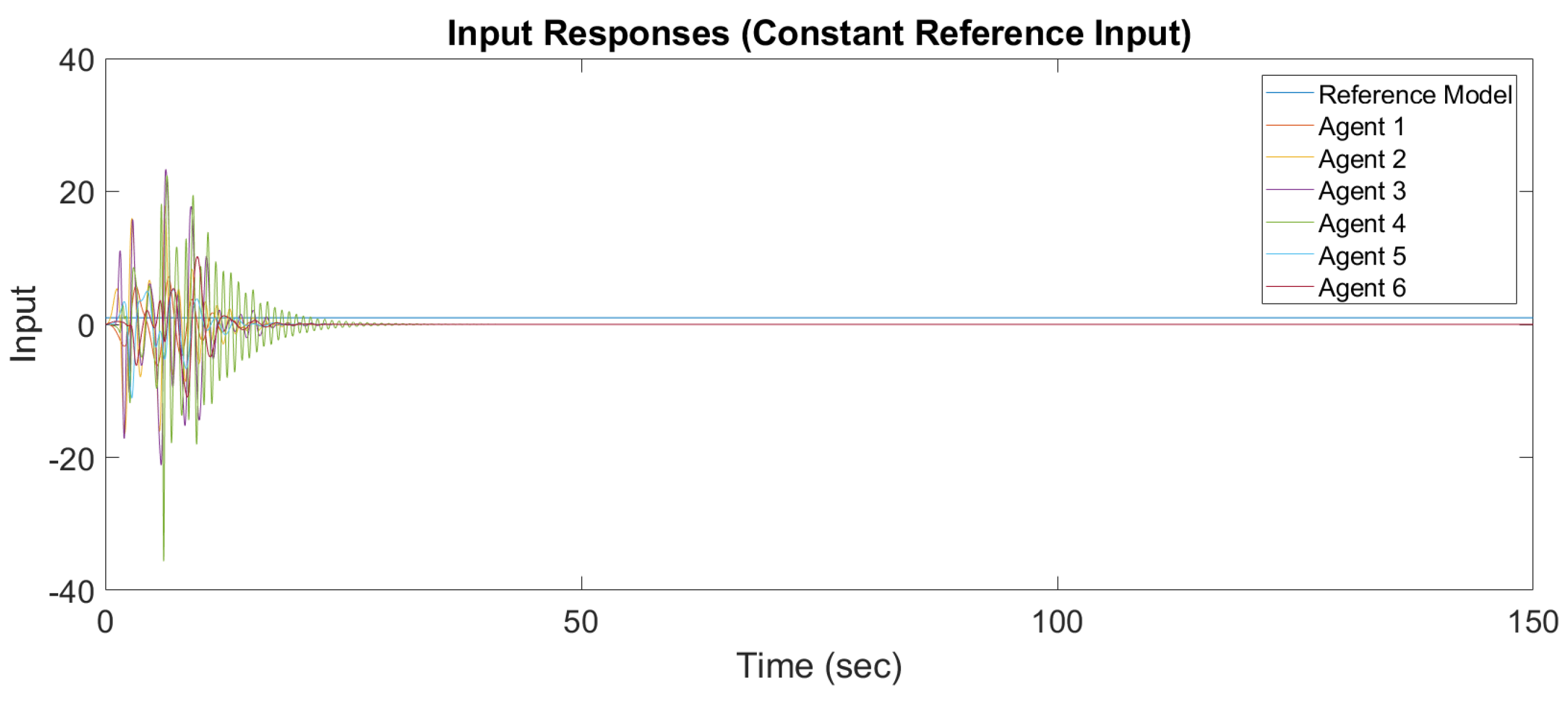
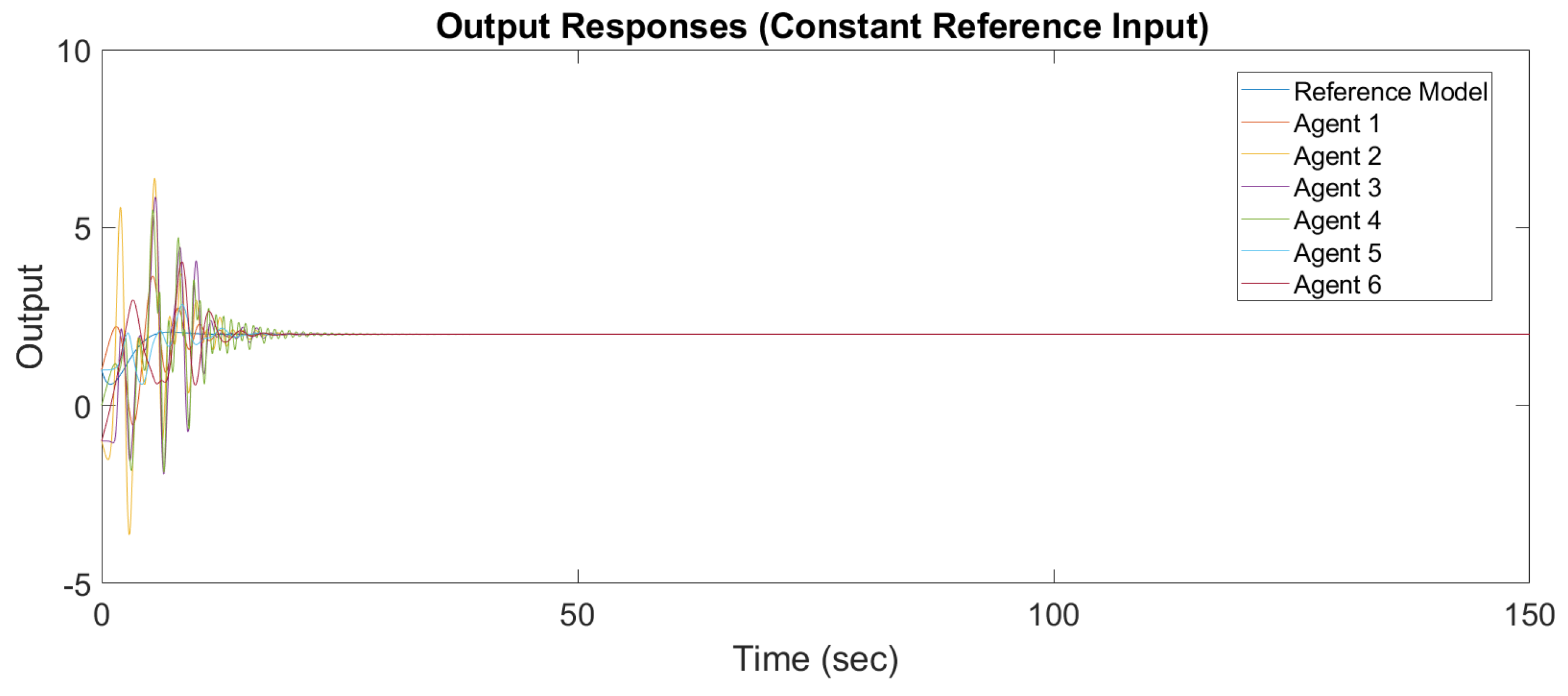
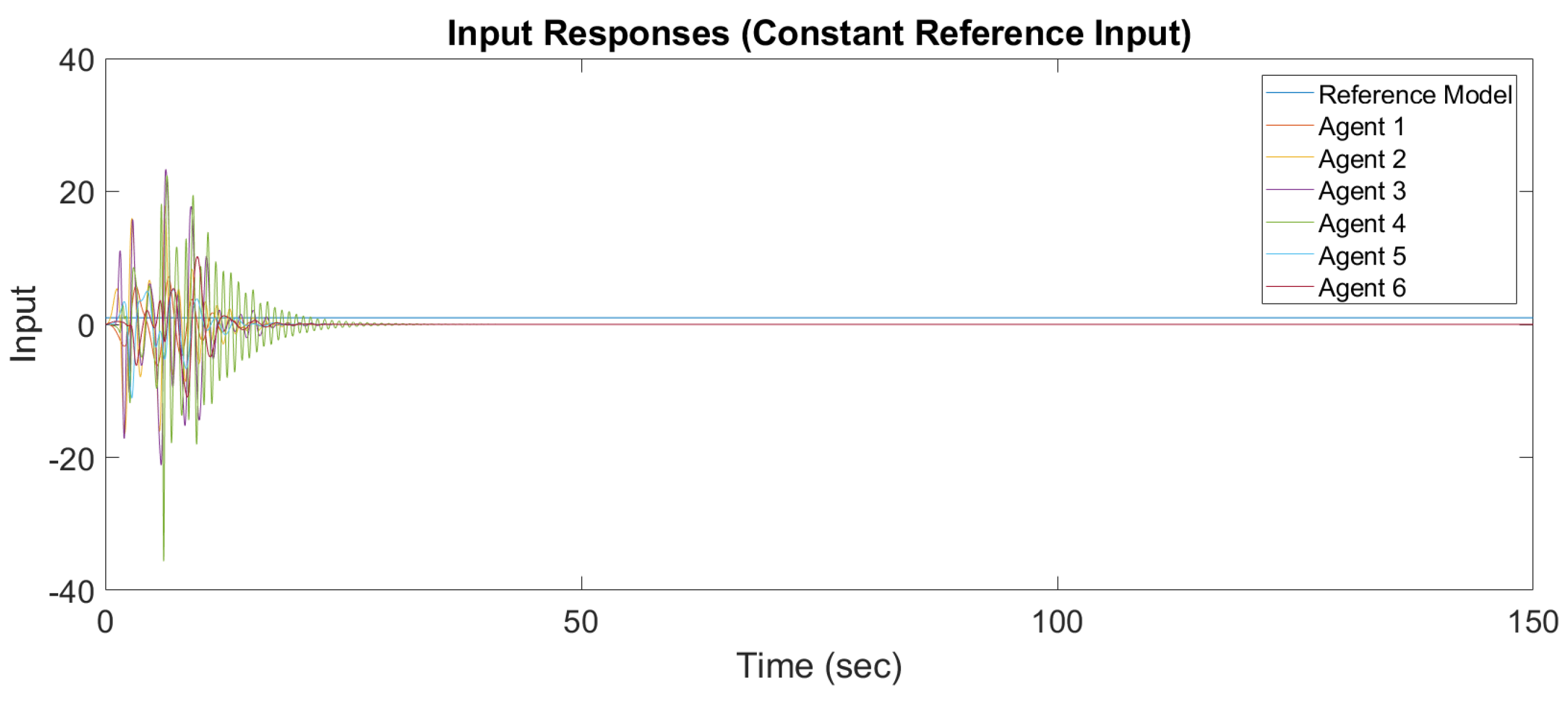
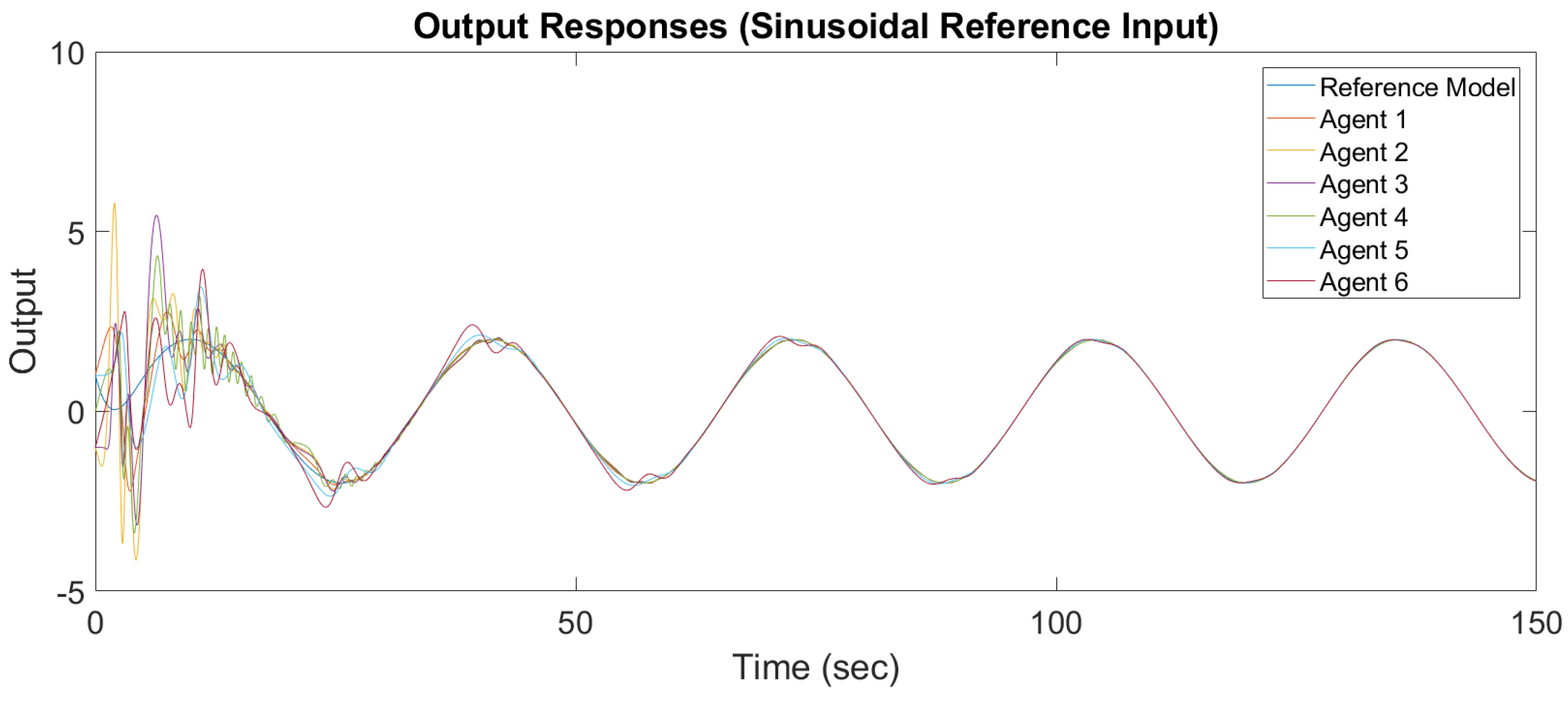
Figure 6 and
Figure 7 show the output response and input response of synchronization with a constant reference input, and
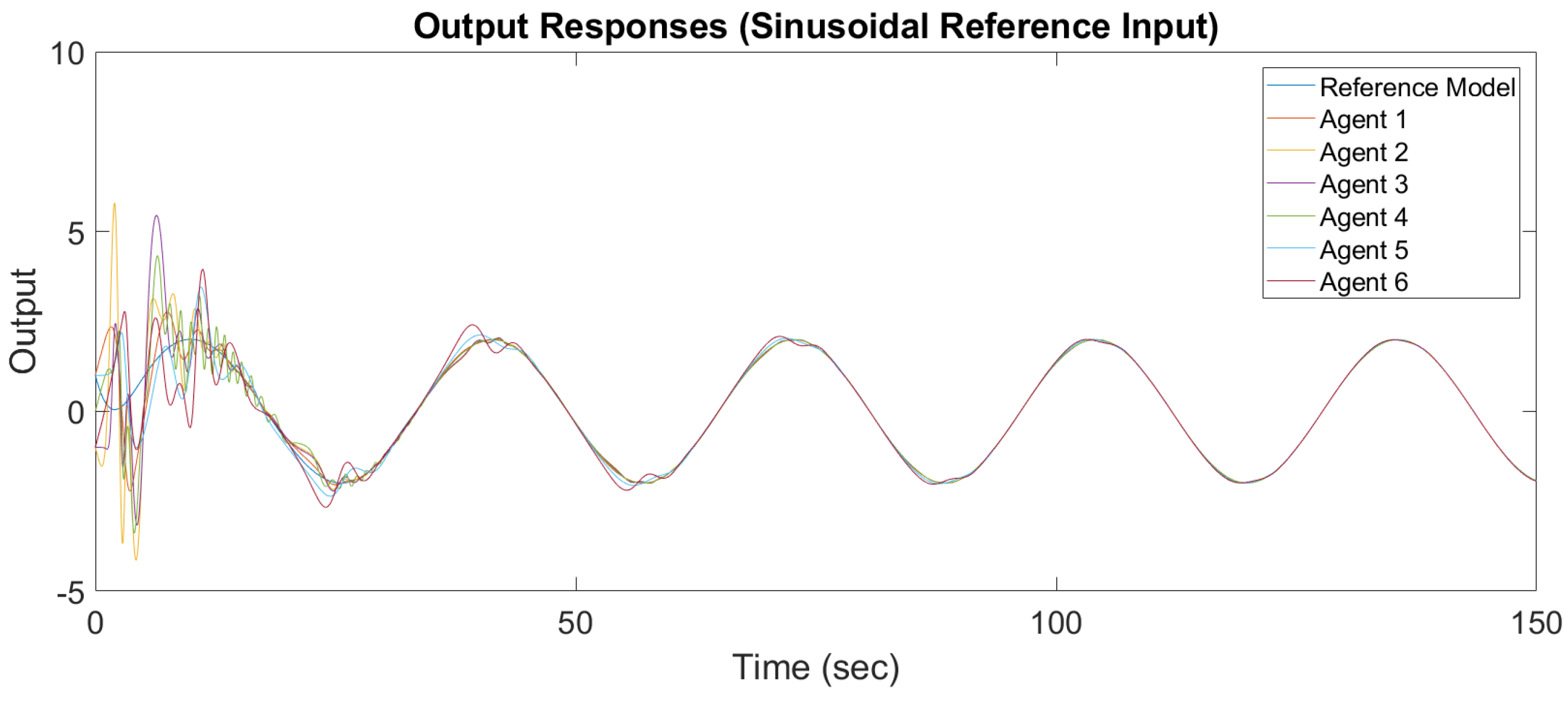
Figure 8 and
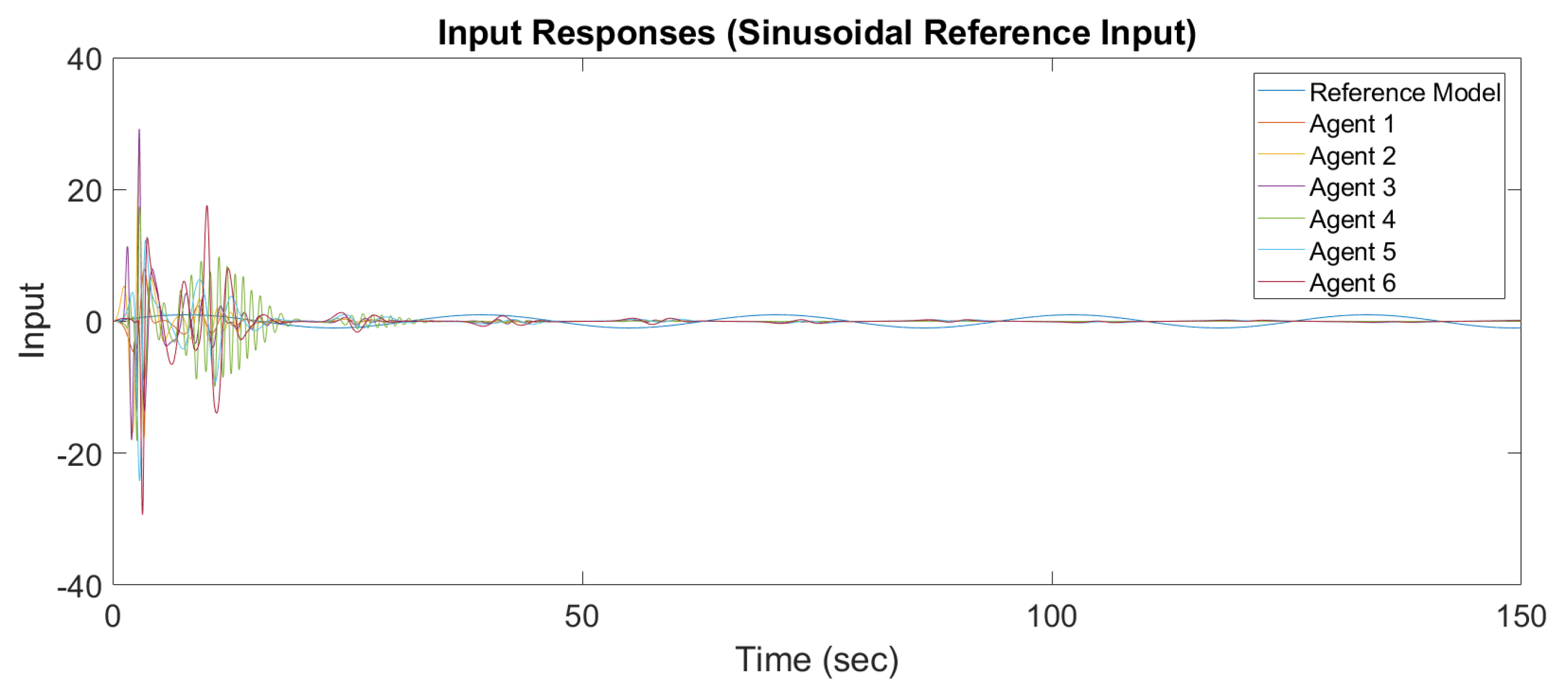
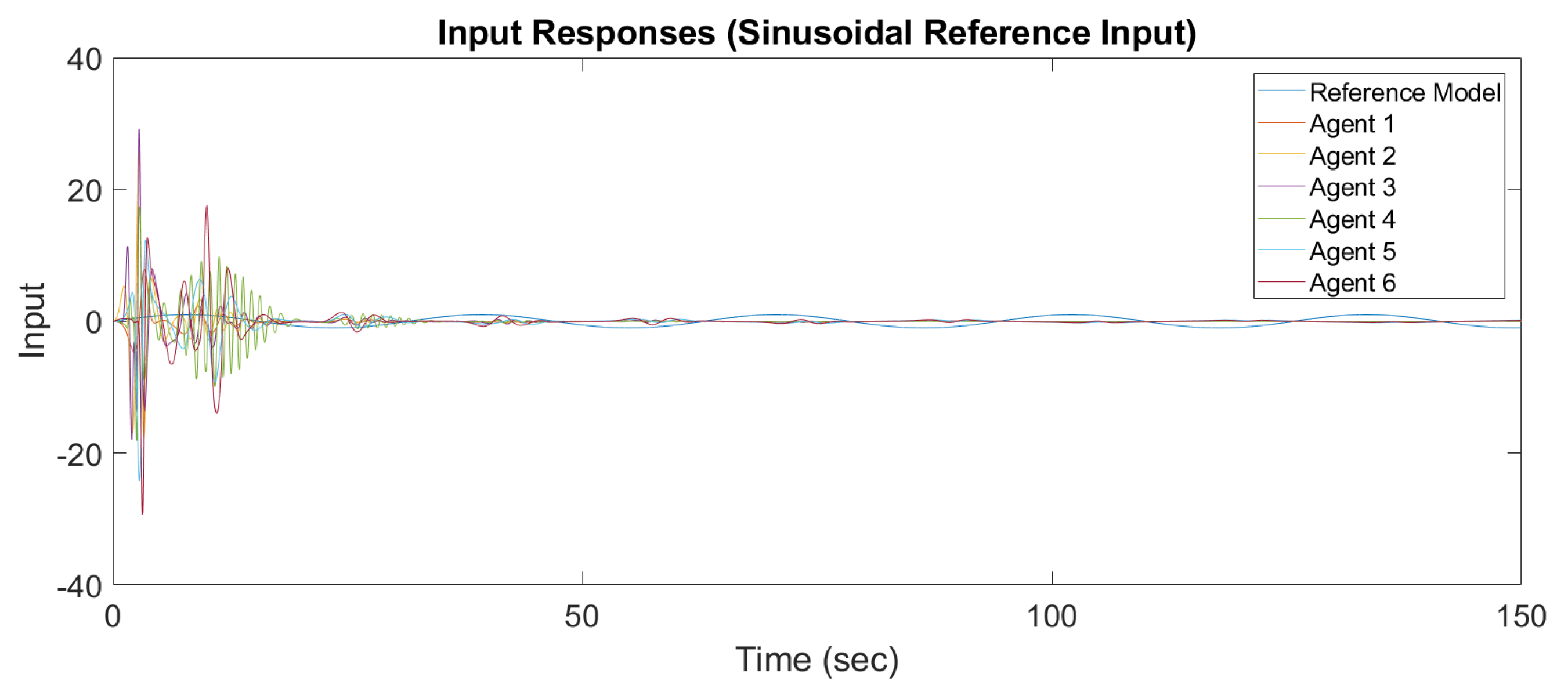
Figure 9 show the output response and input response of synchronization with a sinusoidal reference input
It is observed that all outputs converge asymptotically to the output of the leader for constant and sinusodal leader inputs, respectively. The following subsection will illustrate the synchronization of the MAS with switching topology based on output-feedback MRAC.
4.2. Multi-Agent Output-Feedback MRAC with Switching Topology
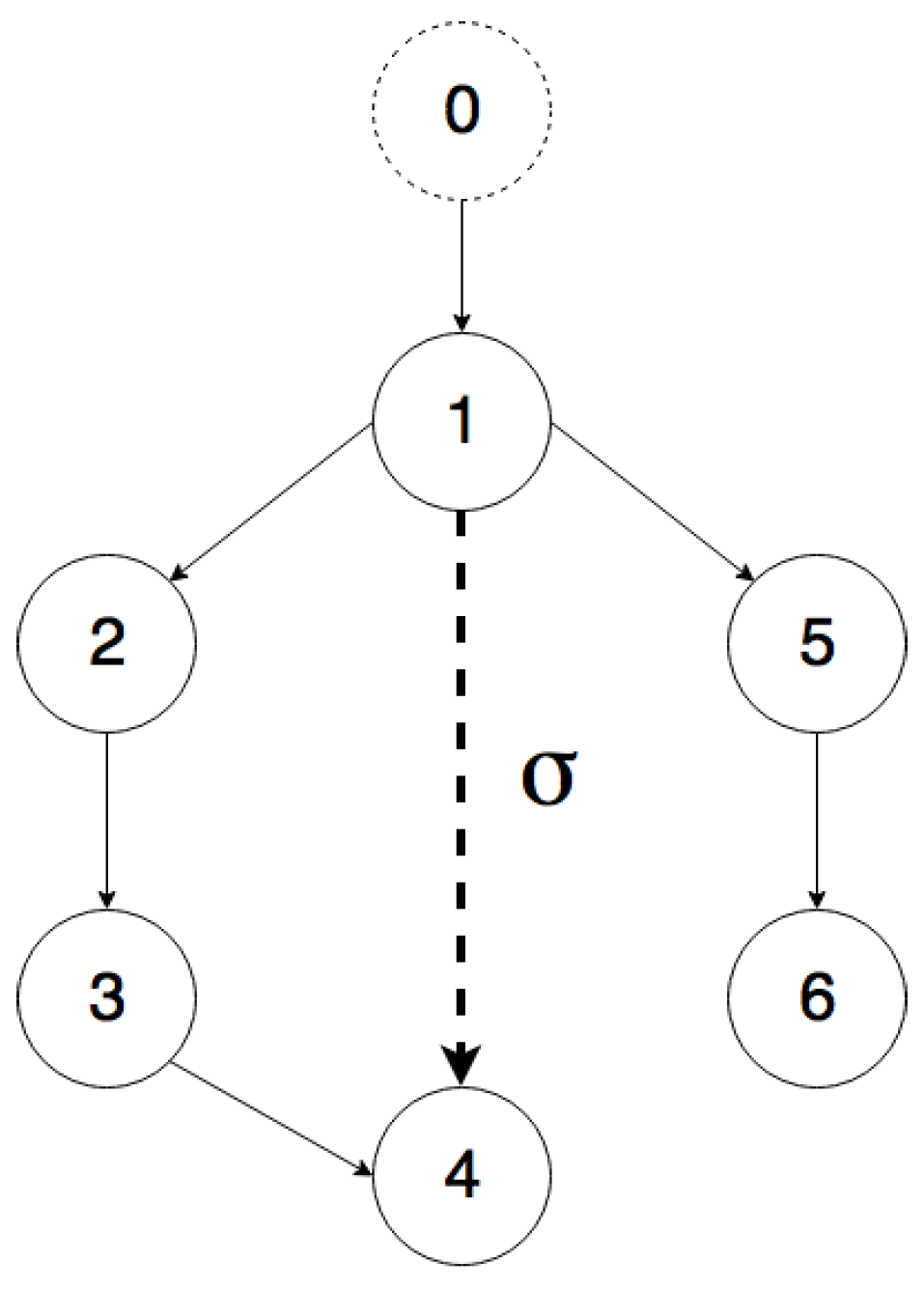
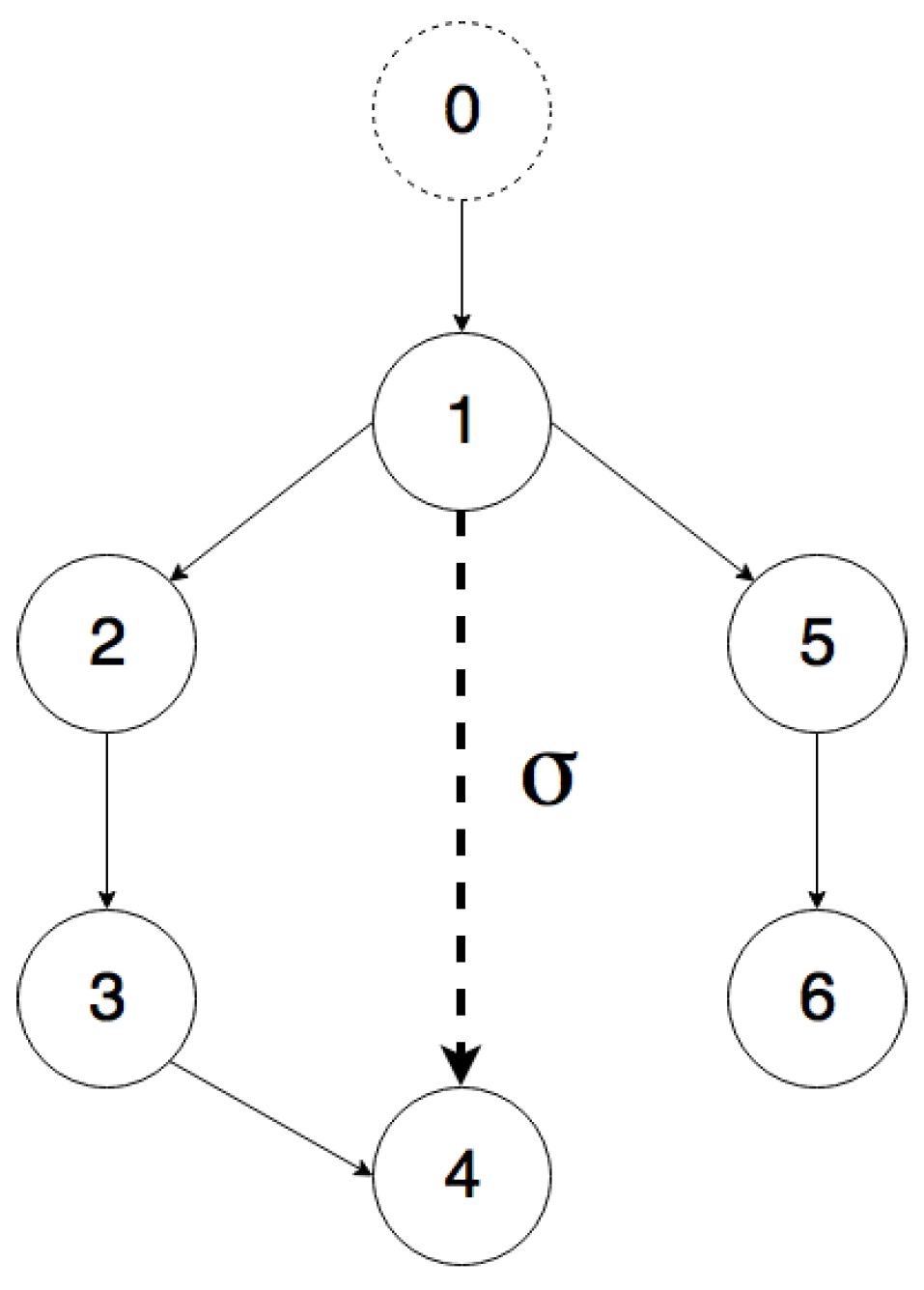
The simulations for multi-agent output-feedback MRAC with switching topology are carried out on the directed graph shown in
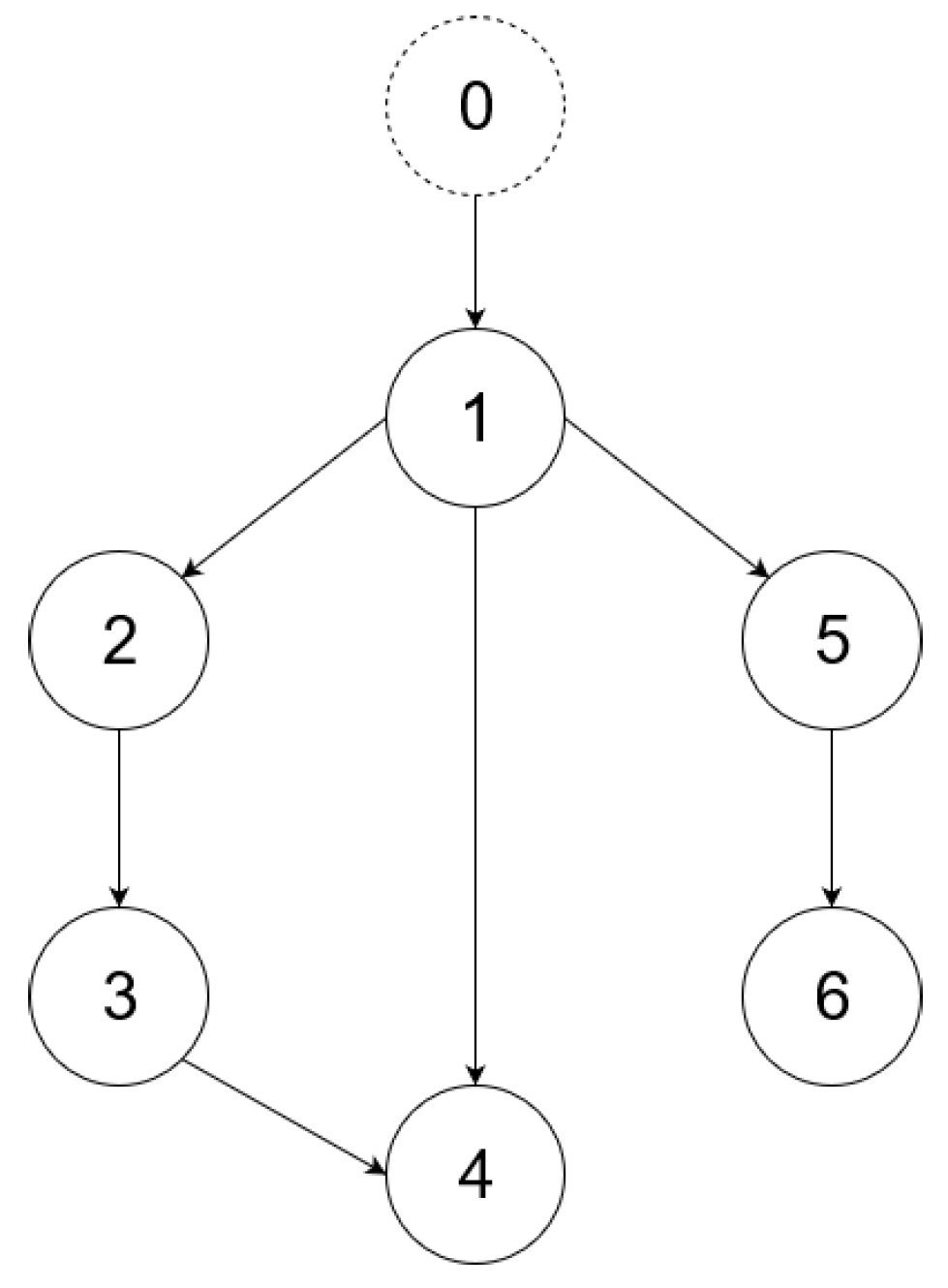
Figure 10. The communication between Node 4 and Node 1 varies with time, e.g., due to communication losses. It must be noted that Agent 4 only has one parent neighbor if the edge is inactive and has two parents if the edge is active.
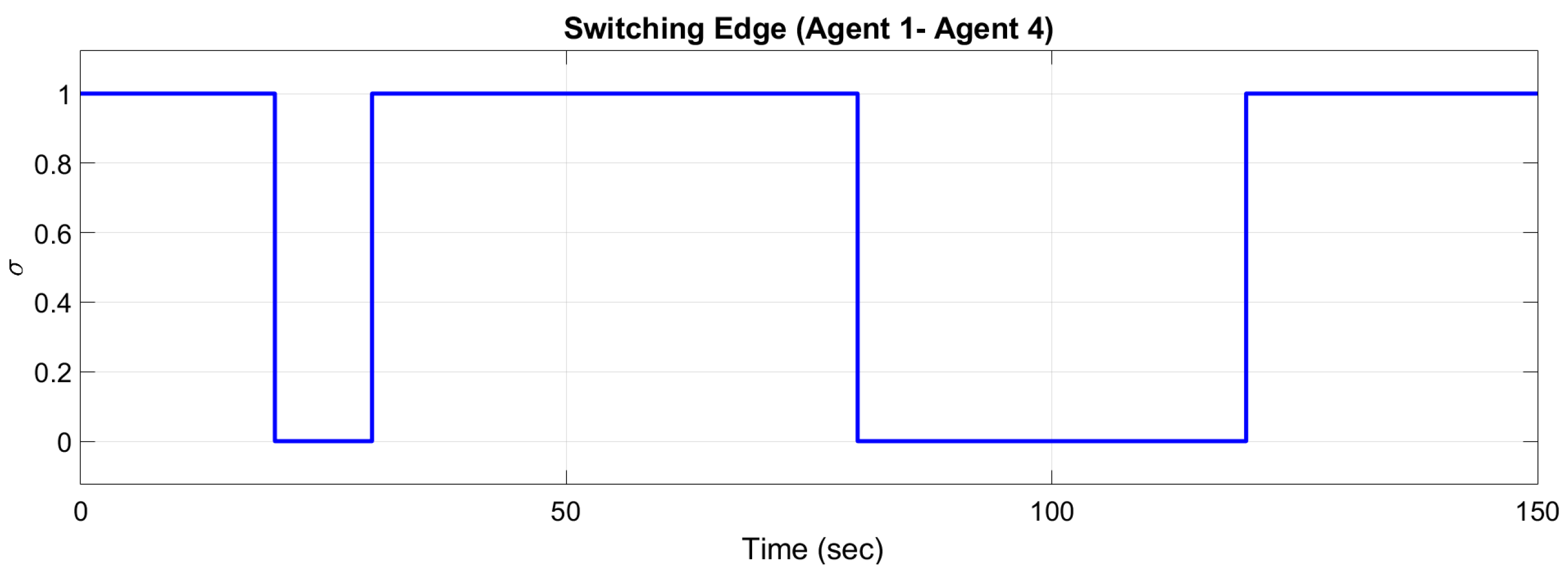
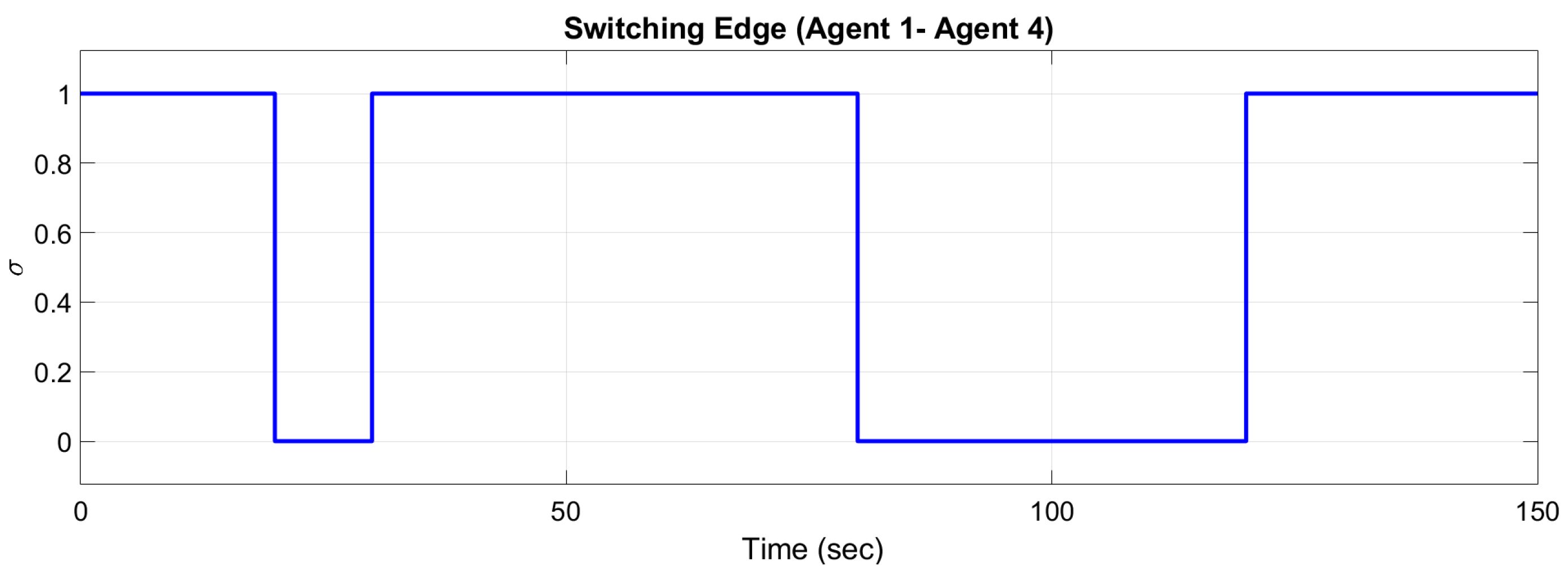
The activity or inactivity of the edge is defined by the switching edge of
Figure 10 (
, edge is active and
, edge is inactive). The switching edge signal is shown in
Figure 11. If the controller is not switching, Agent 4 continues to use the controller for two neighbors instead of only one. Note that the parameters of Agent 1 are equal to zero when there is no connection.
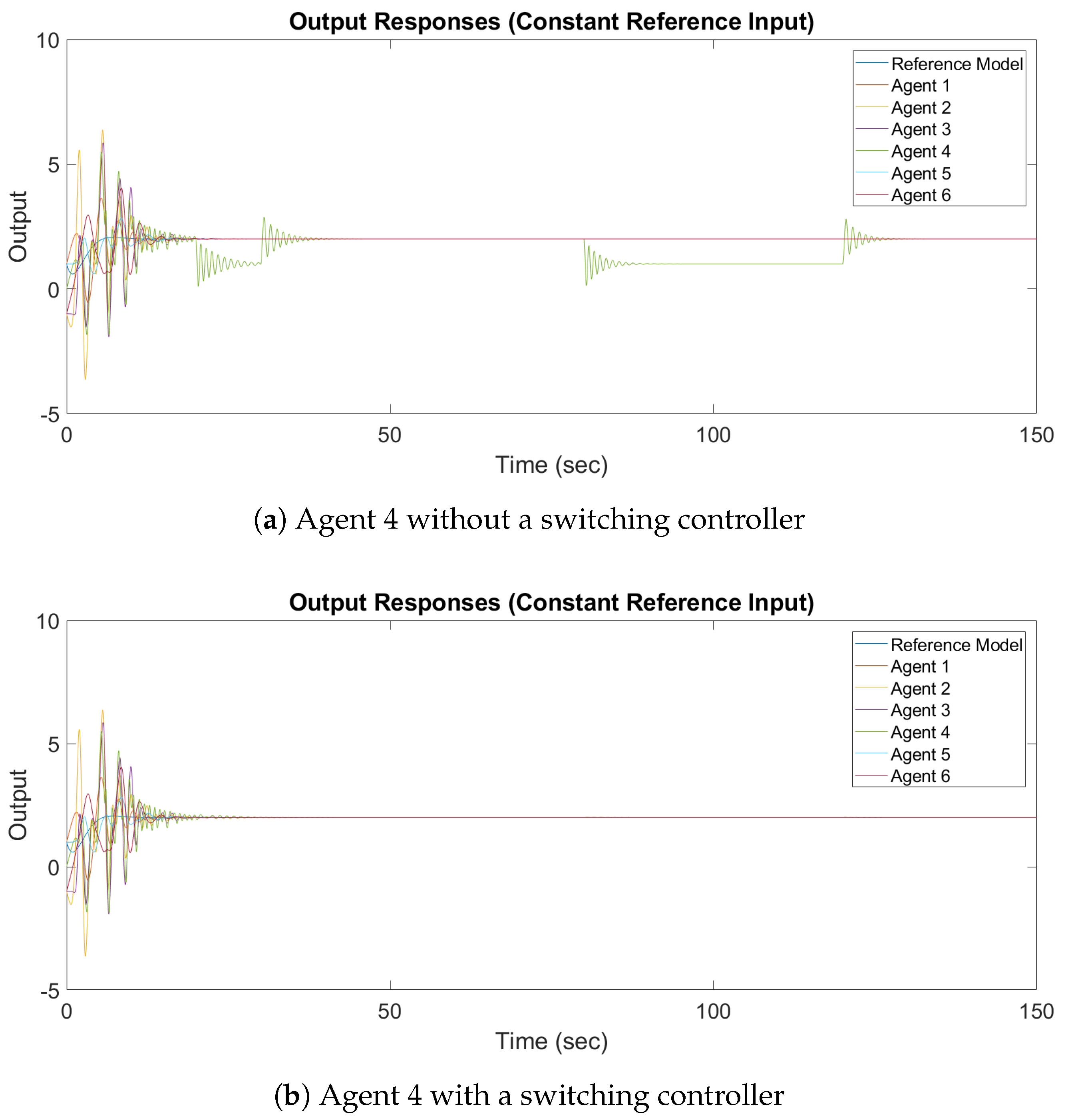
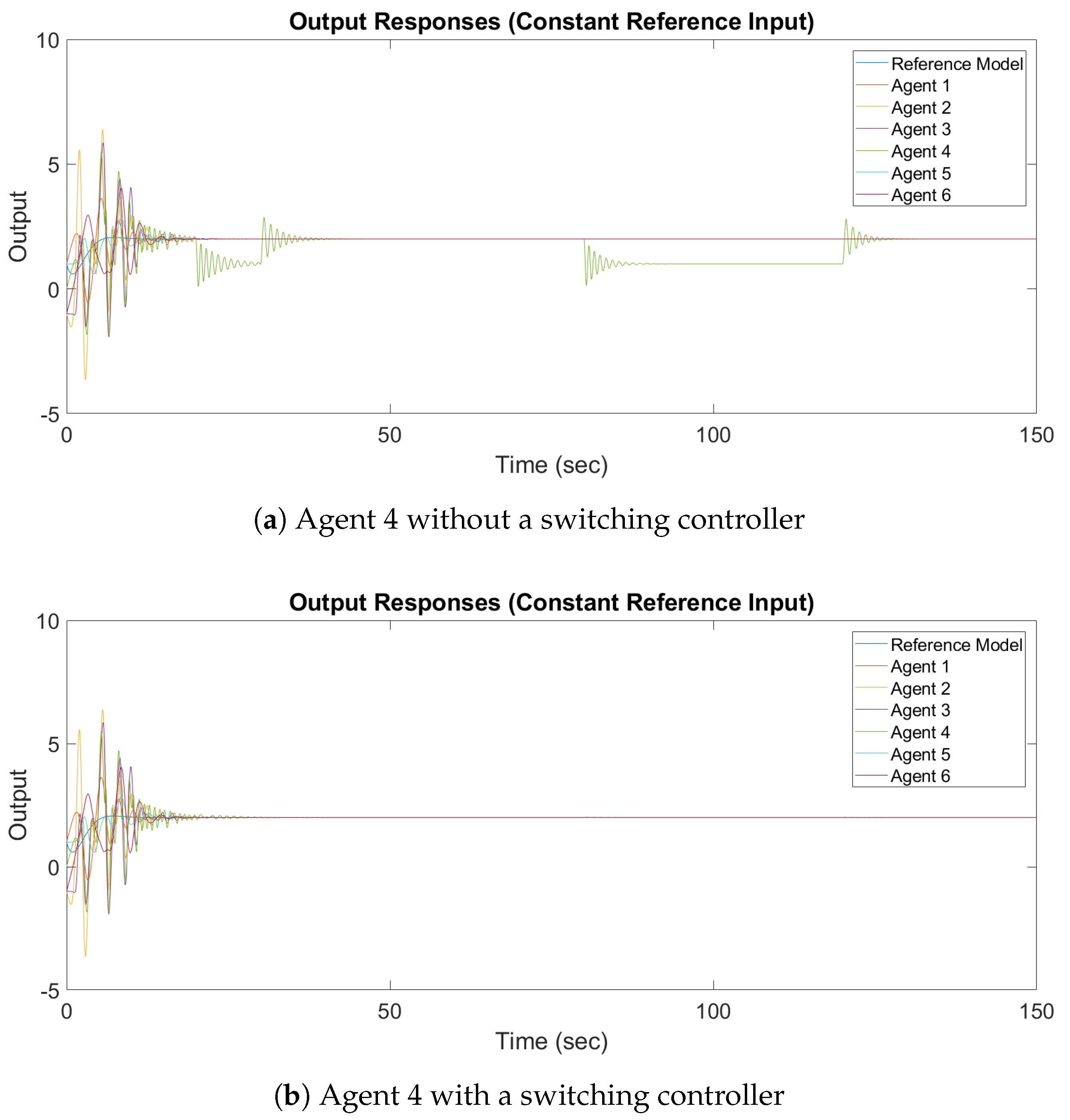
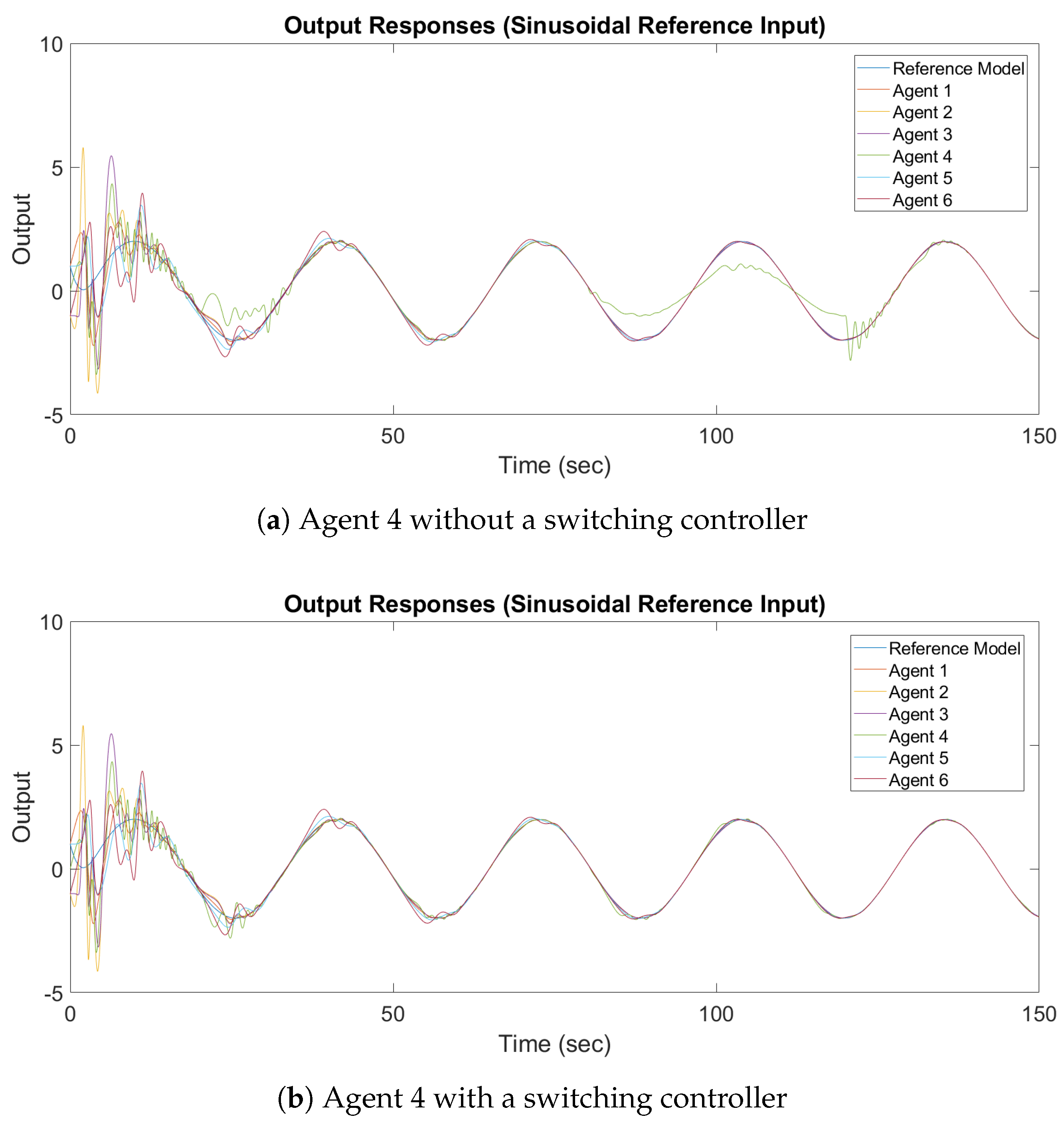
The design parameters and the reference inputs are the same as the design parameters and the reference inputs in the previous subsection. The output response of synchronization with a constant reference input and a sinusoidal reference input are shown in
Figure 12 and
Figure 13, respectively.
It can be observed in
Figure 12a and
Figure 13a that the output of Agent 4 does not converge to the output of the leader, while in
Figure 12b and
Figure 13b all the outputs converge asymptotically to the output of the leader. It can be concluded that, in the case of switching topologies, the switching adaptive controller must be implemented.
5. Conclusions
In this work, it was shown that the output synchronization of a heterogeneous MAS with unknown dynamics can be achieved through output-feedback MRAC. New adaptive laws were formulated for the controller parameter vector by using a matching condition assumption. In contrast with standard MRAC, where the adaptive gain is scalar-valued, in this work, the adaptive gain is a diagonal matrix. By using the proposed control law, the agents only require the output and the control input of its neighbors. This approach provides much convenience in the design and application of MAS synchronization because it does not require global information (e.g., the Laplacian matrix or algebraic connectivity). In order to have the synchronization error converge asymptotically to zero and to achieve bounded stability, a Lyapunov-based approach was derived analytically. In addition, a distributed switching controller was proposed to handle communication losses that deteriorate the synchronized response. Finally, numerical simulations were provided to validate the proposed method. It was shown that the convergence of the synchronized response can be achieved for a network with fixed or switching topologies.
Future work will include handling networks with possibly directed cycles; in the presence of cycles or loops, we expect a specific condition to ensure the stability of the proposed approach. The study of robustness in the presence of bounded disturbances could be an extension of the proposed output-feedback MRAC. Another exciting research direction could consist in exploring the possibility of handling system constraints (e.g., input constraints/actuator position saturation) for synchronization of MASs [
27,
28]. Another avenue worth investigating is the extension to state/output synchronization of nonlinear systems.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}